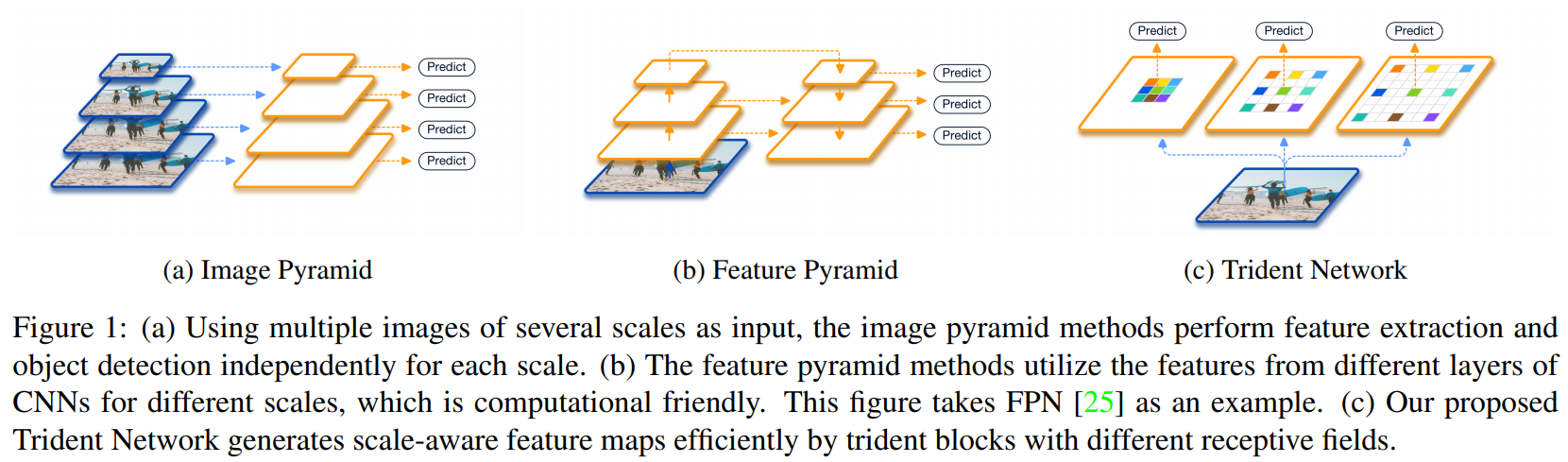
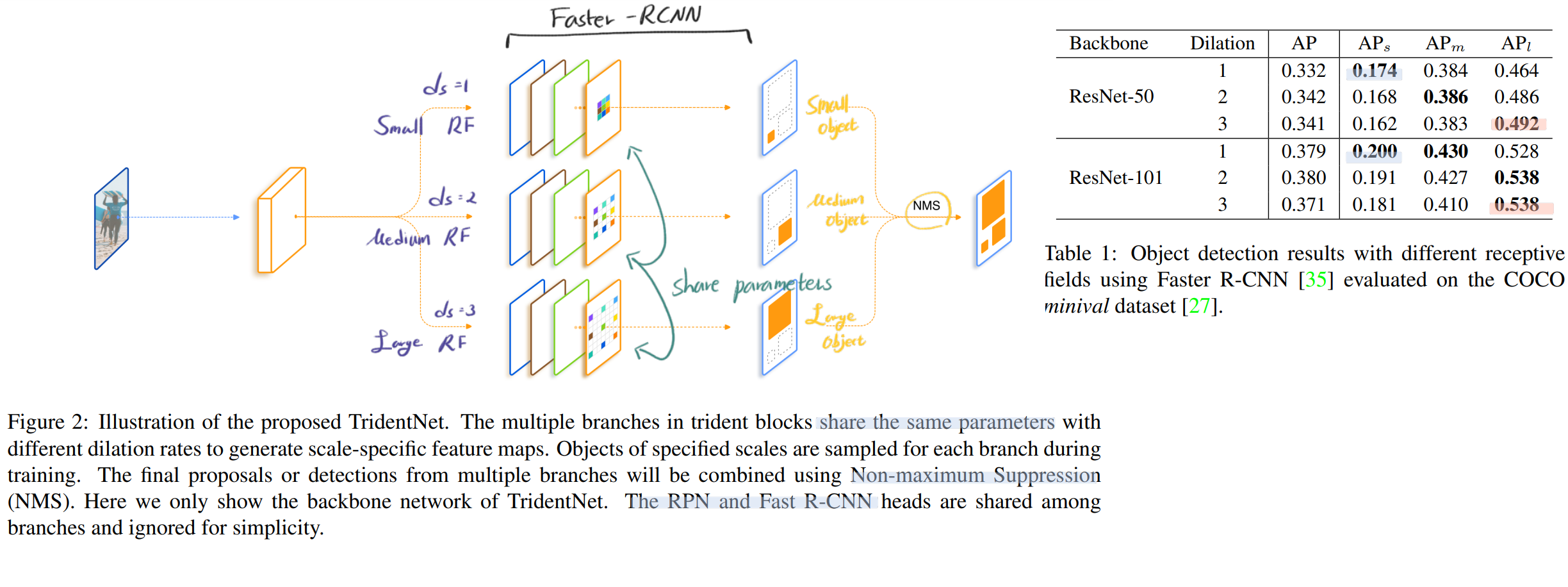
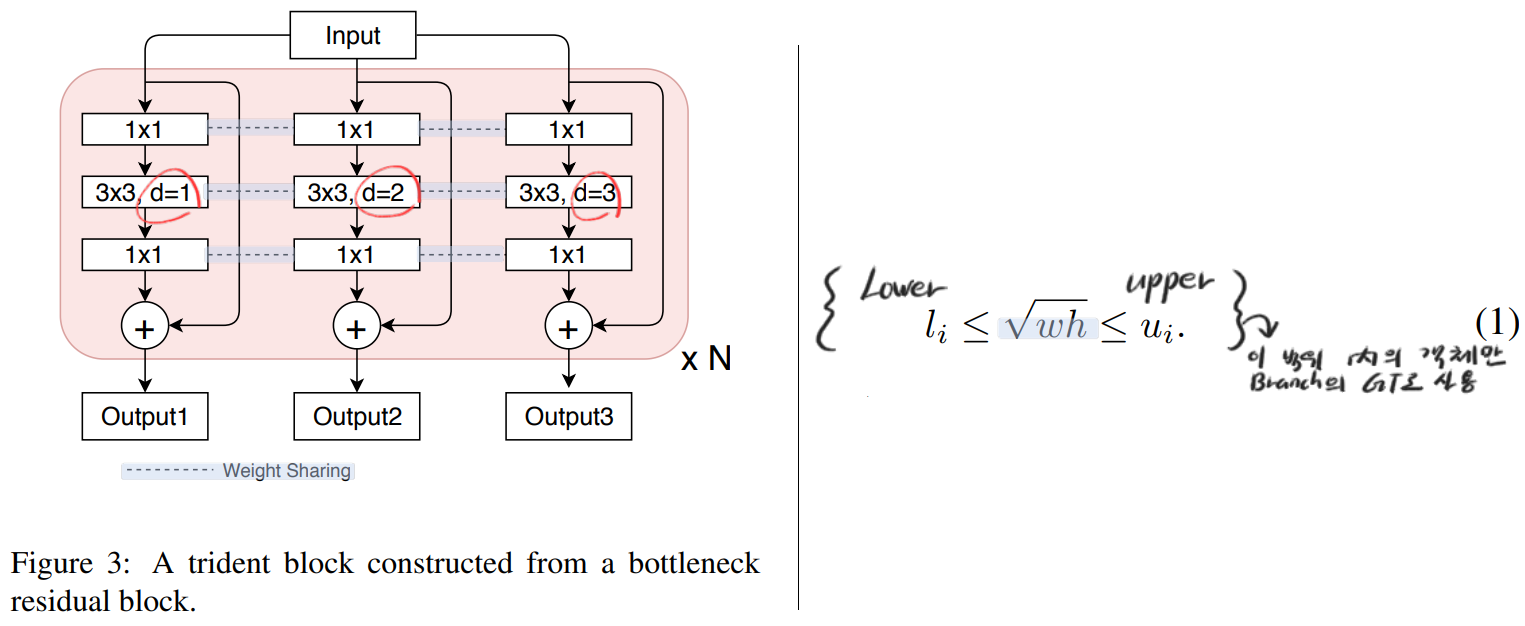
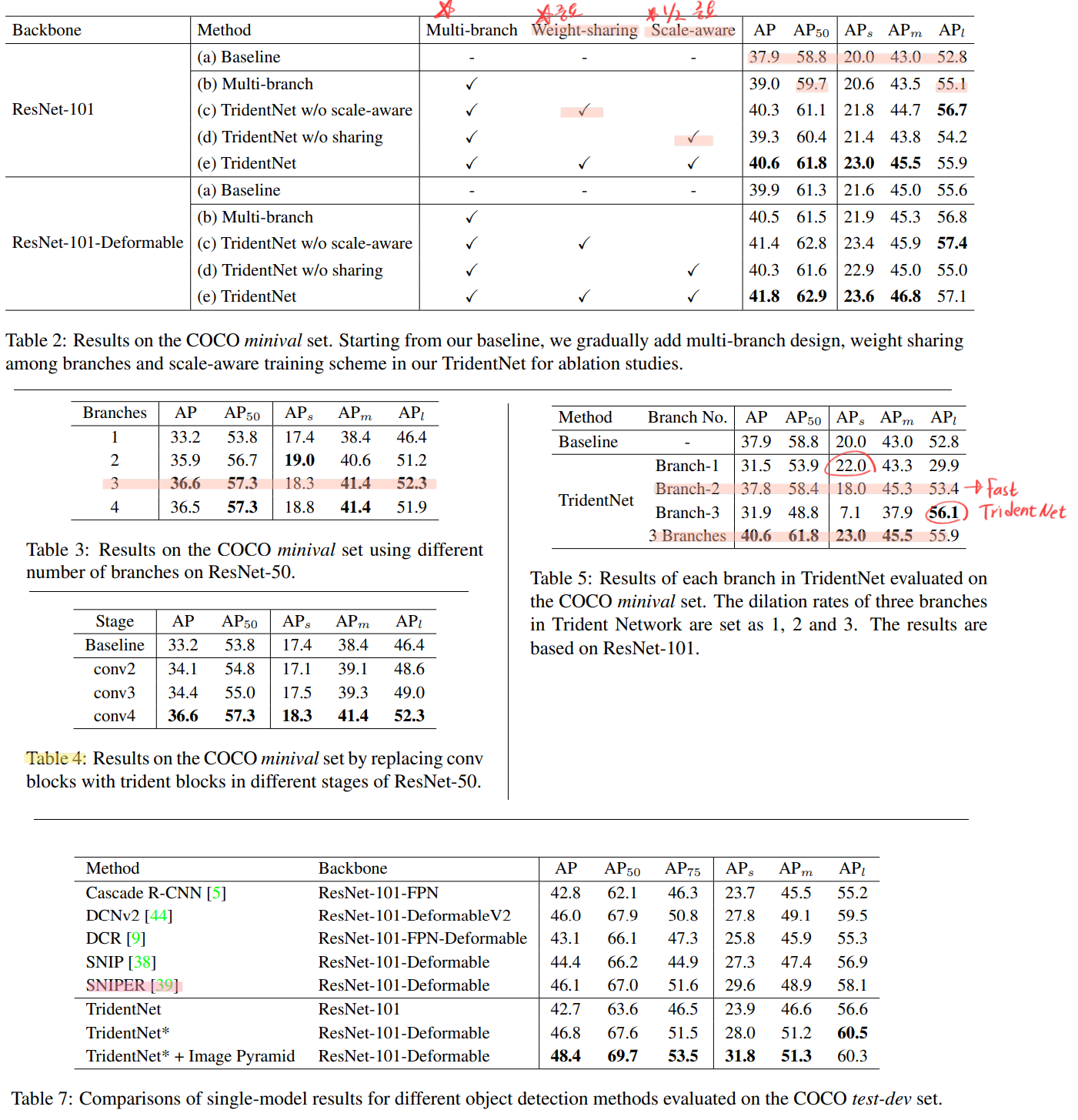
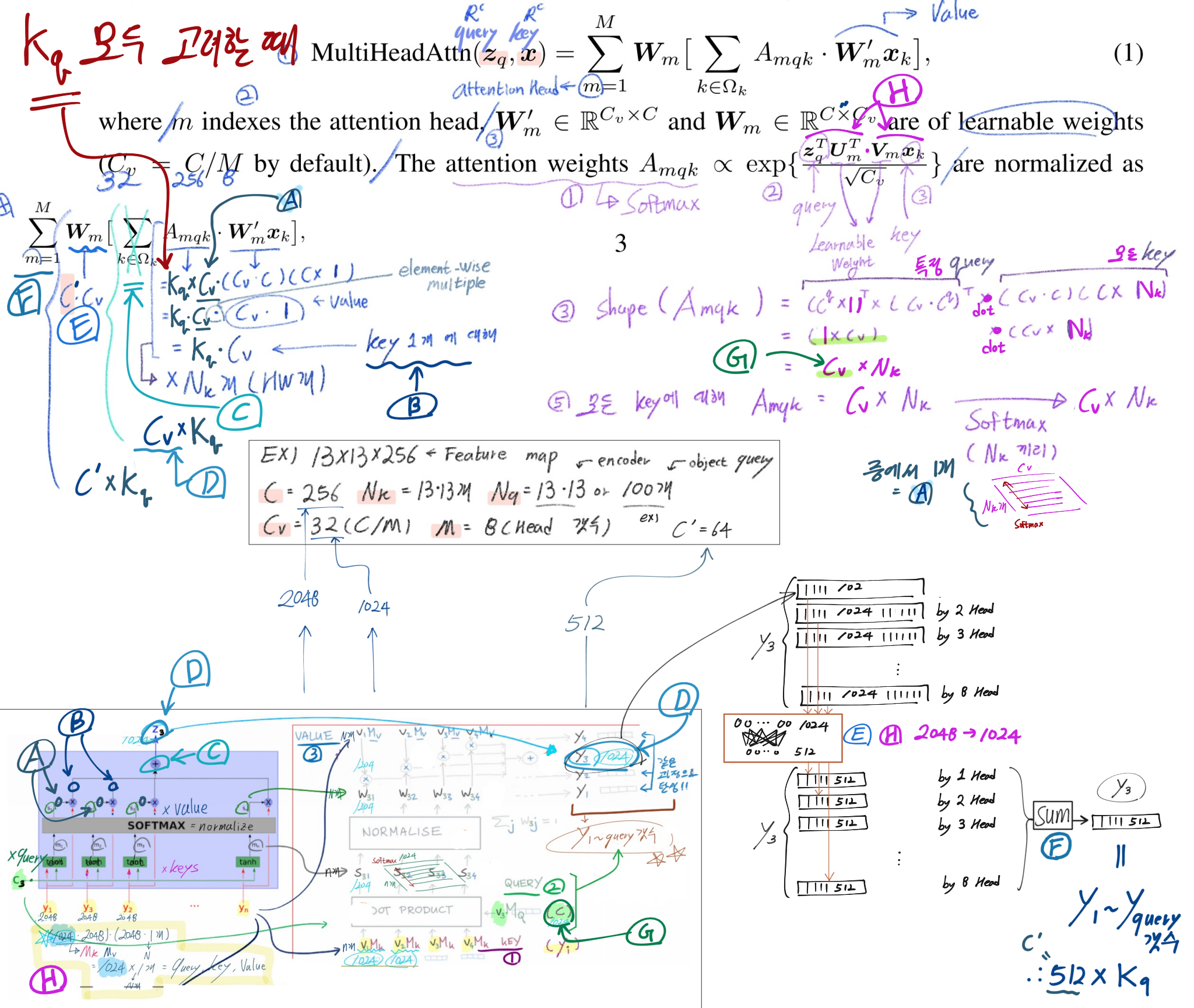
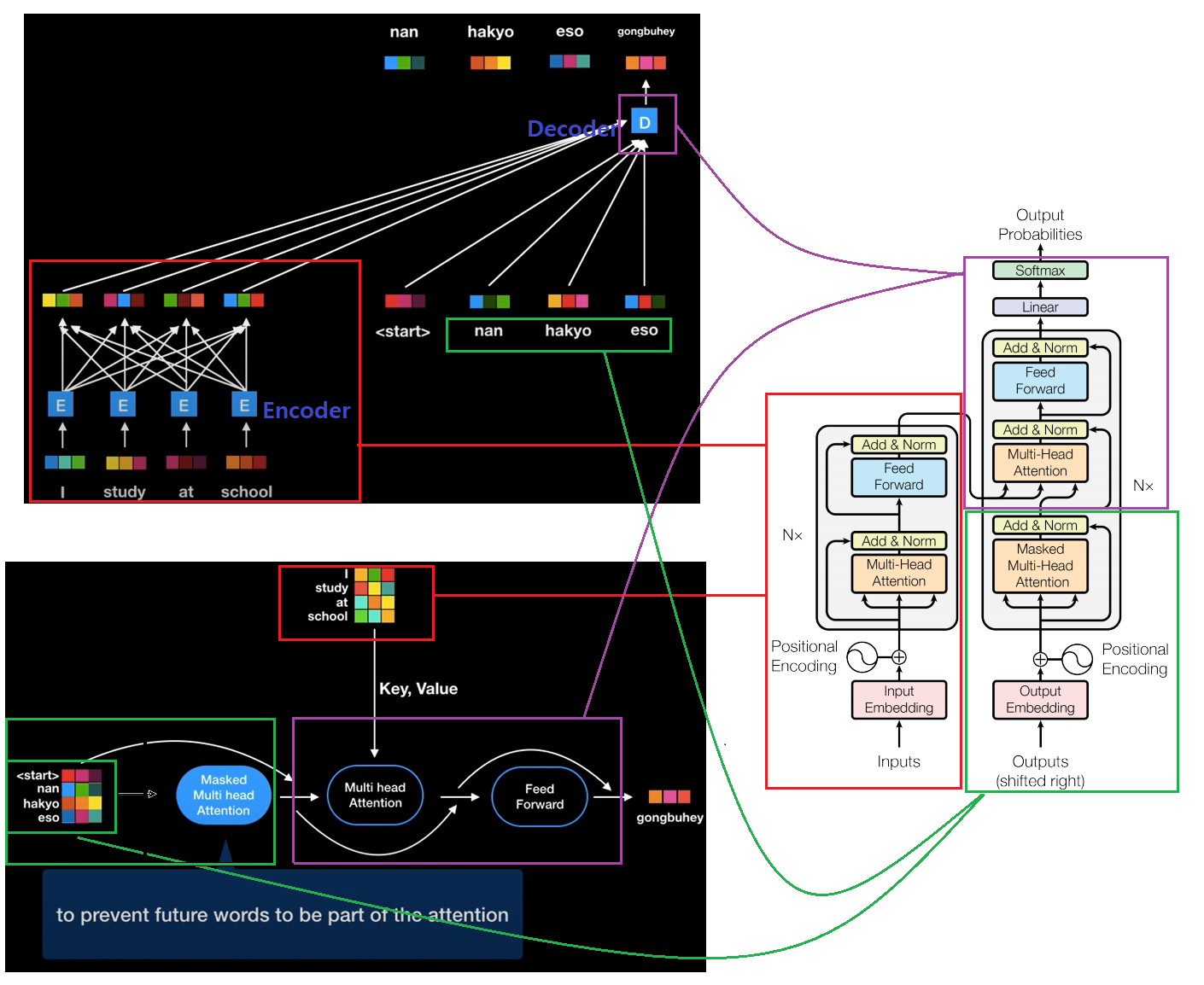
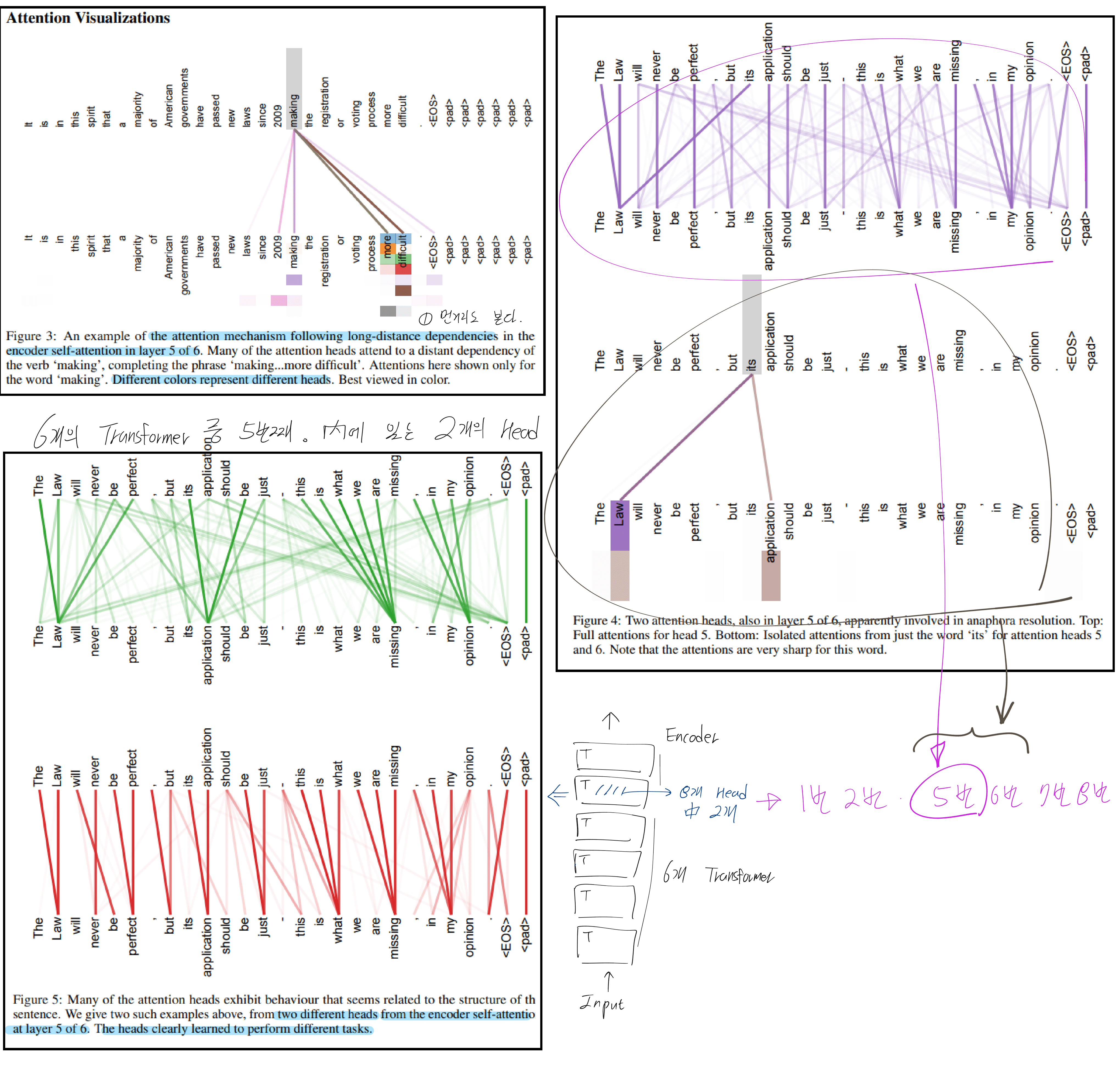
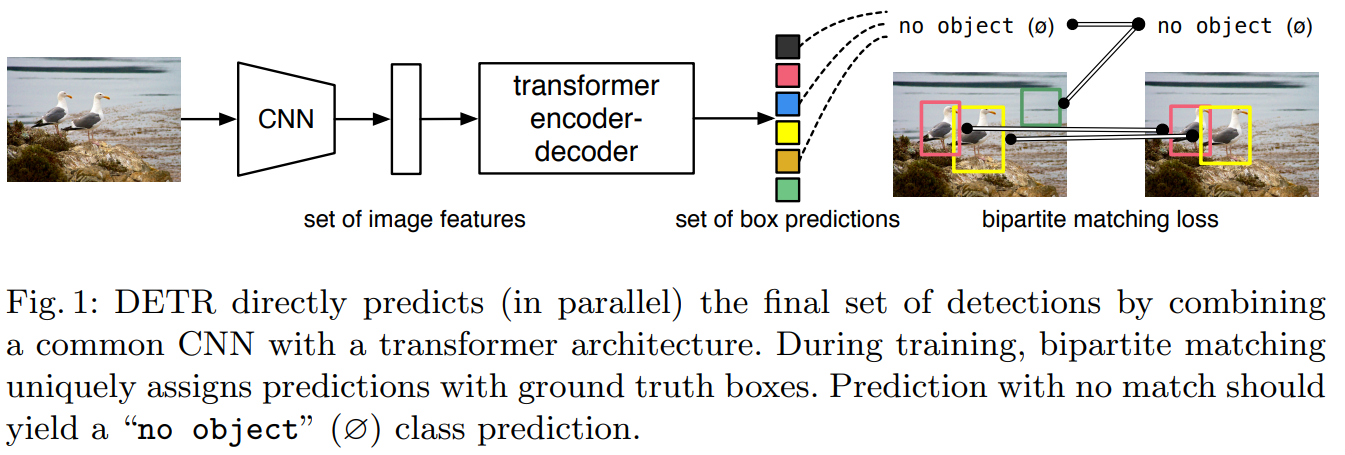
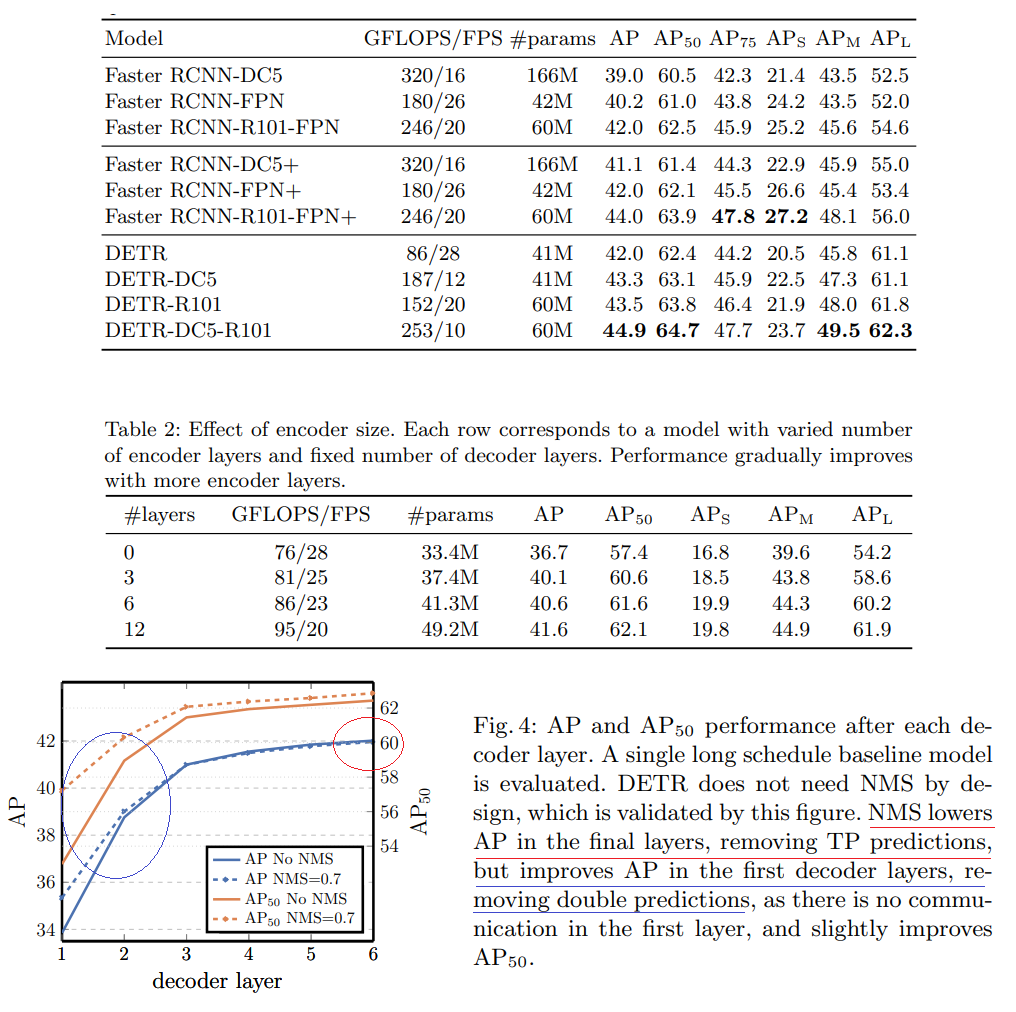
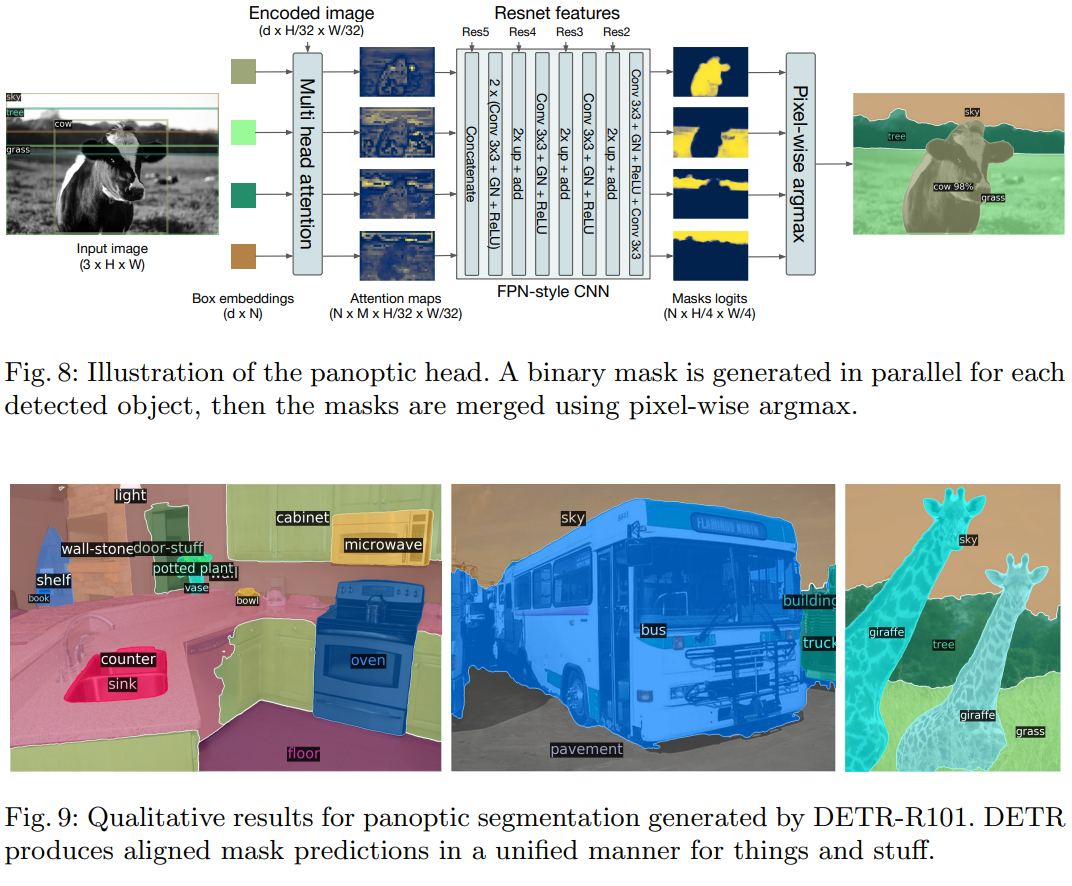
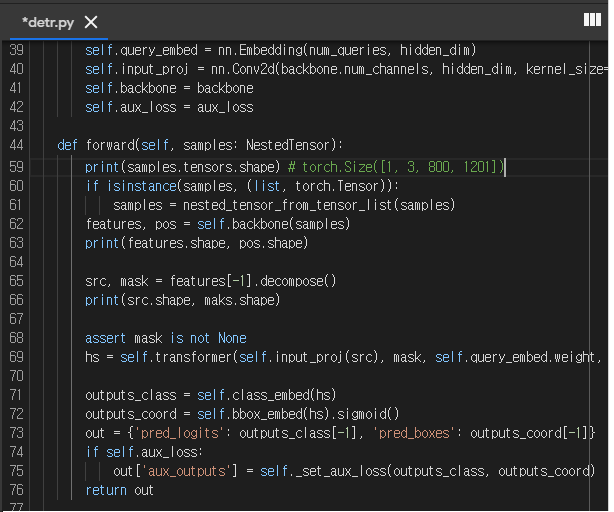
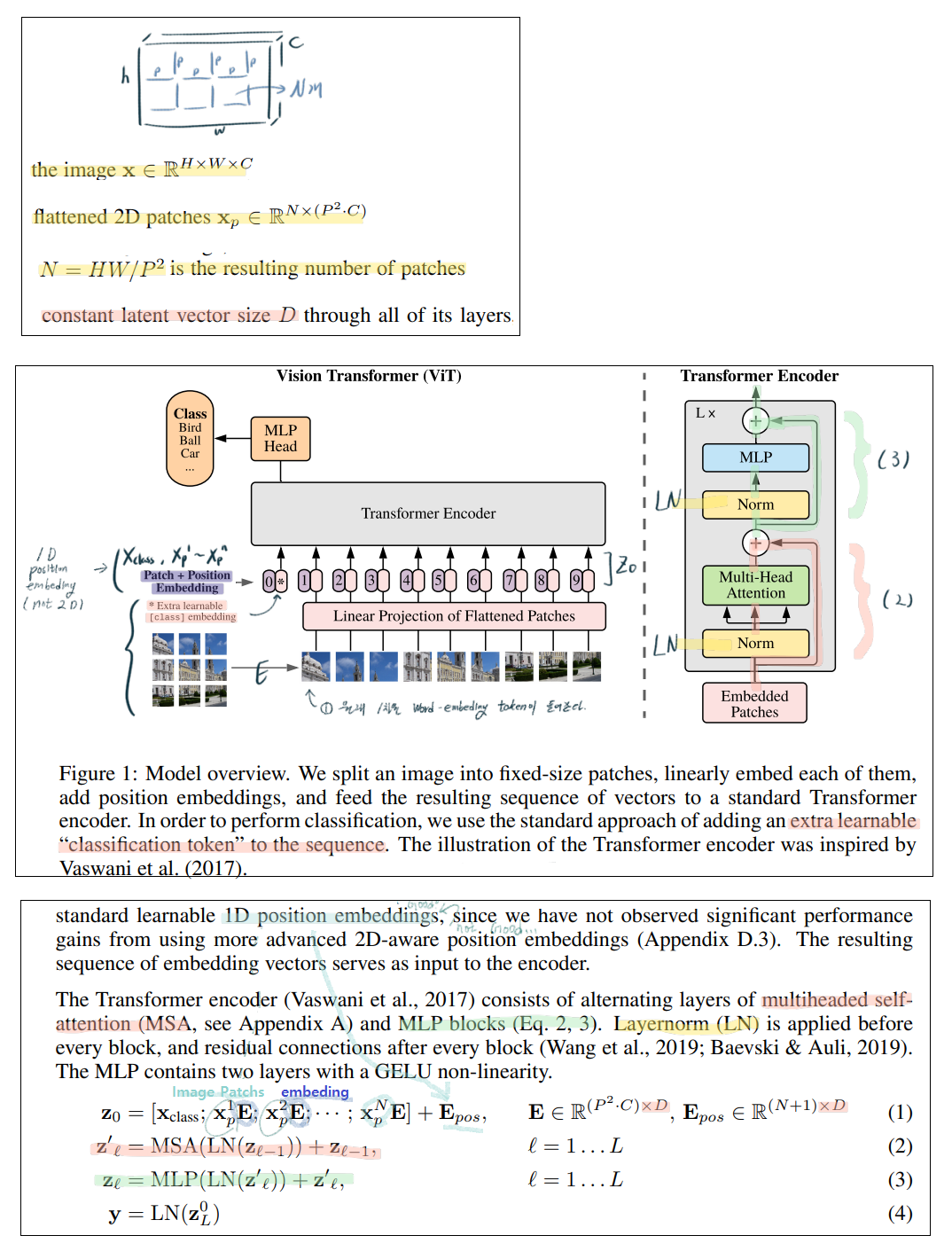
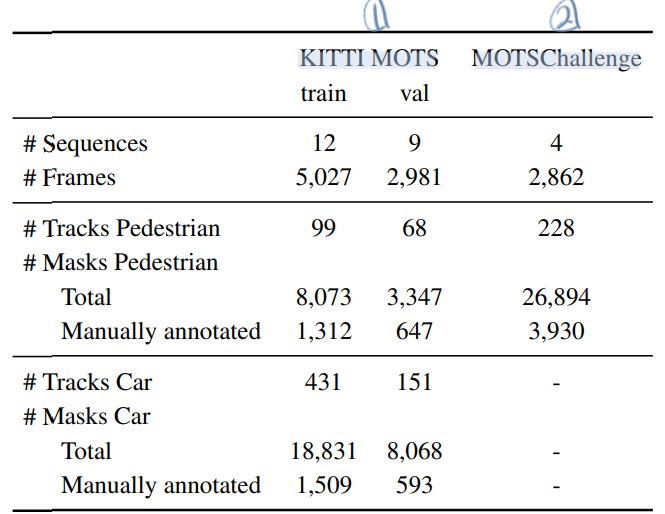
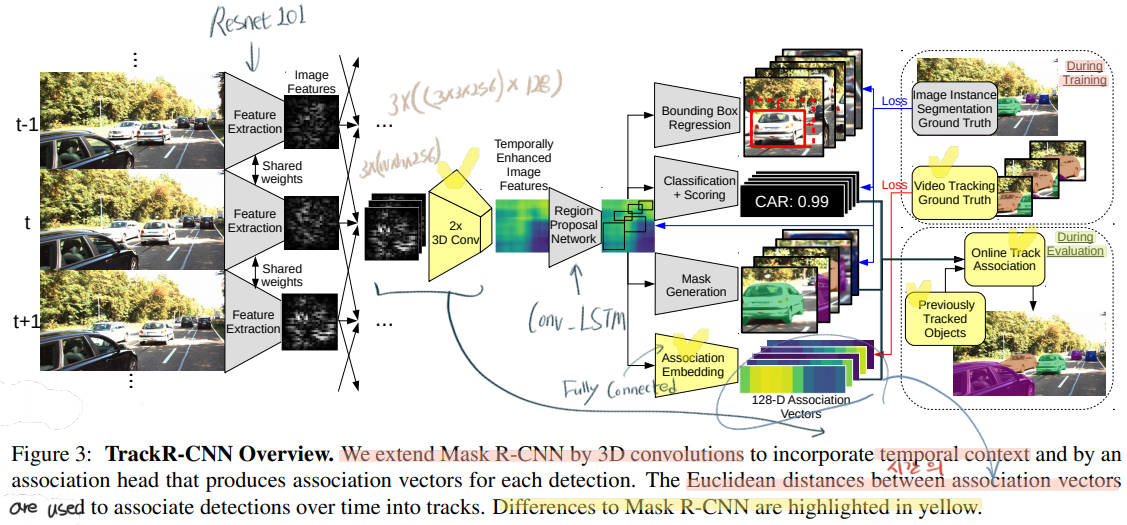
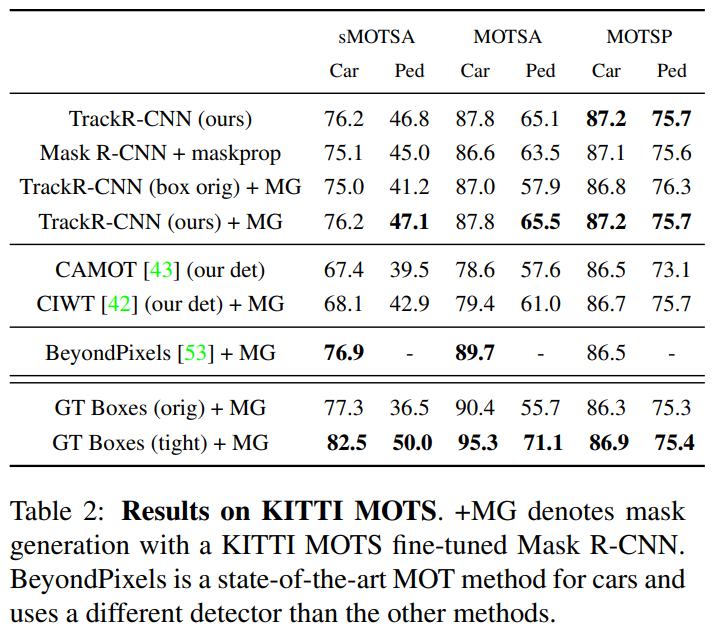
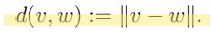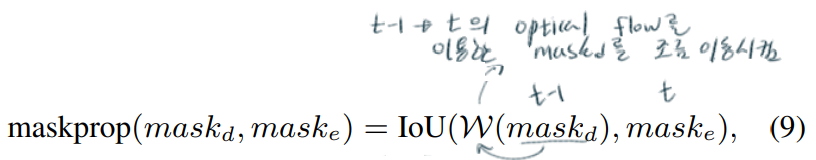class Attention(nn.Module):
def __init__(self, dim, heads = 16, dim_head = 64, dropout = 0.):
'''
dim = patch를 1차원화 백터 원소의 갯수 = 1024 개
heads = 1, 2, 3 ... ~ h (Multi-head Attention)에서 h 갯수
처음 들어가는 1개 image patch의 차원 [1, 1024]
[x1 ~ x65] = [1, 65, 64] # 원래 patch갯수는 64개 + extra class embedding 1개 = 65개
하나의 Head에 의해 나오는 y_i의 차원 [1, 64]
[y1 ~ y65] = [1, 65, 64]
'''
super().__init__()
inner_dim = dim_head * heads # 64*16 = 1024
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5 # 0.125
"""
# qkv의 nn.linear 를 그림처럼 따로 하는게 아니라, 한꺼번에 해버린다.
# 아래의 *3 이 의미하는 것은 qkv 3개를 말하는 건가?
# inner_dim 은 qkv 중 하나의 linear를 통과했을 때 나오는 총 원소의 갯수
# 즉 dim_head는 위 Transformer 이미지에서, 하나의 작은 linear를 통과했을 때 나오는 원소의 갯수 이다.
# input은 queries, keys, values와 연산되어 (nn.linear), forward 코드와 같이 각각 q, k, v 변수가 된다.
# by queries : (input)1024 vectors -> 64 vectors * 16개 head
# by keys : 1024 vectors -> 64 vectors * 16개 head
# by values : 1024 vectors -> 64 vectors * 16개 head
"""
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim), # (64*16 = 1024) -> 1024개
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x, mask = None):
"""
# heads의 갯수 설정으로 내부에서 다수의 head가 알아서 돌아간다.
# 주의! heads는 Transformer Encoder의 Lx에서 L이 아니다! 맨 위 사진의 1~h에서 h 이다!
# 따로 분류해서 연산하지 않고, 한꺼번에 묶어서 연산해 버린다.
# 그래서 이 코드로는 위 그림의 이해가 한방에 되지 않을 수 있다.
# 따라서 아래 내용이 복잡하지만... "이거 다 통과하면 하나의 Multi Head Attention 을 통과하는 구나! 라고 알아두자."
"""
b, n, _, h = *x.shape, self.heads
# print(x.shape) # torch.Size([1, 65, 1024])
qkv = self.to_qkv(x).chunk(3, dim = -1)
# print(qkv.shape, qkv[0].shape) # (3,) torch.Size([1, 65, 1024])
# torch.chunk Tensor를 자른다.
# q, k, v 각각, input에서 by queries, keys, values 처리를 하고 나오는 '결과'
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)
# print(q.shape,k.shape,v.shape) # torch.Size([1, 16, 65, 64]) torch.Size([1, 16, 65, 64]) torch.Size([1, 16, 65, 64])
# torch.einsum (https://pytorch.org/docs/stable/generated/torch.einsum.html)
# tensor를 원하는 형태로 변환해줘!
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
mask_value = -torch.finfo(dots.dtype).max
if mask is not None:
mask = F.pad(mask.flatten(1), (1, 0), value = True)
assert mask.shape[-1] == dots.shape[-1], 'mask has incorrect dimensions'
mask = rearrange(mask, 'b i -> b () i ()') * rearrange(mask, 'b j -> b () () j')
dots.masked_fill_(~mask, mask_value)
del mask
attn = dots.softmax(dim=-1)
out = einsum('b h i j, b h j d -> b h i d', attn, v)
"""
여기까지 out = torch.Size([1, 16, 65, 64])
<맨 위의 Transformer 최종 정리 사진과 꼭 함께 보기>
이 말은 하나의 Head에 의해 나오는 y_i는 64개의 백터를 가진다. 총 [y1 ~ y65] = [1, 65, 64] 차원을 가지게 된다.
"""
out = rearrange(out, 'b h n d -> b n (h d)')
out = self.to_out(out)
# print(out.shape) # torch.Size([1, 65, 1024])
return out