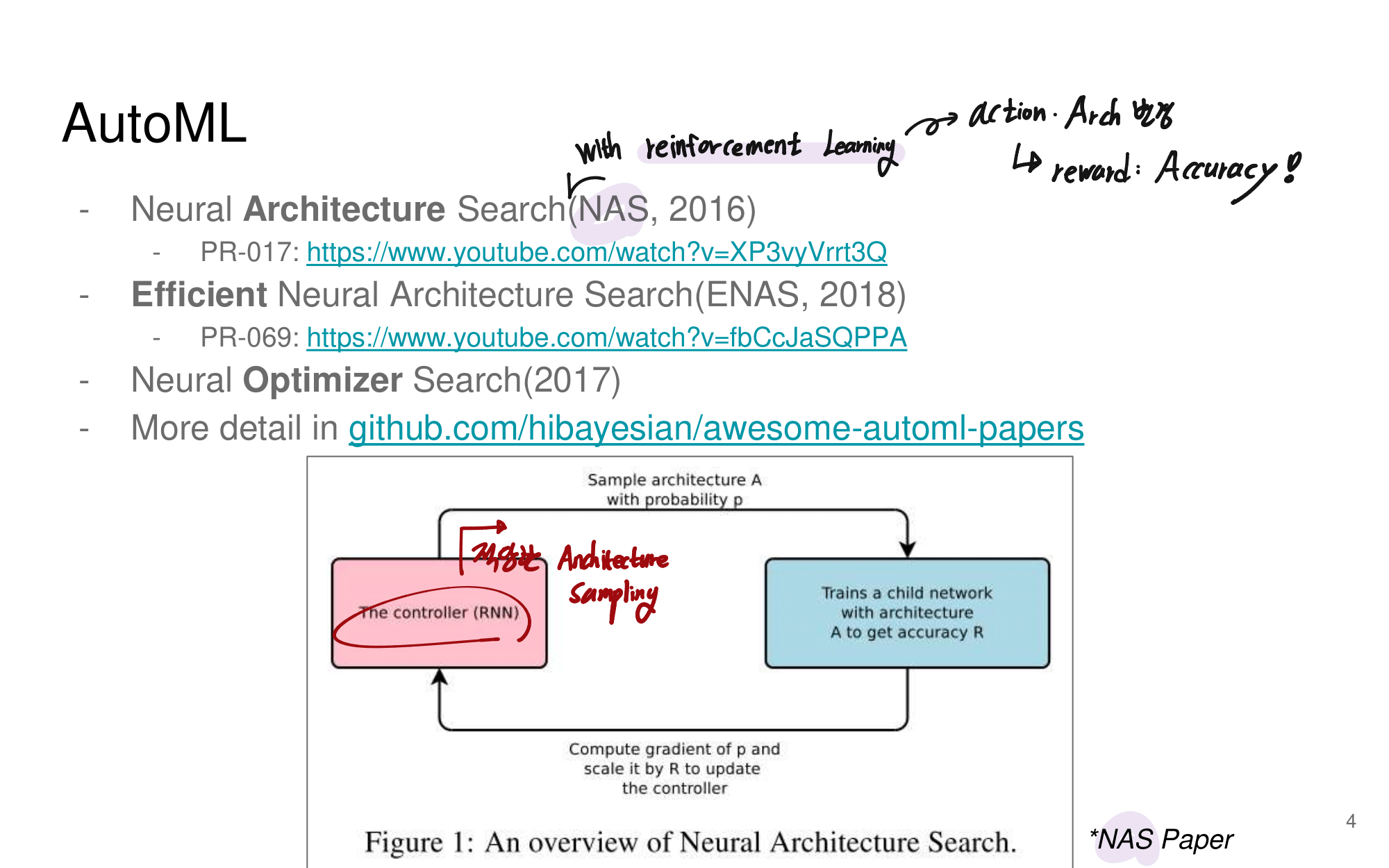
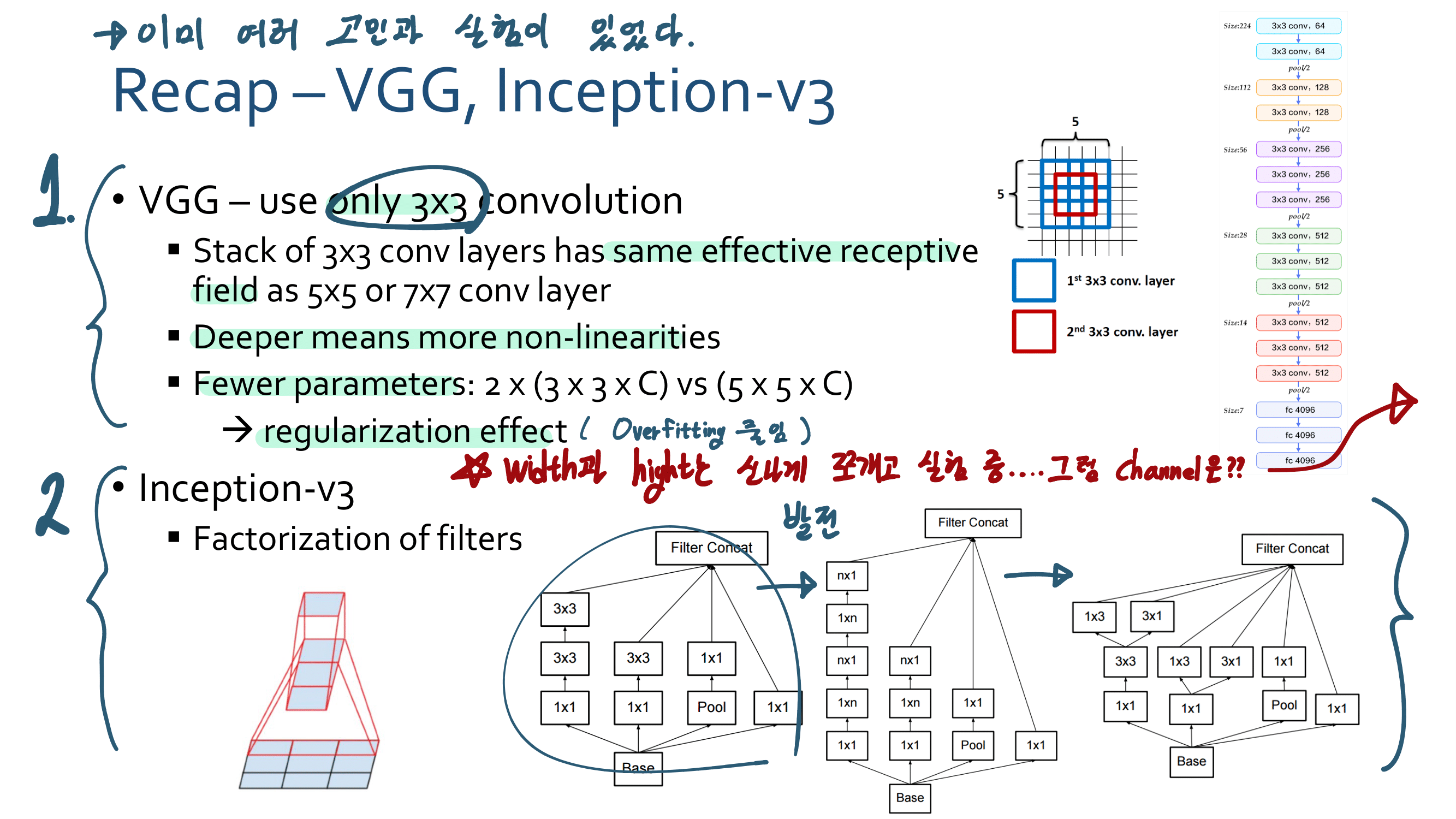
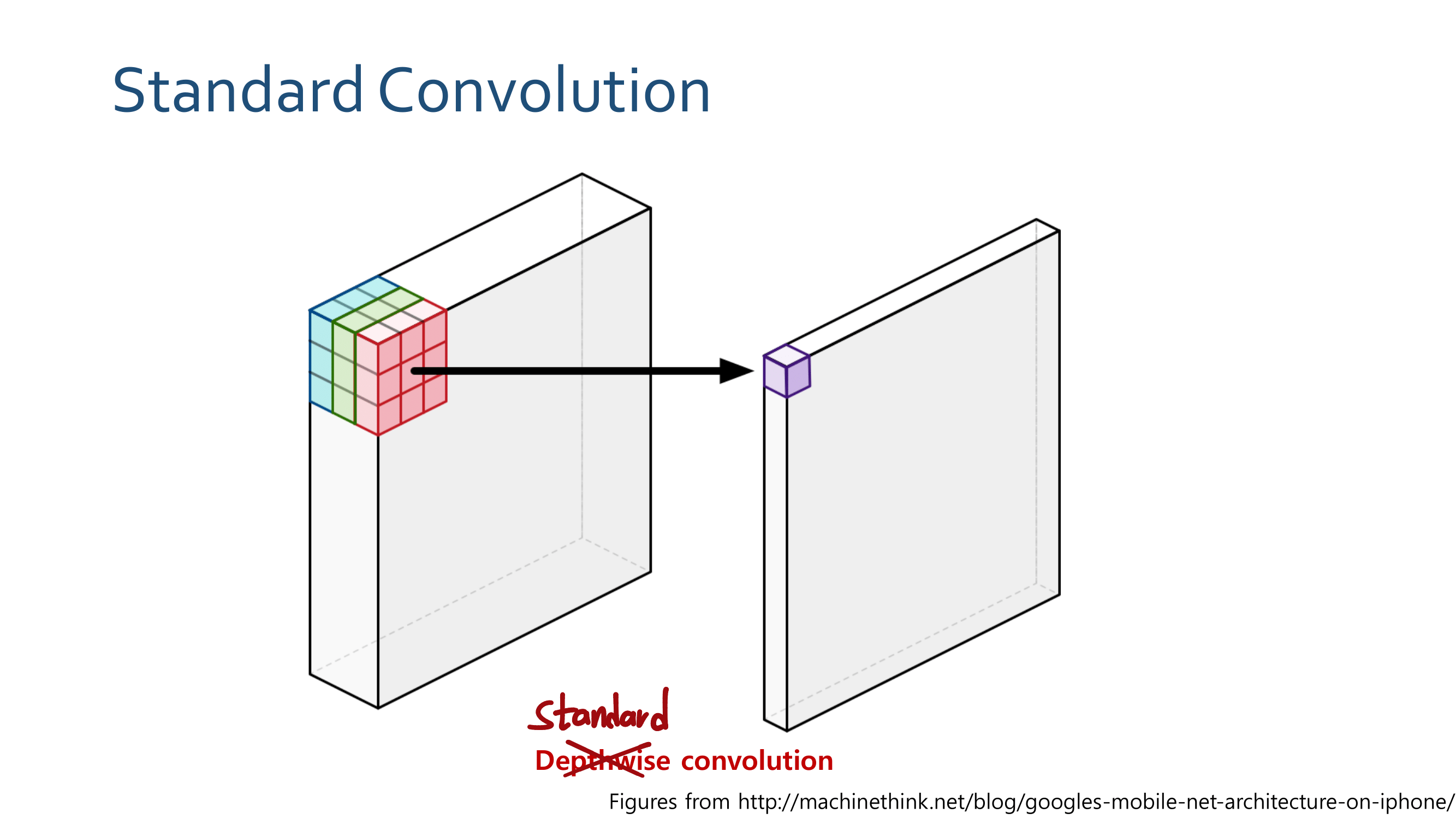
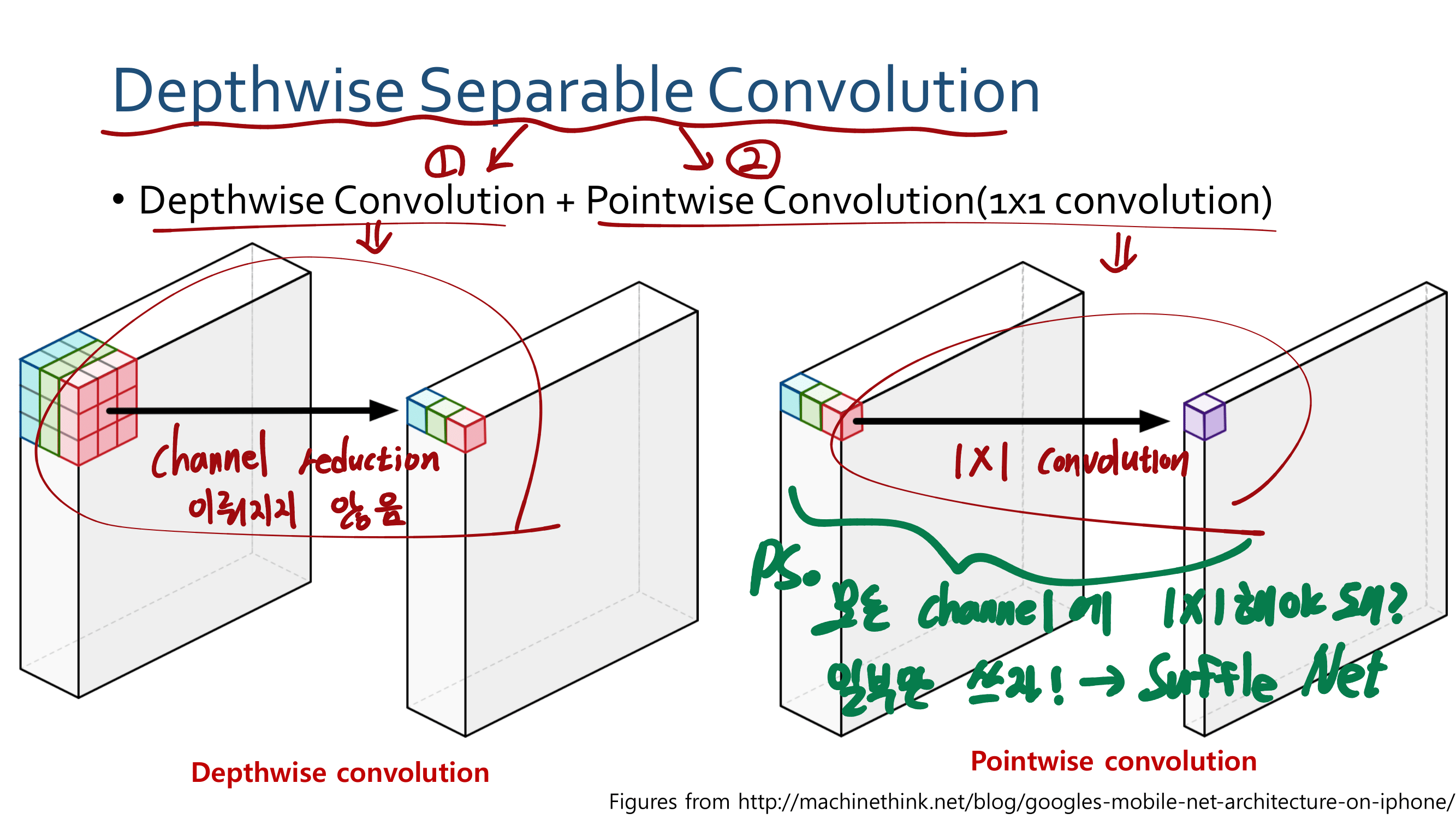
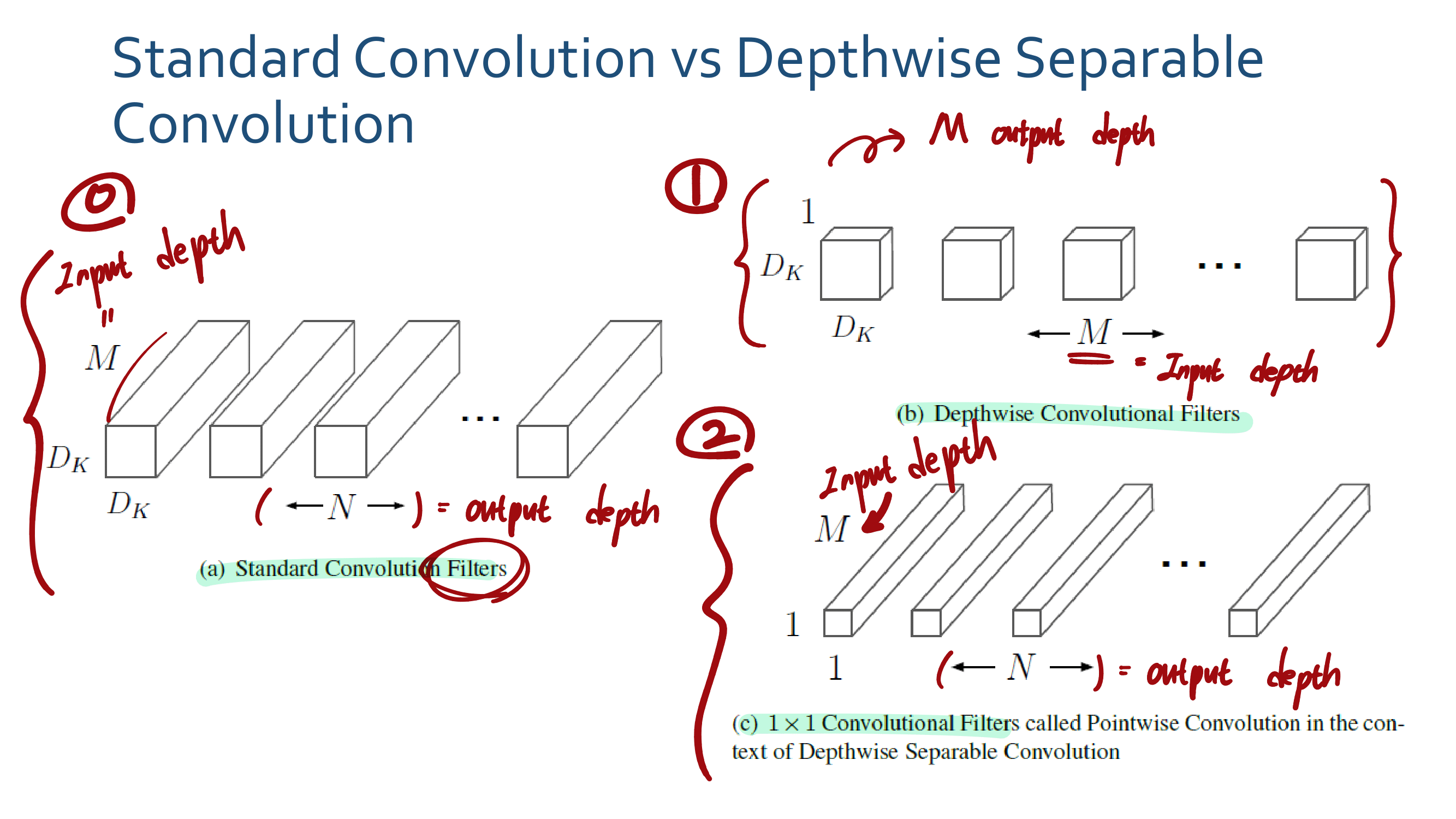
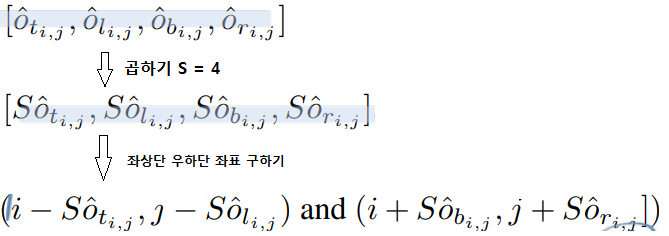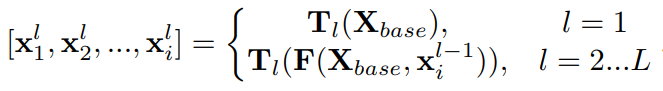이 논문의 특징은, reference가 200개가 넘는다. 정말 자세하고 많은 것을 담고 있는 논문이다. 어차피 이 것을 다 이해하려면 1년이 더 걸린다. 따라서 지금 하나하나 이해해서 다 기록해 두려고 하지말고, 전체 그림만 그릴 수 있도록 스키밍을 하면서 빠르게 읽어나간다. 그리고 정리는 핵심과 큰 윤곽만 정리해 나간다.
이 논문의 Reference의 핵심 논문이 너무 너무 많아서, 뭐 읽어야 겠다.. 라는 생각이 드는 논문이 거의 없다. 결국에는 나중에 SOTA 찍는 모델과 논문을 다시 보면서 공부해야한다. 여기서는 아주아주 큰 그림만 잡는다.
이 논문을 읽다보니, 나는 우주 속 먼지보다 작은 존재로 느껴졌다. 정말 보고 읽어야 할게 산더미다!! 근데 차라리 이래서 더 안심이다. 차라리 이렇게 산더미니까 다 읽지는 못한다. 따라서 그냥 하루하루 하나씩 꾸준히 읽어가는 것에 목표를 둬야 겠다. 논문은 “다 읽어버리겠다!가 아니다. 꾸준히 매일 읽겠다! 이다.” 라는 마음을 가지자!
0. Abstract
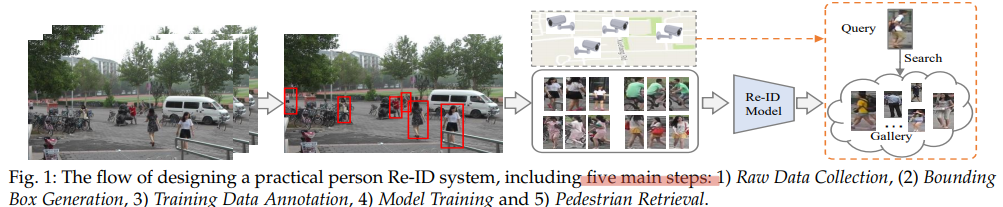
Person re-ID란? 겹치지 않는 다중 카메라들 사이에 person of interest를 검색(retrieving)하는 것
쉽게 설명해 보겠다. 3개의 카메라가 있다. 각 카메라는 구도와 공간이 다르다. 3개 이미지에는 많은 사람이 들어가 있고, 공통적으로 query person이 들어가 있다. 만약, 첫번째 이미지안의 query person이 query로 주어졌을 때, 나머지 2개의 이미지에서 다른 사람(boudning box는 이미 제공됨)이 아닌, 같은 query를 찾는 것이 Re-ID 과제 이다.
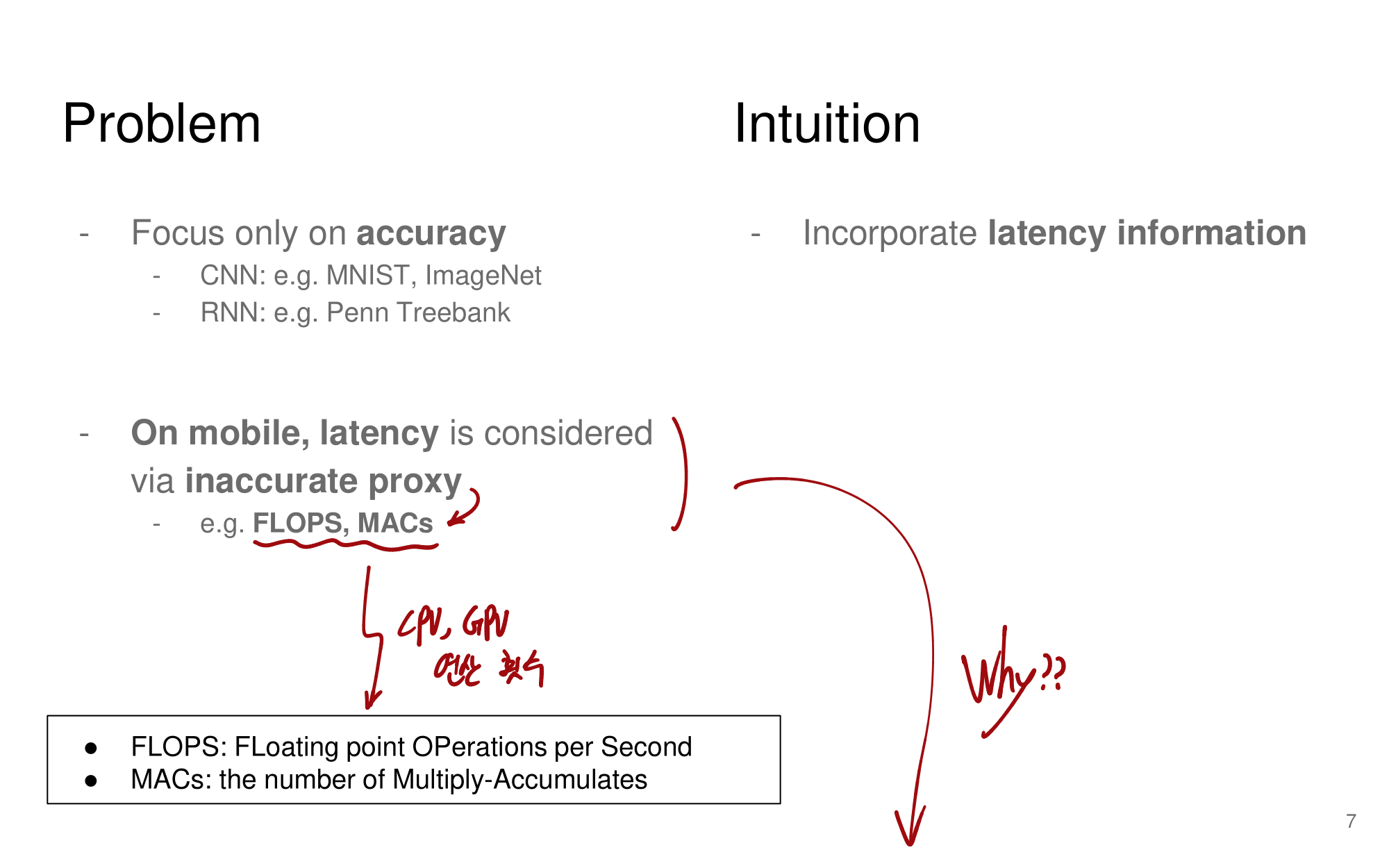
3개의 다른 perscpecitve를 가지는 closed world Person-Re-ID (상용화를 위한 것이 아닌 연구 단계의 연구들 = research-oriented scenarios)에 대한 종합적 개요가 있다. with (1) in-depth analysis (2) deep feature representation learning (3) deep metric learning (4) ranking optimization. 이 연구는 이미 거의 포화 상태다.
그래서 5개의 다른 perscpective를 가지는 Open-world setting으로 넘어가고 있다. (상용화를 위한 연구 단계의 연구 = practical applications)
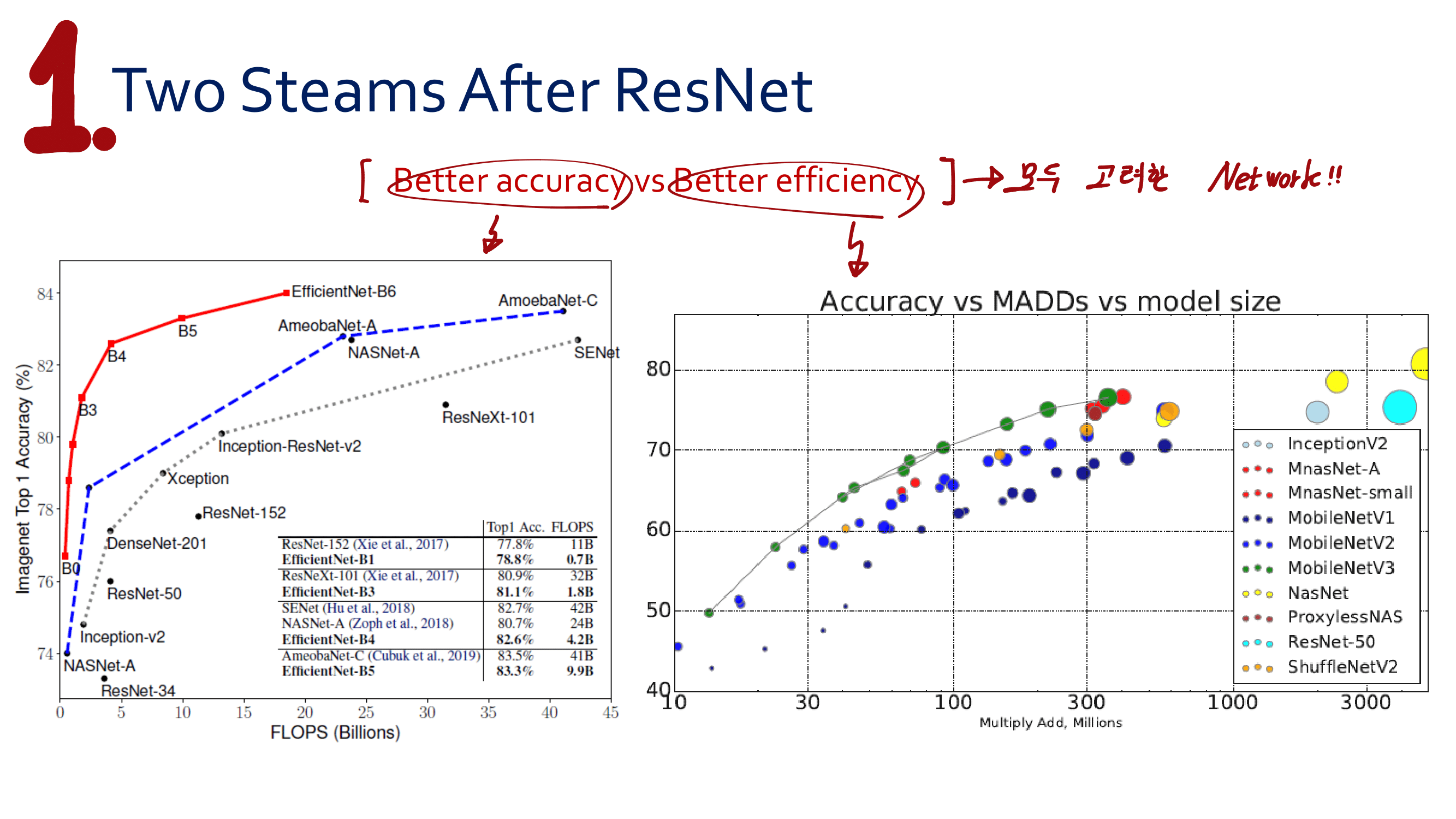
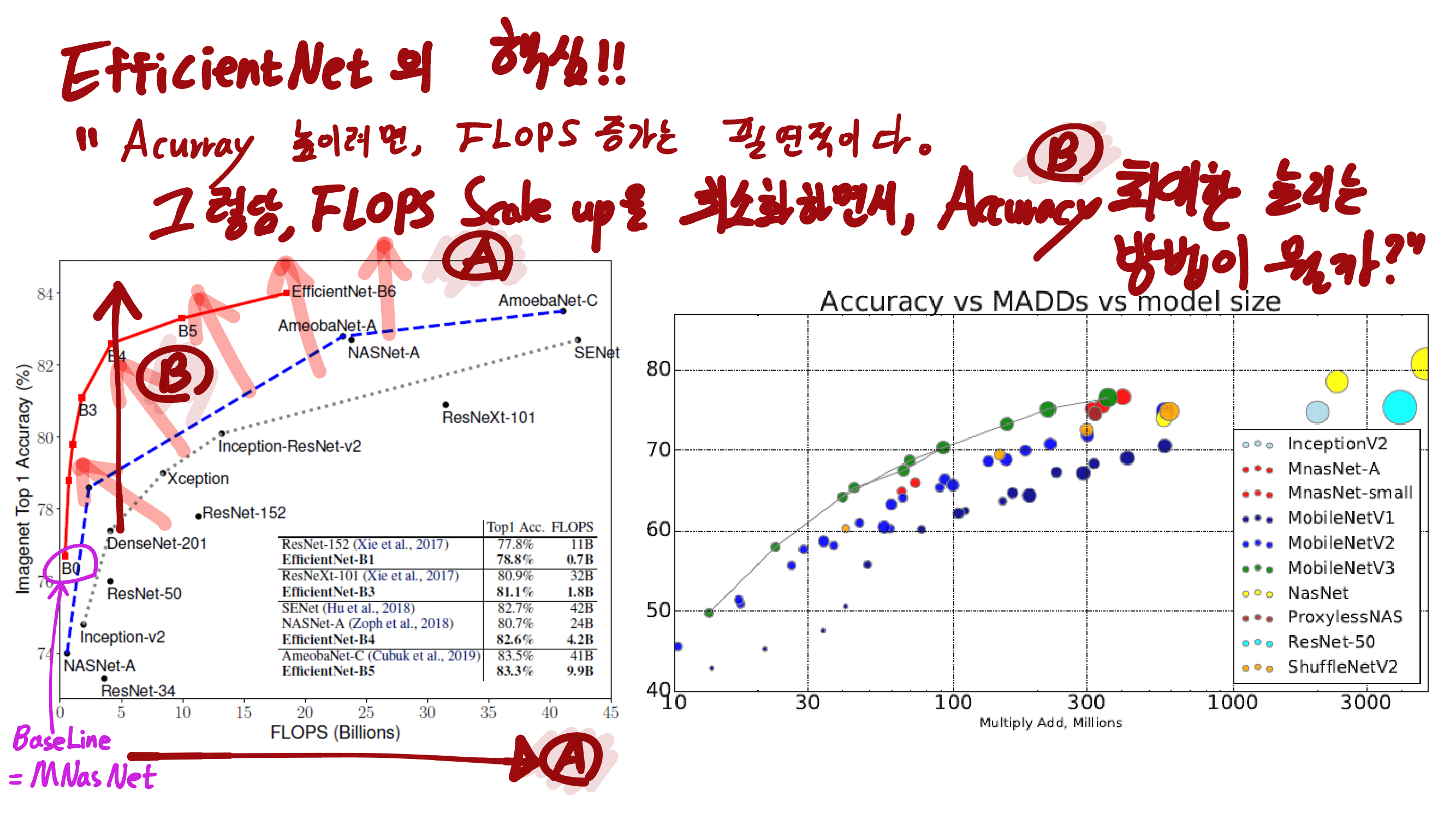
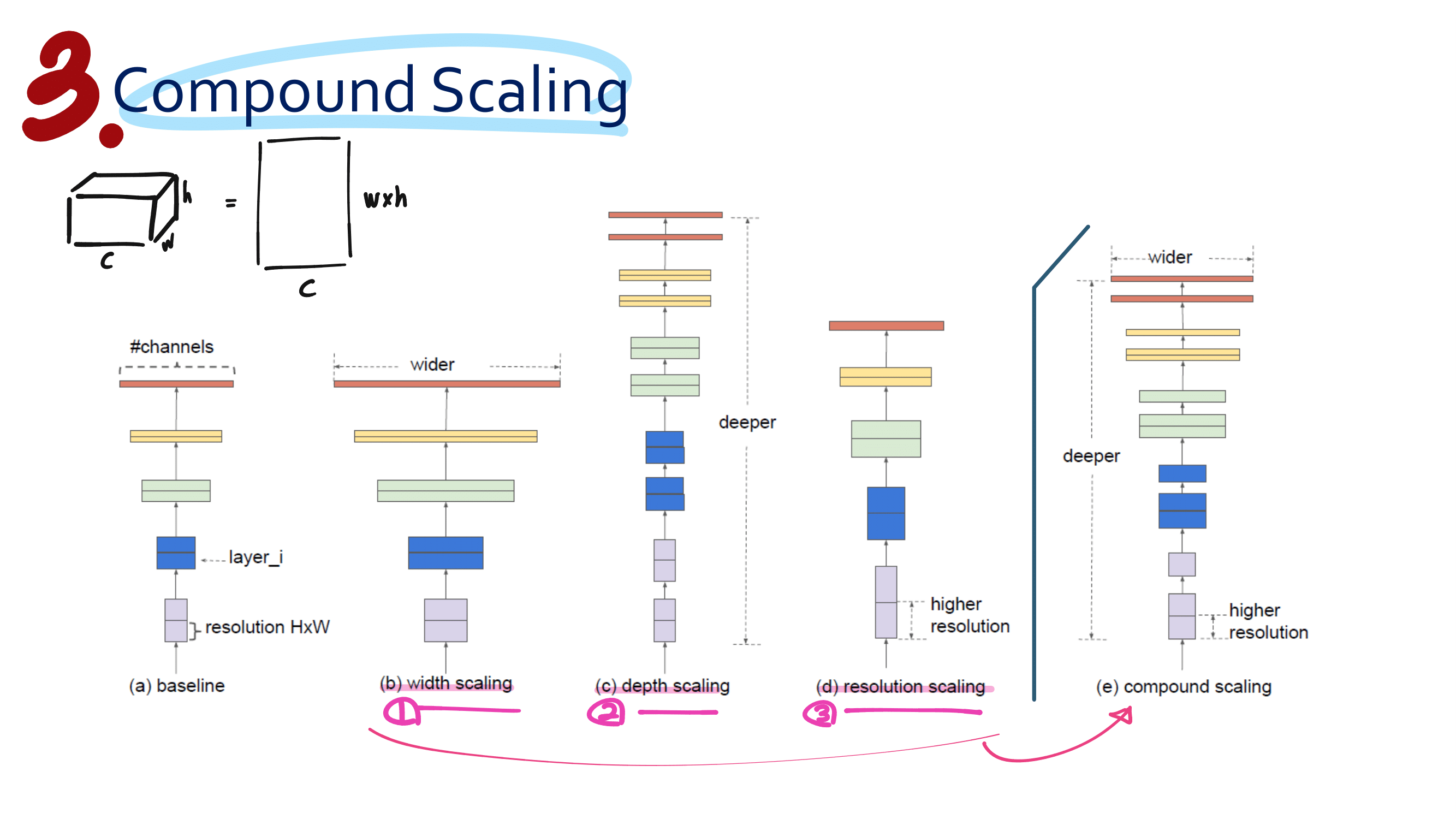
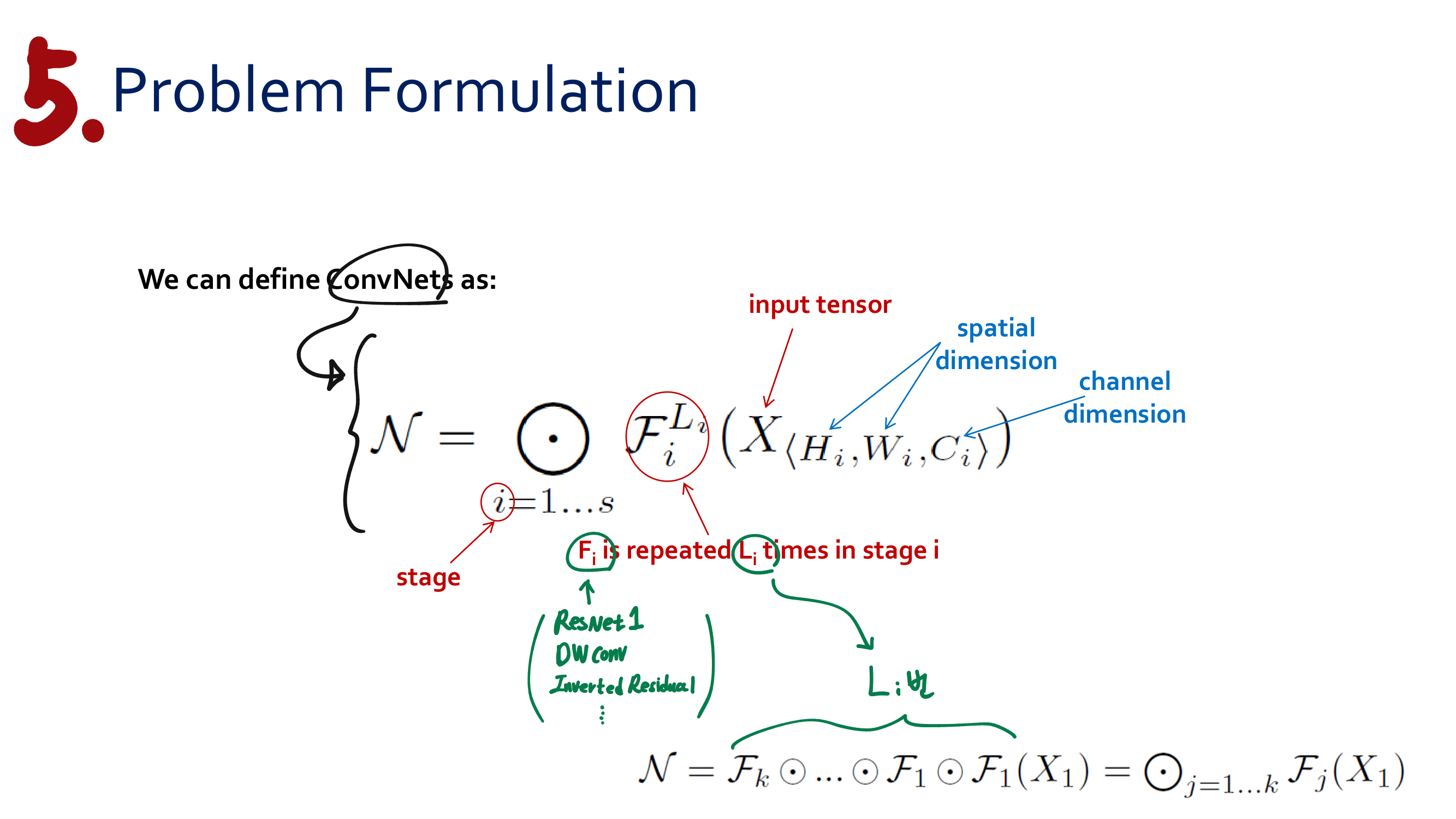
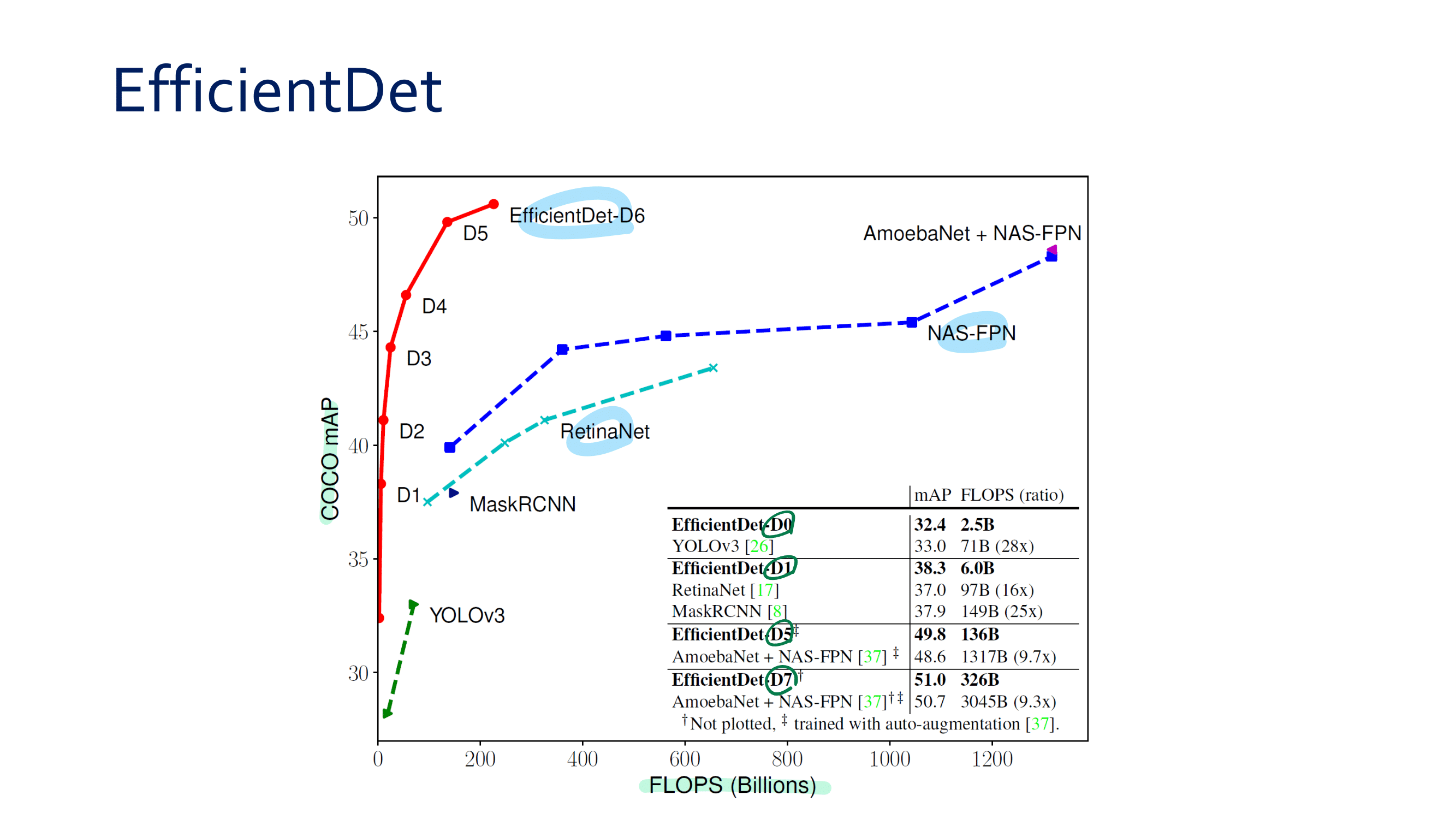
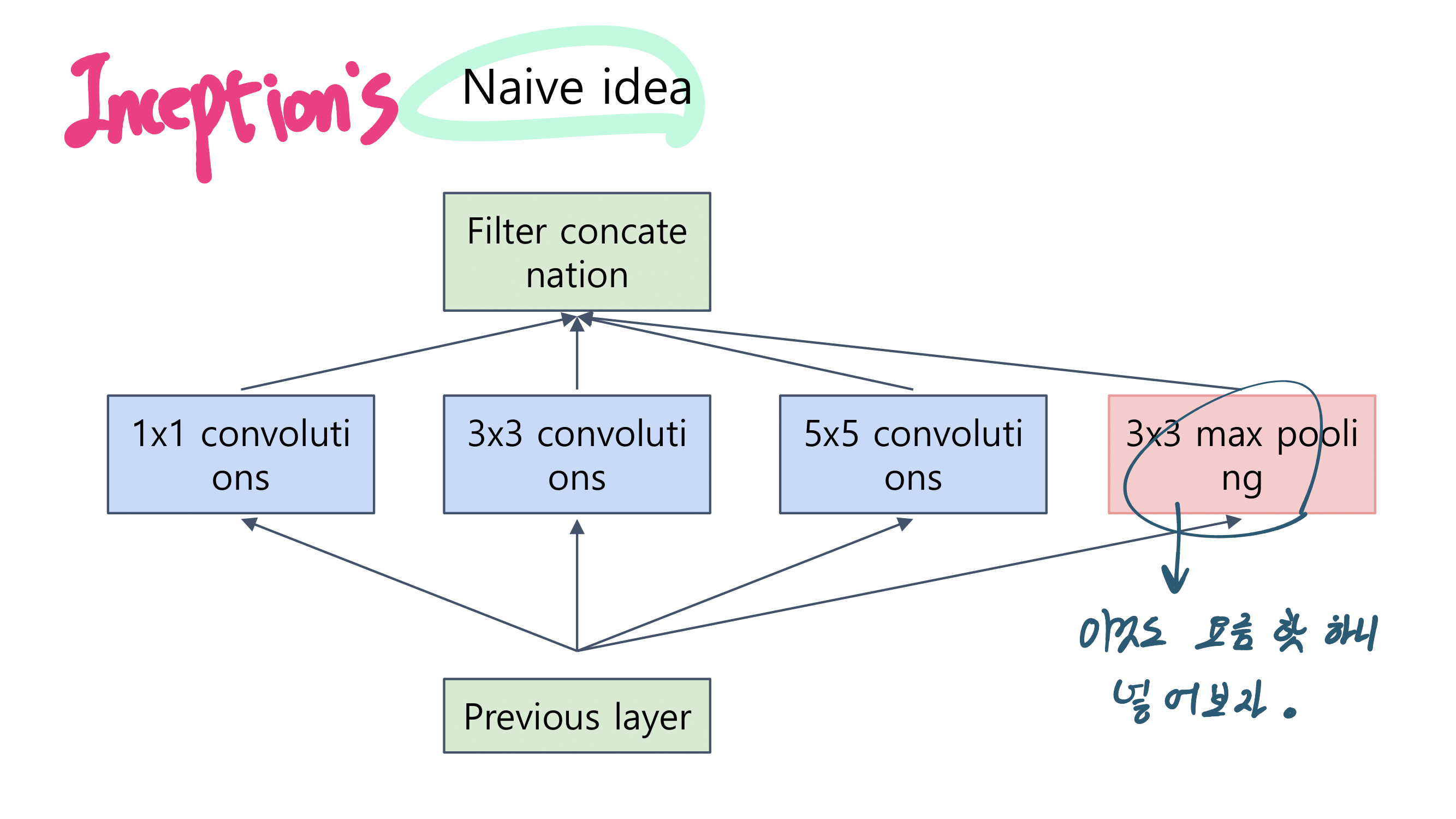
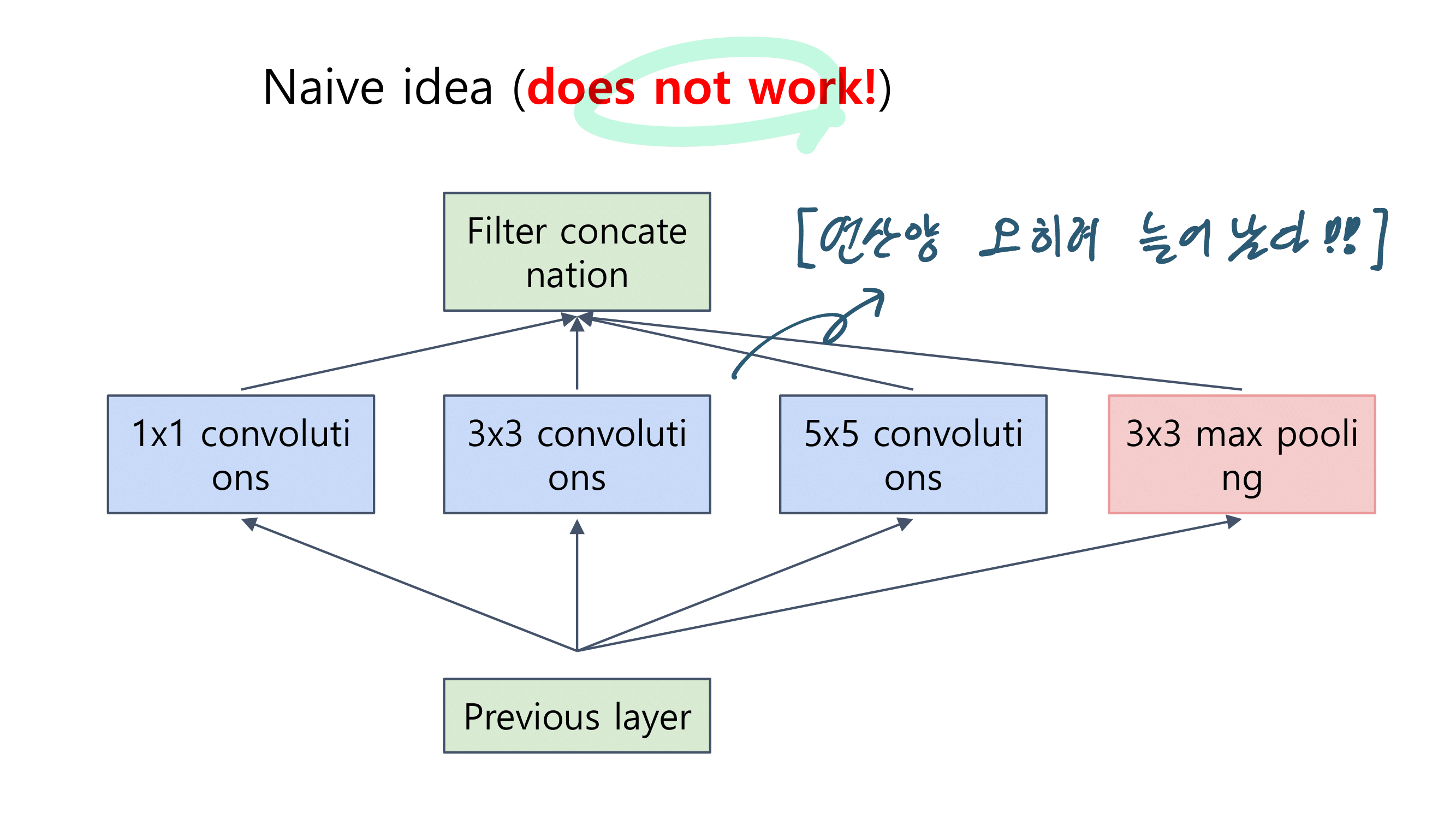
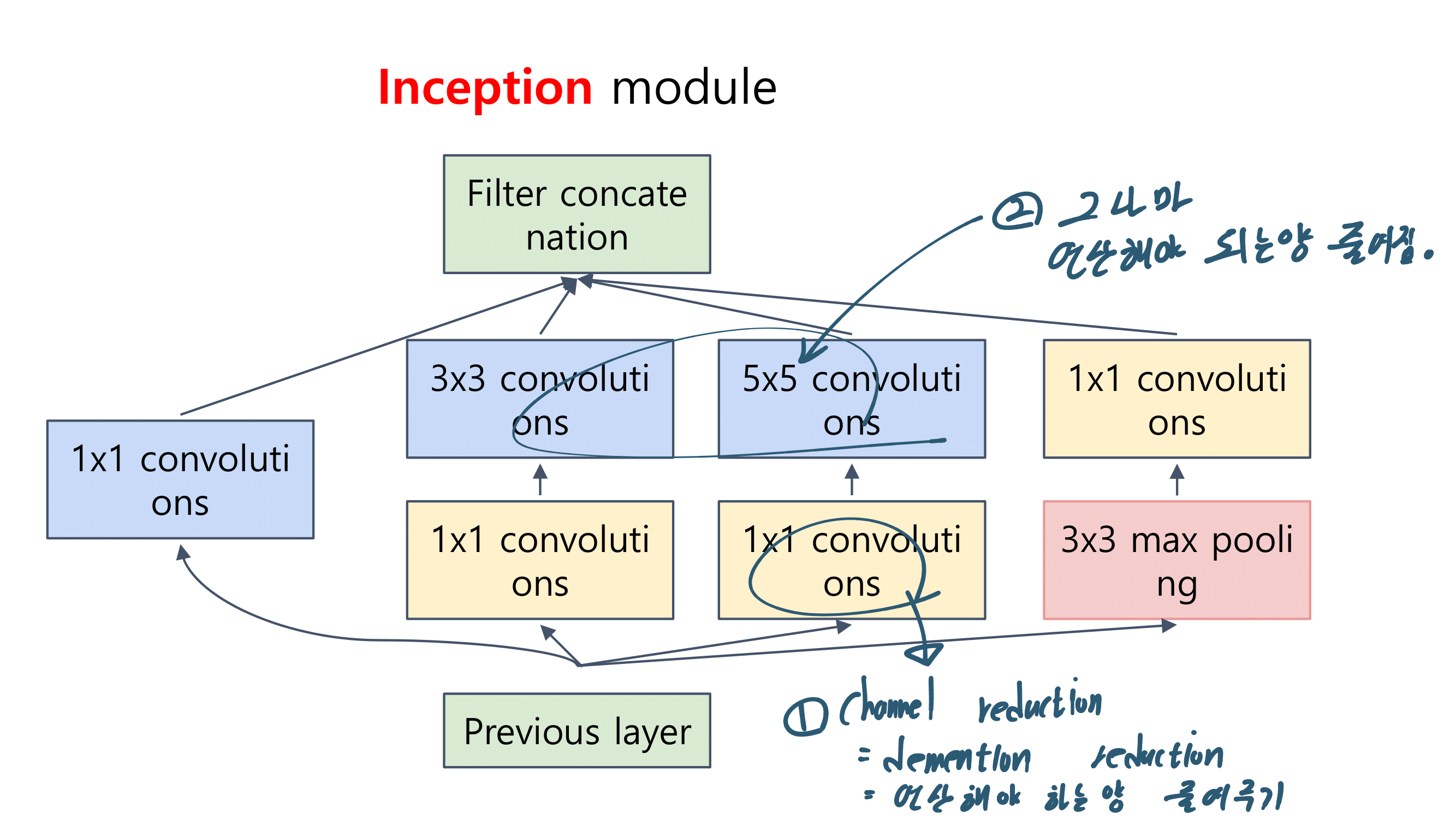
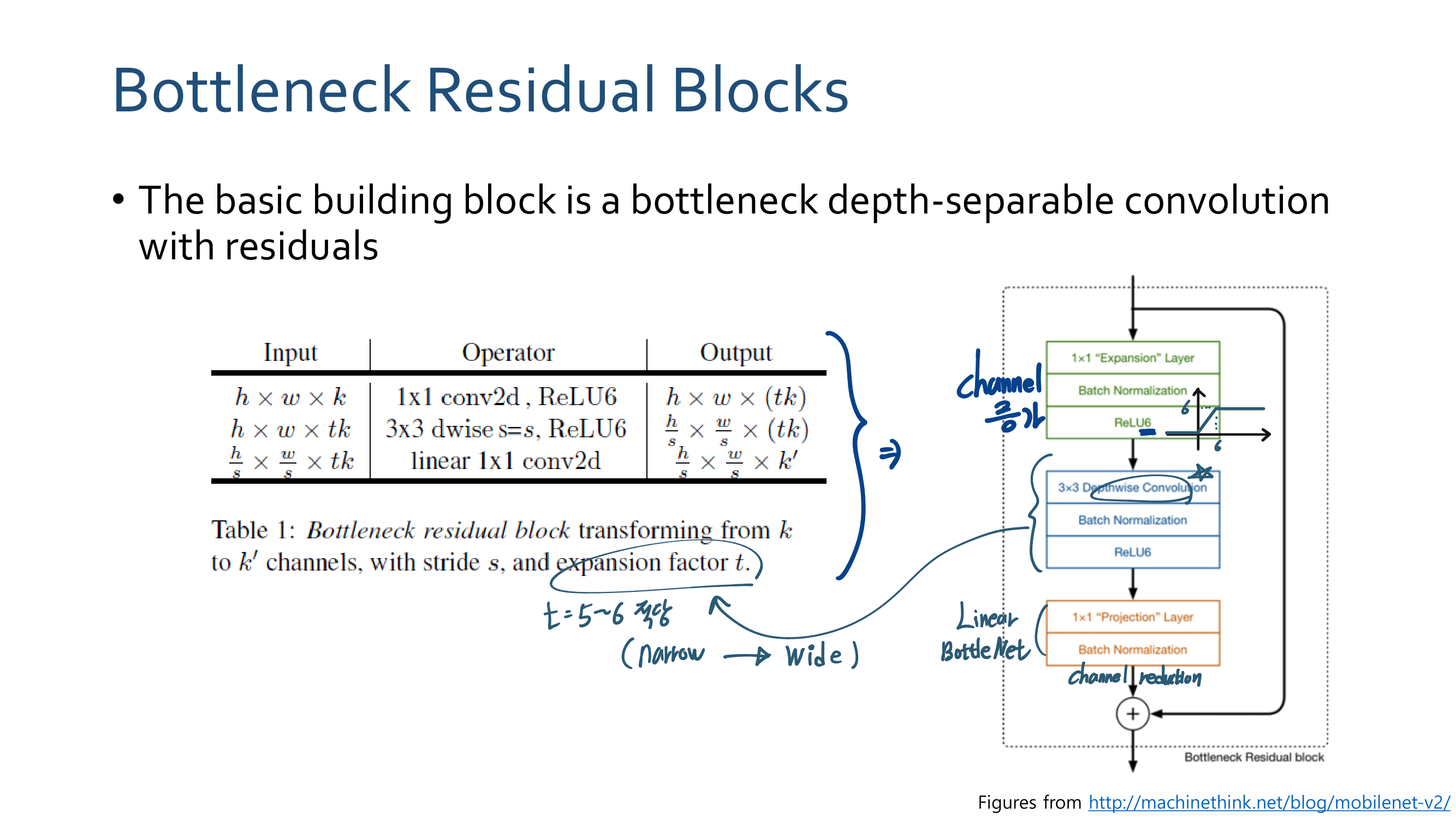
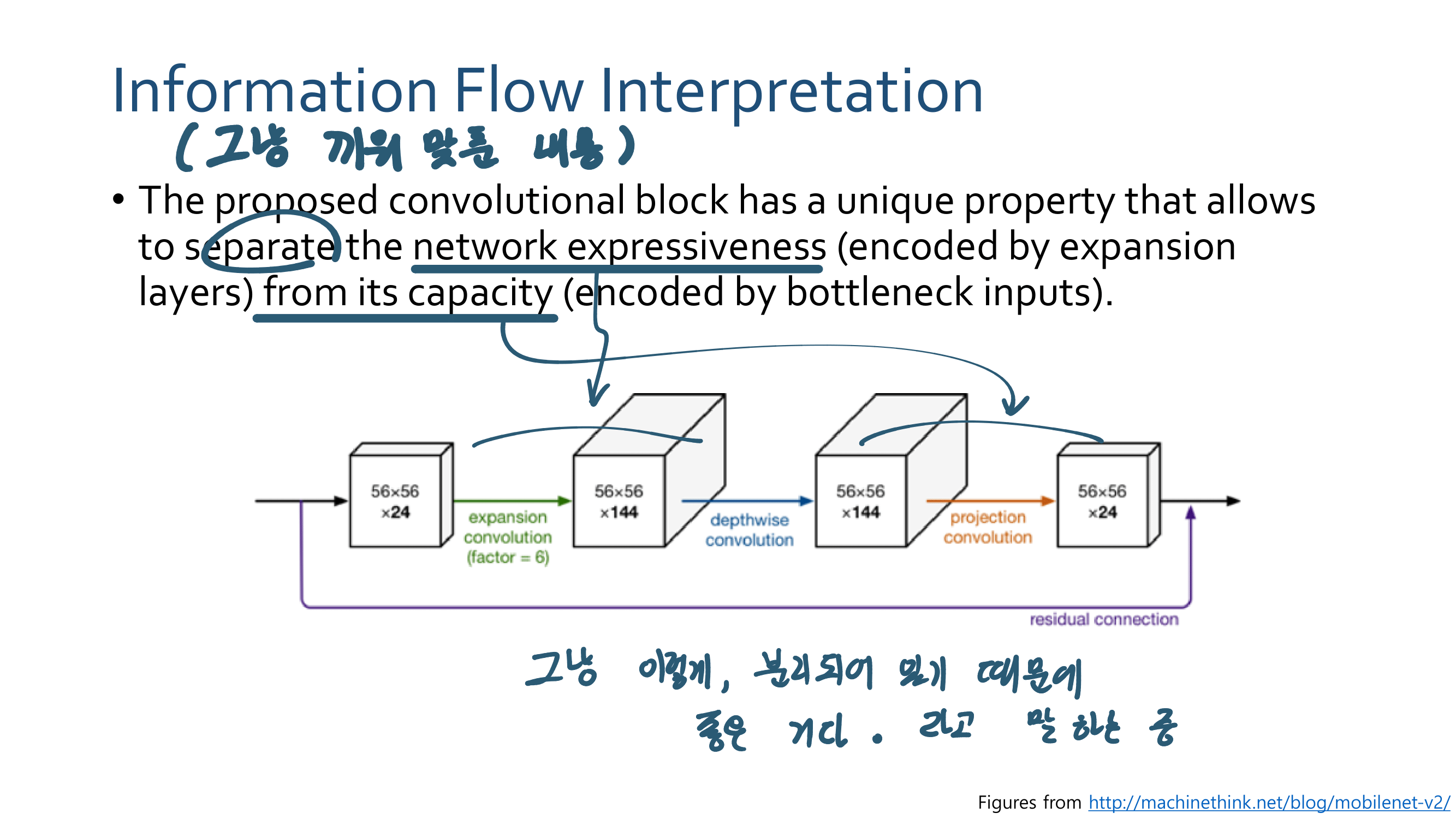
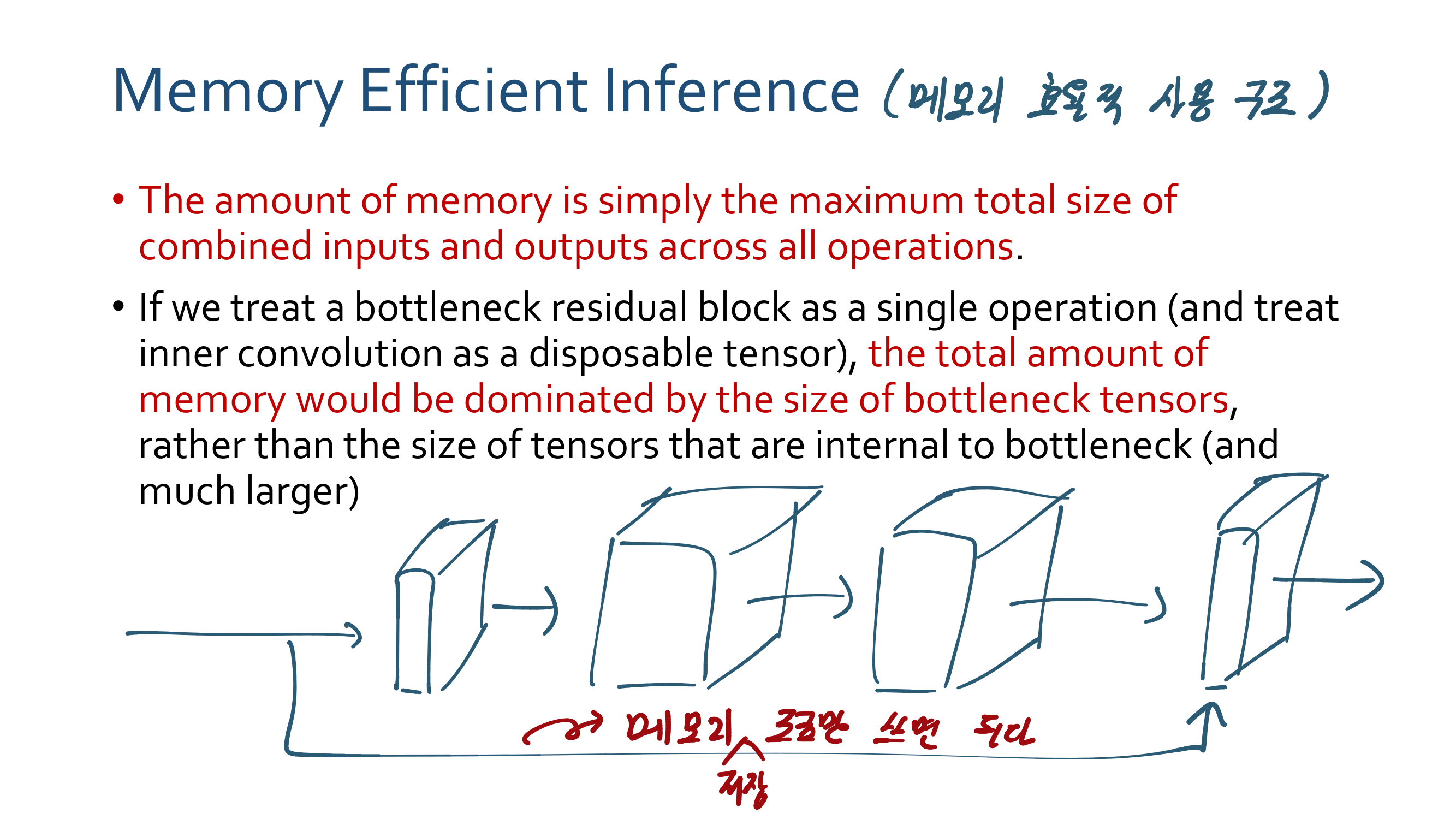
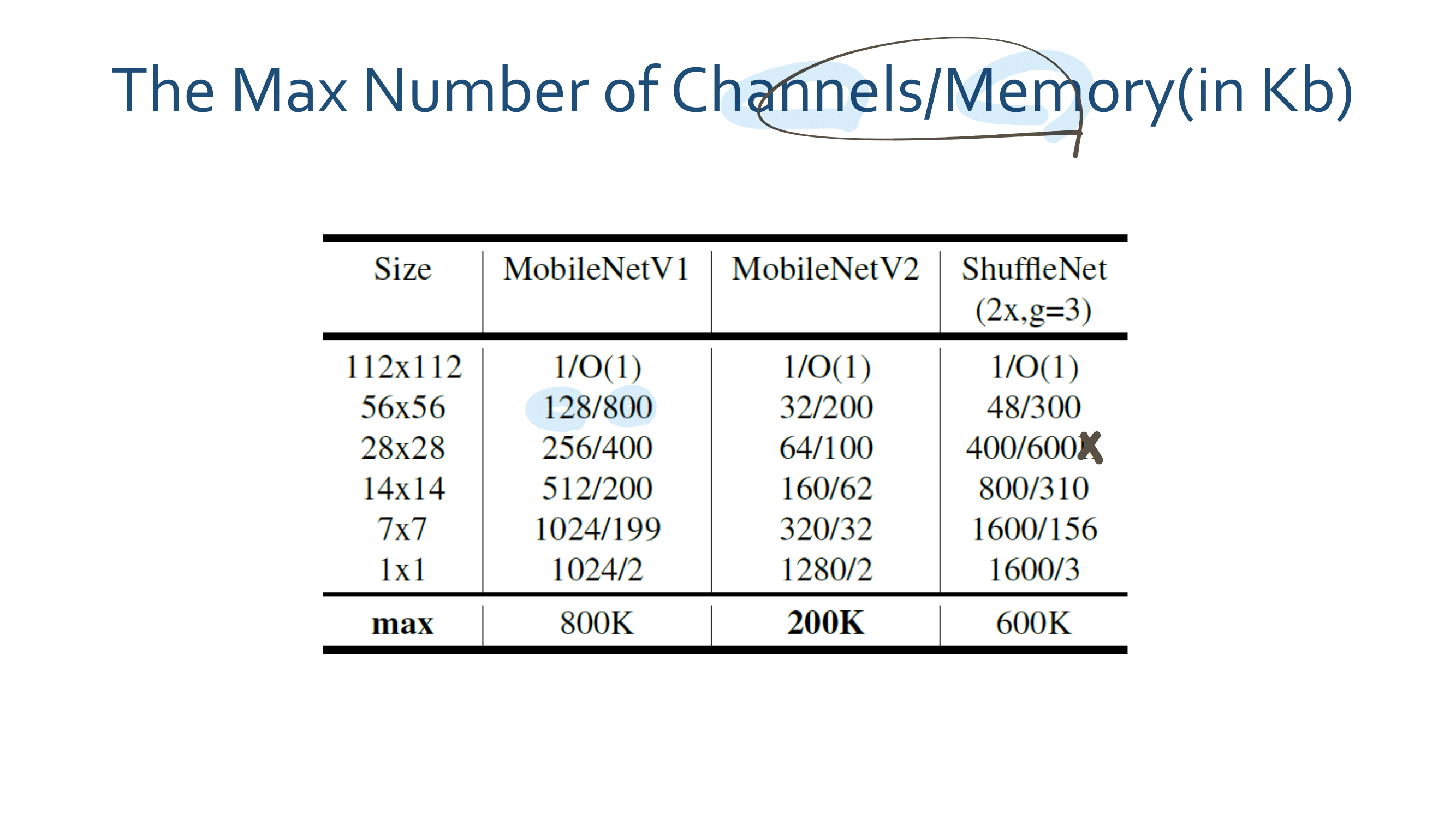
이번 논문에서 새로 소개하는 것은 이런 것이 있다.
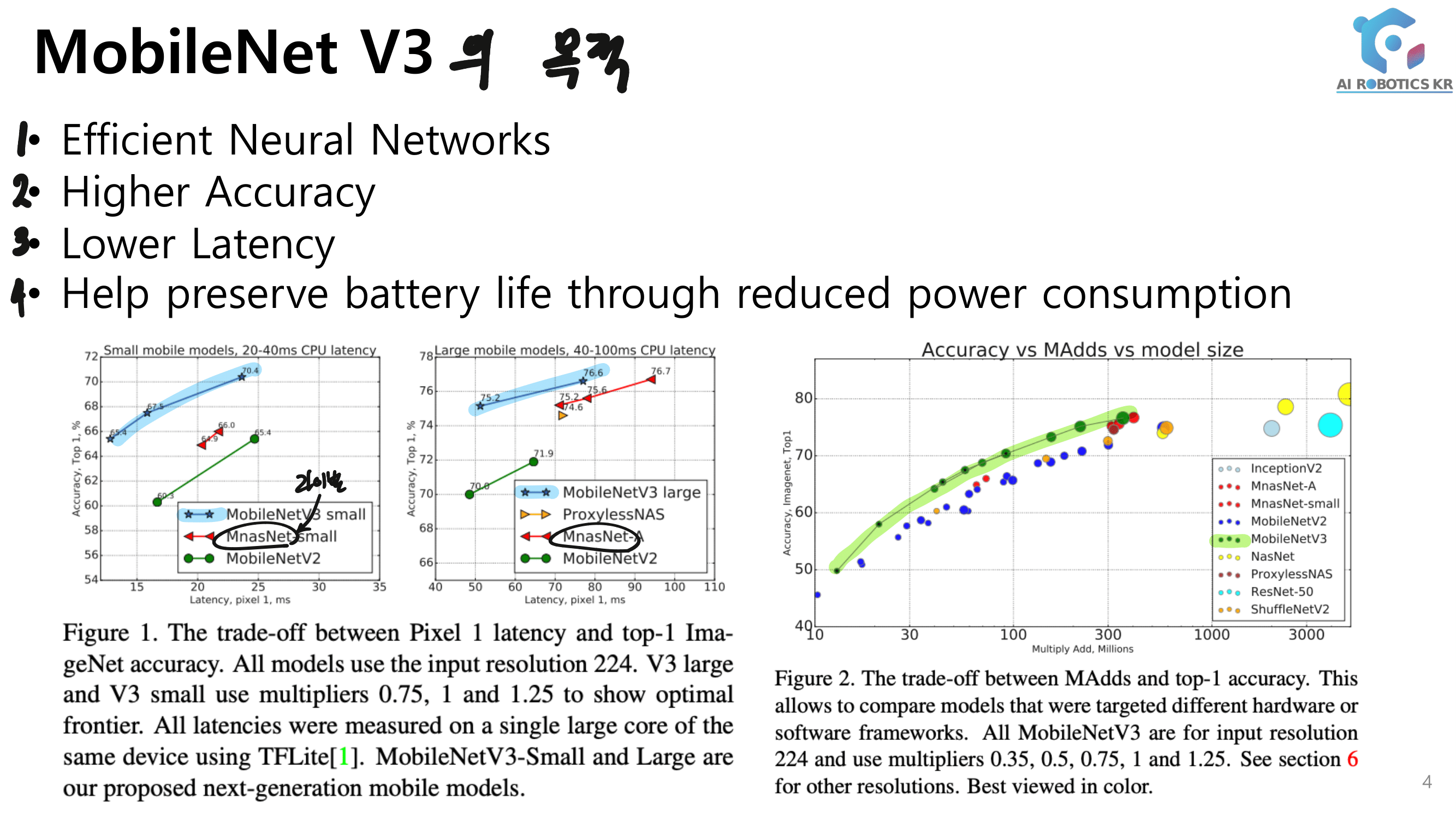
a powerful AGW baseline
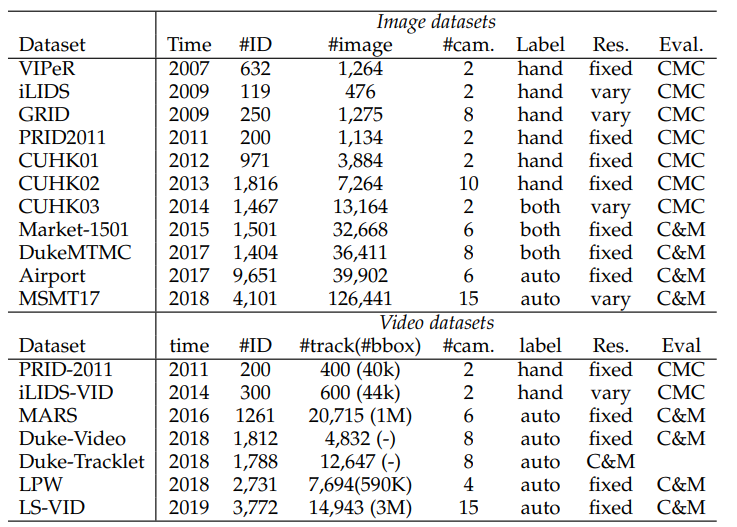
12개의 Dataset
4개의 다른 Re-ID task
e a new evaluation metric (mINP)
1. Introduction
<Introduction 서론>
초기에는 a! specific person를 찾기 위함이었다. 시대의 발전과 공공 안전 중요도의 증가, 지능형 감시 시스템 need에 의한 기술 발전이 이뤄지고 있다.
Person Re-ID의 Challenging task (방해요소들) : [the presence of different viewpoints [11], [12], varying low-image resolutions [13], [14], illumination changes [15], unconstrained poses [16], [17], [18], occlusions [19], [20], heterogeneous modalities [10], [21], complex camera environments, background clutter [22], unreliable bounding box generations, etc. the dynamic updated camera network [23], [24], large scale gallery with efficient retrieval [25], group uncertainty [26], significant domain shift [27], unseen testing scenarios [28], incremental model updating [29] and changing cloths [30] also greatly increase the difficulties.] 이런 요소들이 있기 때문에 연구들은 더욱 더 이뤄져야 한다.
딥러닝 이전에는 이런 기술들을 사용했다. the handcrafted feature construction with body structures [31], [32], [33], [34], [35] or distance metric learning [36], [37], [38]
딥러니 이후에는 [5], [42], [43], [44] 이 논문이 놀라운 성능을 내었다
이 Survey 논문의 특별한 차별점
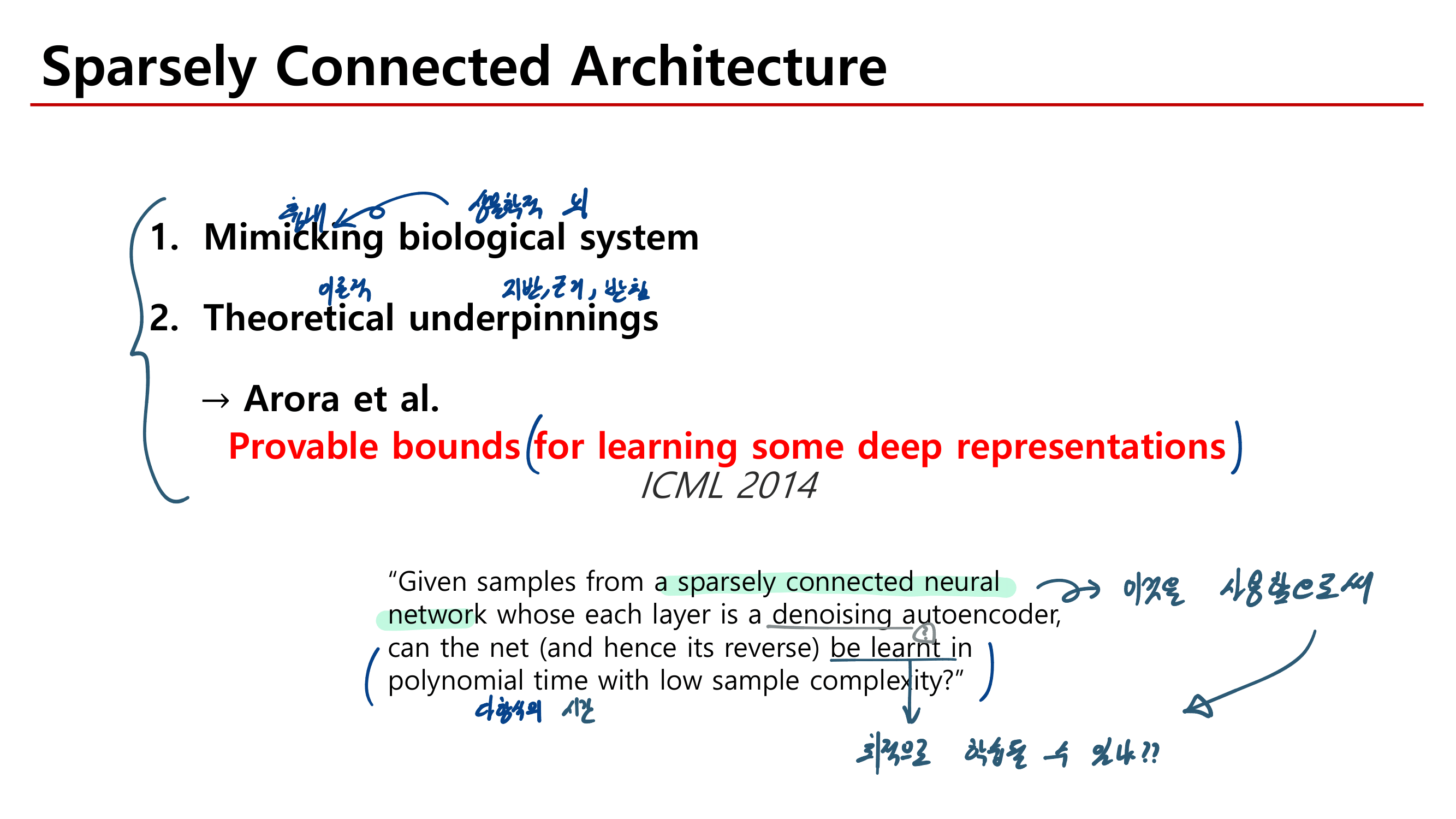
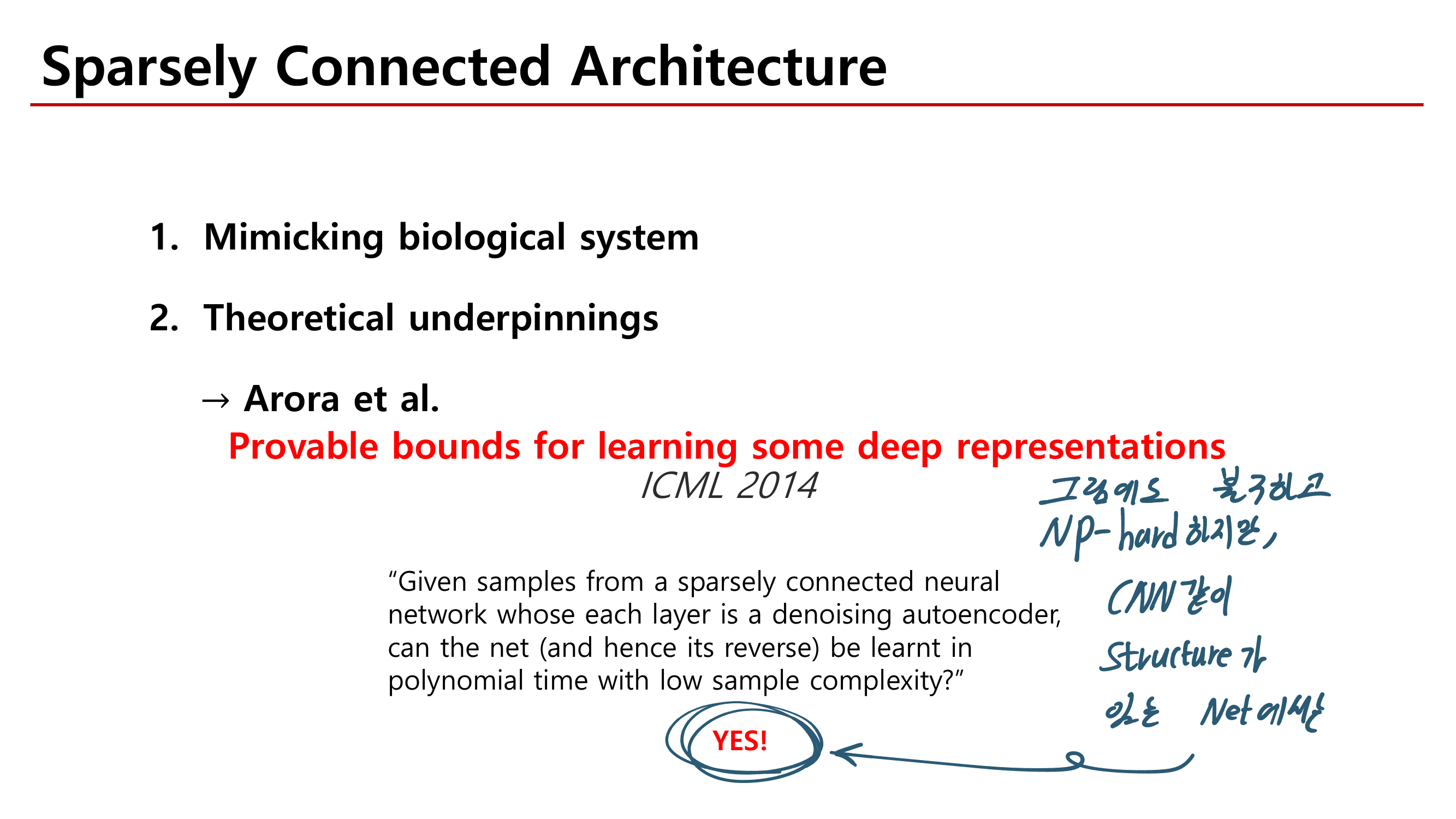
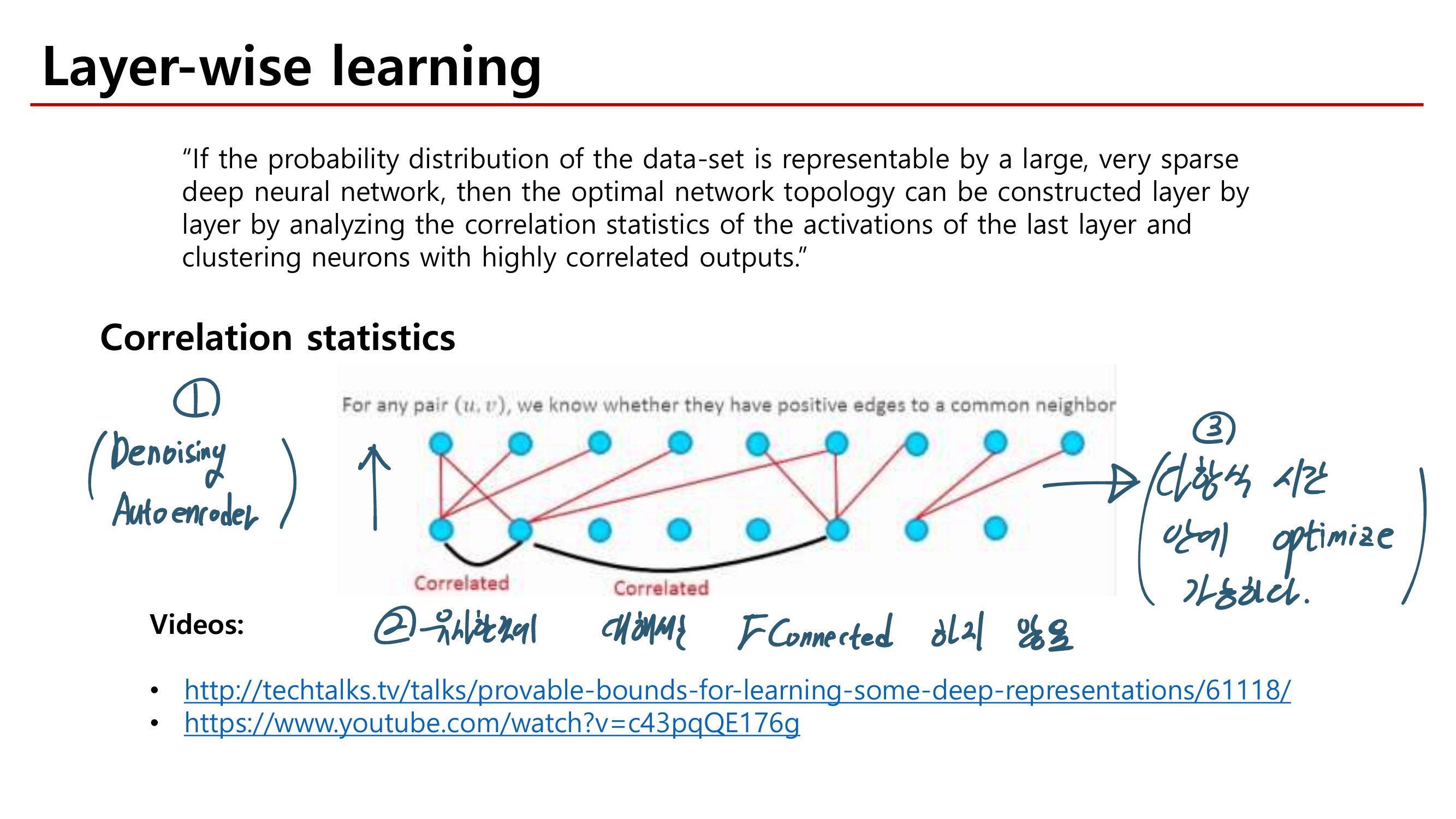
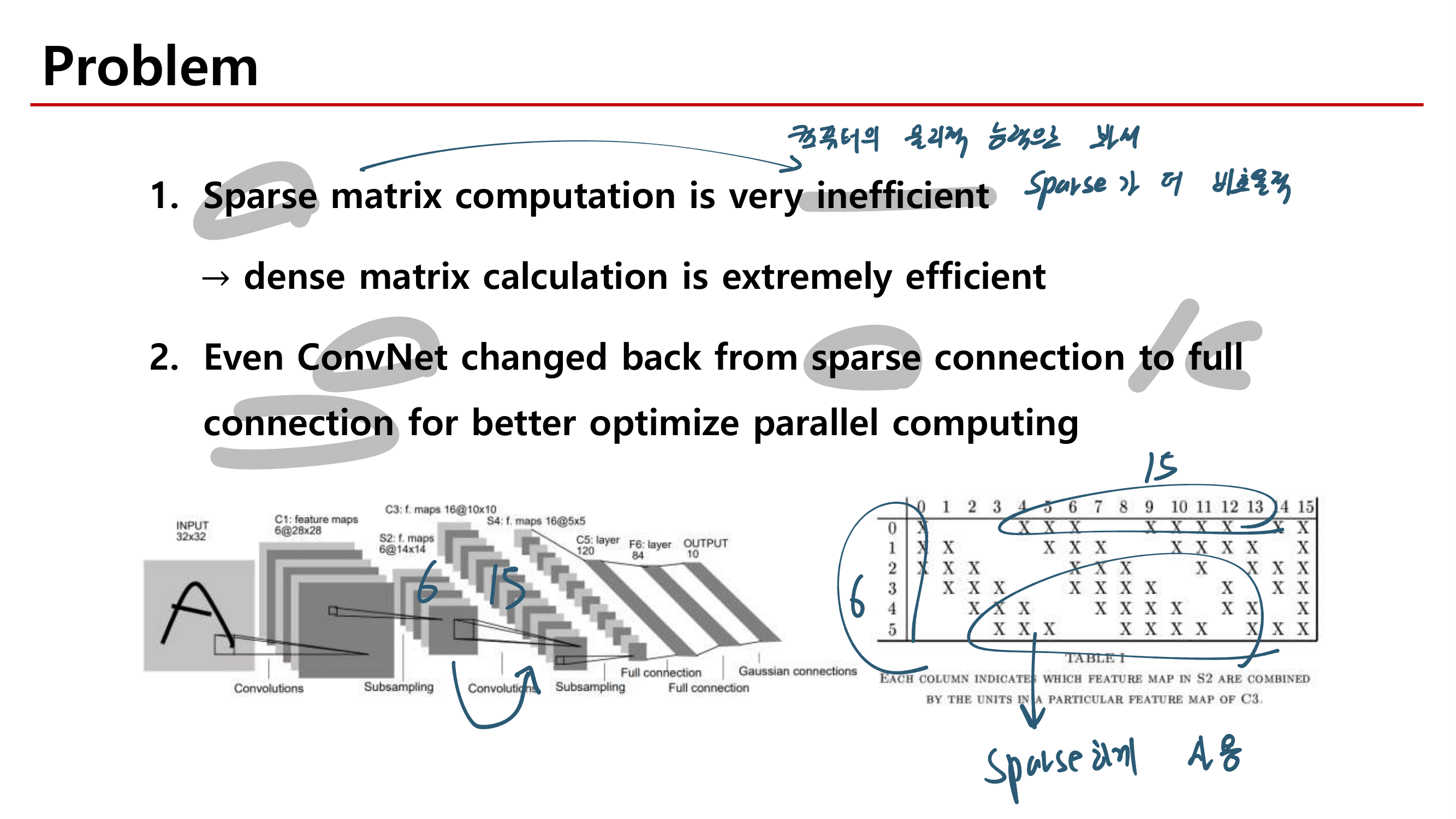
powerful baseline (AGW: Attention Generalized mean pooling with Weighted triplet loss) 제시한다.
new evaluation metric (mINP: mean Inverse Negative Penalty) 제시한다. mINP는 현재 존재하는 지표인 CMC/mAP를 보충하는 것으로써, 정확한 matches를 발견하는 cost를 측정한다.
Training Data Annotation : Close world에서는 Classification 수행하기. Open world에서는 unlabel classification 수행하기
Model Training : Re-ID 수행하기 (다른 카메라, 같은 Label data를 묶고, 전체를 Gallery에 저장하기.
Pedestrian Retrieval : Query person 검색하기(찾기). 여기서 query-to-gallery similarity를 비교해서 내림차순으로 나열하는 A retrieved ranking를 수행한다. 이 작업을 위해 retrieval performance를 향상시키기 위한, the ranking optimization을 수행해야 한다.
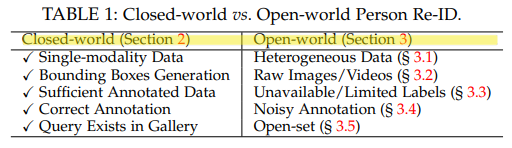
Closed-world 에서 Open-world Person Re-ID 으로의 필요한 핵심 포인트(또는 closed-world 연구에서의 핵심 가정 - 미리 위와 같은 5개의 과정을 해놓고 연구를 진행했던 것이다. 하지만 Open World에서의 저 가정은 옳지 않을 것이다.)
ingle-modality vs. Heterogeneous Data : 지금은 카메라 영상 만을 이용하는데, infrared images [21], [60], sketches [61], depth images [62] 등을 활용한 Re-ID연구와 사용이 필수적이다.
Bounding Box Generation vs. Raw Images/Videos : close world에서는 “Search + Predict + Bouning Box는 이미 되었다” 라고 가정하고 Re-ID를 수행한다. 하지만 이제는 이 모두를 수행하는 end-to-end person search가 필요하다.
Sufficient Annotated Data vs. Unavailable/Limited Labels : label classification은 실생활에서 불가능하다. limited labels이기 때문이다. 따라서 unsupervised and semi-supervised Re-ID 연구가 필요하다.
Correct Annotation vs. Noisy Annotation : close world에서는 정확한 Bounding Box가 주어진다. 하지만 실제 Detection 결과는 부정확하고 Noise가 있다. noise-robust person Re-ID를 만드는 연구가 필요하다.
Query Exists in Gallery vs. Open-set : close world에서는 Gallery에 query person이 무조건 존재한다고 가정한다. 하지만 없을 수도 있는거다. 검색(retrieval)보다는 the verification(존재 유무 확인 및 검색)이 필요하다.
<Introduction 결론>
논문 전체 목차
§ 2 : closed-world person Re-ID
§ 2.4 : datasets and the state-of-the-arts
§ 3 : the open-world person Re-ID
§ 4 : outlook(견해) for future Re-ID
§ 4.1 : new evaluation metric
§ 4.2 : new powerful AGW baseline
§ 4.2 : under-investigated open issues (아직 연구가 덜 된 분야)
2. Closed-world Person Re-ID
2-1 Feature Representation Learning
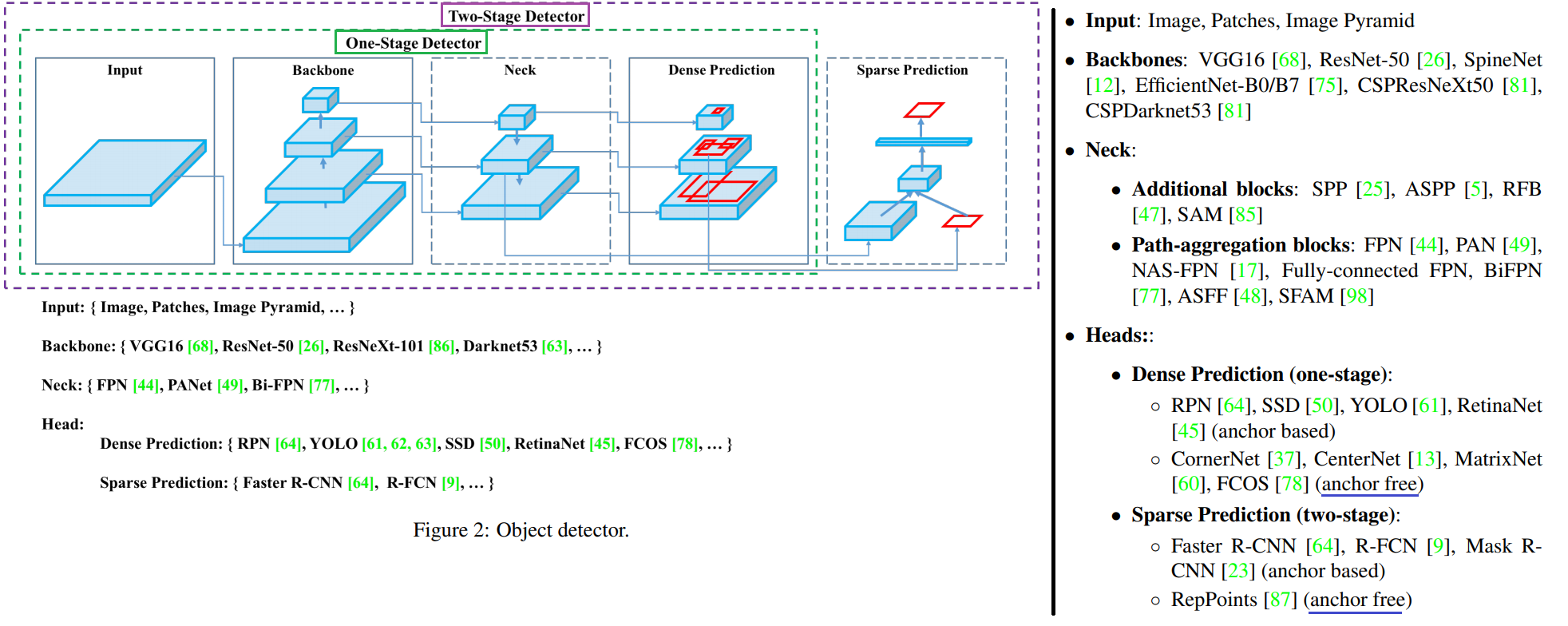
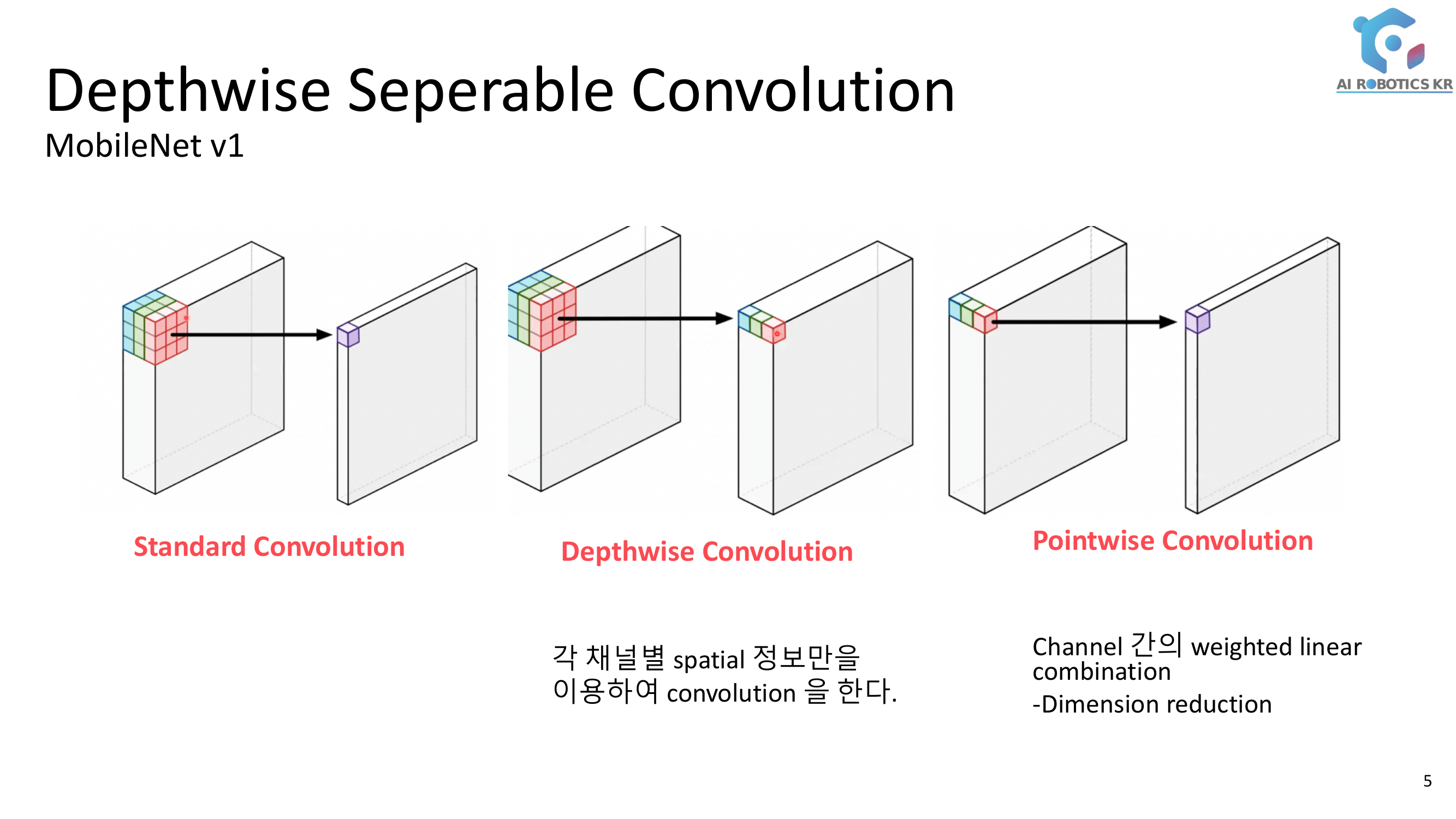
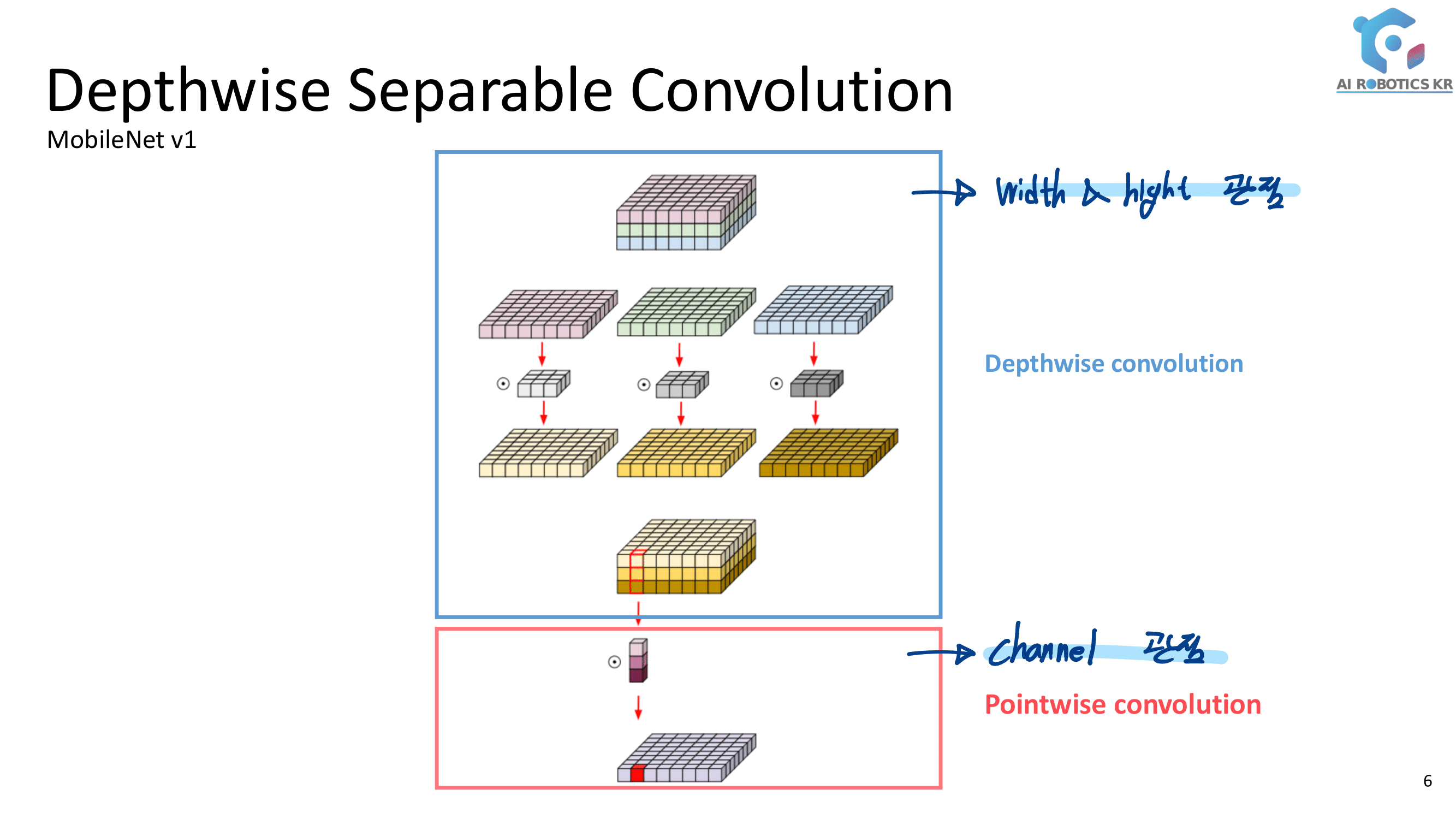
이미 Detected 된 사람의 Bounding box에 대해, 이 Feature Representation(이하, Feature)을 어떻게 추출할 것인가? 사람의 포즈가 변해도, 바라보는 방향이 변해도, 카메라의 조도 등이 변해도 같은 Feature(descriptor)가 나오도록 하는 방법이 무엇일까? 크게 아래와 같이 4가지 방법이 있다.
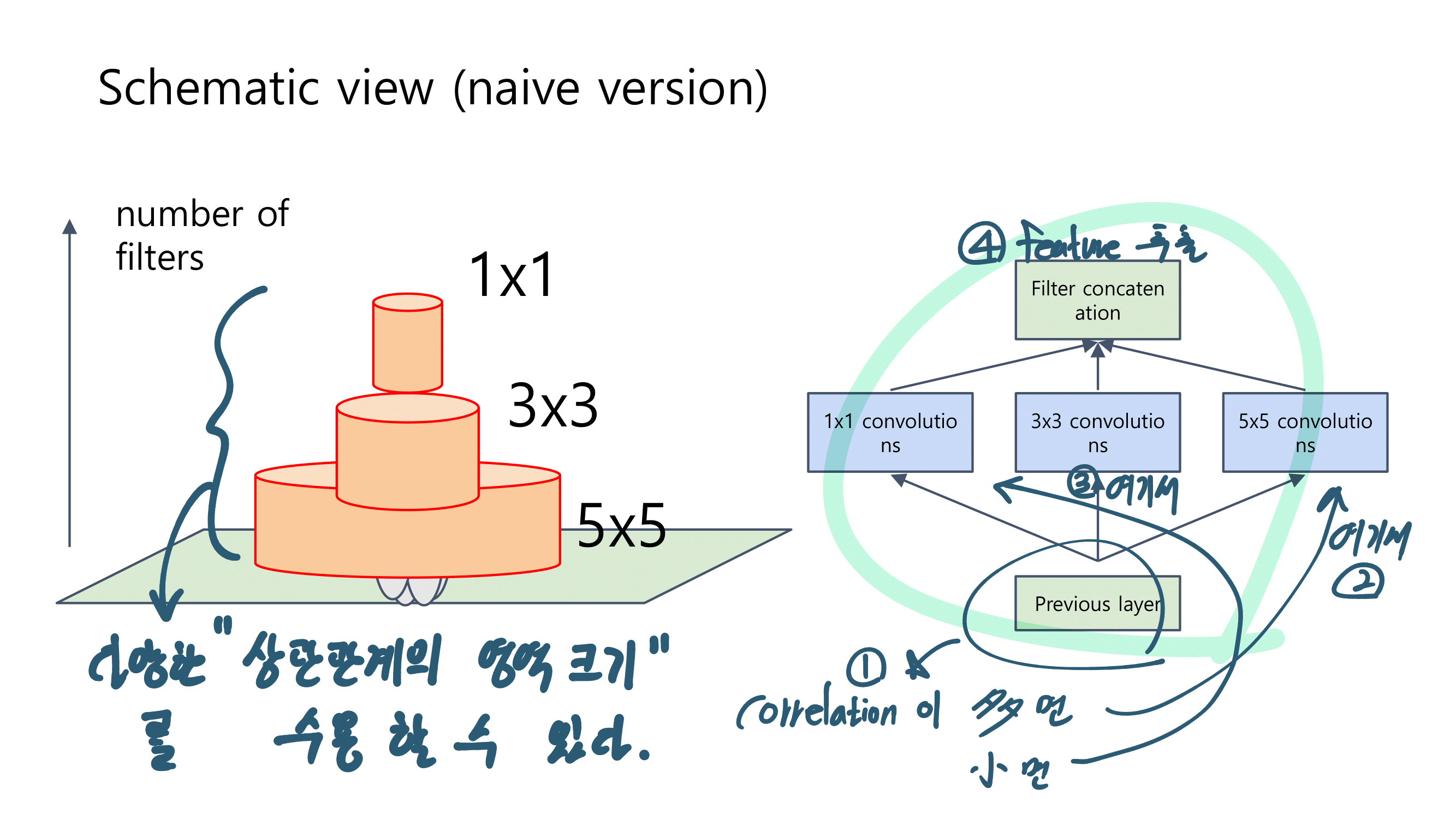
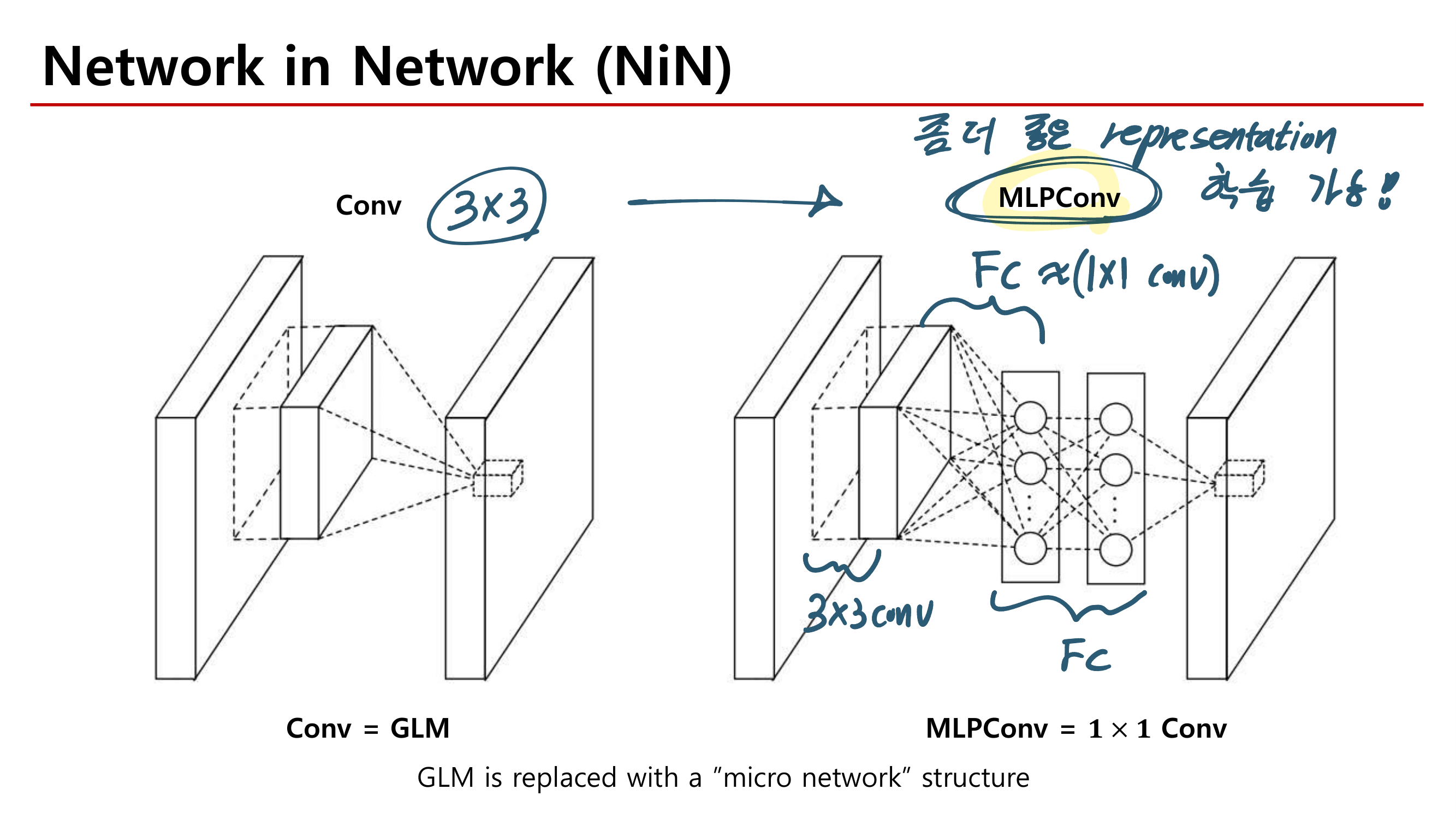
Global Feature Representation Learning
Box 전체를 이용해서 Feature를 뽑아 낸다.
대표적인 논문 : (1) ID-discriminative Embedding (IDE) model [55, 2017] (2) a multi-scale deep representation learning [84, 2017]
Attention Information는 feature 향상을 위해서(좀더 의미있는 정보추출) 사용된다. 아래 2개 논문이 핵심.
A context-aware attentive feature learning : multiple images 사용 [95, 2019], the feature learning 향상시켜줌.
Local Feature Representation Learning
과거에는 human parsing/pose detector를 이용해 human parsing/pose을 먼저 추출하고, 각 부분에 대해서 Feature를 뽑아냈다. 이렇게 하면 성능은 좋지만 추가적인 detector가 필요하고, 이 detector 또한 완벽하지 않으므로 추가의 Noisy를 만들어 냈다.
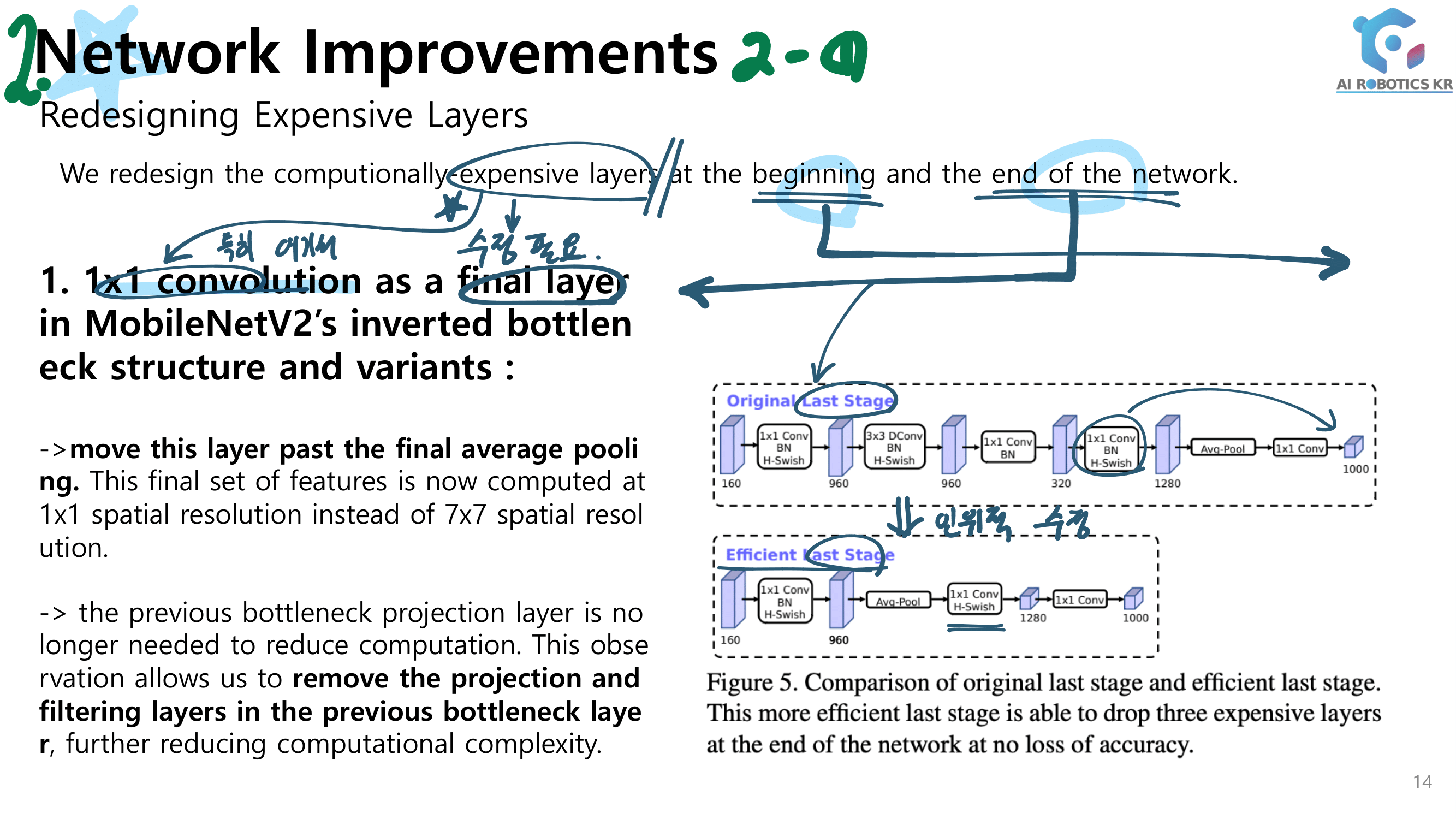
위와 같은 단점 때문에 horizontal-divided region features 를 사용한다. Fig2(b) 처럼. 가장 기초 논문은 Part-based Convolutional Baseline (PCB) [77]이고, 이것으로 SOTA를 찍은 논문은 [28], [105], [106]이다. 이 방법은 more flexible하다는 장점이 있지만, occlusions and background clutter(box내부 사람이 차지하는 공간이 아닌 다른 공간)에는 약한 단점이 있다.
Auxiliary Feature Representation Learning = 추가 데이터를 활용한 Feature Learning = 아래의 방법으로 모두 좀 더 좋은 성능의 the feature representation를 추출할 수 있었다.
Semantic Attributes : male, short hair, red hat 과 같은 추가 정보를 이용하는 것이다.
Viewpoint Information
Domain Information : 다른 카메라 이미지를 다른 도메인이라고 여기고, 최종적으로 globally optimal Feature를 얻는다.
GAN Generation : the cross camera variations를 해결하고 robustness를 추가하기 위해서, the GAN generated images를 사용한다.
Data Augmentation
Video Feature Representation Learning
a video sequence with multiple frames를 사용함으로써, 더 강력한 feature와 temporal information를 추출한다.
Challenge1 : the unavoidable outlier tracking frames(?뭔지 모름) 그리고 이것을 해결하려는 논문들 소개. 특히 매우 흥미로운 논문인 [20] [Vrstc: Occlusion-free video person re-identification in CVPR, 2019] 에서는 auto-complete occluded region를 수행하기 위해서, the multiple video frames를 사용한다.
Challenge2 : handle the varying lengths of video sequences. 그리고 이것을 해결하려는 논문들 소개.
Architecture Design
Re-ID features를 더 잘 추출하기 위해서, Backbone을 수정하는 논문들
the last convolutional stripe/size to 1 [77]
adaptive average pooling in the last pooling layer [77], [82]
Re-ID 전체 과정 수행 논문 추천 : [112], [137], An efficient small scale network [138]
Auto-ReID [139] model : NAS를 사용하여, 효율적이고 효과적인 model architecture 추출.
2.2 Deep Metric Learning
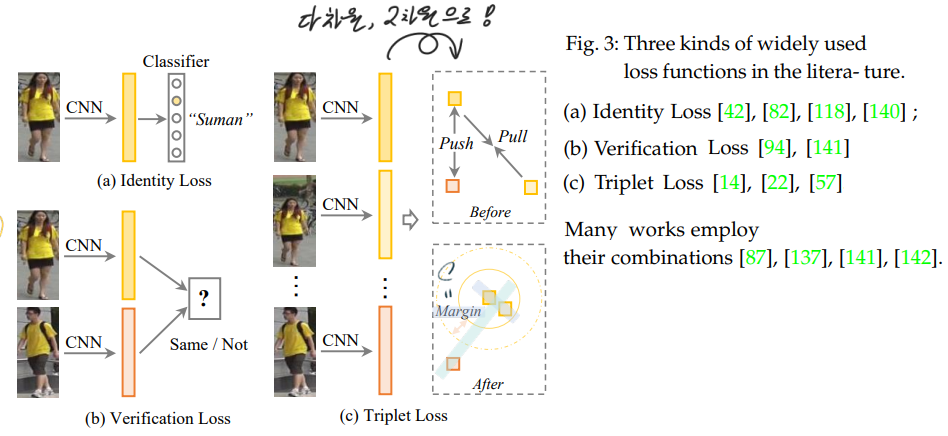
(a) Identity Loss.
an image classification problem 사용함. 이 Loss를 바꿔서 만든 다른 Loss 수식 또한 이와 같이 있다. (1) the softmax variants (2) the sphere loss (3) AM softmax (4) label smoothing(overfitting을 피하는데 효과적인 Loss) 과 같은 방법이 있다.
(b) Verification Loss :
The contrastive loss :
The verification loss with cross-entropy
사실 이 수식의 p 가 무슨 함수를 사용한 건지 모르겠다. 논문을 몇번이나 다시 읽고, reference paper도 확인해 봤는데, 어떤 곳에서도 p는 그냥 probability of an input pair (xi and xj) being recognized as δij (0 or 1) 이라고만 적혀 있다. 나중에 코드를 통해서 확인해 봐야겠다.
(c) Online Instance Matching (OIM) loss
unlabelled identities들이 존재할 때 = unsupervised domain adaptive Re-ID에서 사용하는 방법
아래의 memory bank가 unlabeled classes에 대해서, 각각의 class를 표현하는 feature(representation)의 정보를 저장하고 있는 memery가 되겠다. labeled class라면, 저 memory bank의 v값들이 one-hot-encoding으로 되어있을 텐데…
2.2.2 Training strategy
핵심 문제점 : the severely imbalanced positive and negative sample pairs 그리고, 이것을 해결하는 방법들.
The batch sampling strategy (the informative positive and negative minings)
adaptive sampling (adjust(조정하기) the contribution(기여도) of positive and negative samples)
위의 Loss들을 하나만 쓰는게 아니라, , a multiloss dynamic training strategy를 사용한다.
adaptively reweights the identity loss and triplet loss. 두 loss에 적절한 알파, 배타 값을 곱하고 이 알파, 배타 값을 이리저리 바꿔가면서, 학습을 진행하는 방법.
consistent performance gain 을 얻을 수 있다.
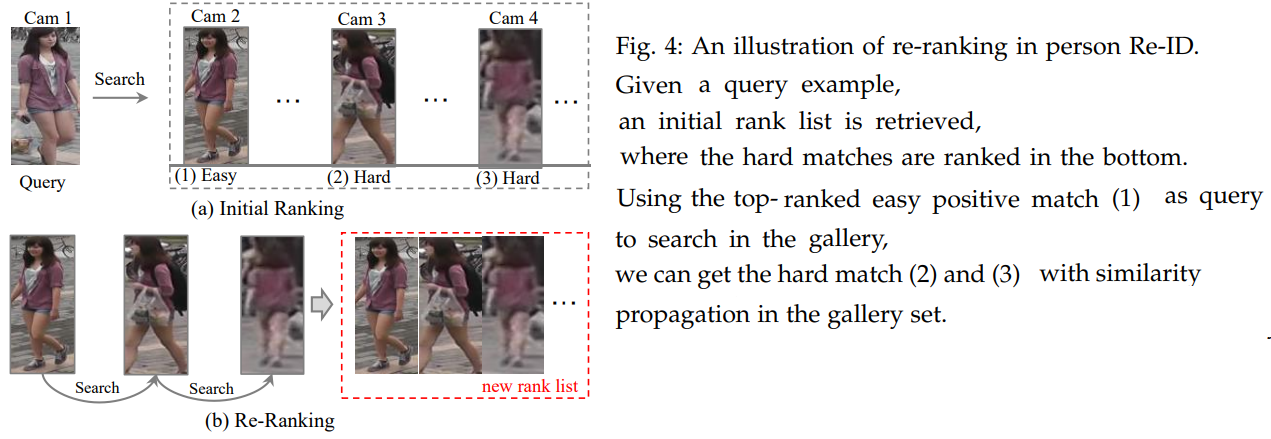
2.3 Ranking Optimization
testing stage에서 검색 성능(retrieval performance)를 증가시키기 위해서(=ranking list의 순서를 다시 정렬하는 방법들) 필요한 작업을 아래에 소개한다. 그냥 저런 방법과 이미지가 있다 정도로만 알아두자. 정확하게 이해는 안된다.
optimizes the ranking order [58], [157]
by automatic gallery-to-gallery similarity mining : 위의 이미지 (b) 처럼 초기의 주어진 ranking list를 기준으로 Gallery안에서 계속 기준 Query를 바꿔가며 Search를 진행해 나간다. 그렇게 list를 다시 획득하는 방법. (?? 정확히 모르겠다.)
human interaction : using human feedback을 계속 받으므로써, supervised-learning을 진행하며 Re-ID ranking performance를 높힌다.
Evaluation Metrics : (1) Cumulative Matching Characteristics (CMC) (2) mean Average Precision (mAP)
CMC-k (a.k.a, Rank-k matching accuracy) : ranked된 retrieved results에서 top-k안에 정확한 match가 몇퍼센트로 일지하는가? 예를 들어서 ranked된 retrieved results에 100장의 BB가 있고, 그 중 query를 정확하게 맞춘 BB가 80장이라면 0.8 이다.
CMC = CMC-1 , the first match 만을 고려한다. 하지만 the gallery set에는 다수의 GT bounding box in image가 존재하기 때문에 이것으로는 multiple camera setting에서 정확한 지표라고 할 수 있다.
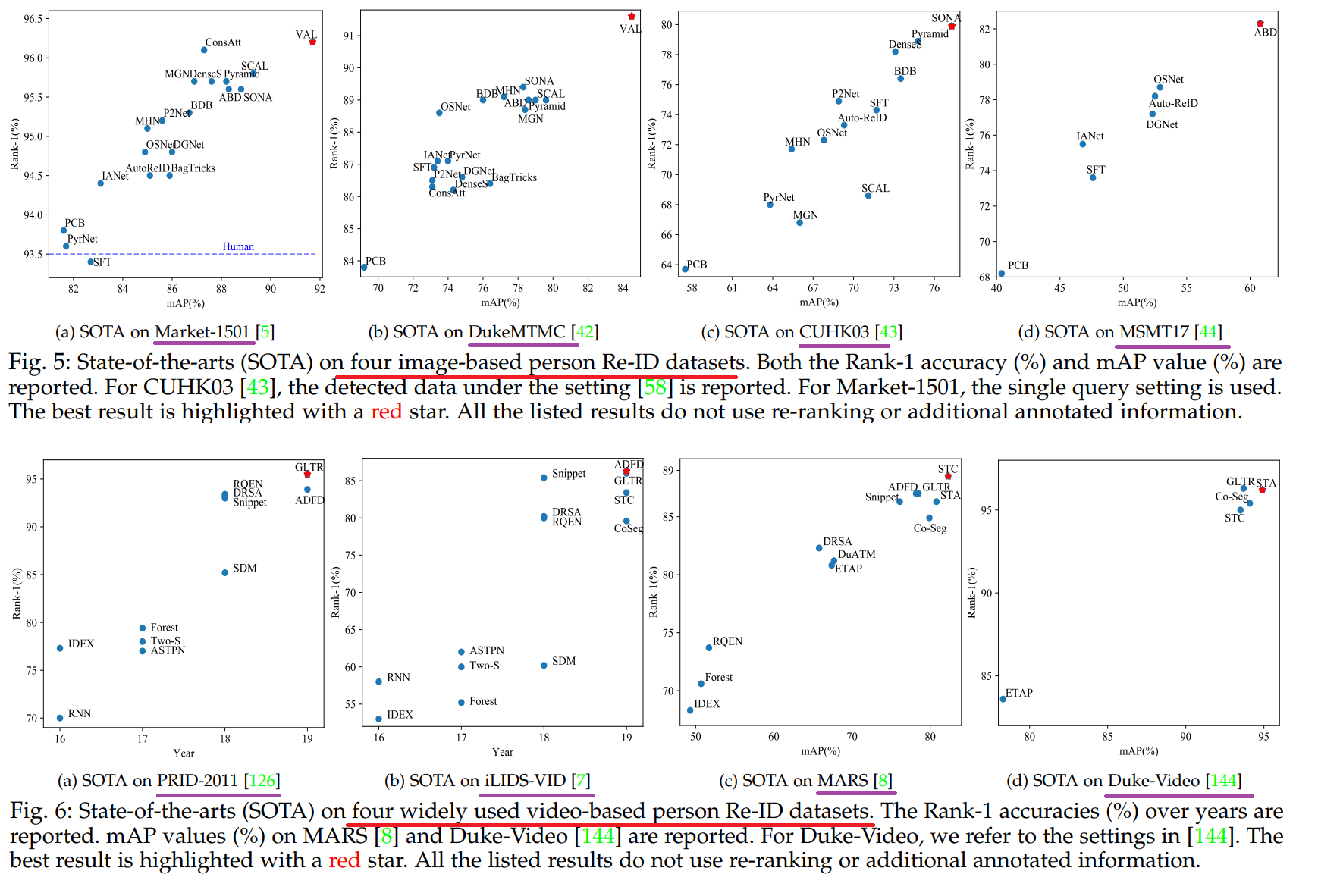
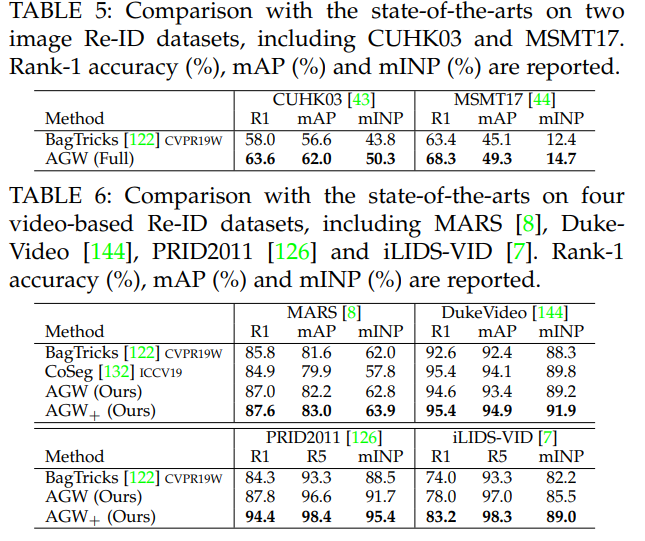
2.4.2 In-depth Analysis on State-of-The-Arts
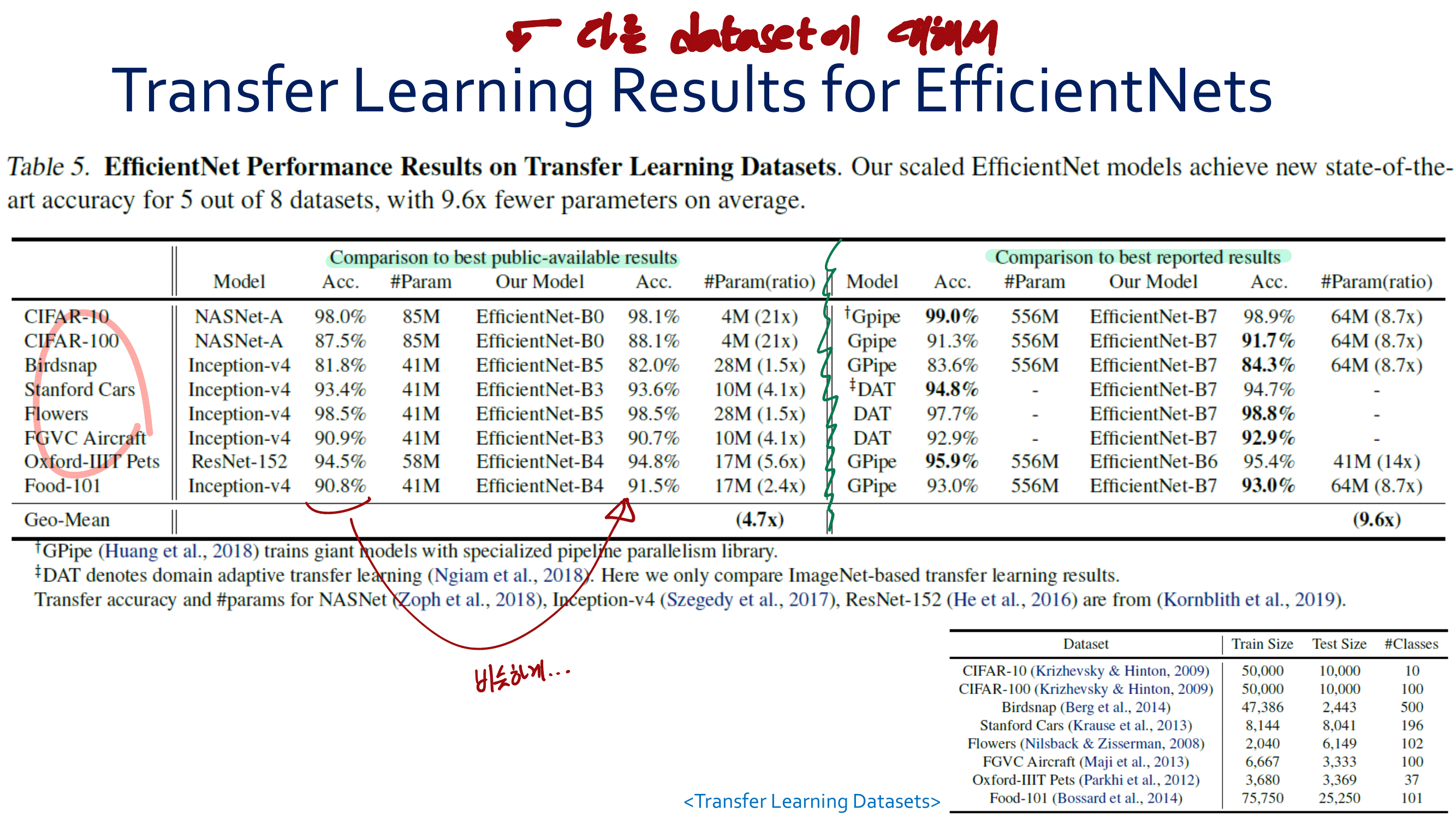
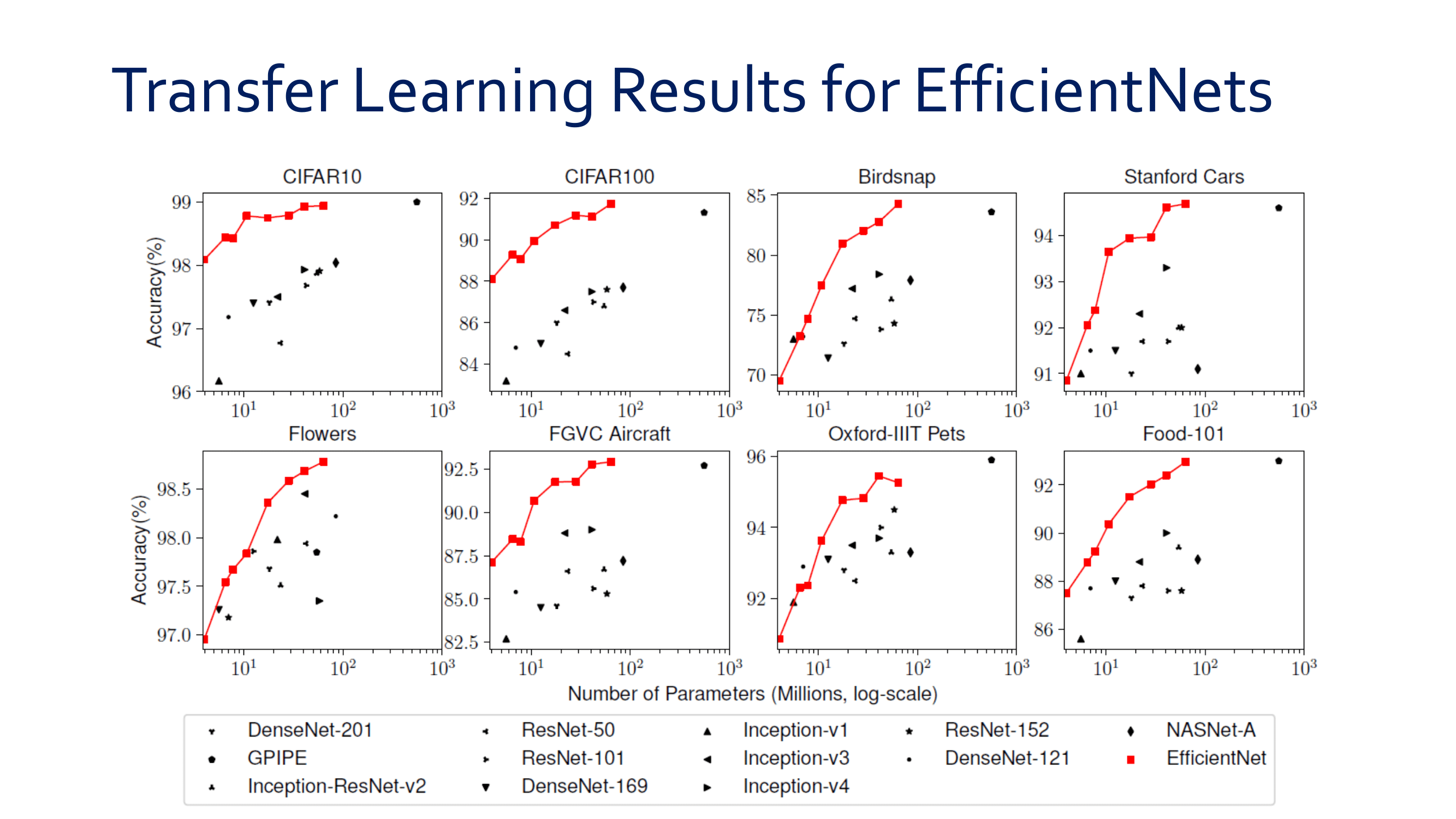
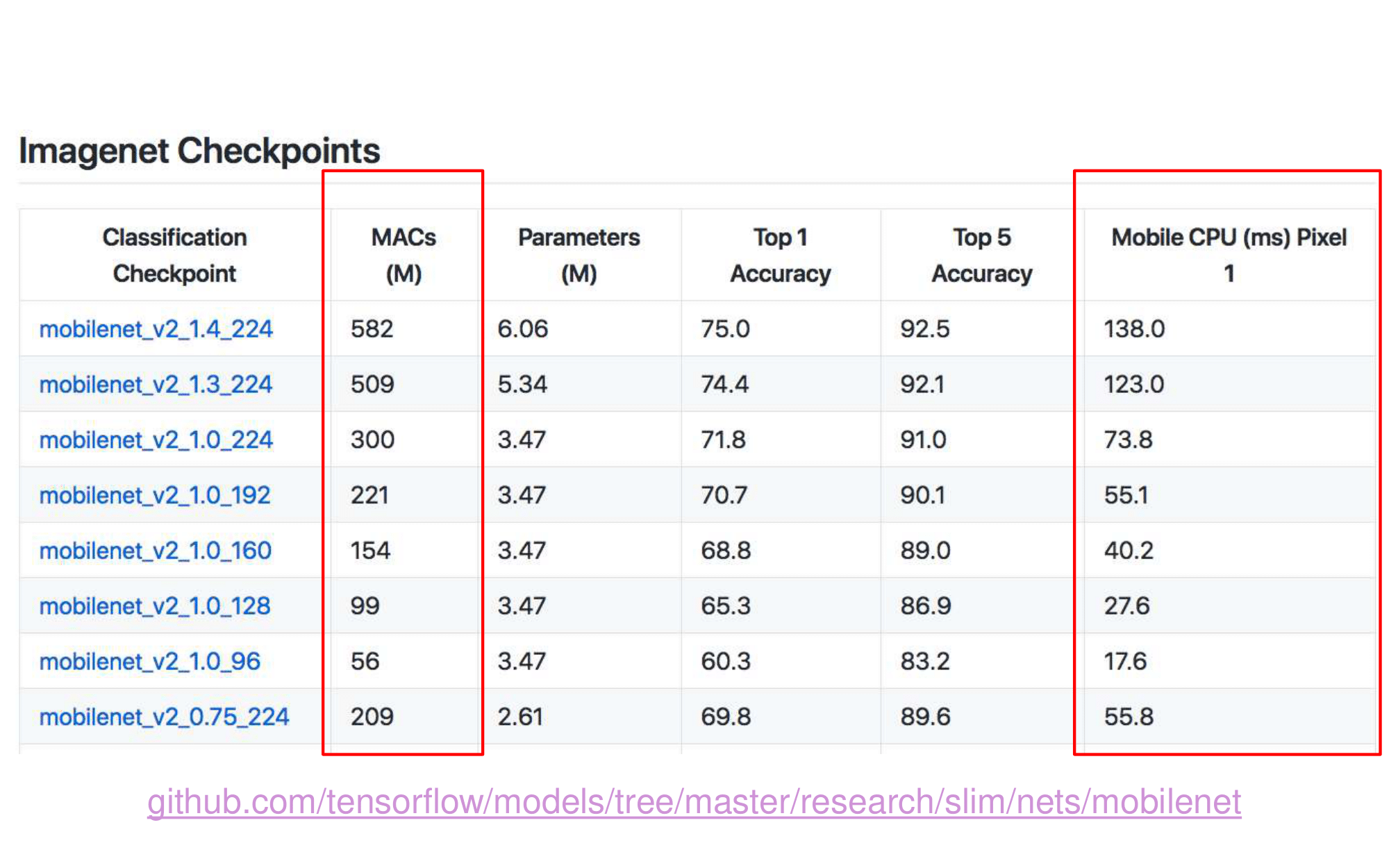
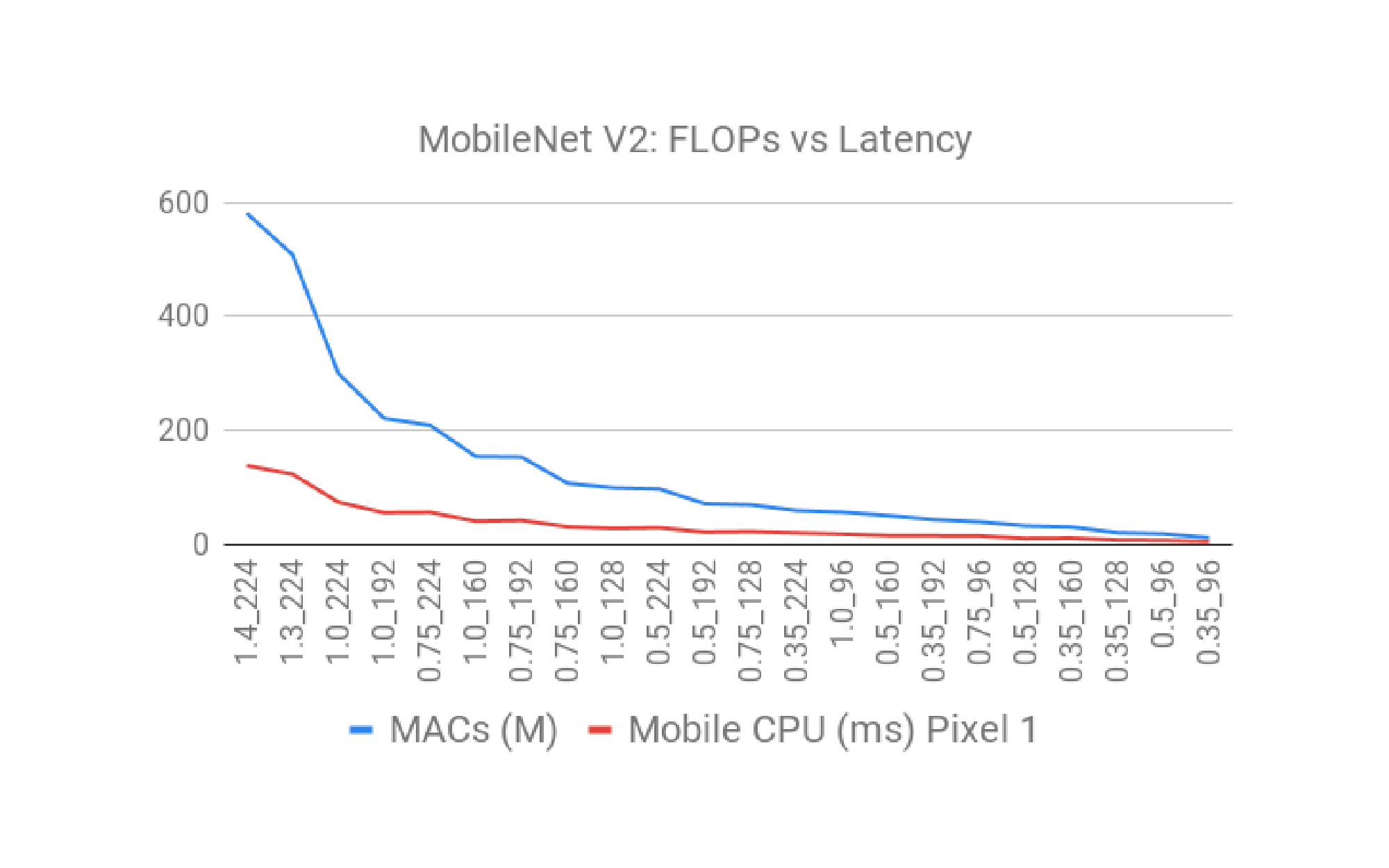
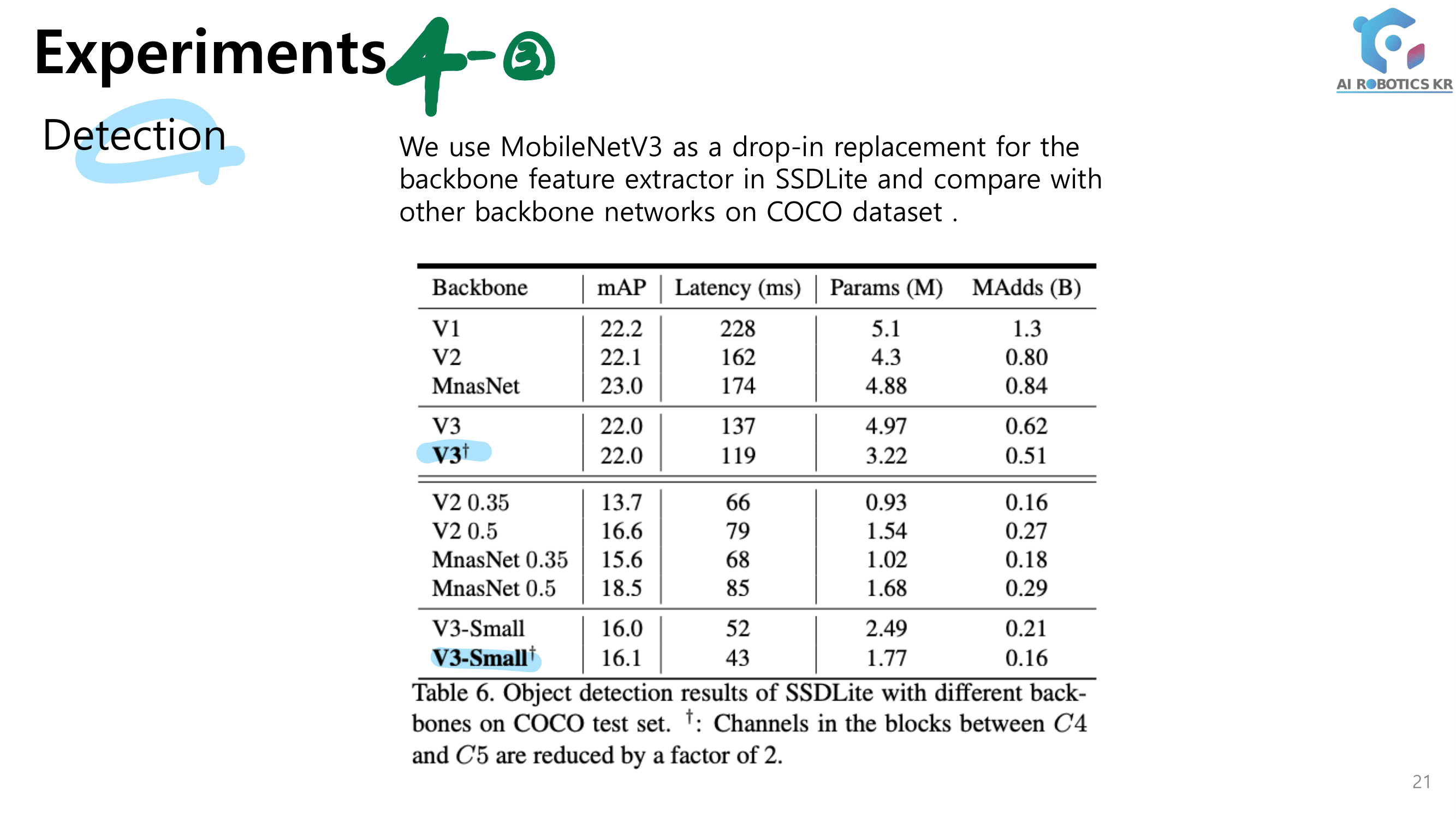
빨간색 줄은 데이터셋 종류, 보라색 줄은 데이터셋 이름.
image-based(위 사진) and video-based(아래 사진) 이렇게 2개의 관점에서 SOTA 모델이 무엇인지 확인해 본다.
이 논문의 8 Page를 살표보면, 각 그래프에 대해서, 왜 SOTA 빨간색점의 모델이 최고의 성능을 낼 수 있었던 이유에 대해서 짧게 설명하는 부분도 있다. 따라서 필요하면 참고하기.
이 성능 비교는, 저자가 직접, 많은 데이터셋 중, 가장 핵심이 되는 4개의 데이터셋을 이미지와 비디오에서 각각 선별하고, 모델을 돌려 성능을 확인하고 나온 결과를 기록한 것이다.
3. Open World Person Re-ID
윗 내용 중 Closed-world 에서 Open-world Person Re-ID 으로의 필요한 핵심 포인트 꼭꼭 다시 읽고 아래 내용 공부하기
3.1 Heterogeneous Re-ID
[3.1.1] Depth-based Re-ID
Depth images 를 활용한 몇가지 논문들 소개
RGB and depth info.를 결합합으로써, Re-ID 성능을 높이고 the clothes-changing challenge 를 해결했다.
몇가지 논문이 제시되어 있는데, 직접 찾아 확인을 해보니, 6m정도 이내에서 사람을 검출한다. 작은 복도 구석에 카메라를 설치해서 사용하는 방법이다. 확실히 Depth 카메라의 Range를 고려한 것 같다.
[3.1.2] Text-to-Image Re-ID
visual image of query를 얻을 수 없고, only a text description만이 주워질 때 필수적으로 사용해야하는 방법이다.
the shared features (between the text description and the person images)를 학습한다.
[3.1.3] Visible-Infrared Re-ID (적외선)
the cross-modality matching(= modality sharable features) between the daytime visible and night-time infrared images 를 다루는 방법이다.
GAN을 사용해서 cross-modality person images 를 생성해서, the cross-modality discrepancy 를 제거하는 방법도 있다.
2019 ~ 2020 논문들이 많다. 이 쪽 연구가 활발히 이뤄지는 것 같다. 필요하면 참고할 것.
[3.1.4] Cross-Resolution Re-ID
높고 낮은 해상도 이미지 사이의, the large resolution variations 를 해결하기 위한 목적의 논문들 소개
3.2 End-to-End Re-ID
Re-ID in Raw Images/Videos
the person detection and reidentification 을 모두 수행하애 한다.
2017 년도에 나온 [55], [64] 논문이 기초 논문
[196, 2019] a graph learning framework
[197, 2019] squeeze-and-excitation network to capture the global context info
[198, 2019] generate more reliable bounding boxes
Multi-camera Tracking
1개 query가 아니라 multi-person, multi-camera tracking [52, 2018] 에 대한 고려 논문.
이 외 다른 논문 소개 A graph-based formulation [201, 2017], a locality aware appearance metric [202, 2019]
3.3 Semi-supervised and Unsupervised Re-ID
[3.3.1] Unsupervised Re-ID
invariant components(각 Label에 대해서 변함없는 feature 저장 구성) (i.e., dictionary [203], metric [204] or saliency [66]) 를 학습하는데 목적이 있다.
이런 많은 논문들과 연구들에도 불구하고, newly arriving unlabelled data를 model updating하는데 아직도 어려움이 많다.
(3) 일부 end-to-end unsupervised Re-ID 방법들 중에서, 특히 learn a part level representation ( local parts than that of a whole imag ) 를 학습하려고 하는 모델들이 있다. [153, 212]
Semi-/Weakly supervised Re-ID : (1) With limited label information, a one-shot metric learning [213] (2) A stepwise one-shot learning method [144] (3) A multiple instance attention learning framework uses the video-level labels [214]
[3.3.2] Unsupervised Domain Adaptation
a labeled source dataset의 지식(Feature Extractor)을 the unlabeled target dataset에게 넘겨주는데 목적을 가지고 있는 모델들이다. = unsupervised Re-ID without target dataset labels
Target Image Generation : GAN을 사용해서, source-domain 이미지를 target-domain style이미지로 transfer generation한다. 이러한 방식을 사용하는 9가지 논문 소개
Target Domain Supervision Mining : source dataset을 이용해서 아주 잘 학습된 model을 사용해서 target dataset의 supervision(annotation정보)룰 직접적으로 mining(추출하는) 하는 방법이다. 이러한 방식을 사용하는 7가지 논문 소개
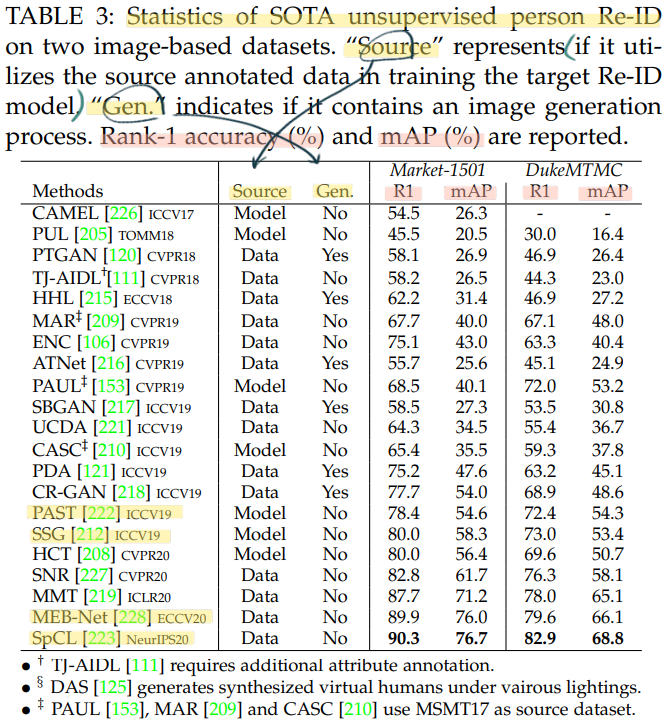
[3.3.3] State-of-The-Arts for Unsupervised Re-ID
우선 아래의 전체 모델 성능 비교 참조.
최근, He et al. [229, 2020] 논문을 보면 large-scale unlabeled training data를 사용하여 unsupervied learning을 적용하면, 다수의 tasks에서 supervised learning을 이용한 것보다 훨씬 더 좋은 성능이 나올 수 있다고 증명한다. 따라서 앞으로도 미래의 breakthroughs가 될 것으로 기대된다.
3.4 Noise-Robust Re-ID
여기서는 3가지 관점으로 noise-robust Re-ID 논문들에 대해서 소개한다.
논문에서는, 여러 다른 기술이 들어간 논문들을 아주 짧게 소개한다. 그러니 내가 이해못하는게 너무 당연하다. 정독을 하던, 스키밍을 하던 이해 안되는 것은 똑같았고, 그래서 큰 그림만을 아래에 적어 놓았다.
the Re-ID problem with heavy occlusions (Partial Re-ID) : Deep Spatial feature Reconstruction (DSR) [232], Visibility-aware Part Model (VPM) [67], A foreground-aware pyramid reconstruction scheme [233]
the problem caused by poor detection/inaccurate tracking results : Detected BB에서 noisy regions이 기여하는 정도를 suppress 하는것이 Basic Idea 이다. 특히 [20]에서는 multiple video frames to auto-complete occluded regions(비디오 이미지를 사용해서, 한 프레임에서는 보이지 않는 occulded 부분을, 여러 프레임을 사용해서 자동 복원하는 방법이다.)
the problem due to annotation error : [42], [235], [236] 위에 처럼 각 논문에 따른 이름을 적어 놓는게 무슨 의미가 있나… 안 적었다. 필요하면 알아서 참고.
3.5 Open-set Re-ID and Beyond
Open-set Re-ID를 처리하는 가장 기본적인 방법은, a learned condition τ를 사용해서, similarity(query, gallery) > τ (τ보다 크면, matching시키고, τ보다 작으면 gallery에 query가 없다고 판단.)를 이용하는 것이다.
위와 같은 방법을 handcrafted systems이라고 하며 [26], [69], [70] 이런 논문들이 있다.
handcrafted 가 아닌, deep learning methods를 사용한 Adversarial PersonNet (APN) [237] 이라는 방법도 있다. GAN module and the Re-ID feature extractor를 사용해서, similarity를 판별하고, gallery에 query가 있는지 없는지 판단한다.
Group Re-ID : associating the persons in groups rather than individuals. Group을 associationg(?) 하는 방법으로는, (1) sparse dictionary learning 기반, (2) the group as a graph 기반. 2개이다. 각 기반 방법에 해당하는 논문들이 소개 되어 있다.
Dynamic Multi-Camera Network : new cameras or probes(데이터 분포&유사도)에 대한 adaptation challenging를 고려하는 몇가지 논문들 소개되어 있음.
4. An Outlook Re-ID (new metric, baseline)
4.1 - mINP: A New Evaluation Metric for Re-ID
computationally efficient metric 를 표현하는 metric
여기서 R은 Rank position of the hardest match, G는 correct matches for query의 총 갯수이다. 아래의 예시를 참고하자.
이런 성능 지표가 필요한 이유는 다음과 같다. 위 그림의 Rank List 1은 Rank List 2에 비해서 AP가 높다. (AP수식은 논문의 초반부분에서 참고) 하지만 NP를 계산해보면, Rank List 1이 더 높다. (NP는 낮아야 좋은것)이 말은 즉, “hardest true matching를 찾기 이전까지, too many false matchings 이 포함되었다.”를 의미한다. 따라서 Rank List 1의 computing 효울은 낮다고 판단할 수 있다.
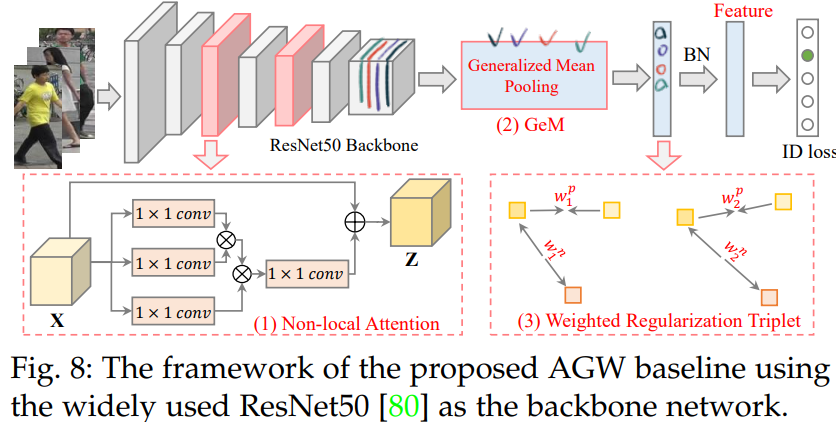
4.2 - A New Baseline(AGW) - Single-/Cross-Modality Re-ID
generalized-mean (GeM) pooling [247, 2018] 를 참고했다.
여기서 Xk는 feature map의 각 channel들이다. pk는 training 중에 학습되는 pooling hyper-parameter이다. 만약 Pk가 무한하게 크면, Max pooling이 이뤄지는 것이고, Pk가 1이면, average pooing이 이뤄지는 것이다.
Weighted Regularization Triplet (WRT) loss
weighted regularized triplet loss.
위의 수식을 사용한다. (i, j, k)가 의미하는 것은 a hard triplet within each training batch 이다.
3개의 이미지 중, 서로 2개가 같은 ID의 이미지이면 positive, 다르면 Negative이다. 위의 수식을 사용해서 positive인 weight 끼리는 거리가 가깝도록, negative인 weight 끼리는 거리가 멀더록 만든다.
좀 더 확실한 이해는, 논문을 통해서도 힘들다. 나중에 코드도 함께 봐야겠다.
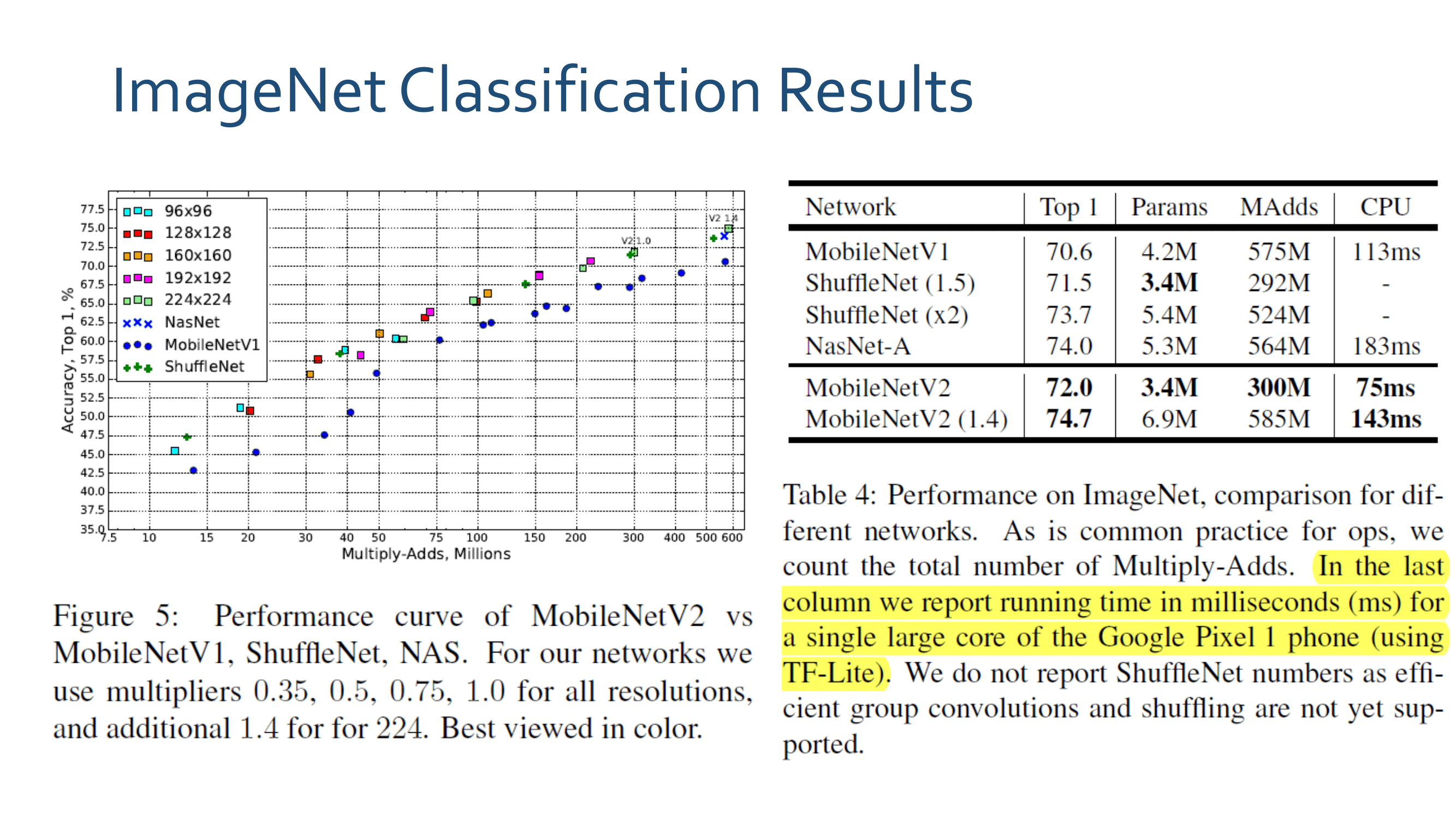
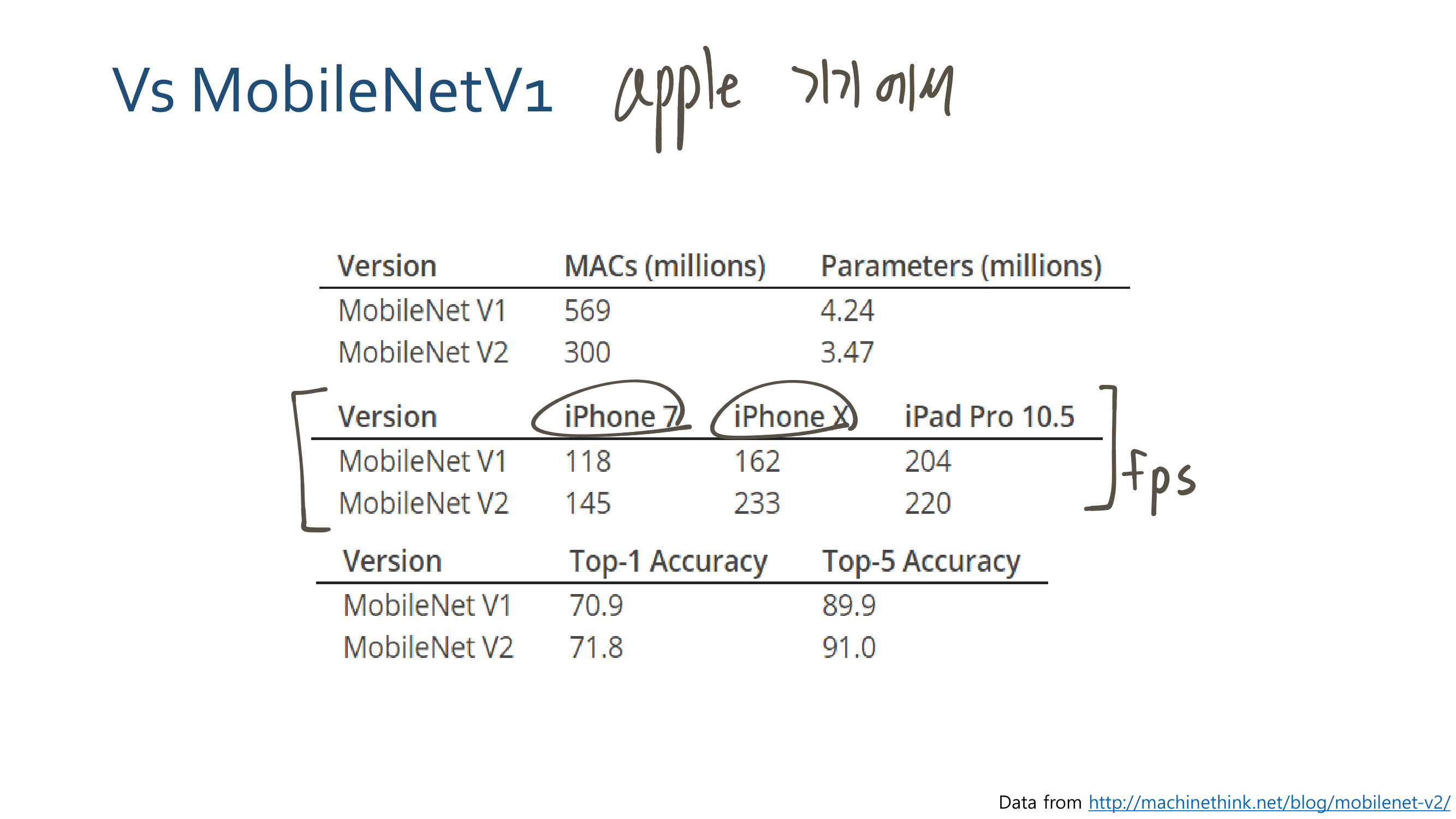
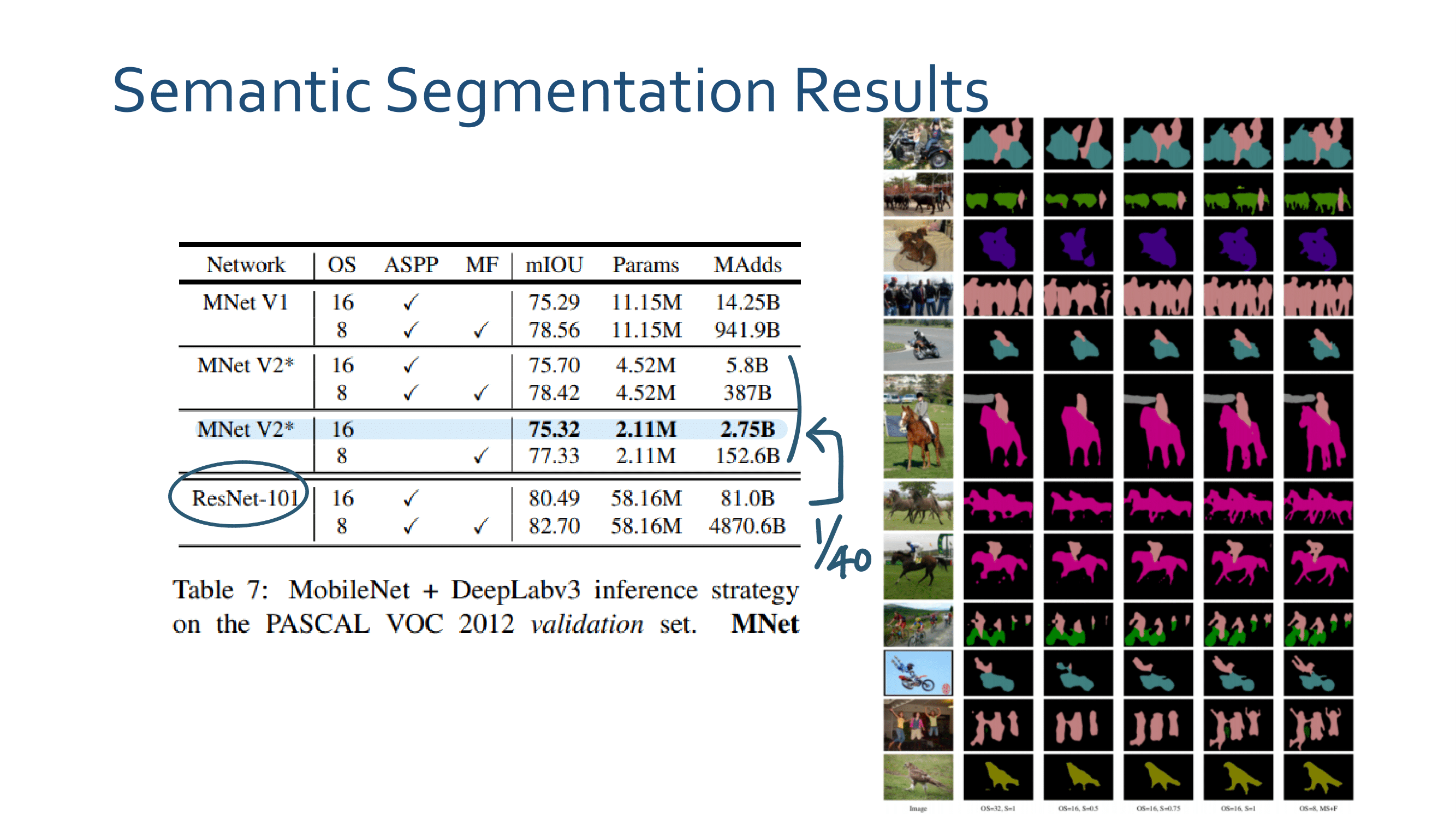
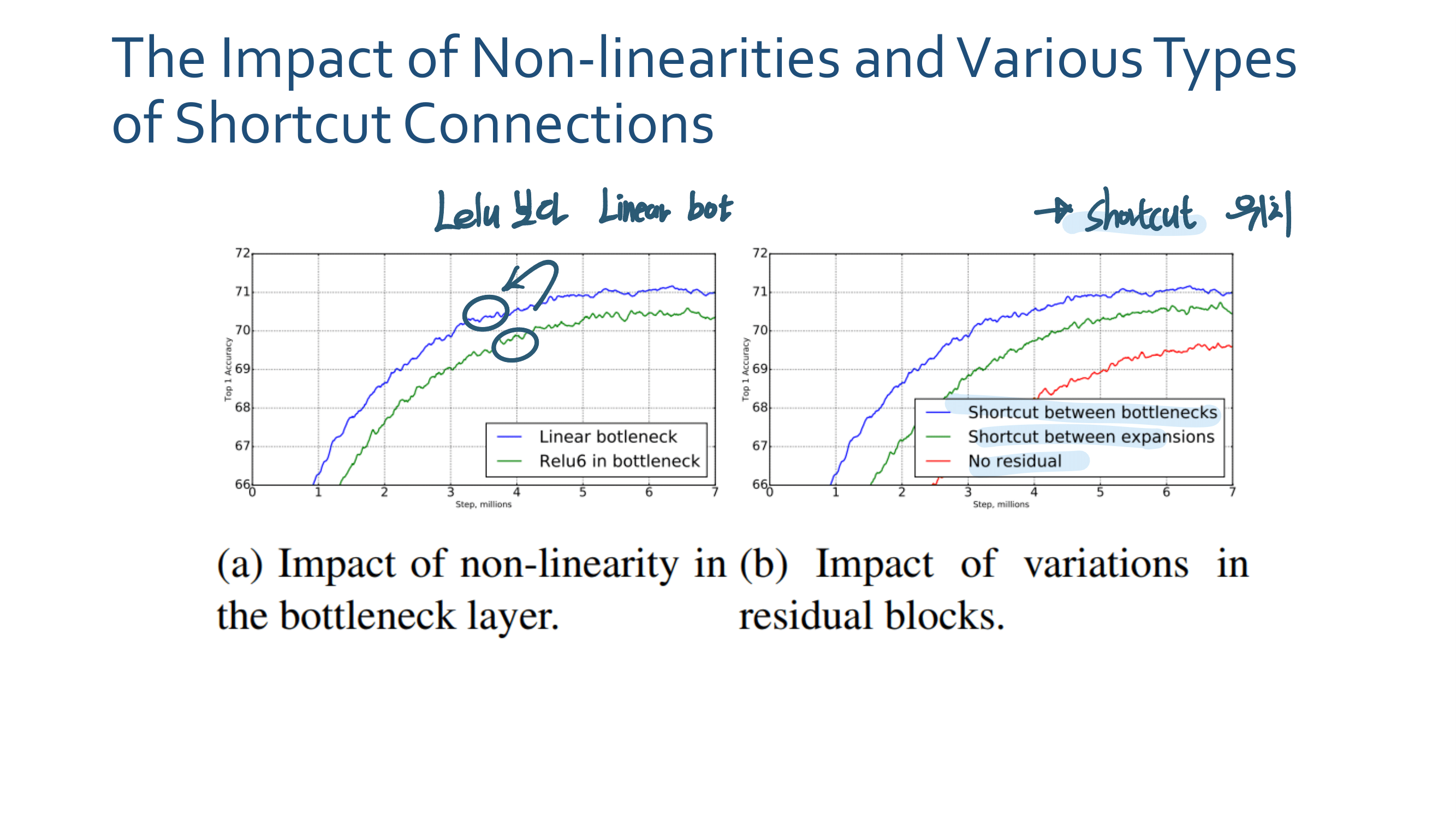
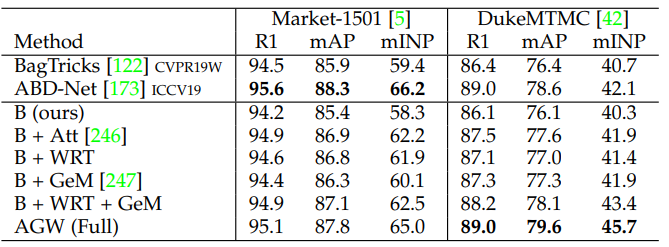
4.2.a - Results
4.3 Under-Investigated Open Issues (challenge)
4.3.1 Uncontrollable Data Collection - 자동 데이터 수집기 필요
4.3.2 Human Annotation Minimization - 비용 절감을 위해 사람의 라벨링 작업 최소화 필요
4.3.3 Domain-Specific/Generalizable Architecture Design - Domain 변화에도 일정한 성능을 가지는 NN
4.3.4 Dynamic Model Updating - online learning 필요
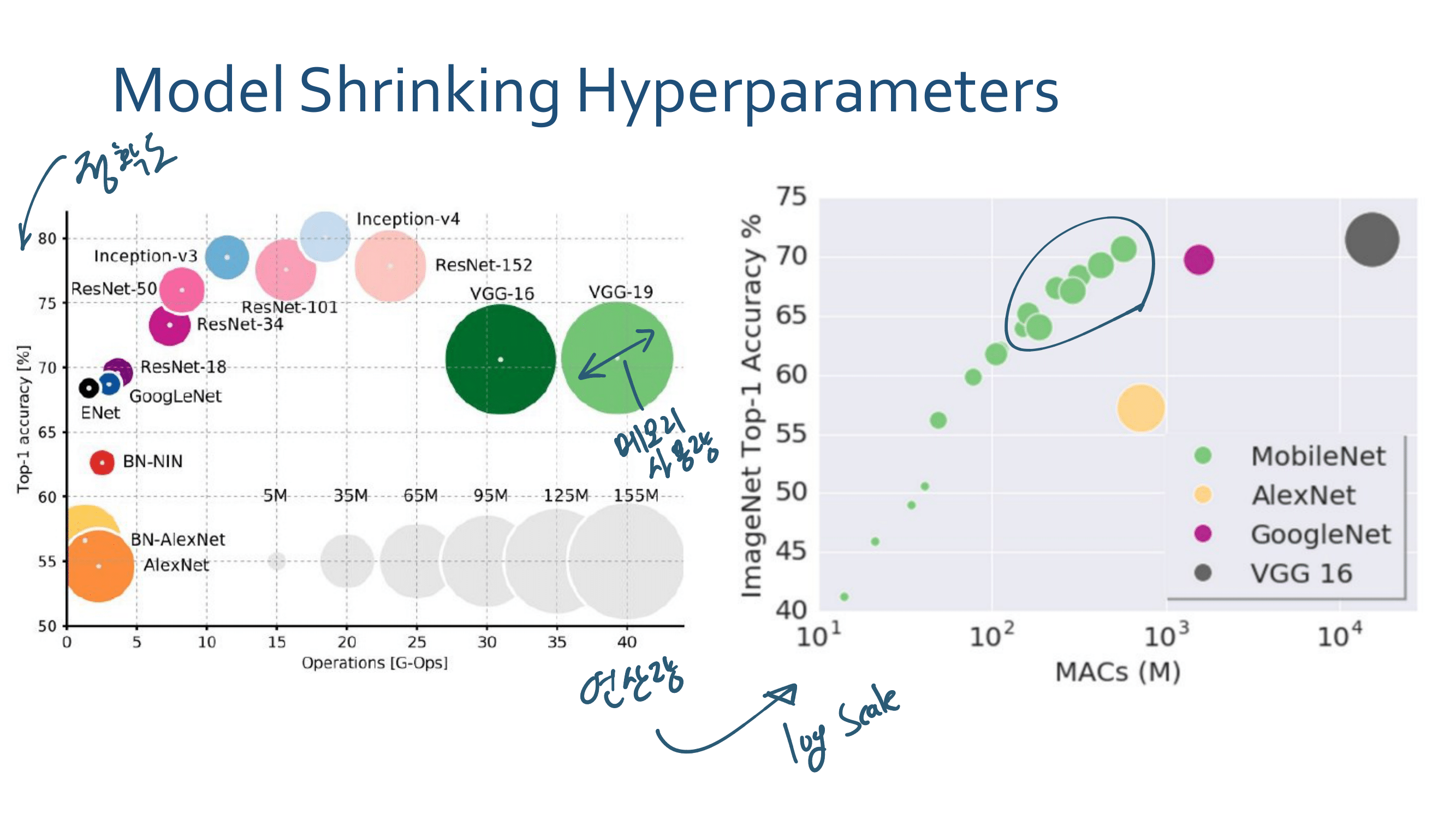
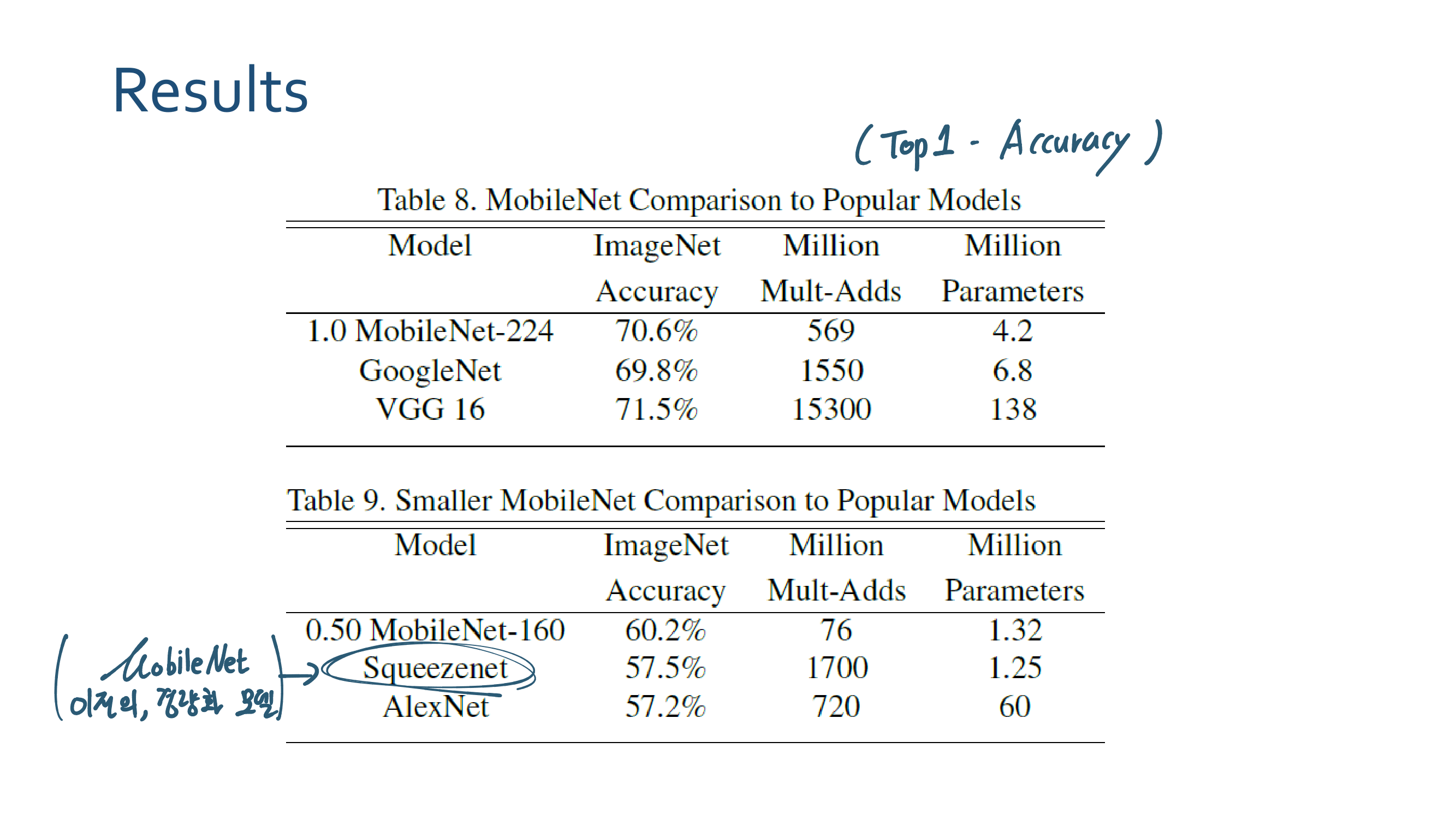
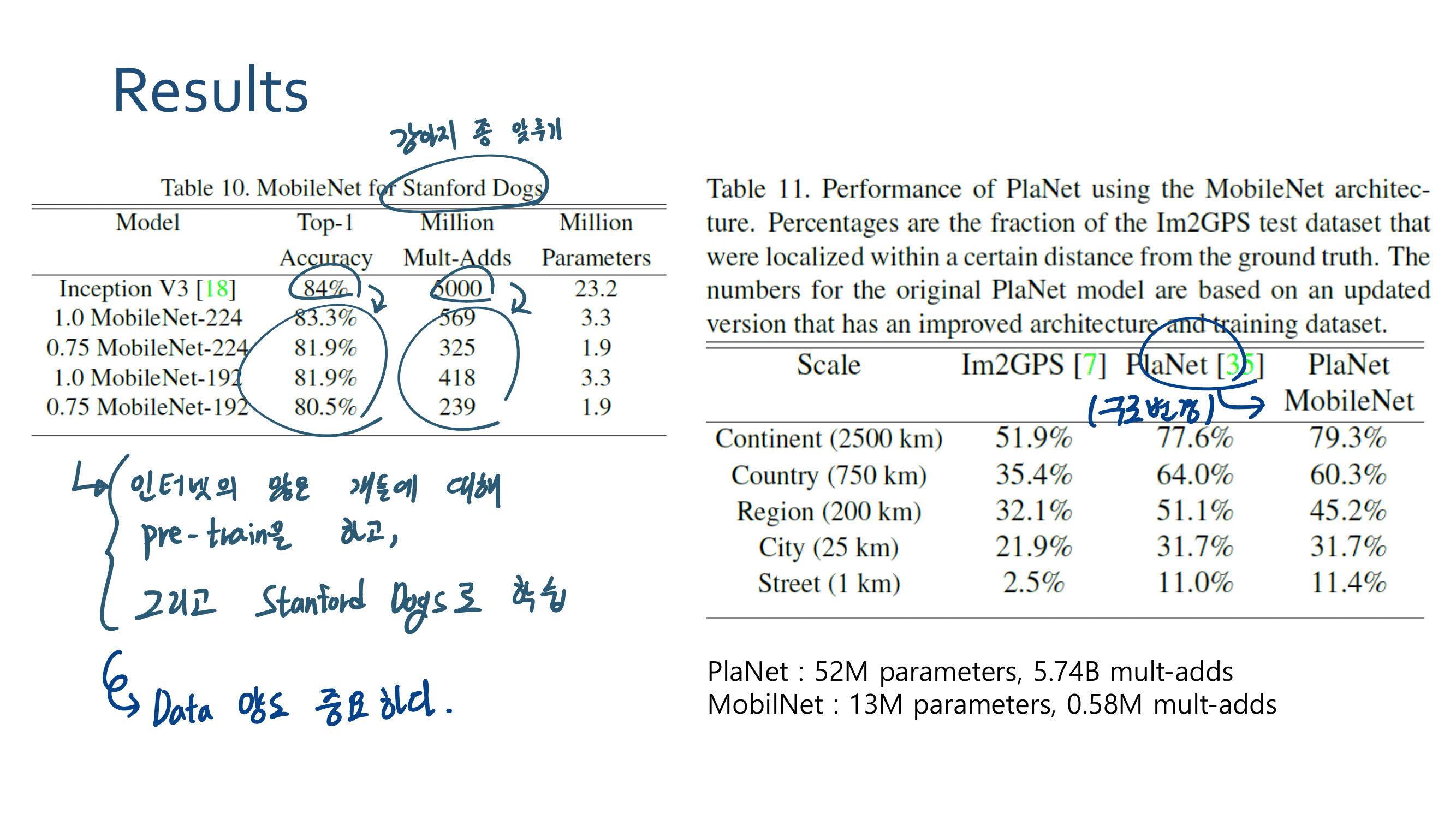
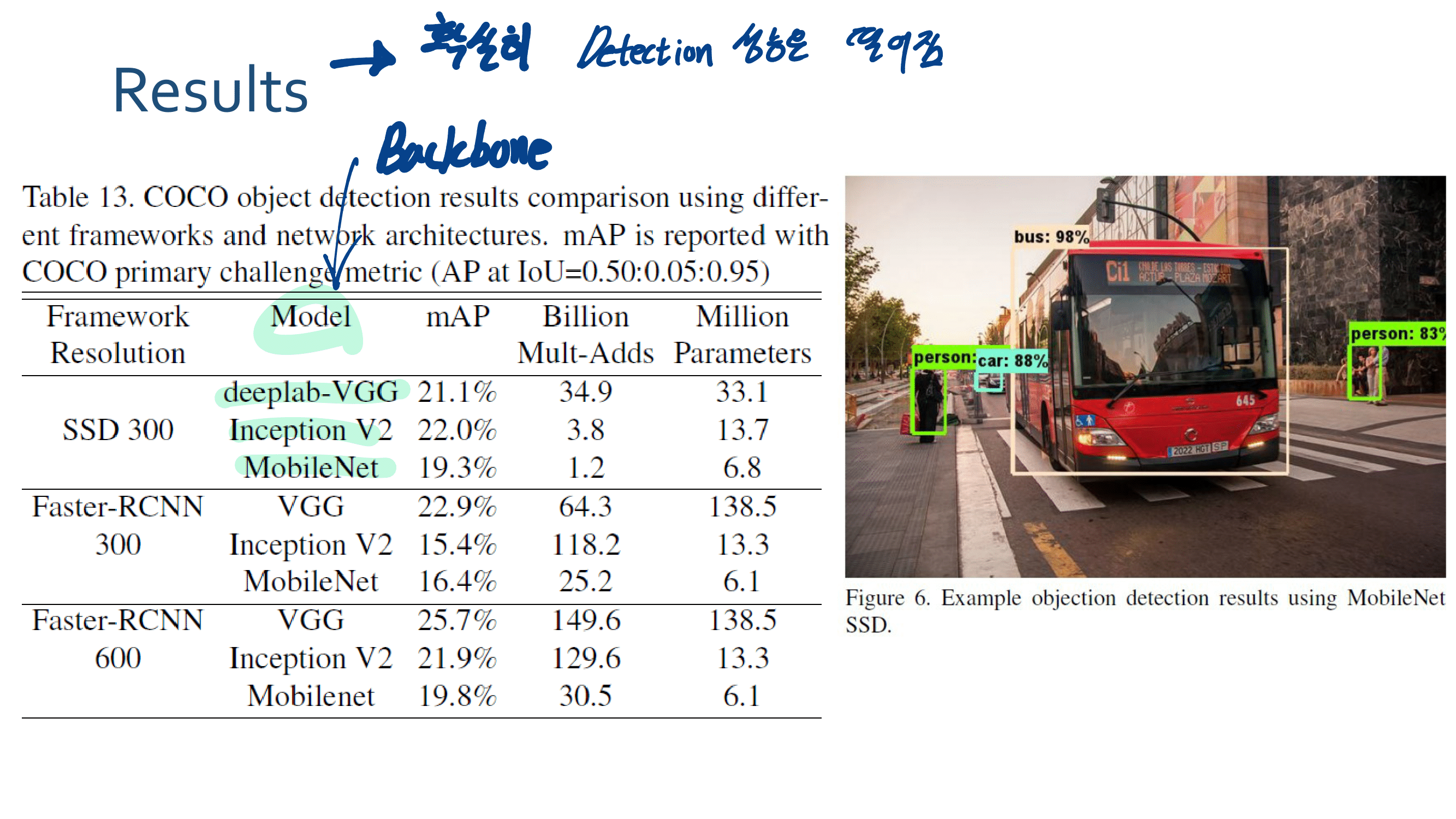
4.3.5 Efficient Model Deployment - fast and efficient 한 모델. 작고 강한 모델.
이 논문은 전체를 다~ 봐야지. 라는 마음으로 보지 않았다. 아래의 순서로 핵심만 찾아보앗다.
Conclution -> Introduction -> Abstract 순서대로 읽으면서, 에서 핵심이 뭐지? - 이 논문이 해결하려는 문제점이 뭐지? 이 방식의 목표는 뭐지?
Related Work에서 거의 무시. 거의 마지막 문단과 문장만 읽음.
Figure1, Figure2 주석 읽기. 본문에서 Firgure2에 대한 추가 설명 찾아 읽기
Method 읽기 시작! 이 논문의 method는 3페이지 이내이다.
Ablation, Result에서 위에서 말한 문제점 해결이 잘 해결되었고, 목표를 잘 달성했는지 확인한다. 다시 말해서, 이 논문에서 제안한 각각의 몇가지 새로운 모듈에 대해서 결과론적으로 각각 좋은 결과를 얻었는지 확인.
저번의 정리해놓은 논문 정리방법 과는 추가로, “같은 문장, 같은 문단에서도 비슷한 영어단어를 써가며 같은 말을 반복한다. 이걸 다 다른거라고 생각하지 말고 하나의 단어로 통일해서 정리해 두자” 예를 들어서 Extracted Feature = representation = Feature maps 뭐 이런 동의어를 반복해서 사용한다. 예전의 나는 이것들을 모두 따로따로 분리해서 생각했는데, 결국에는 같은 동의어이다. 아래 Conclution에서도 heuristic feature selection 고안하여~라는 말이 나오고 2문장 이후에 online feature selection 만들었다~라는 말이 나온다. 내가 이걸 따로 정리할 필요 없이 heuristic/online feature selection를 만들었다 라고만 적으면 끝이다.
항상 논문을 끝까지 다 읽어봐야 한다. Conclution -> Introduction -> Abstract 은이 순서대로 다 읽고 나서, ‘논문 정리 문서 작성’을 해야한다. Abstract에서는 절대 이해가 안되던게, Introduction을 읽고 이해가 되기 시작한다. 그리고 Method를 읽으면 또 다시 이해가 되기 시작한다. 그니까 Conclution, Abstract, Introduction 여기서 이해 안되면, 안되는데로 읽거나 아니면 아에 읽지말고 넘어가라. 그리고 Method 읽고 다시 와서 읽어라. 그렇게 하면 “와… Abstract, Introduction에서 말만 삐까번쩍하게 해놨네… 쓸데없는 소리 엄청했네… 이렇게 써놓으면 처음보는 사람은 절대 이해 못하지… Method부터 읽길 잘했다…” 라는 생각이 엄청든다.
Conclution -> Method -> Introduction -> Abstract 순서대로 보았다면, Introduction, Abstract 에서 충분히 시간을 절약할 수 있었을 것 같다. Method 를 읽는데, Introduction, Abstract 부분의 지식은 하나도 필요없었다. 물론 알고 보면 좋은 건 있지만, 시간 절약으로 Method 공부 다~ 하고 Introduction, Abstract를 봤다면 좀더 정확한 Introduction, Abstract 부분의 이해와 정확한 정리가 가능하지 않았나.. 싶다. 좀 내가 아는 Object Detecion, Instance Segmentation 에서는 Conclution -> Method -> Introduction -> Abstract 순서로 논문을 공부하자!
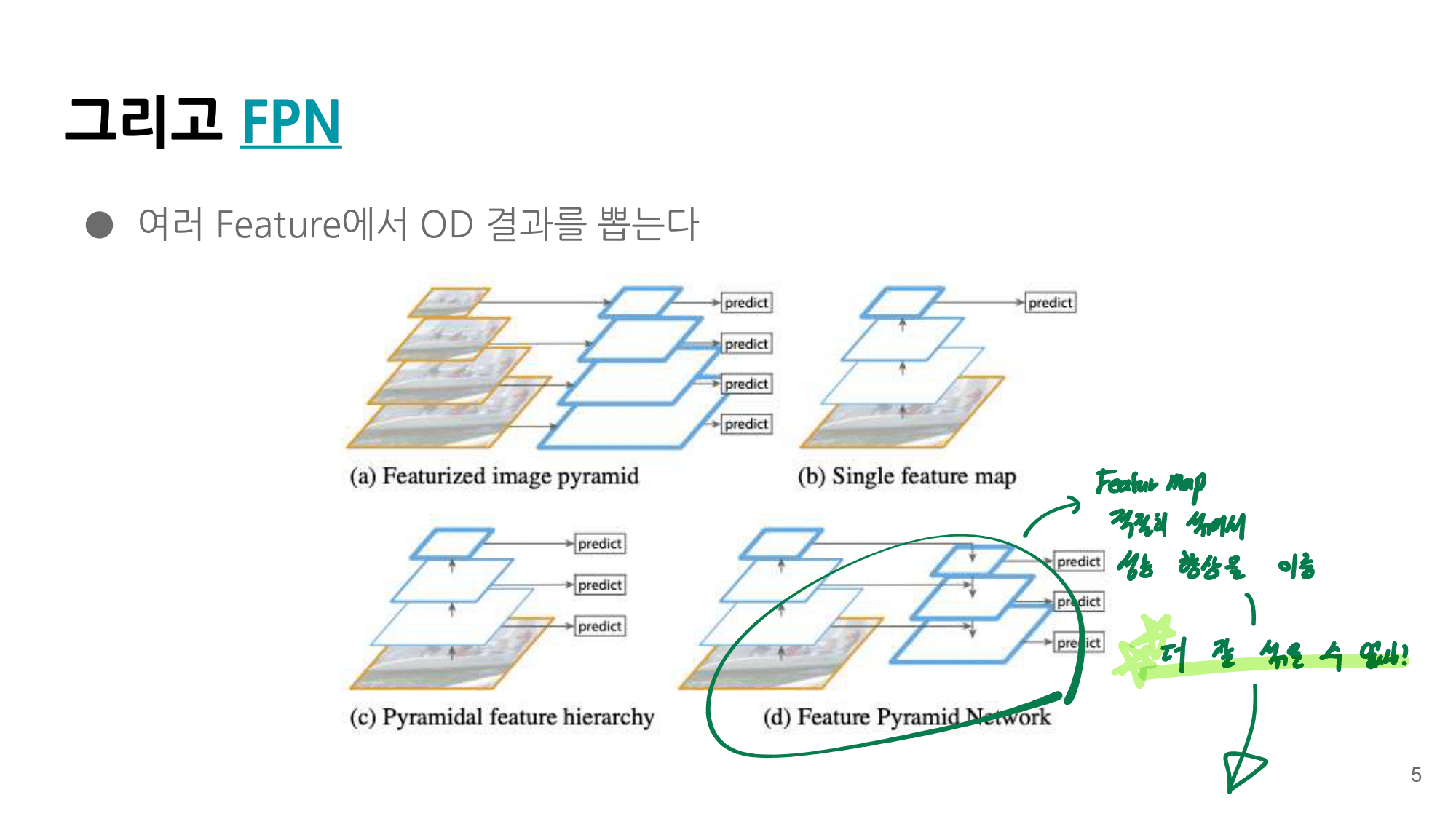
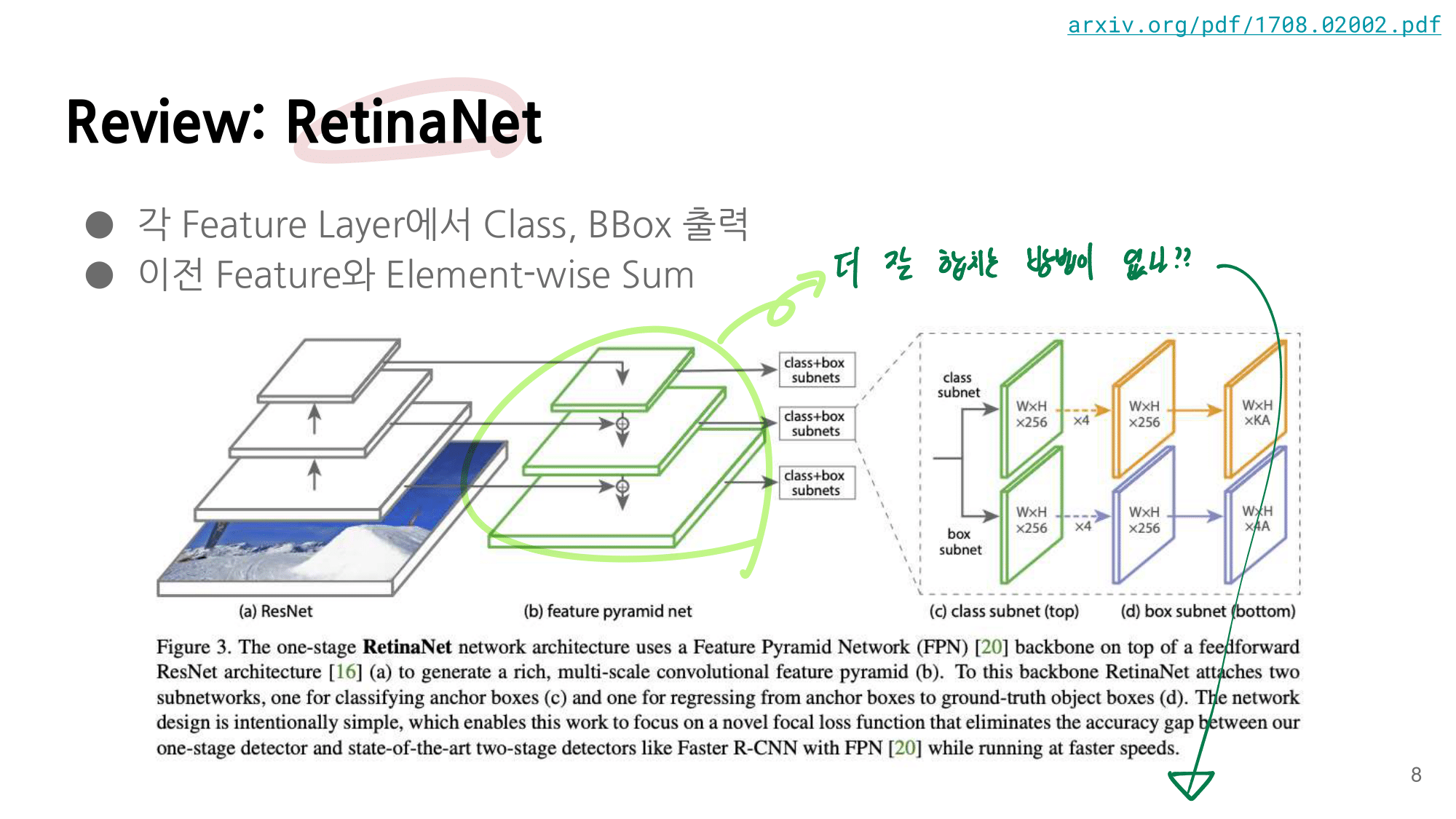
Feature Selective Anchor-Free Module
0. conclution
(PS. 이 논문에 계속 나오는 feature selection은 사실 feature level (in Pyramid = P_l)selection이라고 계속 이해하자 )
heuristic feature selection의 문제점,한계를 찾아내고, 이 문제 해결을 위해 online feature selection을 고안하며, FSAF 모듈을 만들어 냈다.
(1) Tiny inference overhead (2) SOTA / Strong baselines 얻었다.
1. Introduction, Abstract
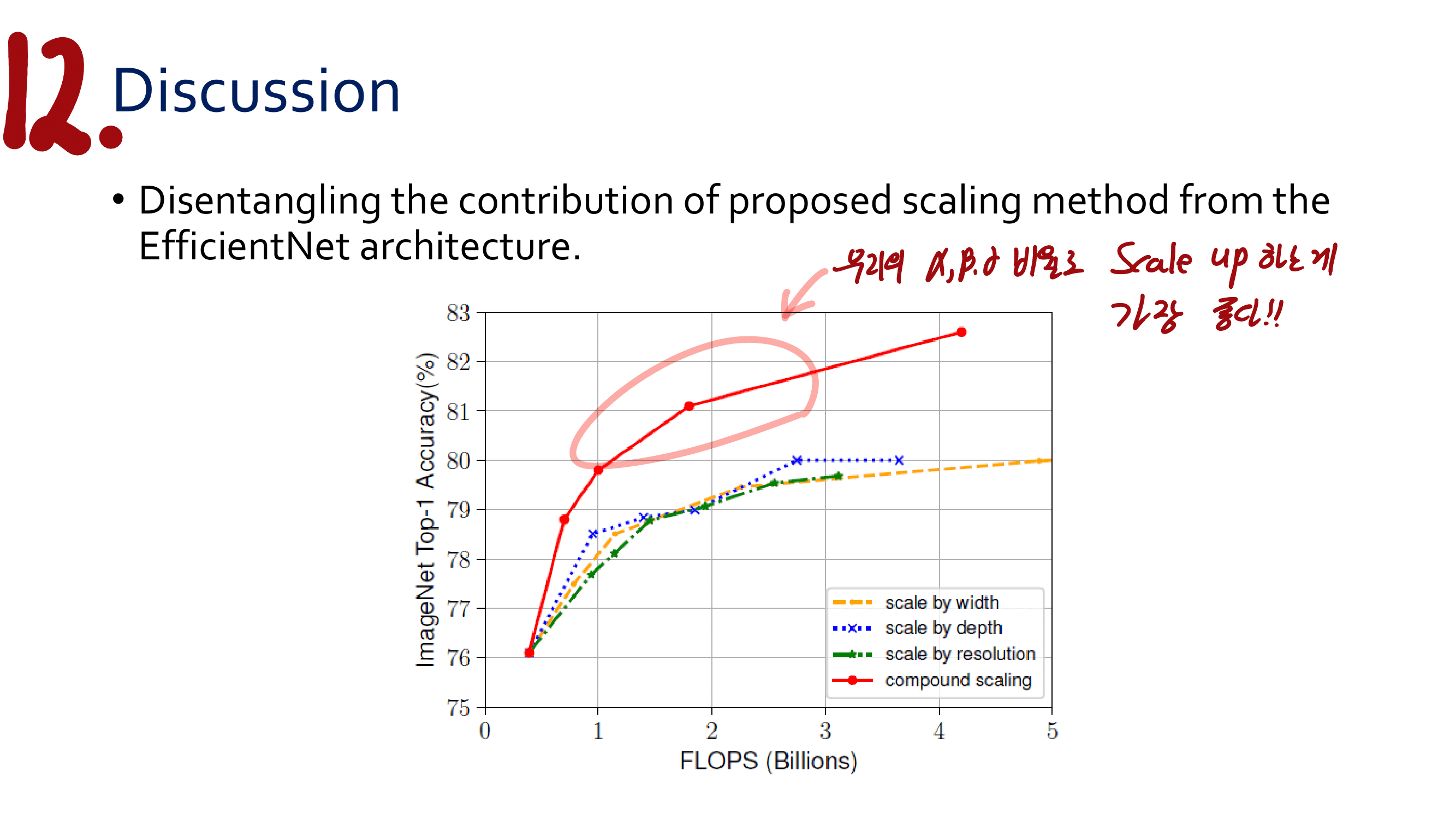
우리의 해결하려는 문제점이자 목표는, scale variation이다. 즉 scale invariability (객체의 크기가 커지더라도, 작아지더라도 객체를 안정되게 잘 탐지할 수 있는 능력) 성능을 가지는 모델을 만들어내고자 한다.
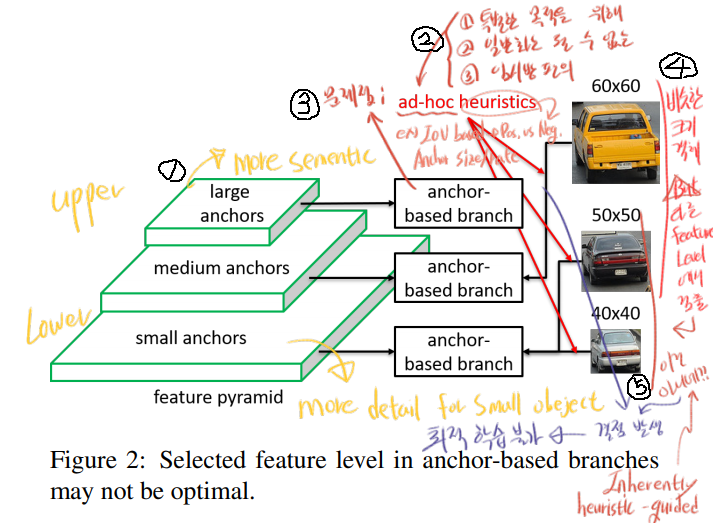
최근 기법들의 한계점 (two limitations) (아래 그림의 (4)에서 발생하는 문제점이 핵심이다)
inherently heuristic-guided feature selection : anchor의 size, rate는 이미 정해져있다. 때문에, 각각의 instance에 대해서 선택되는 (selected) feature level [PFN에서 upper(small, smentic), lower(large, deteail) 이 다른 feature map을 의미함] 이 최적의 level이 아닐 수 있다.
overlap(IOU)-based anchor sampling : 각각의 instacne 들은 가장 가깝고 IOU가 높은 anchor box에 의해 detect / match 된다. 9
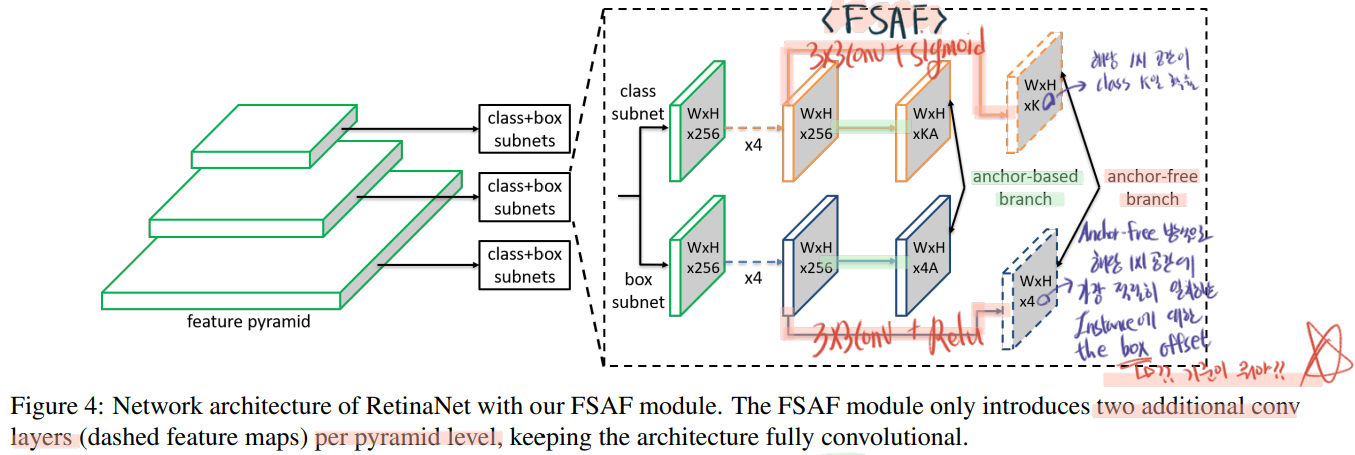
Feature selective anchor-free (FSAF)
이 모듈을 통해서, 각각의 instance가 the best feature level을 선택하도록 돕는다.
FSAF 모듈은 classification subnet 과 regression subnet 으로 구성되어 있다.
During training, 각 instance에 대해서 the most suitable feature level을 찾는다 Dynamically, Non-heuristically. 단순하게 instance box size를 기반으로 하는게 아니라, the instacne content (instance에 해당하는 feature 내용들) 를 기반으로 feature level을 찾는다.
Durring Inference, anchorbased branches와 독립적이면서 공동으로 평행하게 run 된다.
FSAF의 장점과 특징 (Abstract 참조)
simple and effective building block for single-shot object detectors.
FPN를 가지는 Network에는 모두 적용가능하다.
Feature Level Selection에서 online feature selection 을 수행한다. (Dynamically, Non-heuristically)
state-of-the-art 44.6% mAP, SOTA in single-shot detectors on COCO.
2. Related work
초반 내용 안 읽음
The idea of anchor-free detection는 새로운게 아니다. DenseBox [15, 2015]에 처음 나온 방식이다. Anchor Box를 사용하지 않고, directly predicted bounding boxes를 사용한다.
위의 방법이 발전되어서 2개의 논문이 나왔다. 하지만 아래 2 논문은 여전히 heuristic feature level selection strategies을 취하고 있다. 우리는 heuristic 에 의해 발생하는 문제점을 최소화 하도록, heuristic 을 최소화 하는 것을 목표로 한다.
CornerNet [17, 2018] : detect an object bounding box as a pair of corners. SOTA in single-shot detectors.
SFace [32, 2018] : the anchor-based method and anchor-free method 를 모두 융합하기 시작.
3. Feature Selective Anchor-Free Module
3.1 Network Architecture
how to create the anchor-free branches in the network
surprisingly simple
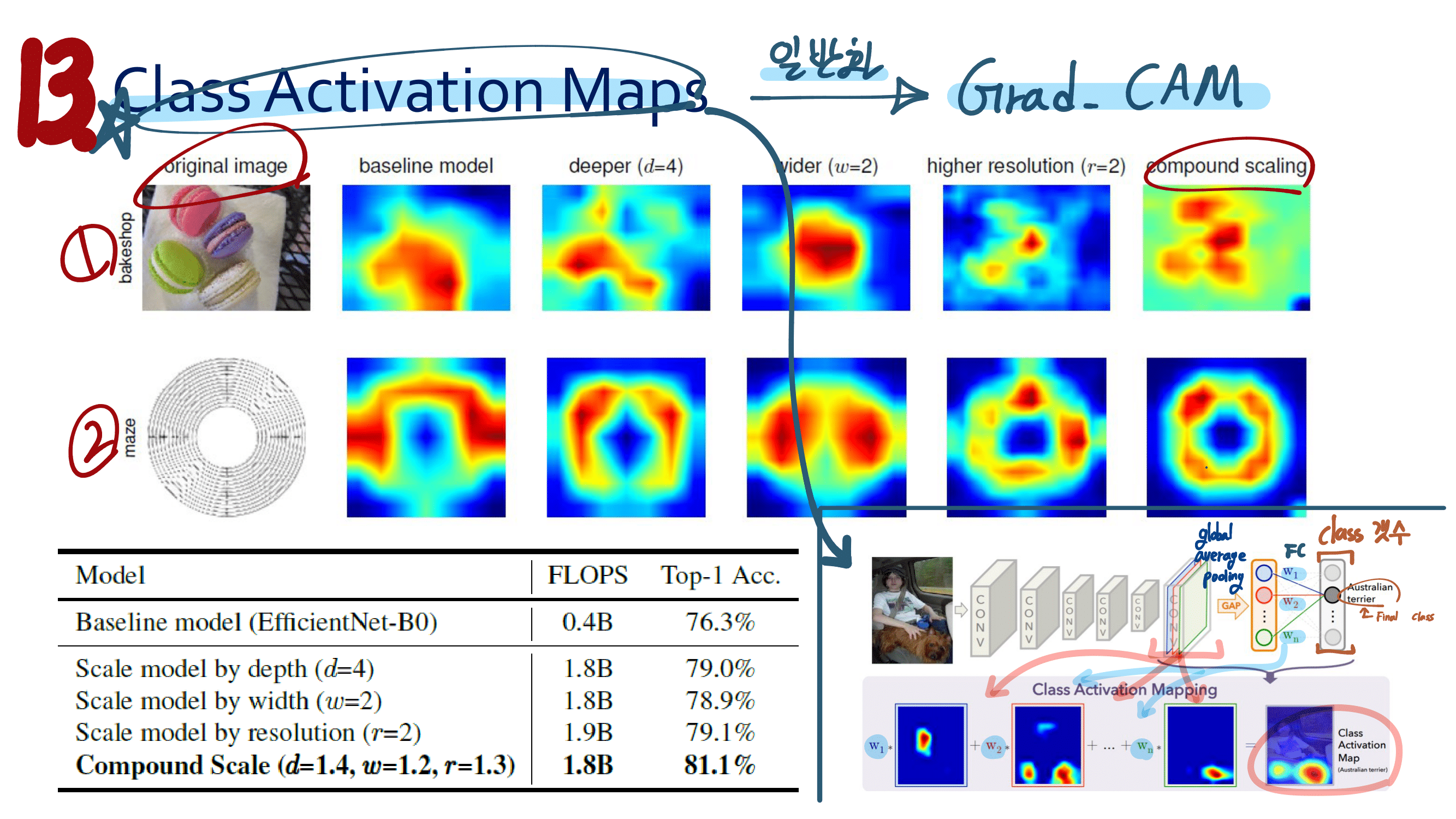
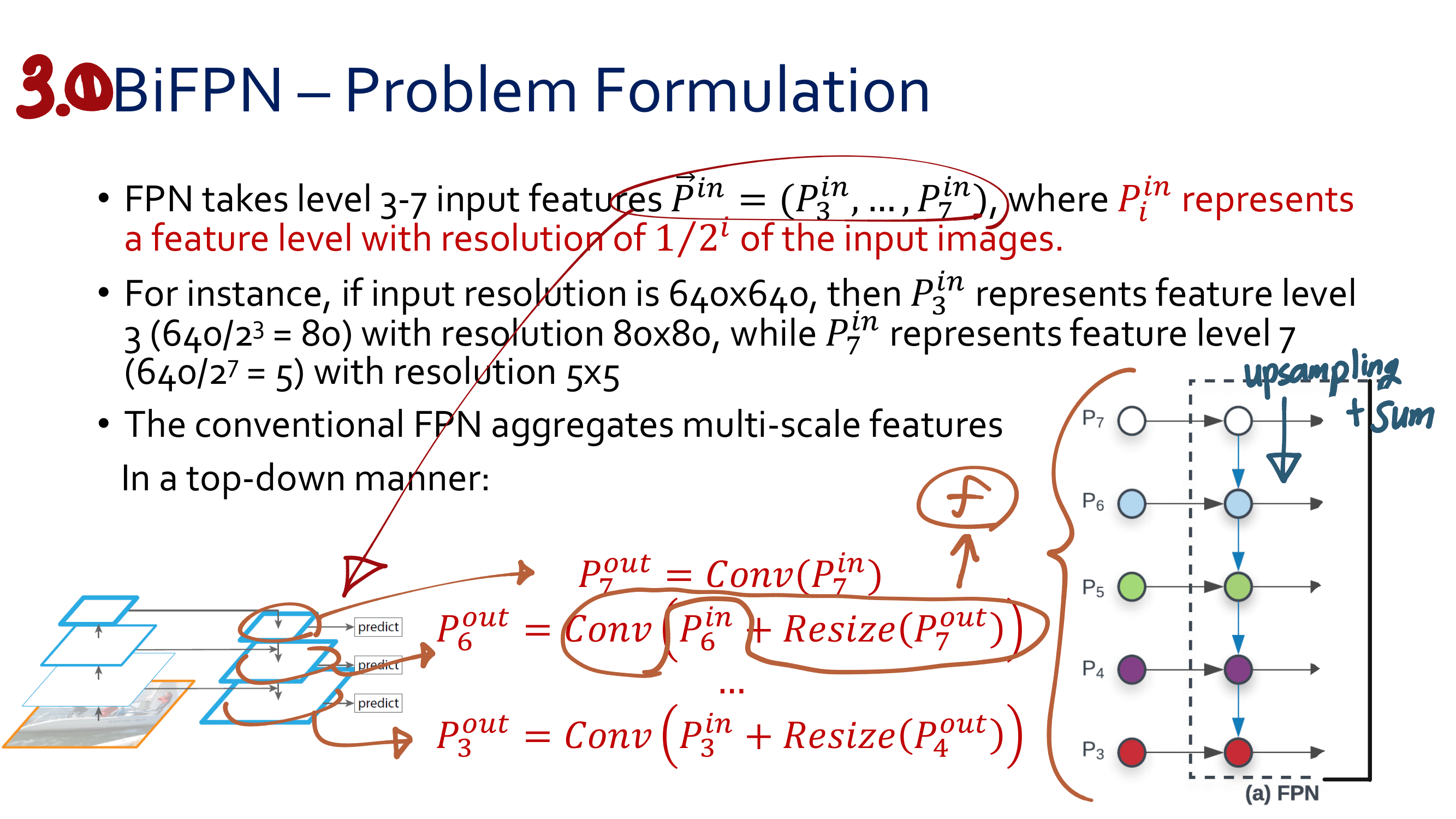
FPN에서 나오는 feature map P_3 부터 P_7 까지. 3~7을 ‘l (small L)‘이라고 하자. P_l은 the input image에 대해서 1 / (2^l) resolution 을 가진다.
아래 그림에, Class subnet, Box subnet 의 1x1 공간의 의미는 잘 적어두었으니 참조하기.
아래 그림에 왼쪽 하단 질문 기준이 뭐야?의 해답은 : “[instance GT BB’를 1 / (2^l) 비율로 나눈, BB]가 Anchor역할을 한다.” 이다.
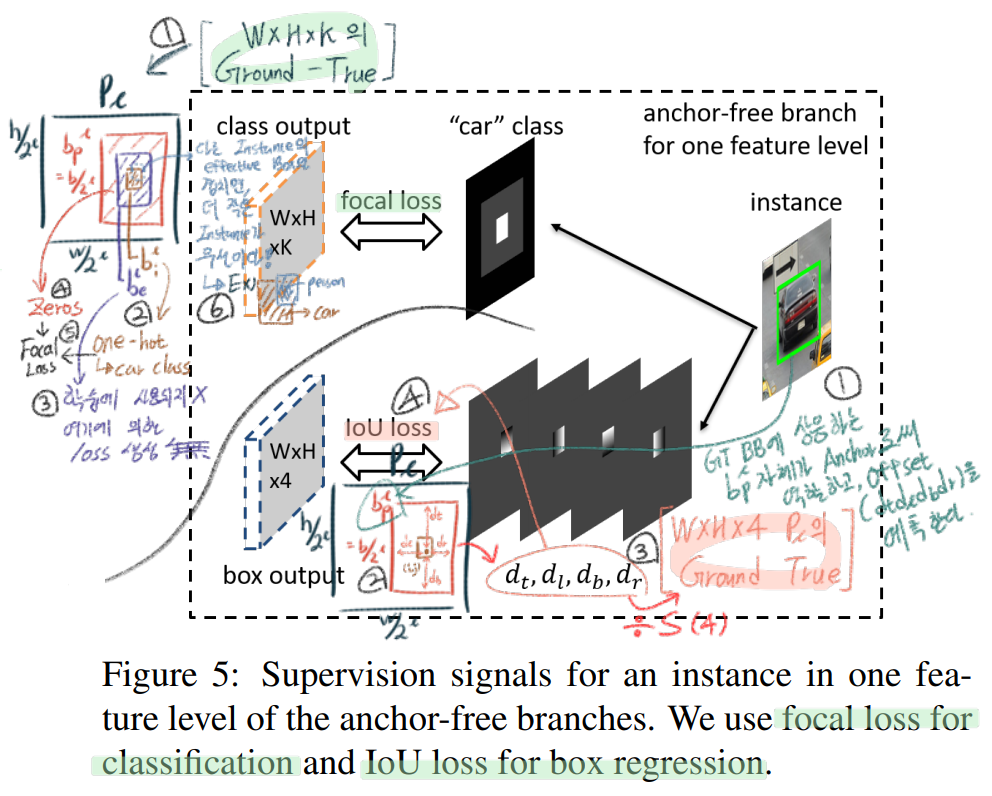
3.2 Ground-truth and Loss
how to generate supervision signals for anchor-free branches
아래 그림에서 중앙의 검은색 곡선 라인을 기준으로, (1) 위 왼쪽은 Classification 에 해당하는 P_l의 GT가 무엇이 되어야 하는지. (2) 아래 오른쪽은 Box Regression에 해당하는 P_l의 GT가 무엇이 되어야 하는지. 를 나타낸다.
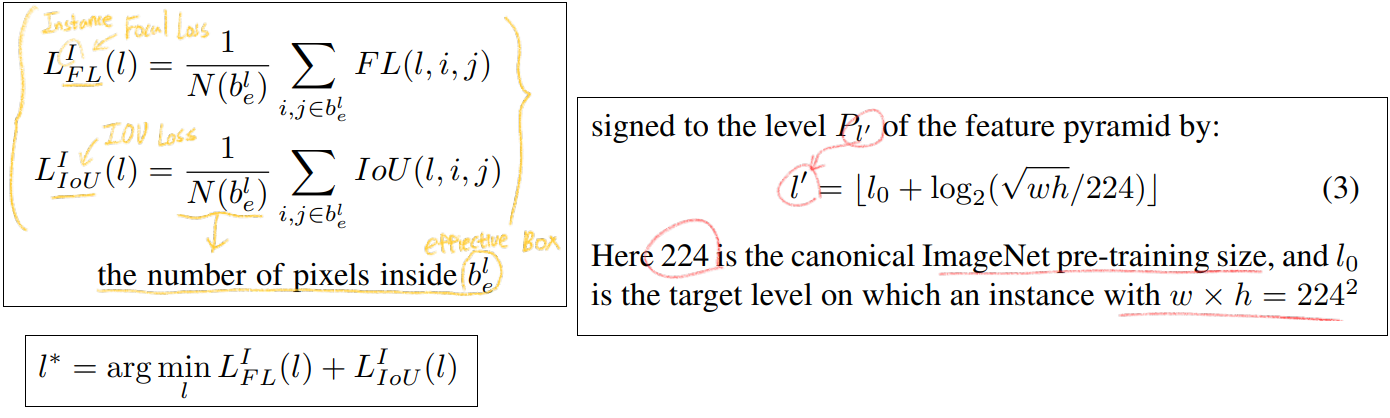
Classification Output : 아래 그림의 설명에서 추가적으로 Focal Loss에서 α = 0.25 and γ = 2.0 를 사용했다. 하나의 instance에 의해서 생성되는, 최종적 loss는 the summation of the focal loss over all non-ignoring regions(빨간색 내부 중, 보라색 부분 제외 모든 곳) 이다.
Box Regression Output : 아래 그림의 설명에서 추가적으로, S는 a normalization constant 이다. S는 경험적으로 4라고 찾아냈다고 한다. S를 왜 사용했는지는 구체적으로 나와있지 않는다. (대략 최종으로 나오는 d_t, d_l .. 값들이, objectness score와 비슷한 값 분포를 가지게 하려는 건가?)
inference 를 수행하는 동안에는…
straightforward to decode the predicted boxes (위에서 했던 방식을, 그대로 반대로 해주면 된다. 마치 조립은 분해의 역순처럼!)
Box Regression 예측값 찾기
Classification Score : 각 1x1 공간에 대해서 the maximum score 를 사용한다.
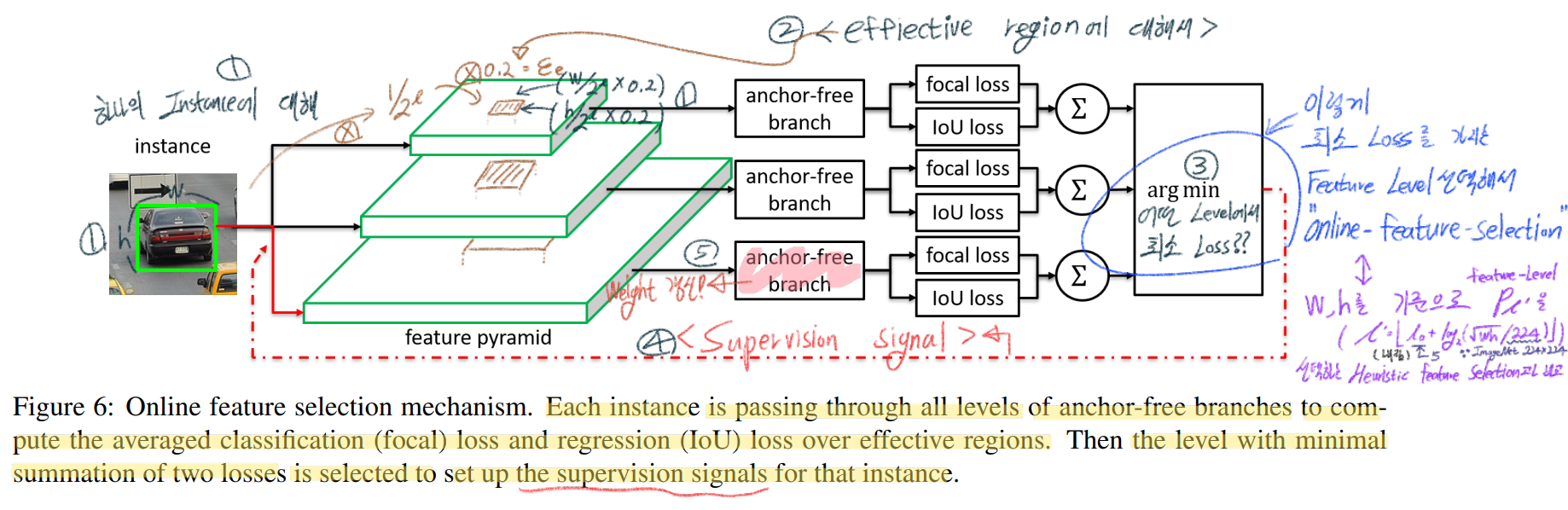
3.3. Online Feature Selection
how to dynamically select feature level for each instance
위 그림에서 보라색 필기를 추가 설명하자면, online-feature-selection 방법이 효과적이다. 라는 것을 증명하기 위해서, 자체적으로 heuristic feature selection을 만들어 실험해 보았다. 두 방법을 비교한 결과는 아래의 Result에서 소개될 예정이다.
Supervision siginal을 보내는 방법은, 이렇다. 최소 Loss를 가지는 Lavel을 l* 라고 하자. 그렇다면 P_l*의 effective region의 결과에 대해서만 Loss를 계산하고 nn.optimize(Loss) 를 적용해주면 된다.
3.4. Joint Inference and Training
how to jointly train and test anchor-free and anchor-based branches
Inference
each pyramid level에 대해서 top-score를 가지는 1k를 선출한다.
그것들에 대해서, (0.05 confidence score) thresholding을 수행한다.
anchor-based branches에서도 위의 1번2번 과정과 같은, “top predictions”을 수행한다.
이렇게 찾아낸, 모든 BB들에 대해서, non-maximum suppression을 수행한다.
Initialization
(정확히 뭔소린지 모르겠다. 이걸 코드로 확인해 보아야 하나?)
classification 에 대해서, bias = log((1 − π)/π) and a Gaussian weight filled with σ = 0.01. 여기서 π는 학습 초기에 모든 픽셀에 대한 objectness score output을 π라고 했단다.
box regression 에 대해서, bias = b, and a Gaussian weight filled with σ = 0.01.
initialization을 정확하게 하는 것은, 학습 초기에 large loss를 막음으로써, network learning을 안정화시키는데 도움을 준다.
Optimization:
Loss는 Total Loss로써 아래의 수식을 사용한다.
아래에서, Iterations 가 의미하는게 정확하게 뭔지는 모르겠지만, epoch는 아닌것 같고, 1 mini-batch 학습을, 1 iterations라고 보면 될 듯 하다.
4. Experiments
COCO dataset 을 사용해서, 성능을 비교하였다.
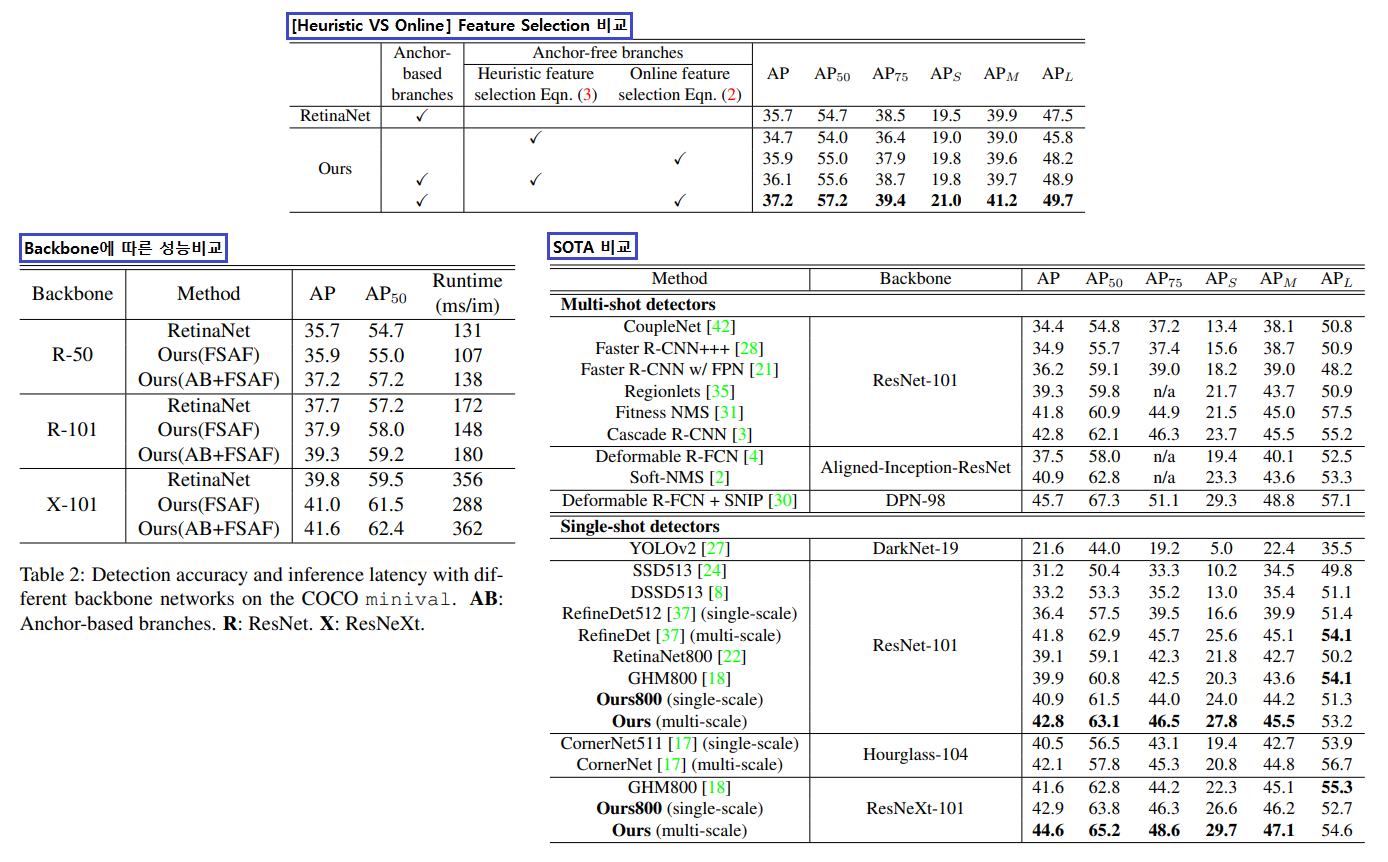
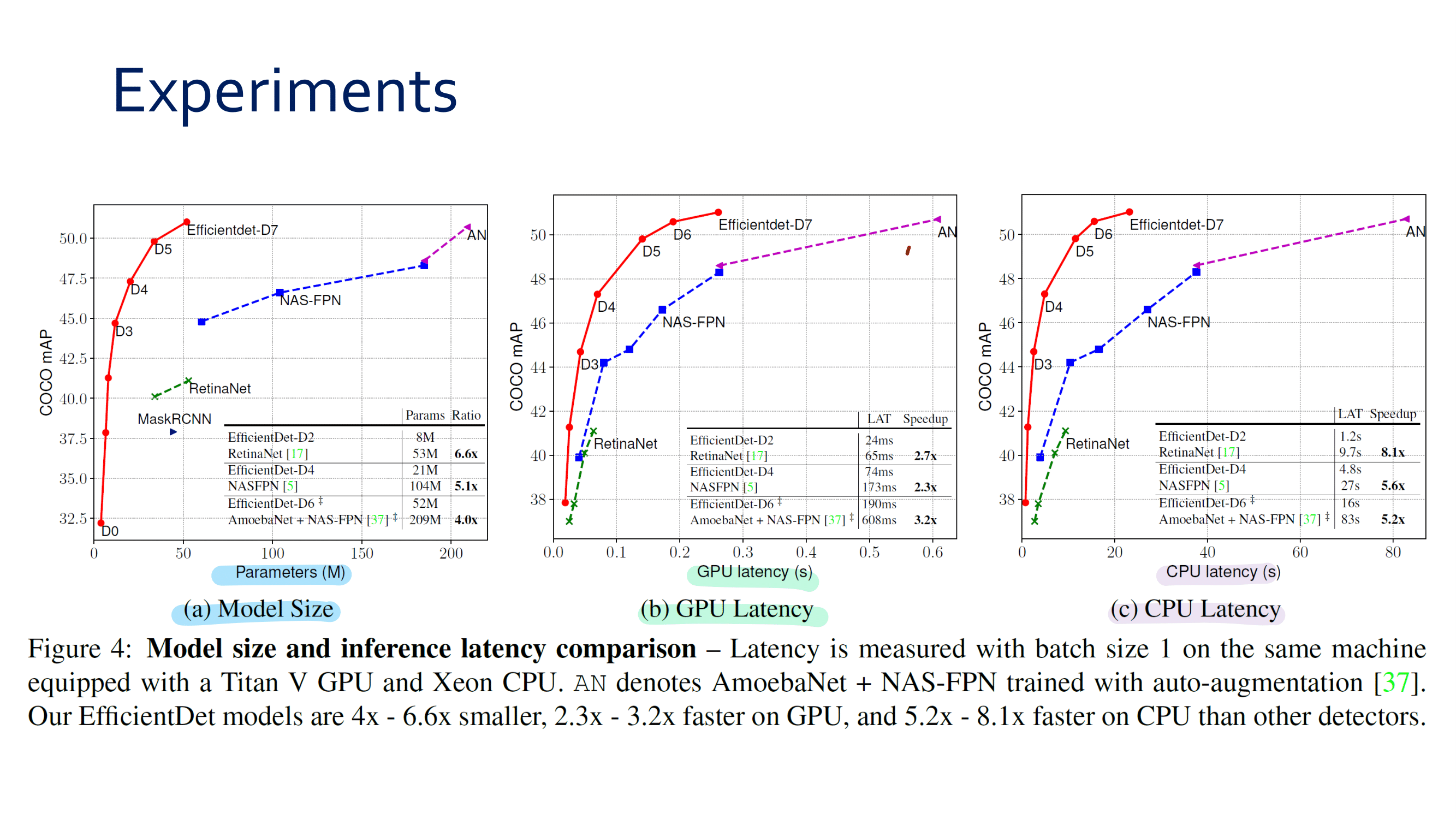
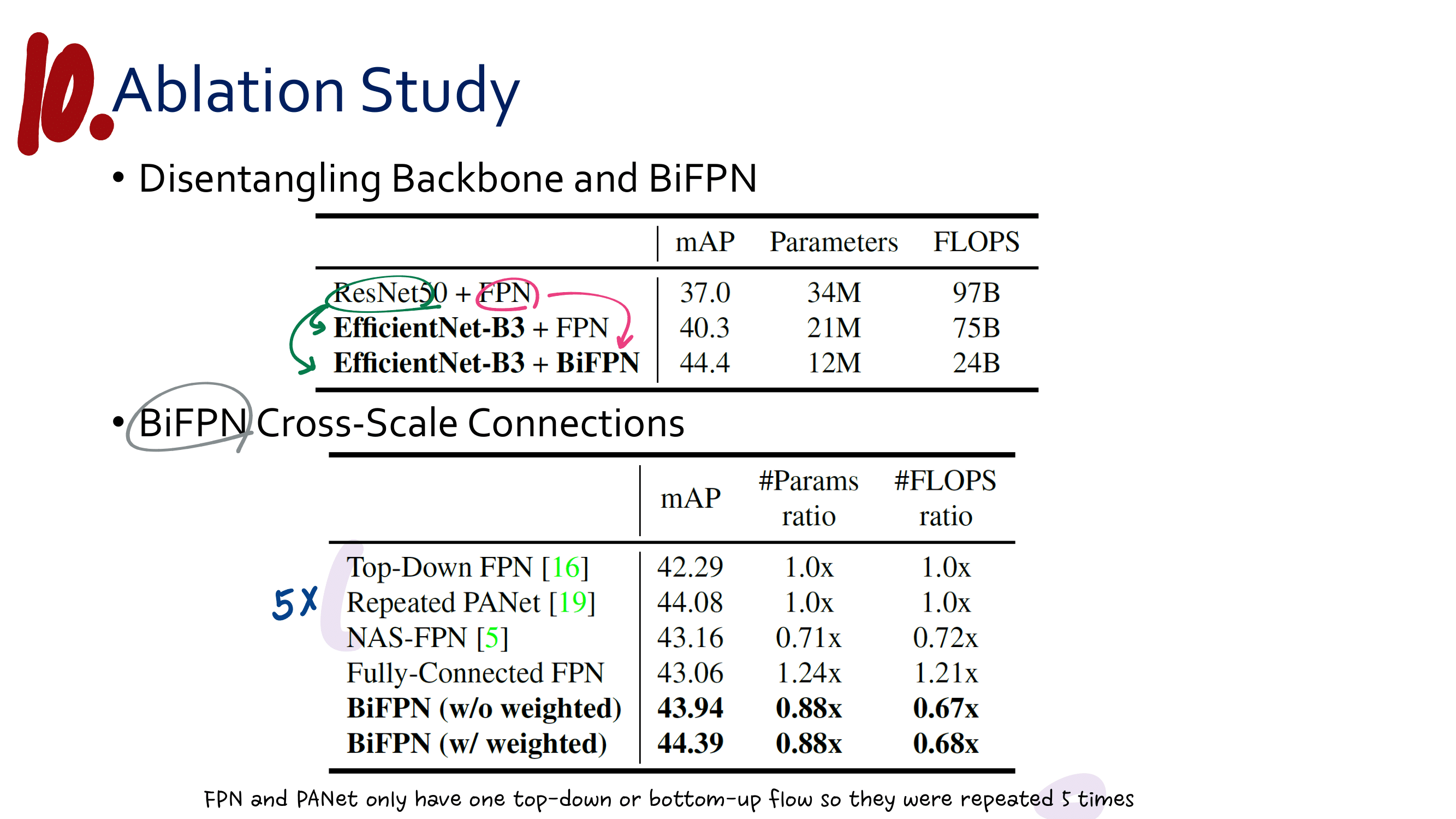
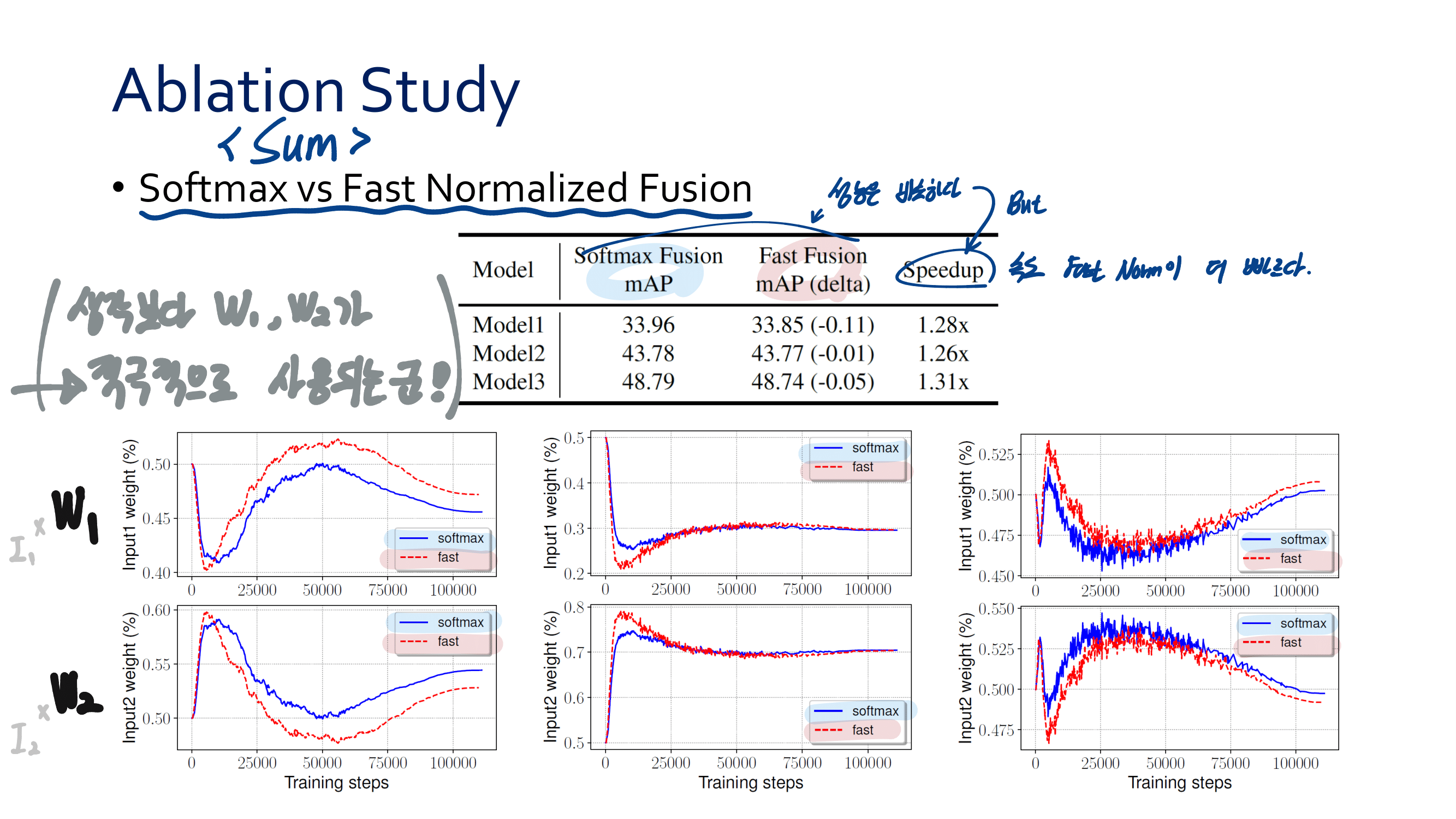
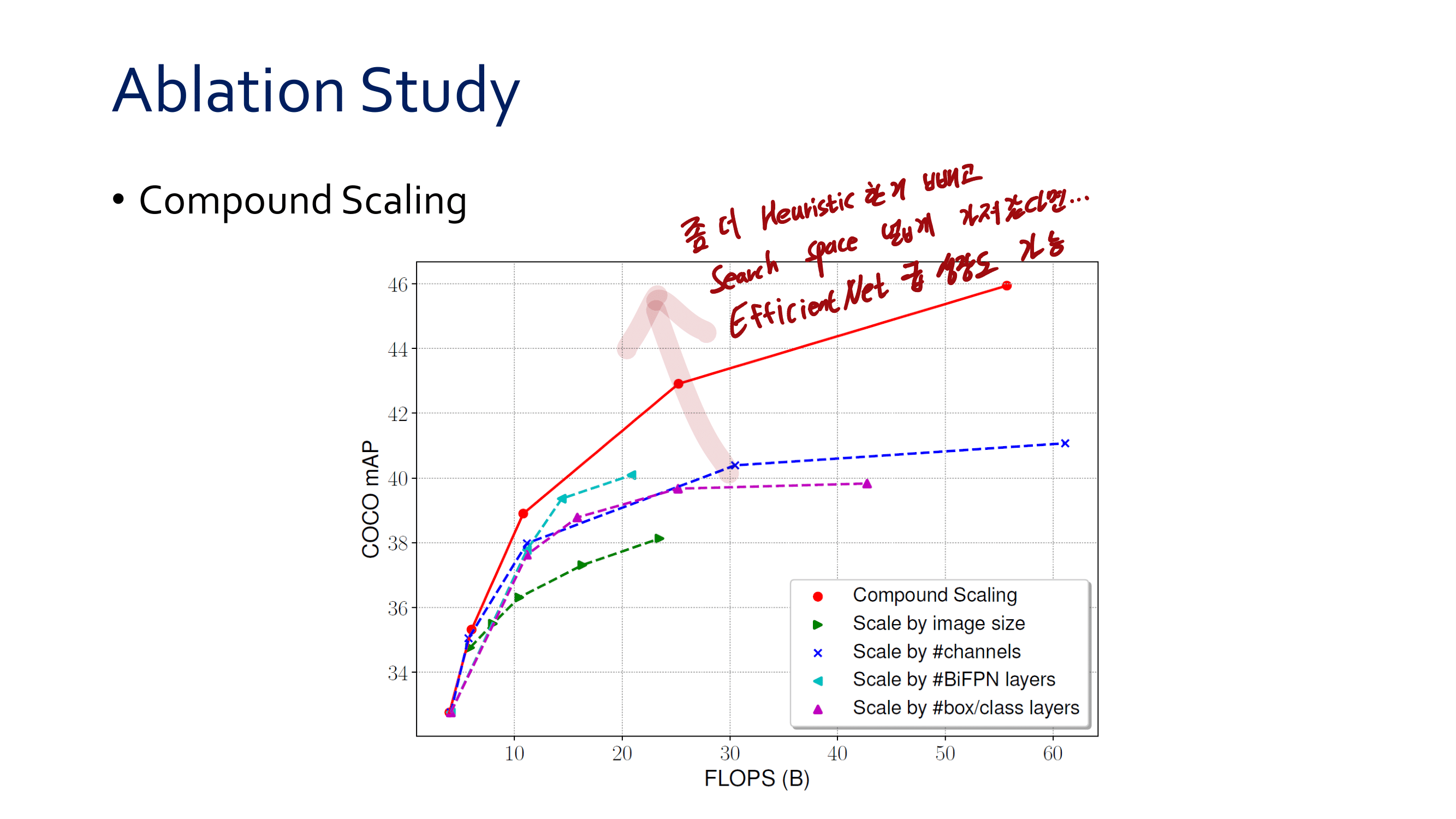
Ablation studies 를 통해서 내린 결론 (맨 위 표)
Anchor-free branches are necessary.
Online feature selection is essential.
How fast? : 위 표 중, 아래 오른쪽 표를 살펴보면 RetinaNet(AB) 와 Ours(AB + FSAP) 의 Runtime 차이가 그리 크지 않은 것을 확인할 수 있다.
How is optimal feature selected?
아래의 그림을 참고하자.
the optimal pyramid level selected for instances 을 선택하는 것이 과연 얼마나 중요할까? 물론 왼쪽아래 표를 참고하면 이해할 수도 있기도 하지만, 아래의 사진을 통해서 이해해보자.
아래의 그림의 Bounding box annotation에서 Class 이름 옆에 있는 숫자는 P_l에서 l (feature level)을 의미한다.
아래의 그림을 통해서, 대체적으로 online feature selection 또한 [ 크기가 큰 객체는 높은 l 에서 검출이 되고, 크기가 작은 객체는 낮은 l 에서 검출되는, 아주 기본적인 원리 ] 를 만족하는 것을 확인할 수 있다.
하지만 빨간색 박스는, anchor-based branch에서 선택된 l (feature level) 과 FSAF module에서 선택된 l 이 다른 경우에 빨간색 박스를 처 놓았다. 이런 것을 봤을 때, 그리고 FSAF를 사용해 성능향상이 되는 것을 보았을 때, heuristic 뿐만아니라, online feature level selection 도 Object Detection에 필요하다는 것을 확인할 수 있다.
Comparison to State of the Art
scale jitter over scales {640, 672, 704, 736, 768, 800} and for 1.5× longer than the models 이라는 방법을 사용해서 모델을 학습시켰다. 라고 논문에 나와있다.
내 추축으로 생각해봤을 때, 우선 네트워크는 an image scale of 800 pixels for both training and testing에 특화되게 학습시킨다.
그리고 원본이미지를 좀 더 작은 {640, 672, 704, 736, 768, 800} 사이즈를 가지는 이미지로 바꿔서 학습시킨 후. 나중에 원래 이미지 크기인 {400, 500, 600, 700, 900, 1000, 1100, 1200} 사이즈를 가지는 이미지를 가지는 이미지를 학습시킴으로써, 좀 더 small scale instance 를 검출하는데 효과적인 Network로 학습시키지 않았나 싶다.
여기서도 single-scale testing (800 pixels) 그리고 multi-scale testing ({400, 500, 600, 700, 900, 1000, 1100, 1200}) 를 적용했을때의 성능비교가 위의 (왼쪽 아래) 표에 잘 적혀있다.
2월 22일~26일에 현대 모비스 마북연구소로 현장실무연수를 다녀오기로 배정이 났다. 5일 동안 연구할 주제를 정해야 한다고 이야기를 들었다. 원래는 Object Detection(이미 거의 다 봤고), Image Segmentation을 이번달 까지 계속 보고, 다음달 부터 내가 하고 싶은 분야를 딱 정해서 공부할 예정이었으나, 예정보다 빠르게 연구주제를 정해야할 듯 하다. 내가 해야야 할 것들을 아래와 같이 정리해보았다.
Object Detection 계보 다 읽기
(계보는 어느정도 다 읽음) YoloV4에 있던, 추가로 읽어야 하는 논문 찾아 읽기 (AnchorFree)
연구실
연구실 과제
내가 맡을 과제 or 나중에 하고 싶은 과제 알아보기
과제와 관련된 논문 미리 읽고 공부하기
연구실 선배님들 연구주제 알아두기
$ 메모
- depth 라는 표현은 좋지 않다. 우리 연구실에서 거의 아무도 하지 않는다.
- 3D로 접급해보자.3D도 indoor area(3D reconstruction)가 있고 outdoor area(self-driving)이 있다.
- 3D를 하시는 분도 너무 제한적이다.(reconstruction하시는 분들이 대부분이다.) 같은 주제로 가져가려고 하기보다는, 비슷하면서도 내가 정말 하고 싶은 분야로 선택해서, 원하는 분야의 다른 논문들을 찾아보는것도 좋겠다.
- 라고 생각하면서도, 석사 과정 동안은 꼭 내가 원하는 분야를 해야하나?? 라는 생각이 든다. 현명한 선택은 최대한선배님들과 유사한 연구방향으로 선택하는 것 같다. 하고 싶은건 나중에 하면 되는 거다.
- 어차피 과제가 정해진다 하더라도, 꼭 과제랑 내 분야가 일치할 수는 없다. 꼭 원하는 과제만 할 수 있는 것도 아니다.
- RGB-Depth camera가 쓸모가 없다. 최대 거리가 겨우 4~9m ...
- 그렇담.. 내가 정말 하고 싶은게 뭐냐?
- Google Scholar -> 3d object detection survey driving
- paper : A Survey on 3D Object Detection Methods for Autonomous Driving Applications
- https://paperswithcode.com/task/3d-object-detection-from-stereo-images
3D-Object Detection 논문 읽기 찾아 읽기
Vision Transformer 논문 읽기
vision transform
Domain adaptation / Active Learning 논문 읽기
Domain Adaptive Semantic Segmentation Using Weak Labels
ViewAL: Active Learning With Viewpoint Entropy for Semantic Segmentation
Object Tracking + 추천 받은 논문 읽기
bert
rethinking sementic segmentation
Trackformer - multi object tracking
re-ID
Image Segmentation 논문 다 읽기
Instance Segmentation 계보 다 읽기
혹은 the devil in boundary 논문에 있던, 추가로 읽어야 하는 논문 찾아 읽기
이렇게 정리를 하고 나서, 이런 결론을 내릴 수 있었다. [일단 2번의 ‘내가 맡을 과제 or 나중에 하고 싶은 과제 알아보기’ 를 하는게 가장 시급하다. 월.15, 화.16, 수.17 이내에 이것이 확정되면 그 이후에 다시 생각해 보자.] 그 전에는 그냥 그날 읽고 싶은 논문 순서대로 읽자 어차피 다~ 읽을 건데, 뭘 먼저 읽고 뭘 나중에 읽고는 의미가 없는 것 같다. 그냥 읽자. 계획 짜고 순서 짠다고 시간 버리지 말고. 그냥 하자.
그리고 교수님과의 면담과 1학기 수업에서 개인 프로젝트 및 과제를 하기 위해서는, 일단 연구 주제 확정해서 지금부터 한달 동안은 확정한 연구 주제만 미친 듯이 공부해야겠다.
Basic한 기초 내용 (선형대수, Basic Segmentation)는 나중에 시간날 때마다 틈틈히 공부하면 된다.
“나 자신을 위해 살지 말아라. 이미 놀거 다 놀고, 잘거 다 잤다. 사랑하는 사람을 위해 누구보다 독하게 살아라. 너의 부족함으로 인해 생기는 ‘이별의 고통’ 또는 ‘사랑하는 사람의 피눈물을 바라봐야 하는 고통’은 이 세상 그 어떤 고통보다 힘들고 아픈 고통이니까.”
“그냥 해라. 그냥 시작해라. 아무 생각도 하지 말아라. 그냥 읽어라. 그리고 조금만 더 해라.”
막연하게 3D detection이라는 한 분야가 있는 줄 알았는데, 생각보다 많은 분류가 존재했다. 그리고 상용화까지는 힘든 성능의 모델들이 대부분이었다. 이 분야도 거의 다 완성된게 아니라.. 아직도 연구할게 많구나. 라는 생각이 들었다.
만약 3D를 하고 싶다면, 그냥 가장 최신 논문 먼저 읽고 하나하나 따라 내려가는게 나을듯 하다. 여기 있는 논문 계보는 배경지식으로만 가지고 있자.
PS : 필기된 논문은 [21.겨울방학\RCV_lab\논문읽기] 참조
A Survey on 3D Object Detection for Autonomous Driving
1. Conclusion, Abstract, Introduction
논문 전체 과정 : sensors들의 장단점, datasets에 대해서 알아보고, (1) monocular (2) point cloud based (3) fusion methods 기반으로 Relative Work를 소개한다.
3D object Detection에서 나오는 depth information 정보를 통해서 만이, path planning, collision avoidance 를 정확히 구현할 수 있다. 자율주행을 하려면 (1) identification=classification (2) recognition of road agents positions (e.g., vehicles, pedestrians, cyclists, etc.) (3) velocity and class 들을 정확히 알아야 한다.
failure in the perception(인식 실패)는 sensors limitations 그리고 environment(domain) variations에 의해서, 또는”objects’ sizes”, “close or far away from the object” 등과 같은 요인에 의해서 발생한다.
2. Sensors and Dataset
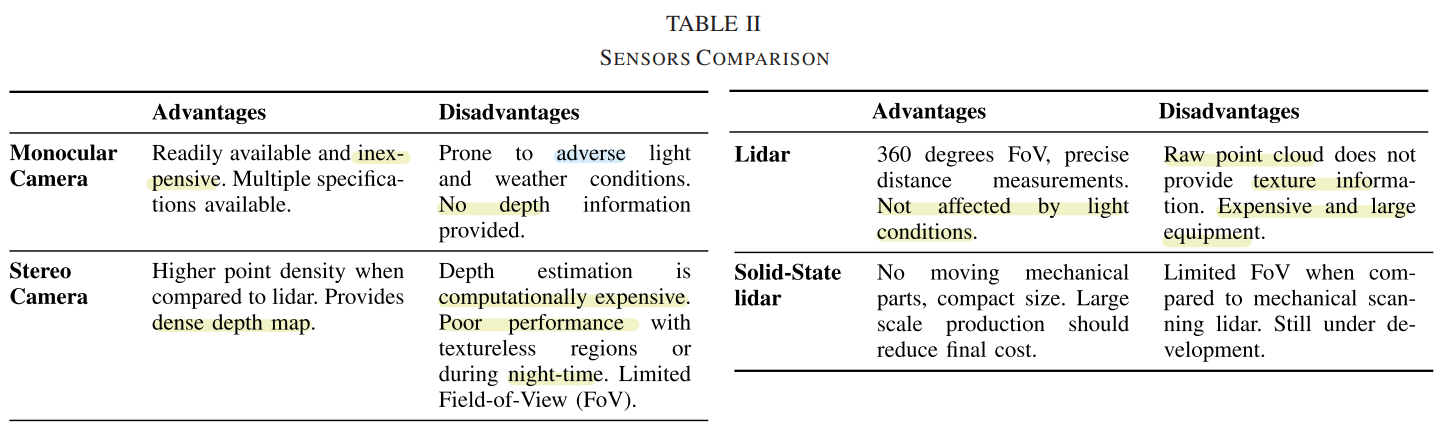
Sensors
각 센서의 장단점 비교.
Calibration 추천 논문 : “LiDAR and camera calibration using motion estimated by sensor fusion odometry”
Dataset
KITTI
Sensor calibration, Annotated 3D bounding box 를 제공한다.
Categrized in easy, moderate, hard (객체 크기, 겹칩, 가려짐의 정도에 따라서).
거의 대부분 주간 주행. Class unbalance가 심각하다. Predominant orientation 이다. (대부분의 객체가 같은 방향을 바라보고 있다.)
Virtual KITTI
직접 게임 엔진을사용해서 KITTI의 이미지와 똑같은 가상 사진을 만들었다.
이 사진에서 Lighting, 날씨 조건, 차의 색 등을 바꿀 수 있다.
두개 데이터에 대해서 Transferability를 측정해본 결과, 학습과 테스트를 서로에게 적용했을때 성능 감소가 크게 있지 않았다.
Virtual KITTI로 학습시키고, KITTI로 fine-tunning을 해서 나온 모델로 test해서 가장 좋은 성능을 얻었다.
Simulation tool
game-engines GTA5 (SqueezeSeg [34])
Multi Object Tracking Simulator : “Virtual worlds as proxy for multi-object tracking analysis,”
autonomous driving simulator : CARLA-“CARLA: An open urban driving simulator-2017”, Sim4CV-“Sim4CV: A photo-realistic simulator for computer vision applications-2018”
3. 3D Object Detection Methods
아래의 전체 분류 Table 참조
3-A Monocular Image Based Methods
우선 아래의 Table 참조
대부분의 탐지 방식 : Region Proposal(2D) -> 3D model matching(3D detection) -> Reprojection to obtain 3D bounding boxes
문제점(이것을 해결하기 위해 아이디어를 계속 생각해 봐야겠다) : 이미지에 Depth 단서가 부족해서, 먼 객체, 멀어서 작은 객체, 겹치는 객체, 잘리는 객체 탐지에 힘듬. Lighting과 Weather condition에 매우 제한적임. 오직 Front facing camera만을 사용해서 얻는 정보가 제한적이다. (Lidar와 달리)
3DOP [43, 2015] : 원본 이미지에서 3D 정보를 추출하는 가장 기본적인 방법. 필기에서는 이 방법을 0번이라고 칭함.
Mono3D [39, 2016] : 3DOP를 사용한다. Key Sentence-“simple region proposal algorithm using context, semantics, hand engineered shape features and location priors.”
Pham and Jeon [44, 2017] : Keypoint-“class-independent proposals, then re-ranks the proposals using both monocular images and depth maps.” 위의 1번 2번보다 좋은 성능 얻음.
3D Voxel Pattern = 3DVP [41, 2015] : 3D detection의 가장 큰 Challenge는 severe occlusion(객체의 겹침, 잘림이다) 이것을 문제점을 해결하기 위한 논문. 객체가 가려진 부분을 recover하기 위해 노력했다. 2D detect결과에 3D BB결과를 project할 때의 the reprojection error를 최소화함으로써 성능을 높였다.
SubCNN [45, 2017] : 3DVP의 저자가 만든 방법으로, Class를 예측하는 RPN을 사용한다. 그리고 3DVP를 사용해서 똑같은 3D OD를 거친다.([45]논문에 의하면, 2D Image와 Detection결과에서 Camera Parameter를 사용해서 3D 정보를 복원한다고 한다.)
Deep MANTA [42, 2017] : a many task network to estimate vehicle position, part localization and shape. 다음의 과정을 순서대로 한다고 한다. 2D bounding regression -> Localization -> 3D model matching (Imbalance한 vehicle pose(데이터에서 vehicle pose가 거의 비슷)의 문제점을 해결하기 위해서)
Mousavian et al. [40, 2017] : standard 2D object detect 결과에다가 추가로 3D orientation (yaw) and bounding box sizes regression (the network prediction Branch)만을 추가해서 3D bounding box결과를 추론한다. orientation을 예측하는데, L2 regression 보다는 a Multi-bin method 라는 것을 제안해서 사용했다고 한다.
360 Panoramic [46, 2018] : 옆, 뒤 객체도 탐지하기 위해서, 360 degrees panoramic image 사용한다. 데이터 셋 부족 문제를 해결하기 위해서 KITTI 데이터를 Transformation한다.
3-B. Point Cloud Based Methods
우선 아래 테이블 참조
Projection 방법은 Bird-eye view를 사용하거나, 이전에 공부했던 SqueezeSeg와 같은 방법으로 3D는 2D로 투영하여 Point Clouds를 사용한다. 이러한 변환 과정에서 정보의 손실이 일어난다. 그리고 trade-off between time complexity and detection performance를 맞추는 것이 중요하다.
Volumetric methods는 sparse representation(빈곳들이 대부분이다)이므로 비효율적이고 3D-convolutions를 사용해야한다. 그래서 computational cost가 매우 크다. 3D grid representation. shape information를 정확하게 encode하는게 장점이다.
PointNet과 같은 방법은 using a whole scene point cloud as input 이므로, 정보 손실을 줄인다. 아주 많은 3D points를 다뤄야 하고 그 수가 가변적이다. 정해진 이미지 크기가 들어가는 2D-conv와는 다르다. 즉 points irregularities를 다뤄야 한다 [61]. 최대한 Input information loss를 줄이면서.
Projection via plane [47, 2017]
Projection via cylindrical [48, 2016] : bird-eye view 이미지를 FCN하여 3D detection을 수행한다. 자동차만 탐지한다. channel은 Point의 hight(높이)에 맞춰서 encoding된다. (예를 들어 3개의 채널을 만들고, 높은 points, 중간 높이 points, 낮은 높이 points) FCN을 통해서 나오는 결과는 BB estimates이고 NMS를 거쳐서 objectness and bounding box를 추론한다.
Projection via spherical [49, 2017]
3D-Yolo [30, 2018] : Encoding minimum, median and maximum height as channels. 그리고 추가로 2개의 channels은 intensity and density(해당 bird-eye view구역에 겹쳐지는 point의 객수 인듯). yolo에서 the extra dimension and yaw angle를 추가적으로 더 예측하는 inference 속도를 중요시하는 모델.
BirdNet [51, 2018] : [50, project이미지를 Faster RCNN처리]을 기반(기초논문)으로 해서, Normalizes the density channel를 해서 성능 향상을 얻음.
TowardsSafe [53, 2018] : Noise와 같은 불확실성을 보완할 수 있는 dropout을 적극적으로 사용하는 Bayesian Neural Network을 사용. 이러한 ‘확률적 랜덤 불확실성 모델’을 사용함으로써 noisy sample에 대해서 성능 향상을 얻을 수 있었다. [여기까지가 Projection Methods]
3DFCN [54, 2017] : 이미 가공된 a binary volumetric input를 사용한다. 해당 voxel에 vehicle이 ‘있고 없고’를 판단하는 binary 값을 사용해서, vehicle 밖에 검출하지 못한다. objectness and BB vertices predictions를 예측한다.
Vote3Deep [55, 2017] : one-stage FCN. class는 차, 보행자, 자전거 끝. 각각의 Class에 대해서 고정된 크기의 BB만을 사용한다. 그리고 하나의 class만을 감지하는 모델을 각각 학습시킨다. 복잡성을 감소시키고 효율성을 증가시키기 위해 sparse convolution algorithm라는 것을 사용한다. Inference할때는 위의 각각의 모델을 parallel networks로써 추론을 한다. data augmentation, hard negative mining을 사용한다. [여기까지가 Volumetric Methods]
PointNet[56, 2017], PointNet++ [59, 2017]. 더 발전된 것 [60, 2018] convolutional neural networks for irregular domains [61, 2017] : Segmented 3D PCL(전통적인 기법의 Point cloud library를 사용한) 기법을 사하여 classification(not detection) and part-segmentation을 수행한다. 그리고 Fully-Connnected layer를 통과시키고, max-pooling layer를 통과시킨다.
VoxelNet [62, 2017] : classification(PointNet)이 아니라, detection을 수행. raw point subsets사용한다. each voxel에서 랜덤으로 하나의 point를 설정한다. 그리고 3D convolutional layer를 통과시킨다. cars and pedestrians/cyclists 탐지를 위해서 Different voxel size를 가지는 3개의 model을 각각 학습시킨다. 그리고 Inference에서는 3개의 model을 simultaneously 사용한다.
Frustum PointNet [63, 2018] : imaged에서 추론한 결과를 기준으로 sets of 3D points를 선별해 사용하기 때문에 Fusion method로 나중에 다룰 예정이다. [여기까지가 PointNet Methods]
3-C. Fusion Based Methods
우선 아래 테이블 참조
Points는 texture 정보를 주지 않는다. 즉 classification하기엔 힘들다. 또한 먼 곳에 있는 객체는 point density가 떨어져서, 객체라고 탐지하지 않는다. 이러한 판단은 Image에서의 detect도 방해될 수 있다.
fusion방식에는 아래와 같은 3가지 방법이 있다.(3 strategies and fusion schemes)
Early fusion : 초기에 데이터를 융합하는 방법. 모든 센서데이터에 의존되는 representation 만들고 그것으로 detect를 수행한다.
Late fusion : 각각 predictions을 수행하고 나중에 융합하는 방법. 이 방법의 장점은 ‘꼭 모든 센서 데이터가 있어야만 detect가 가능한 것은 아니다’라는 것이다.
Deep fusion : 계층(hierarchically)적으로 각 센서데이터로 부터 나오는 Feature들을 융합하는 방식이다. Interact over layers라고도 표현한다.
이런 3가지 strategies and fusion schemes에 대해서 [65, 2016]에서 무엇이 좋은지 테스트 해봤다. 2번 late fusion에서 가장 좋은 성능, early fusion에서 가장 안 좋은 성능을 얻었다고 한다.
어찌 됐든, Fusion 방식은 SOTA 성능 결과를 도출해 준다. 라이더와 카메라가 각각 상호보완이 역할을 하기 때문이다.
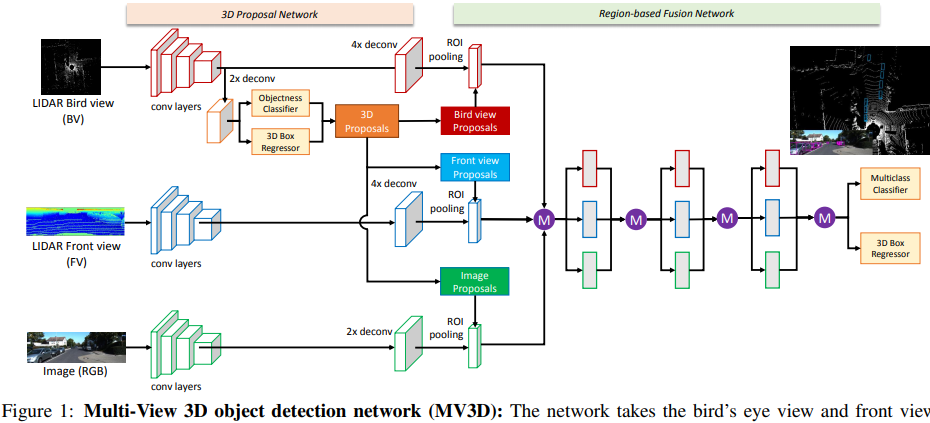
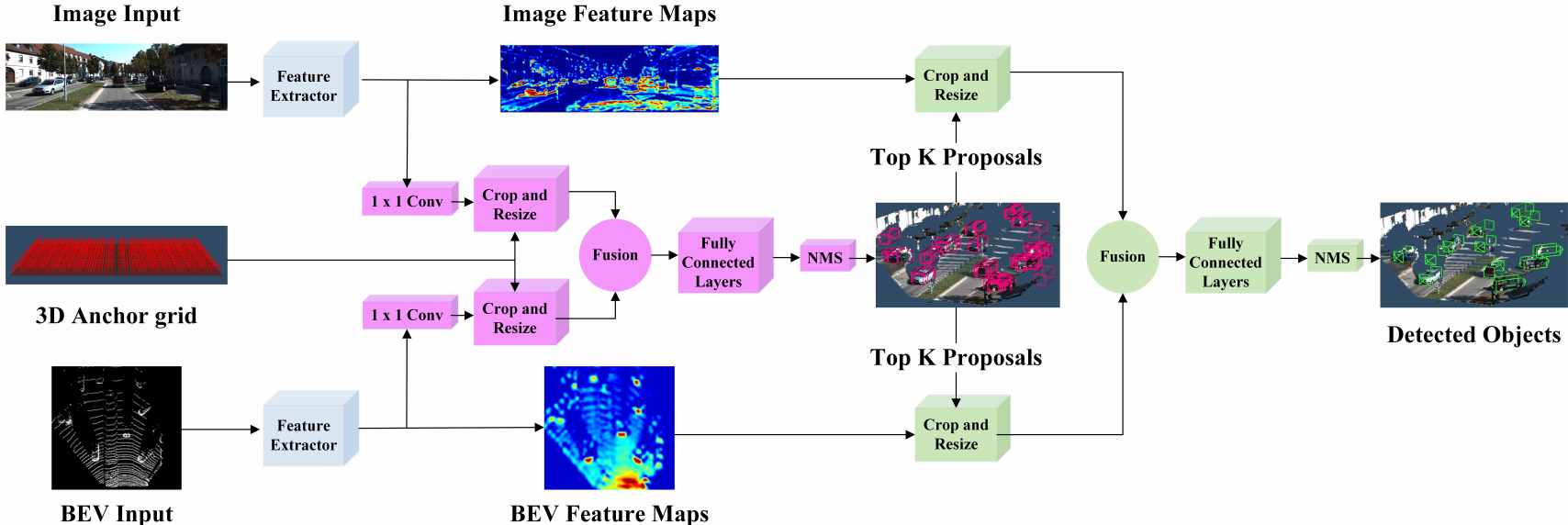
MV3D [64, 2017] : 아래 그림 참조. 아래와 같은 3가지 종류의 input과 3가지 Branch를 가진다. 이 방법은 대표적인 deep fusion 방법이다. 후반의 작업을 보면, 계층적으로 서로서로 상호작용을 하면서 Feature를 얻어가는 것을 볼 수 있다. 이 방법을 통해서 저자는 ‘deep fusion을 통해서 the best performance를 얻었다. 다른 센서로 부터 얻은 정보를 융합하여, more flexible mean을 제공받기 때문이다.’라고 말한다.
AVOD [6, 2018] : 아래 그림 참조. 대표적인 Early fusion방식이다. 중간에 한번 3D RPN과정을 위해 각 센서의 Feature map을 융합하여 the highest scoring region proposals을 얻는다. 이것을 사용해서 최종 Detection 결과를 얻는다. 저자는 small scale 객체 탐지를 위해서 FPN의 upsampling된 feature maps을 사용한다. 또한 이 방법을 통해서 악 조건의 날씨에서도 robustness한 결과를 얻을 수 있다고 한다.
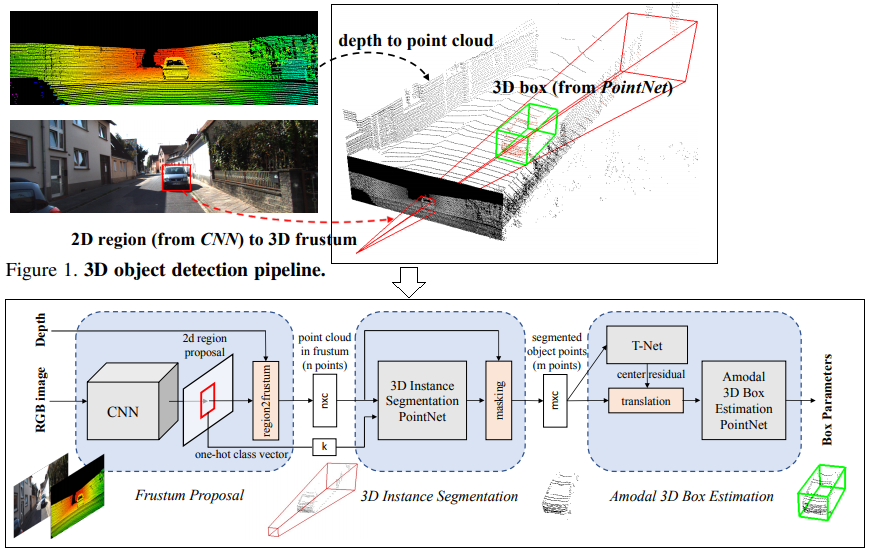
F-PointNet [63, 2018] : 2D 이미지로 부터 region proposals을 뽑아낸다. detected 2D box에 대해서, Camera calibration parameters를 사용해서 3D box ROI를 얻어낸다. 그리고 2번의 PointNet instance를 수행하여, Classification과 3D BB regression 정보를 추출한다.
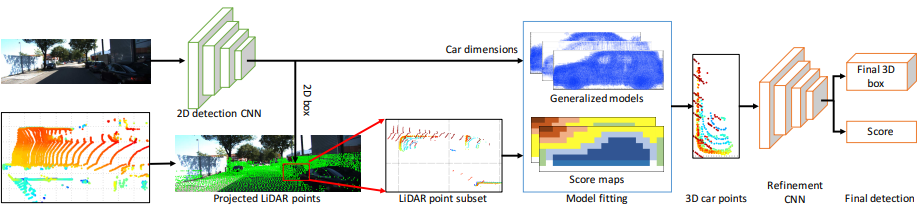
General Pipeline 3D [67, 2018] (상대적으로 인용수 적음) : 이 모델도 위의 F-PointNet과 같이 Image로 부터 Region proposals을 받는다. 이것과 F-PointNet은 Image로 부터 ROI를 받기 때문에 Lighting conditions 요인에 큰 영향을 받는다는 단점이 있다.
4. Evaluation Matrix and Results
Recall과 Precision 그리고 AP = AP2D
Average Orientation Similarity (AOS) : AP2D에서 Orientation performance까지 추가하는 방법. (weighting the AP2D score with the cosine similarity between the estimated and ground-truth orientations.)
3D localization metric (APBV) : localization and bounding box sizes 까지 고려하기 위한 Matrix. bird-eye view로부터 결과를 얻는다.
AP3D : 3D box에 대해서 3D IOU를 계산해서 AP2D와 같은 공식을 적용한다. 하지만 이 방법은 IOU만 고려하고, GT와 predict box의 Orientation estimation을 고려하지 않는다. (Orientation이 많이 달라도 IOU만 크면 Positive라고 판단하는 문제점)
AHS : 4.AP3D와 2.AOS를 융합한 방법이다. (AP3D metric weighted by the cosine similarity of regressed and ground-truth orientations)
[Ps. 논문에서 그림 수식을 제공하는 Matrix만 그림 첨부]
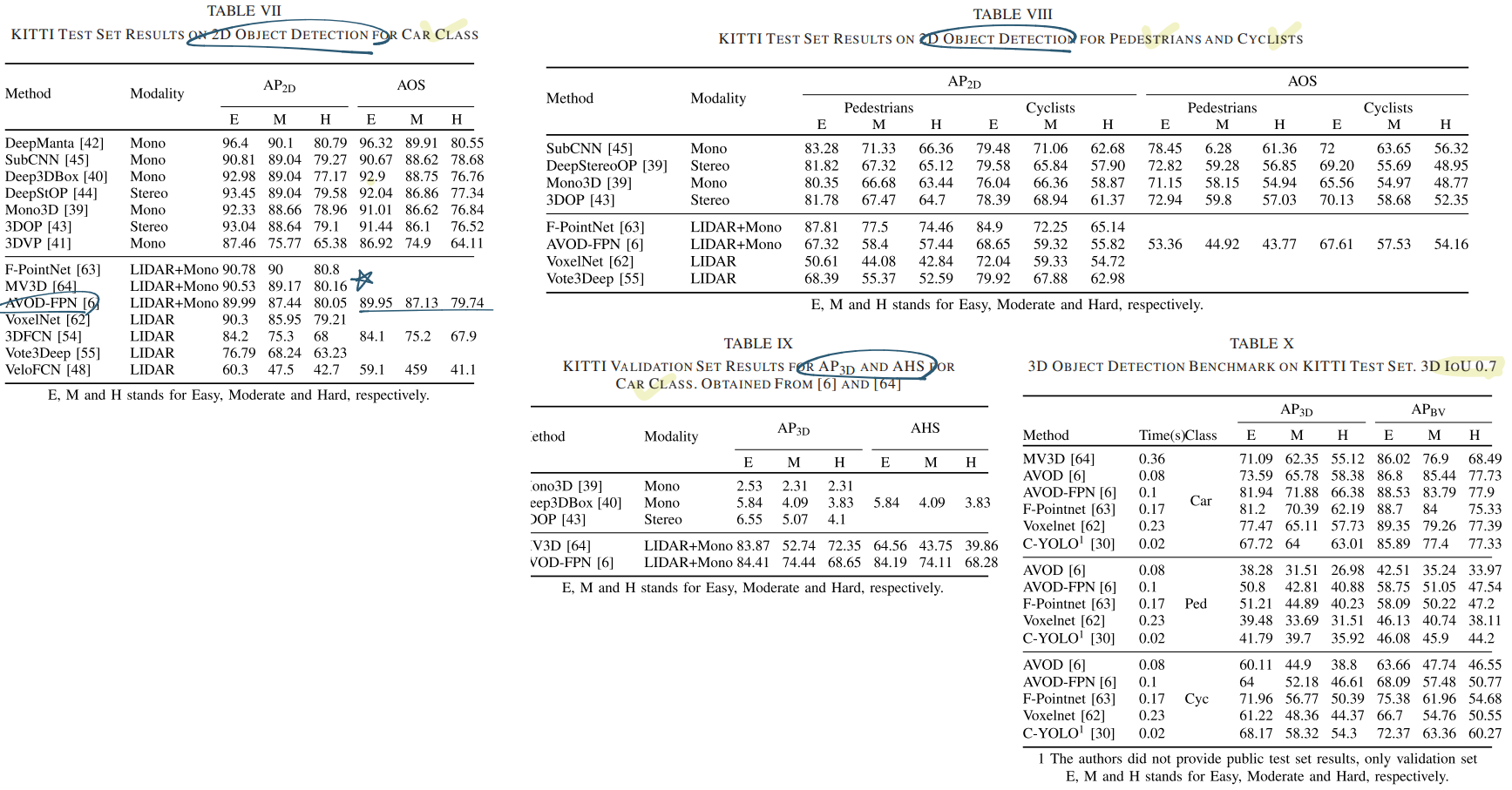
성능 비교를 여기서 보지말고, 최신 3D-Detection 논문을 찾고 거기서 나오는 Results와 Matrix를 공부하자. (일단 아래와 같이 표만 정리해 두었다)
5. Research Challenges
자율주행에 사용할 수 있을 정도로의 Detection performance levels를 획득해야 한다. 따라서 주행의 안정성과 Detection performance를 연관시켜서 정량화 할 것 인지? 에 대한 연구도 필요하다. (how detection performance relates to the safety of driving)
Points에 대한 the geometrical relationships가 탐구되어야 한다. Point clouds를 살펴보면, missing points and occulsion, truncation이 많기 때문이다.
Sensor fusion 뿐만 아니라, V2X 와 같은 multi-agent fusion scheme이 수행되어야 한다.
KITTI는 거의 daylight에 대한 데이터 뿐이다. 일반적이고 전체적인 Conditions에서의 안정적은 성능을 달성하기 위해서 노력해야 한다. 시뮬레이션 툴을 사용하거나, Compound Domain Adaptation 등을 이용한다.
Real time operation을 위해서는 적어도 10fps 이상의 속도 능력이 필요하다. real time operation을 유지해야한다.
uncertainty in detection models을 정확히 정량화해야한다. calibrated confidence Score on predictions와 실제 주행 인지에서의 Uncertainty와의 gap은 분명히 존재한다.
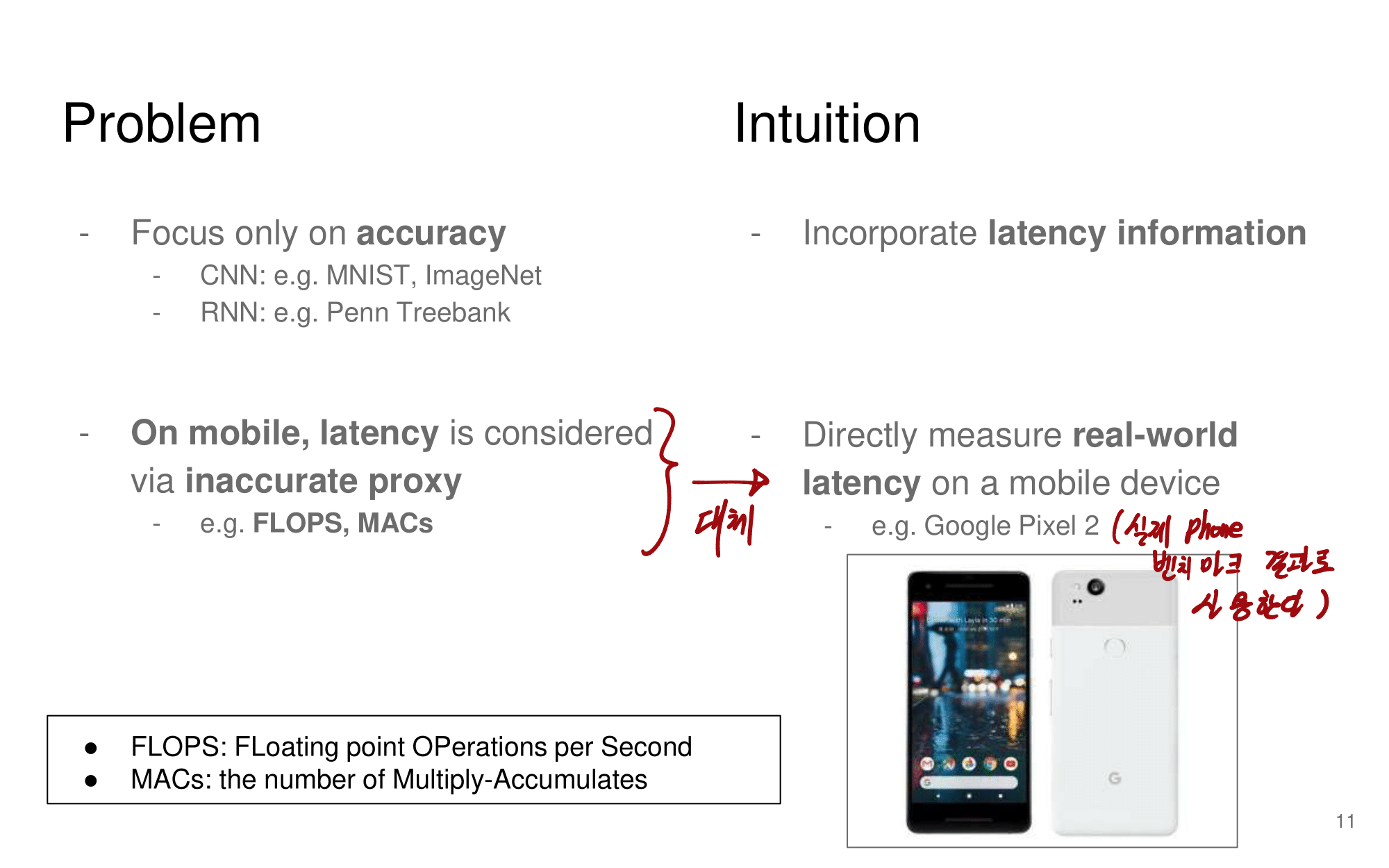
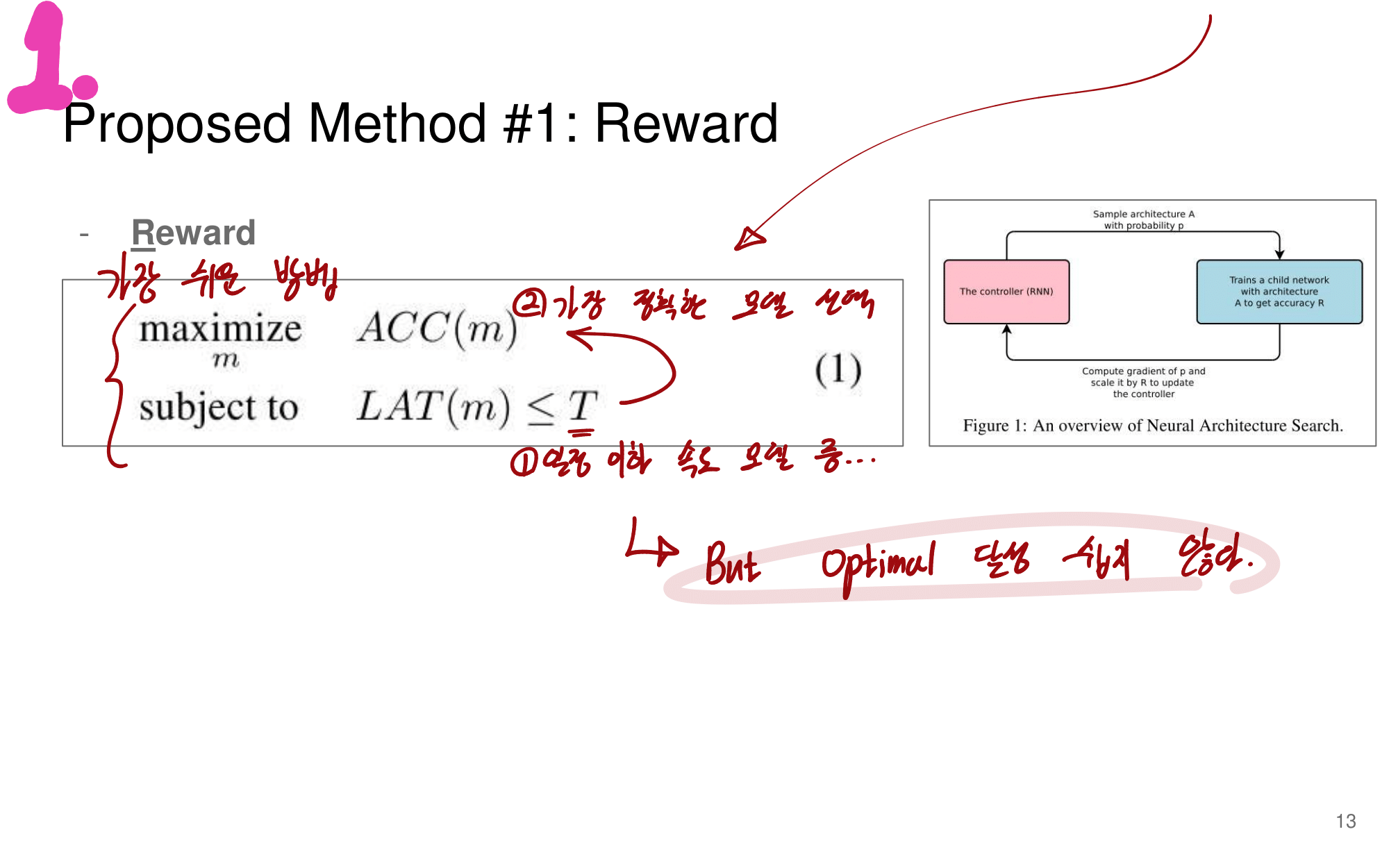
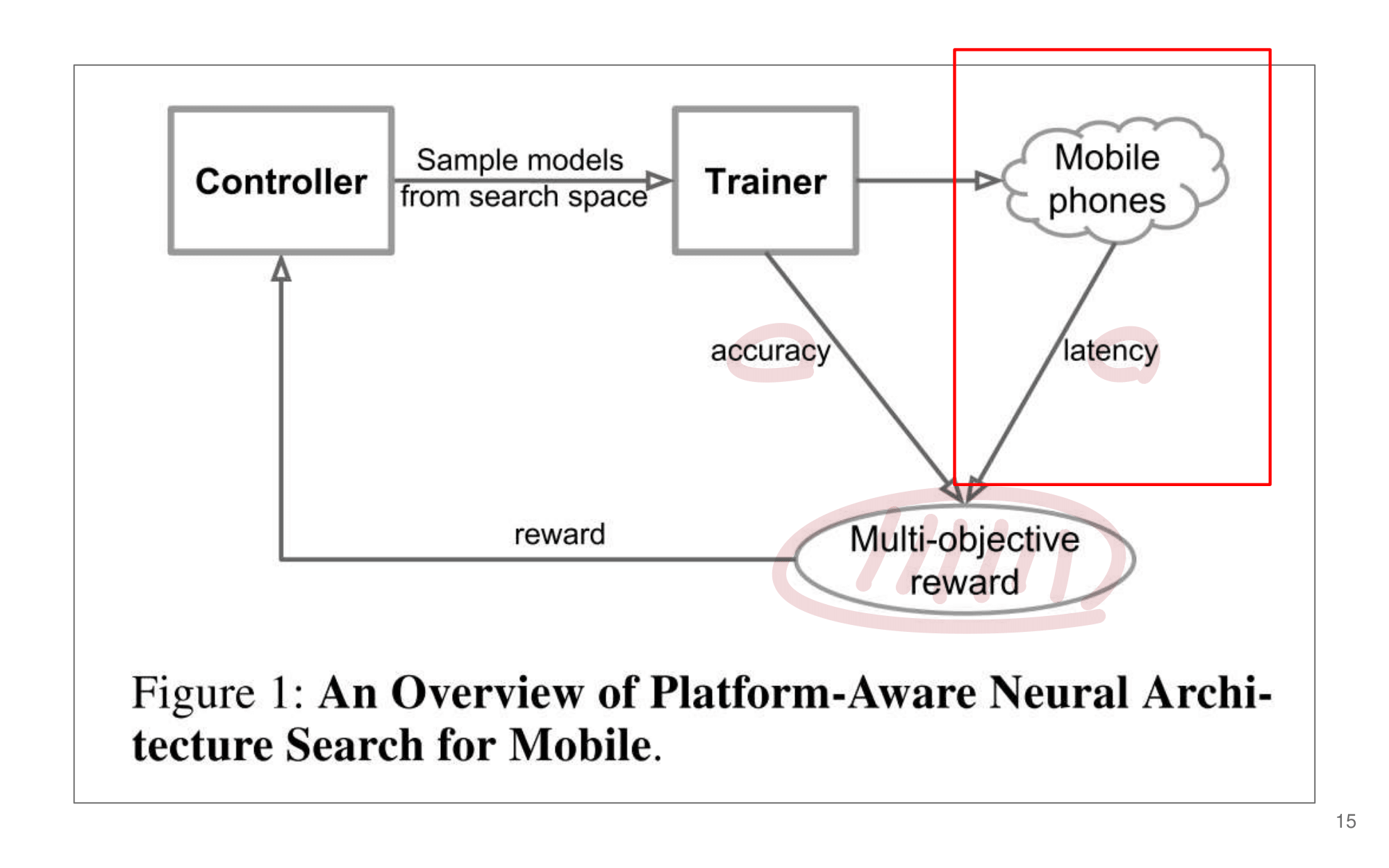
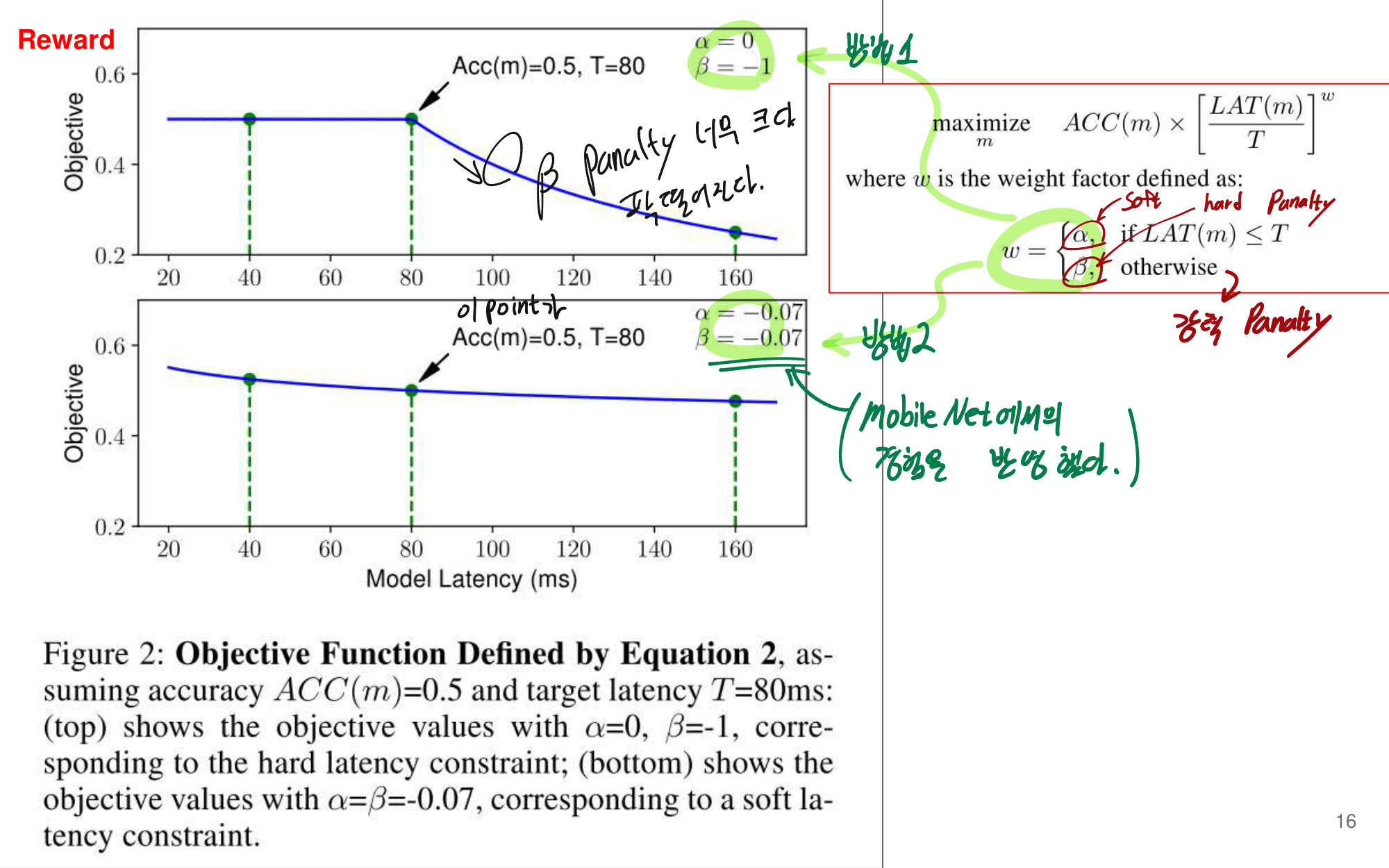
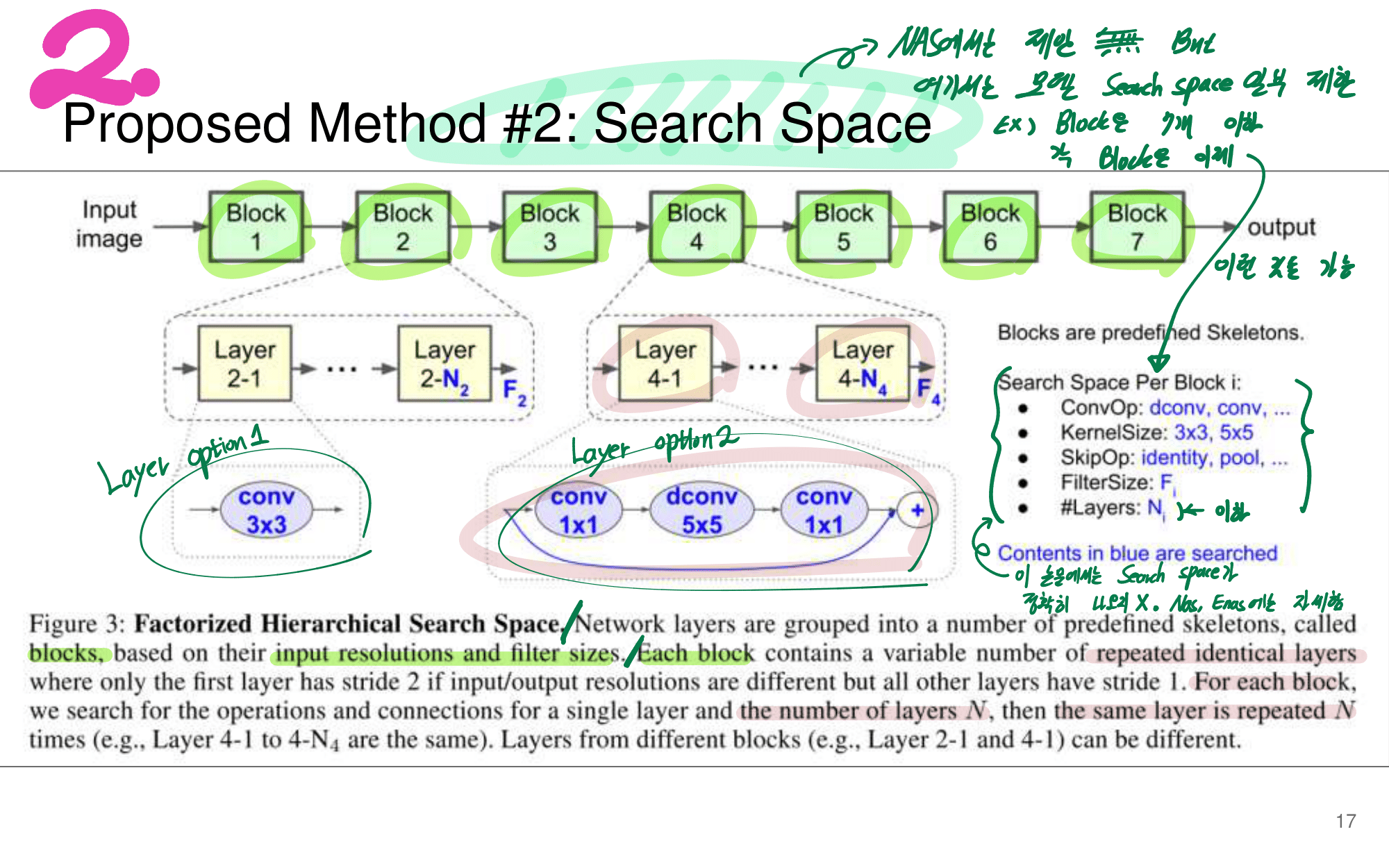
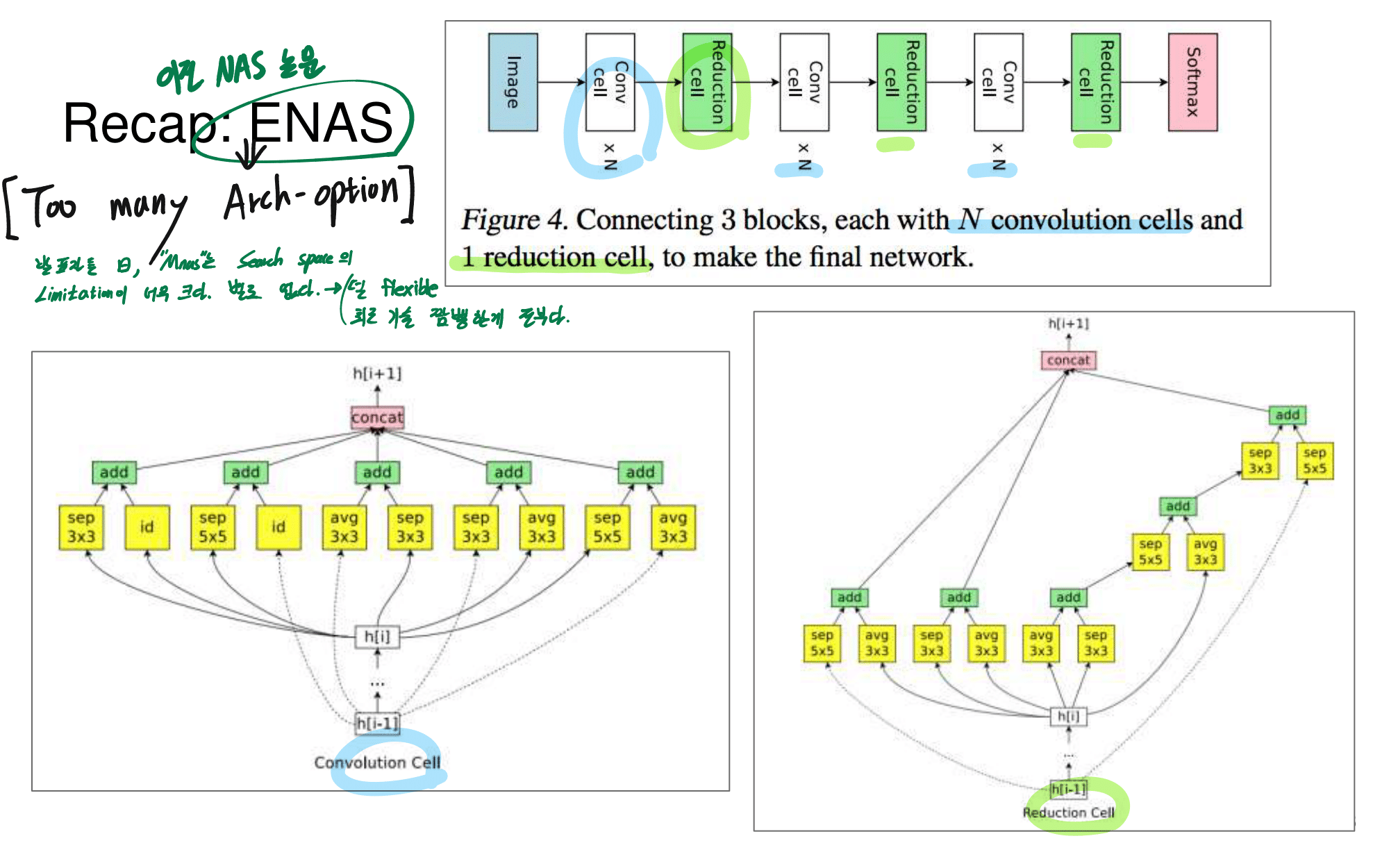
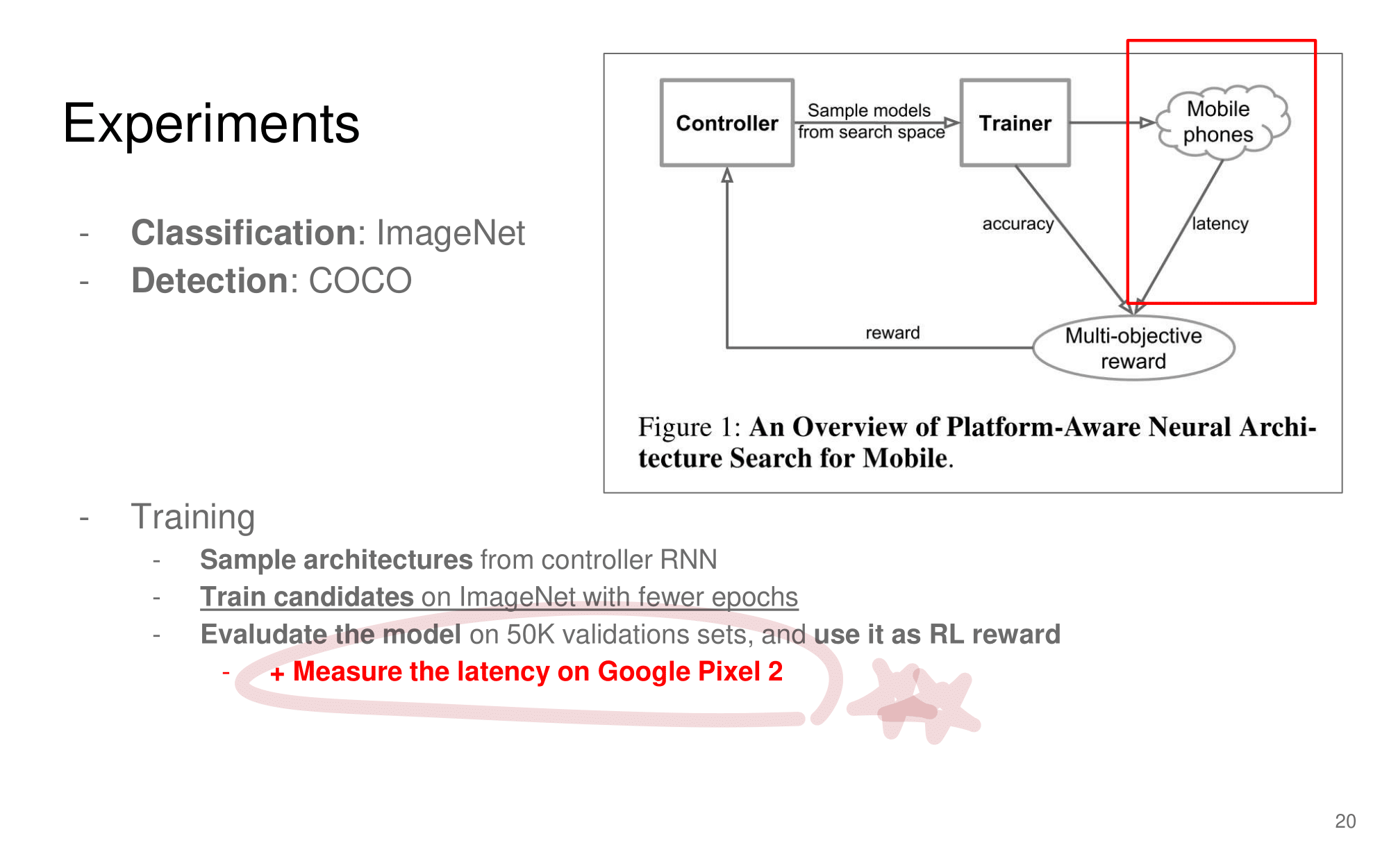
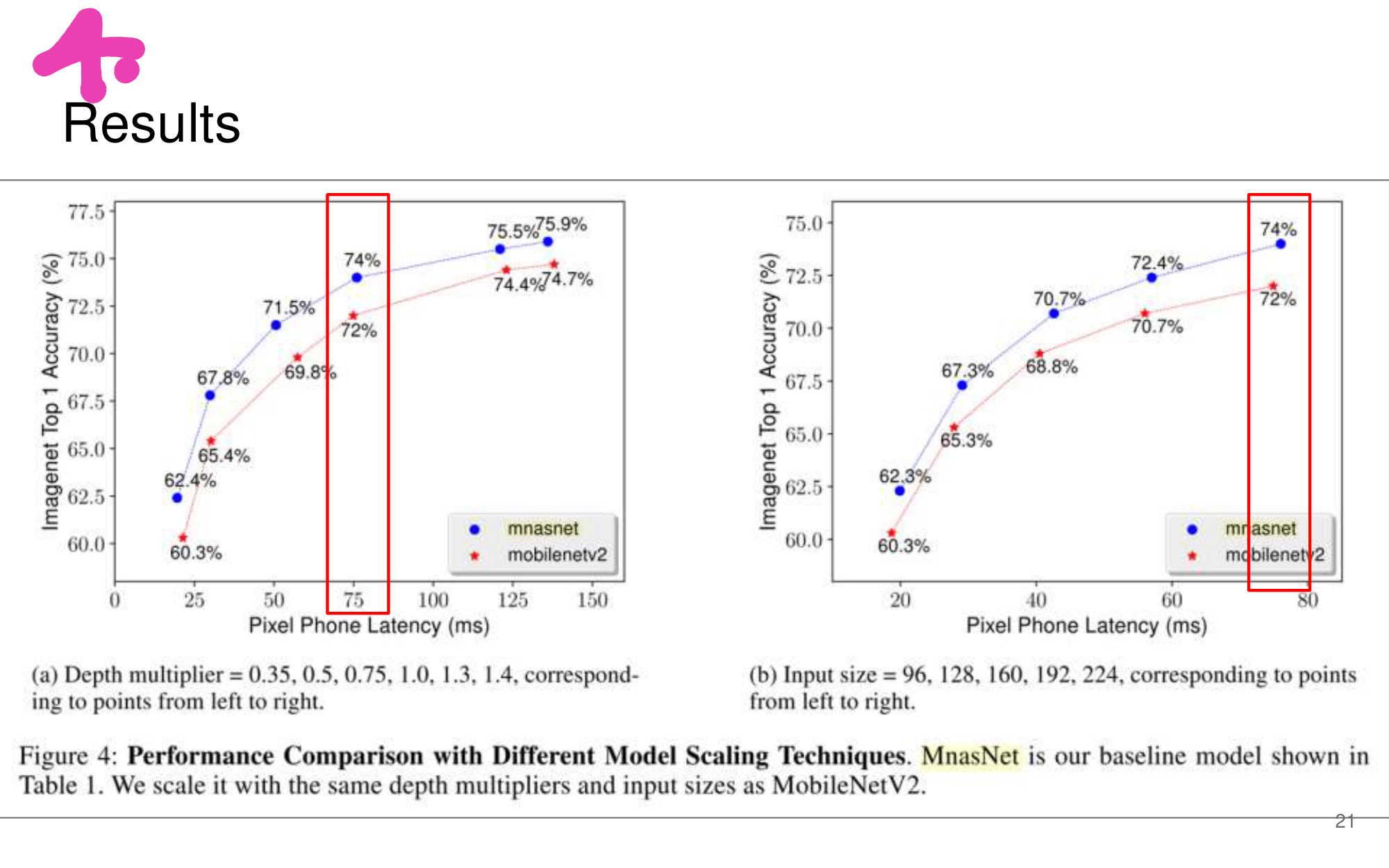
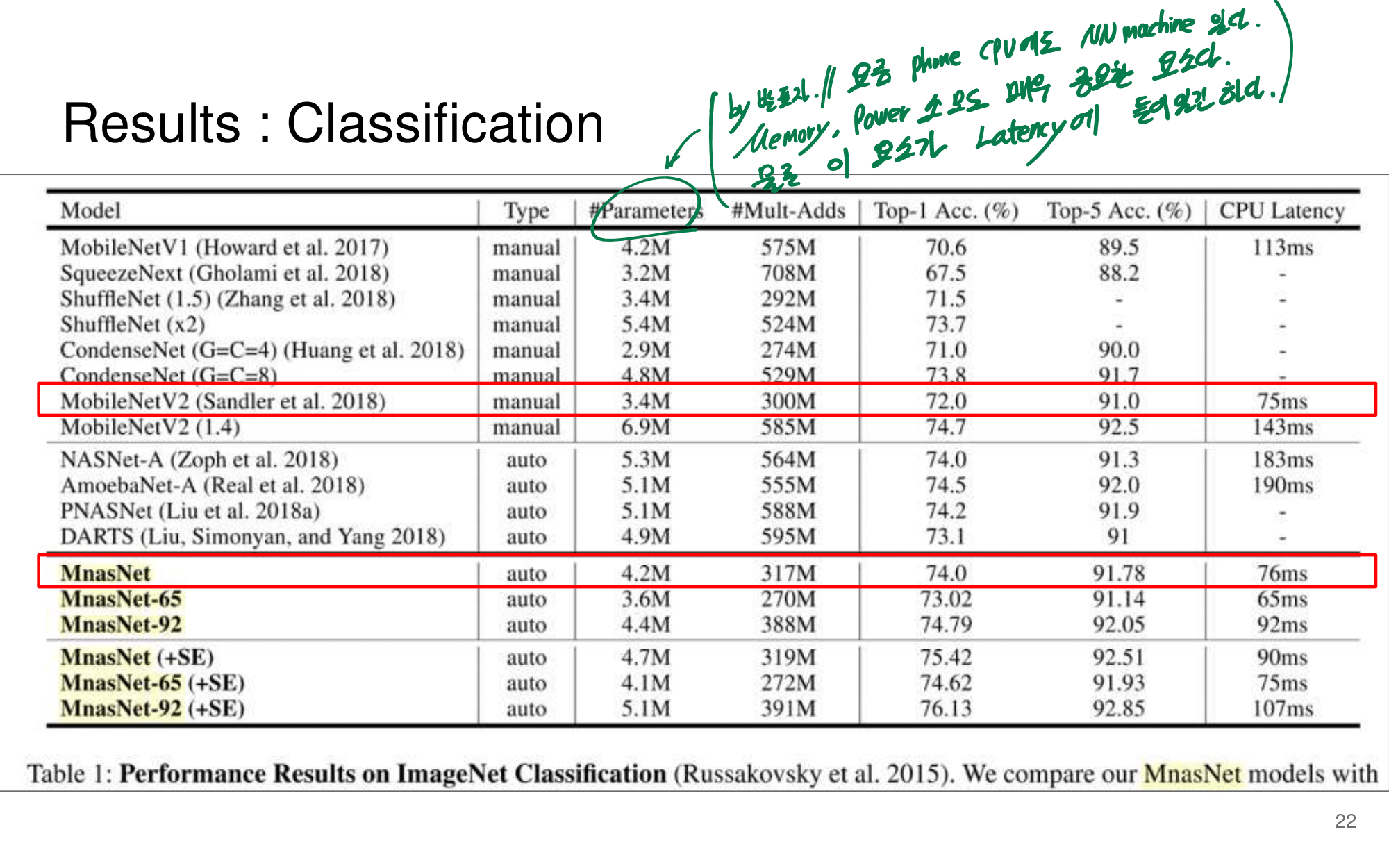
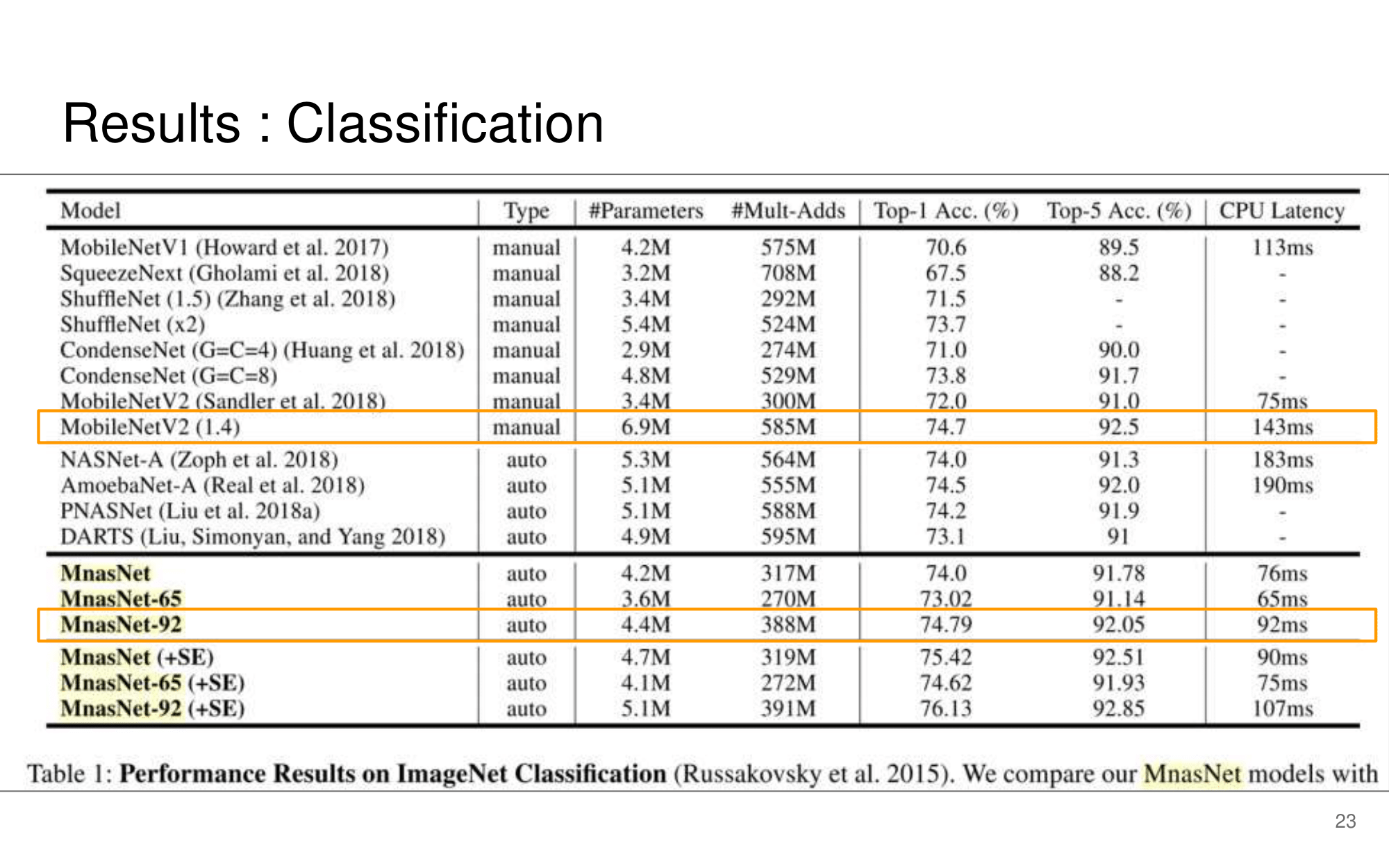
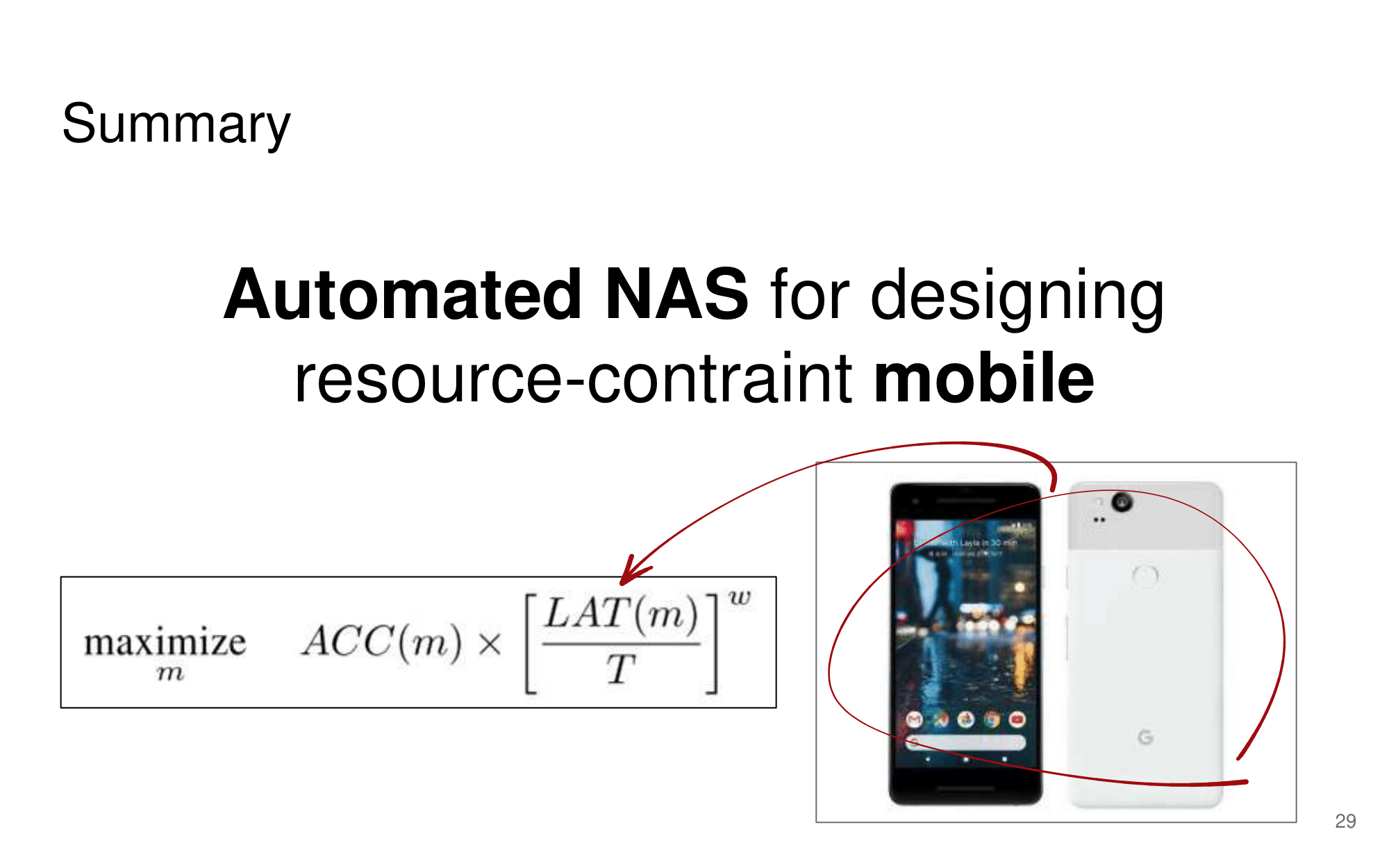
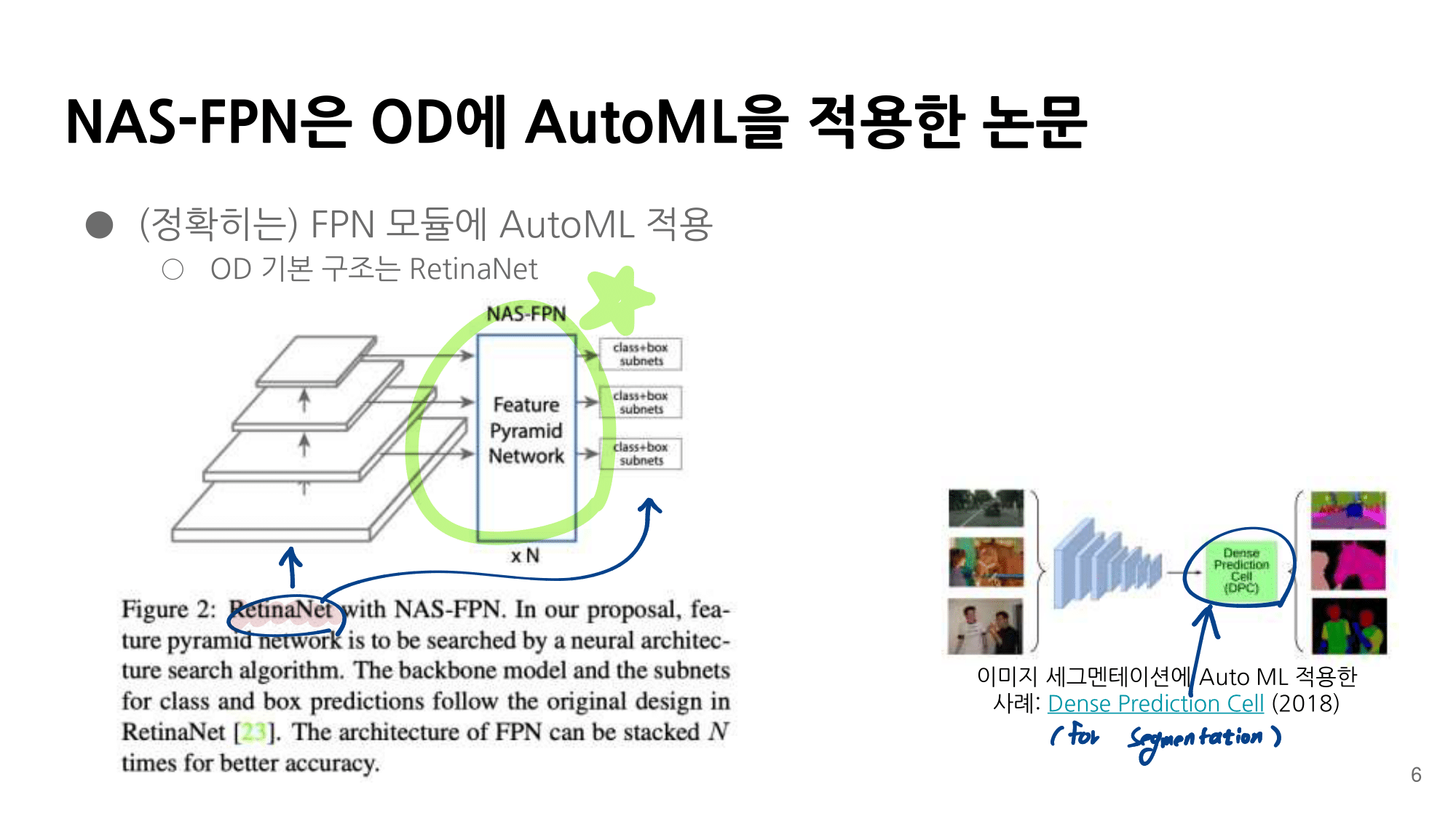
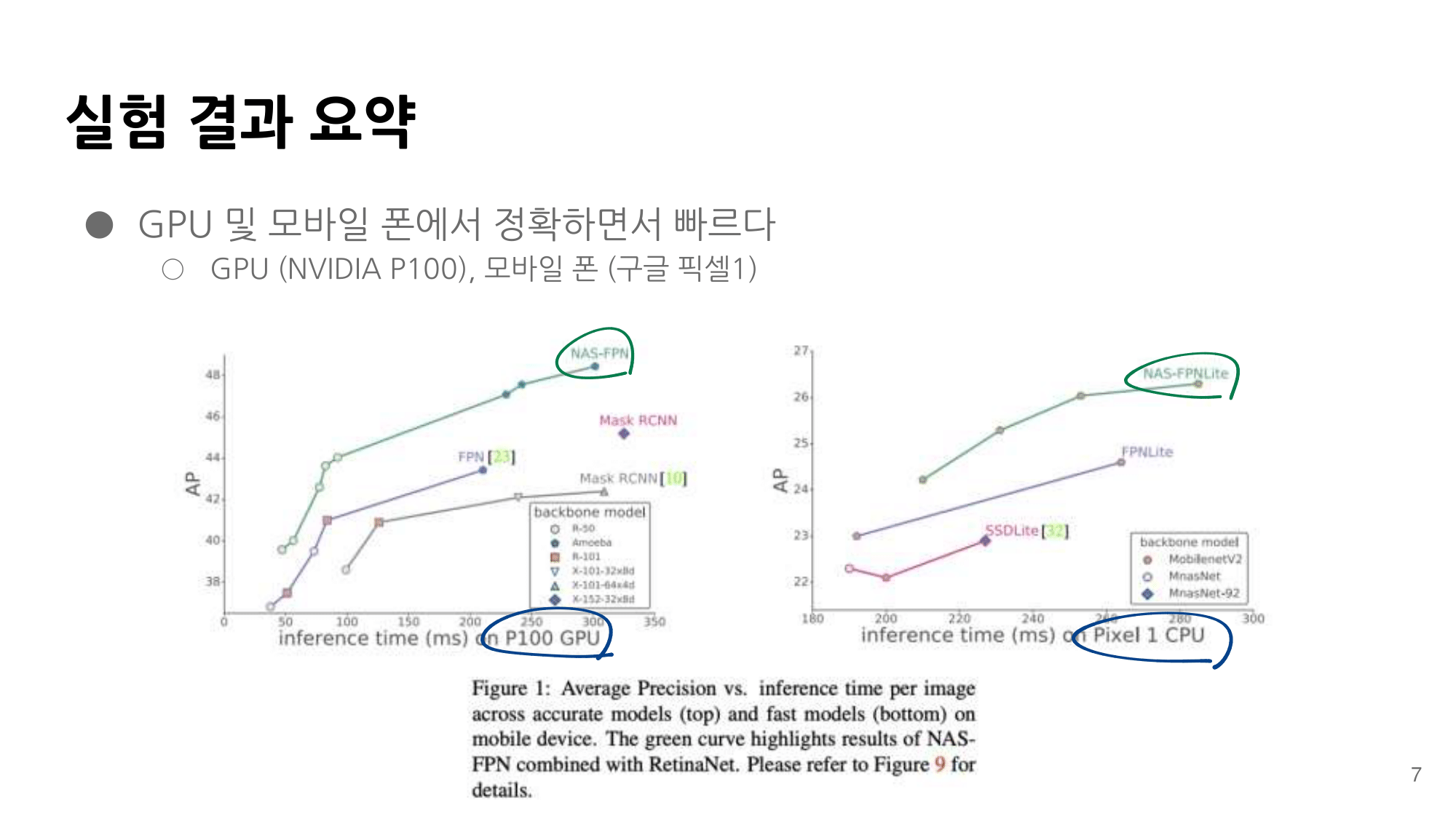
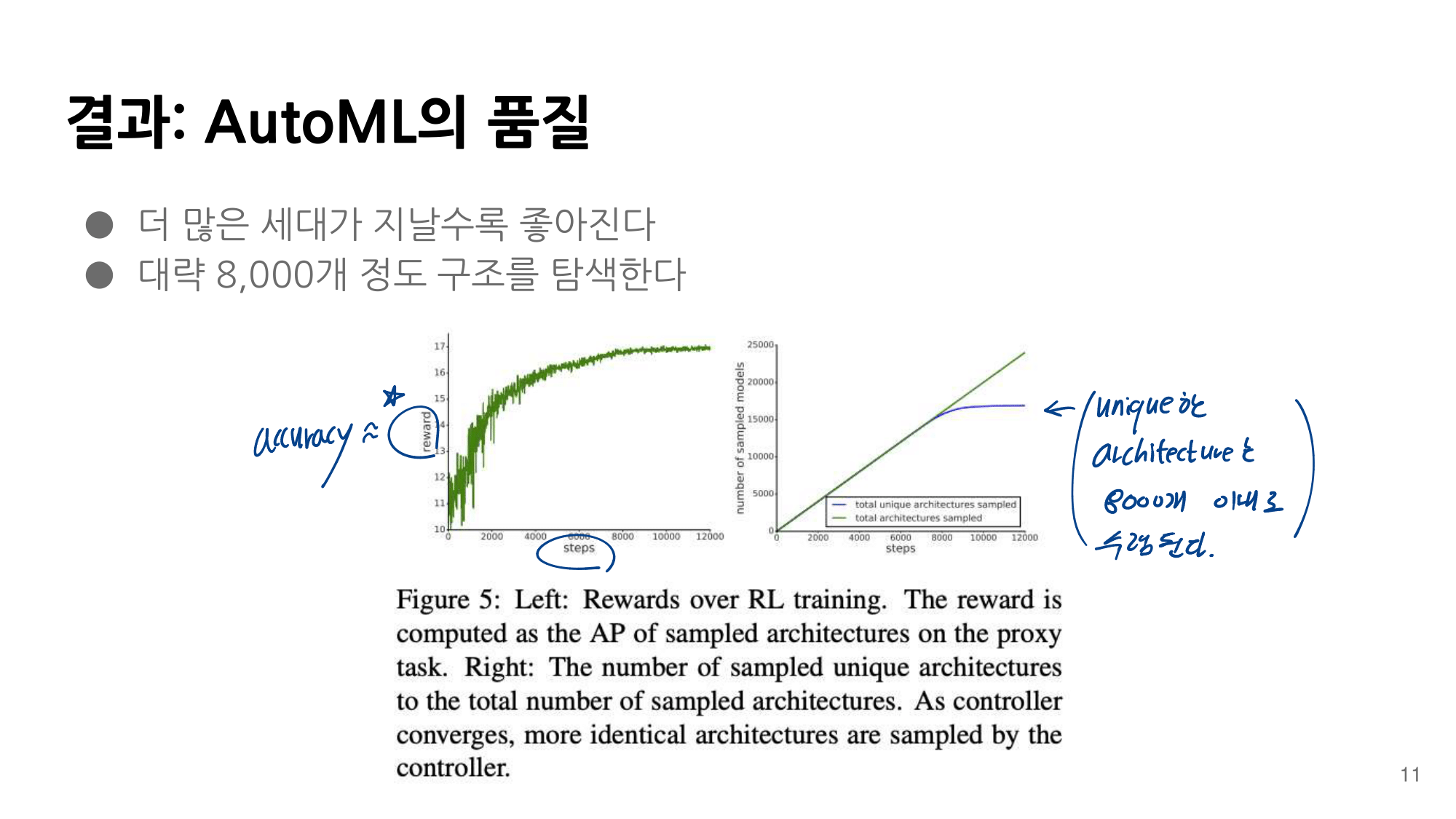
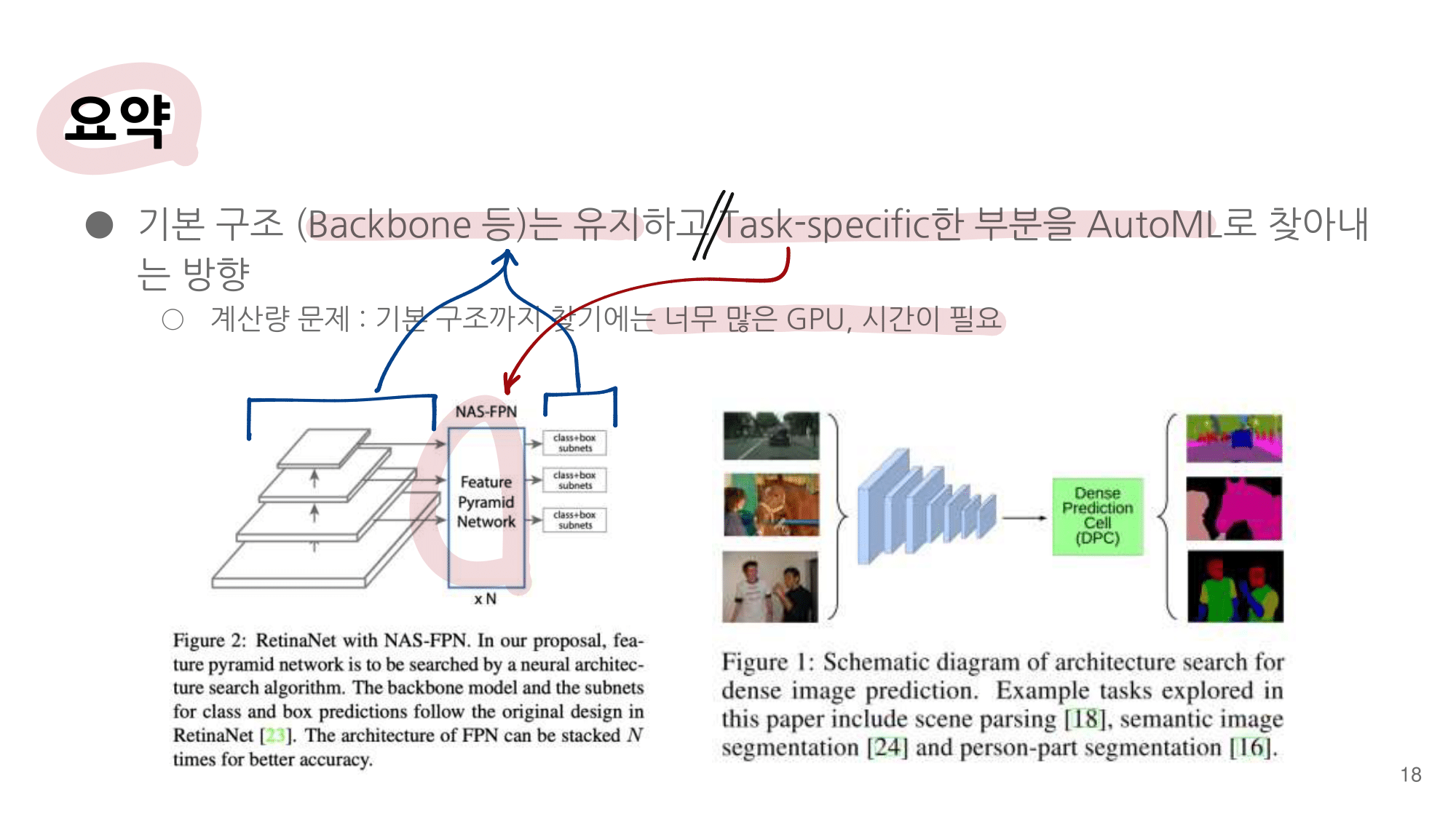
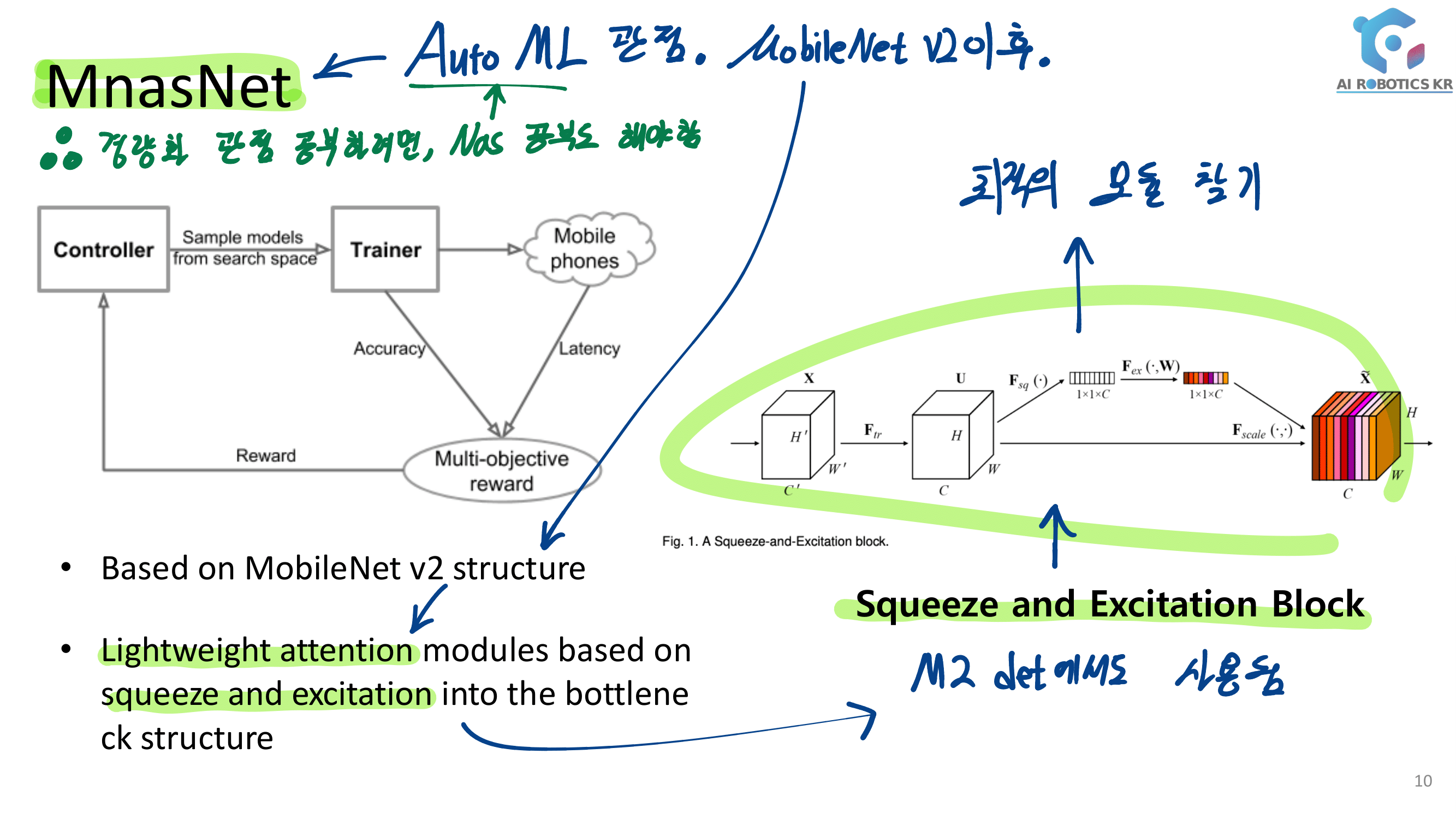
발표자분들끼리 하는 이야기로, 이런 NAS 작업을 우리같은 일반인이 하기는 쉽지 않다. 구글의 목표는 “너네가 원하는 신경망을 최적으로 찾고 싶다면, 너네 스스로 하지말고 돈 좀 내고 우리가 만든 플랫폼을 사용해서 최적의 신경망을 찾아” 라는 것을 목표로 한다고 한다. 따라서 NAS를 일반인이 하기에는 더욱 어려운 것 같다.
그럼에도 불구하고 이 논문이 나오기 전, EnasNet은 [기존에 800개의 GPU로 21일을 학습시켜서 최적의 모델을 찾은 NAS]에 비해서 학습 효율이 더 좋게 만들기 위한 목적을 가지고 있다. 1개의 GPU로 8시간을 학습했다고 한다. 나중에 정말 NAS를 공부해야한다면 EnasNet 또한 읽어보는 것도 좋겠다.
강의 필기 자료
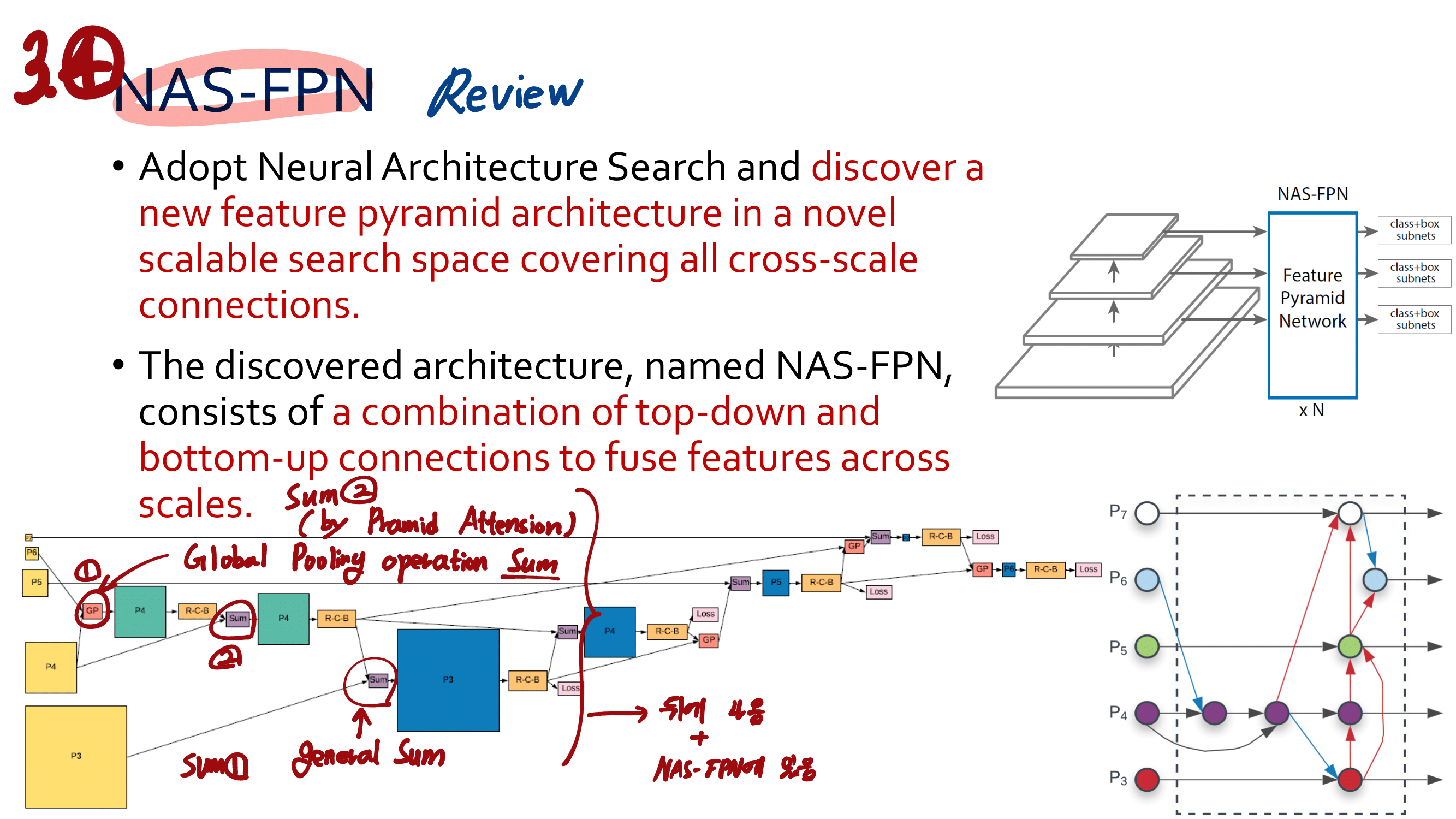
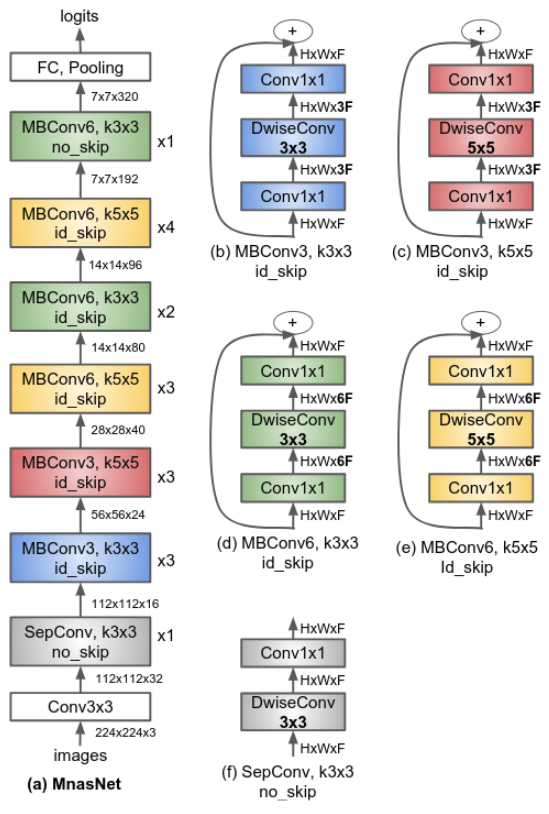
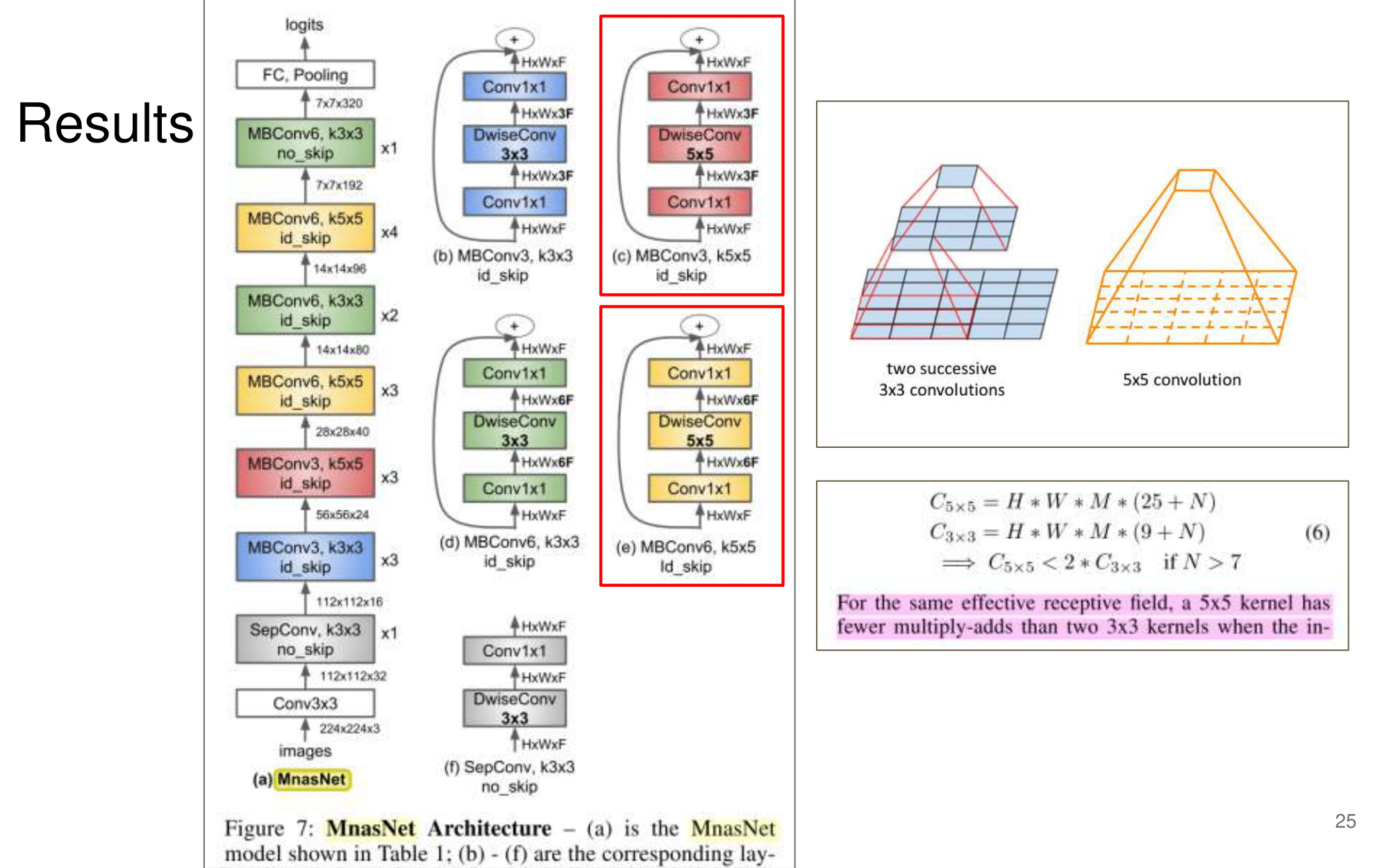
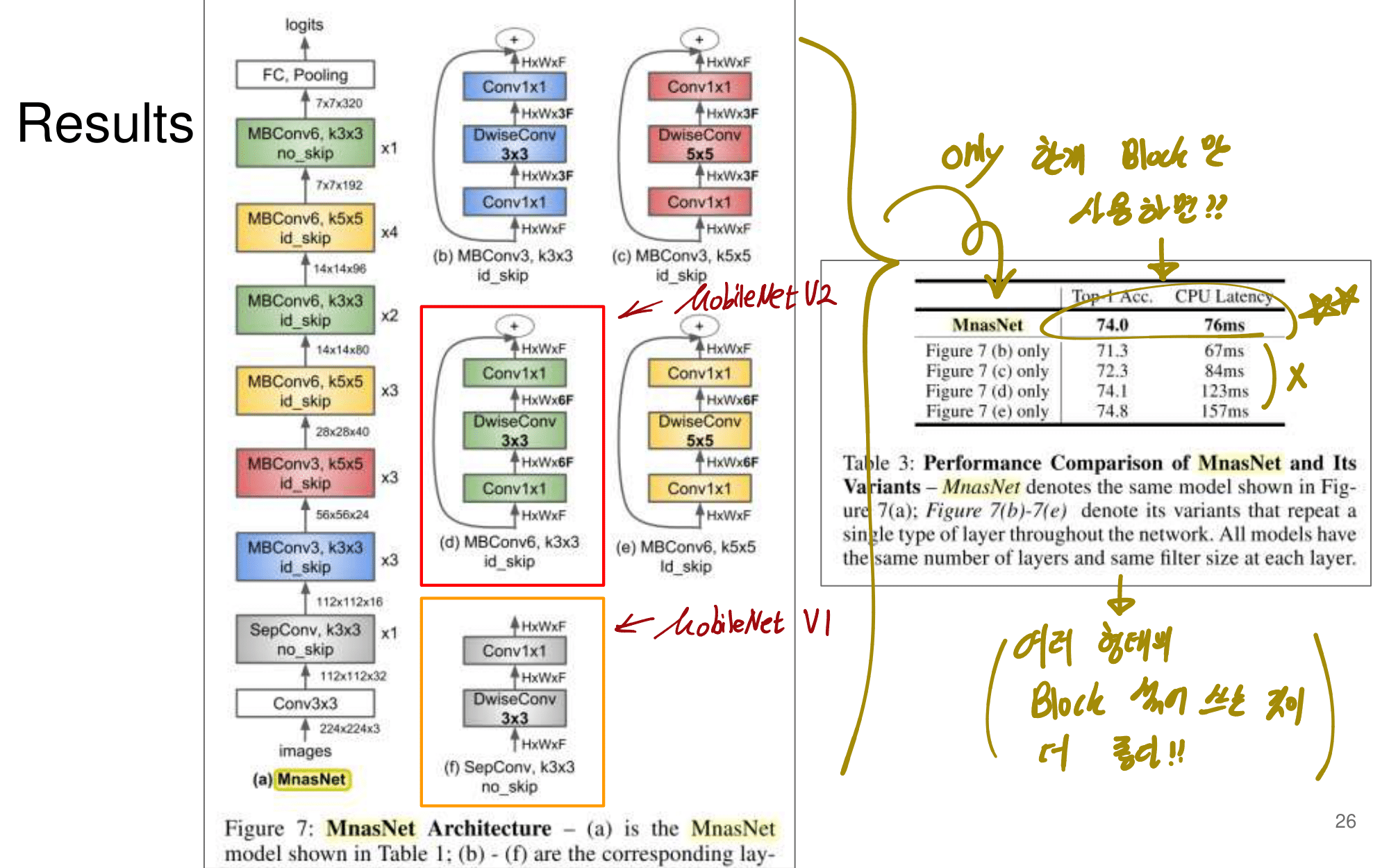
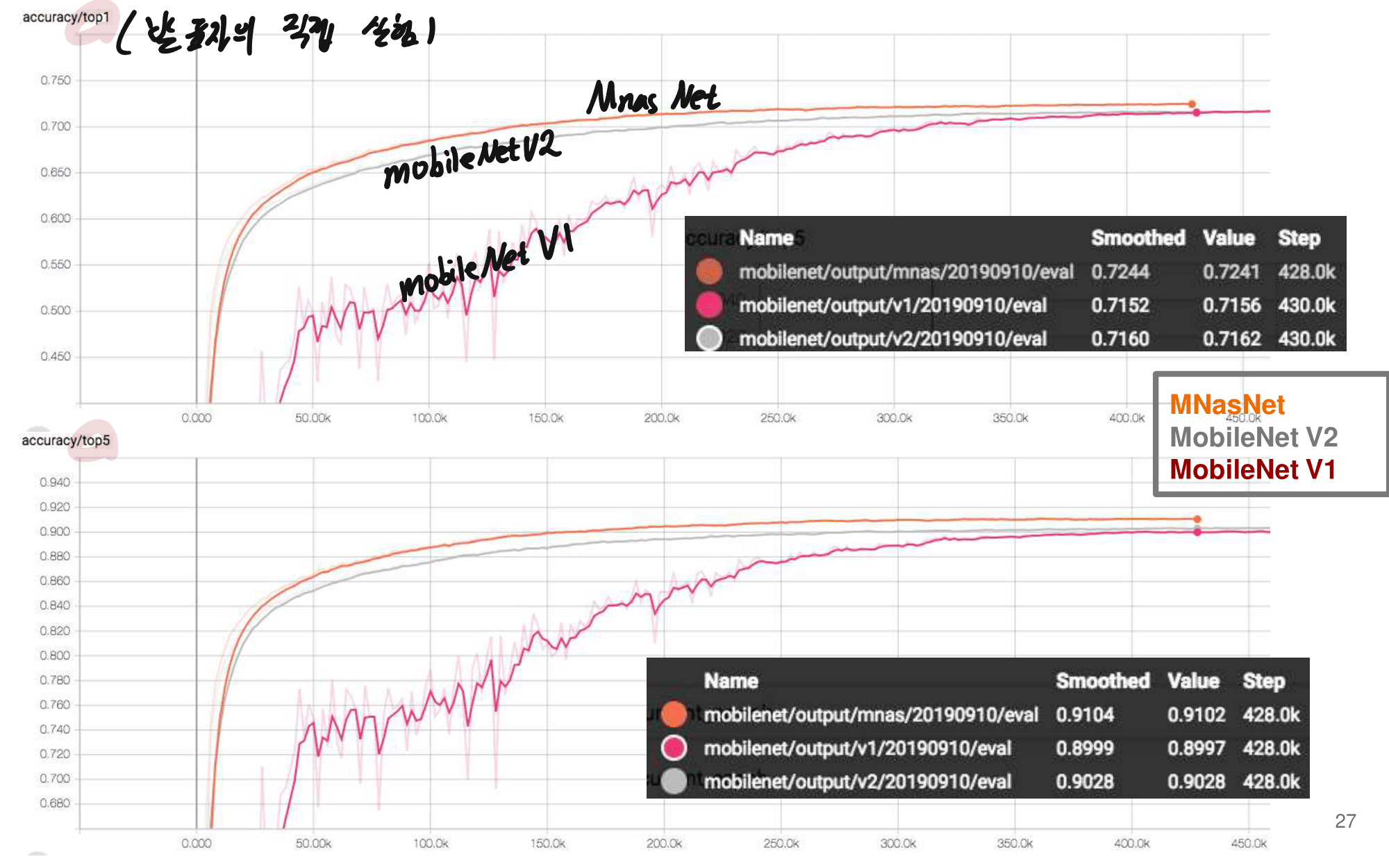
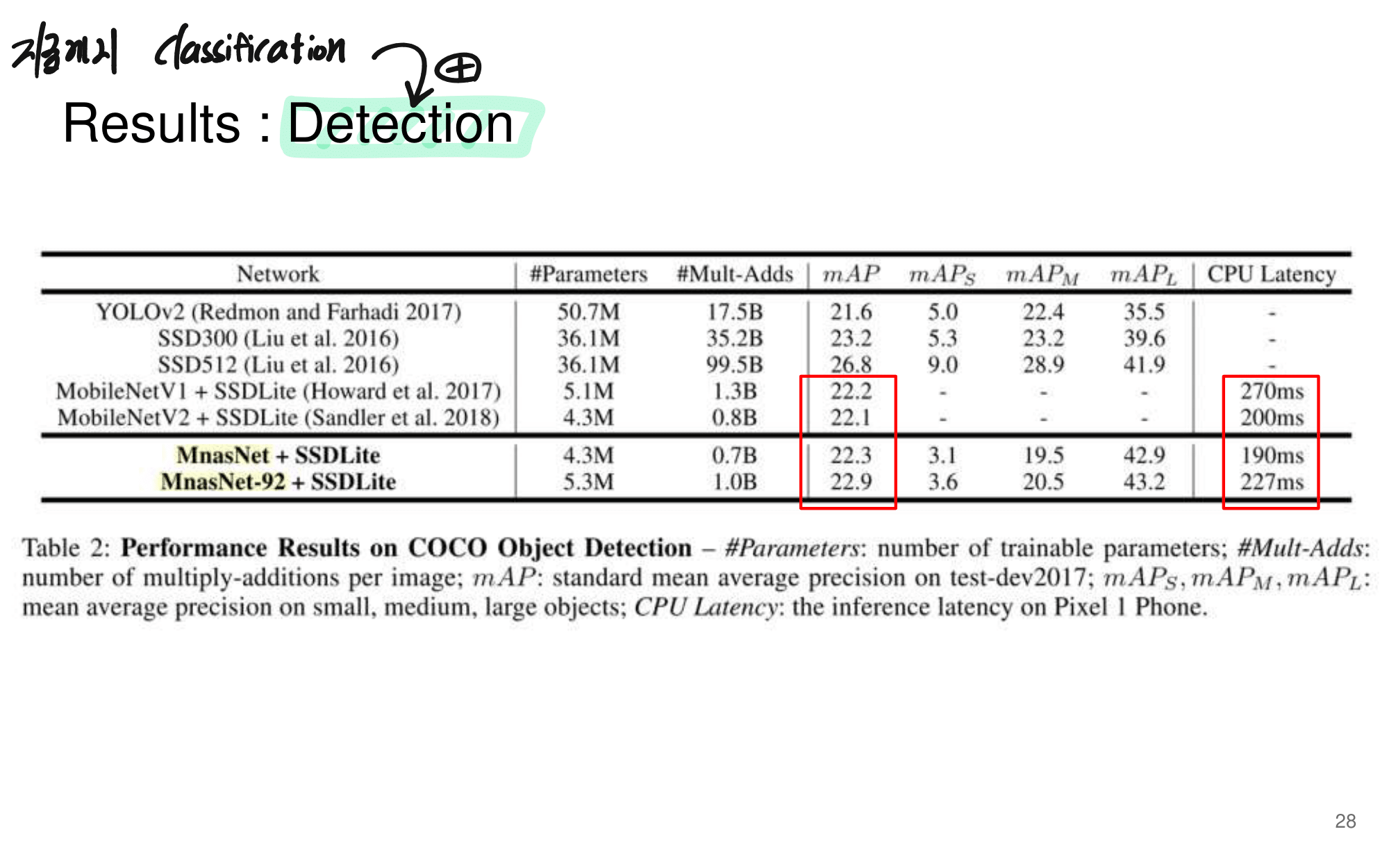
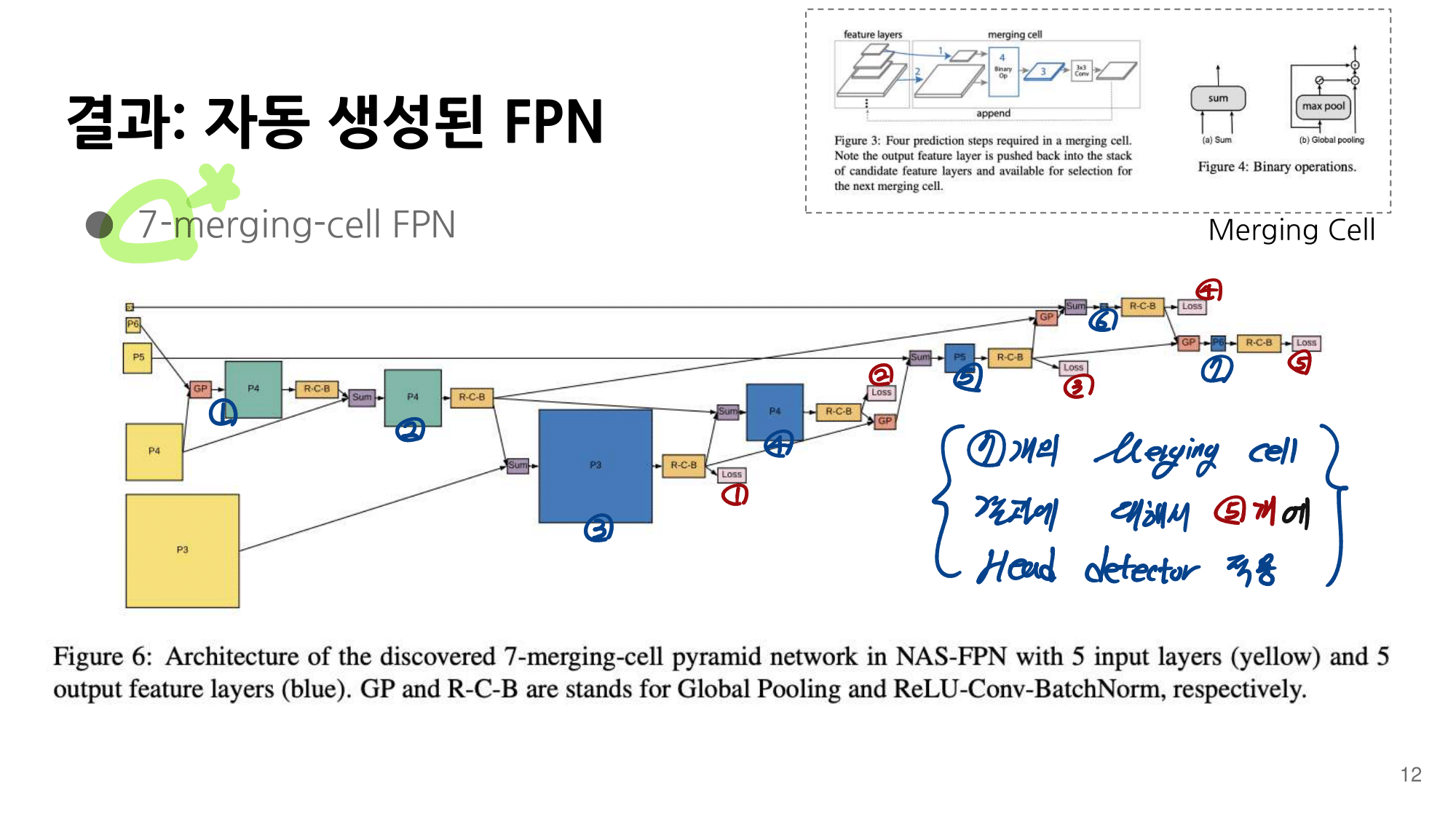
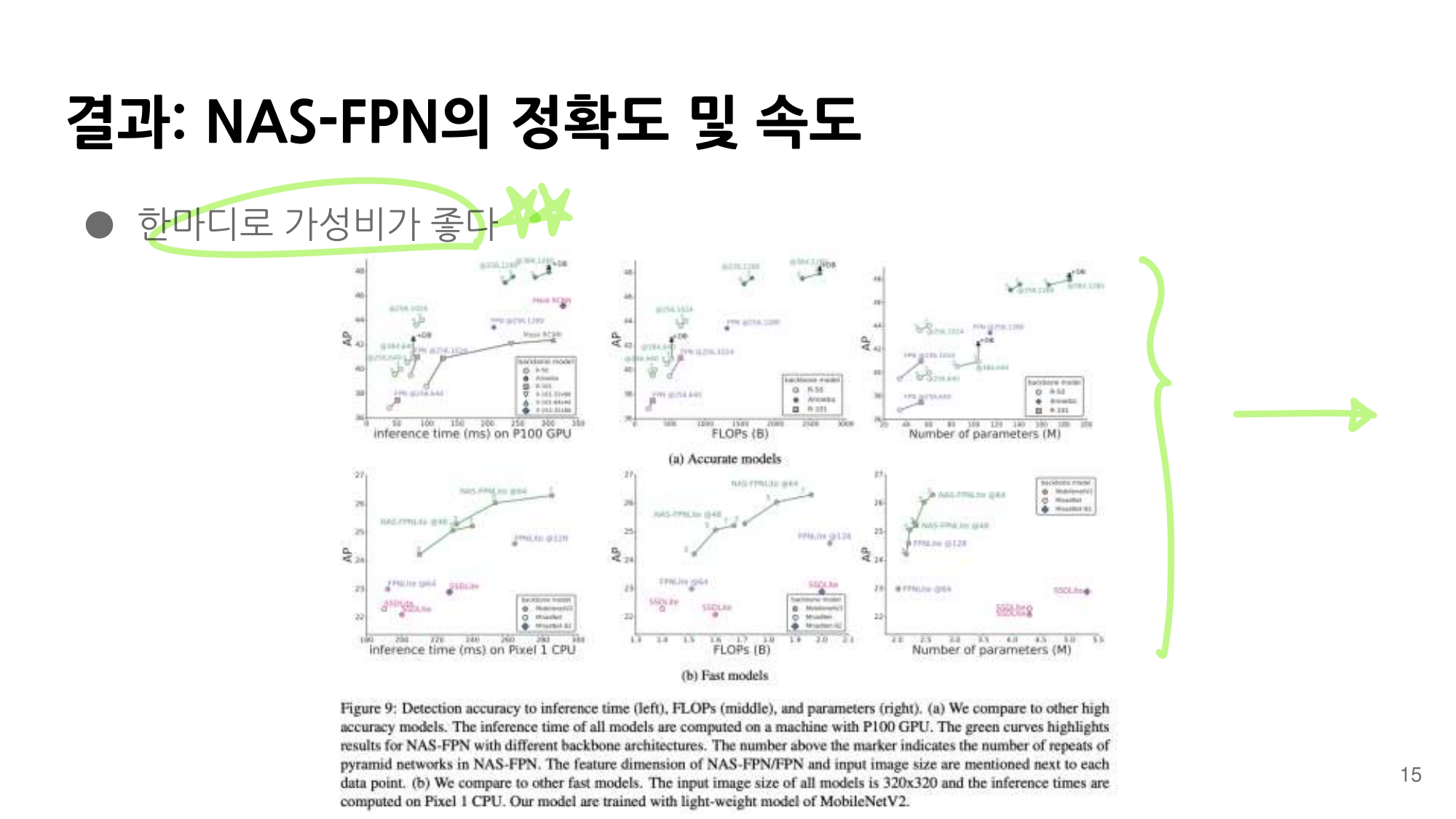
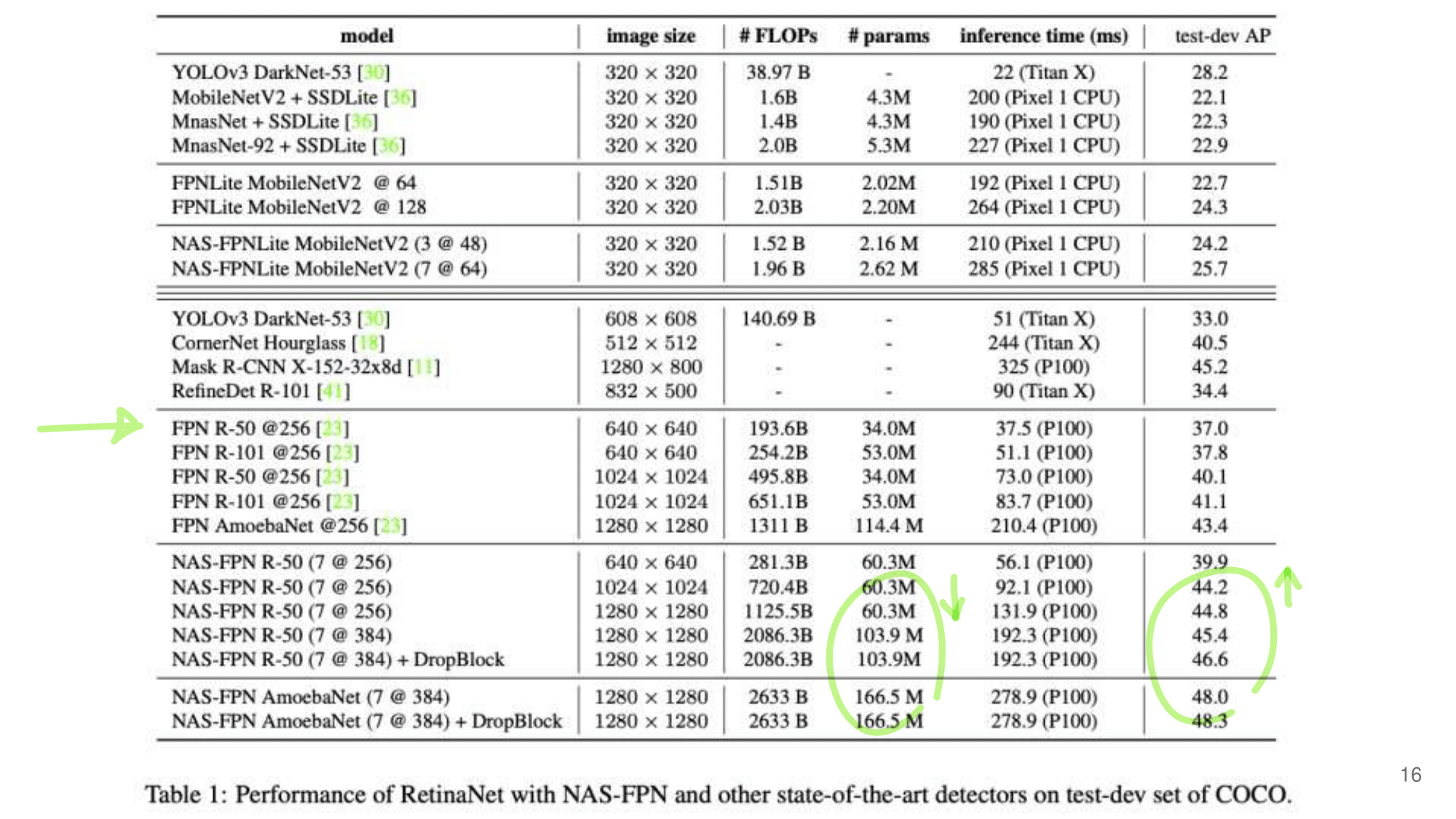
2. NAS-FPN from youtube
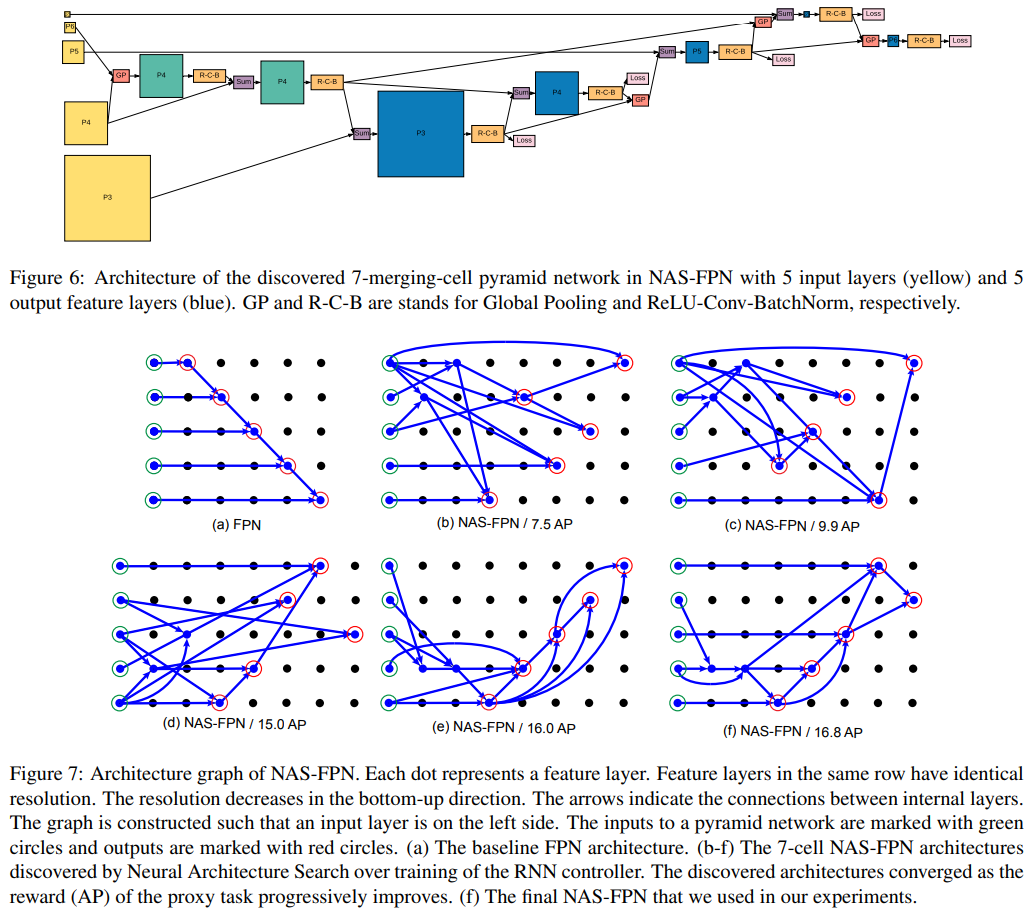
논문에 나오는 최종 모델 (아래 그림에서 (a) -> (f)는 모델의 발전 과정이다.)
강의 필기 자료
3. code - MnasNet-PyTorch
Github1 - AnjieCheng/MnasNet-PyTorch <- MnasNet.py 파일 1개만 있다.
Github2- Cadene/pretrained-models.pytorch <- NASNet 뿐만 아니라, Backbone으로 사용하기 좋은 pretrained-model들이 다앙햐게 있다.
# MnasNet.py
classMnasNet(nn.Module):def__init__(self,n_class=1000,input_size=224,width_mult=1.):super(MnasNet,self).__init__()# setting of inverted residual blocks
self.interverted_residual_setting=[# t, c, n, s, k
[3,24,3,2,3],# -> 56x56
[3,40,3,2,5],# -> 28x28
[6,80,3,2,5],# -> 14x14
[6,96,2,1,3],# -> 14x14
[6,192,4,2,5],# -> 7x7
[6,320,1,1,3],# -> 7x7
"""
t : expand_ratio(Channel 몇 배로 확장 후 축소)
c : output_channel
n : 같은 block 몇번 반복?
s : stride
k : kernel
"""]assertinput_size%32==0input_channel=int(32*width_mult)self.last_channel=int(1280*width_mult)ifwidth_mult>1.0else1280# building first two layer
# 여기서 Conv_3x3, SepConv_3x3 함수는 nn.Sequential( ... )를 return 하는 함수이다.
self.features=[Conv_3x3(3,input_channel,2),SepConv_3x3(input_channel,16)]input_channel=16# building inverted residual blocks (MBConv)
fort,c,n,s,kinself.interverted_residual_setting:output_channel=int(c*width_mult)foriinrange(n):ifi==0:self.features.append(InvertedResidual(input_channel,output_channel,s,t,k))else:self.features.append(InvertedResidual(input_channel,output_channel,1,t,k))input_channel=output_channel# building last several layers
self.features.append(Conv_1x1(input_channel,self.last_channel))self.features.append(nn.AdaptiveAvgPool2d(1))# make it nn.Sequential
self.features=nn.Sequential(*self.features)# building classifier
self.classifier=nn.Sequential(nn.Dropout(),nn.Linear(self.last_channel,n_class),)self._initialize_weights()defforward(self,x):x=self.features(x)x=x.view(-1,self.last_channel)x=self.classifier(x)returnx
저자 : Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao
읽는 배경 : Recognition Basic. Understand confusing and ambiguous things.
읽으면서 생각할 포인트 : 코드와 함께 최대한 완벽히 이해하기. 이해한 것 정확히 기록해두기.
느낀점 :
논문 리뷰 정리를 할 때. 자꾸 같은 내용은 여기저기 쓰지 말아라. 한 곳에 몰아 정리하자.
예를 들어 A,B라는 Key Idae가 있다고 치자. 그럼 아래 처럼 실제 논문에는 “같은 내용 반복하거나, 어디 다른 곳에서 추가 특징을 적어 놓는다” 그렇다고 나도 따로따로 분산해서 정리해 두면 안된다. “깔끔하게 정말 핵심만 한곳에 모아 정리해야 한다” 즉. 굳이 논문과 같은 목차로 정리해야한다는 강박증을 가지지 말아라. 어차피 핵심만 모으면 별거 없고, 한곳에 모인다.
$ 실제 논문에는 이렇게 적혀 있다.
1. Conclusion ,abstract
- A idea
- A의 장점1
- A의 장점2
- B idea
- B의 장점1
2. introduction
- A의 장점1
- A의 장점2
- B의 장점1
- B의 장점2
3. Relative Work
- A의 장점3
- B의 장점2
- B의 장점3
$ ** 내가 정리해야 하는 방법 **
1. Conclusion ,abstract
- A idea
- A의 장점1
- A의 장점2
- A의 장점3
- B idea
- B의 장점1
- B의 장점2
- B의 장점3
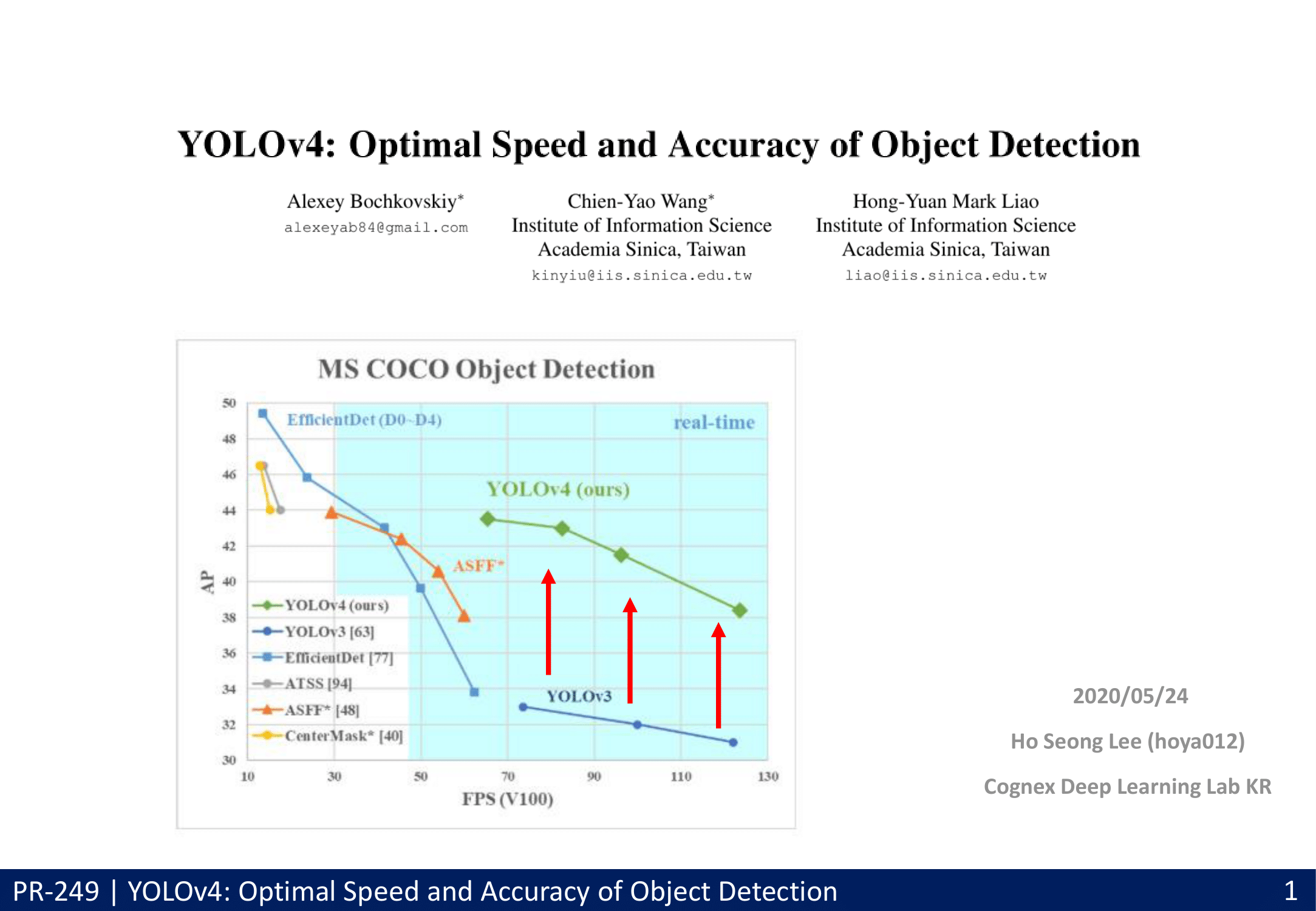
YoloV4 는 새로운 기법을 공부하기 위해서 읽는 논문이 아니로, 그냥 Object Detection Survey 논문이다.
이 정도 논문이면, 내가 직접 읽어보는게 좋을 것 같아서 발표자료 보고 블로그는 안 찾아보기로 함
강의 필기 PDF는 “OneDrive\21.겨울방학\RCV_lab\논문읽기”
2. YoloV4 Paper Review
1. Conclustion, Abstract, Introduction
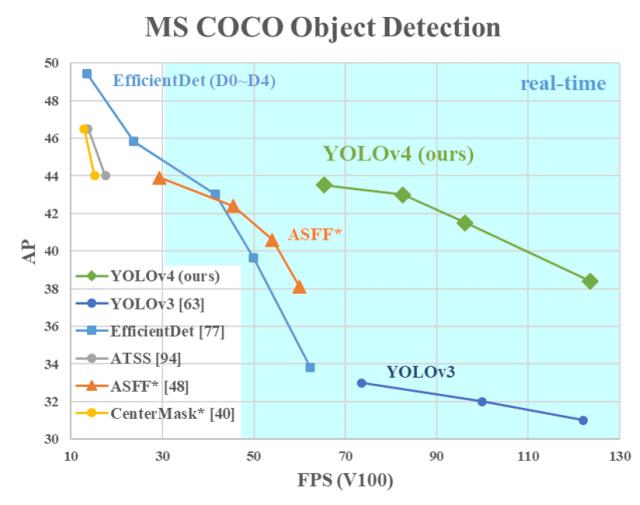
Faster / more Accurate(AP_(50…95) and AP_(50)) / best-practice with only one conventional GPU (1080 Ti or 2080 Ti GPU)
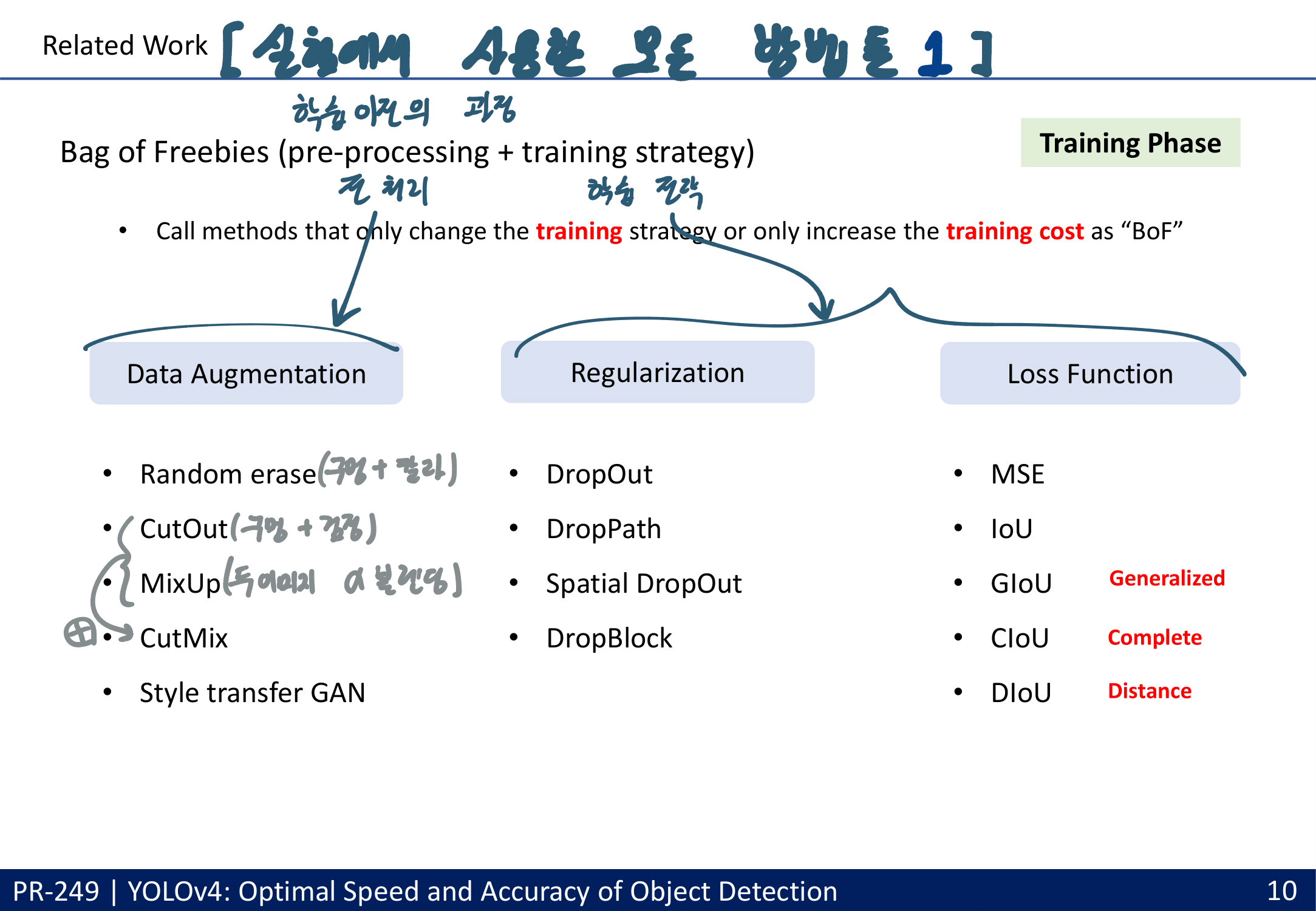
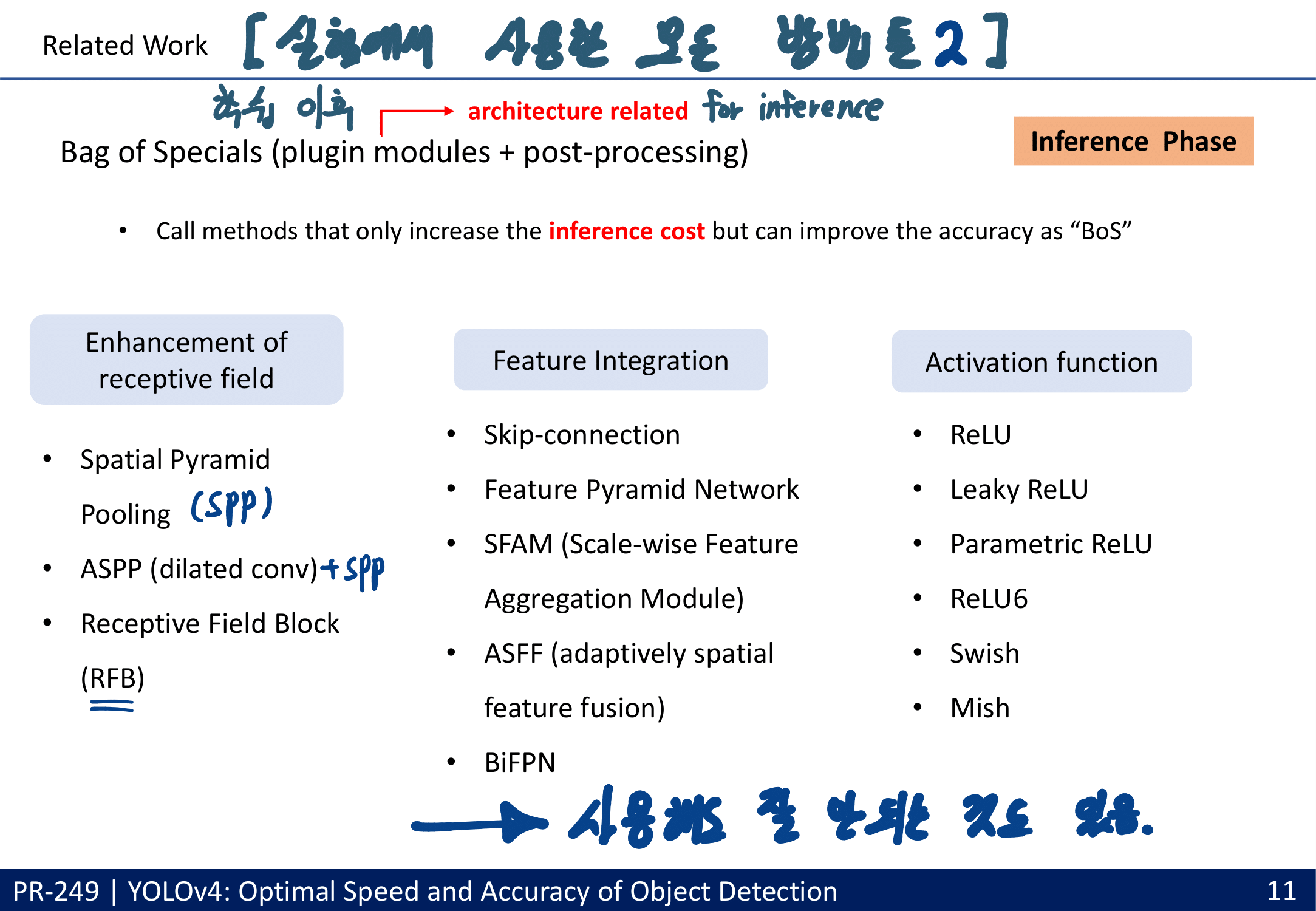
batch-normalization and residual-connections 과 같은 통념적으로 사용되는 Feature(여기서는 특정기술,특정방법론 이라고 해석해야함. Feature Map의 Feature 아님)뿐만 아니라, 아래와 같이 YoloV4에서 많은 성능향상을 준 Feature들이 있다.
무시가능한 특정기술 : Self-adversarial-training (SAT) (-> 좋다는 결과 없음. 일단 무시)
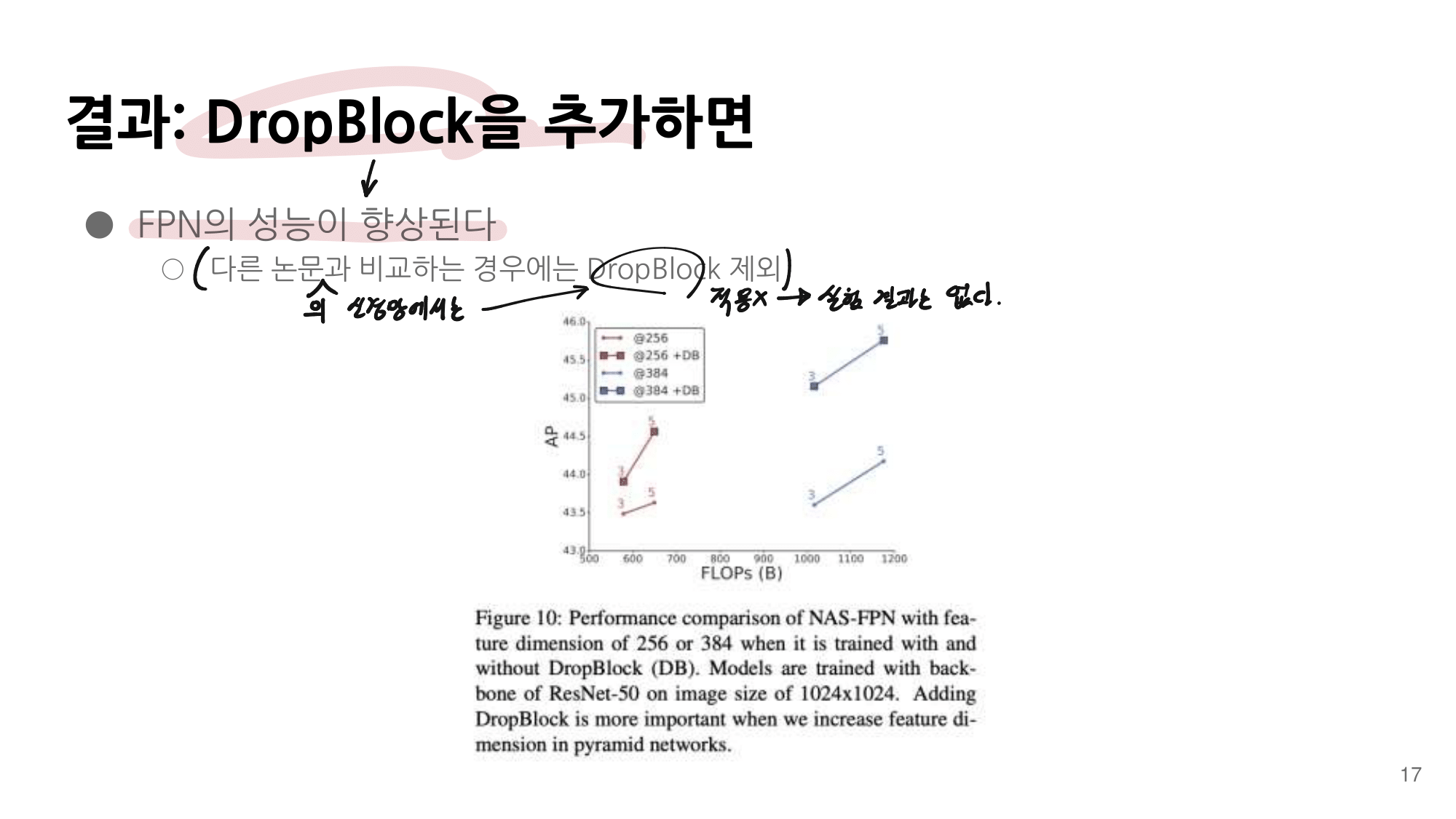
중간 중요도의 특정기술 : CmBN, DropBlock regularization, and CIoU loss. 기법들
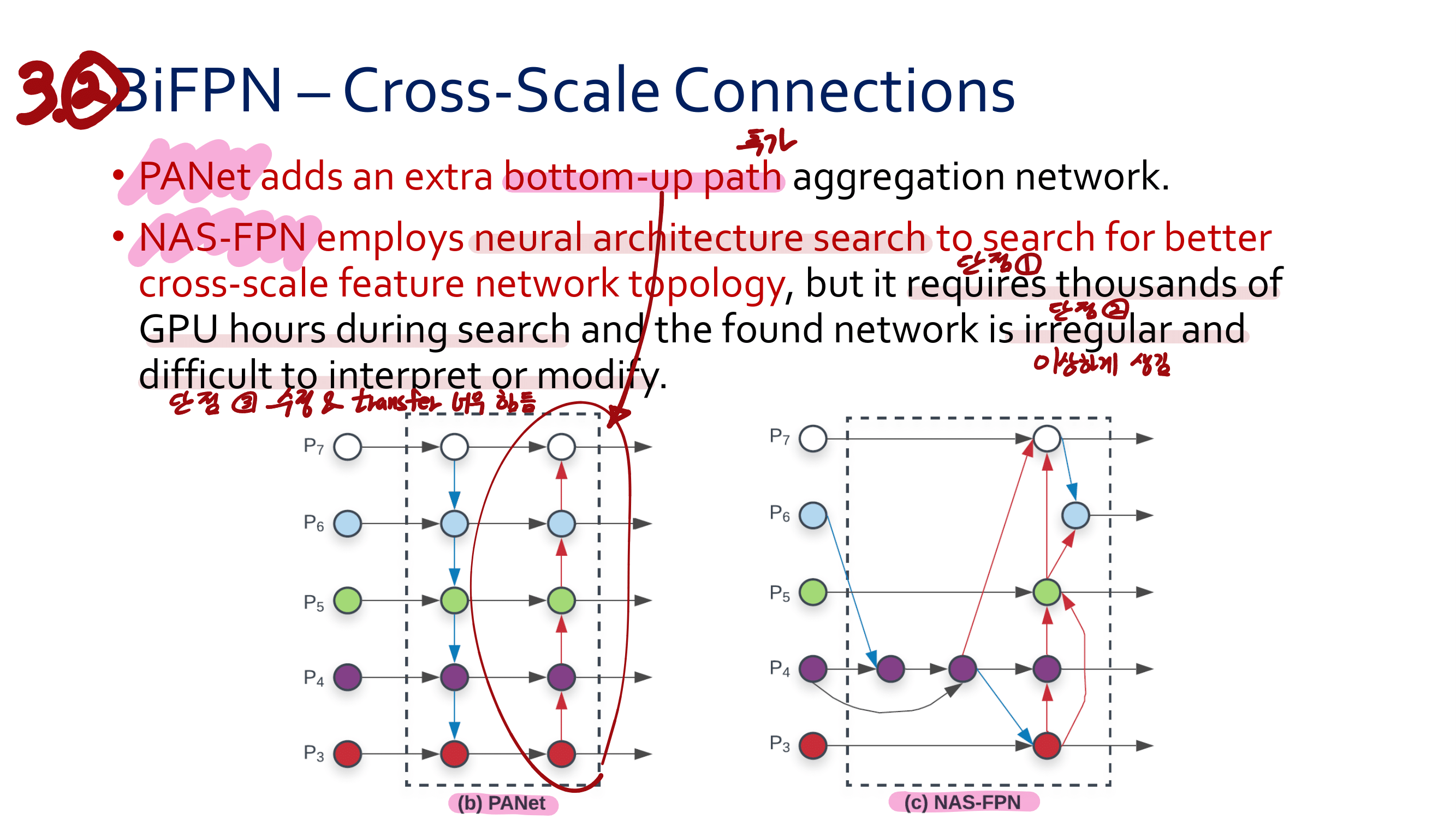
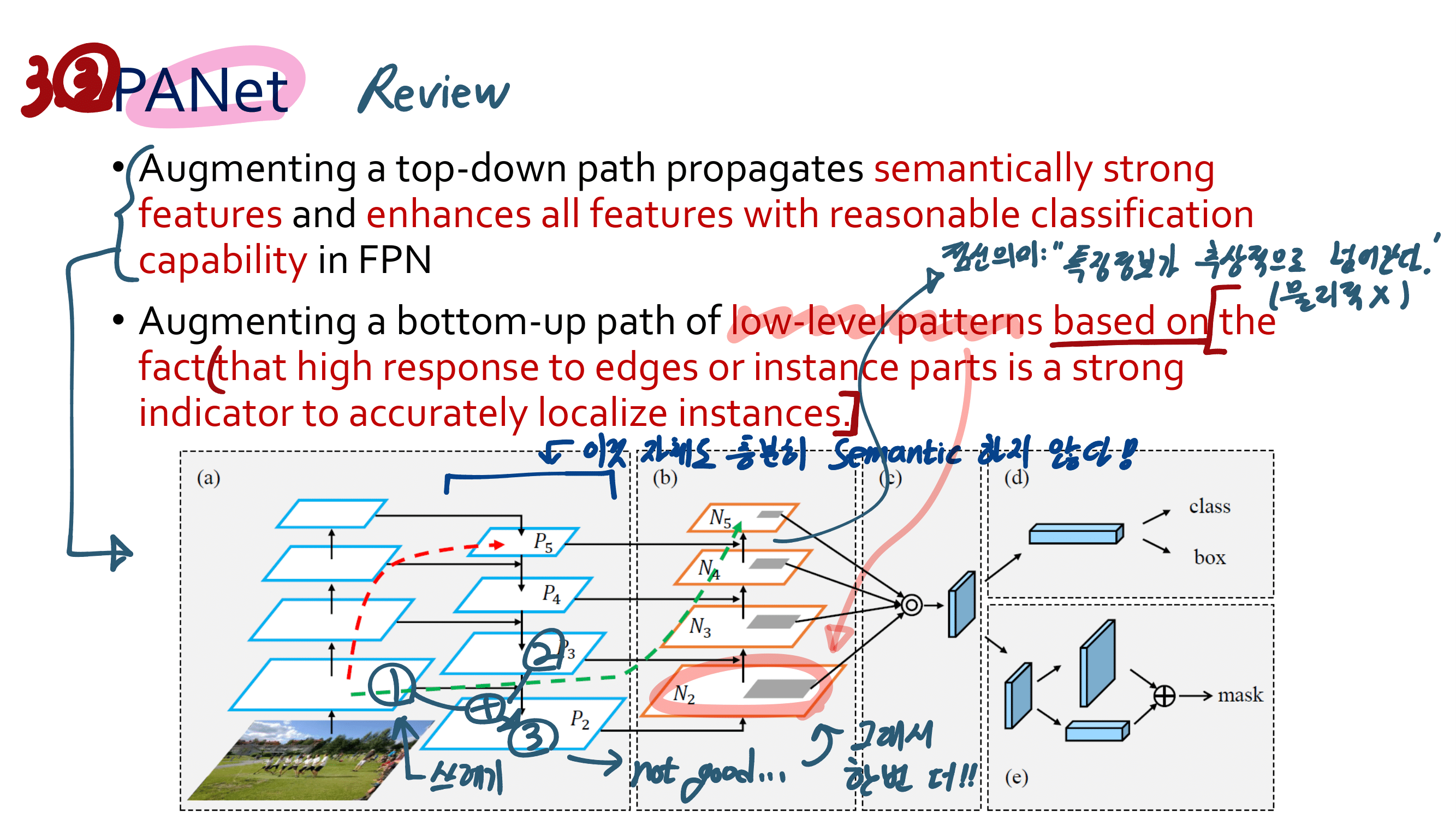
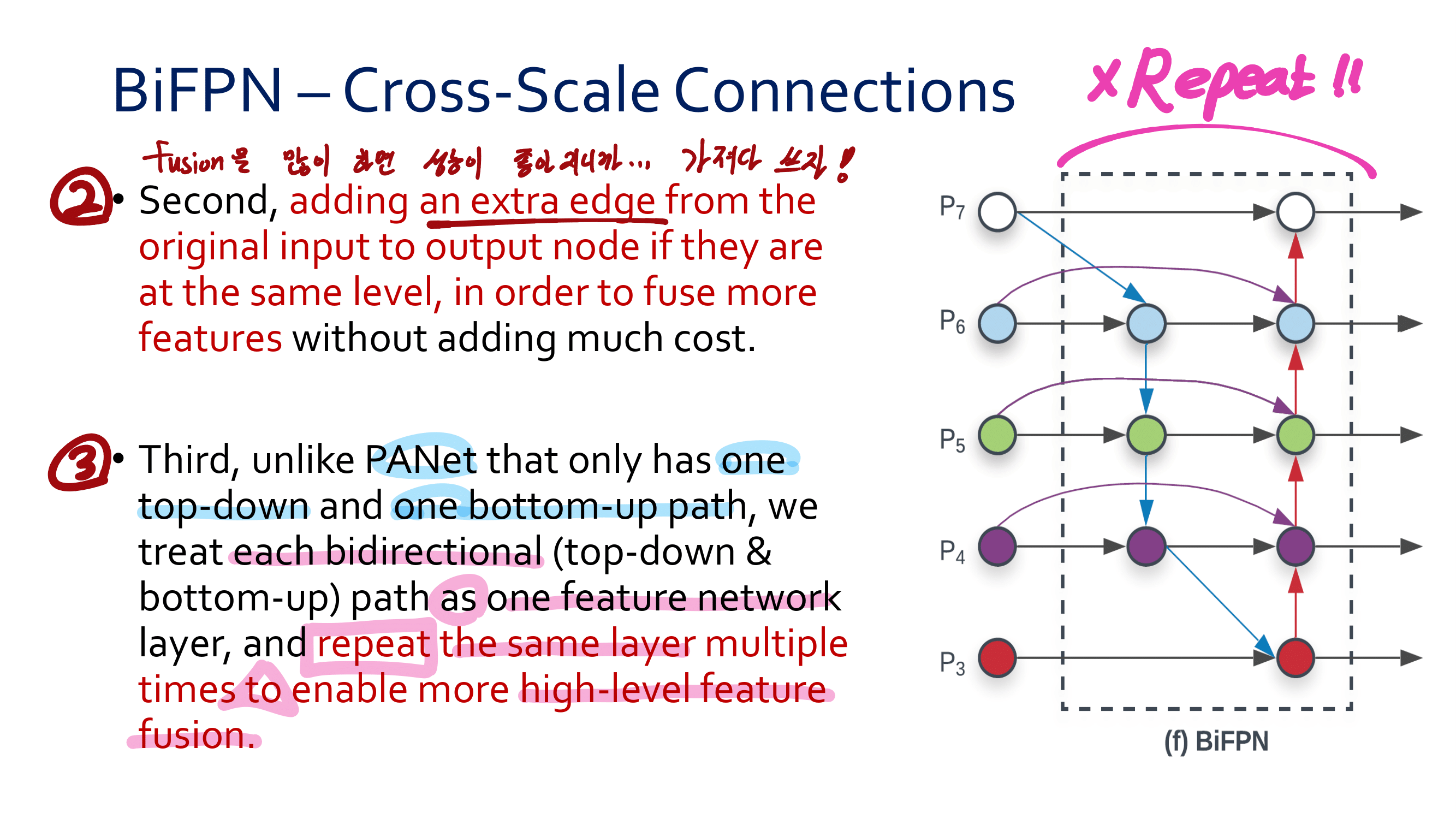
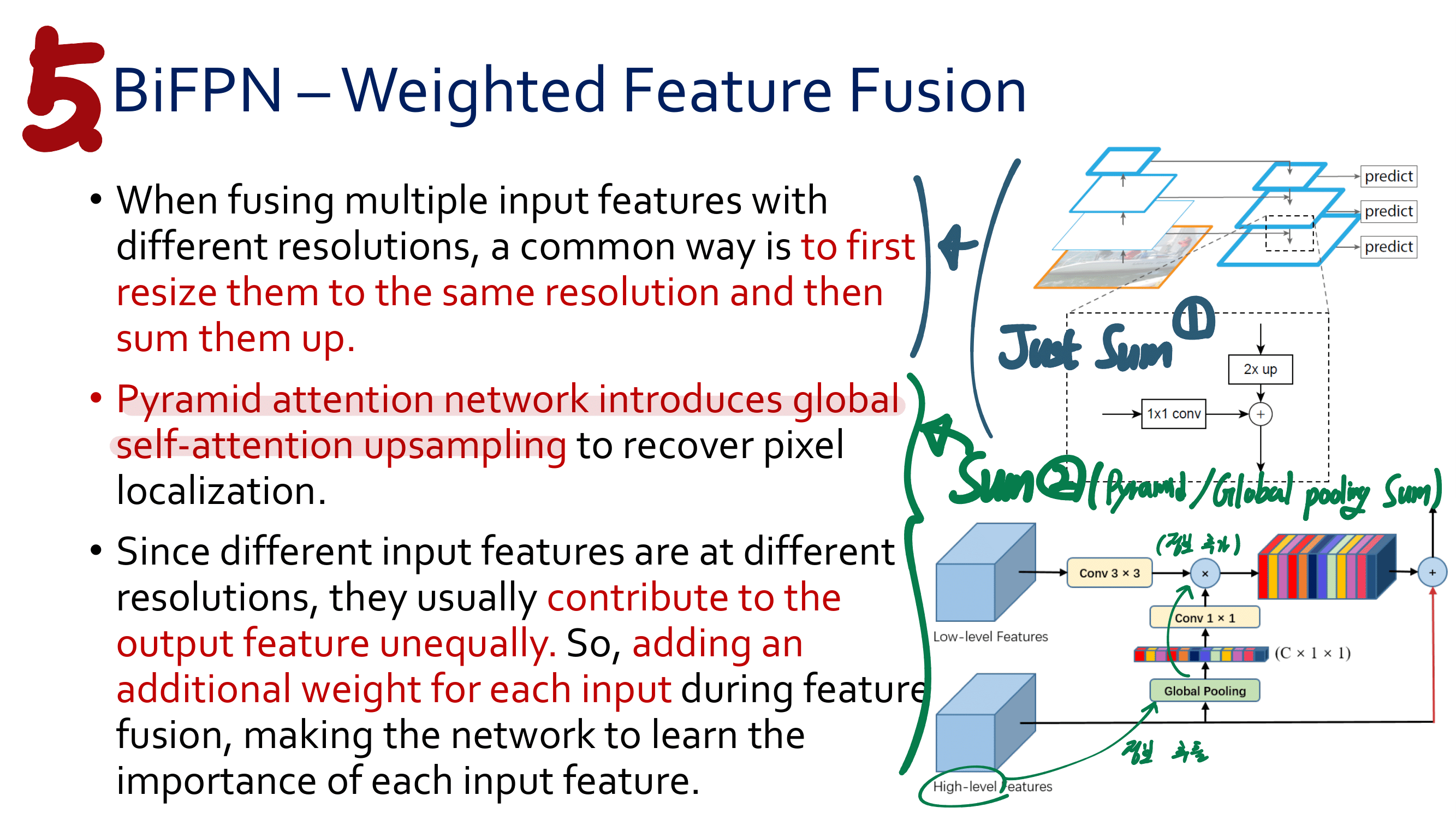
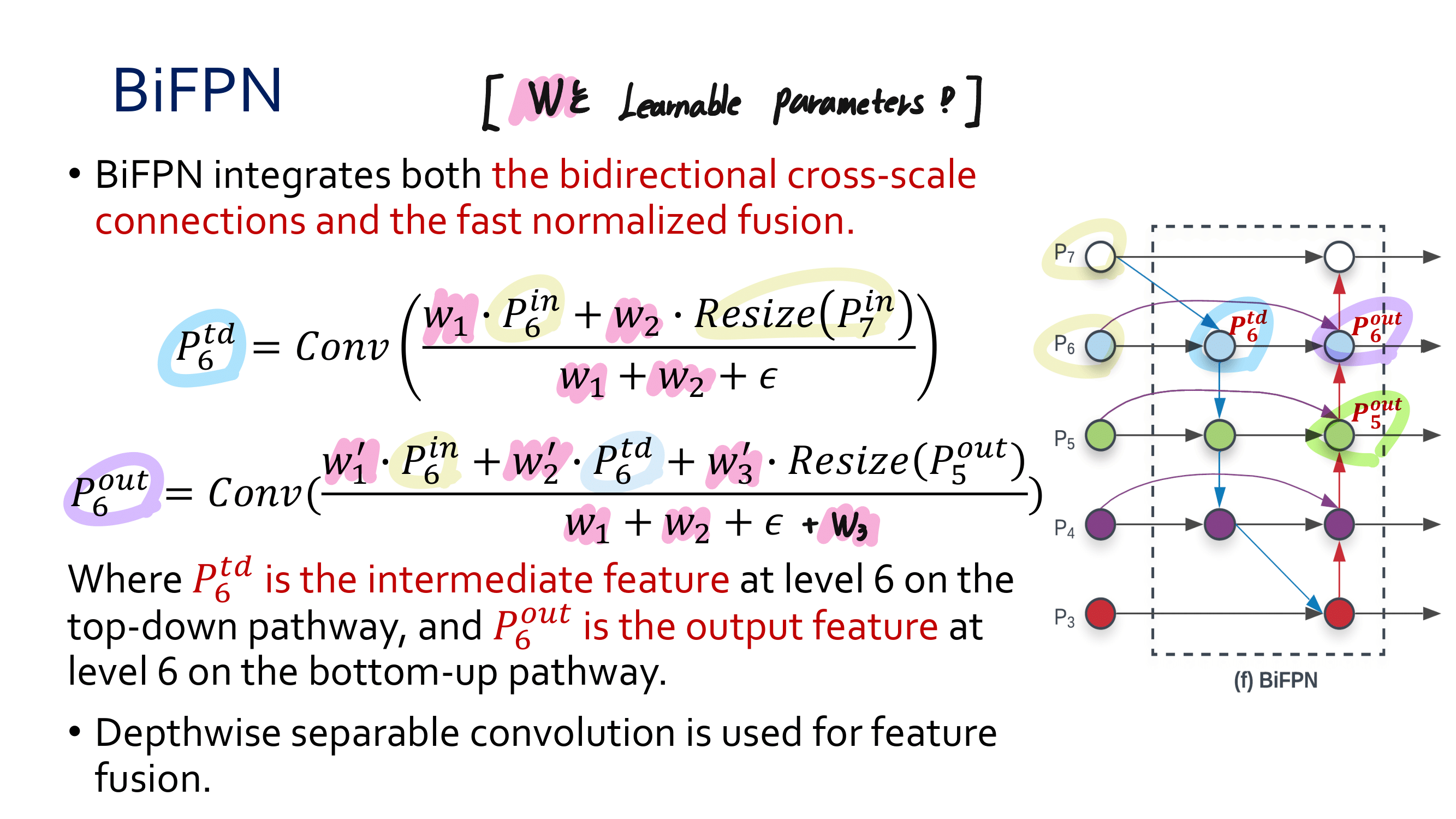
새로운 관점의 FPN : SFAM(SE module to execute channelwise level) [98] , ASFF(point-wise level reweighting) [48], and BiFPN(scale-wise level re-weighting and Adding feature maps of different scales) [77].
activation function
LReLU [54], PReLU [24] : zero gradient problem 해결
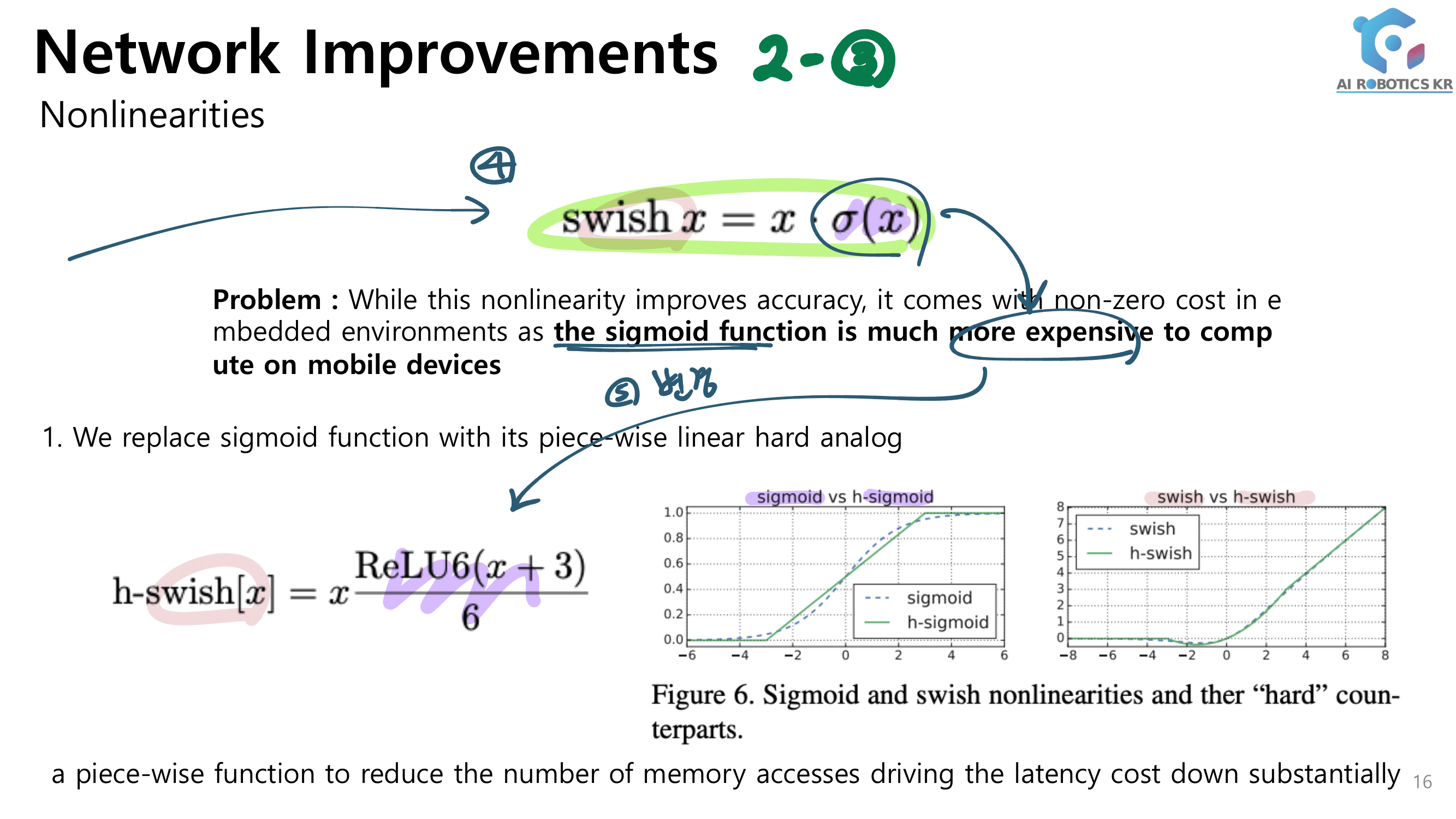
ReLU6 [28], Scaled Exponential Linear Unit (SELU) [35], hard-Swish [27]
Swish and Mish : continuously differentiable activation function.
post-processing
greedy(origin) NMS : optimizing & objective function 두개가 일관(일치)되게 만든다. by Confidence score
soft NMS : greedy NMS가 Confidence score의 저하 문제를 고려함
DIoU NMS : soft NMS에서 the center point distance개념을 추가
하지만 anchor-free method 에서는 더 이상 post-processing을 필요로 하지 않는다.
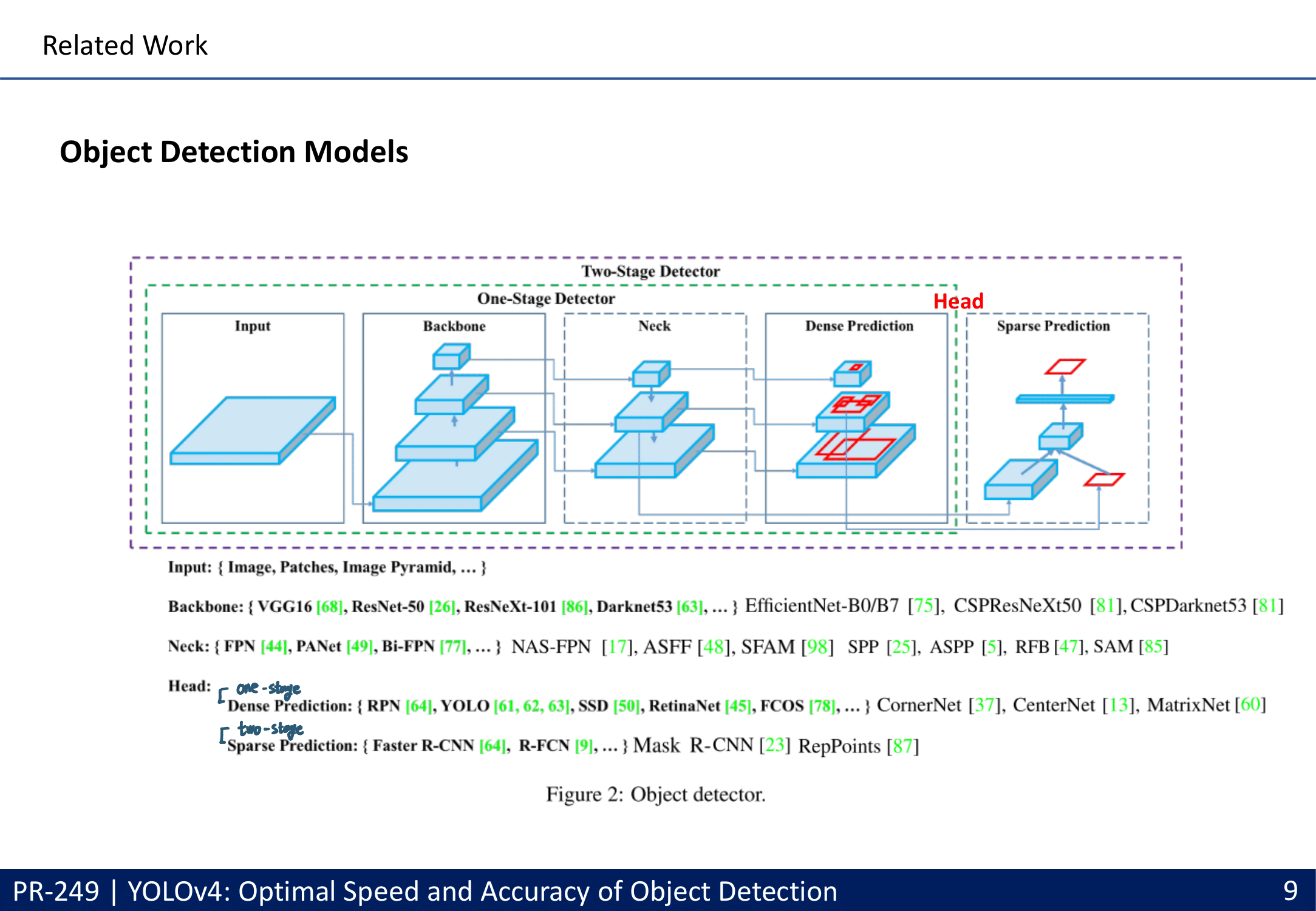
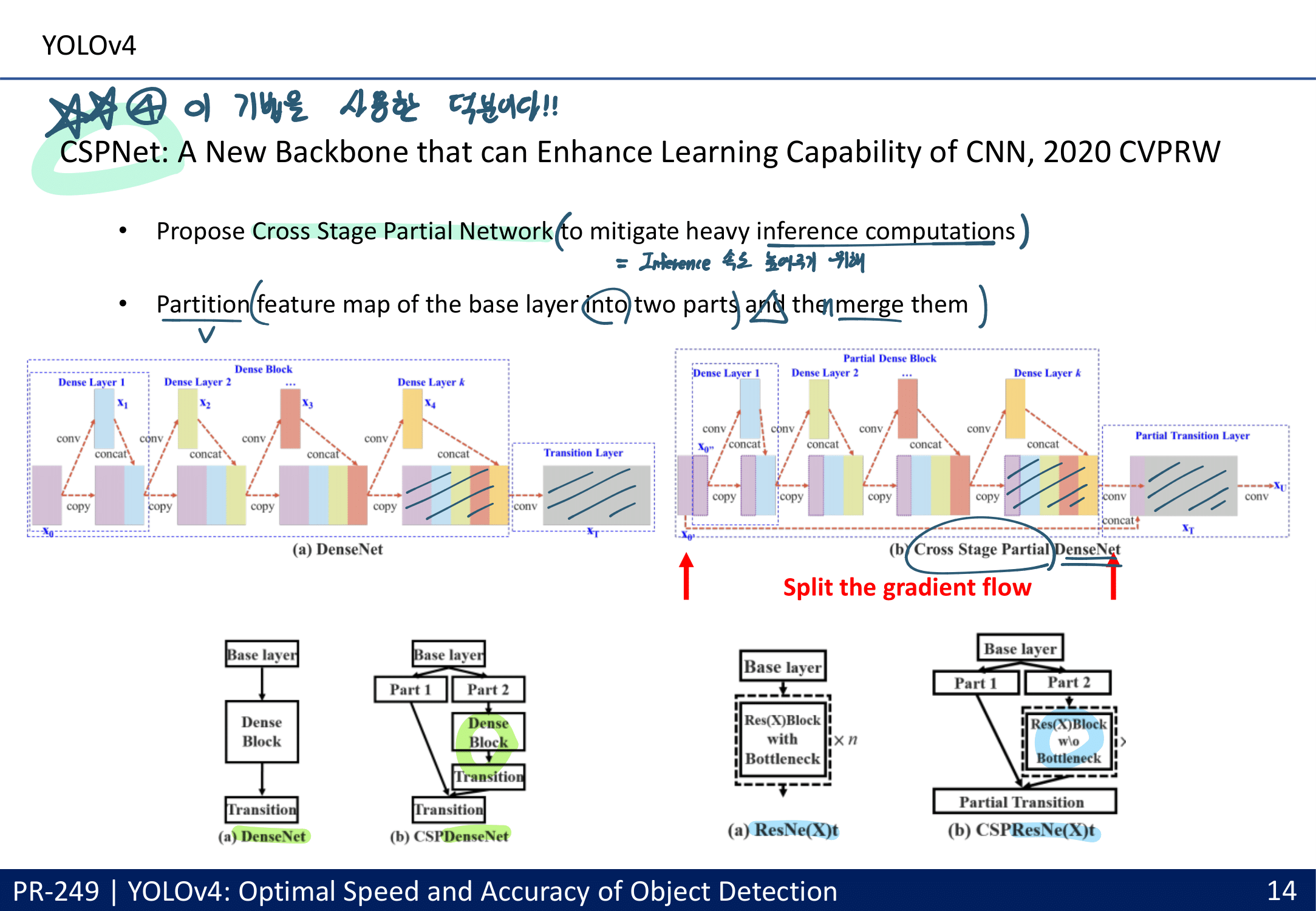
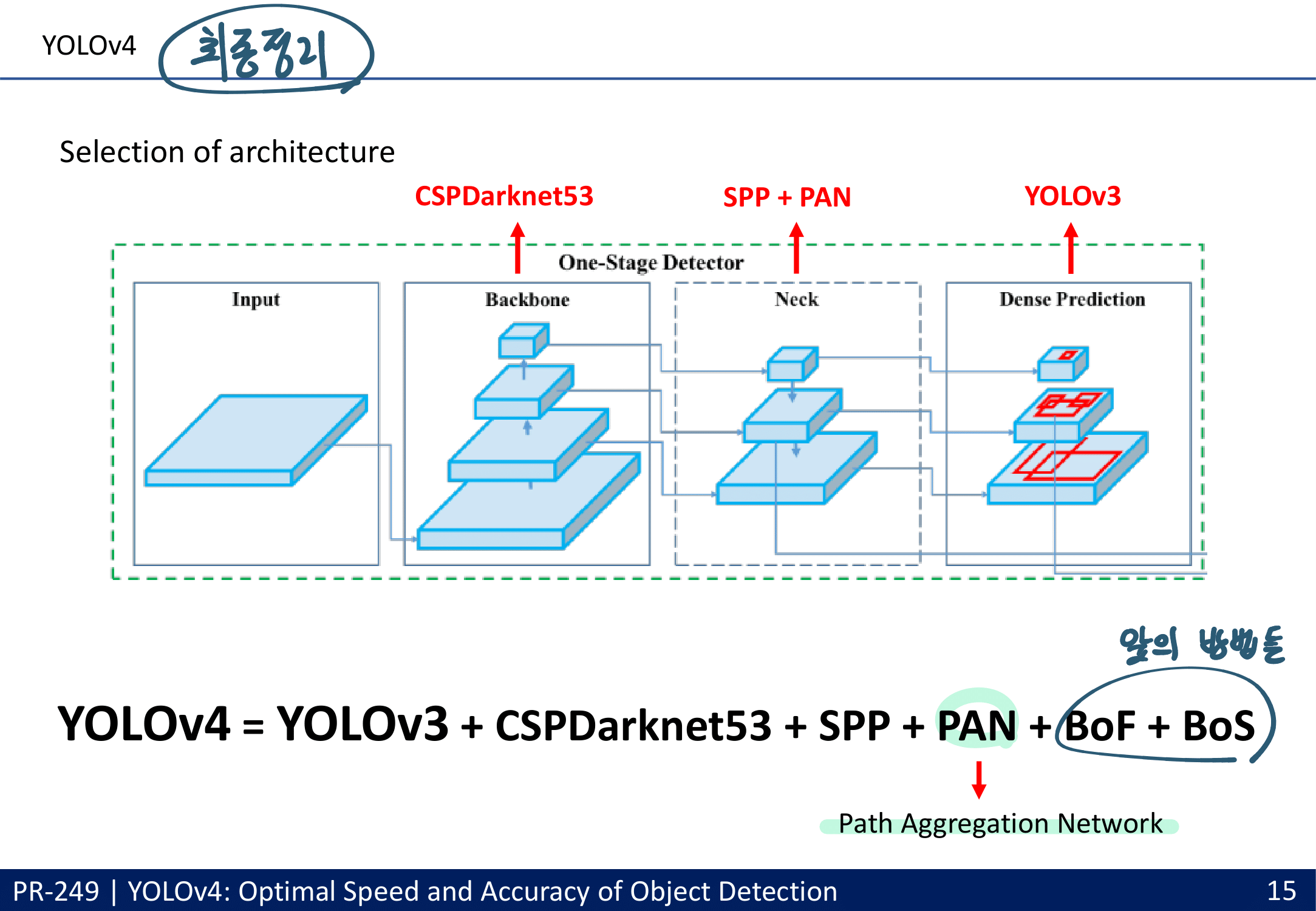
아래의 조건을 만족하는 Cross-Stage-Partial-connections (CSP) (DenseNet의 경량화 버전) 과 DarkNet을 접목시켜서 사용. or CSPResNext50
Higher input Resolution For Small-objects
More Layers For Higher receptive field
More parameters For more accurate
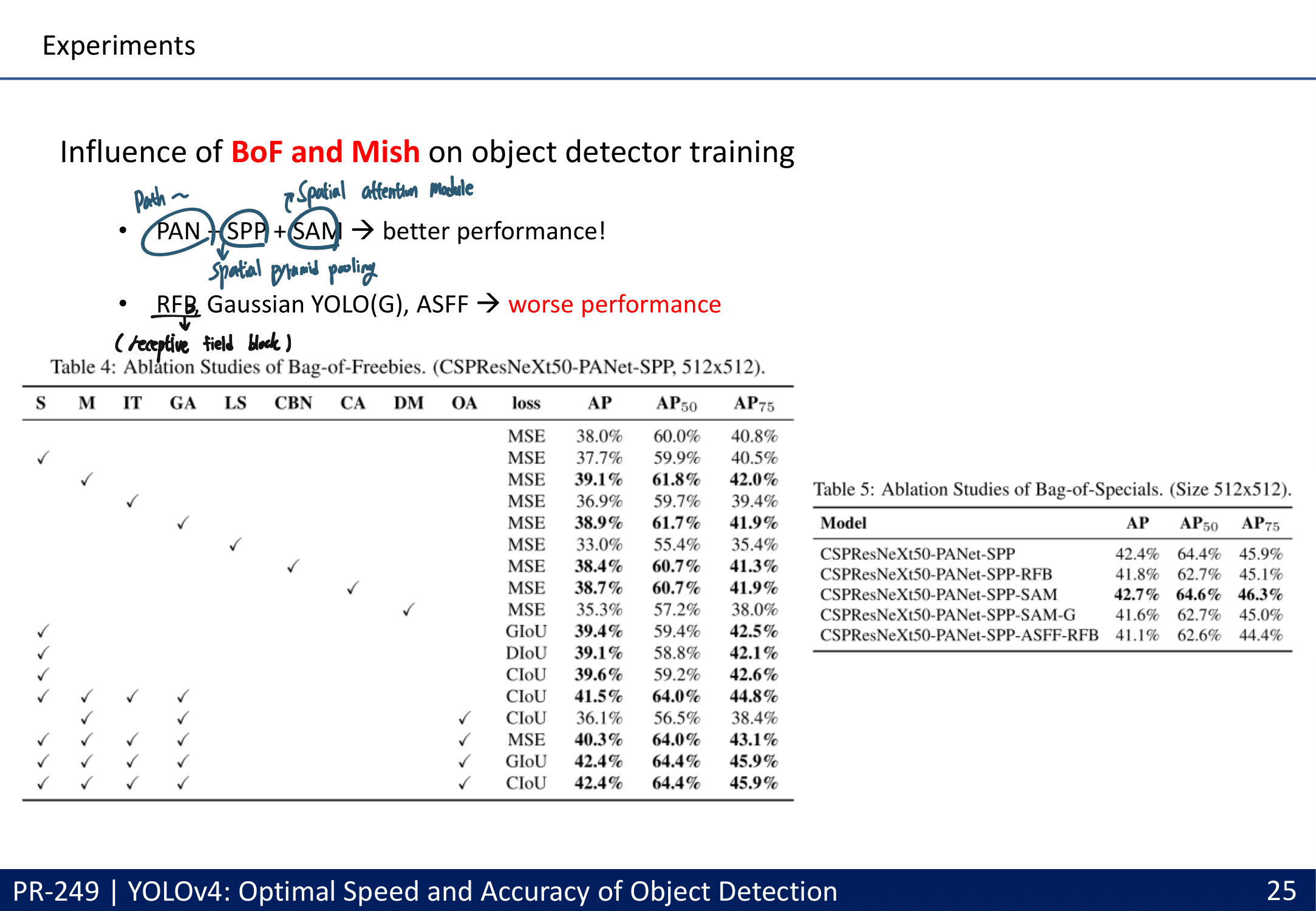
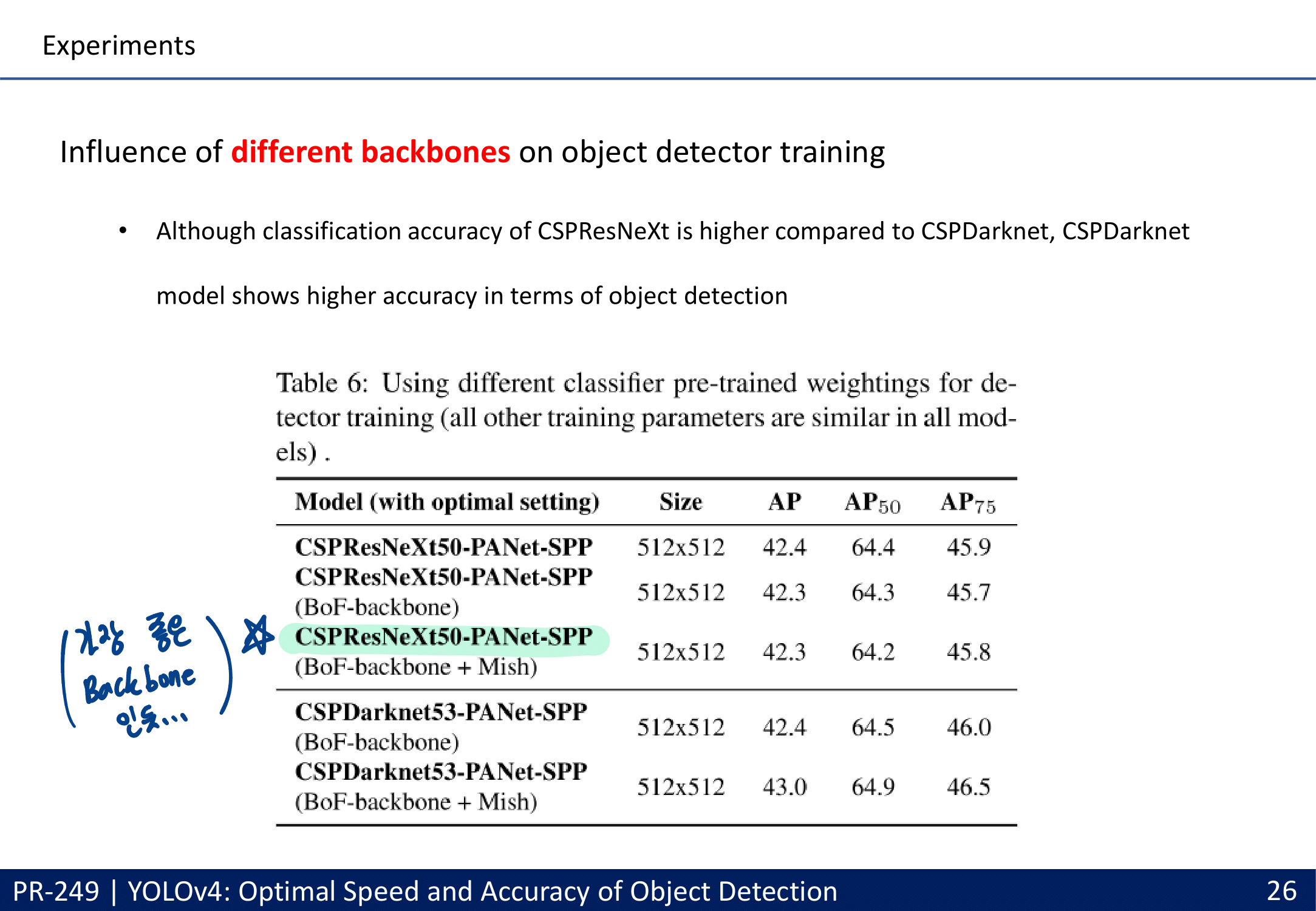
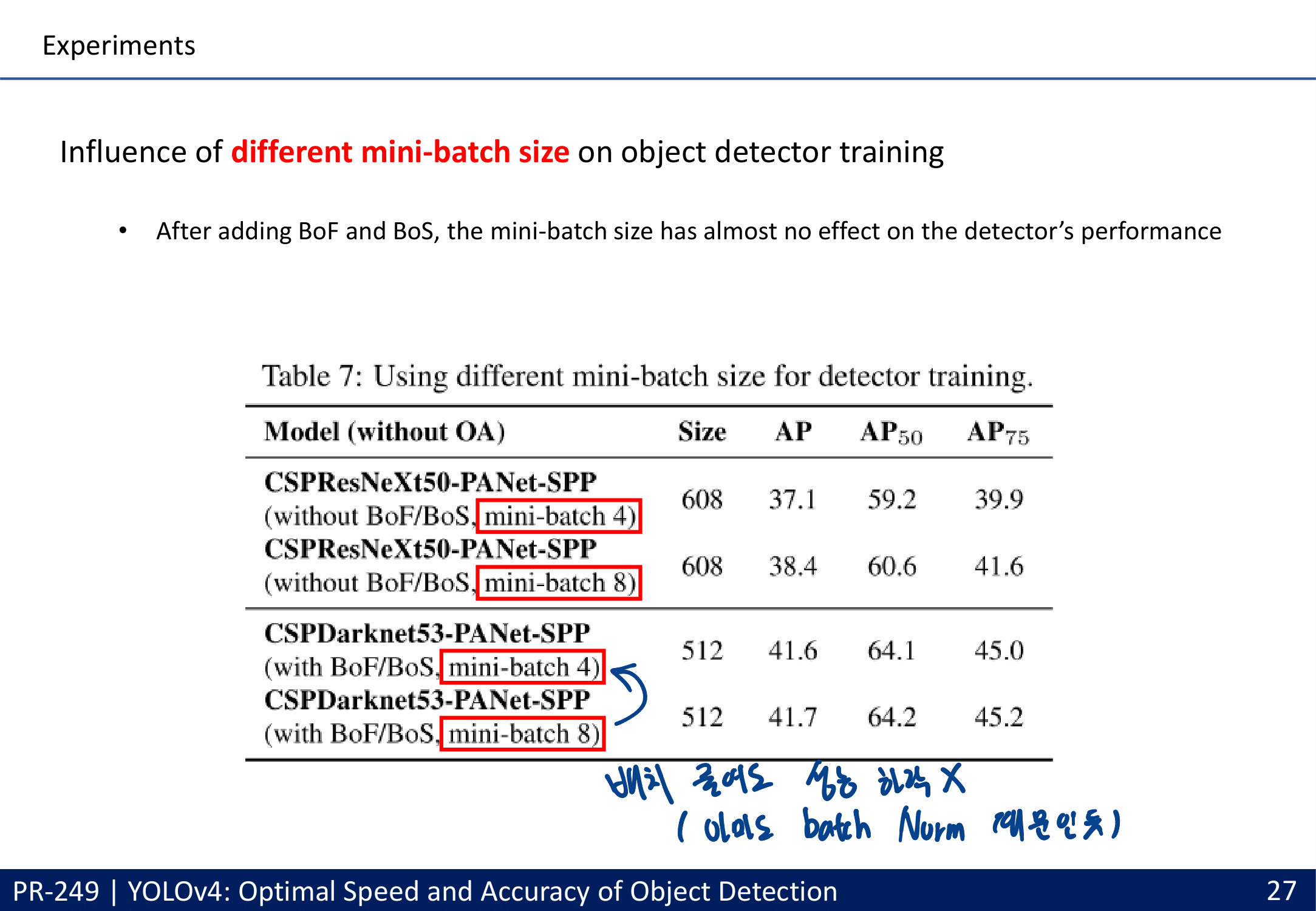
많은 실험을 통한 Selection of BoF and BoS (주의할점 : 여기에서 좋은 결과를 내어야만 좋은 Method인 것은 아니다. 저자가 코드를 잘 못 이해하고 코드 적용이 잘못 됐을 수도 있는 거니까. By PPT발표자)
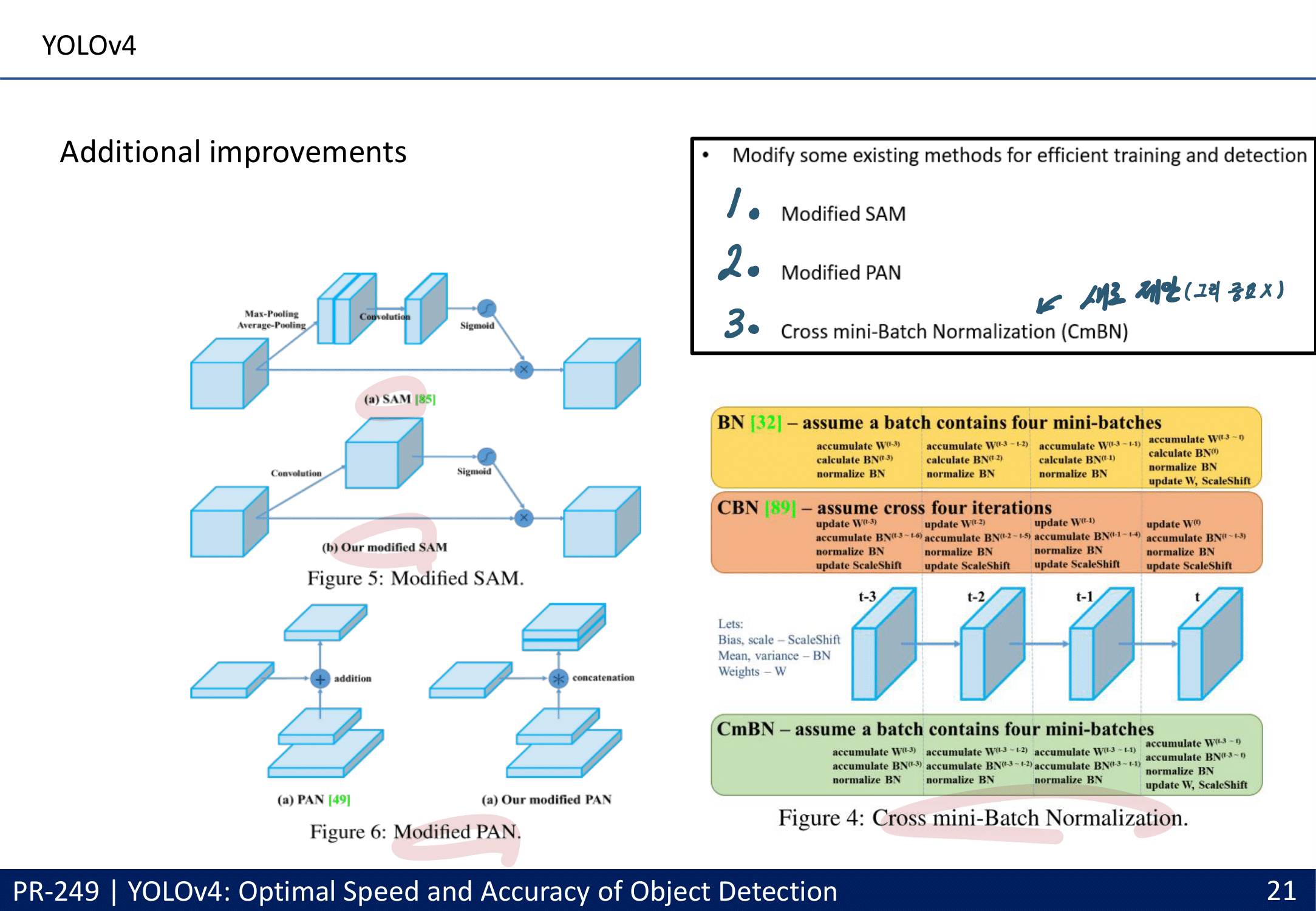
Additional improvements
data augmentation Mosaic : 4개의 이미지 합치기, batch normalization에 효과적
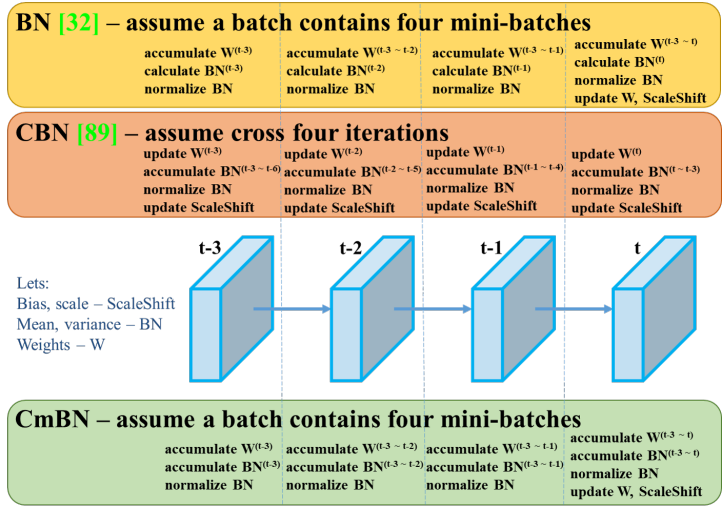
CmBN collects statistics only between mini-batches within a single batch. Batch No
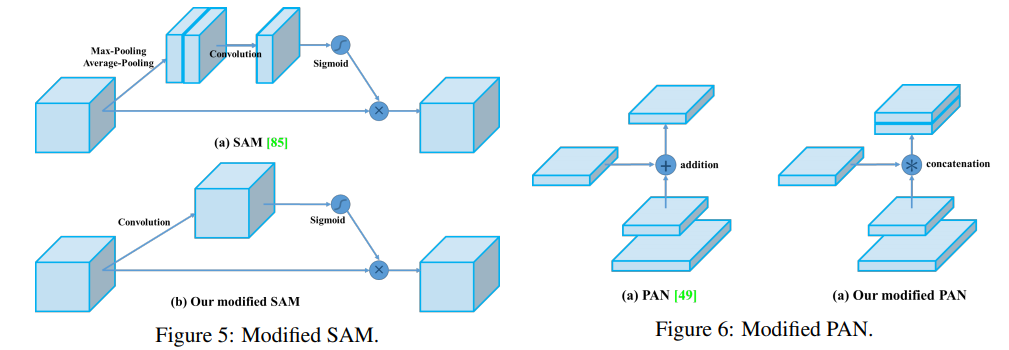
SAM(CBAM) 그리고 PAN을 아래와 같이 수정했다. (그림만 나오지 구체적인 방법 없다.)
최종적으로 YoloV4에서 사용한 방법론
시간이 날 때마다, 위의 방법론들에 대해서 찾아 공부하는 것도 좋을 것 같다.
실험결과는 윗 목차의 PPT 내용 참조
3. Tianxiaomo/pytorch-YOLOv4
Github Link : Tianxiaomo/pytorch-YOLOv4 (중국어 Issue가 많아서 아쉬웠지만, 이거말고 1.1k star를 가지고 있는 YoloV4-pytorch repo도 대만사람이여서 그냥 둘다 비슷하다고 판단. 2.6k star인 이 repo보는게 낫다)
2021.02.08 : ONNX와 YoloV4에 대한 코드 공부는 지금 당장 필요 없다. 위에서 사용된 Method들 중 모르는 것은 일단 논문을 읽어야 한다. 그리고 각 Method에 따른 코드를 Github에서 다시 찾던지, 혹은 이 YoloV4 repo에서 찾아서 공부하면 된다.
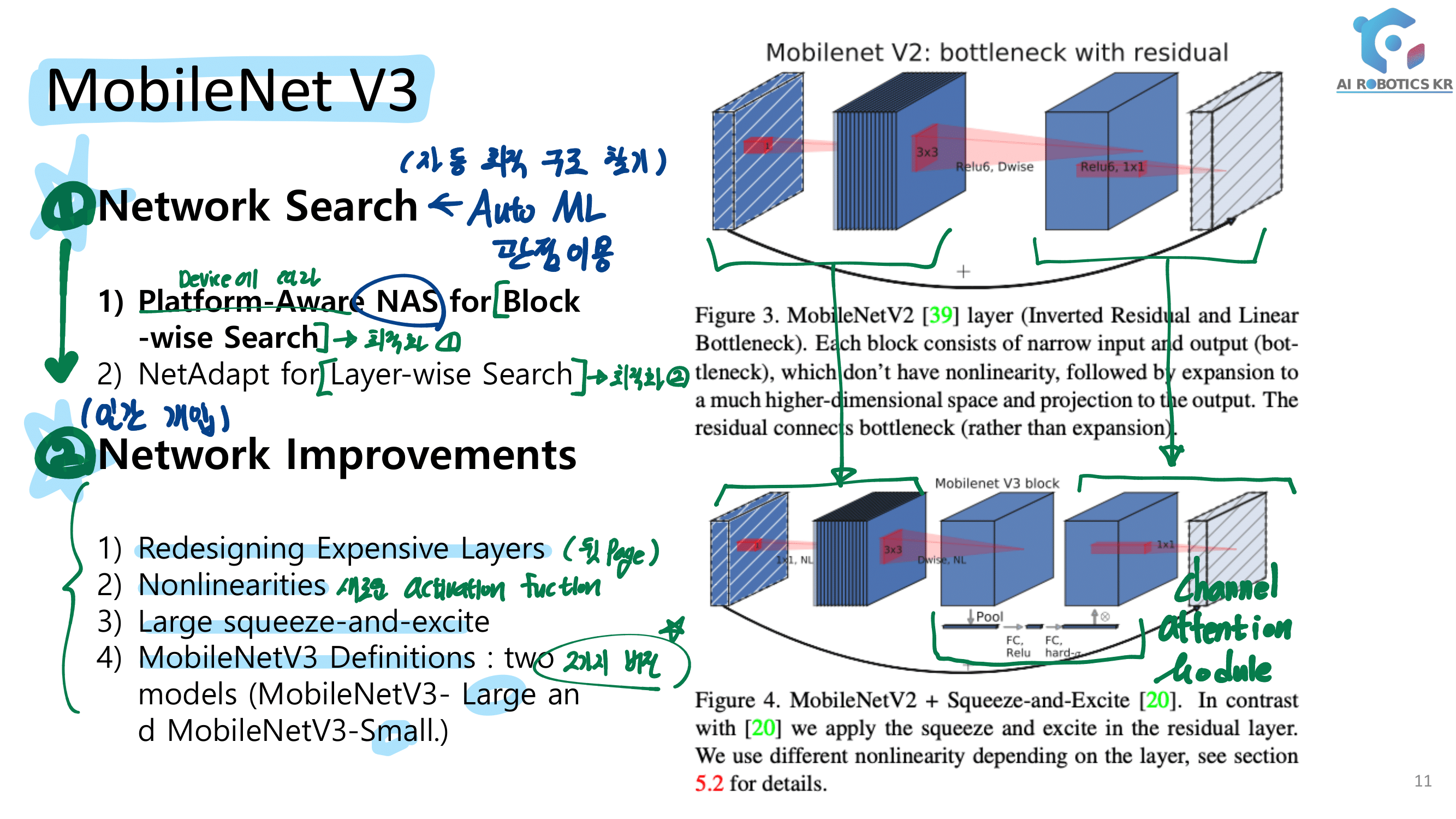
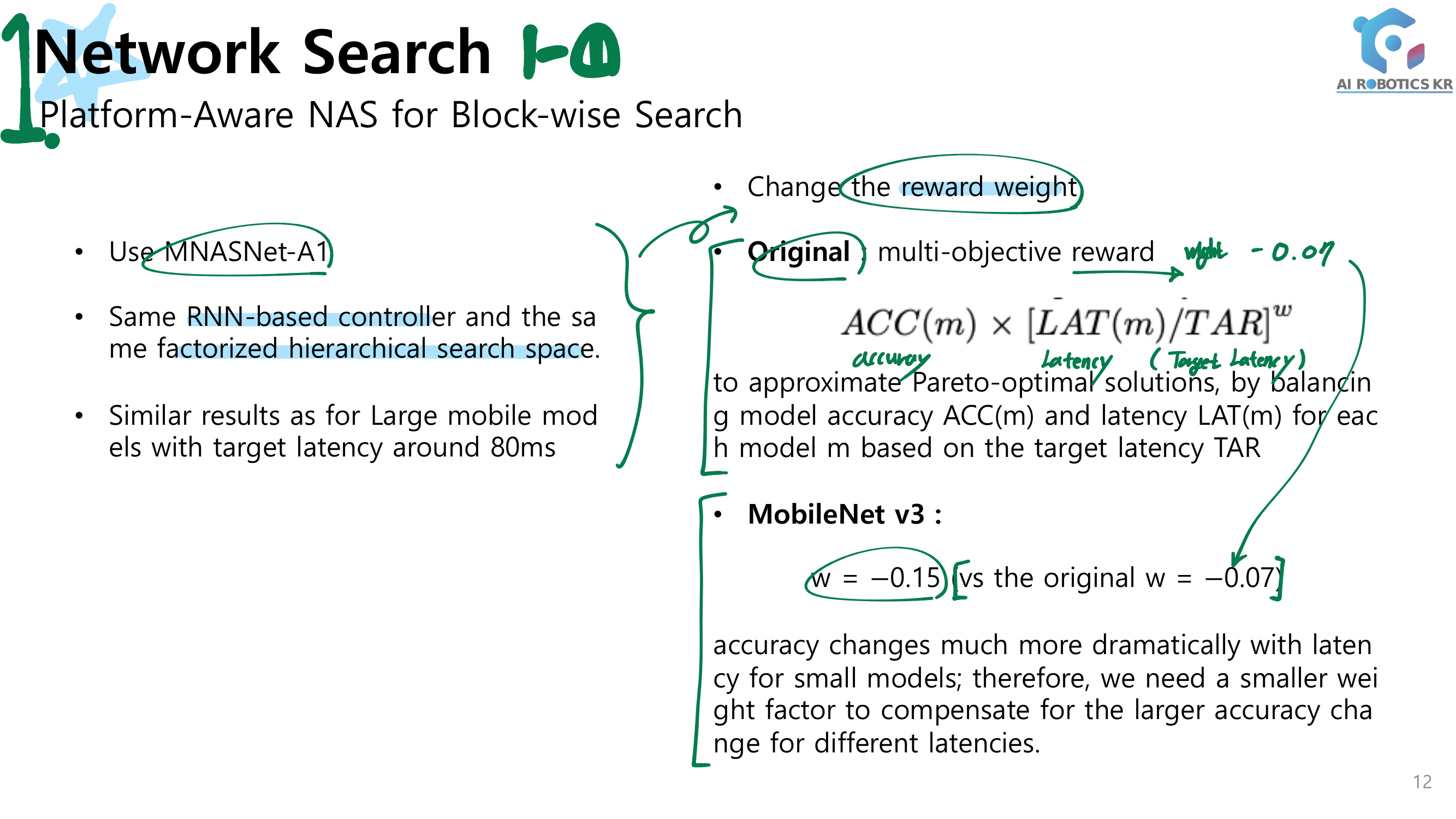
공부 배경 : MobileNetV3 Paper 읽기 전 선행 공부로 youtube 발표 자료 보기
선배님 조언:
삶의 벨런스? 석사 때는 그런거 없다. 주말? 무조건 나와야지. “가끔은 나도 쉬어야 돼. 그래야 효율도 올라가고…” 라고 생각하니까 쉬고 싶어지는 거다. 그렇게 하면, 아무것도 없이 후회하면서… 석사 졸업한다. “딱 2년만 죽었다고 생각하고 공부하자! 후회없도록! 논문도 1학년 여름방학 안에 하나 써보자!”
평일에는 1일 1페이퍼 정말 힘들다. 평일에는 개인 연구 시간 하루에 1시간도 찾기 힘들다. 그나마 주말에라도 해야한다. 지금이야 논문 읽고 배운 것을 정리하는게 전부지만, (1) 학교 수업 듣기 (2) 논문 읽기 (3) 코딩 공부 하기 (4) 코드 직접 수정하고 돌려보기 (5) 논문 쓰기. 까지 모두 모두 하려면 끝도 없다.
이번 여름방학 이전에, 아이디어 내고 코드 수정해서 결과 내보고 빠르게 제출하든 안하든 논문 한편 써보자.
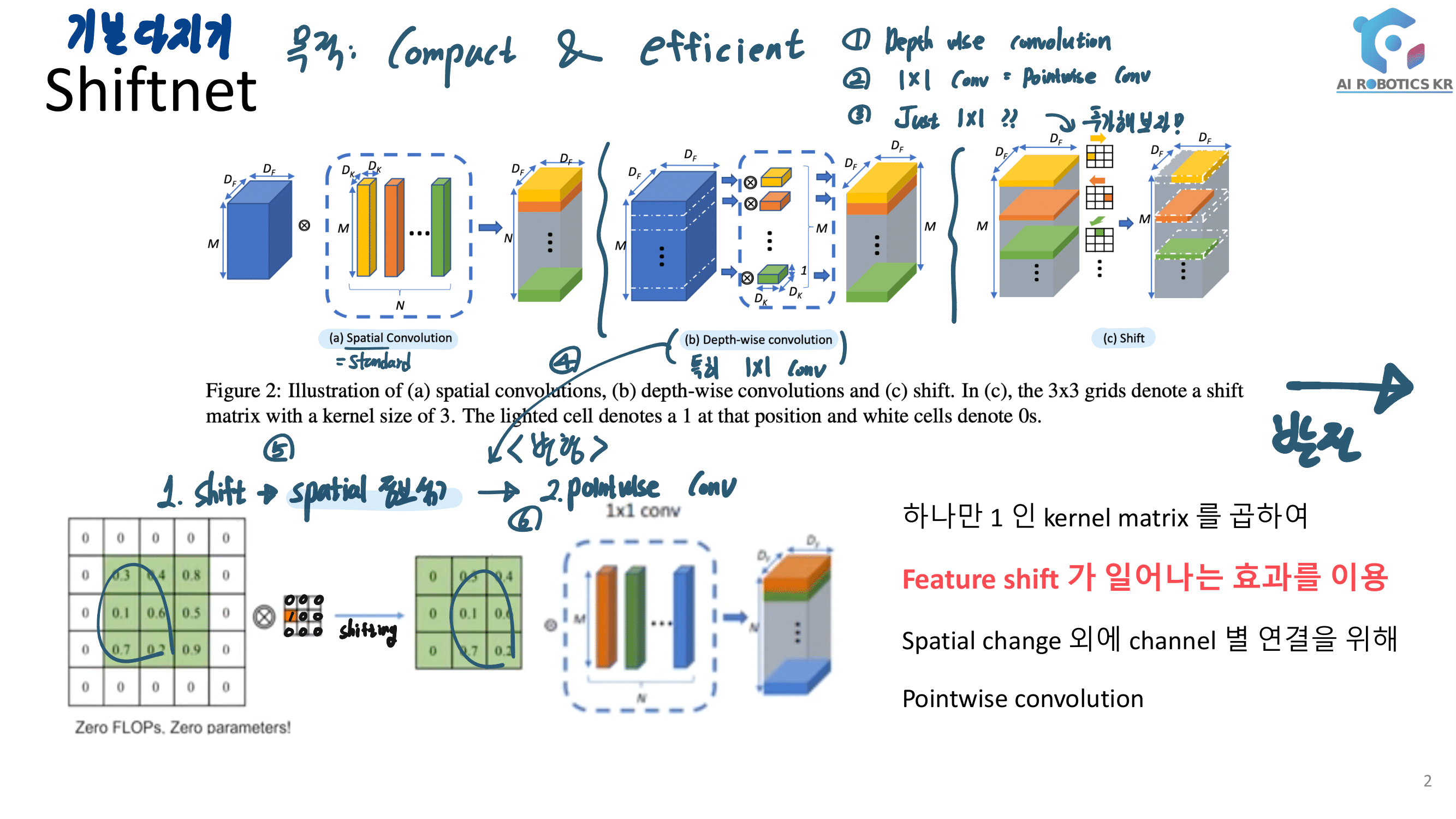
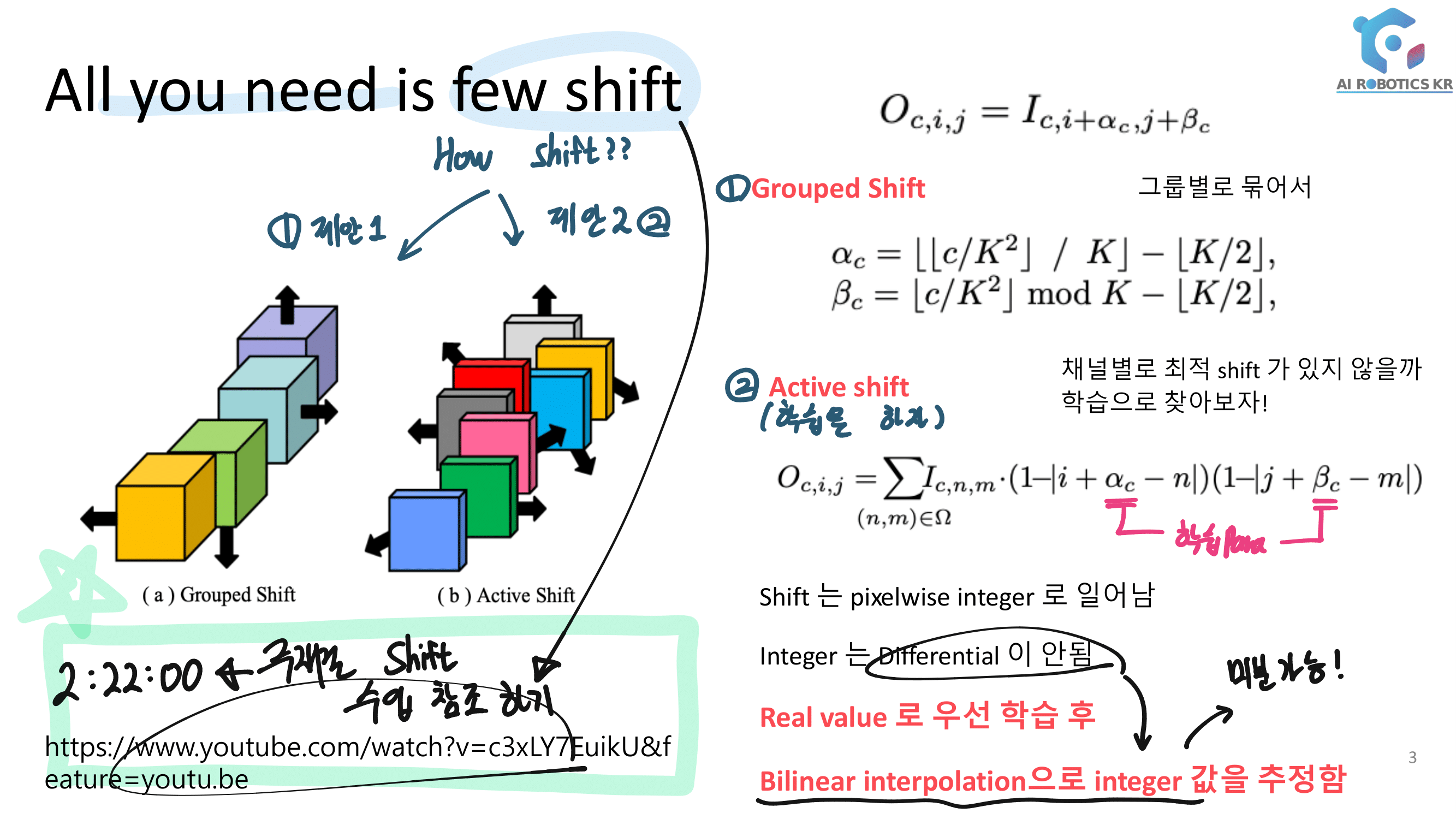
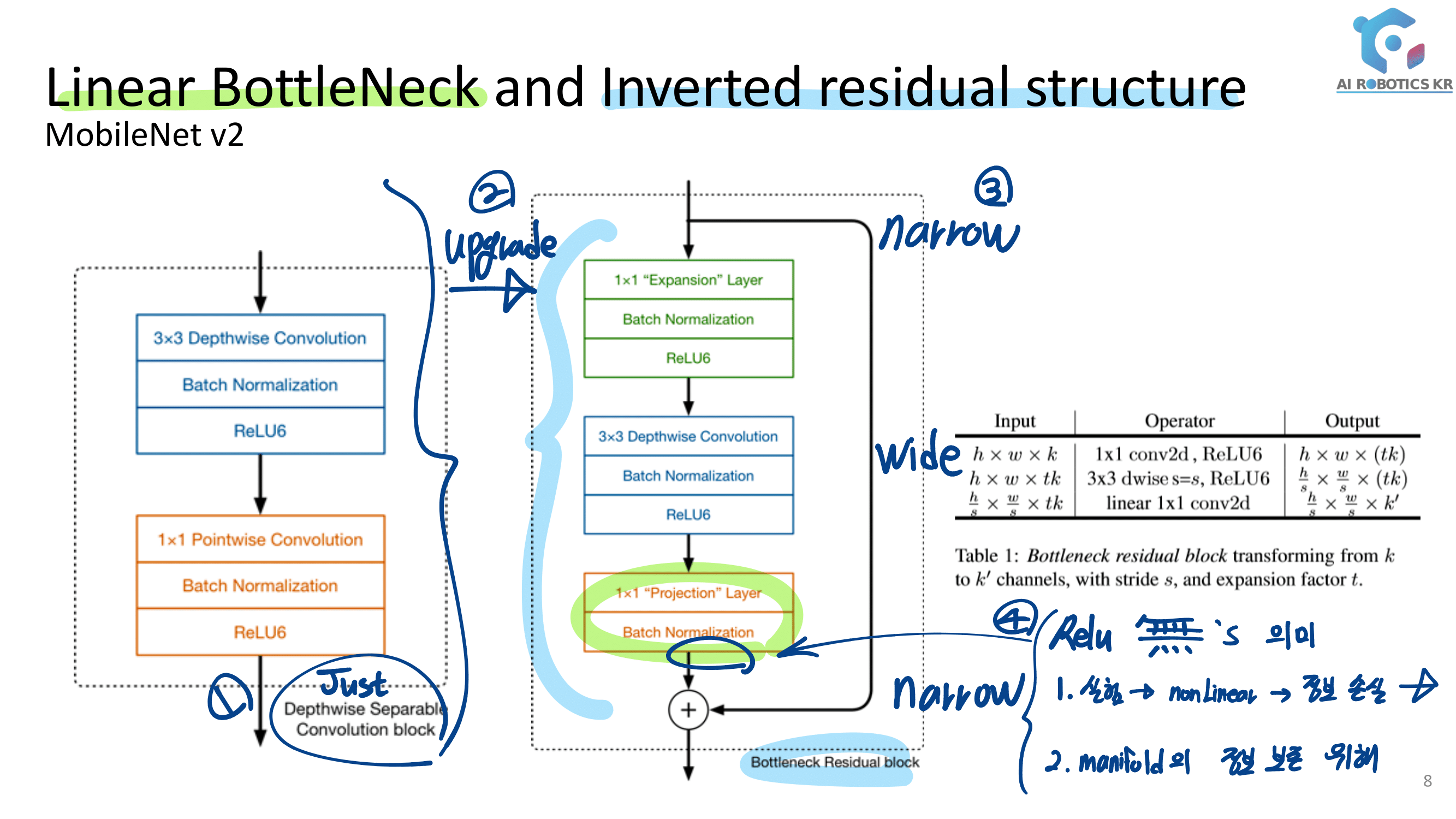
결국 Relu안하는 Convolution Layer이다. ㅅ… 욕이 나온네. “별것도 아닌거 말만 삐까번쩍하게 한다. 이게 정말 수학적으로 증명을 해서 뭘 알고 논문에서 어렵게 설명하는건지?, 혹은 그냥 그럴 것 같아서 실험을 몇번 해보니까 이게 성능이 좋아서 멋진 말로 끼워맞춘건지 모르겠다.
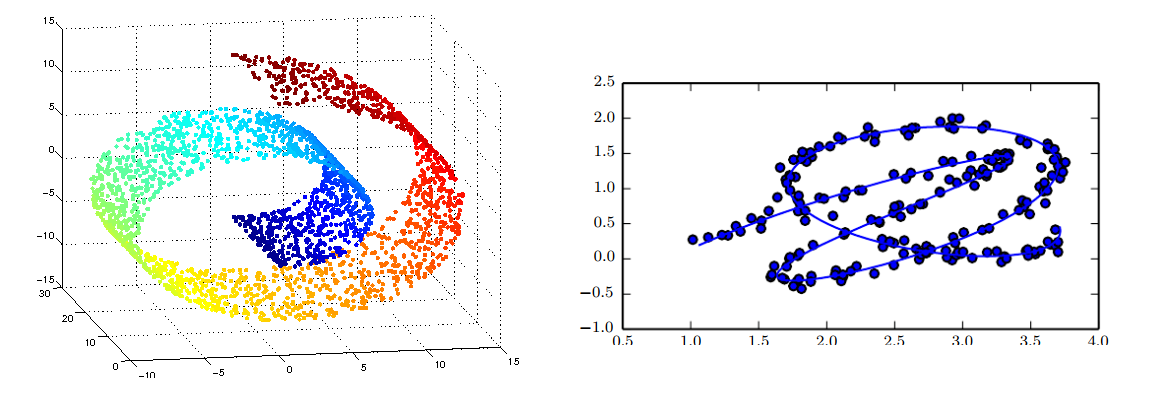
매니폴드 학습이란, <그림 1>과 같은 형태로 수집된 정보로부터 <그림 2>와 같이 바르고 곧은 유클리디안 공간을 찾아내는 것을 말합니다.
아래의 그림처럼, 100차원 vector들이 100차원 공간상에 놓여있다. 하지만 유심히 보면, 결국 백터들은 2차원 평면(왼쪽 그림) 혹은 3차원 공간(오른쪼 그림) 으로 이동 시킬 수 있다. 즉 100차원 공간이라고 보여도 사실은 2차원 3차원으로 더 잘 표현할 수 있는 백터들 이었다는 것이다.
이렇게 높은 차원의 백터들을, 낮은 차원의 직관적이고 곧은 공간으로 이동시킬 수 있게 신경망과 신경망의 파라메터를 이용한다.
실용적으로 말해서! “conv혹은 fc를 통과하고 activation function을 통과하고 나온 (Subset) Feature가 Manifold 이다!” 그리고 “그 Manifold 중에 우리가 관심있어하는 부분, 가장 많은 이미지의 정보를 representation하는 일부를 논문에서는 Manifold of interest 라고 한다.”
논문 설명 + 나의 이해 : Input data = x 가 맨 왼쪽과 같이 표현 된다고 하자. 그리고 Activation_Function( T * x) 를 수행한다. 여기서 T는 Input data의 차원을 위 사진의 숫자와 같이 2,3,5,15,30 차원으로 늘려주는 FC Layer라고 생각하자.
결과를 살펴보면, 낮은 차원으로 Enbeding하는 작업은, 특히 (비선형성 발생하게 만드는) Relu에 의해서 (low-dimensional subspace = 윗 이미지 그림을 살펴 보면) 정보의 손실이 많이 일어난다. 하지만 고차원으로의 Enbeding은 Relu에 의해서도 정보의 손실이 그리 많이 일어나지 않는다.
솔직히 논문이나 PPT내용이 무슨소리 하는지는 모르겠다.
결국에는 위와 같은 “정보 손실”을 줄이기 위해서, 비선형이 Relu를 쓰지 않고 Linear Function을 쓰겠다는 것이다.
ResNet의 Improving 형태 -> Srochastic Depth : 오른쪽 그림의 회색과 같이, 랜덤하게 일부 Layer를 끄고 학습일 시킨다. 더 좋은 결과가 나오더라
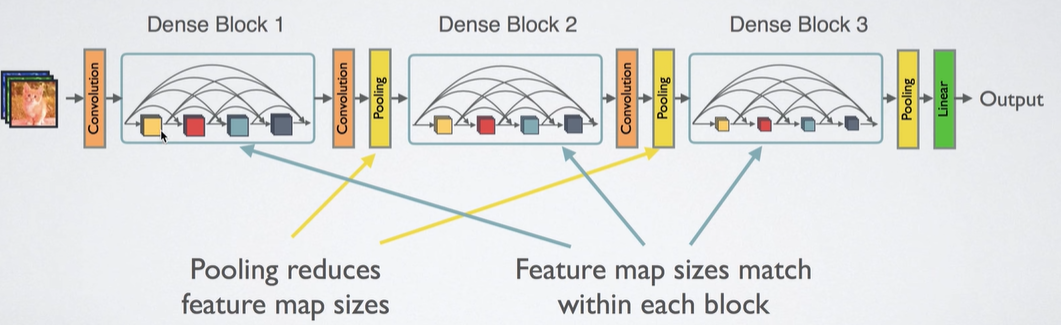
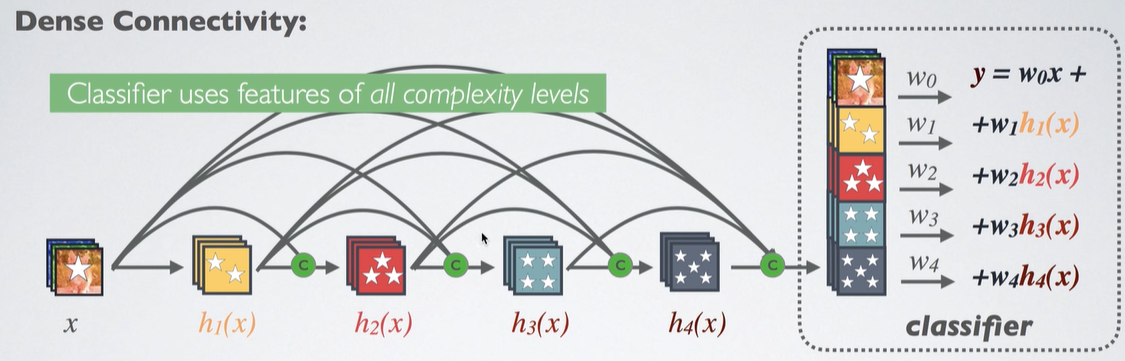
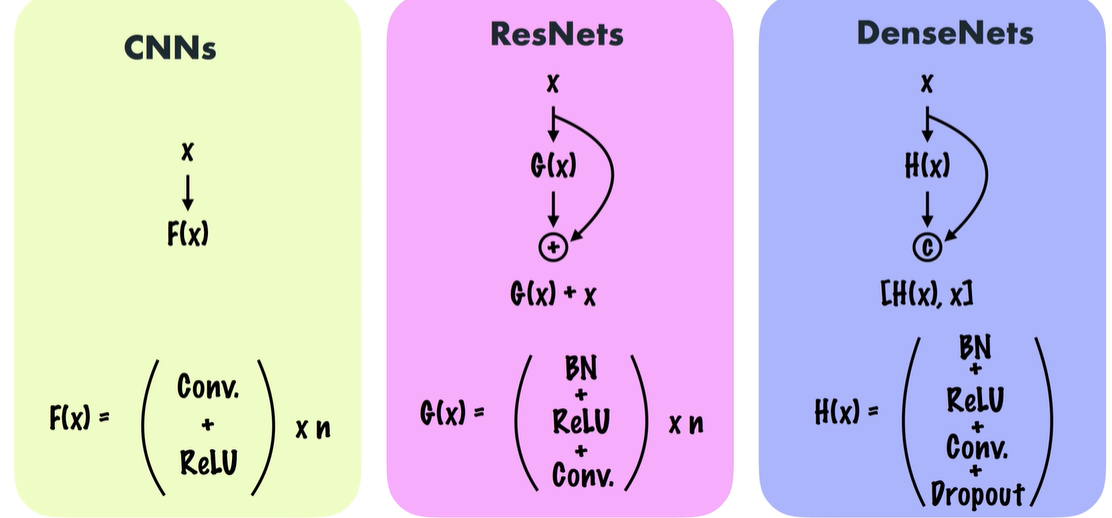
Densely Connected Convolutional Networks
ResNet 처럼 다음단만 연결하지 말고, 모조리 다 연결해보자.
Element-wise addition 하지 말고, Channel-wise Concatenation 하자!
Dense And Slim하다! 왜냐면 Channel을 크게 가져갈 필요없기 때문이다. Layer를 통과할 때마다 k(=12)개씩 Channel 수가 증가하도록만 만들어도 충분히 학습이 잘 되니까.
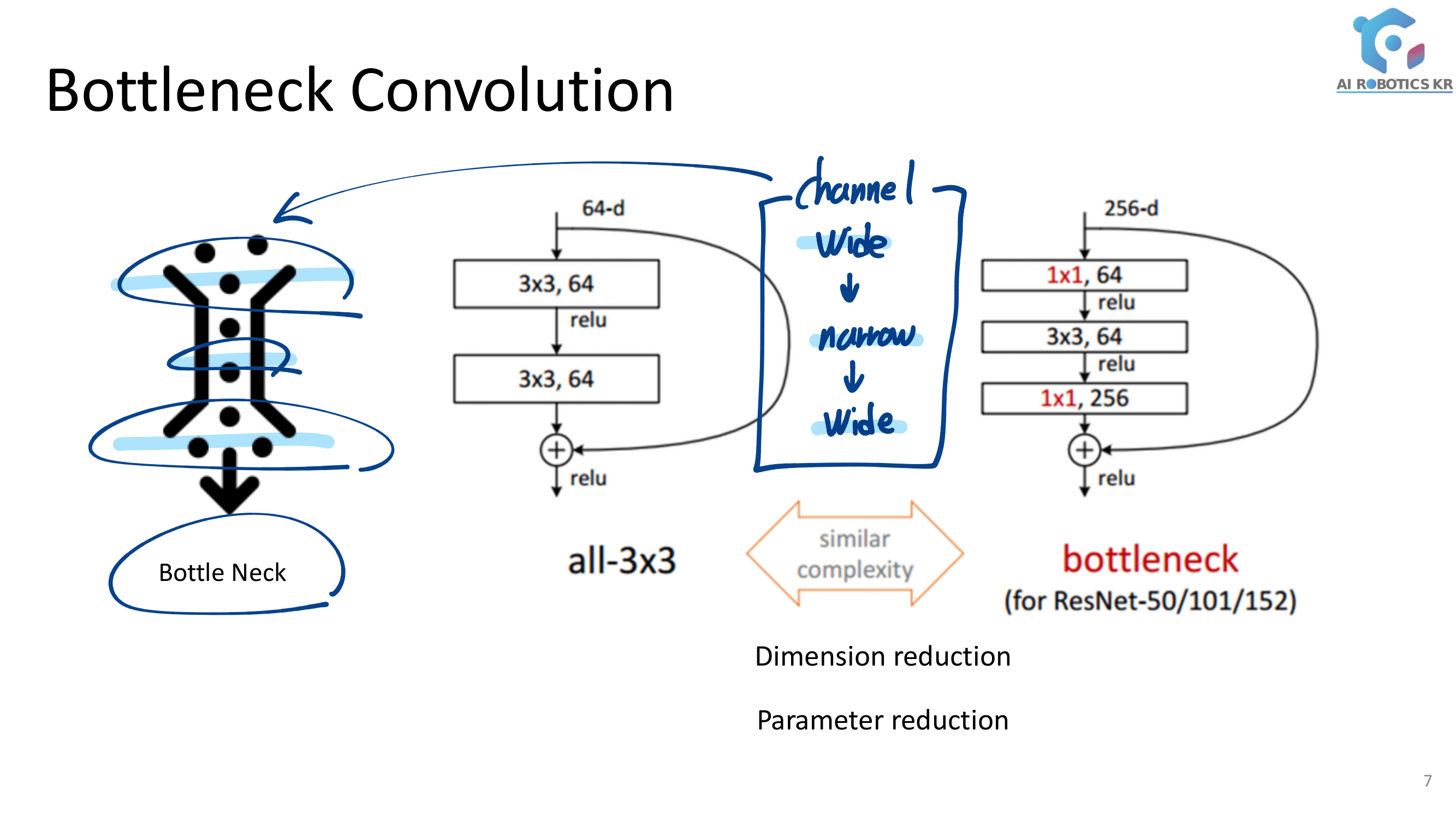
또는 아래와 같이 BottleNetck Layer를 사용하면 아래와 같다.
위의 모든 연산을, 하나의 Layer를 통과한 것으로 본다면, 모든 연산후에는 항상 k개의 channel이 생기게 만든다. (어차피 나중에 (l = 이전에 통과한 Layer 갯수) l x k 개의 Channel과 합쳐야 하므로 새로 생긴 k가 너무 크지 않도록 만든다. 여기서 k는 12를 사용했다고 함)
위의 작업들을 모듈화로 하여, 여러번 반복함으로써 다음과 같은 전체 그림을 만들 수 있다. 논문에서는 일반적으로 DenseBlock을 3개 정도 사용하였다.
장점
학습이 잘된다. Error Signal의 전달 = Backpropa가 잘된다.
기존의 것들은 중간 Layer의 Channel의 size가 매우 커야 학습이 잘 됐는데, 우리의 Channel은 작은값 k를 이용해서 최대 lxk개의 Channel만을 가지도록 만들었다.
그마큼 사용되는 # parameters 또한 줄어진다. O(C*C(중간 Layer의 channel 갯수)) » O(L*k*k)
아래의 그림처럼 모든 Layer의 Feature들을 사용한다. 아래 그림의 ‘별’은 Complex정도를 의미한다. 원래 다른 network는 Classifier에서 가장 마지막 별5개짜리 Layer만을 이용한다. 하지만 우리의 Classifier는 지금까지의 모든 Layer결과를 한꺼번에 이용한다. 따라서 굉장히 효율성이 좋다.
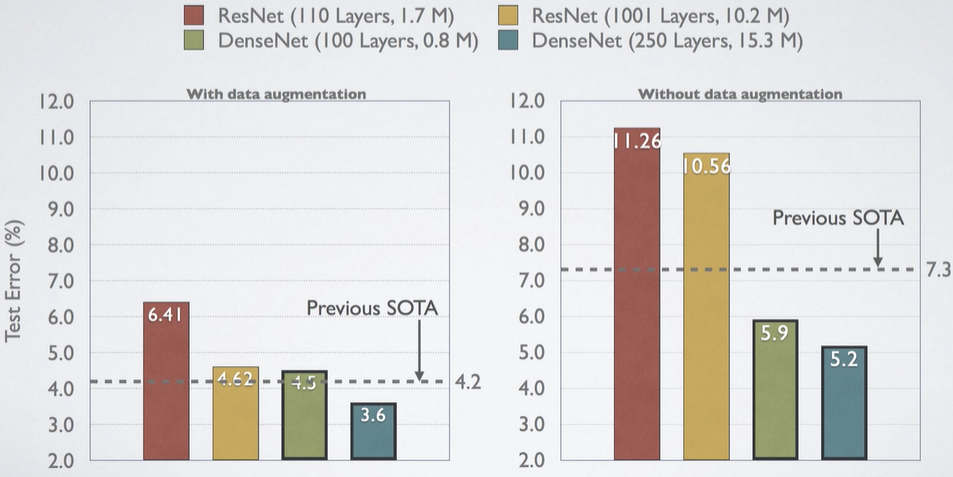
결과
논문에 없는 추가 내용
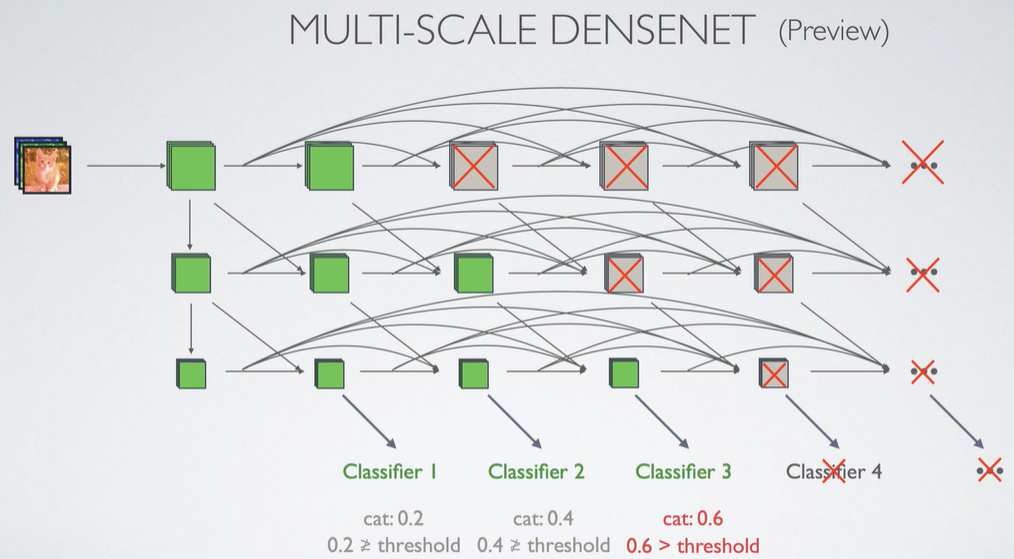
Easy Example은 앞의 Classifier1에서 처리하고, Hard Example은 뒤의 Classifier3에서 처리하도록 만들면, 더 빠른 예측이 가능하다. 그니까.. Classifier1에서 일정 이상의 값이 나온 것은 예측값 그대로 결과에 사용하고 거기서 Stop.(빨리 끝. 전체 평균 처리 속도 상승) 반대로 모든 클래스에서 일정 threshold값 이상이 나오지 않는다면, 다음 Classifier에서 분류를 다시 해보는 작업을 수행한다.
공부 배경 : MobileNetV3 Paper 읽기 전 선행 공부로 youtube 발표 자료 보기
선배님 조언:
Experiment와 Result 그리고 Ablation는 구체적으로 보시나요? 핵심 부분을 읽다가, 핵심이 되는 부분을 캐치하고 이것에 대해서 호기심이 생기거나, 혹은 이게 정말 성능이 좋은가? 에 대한 지표로 확인하기 위해서 본다. 따라서 필요거나 궁금하면 집중해서 보면 되고 그리 중요하지 않은 것은 넘기면 된다. 만약 핵심 Key Idea가 Experiment, Result, Ablation에 충분히 설명되지 않는다면 그건 그리 좋지 않은 아이디어 혹은 논문이라고 판단할 수 있다.
공부와 삶의 균형이 필요하다. 여유시간이 나서 유투브를 보더라도 감사하고 편하게 보고 쉴줄 알아야 하고, 공부할 때는 자기의 연구분야에 대한 흥미를 가지는 것도 매우 중요하다. 또한 취미나 릴렉스할 것을 가지고 가끔 열심히 공부하고 연구했던 자신에게 보상의 의미로 그것들을 한번씩 하는 시간을 가지는 것도 중요하다.
여러 선배들과 소통하고, 완벽하게 만들어가지 않더라도 나의 아이디어로 무언가를 간단하게 만들어 보고 제안해 보는것도 매우 중요하다. 예를 들어서, “나에게 이런 아이디어가 있으니, 이 분야 논문을 더 읽어보고 코드도 만들어보고 연구도 해보고 비교도 해보고 실험도 많이 해보고, 다~~ 해보고 나서 당당하게! ㅇㅇ선배님께 조언을 구해봐야겠다!” 라는 태도 보다는 “나에게 이런 아이디어가 있고… 논문 4개만 더 읽고 대충 나의 아이디어를 PPT로 만들어서 ㅇㅇ선배님께 보여드려보자! 그럼 뭐 좋은건 좋다고 고칠건 고치라고 해주시겠지…! 완벽하진 않더라도 조금 실망하실지라도 조금 철면피 깔고 부딪혀 보자!!” 라는 마인드.
논문. 미리미리 써보고 도전하자. 어차피 안하면 후회한다. 부족한 실력이라고 생각하지 말아라. 어려운 거라고 생각하지 말아라. 일단 대가리 박치기 해봐라. 할 수 있다. 목표를 잡고 도전해보자.
느낀점 : 말만 삐까번쩍, 번지르르 하게 해놓은 글이 너무 많다. 사실 몇개 대충 실험해보고 성능 잘나오니까.. 이거를 말로 포장을 해야해서 뭔가 있어보이게 수학적으로 마치 증명한것 마냥 이야기하는 내용이 머신러닝 논문에 너무 많다. 정말 유용한 지식만 걸러서 듣자. Experiment, Result, Ablation 를 통해서 증거를 꼭 찾아보자.
결국 Relu안하는 Convolution Layer이다. ㅅ… 욕이 나온네. “별것도 아닌거 말만 삐까번쩍하게 한다. 이게 정말 수학적으로 증명을 해서 뭘 알고 논문에서 어렵게 설명하는건지?, 혹은 그냥 그럴 것 같아서 실험을 몇번 해보니까 이게 성능이 좋아서 멋진 말로 끼워맞춘건지 모르겠다.
매니폴드 학습이란, <그림 1>과 같은 형태로 수집된 정보로부터 <그림 2>와 같이 바르고 곧은 유클리디안 공간을 찾아내는 것을 말합니다.
아래의 그림처럼, 100차원 vector들이 100차원 공간상에 놓여있다. 하지만 유심히 보면, 결국 백터들은 2차원 평면(왼쪽 그림) 혹은 3차원 공간(오른쪼 그림) 으로 이동 시킬 수 있다. 즉 100차원 공간이라고 보여도 사실은 2차원 3차원으로 더 잘 표현할 수 있는 백터들 이었다는 것이다.
이렇게 높은 차원의 백터들을, 낮은 차원의 직관적이고 곧은 공간으로 이동시킬 수 있게 신경망과 신경망의 파라메터를 이용한다.
실용적으로 말해서! “conv혹은 fc를 통과하고 activation function을 통과하고 나온 (Subset) Feature가 Manifold 이다!” 그리고 “그 Manifold 중에 우리가 관심있어하는 부분, 가장 많은 이미지의 정보를 representation하는 일부를 논문에서는 Manifold of interest 라고 한다.”
논문 설명 + 나의 이해 : Input data = x 가 맨 왼쪽과 같이 표현 된다고 하자. 그리고 Activation_Function( T * x) 를 수행한다. 여기서 T는 Input data의 차원을 위 사진의 숫자와 같이 2,3,5,15,30 차원으로 늘려주는 FC Layer라고 생각하자.
결과를 살펴보면, 낮은 차원으로 Enbeding하는 작업은, 특히 (비선형성 발생하게 만드는) Relu에 의해서 (low-dimensional subspace = 윗 이미지 그림을 살펴 보면) 정보의 손실이 많이 일어난다. 하지만 고차원으로의 Enbeding은 Relu에 의해서도 정보의 손실이 그리 많이 일어나지 않는다.
솔직히 논문이나 PPT내용이 무슨소리 하는지는 모르겠다.
결국에는 위와 같은 “정보 손실”을 줄이기 위해서, 비선형이 Relu를 쓰지 않고 Linear Function을 쓰겠다는 것이다.
읽는 배경 : Recognition Basic. Understand confusing and ambiguous things.
읽으면서 생각할 포인트 : 코드와 함께 최대한 완벽히 이해하기. 이해한 것 정확히 기록해두기.
느낀점 :
최근 논문을 많이 읽어서 느끼는 점은, 각 논문은 특별한 목표가 1,2개 있다. (예를 들어 Cascade는 close false positive 객체를 줄이기 위함이 목표이고, FPN는 Multi-scale object detect를 목적으로 한다.) 그리고 그 목표 달성을 위해, 이전 신경망들의 정확한 문제점을 파악한다. 그 문제점을 해결하기 위해 새로운 아이디어를 첨가한다. Cascade에서 배운 것 처럼, 복잡한 아이디어를 마구 넣는다고 성능이 좋아지지 않는다. 핵심은 목표를 확실히 잡고, 문제점을 확실히 분석하고, 그것을 해결하기 위해 아이디어를 넣어보는 일렬이 과정이 정말 중요한 것 같다.
가장 이해하기 쉽게 씌여져 있는 논문 같다. 문법이나 용어가 쉽고, 같은 단어가 많이 반복되서 나에게는 너무 편했다. 또한 그림도 이미 완벽해서 더이상 다른 논문 글로 이해할 필요가 없었다. 이런 논문이 Top-Conference논문이 아니라, AAAI 논문이라는게 조금 아쉽다.
1. M2Det Paper Review
1. Conclusoin
Multi-Level Feature Pyramid Network (MLFPN) for different scales
New modules
Multi-lebel features by Feature Fusion Module (FFM v1)
multi-level multi-scale features (= 즉! the decoder layers of each TUM)
multi-level multi-scale features With the same scale (size) by a Scale-wise Feature Aggregation Module (SFAM)
SOTA Among the one-stage detectors on MS-COCO
2. Abstract, Introduction
Scale-variation problem -> FPN for originally classification tast
MLFPN construct more effective feature pyramids then FPN for Objec Detection tast
3.Introduction
conventional method for Scale variation
image pyramid at only testing time -> memory, computational complexity 증가
feature pyramid at both training and testing phases
SSD, FPN 등등은 for originally classification(backbone이니까) tast -> 한계가 존재한다.
그냥 backbone 중간에서 나온 형태 이용 - 정보 불충분 - object detection 하기 위해 정보 불충분
FPN의 p1, p2, p3는 Single-Level Feature 이다. 우리 처럼 Multi-Level Feature Pyramid가 아니다.
Low level feature -> simple appearances // high-level feature -> complex appearances. 유사한 scale의 객체는 complex appearances로써 구별되어야 하는데, Single-Level Feature로는 충분하지 않다.
Related Work : Faster R-CNN, MS-CNN, SSD, FPN, DSSD, YOLOv3, RetinaNet, RefineDet
우리의 진짜 목적은effective feature pyramid for detecting objects of different scales 이다.
우리 모델은 위의 한계를 해결한다. 어차피 뒤에 똑같은 내용 또 나올 듯.
4. Proposed Method
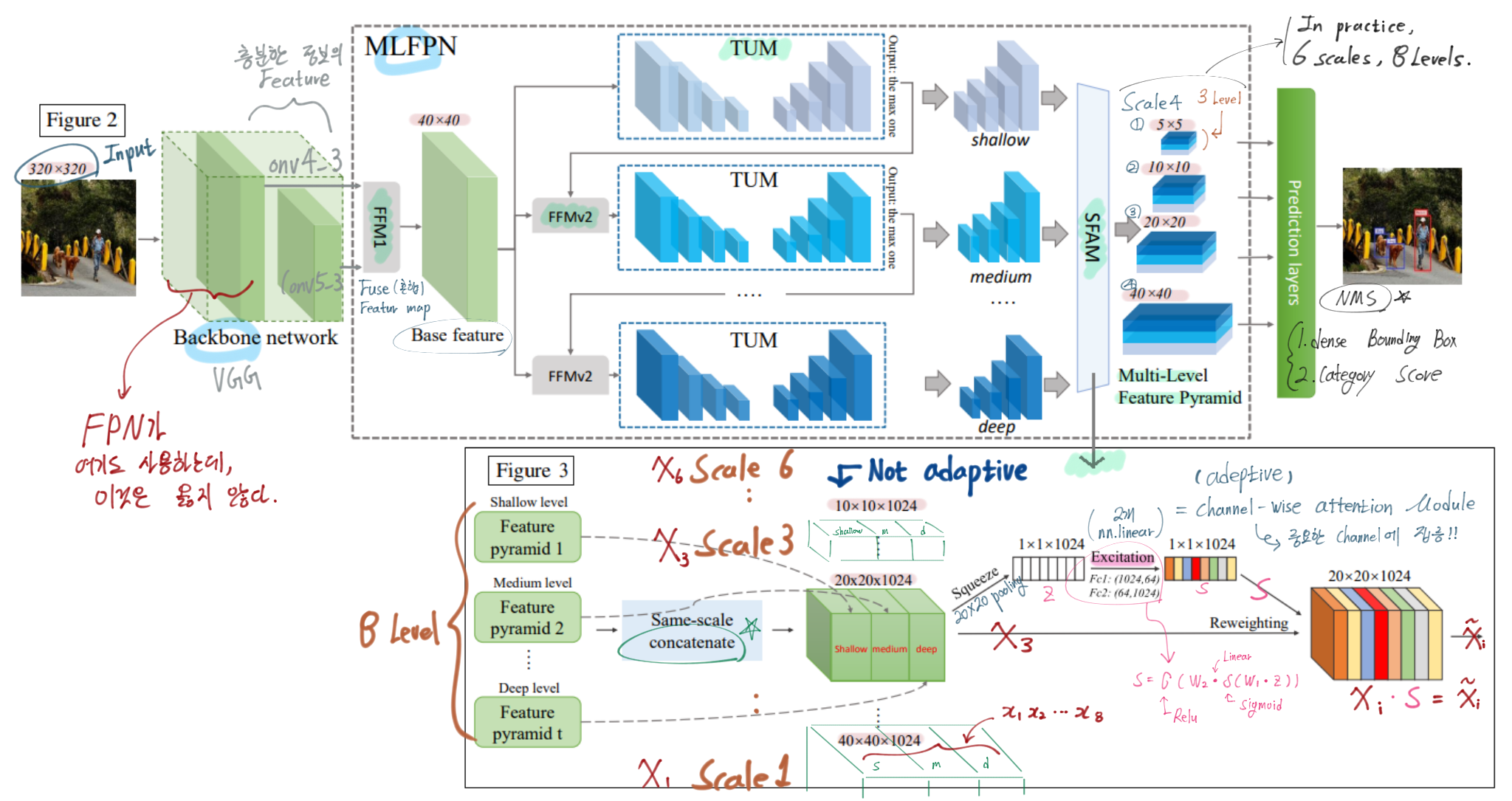
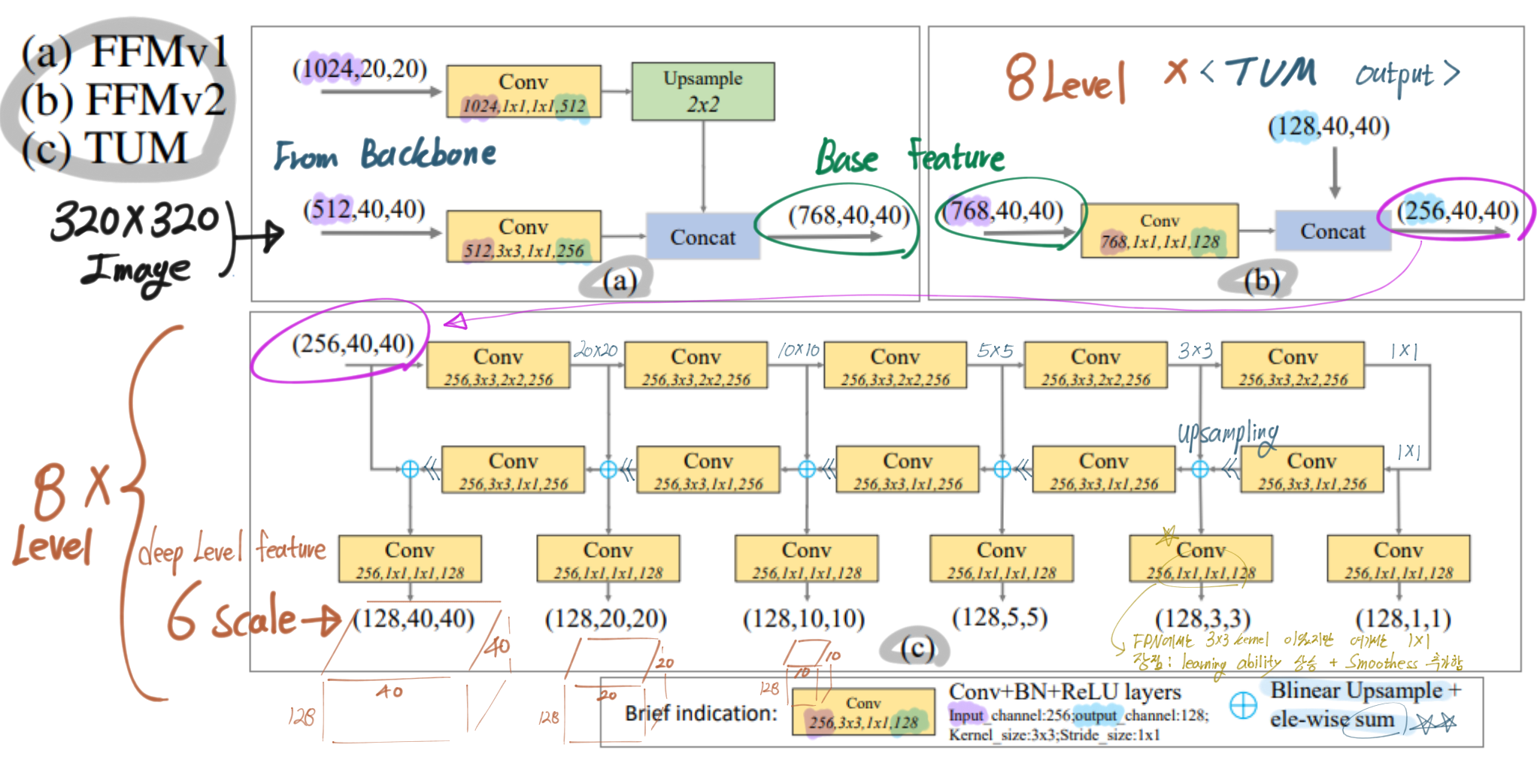
꼭 아래의 그림을 새탭으로 열어서 이미지를 확대해서 볼 것. 논문에 있는 내용 중 중요한 내용은 모두 담았다. 정성스럽게 그림에 그리고 필기해놨으니, 정성스럽게 참고하고 공부하기.
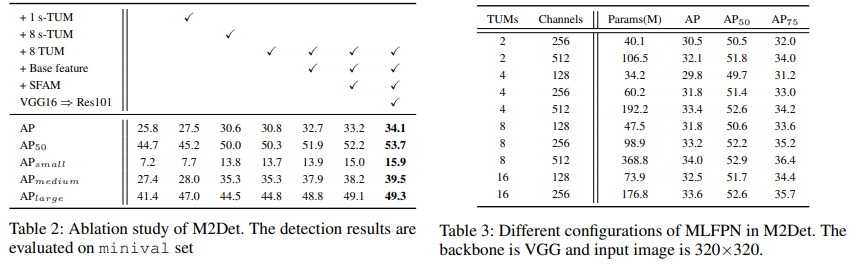
MLFPN 내용 추가
FFMv1 : VGG에서 나오는 2개의 semantic Feature map 융합. FPN은 여기서 low feature map data를 사용하는데, 이건 충분한 정보가 아니다. 그 feature map은 classification을 위한 feature이지, object detection을 위한 feature이 아니다.
TUM : several feature maps 생성
first TUM : learn from X_base only. AND second … third.. 8th.
L = # Levels, (=8) = # TUM. 어찌보면 여기가 진짜 FPN와 유사한 작업이 수행된다.
마지막에 1x1 conv를 수행해서, smoothness를 추가한다.
SFAM
Channel-wise Attention Module (Hu, Shen, and Sun 2017)
In order to Encourage features to focus on channels (that they benefit most) - 가장 중요한 channel에 집중!
global average pooling 그리고 excitation step(2개의 nn.Linear Layer)
Network Configurations
To reduce the number of parameters, FFMv2를 통과하고 나오는 Channel을 256으로 설정했다. 이 덕분에 GPU로 학습하기 쉬워졌다.
Original input size는 320, 512, 800 을 받을 수 있게 설정하였다.
Detection Stage
6 scale 즉 Multi-Level Feature Pyramid에서, 2개의 Convolution layer를 통과시켜서, location regression and classification 정보를 얻어 내었다.
default(anchor) boxes 설정 방법은 SSD를 따랐다. (2개 size + 3개 ratios = 6 Anchor).
코드에 의하면, 마지막에 objectness score같은거 사용 안함. 딱 4 * 6 + self.num_classes * 6 값만 나옴.
Anchor 중에서 (objectness score) 0.05이하의 anchor들은 low score로써 Filter out 시켜버렸다. (아에 Backgound라고 판단하여 이 Anchor로는 학 및 추론에 사용을 안해버리는 방법. 이 작업만으로도 많은 Negative Anchor들을 필터링 할 수 있다고 함.)
근데.. 코드를 봤는데 위와 같이 objectness score와 같은 것도 없다. 이상하다. Detect최종 결과에는 위의 (4+#class) x 6 개의 정보 밖에 없다. 그리고 0.05를 기준으로 특별하게 하는 작업도 없다. 0.05를 github repository에서 검색해보면 아무 정보도 없다. 대신 Negative Mining을 적극적으로 사용한다.
0.01까지 낮춰 보았지만, 너무 많은 detection results발생으로, inference time에 영향을 크게 주어서 0.05를 사용하였다.
그리고 Input size가 800x800이면, scale ranges를 6에서 조금 더 늘렸다.
더 정확하게 BB를 남기기 위해서, soft-NMS (Bodla et al. 2017) 를 사용했다.
5. Experiments
Implementation details
5 epoch -> learning rate : 2 × 10^−3
2 × 10−4 and 2 × 10−5 까지 감소 그리고 150 epochs에서 stop
Image 320, 512 size -> Titan X GPUs / Image 800 size -> NVIDIA Tesla V100
batch size : 32
VGG-16 backbone 5일 학습, ResNet-101 backbone 6일 학습
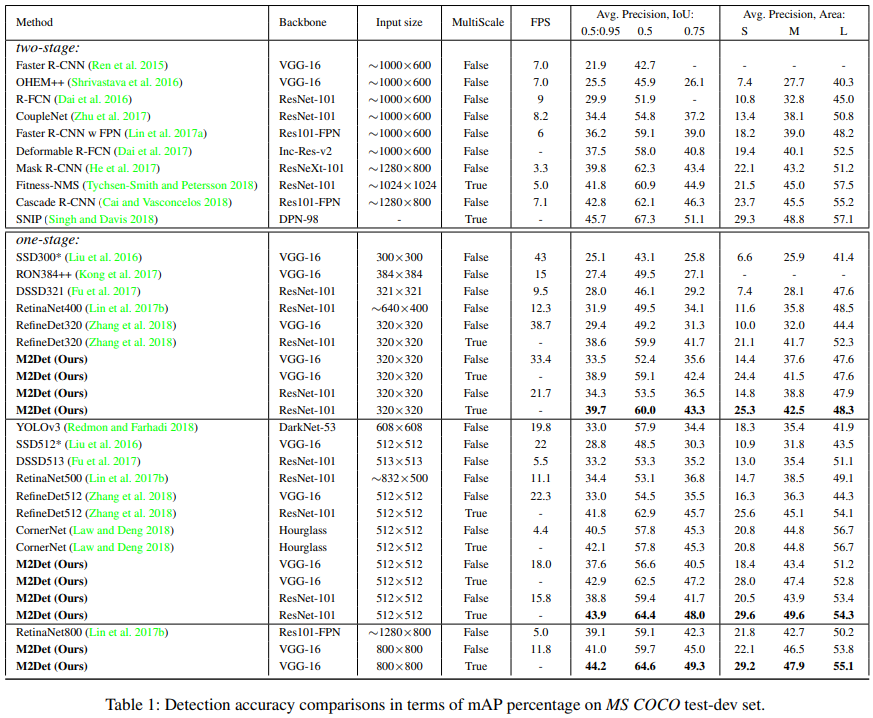
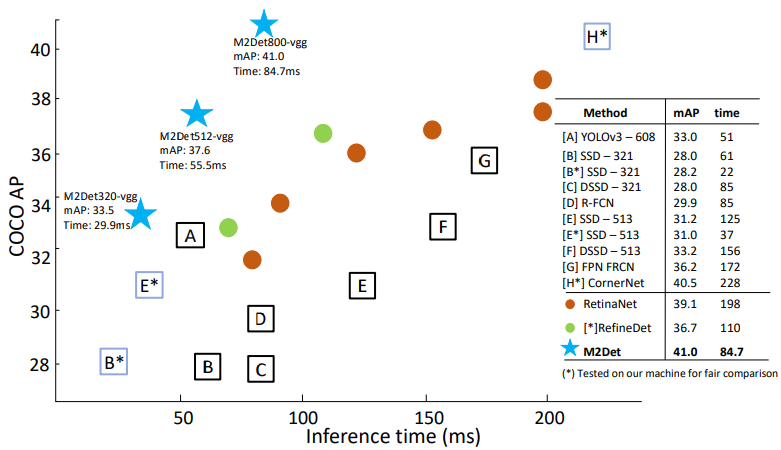
Comparison with State-of-the-art
성능 비교 표를 보면 확실히 성능은 좋다. 특히나 Small object에 대해서 아주 성능이 좋은 것을 알 수 있다. 다만.. FPS가 좀 떨어진다. 320에서 30, 512에서 15, 800에서 10정도 나온다.
특히나 Multi Scale test를 사용하면 훨씬 좋은 성능이 나오는 것을 확인할 수 있었다.
M2Det가 매우 깊은 depth때문에 좋은 성능이 나오는 것만은 아니라고 한다. 파라미터수를 비교해보면 M2Det 800은 147M이다. ResNetXt-101-32x8d-FPN은 205M, Mask R-CNN은 s 201M parameters인 것과 비교해보면 파라메터 수는 적당하다고 한다.
논문의 내용이 충분히 자세했기 때문에… 논문 이해가 잘 안되서 코드에서 찾아보고 싶은 부분이 없다. 위의 논문 내용을 어떻게 구현했는지 코드구현 공부로써는 엄청 좋을 것 같다. torch를 공부하는 개념으로…
적당한 모듈화가 아주 잘 되어 있다.
M2Det/configs/CC.py : config 파일 제작 클래스를 아주 간단하게 직접 제작
classConfigDict(Dict):def__setattr__(self,name,value):ifisinstance(value,dict):value=ConfigDict(value)self._cfg_dict.__setattr__(name,value)# 이런 함수도 직접 제작함 따라서
# setattr(self, key, value) 이런식의 함수 사용도 가능.
M2Det/m2det.py : 신경망 구현의 핵심 틀이 다 들어 있음.
"""
from layers.nn_utils import * 에 TUM, SFAM와 같은 핵심 모듈이 구현되어 있있음
여기서 함수를 그대로 가져와서 모델 구현에 사용
"""classM2Det(nn.Module):defbuild_net(phase='train',size=320,config=None):returnM2Det(phase,size,config)
M2Det/layers/modules/multibox_loss.p
classMultiBoxLoss(nn.Module):"""
1. (default threshold: 0.5) 로써 IOU 0.5이상의 BB만을
Positive로 판단. 나머지는 다 Negative .
2. Hard negative mining to filter the excessive number of negative examples
"""
classMultiBoxLoss(nn.Module):"""SSD Weighted Loss Function
Compute Targets:
1) Produce Confidence Target Indices by matching ground truth boxes
with (default) 'priorboxes' that have jaccard index > threshold parameter
(default threshold: 0.5).
2) Produce localization target by 'encoding' variance into offsets of ground
truth boxes and their matched 'priorboxes'.
3) Hard negative mining to filter the excessive number of negative examples
that comes with using a large number of default bounding boxes.
(default negative:positive ratio 3:1)
"""# Hard Negative Mining
loss_c[pos.view(-1,1)]=0# filter out pos boxes for now
loss_c=loss_c.view(num,-1)_,loss_idx=loss_c.sort(1,descending=True)_,idx_rank=loss_idx.sort(1)num_pos=pos.long().sum(1,keepdim=True)num_neg=torch.clamp(self.negpos_ratio*num_pos,max=pos.size(1)-1)neg=idx_rank<num_neg.expand_as(idx_rank)# MultiBoxLoss 를 reference하는 코드 부분
# M2Det/utils/core.py
defset_criterion(cfg):returnMultiBoxLoss(cfg.model.m2det_config.num_classes,overlap_thresh=cfg.loss.overlap_thresh,prior_for_matching=cfg.loss.prior_for_matching,bkg_label=cfg.loss.bkg_label,neg_mining=cfg.loss.neg_mining,neg_pos=cfg.loss.neg_pos,neg_overlap=cfg.loss.neg_overlap,encode_target=cfg.loss.encode_target)

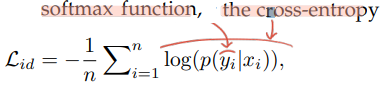


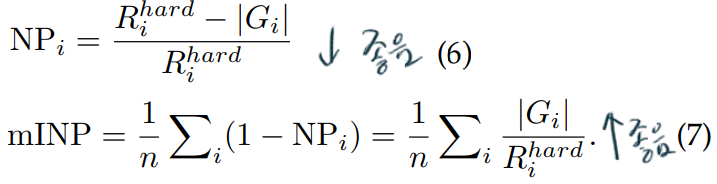

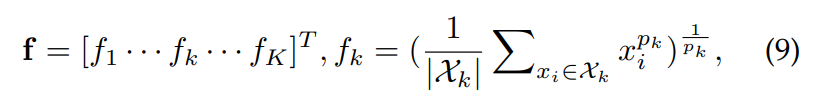
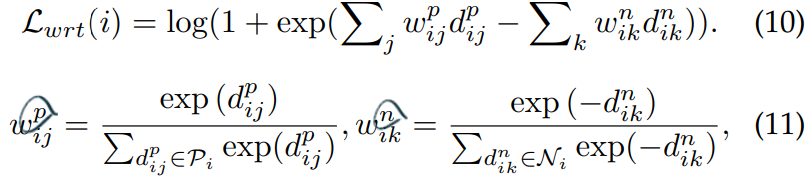

 9
9