그리고 논문의 영어문장 난이도도 높은 편이다. 모든 세세한 내용들이 다 적혀있는 게 아니므로, 코드를 찾아보고 확실히 알아보는 시간도 나중에 필요할 듯하다.
1. Conclusion, Abstract, Introduction
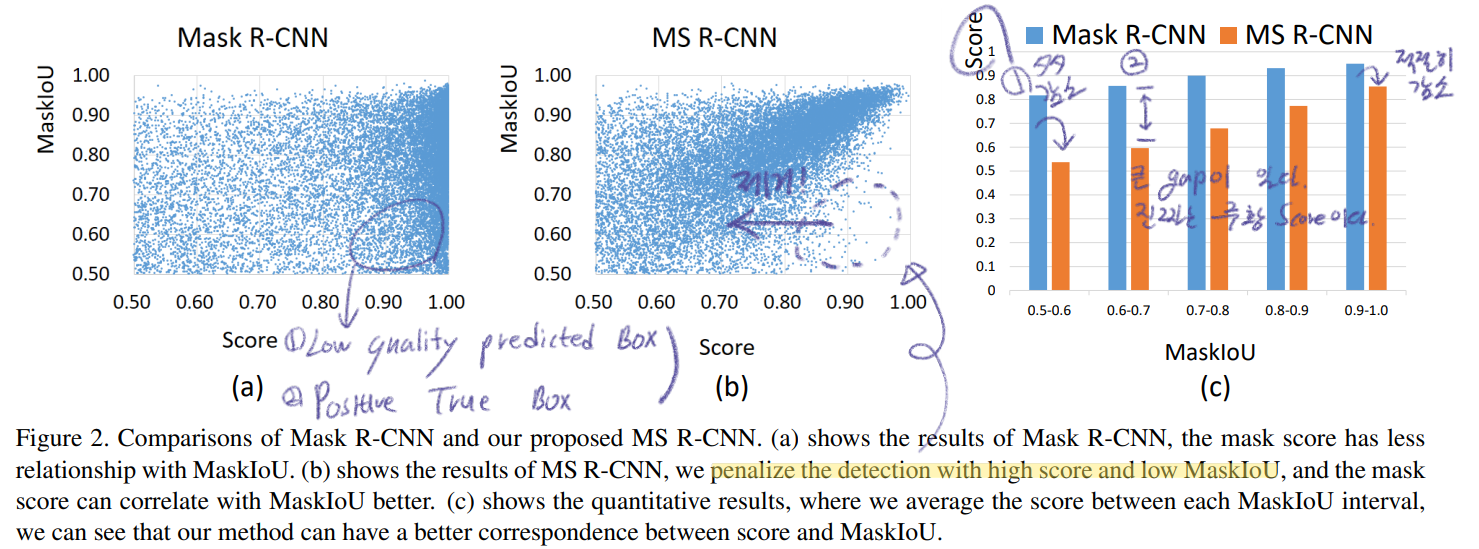
현재 instance segmentation 의 score 문제점을 파악하고, 이를 해결하는 방법으로 Mask Scoring을 제안했다.
(마스크 예측을 얼마나 잘했는지) the quality of the predicted instance masks를 체크하는 MaskIOU head를 추가했다.
mask quality 와 mask score 를 명확하게 규정하고 정의하여, evaluation하는 동안에 더 정확한 Mask를 Prioritizing (우선 순위 지정)을 통해서 전체 성능을 향상시킨다.
현재 Mask RCNN의 문제점을 파악해 보자.
very simple and effective (하지만, 논문의 결과들을 보면 MaskIOU head를 추가해서 속도와 파라메터의 증가가 얼마나 일어났는지는 나와있지 않다.)
2. Method
3.1. Motivation
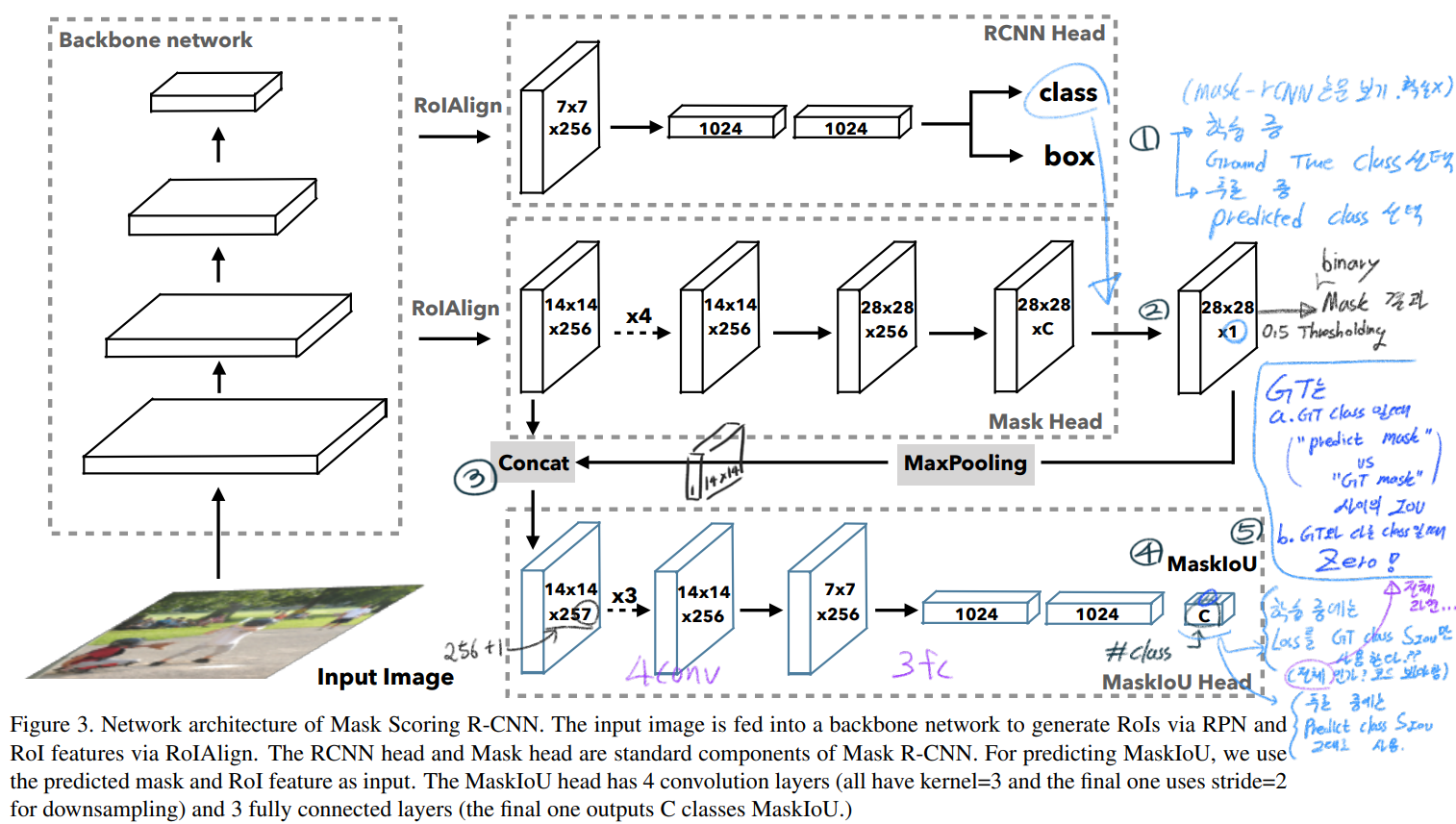
3.2. Mask scoring in Mask R-CNN
Mask scoring = S_mask
S_mask는 Mask head에서 binary segmenation을 얼마나 잘했는지 평가하는 수치이다. (내 생각으로, 이 값이 Final (class&mask) Confidence 인 듯하다. 이 S_mask를 구체적으로 어떻게 사용했는지는 코드를 통해서 확인해야 할 듯 하다. 논문 자체에서도 매우 애매하게 나와있다.)
classification과 mask segmentation 모두에 도움이 될 수 있도록, S_mask = S_cls x S_iou 으로 정의해 사용했다. 여기서 S_cls는 Classification head에서 나온 classification score를 사용하고, S_iou는 MaskIoU head에서 나온 값을 사용한다.
이상적으로는 GT와 같은 Class의 Mask에 대해서 만 Positive value S_mask가 나와야 하고, 나머지 Mask의 S_mask는 0이 나와야 한다.
MaskIoU head
논문을 읽으면서 위와같이 필기했지만, 애매한 부분이 너무 많다. “Training 혹은 Inference 과정에서는 각각 어떻게 행동하는지?, GT는 무엇이고?, 전체를 사용하는지 해당 Class 값만 사용하는지?” 이런 나의 궁금증들은 논문으로 해결할 수 없었다. 코드를 봐야한다.
하지만 전체적인 그림과 핵심 파악은 위의 그림만으로도 파악이 가능하다.
위의 Max pooling은 kernel size of 2 and stride of 2 를 사용한다.
Training
(Mask R-CNN 과정과 같이) GT BB와 Predicted BB의 IOU가 0.5이상을 가지는 것만 Training에 사용한다.
(위 그림의 숫자 2번과정) target class 에 대해서만 channel을 뽑아오고, 0.5 thresholding을 통해서 binary predicted mask 결과를 찾아낸다.
binary predicted mask 과 GT mask결과를 비교해서 MaskIoU를 계산한다. 이것을 GT MaskIoU로써 Mask Head의 최종값이 나와야 한다. 이때 Mask head의 최종결과 값 predicted MaskIOU값이 잘 나오도록 학습시키기 위해서, L_2 loss를 사용했다. (구체적 수식 없음)
Inference
지금까지 학습된 모델을 가지고, 이미지를 foward하여, Class confidence, box 좌표, binary mask, Predicted MaskIOU를 얻는다.
Class confidence, box 좌표만을 가지고, SoftNMS를 사용해서 top-k (100)개의 BB를 추출한다.
이 100개의 BB를 MaskIOU head에 넣어준다. 그러면 100개에 대한 predicted MaskIOU를 얻을 수 있다.
predicted MaskIOU x Class confidence 를 해서 Final Confidence를 획득한다.
Final Confidence에서 다시 Thresholding을 거치면 정말 적절한 Box, Mask 결과 몇개만 추출 된다.
3. Experiments and Results
Experiments
resized to have 600px along the short axis and a maximum of 1000px along the long axis for training and testing
18 epochs
(초기 learning rate는 안나와있다. 0.1 이겠지뭐..) decreasing the learning rate by a factor of 0.1 (10분의 1) after 14 epochs and 17 epochs
SGD with momentum 0.9
SoftNMS
Quantitative Results And Ablation Study
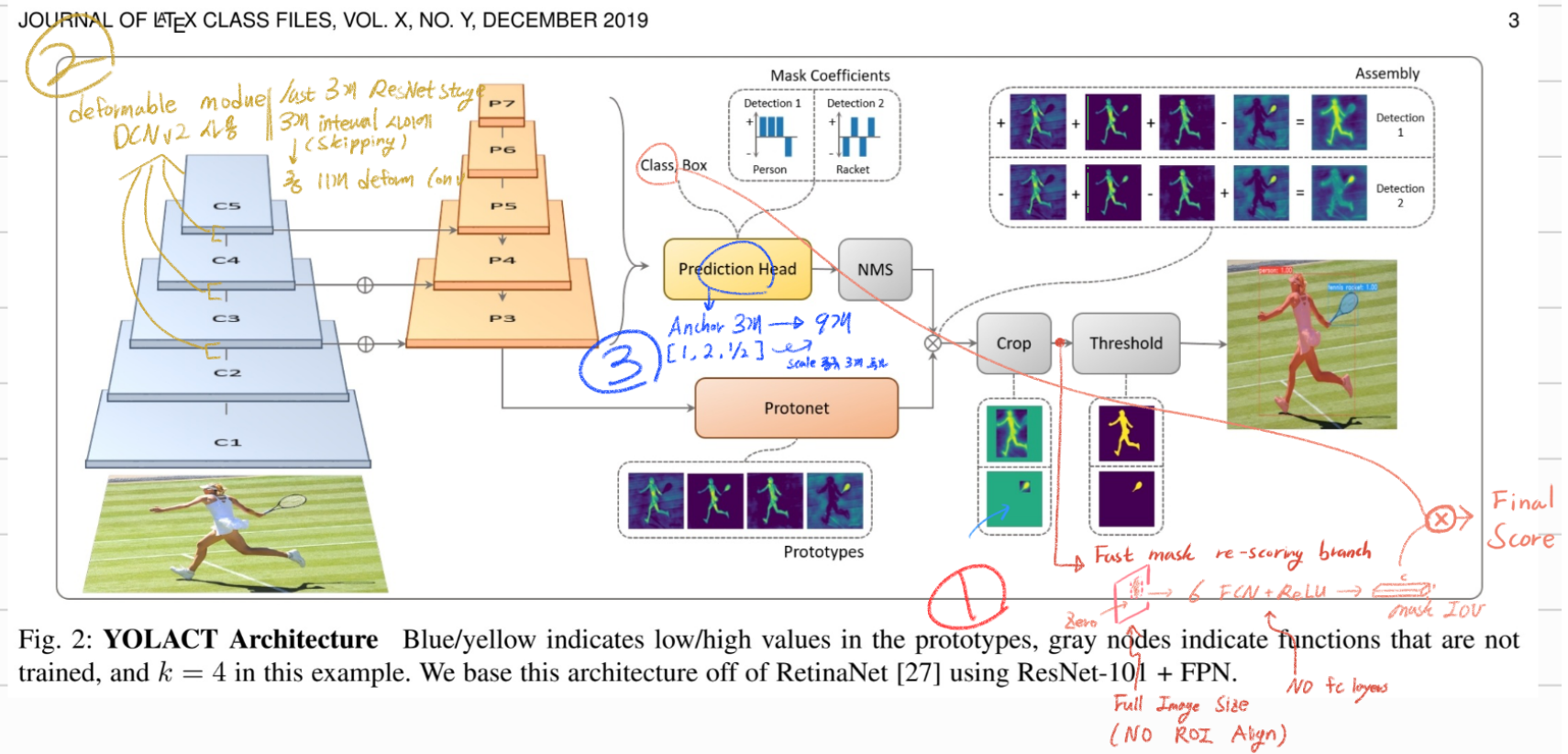
B. YOLACT++
위의 그림과 같이 그냥 YOLACT과 다른 점은 크게 3가지이다.
efficient and fast mask rescoring network : mask quality를 고려해서, mask predictions에 대한 re-ranking을 한다.
backbone network : deformable convolutions를 사용해서, instances검출을 위한 더 나은 feature sampling을 수행한다.
anchors 종류를 새롭게 하였다.
Fast Mask Re-Scoring Network
Mask Scoring RCNN의 방법을 채용했다.
(Bounding box 영역 이외는 zero) crop이 된 이후를 input (YOLACT’s cropped mask prediction (before thresholding))으로 받은 FCN 을 통과해서, 마지막에 MaskIOU를 추론하는 모듈을 추가했다.
전체 모듈의 Architecture는 위와 같다. a 6-layer FCN with ReLU + final global pooling layer.
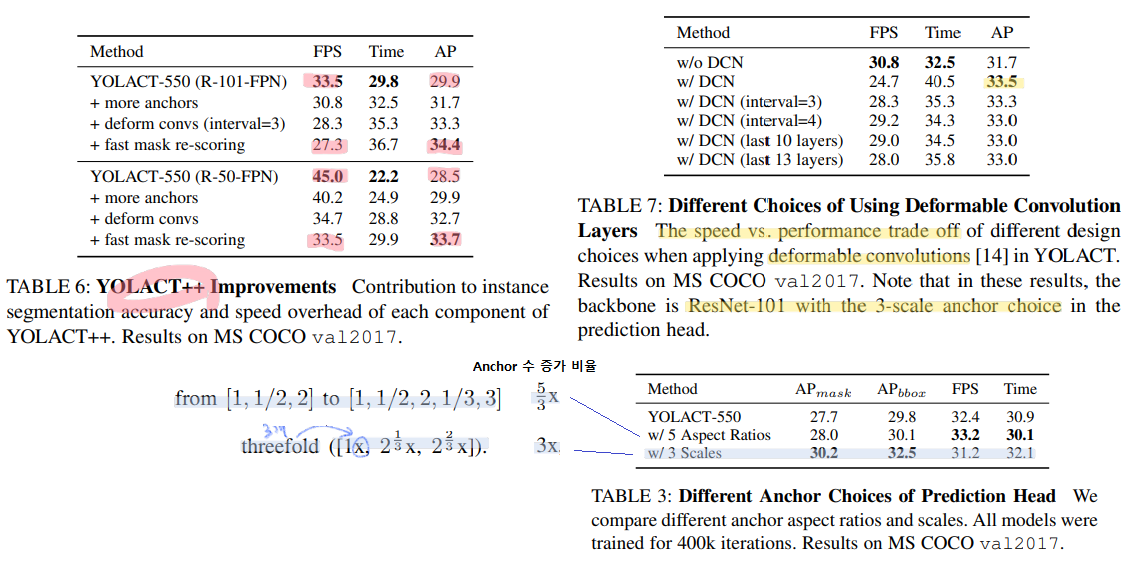
이 과정을 통해서 our ResNet-101 model에서, fps from 34.4 to 33 이 된다.
만약에 그냥 Mask Scoring RCNN의 방법을 그대로 사용하면, fps from 34.4 to 17.5이 된다.
여기선는 ROI align과 fc layers를 사용하지 않았기 때문에, efficient and fast 하다고 한다.
Deformable Convolution Networks (DCNs)는 free-form sampling을 수행하며, 정말 필요한 Feature에만 집중해 sampling이 수행된다.
a speed overhead of 8 ms 만으로 +1.8 mask mAP 성능향상을 이뤘다. 성능 향상의 이유를 추론해보면 다음과 같다.
DCN는 different scales, rotations, and aspect ratios 의 객체를 다루는데 강할 만큼, 정말 Instance가 있는 부분을 sampling하는 능력을 가지고 있다.
2 stage detector는 RPN과 같은 proposal network가 없다. (does not have a re-sampling process = ROI pooling?) 따라서 처음부터 sampling을 잘하는게 필요한다. DCN이 이것을 도와준다.
하지만 이 DCN 과정 자체가 parameter를 더 많이 사용해야하기 때문에, DCN을 전체 신경망에 사용하기에는 속도 감소의 단점이 있다. 따라서 일정 layer 부분에만 DCN을 사용해야했고, 어느 부분에 사용하는게 가장 적절한 성능향상과 속도감소를 가져와 주었는지 아래와 같이 테스트 해보았다.
아래의 Table 7 을 참조해보자.
just DCN : 30 layers with deformable convolutions when using ResNet-101
speed up을 위해서 몇가지 실험을 해보았다. 여기서 가장 좋은 Trade-off 결과를 가져다 준 모델은 w/ DCN (interval=3) 이었다.
아래의 각각의 method가 무엇인지 글로 설명이 되어 있지만, 정확한 이해는 힘들었다. 코드를 봐야한다. (내용 복붙 : (1) in the last 10 ResNet blocks, (2) in the last 13 ResNet blocks, (3) in the last 3 ResNet stages with an interval of 3 (i.e., skipping two ResNet blocks in between; total 11 deformable layers), and (4) in the last 3 ResNet stages with an interval of 4 (total 8 deformable layers). )
Optimized Prediction Head
아래의 Table 3 참조.
아무래도 YOLACT은 anchor-based 이다. 따라서 적절한 Anchor를 선택하는 것은 매우 중요했고, 몇가지 실험을 통해서 성능향상을 가장 많이 가져다 준 방법을 찾아 보았다.
비율을 다르게 하거나 vs Anchor scale 을 다르게 하거나. 둘 다 실험해 본 결과, 후자가 더 좋은 성능 향상을 가져다 주었다고 한다.