【Transformer+OD】DETR-End-to-End Object Detection with Transformers w/ my advice
- 논문 : End-to-End Object Detection with Transformers
필기 완료된 파일은OneDrive\21.1학기\논문읽기에 있다. - 분류 : Transformer + Object Detection
- 저자 : Nicolas Carion, Francisco Massa, Gabriel Synnaeve
- 읽는 배경 : Visoin Transformers 를 사용한 Object Detection
- 느낀점 :
- 연산이 좀 더 구체적으로 어떻게 이뤄지는 건지 궁금하면, Deformable DETR 부분의 내용정리를 참고하면 좋다
- Conclution -> Method -> Introduction -> Abstract 순서로 논문을 공부하자!
- 실제 공부 순서
- Conclusion, Abstract
- Introduction : Fig 1 과 Fig 1을 설명하는 논문의 부분. 1문단만 읽음
- Introduction : 거의 마지막 부분
- Related work : 큰 제목이 의미하는 것이 무엇인지만, 알아봤다.
- The DETR model
- 나머지
- 아직 이해가 안 되는 것 : auxiliary losses
- 논문이 정말 깔끔하다. 이전의 ViT (16x16 vision transfomer) 논문을 보다가, 이 논문을 보니까 문장도 정말 잘 써놨고 이해도 정말 잘되게 써놨다. 일부러 어렵게 써놓지도 않아서 너무 좋다. 이렇게 아주아주 유명하고 유용한 논문도 이렇게 쉽게 써 놓을 수 있고, 쉽게 이해가 될 수 있는데…. 내가 논문을 읽으면서 “어렵고, 이해가 안되고, 논문 읽기 싫다” 라는 생각이 들때면, 이 DERT 논문을 떠올리자. 논문을 개같이 써놔서 이해가 안되고, 어려운거지, 코드를 보고 실제를 확인하면 정말 별거 없다. 내가 부족해서 어려운거 라고 생각하며 우울해하지말고, “논문을 개같이 써서 어려운거다! 이 논문만 그런거다! 또 다른 논문은 쉽게 이해되고 재미있을 수 있다!” 라고 생각하자. 왜 우울해 해. 모르면 배우면 되지. 생각하지 말고 그냥 하자.
- 목차 :
- Paper Review
- Code
- https://github.com/facebookresearch/detr
End-to-End Object Detection with Transformers
1. Conclusion, Abstract, Introduction
- 이 논문의 핵심 2가지
- Transformers(encoder-decoder architectures)를 기반으로 한, object detection systems.
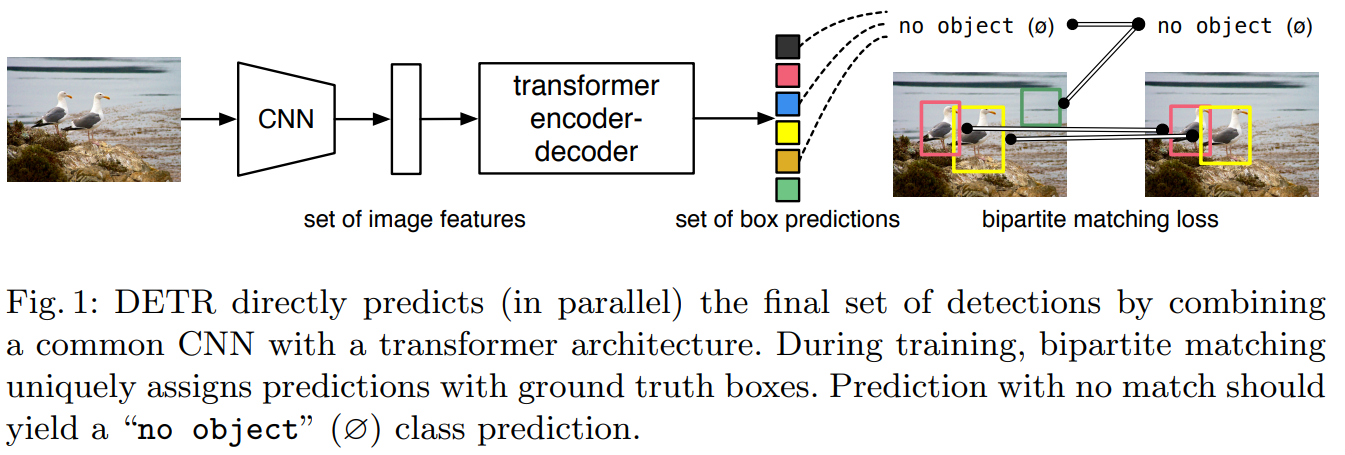
- Direct set prediction (NMS 따위 안쓰고, Class, BB 한방에 예측해버림) : bipartite(Predicted BB and GT) matching을 수행하는, set-based global loss 를 정의해 사용했다.
- Fixed small set of learned object queries 를 사용한다 : DERT가 ‘객체와 Global Image context’ 와의 관계를 추론하여, Parallel하게 (N개의 Query에 대해서 N개의 예측 결과를 출력한다. Figure2에서 빨,초,노,파 박스) final predictions을 하게 만든다.
- 특장점
- Powerful : optimized Faster R-CNN 와 유사한 성능 결과를 가진다. (하지만 Small object에 대해서는 성능이 매우 낮다)
- straightforward, simple :
- detection pipeline을 간소화했다. 코드가 단순하다.
- Task에 필요한 prior knowledge(사전적 지식 = 인간의 지식 = Heuristics Network)을 정확히 Encoding 해야하는, 많은 hand-designed components (= NMS, anchor generation) 를 제거했다.
- any customized layers (heuristic한 접근법들) 을 사용하지 않았다.
- 한방에 모든 객체를 예측한다. (Direct set prediction)
- flexible : 원래의 DERT 모델에서, simple segmentation head 를 추가함으로써, 쉽게 panoptic segmentation 구현했다.
- large objects : self-attention을 활용해서, global information을 이용해서, 큰 객체 아주 예측을 잘한다.
- 추가 특징
- extra-long training schedule 이 필요하다.
- auxiliary/parallel decoding losses 으로 부터 오는 이익이 있다.
- 해결해야 할 도전과제들(challenge)
- small objects
2. Related work
- 2.1 Set Prediction (한방에 예측 세트를 찾아내는 것 = directly predict sets)
- 2.2 Transformers and Parallel Decoding
- 2.3 Object detection
- Set-based loss
- Recurrent detectors.
3. The DETR model
3.1 Object detection set prediction loss
- DERT에서는 Single pass through the decoder를 통해서 N개의 고정된 크기 Predictions을 추출한다. 여기서 N은 평균 이미지 내부의 객체 수 보다 훨씬 크다.
- (1) optimal bipartite matching

- 위 이미지에서 Hungarian algorithm 노동자와 일이 있을 때, 노동자에게 일을 할당하는 방법을 고르는 알고리즘이란다. (O(n!)의 경우의 수 시간을, O(n^3)으로 바꾸는 방법) 정말 필요하면, [43] 논문을 보면 될 것 같다. (내가 예측한 결과 N개와 GT N개에 대해서 1대1 대칭을 만들어 줄 때, 그 경우의 수는 n! 이다. 100! = 9.332622e+157. 100^3 = 1e+9.)
- (문제점 발견!) 여기서 1대1 대응을 할 때, 문제가 발생할 수 있는게, 예측한 N개의 결과에서 Bounding box 위치와 Class confident만 조금 다르고 거의 같은 예측을 했다면, 하나만 정답 GT에 대응되고 나머지는 버려진다. 하지만 다르게 생각하면, N개의 예측 결과 중에서 딱 Instance의 갯수만 객체라고 예측하고 나머지는 no object라고 예측하도록 만드는 것 이기도 하다.
- 위 이미지, 맨 아래의 수식처럼, P_i (c_i) 즉 just probabilities 값을 사용한게 아니라 log-probabilities 값을 사용했다. 경험적으로 더 좋은 성능일 보여서 log-probabilities를 최종 Loss 수식으로 정했다.
- Class imbalance를 해결하기 위해서, no object라고 나오는 결과들의 log-probabilities는 10배 감소시켰다.
- (2) object-specific (bounding box) losses = Bounding box loss
- L1을 사용하면, relative scaling of the loss 문제점이 발생한다. : 만약 각각 2개의 GT BB와 Predicted BB가 있다고 하나. 하나는 박스가 Large하고 하나는 Small 하다. 만약 L1 loss를 사용하면, 2개의 BB pair에 따른 IOU가 비슷하다고 하더라도, Large Box에 대한 Loss가 더 크기 마련이다.
- 그래서 linear combination of the L1 loss & the generalized IoU loss 를 사용한다.
- normalization에 대해서는 4개이미지. 400개의 prediction. 의 Total loss를 400으로 나눠서 사용했다는 건가? 이건 코드를 봐야겠다.

3.2 DETR architecture
- surprisingly simple
- transformer architecture implementation with just a few hundred lines (코드 몇줄에 네트워크 완성 가능)
- Inference code for DETR can be implemented in less than 50 lines (코드 몇줄에 Inference 가능)
- Transformer encoder.
- transformer architecture는 permutation-invariant 치환불변 하기 때문에(순서에 대한 정보가 없이 Input이 들어가기 때문에), fixed positional encoding을 추가해 준다.
- Transformer decoder.
- 그림의 Encoder 부분에는 x N이라고 적혀있다.
이게 누적적으로 이뤄지는게 아니라, 이미지의 인풋이 계속들어가며 독립적으로 N개의 dxWH feature를 만들어 내고, 각각의 dxWH가 Decoder에 들어가는 건가? 코드를 보면서 확인해야 할 듯하다.코드를 보니, 누적되어 결과가 나온다. 예를 들어서 Feature map input이 dxHW이면, Encoder를 계속 반복해서 최종 Encoding 값으로 (차원은 모르겠고) N개가 나온다. 그리고 이게 Decoder로 들어가서 (NLP는 Sequencail하게 결과값이 Decoder의 맨아래 outpus로 들어가지만 여기서는 그런거 없고) 한방에 N개의 Prediction 결과가 나온다. - (youtube) Object query : N 명의 사람들 각각이, 자기가 하고 싶은 질문은 한다. 고 상상하라. 예를 들어서 첫번째 query가 묻는다. ‘헤이 이미지! 아래 왼쪽에 있는 객체는 뭐야?’ 이런한 질문을 N번 받고, 그 결과가 N번 출력된다. 그게 Prediction set 이다. 또한 N명의 사람들은 Multi-Head Self-Attention을 통과하면서 서로서로 Communication 한다. 그래서 나오는 최종 질문이 Decoder의 Multi-Head Attention으로 들어간다.

- 따라서 아래의 그림을 보면, 하나의 query에서 하나의 결과가 나오는 것을 알 수 있다. 1사람이 물어본 것에 대해서 1가지 답변을 해주니까!
- 위에 Query 이미지 figure 7 참조 (Decoder output slot analysis) : 각각의 query는 자신만의 질문 ‘특별함’을 가진다. 각각 다른 box size와 box center position 에 집중하는 것을 확인할 수 있다.
- 그림의 Encoder 부분에는 x N이라고 적혀있다.
- Prediction feed-forward networks (FFNs).
- 3-layer perceptron with ReLU activation function
- ∅ is used to represent that no object 이것은 다른 OD 모델에서 the “background” class라고 예측하는 것과 비슷하다.
- Auxiliary decoding losses.
- use auxiliary losses [1] in decoder during training. (?)
- 아래의 필기에서, 핫핑크 영어단어는 코드에 있는 변수이름을 그대로 적어놓은 것이다.
![]()
4. Experiments
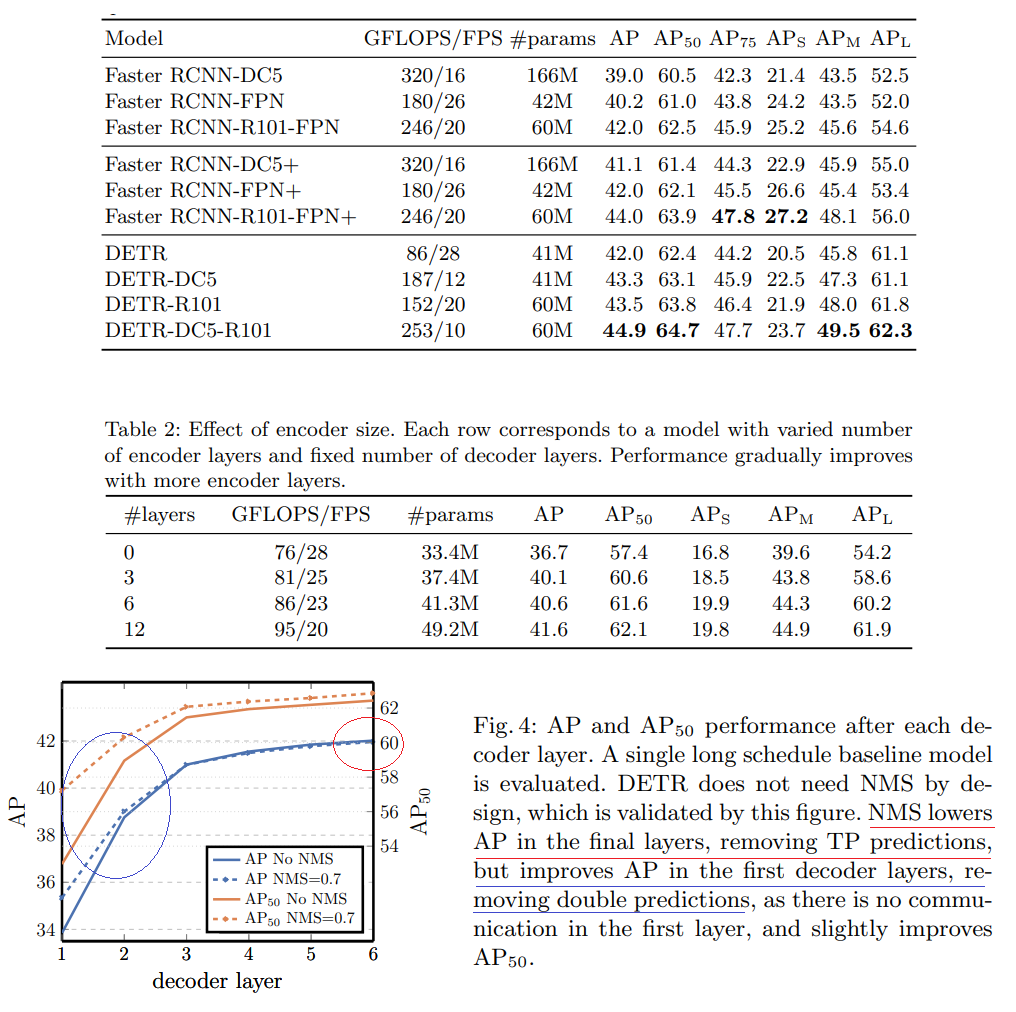
- DERT = ResNet50 을 backbone으로 가짐. R101 = ResNet101. DC5 = 마지막 Feature map의 Resolution을 높혀서 Small object에서도 강한 성능을 보이게 만들기 위해서, dilation 을 마지막 Layer에 추가하고( (dilated C5 stage)), 초반 conv에 stride를 적용하지 않는다.
4.2 Ablations
- ResNet-50-based DETR model 에 대해서 최종적으로 6 encoder, 6 decoder layers and width 256를 골랐다.
- Number of encoder layers
위의 Table2이미지 보기. Encoder의 사용 갯수를 다르게 해봄으로써, “global image level self-attention”이 얼마나 중요한지 확인할 수 있었다.- encoder 과정에서 global scene reasoning (전체 장면 추론)이 이뤄지고, objects들끼리 disentangling (서로 풀림) 이 이뤄진다고 추론했다.
- 아래 이미지는, 마지막 encoder layer에서 출력되는 attention maps을 시각화한 것이다. (아래 이미지를 어떤 방식으로 시각홰 했는지 모르겠다.)

- Number of decoder layers
- 6개의 decoder layer 각각을 한 후에 auxiliary losses (?) 를 수행했다. (위에 설명 및 논문 참조)
위의 Table4이미지 보기. Decoder를 통해서 Encoding 결과와 Object query간의 소통(communication)이 이뤄지고, cross-correlations를 서로서로 파악해가며, 성능이 좋아진다.- NMS를 사용하면, 초반에는 중복 예측 중 좋은 예측을 골라주므로 성능이 좋아지지만, Decoder layer(Depth)가 증가하면 NMS에 의한 성능 증가가 작아지는 것을 확인했다. 마지막에는 NMS가 성능을 더 낮추는 일이 발생해서 NMS를 쓰지 않는 것으로 결정했다.
- Decoder에서도 어떻게 attention이 이뤄지는지 시각화를 해 놓았다. 객체의 머리 팔다리 사지(extremities) 에 집중하는 것을 확인할 수 있다.

- 저자의 추론을 정리하자면, Encoder에서 global attention을 이용해, Instance의 분리가 이뤄지고, decoder에서는 class and object boundaries를 검출하기 위해서, 객체의 팔, 다리, 머리 (extremities)에 집중한다.
- Importance of FFN
- tranformers안의 FFN은 attention module에서 1x1 conv를 하는 작업과 비슷하고 생각할 수 있다.
- tranformers안의 FFN을 제거했을 때, parameters는 25프로가 줄었지만, AP 성능이 2.3% 감소했다. 따라서 tranformers안의 FFN는 중요하다
- Importance of positional encodings / Loss ablations

4.4 DETR for panoptic segmentation
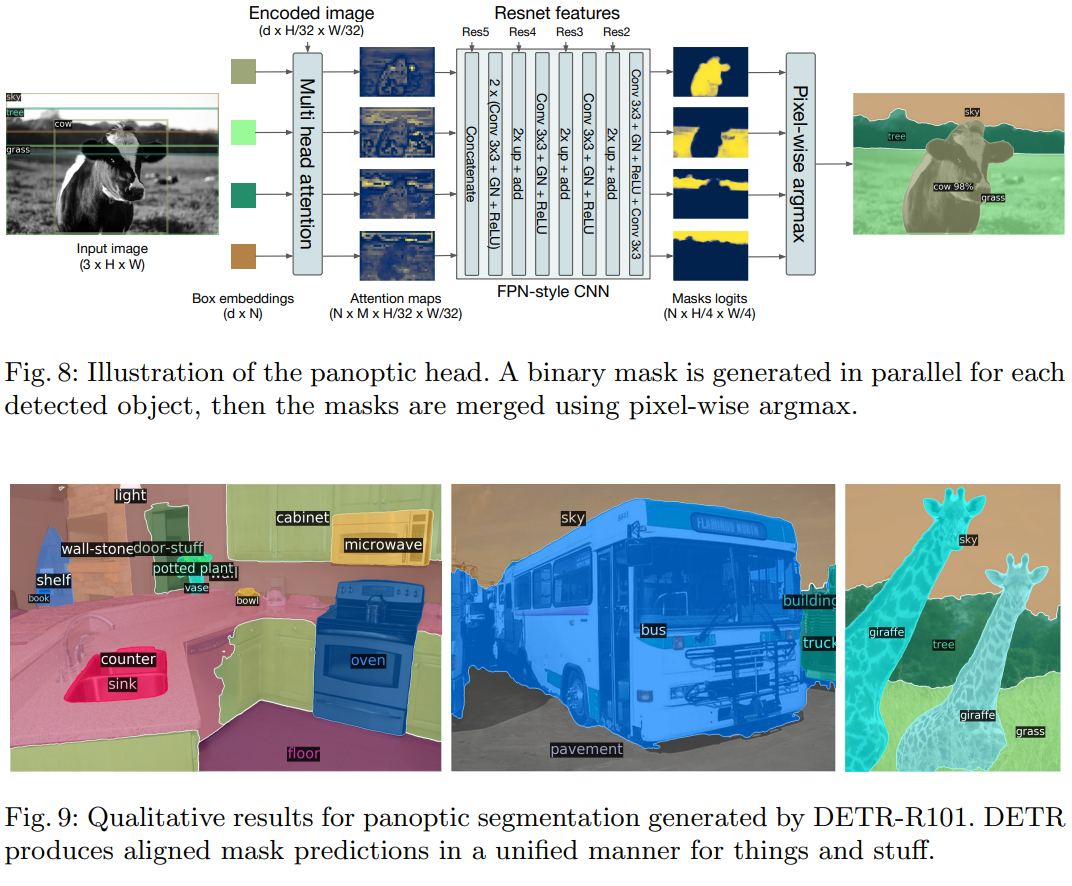
- We also add a mask head which predicts a binary mask for each of the predicted boxes.
- 아래의 이미지처럼, transformer decoder에서 나오는 ouput과 the output of the encoder 또한 input으로 받는다.
- N개의 box embeding 결과로 부터, M개의 attention heatmaps를 생성한다. 여기까지는 small resolution 이다. resolution을 증가시키기 위해서, FPN-like 아래의 architecture를 사용하고, 이것에 대해서는 부록에 추가설명이 있다.
DETR Code Review
- Github link : https://github.com/facebookresearch/detr
1. DETR_demo.ipynb
아주 짦은 코랩 파일이다. 이해하기도 아주 쉽다. Dert Github 내용을 전혀 사용하지 않았다. nn.Transformer 만을 사용한게 전부이다.
## Network 설정 class DETRdemo(nn.Module): def __init__(self, num_classes, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6): super().__init__() # create ResNet-50 backbone self.backbone = resnet50() del self.backbone.fc # create conversion layer self.conv = nn.Conv2d(2048, hidden_dim, 1) # create a default PyTorch transformer self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers) # prediction heads, one extra class for predicting non-empty slots # note that in baseline DETR linear_bbox layer is 3-layer MLP self.linear_class = nn.Linear(hidden_dim, num_classes + 1) self.linear_bbox = nn.Linear(hidden_dim, 4) # output positional encodings (object queries) self.query_pos = nn.Parameter(torch.rand(100, hidden_dim)) # spatial positional encodings # note that in baseline DETR we use sine positional encodings self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2)) self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2)) def forward(self, inputs): # propagate inputs through ResNet-50 up to avg-pool layer x = self.backbone.conv1(inputs) x = self.backbone.bn1(x) x = self.backbone.relu(x) x = self.backbone.maxpool(x) x = self.backbone.layer1(x) x = self.backbone.layer2(x) x = self.backbone.layer3(x) x = self.backbone.layer4(x) # convert from 2048 to 256 feature planes for the transformer h = self.conv(x) # construct positional encodings H, W = h.shape[-2:] pos = torch.cat([ self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1), self.row_embed[:H].unsqueeze(1).repeat(1, W, 1), ], dim=-1).flatten(0, 1).unsqueeze(1) # propagate through the transformer h = self.transformer(pos + 0.1 * h.flatten(2).permute(2, 0, 1), self.query_pos.unsqueeze(1)).transpose(0, 1) # finally project transformer outputs to class labels and bounding boxes return {'pred_logits': self.linear_class(h), 'pred_boxes': self.linear_bbox(h).sigmoid()} ## 과거 학습된 Parameter 가져옴. detr = DETRdemo(num_classes=91) state_dict = torch.hub.load_state_dict_from_url( url='https://dl.fbaipublicfiles.com/detr/detr_demo-da2a99e9.pth', map_location='cpu', check_hash=True) detr.load_state_dict(state_dict) detr.eval(); ## 예측 및 결과 추출 outputs = model(img)
2. Evaluation 을 통해서 debugging 수행하기
Dataset 다운받기
detr/cocodata annotations/ # annotation json files train2017/ # train images val2017/ # val imageseval 수행하기
!python main.py --batch_size 1 --no_aux_loss --eval --resume https://dl.fbaipublicfiles.com/detr/detr-r50-e632da11.pth --coco_path ./cocodata참고사항
engine.py -> def evaluate -> outputs = model(samples)
아래의 코드 설명은, 내가 코드의 흐름을 파악하기 위해서 하나하나 함수와 클래스를 따라가면서, 필심부분만 적어놓은 것이다.
import main.py test_stats, coco_evaluator = evaluate(model, ...) import engine.py def evaluate(..) : outputs = model(samples) # ----------------------------------------------------------------------- # import main.py model, criterion, postprocessors = build_model(args) import model.detr.py def build(args): transformer = build_transformer(args) model = DETR( backbone, transformer, num_classes=num_classes, num_queries=args.num_queries, aux_loss=args.aux_loss, ) import models.transformer.py def build_transformer(args): return Transformer(...) import models.detr.py class DETR(nn.Module): features, pos = self.backbone(samples) src, mask = features[-1].decompose() hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0] outputs_class = self.class_embed(hs) outputs_coord = self.bbox_embed(hs).sigmoid() out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]} return out그래서 아래와 같이 models.detr.py에 class DETR(nn.Module): 를 디버깅 해보았다. (디버깅 중 에러 해결. NestedTensor’ object has no attribute ‘shape)
- 처음의 sample에는 이미지 1개가 딱 들어가는 shape를 확인할 수 있었다. 하지만 아래의 작업을 수행하기에는, 보고 싶은 변수의 type이 tensor도 아니고, 그래서 shape도 한방에 볼 수 없고, 복잡해서 디버깅은 나중에 VScode에서 진행하기로 마음먹었다.