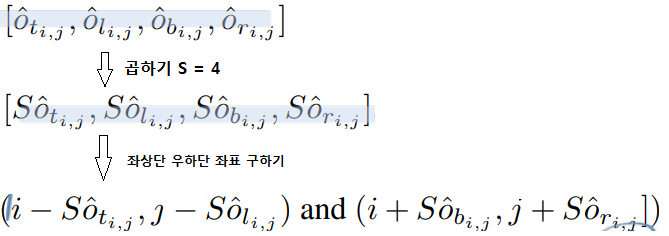이 논문은 전체를 다~ 봐야지. 라는 마음으로 보지 않았다. 아래의 순서로 핵심만 찾아보앗다.
Conclution -> Introduction -> Abstract 순서대로 읽으면서, 에서 핵심이 뭐지? - 이 논문이 해결하려는 문제점이 뭐지? 이 방식의 목표는 뭐지?
Related Work에서 거의 무시. 거의 마지막 문단과 문장만 읽음.
Figure1, Figure2 주석 읽기. 본문에서 Firgure2에 대한 추가 설명 찾아 읽기
Method 읽기 시작! 이 논문의 method는 3페이지 이내이다.
Ablation, Result에서 위에서 말한 문제점 해결이 잘 해결되었고, 목표를 잘 달성했는지 확인한다. 다시 말해서, 이 논문에서 제안한 각각의 몇가지 새로운 모듈에 대해서 결과론적으로 각각 좋은 결과를 얻었는지 확인.
저번의 정리해놓은 논문 정리방법 과는 추가로, “같은 문장, 같은 문단에서도 비슷한 영어단어를 써가며 같은 말을 반복한다. 이걸 다 다른거라고 생각하지 말고 하나의 단어로 통일해서 정리해 두자” 예를 들어서 Extracted Feature = representation = Feature maps 뭐 이런 동의어를 반복해서 사용한다. 예전의 나는 이것들을 모두 따로따로 분리해서 생각했는데, 결국에는 같은 동의어이다. 아래 Conclution에서도 heuristic feature selection 고안하여~라는 말이 나오고 2문장 이후에 online feature selection 만들었다~라는 말이 나온다. 내가 이걸 따로 정리할 필요 없이 heuristic/online feature selection를 만들었다 라고만 적으면 끝이다.
항상 논문을 끝까지 다 읽어봐야 한다. Conclution -> Introduction -> Abstract 은이 순서대로 다 읽고 나서, ‘논문 정리 문서 작성’을 해야한다. Abstract에서는 절대 이해가 안되던게, Introduction을 읽고 이해가 되기 시작한다. 그리고 Method를 읽으면 또 다시 이해가 되기 시작한다. 그니까 Conclution, Abstract, Introduction 여기서 이해 안되면, 안되는데로 읽거나 아니면 아에 읽지말고 넘어가라. 그리고 Method 읽고 다시 와서 읽어라. 그렇게 하면 “와… Abstract, Introduction에서 말만 삐까번쩍하게 해놨네… 쓸데없는 소리 엄청했네… 이렇게 써놓으면 처음보는 사람은 절대 이해 못하지… Method부터 읽길 잘했다…” 라는 생각이 엄청든다.
Conclution -> Method -> Introduction -> Abstract 순서대로 보았다면, Introduction, Abstract 에서 충분히 시간을 절약할 수 있었을 것 같다. Method 를 읽는데, Introduction, Abstract 부분의 지식은 하나도 필요없었다. 물론 알고 보면 좋은 건 있지만, 시간 절약으로 Method 공부 다~ 하고 Introduction, Abstract를 봤다면 좀더 정확한 Introduction, Abstract 부분의 이해와 정확한 정리가 가능하지 않았나.. 싶다. 좀 내가 아는 Object Detecion, Instance Segmentation 에서는 Conclution -> Method -> Introduction -> Abstract 순서로 논문을 공부하자!
Feature Selective Anchor-Free Module
0. conclution
(PS. 이 논문에 계속 나오는 feature selection은 사실 feature level (in Pyramid = P_l)selection이라고 계속 이해하자 )
heuristic feature selection의 문제점,한계를 찾아내고, 이 문제 해결을 위해 online feature selection을 고안하며, FSAF 모듈을 만들어 냈다.
(1) Tiny inference overhead (2) SOTA / Strong baselines 얻었다.
1. Introduction, Abstract
우리의 해결하려는 문제점이자 목표는, scale variation이다. 즉 scale invariability (객체의 크기가 커지더라도, 작아지더라도 객체를 안정되게 잘 탐지할 수 있는 능력) 성능을 가지는 모델을 만들어내고자 한다.
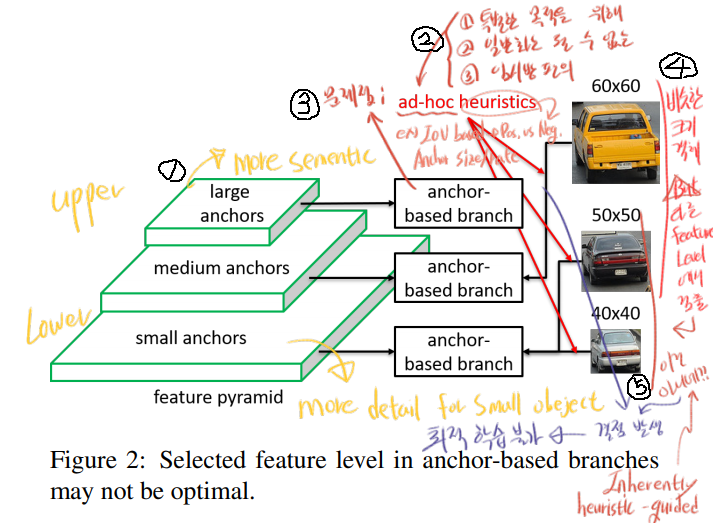
최근 기법들의 한계점 (two limitations) (아래 그림의 (4)에서 발생하는 문제점이 핵심이다)
inherently heuristic-guided feature selection : anchor의 size, rate는 이미 정해져있다. 때문에, 각각의 instance에 대해서 선택되는 (selected) feature level [PFN에서 upper(small, smentic), lower(large, deteail) 이 다른 feature map을 의미함] 이 최적의 level이 아닐 수 있다.
overlap(IOU)-based anchor sampling : 각각의 instacne 들은 가장 가깝고 IOU가 높은 anchor box에 의해 detect / match 된다. 9
Feature selective anchor-free (FSAF)
이 모듈을 통해서, 각각의 instance가 the best feature level을 선택하도록 돕는다.
FSAF 모듈은 classification subnet 과 regression subnet 으로 구성되어 있다.
During training, 각 instance에 대해서 the most suitable feature level을 찾는다 Dynamically, Non-heuristically. 단순하게 instance box size를 기반으로 하는게 아니라, the instacne content (instance에 해당하는 feature 내용들) 를 기반으로 feature level을 찾는다.
Durring Inference, anchorbased branches와 독립적이면서 공동으로 평행하게 run 된다.
FSAF의 장점과 특징 (Abstract 참조)
simple and effective building block for single-shot object detectors.
FPN를 가지는 Network에는 모두 적용가능하다.
Feature Level Selection에서 online feature selection 을 수행한다. (Dynamically, Non-heuristically)
state-of-the-art 44.6% mAP, SOTA in single-shot detectors on COCO.
2. Related work
초반 내용 안 읽음
The idea of anchor-free detection는 새로운게 아니다. DenseBox [15, 2015]에 처음 나온 방식이다. Anchor Box를 사용하지 않고, directly predicted bounding boxes를 사용한다.
위의 방법이 발전되어서 2개의 논문이 나왔다. 하지만 아래 2 논문은 여전히 heuristic feature level selection strategies을 취하고 있다. 우리는 heuristic 에 의해 발생하는 문제점을 최소화 하도록, heuristic 을 최소화 하는 것을 목표로 한다.
CornerNet [17, 2018] : detect an object bounding box as a pair of corners. SOTA in single-shot detectors.
SFace [32, 2018] : the anchor-based method and anchor-free method 를 모두 융합하기 시작.
3. Feature Selective Anchor-Free Module
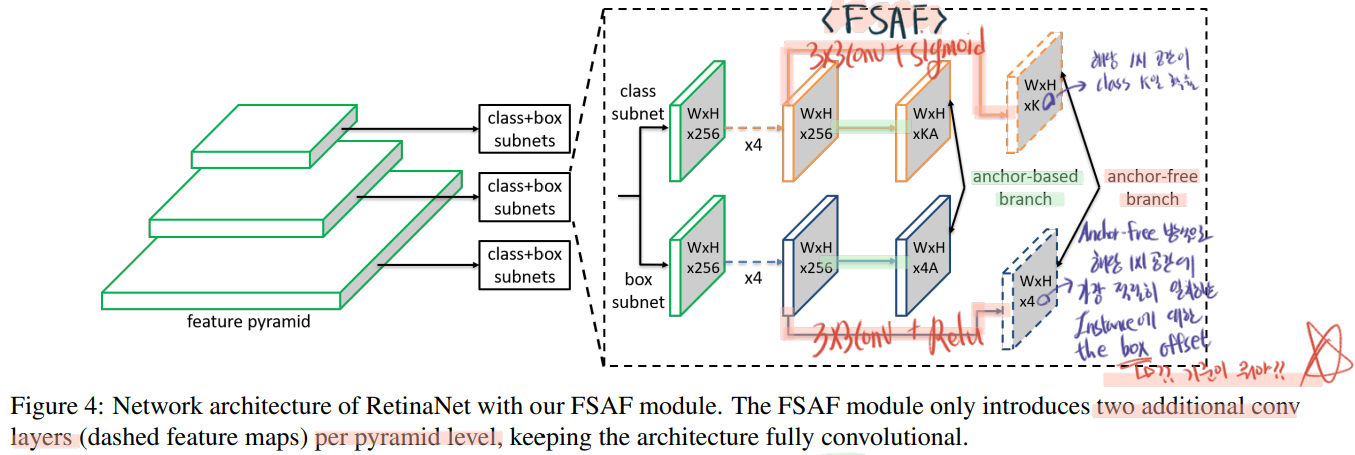
3.1 Network Architecture
how to create the anchor-free branches in the network
surprisingly simple
FPN에서 나오는 feature map P_3 부터 P_7 까지. 3~7을 ‘l (small L)‘이라고 하자. P_l은 the input image에 대해서 1 / (2^l) resolution 을 가진다.
아래 그림에, Class subnet, Box subnet 의 1x1 공간의 의미는 잘 적어두었으니 참조하기.
아래 그림에 왼쪽 하단 질문 기준이 뭐야?의 해답은 : “[instance GT BB’를 1 / (2^l) 비율로 나눈, BB]가 Anchor역할을 한다.” 이다.
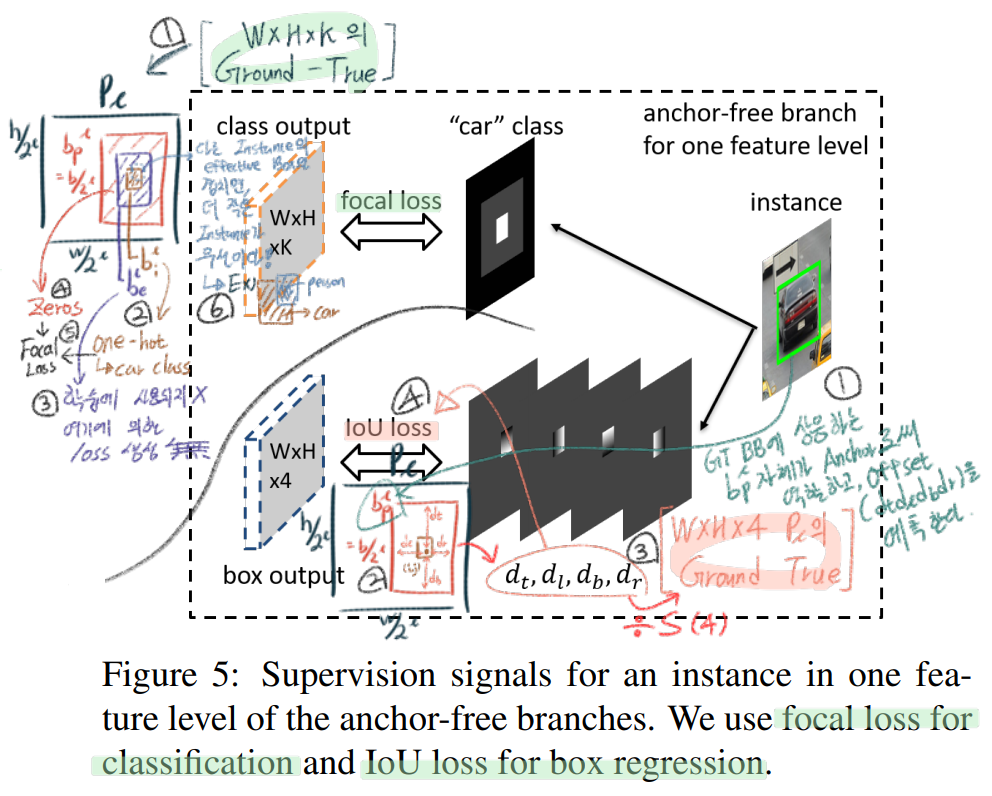
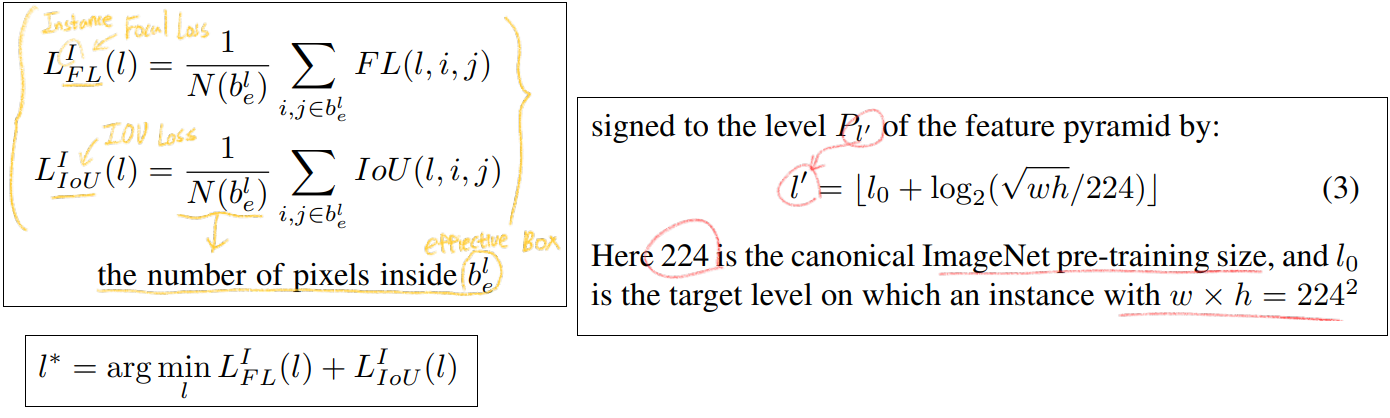
3.2 Ground-truth and Loss
how to generate supervision signals for anchor-free branches
아래 그림에서 중앙의 검은색 곡선 라인을 기준으로, (1) 위 왼쪽은 Classification 에 해당하는 P_l의 GT가 무엇이 되어야 하는지. (2) 아래 오른쪽은 Box Regression에 해당하는 P_l의 GT가 무엇이 되어야 하는지. 를 나타낸다.
Classification Output : 아래 그림의 설명에서 추가적으로 Focal Loss에서 α = 0.25 and γ = 2.0 를 사용했다. 하나의 instance에 의해서 생성되는, 최종적 loss는 the summation of the focal loss over all non-ignoring regions(빨간색 내부 중, 보라색 부분 제외 모든 곳) 이다.
Box Regression Output : 아래 그림의 설명에서 추가적으로, S는 a normalization constant 이다. S는 경험적으로 4라고 찾아냈다고 한다. S를 왜 사용했는지는 구체적으로 나와있지 않는다. (대략 최종으로 나오는 d_t, d_l .. 값들이, objectness score와 비슷한 값 분포를 가지게 하려는 건가?)
inference 를 수행하는 동안에는…
straightforward to decode the predicted boxes (위에서 했던 방식을, 그대로 반대로 해주면 된다. 마치 조립은 분해의 역순처럼!)
Box Regression 예측값 찾기
Classification Score : 각 1x1 공간에 대해서 the maximum score 를 사용한다.
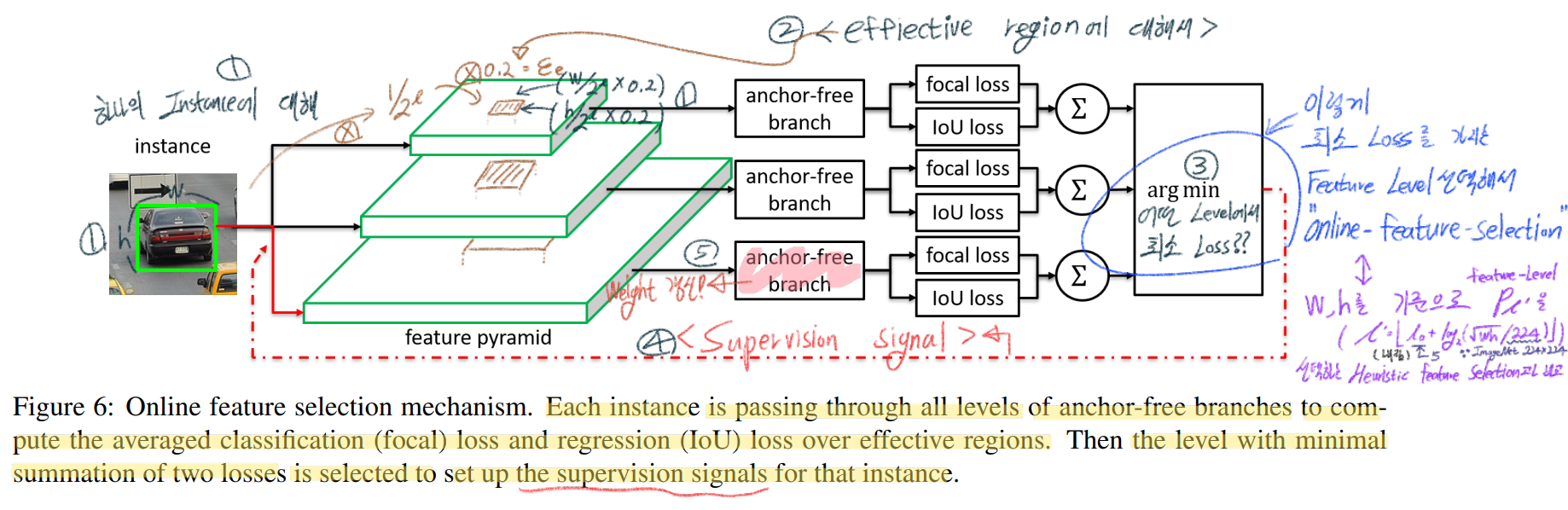
3.3. Online Feature Selection
how to dynamically select feature level for each instance
위 그림에서 보라색 필기를 추가 설명하자면, online-feature-selection 방법이 효과적이다. 라는 것을 증명하기 위해서, 자체적으로 heuristic feature selection을 만들어 실험해 보았다. 두 방법을 비교한 결과는 아래의 Result에서 소개될 예정이다.
Supervision siginal을 보내는 방법은, 이렇다. 최소 Loss를 가지는 Lavel을 l* 라고 하자. 그렇다면 P_l*의 effective region의 결과에 대해서만 Loss를 계산하고 nn.optimize(Loss) 를 적용해주면 된다.
3.4. Joint Inference and Training
how to jointly train and test anchor-free and anchor-based branches
Inference
each pyramid level에 대해서 top-score를 가지는 1k를 선출한다.
그것들에 대해서, (0.05 confidence score) thresholding을 수행한다.
anchor-based branches에서도 위의 1번2번 과정과 같은, “top predictions”을 수행한다.
이렇게 찾아낸, 모든 BB들에 대해서, non-maximum suppression을 수행한다.
Initialization
(정확히 뭔소린지 모르겠다. 이걸 코드로 확인해 보아야 하나?)
classification 에 대해서, bias = log((1 − π)/π) and a Gaussian weight filled with σ = 0.01. 여기서 π는 학습 초기에 모든 픽셀에 대한 objectness score output을 π라고 했단다.
box regression 에 대해서, bias = b, and a Gaussian weight filled with σ = 0.01.
initialization을 정확하게 하는 것은, 학습 초기에 large loss를 막음으로써, network learning을 안정화시키는데 도움을 준다.
Optimization:
Loss는 Total Loss로써 아래의 수식을 사용한다.
아래에서, Iterations 가 의미하는게 정확하게 뭔지는 모르겠지만, epoch는 아닌것 같고, 1 mini-batch 학습을, 1 iterations라고 보면 될 듯 하다.
4. Experiments
COCO dataset 을 사용해서, 성능을 비교하였다.
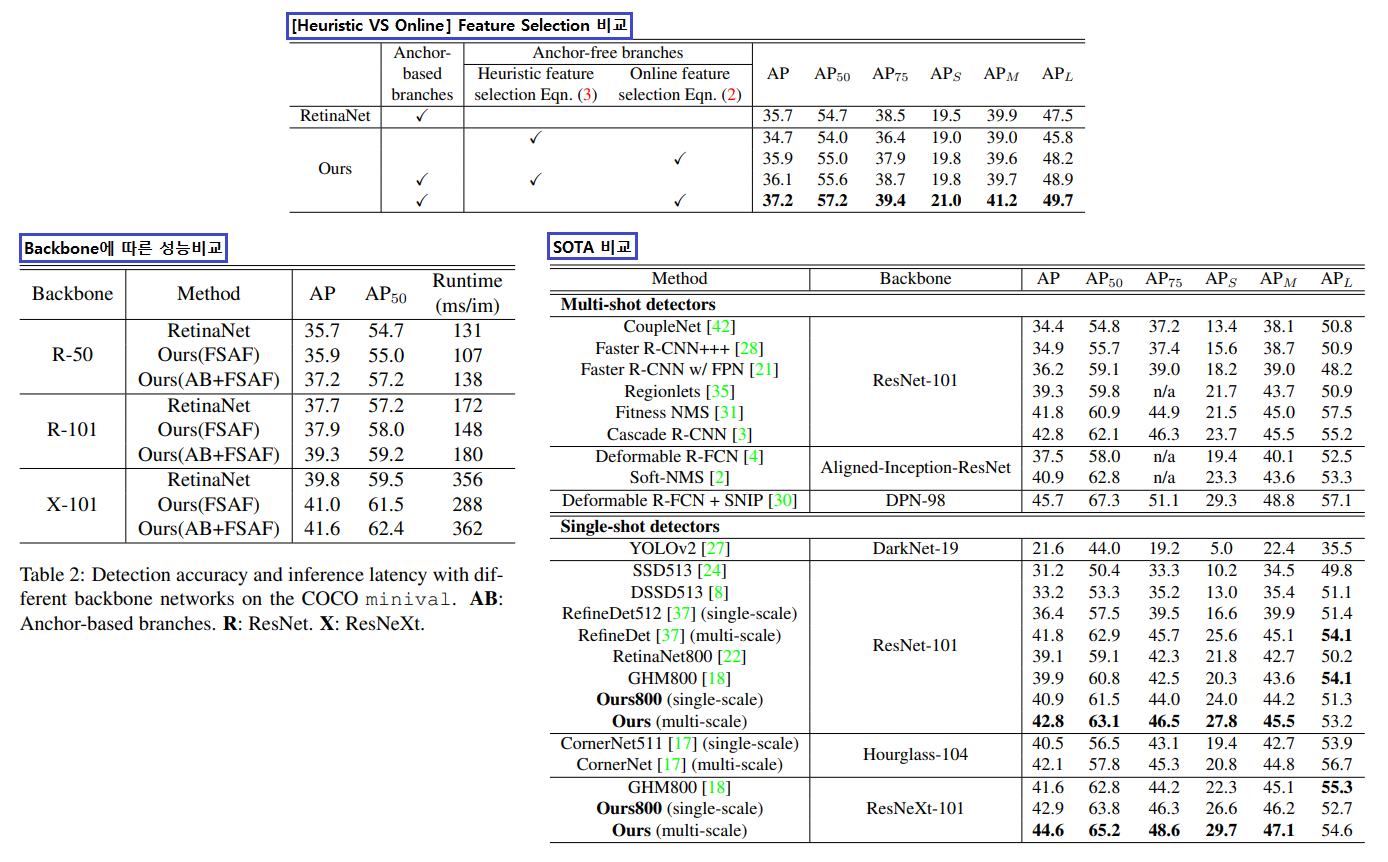
Ablation studies 를 통해서 내린 결론 (맨 위 표)
Anchor-free branches are necessary.
Online feature selection is essential.
How fast? : 위 표 중, 아래 오른쪽 표를 살펴보면 RetinaNet(AB) 와 Ours(AB + FSAP) 의 Runtime 차이가 그리 크지 않은 것을 확인할 수 있다.
How is optimal feature selected?
아래의 그림을 참고하자.
the optimal pyramid level selected for instances 을 선택하는 것이 과연 얼마나 중요할까? 물론 왼쪽아래 표를 참고하면 이해할 수도 있기도 하지만, 아래의 사진을 통해서 이해해보자.
아래의 그림의 Bounding box annotation에서 Class 이름 옆에 있는 숫자는 P_l에서 l (feature level)을 의미한다.
아래의 그림을 통해서, 대체적으로 online feature selection 또한 [ 크기가 큰 객체는 높은 l 에서 검출이 되고, 크기가 작은 객체는 낮은 l 에서 검출되는, 아주 기본적인 원리 ] 를 만족하는 것을 확인할 수 있다.
하지만 빨간색 박스는, anchor-based branch에서 선택된 l (feature level) 과 FSAF module에서 선택된 l 이 다른 경우에 빨간색 박스를 처 놓았다. 이런 것을 봤을 때, 그리고 FSAF를 사용해 성능향상이 되는 것을 보았을 때, heuristic 뿐만아니라, online feature level selection 도 Object Detection에 필요하다는 것을 확인할 수 있다.
Comparison to State of the Art
scale jitter over scales {640, 672, 704, 736, 768, 800} and for 1.5× longer than the models 이라는 방법을 사용해서 모델을 학습시켰다. 라고 논문에 나와있다.
내 추축으로 생각해봤을 때, 우선 네트워크는 an image scale of 800 pixels for both training and testing에 특화되게 학습시킨다.
그리고 원본이미지를 좀 더 작은 {640, 672, 704, 736, 768, 800} 사이즈를 가지는 이미지로 바꿔서 학습시킨 후. 나중에 원래 이미지 크기인 {400, 500, 600, 700, 900, 1000, 1100, 1200} 사이즈를 가지는 이미지를 가지는 이미지를 학습시킴으로써, 좀 더 small scale instance 를 검출하는데 효과적인 Network로 학습시키지 않았나 싶다.
여기서도 single-scale testing (800 pixels) 그리고 multi-scale testing ({400, 500, 600, 700, 900, 1000, 1100, 1200}) 를 적용했을때의 성능비교가 위의 (왼쪽 아래) 표에 잘 적혀있다.

 9
9