【In-Segmen】CenterMask - Real-Time Anchor-Free Instance Segmentation
- 논문 : CenterMask : Real-Time Anchor-Free Instance Segmentation
- 분류 : Real Time Instance Segmentation
- 저자 : Youngwan Lee, Jongyoul Park
- 느낀점 :
- mask scoring [15] 논문을 꼭 한번 읽어야 겠다.
- 목차
- Paper Review
- Code Review
- Github link : https://github.com/tianzhi0549/FCOS
CenterMask
1. Conclusion, Abstract, Introduction
- Real-time anchor-free one-stage
- VoVNetV2 backbone : (1) residual connection (2) effective Squeeze-Excitation (eSE, Squeeze and Excitation Block (M2Det, MobileNetV3, EfficientDet 참조))
- Spatial attention guided mask (=SAG-Mask) : Segmentation Mask를 예측한다. spatial attention을 사용함으로써 집중해야할 Informative Pixel에 집중하고, Noise를 Suppress한다.
- ResNet-101-FPN backbone / 35fps on Titan Xp
- (PS) Introduction은 읽을 필요 없는 것 같고, Relative Work는 아에 없다. Introduction에 Relative Work의 내용들이 가득해서 그런 것 같다.
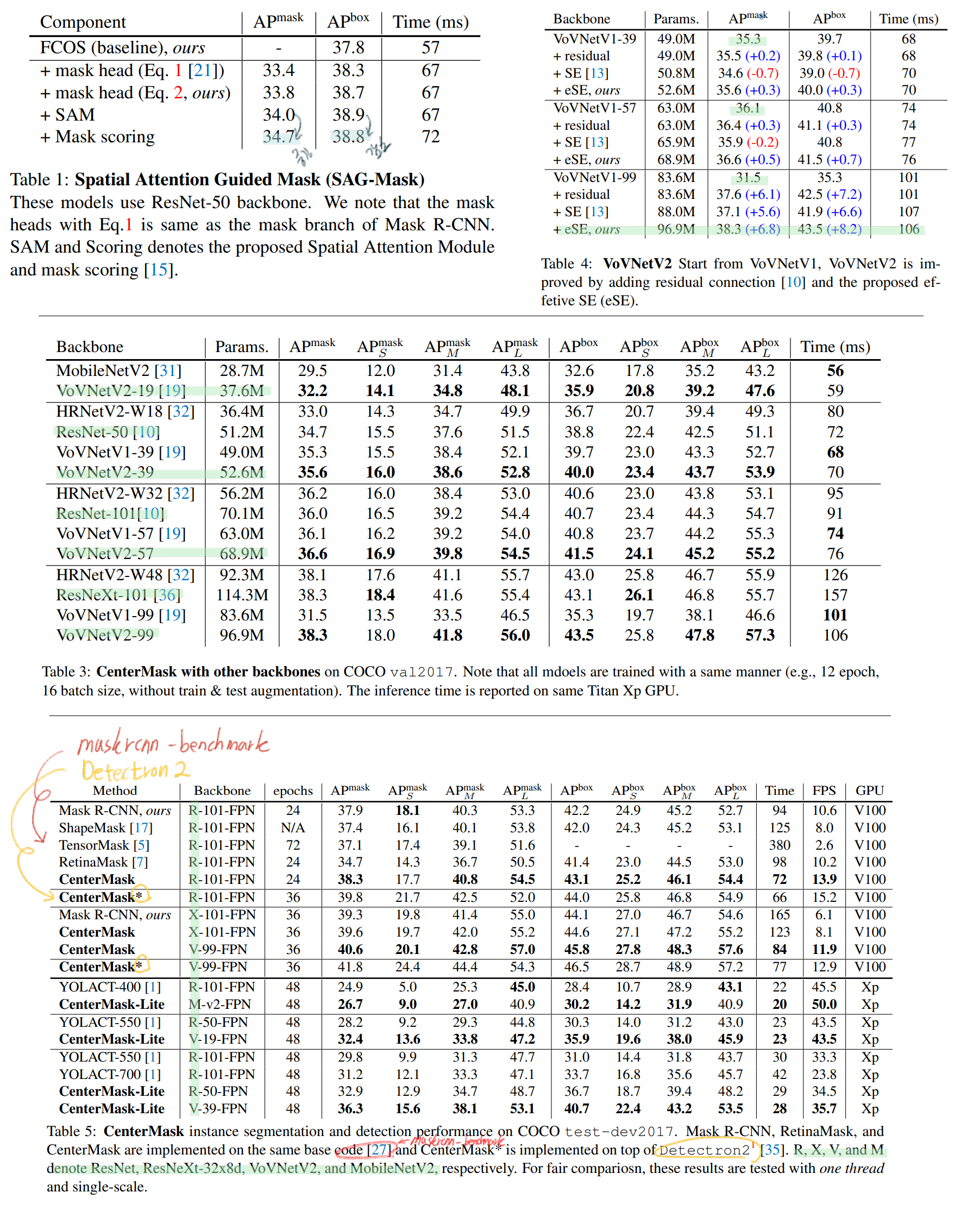
2. CenterMask architecture
- 논문의 그림에서 P7~P3의 그림이 이상해서 내가 다시 표시했다. 내가 수정한게 더 맞는 것 같다.
2.3. Adaptive RoI Assignment Function
위 필기 갈색5번을 참조하면 ROI는 구했고, 그 ROI를 가져올 때, 어떤 Feature Level을 사용해야하는가?

위 Equation1 은 Mask rcnn에서 사용하던 방식이다. 하지만 이것을 그대로 사용하기에는 문제가 있다. 첫째로, 이 방식은 feature levels of P2 (stride of 2^2) to P5를 사용하는 2 stage detector에 더 적합하다. 우리는, P3 (2^3) to P7 (2^7)를 사용하는 one stage detector를 개발해야한다.
게다가 위의 224는 ImageNet Image size이다. 이것은 굉장히 Heuristic한 설정이고, 이와 같은 설정을 유지해서 계산을 해보면, 특정 wh에 따라 선택된 k 값은 상대적으로 작은 값이다. 다시 말해, 좀 더 큰 resolution의 Feature map에서 ROI feature를 가져와야 하는데, 작은 Resolution의 Feature map에서 ROI feature를 가져오므로 작은 객체 탐지를 어렵게 만든다.
따라서 우리는 Equation2를 새로운 Feature Level 설정 방법으로 사용한다. 몇가지 경우와 수를 고려해보면, Image area의 절반이상의 ROI area를 가지는 객체는 무조건 P7에서 Feature를 가져오고, 상대적으로 Equation 1보다 작은 k값의, P_k에서 feature를 가져와 small object detection에 도움을 준다.
ablation study를 통해서 k_max to P5 and k_min to P3 를 사용하는게 가장 좋은 결과를 가져다 주었다고 한다.
2.4. Spatial Attention-Guided Mask
- 최근 attention methods은 Detector가 중요한 Feature에 집중하는데 도움을 준다. ‘what’을 강조해주는 channel attention과 ‘where’을 강조해주는 spaital attention이 있다. CBAM이 위의 2가지 방법을 적절히 잘 섞은 방법이다.
- 이 논문에서는 spaital attention를 사용해서, Mask head가 정말 의미있는 Pixel에 집중하고, 무의미한 Pixel은 억압되도록 만들었다.
- 그것이 SAG-Mask (a spatial attention-guided mask) 부분이고 위의 Architecture 그림에 잘 그려져 있다.

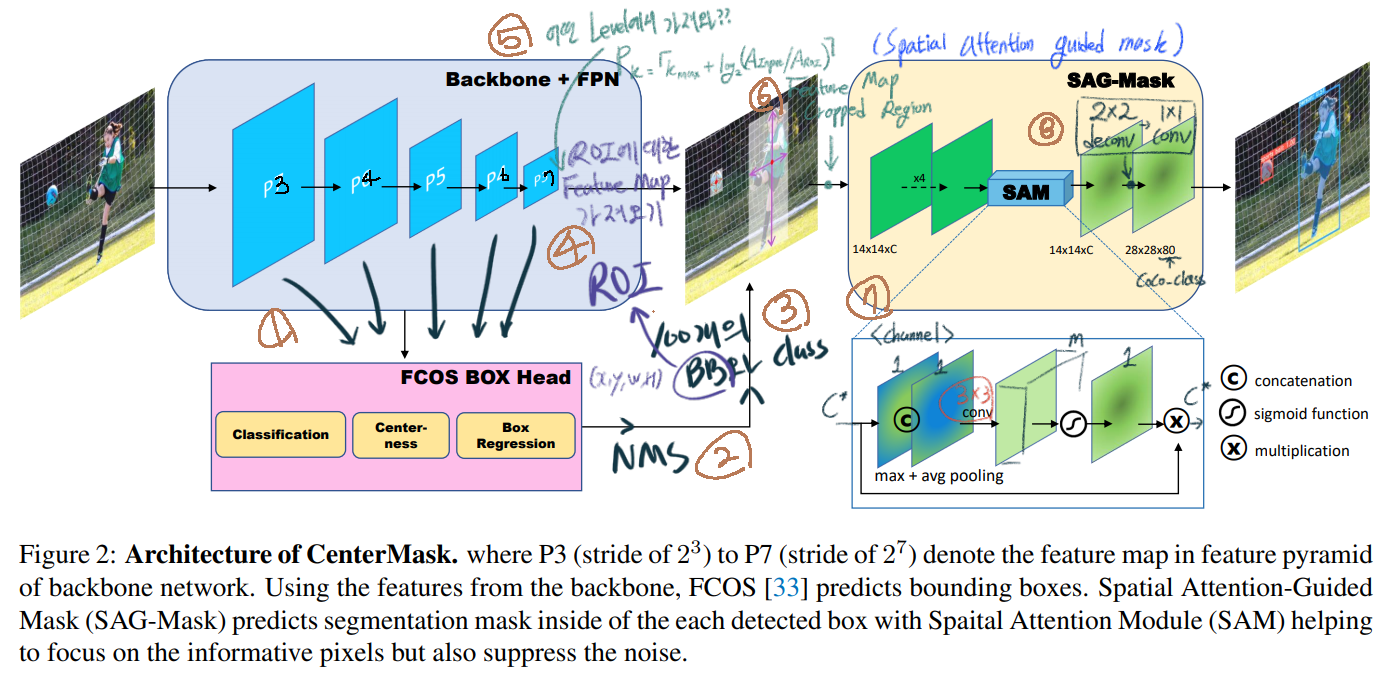
2.5. VoVNetV2 backbone
- VoVNet는 ‘computation + energy’ efficient backbone network 이다. 이 네트워크는 효율적으로 다양한 feature representation(map)들을 보존한다. VoVNetV1 또한 이 논문 저자가 발표한 논문의 방법이다.
- 이번 VoVNetV2에서는 특별하게 effective SE 모듈을 추가했다. effective SE 모듈은 기존의 SE 이 2번의 fc layer를 통과시키면서, dimension reduction 과정을 거치고 이 과정에서 정보의 손실이 생긴다고 주장한다. 따라서 1번의 fc layer만 통과시키는 effective SE 모듈를 주장한다.
- Architecture의 모습은 아래와 같다.
2.6. Implementation details
- mask scoring [15] 를 사용했다. 예측한 mask의 quality (e.g., mask IoU)를 고려하여, classification score를 재조정하는 방법이다. (이 방법을 어떻게 사용했는지 구체적인 방법에 대해서는 안 나와 있다. mask scoring [15] 논문을 봤다는 전제를 하는 것 같으므로 나중에 mask scoring [15] 논문을 꼭 읽어봐야겠다.)
- CenterMask-Lite : backbone, box head, and mask head 에 대해서, down-sizing을 하여 성능은 조금 낮아져도, 속도가 빨라지도록 만들었다. 구체적으로 어떻게 down-sizing 했는지는 논문에 간략히 적혀있으니 필요하면 참조.
- Training :
- FCOS에서 나오는 100개의 박스를 SAG-mask branch에 fed한다.
- Mask R-CNN과 같은 mask-target을 사용했다. 이 mask-target은 Mask-IOU를 이용해 정의 된다.
- Loss_total = L_cls + L_center + L_box + L_mask
- input image는 가로 세로 중 짧은 쪽이 800이 되도록 resize된다. 긴쪽은 1333이 되거나 1333보다 작은 pixel크기가 된다.
- 90K iterations (∼12 epoch) with a mini-batch of 16 images
- SGD, weight decay of 0.0001 and a momentum of 0.9
- initial learning rate 0.01 which is decreased by a factor of 10 at 60K and 80K iterations, respectively
- All backbone models 은 ImageNet pre-trained weights 를 사용했다.
- Inference :
- FCOS에서 나오는 50개의 박스를 SAG-mask branch에 fed한다.
- CenterMask/CenterMask-Lite use a single scale of 800/600 pixels for the shorter side
3. Results