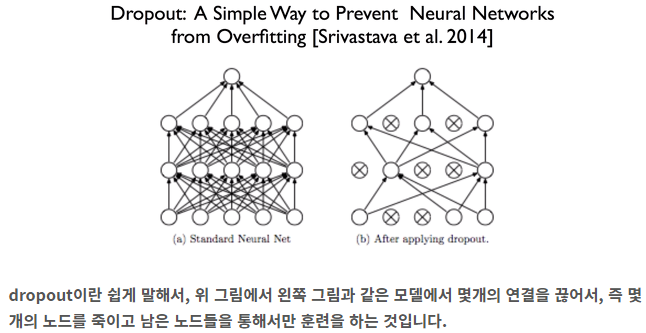
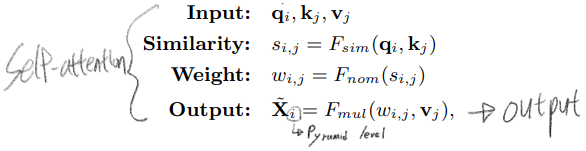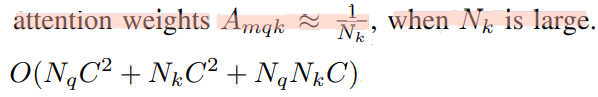Learning to adapt structured output space for semantic segmentation [49] : 이 논문에서 Sementic Segmentation을 위해서 여기서 사용하는 Architecture를 사용했다. 이 코드를 base code로 사용한 듯 하다.
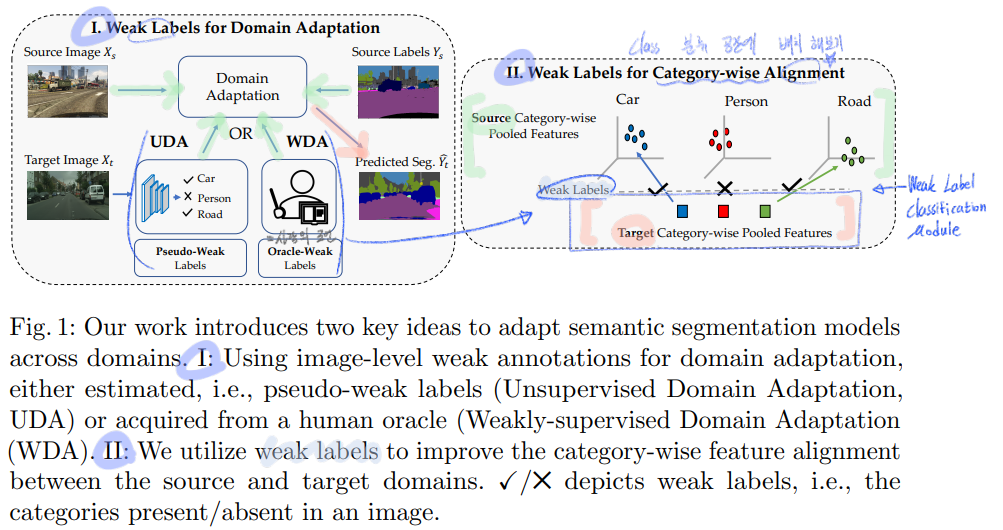
DA Semantic Segmentation Using Weak Labels
이 논문의 핵심은 weak labels in a Image( 이미지 내부의 객체 유무 정보를 담은 List(1xC vector)를 이용하는것 ) 이다.
1. Conclusion, Abstract
논문의 핵심만 잘 적어 놓은 그림이다.
하지만 Weak label for category-wise Alignment, Weak label classification Module은 그림으로 보고 이해하려고 하지말고, 아래 Detail과 Loss함수를 보고 이해하도록 해라.
당연한 Domain Adatation의 목표 : lacking annotations in the target domain
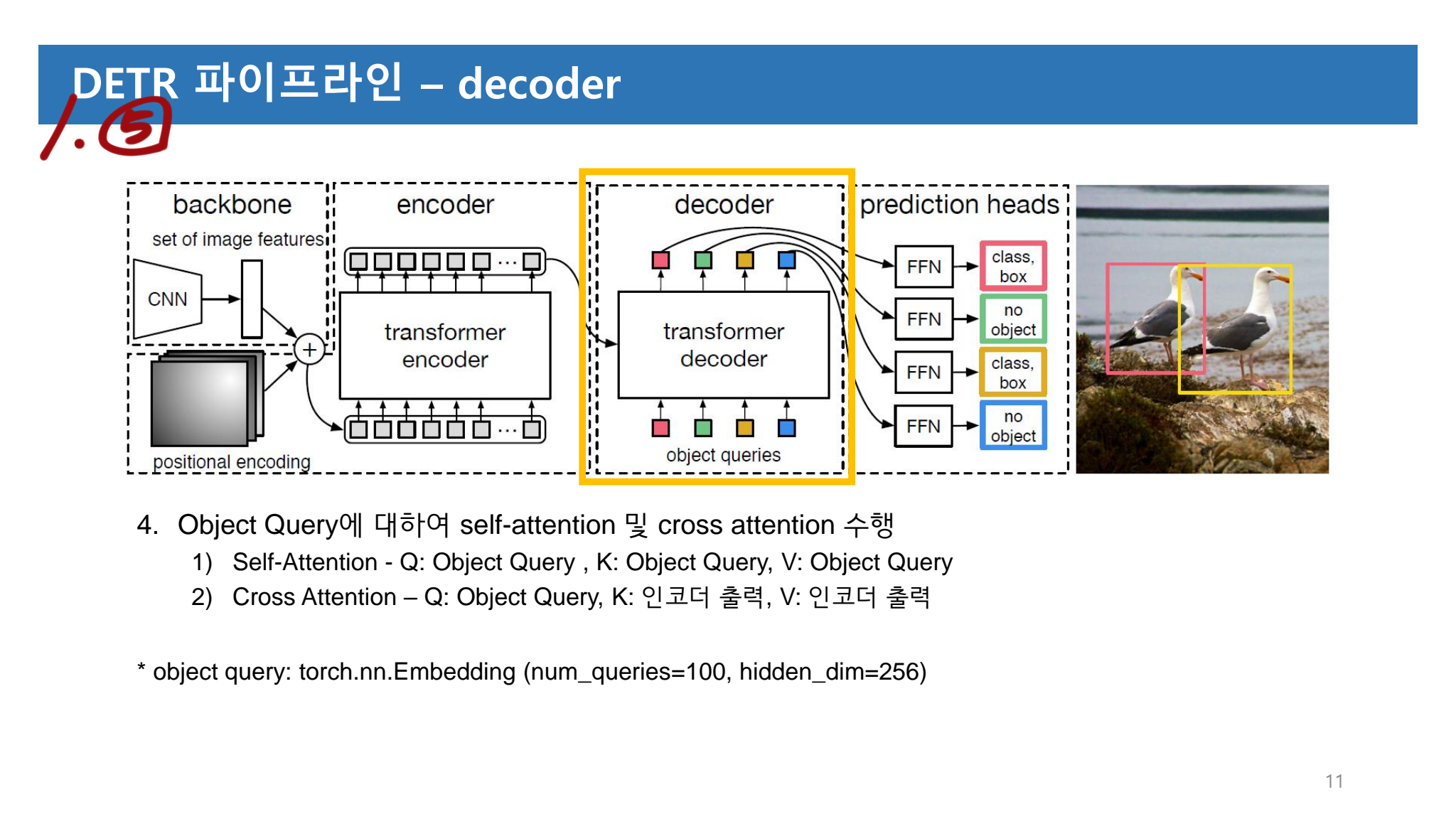
3. DA with Weak Labels Method
3.1 Problem Definition
3.2 Algorithm Overview
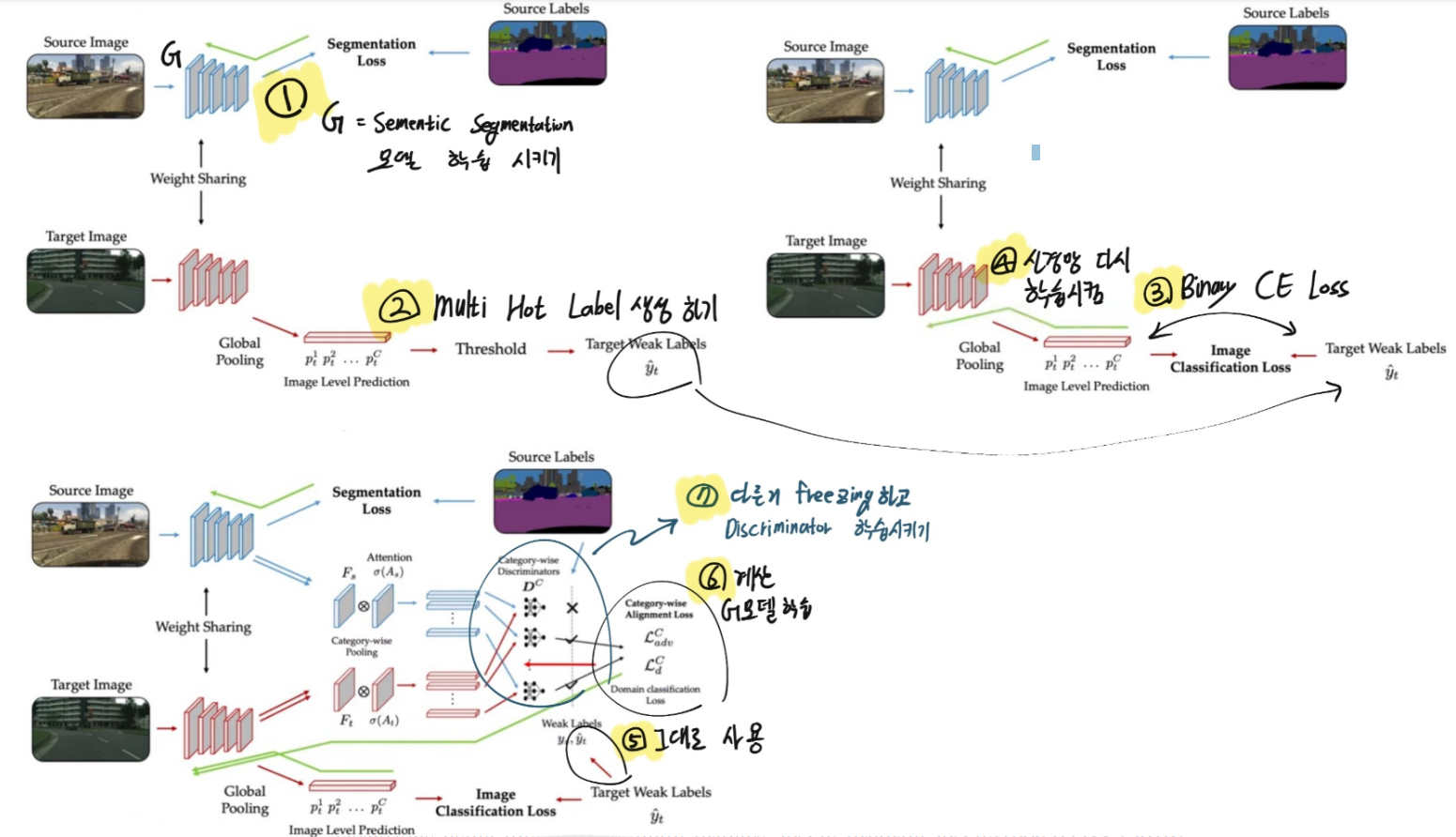
Model Architecture
이 이미지에서 Domain Adaptation에서 많이 사용되는 Adversarial Discriminative Domain Adaptation이 핵심적으로 무엇인지 오른쪽 필기에 적어 놓았다. 진정한 핵심이고 많이 사용되고 있는 기술이니 알아두도록 하자.
이 과정의 목적은 segmentation network G can discover those categories즉 segmentation network인 G가 domain이 변하더라고 항상 존재하는 Object/Stuff에 pay attention 하도록 만드는 것을 목표로 한다. G가 이미지 전체의 environment, atmosphere, background에 집중하지 않도록 하는데에 큰 의의가 있는 방법이다.
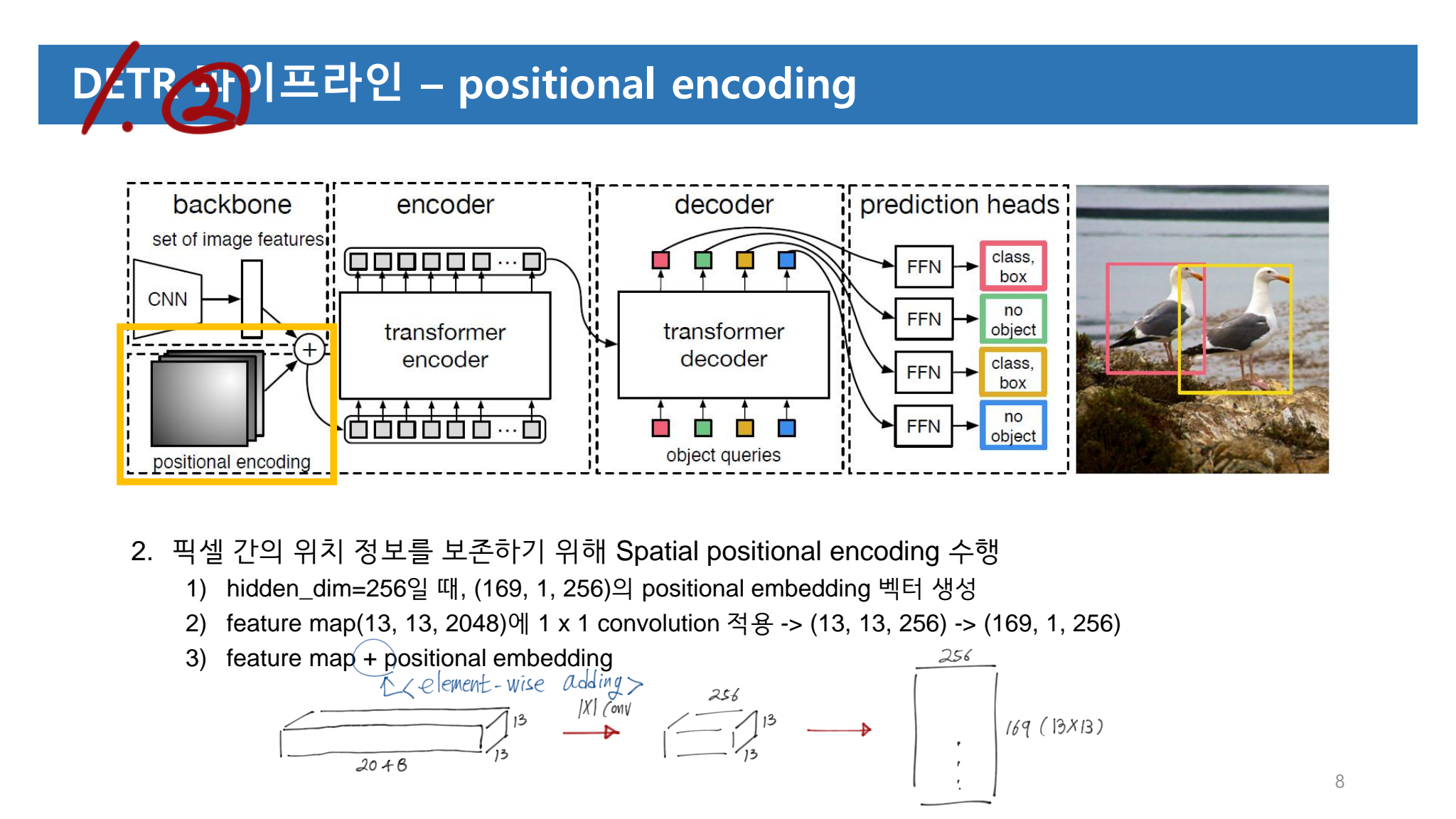
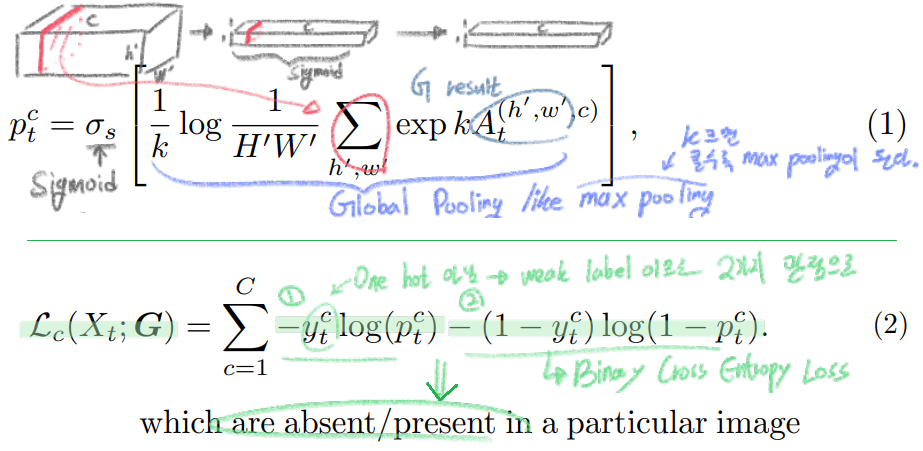
(Eq1) Global Pooling이 적용되는 방법과, (Eq2) Loss 수식에 대한 그림이다.
이미지에 특정 class가 있는지 없는지에 대해서 집중하기(판단하기) 위해서 Global Pooling이 사용되었다.
위에 (1)식에 사용되는 수식은 smooth approximation of the max function이다. k가 무한대로 크면 max pooing이 적용된 것이라고 할 수 있다. 하지만 하나의 값으로 pooling 값이 정해지는 max pooling을 사용하는 것은 Noise에 대한 위험을 안고 가는것이기 때문에, 적절하게 k=1로 사용했다고 한다.
Pooling에 의해서 적절한 값이 추출되게 만들기 위해서는 Loss함수가 필요한데, 그 함수를 (2)번과 같이 정의하였다. category-wise binary cross-entropy loss를 사용했다고 말할 수있다.
3.4 Weak Labels for Feature Alignment
image-level weak labels의 장점과 특징
위의 방법을 보면 distribution alignment across the source and target domains(domain 변함에 따른 데이터 분포 변화를 고려한 재정비 기술들) 이 고려(적용)되지 않은 것을 알 수 있다.
적용되지 않은 이유는, 우리가 category를 이용하기 때문이다. performing category-wise alignment를 적용하는 것에는 큰 beneficial이 있다. (3.3의 내용과 같이, class에 대한 특성은 domain이 변하더라도 일정하기 때문에)
과거에 performing category-wise alignment을 수행한 논문[14]이 있기는 하다. 하지만 이 방법은 pixel-wise pseudo labels을 사용했다.(?)
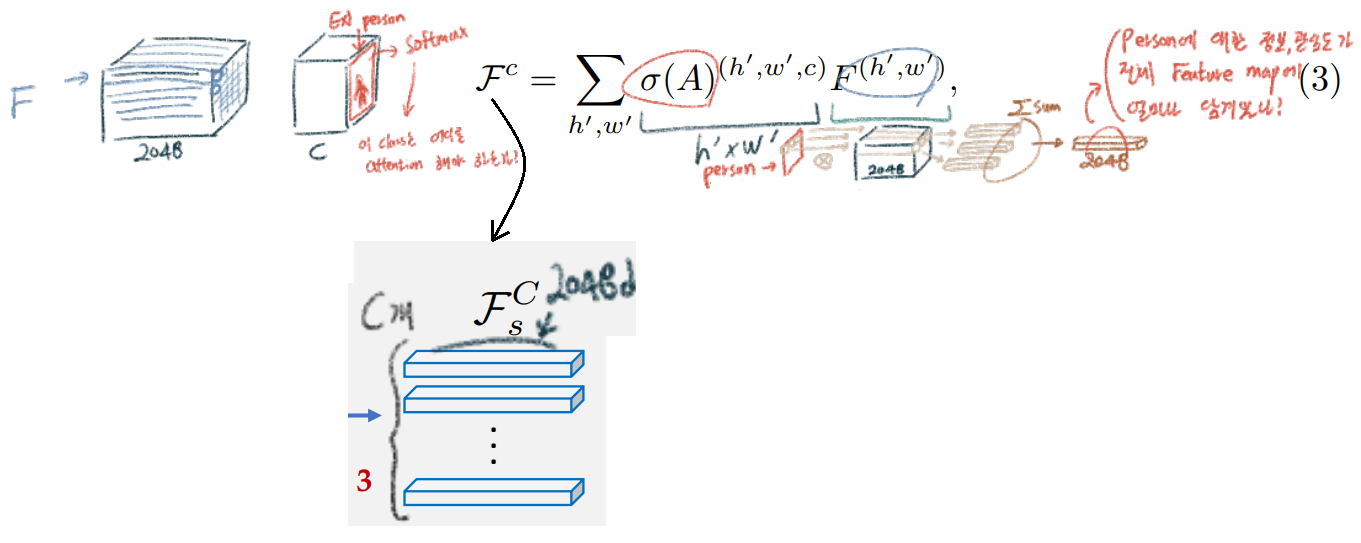
반면에 우리는 pixel-wise가 아니라 image-level weak labels를 사용했다. 그냥 단순하게 사용한 것이 아니라. an attention map guided by our classification module(global pooling) using weak label을 사용한 것이므로 매우 합리적이고 make sense한 방법이라고 할 수 있다.
Category-wise Feature Pooling
Category-wise Feature Alignment
핵심은 Discriminator를 하나만 정의하지 않고, each category-specific discriminators independently를 사용했다는 점이다.
이렇게 하면 the feature distribution for each category가 독립적으로 align되는 것이 보장될 수 있다. (맨위의 이미지를 보면 이해가 될 거다.)
a mixture of categories를 사용하면 the noisy distribution 문제점이 존재한다.
그 이외의 내용들은 위 사진의 필기에 잘 적혀있으니 잘 참고할 것
3.5 Network Optimization
3.6 Acquiring Weak Labels
Pseudo-Weak Labels (UDA)
the unsupervised domain adaptation (UDA)
T는 threshold이다. 실험적으로 0.2로 세팅해서 좋은 결과를 얻었다.
학습하는 동안에 the weak labels은 online 으로 생성해서 사용했다.
Oracle-Weak Labels (WDA)
사람의 조언(Human oracle)이 이미지 내부에 존재하는 카테고리의 리스트를 만들도록 한다.
weakly-supervised domain adaptation (WDA)
pixel-wise annotations 보다는 훨씬 쉽고 효율적이다.
위의 방법 말고도 이 논문에서 Fei-Fei, L.: What’s the point: Semantic segmentation with point supervision. In: ECCV (2016) 논문에 나오는 기법을 WDA로 사용했다. (아래 Results의 성능 비교 참조)
이 기법은 사람이 이미지 일정 부분만 segmentation annotation한 정보만을 이용하는 기법이다.
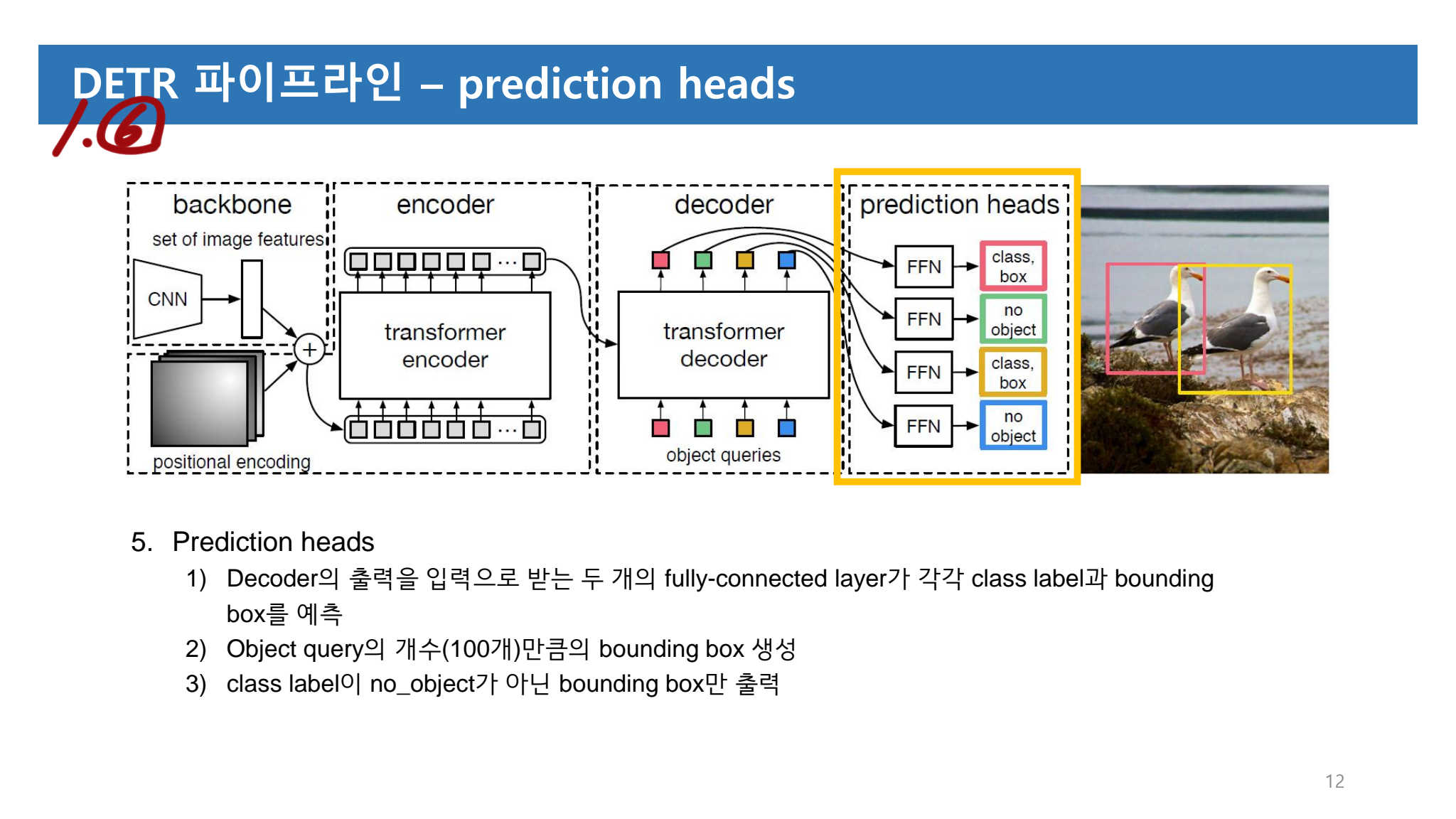
4. Results
당연히 성능이 올라갔다. 자세한 내용은 논문을 참조 하거나 혹은 conference presentation 자료를 아래에서 참조하자.
여기서 사용한 Weak Label은 2가지 이다. 아이러니 하게도… 이 논문에서 제안된 핵심 Weak label 기법보다 2016년에 Fei-Fei가 작성한 what’s the point 논문 기법으로 더 좋은 결과를 얻어냈다. (하지만 논문에서는 자기들 기법이 더 빠르게 anotaion할 수 있다고 한다. (?)
WLS2와 docker desktop을 설치한다. 이 과정이 꼭 필요한 과정인지는 모르겠다. vscode에서 attach container를 하면 make sure docker deamon is running 이라는 에러가 났다. 이 문제를 해결하기 위해서 docker desktop을 설치해야하는 듯 했다.
windows home을 사용하기 때문에 WLS2를 설치해야만 docker desktop을 설치할 수 있었다.
사이트 순서를 정리하면 다음과 같다
Windows Terminal 설치하기
WSL 활성화를 위해서 PowerShell에서 두개의 명령어를 복붙 처주기
WSL 설치하기 = MS store에서 Ubuntu 설치하기
WSL1을 2로 업데이트 시켜주기 (커널을 설치해주고 PowerShell에서 $ wsl --set-version/default 처리 해주기 )
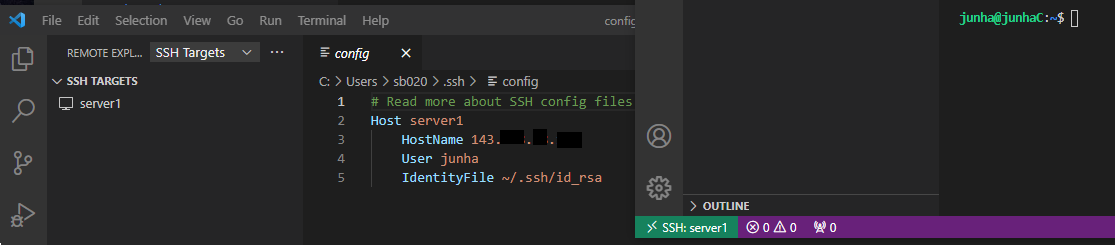
여기에 그~대로 key 복붙해서 저장해두기 (아래 이미지 참조) - (에러 발생 및 문제 해결) 같은 아이피를 사용하는 우분투 케이스를 바꿔서 다시 연결하려니 안됐다. 이때 해결책 : 윈도우에서 known_hosts파일 삭제하기. $ cd C:\Users\sb020\.ssh && rm ./known_hosts
윈도우 VScode ssh config
VScode -> ctrl+shift+p == F1 -> Remote-SSH: Connect to Host
VScode -> ctrl+shift+p == F1 -> Preferences: Open Settings (JSON)
{"docker.host":"ssh://junha@143.283.153.11"}
이렇게 수정해두기. 위에서 junha로 하는 대신 우분투에서 아래의 작업 진행
$ sudo usermod -aG docker junha
VScode -> ctrl+shift+p == F1 -> Remote-Containers: Attach to Running Container
존버타고 있으면, 서버에 실행되고 있는 container 목록이 뜬다. 원하는거 선택하고 Open 및 설정이 완료되기까지 시간이 좀 걸린다.
그러면 최종 성공!
6. 완성!
Windows10
Ubuntu
7. VS code 환경설정
아래와 같이 Python Interpreter 설정을 해야한다.
ML-workspace자체에 conda가 설치되어 있고, base env는 opt/conda/bin/python 에 존재한다. interpreter에 마우스 길게 갖다 대고 있으면 path가 나온다. 나의 window conda path와 겹칠일은 없겠지만 그래도 조심하자.
$ ls ~/.vscode-server/bin # hash name 파악하기$ export PATH="$PATH:$HOME/.vscode-server/bin/<hash name>/bin/"(예시)$ export PATH="$PATH:$HOME/.vscode-server/bin/08a217c4d27a02a5bcde8555d7981bda5b49391b/bin/"`$ code ~/.bashrc
(Addding in the file)export PATH="$PATH:$HOME/.vscode-server/bin/08a217c4d27a02a5bcde898555981bda5b49391b/bin/"`
9. –shm-size 의 중요성
mmclassification 을 돌리면서 만난 에러가 다음과 같았다. RuntimeError: DataLoader worker (pid 167565) is killed by signal: Bus error. It is possible that dataloader's workers are out of shared memory. Please try to raise your shared memory limit
찾아보니 원인은 다음과 같았다.
도커로 컨테이너를 생성하게 되면 호스트와 컨테이너는 공유하는 메모리 공간이 생기게 되는데 이 공간에 여유가 없어서 발생되는 에러이다.(참조사이트)
container $ df -h 명령어로, shm가 얼마인지 확인할 수 있다.
container run 할 때 충분한 -shm-size 를 설정해주는 방법이 답이다.
ML-workspace github 참조
찾아보니, 대강 이 문제가 발생한 사람들은 docker run --shm-size=2G 설정한다. 어떤 글을 보니 docker run --ipc=host 이런식으로 설정해주는 사람도 있었다. 어떤 사람은 8G로 설정하는 경우도 있었다. (문제 안생기나?)
# 최종 실행 터미널 코드$ sudo docker run -d-it\--gpus all \--restart always \-p 8000:8080 \--name"mmcf"\--shm-size 2G \-v ~/docker/mmclf/mmclassification:/workspace \-v ~/hdd1T:/dataset \
pytorch/pytorch:1.5.1-cuda10.1-cudnn7-devel
또한 $ watch -d- n 1 df -h 명령어를 사용해서 현재 container가 어느정도의 –shm-size를 사용하고 있는지 알 수 있다.
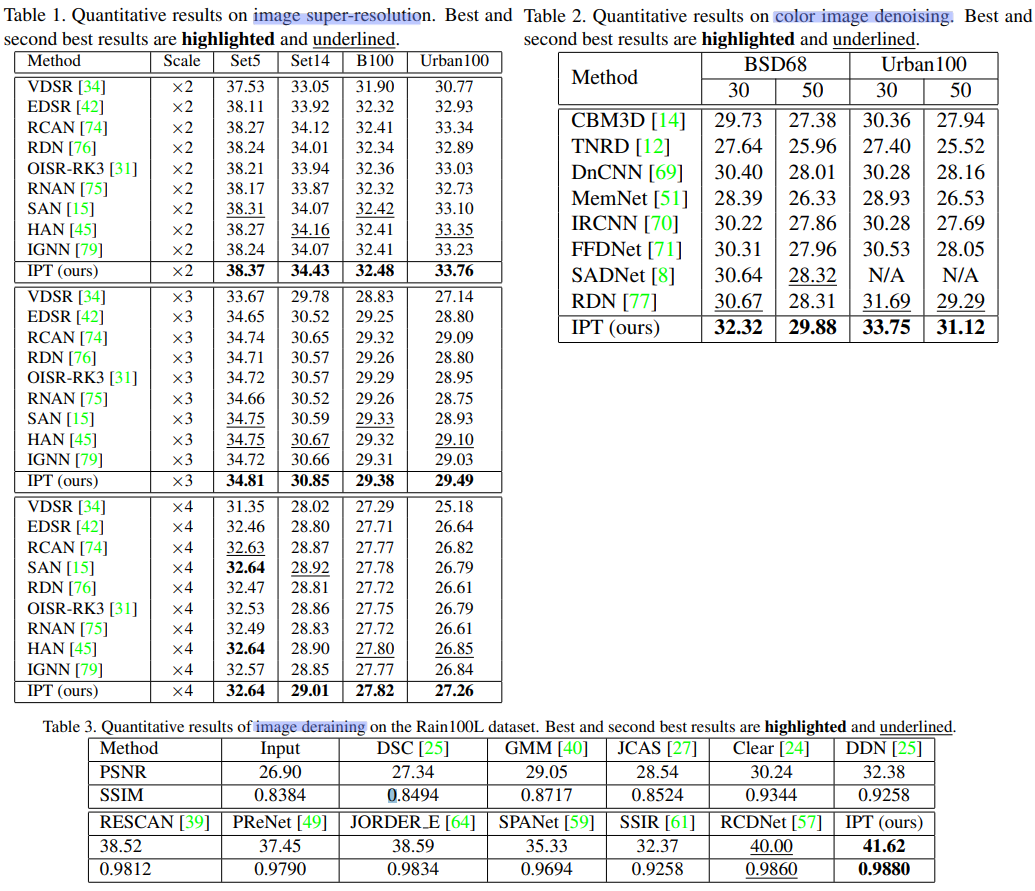
pre-trained transformer model (IPT)을 사용해서, 기본적인 이미지 프로세싱 문제(Denoising, Deraining, SRx2=super resolution 2배, SRx4)를 해결한다.
Class, Image Color도 다양하게 가지고 있는 종합적인 ImageNet datesets를 degraded한 이미지 데이터를 pre-trained dataset으로 사용했다. 모델이 low-level image processing을 위한 intrinsic features를 capture하는 능력을 향상시킬 수 있었다.
(1) supervised and self-supervised approaches (2) contrastive learning approaches 모두 융합해서 모델을 학습시킨다.
Abstract
pre-trained deep learning models을 사용해서, 원하는 Task의 모델을 만드는 것은 좋은 방법이다. 특히나 transformer module을 가지고 있는 모델은 이런 과정이 주요한 이바지를 할 것이다.
그래서 우리가 image processing transformer (IPT)을 개발했다.
다른 image processing task들에서도 금방 적응할 수 있도록, Contrastive learning을 수행했다!
3. Image Processing Transformer
위 이미지 그림과 필기 먼저 확실히 파악하기
3.1 IPT architecture
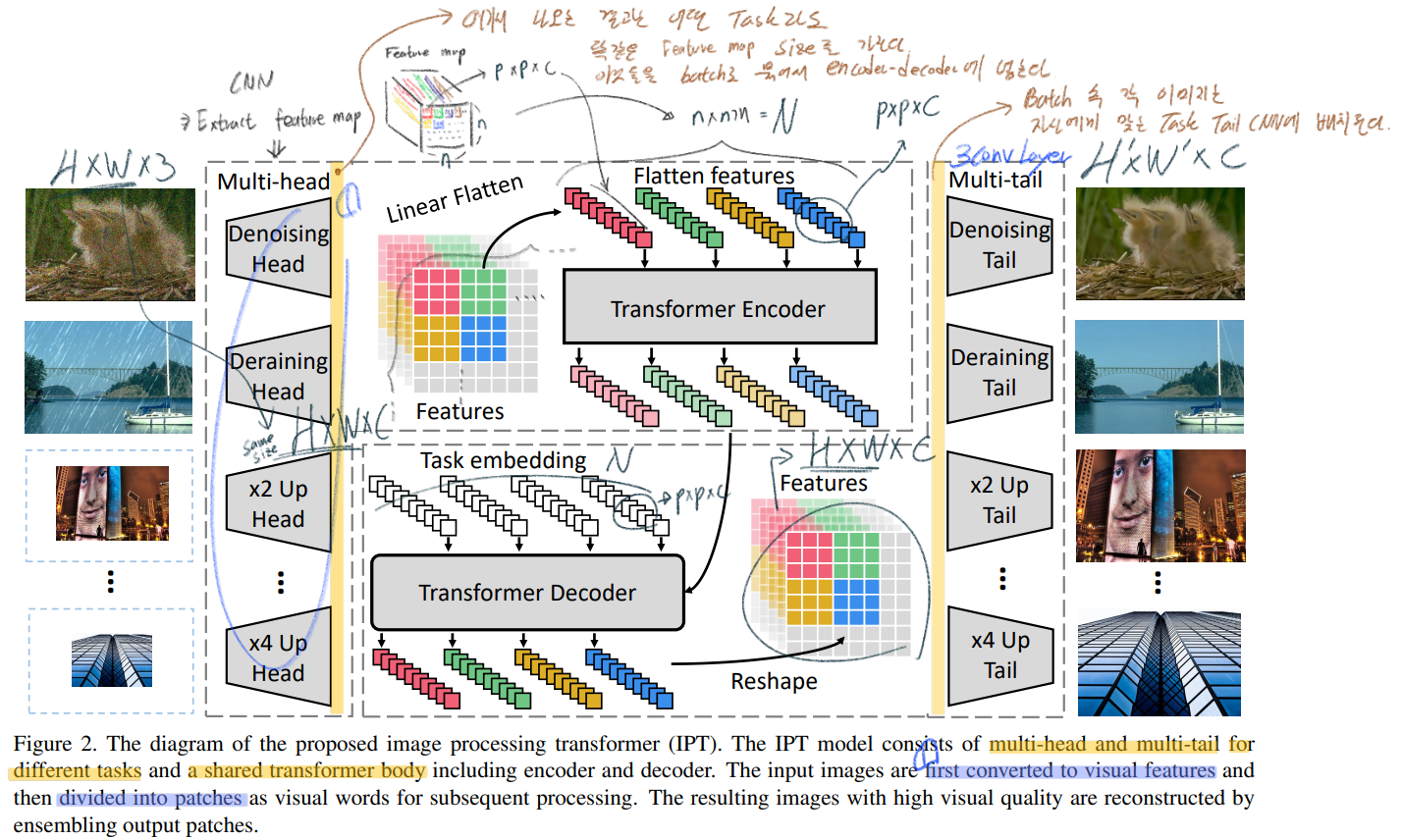
4개의 components : (1) Head = extract features from input imaeg) (2) Encoder = (3) Decoder = 이미지에 중요한 missing 정보를 capture&recover 한다. (4) tails = Final restored images를 만들어 낸다.
Head
각각의 Task에 대해, 3 conv layer로 이뤄진다. 이미지 x가 input으로 들어가서 f_H가 만들어진다.
Transformer encoder
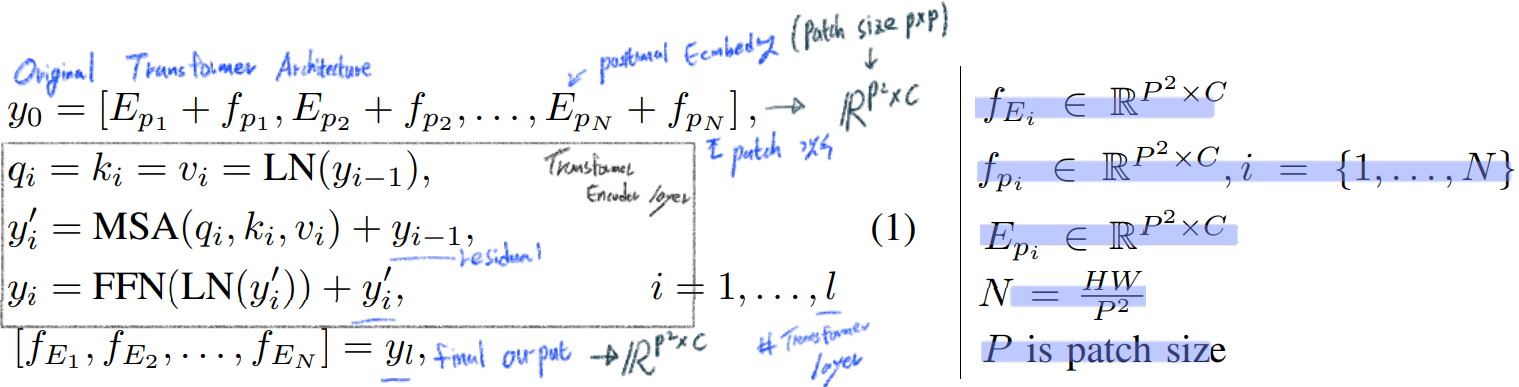
Almost same Transformer in All you need is Attention
Split the given features into patches
Learnable position encodings -> Element-wise SUM
Transformer decoder
Almost same encoder Transformer : 다른 점은 a task-specific embedding (Task에 따라서 다른 emdedding 백터 사용)
two multi-head self-attention (MSA)
Tails
Head와 같이 3 conv layer로 이뤄진다.
여기서 H’그리고 W’는 각 Task에 적절한 Size가 되면 된다. 예를 들어 Task가 SRx2 이라면 W’ = 2W, H’ = 2H가 되겠다.
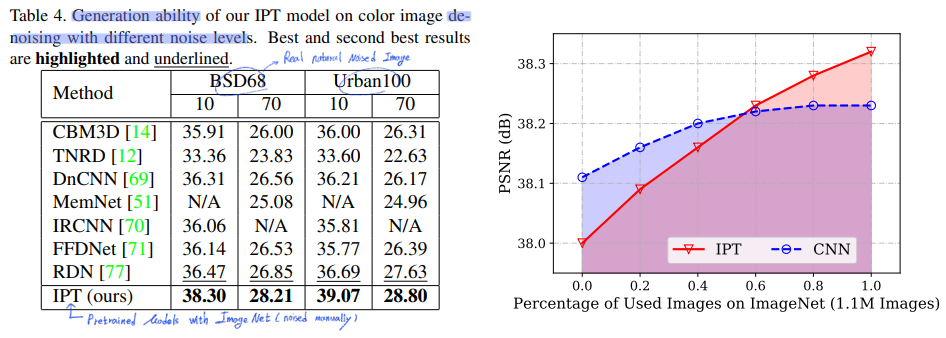
3.2 Pre-training on ImageNet
the key factors for successfully training은 바로, the well use of large-scale datasets 이다!
하지만 image processing task에 특화된 Dataset 별로 없다. 예를 들어 DIV2K (only 2000 Images). (이 Dataset은 ImageNet을 manually degrading한 것과는 다르다고 한다. 이러한 다름을 고려하여 추후에 generalization ability에 대해 분석해본다.)
따라서 ImageNet을 사용해서 we generate the entire dataset for several tasks. 이것을 이용해서 Pre-training model을 만든다!
ImageNet에서 Label에 대한 정보는 버려버리고,, 인위적으로 여러 Task에 맞는 a variety of corrupted images를 만들었다.
이 과정을 통해서, Model은 a large variety of image processing tasks에 대해서 the intrinsic features and transformations을 capture할 수 있는 능력이 생긴다. 그리고 추후에 Fine-tuning과정을 거치기는 해야한다. 그때는 당연히 원하는 Task에 맞는 desired task using the new provided dataset를 사용하면 된다.
Contrastive Learning
we introduce contrastive learning for learning universal features.
이 과정을 통해서 the generalization ability (= adaptation, robustness of Tasks or Image domains)을 향상하는데 도움을 준다. 다시 말해, pre-trained IPT 모델이 unseen task에 빠르게 적응하고 사용되는데 도움을 받는다.
한 이미지로 나오는 Feature map의 Patch들의 관계성은 매우 중요한 정보이다. NLP에서 처럼(?) 하나의 이미지에서 나오는 patch feature map은 서로 비슷한 공간에 최종적으로 embeding되어야 한다.
We aims to (1) minimize the distance between patched features from the same images (2) maximize the distance between patches from different images
최종 수식은 아래와 같이 표현할 수 있다. 맨아래 수식이 Final 목적 함수이다
4. Experiments and Results
각 Task에 따른, 결과 비교는 아래와 같다.
Generalization Ability
비록 우리가 ImageNet으로 currupted image를 만들었지만, 이 이미지와 실제 DIV2K와 같은 dataset과는 차이가 존재하고 실제 데이터셋이 더 복잡하다.
데이터셋에 따라서, 모델의 성능에서도 차이가 존재할 것이기에, generalization ability를 실험해보았다. 실험은 denoised Image Task에 대해서 실험한 결과가 나와있다.
Performer ViT: 1. Rethinking transformer-based set prediction for object detection, 2. Rethinking attention with performers
Tokens-to-Token ViT
1. Conclusion, Abstract
Conclusion
the novel tokens-to-token (T2T) 이란?? proggressively image/feature 를 tokenizing 하는 것
장점(1) 이미지의 구조정보를 파악할 수 있다. (2) feature richness를 향상시킬 수 있다.
특히 backbone에서는 the deep-narrow architecture = transformer layer는 많이 hidden dimention은 작게 가져가는 것이 효율적이다.
Abstract
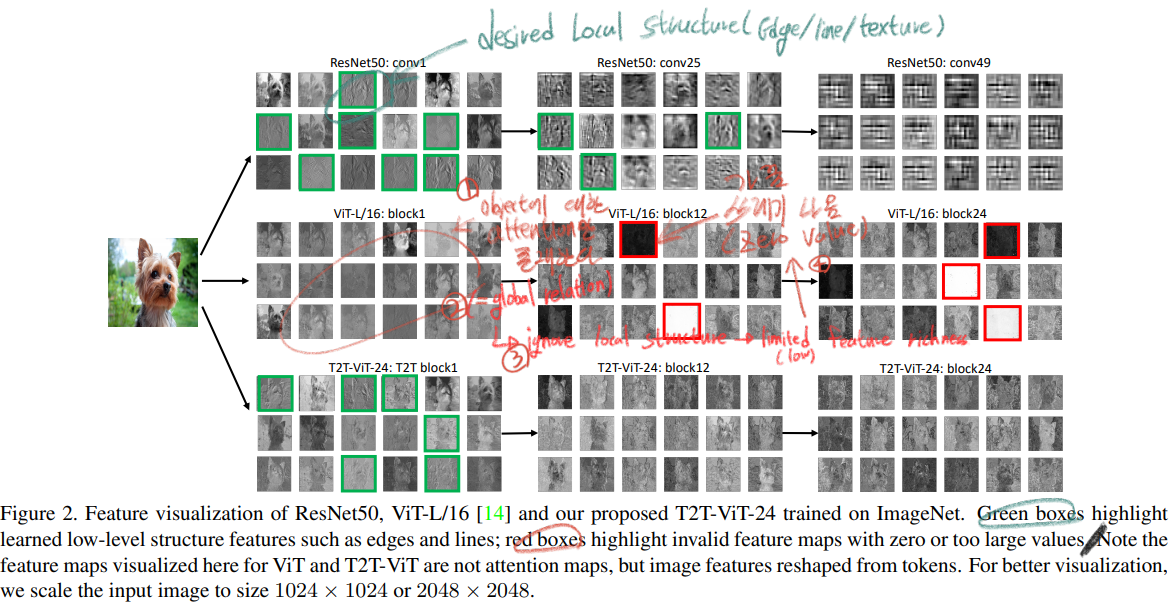
ViT 문제점 : midsize dataset으로 학습시키면, CNN 보다 성능이 낮다.
문제점 이유1 : Image patch를 그대로 tokenization해서 important local structure(edge, line, 주변 픽셀과의 관계) 등을 파악할 수 없다.
문제점 이유2 : redundant attention backbone(너무 많은 Attention layer, 여기서 backbone은 Transformer encoding 앞에 있는 layer가 아니라, 그냥 Image patch의 PE이후에 Transformer encoding 전체를 의미하는 것이다.)
2. Instruction, Relative work
위 그림은 (1) ResNet (2) ViT (3) T2T-ViT 내부를 각각 들여다 본 그림이다.
확실히 녹색 박스와 같이 ResNet과 T2T에서는 Desired Local Structure를 잘 파악하는 것을 알 수 있다.
하지만 ViT에서는 너무 Global attention에만 집중해서 Local Structure에 대해서 잘 파악하지 못한다. 심지어 빨간 박스처럼 쓰레기 같은 결과가 나오기도 한다.
our contributions
visual transformers이 진짜 CNN을 띄어넘게 만들기 위해서, (1) T2T module (2) efficient backbone 을 만들었다.
a novel progressive tokenization
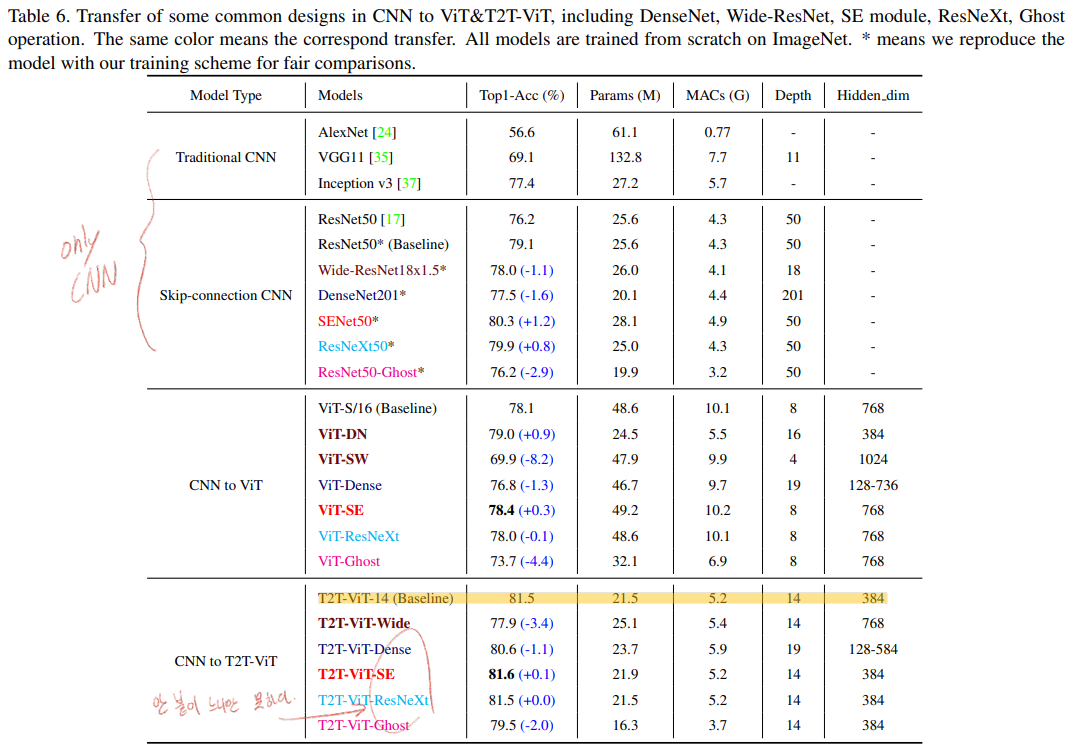
Backbone으로 Transformer encoder와 같은 구조를 차용하기도 하지만, the architecture engineering of CNNs 을 사용해서 비슷한 성능(ResNeXt)혹은 조금더 나은 성능(SENet)을 얻는다.
3. Method
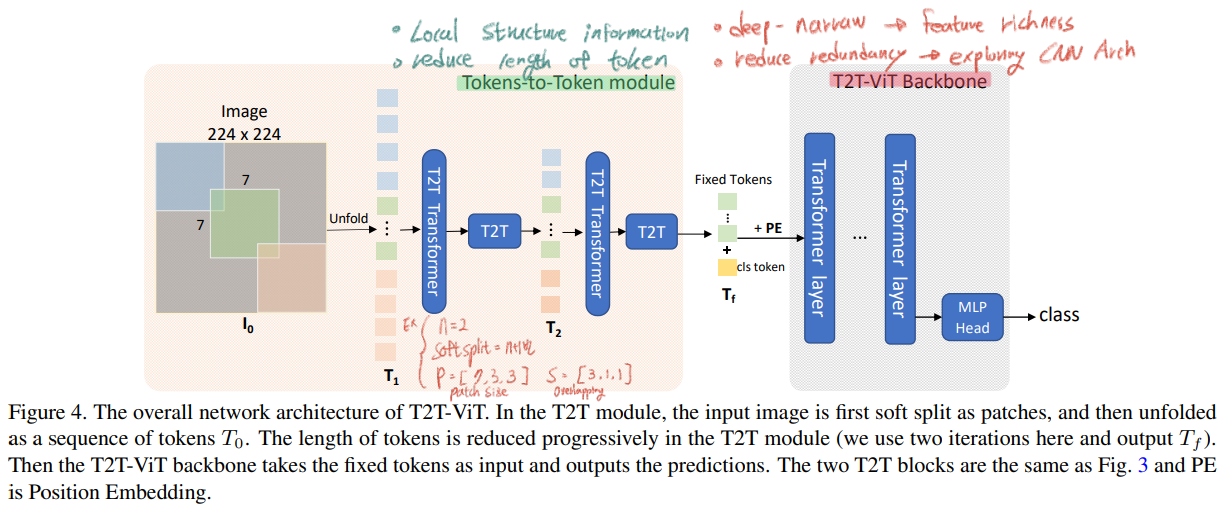
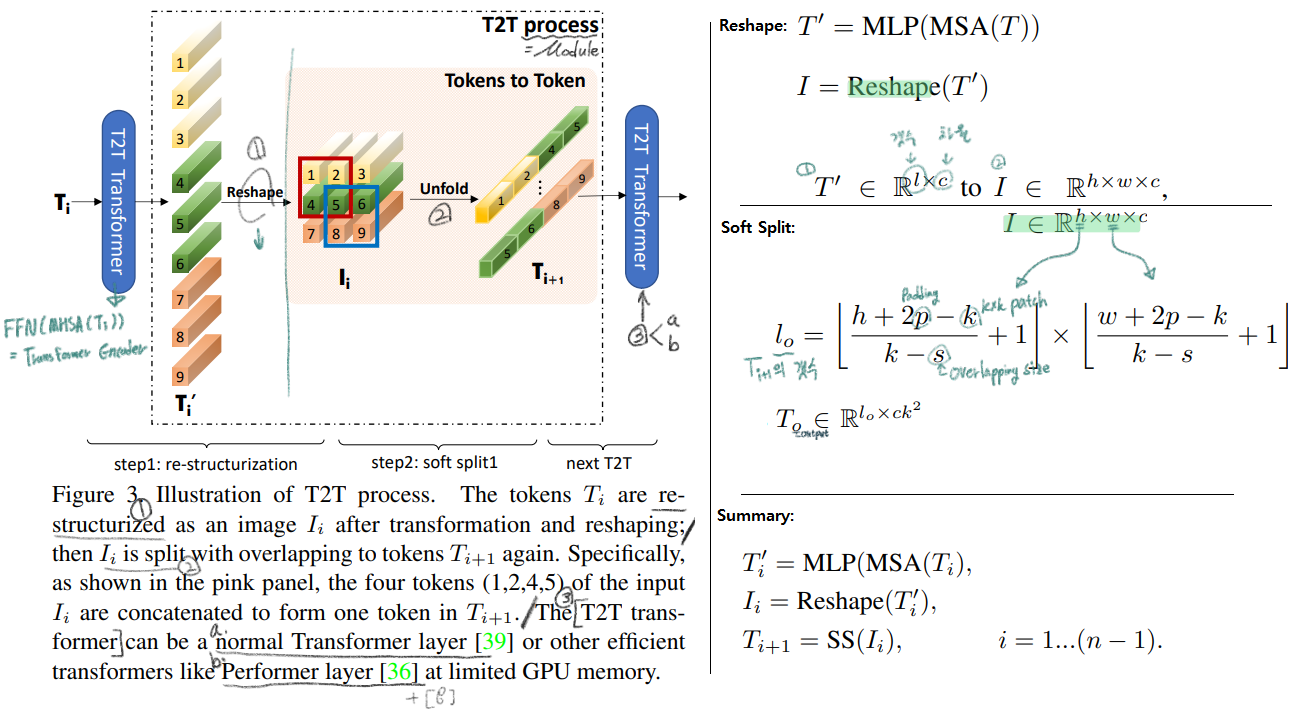
논문의 핵심 전체 Architecture는 아래의 이미지라고 할 수 있다.
아래의 그림과 같이 T2T-ViT는 2개의 구성으로 나눌 수 있다. (1) Tokens To Token Module (2) T2T-ViT Backbone 각각의 목적과 목표는 아래 필기에 정확하게 정리해 적어놓았으니, 녹색과 빨간색 필기를 꼭 참고하기 바란다.
참고로 여기서 length는 vector dimention을 의미하는게 아니라, vector의 갯수를 말한다.
T2T module(process) : 위 그림에서 T2T
Step1 : spatial 형상의 이미지처럼 토큰을 reshape한다.
Step2 : Soft split처리를 함으로써 이미지의 지역정보를 학습하고 토큰의 length(갯수)를 줄일 수 있다. 토큰을 overlapping을 해서 patch 형태로 split 하는 것이다. 이렇게 함으로써 주변 tokens들과의 더 강한 correlation을 파악 할 수 있다. (ViT처럼 patch로 처음에 자르고 그 patch들 (특히 주변 patch들간의 관계성에 대한 정보를 넣어주지 않으면 지역정보(edge, line)를 파악할 수 없다.)
전체를 정리하면, 위 그림의 오른쪽 아래 식과 같이 나타낼 수 있다.
ViT에서는 Patch의 수가 16*16 즉 256개였다. 이것또한 메모리 관점으로 굉장히 많은 숫자였다. 그래서 우리의 T2T 모둘은 patch수는 어쩔 수 없고, the channel dimension을 small (32 or 64)으로 설정함으로써 메모리 효율을 높이고자 노력했다.
T2T-ViT Backbone
reduce the redundancy / improve the feature richness
Transformer layer를 사용하기는 할 건데, 그들의 조합을 어떤 구조로 가져갈 것인가? (자세한 구조는 Appendix를 참조)
DenseNet
ResNets
(SE) Net
ResNeXt = More split heads in multi-head attention layer
GhostNe
많은 실험을 통해서 the deep-narrow architecture = transformer layer는 많이 hidden dimention은 작게 가져가는 것이 효율적이라는 결론을 얻었다.
여기서는 fixed length T_f가 이뤄진다. 그리고 concatenate a class token 마지막으로 Sinusoidal Position Embedding (PE)을 사용하는게 특징이다.
T2T-ViT Architecture
n = 2 re-structurization
n+1 = 3 soft spli
patch size P = [7, 3, 3]
overlapping is S = [3, 1, 1]
Reduces size of the input image = from 224 × 224 to 14 × 14
batch size 512 or 1024 with 8 NVIDIA
4. Results
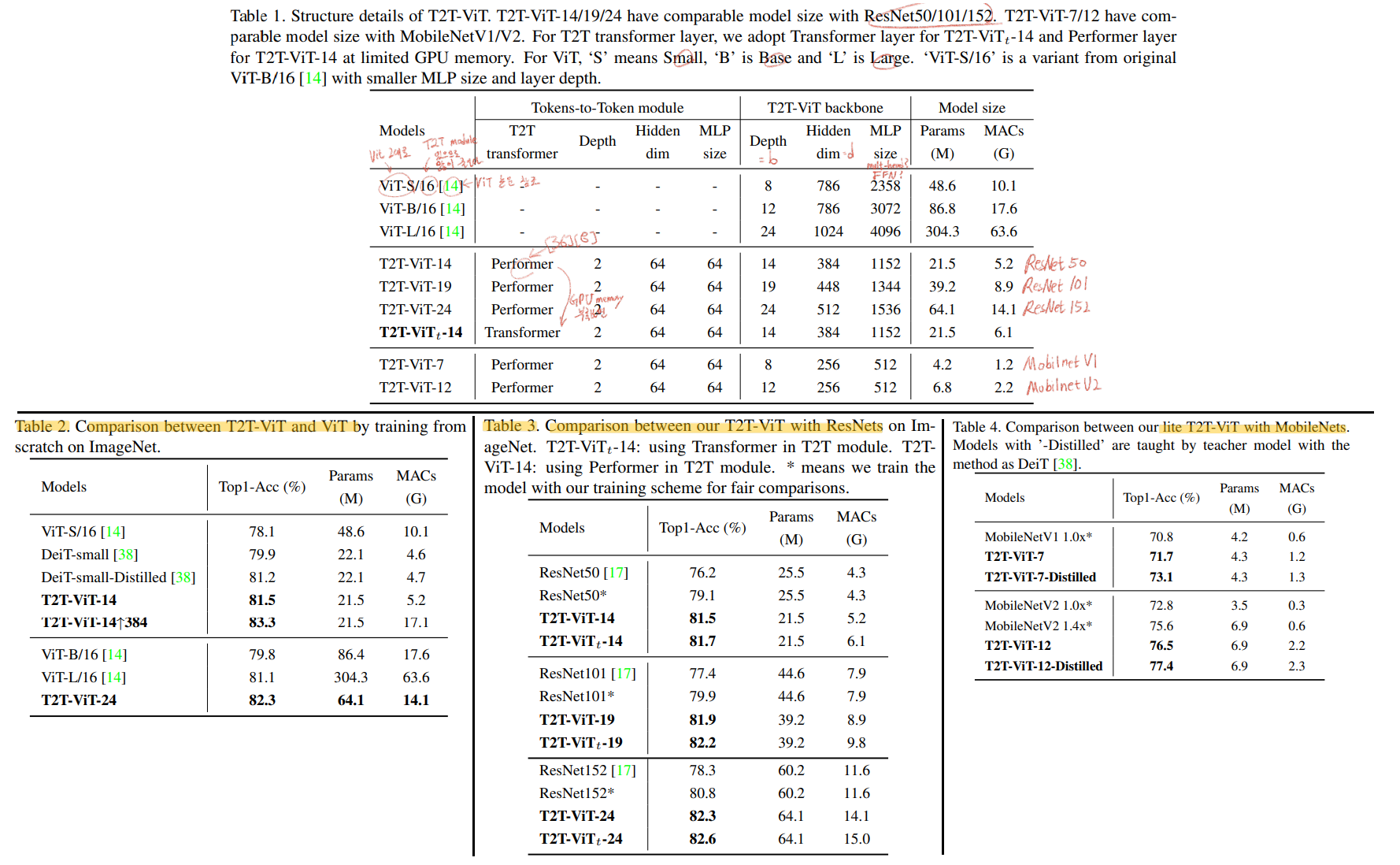
Table1: 다양한 구조의 T2T-ViT 모델들
Table2,3,4 : 기존의 모델(1. ViT 2. ResNet 3. MobileNet)들과 비교 결과
이 논문도 약간 M2Det같다. 뭔가 오지게 많이 집어넣으면 성능향상이 당연하긴하지.. 약파는 것 같다.
비교도 무슨 Faster-RCNN, Mask-RCNN 이런거 써서 비교하는게 전부이고 약간 많이 부족하고 아쉬운 논문이다.
Feature Pyramid Transformer
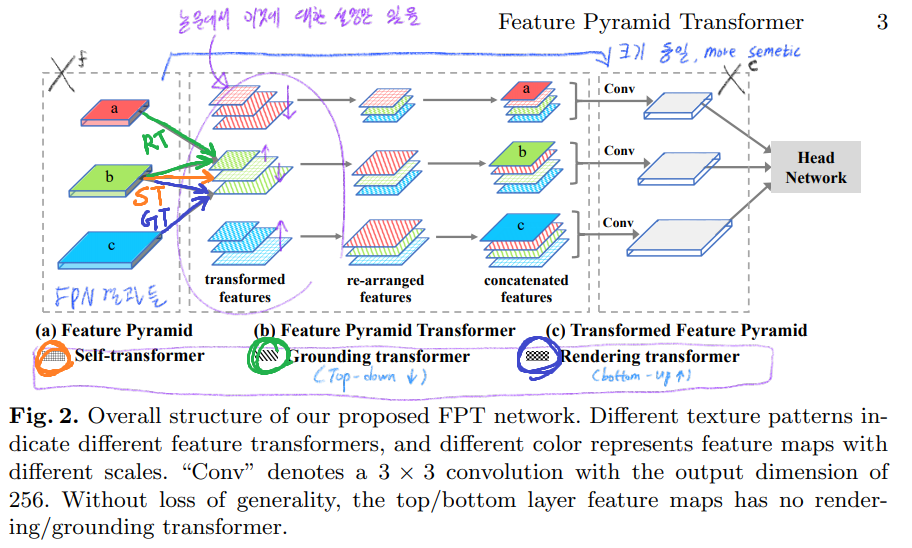
이 그림이, 이 논문의 전부. FPN의 결과에 Same size + richer contects 를 가지는 feature map 만드는 것을 목표로 한다.
보라색 동그라미 부분과 같이, (1) feature map 그대로 self-attention을 수행하는 Self-transformer (2) Up! 하는 Rendering Transformer (3) Down! 하는 Grounding transformer 를 제안했다. (개인적인 생각으로, 이 방법이 약간 어설프고? 약간 너무 파라메터와 레이어를 무작정 늘리는 행동? 같다.)
1. Conclusion, Abstract
efficient feature interaction approach
3개의 Step : Encoder(Self-Transformer), Top-down(Grounding Transformer), Bottom-up(Rendering Transformer)
FPN(feature pyramid network)에서 나온 P2~P5에 FPT(feature pyramid transformer)를 적용해서 P2~P5는 크기는 보존되는데 좀더 Sementic한 Feature map이 되게 만든는 것을 목표로 한다.(the same size but with richer contexts) 따라서 이 모듈은 easy to plug-and-play 한 모델이다. (대신 파라메터수가 엄청 많아 진다. 결과 참조)
the non-local spatial interactions (2017년에 나온 논문으로 MHSA과 비슷한 구조를 가지고 있지만 좀 다르다 예를들어서 Multi head를 안쓴다던지…)는 성능향상에는 도움이 된다. 하지만 across scale 정보를 이용하지 않는다는 문제점이 있다.
이 문제점을 해결하고자 interaction across both space and scales을 수행하는 Feature Pyramid Transformer (FPT) 모듈을 만들었다.
2. Instruction, Relative work
위의 그림이 개같으니 굳이 이해하지 못해도 상관하지 말기
Fig. 1 (d) : non-local convolution을 통해서 상호 동시 발생 패턴 (reciprocal co-occurring patterns of multiple objects)을 학습할 수 있다고 한다. 예를 들어서, 컴퓨터가 이미지에 있으면 주변에 책상이 있는게 옮바르지, 갑자기 도로가 예측되는 것을 막는다고 한다. (Self-attention 구조를 약간 멋지게 말하면 이렇게 표현할 수 있는건가? 아니면 ` non-local convolution논문에 이러한 표현을 하고 증명을 해놓은 건가? 그거까지는 모르겠지만 non-local convolution`은 Transformer 구조에 진것은 분명한 것 같다.)
Fig. 1 (e) : 이와 같이 cross scale interactions을 유도할 것이라고 한다.
Feature Pyramid Transformer (FPT) enables features to interact across space and scales. 내가 지금 부정적으로 생각해서 그렇지, 파라메터 오지게 많이 하고 깊이 오지게 많이 한다고 무조건 성능이 올라가는 것은 아니다. 그렇게 해서라도 성능이 올랐으니 일단은 긍정적으로 봐도 좋다. 하지만 FPN을 차용해서 아이디어를 짠것은 좋은데 좀더 깔끔하고 신박하고 신기하게 설계한 구조와 방법이 필요한 듯 하다.
3. Method
3.1 Non-Local Interaction Revisited
typical non-local interaction 은 다음과 수식으로 이뤄진다고 할 수 있다. (하나의 level Feature map에 대해서) 하지만, 논문에서는 이 공식을 그대로 사용하지 않는다.
(사실 self-attention과 거의 같은 구조이다. 차이점에 대해서는 BottleneckTransformer를 참조하면 도움이 될 수 있다.)
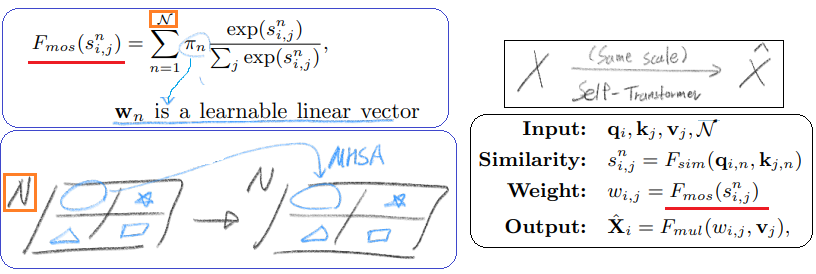
3.2 Self-Transformer
위의 typical non-local interaction공식에서 하나만 바꿔서, 새로운 이름을 명명했다.
위에서 weight를 계산하는것이 그냥 softmax를 사용했다. 이것을 the Mixture of Softmaxes (MoS) [34] 로 바꾼다.
위의 N에 대한 설명은 자세히 나와있지 않다. the same number of divided parts N 이라고 나와있는게 전부이다. 따라서 위에 내가 생각한게 맞는지 잘 모르겠다. [34] 논문을 참고하면 알 수도 있다.
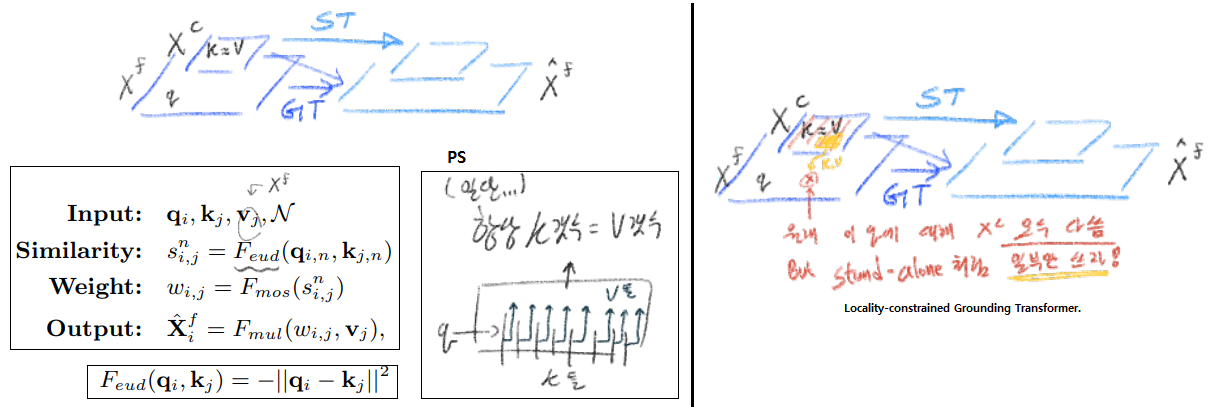
3.3 Grounding Transformer
a top-down non-local interactio을 수행하는 방법이 위와 같다.
어렵게 생각할거 없고 위에 그림과 같이 q, k, v를 설정하여 self-attention을 적용한 모듈이다.
예를 들어서 변수 = 변수.shape로 표현해 정리한다면, q = H * W * d, K = h * w * d 차원을 가진다고 하면, q_i = 1 * d, k_j = 1 * d 가 된다고 할 수 있다. d를 맞추는 것은 channel 크기를 맞춰주면 되는 것이기 때문에 그리 어려운 문제는 아니다.
Locality-constrained Grounding Transformer : 그냥 Grounding Transformer를 적용하는 방법도 있고, Locality 적용하는 방법이 지들이 제안했다고 한다. stand-alone에 있는 내용아닌가…
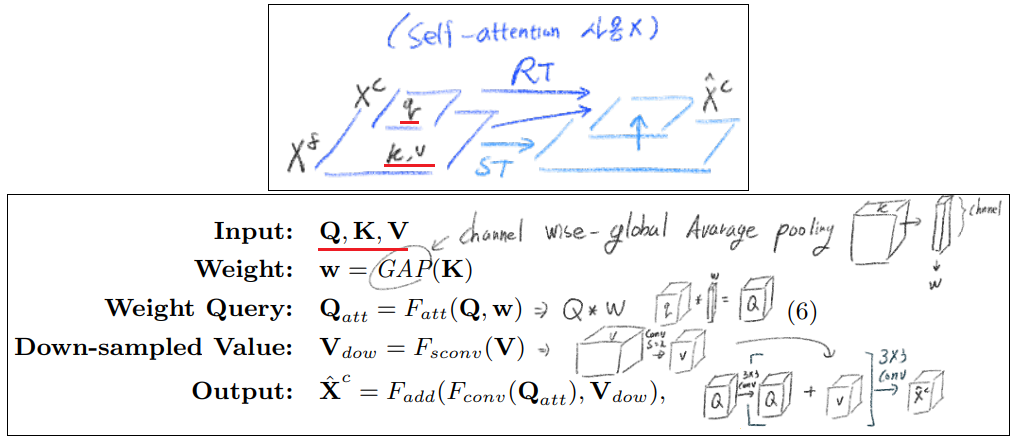
3.4 Rendering Transformer
a bottom-up fashion. self attentino을 적용한 방법이 아니다. 과정은 아래와 같다. (논문의 내용을 정리해놓은 것이고 헷갈리면 논문 다시 참조)
3.5 Overall Architecture
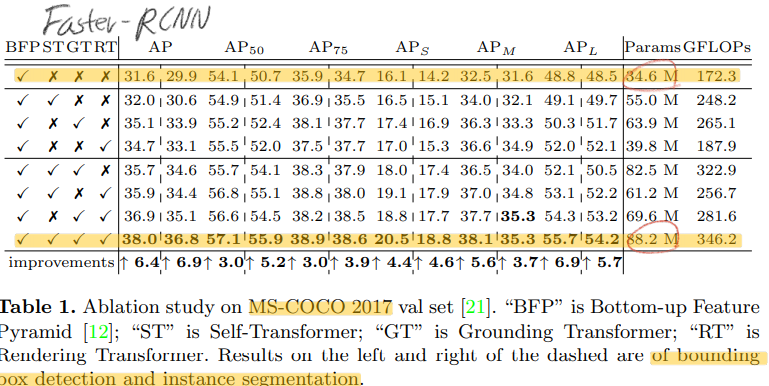
FPT for object detection and instance segmentation
BFP = FPN 지들맘대로 이름 바꿔서 사용함.
divided parts of N은 ST에서는 2 그리고 GT에서는 4로 설정했다.
FPT를 통해서 나오는 Pyramid Feature map들을 head networks에 연결되어서 예측에 사용된다.
head networks는 Faster R-CNN 그리고 Mask RCNN에서 사용되는 head를 사용한다.
(분명 retinaNet과 같은 head도 해봣을텐데, 안 넣은거 보니 성능이 그리 안 좋았나? 라는 생각이 든다.)
FPT for semantic segmentation.
dilated ResNet-101 [4]
Unscathed Feature Pyramid (UFP) - a pyramidal global convolutional network [29] with the internal kernel size of 1, 7, 15 and 31
self-attention(MHSA) 모듈을 사용하는 backbone을 만들었다. 그것들을 사용해서 몇가지 task에서 성능향상을 가져왔다. 미래에 추천하는 연구로는 (1) self-attention for self-supervised (2) combining botNet backbone with DETR (3) smalll object detection 와 같은 연구들이 있다.
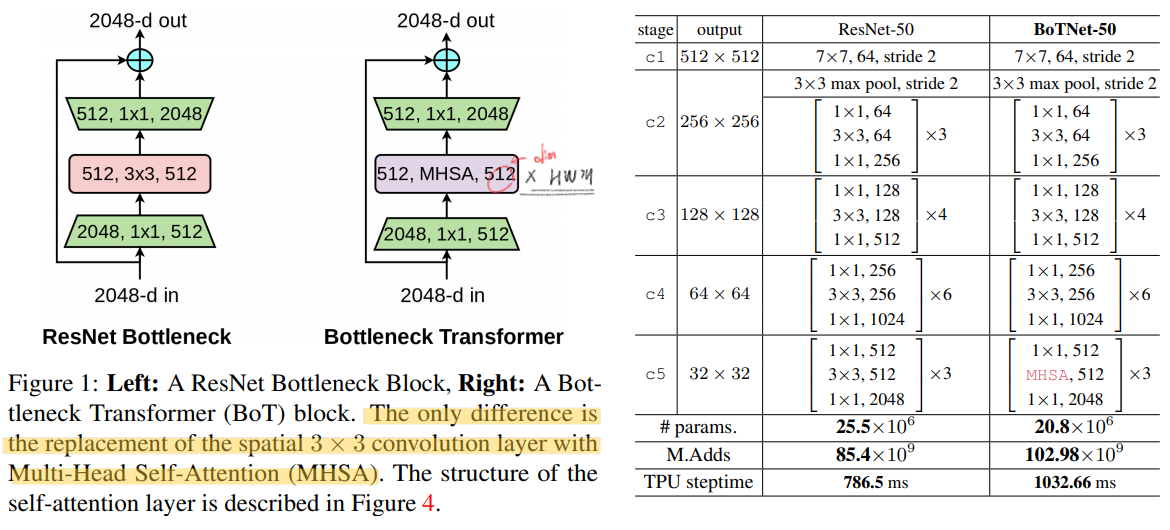
ResNet 에서 일반적은 Conv2d(= spatial convolution) 연산을 global self-attention으로 바꾼것이 전부이다. 이렇게 만든 backbone을 사용함으로써 성능 향상, (상대적인?) 파라미터 감소, 연산 시간 증가 등의 효과를 볼 수 있었다.
Result : Mask R-CNN 44.4 Mask AP on COCO / BoTNet for image classification 84.7% top-1 accuracy on ImageNet
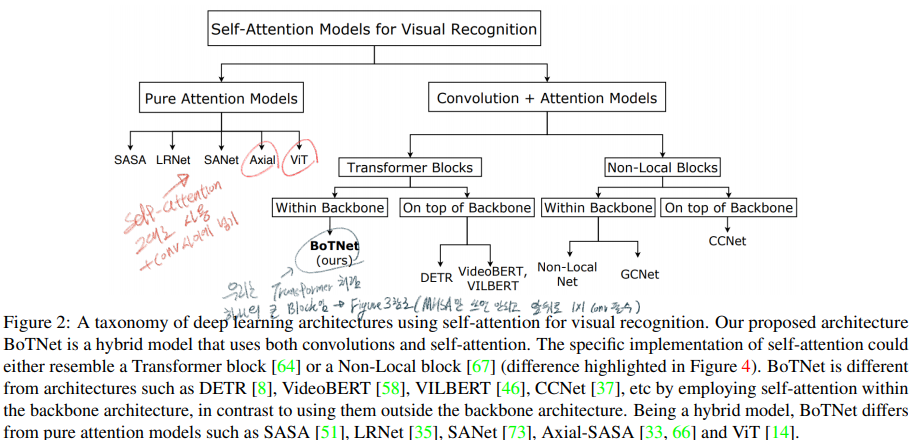
2. Instruction, Relative work
Related Work에서는 (1) Transformer vs BoTNet; (2) DETR vs BoTNet; (3) Non-Local vs BoTNet 에 대한 비교를 한다. 이 비교에 대한 정리는 아래에 블로그 정리 부분에 추가해 놓았으니 거기서 참고할 것
3. Method
BoTNet은 아주 심플하게 만들여졌다. 맨위의 표처럼 resnet의 c5의 3x3 conv를 global (all2all) self-attention over a 2D featuremap을 수행하는 MHSA으로 바꾼것이 전부이다.
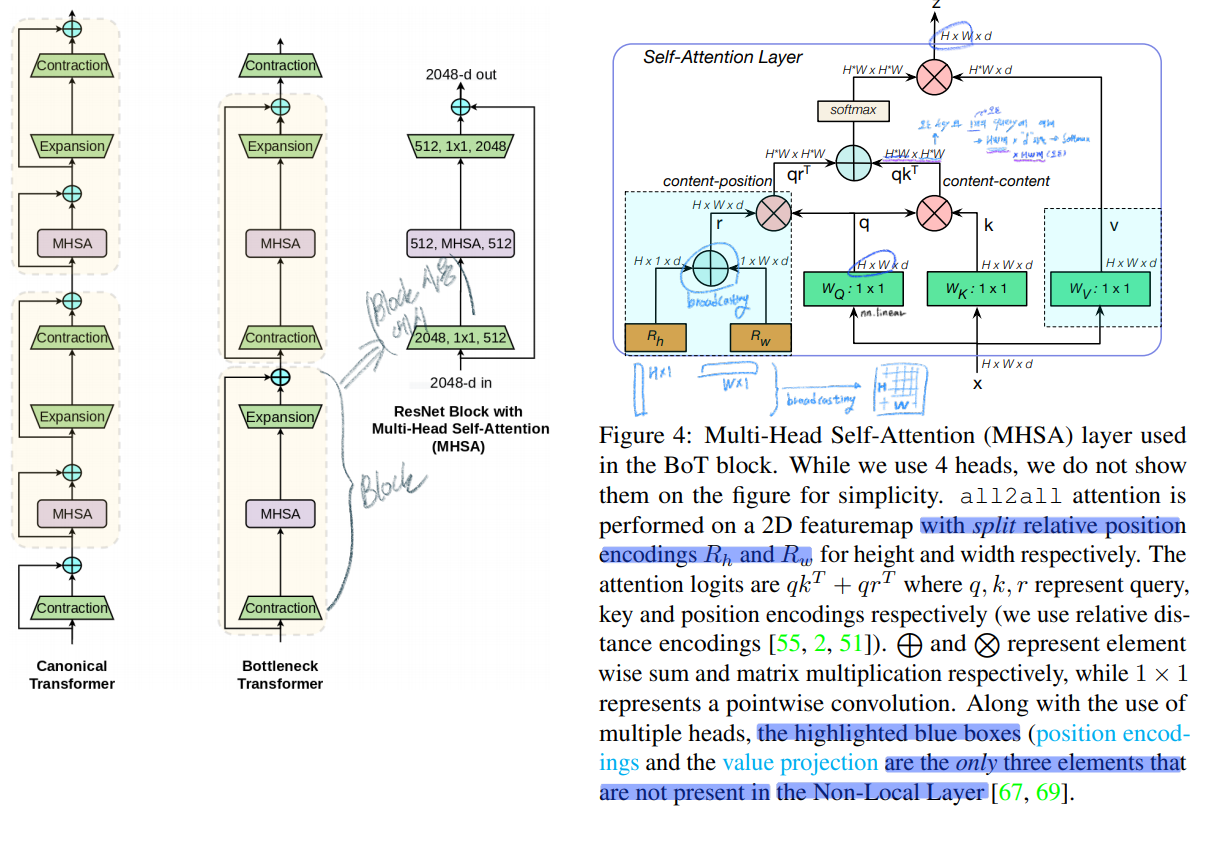
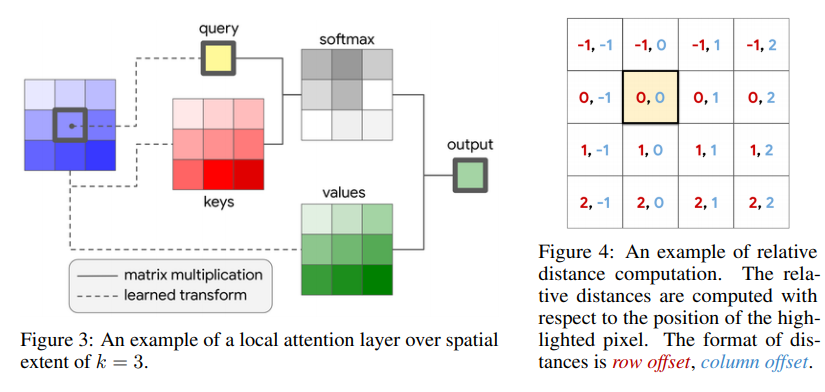
In BoTNet, the 2D relative position self-attention [51, 2] 을 사용했다. (absolute, relative position embeding에 대한 차이를 아직 모르겠다. 이 차이를 알기 위해서 코드를 확인해봤짐나)
4. Experiments & Results
여기에서 나오는 4.1 ~ 4.8 까지, 지금까지 실험해본 결과(= the benefits of BoTNet for instance segmentation and object detection )를 요약해놓는 식으로 논문을 정리해보았다. 하나하나씩 간력하게 살펴보고 넘어가자
BoTNet improves over ResNet on COCO Instance Segmentation with Mask R-CNN
multi-scale jitter 란, 이미지를 자유자제로 scaling하는 것이다. 예를들어, Input Image : 1024x1024 / multi-scale jitter : [0.8, 125] 조건에서는 이미지를 820~1280 크기로 이미지로 scaling 한다.
Scale Jitter helps BoTNet more than ResNet
multi-scale jitter의 범위를 심하게 하면 할 수록 더 높은 성능향상을 가져다 주었다.
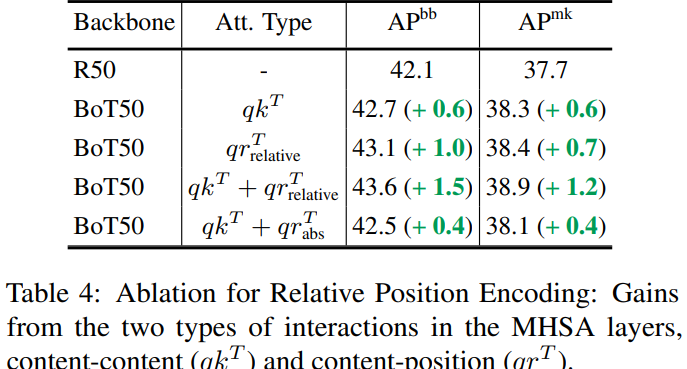
Relative Position Encodings Boost Performance
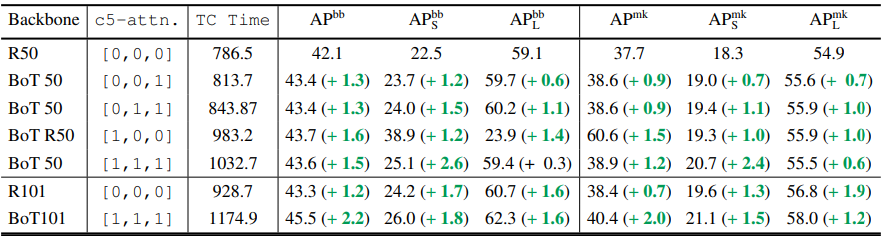
Why replace all three c5 spatial convolutions?
BoTNet improves backbones in ResNet Family
BoTNet scales well with larger images (1024보다 1280 크기에 이미지에 multi-scale-jitter 심하게 주고 학습시키면 더 좋은 성능이 나온다.)
Non-Local Neural Networks 보다 훨씬 좋은 성능이 나온다.
이것을 보면, 버클리와 구글에서 이미지 처리에 가장 좋은 MHSA 구조를 사용하는 방법에 대해서 많은 실험을 해서 나온 결과가 BoTNet이라는 것을 짐작할 수 있다. MHSA를 그냥 사용하는 게 아니라, BottleNet구조로 바꿔고, BottleNet Transformer라는 새로운 Block을 만들고 이름까지 명명해버렸다. (이미지 처리를 위해서 가장 완벽하게 Transformer를 사용하는 구조를 많은 실험을 통해 최종적으로 찾아낸 BottleNet Transformer 이라고 말할 수도 있을 것 같다.)
visibly good gains on small objects (상대적 작은객체 탐지 더 좋음)
NL(Non-Local)Net과 BoTNet의 차이점
NL(Non-Local)Net
BoTNet
channel reduction ration
2
4
Role
네트워크에 추가로 삽입
convolutional block을 대체
또 다른 차이점 (1) multiple head
(2) value projection
(3) posutuib encodings
Method
ResNet의 가장 마지막 c5 stage에서 마지막 3개의 saptial convolution = conv2d을 모두 MHSA로 대체한다. 단, c5 stage는 stride 2가 적용된 conv연산이 있음으로, 똑같이 MHSA를 하기 전에 2x2 average pooling을 수행한다.
2D relative position encoding 를 사용했다. figure4에서 확인 할 수 있다.
논문에서는 ResNet구조를 바꾸는 것만 보여주지 않고, BoTNet의 영향력을 보여주고자 노력했다. Detection 또는 Segmentation에서도 좋은 성능을 확인할 수 있었다.
Experiments
여러 논문에서 Vision Transformer에서 hard augmentation이 성능 향상에 도움을 준다고 이야기 하고 있다.
여기서도 강한 multi-scale jitter기법을 적용해서 (적은 epoch으로) 더 빠른 성능 수렴 을 얻었다고 한다.
content-content interaction = self attention과 content-position interaction = position encoding이 성능에 영향을 미치는 정도를 비교하였다. position encoding이 영향을 미치는 정도가 더 컸으며 둘을 함께 사용했을 때가 성능이 가장 좋았다.
absolute position encoding의 relative encoding에 비해 성능이 좋지 않았다.
Code 참조
absolute positional embeding
classAbsPosEmb(nn.Module):def__init__(self,fmap_size,dim_head):super().__init__()height,width=pair(fmap_size)scale=dim_head**-0.5self.height=nn.Parameter(torch.randn(height,dim_head)*scale)self.width=nn.Parameter(torch.randn(width,dim_head)*scale)defforward(self,q):"""
from einops import rearrange
에 의해서 만들어진 rearragne 함수 어려워 보이지만 어렵지 않다.
처음 원본의 shape -> 내가 바꾸고 싶은 shape
로 쉽게 shape를 변형할 수 있다.
"""emb=rearrange(self.height,'h d -> h () d')+rearrange(self.width,'w d -> () w d')# 1*h +(element wise sume) 1*w = h*w ?! 브로드 케스팅에 의해서 연산된 결과이다
emb=rearrange(emb,' h w d -> (h w) d')# from torch import nn, einsum = element wise sum (multiple은 그냥 * 곱 연산)
logits=einsum('b h i d, j d -> b h i j',q,emb)returnlogits
relative positional embeding (stand-alone attention 논문에서 나오는 것이라 한다. 아직은 아래 코드가 무슨 행동을 하는지 이해 안 함 = 코드도 복잡하고 논문도 복잡하니 필요하면 그냥 가져와서 사용해야겠다. Axial deeplab에서 추천하는 논문들 (stand-alone, Position-Sensitivity 논문이 이에 관한 좋은 코드 정보로 제공해줄 것 같다.) ㄷ
classRelPosEmb(nn.Module):def__init__(self,fmap_size,dim_head):super().__init__()height,width=pair(fmap_size)scale=dim_head**-0.5self.fmap_size=fmap_sizeself.rel_height=nn.Parameter(torch.randn(height*2-1,dim_head)*scale)self.rel_width=nn.Parameter(torch.randn(width*2-1,dim_head)*scale)defforward(self,q):h,w=self.fmap_sizeq=rearrange(q,'b h (x y) d -> b h x y d',x=h,y=w)rel_logits_w=relative_logits_1d(q,self.rel_width)rel_logits_w=rearrange(rel_logits_w,'b h x i y j-> b h (x y) (i j)')q=rearrange(q,'b h x y d -> b h y x d')rel_logits_h=relative_logits_1d(q,self.rel_height)rel_logits_h=rearrange(rel_logits_h,'b h x i y j -> b h (y x) (j i)')returnrel_logits_w+rel_logits_h
확실하게는 이해 안되지만, absolute positional embeding는 각 query(1xd)에 대해서 그냥 절대적인 하나의 1xd positional embeding을 element wise sum 해준것이다. relative positional embeding은 각 query(1xd)에 대해서, 각 query(1xd)가 전체 key에 대해서 상대적으로, 어디에 위치하는지에 대한 정보를 가지고(=input사이에 pair-wise relationship을 고려) positional embeding 값을 만드는 것 인것 같다. (아래 그림은 stand-alone attention 논문 참조)
sequence-to-sequence prediction framework를 사용해서 Semantic Segmentation을 수행해 보았다.
기존의 FCN들은
Encoder, Decoder 구조를 차용한다. CNN을 통과하면서 resolution을 줄이고 abstract/semantic visual concept을 추출한다.
receptive field를 넓히기 위해서 dilated convolutions and attention modules 를 사용했다.
하지만 우리는 global context 를 학습하기 위해 (= receptive field를 넓히기 위해서) every stage of feature learning에서 Transformer 를 사용했다. pure transformer (without convolution and resolution reduction)
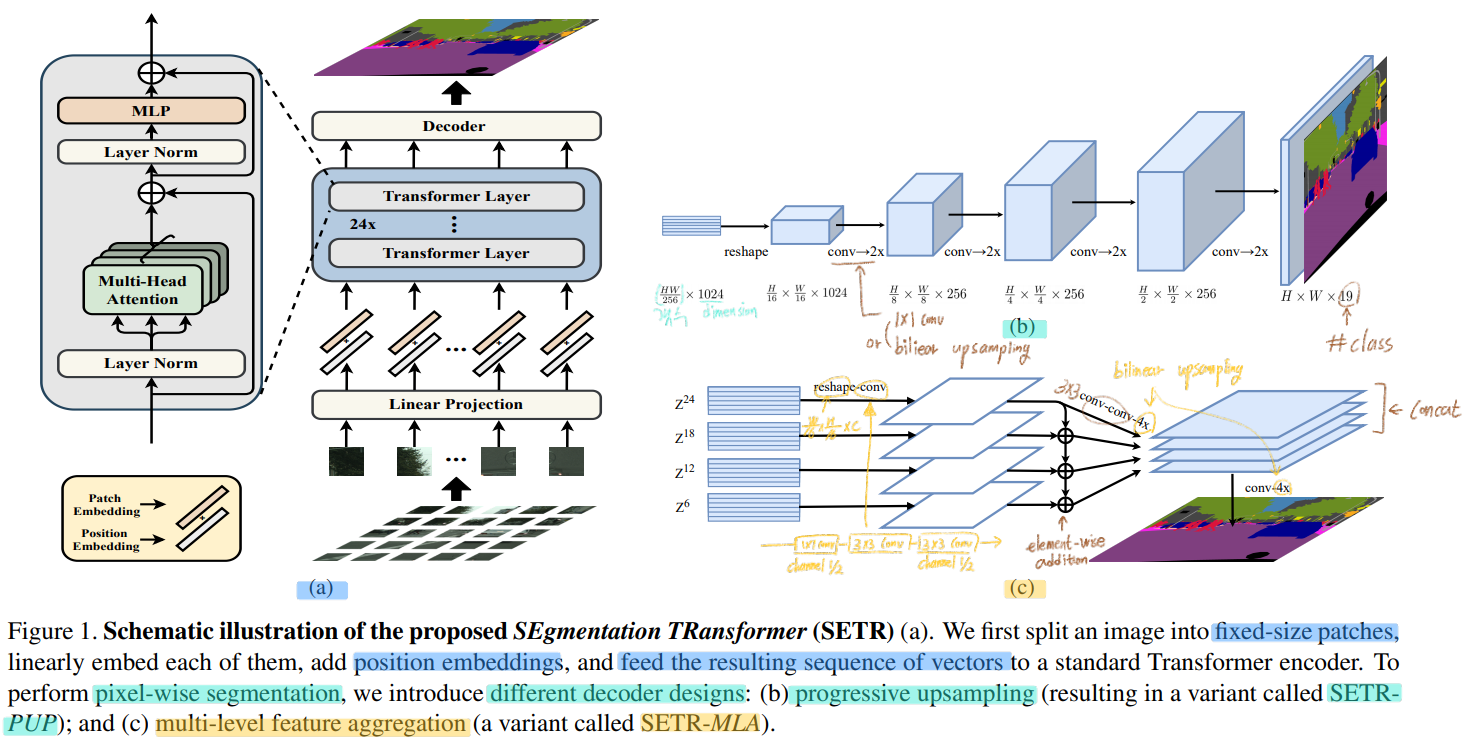
(Panoptic deeplab 처럼) 엄청나게 복잡한 구조를 사용하지 않고, decoder designs을 사용해서 강력한 segmentation models = SEgmentation TRansformer (SETR) 을 만들었다.
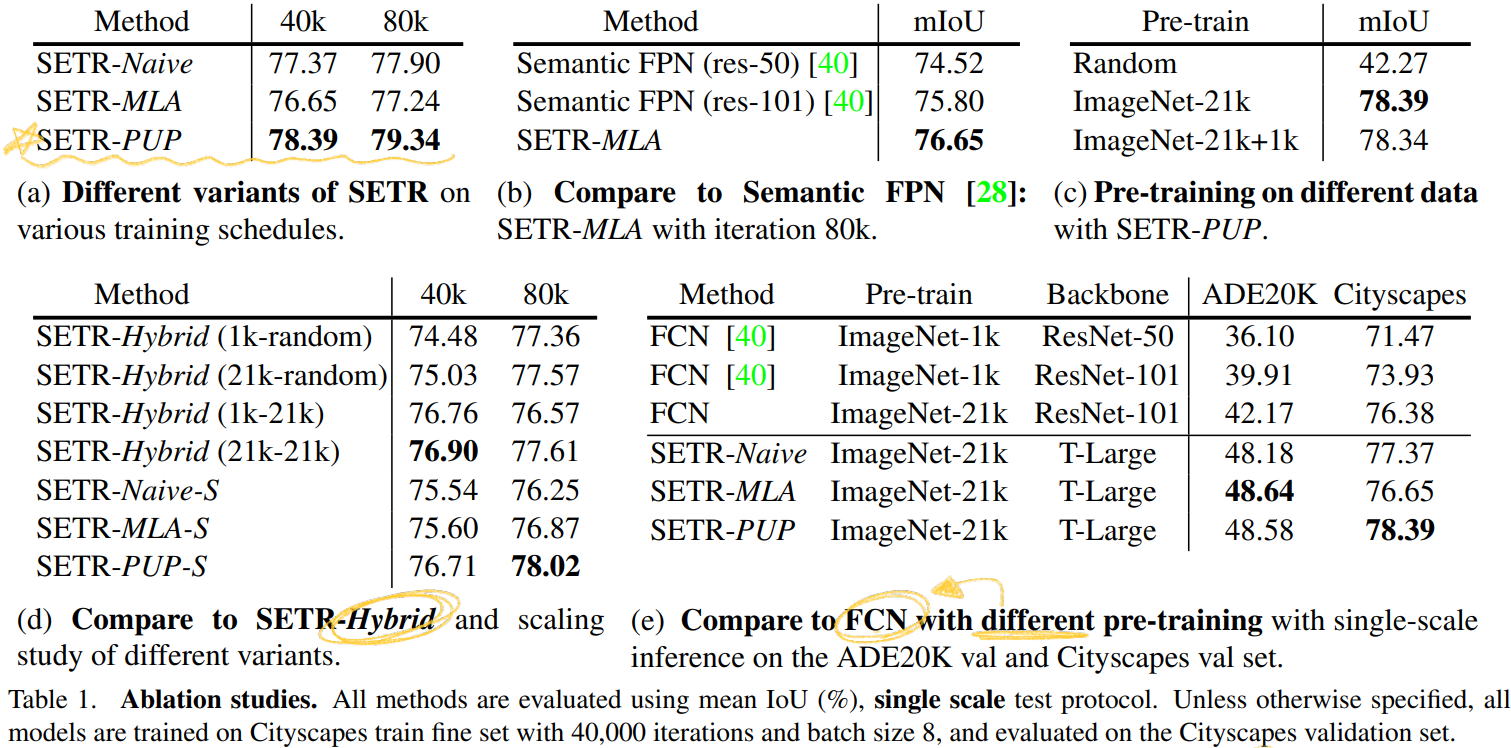
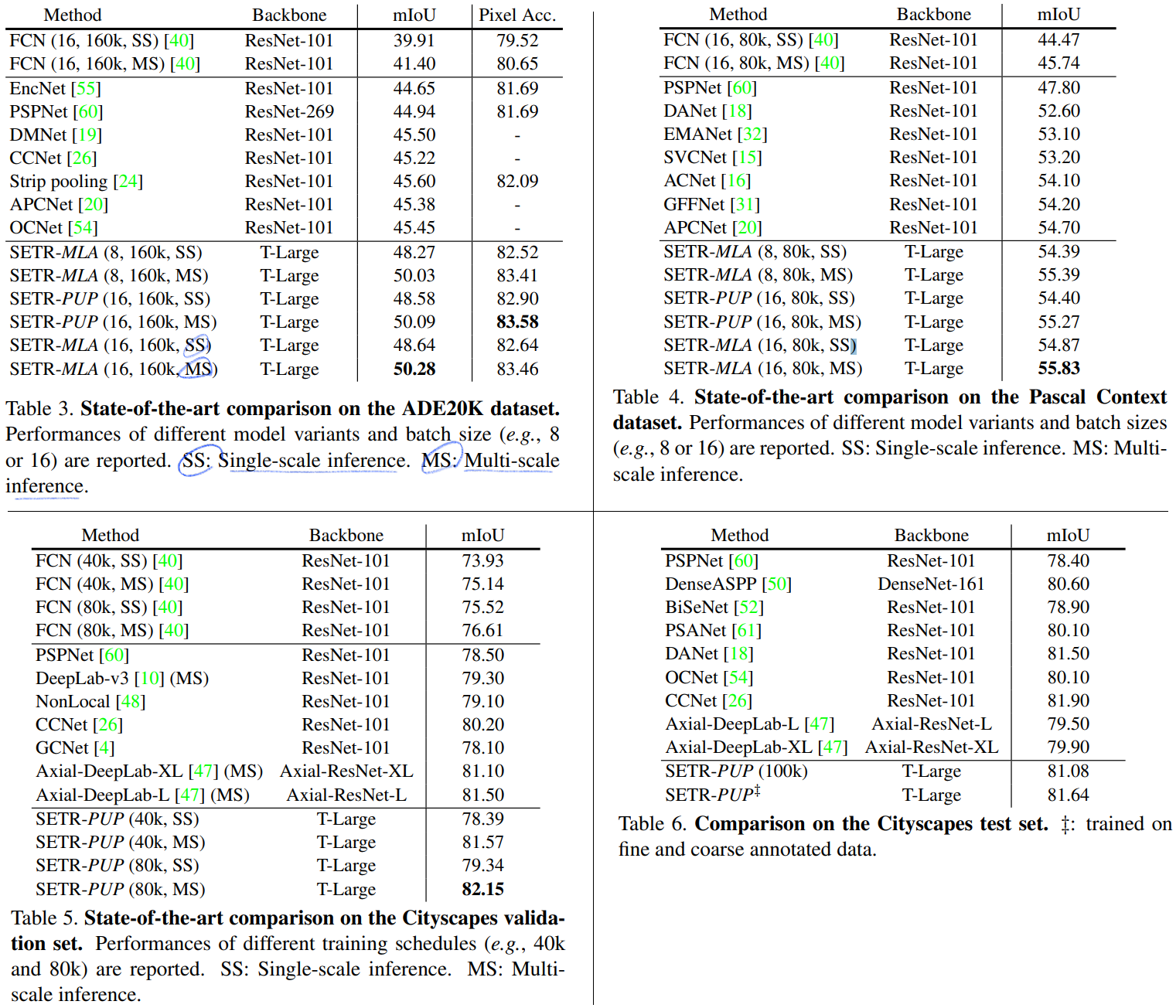
Dataset에 따른 결과 : ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU), ADE20K test server(1 st, 44.42% mIoU)
3. Method
위의 이미지는 아래의 것에 대한 이미지 이다.
(맨왼쪽) Transformer layer
Image (transformer) Encoder
(오른쪽 위) 두번째 Decoder : SETR-PUP
(오른쪽 아래) 세번째 Decoder : SETR-MLA
첫번쨰 Decoder인 Naive에 대한 이미지는 없다.
3.1. FCN-based semantic segmentation
About receptive field
typically 3×3 conv를 사용하는 layer를 deep하게 쌓으면서 linearly하게 receptive field를 증가시킨다.
결과적으로, 높은 layer에서 더 큰 receptive fields를 가지게 되서 layer depth dependency가 생기게 된다.
하지만 layer를 증가시킴으로써 얻는 benefits에는 한계가 있고, 특히 특정 layer이상으로 가면 그 benefits가 빠르게 감소하는 형상을 볼 수 있다.
따라서, 제한적인 receptive fields (for context modeling)가 FCN의 본질적인 한계라고 할 수 있다.
Combination of FCN with attention mechanism
하지만 이런 attention mechanism는 quadratic complexity 때문에 higher layers with smaller input sizes 를 가져야한다는 한계점이 존재한다.
이로 인해, 전체 모델은 lower-level feature만이 가지고 있는 정보들을 learning하지 못하게 된다.
이러한 한계점을 극복하게 위해서, 우리의 모델은 pure self-attention based encoder를 전적으로 사용하였다.
3.2. Segmentation transformers (SETR)
Image to sequence
image sequentialization : flatten the image pixel -> 총 1D vector with size of 3HW 가 만들어진다.
하지만 a typical image가 480(H) × 480(W) × 3 = 691,200 차원의 1차원 백터이다. 이것은 너무 high-dimensional vector이므로 handle하기가 쉽지 않다. 따라서 transformer layer에 들어가기 전에, tokenizing (to every single pixel) 할 필요가 있다.
FCN에서는 H×W×3 이미지를 FCN encoder에 통과시켜서, H/16 × W/16 ×C 의 feature map을 뽑아 낸다. 이와 같은 관점으로 우리도 transformer input으로는 H/16 × W/16 (백터 갯수) x C(백터 차원) 으로 사용하기로 했다.
우리는 FCN의 encoder를 사용하는게 아니라 fully connected layer (linear projection function)을 사용해서 tokenizing을 한다.
이미지를 가로 16등분, 세로 16등분을 해서 총 256개의 이미지 patchs를 얻어낸다. 그리고 이것을 flatten하면, HW/256 (백터 갯수) x C*(백터 차원) 를 얻을 수 있고, 이것을 linear projection function를 사용해서 HW/256 (=L: 백터 갯수) x C(백터 차원 < C*) 의 patch embeddings 결과를 뽑아 낸다.
positional embeding : specific embedding p_i를 학습한다. i는 1~L개가 존재하고 차원은 C이다. 따라서 Transformer layer에 들어가기 전 final sequence input E = {e1 + p1, e2 + p2, · · · , eL + pL} 가 된다. 여기서 e는 patch embeding 결과 그리고 p는 positional emdeing 값이다.
Transformer
a pure transformer based encoder
여기서 말하는 transformer layer는 위 이미지 가장 왼쪽의 Block 하나를 의미한다. 이것을 24개 쓴다.
즉 Transformer layer를 통과하고 나온 output 하나하나가 Z_m 이다.
3.3. Decoder designs
three different decoder를 사용했다. 1. Naive upsampling (Naive) 2. Progressive UPsampling (PUP) 3. Multi-Level feature Aggregation (MLA)
이 decoder의 목표는 pixel-level segmentation을 수행하는 것이다. Decoder에 들어가기 전에, HW/256(갯수) × C(차원) 의 feature를 H/16 × W/16 ×C로 reshape하는 과정은 필수적이다.
` Naive upsampling (Naive)`
simple 2-layer network (1 × 1 conv + sync batch norm (w/ ReLU) + 1 × 1 conv )를 사용해서 #class의 수를 가지는 channel로 만든다.
그리고 간단하게 bilinearly upsample을 사용하여 가로세로 16배를 하여 full image resolution을 만들어 낸다.
그리고 pixel-wise cross-entropy loss 를 사용해서 pixel-level classification을 수행한다.
Progressive UPsampling (PUP)
쵀대한 adversarial effect (어떤 작업을 해서 생기는 역효과) 를 방지하기 위해서, 한방에 16배를 하지 않는다.
2배 upsampling 하는 작업을 4번을 수행한다.
이 작업에 대한 그림은 Figure 1(b)에 있고, progressive(순차적인, 진보적인) upsampling 으로써 SETR-PUP 이라고 명명했다.
Multi-Level feature Aggregation (MLA)
feature pyramid network와 비슷한 정신으로 적용하였다.
물론 pyramid shape resolution을 가지는 것이 아니라, FPN와는 다르게 every SETR’s encoder transformer layer는 같은 resolution을 공유한다.
Figure 1(c) 와 같이, {Z_m} (m ∈ { L_e/M , 2*L_e/M , · · · , M*L_e/M }) 를 사용한다. 이미지에 나와있는 것과 같이, 다음의 과정을 수행한다. (1) reshape (2) ` top-down aggregation via element-wise addition (3) channel-wise concatenation`
4. Experiments
Dataset : Cityscapes, ADE20K, PASCAL Context
Implementation details
public code-base mmsegmentation [40],
data augmentation : random resize with ratio between 0.5 and 2, random cropping, random horizontal flipping
training schedule : iteration to 160,000 and 80,000, batch size 8 and 16
polynomial learning rate decay schedule [60, 이건뭔지 모르겠으니 필요하면 논문 참조], SGD as the optimizer
Momentum and weight decay are set to 0.9 and 0
learning rate 0.001 on ADE20K, and 0.01 on Cityscapes
Auxiliary loss
auxiliary losses at different Transformer layers
SETRNaive (Z_10, Z_15, Z_20)
SETR-PUP (Z_10, Z_15, Z_20, Z_24)
SETR-MLA (Z_6 , Z_12, Z_18, Z_24)
이렇게 각 layer에서 나오는output을 새로 만든 decoder에 넣고 나오는 결과와 GT를 비교해서 Auxiliary loss의 backpropagation를 수행한다.
당연히 이후의 각 dataset 당 사용하는 Evaluation metric을 사용해서 main loss heads에 대한 학습도 수행한다.
Baselines for fair comparison
dilated FCN [37] and Semantic FPN [28]
Multi-scale test
the default settings of mmsegmentation [40] 를 사용했다.
일단, uniform size 의 input Image를 사용한다.
scaling factor (0.5, 0.75, 1.0, 1.25, 1.5, 1.75)를 이용하여, Multi-scale scaling and random horizontal flip 을 수행한다.
그리고 test를 위해서 Sliding window를 사용했다고 하는데, 이게 뭔소리인지 모르겠다. (?)
SETR variants
encoder “T-Small” and “T-Large” with 12 and 24 layers respectively.
SETR-Hybrid 는 ResNet-50 based FCN encoder 를 사용해서 뽑은 Feature map을 Transformer input으로 사용하는 모델이다. 이후에 언급하는 SETR-Hybrid는 ResNet50 and SETR-Naive-S 를 의미하는 것이다.
Pre-training
the pre-trained weights provided by [17, ViT]
Evaluation metric
cityscape : mIoU 사용
ADE20K : additionally pixel-wise accuracy 까지 사용한 loss
position-sensitive + axial attention, without cost이 Classification과 Segmentation에서 얼마나 효율적인지를 보여주었다.
Convolution은 global long range context를 놓치는 대신에 locality attention을 효율적으로 처리해왔다. 그래서 최근 work들은, local attention을 제한하고, fully attention, global relativity 을 추가하는 self-attention layer 사용해왔다.
우리는 fully, stand-alone + axial attention은 2D self-attention을 1D self-attention x 2개로 분해하여 만들어 진 self-attention 모듈이다. 이로써 large & global receptive field를 획득하고, complexity를 낮추고, 높은 성능을 획득할 수 있었다.
introduction, Related Work는 일단 패스
3. Method
Key Order :
stand-alone Axial-ResNet
position-sensitive self-attention
axial-attention
Axial-DeepLab
3.1 Self-attention mechanism
여기서 N은 모든 이미지 픽셀(HxW)
장점 : non-local context 를 보는것이 아니라, related context in the whole feature map 을 바라본다. conv가 local relations만을 capture하는 것과는 반대이다.
단점
(단점 1) extremely expensive to compute O(h^2*w^2 = hw(query) x hw(key))
(단점 2) (position embeding이 충분하지 않다) positional information를 사용하지 못한다. vision task에서 spatial structure(이게 이미지의 어느 위치 인지)를 capture하고 positional imformation 을 사용하는 것이 매우 중요하다.
3.2 stand-alone(독립형) self attention
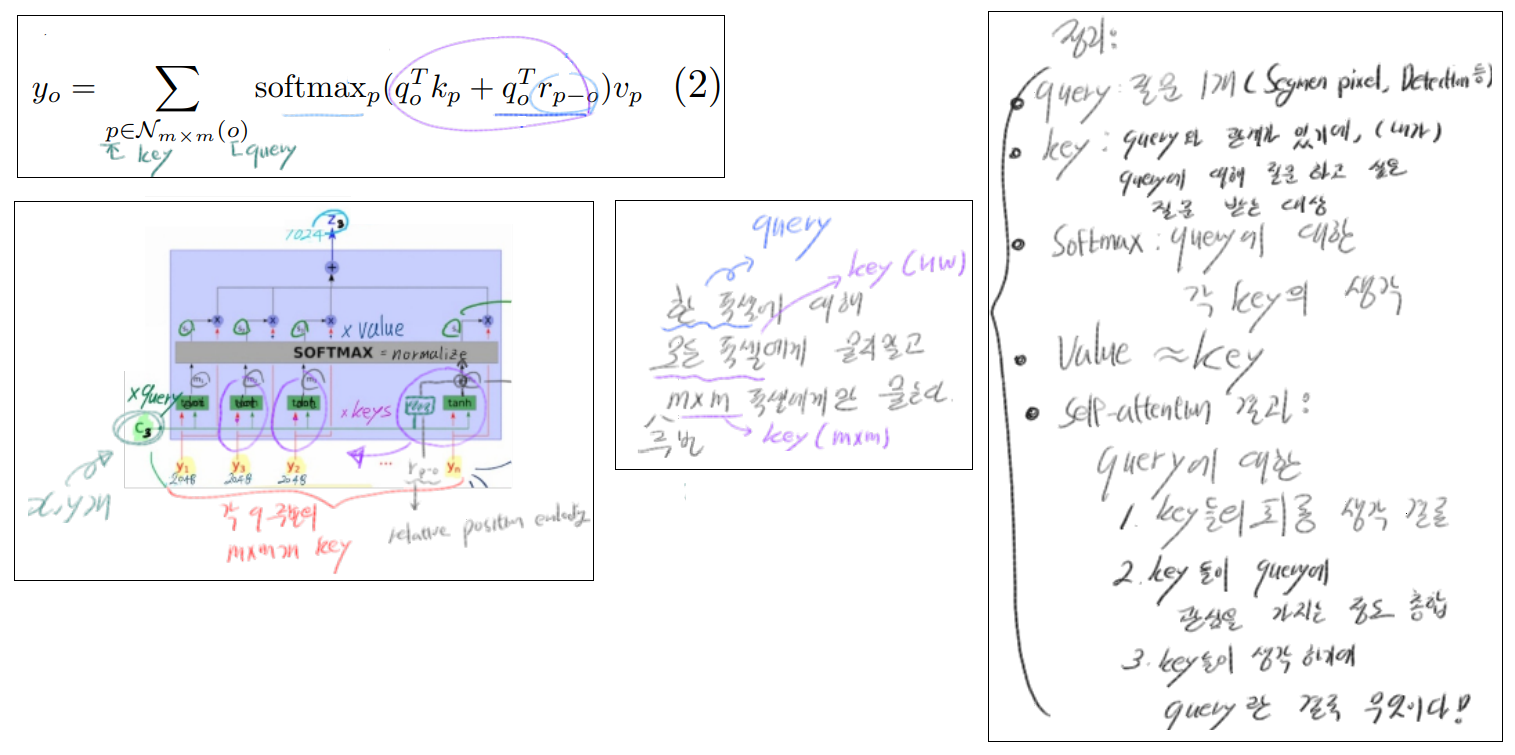
위의 문제점을 해결하기 위해, 개발되었다. 모든 Feature map pixel을 key로 가져가지말고, query 주변의 MxM개만을 key로 사용한다. 이로써. computation 복잡도를 O(hw(query갯수) x m^2(key갯수) ) 까지 줄일 수 있다.
추가적으로, relative positional encoding을 주었다. 즉 query에 positional 정보를 주는 term을 추가한 것이다. 각 pixel(query)들은 주변 MxM공간을 receptive field로써 확장된 정보를 가지게 되고, 이 덕분에 softmax이후에 dynamic prior를 생산해낼 수 있다.
qr 항이 추가되어, key(p) location에서 query(o) location까지의 양립성(compatibility)에 대한 정보가 추가되었다. 특히 r인 positional encodings는 heads끼리 각 r에 해당하는 parameter를 공유해서 사용하기 때문에, cost 증가가 그렇게 크지는 않다고 한다.
위의 계산 식은 one-head-attention이다. multi-head attention 를 사용해서 혼합된 affinities (query에 대한 key들과의 애매하고 복잡한 관계로, 인해 발생하는, 다양한 선호도)를 capture할 수 있다.
지금까지 transformer 모델들은 one-head에서 나온 결과를 y_o1이라고 하고, y_o 1~y_o 8 까지 8개의 head로 인해 나오는 결과를 sum했는데, 여기서는 concat을 한다. 따라서 이런 식이 완성된다. z_o = concatn(y_o n).
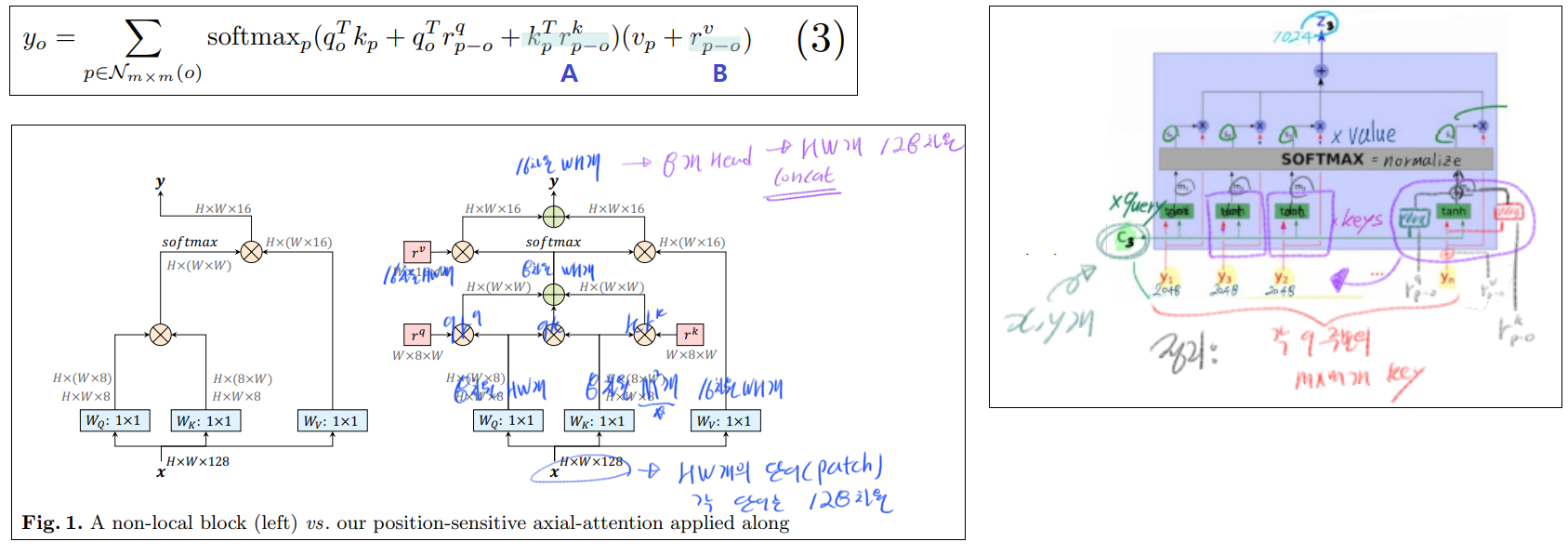
3.3 Position-Sensitivity self attention
(파랑 A) 위에서 query에게만 positional embeding을 해주었다. 여기서 저자는 ‘그렇다면 key에게도 해줘야하는거 아닌가?’ 라는 생각을 했다고 한다. 따라서 key에게도 previous positional bias를 주기 위해 key-dependent positional bias term을 추가해줬다.
(파랑 B) y_o 또한 precise location정보를 가지면 좋겠다. 특히나 stand-alone을 사용하면 MxM (HW보다는 상대적으로) 작은 receptive fields를 사용하게 된다. 그렇기에 더더욱 value또한 (내생각. 이 MxM이 전체 이미지에서 어디인지를 알려줄 수 있는) precise spatial structures를 제공해줘야한다. 이것이 retrieve relative positions = r 이라고 할 수 있다.
위의 A와 B의 positional embeding 또한 across heads 사이에 parameter를 share하기 때문에 큰 cost 증가는 없다.
이렇게 해서 1. captures long range interactions 2. with precise positional information 3. reasonable computation overhead를 모두 가진 position-sensitive self-attention를 만들어 내었다.
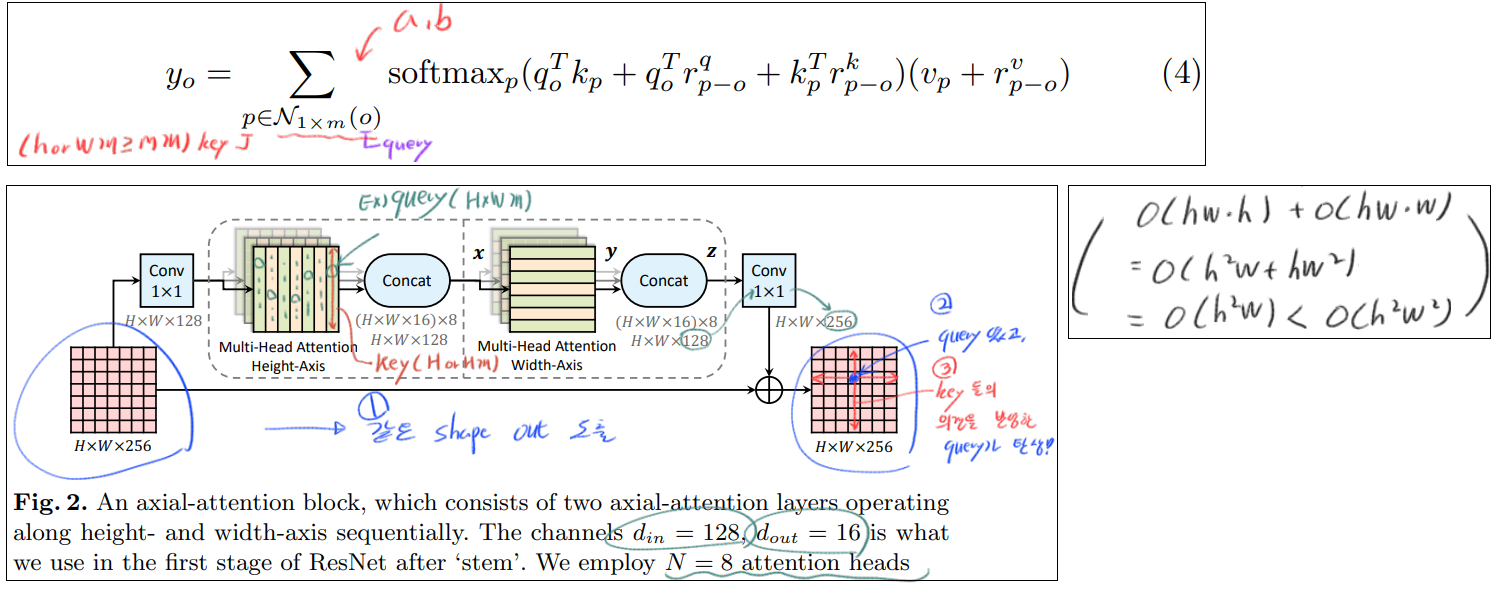
3.4 Axial-Attention
어찌보면, Stand-alone은 MxM만을 고려하니까, 이러한 receptive field가 local constraint로써, 단점으로 작용할 수 있다. 물론 global connection (HW 모두를 key로 사용하는 것)보다는 computational costs를 줄일 수 있어서 좋았다.
Axial-attention의 시간 복잡도는 O(hw(query갯수) x m^2(key갯수=H or W) ) 이다. m에 제곱에 비례한 시간 복잡도를 가지고 있다.
axial-attention를 이용해서
(장점1) global connection(=capture global information) 을 사용하고
(장점2) 각 query에 HW를 모두 key로 사용하는 것 보다는, efficient computation 을 획득한다. 위 그림과 같이 width-axis, height-axis 방향으로 2번 적용한다.
3.5 Axial-ResNet
별거 없고, residual bottleneck block 내부의 일부 conv연산을 Axial atention으로 대체한다.
사실 위의 Fig2가 conv연산을 대체하는 Axial atention의 모습이다. 확실히 Input과 ouput의 shape가 같으므로, 어디든 쉽게 붙이고 때며 적용할 수 있는 것을 확인할 수 있다.
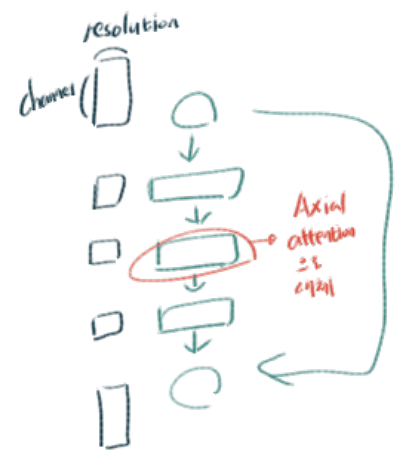
Full Axial-ResNet : simply stack three axial-attention bottleneck blocks. 즉 residual block의 전체 conv를 Axial atention으로 대체하여 사용하는 것이다.
3.6 Axial-DeepLab:
Panoptic-DeepLab이란? : 각 Final head는 (1) semantic segmentation (2) class-agnostic instance segmentation 결과를 생성해 내고, 이 결과들을 majority voting 기법을 이용해서 merge 하는 방법론이다. Panoptic-DeepLab논문 참조.
DeepLab에서 stride를 변경하고 atrous rates를 사용해서 dense feature maps을 뽑아내었다. 우리는 axial-attention을 사용함으로써 충분한 global information을 뽑아내기 때문에, ‘atrous’ attention (?)을 사용하지 않았고, stride of the last stage (?)를 제거했다고 한다.
같은 이유로, global information은 충분하기 때문에, atrous spatial pyramid pooling module를 사용하지 않았다.
extremely large inputs 에 대해서는 m = 65을 가지는 mxm주변의 영역에 대해서만 axial-attention blocks 을 적용했다. (? 정확하게 맞는지 모르겠다)
과거의 기법들이, ImageNet에서의 성능 향상을 위해서, 수십억장의 web-scale extra labeled images와 같은 많은 weakly labeled Instagram images 이 필요한 weakly-supervised learning 을 수행했었다.
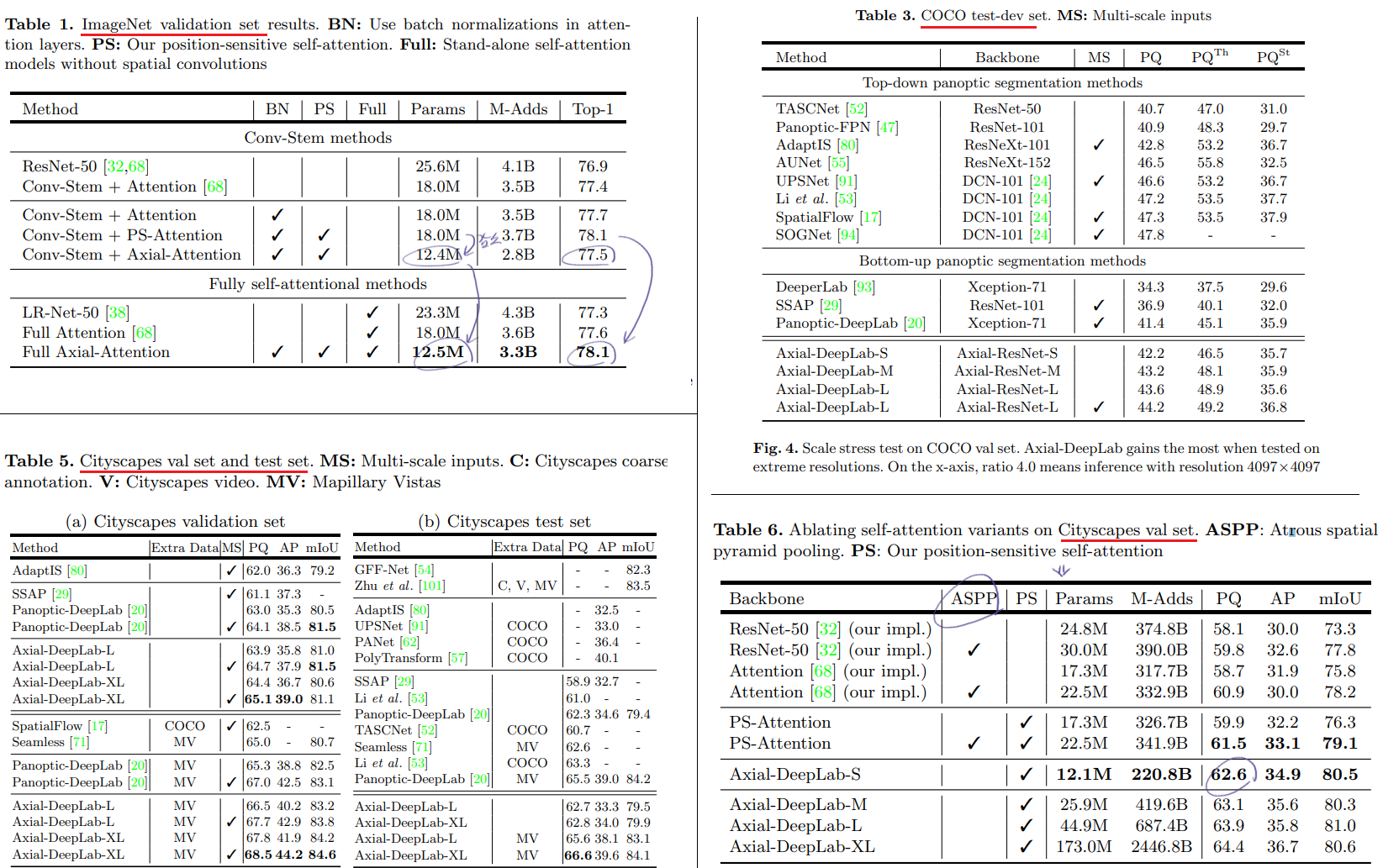
하지만 우리는 unlabeled images을 사용함으로써, 상당한 성능향상을 얻어내었다. 즉 the student에게 Nosie를 추가해 줌으로써, 성능향상을 이루는, self-training = Noisy Student Training = semi-supervised learning 기법을 사용하였다.
EfficientNet에 Noisy Student Training를 적용함으로써 accuracy improvement와 robustness boost를 획득했다.
전체 과정은 다음과 같다. (아래 그림과 함께 참조)
우선 Labeled Image를 가지고 EfficientNet Model(E)을 학습시킨다.
E를 Teacher로 사용하여, 가지고 300M개의 unlabeled images에 대해서, Pseudo labels를 생성한다. (self-training 을 하고 있다고 볼 수 있고, Soft (a continuous distribution) or Hard (a one-hot distribution) 둘 다 될 수 있다.)
Knowledge Distillation 기법과 차이점을 다시 고려해보면, Knowledge Distillation에서는 Teacher보다 작은 Size(complexity)의 Student Model을 학습시킨다. 그리고 Student에서도 Labeled dataset만 사용해 학습시킨다.
Fix train-test resolution discrepancy 기법 : 이 기법은 먼저 첫 350 epoch 동안에는 이미지를 작은 resolution으로 학습시킨다. 그리고 1.5 epoch 동안, 큰 resolution을 가지는 unaugmented labeled images 를 가지고 학습시키며 fine-tuning을 진행한다. (이 방법을 제안한 논문과 마찬가지로) fine-tuning하는 동안에 shallow layer(input에 가까운 Layer)는 freeze하여 학습시켰다고 한다.
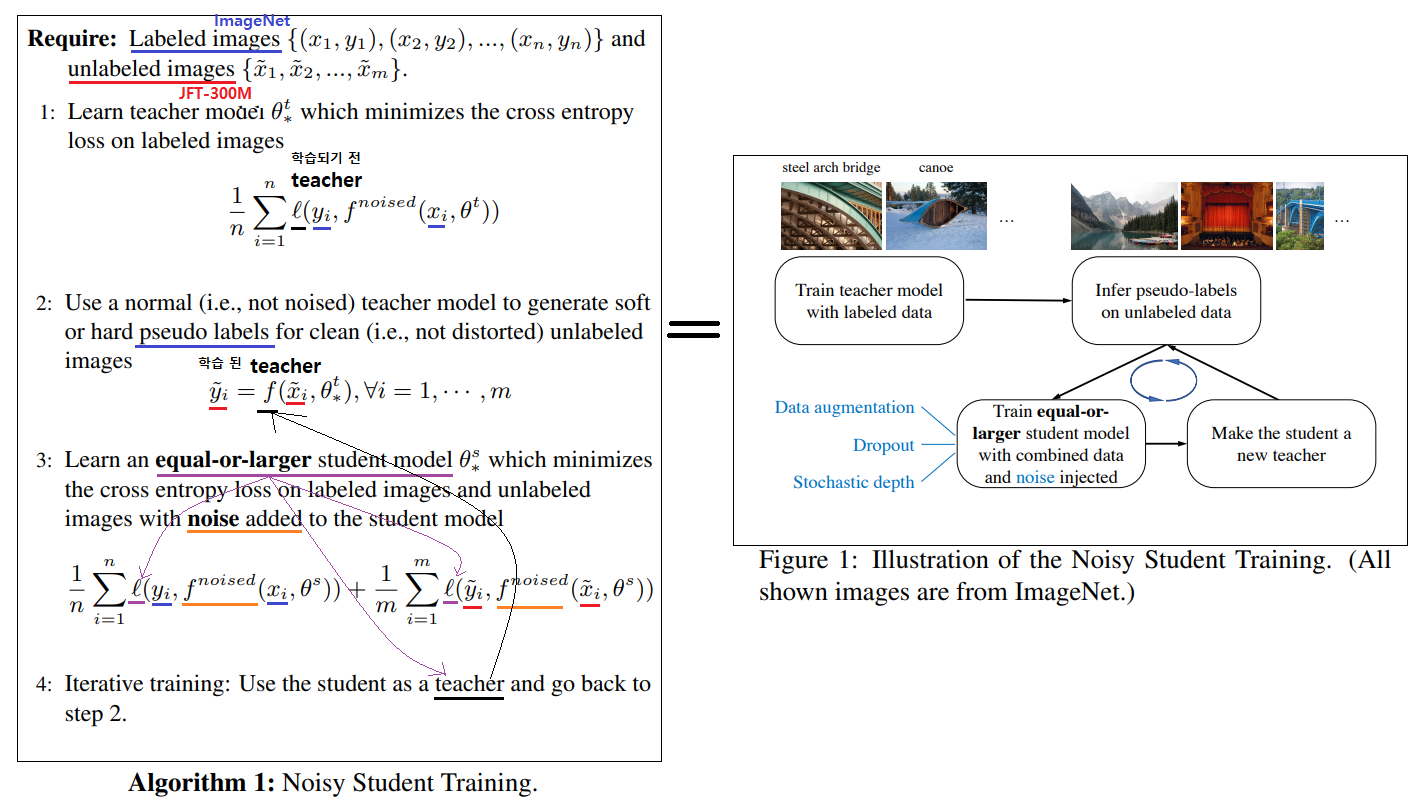
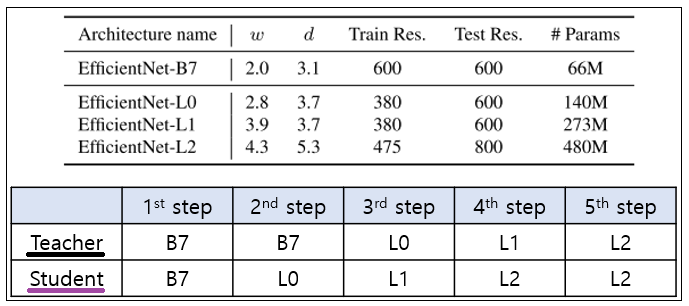
Iterative Training : 위의 알고리즘을 한단어로 표현하면, 반복학습(iterative training)이라고 할 수 있다. 처음에 EfficientNet-B7을 Teacher로 사용하고, 더 큰 모델의 student 모델이 L0, L1, L2가 된다. 그 전체 과정과 모델의 [파라메터 수, width, depth, resolution]는 아래와 같다.
결과
Noisy Student (L2)은 SOTA를 달성했고, 기존 SOTA보다 적은 Parameter를 보유한다. 그리고 Extra Data가 label이 아닌 unlabel이며 그 크기도 적다.
모델의 신빙성과 Robustness를 측정하기 위해 Dan Hendrycks에 의해 제안된, ImageNet-C, ImageNet-P(blurring, fogging, rotation, scaling과 같은 대표적인 Corruption과 Perturbation 이용), ImageNet-A(Natural Image=자연 그 상태에서 찍은 사진. 단색 배경이나, 큰 객체가 아니라) 데이터 셋이 있다.
위와 같은 Robustness 테스트에서도 좋은 성능을 보여주고 있고, Adversarial Attack에 대해서 얼마나 강건한지에 대한 실험 그래프(Figure 3)를 보더라도 좋은 robustness를 가지는 것을 확인할 수 있다. Noise에 학습된 데이터라서 그런지 확실히 EfficientNet보다 좋은 robustness를 보인다.
Noisy Student Training
self-training 의 향상된 버전이라고 할 수 있다.
(noise를 사용하지 않고, Smaller student를 만드는) Knowledge Distillation 과는 다르다. 우리의 방법은 Knowledge Expansion이라고 할 수 있다.
Pseudo code의 Algorithm 위의 이미지에서 참고
Noising Student (명석한 분석)
input noise로써 RandAugment를 사용했고, model noise로써 dropout [76] and stochastic depth [37] 을 사용했다. 이런 noise를 통해서, stduent가 Invariances, robustness, consistency 를 획득하게 된다. (특히 Adversarial Attack에 대해서도)
(First) data augmentation : teacher은 clean image를 보고 high-quality pseudo label을 생성할 때, Student는 augmented image를 봐야한다. 이를 통해서 student 모델은 비교적 정확한 label을 기준으로, consistency를 가질 수 있게 된다.
(Second) dropout & stochastic depth : teacher은 ensemble 처럼 행동한다. student는 single model 처럼 행동한다. student는 powerful ensemble model을 모방하는 꼴이라고 할 수 있다.
Other Techniques
data filtering : 초반에 (지금까지 봐온 (labeled) 이미지와는 조금 많이 다른) out-of-domain image 때문에 teacher모델에서도 low confidence를 가지는 image를 필터링 한다. (나중에 차차 학습한다.)
balancing : labeled images에서 class에 따른 이미지 수와, unlabeled images에서 class에 따른 이미지 수를 맞춘다. (내 생각으로, labeled image에 별로 업는 class가 unlabeld image에 많으면 teacher의 pseudo label 자체가 불안정하기 때문에. 이러한 작업을 수행해준다.)
soft or hard pseudo labels : out-of-domain unlabeled data 에 대해서 soft pseudo label이 좀 더 student 모델에게 도움이 되는 것을 경험적으로 확인했다. (예를들어, confident가 충분히 높지 않으면 soft pseudo labels를 사용하여 student 모델을 학습시키는 방식. )
Comparisons with Existing SSL(self-supervised learning) Methods
SSL은 특정한 teacher 모델이 없다. 그냥 자기 자신이 teacher이자 student일 뿐이다. 이전의 모델(teacher)이 low accuracy and high entropy를 가졌다면, 새로운 모델(student) 또한 (Noise 까지 받으며) high entropy predictions 을 하게 만들 뿐이다.
3. Experiments
3.1Experiment Details
Labeled dataset : ImageNet, 2012 ILSVRC
Unlabeled dataset : JFT dataset (300M images) public dataset YFCC100M
data filtering and balancing
confidence of the label higher than 0.3. 각 클래스에 대해서, 그 중에서 높은 confidence를 가지는 130K 이미지를 선택. 만약 130K 개가 안되면 이미지 복제를 해서라도 130K 맞추기
최종적으로 each class can have 130K images 를 가지도록 만든다. (ImageNet 또한 class마다 비슷한 수의 이미지를 가지고 있다고 함)
Architecture
EfficientNet-B7에서 wider, deeper, lower resolution을 가지는 Network를 만들어서 최종적으로 EfficientNet-B7를 만들었다고 함.
아래는 EfficientNet-B0 인데, 여기서 Block을 더 넣는 방식으로 더 깊게 만들고, channel을 인위적으로 늘린다.
특히, lower resolution을 사용하는 이유는 2가지인데, (1) 파라메터 수를 너무 과다하지 않게 만들기 위해서 (2) 아래의 ` fix train-test resolution discrepancy` 기법을 사용하기 때문에
Training details
epochs : EfficientNet-B4보다 작은 모델은 350. EfficientNet-B4 보다 큰 모델은 700.
learning rate : labeled batch size 2048 를 학습시킬때, 0.128 로 시작하고, 위의 모델에 대해서 각각 2.4 epochs, 4.8 epochs마다 0.97씩 감소시켰다.
large batch size for unlabeled images : make full use of large quantities of unlabeled images.
6 days on a Cloud TPU v3 Pod, which has 2048 cores, if the unlabeled batch size is 14x the labeled batch size
ImageNet-C의 평가에 사용된 mCE 지표와 ImageNet-P의 평가에 사용된 mFR 지표는 낮을수록 좋은 값이다.
성능지표 표는 첨부하지 않겠다. 쨋든 다 성능이 향상한다.
Noise 기법 정리
Dropout [2014]
overfitting 방지
hidden unit을 일정 확률로 0으로 만드는 regularization 기법이다.
후속 연구로, connection(weight)를 끊어버리는 (unit은 다음층 다른 unit과 모두 연결되어 있는데, 이 중 일부만 끊어 버리는 것이다. dropout 보다는 조금 더 작은 regularization(규제)라고 할 수 있다. )
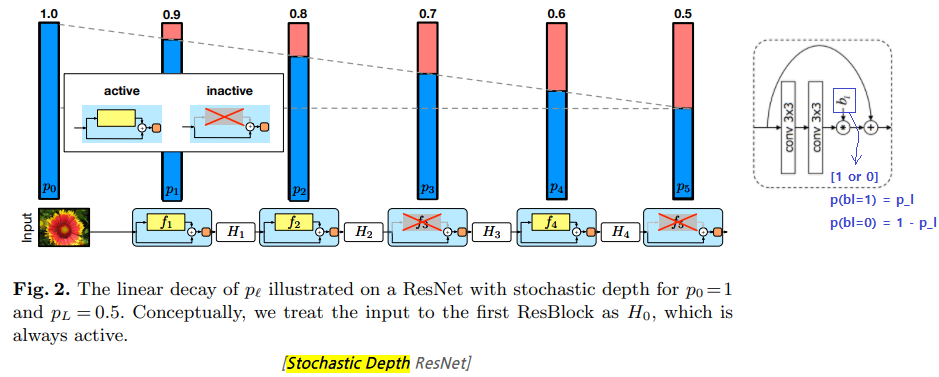
stochastic depth [2016]
ResNet의 layer 개수를 overfitting 없이 크게 늘릴 수 있는 방법이다. ResNet1202 를 사용해도 정확도가 오히려 떨어지는 것을 막은 방법이다.
ResNet에 있어서 훈련할 때에 residual 모듈 내부를 랜덤하게 drop(제거)하는 모델이다. (모듈 내부가 제거되면 residual(=shortcut)만 수행되며, 그냥 모듈 이전의 Feature가 그대로 전달되는 효과가 발생한다.)
Test시에는 모든 block을 active하게 만든 full-length network를 사용한다.
p_l = 1 - l/2L
residual 모듈이 drop하지 않고 살아남을 확률이다.
L개의 residual 모듈에서 l번째 모듈을 의미한다.
input에 멀어질 수록, l은 커지고, p_l은 작아진다. 즉 drop 될 확률이 커진다.
p_l의 확률값에 의해서 b_l (0 or 1 = drop_active or Non_active)이 결정된다.
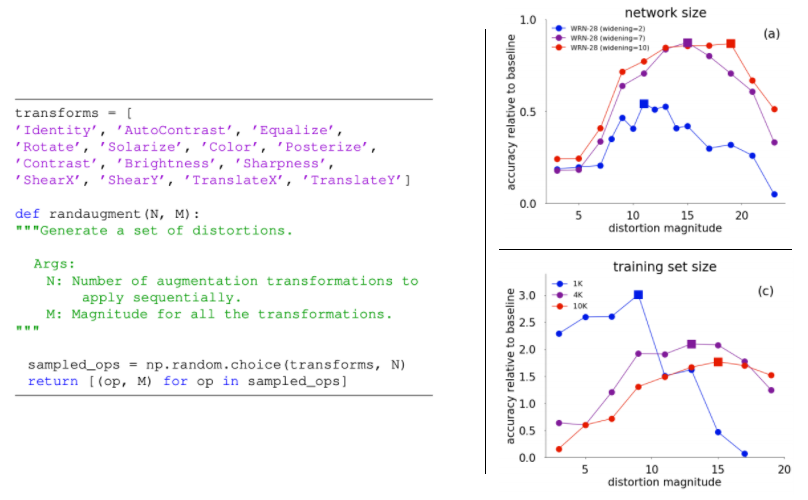
RandAugment data augmentation [2019]
간략하게 말하면, 기존에 다양한 Data Augmentation을 싹 정리해놓은 기법이다.
아래와 같은 14가지 Augmetation 기법들을 모아놓고, 랜덤하게 N개를 뽑고, 얼마나 강하게 Transformation(distortion magnitude)를 줄 것인지 M (Magnitude)를 정해준다. (아래 왼쪽의 수도코드 참조)
그렇다면 M을 얼마나 주어야 할까? (1) 매번 랜덤하게 주는 방법 (2) 학습이 진행될수록 키우는 방법 (3) 처음부터 끝까지 상수로 놔두는 방법 (4) 상한값 이내에서 랜덤하게 뽑되, 상한가를 점점 높히는 방법
모두 실험해본 결과! 모두 같은 성능을 보였다. 따라서 가장 연산 효율이 좋은 (3)번을 사용하기로 했고, 상수 값 M을 몇으로 하는게 가장 좋은 성능을 내는지 실험해 보았다. (아래 오른쪽 그래프 참조) 그래프 분석에 따르면, 최적의 M은 10~15 정도인 것을 알 수 있다.
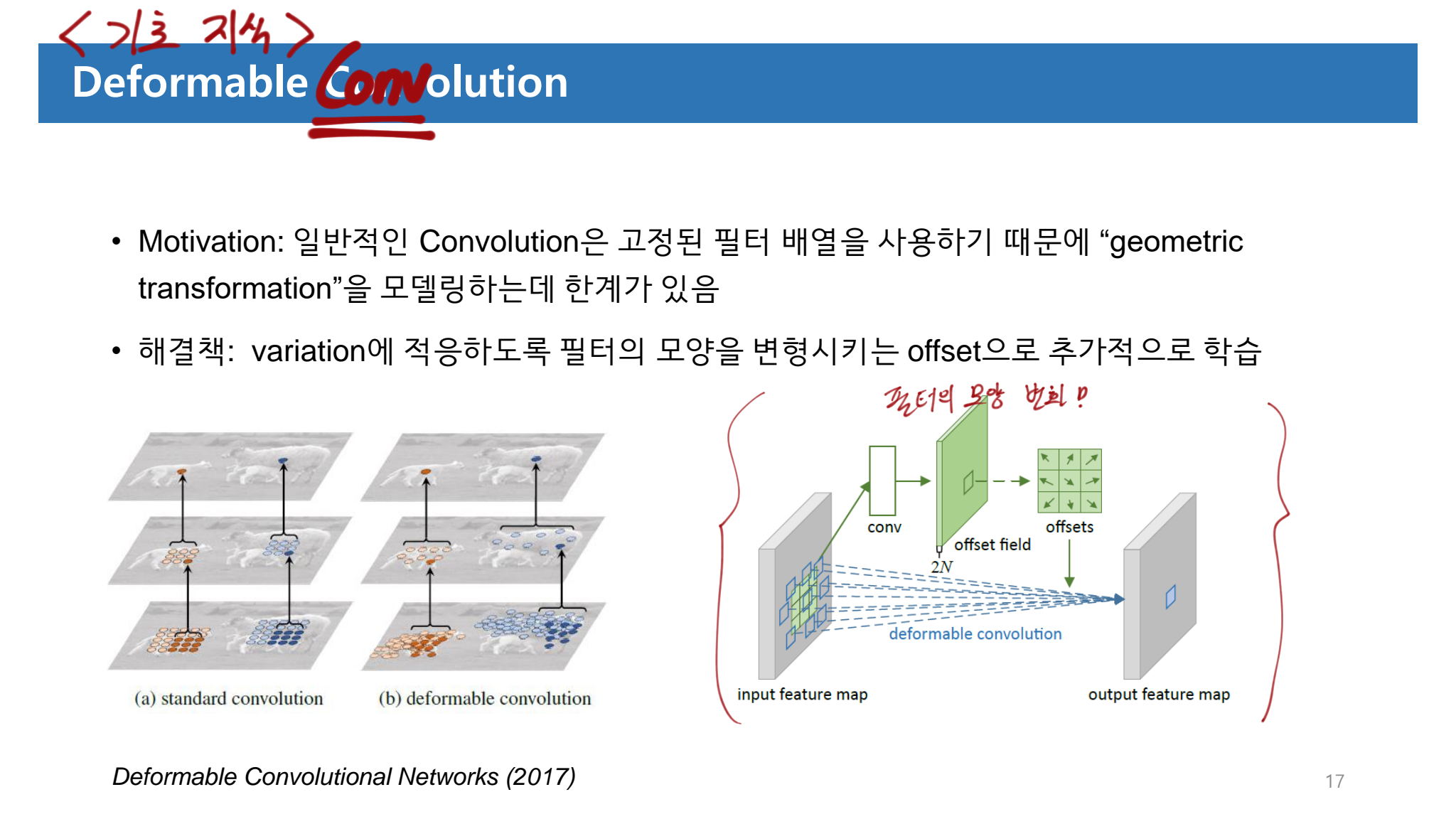
핵심은 “the (multi-scale) deformable attention modules” 이다. 이것은 image feature maps를 처리하는데 효율적인 Attention Mechanism 이다.
아래의 Transformer attention modules 의 가장 큰 단점을 a small set of key sampling 를 사용함으로써 해결 했다.
slow convergence
limited feature spatial resolution
장점으로 fast convergence, and computational and memory efficiency 를 가지고 있다.
two-stage Deformable DETR 를 만들기도 하였다. region proposal이 먼저 생성되고, 그것들을 Decoder에 넣는 방식으로 만들었다.
2. Revisiting Transformers and DETR
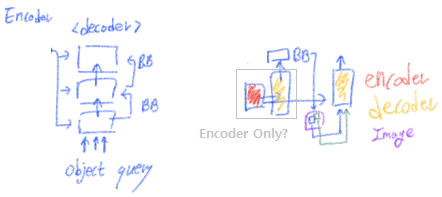
특히 이 부분의 수학적 수식을 통해서, 지금까지 직관적으로만 이해했던 내용을 정확하게 이해할 수 있었다. 왜 NIPS에서 수학 수식을 그렇게 좋아하는지 알겠다. 정확하고 논리적이다.
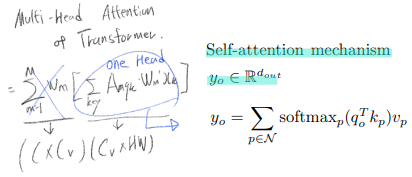
2.1 Multi-Head Attention in Transformers
z_q, query element : a target word in the output sentence (“이 단어에 대해서는 어떻게 생각해?” 질문용 단어) =
x_k, key elements : source words in the input sentence (문장 안에 있는 모든 단어. 모든 단어들에게 위의 query에 대해 질문할 거다.)
특히 Encoder에서 z_q와 x_k는 element contents(word in 문장, patch in Image) 와 positional embeddings(sin, learnable) 의 concatenation or summation 결과이다.
multi-head attention module : query-key pairs 에 대한 Attention(= compatibility, Softmax) 정도 를 파악해 그것을 attention weights 라고 하자. 이 attention weights와 각각의 the key와 융합하는 작업을 한다.
multi-head : 단어와 단어끼리의 compatibility(상관성 그래프)를 한번만 그리기엔, 애매한 문장이 많다. 그래서 그 그래프를 여러개 그려서 단어와 단어사이의 관계를 다양하게 살펴봐야한다. 이것을 가능하게 해주는 것이 multi-head 이다. Different representation subspaces and different positions을 고려함으로써, 이 서로서로를 다양하게 집중하도록 만든다.
multi-head에서 나온 값들도 learnable weights (W_m)를 통해서 linearly하게 결햅해주면 최종 결과가 나온다. 아래의 필기와 차원 정리를 통해서, 한방에 쉽게 Attention module과 MHA(multi head attention)에 대해서 명확히 알 수 있었다.
아래 필기 공부 순서 : 맨 아래 그림 -> 보라색 -> 파랑색 -> 대문자 알파벳 매칭 하기. 위의 보라색 필기는, Softmax 까지의 Attention weight를 구하는 과정을 설명한다. 파랑색 필기는 MHA의 전체과정을 설명한다.
하지만 이 방법에는 2가지 문제점이 존재한다.
long training schedules : 학습 초기에 attention weight는 아래와 같은 식을 따른다. 만약 Key가 169개 있다면, 1/169 너무 작은 값에서 시작한다. 이렇게 작은 값은 ambiguous gradients (Gradient가 너무 작아서, 일단 가긴 가는데 이게 도움이 되는지 애매모호한 상황) 이 발생한다. 이로 인해서 오랜 학습을 거쳐야 해서, long training schedule and slow convergence가 발생한다.
computational and memory complexity(복잡성, 오래걸림, FPS 낮음) : 위의 MHA의 시간 복잡도를 계산하면 아래와 같다. 만약 N_q가 100 or 169개, N_k가 169개 라면, N_q x N_k 에 의해서 quadratic(제곱) complexity growth with the feature map size 이 발생한다.
2.2 DETR
input feature maps x ∈ R ^ (C=256×H=13×W=13) extracted by a CNN backbone
각 모듈의 시간복잡도
Encoder's MHA
query and key는 모두 pixels in the feature maps 이다.
시간 복잡도는 O(H^2 * W^2 * C) 이다. 따라서 이것도 Feature Size 증가에 따른 quadratic(제곱) complexity 를 가진다.
query's Masked MHA
self-attention modules
Nq = Nk = N, and the complexity of the self-attention module
decoder's MHA
cross-attention
N_q = N=100, N_k = H × W (encoder에서 나온 차원이, (HxW) xC 라는 것을 증명한다!)
시간 복잡도 : O(H*W*C^2 + N*H*W*C)
(anchor & NMS와 같은) many hand-designed components 의 필요성을 제거했다.
하지만 아래와 같은 2가지 문제점이 있다.
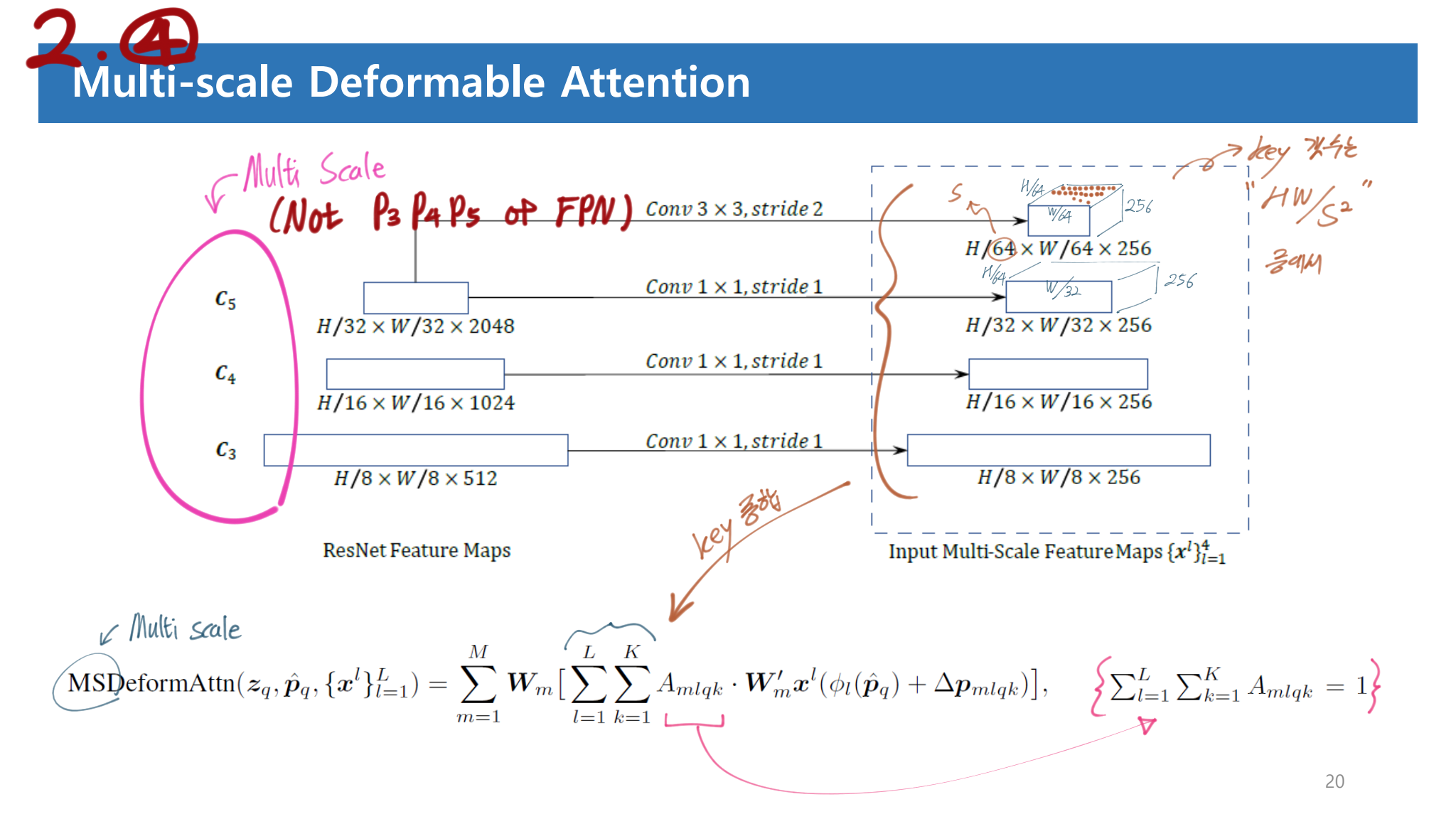
Low performance in detecting small objects : 다른 모델들에서는 Multi Scale Feature (C_3 ~ C_5) 혹은 FPN (P_3 ~ P_5) 를 사용하는데 여기서는 그럴수 없다. 시간복잡도가 quadratic(제곱) complexity 로 증가하기 때문이다.
many more training epochs to converge
4. Method
DETR에서 Key를 all possible spatial locations 로 모두 가져간다. 하지만 deformable DETR에서는 only attends to a small set of key 로 Keys를 사용한다. 이를 통해서 우리는 원래 DETR의 가장 큰 문제점이었던, the issues of convergence 그리고 feature spatial resolution 을 키울 수 없는 상황을 해결할 수 있게 되었다.
Deformable Attention Module 그리고 Multi-scale Deformable Attention Module 의 수식은 아래와 같다. 수식을 이해하는 것은 그리 어렵지 않지만, 실제로 어떻게 정확하게 사용하는지는 코드를 통해서 이해할 필요가 있다. 코드를 확인하자.
(아래 내용을 추가 의견) BlendMask 또한 '모든' Feature Pixel에게 "RxR에 대해서 어떻게 생각해" 라고 물어본다. 이것을 '모든' 으로 하지말고, 일부만 (like small K set) 선택하는건 어떨까? 아니면 query를 RxR ROI 라고 치고 Transformer를 사용해보니는 것은 어떨까?
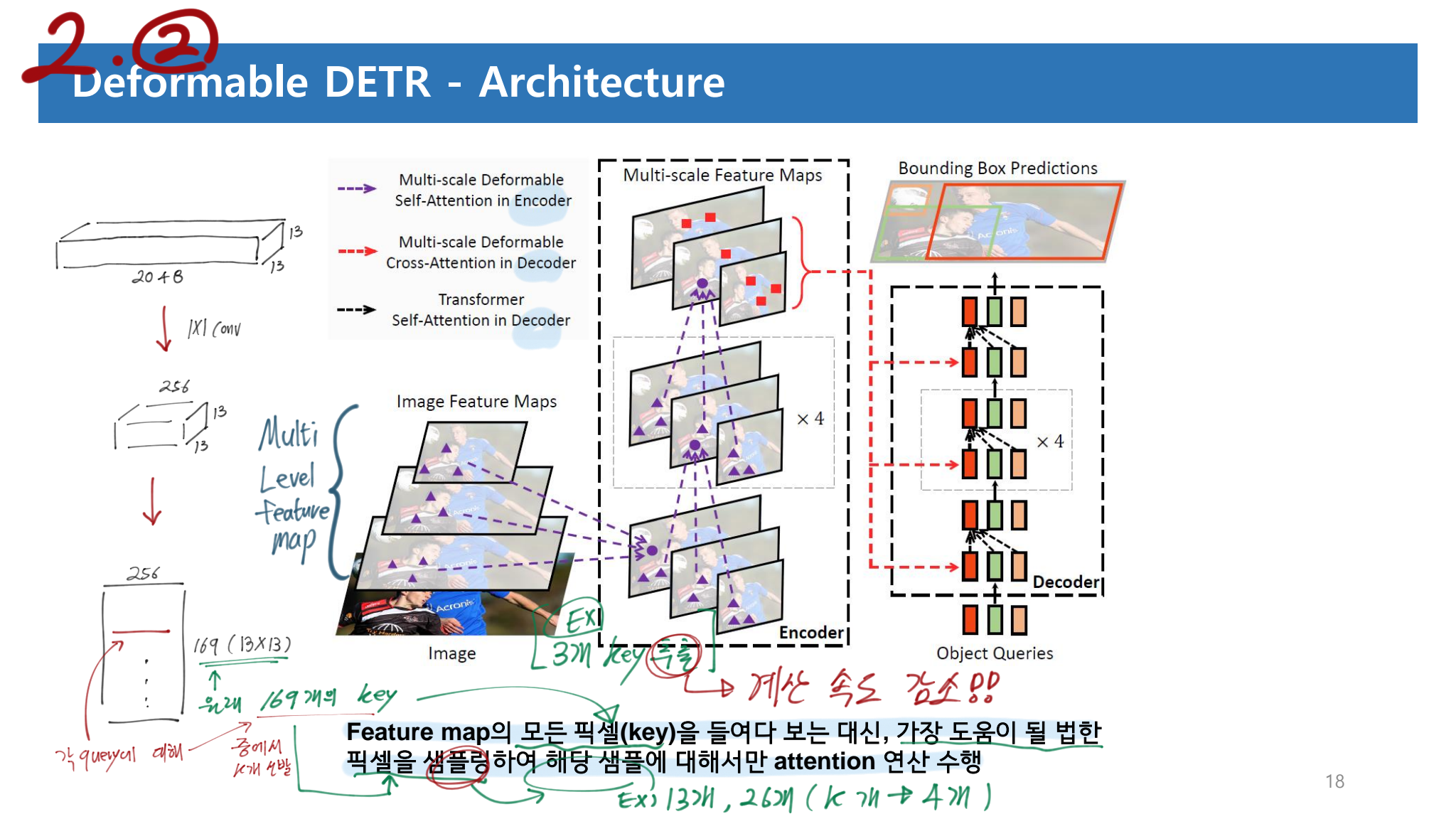
Deformable Transformer Encoder
Input과 Output 모두 multi-scale feature maps with the same resolution(256 channel) 이 들어간다.
특히 Input은 stages C3 through C5 in ResNet 의 Feature map을 선발 사용한다. 위 이미지 참고할 것. 그리고 FPN을 사용해서 P3~P5를 이용하지는 않는다. 사용해봤지만, 성능 향상이 거의 없기 때문이다.
query로 Feature map을 줄때, feature level each query pixel 에 대한 정보를 담기 위해서, e_i 라는 positional embeding을 추가했다. e_i은 L의 갯수 만큼 있으며, 초기에는 랜덤하게 initialize가 되고, Learnable parameter로 학습이 된다.
Deformable Transformer Decoder
2가지 모듈이 있다. cross attention modules : object-query와 Encoder의 출력값이 들어간다., self-attention modules : object-query 끼리 소통하여 N=100개의 output을 만들어내는 모듈이다.
we only replace each cross-attention module to be the multi-scale deformable attention module
어차피 self-attention module은 HW개의 query가 들어가는게 아니라 key, value, query가 모두 100개 일 뿐이다.
multi-scale deformable attention module 은 reference point 주변에 image features를 추출하는 모듈이다. 따라서 decoder 마지막 FFN의 detection head가 그냥 BB의 좌표를 출력하는 것이 아니라, the bounding box as relative offsets을 출력하도록 만들었다. 이를 통해서 optimization difficulty를 줄이는 효과를 얻을 수 있었다. (slow converage) (reference point 를 BB center로써 사용했다고 하는데, BB center는 어디서 가져오는거지?)
Additional Improvements and variants for deformable DETR
많은 성능향상 방법을 실험해보았는데, 도움을 주었던 2가지 방법에 대해서만 소개한다. (추가 설명은 Appendix A.4 를 참고 하라.) (솔직히 아래의 내용만으로는 이해가 안됐다. 코드를 보기 전에 부록을 보면서 함께 공부하도록 하자. 아래의 그림은 설명을 보고 그럴듯하게 그려놓은 것이지, 정답이 아니다.)
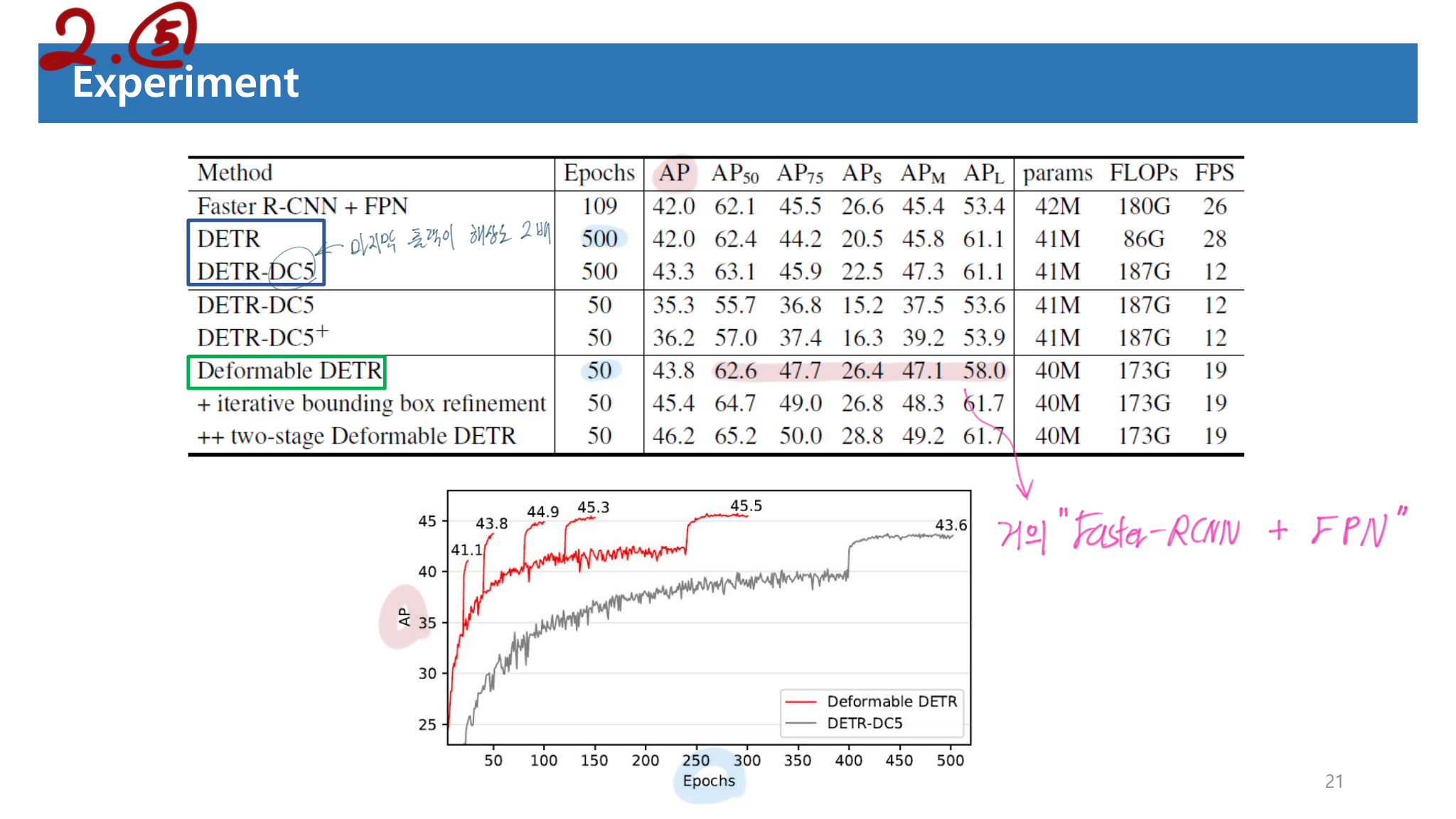
Iterative Bounding Box Refinement : optical flow estimation (Teed & Deng, 2020) 에서 영감을 받아서 만들었다. 간단하고 효율적으로 각 decoder layer에서 나오는 detect BB결과를 다음 Layer에 넘겨서 다음 Layer는 이 BB를 기반으로 더 refine된 BB를 출력한다.
Two-Stage Deformable DETR :
첫번째 stage에서는 region proposal과 objectness score를 예측하고 이 값을 다음 stage에 넘김으로써, 정확한 BB와 Class를 출력하는 2-stage Deformable DETR를 만들었다.
시간과 메모리 복잡도가 너무 올라가는 것을 막위해서 encoder-only of Deformable DETR을 region proposal Network로 사용한다.(?)
그리고 그 안의 each pixel is assigned as an object query. 그래서 시간, 메모리 복잡도가 급등하는 것을 막는다. (?)



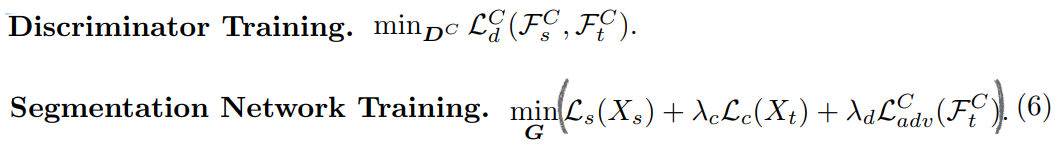




 ```
```