【Detection】Tokens-to-Token ViT
- 논문 : Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
- 분류 : Classification
- 읽어야 할 논문
- Performer ViT: 1.
Rethinking transformer-based set prediction for object detection, 2.Rethinking attention with performers
- Performer ViT: 1.
Tokens-to-Token ViT
1. Conclusion, Abstract
- Conclusion
- the novel tokens-to-token (T2T) 이란?? proggressively image/feature 를 tokenizing 하는 것
- 장점(1) 이미지의 구조정보를 파악할 수 있다. (2) feature richness를 향상시킬 수 있다.
- 특히 backbone에서는
the deep-narrow architecture = transformer layer는 많이 hidden dimention은 작게가져가는 것이 효율적이다.
- Abstract
- ViT 문제점 : midsize dataset으로 학습시키면, CNN 보다 성능이 낮다.
- 문제점 이유1 : Image patch를 그대로 tokenization해서 important local structure(edge, line, 주변 픽셀과의 관계) 등을 파악할 수 없다.
- 문제점 이유2 : redundant attention backbone(너무 많은 Attention layer, 여기서 backbone은 Transformer encoding 앞에 있는 layer가 아니라, 그냥 Image patch의 PE이후에 Transformer encoding 전체를 의미하는 것이다.)
2. Instruction, Relative work
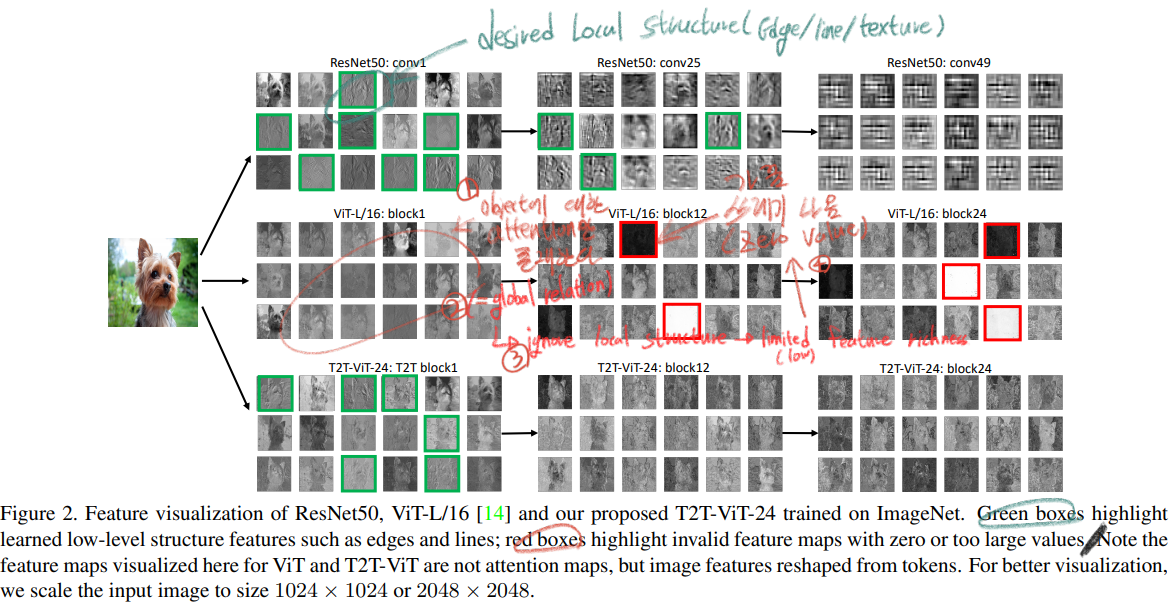
- 위 그림은 (1) ResNet (2) ViT (3) T2T-ViT 내부를 각각 들여다 본 그림이다.
- 확실히 녹색 박스와 같이 ResNet과 T2T에서는 Desired Local Structure를 잘 파악하는 것을 알 수 있다.
- 하지만 ViT에서는 너무 Global attention에만 집중해서 Local Structure에 대해서 잘 파악하지 못한다. 심지어 빨간 박스처럼 쓰레기 같은 결과가 나오기도 한다.
- our contributions
- visual transformers이 진짜 CNN을 띄어넘게 만들기 위해서, (1) T2T module (2) efficient backbone 을 만들었다.
- a novel progressive tokenization
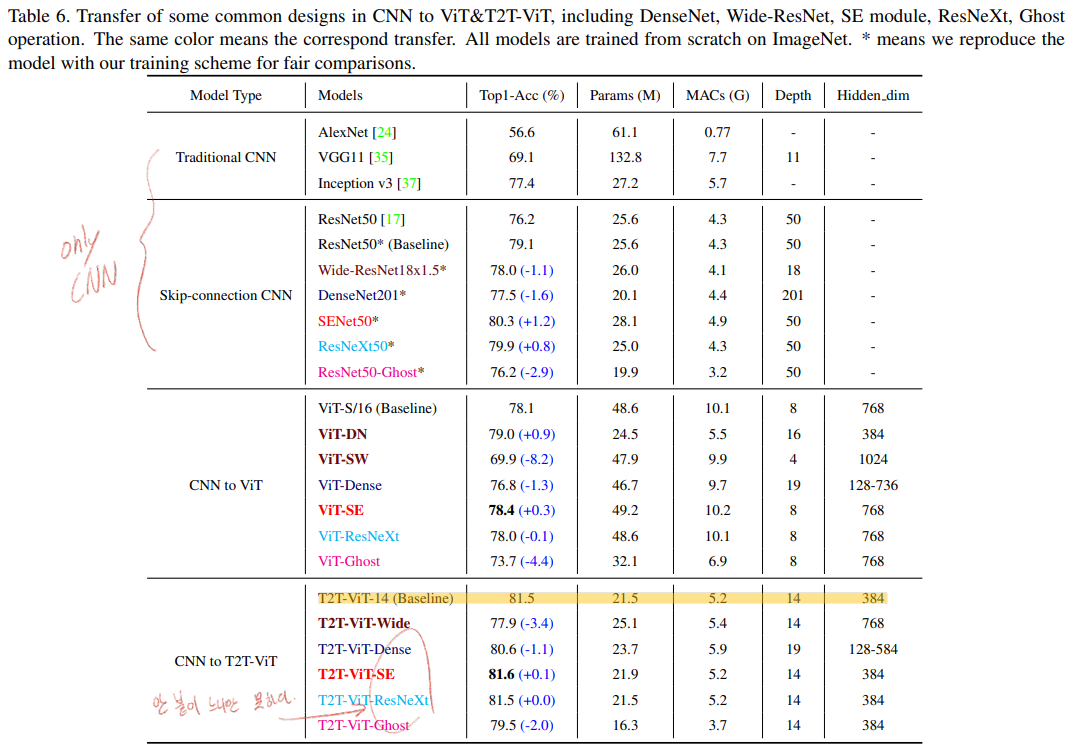
- Backbone으로 Transformer encoder와 같은 구조를 차용하기도 하지만, the architecture engineering of CNNs 을 사용해서 비슷한 성능(ResNeXt)혹은 조금더 나은 성능(SENet)을 얻는다.
3. Method
- 논문의 핵심 전체 Architecture는 아래의 이미지라고 할 수 있다.
- 아래의 그림과 같이 T2T-ViT는 2개의 구성으로 나눌 수 있다. (1)
Tokens To Token Module(2)T2T-ViT Backbone각각의 목적과 목표는 아래 필기에 정확하게 정리해 적어놓았으니, 녹색과 빨간색 필기를 꼭 참고하기 바란다. - 참고로 여기서 length는 vector dimention을 의미하는게 아니라, vector의 갯수를 말한다.
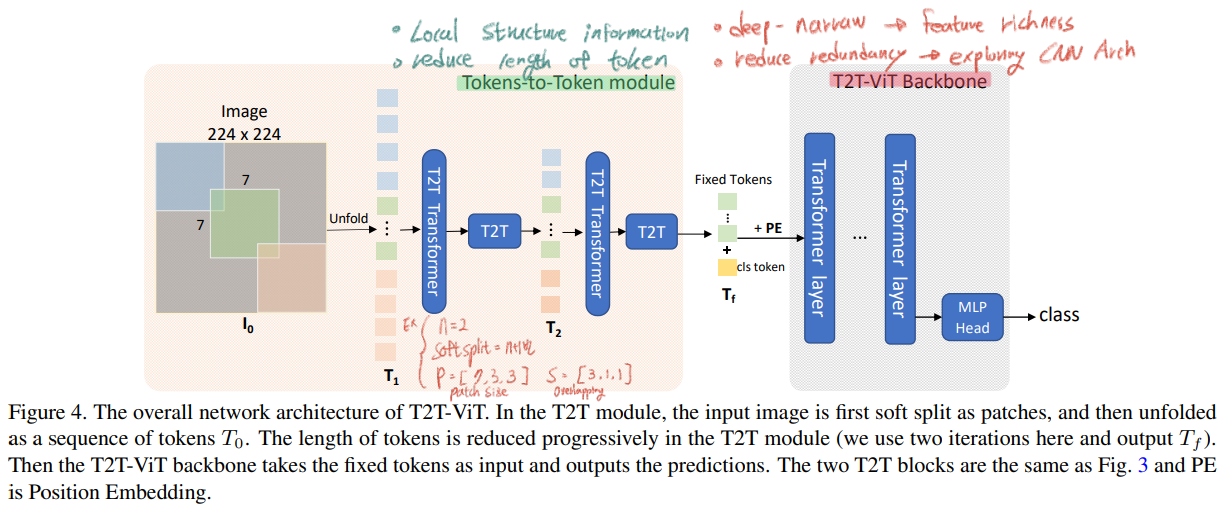
- 아래의 그림과 같이 T2T-ViT는 2개의 구성으로 나눌 수 있다. (1)
- T2T module(process) : 위 그림에서
T2T
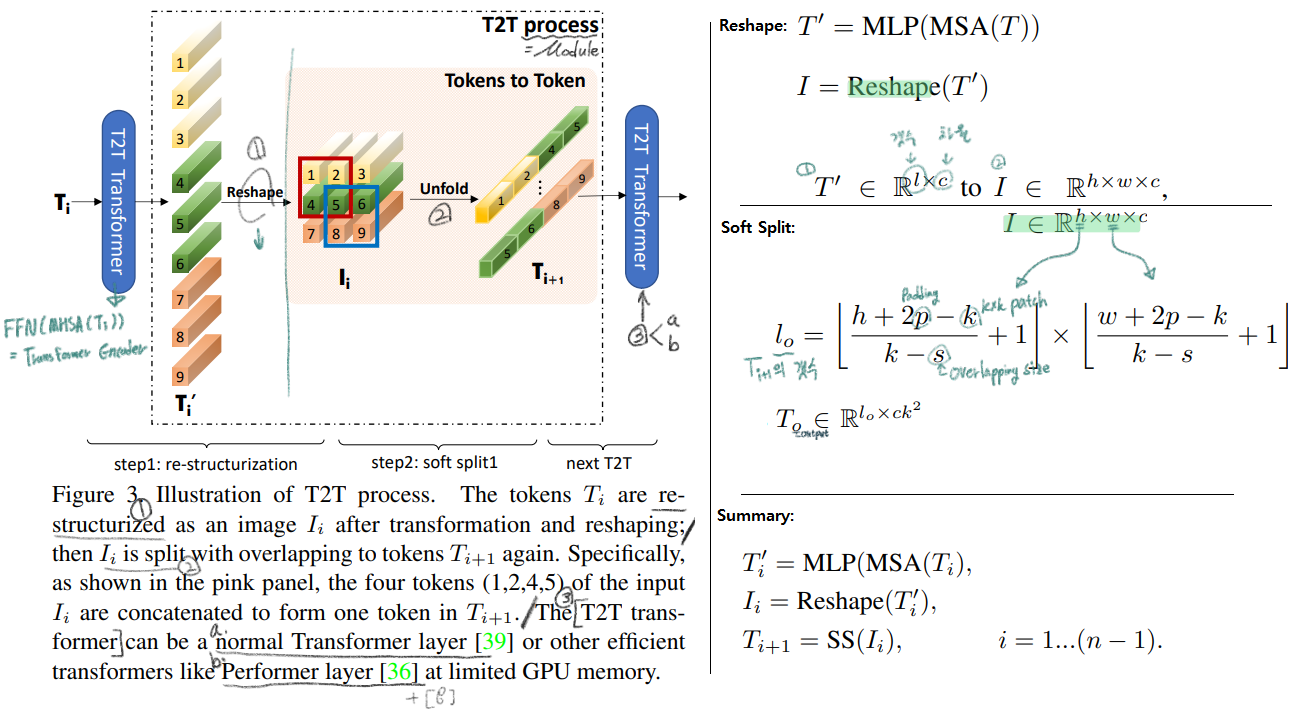
- Step1 :
spatial 형상의 이미지처럼 토큰을 reshape한다. - Step2 : Soft split처리를 함으로써 이미지의 지역정보를 학습하고 토큰의 length(갯수)를 줄일 수 있다. 토큰을 overlapping을 해서 patch 형태로 split 하는 것이다. 이렇게 함으로써 주변 tokens들과의 더 강한 correlation을 파악 할 수 있다. (ViT처럼 patch로 처음에 자르고 그 patch들 (특히 주변 patch들간의 관계성에 대한 정보를 넣어주지 않으면 지역정보(edge, line)를 파악할 수 없다.)
- 전체를 정리하면, 위 그림의 오른쪽 아래 식과 같이 나타낼 수 있다.
- ViT에서는 Patch의 수가 16*16 즉 256개였다. 이것또한 메모리 관점으로 굉장히 많은 숫자였다. 그래서 우리의 T2T 모둘은 patch수는 어쩔 수 없고, the channel dimension을 small (32 or 64)으로 설정함으로써 메모리 효율을 높이고자 노력했다.
- Step1 :
- T2T-ViT Backbone
- reduce the redundancy / improve the feature richness
- Transformer layer를 사용하기는 할 건데, 그들의 조합을 어떤 구조로 가져갈 것인가? (자세한 구조는 Appendix를 참조)
- DenseNet
- ResNets
- (SE) Net
- ResNeXt = More split heads in multi-head attention layer
- GhostNe
- 많은 실험을 통해서
the deep-narrow architecture = transformer layer는 많이 hidden dimention은 작게가져가는 것이 효율적이라는 결론을 얻었다. - 여기서는
fixed length T_f가 이뤄진다. 그리고concatenate a class token마지막으로Sinusoidal Position Embedding (PE)을 사용하는게 특징이다.

- T2T-ViT Architecture
- n = 2 re-structurization
- n+1 = 3 soft spli
- patch size P = [7, 3, 3]
- overlapping is S = [3, 1, 1]
- Reduces size of the input image = from 224 × 224 to 14 × 14
- batch size 512 or 1024 with 8 NVIDIA
4. Results
- Table1: 다양한 구조의 T2T-ViT 모델들
- Table2,3,4 : 기존의 모델(1.
ViT2.ResNet3.MobileNet)들과 비교 결과
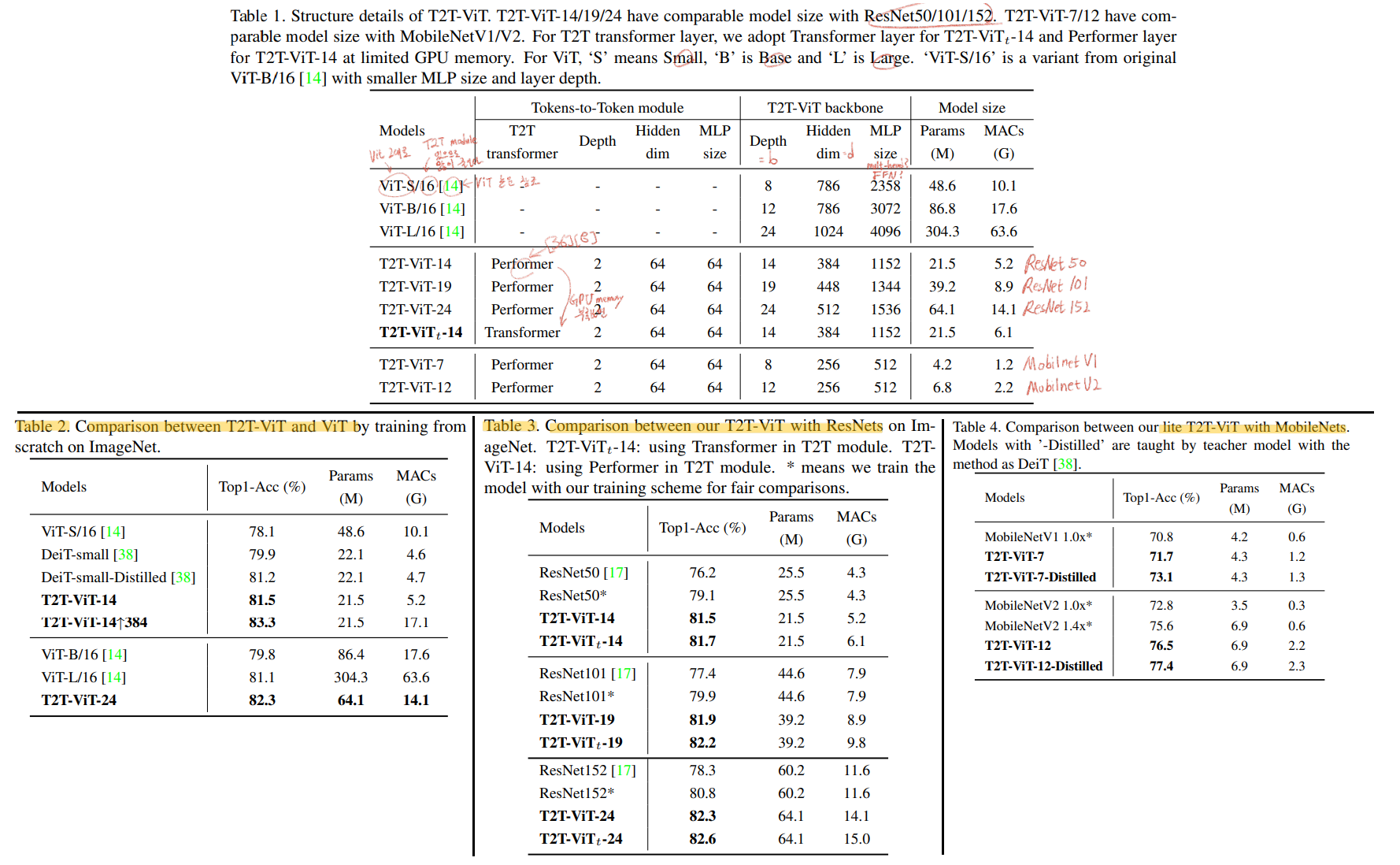
어떤 구조가 가장 좋은지 비교
좀 더 자세한 설명은 필요하면 나중에 논문 참조하기
Youtube 참고 정리
- Youtube Link : https://www.youtube.com/watch?v=eaZt9asVYH0
