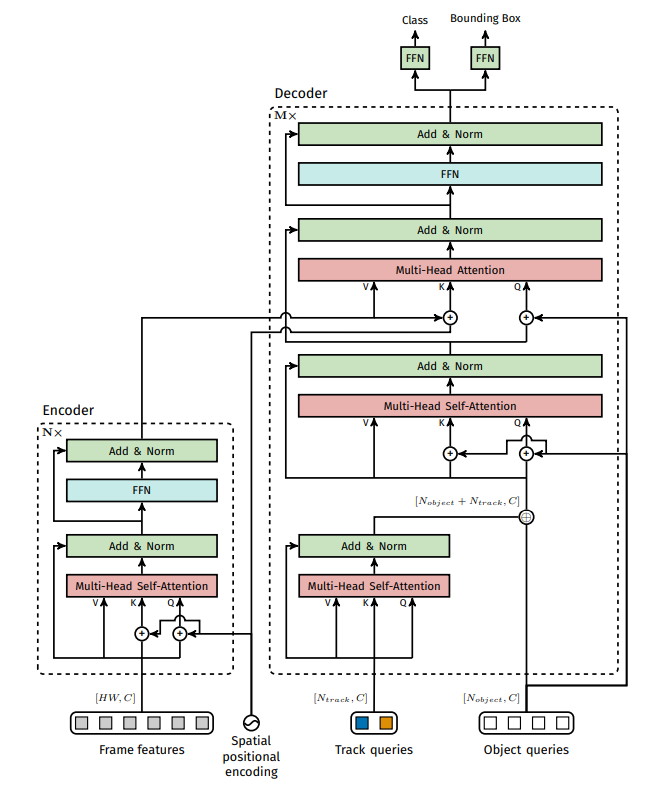
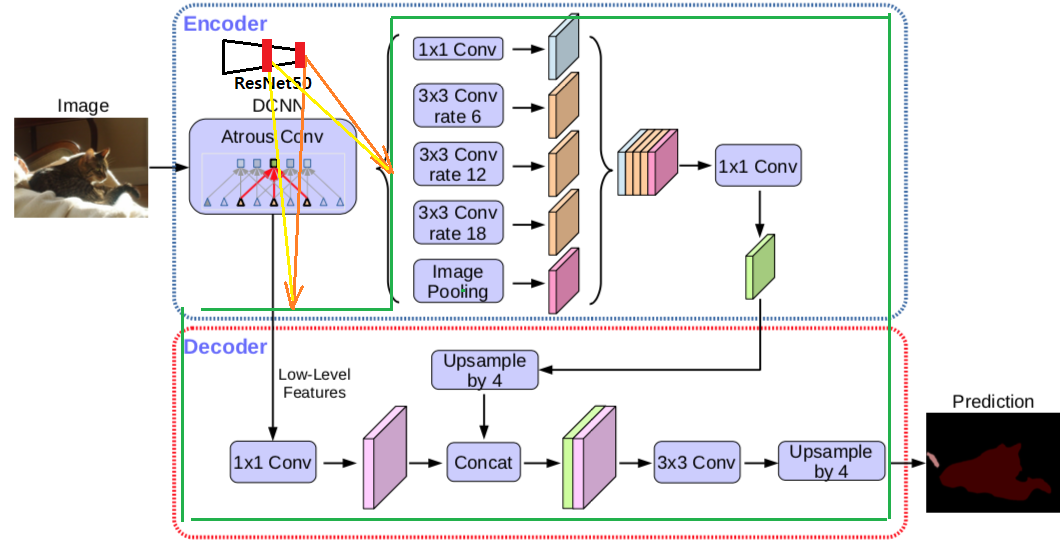
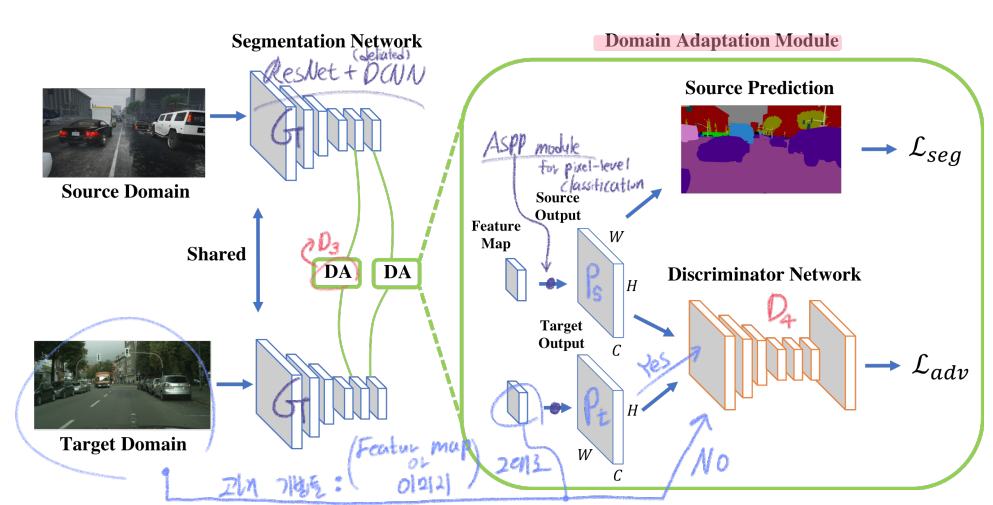
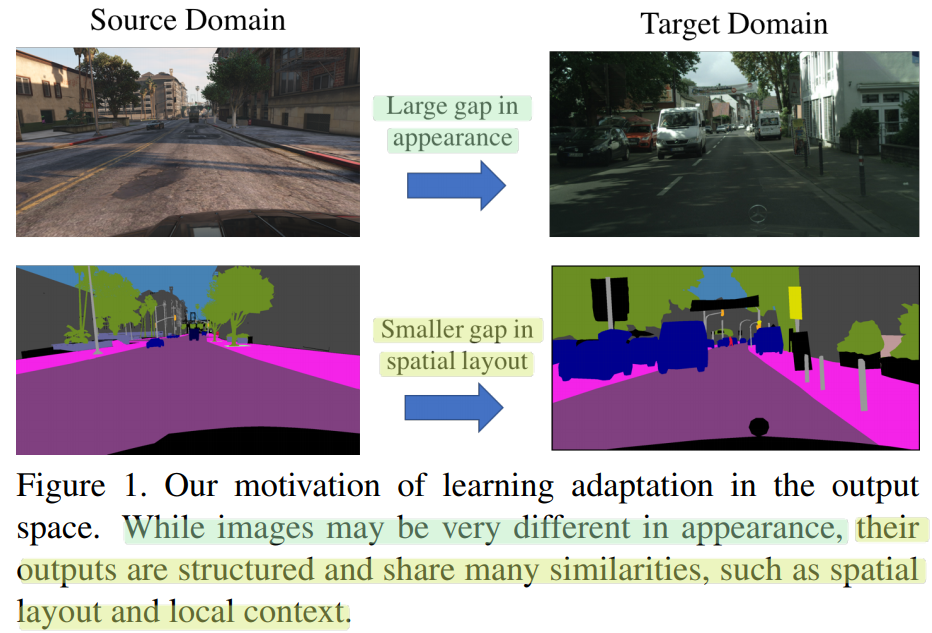
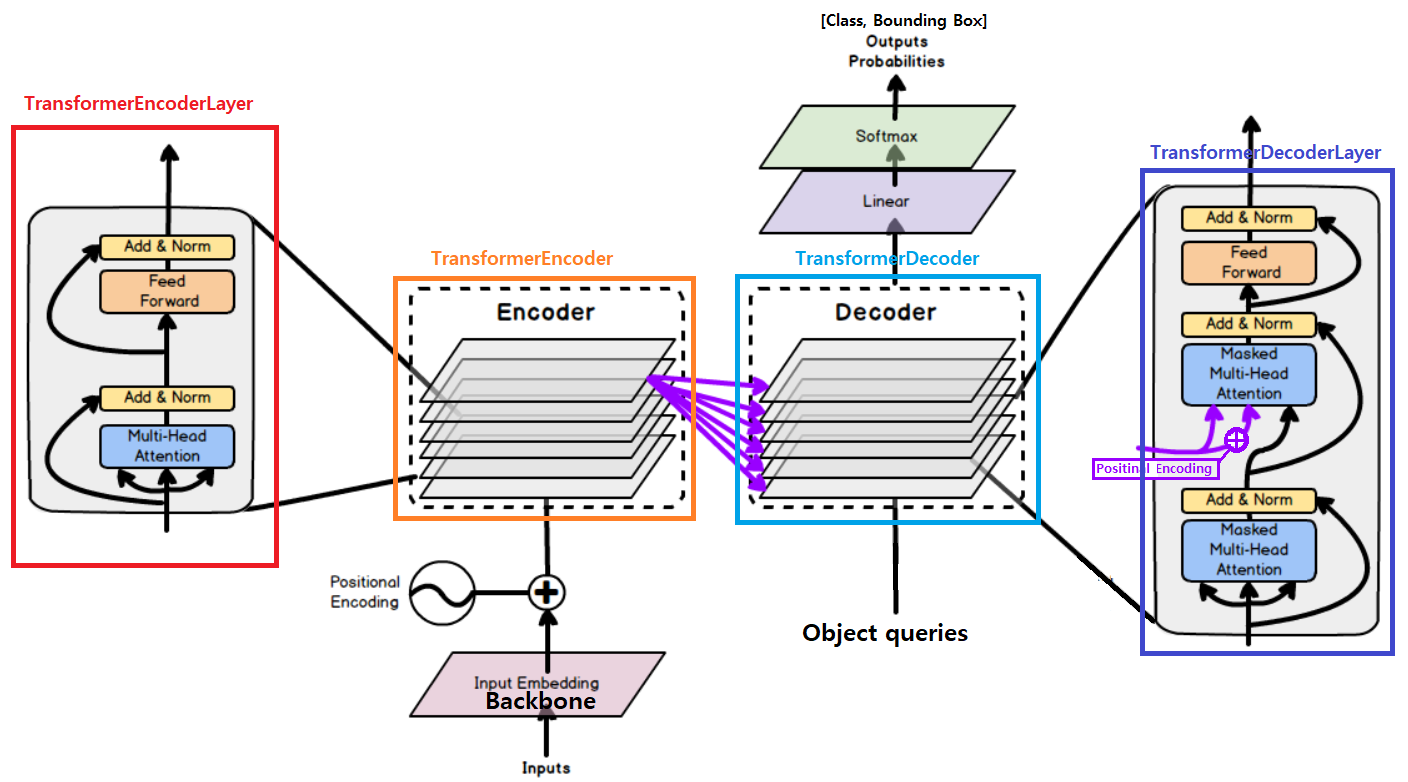
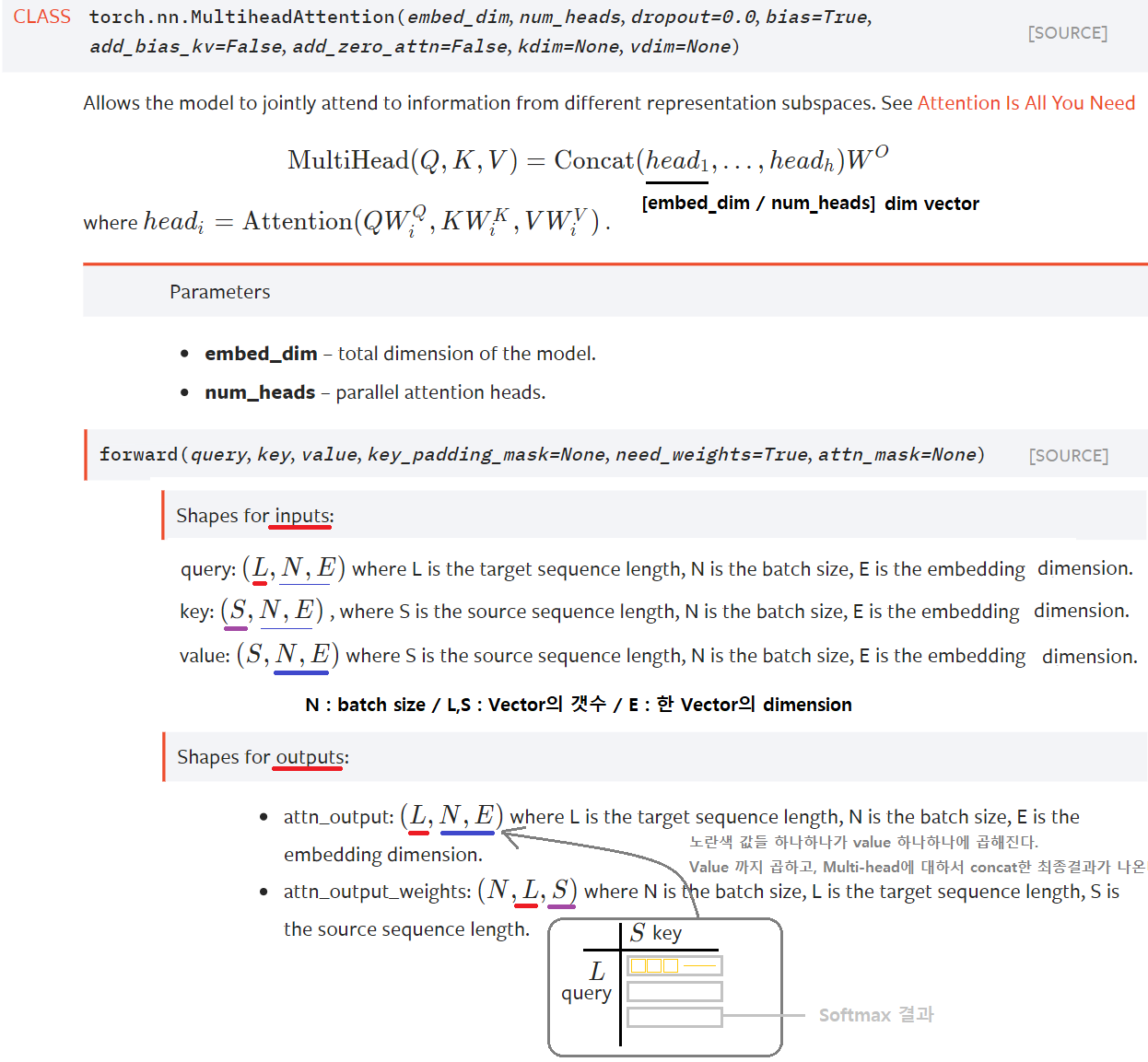
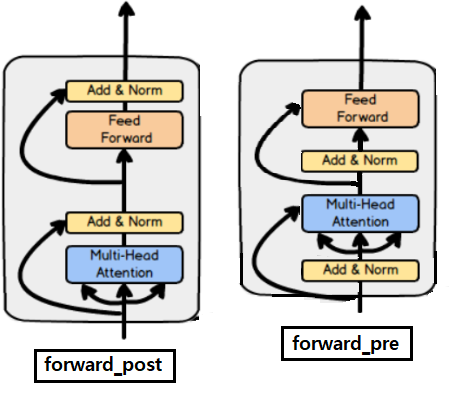
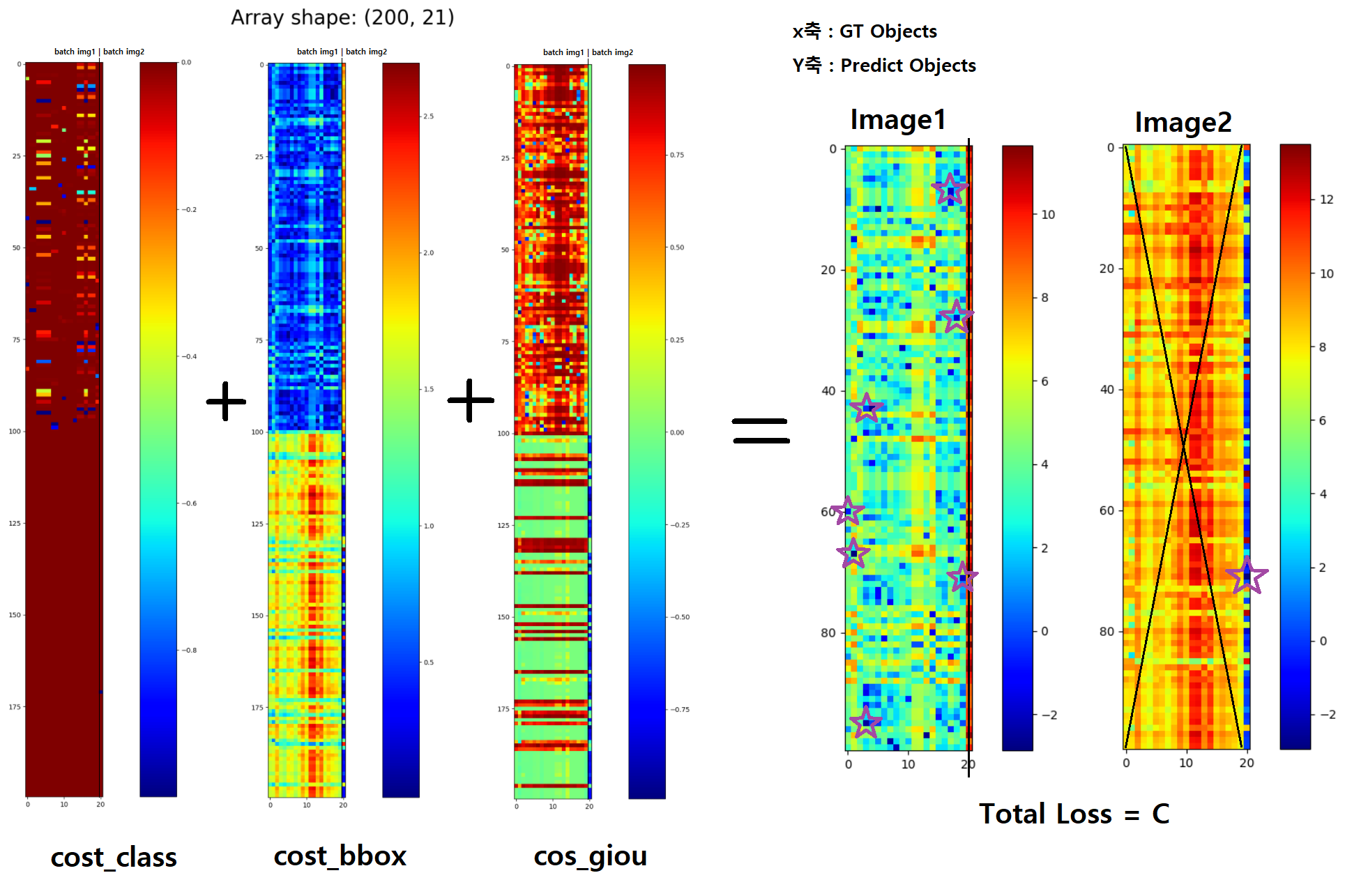
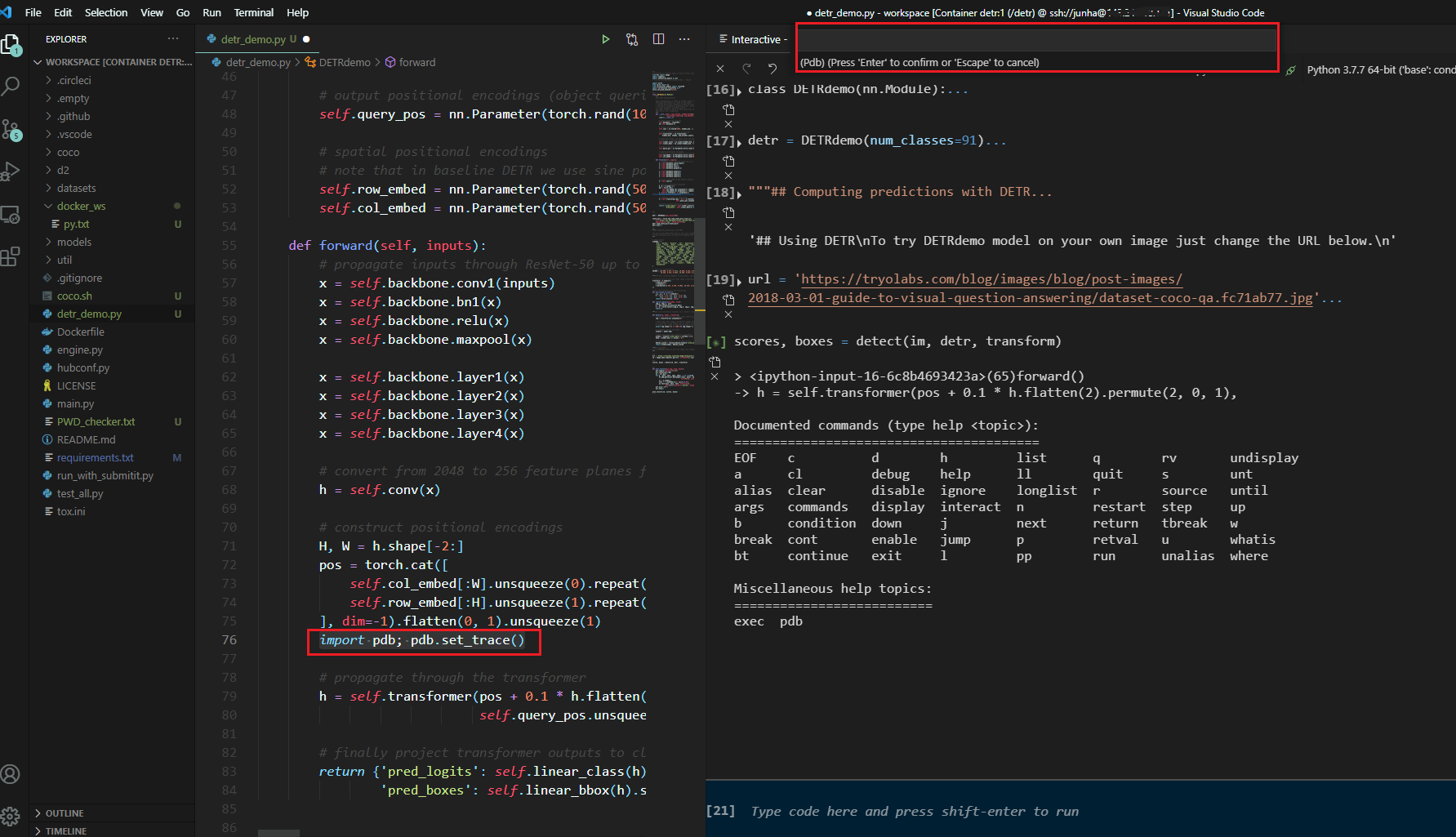
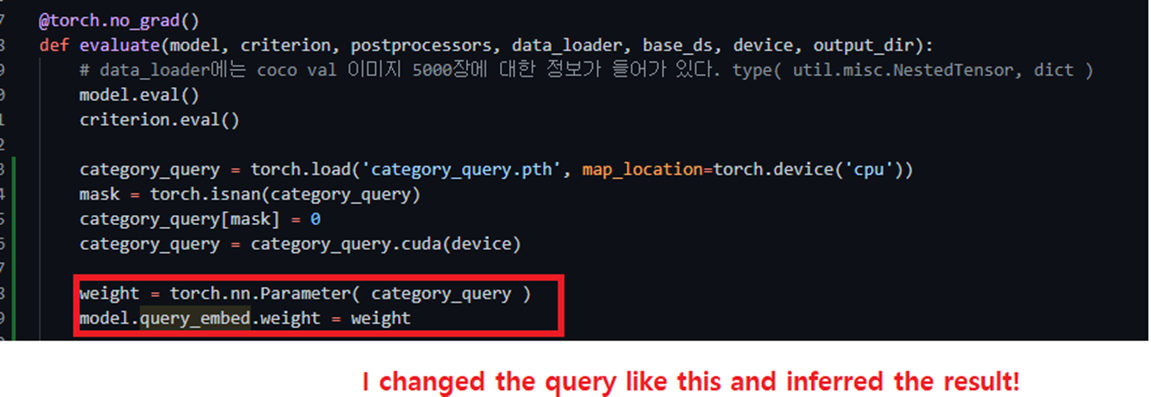
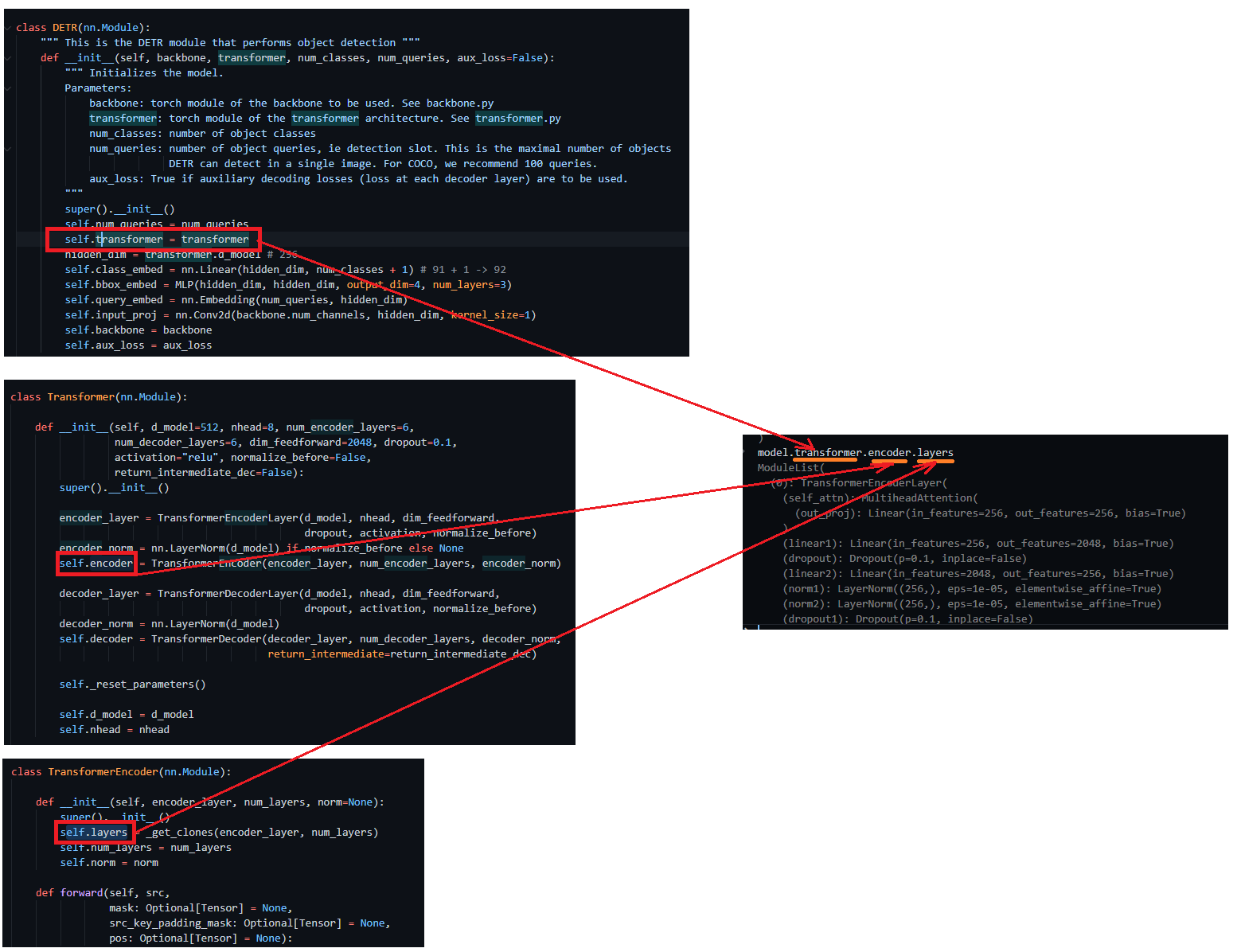
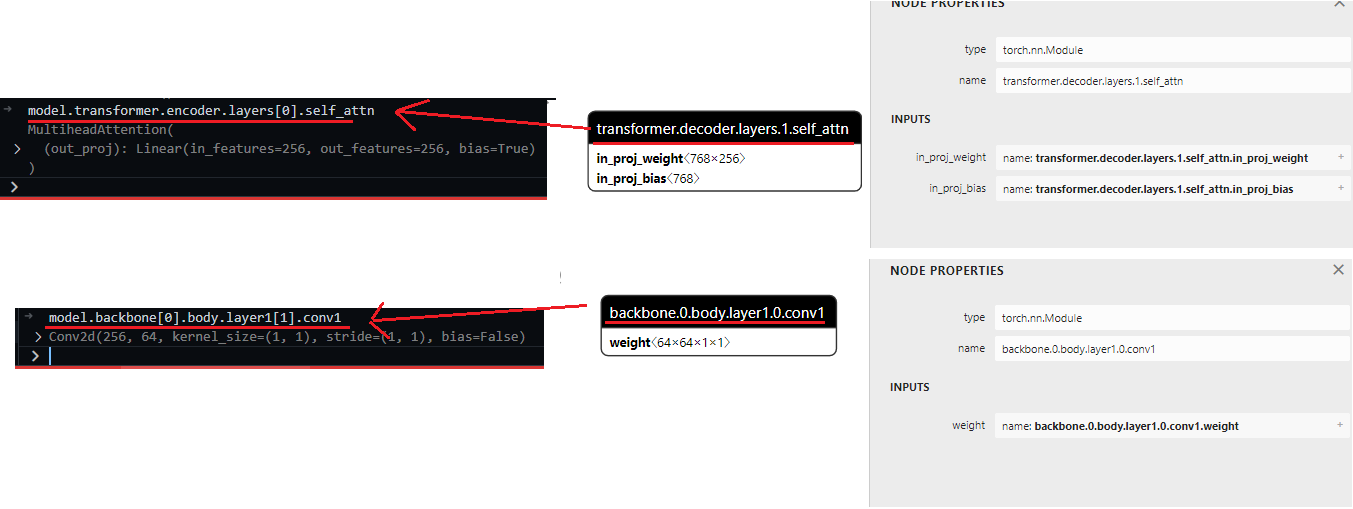
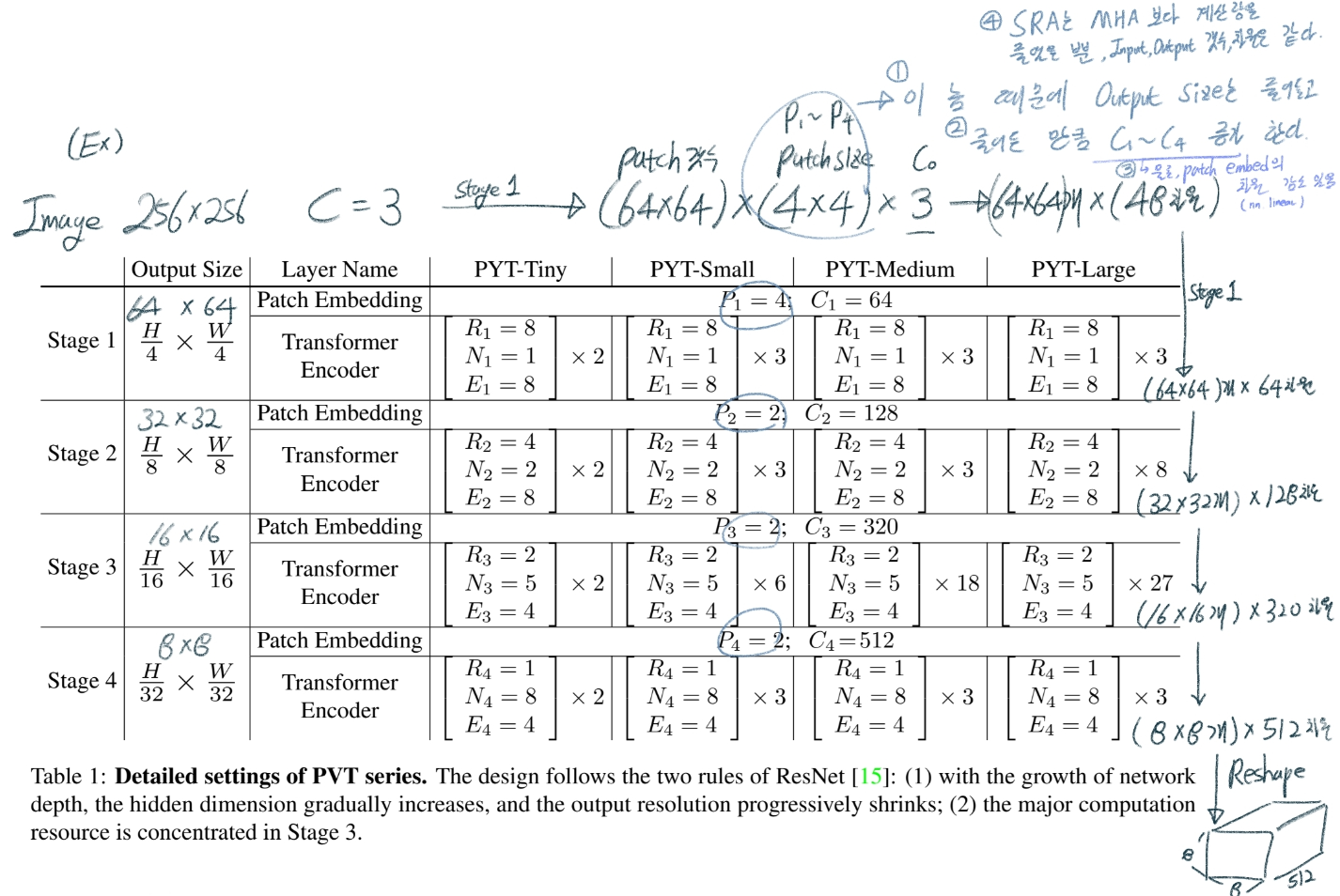
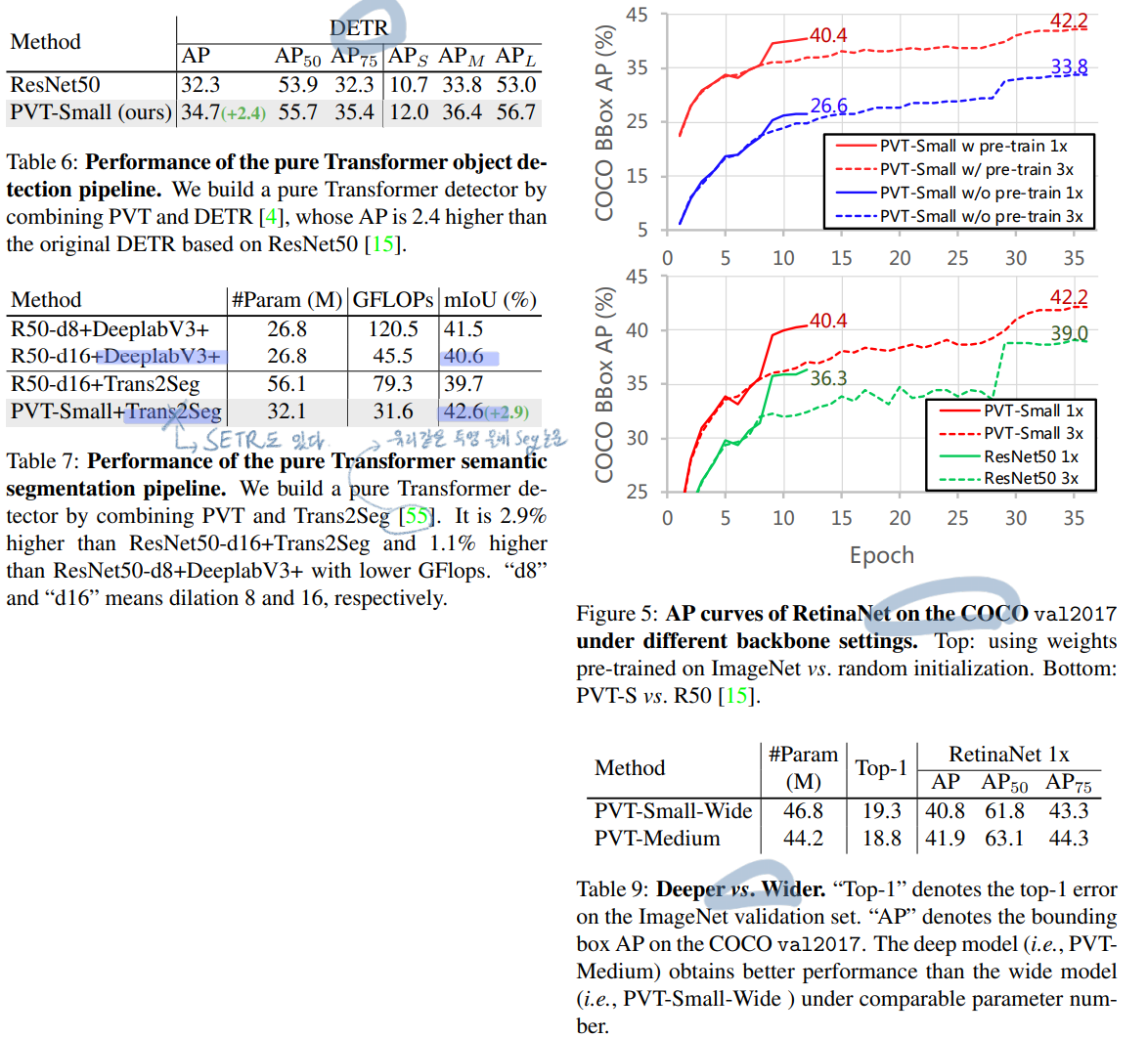
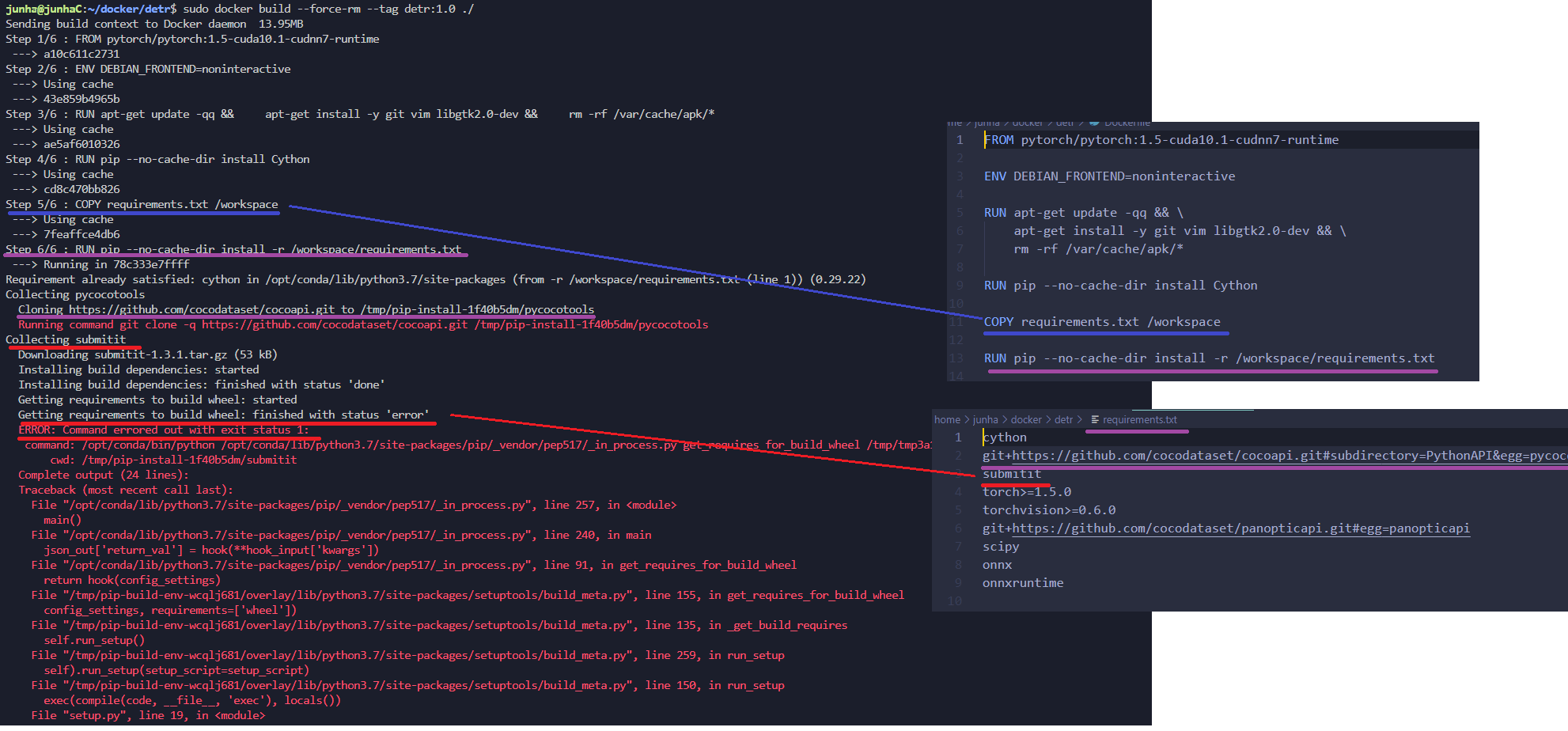
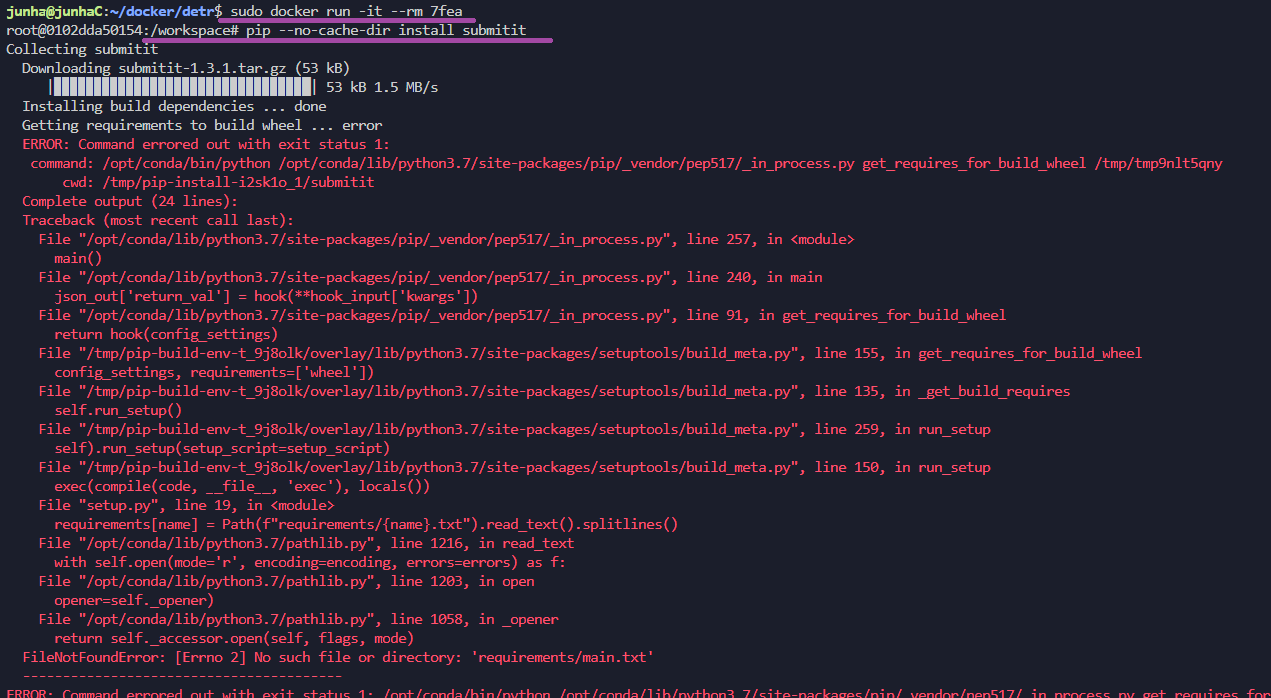
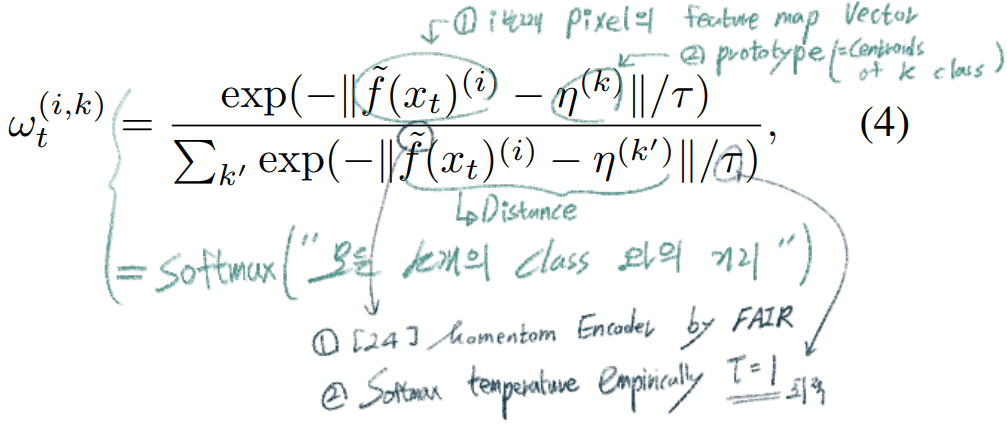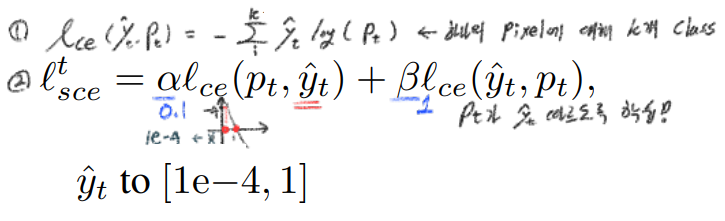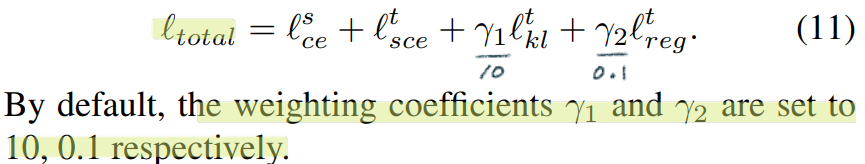########## '../_base_/models/resnet50.py' ##########
model = dict(
type='ImageClassifier',
backbone=dict(
type='ResNeSt',
depth=50,
num_stages=4,
out_indices=(3, ),
style='pytorch'),
neck=dict(type='GlobalAveragePooling'),
head=dict(
type='LinearClsHead',
num_classes=1000,
in_channels=2048,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
topk=(1, 5),
))
########## '../_base_/datasets/imagenet_bs32.py' ##########
dataset_type = 'ImageNet'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
# 원하는 Transformer(data agumentation)은 아래와 같이 추가하면 된다.
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='RandomResizedCrop', size=224),
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]
# 위에 내용은 이 아래를 정의하기 위해서 사용된다. cfg.data.test, cfg.data.val 이 사용된다.
data = dict(
samples_per_gpu=32,
workers_per_gpu=2,
train=dict(
type=dataset_type,
data_prefix='data/imagenet/train',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_prefix='data/imagenet/val',
ann_file='data/imagenet/meta/val.txt',
pipeline=test_pipeline),
test=dict(
# replace `data/val` with `data/test` for standard test
type=dataset_type,
data_prefix='data/imagenet/val',
ann_file='data/imagenet/meta/val.txt',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='accuracy')
########## '../_base_/schedules/imagenet_bs256.py' ##########
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(policy='step', step=[30, 60, 90])
runner = dict(type='EpochBasedRunner', max_epochs=100)
########## '../_base_/default_runtime.py' ##########
# checkpoint saving
# 1번 epoch씩 모델 파라미터 저장
checkpoint_config = dict(interval=1)
# yapf:disable
# 100번 iteration에 한번씩 log 출력
log_config = dict(
interval=100,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)] # [('train', 2), ('val', 1)] means running 2 epochs for training and 1 epoch for validation, iteratively.
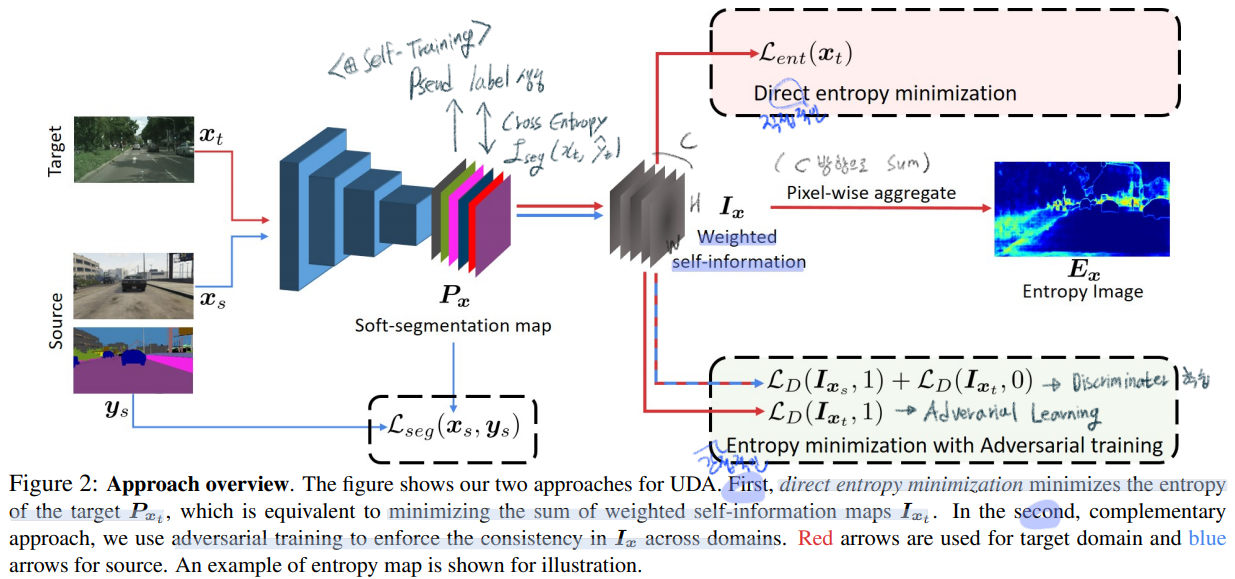

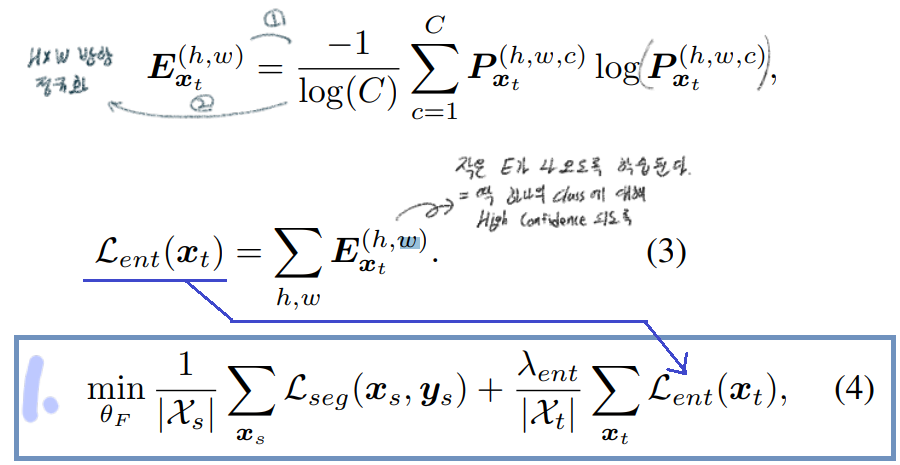
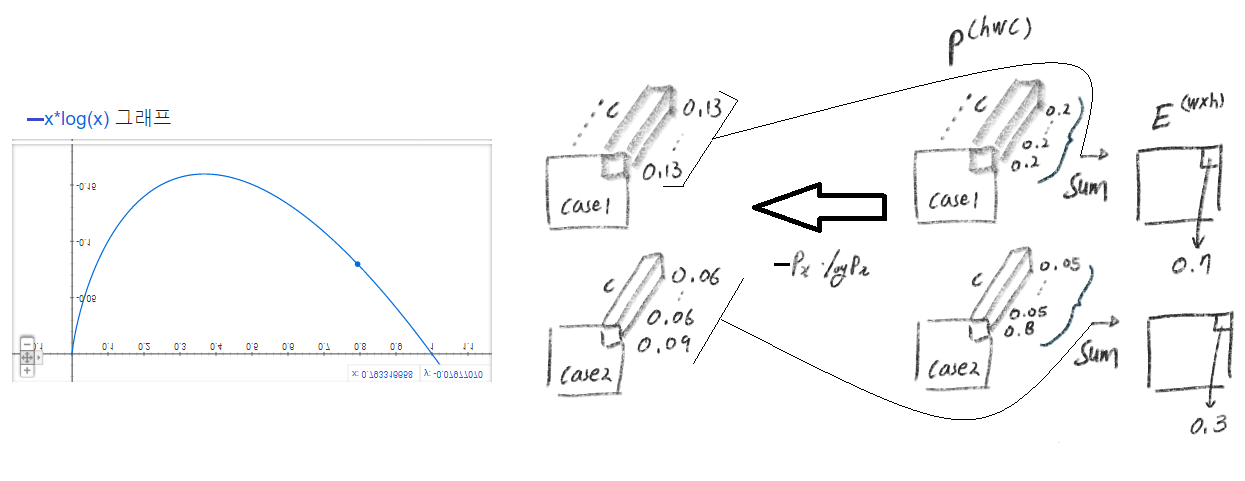

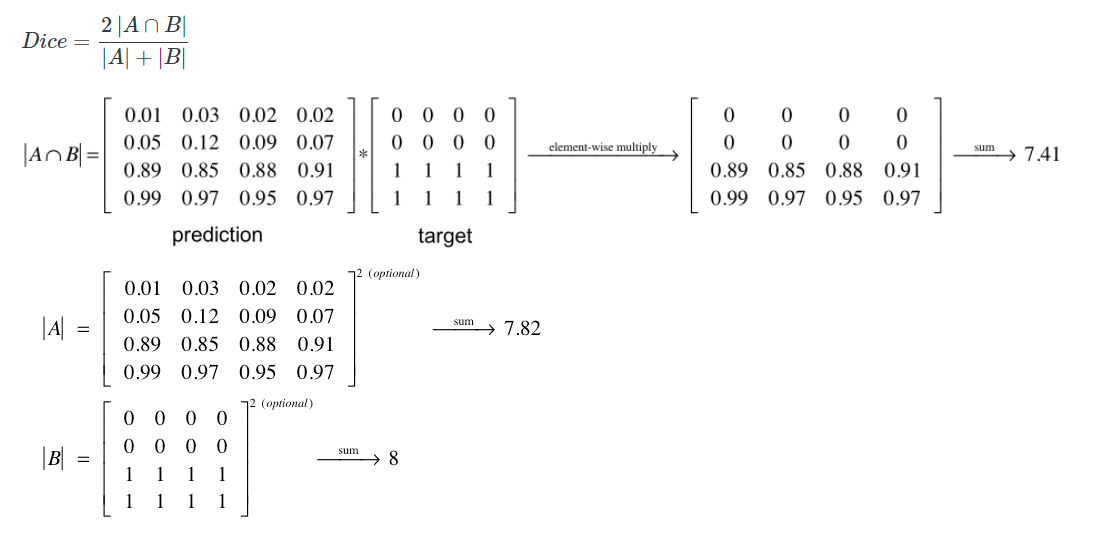
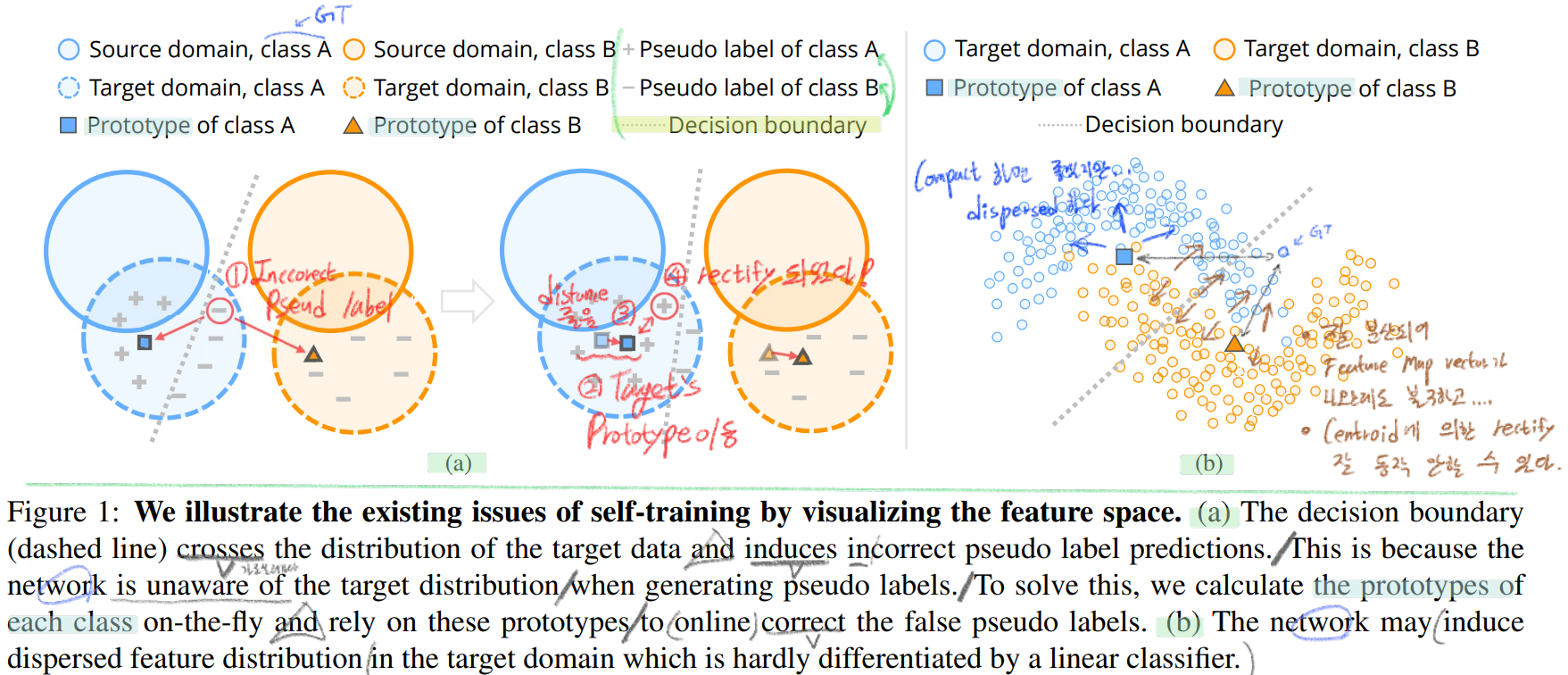
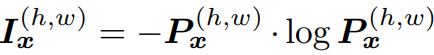 (단순하게 생각해서, 그냥 각 픽셀마다 이 연산이 수행됐다고 생각하면 되겠다.) 이것을 사용하는 장점은 아래와 같다.
(단순하게 생각해서, 그냥 각 픽셀마다 이 연산이 수행됐다고 생각하면 되겠다.) 이것을 사용하는 장점은 아래와 같다.