【Detection】Understanding YOLOv4 paper w/ code, my advice
분류 : Object Detection
저자 : Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao
읽는 배경 : Recognition Basic. Understand confusing and ambiguous things.
읽으면서 생각할 포인트 : 코드와 함께 최대한 완벽히 이해하기. 이해한 것 정확히 기록해두기.
느낀점 :
논문 리뷰 정리를 할 때. 자꾸 같은 내용은 여기저기 쓰지 말아라. 한 곳에 몰아 정리하자.
예를 들어 A,B라는 Key Idae가 있다고 치자. 그럼 아래 처럼 실제 논문에는 “같은 내용 반복하거나, 어디 다른 곳에서 추가 특징을 적어 놓는다” 그렇다고 나도 따로따로 분산해서 정리해 두면 안된다. “깔끔하게 정말 핵심만 한곳에 모아 정리해야 한다” 즉. 굳이 논문과 같은 목차로 정리해야한다는 강박증을 가지지 말아라. 어차피 핵심만 모으면 별거 없고, 한곳에 모인다.
$ 실제 논문에는 이렇게 적혀 있다. 1. Conclusion ,abstract - A idea - A의 장점1 - A의 장점2 - B idea - B의 장점1 2. introduction - A의 장점1 - A의 장점2 - B의 장점1 - B의 장점2 3. Relative Work - A의 장점3 - B의 장점2 - B의 장점3 $ ** 내가 정리해야 하는 방법 ** 1. Conclusion ,abstract - A idea - A의 장점1 - A의 장점2 - A의 장점3 - B idea - B의 장점1 - B의 장점2 - B의 장점3- YoloV4 는 새로운 기법을 공부하기 위해서 읽는 논문이 아니로, 그냥 Object Detection Survey 논문이다.
목차
PS
- IOU loss paper1 - origin, IOU loss paper2
- IOU loss = 1 − IoU
- GIOU 정의됨. CIOU DIOU는 여기서 정의 안됨.
- SAM = CBAM 이전 Post
- IOU loss paper1 - origin, IOU loss paper2
추가로 읽어야겠다고 생각되는 논문
- PAN - path aggregation network
- ATSS : Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection (citation : 74)
- RFB : Receptive Field Block Net for Accurate and Fast Object Detection (ASPP의 발전된 형태)
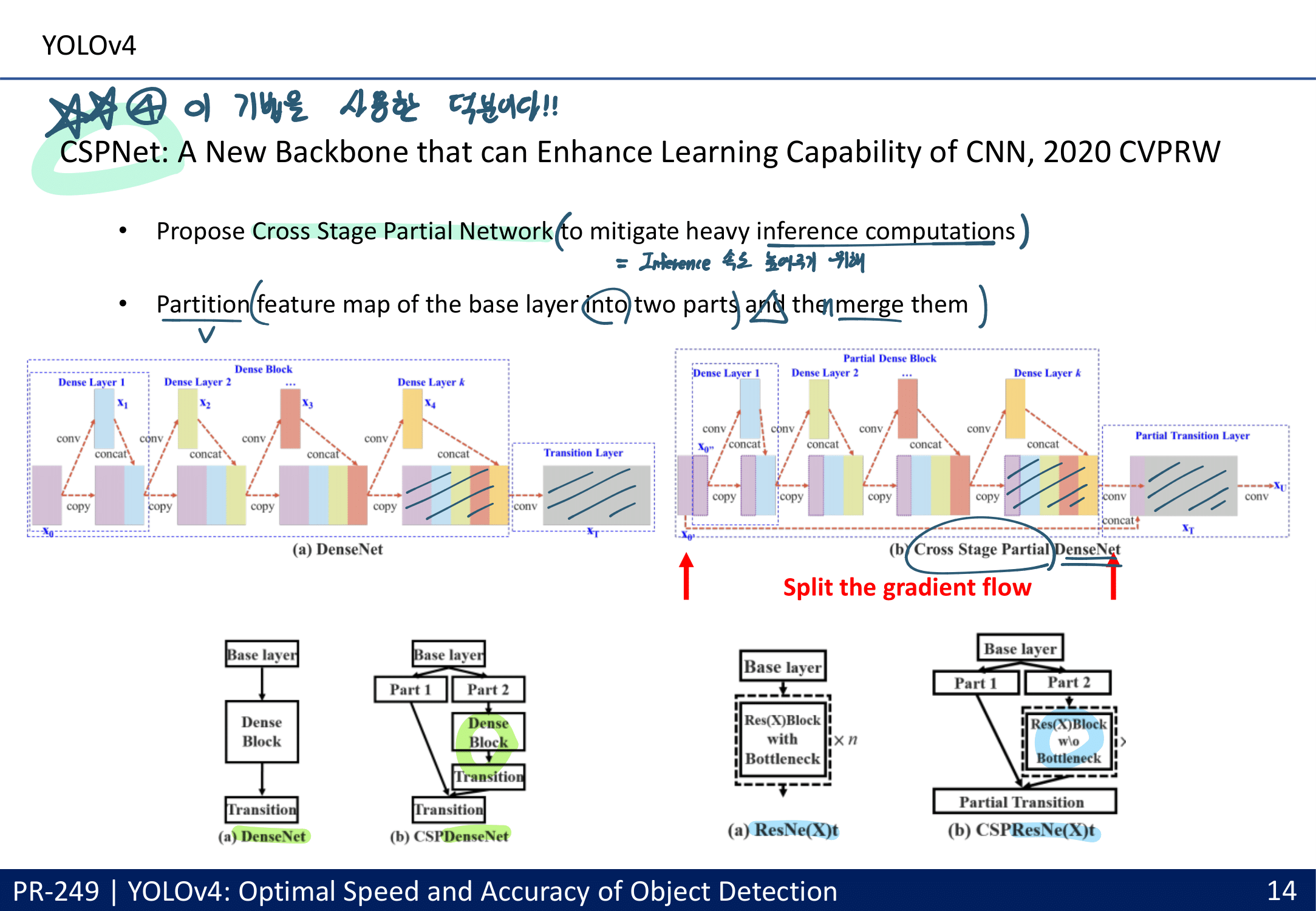
- Cross stage partial connections (DenseNet의 경량화 버전)
- Batch Normalization 블로그 & 동영상, CBN (Cross Batch Normalization)
- Soft-NMS -> DIoU-NMS
- CIoU-loss
- Mish Activation
- DropBlock regularization
- Class label smoothing
1. YoloV4 from youtube
- youtube 논문 발표 링크 - 설명과 정리를 잘해주셨다.
- 이 정도 논문이면, 내가 직접 읽어보는게 좋을 것 같아서 발표자료 보고 블로그는 안 찾아보기로 함
- 강의 필기 PDF는 “OneDrive\21.겨울방학\RCV_lab\논문읽기”

















2. YoloV4 Paper Review
1. Conclustion, Abstract, Introduction
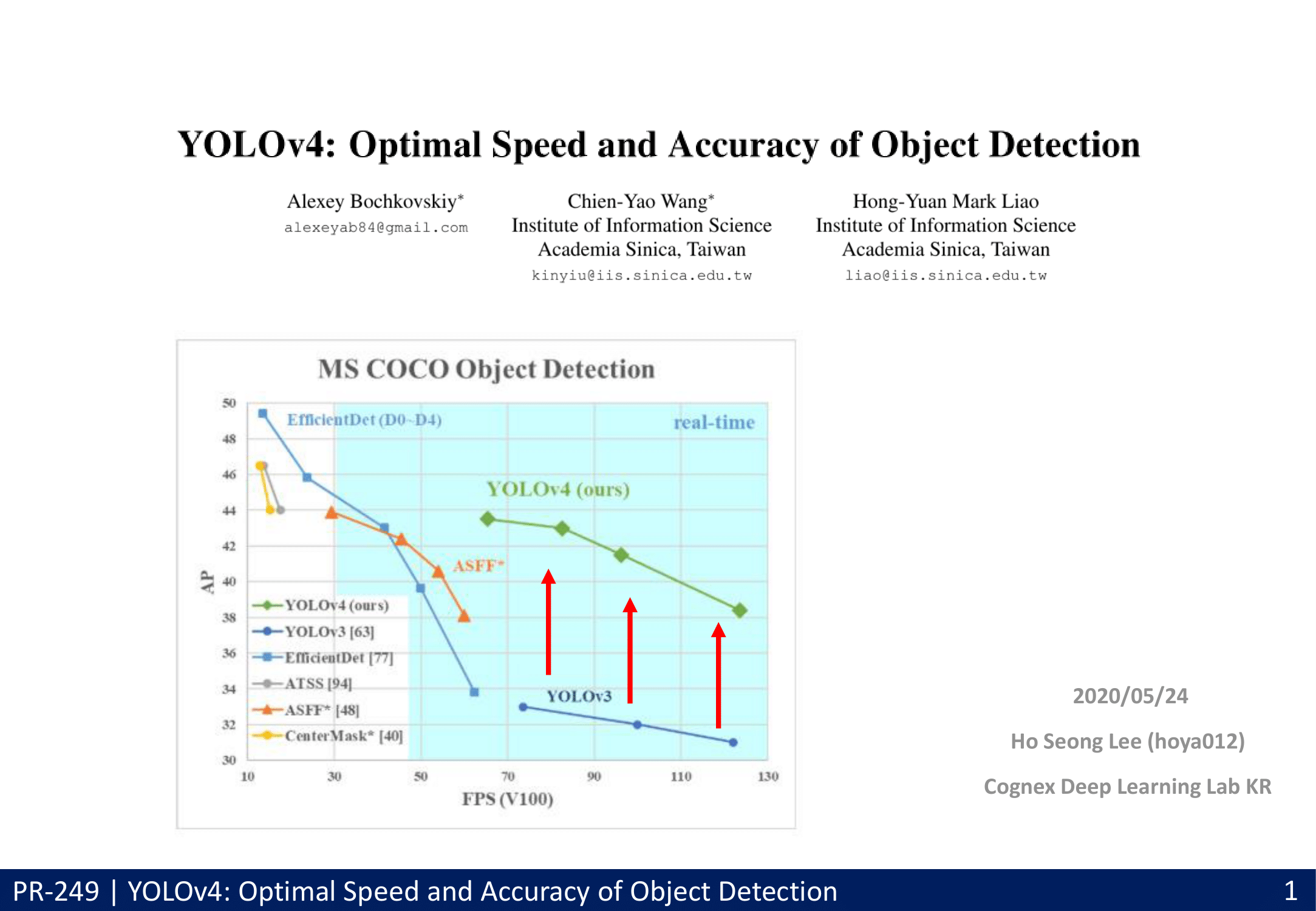
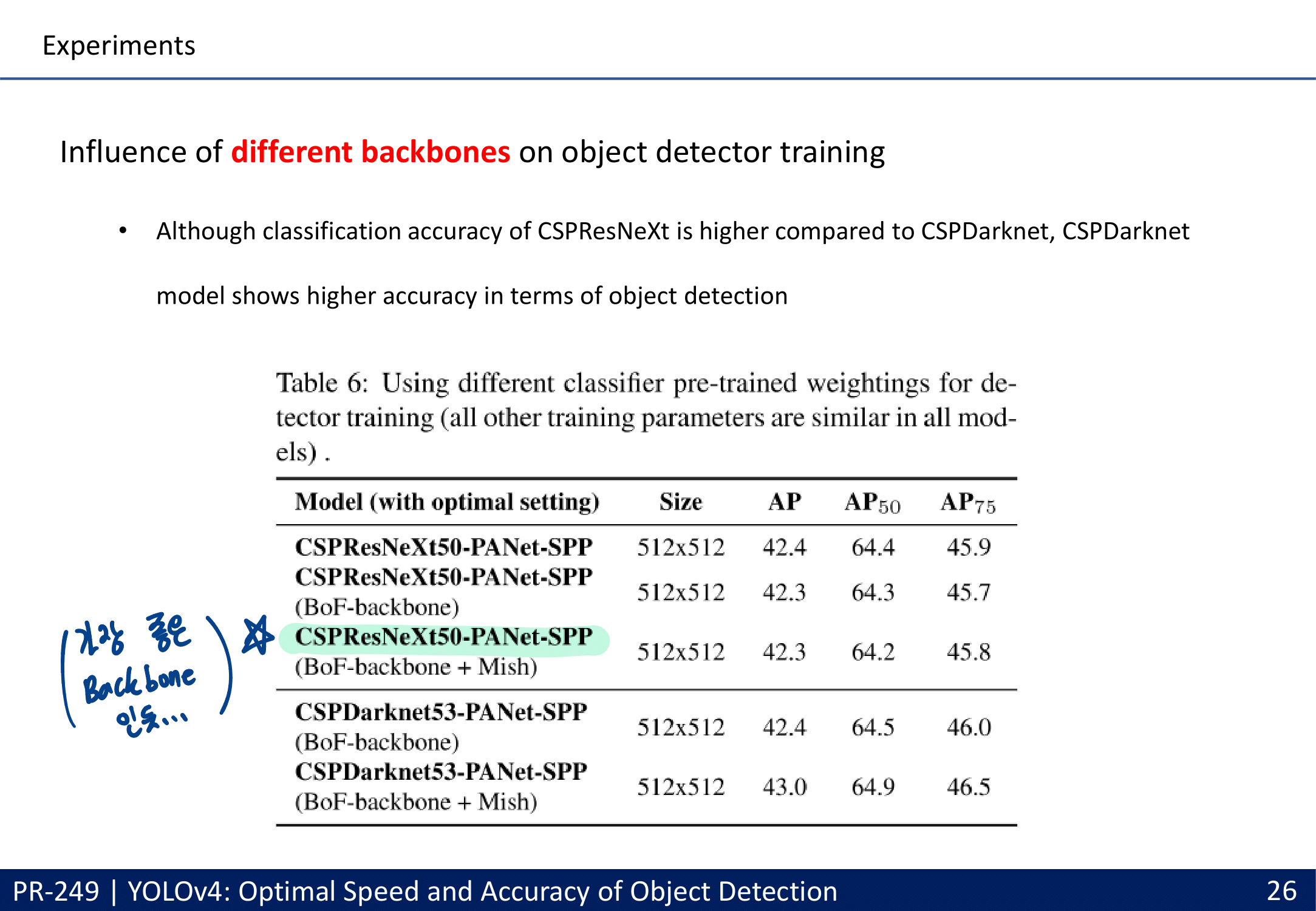
- Faster / more Accurate(AP_(50…95) and AP_(50)) / best-practice with only one conventional GPU (1080 Ti or 2080 Ti GPU)
- batch-normalization and residual-connections 과 같은 통념적으로 사용되는 Feature(여기서는 특정기술,특정방법론 이라고 해석해야함. Feature Map의 Feature 아님)뿐만 아니라, 아래와 같이 YoloV4에서 많은 성능향상을 준 Feature들이 있다.
- 무시가능한 특정기술 : Self-adversarial-training (SAT) (-> 좋다는 결과 없음. 일단 무시)
- 중간 중요도의 특정기술 : CmBN, DropBlock regularization, and CIoU loss. 기법들
- 중상 중요도 특정기술 : Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Mish-activation
- 자신들이 Modified한 특정기술 : Cross Batch Normalization (CBN), Path aggregation network(APN), CBAM(SelfAttentionModul)
- 자신들이 추가하거나 수정한 특정기술: Mosaic data augmentation
- (1) Bag-ofFreebies and (2) Bag-of-Specials methods : 아래 목차에서 차근히 다룰 예정
- 최종 성능 : 43.5% AP (65.7% AP50) for the MS COCO / speed of ∼65 FPS on Tesla V100.
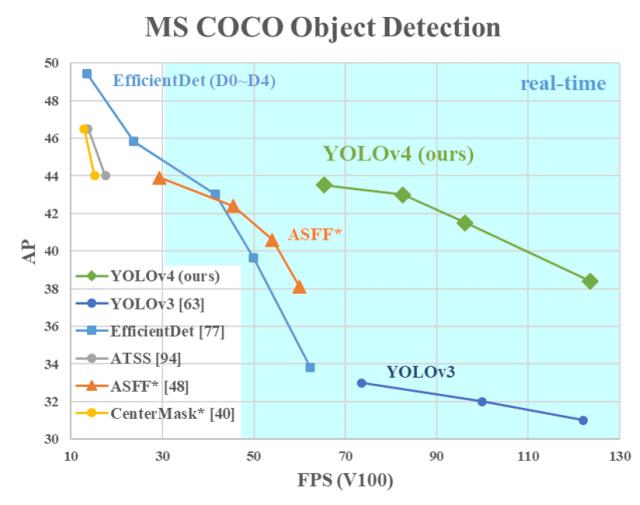
- ASFF : Learning Spatial Fusion for Single-Shot Object Detection (citation : 14)
- ATSS : Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection (citation : 74)
2. Related work = Object Detection Survey
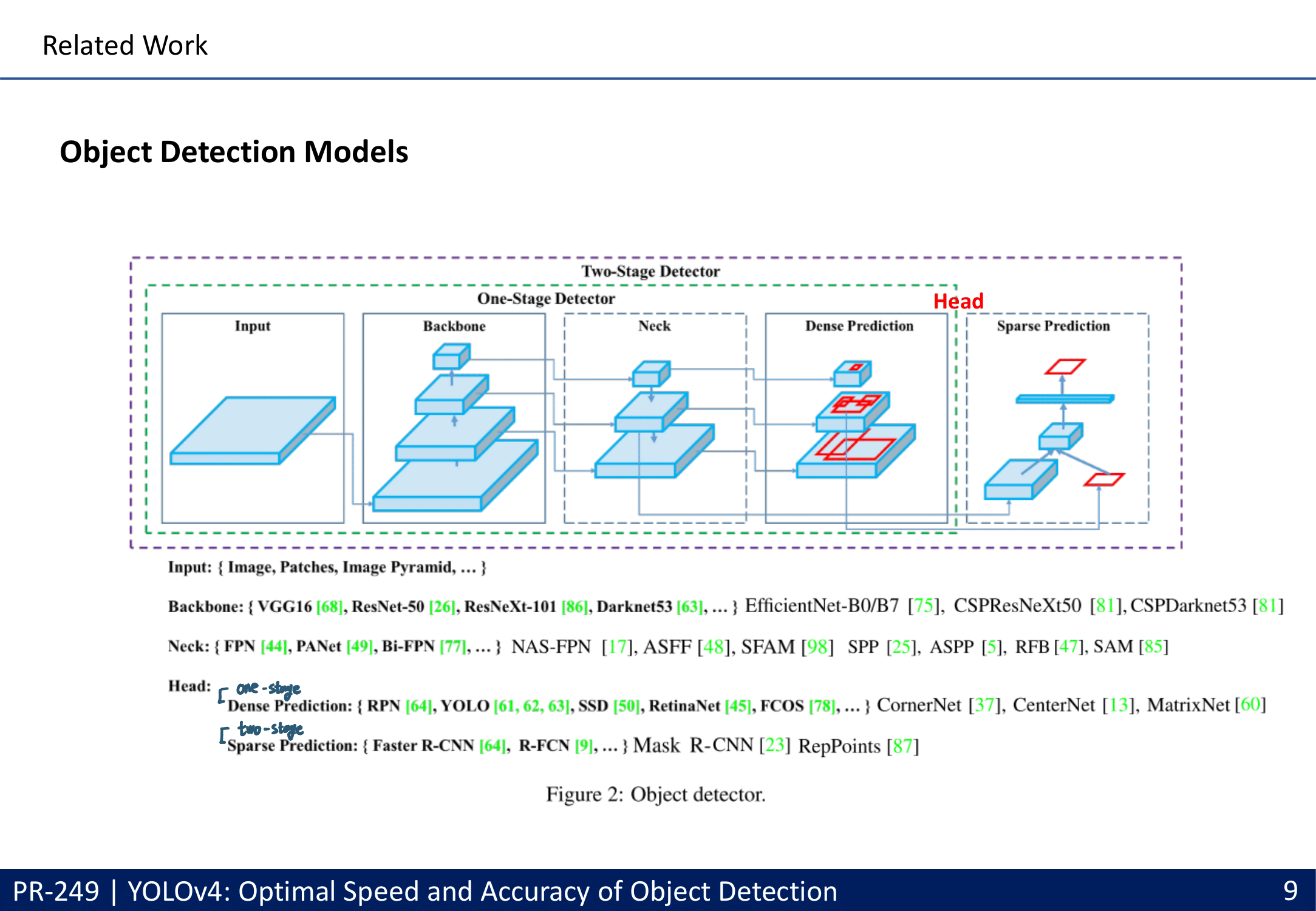
- Object detection models
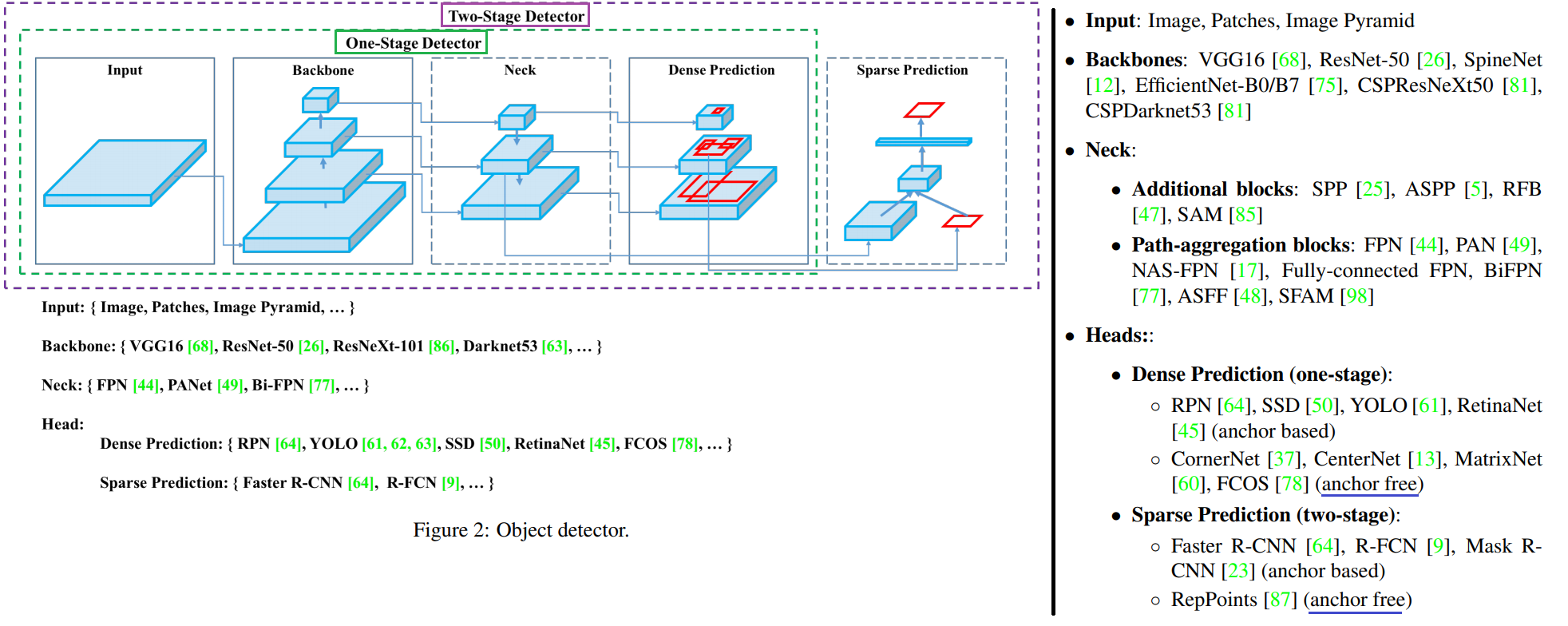
- 최근에 핫한 기술에 이런 것들이 있다.
- 특히 Neck 이란? different stages로부터 Feature Maps 정보를 Collect한다.
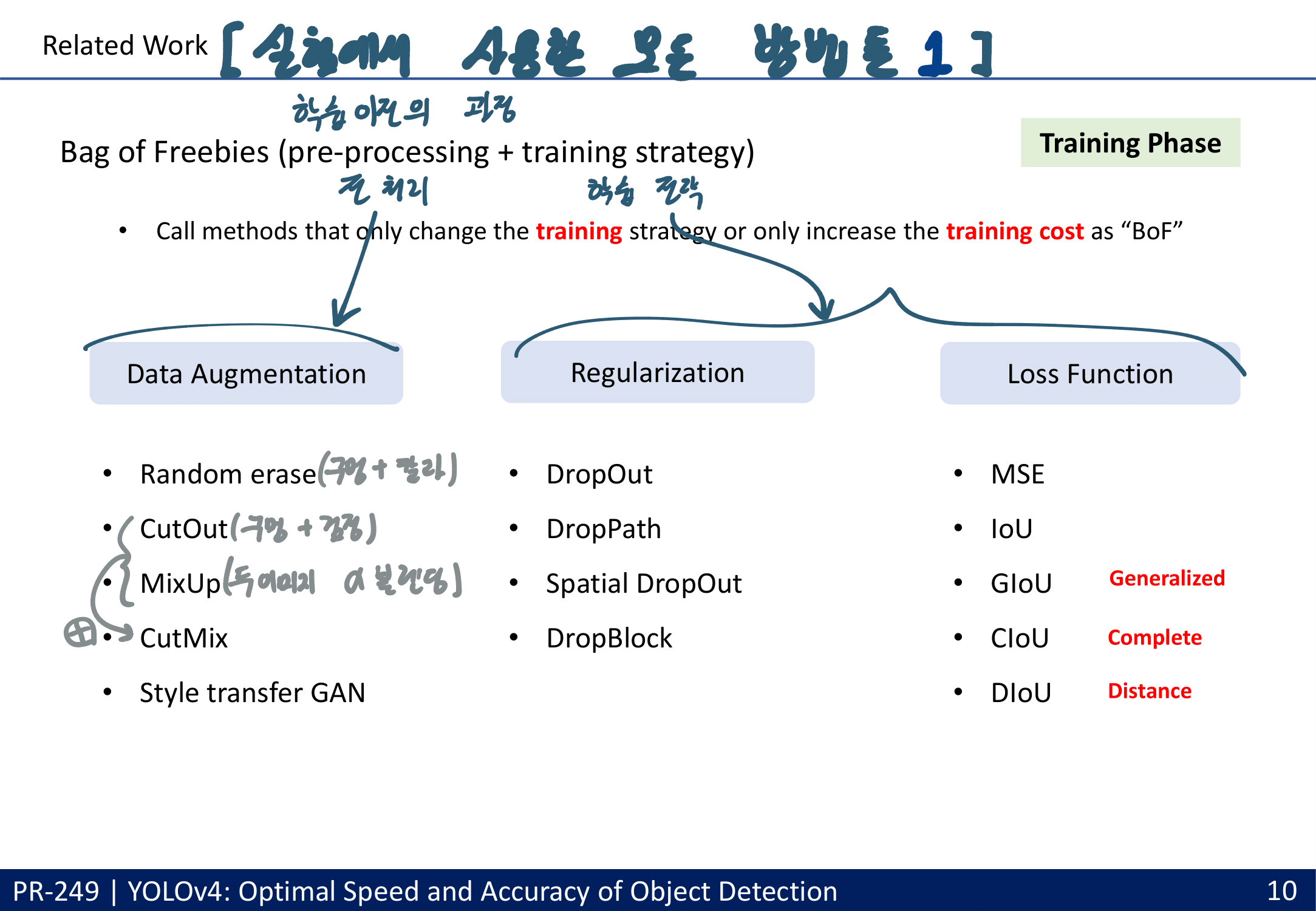
- Bag of freebies
- change the training strategy or increase the training cost 하는 방법들
- data augmentation
- pixel-wise adjustments
- photometric distortions : the brightness, contrast, hue, saturation, and noise of an image.
- geometric distortions : random scaling, cropping, flipping, and rotating 2. simulating object occlusion issues
- random erase(칼라 구멍), CutOut(검정 구멍)
- hide-and-seek, grid mask : 일부 사각형 구역 검정
- DropOut, DropConnect, and DropBlock 위 기법과 비슷한 컨셉
- MixUp(두 이미지 blending), CutMix(구멍 - 다른 사진+Label) : multiple images together 사용하기
- style transfer GAN : 현재 내가 가진 the texture bias 줄인다.
- the problem of semantic distribution bias (예를들어, data imbalance)
- Only two-stage : hard negative example mining & online hard example mining
- one-stage : focal loss
- label smoothing [73] , label refinement network [33]
- the objective function of Bounding Box (BBox) regression
- MSE : corresponding offset를 예측하는 것은, 온전체 객체 그 자체의 정보를 이용하는 것이 아니다.
- IoU loss : IOU가 커지도록 유도됨. offset Loss는 (GT 박스가) 큰 객체에서는 상대적으로 loss가 커지는 경향이 있었는데, IOU loss에서는 이런 문제가 없음.
- G_IOU : 객체의 모양이나 회전 정보를 포함
- DIoU : GT와 BB의 center간의 distance 고려
- CIoU : overlapping area, center distacne, the aspect ratio 모두 고려 (GOOD)
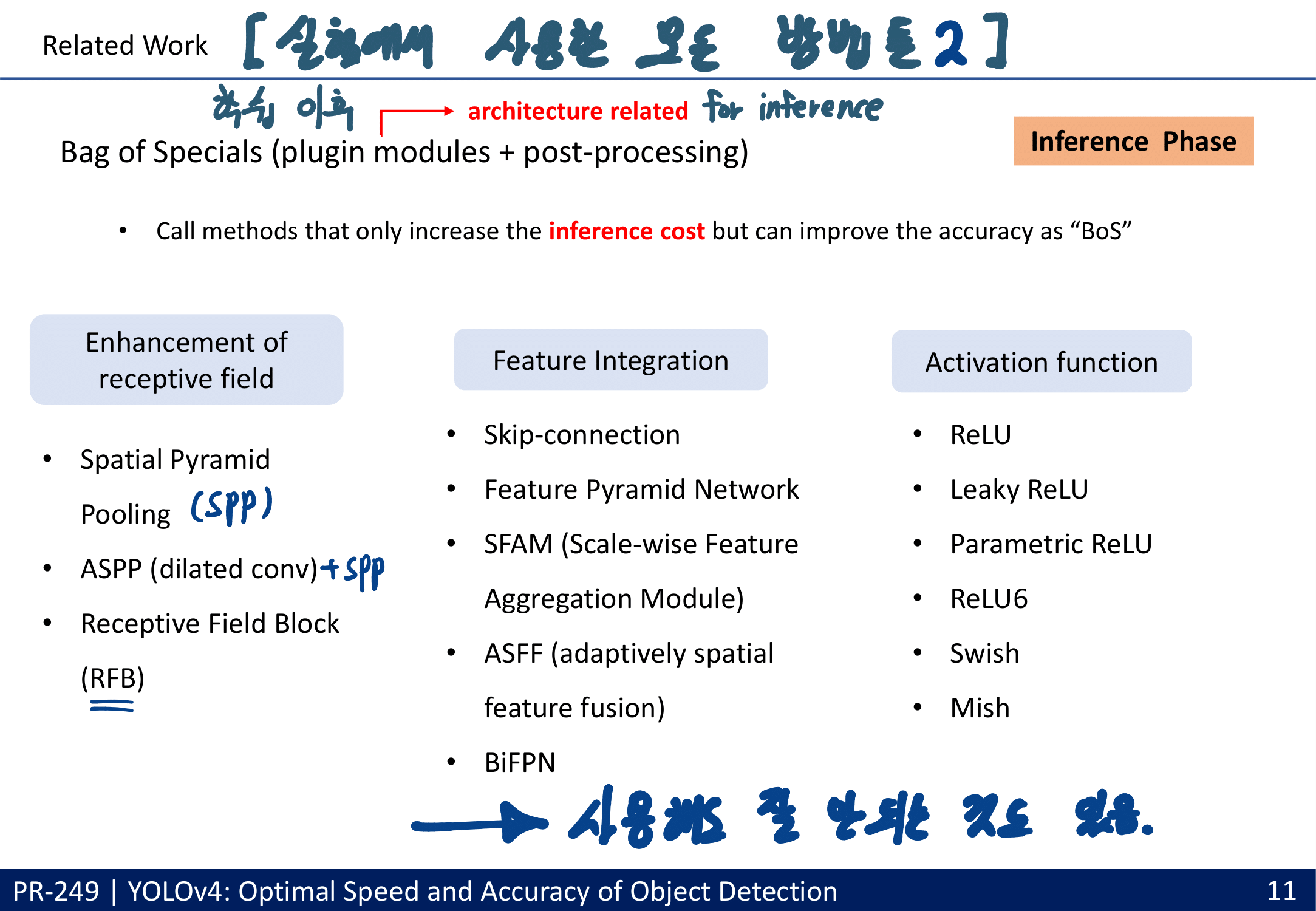
- Bag of specials
- increase the inference cost 하는 방법들
- enhance receptive field
- SPP [25], ASPP(dilated ratio) [5] -> RFB(가장 종합적 이해와 낮은 Cost 좋은 성능 향상)[47]
- attention module
- channel-wise attention(channel 기준 pooling) and pointwise-wise attention(1x1xdepth의 cell 기준 pooling)
- Squeeze-and-Excitation (SE) -> Spatial Attention Module (SAM=CBAM) (extra calculation 적음. GPU 연산 속도에 영향 없음)
- feature integration
- skip connection, hyper-column [22], FPN
- 새로운 관점의 FPN : SFAM(SE module to execute channelwise level) [98] , ASFF(point-wise level reweighting) [48], and BiFPN(scale-wise level re-weighting and Adding feature maps of different scales) [77].
- activation function
- LReLU [54], PReLU [24] : zero gradient problem 해결
- ReLU6 [28], Scaled Exponential Linear Unit (SELU) [35], hard-Swish [27]
- Swish and Mish : continuously differentiable activation function.
- post-processing
- greedy(origin) NMS : optimizing & objective function 두개가 일관(일치)되게 만든다. by Confidence score
- soft NMS : greedy NMS가 Confidence score의 저하 문제를 고려함
- DIoU NMS : soft NMS에서 the center point distance개념을 추가
- 하지만 anchor-free method 에서는 더 이상 post-processing을 필요로 하지 않는다.
- Normalization
- Batch Normalization에 대해서는 나중에 다시 진지하게 공부해 봐야겠다.
- Batch Normalization (BN) [32], Cross-GPU Batch Normalization (CGBN or SyncBN) [93], Filter Response Normalization (FRN) [70], or Cross-Iteration Batch Normalization (CBN) [89]
- Skip-connections
- Residual connections, Weighted residual connections, Multi-input weighted residual connections, or Cross stage partial connections (CSP)
3. Methodology
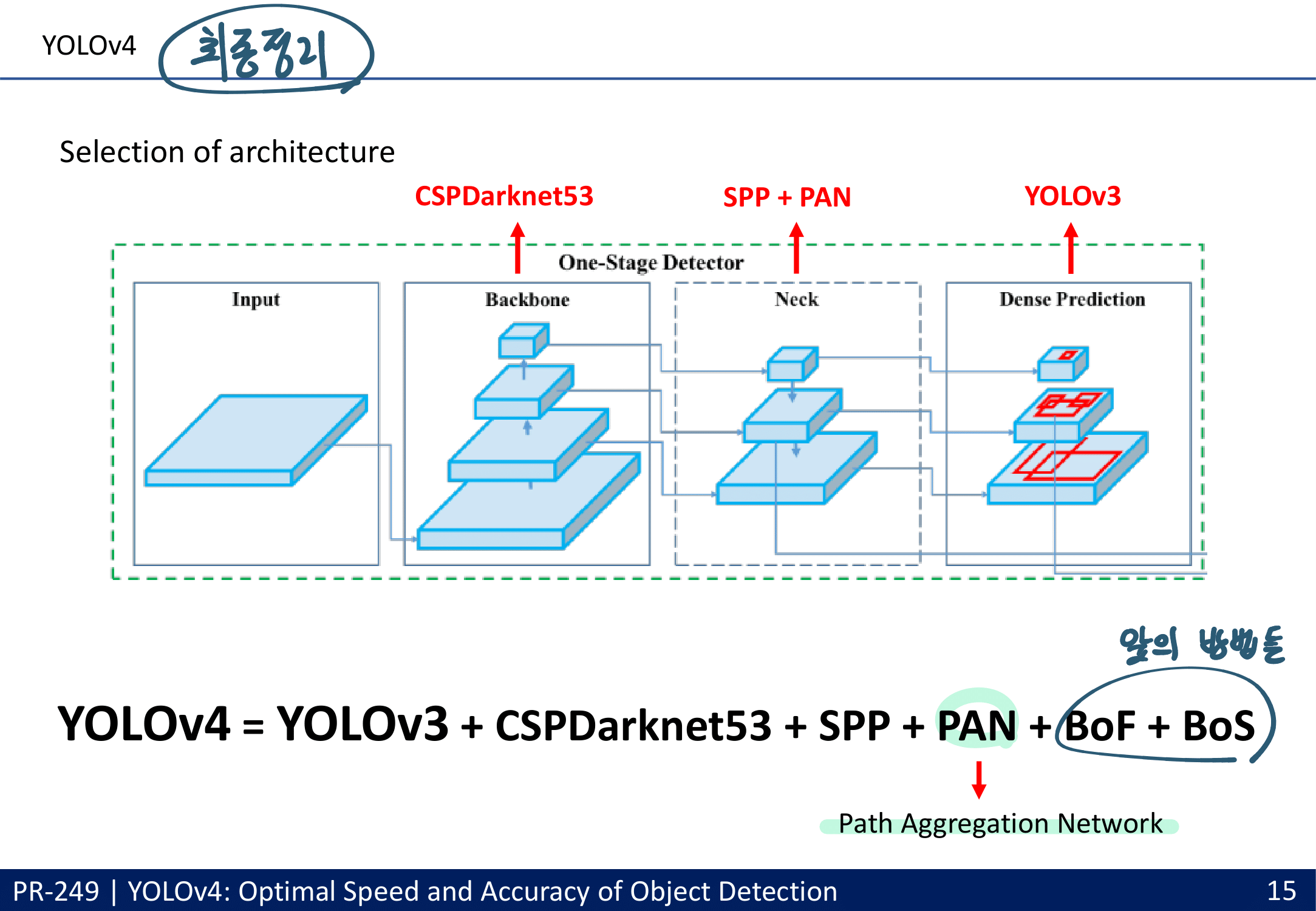
- Backbone 선택
- 아래의 조건을 만족하는 Cross-Stage-Partial-connections (CSP) (DenseNet의 경량화 버전) 과 DarkNet을 접목시켜서 사용. or CSPResNext50
- Higher input Resolution For Small-objects
- More Layers For Higher receptive field
- More parameters For more accurate
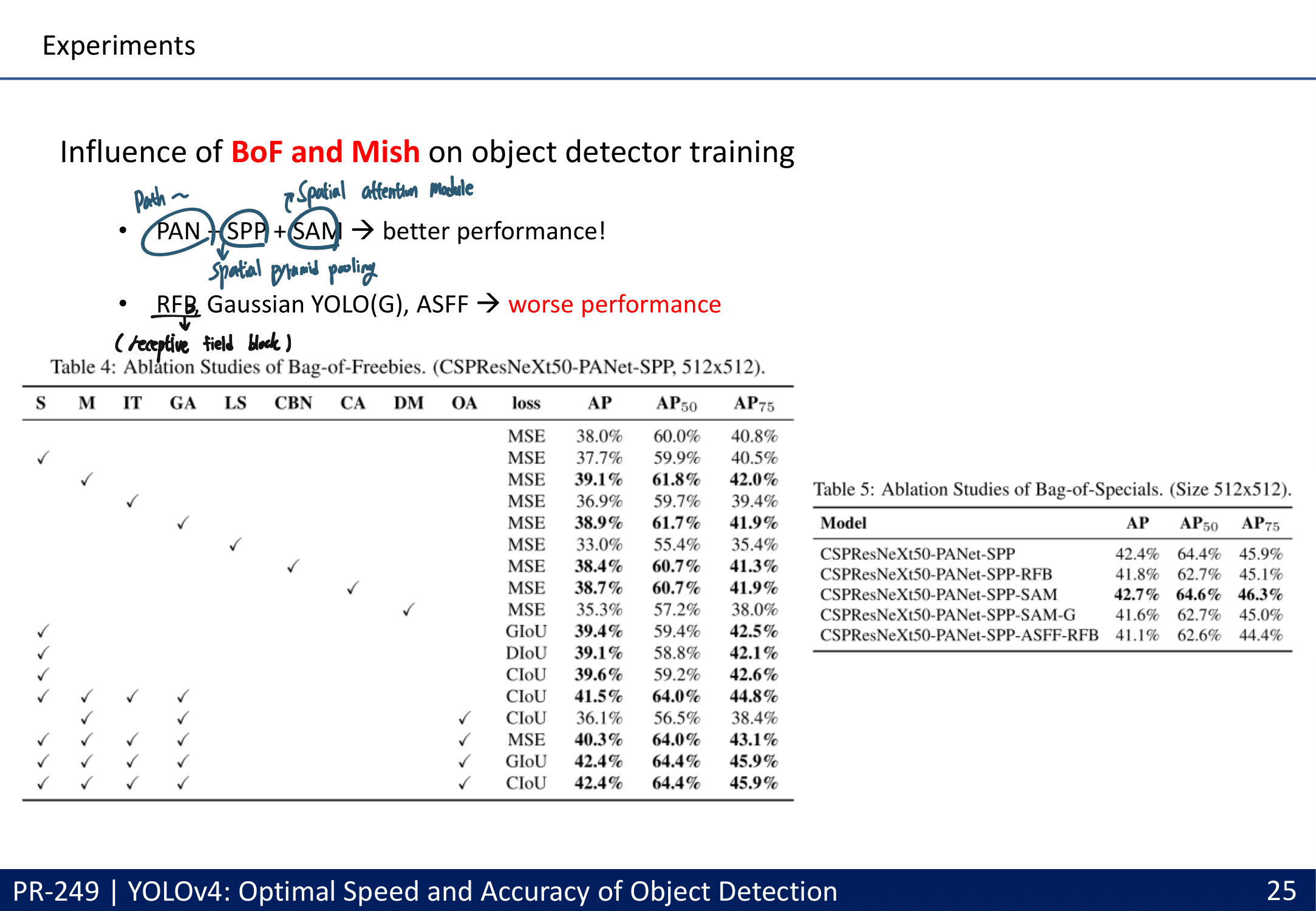
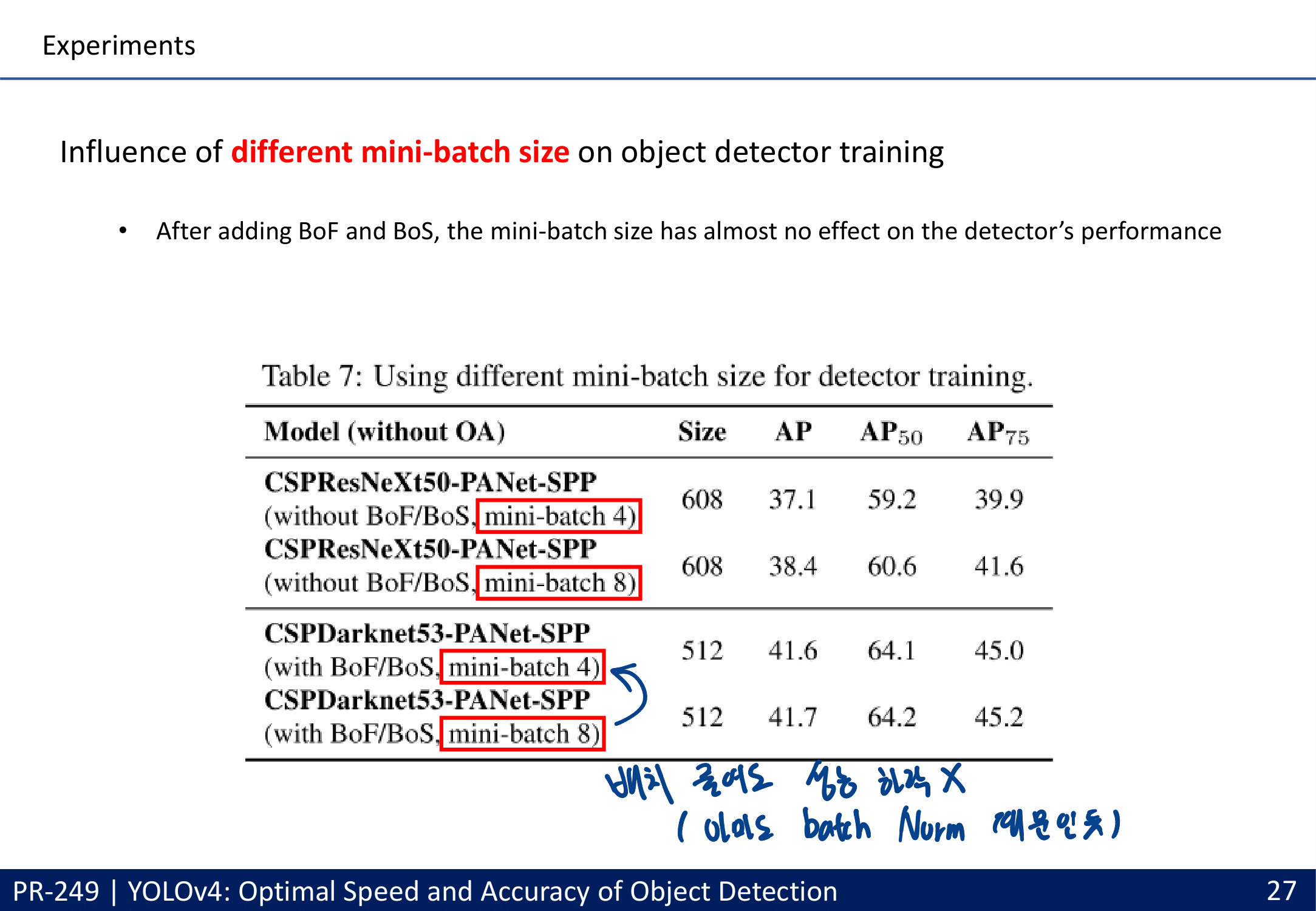
- 많은 실험을 통한 Selection of BoF and BoS (주의할점 : 여기에서 좋은 결과를 내어야만 좋은 Method인 것은 아니다. 저자가 코드를 잘 못 이해하고 코드 적용이 잘못 됐을 수도 있는 거니까. By PPT발표자)
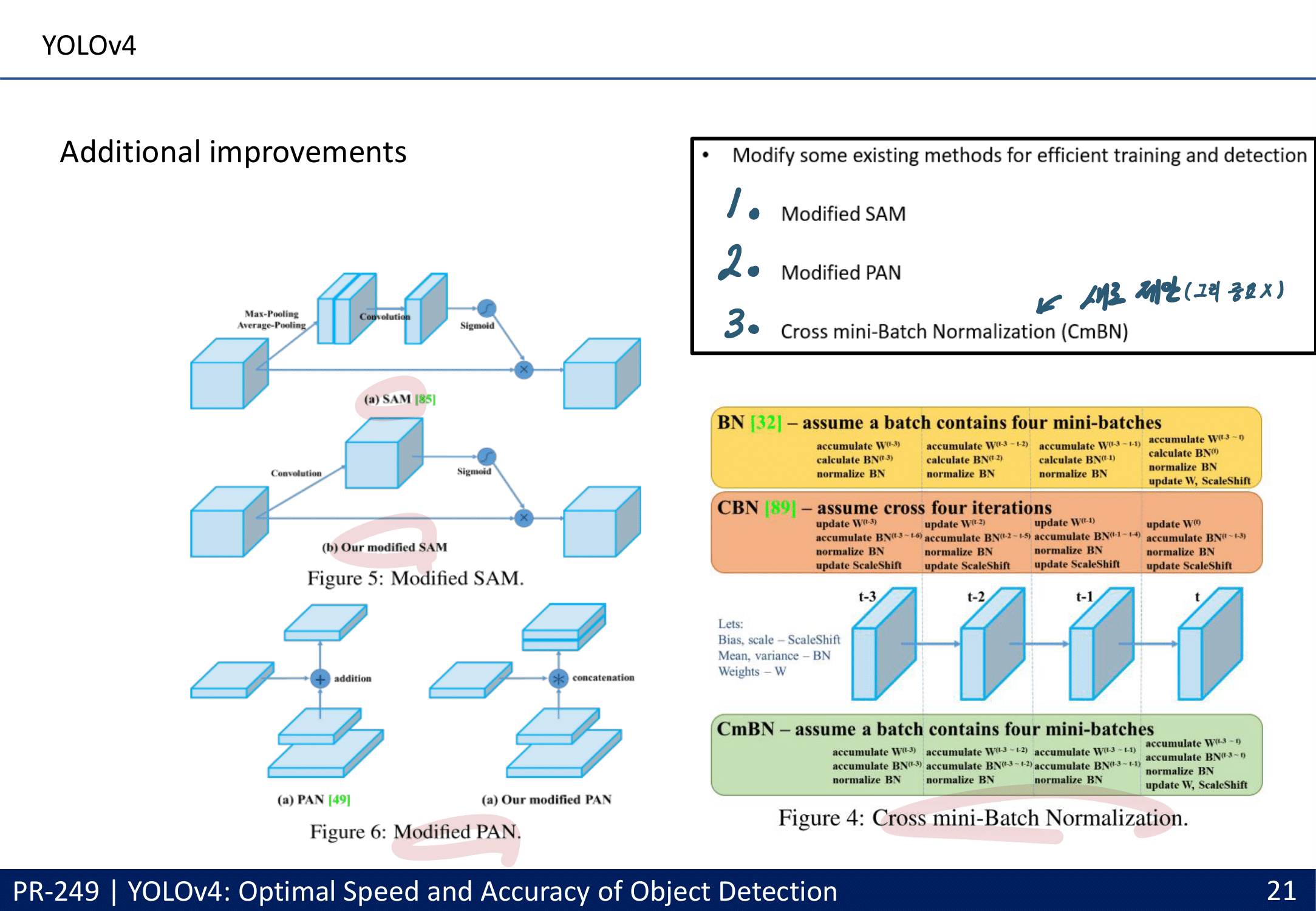
- Additional improvements
- data augmentation Mosaic : 4개의 이미지 합치기, batch normalization에 효과적
- CmBN collects statistics only between mini-batches within a single batch. Batch No
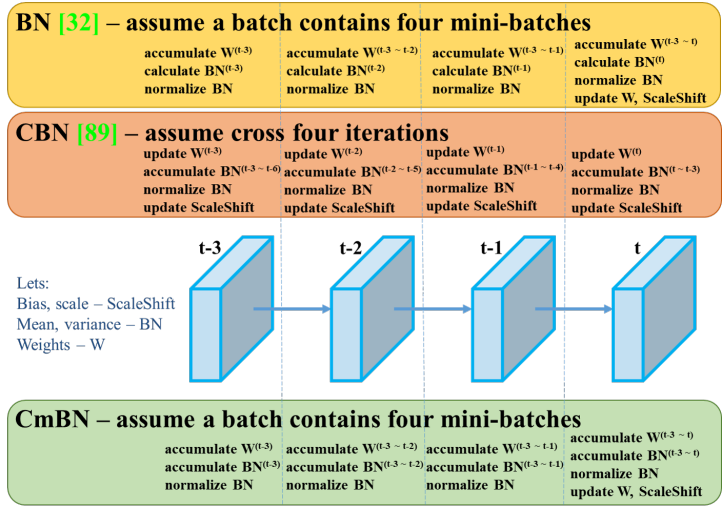
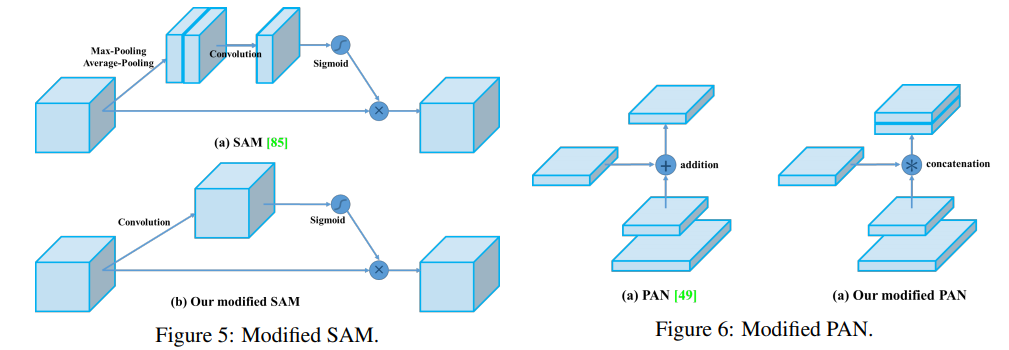
- SAM(CBAM) 그리고 PAN을 아래와 같이 수정했다. (그림만 나오지 구체적인 방법 없다.)
- 최종적으로 YoloV4에서 사용한 방법론

- 시간이 날 때마다, 위의 방법론들에 대해서 찾아 공부하는 것도 좋을 것 같다.
- 실험결과는 윗 목차의 PPT 내용 참조
3. Tianxiaomo/pytorch-YOLOv4
- Github Link : Tianxiaomo/pytorch-YOLOv4 (중국어 Issue가 많아서 아쉬웠지만, 이거말고 1.1k star를 가지고 있는 YoloV4-pytorch repo도 대만사람이여서 그냥 둘다 비슷하다고 판단. 2.6k star인 이 repo보는게 낫다)
- ONNX : Open Neural Network Exchange
- machine learning frameworks(Pytorch, Caffe, TF)들 사이의 Switching을 돕기 위해 만들어진 툴 by Facebook, Microsoft
- onnx라는 파일 형식이 있다. Convert Pytorch into ONNX Tutorial
- 그래서 아래와 같은 파일이, 이 깃허브 파일에 존재한다.
demo_pytorch2onnx.py: tool to convert into onnxdemo_darknet2onnx.py: tool to convert into onnx
- 이렇게 정리 되어 있어서 너무 좋다. 우리가 여기서 집중해야 할 파일은
models.py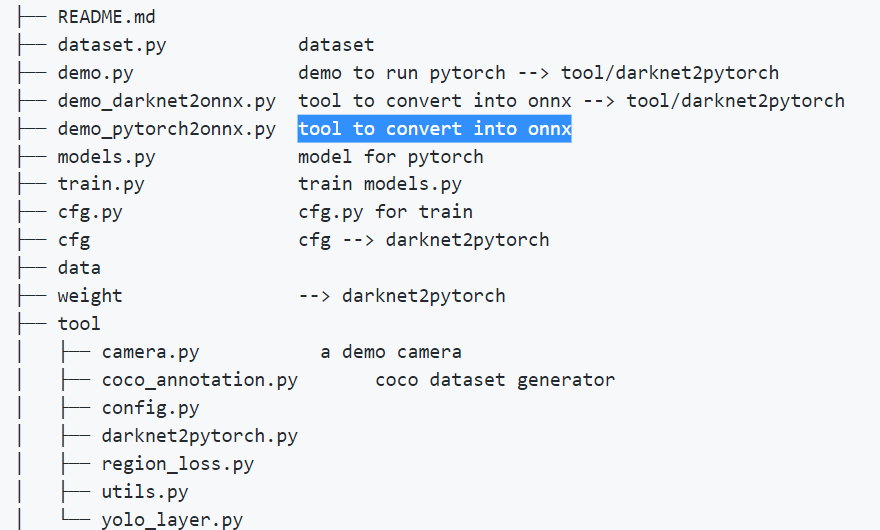
- 2021.02.08 : ONNX와 YoloV4에 대한 코드 공부는 지금 당장 필요 없다. 위에서 사용된 Method들 중 모르는 것은 일단 논문을 읽어야 한다. 그리고 각 Method에 따른 코드를 Github에서 다시 찾던지, 혹은 이 YoloV4 repo에서 찾아서 공부하면 된다.
4. About YoloV5
- YoloV5 Git issue : Where is paper? // The project should not be named yolov5
- 위의 Issues를 읽어보면, 다음과 같은 것을 알 수 있다.
- 논문은 아직 나오지 않았다.
- yoloV5에 대한, 사람들의 불만이 있다. yoloV4에서 특별히 새로울게 없다.
- 그럼에도 불구하고, YoloV5 github는 8500k의 star를 가지고 있다. YoloV4가 2600개의 star인것에 비해서.
- 우선은 YoloV4 까지만 공부하자. 나중에 모델 사용에 있어서는 YoloV5를 사용하는게 맞는 듯 하다.
- 어차피 YoloV4, YoloV5 모두, YoloV1,2,3의 저자인 Joseph Redmon에 의해서 만들어진 모델은 아니다.
