【3D-Detect】A Survey on 3D object-detection for self-driving
- 논문 : (Oct. 2019) A Survey on 3D Object Detection Methods for Autonomous Driving Applications
- 분류 : 3D Object Detection for self-driving
- 저자 : Eduardo Arnold, Omar Y. Al-Jarrah, Mehrdad Dianati, Saber Fallah
- 읽는 배경 : 연구 주제 정하기 첫걸음
- 느낀점 :
- 막연하게 3D detection이라는 한 분야가 있는 줄 알았는데, 생각보다 많은 분류가 존재했다. 그리고 상용화까지는 힘든 성능의 모델들이 대부분이었다. 이 분야도 거의 다 완성된게 아니라.. 아직도 연구할게 많구나. 라는 생각이 들었다.
- 만약 3D를 하고 싶다면, 그냥 가장 최신 논문 먼저 읽고 하나하나 따라 내려가는게 나을듯 하다. 여기 있는 논문 계보는 배경지식으로만 가지고 있자.
- PS : 필기된 논문은 [21.겨울방학\RCV_lab\논문읽기] 참조
A Survey on 3D Object Detection for Autonomous Driving
1. Conclusion, Abstract, Introduction
- 논문 전체 과정 : sensors들의 장단점, datasets에 대해서 알아보고, (1) monocular (2) point cloud based (3) fusion methods 기반으로 Relative Work를 소개한다.
- 3D object Detection에서 나오는 depth information 정보를 통해서 만이, path planning, collision avoidance 를 정확히 구현할 수 있다. 자율주행을 하려면 (1) identification=classification (2) recognition of road agents positions (e.g., vehicles, pedestrians, cyclists, etc.) (3) velocity and class 들을 정확히 알아야 한다.
- failure in the perception(인식 실패)는 sensors limitations 그리고 environment(domain) variations에 의해서, 또는”objects’ sizes”, “close or far away from the object” 등과 같은 요인에 의해서 발생한다.
2. Sensors and Dataset
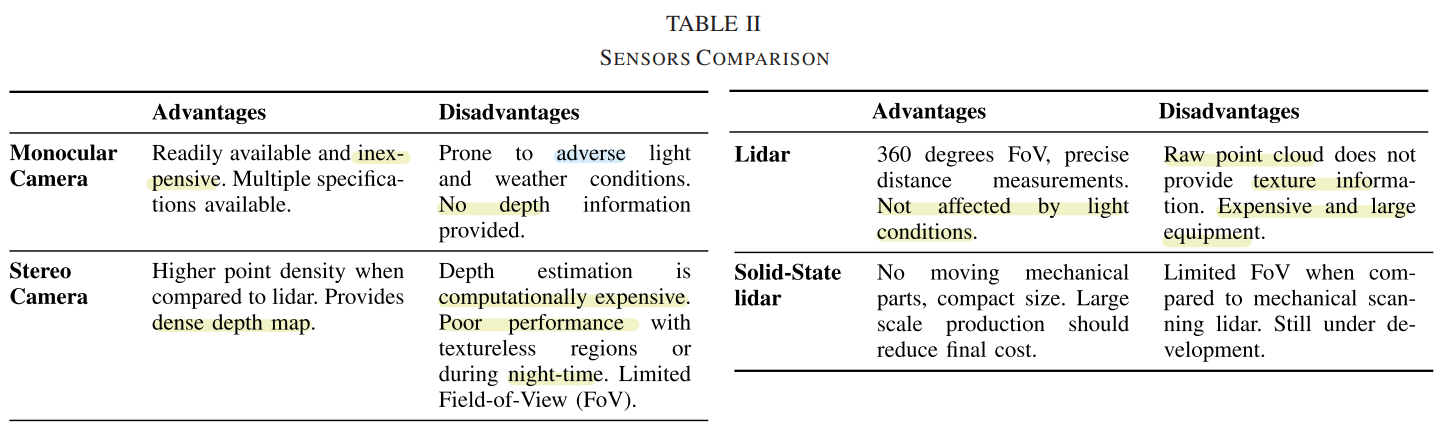
- Sensors
- 각 센서의 장단점 비교.
- Calibration 추천 논문 : “LiDAR and camera calibration using motion estimated by sensor fusion odometry”
- 각 센서의 장단점 비교.
- Dataset
- KITTI
- Sensor calibration, Annotated 3D bounding box 를 제공한다.
- Categrized in easy, moderate, hard (객체 크기, 겹칩, 가려짐의 정도에 따라서).
- 거의 대부분 주간 주행. Class unbalance가 심각하다. Predominant orientation 이다. (대부분의 객체가 같은 방향을 바라보고 있다.)
- Virtual KITTI
- 직접 게임 엔진을사용해서 KITTI의 이미지와 똑같은 가상 사진을 만들었다.
- 이 사진에서 Lighting, 날씨 조건, 차의 색 등을 바꿀 수 있다.
- 두개 데이터에 대해서 Transferability를 측정해본 결과, 학습과 테스트를 서로에게 적용했을때 성능 감소가 크게 있지 않았다.
- Virtual KITTI로 학습시키고, KITTI로 fine-tunning을 해서 나온 모델로 test해서 가장 좋은 성능을 얻었다.
- Simulation tool
- game-engines GTA5 (SqueezeSeg [34])
- Multi Object Tracking Simulator : “Virtual worlds as proxy for multi-object tracking analysis,”
- autonomous driving simulator : CARLA-“CARLA: An open urban driving simulator-2017”, Sim4CV-“Sim4CV: A photo-realistic simulator for computer vision applications-2018”
- KITTI
3. 3D Object Detection Methods
- 아래의 전체 분류 Table 참조

3-A Monocular Image Based Methods
- 우선 아래의 Table 참조
- 대부분의 탐지 방식 : Region Proposal(2D) -> 3D model matching(3D detection) -> Reprojection to obtain 3D bounding boxes
- 문제점(이것을 해결하기 위해 아이디어를 계속 생각해 봐야겠다) : 이미지에 Depth 단서가 부족해서, 먼 객체, 멀어서 작은 객체, 겹치는 객체, 잘리는 객체 탐지에 힘듬. Lighting과 Weather condition에 매우 제한적임. 오직 Front facing camera만을 사용해서 얻는 정보가 제한적이다. (Lidar와 달리)

- 3DOP [43, 2015] : 원본 이미지에서 3D 정보를 추출하는 가장 기본적인 방법. 필기에서는 이 방법을 0번이라고 칭함.
- Mono3D [39, 2016] : 3DOP를 사용한다. Key Sentence-“simple region proposal algorithm using context, semantics, hand engineered shape features and location priors.”
- Pham and Jeon [44, 2017] : Keypoint-“class-independent proposals, then re-ranks the proposals using both monocular images and depth maps.” 위의 1번 2번보다 좋은 성능 얻음.
- 3D Voxel Pattern = 3DVP [41, 2015] : 3D detection의 가장 큰 Challenge는 severe occlusion(객체의 겹침, 잘림이다) 이것을 문제점을 해결하기 위한 논문. 객체가 가려진 부분을 recover하기 위해 노력했다. 2D detect결과에 3D BB결과를 project할 때의 the reprojection error를 최소화함으로써 성능을 높였다.
- SubCNN [45, 2017] : 3DVP의 저자가 만든 방법으로, Class를 예측하는 RPN을 사용한다. 그리고 3DVP를 사용해서 똑같은 3D OD를 거친다.([45]논문에 의하면, 2D Image와 Detection결과에서 Camera Parameter를 사용해서 3D 정보를 복원한다고 한다.)
- Deep MANTA [42, 2017] : a many task network to estimate vehicle position, part localization and shape. 다음의 과정을 순서대로 한다고 한다. 2D bounding regression -> Localization -> 3D model matching (Imbalance한 vehicle pose(데이터에서 vehicle pose가 거의 비슷)의 문제점을 해결하기 위해서)
- Mousavian et al. [40, 2017] : standard 2D object detect 결과에다가 추가로 3D orientation (yaw) and bounding box sizes regression (the network prediction Branch)만을 추가해서 3D bounding box결과를 추론한다. orientation을 예측하는데, L2 regression 보다는 a Multi-bin method 라는 것을 제안해서 사용했다고 한다.
- 360 Panoramic [46, 2018] : 옆, 뒤 객체도 탐지하기 위해서, 360 degrees panoramic image 사용한다. 데이터 셋 부족 문제를 해결하기 위해서 KITTI 데이터를 Transformation한다.
3-B. Point Cloud Based Methods
- 우선 아래 테이블 참조
- Projection 방법은 Bird-eye view를 사용하거나, 이전에 공부했던 SqueezeSeg와 같은 방법으로 3D는 2D로 투영하여 Point Clouds를 사용한다. 이러한 변환 과정에서 정보의 손실이 일어난다. 그리고 trade-off between time complexity and detection performance를 맞추는 것이 중요하다.
- Volumetric methods는 sparse representation(빈곳들이 대부분이다)이므로 비효율적이고 3D-convolutions를 사용해야한다. 그래서 computational cost가 매우 크다. 3D grid representation. shape information를 정확하게 encode하는게 장점이다.
- PointNet과 같은 방법은 using a whole scene point cloud as input 이므로, 정보 손실을 줄인다. 아주 많은 3D points를 다뤄야 하고 그 수가 가변적이다. 정해진 이미지 크기가 들어가는 2D-conv와는 다르다. 즉 points irregularities를 다뤄야 한다 [61]. 최대한 Input information loss를 줄이면서.

- Projection via plane [47, 2017]
- Projection via cylindrical [48, 2016] : bird-eye view 이미지를 FCN하여 3D detection을 수행한다. 자동차만 탐지한다. channel은 Point의 hight(높이)에 맞춰서 encoding된다. (예를 들어 3개의 채널을 만들고, 높은 points, 중간 높이 points, 낮은 높이 points) FCN을 통해서 나오는 결과는 BB estimates이고 NMS를 거쳐서 objectness and bounding box를 추론한다.
- Projection via spherical [49, 2017]
- 3D-Yolo [30, 2018] : Encoding minimum, median and maximum height as channels. 그리고 추가로 2개의 channels은 intensity and density(해당 bird-eye view구역에 겹쳐지는 point의 객수 인듯). yolo에서 the extra dimension and yaw angle를 추가적으로 더 예측하는 inference 속도를 중요시하는 모델.
- BirdNet [51, 2018] : [50, project이미지를 Faster RCNN처리]을 기반(기초논문)으로 해서, Normalizes the density channel를 해서 성능 향상을 얻음.
- TowardsSafe [53, 2018] : Noise와 같은 불확실성을 보완할 수 있는 dropout을 적극적으로 사용하는 Bayesian Neural Network을 사용. 이러한 ‘확률적 랜덤 불확실성 모델’을 사용함으로써 noisy sample에 대해서 성능 향상을 얻을 수 있었다. [여기까지가 Projection Methods]
- 3DFCN [54, 2017] : 이미 가공된 a binary volumetric input를 사용한다. 해당 voxel에 vehicle이 ‘있고 없고’를 판단하는 binary 값을 사용해서, vehicle 밖에 검출하지 못한다. objectness and BB vertices predictions를 예측한다.
- Vote3Deep [55, 2017] : one-stage FCN. class는 차, 보행자, 자전거 끝. 각각의 Class에 대해서 고정된 크기의 BB만을 사용한다. 그리고 하나의 class만을 감지하는 모델을 각각 학습시킨다. 복잡성을 감소시키고 효율성을 증가시키기 위해 sparse convolution algorithm라는 것을 사용한다. Inference할때는 위의 각각의 모델을 parallel networks로써 추론을 한다. data augmentation, hard negative mining을 사용한다. [여기까지가 Volumetric Methods]
- PointNet[56, 2017], PointNet++ [59, 2017]. 더 발전된 것 [60, 2018] convolutional neural networks for irregular domains [61, 2017] : Segmented 3D PCL(전통적인 기법의 Point cloud library를 사용한) 기법을 사하여 classification(not detection) and part-segmentation을 수행한다. 그리고 Fully-Connnected layer를 통과시키고, max-pooling layer를 통과시킨다.
- VoxelNet [62, 2017] : classification(PointNet)이 아니라, detection을 수행. raw point subsets사용한다. each voxel에서 랜덤으로 하나의 point를 설정한다. 그리고 3D convolutional layer를 통과시킨다. cars and pedestrians/cyclists 탐지를 위해서 Different voxel size를 가지는 3개의 model을 각각 학습시킨다. 그리고 Inference에서는 3개의 model을 simultaneously 사용한다.
- Frustum PointNet [63, 2018] : imaged에서 추론한 결과를 기준으로 sets of 3D points를 선별해 사용하기 때문에 Fusion method로 나중에 다룰 예정이다. [여기까지가 PointNet Methods]
3-C. Fusion Based Methods
- 우선 아래 테이블 참조
- Points는 texture 정보를 주지 않는다. 즉 classification하기엔 힘들다. 또한 먼 곳에 있는 객체는 point density가 떨어져서, 객체라고 탐지하지 않는다. 이러한 판단은 Image에서의 detect도 방해될 수 있다.
- fusion방식에는 아래와 같은 3가지 방법이 있다.(3 strategies and fusion schemes)
- Early fusion : 초기에 데이터를 융합하는 방법. 모든 센서데이터에 의존되는 representation 만들고 그것으로 detect를 수행한다.
- Late fusion : 각각 predictions을 수행하고 나중에 융합하는 방법. 이 방법의 장점은 ‘꼭 모든 센서 데이터가 있어야만 detect가 가능한 것은 아니다’라는 것이다.
- Deep fusion : 계층(hierarchically)적으로 각 센서데이터로 부터 나오는 Feature들을 융합하는 방식이다. Interact over layers라고도 표현한다.
- 이런 3가지 strategies and fusion schemes에 대해서 [65, 2016]에서 무엇이 좋은지 테스트 해봤다. 2번 late fusion에서 가장 좋은 성능, early fusion에서 가장 안 좋은 성능을 얻었다고 한다.
- 어찌 됐든, Fusion 방식은 SOTA 성능 결과를 도출해 준다. 라이더와 카메라가 각각 상호보완이 역할을 하기 때문이다.

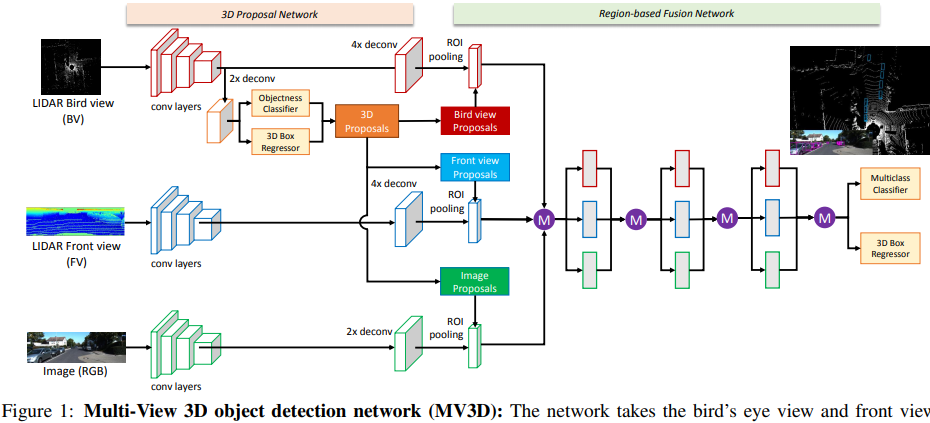
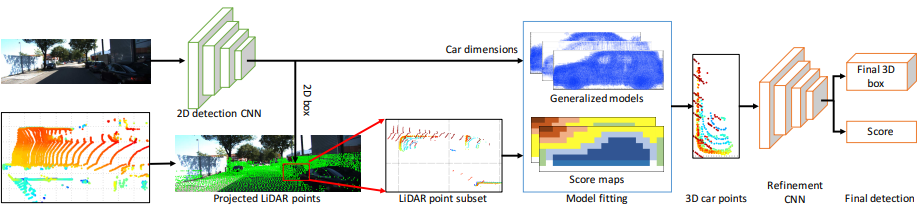
- MV3D [64, 2017] : 아래 그림 참조. 아래와 같은 3가지 종류의 input과 3가지 Branch를 가진다. 이 방법은 대표적인 deep fusion 방법이다. 후반의 작업을 보면, 계층적으로 서로서로 상호작용을 하면서 Feature를 얻어가는 것을 볼 수 있다. 이 방법을 통해서 저자는 ‘deep fusion을 통해서 the best performance를 얻었다. 다른 센서로 부터 얻은 정보를 융합하여, more flexible mean을 제공받기 때문이다.’라고 말한다.
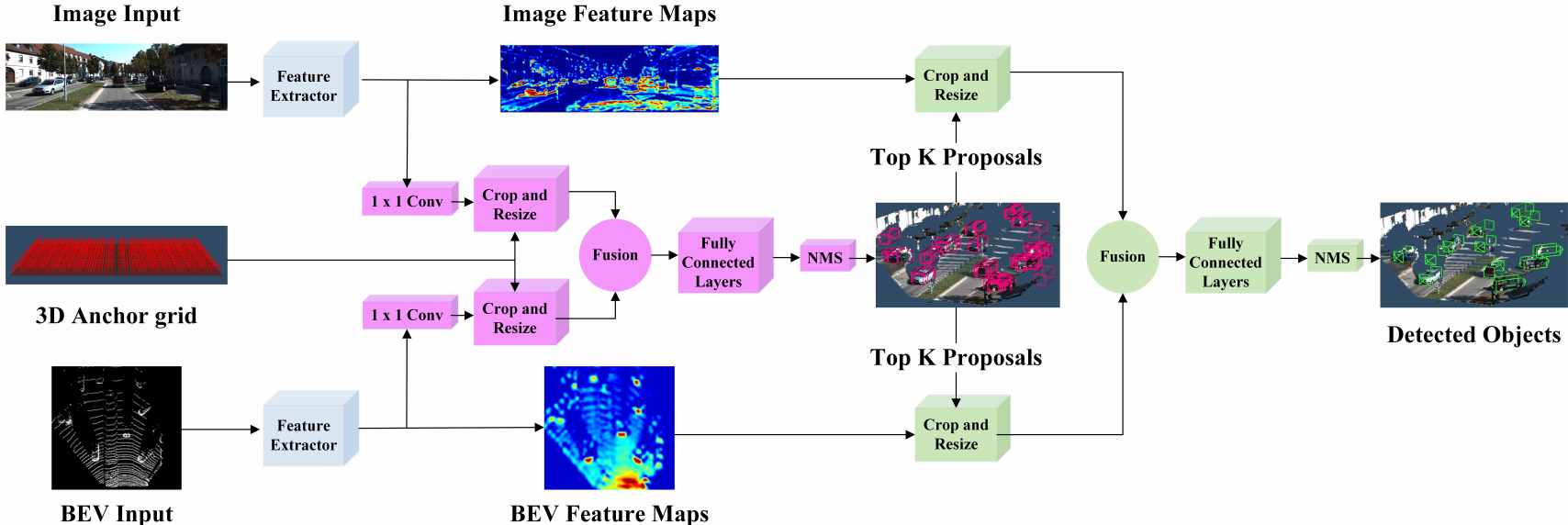
- AVOD [6, 2018] : 아래 그림 참조. 대표적인 Early fusion방식이다. 중간에 한번 3D RPN과정을 위해 각 센서의 Feature map을 융합하여 the highest scoring region proposals을 얻는다. 이것을 사용해서 최종 Detection 결과를 얻는다. 저자는 small scale 객체 탐지를 위해서 FPN의 upsampling된 feature maps을 사용한다. 또한 이 방법을 통해서 악 조건의 날씨에서도 robustness한 결과를 얻을 수 있다고 한다.
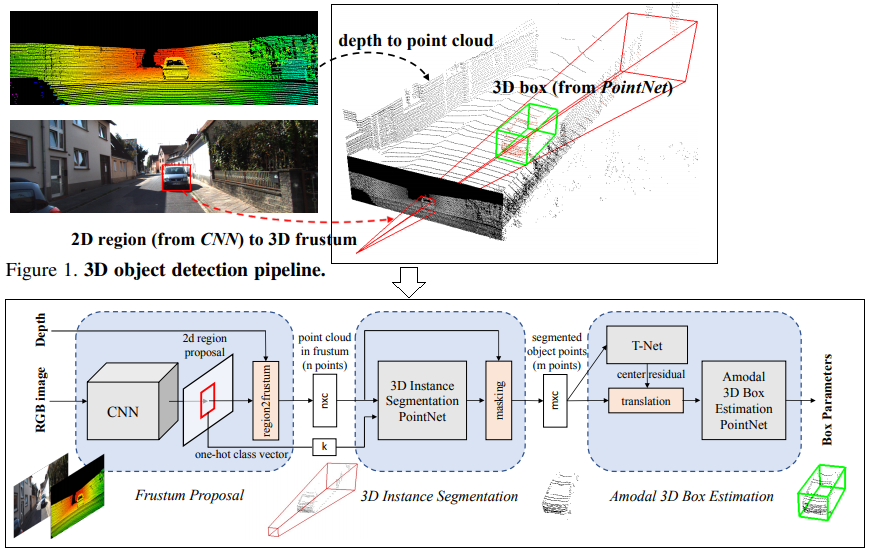
- F-PointNet [63, 2018] : 2D 이미지로 부터 region proposals을 뽑아낸다. detected 2D box에 대해서, Camera calibration parameters를 사용해서 3D box ROI를 얻어낸다. 그리고 2번의 PointNet instance를 수행하여, Classification과 3D BB regression 정보를 추출한다.
- General Pipeline 3D [67, 2018] (상대적으로 인용수 적음) : 이 모델도 위의 F-PointNet과 같이 Image로 부터 Region proposals을 받는다. 이것과 F-PointNet은 Image로 부터 ROI를 받기 때문에 Lighting conditions 요인에 큰 영향을 받는다는 단점이 있다.
4. Evaluation Matrix and Results
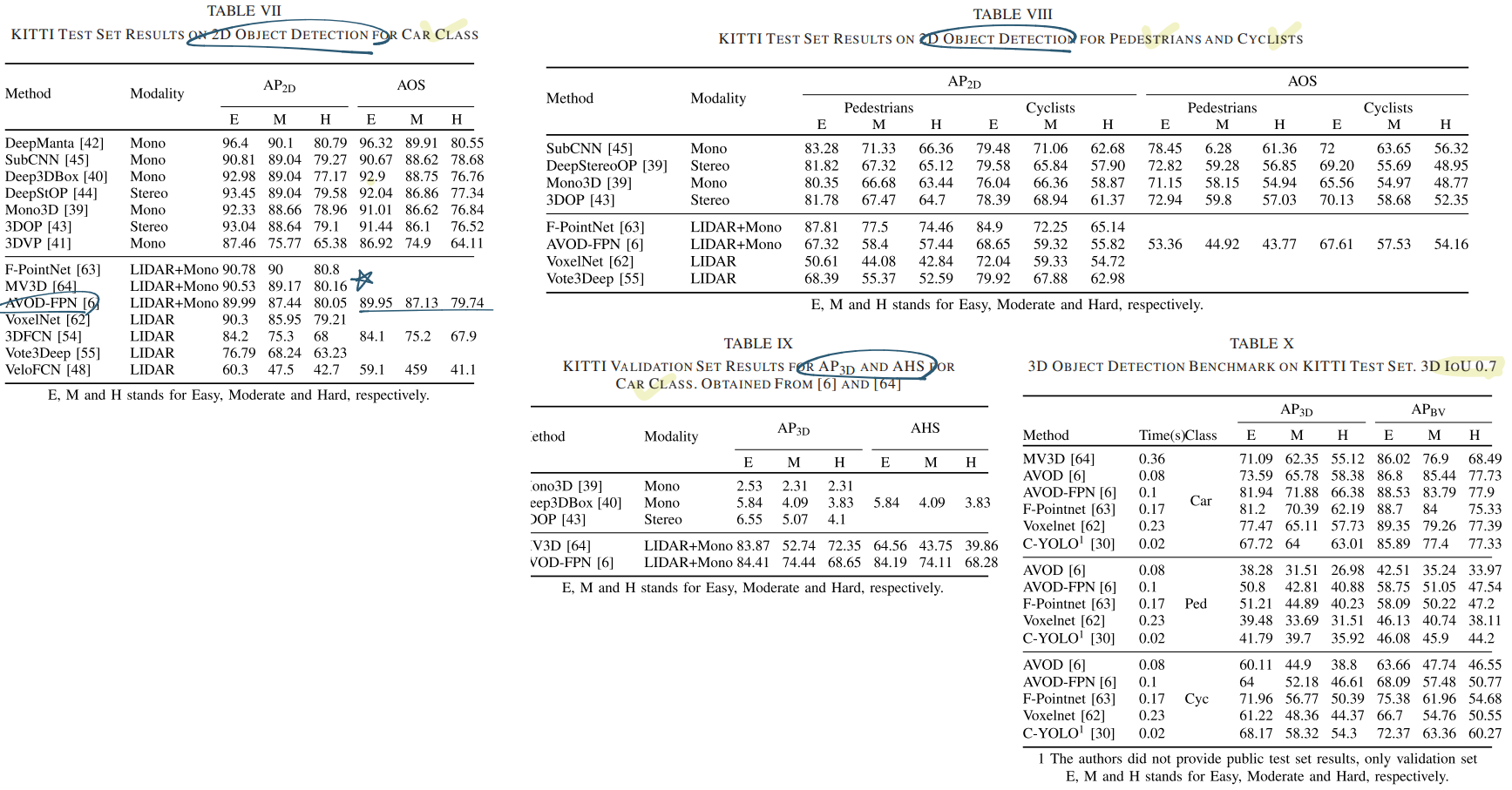
Recall과 Precision 그리고 AP = AP2D

Average Orientation Similarity (AOS) : AP2D에서 Orientation performance까지 추가하는 방법. (weighting the AP2D score with the cosine similarity between the estimated and ground-truth orientations.)
3D localization metric (APBV) : localization and bounding box sizes 까지 고려하기 위한 Matrix. bird-eye view로부터 결과를 얻는다.
AP3D : 3D box에 대해서 3D IOU를 계산해서 AP2D와 같은 공식을 적용한다. 하지만 이 방법은 IOU만 고려하고, GT와 predict box의 Orientation estimation을 고려하지 않는다. (Orientation이 많이 달라도 IOU만 크면 Positive라고 판단하는 문제점)
AHS : 4.AP3D와 2.AOS를 융합한 방법이다. (AP3D metric weighted by the cosine similarity of regressed and ground-truth orientations)

[Ps. 논문에서 그림 수식을 제공하는 Matrix만 그림 첨부]
- 성능 비교를 여기서 보지말고, 최신 3D-Detection 논문을 찾고 거기서 나오는 Results와 Matrix를 공부하자. (일단 아래와 같이 표만 정리해 두었다)
5. Research Challenges
- 자율주행에 사용할 수 있을 정도로의 Detection performance levels를 획득해야 한다. 따라서 주행의 안정성과 Detection performance를 연관시켜서 정량화 할 것 인지? 에 대한 연구도 필요하다. (how detection performance relates to the safety of driving)
- Points에 대한 the geometrical relationships가 탐구되어야 한다. Point clouds를 살펴보면, missing points and occulsion, truncation이 많기 때문이다.
- Sensor fusion 뿐만 아니라, V2X 와 같은 multi-agent fusion scheme이 수행되어야 한다.
- KITTI는 거의 daylight에 대한 데이터 뿐이다. 일반적이고 전체적인 Conditions에서의 안정적은 성능을 달성하기 위해서 노력해야 한다. 시뮬레이션 툴을 사용하거나, Compound Domain Adaptation 등을 이용한다.
- Real time operation을 위해서는 적어도 10fps 이상의 속도 능력이 필요하다. real time operation을 유지해야한다.
- uncertainty in detection models을 정확히 정량화해야한다. calibrated confidence Score on predictions와 실제 주행 인지에서의 Uncertainty와의 gap은 분명히 존재한다.
