【Pytorch】 mmclassification teardown reports & Ubuntu re-install
Ubuntu re-install & mmclassification teardown reports
1. New ubuntu setting List
- 우분투 설치
- gpu graphic driver 설치
- docker, docker-nvidia 설치
- Vscode 설치
- anaconda 설치
- docker image, container 필요한거 다운 및 설치 (MLworkspace, pytorch-cuda)
- dataset 다운로드 (coco, imagenet)
2. Docker setting
Docker hub naming (참고 사이트)
- devel : 속편하지만 용량이 너무 큼
- base : 가장 낮은 용량
- runtime : 사용하기에 적절한 용량
- 이유는 모르겠지만
pytorch-1.5.1-cuda10.1-runtime에서는cat /usr/local/cuda/version.txt가 동작하지 않는다. 그럼에도 불구하고 예전에 detr을 cuda로 돌렸었다. mmclf에서는 cuda문제가 발생했으므로 속편하게pytorch-1.5.1-cuda10.1-devel사용해야겠다.
docker run –shm-size
- shared memory 사용 공간 ML-workspace에서 512MB를 주니, 대충 그정도 사용하면 될 듯하다.
docker run
- detr에서 준 dockerfile을 build해서 사용했다. 하지만 cuda 문제가 발생했다.
- detr에서 준 docker image 부터가 잘못 됐다. 재설치 필요
- docker hub - pytorch 1.5.0 - devel 을 사용한다. runtime에는
cat /usr/local/cuda/version.txt가 동작하지 않는다. 맘편하게 devel사용한다. - 아래와 같이 -v를 2번 가능하다. <my path>/<container path> 에서, <container path>는 path가 존재하지 않으면 자동으로 mkdir된다.
$ sudo docker run -d -it \ --gpus all \ --restart always \ -p 8000:8080 \ --name "mmcf" \ --shm-size 2G \ -v ./home/junha/docker/mmclf/mmclassification \ # 가능하면 무조건 절대경로 사용할 것 -v /hdd1T:/dataset \ pytorch/pytorch:1.5.1-cuda10.1-cudnn7-devel $ sudo docker run -d -it \ --gpus all \ --restart always \ -p 8080:8080 \ --name "mmcl" \ --shm-size 2G \ -v /home/junha/docker:/workspace \ -v /hdd1T:/dataset \ sb020518/mmcl:0.1
3. mm installation
mmcv installation
$ apt-get update $ apt-get install ffmpeg libsm6 libxext6 -y $ pip install mmcv-full==1.3.0 -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.5.0/index.html$ git clone https://github.com/open-mmlab/mmclassification.git $ cd mmclassification $ pip install -e . # or "python setup.py develop"이런 식으로 install하면, 이 공간의 mmcls 파일을 수정하면,
import mmcls.util.collect_env이것을 새로운 py파일에 적든, 터미널에서 python을 실행해서 적든, 모두 수정된 코드 내용이 적용 된다.mmclasification install Test
python demo/image_demo.py \ /workspace/checkpoints/dog.jpg \ /workspace/configs/resnet/resnet50_b32x8_imagenet.py \ /workspace/checkpoints/resnet50_batch256_imagenet_20200708-cfb998bf.pth
4. 코드 공부 흐름 필수
Github 패키지 이곳저곳 돌아다니면서, 전체적인 구조 눈으로 익히기(좌절하기 말기. 핵심만 파악하려 노력하기)Interence 흐름 따라가기Tranin 흐름 따라가기Dataloader 공부하기Loss, Optimizer, Scheduler 분석하기Model save load, check point 분석하기Batch 구성방법, GPU 분산학습 분석하기
[코드에서 다 봐야하는 것] (순서대로 보지 말고. 코드 따라가면서 눈에 보이는 것 부터 부셔버리기)
- Github로 전체적인 구조 눈으로 익히기
- Interence 흐름 따라가기
- Tranin 흐름 따라가기
- Dataloader 공부하기
- Loss, Optimizer, Scheduler 분석하기
- Model save load, check point 분석하기
- Batch 구성방법, GPU 분산학습 분석하기
5. mmclassification github
- parser.add_argument에 대해서, –가 붙여 있는 것은 optional 이다. –가 없는 것은 필수입력인자(positional) 이다.
- add_argument()에 들어가는 인자가 많다.
- 그 인자 중, type= 설정해주지 않으면 str이 default
- 그 인자 중, default= 값이 지정되지 않았을 때, 사용할 디폴트값
config 파일 분석하기 (아래 팁 참조)
configs/resnet/resnet50_b32x8_imagenet.py에는 또 다른 config 파일의 path만 기록 되어 있다.- 어려울 거 없이, 그 path의 config 파일만 다~ 모아서 cfg에 저장된다.
- 이쁘게 출력해보고 싶으면,
print(f'Config:\n{cfg.pretty_text}')
test.py이든 train.py이든 핵심 호출법은 아래와 같다.
- model:
model = build_classifier(cfg.model) - dataset:
dataset = build_dataset(cfg.data.test),datasets = [build_dataset(cfg.data.train)]
- model:
6. mmclassification/getting_started.md
- Prepare datasets
- ImageNet 다운로드. 각 클래스는 같은 폴더에 넣어주기 위한 sh 실행 (참조사이트).
- MNIST, CIFAR10 and CIFAR100와 같은 데이터 셋은, 만약 데이터셋이 없다면 자동으로 다운 받아진다.
- Inference a dataset
- Inference는 이미지를 모델이 넣고 나오는 결과를 직접 눈으로 확인해보는게 목적이다.
- mmclassification에서는 inference.py 파일 없다.
- 굳이 하고 싶다면, demo/image_demo.py를 이용하자.
- Test a datatset
- Test는 val_img들에 대해서 예측결과를 추론해보는 것이 목표이다.
tools/test.py,tools/dist_test.shdist_test.sh는 결국tools/test.py실행한다.$ python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}]이거로 먼저 debuging하고 그 다음에 dist_test.sh 파일을 이용해서 multi-gpu testing을 진행하자.$ python tools/test.py configs/resnet/resnet50_b32x8_imagenet.py checkpoints/resnet50_batch256_imagenet_20200708-cfb998bf.pth --out result/imagenet-val.json
- Train a dataset
$ python tools/train.py configs/resnet/resnet50_b32x8_imagenet.py --load-from checkpoints/resnet50_batch256_imagenet_20200708-cfb998bf.pth
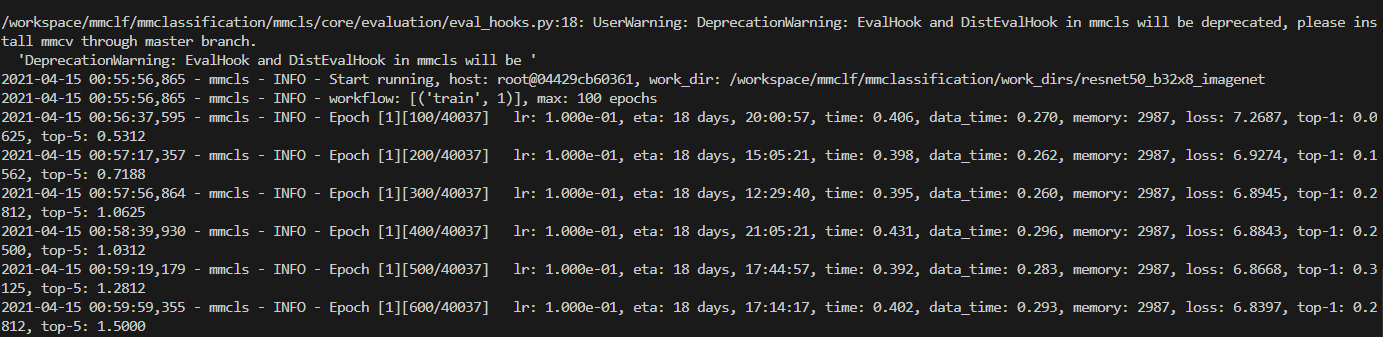
7. tools/test.py 디버깅
- 이제부터 아래의 과정은 디버깅을 통해 알아낸 내용이다,
- [Vscode Debugging] :
tools/test.py+"args" : ["configs/resnet/resnet50_b32x8_imagenet.py", "checkpoints/resnet50_batch256_imagenet_20200708-cfb998bf.pth "], or"args" : ["configs/resnet/resnet50_b32x8_imagenet.py", "checkpoints/resnet50_batch256_imagenet_20200708-cfb998bf.pth", "--metrics", "mAP", "CP", "CR"] - [Terminal] :
python tools/test.py configs/resnet/resnet50_b32x8_imagenet.py checkpoints/resnet50_batch256_imagenet_20200708-cfb998bf.pth --out ./result/imagenet-val-resnet50.json --metrics "accuracy" "precision" "recall" "f1_score" "support"
build_dataset/classifier호출 순서# 아래로 내려갈 수록 define으로 들어가는 것 ## 1. dataset from mmcls.datasets import build_dataloader, build_dataset from mmcv.utils import Registry, build_from_cfg return <class 'mmcls.datasets.imagesnet.ImagesNet'> # cfg.dataset_type 에 적힌 class # return이 완벽하게 되기 이전에 __init__ 가 실행되면서, 맴버 변수가 채워진다. 이때 pipeline(augmentation)이 정의된다. ## 2. classifier from mmcls.models import build_classifier from mmcv.utils import build_from_cfg return <class 'mmcls.models.classifiers.image.ImageClassifier'> # cfg.model.type 에 적힌 class # return이 완벽하게 되기 이전에 __init__ 가 실행되면서, 맴버 변수가 채워진다. 이떄 backbone, neck, head가 정의된다.model.eval() 하고, 테드스 결과 뽑아내기
# tools/test.py model = MMDataParallel(model, device_ids=[0]) outputs = single_gpu_test(model, data_loader)- mmcv/paralled/MMDataParalle == from torch.nn.parallel import DataParallel
- 여기서 model =
<class 'mmcv.paralled.MMDataParalled' object>로 바뀐다. - dataloader =
<class 'torch.utils.data.dataloader.DataLoader' object>
result 결과 뽑기
# from mmcls.apis import single_gpu_test for i, data in enumerate(data_loader): with torch.no_grad(): result = model(return_loss=False, **data) """ type(result) = list len(result) = 32 = batch size = cfg.data.samples_per_gpu type(result[0]) = numpy.ndarray result[0].shape = (1000,) """

8.tools/train.py 디버깅
argparse, config 읽고, 에러 미리 확인.
build_수행하기model = build_classifier(cfg.model) datasets = [build_dataset(cfg.data.train)] # cpu worker 처리만 해주고 train_model( model, datasets, cfg, distributed=distributed, validate=(not args.no_validate), timestamp=timestamp, meta=meta)from mmcls.apis import train_model# /mmcls/apis/train_model """ 1. dataloader = `<class 'torch.utils.data.dataloader.DataLoader' object> 2. model = `<class 'mmcv.paralled.MMDataParalled' object> """ runner = build_runner( cfg.runner, default_args=dict( model=model, batch_processor=None, optimizer=optimizer, work_dir=cfg.work_dir, logger=logger, meta=meta)) runner.run(data_loaders, cfg.workflow)- build_runner=
<mmcv.runner.epoch_based_runner.EpochBasedRunner>(Github link) - runner.run (Github link)
- build_runner=
from mmcv.runner import epoch_based_runner- 아래 코드는, 아래로 차근차근 내려가면서 실행된다고 보면 된다.
# /mmcls/runner/epoch_based_runner class EpochBasedRunner(BaseRunner): def run(self, data_loaders, workflow, max_epochs=None, **kwargs): # kwargs = {None}, self.model 이미 저장되어있음 epoch_runner = getattr(self, mode) epoch_runner(data_loaders[i], **kwargs) # == self.train(data_loaders[i], **kwargs) def train() for i, data_batch in enumerate(self.data_loader): self.run_iter(data_batch, train_mode=True) def run_iter(self, data_batch, train_mode, **kwargs): outputs = self.model.train_step(data_batch, self.optimizer, **kwargs) """ 여기서 model은 <class 'mmcls.models.classifiers.image.ImageClassifier' object> 이자 <class 'mmcv.paralled.MMDataParalled' object> 이다. 따라서 아래의 파일에 들어가면 ""train_step"" 함수 찾기 가능! """mmclassification/mmcls/models/classifiers/base.py# mmclassification/mmcls/models/classifiers/base.py class BaseClassifier(nn.Module, metaclass=ABCMeta): def train_step(self, data, optimizer): losses = self(**data) #== BaseClassifier.fowerd 실행! outputs = dict(loss=loss, log_vars=log_vars, num_samples=len(data['img'].data)) def forward(self, img, return_loss=True, **kwargs): if return_loss: return self.forward_train(img, **kwargs) def forward_train(self, imgs, **kwargs): pass # 즉! torch.nn.Module.forward 그대로 실행된다.
중요하지만, 사소한 추가 팁들 모음
1. config 파일 넌 무엇인가?!
# test.py에서 디버깅 하면서, cfg파일 읽어보기
print(f'Config:\n{cfg.pretty_text}')
########## 예를 들어서 이 파일을 봐보자. configs/resnet/resnet50_b32x8_imagenet.py ##########
_base_ = [
'../_base_/models/resnet50.py', '../_base_/datasets/imagenet_bs32.py',
'../_base_/schedules/imagenet_bs256.py', '../_base_/default_runtime.py'
]
########## '../_base_/models/resnet50.py' ##########
model = dict(
type='ImageClassifier',
backbone=dict(
type='ResNeSt',
depth=50,
num_stages=4,
out_indices=(3, ),
style='pytorch'),
neck=dict(type='GlobalAveragePooling'),
head=dict(
type='LinearClsHead',
num_classes=1000,
in_channels=2048,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
topk=(1, 5),
))
########## '../_base_/datasets/imagenet_bs32.py' ##########
dataset_type = 'ImageNet'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
# 원하는 Transformer(data agumentation)은 아래와 같이 추가하면 된다.
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='RandomResizedCrop', size=224),
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]
# 위에 내용은 이 아래를 정의하기 위해서 사용된다. cfg.data.test, cfg.data.val 이 사용된다.
data = dict(
samples_per_gpu=32,
workers_per_gpu=2,
train=dict(
type=dataset_type,
data_prefix='data/imagenet/train',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_prefix='data/imagenet/val',
ann_file='data/imagenet/meta/val.txt',
pipeline=test_pipeline),
test=dict(
# replace `data/val` with `data/test` for standard test
type=dataset_type,
data_prefix='data/imagenet/val',
ann_file='data/imagenet/meta/val.txt',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='accuracy')
########## '../_base_/schedules/imagenet_bs256.py' ##########
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(policy='step', step=[30, 60, 90])
runner = dict(type='EpochBasedRunner', max_epochs=100)
########## '../_base_/default_runtime.py' ##########
# checkpoint saving
# 1번 epoch씩 모델 파라미터 저장
checkpoint_config = dict(interval=1)
# yapf:disable
# 100번 iteration에 한번씩 log 출력
log_config = dict(
interval=100,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)] # [('train', 2), ('val', 1)] means running 2 epochs for training and 1 epoch for validation, iteratively.
2. Registry는 모두 안다. 난 고르기만 하면 된다.
mmcv.utils.Registry 사실 맴버 변수는 2개 뿐이다,
self._name = ‘backbone’
self._module_dict = 아래 그림 4번처럼 모든 backbone을 다 알고 있다!! 어떻게 알지??
아래 그림 2번과 같이 정의된 class를 모두 담고 있는 것이다.
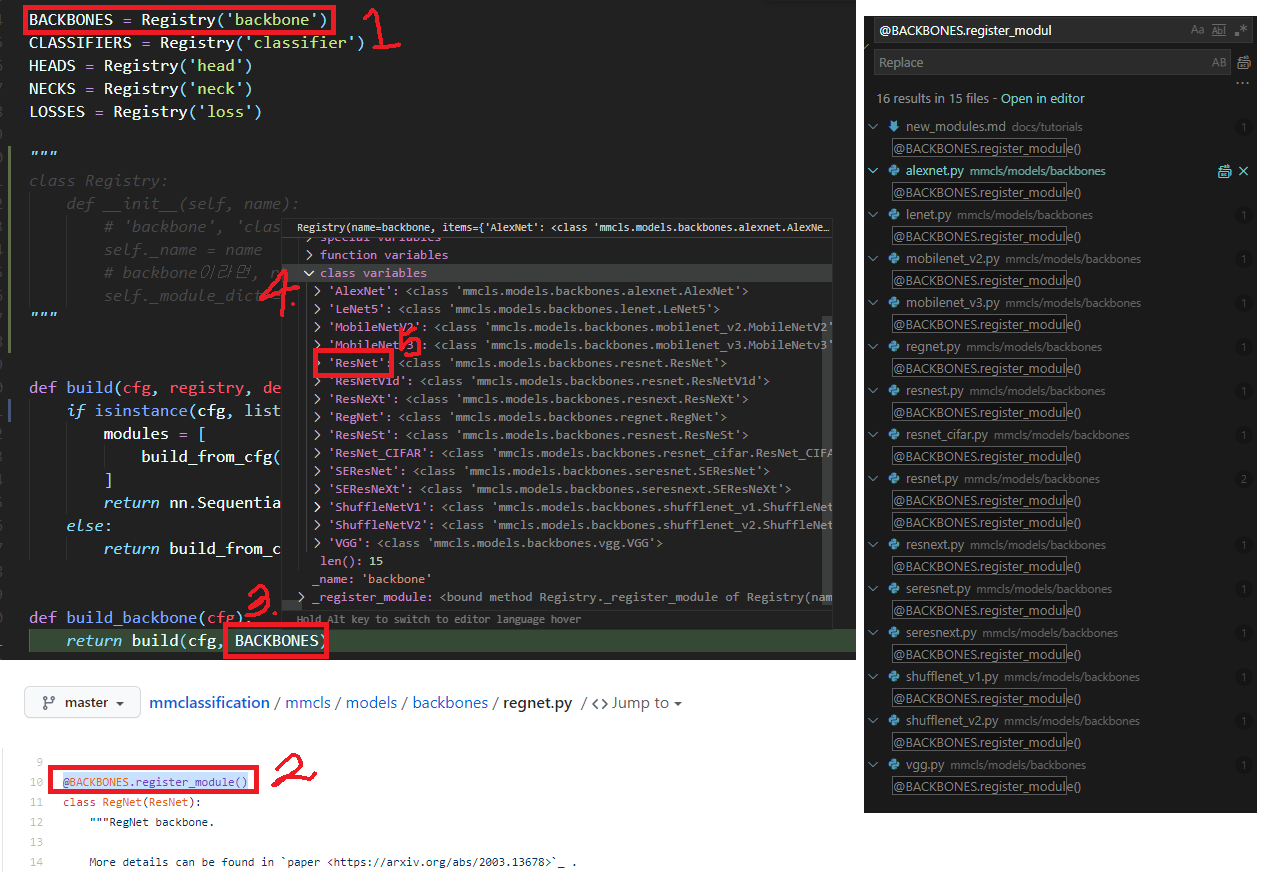
@BACKCONES.register_modules()* 은 언제 실행되는 것 일까? 초반에 import할때 모두 실행된다. 여기*에다가 Breakpoint 걸고 디버깅한 결과는 아래와 같다.
# test.py import mmcls.models import mmcls.models.__init__ import mmcls.models.backbone.__init__ from .regnet import RegNet
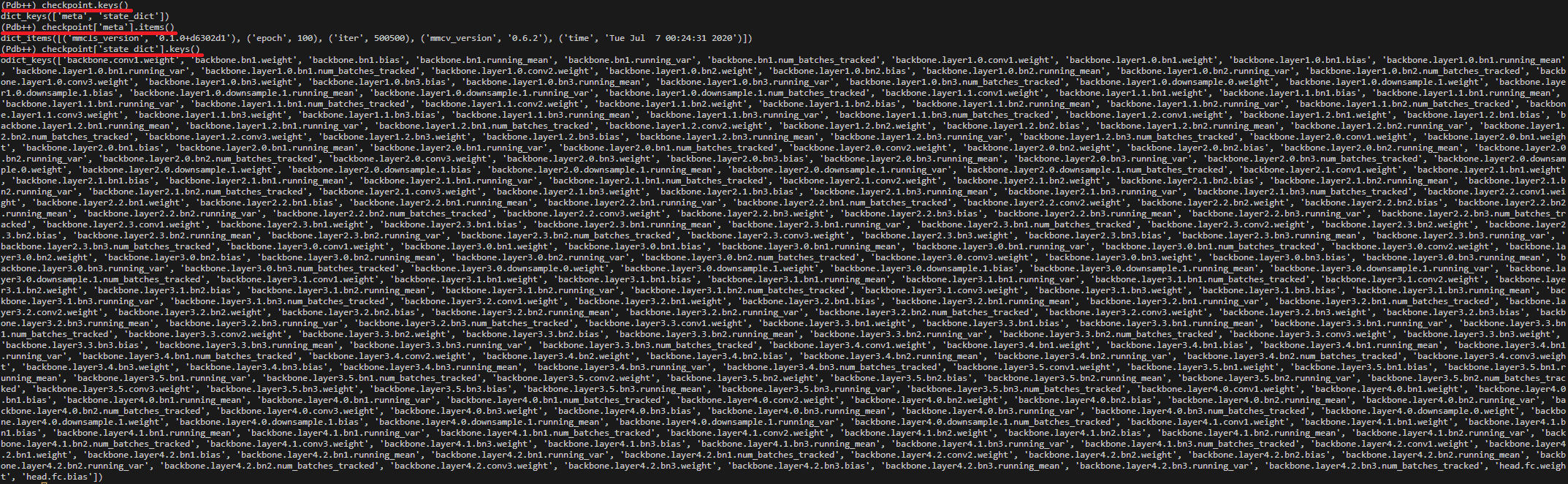
3. checkpoint = load_checkpoint(model, args.checkpoint) 결과는?
- type( checkpoint ) = dictionary
- Netron 이용해서 Visualization 하자
4. 모델 파라미터 가져오기 - “어차피 텐서다 쫄지말자”

How to load part of pre trained model?
pretrained_dict = ... model_dict = model.state_dict() # 1. filter out unnecessary keys pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict} # 2. overwrite entries in the existing state dict model_dict.update(pretrained_dict) # 3. load the new state dict model.load_state_dict(pretrained_dict)
5. mmcls/models/backbones/ResNet.py forward 를 실행하기 까지의 과정은?
tools/test.py의 가장 마지막이,single_gpu_test함수에 들어가는 것이었다.mmcls/models/backbones/ResNet.py에다가 breakpoint 걸어서 디버깅 해본 결과, 아래와 같은 코드 흐름을 확인할 수 있었다.- 알아만 두자.
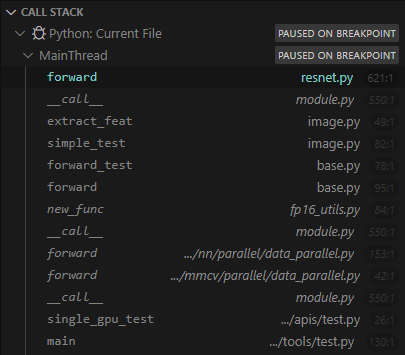
6. python getattr()
# mmcv.runner.epoch_based_runner.py
# ** 아래의 2 코드는 같은 말이다. ** if mode == str('train') **
epoch_runner = getattr(self, mode)
epoch_runner = self.train()
- 따라서 디버깅으로
EpochBasedRunner을 확인해보면train 맴버함수(Github link)를 가지고 있는 것을 알 수 있다.
