【Transformer+Video】VisTR & TrackFormer & 3D conv
- 논문1 : End-to-End Video Instance Segmentation with Transformers
- 논문2 : TrackFormer: Multi-Object Tracking with Transformers
- 분류 : Video & Tracking + Transformer
- 느낀점 :
- 목차
1. VisTR 핵심 및 보충설명
1.1 논문 핵심 정리
- Instance segmentation은 하나의 이미지내에서 Pixel-level similarity를 찾내는 Task이다. Instance tracking는 다른 이미지에서 Instance-level similarity를 찾아내는 Task이다. Transformer는 similarity learning에 매우 특화되어 있다. (Why? softmax(Key*Query) 연산을 통해서 구해지는 Attention 값이 결국에는 query와 얼마나 유사한가를 계산하는 것이다)
- 전체 Architecture는 아래와 같다. 자세한 내용은 PPT에서 찾아보도록 하자.

- 주의할 점으로는, instance queries가 decoder로 들어가서 나오는 최종 결과에 대해서, 각 프레임의 같은 Instance는 같은 i번쨰 query에 의해서 나와야하는 결과들이다. (corresponding indices)
- Sequential Network 이기 때문에 발생하는 특징
- Temporal positional encoding (spatial positional encoding 뿐만 아니라, 이것을 3개 뭉친)
- 3D Convolution
- 36개의 frame이 한꺼번에 들어가므로, 하나의 Sequence of images가 들어가서 총 연산에 걸리는 시간은 조금 걸릴지라도, FPS로 계산하면 상당히 높은 FPS가 나온다.(?)
- VisTR가 가지는 특장점들
- instances overlapping를 매우 잘 잡는다 (DETR에서 코끼리 성능 결과 처럼)
- changes of relative positions에도 강하다. (카메라가 고정되지 않아도 된다)
- confusion by the same category instances (비슷한 고릴라, 코끼리 2개 붙어있어도.. 잘 분류하는 편이다)
- instances in various poses 에 대해서 강하다. (사람이 무슨 포즈를 취하든..)
- Summary
- a much simpler and faster
- Vedio에 대한 Tracking은 Detection과 Tracking이 따로 진행되기 때문에 이음새가 반듯이 필요한데, VisTR은 seamlessly and naturally 한 모델이다.
1.2. 보충 내용
- 3D conv란 ??

- Dice Loss란? (mask loss를 Focal Loss와 Dice Loss의 합으로 계산된다.)
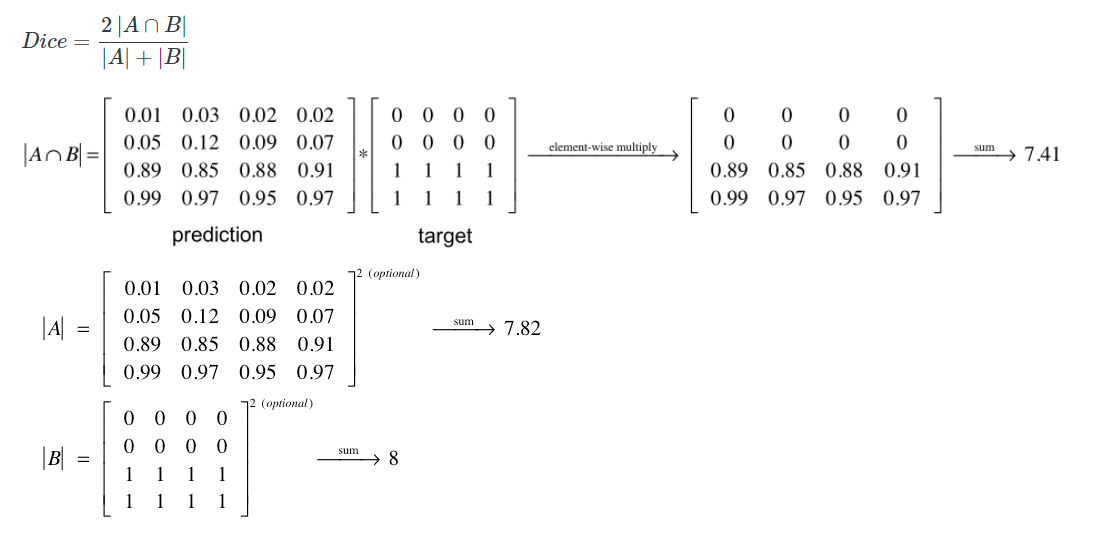
- 굳이 Hungarian Loss?? -> 논문을 봐도 내가 생각한게 맞는 것 같다. 최적의 Assignment를 찾기 위해서 Hungarian algorithm을 쓰고, 찾아진 최적의 matching에 대해서만 Loss를 계산하고 backpro 하는 것이다.
- Train/Inference Setting
- AdamW, learning rate 10−4, trained for 18 epochs (by 10x at 12 epochs 마다 decays 되는 비율로)
- initialize our backbone networks with the weights of DETR
- 8 V100 GPUs of 32G RAM
- frame sizes are downsampled to 300×540
- Faster ??
- 8개 V100 GPU
- ResNet-101 backbone -> 27.7 FPS, Image Process 작업 제외하면 57.7 FPS
- 높은 FPS 원인 (1) data loading을 쉽게 병렬화 처리 할 수 있고 (2) parallel decoding의 가능하고 (3) no post-processing
1.3 코드로 공부해야 할 것들
- Temporal Positional Encoding
- Mask를 생성하기 위한, the self-attention module.
- Self-attetion(O,E)가 B와 Fusion 될때의 연산
- Deform_conv
2. VisTR PPT 공부자료
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
3. TrackFormer 핵심 및 보충설명
3.1 논문 핵심 정리
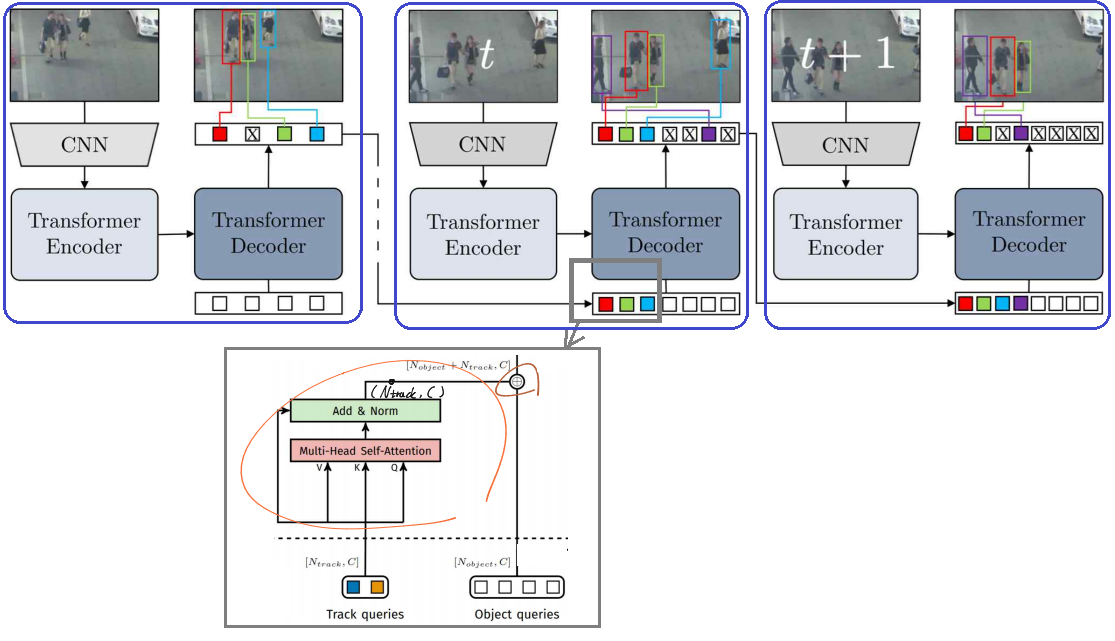
- Key Idea는 track query embeddings을 적용해서, 위의 그림처럼 auto-regressive manner을 사용하는 것이다.
- Transformer의 수학적 수식은 위 VisTR 논문 내용과 같다.
- 전체 순서
- DETR을 그대로 사용해서, 첫번째 Frame에 대해서 Object Detection을 수행한다.
- 첫번째 Frame에 대해, Object query에 의해서 나온 Object decoder output 중 object로 판정되는 output을, 다음 Frame의 Object query로 사용한다. (N_track) 뿐만 아니라, 추가적인 N_object query도 당연히 추가한다.
- 새로운 Frame에 대해서 2번 과정을 반복 수행한다.
- 학습은 2개의 Frame씩만 묶어서 학습한다.
- Track query attention block(= a separate self-attention block) 은 Track queries 끼리 서로 소통하게 만드는 모듈이다. (위 이미지 아래 모듈) 이 모듈을 통해서 t-1 Frame의 Object 위치와 구조에 대한 정보를 그대로 사용하는게 아니게 만들어서, 새로운 Frame에 대한 적응을 좀더 잘하게 만들어 주었다.
- 신박한 학습 기법들
- t-1 Frame을 t 주변의 아무 다른 Frame으로 대체해서 학습시킨다. 객체의 포즈나 위치가 확확 바뀌는 상황에도 잘 적응하게 만들기 위함이다.
- 어떠한 query type(track, object)에서도 잘 반응할 수 있게 만들기 위해서, 가끔 track query를 제거해서 다음 Frame Decoder에 넣어준다. 학습 밸런싱을 맞추는 과정이다. 새로 나타난 객체에 대해서도 잘 Detecion 하게 만들어 주는 방법이다.
- Track queries에 Background에 대한 output도 넣어준다. (내 생각으로 이 과정을 통해서, Track query attention block 과정을 통해서 object occlusion의 문제점을 완화시켜준다.)
- DETR에서 Panoptic Sementation 구조를 그대로 차용해서 Instance에 대한 Mask 예측도 수행하고, MOTS 결과도 출력해보았다.
3.2. 보충 내용
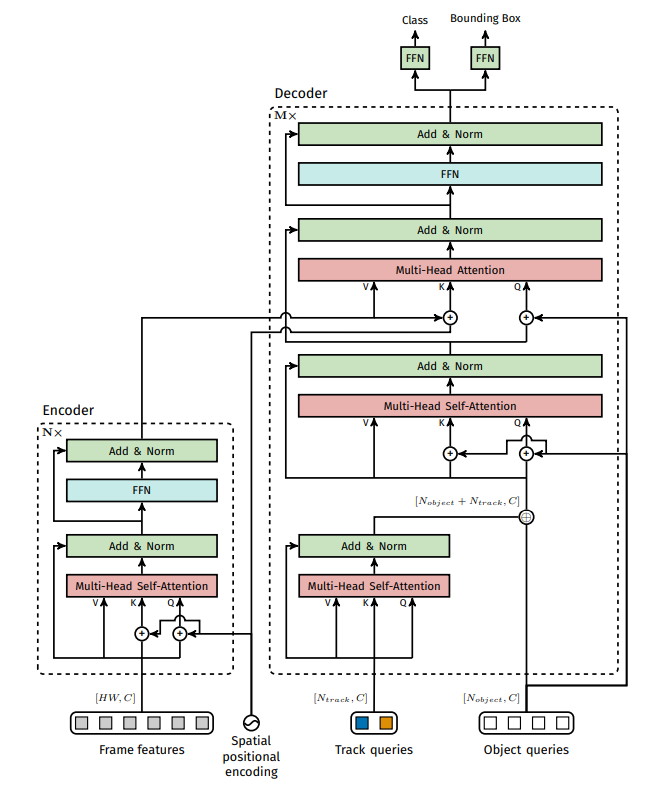
Bipartite track query matching에 대한 부분- MOT dataset, Environment Setting에 대해서는 추후에 필요하면 공부해보자.
4. TrackFormer PPT 공부자료
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
