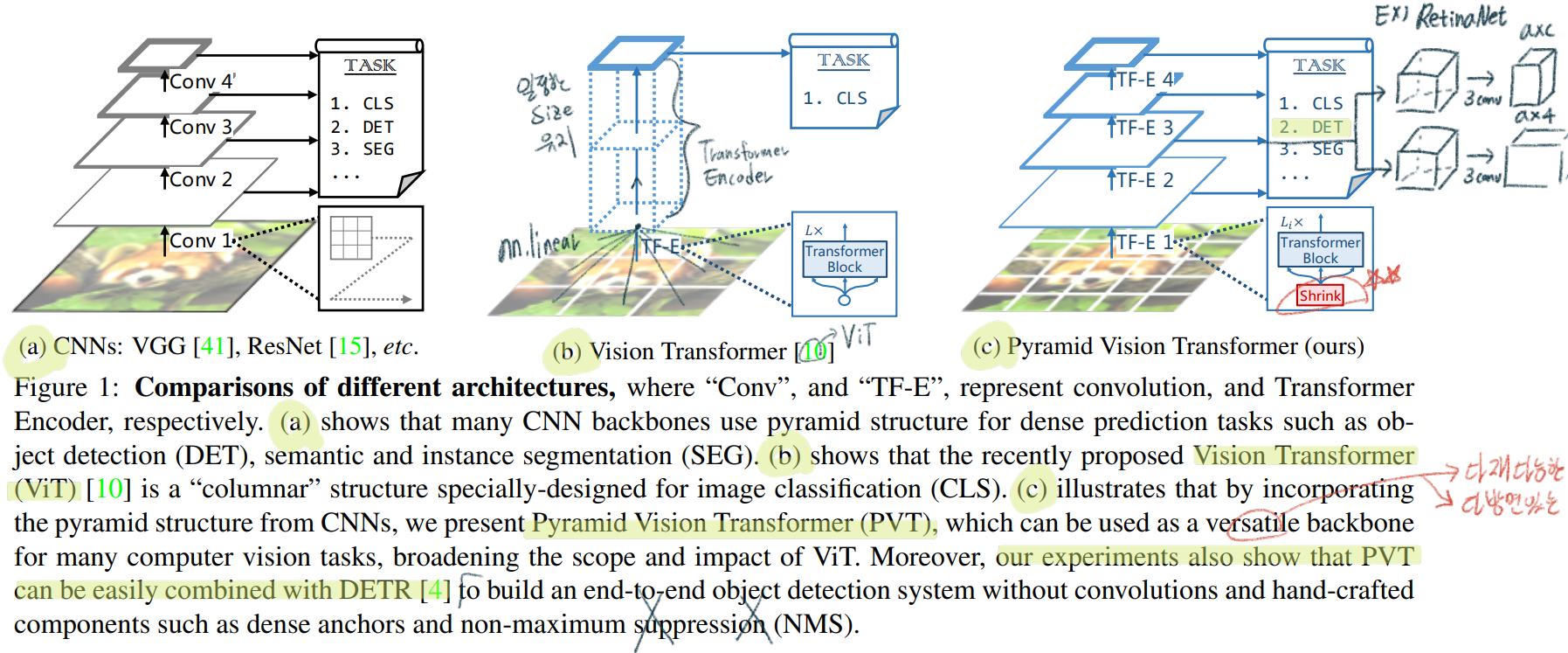
Pure Transformer backbone으로써 사용할 수 있는 PVT 를 제안했다. 특히나 이 backbone을 사용하면 dense prediction task(CNN의 Pyramid구조 그대로 output을 만들어 낼 수 있다.)
새롭게 개발한 아래의 두 모듈을 사용했다. 두 모듈을 사용해서, 다음 2가지 장점을 얻을 수 있었다. (1) Pyramid 구조 생성함으로써 초반의 high resolution output 획득 가능 (2) computation/memory resources의 효율적으로 사용 가능
a progressive shrinking pyramid
spatial-reduction attention layer
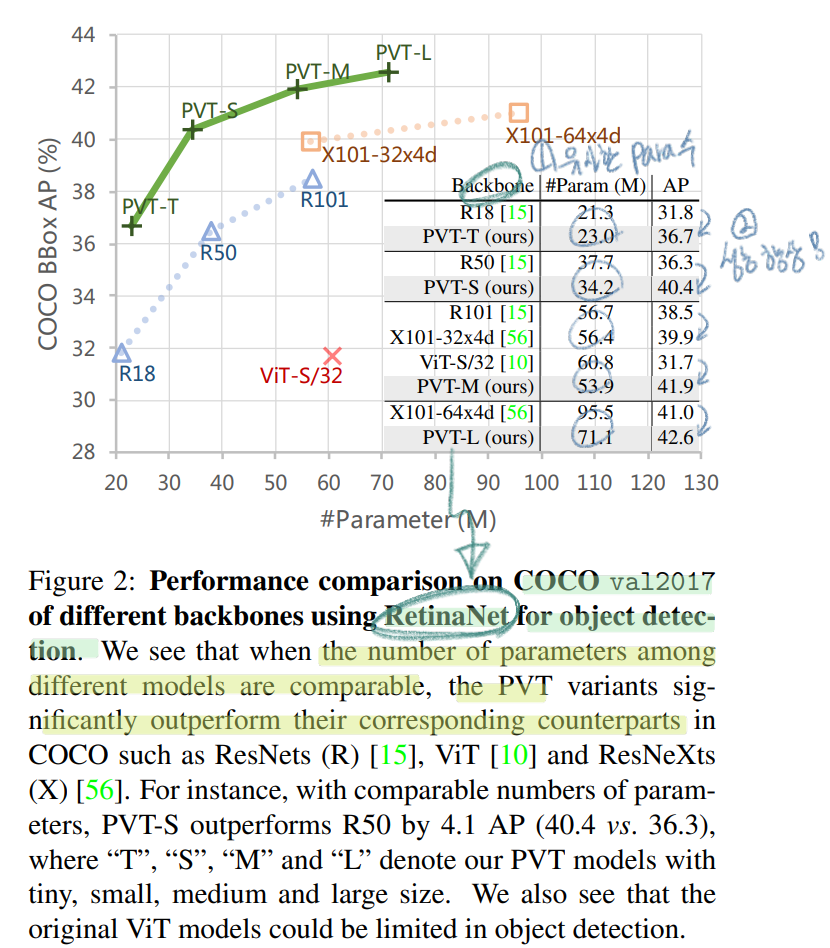
PVT를 비교할 때, ResNet18,50,108 모델과 유사항 파라미터수를 가지는 모델을 만들고 그것과 성능비교를 해보았다.
CNN에는 SE [16], SK [24], dilated convolution [57], NAS [48], Res2Net [12], EfficientNet [48], and ResNeSt [60] 와 같은 많은 발전 모델들이 존재한다. 하지만 Transformer는 여전히 연구 초기 단계이므로 연구 개발의 많은 potential이 존재한다.
PS. 전체적으로 봐서, Deformable DETR과 목적이 같은 논문이다. Deformable DETR에서는 key,value를 pyramid features의 전체를 사용하는 것이 아니라, 모델이 스스로 선택한 4개*(4 level)의 key,value만을 선택해서 MHA을 수행한다. 여기서도 원래 key,value 전체를 shrink하여 갯수를 줄여서 MHA을 수행하겠다는 취지를 가지고 있다. 거기다가 Pyramid 구조를 만들었다는 것에도 큰 의의를 둘 수 있다.
2. Instruction, Relative work
아래 그림이 약간 모호하니, 완벽하게 이해하려고 하지 말기
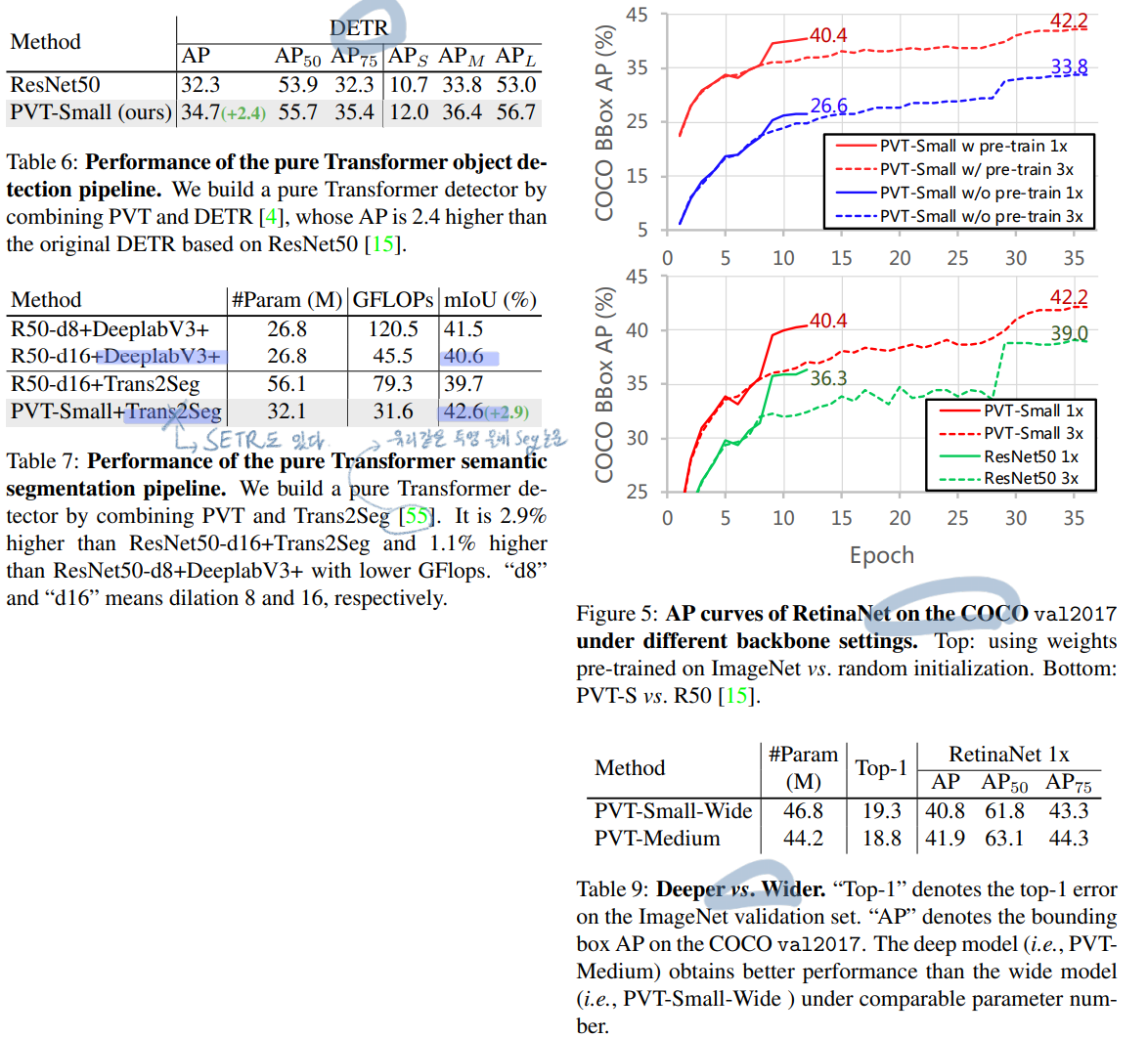
성능 비교
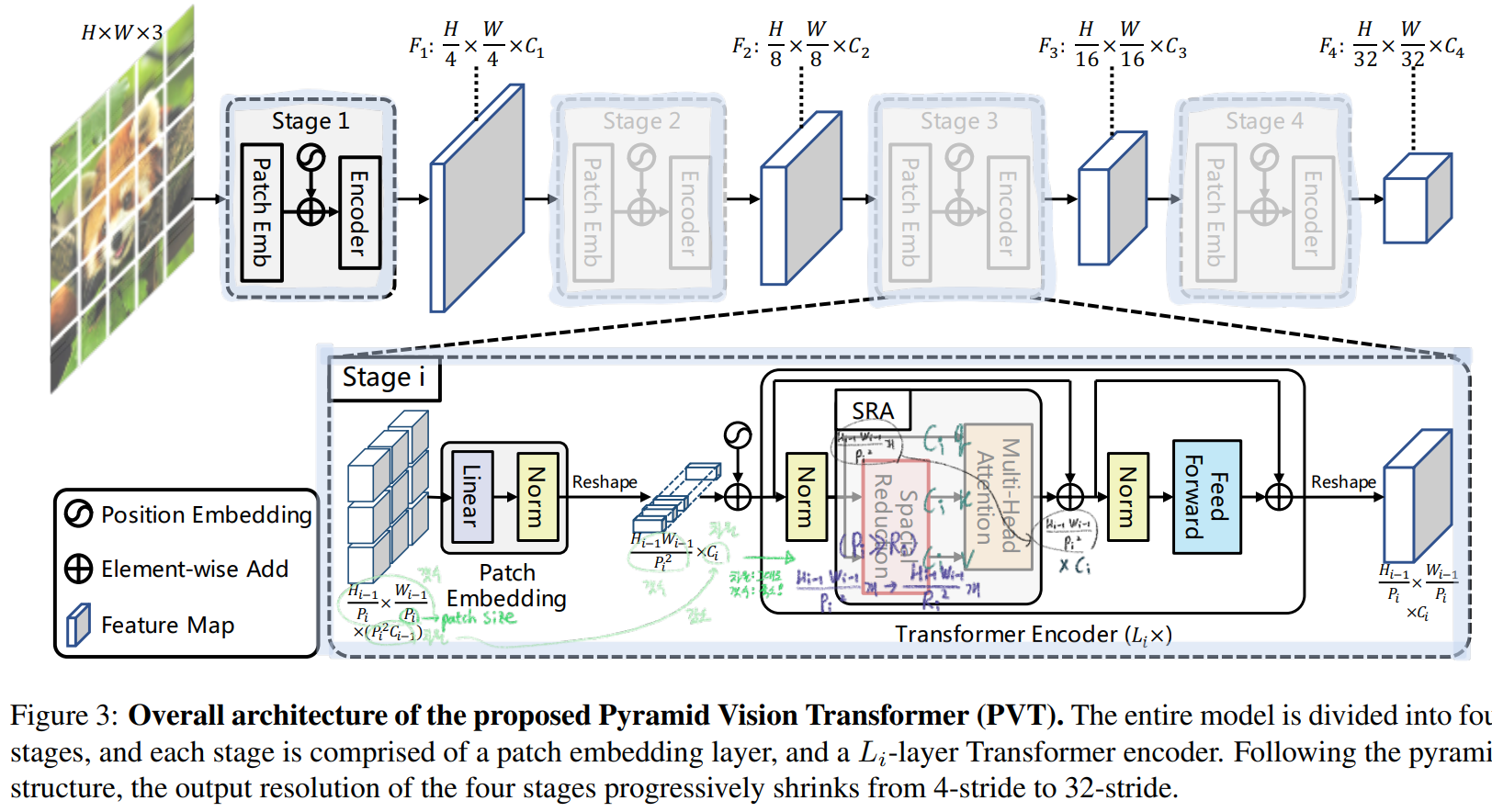
3. Method
아래 그림을 통해서 거의 전부 이해가 가능하다.
a progressive shrinking pyramid : 원래 ViT는 Patchsize = 1 로 하기 때문에, query의 갯수(이미지 HxW resolution)이 항상 일정하다. 하지만 PVT에서는 Patchsize는 1 이상 자연수값을 사용하기 때문에 이미지 resolution이 차츰차츰 감소한다. 따라서 Transformer만을 사용해서 Pyramid구조를 만들 수 있는 것이다.
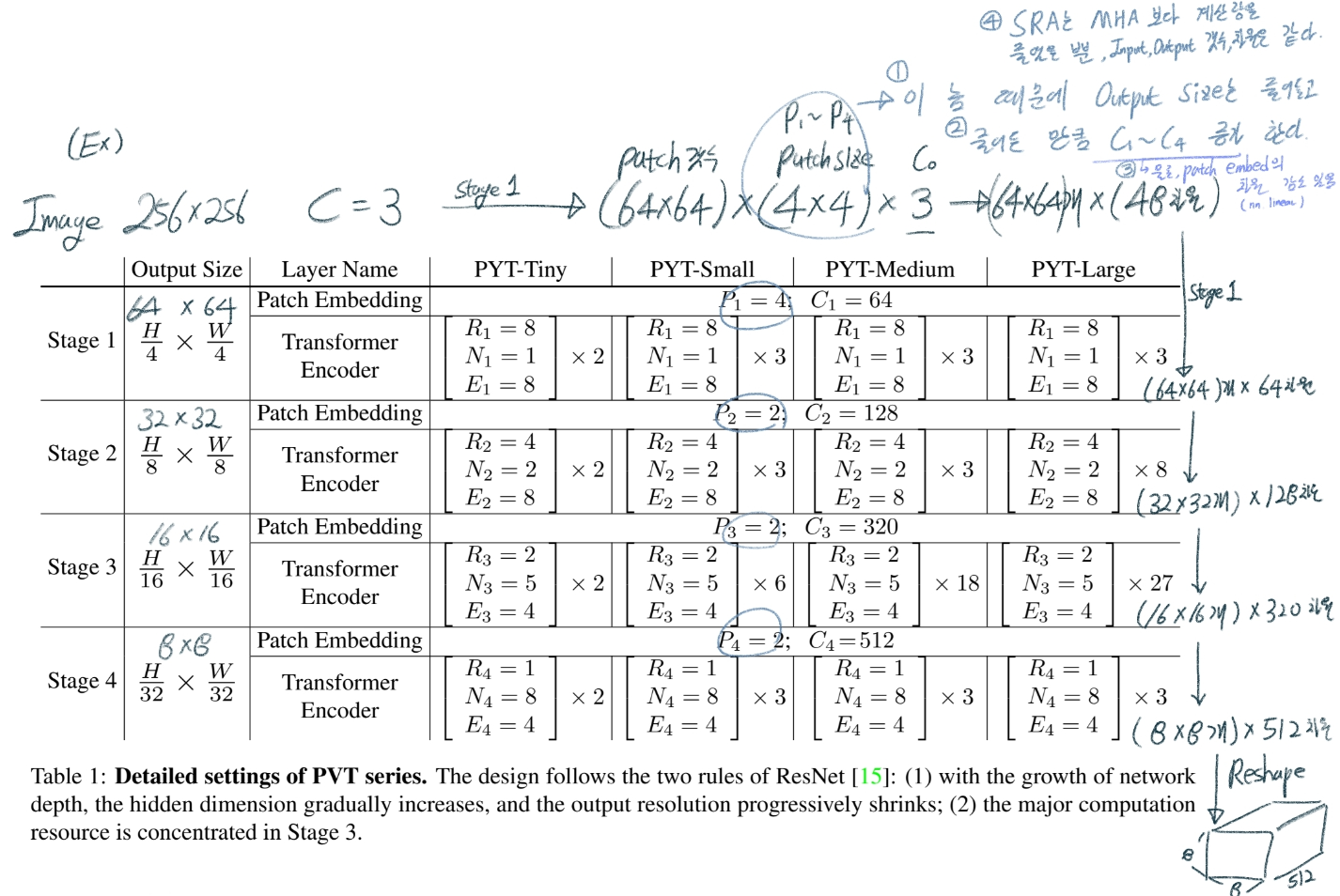
표 이미지의 청자색 필기 1~4번 필기 잘 참조하기 (핵심 및 근거 모음)
spatial-reduction attention layer : reduce the spatial scale(백터 갯수) of K and V 하는 것이다. 이 작업으로 largely reduces the computation/memory 가능하다.
Deformable DETR은 전체 HxW/P^2개의 key,value의 갯수를 특정 방식으로 몇개만 추출해서 사용했다면, 여기서는 전체 HxW/P^2개의 key,value의 갯수를 전체 HxW/R^2 개로 줄여서 사용한다.
4. Experiments
Downstream Tasks
Classification : we append a learnable classification token (positional embeding) to the input of the last stage, and then use a fully connected layer.