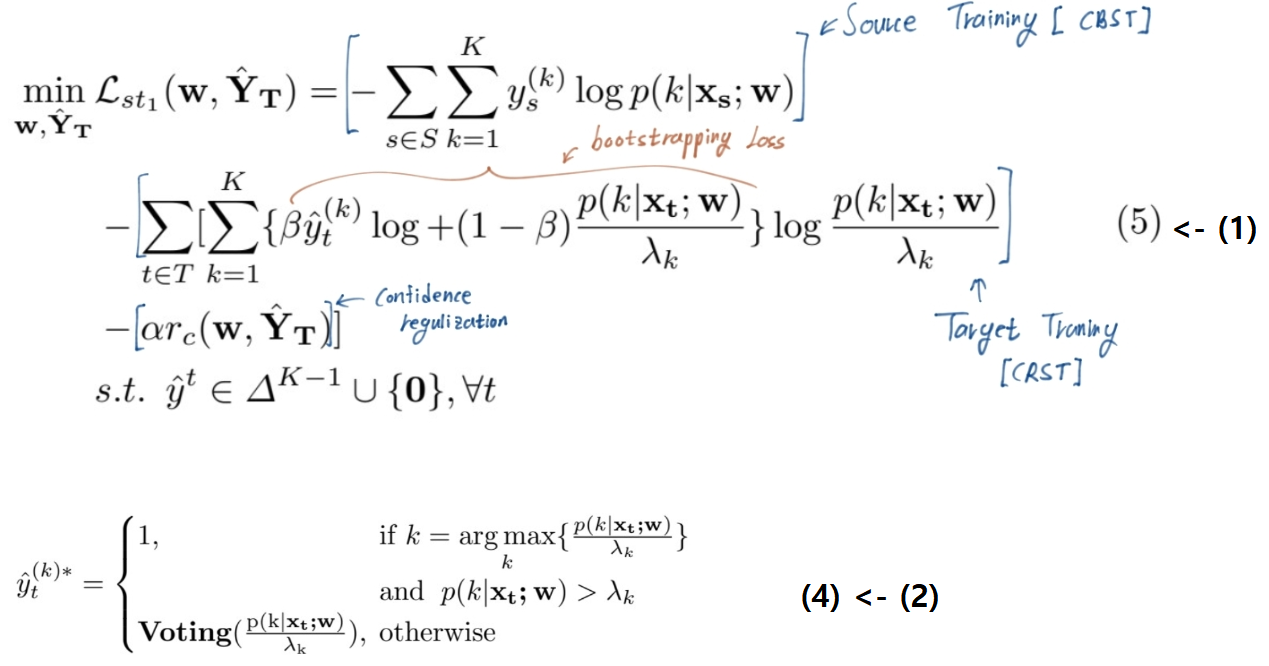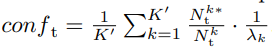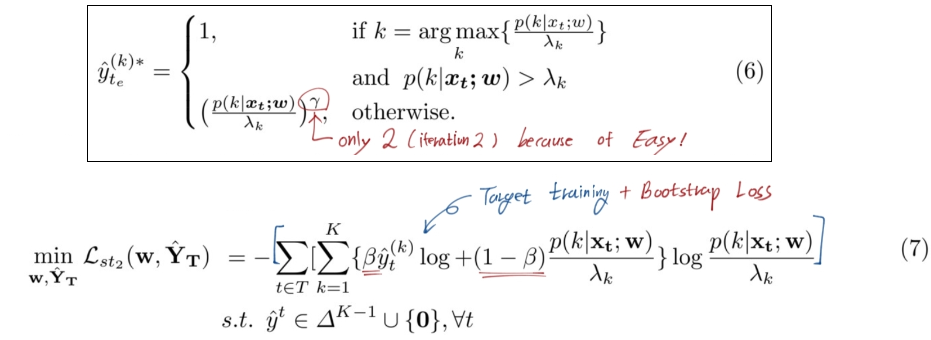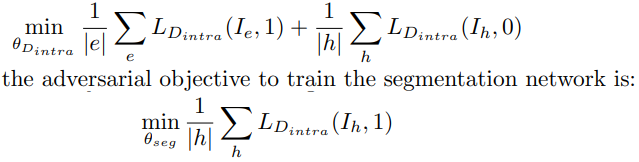대학원과 취업 그리고 나만의 연구분야에 관한 생각나는데로 써보는 일기…
2021년 1월 27일
이전의 2년전 고민이 무색하게, 그리고 대략 6개월 전 취업준비로 고생하며 자존감이 떨어지던 시기가 무색하게 어느덧 대한민국 최고의 카이스트 비전 연구실에 와 있고, 어느덧 모비스 연구원으로 취업이 되어 있었다. 그때는 그렇게 힘들고 걱정과 고민이 많았는데 지금 이렇게 잘 된거를 생각하면 너무너무 행복하고 감사하다. 이 감사함과 행복을 잊지 않도록 노력해야겠다.
최근에 연구실에서 거의 하루 14시간을 공부하며 하루하루를 보내고 있는데, 흥미롭고 재미있지만 똑같은 일상에 지칠 수도 있겠다는 생각이 들 때도 있었다. 근데 위와 같이 다시 생각해보면, 지금 나의 상황이 얼마나 행복하고 즐거운건지를, 그리고 저렇게 생각하면 안된다는 사실을, 다시 한번 깨닫는다.
정말 가끔 블로그나 어떤 경로를 통해서 메일로 진로 상담을 요청하시는 분들이 계신다. 그 분들은 나를 엄청나게 대단한 사람으로 생각하고 자신의 고민에 대해서 말씀해 주신다. 사실은 나도 그렇게 대단한 사람도 아니다. 그저 행운이 많이 좋아서 카이스트에 올 수 있었고, 모비스에 올 수 있었던 건데 말이다. 물론 이충권 선생님이 가르쳐주신 깨달음으로 20살때 부터 항상 최선을 다해서 살아온 것은 맞다. 학점도 활동 경험도 그리고 지금의 연구실과 취업의 결과도 다 그 덕분이다. 하지만 이게 그렇게 대단한 건가? 나는 아니라고 본다. 왜냐면 나는 천재가 아니고 많이 노력파이기 때문이다. 따라서 다른 누군가가 정말 그냥 주어진 하루하루를 최선을 다해 살아가고 노력한다면 누구든 원하는 곳에 취업하고 원하는 대학원에 입학할 수 있다고 생각한다. 하지만 거기에는 ‘행운’이라는 요소가 생각보다 많이많이 필요하다.
행운은 어떻게 얻을 수 있을까? 그것에 대한 답변은 이 동영상을 통해 얻을 수 있다. 이충권-나는운이좋다 적당히 내용을 요약하자면, ‘나는 운이 좋다. 나는 운이 정말 좋다. 모든 일은 내뜻대로 된다.’라고 생각하고 행복하고 즐거운 마음으로 하루하루를 열심히 살아가는 사람에게 행운이 따라온다.라는 이야기 이다. 나는 이것을 믿는다. 책 The secret이라는 정말 소중한 책이 있다. 이 책은 내가 가장 좋아하는 책이다. 이 책에 따르면 ‘바라고 믿고 행복해져라’라고 말한다. 정말 내가 바라고 그것이 이뤄질 수 있다고, 나는 운이 좋다고, 그렇게 무조건 될거라고 생각하며 기쁨과 행복을 느끼면, 정말 내가 바라는 것이 이뤄진다는 마법같은 이야기다. 누구는 이 이야기가 ‘사이비같은 이야기다. 말도 안된다.’라고 생각하지만, 나는 그런 사람과 어울리고 싶지도 않고, 대화도 하기 싫고, 가까이 하고 싶지도 않을 정도로, 저 내용을 절실하게 믿는다. 왜냐면 내가 그 산 증인이니까. 따라서 나는 앞으로도 바라고 믿고 행복할 것이다. 나는 200% 믿는다.
그렇게 해서 나는 (사실 정말 될까? 라고 의심은 조금했었지만, 정말 마법처럼) 원하는 최고의 연구실에 왔고, 취업에 성공했다. 내 이야기가 아닐것만 같았던, 현대모비스 계약학과 장학생이 정말 나의 것이 되었다. 다시 생각해봐도 정말 감사하고 소중하고 행복 하다. 정말 감사하게 연구하고 공부해야겠다. 하루하루 최선을 다해서 꾸준히 해 나간다면, 처음에는 모르고 혹은 어렵다고 느껴질지도 몰라도, 결국에는 깨닫고 재밌어 질 것을 나는 안다. 선생님은 말씀하셨다. ‘세상에 어려운 것은 없다. 니가 모를 뿐이다. 모르면 배우면 된다. 모르면 물어보면 된다. 모르면 공부하면 된다. 우울하고 좌절할거 하나 없다.’
이런 나의 긍정적인 생각과 마음이, 나의 소중하고 사랑하는 사람들에게 전해지리라고 믿고, 그리고 이 글을 읽고 있는 독자분들에게도 전해지리라고 믿는다. 내 주변 모든 사람에게 행복과 기쁨 그리고 행운이 가득하길 바라고 정말 그렇게 되리라 믿는다.
다음에 시간적 여유가 생기면, 현대모비스 계약학과 학생이 되기까지의 준비과정과 노력들에 대해서도 간략하게 적어보려고 한다. 유투브 보고 시간 버리는 시간에 재미로 작성해 볼 계획이다. 그렇게 적어놓는 것이 나에게도 좋을 것이라 생각한다. 내가 어떤 노력을 했는지 어떤 과정을 거쳤는지 기록해 놓을 수 있고, 가끔 생각날 때 읽을 수 있을 테니까.
연구분야에 대한 고민
나의 연구분야에 대해서 진지하게 고민해볼 때가 온 것 같다. 이제는 누구에게 물어보고 조언을 구해서 답변을 정해야 하는 때가 아니다. 마음이 디죽박죽이고 생각이 디죽박죽이여서 이것을 정리해 보고 싶어서 이렇게 일기를 작성한다. 아무래도 사적인 이야기보다는 공부와 연구에 관한 주제이기 때문에 블로그에 기록하는게 낫다고 생각했다. 그래야 나중에 좀 더 쉽게 찾아볼 수 있으니까.ㅎㅎ
이런 고민을 시작하게 된 이유는 다음과 같다. 최근 나는 Domain adaptation, Self-supervised learning에 관련된 공부를 하고, 이와 관련된 논문을 읽어왔다. 물론 내가 이 분야에 관심이 있어서 읽은 이유도 있지만.. 아무래도 연구실 내의 연구원분들이 최근 이 분야에 대해서 많이 연구하기기 때문에, 교수님께서 Self-supervised에 관심이 많으시기 때문에. 이의 논문들을 읽었다. 하지만 이 논문들을 읽으면 마음한 구석에 이런 생각이 들었다. ‘근데 이거 정말 내가 활용할거 맞아? 에이 설마 이 논문내용을 딱 사용하겠어? 이 논문 내용을 어떻게 실용적으로 현실적으로 사용하지?’ 라는 생각을 하였다. 뭔가 눈 앞에 떡이 있는데 먹지는 않고 바라만 보고 냄새맡고 눌러보기만 하는 느낌이었다.
오늘 새로운 논문을 읽으려는데 최근 위와 같은 생각과 느낌 때문에, 갑자기 나는 이런 생각을 했다. ‘오늘은 무슨 논문 읽지? 하 그냥 나도 내가 관심있는 분야를 딱 정해서 그거를 한번 미친듯이 파볼까? 관련된 논문을 줄구장창 읽어볼까?’ 따라서 지금 나에게 가장 중요한건 그냥 눈에 보이는데로 논문을 읽는 것 보다는 나의 흥미분야가 무엇이고, 나의 연구 스토리로 가져갈 핵심 주제를 무엇으로 할지를 정하는 것이다.
나는 관심을 가지는 연구주제가 몇가지 있긴하다. 하지만 솔직히 말해서.. 사실 나는 나의 연구주제를 확정하기 무섭다. 두렵다. 내가 정한 연구주제가 유용한 주제인지, 그리고 나중에 미래에 가서 그 지식이 쓸모가 있을지, 내가 공부한 것들이 잘 한 것이고 ‘공부하기 잘했다.’라고 생각이 들만한 것인지 확정할 수 없기 때문에… 나는 연구주제를 한가지 정해서 파는게 사실 두렵고 무섭다.
이 질문에 대해, 내가 나에게 해줄 수 있는 답변은 이와 같다. 이전의 선배님의 말씀처럼
어떤 분야를 딱 정해서 미친듯이 공부한다고 해도 공부의 왕도와 끝은 없다. 너무 걱정하고 조급해하지 말고 꾸준하게 흥미를 가지는 연구에 대해서 차곡차곡 읽어나가자. 딱 정해진 연구분야에 관련된 논문만 읽어야 하는 것은 아니다.
예를 들어서 3D-Detection, Instance Segmentation 논문을 읽다가, 중간중간 심심하면 Domain Adaptation에 관련된 논문도 읽고 Self-Supervied에 관한 논문도 읽으면 되는거다. 혹은 3D-Detection, Instance Segmentation에 관련된 논문을 1달~2달정도 매일매일 읽고 어느정도 이 분야에 대해서 도가 트이면 Domain Adaptation, Self-Supervied에 대해서도 똑같이 도가 트일 정도로 논문을 읽으면 되는거다.
the devil in the boundary논문도 그렇게 Video Panoptic Segmentation 논문도 그렇게 선배님들이 모두모두 domain-adaptation, self-supervised에 대한 연구만 하시는게 아니다. 심지어 TPLD 논문도 sementic segmentation에 대한 내용을 베이스로 깔고 있다. 이렇게 선배님들도 기본적인 recognition에 대한 논문 지식들은 모두 가지고 있는 상태에서 저러한 Hot한 주제의 내용을 가미해서 논문을 만드시는 것이라고 생각한다면, 내가 지금 당장 Object detection, Segmentation 논문들을 읽으며, ‘패러다임이 또 바뀔텐데.. 굳이? 이거 나중에 계속 쓰이려나? 이거 그냥 의미없는 SOTA싸움 아니야? 지금 핫한건 domain, self-supervise인데 ‘ 생각을 할 필요가 없다. 그냥 시간나는대로 보고 읽으면 된다.
일단 아래 방법으로 나아가 보자.
- Object Detection에 대해서 먼저 좀 알자 ex) Yolo_v4와 다른 논문들
- Instace Segmentation에 대해서도 쭉쭉 읽어나가자.
- 3D object detection 에 대해서 공부하지(3D-detection, 3D-detection from stereo Image)
- 가능하면 Github로 찾아보고, paperswithcode에서 찾아서 공부하자.
- 논문과 코드를 동시해 이해하자.
- 중간중간 추천이 들어오는 domain adaptation, self-supervised에 대한 논문이 있다면 그것도 또 읽자.
- 혹은 ‘이 분야에 대해서는 너무 심각하게 모른다.. Overview에 대한 지식이 너무 없는데?’ 라는 생각이 들면, 관련된 google 정리 post를 보거나, survey논문을 보거나, 관련 탑 티어 논문을 읽어보면 되는거다.
- 3번까지 어느정도 도가 트이면 domain adaptation, self-supervised 내용에 대해서도 도가 트일 수 있도록 논문읽으며 다시 집중해서 읽어보면 된다.
- 일주일에 한 두번씩은 한동안은 무슨 논문 읽지~ 하면서 2개,3개 정도 만 정해두고 논문을 읽다가 나오는 reference paper를 보고, 이 논문도 읽어야 겠다. 라는 생각이 들면 나중에 천천히 그것도 읽으면 되는거다.
1과 2번을 하다 보면 정말 끝도 없을 것이다. 이때 중요한 것은 왕도가 있다고 생각하지 않는 것과 끝장을 내버리고 모든것을 다~읽어버리겠다 라는 생각을 하지 않는 것이다. 항상 마음을 편하게 가지고 그냥 하루하루 끌리는 논문을 읽으면 되는거다. “나는 이걸 다 읽어야 해. 내가 읽을게 이렇게 많아? 이거 언제 다 읽지… 저 주제도 좋은 것 같으니, 저것도 해야할 것 같은데 그건 또 언제 하지” 라는 생각은 절대절대절대 할 필요가 없다. 그냥 하루하루 끌리는 주제와 논문을 꾸준히 하나씩 읽어가면 될 뿐이다. 흥미를 가지고, 꾸준히. 조급해지지 말고, 연구가 일이 되어 재미가 없어지지 않도록. 질리지 않도록.
우선 모비스 배치상담서에는 다음과 같은 내용을 기제했었다. 2021년 1월 25일의 나는 어떤 생각과 희망분야, 관심분야를 가지고 있었는지 기록해 두고자 남겨둔다.
- 연구실 주요 연구분야
- 인식 안정성 확보를 위한 머신 러닝 연구 : 1) 데이터 부족 문제(Data hungry), 2) 현실 세계 일반화, 3) 인식 강건성 확보와 같은 도전과제를 해결하며, 인식 모델의 안정성을 확보하기 위한 연구. Domain adaptation, Semi-supervised Learning, Self-supervised learning, Attention module 연구
- 딥러닝을 이용한 컴퓨터 비전 연구 : 영상 내 객체 탐지(localization)와 객체 인식(detection)을 위한 연구. Visual recognition, Image segmentation(영상 분 할), Object detection, Multi object tracking(다중 객체 추적), 3D object detection, Object depth estimation과 같은 컴퓨터 비전 딥러닝 연구
- 인식 어플리케이션 및 지능형 로봇 개발 연구 : 카메라 영상, RGB-D 카메라, 적외선 카메라를 활용한 인식 어플리케이션 개발 연구 및 과제 수행. 인식 결과를 활용하는 지능형 로봇 개발 연구.
- 희망분야 / 관심분야
- 주석 처리된 데이터 부족 문제, 도메인 변화로 인한 인식 모델 성능 하락 문제들을 해결하기 위한, 인식 모델 안정성 확보 연구 (Self-supervised learning and Domain Adaptation)
- 다중 카메라를 활용한 3차원 객체(보행자, 주변 차량) 탐지 및 인식 연구 (Object localization and detection)
- RGB-D 카메라 또는 적외선 카메라를 융합한 영상 분할(Instance segmentation) 연구 및 객체 탐지 연구
- 학위 예상 논문명
- Robust depth completion & 3D object detection for Unsupervised Domain Adaptation (비지도 학습 도메인 적응 기법을 활용한 환경 변화에 강건한 3차원 객체 탐지 및 깊이 추론 연구)
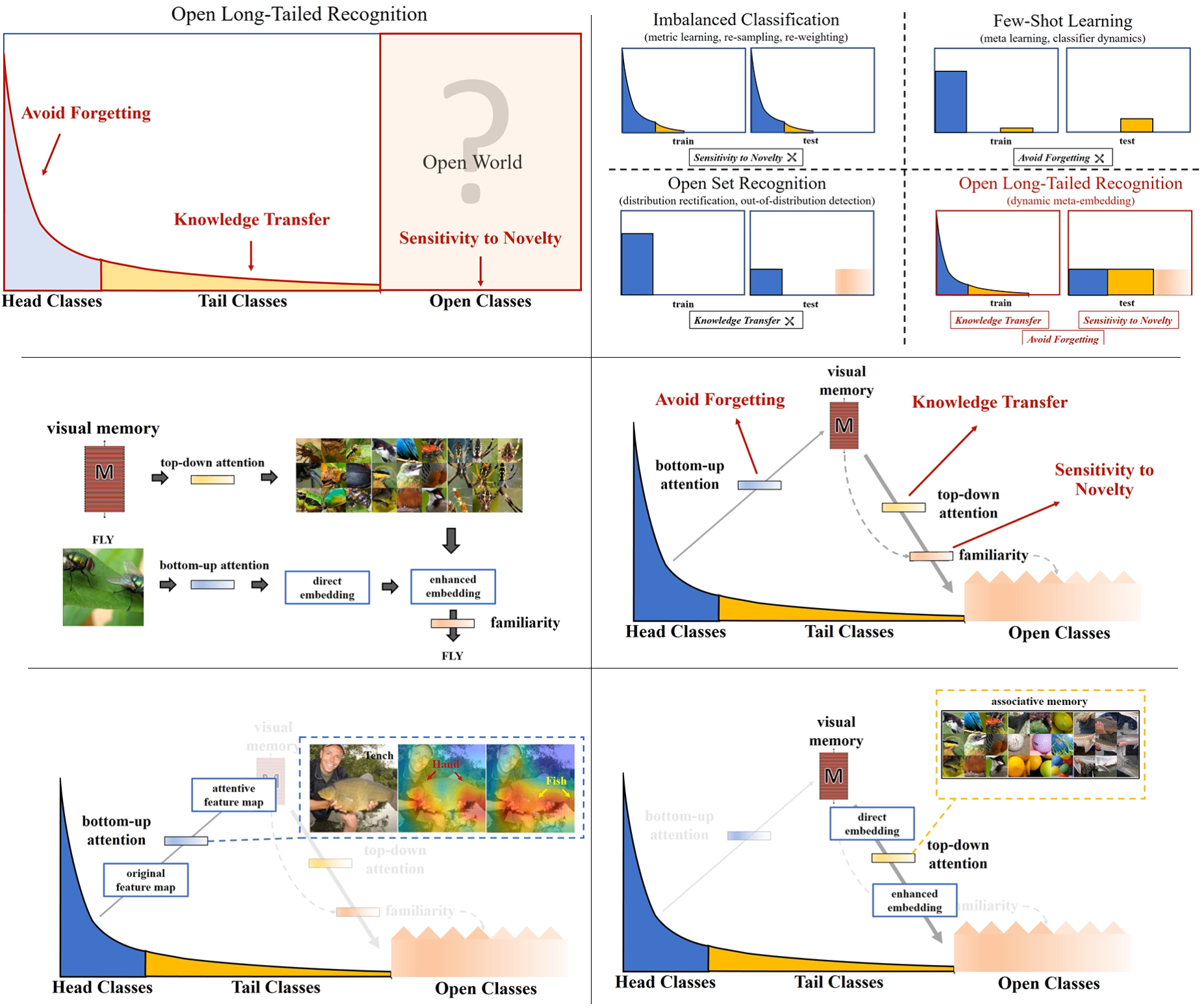
- 논문 : Large-Scale Long-Tailed Recognition in an Open World - y2019-c103
- 분류 : Unsupervised Domain Adaptation
- 저자 : Ziwei Liu1,2∗ Zhongqi Miao2∗ Xiaohang Zhan1
- 읽는 배경 : (citation step1) Open Componunt Domain Adaptation에서 Memory 개념이 이해가 안되서 읽는 논문.
- 읽으면서 생각할 포인트 : 논문이 어떤 흐름으로 쓰여졌는지 파악하자. 내가 나중에 쓸 수 있도록.
- 동영상 자료
- 질문
- 선배님 조언
- 외국에서 사는게 그리 좋은게 아니다. 우리나라 라는 것이 얼마나 큰 축복인지 모른다. 기회가 있다면 나가서 일하고 나중에 다시 돌아오면 된는거다. 우리나라에 대해서 감사함을 가지고 살아가도록 해야겠다.
- 특히나 외국에서 오래 살고 오셨기 때문에, 저 진심으로 해주시는 조언이었다. 그냥 큰 환상을 가지고 거기서 살고 싶다 라는 생각을 해봤자 환상은 깨지기 마련이고, 우리나라 안에서, 우리나라가 주는 편안함과 포근함에 감사하며 살아가는게 얼마나 큰 축복인지 알면 좋겠다. 모비스와 다른 외국 기업과의 비교를 생각하며 감사할 줄 몰랐다. 하지만 감사하자. 모비스에 가서도 정말 열심히 최선을 다해, 최고가 되기 위해 공부하자. 그렇게 해야 정말 네이버든 클로버든 갈 수 있다. 그게 내가 정말 가야할 길이다. 그러다가 기회가 되어 외국 기업이 나를 부른다면, 다녀오면 된다. 그리고 또 한국이 그리워지면 다시 돌아오면 되는거다. 나의 미래를 좀 더 구체적으로 만들어 주신 선배님께 감사합니다.
- 학교에서 너무 많은 것을 배우려고 하지 마라. 수업은 그냥 쉬운게 짱. 하고 싶은 연구하고 하고 싶은 공부하는게 최고다. 그리고 동기와 친구와 같이 수업 듣는 것을 더 추천한다.
느낀점
- Instruction이 개같은 논문은..
- abstract 빠르게 읽고, Introduction 대충 읽어 넘겨야 겠다. 뭔소리하는지 도저히!!!!!! 모르겠다.
- 지내들이 한 과정들을 요약을 해놨는데.. 나는 정확히 알지도 못하는데 요약본을 읽으려니까 더 모르겠다.
- 따라서 그냥 abstract읽고 introduction 대충 모르는거 걍 넘어가서 읽고.
- relative work의 새로운 개념만 빠르게 훑고, 바로 Ours Model에 대한 내용들을 먼저 깊게 읽자. 그림과 함께 이해하려고 노력하면서.
- 그리고! Introduce을 다시 찾아가(👋) 읽으며, 내가 공부했던 내용들의 요약본을 읽자
- 아무리 Abstract, Instruction, Relative work를 읽어도, 이해가 되는 양도 정말 조금이고 머리에 남는 양도 얼마 되지 않는다. 지금도 위 2개에서 핵심이 뭐였냐고 물으면, 대답 못하겠다.
- 현재의 머신러닝 논문들이 다 그런것 같다. 그냥 대충 신경망에 때려 넣으니까 잘된다.
- 하지만 그 이유는 직관적일 뿐이다. 따라서 대충 이렇다저렇다 삐까뻔쩍한 말만 엄청 넣어둔다. 이러니 이해가 안되는게 너무나 당연하다.
- 이런 점을 고려해서, 좌절하지 않고 논문을 읽는 것도 매우 중요한 것 같다. (👋)여기 아직 안읽었다고??? 걱정하지 마라. 핵심 Model 설명 부분 읽고 오면 더 이해 잘되고 머리에 남는게 많을거다. 화이팅.
- 확실히 Model에 더 집중하니까, 훨씬 좋은 것 같다. 코드까지 확인해서 공부하면 금상첨화이다. 이거 이전에 읽은 논문들은, 그 논문만의 방법론에는 집중하지 못했는데, 나중에 필요하면 꼭! 다시 읽어서 여기 처럼 자세히 정리해 두어야 겠다.
- 이 논문의 핵심은 이미 파악했다. 👋 읽기 싫다. 안 읽고 정리 안했으니, 나중에 필요하면 참고하자. 명심하자. 읽을 논문은 많다. 모든 논문을 다 정확하게 읽는게 중요한게 아니다.
0. Abstract
- the present & challenges
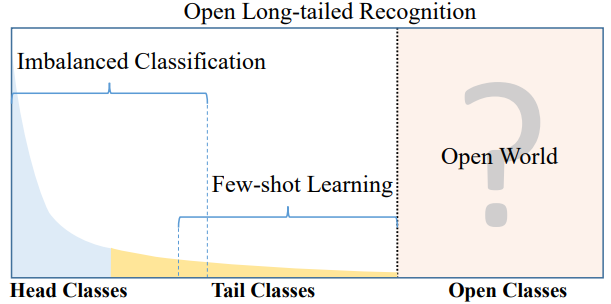
- Real world data often have a long-tailed and open-ended distribution. 즉 아래의 그래프의 x축은 class종류를 데이터가 많은 순으로 정렬한 것이고, y축은 해당 클래스를 가지는 데이터 수. 라고 할 수 있다. Open Class는 우리가 굳이 Annotate 하지 않는 클래스이다.
- Ours - 아래 내용 요약
1. Introduction
3. Our OLTR Model

- 우리 모델의 핵심은 Modulated Attention 그리고 Dynamic meta-embedding 이다.
- dynamic Embedding : visual concepts(transfers knowledge) between head and tail
- modulated Attention : discriminates(구분한다) between head and tail
- reachability : separates between tail and open
- Our OLTR Model
- We propose to map(mapping하기) an image to a feature space /such that visual concepts can easily relate to each other /based on a learned metric /that respects the closed-world classification /while acknowledging the novelty of the open world.
combines a direct image feature and an associated memory feature (with the feature norm indicating the familiarity to known classes)
- CNN feature 추출기 가장 마지막 뒷 단이 V_direct(linear vector=direct feature)이다. (classification을 하기 직전)
- tail classes(data양이 별로 없는 class의 데이터)에는 사실 V_direct이 충분한 feature들이 추출되어 나오기 어렵다. 그래서 tail data와 같은 경우, V_memory(memory feature) 와 융합되어 enrich(좀더 sementic한 정보로 만들기) 된다. 이 V_memory에는 visual concepts from training classes라는게 들어가 있다.
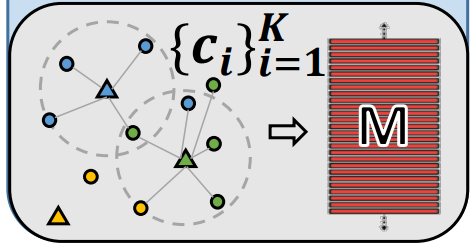
Learning Visual Memory (M)
- [23] 이 논문의 class structure analysis and adopt discriminative centroids 내용을 따랐다.
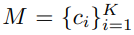 여기서 K는 class의 갯수이다.
여기서 K는 class의 갯수이다.- M은 V_direct에 의해서 학습이 된다. centroids 정보가 계속적으로 Update된다고 한다. 여기서 centroids정보는 아래의 삼각형 위치이다. 아래의 작은 동그라미가 V_direct 정보이고, 그것의 중심이 centroids가 된다.
- 이 centroids는 inter-class에 대해서 거리가 가장 가깝게, intra-class에 대해서는 거리가 최대한 멀게 설정한다.
- centroids를 어떻게 계산하면 되는지는 코드를 좀만 더 디져보면 나올 듯하다. 아래 python코드의 centroids가 핵심이다. centroids는 model의 forward 매개변수로 들어온다.
Memory Feature (V_memory)
V_meta
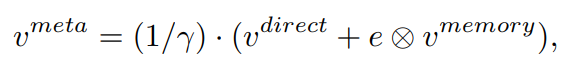
- V_meta이 정보가 마지막 classifier에 들어가게 된다.
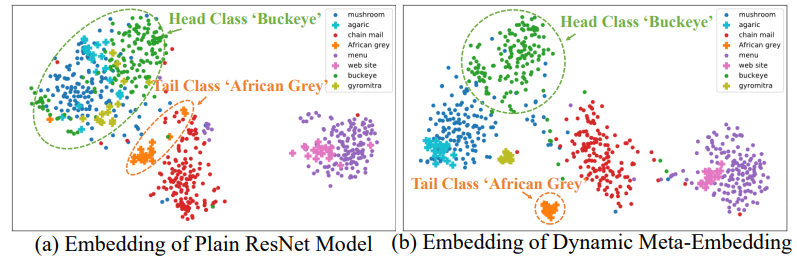
- 왼쪽 이미지 처럼, 그냥 V_direct를 사용하면, inter-class간의 거리가 멀리 떨어지는 경우도 생긴다.
- 오른쪽 그림은, V_meta를 확인한 것인데, inter-class간의 거리가 더 가까워진 것을 확인할 수 있다.
Reachability (γ)
- closed-world class에 open-world class를 적용하는데 도움을 준다.
- 공식은 이와 같고,
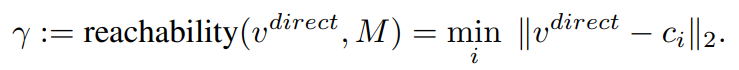
- 이것이 의미하는 바는, class 중에서 어떤 class의 centroids와 가장 가까운지 Open-world data의 V_direct와 비교를 하는 것이다. 가장 가까운 class에 대해서(γ 작음) V_meta에 큰 값을(1/γ큼) 곱해 주게 된다.
- 이것은, encoding open classes를 사용하는데에 더 많은 도움을 준다.
e (concep selector)
- head-data의 V_direct는 이미 충분한 정보를 담고 있다. tail-data의 V_direct는 상대적으로 less sementic한 정보를 담고 있다.
- 따라서 어떤 데이터이냐에 따라서 V_memory를 사용해야하는 정보가 모두 다르다. 이런 관점에서 e (nn.Linear(feat_dim, feat_dim)) 레이어를 하나 추가해준다.
- 따라서 e는 다음과 같이 표현할 수 있다.
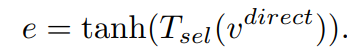
dynamic meta-embedding **facilitates feature sharing** between head and tail classes
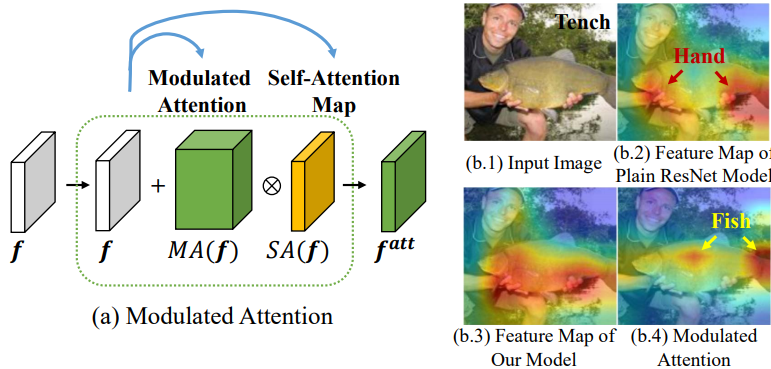
3-2. Modulated Attention
- Modulated attention : encourages different classes to use different contexts(attentions), which helps maintain the discrimination between head and tail classes.
- V_direct를 head와 tail class 사이, 그리고 intra-class사이의 차이를 더 크게 만들어 주는 모듈이다. 위의 이미지에서 f가 f^(att)가 되므로써, 좀 더 자신의 class에 sementic한 feature를 담게 된다. 이 attention모듈을 사용해서 f에 spatial and different contexts를 추가로 담게 된다.
- 아래의 Attention 개념은 논문이나, 코드를 통해 확인
- SA : self-correlation, contextual information [56]
- MA : conditional spatial attention [54]
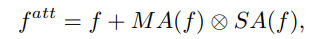 여기서 f는 CNN을 통과한 classifier들어가기 바로 전.
여기서 f는 CNN을 통과한 classifier들어가기 바로 전.- 이 개념은 다른 어떤 CNN모듈에 추가해더라도 좋은 성능을 낼 수 있는 flexible한 모듈이라고 한다.
3.3 Learning
- cosine classifier [39, 15]를 사용한다. 해당 논문 2개는 few-shot 논문이다.
- 이 방법은 아래의 방법을 사용하는 방법이다. V_meta와 classifier의 weight까지 normalize한다.
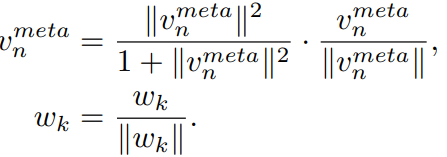
- 이러한 normalize에 의해서, vectors of small magnitude는 더 0에 가까워지고, vectors of big magnitude는 더 1에 가까워 진다. the reachability γ 와 융합되어 시너지 효과를 낸다고 한다.
3.4 Loss function
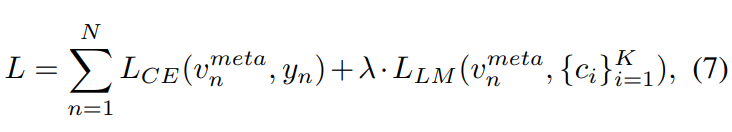
- cross-entropy classification loss, large-margin loss
- 내 생각. 위 식의 v^meta는 classification이 된 결과를 말하는 것일 것이다. vector_meta가 아니라.
- 오른쪽 loss항을 통해서, the centroids {ci} K i=1 를 학습 시킨다.
- 자세한 loss 함수는 부록 참조
4. Experiments
- Datasets
- Image-Net2012를 사용해서 head와 tail을 구성시킨다. 115.8k장의 이미지. 1000개의 카테고리. 1개의 카테고리에 최대 이미지 1280개, 최소 이미지 5개로 구성한다.
- Openset은 Image-Net2010을 사용하였다.
- Network Architecture - ResNet 사용
- Evaluation Metrics
- the closed-set (test set contains no unknown classes)
- the open-set (test set contains unknown classes)
- Train을 얼마나 반복해서 시켰는지에 따라서, many-shot classes / medium-shot classes / few-shot classes를 기준으로 accuracy를 비교해 보았다.
- For the open-set setting, the F-measure is also reported for a balanced treatment of precision and recall following [3]. (혹시 내가 Open-set에 대한 accuracy 평가를 어떻게 하는지 궁금해 진다면 이 measure에 대해서 공부해봐도 좋을 듯 하다.)
- Ablation Study / Result Comparisons / Benchmarking results
은환이의 도움으로 아래의 트위터 글에 대해서 알 수 있었다.
https://twitter.com/bneyshabur/status/1349225440435728385
좋은 conference에 논문을 내보지 않은 학생들에게 좋은 추천을 해주는 글들이 있었다.
이 내용을 정리해 보려고 한다.
Long thread at the risk of being judged
- 급하게 아슬아슬하게 쓴 paper가 Top-conf에 accept가 되고 나서, 아래의 내용들을 깨달을 수 있었다.
- 이건 운 or 논문의 질로 설명할 수 있는게 아니다. 내가 믿기로, 현재의 학회 시스템은 많은 불필요성을 가지고 있으며 해롭고 불공평한 편향들이 존재한다. 특히 새로 이 영역에 들어오는 사람들이나 규범을 지키지 않는 다른 사람들에게는 매우 불공평하다.
- 이러한 문제가 있는 체계에서 나의 논문과 연구를 지키기 위해 했던 노력들을 공유합니다. 더 많은 방법이 있기는 하지만 나중에 공유하겠습니다.
Writing the paper
- ” Make your paper look similar to a typical ML paper.” 아무리 강조해도 지나치지 않다. Figure, table 모두 비슷해야한다. abstract, introduction, phrases, organiation 모두 모두.
- reviewer가 short attention span(짧은 시간의 집중) 하도록 만들어라. reviewer는 5분안에 main results를 알고 싶어 한다. 그니까 abstract 쓰는데 가장 많은 시간을 투자해라. 그리고 first figure & contribution section에 많이 투자해라. 첫인상이 가장 중요하다!
- reviwer들은 combination of theory + experiments을 사랑한다. 이론적인 내용을 쓰고 싶다면 실험도 꼭 추가하고, “if you are writing an empirical paper, Try to add a theoretical component”
- cite(참고하고 인용해라) many papers! 관련된 최대한 많은 논문을 읽고, generous하고 만들어라. 많은 cite를 하고 reviewer들에게 credit을 주어라.
About rebuttal
- In your response to reviewers, be very nice to all of them even those who have attacked you unfairly. 공격적이지 않게, 나의 관점에서 반박된 문제에 대해 설명하고, 당신의 답변이 reviewer가 방어적인 위치에 있도록 두어서는 안됩니다.
- reviewer’s concern을 해소하기 위해서, 내가 추가적인 어떤 것을 했다고 보여주어라. (even if you disagree) score를 올려줄 이유를 줄것이다.
- 너의 답변 끝에, 어떻게 하면 접수를 올릴 수 있는지 reviewer에게 정확하게 물어봐라. 정중하고 존경스럽게 물어봐라. 분명하고 명확하게 행동하는 것이 큰 차이를 만든다.
- 너의 paper가 accept되지 못했다면, AC에게 너가 이 상황을 어떻게 바라보는지 적어놓아라. 만약에 리뷰어가 이 논문을 이해하지 못한것 같고 리뷰어가 unreasonable, 하다면 이 상황을 AC에게 알려라. AC로써 나는 저자로부터 오는 direct message에 많은 관심을 가진다.
- AC에게 글을 쓸 때, 나의 논문이 accepted되어야 한다고 설득시키듯이 메세지를 적어라. 주요 공헌을 설명하고, 나의 관점에서 논문 reviews and response에 대한 정보를 주기 위해 노력하세요.
- rebuttal letter, message to AC를 쓸 때, 그들의 집중가능 시간이 매우 짧다는 것을 인지하고, Try to highlight your main message first, go to details next and end with a conclusion.
느낀점
- 지금 당장은 필요한 내용은 아니 것 같다.
- 당연하면서도, 꼭 명심해야할 내용인 듯 하다.
- 나중에 필요하면 다시 읽어보자.
- 그래도! 최근 논문을 자주 cite&read하고 immitation 하고, reviewer에게 credit을 줄 수 있게 지금부터 주의하면서 논문 읽자.
- FastCampus 사이트의 Computer vision 강의 내용 정리
- 구글링을 해도 되지만은, 필요하면 강의를 찾아서 듣기
- FastCampus - Computer vision Lecture
- 이전 Post Link
chap11 - Machine Learning
머신러닝 이해하기
OpenCV 머신 러닝 클래스
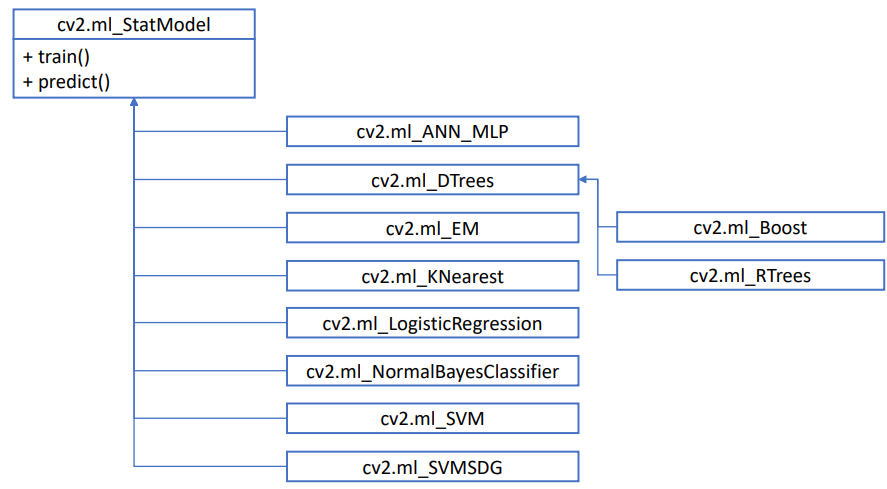
- 위의 어떤 방법으로 머신러닝 알고리즘 객체를 생성한 후, train(), predict() 함수를 사용하면 된다.
- cv2.ml_StatModel.train(samples, layout, responses)
- cv2.ml_StatModel.predict(samples, results=None, flags=None)
- 예제코드를 통해서 공부할 예정이고, 이번 수업에서는 아래를 공부할 예정
- KNearest : K 최근접 이웃 알고리즘은 샘플 데이터와 인접한 K개의 학습 데이터를 찾고, 이 중 가장 많은 개수에 해당하는 클래스를 샘플 데이터 클래스로 지정
- SVM : 두 클래스의 데이터를 가장 여유 있게 분리하는 초평면을 구함
k최근접 이웃 알고리즘
KNearest 이론
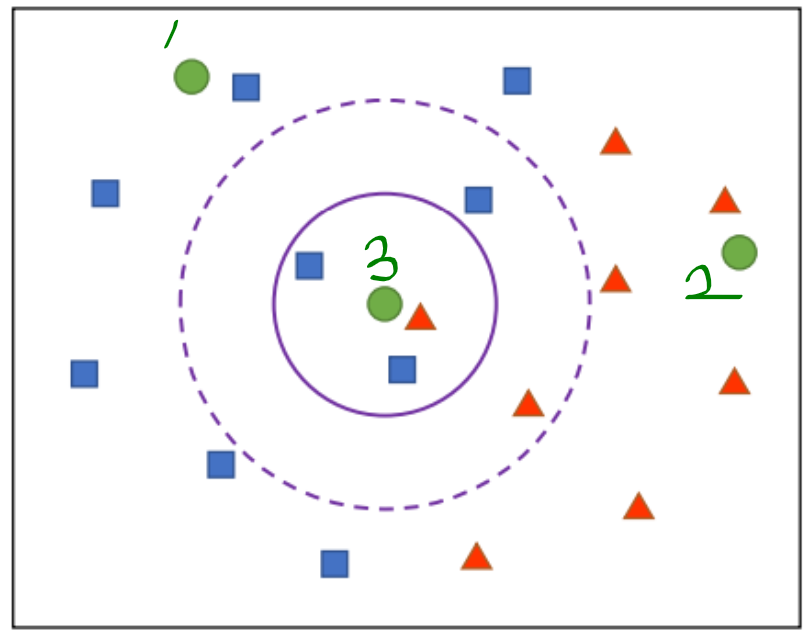
- 원래 파란, 빨간 백터만 있는 공간에, 초록색이 들어왔다고 가정하다.
- 1번은 파랑 클래스, 2번은 빨강 클래스라고 정하면 될 것 같다.
- 3번은 뭘까?? 이것을 결정하기 위해, 초록색에 대해서 가까운 k개의 백터를 찾는다. 그리고 가장 많이 뽑힌 클래스를 3번의 클래스라고 정하는 방법이다.
KNearest 코드
KNN 필기체 숫자 인식 (KNearest 사용)
SVM 알고리즘 (아주 간략히만 설명한다. 자세한 수학적 설명은 직접 찾아공부)
- SVM : 기본적으로 두 개의 그룹(데이터)을 분리하는 방법으로 데이터들과 거리가 가장 먼 초평면(hyperplane)을 선택하여 분리하는 방법 (maximum margin classifier)
- 아래의 1번과 2번 라인이 아닌, 3번의 라인처럼, 직선/평면과 가장 거리가 최소한 서포트 백터와의 거리가 최대maximum가 되도록 만드는 직선/평면(n차원 백터에 대해서 n-1차원 평면)을 찾는다.

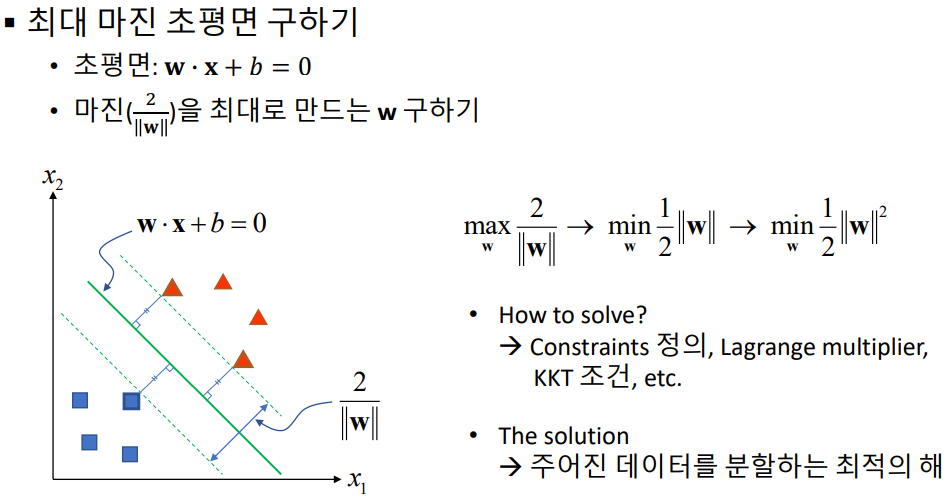
- 수학적 수식은 위와 같다. 자세한 내용은 생략한다. 여기서 w와 x는 백터이다. w*x + b = 0 이 n차원 백터에 대해서 n-1차원 평면식이 되겠다. 자세한 수학적 설명은 강의에서도 가르쳐주지 않으니 직접 찾아서 공부할 것.
- 위의 백터들은 완벽하게 분류가 되어 있는데, 오차가 있는 경우의 SVM을 찾는 방법은 다른 알고리즘을 사용한다. 그 알고리즘은 Soft margin, C-SVM 이라고 부른다.
- 하지만 SVM은 선형 분류 알고리즘이다. 백터들을 분류하기 위해 직선(선형식)으로는 분류가 안된다면 SVM을 사용할 수 없다. 물론 차원을 확장하면 선형으로 분리 가능 할 수 있다. 아래의 예제로만 알아두고 정확하게는 나중에 정말 필요하면 그때 찾아서 공부하기.

- 여기서는 z에 관한 방적식으로 차원을 확장했는데, 일반적으로 z는 조금 복잡하다. kernel trick이라는 방법을 통해서 차원 확장을 이루는데, 이것도 필요함 그때 공부.
OpenCV SVM 사용하기
객체 생성 : cv2.ml.SVM_create() -> retval
SVM 타입 지정 : cv.ml_SVM.setType(type) -> None
SVM 커널 지정 : cv.ml_SVM.setKernel(kernelType) -> None
SVM 자동 학습(k-폴드 교차 검증) : cv.ml_SVM.trainAuto(samples, layout, respo) -> retval
# svmplane.py
# trains and labels 임으로 만들어 주기
trains = np.array([[150, 200], [200, 250], [100, 250], [150, 300], [350, 100], [400, 200], [400, 300], [350, 400]], dtype=np.float32)
labels = np.array([0, 0, 0, 0, 1, 1, 1, 1])
# set SVM
svm = cv2.ml.SVM_create()
svm.setType(cv2.ml.SVM_C_SVC)
svm.setKernel(cv2.ml.SVM_LINEAR) # 직선, 평명 찾기
#svm.setKernel(cv2.ml.SVM_RBF) # 곡선, 곡면 찾기
svm.trainAuto(trains, cv2.ml.ROW_SAMPLE, labels)
print('C:', svm.getC()) # 초평면 계산 결과1
print('Gamma:', svm.getGamma()) # 초평면 계산 결과2
w, h = 500, 500
img = np.zeros((h, w, 3), dtype=np.uint8)
for y in range(h):
for x in range(w):
test = np.array([[x, y]], dtype=np.float32)
_, res = svm.predict(test) # predict
ret = int(res[0, 0])
if ret == 0: img[y, x] = (128, 128, 255)
else: img[y, x] = (128, 255, 128)
color = [(0, 0, 128), (0, 128, 0)]
for i in range(trains.shape[0]):
x = int(trains[i, 0])
y = int(trains[i, 1])
l = labels[i]
cv2.circle(img, (x, y), 5, color[l], -1, cv2.LINE_AA)
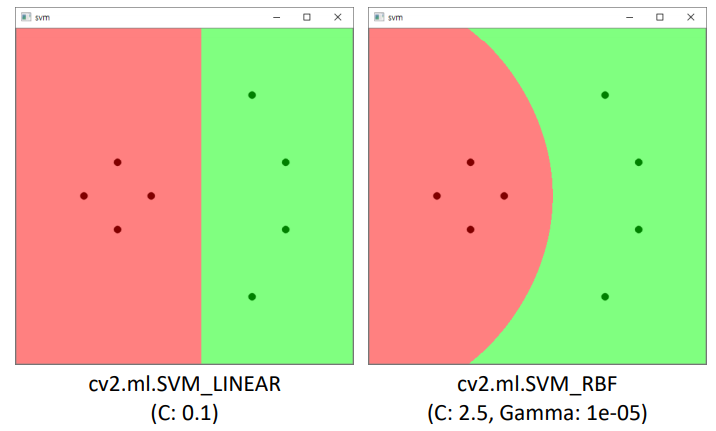
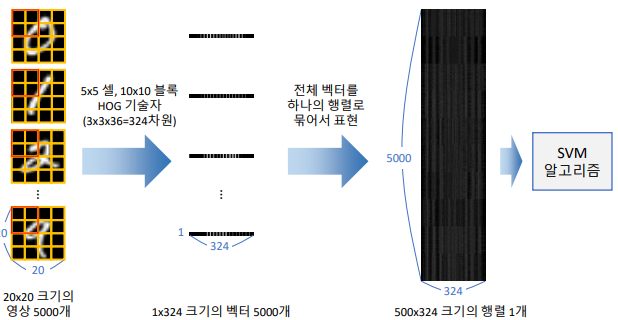
HOG(descriptor = 특징값 vector로 추출)를 이용한, SVM 기반 필기체 숫자 인식
숫자 영상 정규화
숫자 이미지는 숫자의 위치, 회전,크기 등등에 따라서 다양한 모습을 갖추기 때문에, 숫자 위치를 정규화할 필요가 있음
숫자 영상의 무게 중심이 전체 영상 중앙이 되도록 위치 정규화
무게 중심을 찾아주는 함수 사용 m = cv2.moments(img)
def norm_digit(img):
# cv2.moments의 사용법은 아래와 같다
m = cv2.moments(img)
cx = m['m10'] / m['m00']
cy = m['m01'] / m['m00']
h, w = img.shape[:2]
aff = np.array([[1, 0, w/2 - cx], [0, 1, h/2 - cy]], dtype=np.float32)
dst = cv2.warpAffine(img, aff, (0, 0))
return dst
desc = []
for img in cells:
img = norm_digit(img)
desc.append(hog.compute(img))
# 나머지는 윗 코드와 같다
k-평균 알고리즘
- 주어진 데이터가지고, 이미지를 k개의 구역으로 나누는 군집화 알고리즘 (비지도 학습으로 고려)

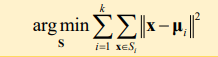
- 동작순서
- 임의의 (최대한 서로 멀리) K개 중심을 선정 (분할 평면도 대충 적용. Ex) 두 임의의 점의 중점을 지나는 수직 선)
- 모든 데이터에 대해서 가장 가까운 중심을 선택 (추적 때 배운 평균 이동 알고리즘과 비슷)
- 각 군집에 대해 중심을 다시 계산
- 중심이 변경되면 2번과 3번 과정을 반복
- 중심 변경이 적어지면 종료
- 컬러 영상 분할
- 컬러영상에서 대표가 되는 칼라 픽셀 값을 선택하는 알고리즘. 원본 이미지에서 위의 k-mean 알고리즘을 수행하는게 아니라, RGB&HS 공간에서 위의 알고리즘을 수행해 ‘대표필셀값’을 찾는다
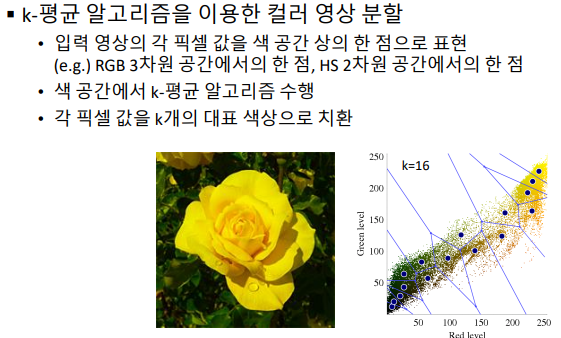
- cv2.kmeans(data, K, bestLabels, criteria, attempts) -> retval, bestLabels, centers (자세한 파라메터 설정은 강의나 공식 문서 참고)
- k-means 알고리즘을 이용한 컬러 영상 분할 예제 실행 결과 - kmeans.py 파일 참고 (코드는 매우 간단)

실전 코딩: 문서 필기체 숫자 인식

- 앞에서 배운것 만을 잘 활용한다.
- 순서 요약
- 레이블링 이용 → 각 숫자의 바운딩 박스 정보 추출
- 숫자 부분 영상을 정규화
- HOGDescriptor 로 descriptor 추출
- 이미 학습된 SVM으로 predict 수행
chap - 12, 13 딥러닝
- cv2.dnn 모듈을 사용해서 합습 및 추론
- 필요하면 그때 공부하자.
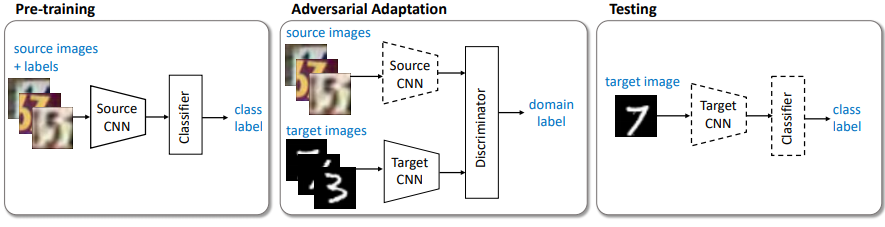
- 논문 : Adversarial Discriminative Domain Adaptation - y2017,c1875
- 분류 : Unsupervised Domain Adaptation
- 저자 : Eric Tzeng, Judy Hoffman, Kate Saenko (California, Stanford, Boston University)
- 읽는 배경 : (citation step1) Open Componunt Domain Adaptation에서 Equ (1), (2) [the domain-confusion loss]가 이해가 안되서 읽는 논문. 근데 introduction읽다가 이해해 버렸다. 좀만 더 읽어보자.
- 읽으면서 생각할 포인트 : 핵심만 읽자. 모든 것을 다 읽으려고 하지 말자. 영어계 저자는 어떻게 썼는지 한번 확인해 보자.
느낀점
- 이해 50프로 밖에 못한것 같다.
이 논문을 읽으면서, “이해안되도 아가리 닥치고 일단 Experience까지 미친듯이 읽어보자. 그리고 다시 과거에 이해는 안되지만 대충이라도 요약했던 내용을, 다시 읽어보면! 이해가 될 가능성이 높다.”- 그래도 이 논문을 통해서 Adversarial 접근이 GAN의 generator와 discriminator만을 두고 얘기하는게 아니라는 것을 깨달았다. 하나는 ‘이러한 목적’을 위해 학습한다면, 다른 한쪽에서 ‘반대의 목적’을 위한 Loss로 학습하게 만드는 것들, 전부가 Adversarial learning이라는 것을 깨달았다.
- 하지만 나는 믿는다. 그냥 아가리 닥치고 계속 읽고 정리하고 많은 논문을 읽어가다 보면 언젠간. 언젠간. 많은 지식이 쌓여 있고, 누구에게 뒤쳐지지 않는 나를 발견할 수 있을거라는 사실을. 그니까 그냥 해보자. 좌절하지말고 재미있게 흥미롭게. 않는 나를 발견할 수 있을거라는 사실을. 그니까 그냥 해보자. 좌절하지말고 재미있게 흥미롭게.**
- (3)번까지 relative work다 읽느라 지쳐서 핵심적인 부분은 거의 이해도 안하고 대충대충 넘겼다. 진짜 중요한 부분이 어딘지 생각해봐라. 초반에 이해안되는거 가지고 붙잡고 늘어지기 보다는, 일단 이 논문이 제시하는 model이 구체적으로 뭔지부터 읽는 것도 좋았겠다.
- 헛소리 이해하려고, 핵심적인 4번 내용은 이해하지도 않았다. 솔직히 여기 있는 relative work를 언제 다시 볼 줄 알고, 이렇게 깔끔하게 정리해 놨냐. 정말 필요하면 이 직접 논문으로 relative work를 다시 읽었겠지. 그러니 **핵심 먼저 파악하고!! 쓸대 없는 잡소리 이해는 나중에 하자.**
- 별거도 아닌거 삐까번쩍하게도 적어놨다... 이래서 아래로 최대한 빨리 내려가서 구체적인 핵심먼저 파악해야한다.
0. Abstract
- 현재 기술들과 문재점
- Adversarial learning(approaches) 사용 및 효과
- generate diverse domain data를 한 후에 improve recognition despite target domain을 수행한다.
- 그렇게 해서 reduce the difference하고 Improve generalization performance한다.
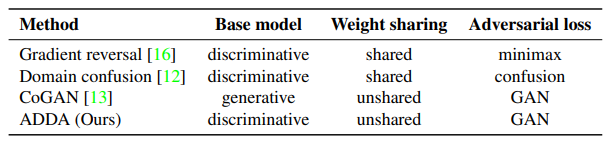
- 하지만 이런 generative approaches의 문제점은 - smaller shifts만 가능하다는 것이다.
- discriminative approaches 문제점 - larger domain shifts가 가증하지만, tied(=sharing) weights, GAN-based loss를 사용하지 않는다.
- **Ours **
- 지금까지의 접근방법들을 잘 융합하고, 적절히 변형한다.
- Use (별거도 아닌거 삐까번쩍하게도 적어놨다… 이래서 아래로 최대한 빨리 내려가서 구체적인 핵심먼저 파악해야한다.)
- **(1) discriminative modeling(base models) **
- **(2) untied weight sharing, **
- (3) GAN loss(adversarial loss)
- 즉 우리 것은 이것이다. general(=generalized, optimized) framework of discriminative modeling(=adversarial adaptation) = ADDA
- SOTA 달성했다. - digit classification, object classification
- 논문 핵심 : (Related work) Adversarial 을 사용하는 방법론들은 항상 같은 고충을 격는다. “Discriminator가 잘 학습이 되지 않는다든지, Discriminator를 사용해서 Adversarial 관점을 적용해도 원한는데로 Model이 target data까지 섭렵하는 모델로 변하지 않는다던지 등등 원하는데로 학습이 잘 이뤄지지 않는 문제점” 을 격는다. 이 논문은 많은 문제점을 고려해서 가장 최적의 Discriminator 공식과 Adversarial 공식을 완성했다고 주장한다.
1. Introduction
- 과거의 방법론들
- dataset bias(source만 데이터 많음 target없음) + domain shift 문제해결은 일반적으로 fine-tune으로 했었다. But labeled-data is not enough.
- 서로 다른 feature space를 mapping 시켜주는 deep neural transformations 방법도 존재한다. 그때 이런 방법을 사용했다. maximum mean discrepancy [5, 6] or correlation distances [7, 8] 또는
- the source representation(source를 encoding한 후 나오는 feature)를 decoder에 집어넣어서, target domain을 reconstruct하는 방법도 있다.[9] (encoding + decoding의 결과가 target data모양이 되도록. 그렇게 만든 data로 classifier 재 학습??)
- 현재의 기술들
- Adversarial adaptation : domain discriminator에서 adversarial objective(Loss)를 사용하여, domain discrepancy를 최소화 했다.
- generative adversarial learning [10] : generator(이미지 생성) discriminator(generated image, real image 구별) 를 사용해서 network가 어떤 domain인지 판단하지 못하게 만든다. [10,11,12,13] 이것들의 방식은 조금씩 다르다. 예를 들어, 어디에 generator를 위치시키고, loss는 무엇이고, weight share for source&target을 하는지 안하는지 등등
- Ours
- 위 Ours의 (1)(2)(3)
- discriminative representation를 학습하는게 우선이다.
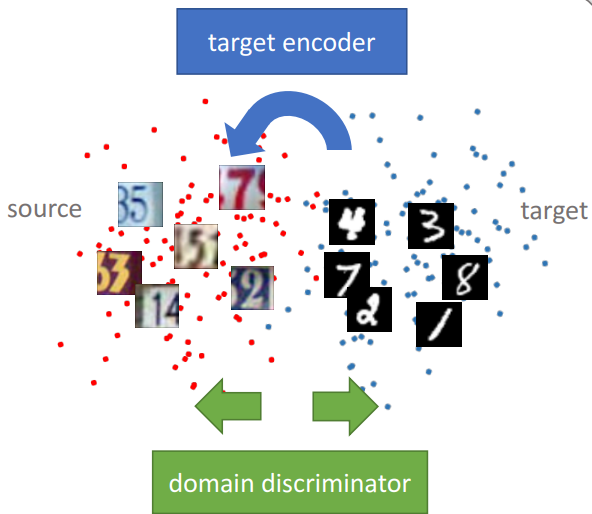
ADDA 간략히 정리하자면…Learn discriminative representation (using the labels in the source domain). -> 그냥 Source classifier 학습시키기.Learn a separate encoding through a domain-adversarial loss. (domain discriminator 학습 및 target CNN 학습시키기)
(이렇게 자세하게 적는게 무슨 의미지? 반성하자. 어차피 머리속에 남은것도 없고, 다시 읽어도 뭔소린지 모르고 머리에도 안남잖아. 시간버린거야.)
- MiniMizing Difference between feature distributions.[MMD사용모델들]
- MMD[3] : Computes the norm of the difference between two domain means.
- DDC[5] : MMD in addition to the regular classification loss for both discriminative and domain invariant.
- The Deep Adaptation Network[6] : effectively matching higher order statistics of the two distributions
- CORAL [8] : match the mean and covariance of the two distributions
- Using adversarial loss to minimize domain shift. & learning a representation not being able to distinguish between domains(어떤 domain이든 공통된 feature extractor 제작) - 2015
- [12] : a domain classifier and a domain confusion loss
- ReverseGrad[11] : the loss of the domain classifier by reversing its gradients
- DRCN[9] : [11]과 같은 방식 + learn to reconstruct target domain images
- GAN - for generating - 2015
- G : capture distribution. D : distinguishes. (Generative Adversarial Network)
- BiGAN [14] : learn the inverse mapping(??) from image to latent space and also learn useful features for image classification task.
- CGAN [15] : generate “a distribution vector” conditional on image features. and G and D receive the additional vector.
- GAN for domain transfer problem - 2013
- CoGAN [13] : generate both source and target images respectively. 이로써 a domain invariant feature space 를 만들어 낼 수 있었다. discriminator output 윗단에 classifier layer를 추가해서 학습을 시켰다. 이게 좋은 성과를 냈지만, source와 target간의 domain 차이가 심하다면 사용하기 어려운 방법이다. 하지만 쓸데없이 generator를 사용했다고 여겨진다.
- Ours (위 figure 참조))
- image distribution(분포, 확률분포, generator)는 필수적인게 아니다.
- 진짜 중요한 것은, discriminative approach 이다.
- 정리표 :
우리의 학습 순서 요약
- Source CNN 학습시키기.
- Adversarial adaptation 수행.
- Target CNN을 학습.
- 먼저 학습시켰던 Discriminator를 사용해서, cannot reliably predict their domain label 하게 만듬으로써 Target CNN을 학습시킨다.
- test 할 때, target encoder to the shared feature space(?) 그리고 source classifier(targetCNN도 원래는 Source CNN을 기반으로 하는 모델이므로)를 사용한다.
- 점선은 Fixed network parameters를 의미한다.
- (Related work) Adversarial 을 사용하는 방법론들은 항상 같은 고충을 격는다. “Discriminator가 잘 학습이 되지 않는다든지, Discriminator를 사용해서 Adversarial 관점을 적용해도 원한는데로 Model이 target data까지 섭렵하는 모델로 변하지 않는다던지 등등 원하는데로 학습이 잘 이뤄지지 않는 문제점” 을 격는다. 이 논문은 많은 문제점을 고려해서 가장 최적의 Discriminator 공식과 Adversarial 공식을 완성했다고 주장한다.
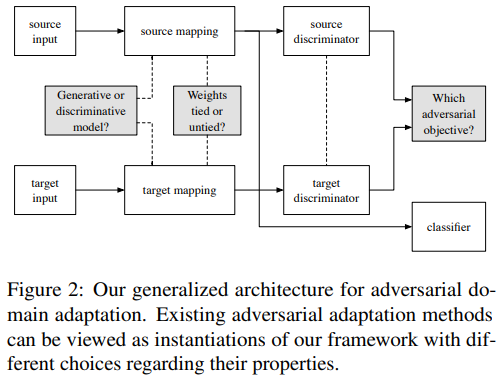
- 일반적인 adversarial adaptation 의 formula
- 3.1. Source and target mappings (Mapping - Ms,Mt는 어떻게 설정해야 하는가?)
- 목적 : mapping 신경망이 source에서든 target에서든 잘 동작하게 만들기. 각각을 위한 mapping 신경망이 최대한 가깝게(비슷하게) 만들기. source에서든 target에서든 좋은 classification 성능을 내기
- 과거의 방법 : mapping constrain = target과 source를 위한 mapping. Ms,Mt = feature extractor = network parameter sharing
- Ours : partial alignment = partially shared weights
- 3.2. Adversarial losses (위의 Loss_adv_M은 무엇으로 해야하는가?)
- [16]
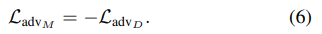 을 사용하기도 했지만, 이 방법에서 Discriminator가 빨리 수렴하기 때문에, (같이 적절하게 학습된 후 동시에 수렴되야 하는데..) 문제가 있다.
을 사용하기도 했지만, 이 방법에서 Discriminator가 빨리 수렴하기 때문에, (같이 적절하게 학습된 후 동시에 수렴되야 하는데..) 문제가 있다. - GAN loss function [17]
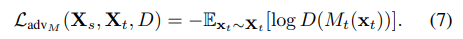 provides stronger gradients to the target mapping.(Mt는 Xt를 잘 classification 하도록 학습되면서도, D가 잘 못 판단하게 만들게끔 학습 된다. ) -> 문제점 : oscillation. 둘다 너무 수렴하지 않음. D가 괜찮아지려면 M이 망하고, M이 괜찮아 지려만 D가 망한다.
provides stronger gradients to the target mapping.(Mt는 Xt를 잘 classification 하도록 학습되면서도, D가 잘 못 판단하게 만들게끔 학습 된다. ) -> 문제점 : oscillation. 둘다 너무 수렴하지 않음. D가 괜찮아지려면 M이 망하고, M이 괜찮아 지려만 D가 망한다. - [12] :
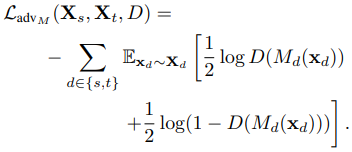
target이 들어오면, D가 잘못 판단하게끔 Mt가 학습되면서도, D가 잘 판단하게끔 Mt가 학습된다. 반대로 source가 들어오면, 또 D가 잘못 판단하게끔 Ms가 학습되면서도, D가 잘 판단하게끔 만드는 항도 있다.
- 이러한 고민들이 계속 있었다. Ours의 결론은 위의 정리표 참조.
4. Adversarial discriminative domain adaptation
- 사용한 objective function ⭐⭐

- 맨위 수식 : Source Dataset의 Classification을 잘하는 모델 탄생시킨다.
- 최적의 Discriminator 공식 : Target이 들어오면 0을 out하고, Source가 들어오면 1을 out하도록 하는 Discriminator를 만들기 위한 Loss 함수이다.
- 심플하게 Source 신경망은 고정시킨다. Target이미지를 넣어서 나오는 Out이 Discriminator가 1이라고 잘못 예측하게 만드는 M_t만 학습시킨다. Ms는 건들지도 않고 source가 들어갔을때, discriminator가 0이라고 잘못 예측하게 만든는 작업 또한 하지 않는다.
- 최종 모델 학습 과정
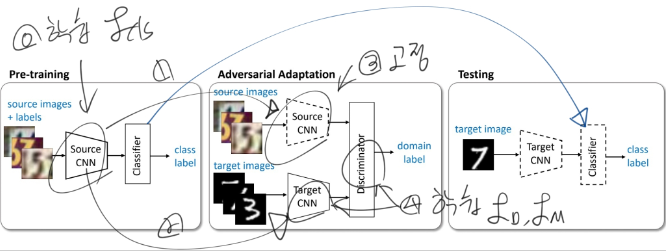
- 헷갈리는 내용은 다시 논문 5 page ⭐⭐참조.
5. Experiments
- 실험을 통해서 왜 논문에서 선택한 위의 objective function이 적절한 function이었는지를 말해준다.
논문 : Open Compound Domain Adaptation - y2020.03,c5
분류 : paperswithcode - Unsupervised Domain Adaptation
저자 : Ziwei Liu1∗, Zhongqi Miao2∗, Xingang Pan, Xiaohang Zhan
읽는 배경 : 판 페이 박사과정 선배가 추천해준 논문이자, 우상현 랩장과 박광영 박사과정 선배님이 최근에 발표하신 ‘Discover, Hallucinate, and Adapt’의 기본이 되는 논문이다.
읽으면서 생각할 포인트 : the present and problems and issues, ours Solution 흐름으로 정리하고 기록해놓자.
- 느낀점
- 이해 60%. 필요 논문을 찾아읽고 다시 읽어야 겠다.
- 다 읽은 후, 읽어야 겠다고 생각이 든 논문
- [45, 36, 28], Memory is storing class centroids.
- 45 -y2017-c1912
- 36 -y2019-c69
- 28 -y2019-c103
- curriculum domain adaptation-y2018-c32 56 - curriculum domain adaptation에서 m이 의미하는것
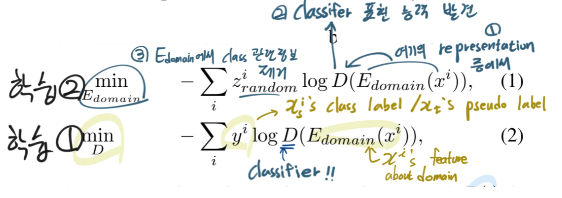
- the domain-confusion loss-y2017,c1875 48 - Equ (1), (2)이 의미하는 수학적 의미 -> 이제 알았음.
- [27, 10], Adopting cosine classifiers, L2 norm before softmax classification.
- t-SNE Visualization
- 이 논문에서 experiment compare하기 위해 사용했던 참고한 논문 자료.
- Digits: conventional unsupervised domain adaptation (ADDA [48], JAN [30], MCD [42])
- Digits: the recent multi-target domain adaptation methods (MTDA [9], BTDA [5], DADA [39])
- segmentation: three state-of-the-art methods, AdaptSeg [47], CBST [58], IBN-Net [35] and PyCDA [26]
논문 핵심
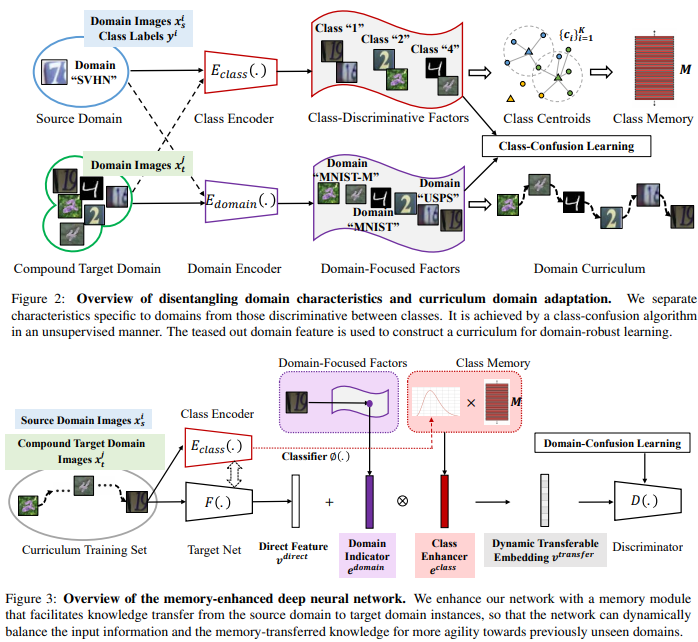
- Domain encoder를 만들어 내는 것. (Equation말고 Algorithm 2 figure 먼저 볼 것)
- 처음에는 Classification을 위한 class encoder와 같은 방식으로 학습시키다가,
Decoder( classEncoder(x), domainEncoder(x) ) = x 이처럼 완벽한 reconstruction이 되게 만들면서,- classification 능력은 random label을 이용한 cross entropy loss로 제거해버린다.
- Domain encoder를 활용해서, target domain image feature와 source domain image feature 사이의 거리 계산하기
- Memory module(class centroids)을 사용해서, taget domain의 feature denoising 하기. (ProDA에서는 class centroids와의 거리 정보를 target domain feature에 곱해서 denoising 해줬지만…) 여기서는 V_transfer feature를 만드는 수식 사용했다.
- 자세한 내용은 코드를 보기. (논문보지 말고)
0. Abstract
- the present
- A typical domain adaptation approach이란?
- Clear distinctions between source and target
- Ours
- open compound domain adaptation (OCDA) 의 2가지 핵심기술
- instance-specific curriculum domain adaptation strategy : generalization across domains / in a data-driven self-organizing fashion(???)
- a memory module : the model’s agility(예민함, 민첩한 적응?) towards novel domains / memory augmented features for handling open domains. (메모리가, 우리가 가진 Feature Extractor 와 classifier 에 더 정확하게 작동하는, feature map이 생성되도록 도움을 준다.)
- 실험을 적용해본 challenges
- digit classification
- facial expression recognition
- semantic segmentation
- reinforcement learning
1. Introduction
- the present & problem
- Supervised learning : 좋은 성능이지만 비현실적
- domain adaptation : 1 source : 1target 에 대해서 clear distinction를 정의하려고 노력하지만 이것도 비현실적. 현실은 많은 요소들(비,바람,눈,날씨)에 의해서 다양한 domain의 데이터가 함께 존재하므로.
- Ours - open compound domain adaptation
- more realistic
- adapt labeled source model /to unlabeled compound target
- 예를 들어 SVHN [33], MNIST [21], MNISTM [7], USPS [19], and SynNum [7] 는 모두 digits-recognition인데, 이들을 모두 다른 domain이라고 고려하는 것은 현실적이지 않다.
- 우리는 compound target domains로써 그들을 고려하고, unseen data까지 test해볼 계획이다.
- 기존의 domain adaptation : rely on some holistic measure of instance difficulty.
- 우리의 domain adaptation : rely on their individual gaps to the labeled source domain
- 네트워크 학습 과정
- classes in labeled source domain를 discriminate(classify) 하는 모델 학습
- (source와 많이 다르지 않은) easy target를 넣어서 domain invariance(domain의 변화에도 강건한)를 capture하게 한다.
- source와 easy target 모두에서 잘 동작하기 시작하면, hard target을 feed한다.
- 이런 방식으로 classification도 잘하고, 모든 domain에서 robust한 모델을 만든다.
- Technical insight
- Tech1 : domain-specific feature representations을 가지는 Classification Network에 대해서, source와의 feature distance가 가까운 target은 Network 변화에 많은 기여를 하지 않는 것을 이용한다. 그래서 distill(증류해 제거해나간다,) the domain-specific factors (즉 domain에 robust한 Network 제작)
- Tech2 : memory module이 inference를 하는 동안 open-domain에서도 정확한 feature를 추출하도록 도와준다. the input-activated memory features(input에 따라 다르게 행동하는 memory feature)
2. Relative work

- Unsupervised Domain Adaptation :
- 1 source - 1 target
- cannot deal with more complicated scenarios
- 참고 논문들 : latent distribution alignment [12], backpropagation [7], gradient reversal [8], adversarial discrimination [48], joint maximum mean discrepancy [30], cycle consistency [17] and maximum classifier discrepancy [42].
- Latent & Multi-Target Domain Adaptation :
- clear domain distinction&labels(domain끼리의 차이가 분명함-하지만 현실은 continuous함) / not real-world scenario
- 참고 논문들 : latent [16, 51, 32] or multiple [11, 9, 54] or continuous [2, 13, 31, 50] target domains
- Open/Partial Set Domain Adaptation :
- target이 source에 없는 카테고리를 가지거나, subset of categories 를 가지거나.
- “openness” of domains = unseen domain data에 대해서 고려하기 시작
- 참고 논문들 : open set [37, 43] and partial set [55, 3] domain adaptation.
- Domain Generalized/Agnostic Learning :
- Learn domain-invariant universal representations (domain이 변하더라도 같은 특징을 잘 추출하는 신경망 모델)
- 참고 논문들 : Domain generalization [52, 23, 22] and domain agnostic learning [39, 5]
- 바로 위의 논문들의 문제점과 our 해결
- 문제점 : they largely neglect the latent structures inside the target domains
- 해결책 : Modelling the latent structures (figure4의 구조 같음) inside the compound target domain by learning domain-focused factors(domain_encoder)
3. Our Approach to OCDA
3.1. Disentangling Domain Characteristics with class labels in the source domain
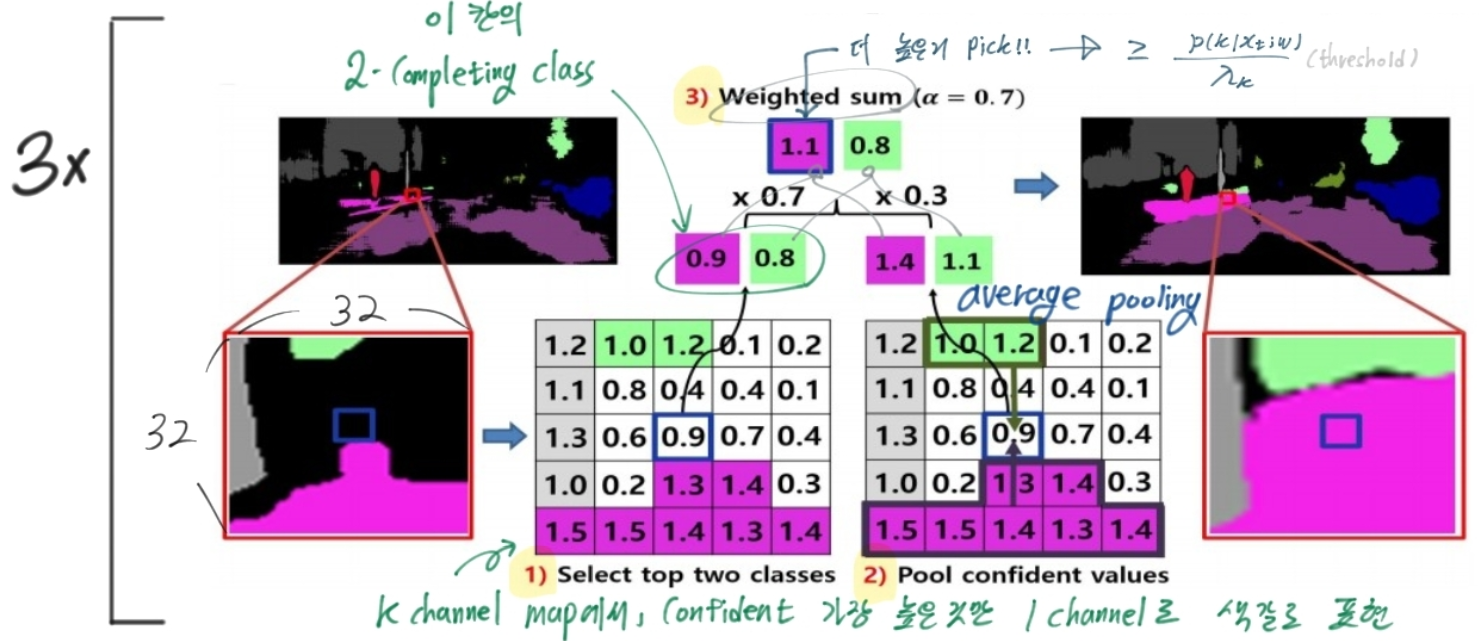
3.2. Curriculum Domain Adaptation
- target domain instance들을 source domain과의 거리를 기준으로 rank(정렬)한다.
- 거리를 측정하는 방법 :

- 가까운 domain instance들부터, Network 학습에 사용한다. 그때 Loss는 아래와 같다.
- Loss1 : One is the cross-entropy loss defined over the labeled source
- Loss2 : the domain-confusion loss[48]
3.3. Memory Module for Open Domains ⭐⭐
- 문제점 : target data를 기존의 신경망(classifier??)에 넣으면?? v_direct 나옴. v_direct 자체는 representation로써 불충분한 정보를 가지고 있다! 즉 신경망이 충분한 feature 추출 불가능!!
- 해결책 : Memory Module은 memory-transferred knowledge를 가지고 있다. 이것이 input으로 들어온 new domain data를 balance하게 만들어 준다.
- Class Memory (M)
- Store the class information from the source domain
- by [45, 36, 28], Store class centroids {c_k}(k = 1~K class number)
- Enhancer (v_enhance)

- 행렬곱 (1 x e) = (1 x d) * (d x e)
- M(d x e) 덕분에, target domain의 data가 source 쪽으로 이동한다.
- Domain Indicator (e_domain)
- 약간 learning Late 처럼, 얼마나 source 쪽으로 vector를 옮길 것인가. 를 말한다. 아래 수식 참조. gap이 크면 input vector를 크게 옮겨 놓고, gap이 작으면 input vector를 작게 옮긴다.
- Domain indicator =

- Source-Enhanced Representation (v_transfer)
- v_direct에서 source를 중심으로 balance가 맞춰진 vector
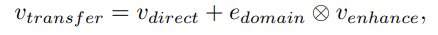
- ⊗ is element-wise multiplication
- Adopting cosine classifiers [27, 10], 이렇게 만들어지 v_transfer를 l2-normalize한다. 그리고 softmax classification layer에 보낸다.
- domain mismatch 에 효과적이다.
4. Experiments
Datasets
| type | source | target | open |
|---|
| Classify-Digits | SVHN | MNIST, MNIST-M, and USPS | SWIT |
| C-Faces(Multi-PIE) | C05 | C08-C14 | C19 |
| C-Driving | GTA-5 | BDD100K | BDD100K |
| C-Mazes | the GridWorld | | |
Network Architectures
- backbone : LeNet-5, ResNet-18, VGG-16
- Compare with :
- Digits: conventional unsupervised domain adaptation (ADDA [48], JAN [30], MCD [42])
- Digits: the recent multi-target domain adaptation methods (MTDA [9], BTDA [5], DADA [39])
- segmentation: three state-of-the-art methods, AdaptSeg [47], CBST [58], IBN-Net [35] and PyCDA [26]
Ablation Study
- the Domain-Focused Factors Disentanglement - k-nearest neighbors
- the Curriculum Domain Adaptation - USPS is the furthest target domain -> Good Classification
- Memory-Enhanced Representations. - Figure 5
- 논문 : Two-phase Pseudo Label Densification for Self-training based Domain Adaptation
분류 : paperswithcode - Unsupervised Domain Adaptation
저자 : Inkyu Shin, Sanghyun Woo, Fei Pan, In So Kweon
읽는 배경 : 현재 Domain adapation, Self-supervise이 연구실의 중심 연구 주제로 많이 사용되고 있다. 판 페이 박사과정 선배가 추천해준 논문을 읽기 전에, 신인규 석사과정 선배님이 작성하신 논문을 먼저 읽는게 좋을 것 같다고 생각했다. 아래의 배울 포인트 때문이다.
- 읽으면서 생각할 포인트 : Reference를 어떻게 추가했나? domain adaptation과 Self-supervised에 대해서 내가 추가적으로 공부해야하는게 뭘까? Abstract가 가장 중요하다고 하는데 선배님은 어떻게 작성하셨나? relative work에 대해서 얼마나 상세하게 이해하셨고 그 흐름을 어떤 식으로 잡고 가셨나? (어떤 의문, 반박으로 다른 모델이 나왔고 등등… 그래서 핵심 모델은 뭐고 과거 흐름은 뭐였는지 등등…) 석사 1년동안 내가 이정도 논문을 쓰기위해서 가져아할 자세는 무엇일까?
- 느낀점
- 현재 나와있는 모델에 대한 의문, 의심, 질문, 반박에서 논문이 시작했다.
- “Make your paper look similar to a typical ML paper.” 을 지키기 위해 아래와 같이 논문의 흐름. the present and problems and issues, ours Solution 으로 나열해가는 흐름에 대해서 잘 기록해 두자. 지금부터 해야한다.
- 역시나 deeplab을 사용하고 그 위에 CRST를 올리고 그 위에 TPLD를 올린방식이다. 따라서 deeplab까지의 계보 즉, recognition의 계보를 최대한 확실히 알아놔야 겠다.
- 질문&답변
- ^yk가 pseudo targer label이라면 이건 어떤 신경망으로 target data를 예측해놓은 결과이지?? w는 아닐테고…
- w로 예측하는거 맞다. 그리고 대신 ^yk값은 Eq.(2)(4) 번 처럼 1 or 0의 값을 가진다. softmax 확률 값이 아니다.
- 이 분야를 항상 관심을 두고 계셨던 건지? 그래서 그 분야의 논문을 항상 읽어오신 건지?
- 논문을 준비하신 기간?
- 코드 제작은 어떻게 하셨는지? 어떤 코드 참고 및 어떤 방식으로 수정? 몇 퍼센트 수정 및 추가? 코드 제작 긱나?
- 석사기간에 이런 좋은 논문을 쓰는게 쉽지 않은데… 혹시 팁이 있으신지?
- 1선배님조언
- 논문 읽는데 너무 많은 시간을 투자하지 말아라. 핵심만 읽어라
- 최근 논문으로 흐름을 항상 따라라
- 2선배님조언
- AD에서 연결할 수 있는 관심있으신 분야 -> Video, Active learning, Semi-supervise, Labeling down + Performance increment
- Awesome domain adaptation 을 참고해서 괜찮은거 공부해보고, 일부 분야는 발행 논문이 적은데 그 곳을 집중해서 파보는 것도 괜찮다.
- 특히 DA분야는 가짜가 많으니 조심. 정말 모델에 대입 해봤을 때, 성능향상이 이뤄진다면 짜릿.
- 과제!! 현재 과제가 어떤 과제가 있는지 알아보고, 그 과제를 하기 위해서 미리미리 공부해놓고 그 과제를 하고 싶다고 먼저 말해놓는게 좋다. 따라서 몇몇 대화를 해본 선배님들에게 직접 찾아가서 현재 하시는 과제가 무엇인지 무엇을 미리 공부해놓으면 좋은지 알아보기
- 다 읽은 후, 필수로 읽어야 겠다고 생각이 든 논문
- CBST-class-balanced self-training-2018 (class-wise thresholding value λ 가 뭔지 알려줌 [39])
- CRST-Confidence Regularized Self-Training - 2019 [40]
- ADVENT: Adversarial Entropy Minimization for Domain Adaptation - easy vs hard 분별하는 discriminator 왜 사용하는지 적혀 있음 [37]
- Training deep neural networks on noisy labels with bootstrapping (12. 2014) - bootstrapping
- map high-dimensional features to 2D space feature Using t-SNE [27]
- [1] domain adaptation - object detection
- [4] domain adaptation - semantic segmentation
0. Abstract
- the present and problems : The self-training generates target pseudo labels like only the confident predictions(Relative work의 self-training내용 참조). So that this approach produce sparse pseudo labels (희박한/흐릿흐릿한/빈약한 예측 결과) in practice.
- why problem : suboptimal, error-prone model
- Solution : TPLD (Two-phase Pseudo Label Densification) ⭐⭐
- the first phase : Sliding window voting to propagate the confident predictions, Using Image’s intrinsic spatial-correlations.
- the second phase : image-level confidence score -> easy-hard classification.
- easy samples : easy’s full pseudo label. ,while pushing hard to easy.
- hard samples : adversarial learning to enforce hard-to-easy feature alignment.
- additional tech : the bootstrapping mechanism (in order to ease the training process and avoid noisy predictions.)
- result : 다른 self-training 모델에 쉽게 integrated 가능. 최근 self-training framework, CRST에 결합해서 SOTA달성
1. Introduction
- the present models
- Unsupervised domain adaptation (UDA) 는 labeled source 에서 unlabeled target를 학습하는데 도움이 된다. 이 논문에서는 Semantic segmentation 문제에 대해 UDA를 적용한다.
- UDA 의 핵심적으로 adversarial learning에 근간을 둔다. 이 방법을 통해서 source와 target의 feature distributions을 효과적으로 줄일 수 있다.
- 최근에는 다른 방향으로 self-training 이라는 것이 나왔다. pseudo labels corresponding to high prediction scores(예측 결과를 “가짜 label(annotation)”로 사용한 것)을 이용해서 네트워크를 생성한다. 대표적인 모델이 CBST-2018와 CRST-2019 이다. in multiple UDA.
- [labeled source data] VS [pseudo labeled target data]
- CBST’s key word - self-training loss / domain-invariant ‘features and classifiers’ / class balancing strategy and spatial priors.
- CRST’s key word - the feasible space of pseudo labels / regularizer in loss to prevent overconfident predictions.
- 문제점 : excessively cut-out the predictions.
- 문제로 인한 결과 : sparse pseudo labels.
- 멍청한 해결책 : lowering the selection threshold.
- 우리의 해결책 : ⭐⭐
- Abstract의 Solution에 정리 잘해 둠. 그거 다시 읽기.
- 경험적으로, Easy sample(label 예측을 confident자신있게 판단한 이미지)은 ground-true에 가까웠다. 따라서 easy sample’s full pseudo labels(GT은 아니만 그래도 GT와 가까운 예측값=가짜 라벨값)을 사용하기로 했다. 반대로 hard sample에 대해서는 (hard-easy adaption의) adversarial loss를 사용했다.
- the bootstrapping mechanism 사용
- Summarize our contributions
- 이것을 사용한 첫번째 사례이다. / TPLD 요약 / 새로운 loss bootstrapping mech. / ablation studies
- Domain Adaptation
- 목적 : the performance drop by the distribution mismatch
- 계보 : adversarial learning -> minimize the discrepancy between source and target feature -> unsupervised domain adaptation. -> 아래 처럼 3개로 분류 가능.
- input-level alignment [5, 17, 28, 34]
- intermediate feature-level alignment [18, 19, 23, 25, 37]
- output-level alignment [36]
- 하지만 위 방법들은 taget domain signal을 충분히 이용하지 못한다.
- 그래서 self-training based UDA approaches [CBST, CRST]이 나와서, 성능에서 우의를 차지하고 있다.
- Self-training
- 장점 : 위의 문제점 해결. Explore the supervision signals from the target domain.
- 간단 메카니즘 :
- Use prediction target data from the source-trained model (= pseudo-labels).
- Re-train the current model in the target domain. (pseudo-labels를 GT로 설정하여)
- CBST, CRST도 있지만, 우리는 sparse pseudo label 문제에 집중했다. introduction정리와 동일.
3. Preliminaries
- source domain : (xs, ys)
- target domain : (xt)
- we train the network to infer pseudo target label.
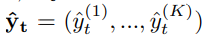 여기서 K는 the total number of classes.
여기서 K는 the total number of classes. 
- (2):
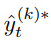 =
=  Pseudo Label은 가짜이지만 ‘정답’값(GT값)이므로 0 or 1 의 값을 가져야 한다.
Pseudo Label은 가짜이지만 ‘정답’값(GT값)이므로 0 or 1 의 값을 가져야 한다.
Noisy label handling
- Training deep neural networks on noisy labels with bootstrapping (12. 2014)
- bootstrapping loss = (-붙어야 함. 아래 수식에 붙음)
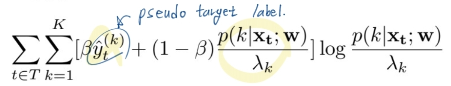
- beta는 그냥 trade-off의 벨런스 조정 값이다. 어떤 값에 집중하게 만들 것 인가.
- 직관적으로 w모델이 pseudo target label을 더 잘 예측하게 만들고, 그 예측값에 더 confident하게 만든다.
4. Method
5. Experiments
- GTA5 [31] to Cityscapes [6]
- SYNTHIA [32] to Cityscapes
- 5.2 - Implementation details (backbone모델(VGG16), segmentation model(deeplab))
- 5.3 - Main Results (with Figure)
- 5.4 - Ablation study, 5.5 - Parameter analysis
- conf에서 1/λ의 역할
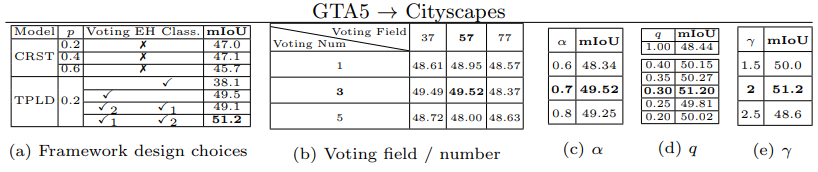
- 5.6 Loss function analysis
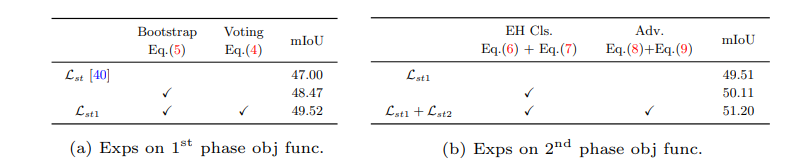
- Especially for the hard sample training, we conduct a contrastive analysis in Fig. 6. (이 FIg 6 그림을 이해하기 위해서는 논문 [26]을 꼭 일어야 겠다.)
- We map high-dimensional features of (c) and (d) to 2-D space features of (e) and (f) respectively using t-SNE [26]

6. Conclusions
- Unsuperivsed Domain Adaptation에서 좋은 성능을 내었다.
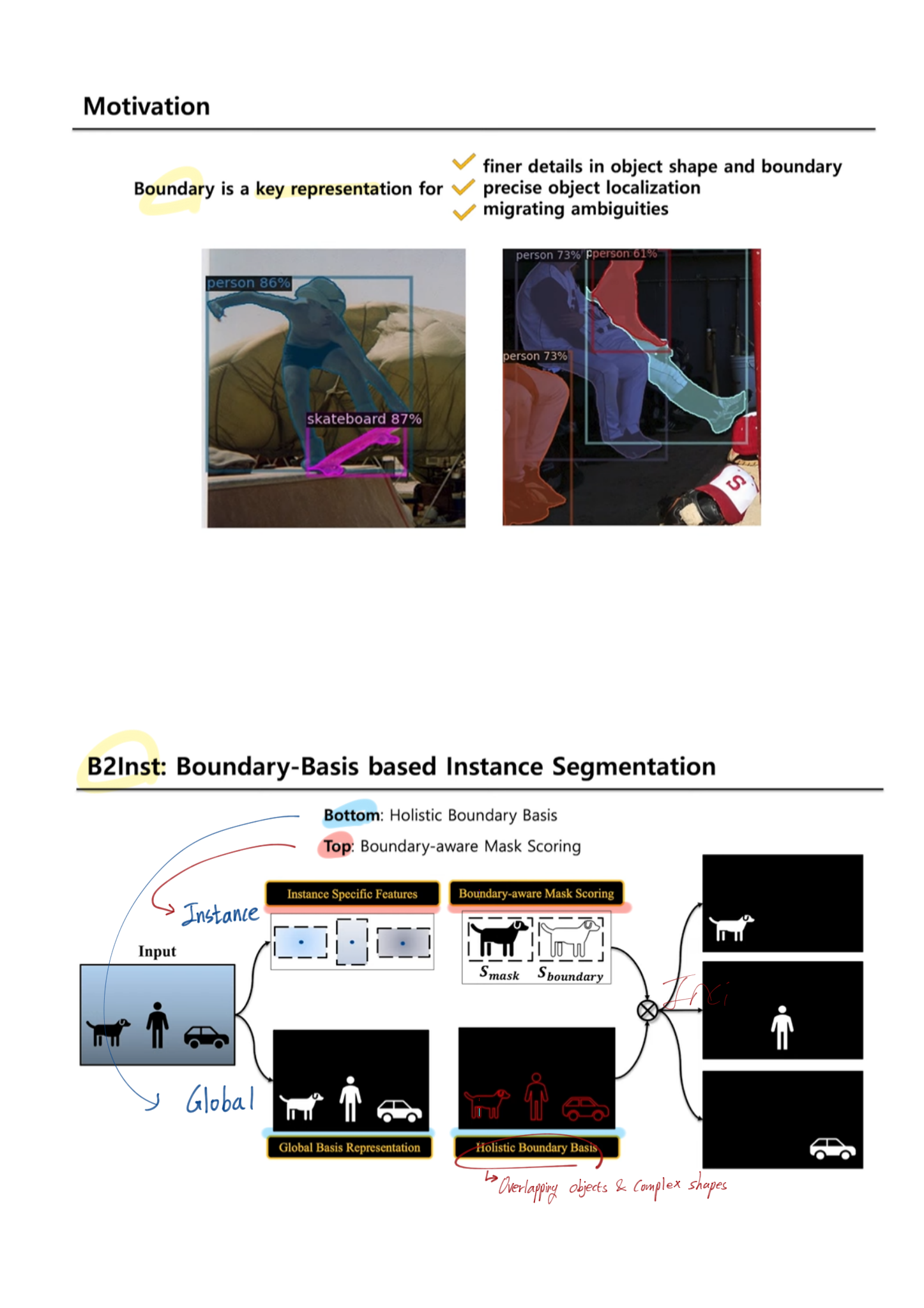
논문 : The Devil is in the Boundary: Exploiting Boundary Representation for Basis-based Instance Segmentation
동영상 : https://www.youtube.com/watch?v=XvLo5WrtHu0 -> why, how, what in the past 에 대한 내용들이 잘 담겨 있으니 꼭 참고.
저자 : Myungchul Kim, Sanghyun Woo, Dahun Kim, In So Kweon
읽는 배경 : 현재 Domain adapation, Self-supervise, Transformer 등에 관심이 가지만, 그래도 가장 구체적이며 많은 지식을 가지고 있는, Segmentation이나 Object Detection과 관련된 이 논문을 먼저 읽어보고 싶었다. 같은 랩 석사 선배님이 적으신 논문으로써, 내가 1년 안에 이런 논문을 만들어야 한다는 마음 가짐으로 논문을 읽어보려고 한다.
읽으면서 생각할 포인트 : Reference를 어떻게 추가했나? 실험은 어떤 것을 어떻게 하였나? Relative work는 어느정도로 작성하였나? 과거 지식은 어느 정도가 필요한가? 코드 개발은 어떻게 하였나?
느낀점
- 논문 안에는 핵심 내용(global 사용, score 사용) 등이 있는데, 최근 논문들의 핵심 내용만 쏙쏙 캐치해서 그것들을 잘~융합해서 개발이 되었다. -> 이런 논문 작성 방식도 추구하자.
논문 많이 읽어야 겠다… 완벽하게 이해는 안되고, 60% 정도만 이해가 간다. 필수적으로 읽어야 하는 논문 몇가지만 읽고 나면 다 이해할 수 도 있을 듯 하다. 지금은 전체다 이해가 안된다고 해도 좌절하지 말자.
정말 많은 노력이 보였다. 내가 과연 이정도를 할 수 있을까? 라는 생각이 들었지만 딱 한달 동안 이와 관련된 매일 논문 1개씩 읽는다면, 잘하면 좀더 창의력과 실험을 가미해서 더 높은 성능을 내는 모델을 만들 수 있지 않을까? 하는 생각은 든다. 따라서 하나의 관심 분야를 가지고 그 분야의 논문 20개는 읽어야 그 쪽은 조금 안다고 할 수 있을 것 같다.
- 만약 Segmentation을 계속 하고 싶다면, 아래의 ‘필수 논문’을 차례대로 읽도록 하자.
질문&답변 ⭐⭐
- 질문
- 논문 내용에 대한 질문은 없다. 왜냐면 내가 찾아 읽는게 먼저이기 때문이다. 필수로 읽어야 겠다고 생각한 논문들을 먼저 읽고 모르는 걸 질문해야겠다.
- 현재도 Segmentation을 매인 주제로 연구하고 계신지? 아니면 다른 과제나 연구로 바꾸셨는지?논문을 준비하신 기간?
- 이 분야를 항상 관심을 두고 계셨던 건지? 그래서 그 분야의 논문을 항상 읽어오신 건지?
- 논문을 준비하신 기간?
- 코드 제작은 어떻게 하셨는지? 어떤 코드 참고 및 어떤 방식으로 수정? 몇 퍼센트 수정 및 추가?
- 아무래도 saturation된 Instance Segmentation에 대해서 계속 공부해나가시는거에 대한 두려움은 없으신지?
- 석사기간에 이런 좋은 논문을 쓰는게 쉽지 않은데… 혹시 팁이 있으신지?
- 선배님답변 간략히 정리 (정말 감사합니다)
- 공부에는 왕도가 없다. 어떤 문제와 관심분야를 하나로 정해두고 끝장을 보겠다고 해도 끝이 없다.
- 일정 분야에 대해서 흥미를 가지는 마음가짐이 굉장히 중요하다. 이 마음이 사라지고 의무와 책임만 남는 상황이라면 진정한 나만의 연구, 나만의 결과, 행복한 연구, 행복한 생활을 이뤄나갈 수 없다.
- 조급함 보다는 꾸준함이 중요하다. 꾸준하게 조금씩, 라이프 밸런스를 맞춰가며 취미도 해가며 흥미롭게 나의 연구와 공부를 해 나가는게 중요하다. 연구와 공부에 대한 의무감이 생기면 좋은 연구, 좋은 결과를 낼 수 없다.
- 왜 이런 논문이 나왔지? 지금까지의 계보는 어떻고, 그런 계보가 나온 이유가 무엇이지? 어떤 개념과 어떤 문제, 어떤 정의에 의심을 가지고 시작된 연구이지? 라는 생각을 가지고 논문을 읽고 공부하는 것이 굉장이 중요하다. 예를 들어서 mask score이 나온 이유는 뭐지? boundary score가 사실은 더 중요한거 아닐까? mask-rcnn에서 masking이 왜 잘되지? BB가 이미 잘 만들어지기 때문에? 이걸 없애야 하지 않을까?? 그렇다면 어떻게 없애야지? 이 loss, 이 score가 과연 맞는 건가? 이런 의심, 질문, 반박을 찾아 논문을 읽고, 나도 이런 마음을 가지고 생각하는 것이 굉장히 중요하다.
- 마음을 잡고 논문을 준비한 기간은, 6개월 7개월. 코드 작성도 걱정 할거 없다.
- 다양한 걱정, 고민, 근심이 드는 것은 너무 당연한 생각이다. 너무 걱정하지말고 꾸준히 해나간다면 분명 잘 할 수 있다.
- recognition, reconstruction, reorganization 이라는 3가지 3R 문제가 딥러닝에서 있다. 특히 recognition을 잘 따라간다면, 어떤 문제에서도 적용되어 사용하는 것을 알 수 있다.
- classification 부터 object detection, segmentation 에 대한 계보들을 보면서, 왜?? 라는 생각을 가지고 하나하나를 바라보아야 한다. 이건 왜 쓰였지? 이건 왜 나온거지? 이건 왜 좋지? 이러다보면 정말 과거 계보부터 봐야하기도 하지만 그것도 나의 선택이다. 정말 필요하다고 생각이 들면 찾아서 공부하면 되는거고, 아니다 다른게 더 중요하다 하면, 다른거 새로운 기술을 공부해도 좋은거다. 정답은 없다. 그건 나의 선택이고 걱정하지 말고 흥미를 가지고 꾸준하게 하면 되는 거다.
- 다 읽은 후, 필수로 읽어야 겠다고 생각이 든 논문
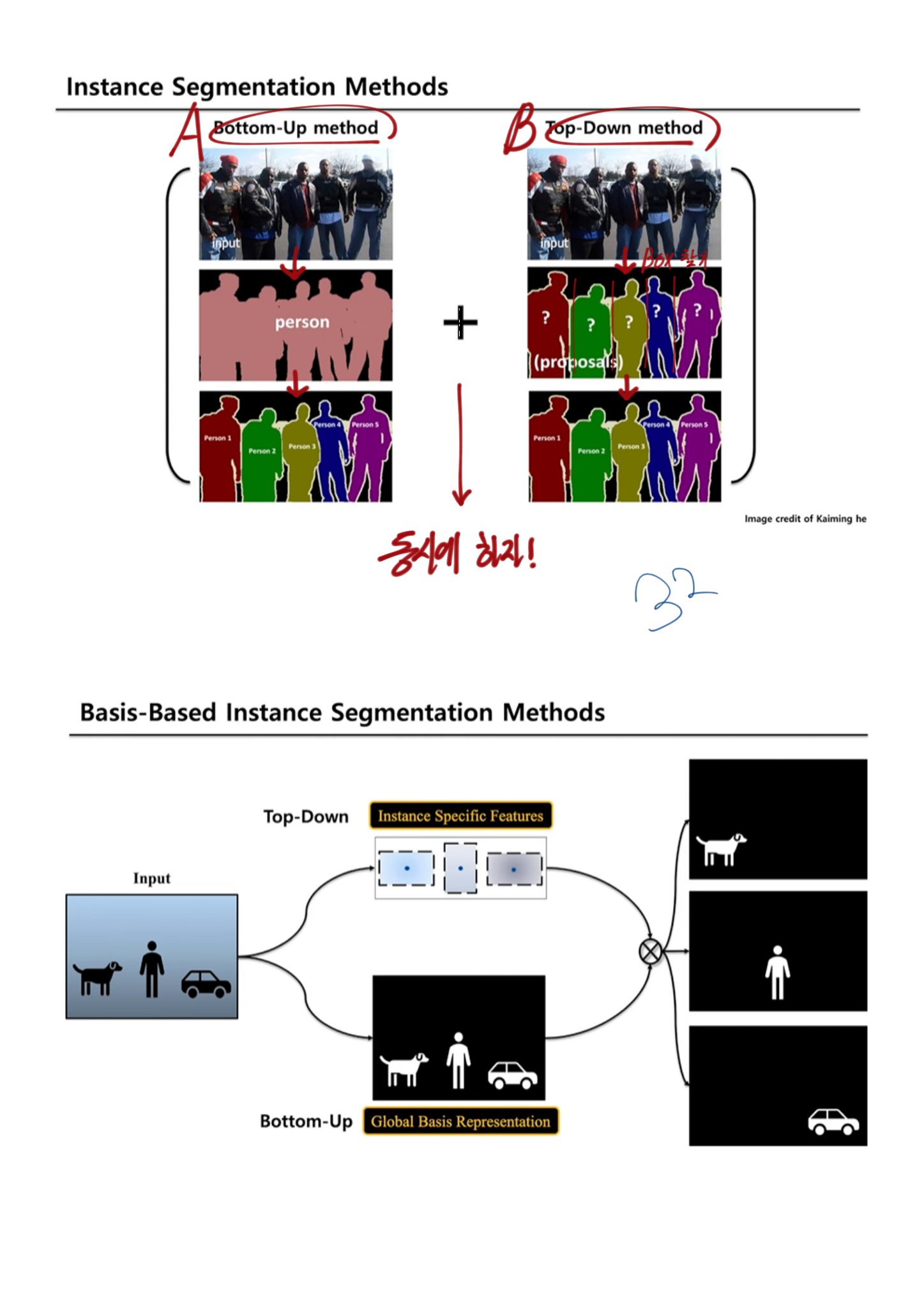
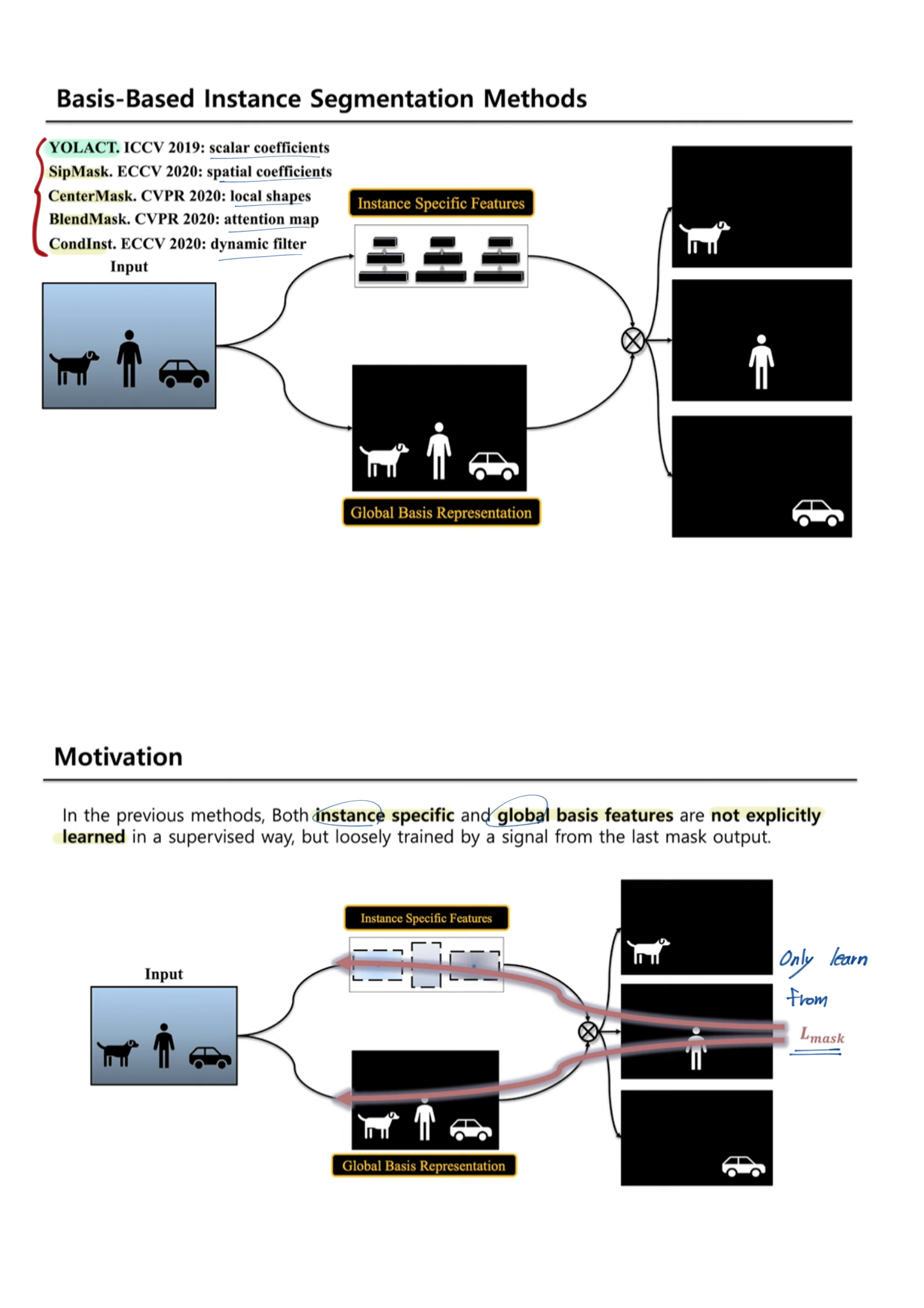
- YOLACT [4]-2019
- BlendMask [6] - 2020
- Boundary-preserving Mask RCNN[11] - 2020
- Mask scoring r-cnn - 2019
- Zimmermann et al.[47] - auxiliary edge loss. Boundary Learning - 2019
- Single shot instance segmentation with point representation [global-area-based methods] 2020
- a Dice metric [13]
- CondInst [37]
- basis 개념 [4, 5, 38, 6, 37] 중에 적당한거 하나
The Devil is in the Boundary
1. Abstract, Introduction
- the present and problems
- most instance segmentation 의 문제점
- two-stages-instance-segmentation은 first-stage’s bounding box에 mask결과값이 많이 의존된다(step-wise).
- 성능이 구리다. region-specific information 만을 사용하고, ROI-pooled features 를 사용하기 때문이다. 이 두가지 문제를 아래의 것들로 해결했다.
- 최근까지 자주 사용되고 있는 [4, 5, 38, 6, 37]
- basis framework : global image-level information 을 사용한다.
- 하지만 정확한 지도학습적 방법으로, 적절한 Loss를 사용하서, global mask representations 를 학습하진 않는다. (?) last mask output signal에 의해서 학습 되므로.
- boundary 관점에서 집중하는 최근 논문으로는 Boundary-preserving Mask RCNN (2-stage) 논문도 있다. a boundary prediction head in ‘mask head’ 를 사용한다.
- 우리의 방법
- a boundary prediction head 를 추가적으로 사용했다.
- holistic image-level instance boundaries( = global boundary representations ) 을 학습한다. 그러기 위해서 우리는 the boundary ground-truths 를 사용한다.
- 새로운 측정지표로써 novel instance-wise boundary-aware mask score 를 사용했다.
- Blend-Mask(strongest single-stage instance segmentation methods)를 보완하여 만듬
- state-of-the art methods on the COCO dataset.
3. Background (single-stage)
- (global-area-based) Basis-based instance segmentation의 시작 :

- Basic Head(=Protonet) : FCN으로 a set of basis mask representations 를 생성한다.
- Detection Head(=Prediction head) : Detected Box를 찾는다. 즉 instance-level parameters(= instance-specific information)를 예측한다.
- (1과 2를 결합해서) instance segmentation을 수행한다.
- 위의 pipeline을 따르는 모델들
- YOLACT : 32 global base, the according instance-specific scalar coefficients, a linear combination among the bases. —>
cause [rich instance features vs effective assembly methods] - improved the assembly parameters : BlendMask [6], SipMask [5], and CenterMask [38]
- instance-specific representation : CondInst [37] (Key word: dynamic filter weights, sliding window, the predicted convolution weight filters)
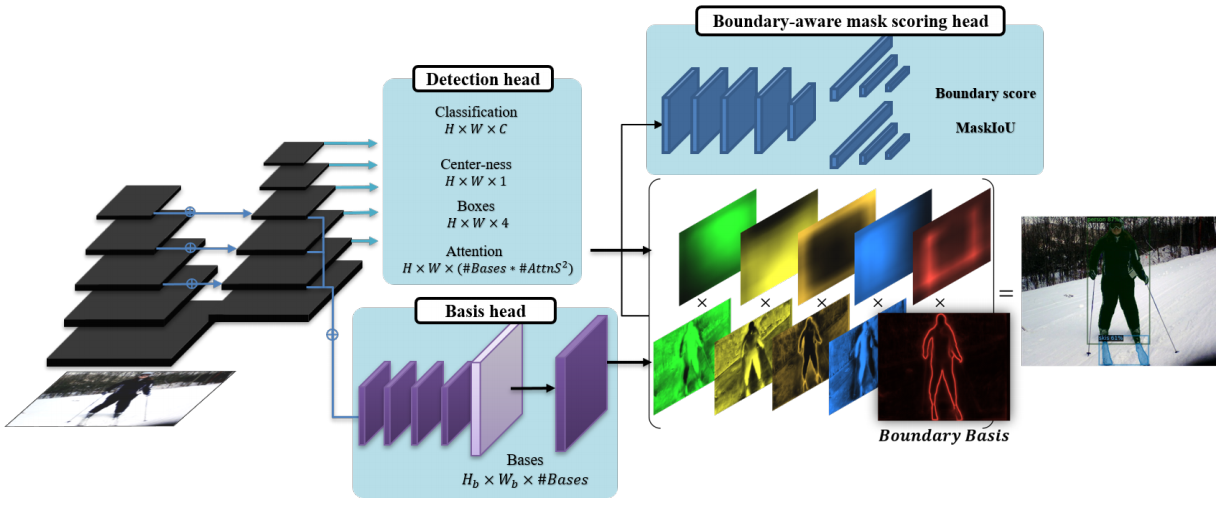
4. Boundary Representation
- B2Inst
- backbone for feature extraction
- instance-specific detection head (Detection head)
- the global basis head, the global image information (Basis head)
- Bundary Basis = mask scoring head
- (2번)과 (3번)을 결합해서, final masks 예측.
BlendMask instantiation (boundary basis)
- Details
- basis head
- FPN feature를 받고, a set of K(=#Bases) global basis features를 생성한다
- 4개의 3x3 conv 통과 + upsampling + reduce the channel-size
- The previous basis head is supervised by the last mask loss only. (?)
- Detection Head
- Basic head와 병렬로, instance-level parameters 들을 추측한다.
- 특히 여기서 나오는 attention map feature는 Boundary Basic (BlendMask 참고)에서 사용된다.
- Loss 함수
- 1) binary cross-entropy loss
- 2) dice loss
- 3) boundary loss
- image boundary (그림에 없음)
- a holistic boundary of all instances (= global boundary representations) in a scene (instance 하나하나 아니라)
- Overlapping objects and complex shapes 문제에서 좋은 성능을 가져다 준다.
- the boundary supervision 은 어렵지 않다. mask annotations를 그냥 이용하면 되므로. the binary mask ground-truths에서 soft boundaries를 찾기 위해서, Laplacian operator 를 사용한다.
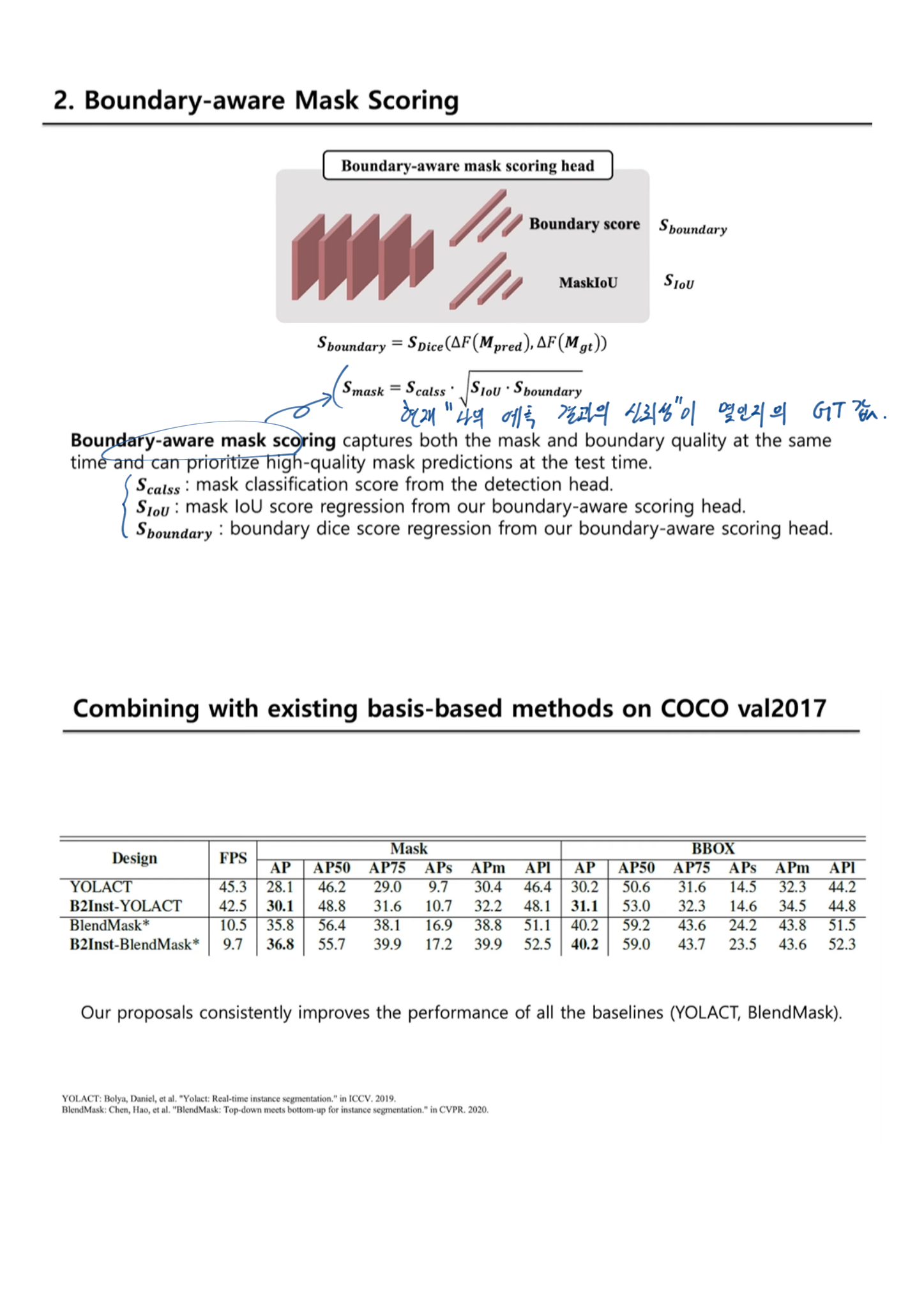
- Boundary-aware mask scoring
- Mask scoring R-CNN 에서 a mask IoU scoring module 이 제안됐었다.
- basis head에서 global view를 바라봤었다면, 이 과정을 통해서, an instance-level(local view)을 바라보게 된다.
- mask IoU score = the IoU + boundary quality 로 분리해 고려했다.
- S_boundary 정의 : Boundary score
- a Dice metric [13] 을 차용했다.

- i는 i번째 pixel을 의미하고, epsilon은 분모가 0이 되는 것을 막는다.
- Scoring head(위 오른쪽 묘듈)
- S_boundary와 S_IOU 를 학습의 Loss 함수로 사용한다.
Input은 concatenation of [predicted mask (M_pred), boundary (B_pred), RoI-pooled FPN features (F_RoI)]- 결론 및 효과 : only for test-time. 학습을 하는 동안 이 score도 추측할 수 있게 만들어 놓으면, test할때 확율값이 얼마인지 확인가능하기도 하고, 학습 성능이 좋아지는 효과도 볼 수 있다.
- Score definition at inference
- Object Detection 모델도 confidence score를 예측하듯이, Mask Score를 예측하는 부분도 만들었다.
GT가 뭐고 아래를 어떻게 사용하는지는 나중에 논문이나, 코드 참고하자. 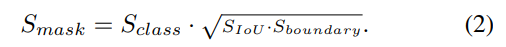
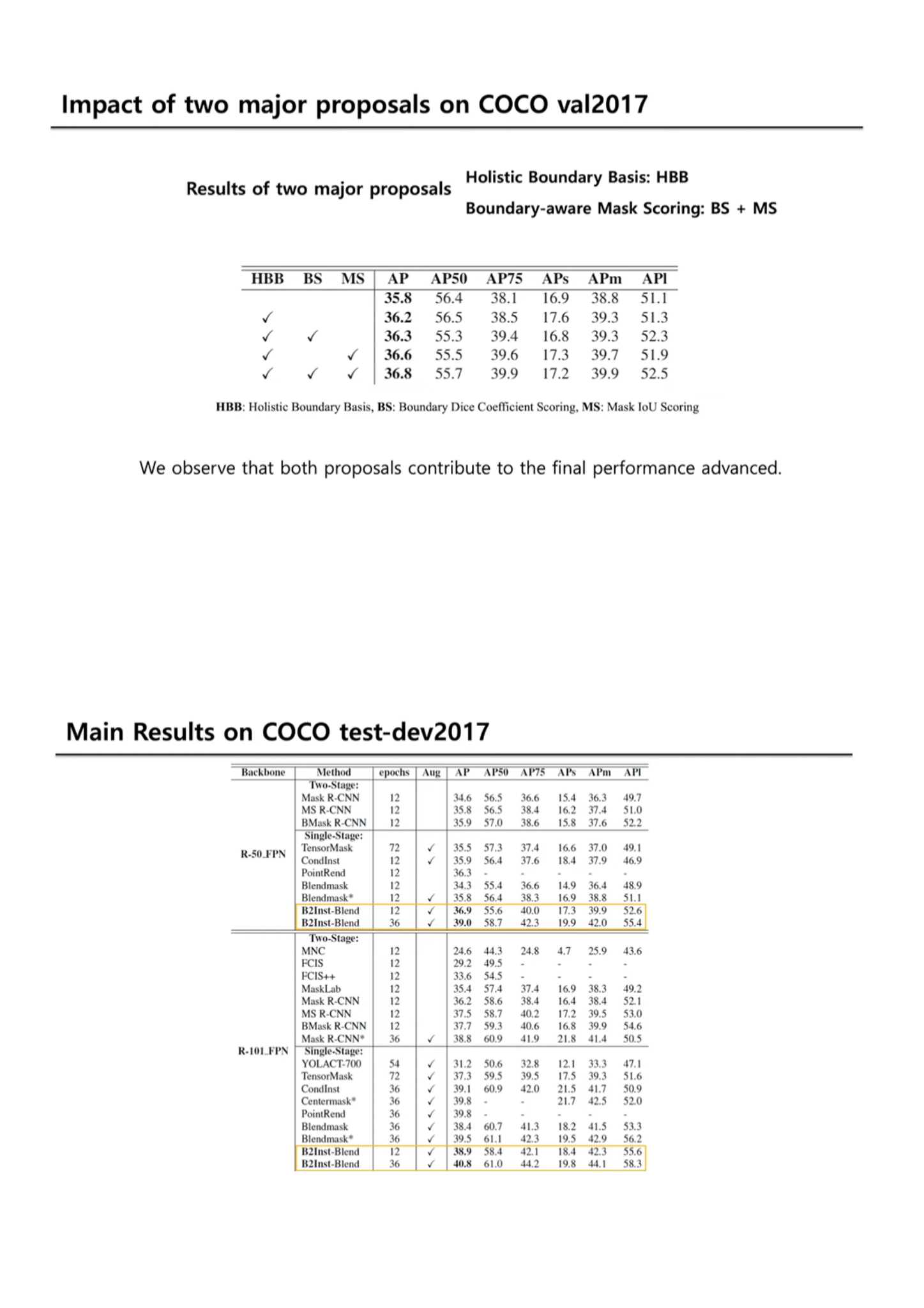
5. Experiment - Ablation study
- 우리 모델에서의 main ‘components’
- Holistic Boundary basis
- Boundary-aware mask scoring (Boundary_S + Mask_S)
- Basis head design choices
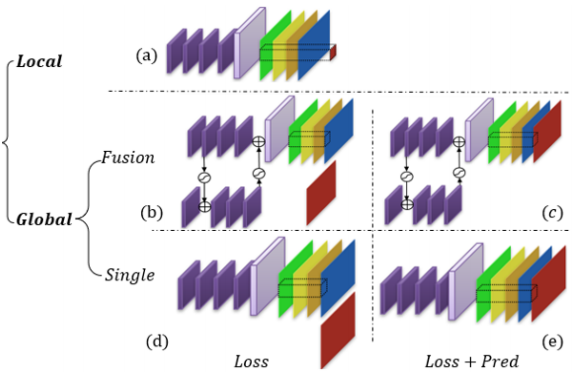
boundary supervision을 globally하고, the boundary supervision_loss and its prediction를 모두 사용하는 (e)에서 가장 성능이 좋았다.마지막 단의 색갈 channel은 original basis를 의미하고, 특히 Red는 the additional image boundary basis를 의미한다.
B2Inst WACV2021 영상

- FastCampus 사이트의 Computer vision 강의 내용 정리
- 구글링을 해도 되지만은, 필요하면 강의를 찾아서 듣기
- FastCampus - Computer vision Lecture
- 이전 Post Link
chap7 - Binary
cv2.threshold(src, thresh, maxval, type, dst=None) -> retval(사용된 임계값), dst
Otsu 방법
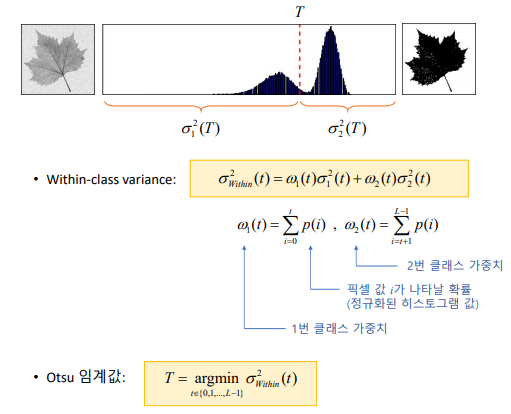
| th, dst = cv2.threshold(src, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU) |
균일하지 않은 조명 환경 - 픽셀 주변에 작은 윈도우를 설정하여 지역 이진화 수행
for y in range(4):
for x in range(4):
src_ = src[y*bh:(y+1)*bh, x*bw:(x+1)*bw]
dst_ = dst2[y*bh:(y+1)*bh, x*bw:(x+1)*bw]
cv2.threshold(src_, 0, 255, cv2.THRESH_BINARY|cv2.THRESH_OTSU, dst_)
- cv2.adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize(슬라이딩 윈도우의 크기), C, dst=None) -> dst
모폴로지(Morphology, 침식과 팽창)
침식 연산 : 영역이 줄어듦. 잡음 제거 효과 - cv2.erode(src, kernel)
팽창 연산 : 영역이 불어남. 구멍이 채워짐 - cv2.dilate(src, kernel)
kernerl 생성 방법 : cv2.getStructuringElement
src = cv2.imread('circuit.bmp', cv2.IMREAD_GRAYSCALE)
se = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 3))
dst1 = cv2.erode(src, se)
dst2 = cv2.dilate(src, None)
모폴로지(열기와 닫기)
- 열기 : 침식 -> 팽창
- 닫기 : 팽창 -> 침식

- 범용 모폴로지 연산 함수 : cv2.morphologyEx(src, op, kernel)
- 열기 연산을 이용한 잡음 제거 : 우선은 지역 이진화!! 필수 -> 그리고 열기 연산
레이블링
- 객체 분활 클러스터링(Connected Component Labeling / Contour Tracing)
- 4-neightbor connectivity / 8-neightbor connectivity
- 레이블링 함수 : cv2.connectedComponents(image)
- 객체 정보 함께 반환하는 레이블링 함수 : cv2.connectedComponentsWithStats(image)
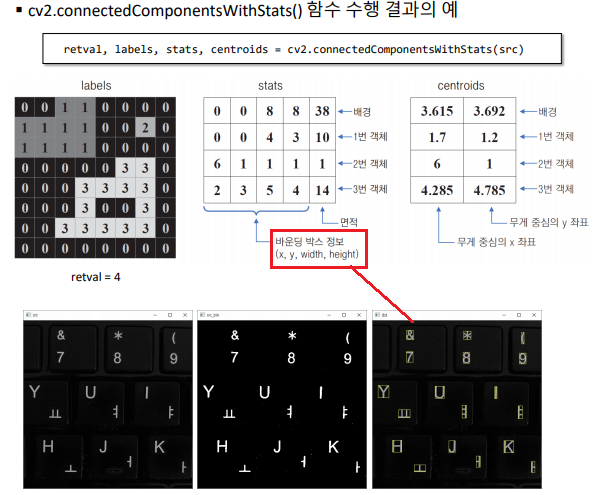
- 바운딩 박스 정보가 나오므로, 숫자 검출 같은 행위가 가능해 진다.
외곽선 검출( Boundary tracking. Contour tracing)
cv2.findContours(image, mode, method)
cv2.drawContours(image, contours, contourIdx, color) : 외각 선만 그려줌 (내부x)
src = cv2.imread('contours.bmp', cv2.IMREAD_GRAYSCALE)
#contours, hier = cv2.findContours(src, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
contours, hier = cv2.findContours(src, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_NONE)
dst = cv2.cvtColor(src, cv2.COLOR_GRAY2BGR)
idx = 0
while idx >= 0:
c = (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))
cv2.drawContours(dst, contours, idx, c, 2, cv2.LINE_8, hier)
idx = hier[0, idx, 0]

외각선 검출 및 도형의 크기나 특징 정보 반환하는 함수
| 함수 이름 | 설명 |
|---|
| cv2.arcLength() | 외곽선 길이를 반환 |
| cv2.contourArea() | 외곽선이 감싸는 영역의 면적을 반환 |
| cv2.boundingRect() | 주어진 점을 감싸는 최소 크기 사각형(바운딩 박스) 반환 |
| cv2.minEnclosingCircle() | 주어진 점을 감싸는 최소 크기 원을 반환 |
| cv2.minAreaRect() | 주어진 점을 감싸는 최소 크기 회전된 사각형을 반환 |
| cv2.minEnclosingTriangle() | 주어진 점을 감싸는 최소 크기 삼각형을 반환 |
| cv2.approxPolyDP() | 외곽선을 근사화(단순화) - 아래 실습에서 사용 예정 |
| cv2.fitEllipse() | 주어진 점에 적합한 타원을 반환 |
| cv2.fitLine() | 주어진 점에 적합한 직선을 반환 |
| cv2.isContourConvex() | 컨벡스인지를 검사 |
| cv2.convexHull() | 주어진 점으로부터 컨벡스 헐을 반환 |
| cv2.convexityDefects() | 주어진 점과 컨벡스 헐로부터 컨벡스 디펙트를 반환 |
다각형 검출 프로그램 실습하기
- 구현 순서
- 이진화
- contour
- 외각선 근사화
- 너무 작은 객체, 컨벡스가 아닌 개체 제외
- 꼭지점 개수 확인 (사각형, 삼각형, 원 검출)
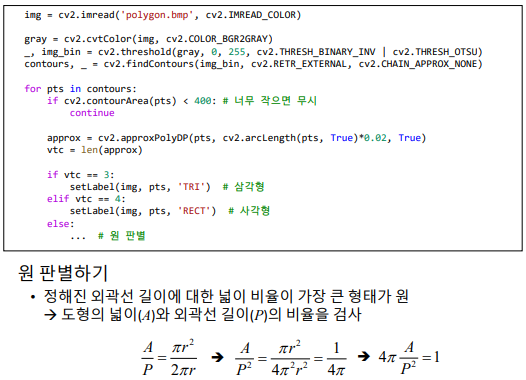
실전 코딩 : 명함 인식 프로그램 만들기
chap8 - Segmentation & Detection
그랩컷 영상분할
- 그래프 알고리즘을 이용해서 Segmentation을 수행하는 알고리즘 (정확한 알고리즘은 논문 참조)
- cv2.grabCut(img, mask, rect)
mask2 = np.where((mask == 0) | (mask == 2), 0, 1).astype(‘uint8’)
dst = src * mask2[:, :, np.newaxis] - 마우스를 활용한 그랩컷 영상 분할 예제 : grabcut2.py 크게 어렵지 않음
모멘트 기반 (비슷한 모양 찾기 기법을 이용한) 내가 찾고자 하는 객체 검출
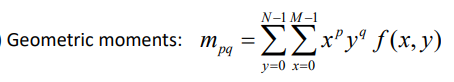
- Hu’s seven invariant moments : 크기, 회전, 이동, 대칭 변환에 불변
- 모양 비교 함수: cv2.matchShapes(contour1, contour2, method, parameter) -> 영상 사이의 거리(distance)
템플릿 매칭
입력영상에서 작은 크기의 템플릿과 일치하는 부분 찾는 기법
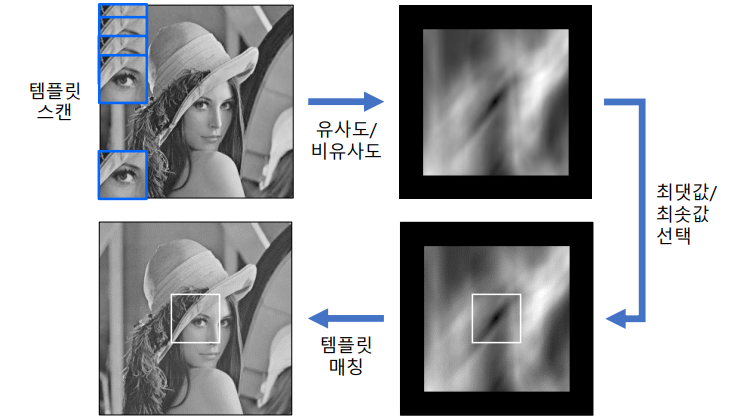
cv2.matchTemplate(image, templ, method, result=None, mask=None) -> result
image의 크기가 W x H 이고, templ의 크기가 w x h 이면 result 크기는 (W - w + 1) x (H - h +1)
method 부분에 들어가야할, distance 구하는 수식은 강의 및 강의 자료 참조
res = cv2.matchTemplate(src, templ, cv2.TM_CCOEFF_NORMED)
res_norm = cv2.normalize(res, None, 0, 255, cv2.NORM_MINMAX, cv2.CV_8U)
_, maxv, _, maxloc = cv2.minMaxLoc(res)
템플릿 매칭 (2) - 인쇄체 숫자 인식
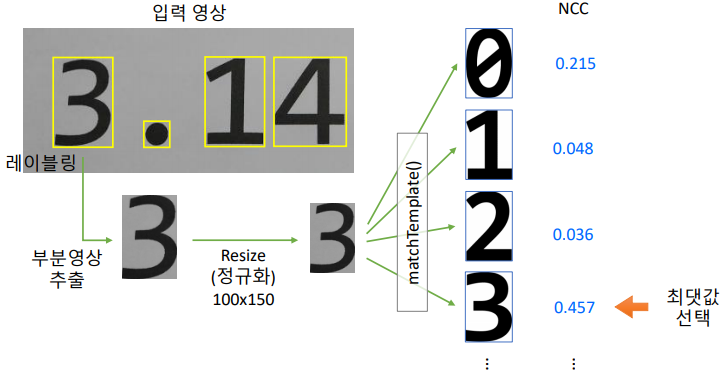
- 오른쪽의 0~9까지는 미리 파일로 저장해놓음
- 자세한 코드 사항은 강의 및 digitrec.py파일 참조
캐스케이드 분류기: 얼굴 검출
Viola - Jones 얼굴 검출기 (이것도 머신러닝 기반)
- 유사 하르 특징(Haar-like features)
Cascade Classifier OpenCV document, 얼굴 검출 시각화 Youtube
cv2.CascadeClassifier.detectMultiScale(image)
미리 학습된 XML 파일 다운로드
src = cv2.imread('lenna.bmp')
classifier = cv2.CascadeClassifier()
classifier.load('haarcascade_frontalface_alt2.xml')
faces = classifier.detectMultiScale(src)
for (x, y, w, h) in faces:
face_img = src[y:y+h, x:x+w]
cv2.rectangle(src, (x, y, w, y), (255, 0, 255), 2)
HOG 보행자 검출
Histogram of Oriented Gradients, 지역적 그래디언트 방향 정보를 특징 벡터로 사용. SIFT에서의 방법을 최적화하여 아주 잘 사용한 방법
2005년부터 한동안 가장 좋은 방법으로, 다양한 객체 인식에서 활용되었다.

- 9개 : 180도를 20도 단위로 나눠서 9개 단위로 gradient 분류
- 1개 셀 8x8, 1개 블록 16 x 16. 블록 1개 는 36개(4블록 x 9개 Gradient)의 히스토그램 정보를 가짐
cv2.HOGDescriptor.detectMultiScale(img)
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
cap = cv2.VideoCapture('vtest.avi')
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
while True:
ret, frame = cap.read()
detected, _ = hog.detectMultiScale(frame)
for (x, y, w, h) in detected:
c = (random.randint(0, 255), random.randint(0, 255),
random.randint(0, 255))
cv2.rectangle(frame, (x, y), (x + w, y + h), c, 3)
실전 코딩: 간단 스노우앱
구현 기능
- 카메라 입력 영상에서 얼굴&눈 검출하기 (캐스케이드 분류기 사용)
- 눈 위치와 맞게 투명한 PNG 파일 합성하기
- 합성된 결과를 동영상으로 저장하기
ch8/snowapp.py 파일 참조
face_classifier = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml')
eye_classifier = cv2.CascadeClassifier('haarcascade_eye.xml')
faces = face_classifier.detectMultiScale(frame, scaleFactor=1.2, minSize=(100, 100), maxSize=(400, 400))
for (x, y, w, h) in faces:
eyes = eye_classifier.detectMultiScale(faceROI)
overlay(frame, glasses2, pos)
def overlay(img, glasses, pos):
# 부분 영상 참조. img1: 입력 영상의 부분 영상, img2: 안경 영상의 부분 영상
img1 = img[sy:ey, sx:ex] # shape=(h, w, 3)
img2 = glasses[:, :, 0:3] # shape=(h, w, 3)
alpha = 1. - (glasses[:, :, 3] / 255.) # shape=(h, w)
# BGR 채널별로 두 부분 영상의 가중합
img1[..., 0] = (img1[..., 0] * alpha + img2[..., 0] * (1. - alpha)).astype(np.uint8)
img1[..., 1] = (img1[..., 1] * alpha + img2[..., 1] * (1. - alpha)).astype(np.uint8)
img1[..., 2] = (img1[..., 2] * alpha + img2[..., 2] * (1. - alpha)).astype(np.uint8)
9. 특징점 검출과 매칭
코너 검출
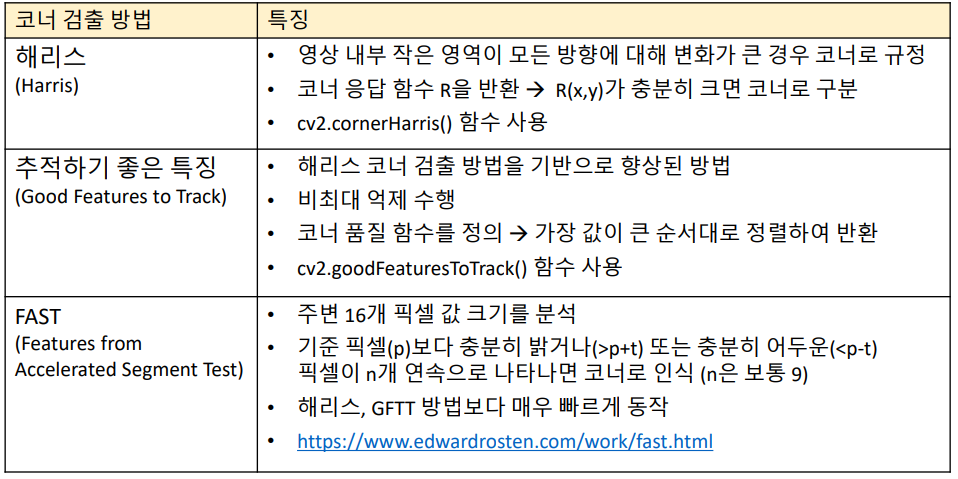
- cv2.cornerHarris(src, blockSize, ksize, k)
- cv2.goodFeaturesToTrack(image, maxCorners, qualityLevel, minDistance)
- cv2.FastFeatureDetector_create(, threshold=None, nonmaxSuppression=None, type=None)
cv2.FastFeatureDetector.detect(image) -> keypoints - 예제 및 사용법은 강의 자료 참조
특징점 검출 (local 영역만의 특징(Discriptor )을 가지는 곳을 특징점 이라고 한다.)
- SIFT, KAZE, AKAZE, ORB
- 아래의 방법들을 사용해서 feature 객체 생성
- cv2.KAZE_create(, …) -> retval
- cv2.AKAZE_create(, …) -> retval
- cv2.ORB_create(, …) -> retval
- cv2.xfeatures2d.SIFT_create(, …) -> retval
- feature.detect(image, mask=None) -> keypoints
- cv2.drawKeypoints(image, keypoints, outImage, color=None, flags=None) -> outImage
기술자 (Descriptor, feature vector)
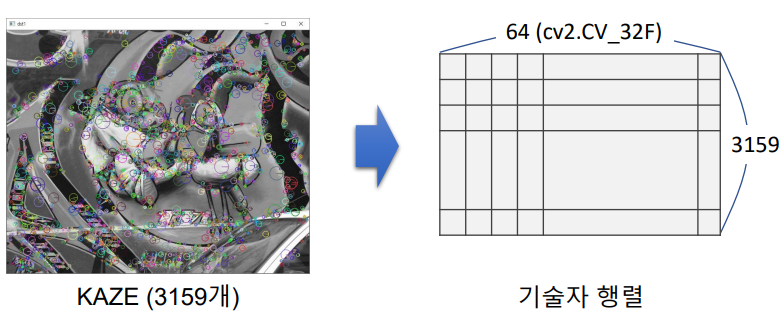
- 특징점 근방의 Local feature을 표현하는 실수 또는 이진 벡터. 위에서는 하나의 특징점이 64개 원소의 백터를 기술자로 가진다.
- 실수 특징 백터. 주로 백터 내부에는 방향 히스토그램을 특징 백터로 저장하는 알고리즘 : SIFT, SURF, KAZE
- Binary descriptor. 주변 픽셀값 크기 테스트 값을 바이너리 값으로 저장하는 알고리즘 : AKAZE, ORB, BRIEF
- 위 2. 특징점 검출에서 만든 feature 객체를 사용
- cv2.Feature2D.compute(image, keypoints) -> keypoints, descriptors (이미 keypoint 있다면)
- cv2.Feature2D.detectAndCompute(image) -> keypoints, descriptors
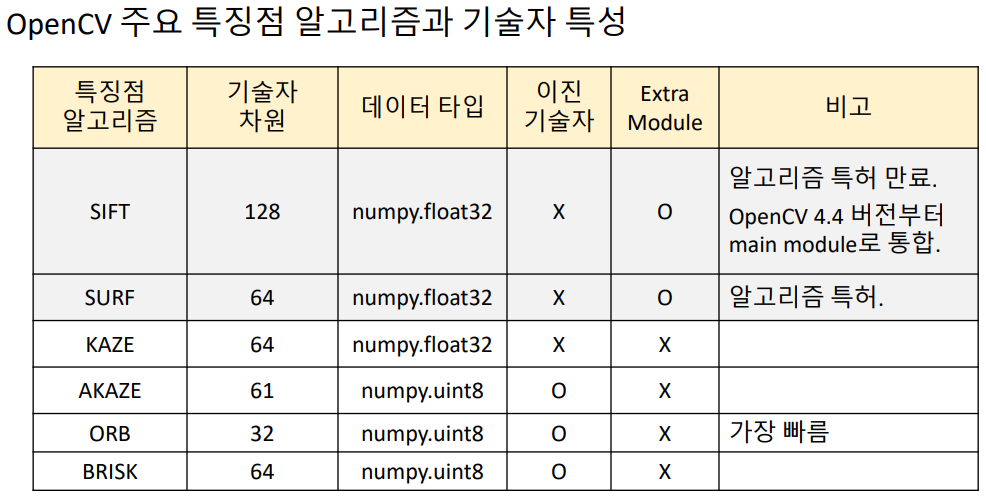
- KAZE, AKAZE이 속도 면에서 괜찮은 알고리즘. SIFT가 성능면에서 가장 좋은 알고리즘
특징점 매칭 (feature point matching)
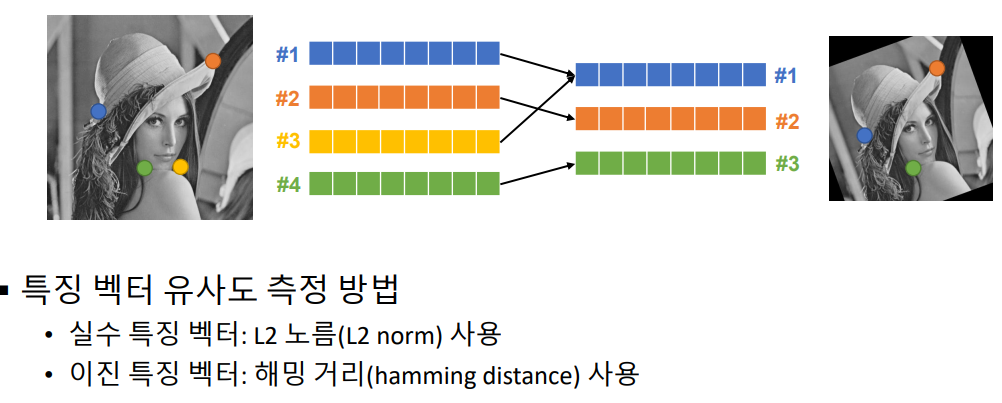
- matcher 객체 생성 : cv2.BFMatcher_create(, normType=None, crossCheck=None)
- matching 함수1 : matcher.match(queryDescriptors, trainDescriptors)
- matching 함수2 : matcher.knnmatch(queryDescriptors, trainDescriptors)
- cv2.drawMatches(img1, keypoints1, img2, keypoints2)
좋은 매칭 선별
호모그래피와 영상 매칭
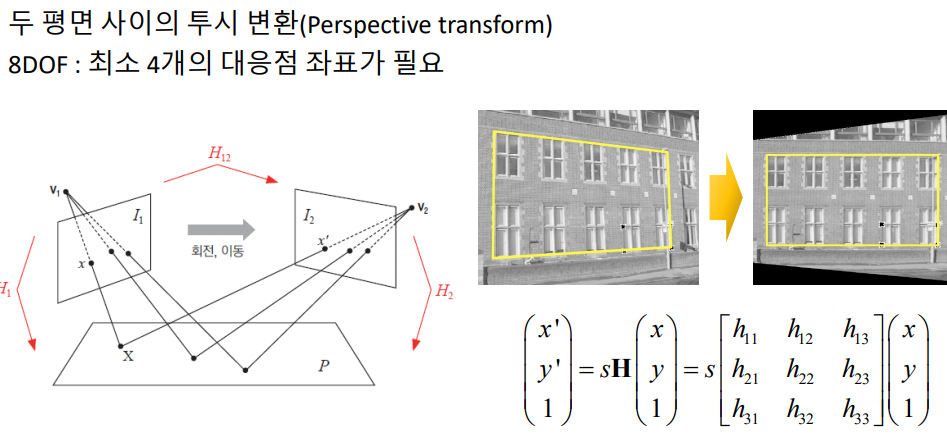
cv2.findHomography(srcPoints, dstPoints) -> retval, mask
good_matches에서 queryIdx, trainIdx 와 같이 2장의 이미지 각각에 대한 특징점 검출 됨.
pts1 = np.array([kp1[m.queryIdx].pt for m in good_matches] ).reshape(-1, 1, 2).astype(np.float32) pts2 = np.array([kp2[m.trainIdx].pt for m in good_matches] ).reshape(-1, 1, 2).astype(np.float32)
H, _ = cv2.findHomography(pts1, pts2, cv2.RANSAC)
# 좋은 매칭 결과 선별
matches = sorted(matches, key=lambda x: x.distance)
good_matches = matches[:80]
# 호모그래피 계산
pts1 = np.array([kp1[m.queryIdx].pt for m in good_matches]
).reshape(-1, 1, 2).astype(np.float32)
pts2 = np.array([kp2[m.trainIdx].pt for m in good_matches]
).reshape(-1, 1, 2).astype(np.float32)
# Find Homography
H, _ = cv2.findHomography(pts1, pts2, cv2.RANSAC)
# 일단 matching된거 그리기
dst = cv2.drawMatches(src1, kp1, src2, kp2, good_matches, None,
flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
# perspectiveTransform 하기 위한 다각형 꼭지점 설정
(h, w) = src1.shape[:2]
corners1 = np.array([[0, 0], [0, h-1], [w-1, h-1], [w-1, 0]]
).reshape(-1, 1, 2).astype(np.float32)
# perspectiveTransform 적용
corners2 = cv2.perspectiveTransform(corners1, H)
corners2 = corners2 + np.float32([w, 0]) # drawMatches에서 오른쪽 영상이 왼쪽 영상 옆에 붙어서 나타나므로, 오른쪽 영상을 위한 coners2를 그쪽까지 밀어 줘야 함
# 다각형 그리기
cv2.polylines(dst, [np.int32(corners2)], True, (0, 255, 0), 2, cv2.LINE_AA)
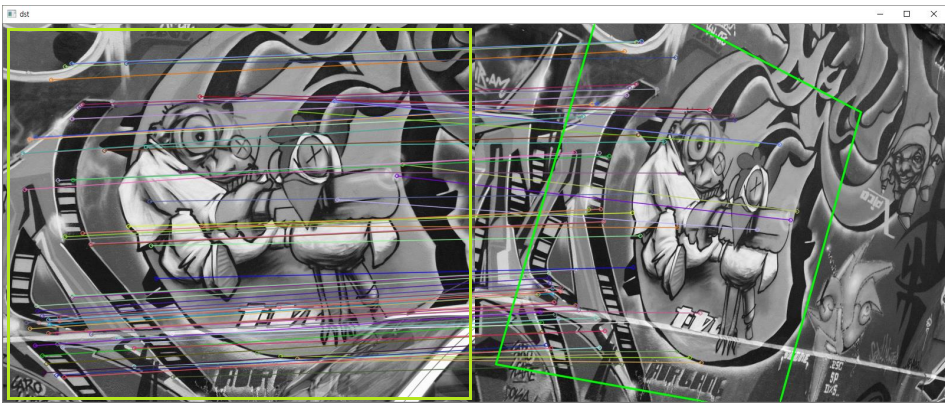
이미지 스티칭
동일 장면의 사진을 자연스럽게(seamless) 붙여서 한 장의 사진으로 만드는 기술
특징점과 matching 등등 매우 복잡한 작업이 필요하지만, OpenCV에서 하나의 함수로 구현되어 있다.
cv2.Stitcher_create(, mode=None) -> retval, pano
# 이미지 가져오기
img_names = ['img1.jpg', 'img2.jpg', 'img3.jpg']
imgs = []
for name in img_names:
img = cv2.imread(name)
imgs.append(img)
# 가져온 이미지, Stitcher에 때려넣기
stitcher = cv2.Stitcher_create()
_, dst = stitcher.stitch(imgs)
cv2.imwrite('output.jpg', dst)
: AR 비디오 플레이어
10. 객체 추적과 모션 백터
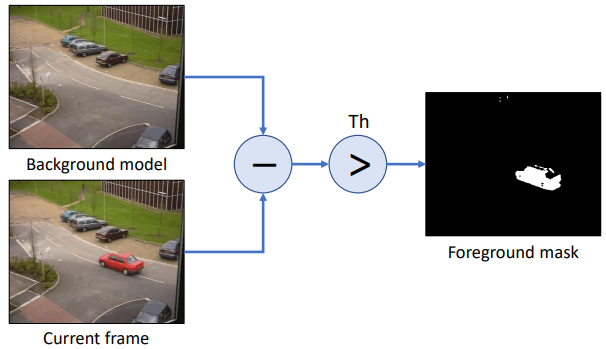
배경 차분 : 정적 배경 차분
- 배경 차분(Background Subtraction: BS) : 등록된 배경 이미지과 현재 입력 프레임 이미지와의 차이(img-src) 영상+Threshold을 이용하여 전경 객체를 검출
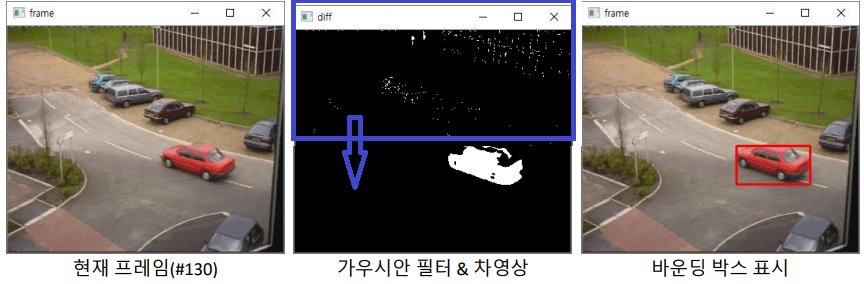
- 위의 Foreground mask에다가, 가이시안 필터 -> 레이블링 수행 -> 픽셀 수 100개 이상은 객체만 바운딩 박스 표시
배경 차분 : 이동 평균 배경
- 위의 방법은, 조도변화에 약하고 주차된 차도 움직이지 않아야 할 민큼 배경 이미지가 불변해야 한다.
- 이와 같은 평균 영상을 찾자
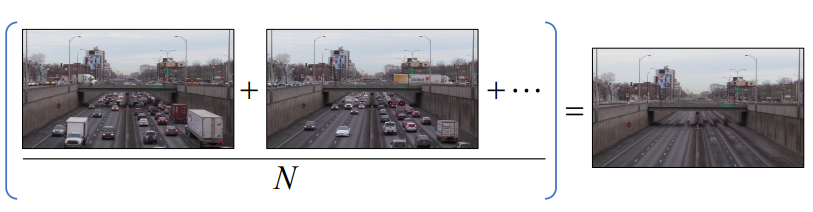
- 매 프레임이 들어올 때마다 평균 영상을 갱신

- cv2.accumulateWeighted(src, dst, alpha, mask=None) -> dst
즉, dst(x ,y ) = (1 - alpha) * dst(x ,y ) + alpha src(x ,y )
배경 차분 : MOG 배경 모델(Mixture of Gaussian = Gaussian Mixture Model))
배경 픽셀값 하나하나가, 어떤 가오시간 분표를 따른다고 정의하고 그 분포를 사용하겠다.
각 픽셀에 대해 MOG 확률 모델을 설정하여 배경과 전경을 구분 (구체적인 내용은 직접 찾아서 공부해보기-paper : Improved adaptive Gaussian mixture model for background subtraction)
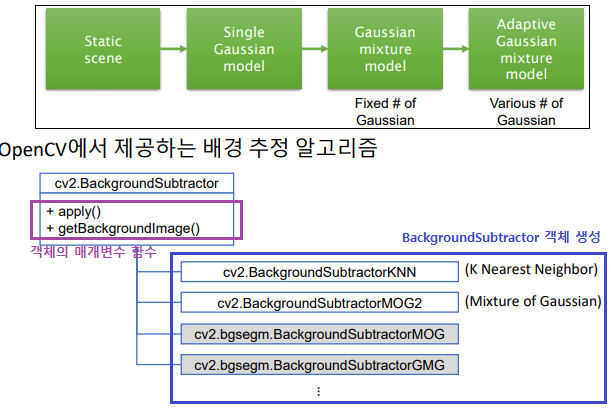
cap = cv2.VideoCapture('PETS2000.avi')
bs = cv2.createBackgroundSubtractorMOG2()
#bs = cv2.createBackgroundSubtractorKNN() # 직접 테스트 하고 사용 해야함. 뭐가 더 좋다고 말 못함.
#bs.setDetectShadows(False) # 125 그림자값 사용 안함
while True:
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
fgmask = bs.apply(gray) # 0(검) 125(그림자) 255(백)
back = bs.getBackgroundImage()
- 동영상을 보면, 생각보다 엄청 잘되고, 엄청 신기하다…
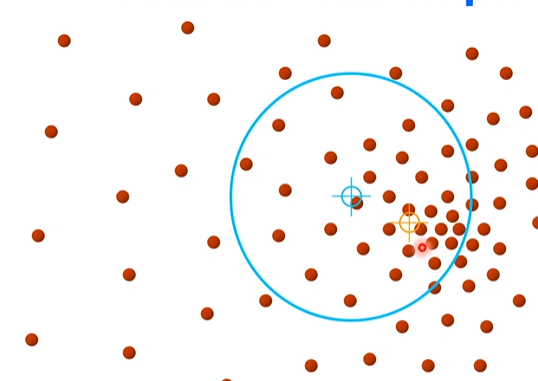
평균 이동(Mean shift) 알고리즘
Tracking : Mean Shift, CamShift, Optical Flow, Trackers in OpenCV 3.x
Mean shift=mode seeking : 데이터가 가장 밀집되어 있는 부분을 찾아내기 위한 방법, 예를 들어 가오시안 이면 평균 위치를 찾는 방법. 아래에 하늘색 원을 랜덤으로 생성한 후, 그 내부의 빨간색 원들의 x,y평균을 찾는다. 그리고 그 x,y평균점으로 하늘색 원을 옮겨 놓는다(이래서 Mean shift). 이 작업을 반복하다 보면, 결국 하늘색 원은 빨간색 원이 가장 밀집한 곳으로 옮겨 가게 된다.
사람의 얼굴 살색을, 히스토그램 역투영법으로 찾은 후 그 영역에 대한 평균점을 찾아가면서 Tracking을 한다.
cv2.meanShift(probImage, window, criteria) -> retval, window
- probImage : 히스토그램 역투영 영생
- window : 초기 검색 영역 윈도우 & 결과 영역 반환
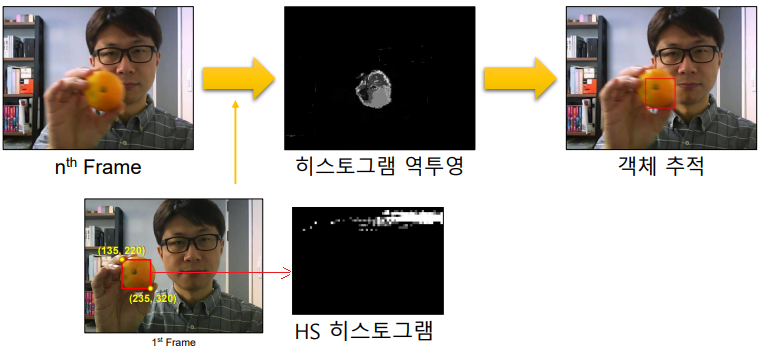
# 첫번째 프레임의 HS 히스토그램 구하기
hist = cv2.calcHist([roi_hsv], channels, None, [45, 64], ranges)
# 히스토그램 역투영 & 평균 이동 추적
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
backproj = cv2.calcBackProject([hsv], channels, hist, ranges, 1)
_, rc = cv2.meanShift(backproj, rc, term_crit)
히스토그램 역투영법, HS 히스토그램에 대해 궁금하면, 동영상 직접 찾아서 보기
- 단점 : 객체가 항상 같은 크기이여야 함. 예를 들어, 위의 귤이 멀어져서 작아지면 검출 안된다.
[Cam Sift(캠시프트)](https://fr.wikipedia.org/wiki/Camshift) 알고리즘
위의 단점을 해결하기 위한 알고리즘, 위의 평균 이동 알고리즘을 이용.
일단 평균 이동을 통해 박스를 이용한다. 그리고 히스토그램 역투영으로 나오는 영역에 대해서, 최적의 타원을 그린다. 만약 타원이 평균이동박스 보다 작으면, 이동박스를 작게 변경한다. 반대로 최적의 타원이 박스보다 크다면, 이동박스를 크게 변경한다. 이 과정을 반복한다.
cv2.CamShift(probImage, window, criteria) -> retval, window
# HS 히스토그램에 대한 역투영 & CamShift
frame_hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
backproj = cv2.calcBackProject([frame_hsv], channels, hist, ranges, 1)
ret, rc = cv2.CamShift(backproj, rc, term_crit)
루카스-카나데 옴티컬 플로우(OneDrive\20.2학기\컴퓨터비전\OpticalFlow.pdf참조)
Optical flow : 객체의 움직임에 의해 나타나는 객체의 이동 (백터) 정보 패턴. 아래 식에서 V는 객체의 x,y방향 움직임 속도이고, I에 대한 미분값은 엣지검출시 사용하는 픽셀 미분값이다. (컴퓨터비전-윤성의교수님 강의 자료에 예시 문제 참고) 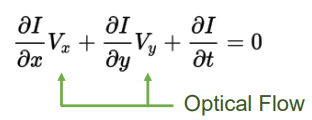
추가 가정 : 이웃 픽셀은 같은 Flow를 가짐 → NxN Window를 사용하면 N^2개 방정식 → Least squares method
루카스-카나데 알고리즘(Lucas-Kanade algorithm)
- cv2.calcOpticalFlowPyrLK(…) : input parameter는 강의자료 + Official document 공부
- Sparse points에 대한 이동 벡터 계산 → 특정 픽셀에서 옵티컬플로우 벡터 계산
- 몇몇 특정한 점들에 대해서만, Optical Flow를 계산하는 방법
파네백 알고리즘(Farneback’s algorithm)
- cv2.calcOpticalFlowFarneback(…) : input parameter는 강의자료 + Official document 공부
- Dense points에 대한 이동 벡터 계산 → 모든 픽셀에서 옵티컬플로우 벡터 계산
이미지 전체 점들에 대해서, Optical Flow를 계산하는 방법
# 루카스-카나데 알고리즘(Lucas-Kanade algorithm)
pt1 = cv2.goodFeaturesToTrack(gray1, 50, 0.01, 10)
pt2, status, err = cv2.calcOpticalFlowPyrLK(src1, src2, pt1, None)
# 2개 이미지 겹친 이미지 만들기
dst = cv2.addWeighted(src1, 0.5, src2, 0.5, 0)
# 화면에 백터 표현하기
for i in range(pt2.shape[0]):
if status[i, 0] == 0:
continue
cv2.circle(dst, tuple(pt1[i, 0]), 4, (0, 255, 255), 2, cv2.LINE_AA)
cv2.circle(dst, tuple(pt2[i, 0]), 4, (0, 0, 255), 2, cv2.LINE_AA)
cv2.arrowedLine(dst, tuple(pt1[i, 0]), tuple(pt2[i, 0]), (0, 255, 0), 2)

밀집 옵티컬플로우 (파네백 알고리즘 예제)
만약 필요하다면, 아래의 코드를 그대로 가져와서 사용하기. 한줄한줄 이해는 (강의자료 보는것 보다는) 직접 찾아보고 ipynb에서 직접 쳐봐서 알아내기, 어렵지 않음
# dense_op1.py
flow = cv2.calcOpticalFlowFarneback(gray1, gray2, None,0.5, 3, 13, 3, 5, 1.1, 0)
mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])
hsv[..., 0] = ang*180/np.pi/2
hsv[..., 2] = cv2.normalize(mag, None, 0, 255, cv2.NORM_MINMAX)
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
cv2.imshow('frame', frame2)
cv2.imshow('flow', bgr)
gray1 = gray2
# # dense_op2.py
def draw_flow(img, flow : calcOpticalFlowFarneback의 out값, step=16):
h, w = img.shape[:2]
y, x = np.mgrid[step/2:h:step, step/2:w:step].reshape(2, -1).astype(int)
fx, fy = flow[y, x].T
lines = np.vstack([x, y, x+fx, y+fy]).T.reshape(-1, 2, 2)
lines = np.int32(lines + 0.5)
vis = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
cv2.polylines(vis, lines, 0, (0, 255, 255), lineType=cv2.LINE_AA)
for (x1, y1), (_x2, _y2) in lines:
cv2.circle(vis, (x1, y1), 1, (0, 128, 255), -1, lineType=cv2.LINE_AA)
return vis

Optical flow를 사용하기 위해서 추천하는 함수들 : 맨 위가 가장 parents,super class이고 아래로 갈 수록 상속을 받는 Derived class,child class,sub class 등이 있다.
OpenCV 트래커
OpenCV 4.5 기준으로 4가지 트래킹 알고리즘 지원 (4.1 기준 8가지 지원. 사용안되는건 지원에서 빼 버린것 같다)
TrackerCSRT, TrackerGOTURN, TrackerKCF, TrackerMIL

cap = cv2.VideoCapture('tracking1.mp4')
tracker = cv2.TrackerKCF_create()
ret, frame = cap.read()
rc = cv2.selectROI('frame', frame)
tracker.init(frame, rc)
while True:
ret, frame = cap.read()
ret, rc = tracker.update(frame)
rc = [int(_) for _ in rc]
cv2.rectangle(frame, tuple(rc), (0, 0, 255), 2)

실전 코딩: 핸드 모션 리모컨
움직임이 있는 영역 검출 / 움직임 벡터의 평균 방향 검출
cv2.calcOpticalFlowFarneback() -> 움직임 벡터 크기가 특정 임계값(e.g. 2 pixels)보다 큰 영역 안의 움직임만 고려
움직임 벡터의 x방향 성분과 y방향 성분의 평균 계산
mx = cv2.mean(vx, mask=motion_mask)[0]
my = cv2.mean(vy, mask=motion_mask)[0]
m_mag = math.sqrt(mx*mx + my*my)
if m_mag > 4.0:
m_ang = math.atan2(my, mx) * 180 / math.pi
m_ang += 180
- FastCampus_CV\opencv_python_ch06_ch10\ch10\hand_remocon.py

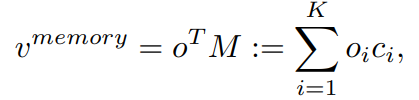



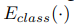 : classifier encoder up to the second-to-the-last layer
: classifier encoder up to the second-to-the-last layer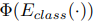 : the classifier
: the classifier : domain encoder. 아래의 성질은 만족하게 encoder를 만들어 낸다.
: domain encoder. 아래의 성질은 만족하게 encoder를 만들어 낸다.