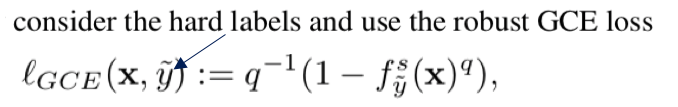【DG】 Survey DG papers 7 - recent papers
- DG survey
- TENT 관련 논문을 읽고 High Level에 대한 이해 & 정리
- 각 논문에서 집중해야할 사항: TTA에서 무엇을 개선한건가? 어디를 본건가? TTA에서 어떤 점이 아쉬워서 깊게 Following 했는가? Setting과 Method가 무엇인가? 무엇이 문제라고 생각하여 어디를 건들였는가?
High Level 정리
- (#7.1) Instance Adaptive Self-Training for Unsupervised Domain Adaptation (IAST)
- (#7.2) Test-Time Personalization with a Transformer for Human Pose Estimation
- (#7.3) Pixel-Level Cycle Association: A New Perspective for Domain Adaptive Semantic Segmentation
- (#7.4) Label-Driven Reconstruction for Domain Adaptation in Semantic Segmentation
- (#7.5) Mixnorm: test-time adaptation through online normalization estimation
- Small batch에서 TTA를 해서도, Normalization statistics 을 최적으로 만들 수 있는 Momentun Normalization statistics 방법 제안
- Loss 및 Affine Parameter (α, β)는 TTA에 고려하지 않는다.
7.1 Instance Adaptive Self-Training for Unsupervised Domain Adaptation (IAST)
종기 PDF 필기본 참조
7.2 Test-Time Personalization with a Transformer for Human Pose Estimation
종기 PDF 필기본 참조
7.3 Pixel-Level Cycle Association: A New Perspective for Domain Adaptive Semantic Segmentation
종기 PDF 필기본 참조
7.4 Label-Driven Reconstruction for Domain Adaptation in Semantic Segmentation
종기 PDF 필기본 참조
7.5 Mixnorm: test-time adaptation through online normalization estimation
Abstract
- 과거 method들은 large batch를 사용하고 single test distribution을 고려한다. 하지만 이 두 가정은 TTA에서 적절치 못하다.
- 이 논문의 Method에서는 (1) 적은 batch만으로도 적절한 batch-norm statistics (BN normalization위한 statistics) 을 추정하고, (2) Multi distribution 을 고려한다.
- 즉, 논문 Setting은 Small batch && Multi target (ImageNet-C) 이다.
- Loss는 사용하지 않는다. 따라서 Weight, Bias는 Update하지 않는다. Running_stack statistics을 점점 target에 맞추어 바꿔감으로써 Evaluation 성능을 높히는 것을 목적으로 한다.
Method
- Pretrained weight를 가져올 때, 모든 weight들은 copy한 후 (BN statistics + weight/bias까지) BatchNorm은 Mix-Norm-layer 으로 바꾼다.
- 자세한 method는 위 그림 혹은 논문 참조.
- 정확히 안 나와 있지만, 이 논문에서는 TENT training /Evaluation operation을 어떻게 다르게 했는지는 이야기 하지 않고 있다. (S4T 처럼) 근데 사실 이게 맞다. Operation을 바꾼다는게 사실 더 웃기다. {Training / Test time Training / Test} 이 중 뒤에 2개는 당연히 operation이 같아야 하지 않을까? 그럼에도 불구하고 나는 Test 단계에서는 running statistics를 고정하고 Test time Training에서는 running statistics 를 Adaptation하는게 “Evaluation (지금까지 학습한게 전혀 다른 dataset에 대해서, 새로 만날 dataset에 대해서 잘 동작할 weight인가? )”이라는 목적에서는 더 그럴듯 한 것 같다.
Results
- [Table1] Moving Speed, Global scale, Local Scale을 바꿔서 Mixed Norm이 얼마아 좋은지 실험하였다. Running_stack statistics을 target feature statistics 그대로 사용하면 가장 성능이 낮다. source tracked statistics을 사용하면 중간 성능이다. source와 target statistics을 적절히 섞어서 Normalization parameter를 최적으로 맞춘게 가장 성능이 좋다.
- [Table1] 가장 아래 행의 수치가 TENT를 적용해 de-norm parameter를 Update한 결과이다. 성능향상에 큰 의미가 없다. (TENT의 Key가 Normalization parametor인지 / de-norm parametor인지 실험이 필요한 듯 하다.)
- [Table2] Local Mean/Var를 만들기 위해 몇개의 Augmentation 기법을 사용한지에 따른 성능 변화이다. 많이 한다고 의미없고 1개만 해도 충분히 좋은 성능이 나온다고 한다. 그럴만 하다. 딱 예측에 필요한, 현재 Batch를 위한 Normalization parameter를 만들고 싶다면 사실 augmenation feature 무쓸모다.
- ( ImageNet-C에 대한 성능 수치를 제시한다. 이게 정말 Multi target (distributions)을 고려했다고 할 수 있는 것인지 모르겠다. )
7.6 Test-time batch statistics calibration for covariate shift

Abstract
- 기존 Method들은 Source의 running_statistics를 Target running_statistics으로 덮어버린다. 이는 target batch statistics (running_track)과 source parameter (CNN weights) 간에 Mismatch를 야기한다.
- 때문에 (1) α-BN이라는 BN-calibration 기법을 새로 제안한다. (2) Novel loss function으로 Core (the pairewise class correlation online optimization) 기법을 제안한다.
- 어떤 Training도 하지 않고, α-BN 만 적용해서 {GTA5 -> Cityscape} {28.4% -> 43.9%} 성능 향상을 이뤄냈다.
Understanding Test Time Normalization
- T-BN (Test-time normalization) 은 항상 free launch를 주지 않는다. 장점 만을 가지고 있지 않다. CNN weight들은 source꺼고 BN normalization연산은 target을 위한 것으로 완전히 대체되다 보니 모델 내부의 Mismatch가 발생할 수 있다.
Test-Time Batch statistics calibration
- 지금까지 TTA는 Source-statistics를 버리고, Target-statistics를 running tracking 했었다. 이것은 “alleviates domain shift” 장점이 있지만, “perturbs the discriminative structures” 하는 단점을 야기할 수 있다.
- 이러한 문제점을 해결하고자 심플하면서 강력한 Method인 α-BN 을 제시한다.
Results
- 성능 결과는 매우 놀랍다.
- Entropy Loss와 같은 Self-loss로 Training하지 않고 α-BN 만 적용한 것 만으로도 5miou성능 향상이 일어난다.
- Segmentation 에서는 Core loss 적용 결과는 제시되어 있지 않다. Semantic segmentation을 위한 Core loss가 아니여서 그런 듯 하다.
7.6 Adaptive generalization for semantic segmentation
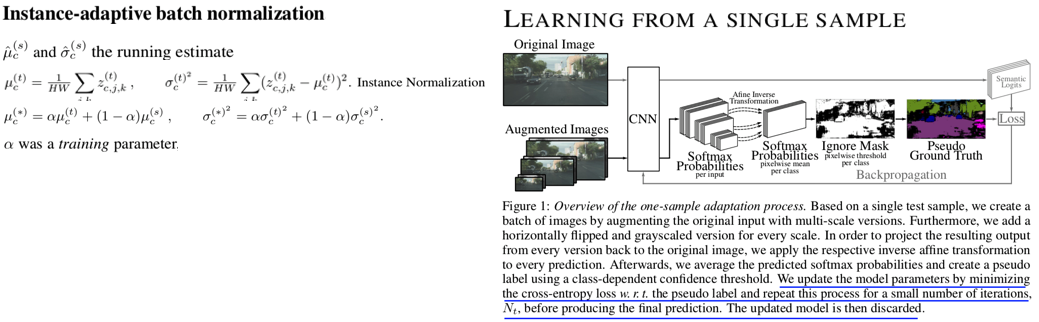
Abstract
- Instance adaptive batch normalization
- Self-supervised loss for SegTTT (Segmentation Test time training)
Method
- Instance-adaptive batch normalization : 위 α-BN과 비슷하지만, Target normalization parm는 Instance Normalization 값을 사용한다. 그리고 여기서 α는 learnable 하고, Test time 때 training된다.
- Learning from a single sample :
- 한 batch를 하나의 이미지와 그 이미지의 augmentation (horizontal flipping, multi-scaling, grayscaling) 으로 구성한다.
- 한 Batch에서 forward해서 나오는 결과의 전부를 Average해서 Soft-max score를 추출한다.
- 각 Class를 위한 Threshold를 설정하고 ignore-nonignore mask를 만든다. mask를 적용한 pseudo label 을 만든다.
- 이 mask를 사용해서 Cross entropy loss를 걸어서 모델을 갱신한다. 이 과정을 Nt번 수행한다.
- Updated image를 가지고, 위의 같은 이미지를 다시 Inference해서 나오는 결과를 prediction result로 사용한다.
- (아마 α를 제외하고) 모든 파라미터를 source 로 다시 reset한다.
- 새로운 이미지가 들어오면 1번부터 6번까지의 과정을 다시 반복한다.
Results
- Instance-adaptive batch normalization에 의한 Miou 성장률은 1 정도 이다.
- Learning from a single sample 으로 인한 성능 향상은 2 정도 이지만, 정말 말도 안되는 웃긴 학습 전략이다. 따라서 의미없다.
7.7 Memo: Test time robustness via adaptation and augmentation
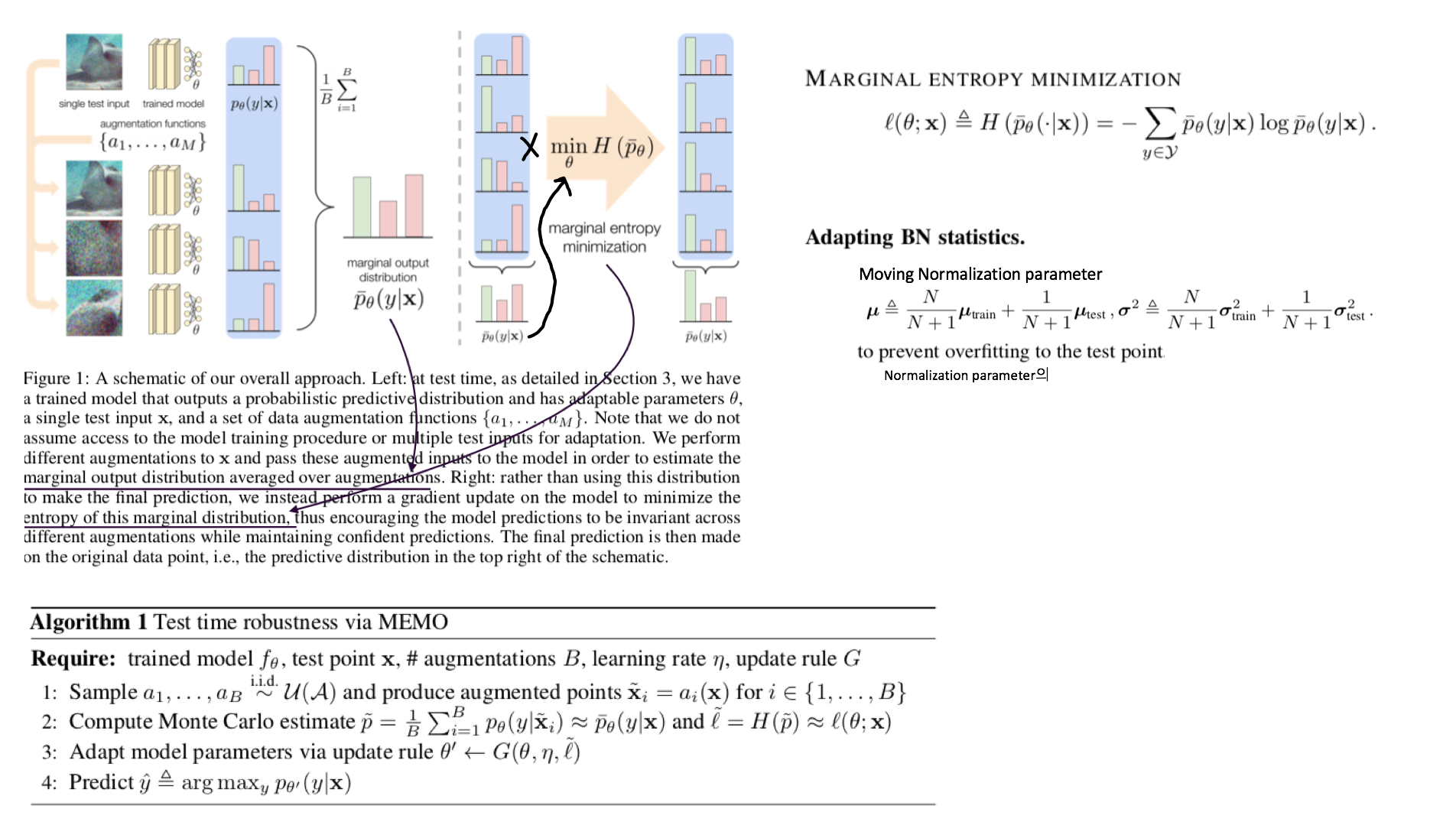
Abstract
- Prior works의 가정: Access to multiple test points (Video 시나리오 처럼 한장의 이미지가 들어오는게 아니라 다른 종류의 이미지가 다수로 들어오는 컨셉)
- 한장의 이미지와 그 이미지의 Augmentation을 어러게 만들어서 Predict 한다. 나온 결과의 average를 사용해서 Marginal ntropy minimization 하여 Adaptation한다. (그림 확인)
- Memo = Marginal Entropy Minimization with One test point
- Ps. Marginal distribution의 의미는? = Augmentation 결과에 대해서 Consistent한 Label을 예측하게 유도하다 보면 기존 Source distribution에 추가적인 (Marginal) distribution 까지 학습할 수 있게 된다.
Method
- [#7.6] 논문과 유사하게, Test set 내부의 이미지 각각을 model에 독립적으로 학습시켜서 Inference한다. 한장 Adpataion하고 Infernece하고를 반복한다.
- Marginal Entropy minimization이라고 함은, 간단하게 Multi augmented Image의 Prediction results 들의 평균을! Entropy Minimization하는 것이다.
Results
- Classification에서 2~3정도의 Error 감소가 존재한다. (그리 큰 감소는 아닌 듯 하다.)
7.8 If your data distribution shifts, Use self-learning
Abstract & Instruction 에서 중요한 이야기 없다.
- Standard cross-enropy loss / Entropy minimizaion 기법은 label noise에 매우 민감하다.
- Robust Pseudo-Labeling 기법으로 Generalized Cross Enropy Loss를 사용했다.