【Detection】Sparse R -CNN-End-to-End Object Detection with Learnable Proposals
- 논문 : Sparse R-CNN, End-to-End Object Detection with Learnable Proposals
- 분류 : Object Detection
- 요즘에 계속 Transformer만을 이용하겠다고 아이디어 생각하고 그랬는데, GPU 성능을 생각하고 학습시간을 생각한다면, 다시 과거로 돌아가는 이런 아이디어도 굉장히 좋은 것 같다.
Sparse R-CNN
1. Conclusion
- PS. 이 논문에서 의문이 드는 몇가지 사항들은 코드을 통해서 알아야 할 것 같다. 논문을 통해서 알 수 없다. 하지만 논문이 Detectron2를 사용하기 때문에.. 궁굼한 점은 나중에 알아보자.
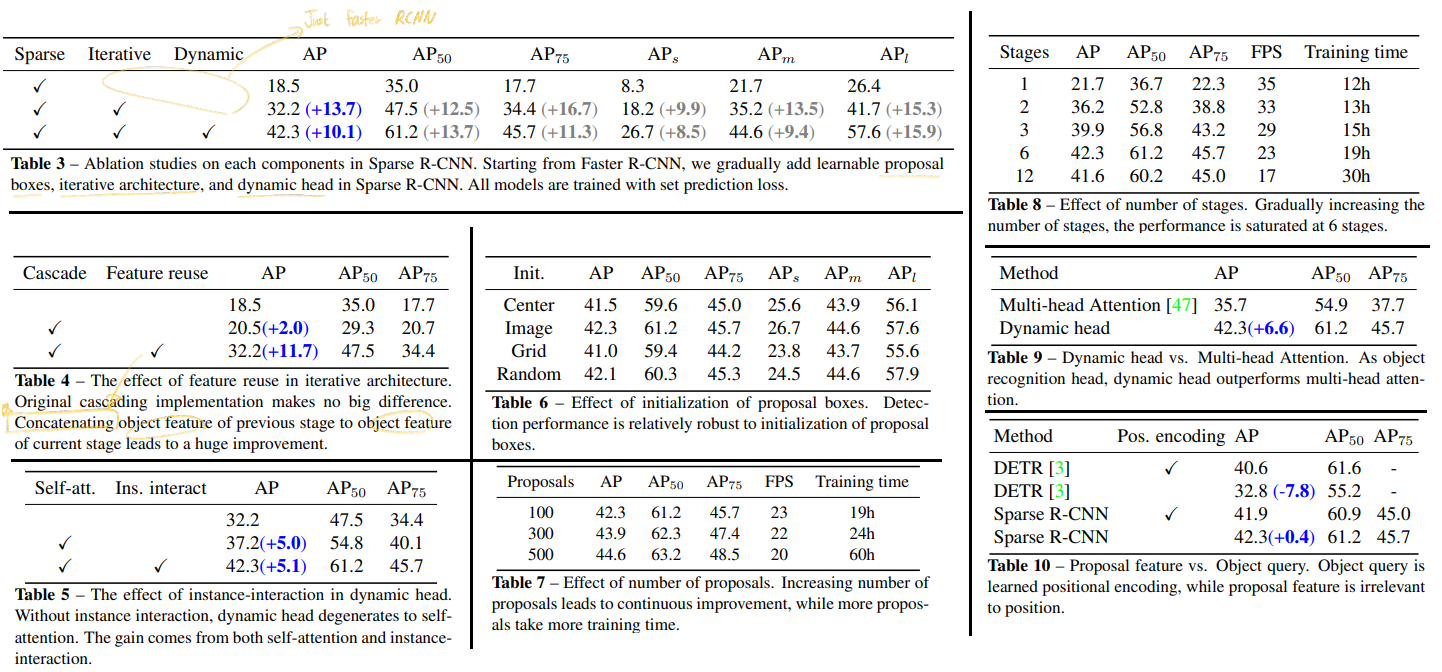
- 고정된 적은 갯수(sparse set = N개 대략 100개)의 learned object proposals(아래 (1), (2)) 을 이용한다.
- (1)
Proposal Boxes - (2)
Proposal Features - (3)
Dynamic Instance Interactive Head - (4)
iteration structure
- (1)
- final predictions은 NMS를 하지 않은 100개(N)의 결과를 사용한다.
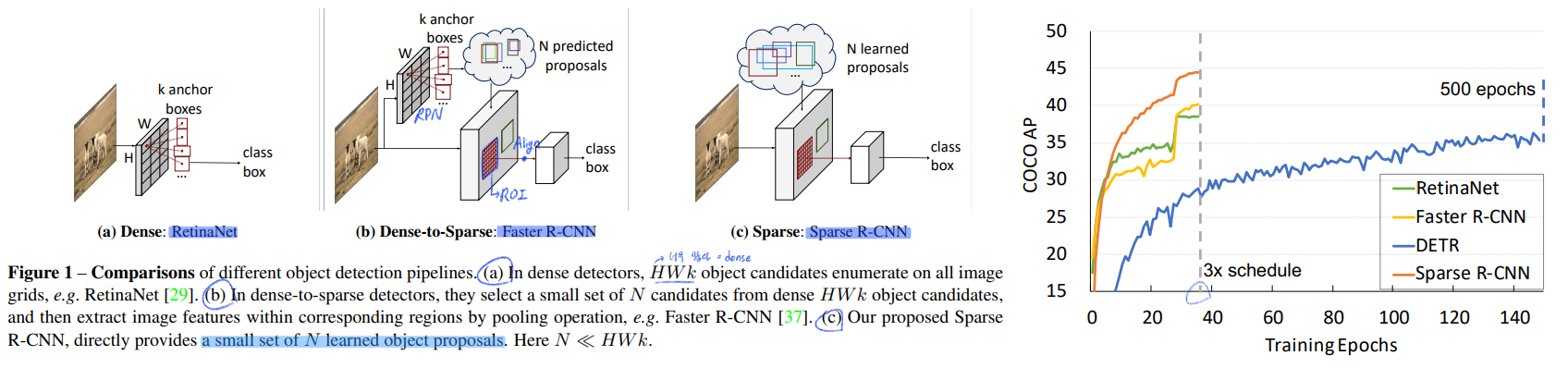
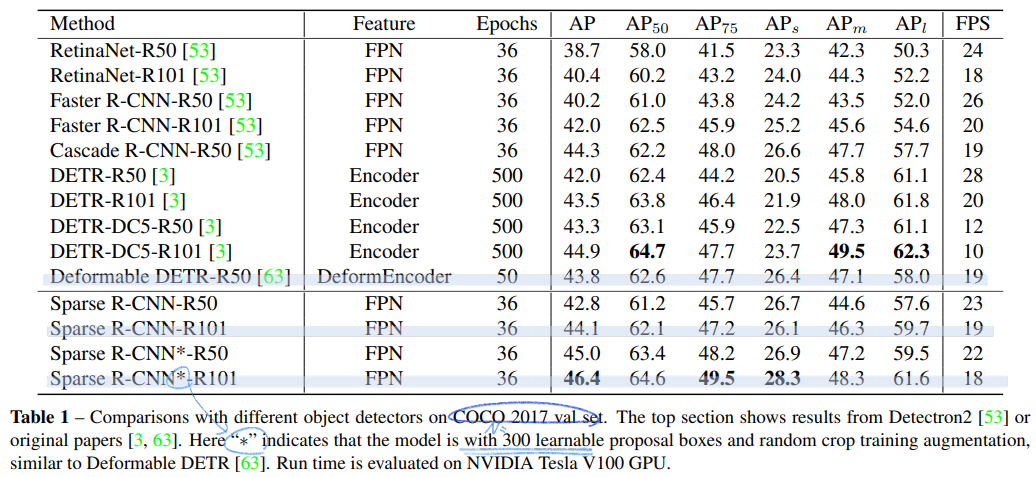
- Detectron2 사용. 45AP. 3x training schedule, 22 fps using ResNet-50 FPN
2. Instruction, Relative work
- learnable parameter로써 다음의 2개를 이용한다. sparse property
- (1) sparse boxes: 많은 이미지를 학습해서 얻은 이미지에서 객체가 위치할 만한 100개의 박스 좌표
- (2) sparse features: 각 box에 좀더 구체적인 정보를 제공해 준다. 모양, 형태 등. ROI Align된 feature map을 conv 1x1의 형식으로 통과시킬때 layer의 weight 역할을 한다.
- DETR은 pure sparse가 아니다. 왜냐면 하나의 객체를 탐지하기 위해서 모든 full images feature map을 사용하기 때문이다.
- 이래의 2개의 proposal = learnable parameter을 사용해서
Dynamic Instance Interactive Head에서 연산 후 예측 결과를 도출한다.proposal boxs: Sparse RCNN은 pure sparse method이다.a fixed small set of learnable bounding boxes represented를 사용하고, ROIPool, ROIAlign을 사용해서 해당 영역의 feature를 뽑아서(모두 같은 resolution s x s) 그것만을 사용한다.proposal features: 4개의 좌표값만을 사용한sparse boxs=proposal boxs정보만으로는 부족한 정보를 담고 있으므로,proposal feature를 사용한다. 이것은 256차원과 같은 높은 차원의 Vector이고 동일하게 N개를 사용한다.proposal feature에는 rich instance characteristics이 저장되어 있다.
- 처음에 필요한 Input은 (1) backbone에서 나온 feature map, coco train dataset를 통해 학습된 a sparse set of (적은 수의) (2) proposal boxes, (3) proposal features 이다.
- dense VS sparse : RetinaNet과 같이 WxHxk 개의 anchor와 같은
dense candidates와 DETR에서 full image feature map을 사용하는global dense feature와 같은 모듈은 존재하지 않는다. Deformable-DETR은 일부의 key만을 사용하기 때문에 sparse method라고 할 수 있다.
3. Sparse R-CNN
PS1. 6번의 iteration을 돈다. 0~5 중 하나를 k라고 정의할 때, 아래와 같이 k번째 iteration head가 아래의 그림과 같이 나와 있는 것이다.
PS2. k번째 head는 (1) proposal boxes(Nx4), (2) Proposal Featuers(Nxc), (3) Dynamic Convolution 이렇게가 한쌍이다.
PS3. Inference 중, 1번째 head는 (1) Learned init proposal boxes(Nx4), (2) Learned init Proposal Featuers(Nxc), (3) 1번째 head의 Dynamic Convolution가 사용된다.
**PS3. Inference 중 k번째 head는 (1) 이전 head에서 추출된 regrassion boxes(Nx4), (2) 이전 head의 Dynamic conv에서 추출된 obj_features(NxC), (3) k번째 head의 Dynamic convolution이 사용된다. **

전체 구조는 위와 같고 하나하나의 모듈에 대해서 간략히 알아가보자.
- Backbone
- FPN
- P2~P5, P_l 은 input image보다 2^n배 작은 resolution을 가진다.
- 모든 level features은 256channel이다.
- stacked encoder layers, deformable convolution network 와 같은 접근법을 사용할 수 있지만, 우리는 simplicity에 집중하여 우리 method의 effectiveness를 증명할 것이다.
- Learnable proposal box
- proposal boxes (N ×4)
- 4-d [0, 1] 범위 값을 가지는 파라미터, normalized center coordinates, height and width
- proposal boxes를 추출하는 다른 모듈은 존재하지 않는다. 그냥 초기 initialization에서 ROIAling을 적용하여 Dynamic head에 의해서 연산이 되고 결과를 추출한다. 그리고 loss에 의해서 자동으로 backpropagation에 의해서 학습된다.
- 원래 Faster-RCNN에서는 the proposals from RPN이다. 하지만 RPN까지 구현하는 것은 사치라고 생각한다. proposal boxes면 potential object location을 찾기에는 충분하다.
- Learnable proposal feature
- proposal feature (N x d(=256))
- box 4개의 좌표만으로는 뭔가 부족하다. a lot of informative details을 가진 무엇인가가 필요하다.
- proposal feature가
object pose and shape = rich instance characteristics에 대한 정보를 담고 있다. - object query와 유사한 역할을 한다고 생각하면 된다.
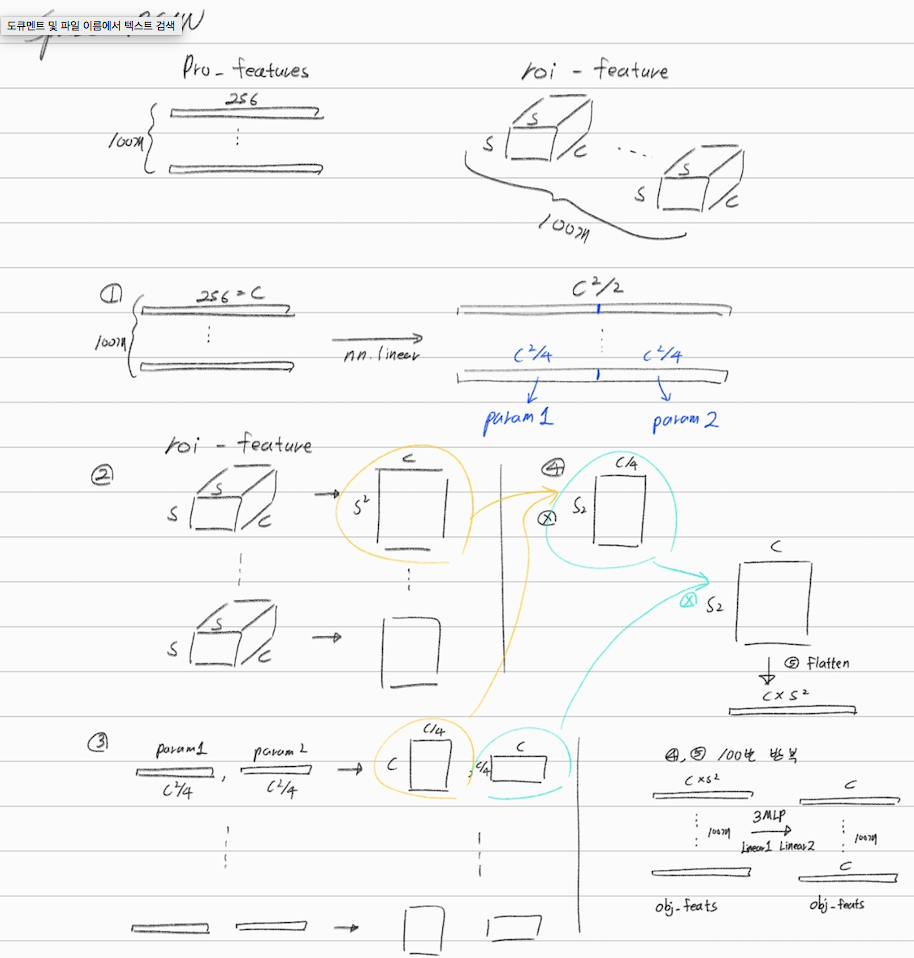
- Dynamic instance interactive head.
- 위의 이미지가 Danamic head가 하는 역할이다.
- N개의 독자적인 head가 존재한다.
- 이 내부에서 이뤄지는 연산은 아래와 같다. (bmm이 저렇게 연산되는게 맞는지 불확실.)
- 아래의 연산은 parallel operation이 많이 아뤄지기 때문에 매우 효율적이다.

- 추가적으로 논문에서는 아래의 2가지 기법도 사용했다. (구체적으로 어떻게 사용했는지는 좀더 논문을 통해 알아봐야할 듯 하다.)
- Cascade-RCNN에서 사용하는 iteration structure: 위 dynamic head 보라색 라인과 같이,
newly generated object boxes and object features(score 사용 x)가 다음의 같은 dynamic head의the proposal boxes and proposal features로써 전달 된다. - Multi head self attention model 사용: objects사이의 관계를 추론하기 위해서
dynamic instance interaction(위 Architecture의 사다리꼴 module)를 하기 전에the set of object features(~ Proposal feature ) 들에 대하여 MultiheadAttention을 적용하여 서로가 communication하게 만든다.
- Cascade-RCNN에서 사용하는 iteration structure: 위 dynamic head 보라색 라인과 같이,
- Set prediction loss
- Focal loss
- L1 loss
- generalized IoU
- matching cost만을 적용한다. = Hungarian Loss

4. Experiments
- Dataset
- MS COCO
- Training details
- ResNet-50/ AdamW/ 8 GPUs/ Default training schedule is 36 epochs(3x training schedule)/ 짧은 쪽 size 480~800, 긴쪽 최대 1333
- λ_cls = 2, λ_L1 = 5, λ_giou = 2
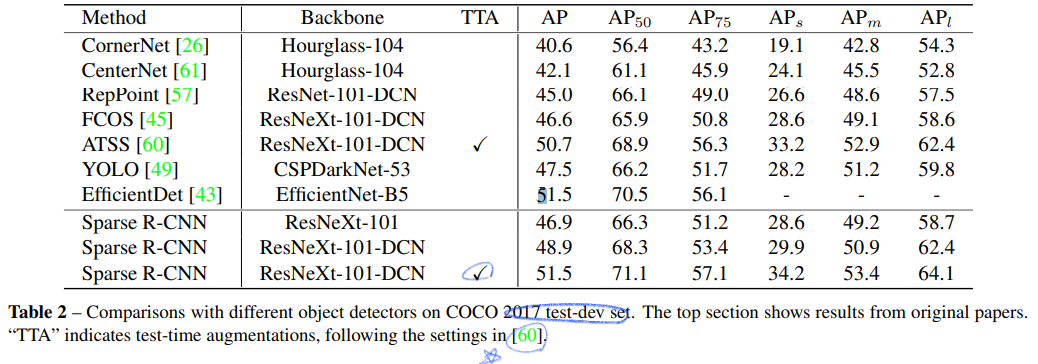
5. Results

여기서 stage는 iteration structure를 얼마나 사용했는가를 의미한다.
 ’
’
6. Ablation study
- 실험을 엄청 많이 했다. 이정도는 해야하는구나.. 라는 생각이 들 정도이다. 배우고 참고하자!
- 각 표에 대한 추가적인 설명이 논문에 이쁘게 적혀 있으므로 필요하면 참고하자.