【DA】Domain Adaptive Semantic Segmentation Using Weak Labels
- 논문 : Domain Adaptive Semantic Segmentation Using Weak Labels
- 분류 : Domain Adaptation
- 느낀점 :
- 참고 사이트 : ECCV Presentation
- 목차
- 일어야할 논문들
- Learning to adapt structured output space for semantic segmentation [49] : 이 논문에서 Sementic Segmentation을 위해서 여기서 사용하는 Architecture를 사용했다. 이 코드를 base code로 사용한 듯 하다.
DA Semantic Segmentation Using Weak Labels
이 논문의 핵심은 weak labels in a Image( 이미지 내부의 객체 유무 정보를 담은 List(1xC vector)를 이용하는것 ) 이다.
1. Conclusion, Abstract
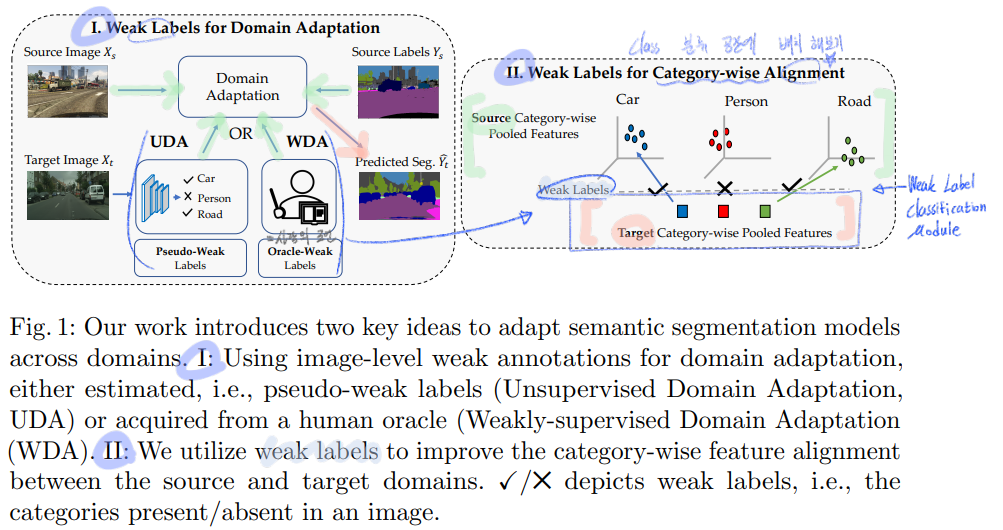
- 논문의 핵심만 잘 적어 놓은 그림이다.
- 하지만
Weak label for category-wise Alignment,Weak label classification Module은 그림으로 보고 이해하려고 하지말고, 아래 Detail과 Loss함수를 보고 이해하도록 해라. - 당연한 Domain Adatation의 목표 : lacking annotations in the target domain
3. DA with Weak Labels Method
3.1 Problem Definition

3.2 Algorithm Overview
- Model Architecture

- 이 이미지에서 Domain Adaptation에서 많이 사용되는
Adversarial Discriminative Domain Adaptation이 핵심적으로 무엇인지 오른쪽 필기에 적어 놓았다. 진정한 핵심이고 많이 사용되고 있는 기술이니 알아두도록 하자. - Conference Presentation 자료 정리
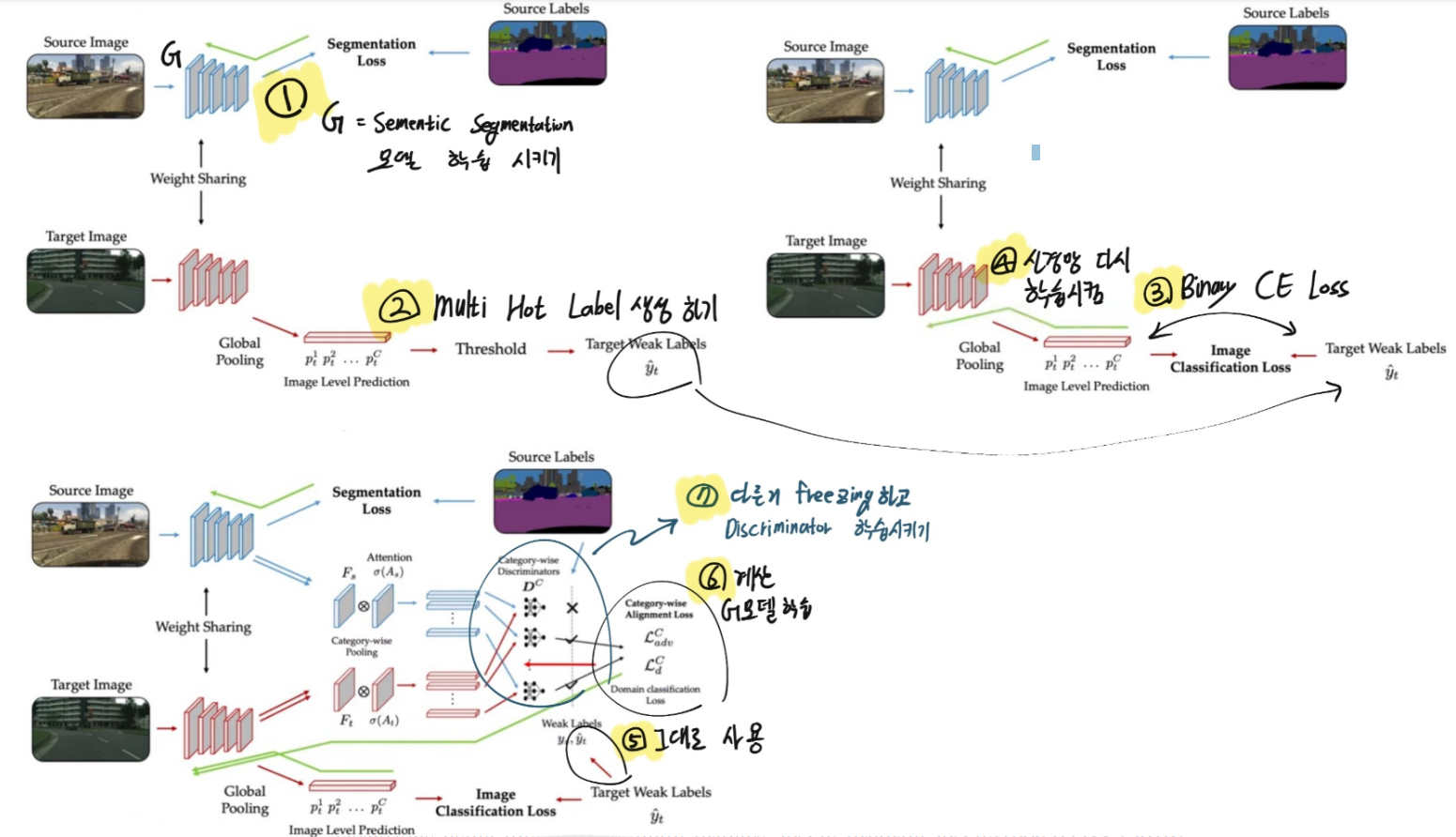
3.3 Weak Labels for Category Classification
- 이 과정의 목적은
segmentation network G can discover those categories즉 segmentation network인 G가 domain이 변하더라고 항상 존재하는Object/Stuff에 pay attention 하도록 만드는 것을 목표로 한다. G가 이미지 전체의 environment, atmosphere, background에 집중하지 않도록 하는데에 큰 의의가 있는 방법이다. - (Eq1) Global Pooling이 적용되는 방법과, (Eq2) Loss 수식에 대한 그림이다.
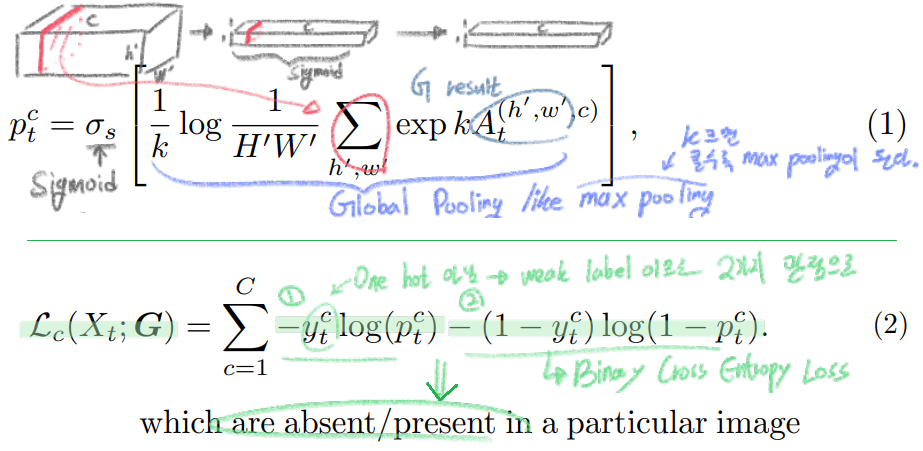
- 이미지에 특정 class가 있는지 없는지에 대해서 집중하기(판단하기) 위해서 Global Pooling이 사용되었다.
- 위에 (1)식에 사용되는 수식은
smooth approximation of the max function이다. k가 무한대로 크면 max pooing이 적용된 것이라고 할 수 있다. 하지만 하나의 값으로 pooling 값이 정해지는 max pooling을 사용하는 것은 Noise에 대한 위험을 안고 가는것이기 때문에, 적절하게 k=1로 사용했다고 한다. - Pooling에 의해서 적절한 값이 추출되게 만들기 위해서는 Loss함수가 필요한데, 그 함수를 (2)번과 같이 정의하였다.
category-wise binary cross-entropy loss를 사용했다고 말할 수있다.
3.4 Weak Labels for Feature Alignment
- image-level weak labels의 장점과 특징
- 위의 방법을 보면
distribution alignment across the source and target domains(domain 변함에 따른 데이터 분포 변화를 고려한 재정비 기술들) 이 고려(적용)되지 않은 것을 알 수 있다. - 적용되지 않은 이유는, 우리가 category를 이용하기 때문이다.
performing category-wise alignment를 적용하는 것에는 큰 beneficial이 있다. (3.3의 내용과 같이, class에 대한 특성은 domain이 변하더라도 일정하기 때문에) - 과거에
performing category-wise alignment을 수행한 논문[14]이 있기는 하다. 하지만 이 방법은pixel-wise pseudo labels을 사용했다.(?) - 반면에 우리는
pixel-wise가 아니라image-level weak labels를 사용했다. 그냥 단순하게 사용한 것이 아니라.an attention map guided by our classification module(global pooling) using weak label을 사용한 것이므로 매우 합리적이고 make sense한 방법이라고 할 수 있다.
- 위의 방법을 보면
Category-wise Feature Pooling
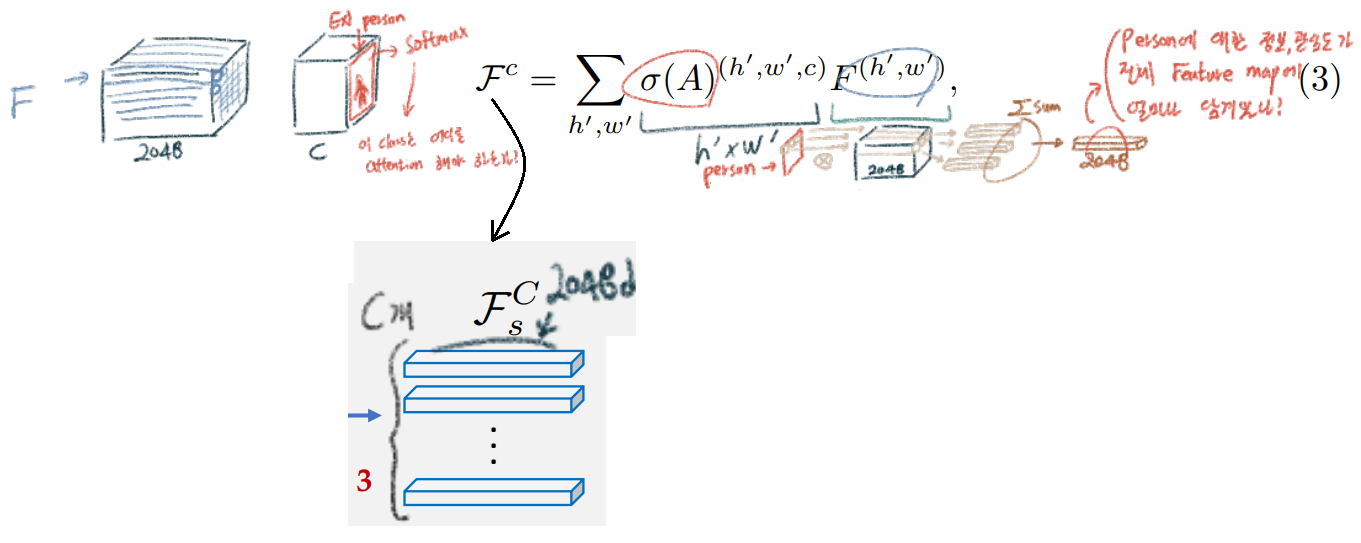
- Category-wise Feature Alignment

- 핵심은 Discriminator를 하나만 정의하지 않고,
each category-specific discriminators independently를 사용했다는 점이다. - 이렇게 하면 the feature distribution for each category가 독립적으로 align되는 것이 보장될 수 있다. (맨위의 이미지를 보면 이해가 될 거다.)
- a mixture of categories를 사용하면 the noisy distribution 문제점이 존재한다.
- 그 이외의 내용들은 위 사진의 필기에 잘 적혀있으니 잘 참고할 것
- 핵심은 Discriminator를 하나만 정의하지 않고,
3.5 Network Optimization
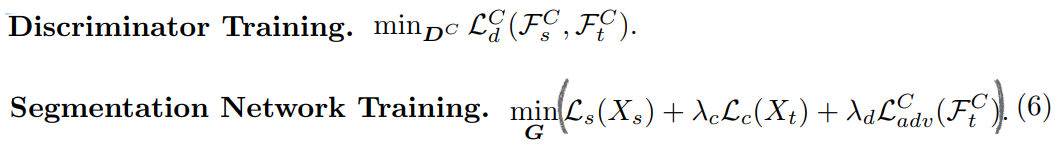
3.6 Acquiring Weak Labels
- Pseudo-Weak Labels (UDA)
- the unsupervised domain adaptation (UDA)

- T는 threshold이다. 실험적으로 0.2로 세팅해서 좋은 결과를 얻었다.
- 학습하는 동안에 the weak labels은 online 으로 생성해서 사용했다.
- the unsupervised domain adaptation (UDA)
- Oracle-Weak Labels (WDA)
- 사람의 조언(Human oracle)이 이미지 내부에 존재하는 카테고리의 리스트를 만들도록 한다.
- weakly-supervised domain adaptation (WDA)
- pixel-wise annotations 보다는 훨씬 쉽고 효율적이다.
- 위의 방법 말고도 이 논문에서
Fei-Fei, L.: What’s the point: Semantic segmentation with point supervision. In: ECCV (2016)논문에 나오는 기법을 WDA로 사용했다. (아래 Results의 성능 비교 참조) - 이 기법은 사람이 이미지 일정 부분만 segmentation annotation한 정보만을 이용하는 기법이다.

4. Results
- 당연히 성능이 올라갔다. 자세한 내용은 논문을 참조 하거나 혹은 conference presentation 자료를 아래에서 참조하자.
- 여기서 사용한 Weak Label은 2가지 이다. 아이러니 하게도… 이 논문에서 제안된 핵심 Weak label 기법보다 2016년에 Fei-Fei가 작성한 what’s the point 논문 기법으로 더 좋은 결과를 얻어냈다. (하지만 논문에서는 자기들 기법이 더 빠르게 anotaion할 수 있다고 한다. (?)