【In-Segmen】BlendMask - Top-Down Meets Bottom-Up w/ my advice
- 논문 : BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation
- 분류 : Real Time Instance Segmentation
- 저자 : Hao Chen, Kunyang Sun, Zhi Tian, Chunhua Shen
- 느낀점 :
- 논문 필기 본은
C:\Users\sb020\OneDrive\21.1학기\논문읽기_21.1참조하기. - 내 생각이 옳다고 200프로 생각하지 말자. 다른 사람의 말과 논리가 맞을 수 있다. 내 논리를 100프로 버리고 상대의 의견과 논리를 들어보자. 인간은 절대 정확할 수 없다. 상대방의 말을 들을 때는, 단어 하나를 곱 씹고 이해하려고 노력하자.
- 확실히 Method를 보고 Conclusion, Abstract, Introduction 를 보면 이해가 훨씬 잘되고, 단어가 바뀌거나, 표현이 바뀌어도 확 이해가 된다. 따라서 제발 Method 부터 읽자. 괜히 깝치지 말고 Method부터 읽자. 왜 같은 실수를 계속 반복하는가? 초반 Conclusion, Abstract, Introduction에서 5분 이상 허비하지 말자.
- 논문 필기 본은
- 읽어야 하는 논문
- FCIS [18]
- 목차
BlendMask
1. Conclusion, Abstract, Introduction
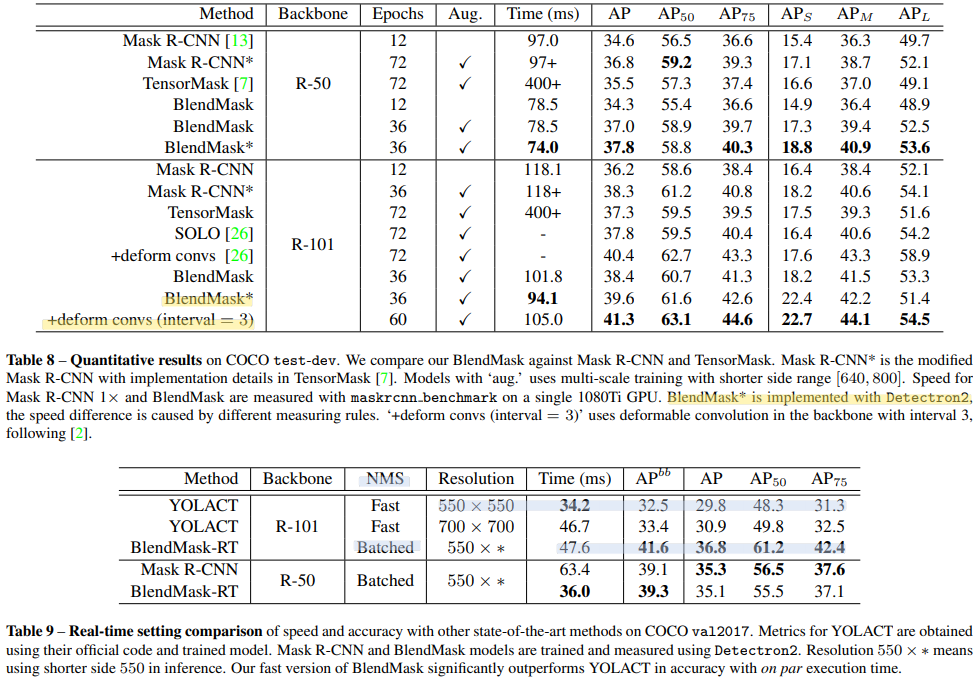
- 성능 : Mask R-CNN 보다 20% faster. BlendMask-RealTime achieves 34.2% mAP at 25 FPS evaluated on a single 1080Ti GPU
- (뭔소리지?) effectively instancelevel information 와 semantic information 를 결합해서 사용했다. top-down과 bottom-up 방법을 아주 적절히 혼합해 사용했다. (hybridizing top-down and bottom-up approaches, FCIS [18] and YOLACT [3] )
- BlendMask는 1번의 conv로 attention map을 학습하고, 이를 이용해 K=4개의 channel만으로 Instance segmentation 예측을 수행한다.
- top-down approach 의 단점 (sementic -> instance) (일단 그래도 복붙. 논문 안 읽어서 뭔소린지 모름)
- DeepMask [23]
- local-coherence between features and masks is lost
- the feature representation is redundant because a mask is repeatedly encoded at each foreground feature
- position information is degraded after downsampling with strided convolutions
- bottom-up approach의 단점 (box -> segmentation)
- heavy reliance on the dense prediction quality (ROI 결과에 너무 많이 의존된다.)
- 많은 수의 class가 담긴 복잡한 장면을 이해하는 능력의 일반화에 제한이 있다. (panoptic segmentation 힘듬)
- 복잡한 post-processing 절체가 필요하다.
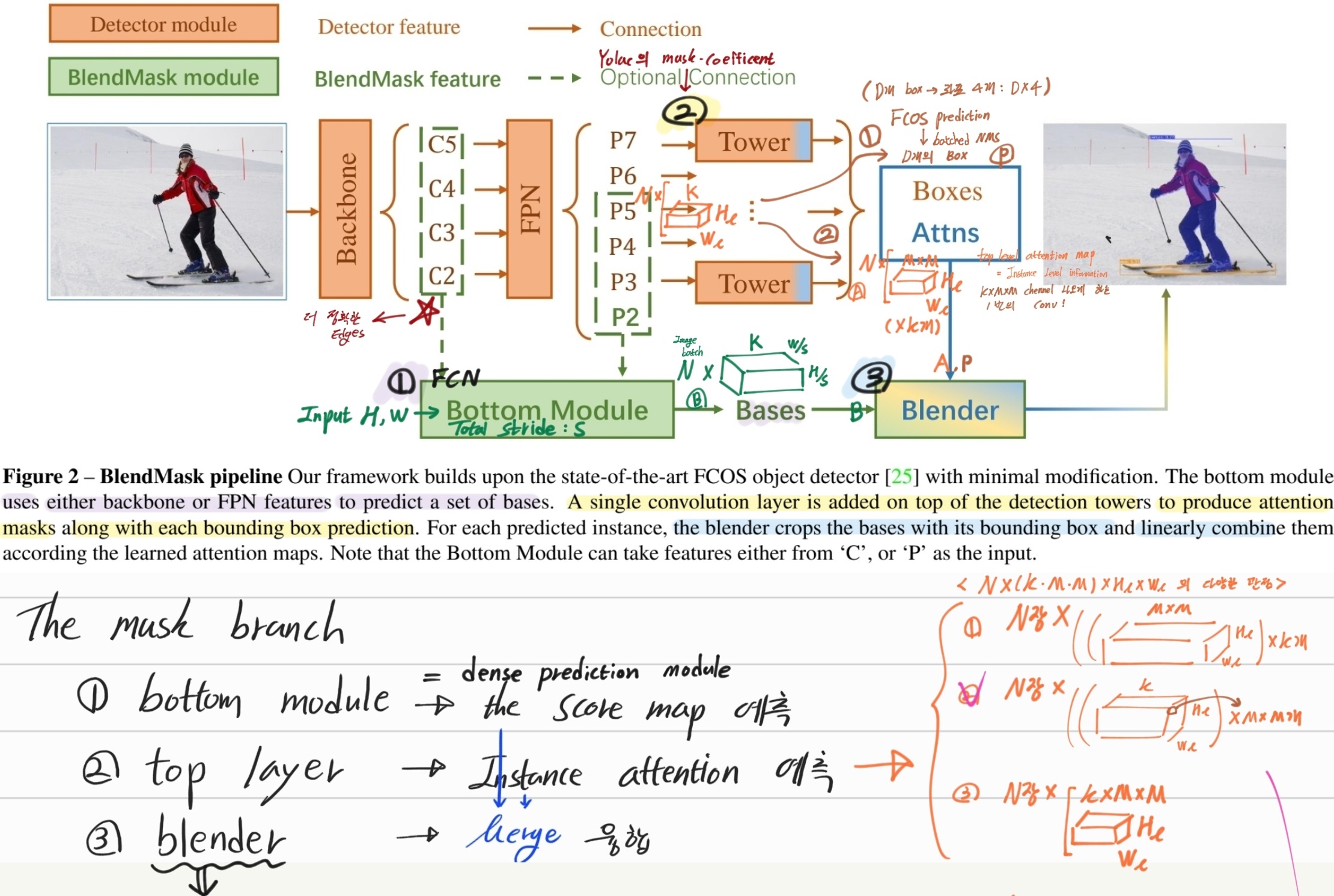
- 우리 모듈의 핵심 Blender module : BlendMask에서는
얕지만 디테일한 정보와깊지만 의미론적인 정보를 융합해사용한다.얕지만 디테일한 정보: better location information, finer details, accurate dense pixel features. (Bottom Module)깊지만 의미론적인 정보: larger receptive field, rich instance-level information (Tower = Top layer)- mask combination! = blender
- FCOS에 simple framework 만 추가해서 BlendMask를 만들었다.
3. Our BlendMask
- the decoder(Backbone) of DeepLabV3+ 을 사용했다.
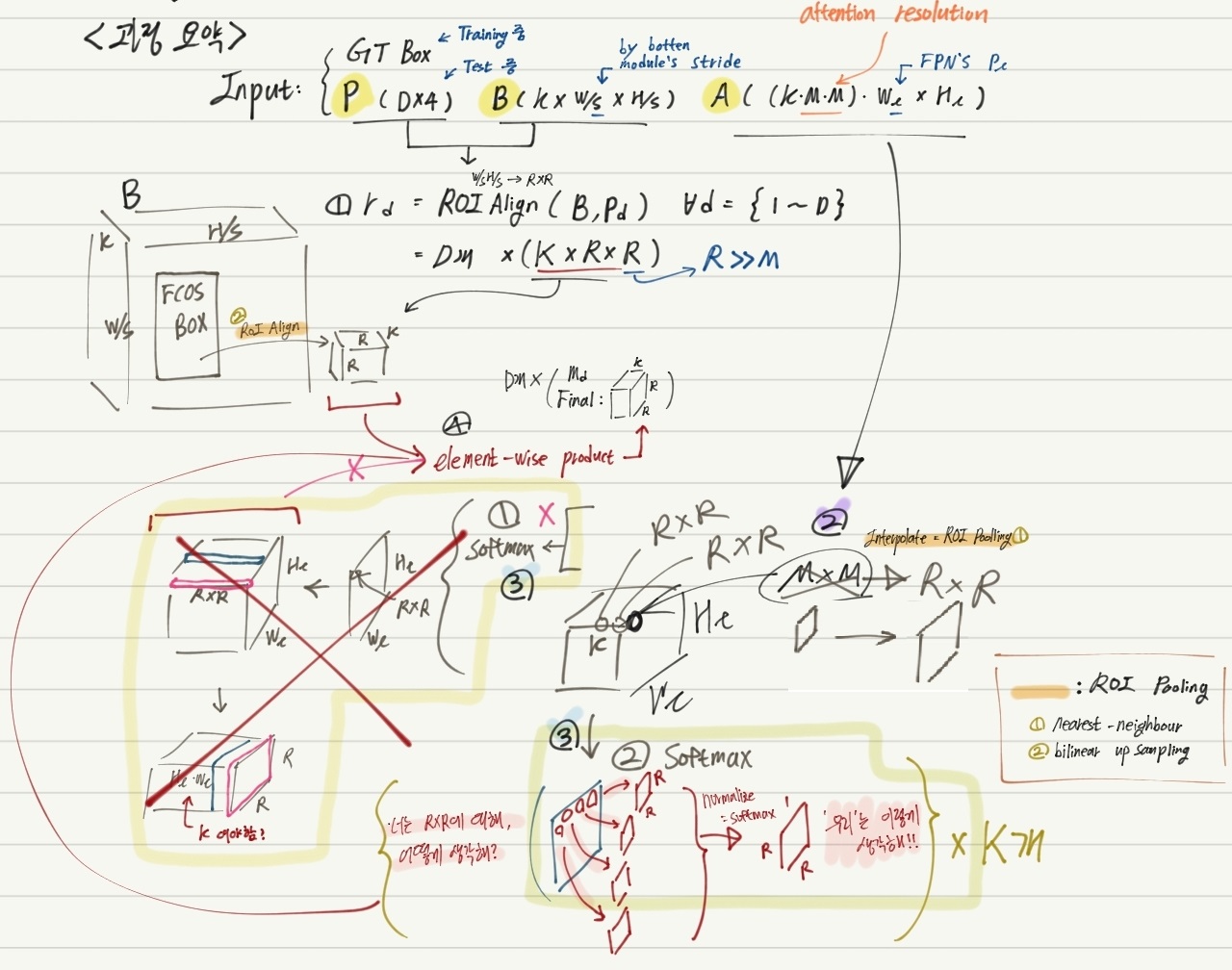
- 아래 그림과 필기 먼저 보기
- M은 Mask prediction (R) 보다 작다. 왜냐면 attention에 대한 rough estimate 만을 모델에게 물어보는것 이기 떄문이다.
- 저 과정을 통해, 어떤 Attention이 이뤄졌다는지 모르겠다. 아! “H_l x W_l 내부의 하나하나의 픽셀들이, R x R에 대해 어떻게 attention 할 필요가 있는가?” 라고 생각하면 되겠다!
- 수정본 (그림 중간에 MxM 에 엑스(X)가 처진것은, MxM ==> RxR 로 Interpolate가 되는 것을 의미한다.)
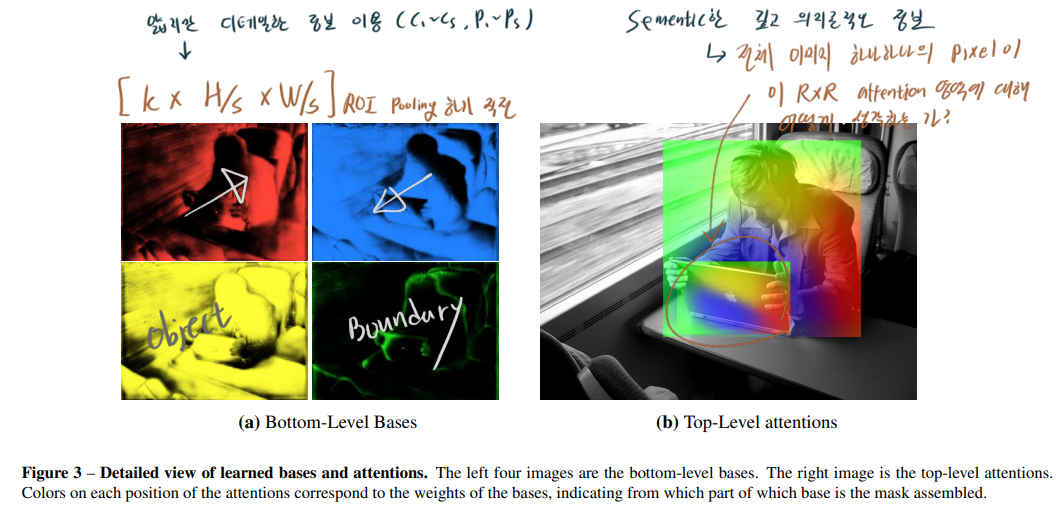
- 3.4 Semantics encoded in learned bases and attentions
4. Ablation Experiments
- 많은 실험을 통해서, 어떤 알고리즘을 사용할지 선택한다.
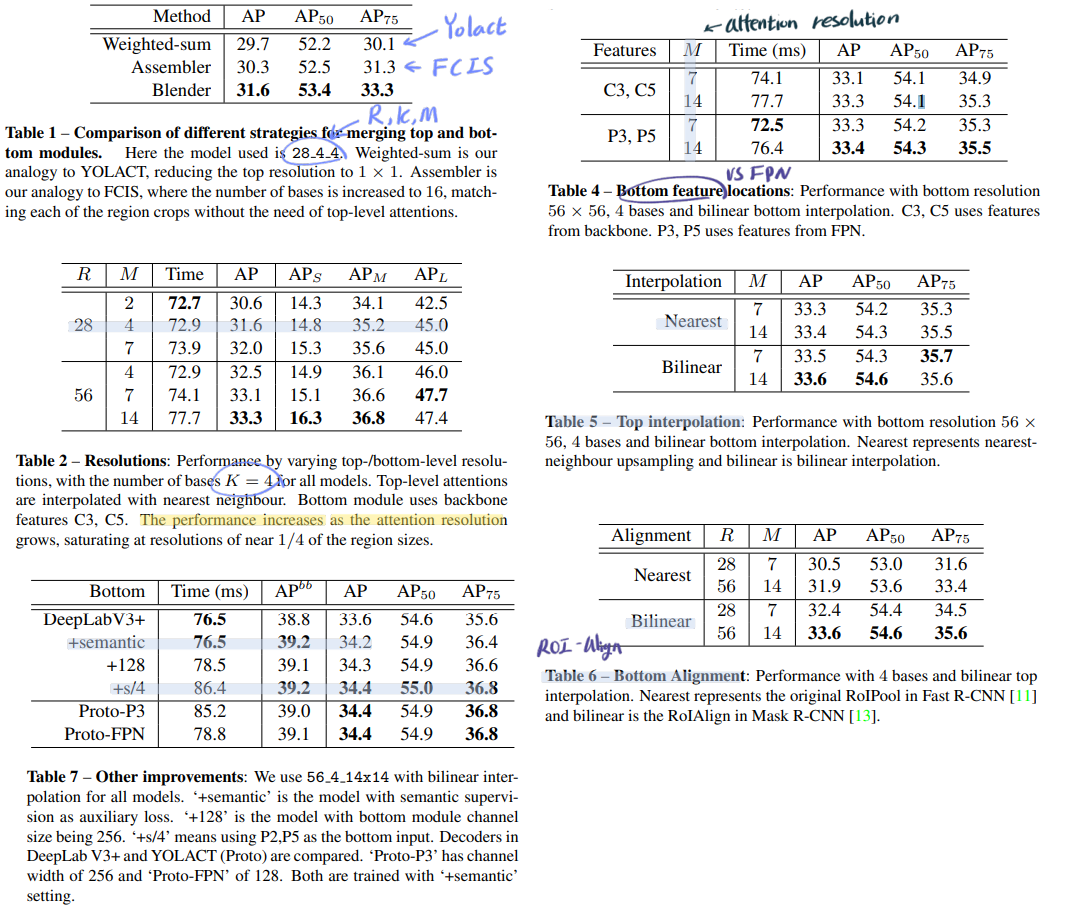
- 특히 Other improvements
- YOLACT에서 사용한, auxiliary semantic segmentation supervision 방법을 활용하여 성능향상을 많이 얻었다.
- 그 외는 필요하면 논문 참조
Fast NMS 을 사용해서 속도 향상을 했지만, 성능감소가 커서 Batched NMS in Detectron2 를 사용했다.
- 잘못 필기한 그림 (혹시나 필요하면 참고하기)

w
