Let the copilot know what types of methods or strategies to use exactly. E.g. “Check if the list is repeating using a set of names.”
Ask the copilot step by step. E.g.\ [No] # return the player at the given rank ⇒ \ [YES] (1) #Sort self.standings by score, then games_played (2) #return the player at the given rank
1. Recursion
recursive function: a function calls itself.
Base case: to stop the recursion
Recursive case: where the function calls on itself
Examples
Easy: Factorial, Fibonacci number, Euclid method
Hard: Towers of Hanoi, Maze, Cells in a Blob, N-Queens, Permutation
Any problem solved recursively can also be solved through the use of iteration.
🪡 Binary search
Finding a needed item from a sorted list, from the right or left. [[logN, bisect]
left right valuable → calculate middle and use it → break when (left≥right)
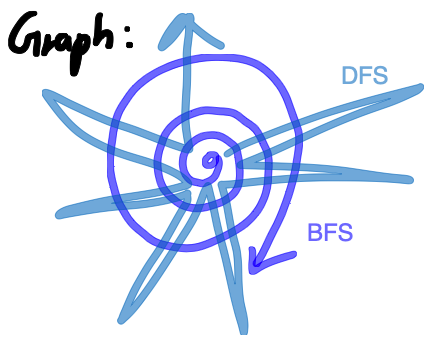
Queue: [pseudo code] (1) While queue is not empty (2) Remove a node v (3) For each unchecked neighbor w_s of v (4) Insert w into the queue and check it.
Shortest path [pseudo code]: Needed valuables are d (distance) and π (predecessor, previous node).
DFS (Depth-First Search)
Recursive: [pseudo code] (1) DFS(G,v) (2) Check v (3) For each adjacent nodes w_s (4) If unchecked w, DFS(G,w)
6. Graph2 - Minimum spanning tree
Node, Edge, Weight(cost) → To connect all nodes, select minimum edges with minimum cost.
Properties: (1) non unique solution (2) non-cycle (3) edges of solutions can represent tree-structure (4) # edges = 1-#nodes
Generic MST algorithms
Goal: Finding a safe edge, which can be contained to A (one MST solution)
Prerequisite: (1) Cut: 2subset S, V-S of nodes (2) Cross: edge cross 2subset (3) Respect: no cross edges in A
Fact: If A is a subset of MST, the lightest edge, among edges cross the cut, respect A.
Kruskal algorithm
Method: Sorted edges are sequentially selected, unless the edge makes a cycle, untill #nodes-1 == #edges.
Proof: Sorting = the lightest edge / no cycle edge = Cross edge
Key: checking whether a cycle exists. (1) Connected nodes represent a subset, e.g. [{a},{b,c,f},{e},{g,h}] (2) Using linked list, check wheter the root is same.
Prim algorithm
Method: From a random node, select the lightest cross-edge.
Key: finding cross-edge: nodes in subset V-S need to contain two valuable, key and pie. ‘key’ is the lightest weight connecting with nodes in S. ‘pie’ is the connected node in S.
Details: (1) Among nodes in V-S, find a node with the lightest ‘key’ value. (2) the node is inserted into S, nodes in V-S connected to the node update the value of ‘key’ and ‘pip’.
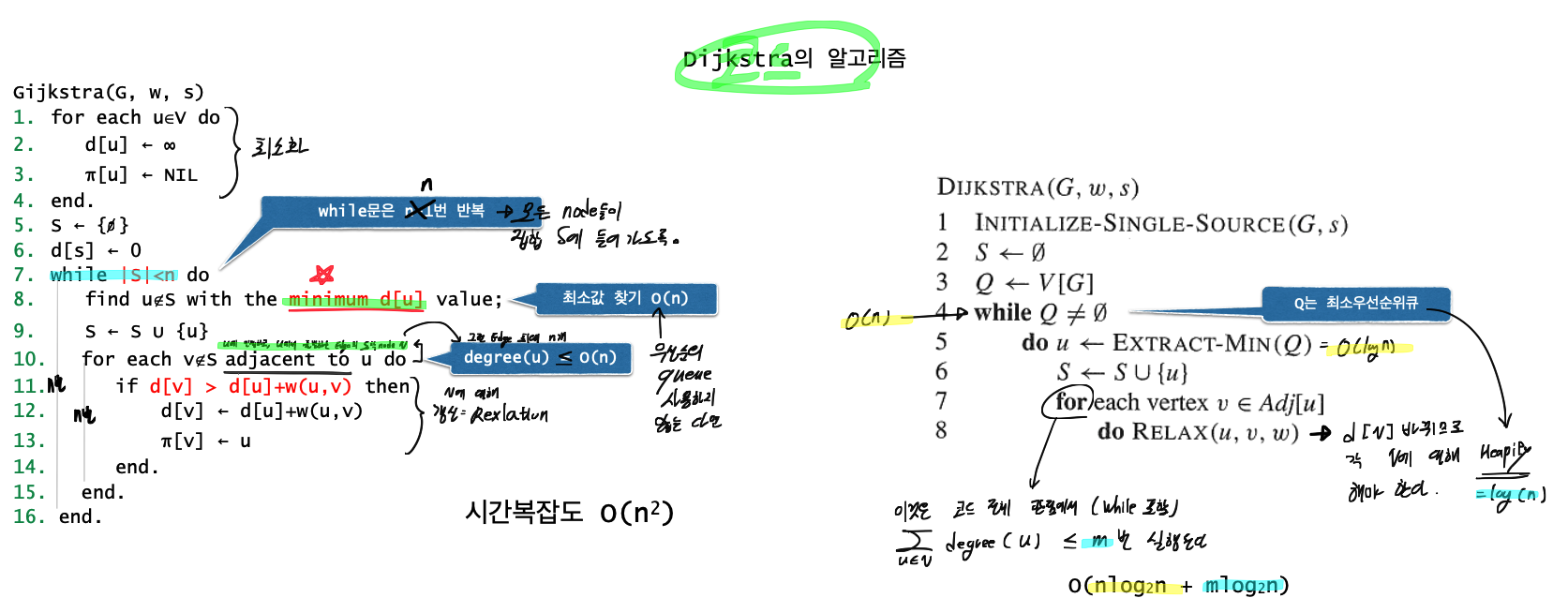
Addition: Methods(1) needs to use Priority Queue (= min-heap, max-heap), so that the MST whole complexity is changed from O(n^2) to O(NlogN).
7. Shortest path
Note: Path is different from Tree. MST is to find a tree with minimum cost. Dijkstra aims to find a path with minimum cost in a directed graph.
Basics
Properties: (1) sub-path inside the lightest path is also the lightest. (2) No-cycle
Needs available: (1) d[node]: initialized ‘inf’, distance from the start node s. (2) π[node]: predecessor
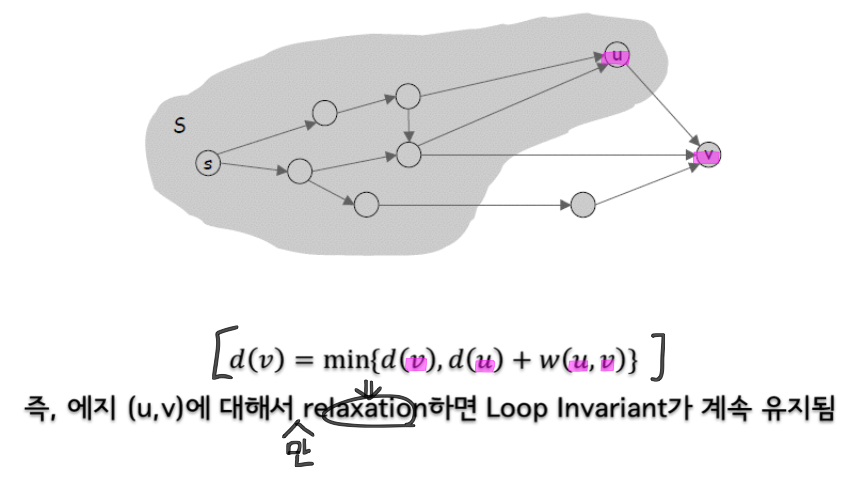
Basic operation: Relaxation (if finding a better path, update d and π)
Bellman-ford algorithm
If there are negative weights.
[Example image] O(n*m) is too big. Thus, Dijkstra does not depend on m!
Dijkstra algorithm
Assume that there is no negative weight.
Checked node is never checked again.
In a set of unchecked nodes, a node with minimum d[node] must be the node for the next step. [reference image]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}