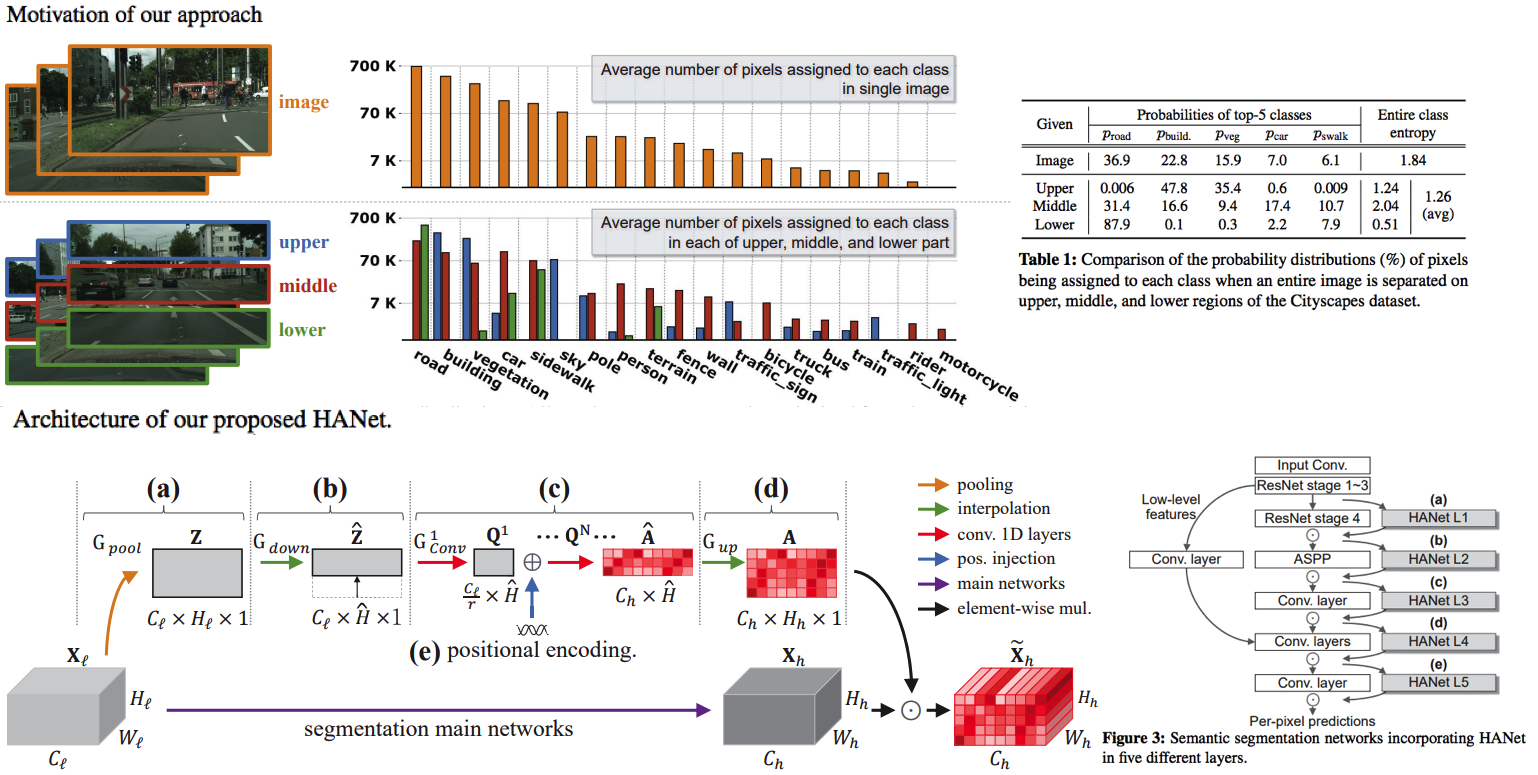
The pixel-wise class distributions are significantly different from each other among horizontally segmented sections. Thus, capturing the height-wise contextual information should be weighted during pixel-level classification.
Most semantic segmentation networks do not reflect unique attributes such as perspective geometry and positional patterns.
Method
Hight-driven attention networks (HANet) is an add-on module that is easy to attach and cost-effective.
As illustrated in Tab. 1 and Fig. 1, the uncertainty (entropy) is reduced if we divide an image into several parts horizontally.
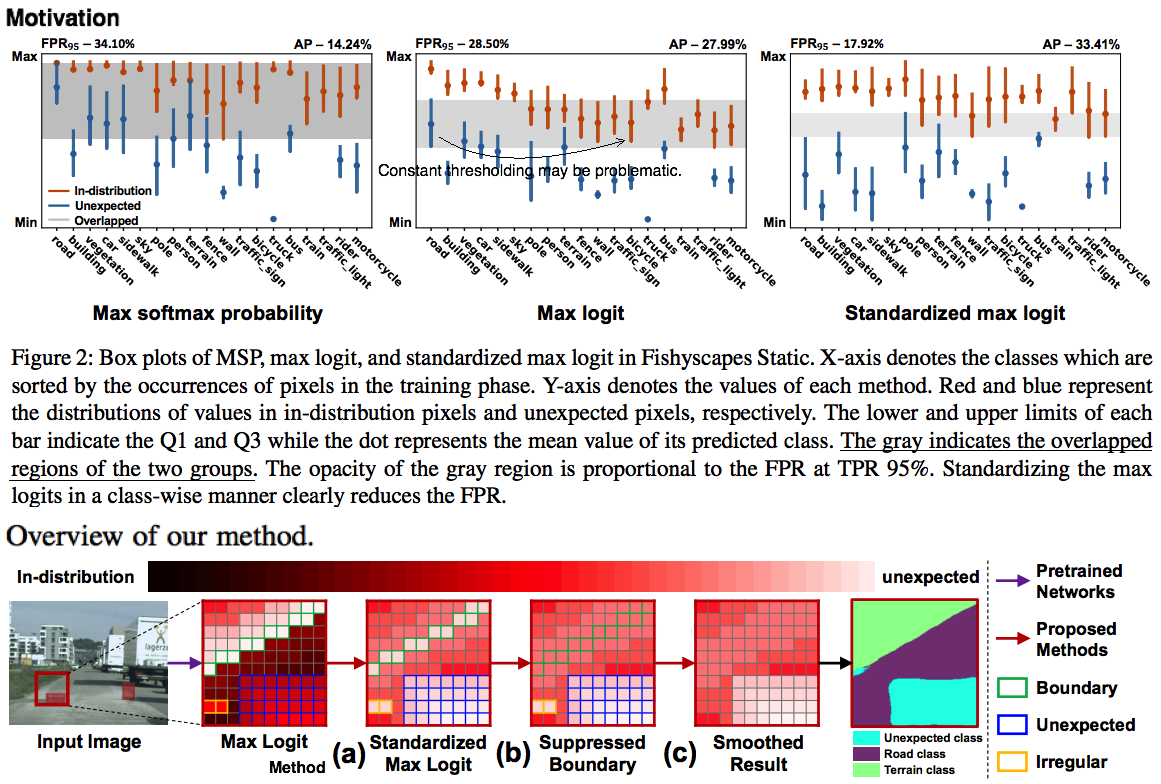
2. Standardized Max Logits for Identifying Unexpected Road Obstacles
[problem1] Existing approaches need external datasets or additional training. → [solution1] One possible alternative is to use max logit (i.e. maximum values among classes before the final softmax layer.) → [problem2] the distribution of max logit of each predicted class is different from each other. → [solution2] standardizing the max logit.
High prediction scores (e.g. softmax probability or max-logit) indicate low anomaly (unexpected object) scores and vice versa.
Methods
Standardized max logits
Iterative boundary suppression: replacing the high anomaly scores of boundary regions with low anomaly scores of non-boundary pixels.
Dilated smoothing: both boundary and non-boundary regions are smoothed.
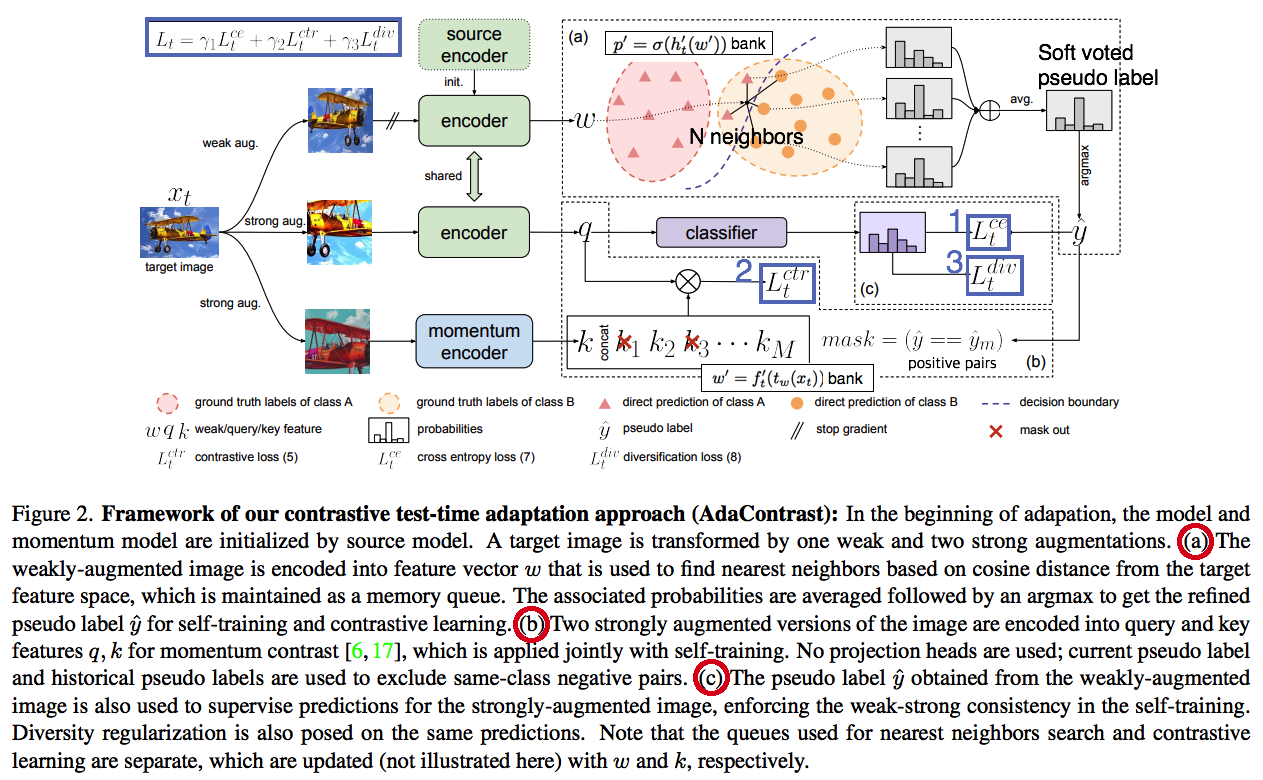
Test-time Adaptation in 2022
이 논문들을 읽으니까 진심으로 ECCV 내 논문에 자신감이 생긴다. 결과가 어떻든 자신감을 가지자. 모두 Method적으로 큰 Novelty 없고.. forward 여러 번하는걸 괜찮은 듯이 넘어가고… 별거 하나 없다. 그냥 논문 조금 잘 썼네. 라는 생각이 든다. 따라서! 다음엔 더 잘 할 수 있겠다. Oral & Best 별거 없다.
따라서 제발 하나의 아이디어, 실험하는데 너무 오랜 시간을 소모하지 말자. 가정이 조금이라도 틀렸다면 빠르게 버리고 넘어가라. 아래 논문들 모두 정말 (1) 간단한 Method로 (2) 간단하게 실험하고 (3) 정교하게 논문써서! 논문이 되버렸다. 그렇담 나는 더 잘 할 수 있다.
1. SHOT: Do we really need to access the source data? ICML, 2020
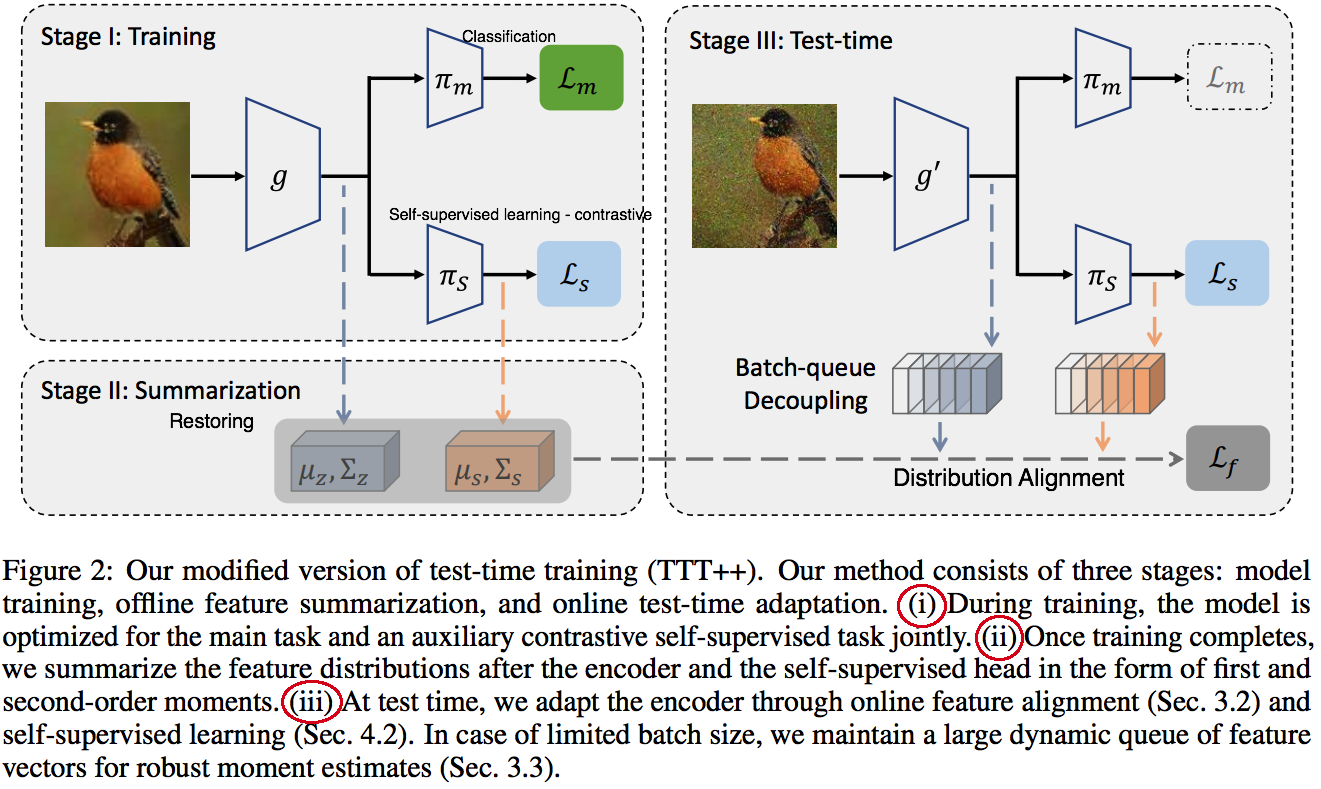
TTT can lead to failures. This is because of the unconstrained update.
(method1) offline feature summarization: Storing the mean and covariance matrix. (no agnostic pre-train model)
(method2) online moment matching: Distribution alignment Loss → BUT, (problem1) this strategy has a problem with a large number of classes.
(solution1) (method3) batch-queue decoupling: maintaining large encoded features in a mini-batch manner. (i.e., Global view alignment, not local (one class) view alignment)
Contrastive self-sup learning
It is applied in both training and testing.
Notes: Classification / Good distribution alignment for specifically TTA
TTA sometimes fails catastrophically. Instead of adapting the parameters of a pre-trained model, they only adapt its output by finding the latent assignments that optimize a manifold-regularized likelihood of the data.
A correction of the output probabilities is more reliable and practical than NAMs (network adaptation methods).
The proposed method is called Laplacian Adjusted Maximum-likelihood Estimation (LAME). This could be viewed as a graph clustering of the batch data, penalized by a KL term discouraging substantial deviations from the source model predictions.
The written method is hard to understand. So, I need to figure it out by the code.
It seems that offline data-access is needed (to find a latent assignment vector z in the paper).
It seems that k nearest neighbors algorithm is used in the code.
Notes: Output optimization, No parameters optimization, No concern about catastrophic failure.