【DG】 Survey DG papers 4 - 8 recent papers
- DG survey
- DG paper list 참조
4.1. Conv: Dynamic Convolution: Attention over Convolution Kernels -CVPR20
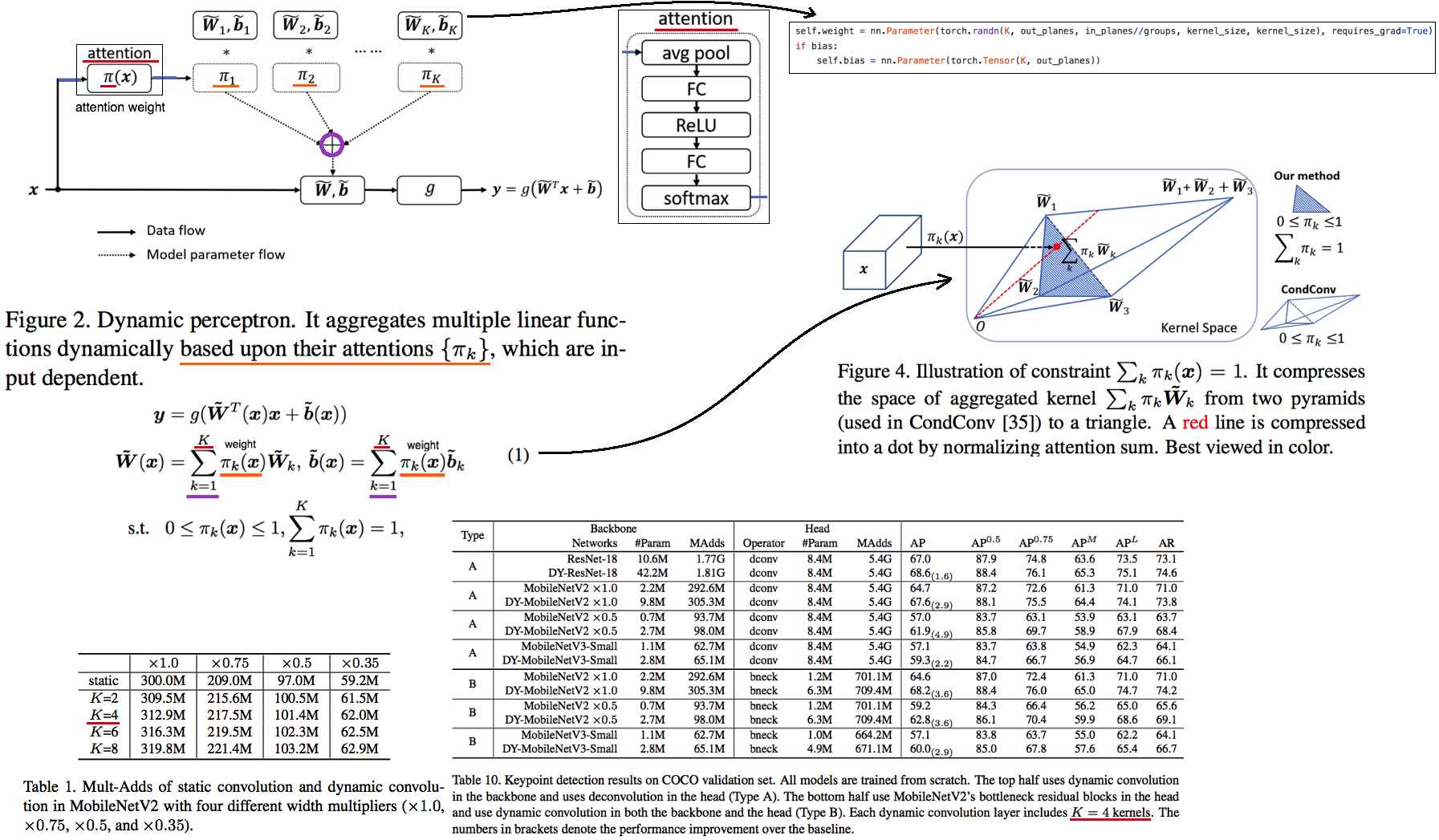
- 모델의 Depth(#Layers)나 Width(#Channel)를 적게 가진 Light weight CNN를 사용하면 성능이 떨어지는 문제점 있었다.
- depth or width를 증가시키지 않고, Model Complexity를 높혀줄 방법으로 Dynamic Convolution을 제시한다.
- 아래의 논문 (#4.2) 를 기반으로 한다. 핵심 차이점은 [kernel attention을 계산하기 위해서 sigmoid]를 사용한다는 점이다. (#4.2) 방법보다,
K, parameter, MAdds를 적게해도 높은 성능을 보인다고 주장한다. 다시 말해, 자신 논문들은 N (experts = #kernels = K) 을 적게 사용해도 더 좋은 성능을 보인다고 한다. - input 정보와 attention을 기반해서, dynamically conv의 (커널) 파라미터를 만들어 사용한다. (Aggregates multiple parallel convolution kernels using attention weight)
- 결과를 보면 신기하게, 파라미터 수는 중가하여도, Computing Cost (MAdds) 가 크게 증가하지 않는것을 볼 수 있다.
- SparseRCNN에서 사용한 Dynamic Convolution 내용 정리 링크. 하지만 위의 내용과는 많이 다르다.
4.2. Conv: CondConv: Conditionally Parameterized Convolutions for Efficient Inference -NIPS19

- Google Brain 논문
- 위 (#4.1) 논문과 다른점은 weight를 어떻게 구하는가? 뿐이다. 여기서는 심플하게 sigmoid 하나만 사용해서 구한다.
4.3. Conv: Conditional Convolutions for Instance Segmentation -ECCV20
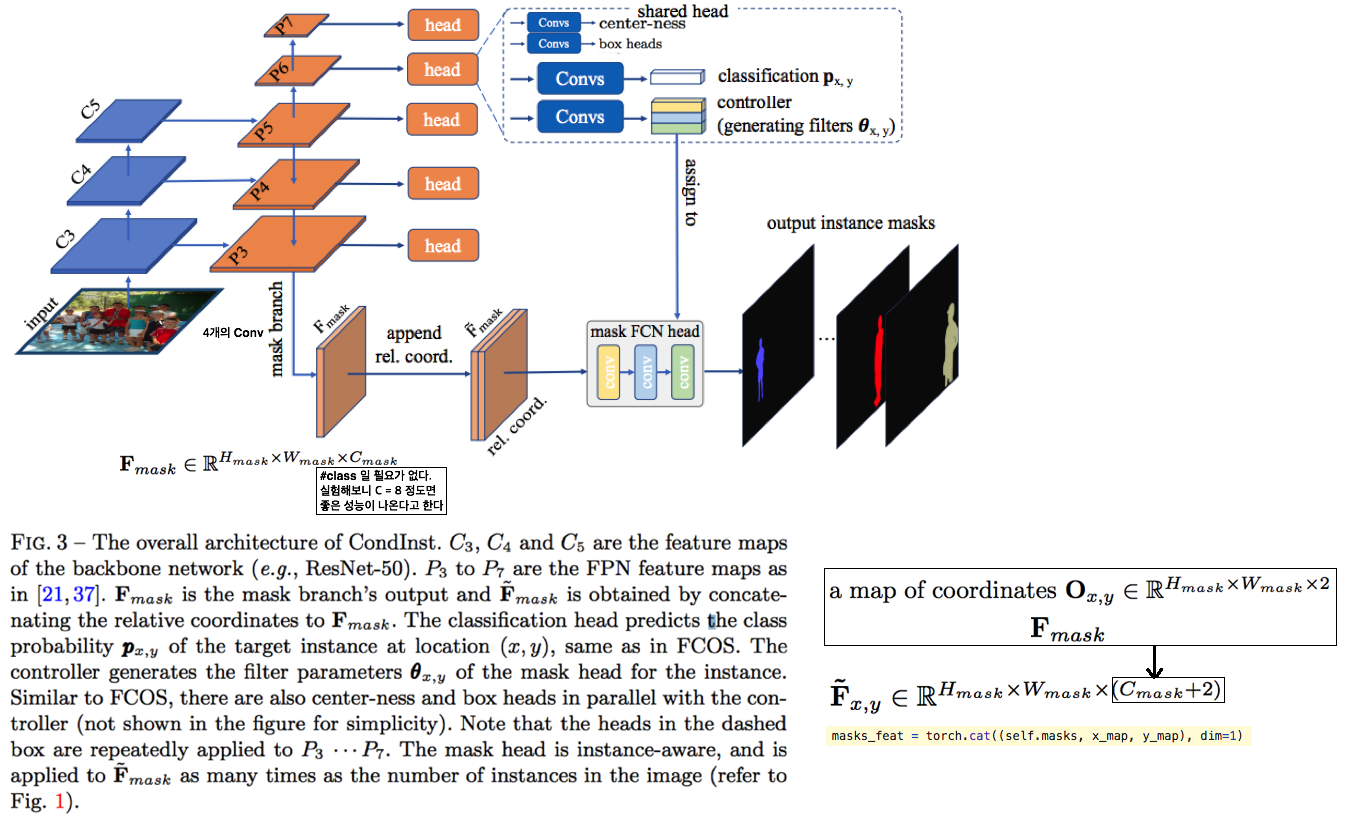
- fixed weights를 가진 Network를 사용해서 추출해서 ROI를 추출하는 것이 아닌,
dynamic instance-aware networks, conditioned on instances를 사용한다. - CondInst를 사용해서 얻는 장점은 2가지이다. (1) ROI align 과정을 제거한다. (2) conditional convolutions 덕분에 mask head의 깊이가 낮아질 수 있었다.
- Github code : Mask branch code, Mask with coordinates
- F_mask의 Channel인 C_mask는 8로 했을때 가장 성능을 보였고, 16일때 성능 감소. 2로 해도 0.3 정도의 성능 하락만 보였다.
4.4. Adaptive DG: Learning to Balance Specificity and Invariance for In and Out of DG -ECCV20
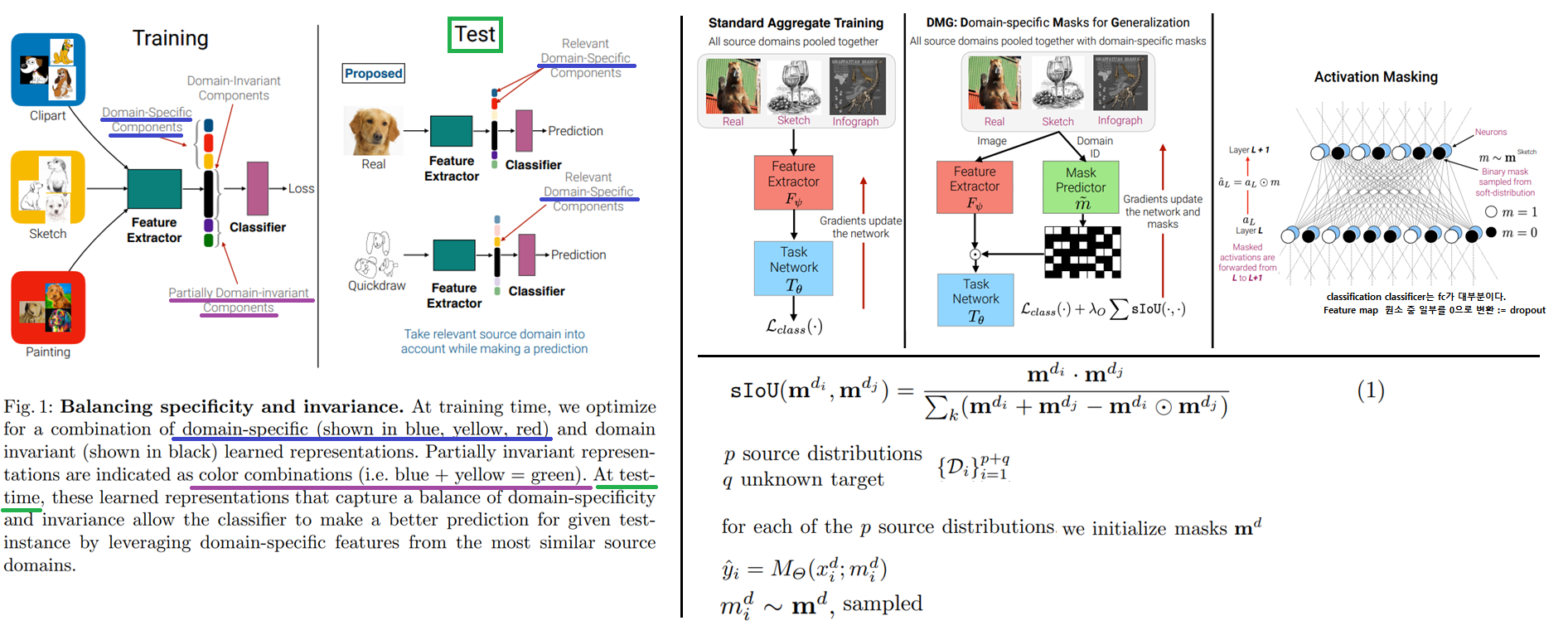
DisentangleRepresentations/ Feature/ Style and content/ domain specific and domain invariant/ Specificity and Invariance 을 수행하는 DG- Introduction
- balanced feature selection
- test 이미지가 왔을 때, 모든 Source의 mask predictor의 결과를 Average한 것을 Mask로 사용함으로써, 모든 source 와 현재 test 이미지와의 비교/대조가 이뤄지며, source 공통점이나 차이점의 특성/특징을 사용할 수 있다고 해석하다.
- 성능은 SOTA는 아니지만, source domain scalable하고 fast 하며, in-domain(source와 동일한 domain) test에서 높은 성능을 보인다는 장점을 가진다고 한다.
- Method
- 각 Source domain에 따라서 독자의 Mask prdiction network가 존재하고, 이 독자 네트워크를 사용해서 각 이미지에 대해서 Mask가 예측된다. 그리고 이 Mask는 classifier에서 나오는 feature map과 element-wise multi로 계산되어 Drop-out과 비슷한 역할을 한다. (Mask=0인 부분은 drop-out 된다.)
- (Ps. prediction 값 ([0,1], continuous mask)에서 ([o or 1], sampled mask) 로 bernoulli distribution에 의해 골라지는 것을 논문에서는
Mask sampleing이라고 표현한다. 하지만 이 Sampling 과정에 의해서 backpropa의 흐름이 끊길 수 있다. 그래서straight-through estimator전략을 사용하는데 이는 sampled mask 에 의해서 예측해 나오는 Loss를 그대로 continuous mask의 Loss라고 가정하여 backpropa를 이어주는 방식을 말한다.) - Training 과정에서 각 source의
domain-specific masks를 사용해서 prediction이 이뤄지므로, Mask를domain-specific sub-networks라고도 할 수 있다. 그리고 soft-overlap-loss (IOU 공식을 그대로 사용하는 것은 backpropa가 안된다고 함)를 사용해서domain-specific masks가 더욱더 각 source 자신만의 독자적인 mask가 되도록 유도한다. (다른 source domain 사이의 mask가 최대한 다르도록 유도하는 Loss) - Mask predictor는 들어온 이미지의 domain을 파악해서 domain-specific 부분이 어디인지 찾아준다. classifier는 이 domain-specific한 부분만 가지고 예측을 수행한다. (물론 classifier는 모든 source에 대해 shared network이다.)
- Test 과정에서는, Target 이미지를 모든 Source domain의 Mask predictor를 사용해서
domain-specific masks를 추출하고 평균을 구해서, 최종 Mask를 추출하고 Feature에 곱함으로써, 해당 target 이미지의 feature map에서 domain에 특화된 feature는 0을 만들어 버리고 classification을 수행한다. - Unseen image가 들어오면, 그 이미지 domain에 대해
domain-specific mask를 예측하여 classification 하는 것이다.
- 내가 생각하는 이 논문의 문제점:
- Adaptive classifier 논문의 메인 그림에서 주장하는 문제점을 완전히 가지고 있는 논문이다. all source’s mask predictor 결과의 평균으로 Universal mask prediction이 가능하다고 주장하지만, 새로운 domain이 universal mask predictor 에 적합하다고, 무조건적으로 말할 수 없다.
- 또한 shared classifier는 multi-source에 특화된 모델이 될 뿐이다.
- 정리하자면, (1) universal fixed mask predictor 를 사용한 것은 adaptive하지 못하다. (2) multi-source에 대한 의존도가 너무 크다.
4.5. DG, GAN: Semantic Segmentation with Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization -CVPR21
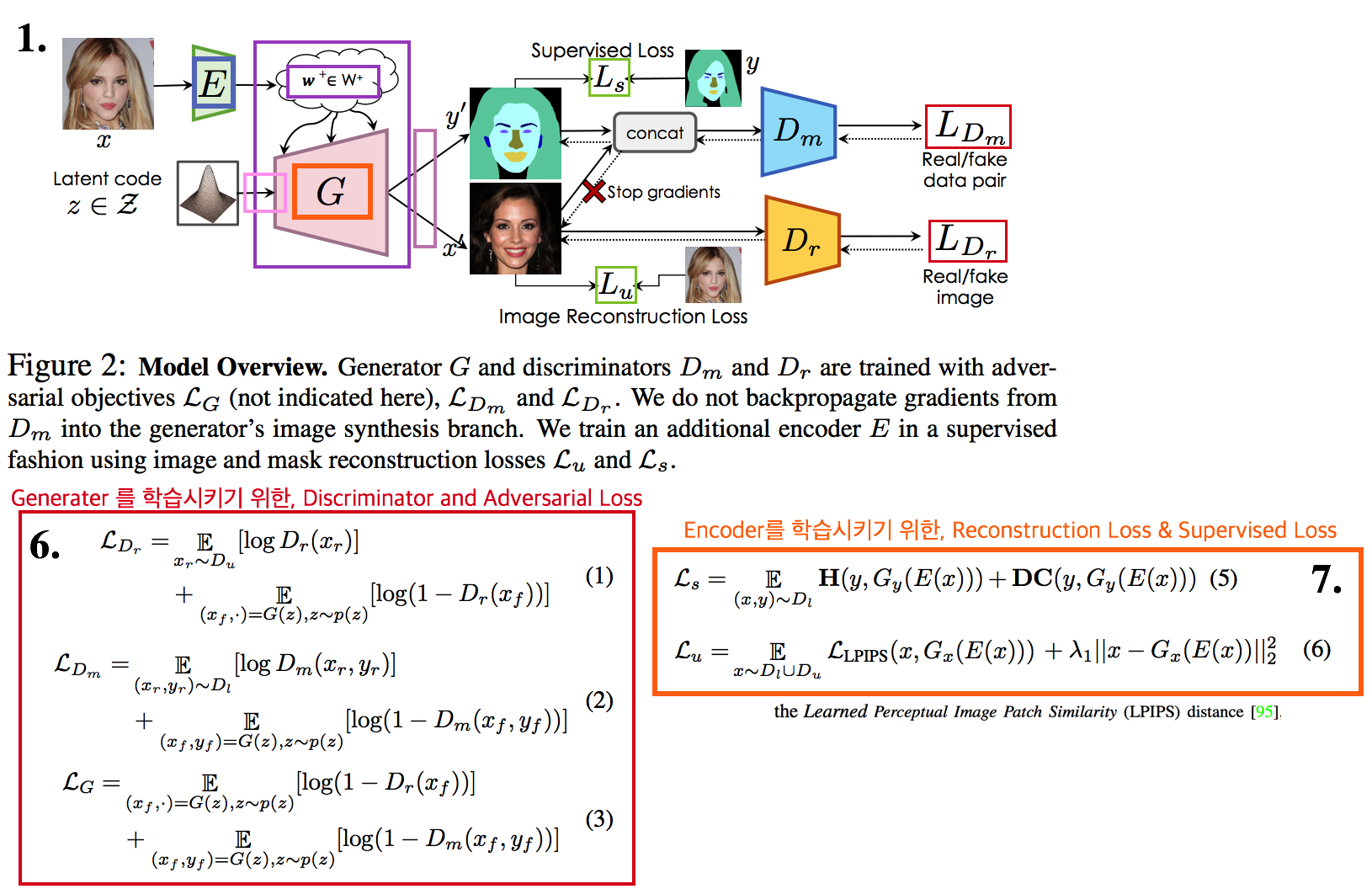

- target 이미지가 들어오면, Iterative 하게
Target Image자체와Target segmentation label을 동시에 생성해주는 GAN의 Generator 모델을 사용하는 DG, Segmentation, Target pseudo label generating model - 성능을 보면 이것이 진짜 DG segmentation 모델이 아닌가… 싶을 정도로 놀랍다. Iterative target adaptive label generating model 이라고 할 수 있으려나?
- NVIDIA 논문 프로젝트 페이지 및 발표 영상
- Abstract & Introduction
- Semi supervised learning의 목표: 적은 Labeled data 0만을 가지고 충분히 optimized/generalized된 모델을 만드는 것
- StyleGAN2를 베이스로 label synthesis branch 를 추가해서 architecture 를 구성했다.
- Method
- Source image와 label을 사용해서 GAN Generator 모델을 먼저 학습시킨다. GAN Generator 모델을 사용해서 targe image와 targe image’s label을 동시에 생성한다. 생성된 target image label은 prediction 결과라고 할 수 있다. 또한 이렇게 이렇게 생성한 target image & label을 가지고 모델을 학습시키기 위해 사용될 수 있다.
- 2번 그림: Generator를 학습시키는 과정을 간략히 표현했다. 실제 학습과정에서는 1번 그림의 w 정보들이 들어가서 generate하며 G 학습이 유도된다.
- 3번 그림: Encoder를 학습시킨다. Encoder는 Image의 Style+Content+Label 정보 모두를 최대한 담고 있는 Feature (W) 가 생성되도록 유도된다.
- 8번 그림: 해당 수식을 minimize하는 w+*으로 optimized 된다. (?) target image와 비슷한 recon 이미지가 생성되는 동시에, 정확한 target label이 생성될 것이다.
- 8번 그림의 Encoder embedding 결과인 W와 w+ 그리고 5번 그림의 StyleGAN2 architecture는 StyleGAN2 논문/코드를 심도 깊게 봐야 이해할 수 있을 것 같다. 이해가 안되는 것은 무시하고 넘어가자.
- code
4.6. Meta DA: MetaAlign: Coordinating Domain Alignment and Classification for Unsupervised Domain Adaptation -CVPR21
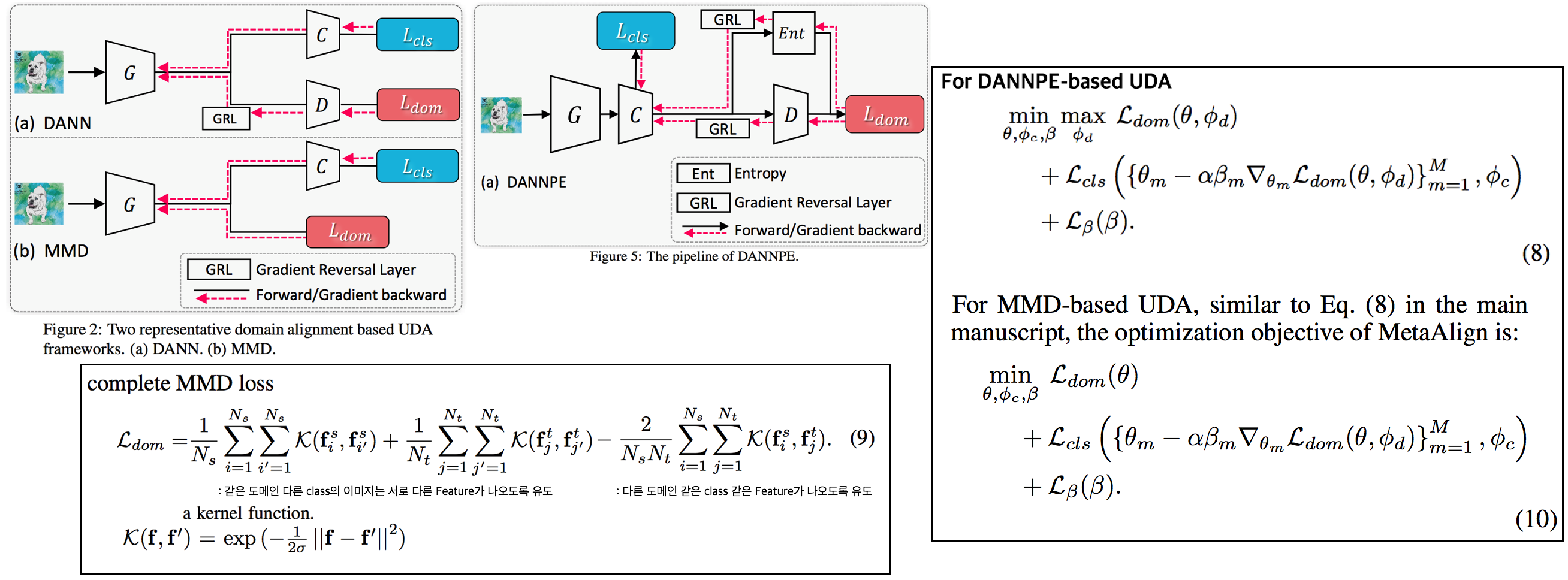
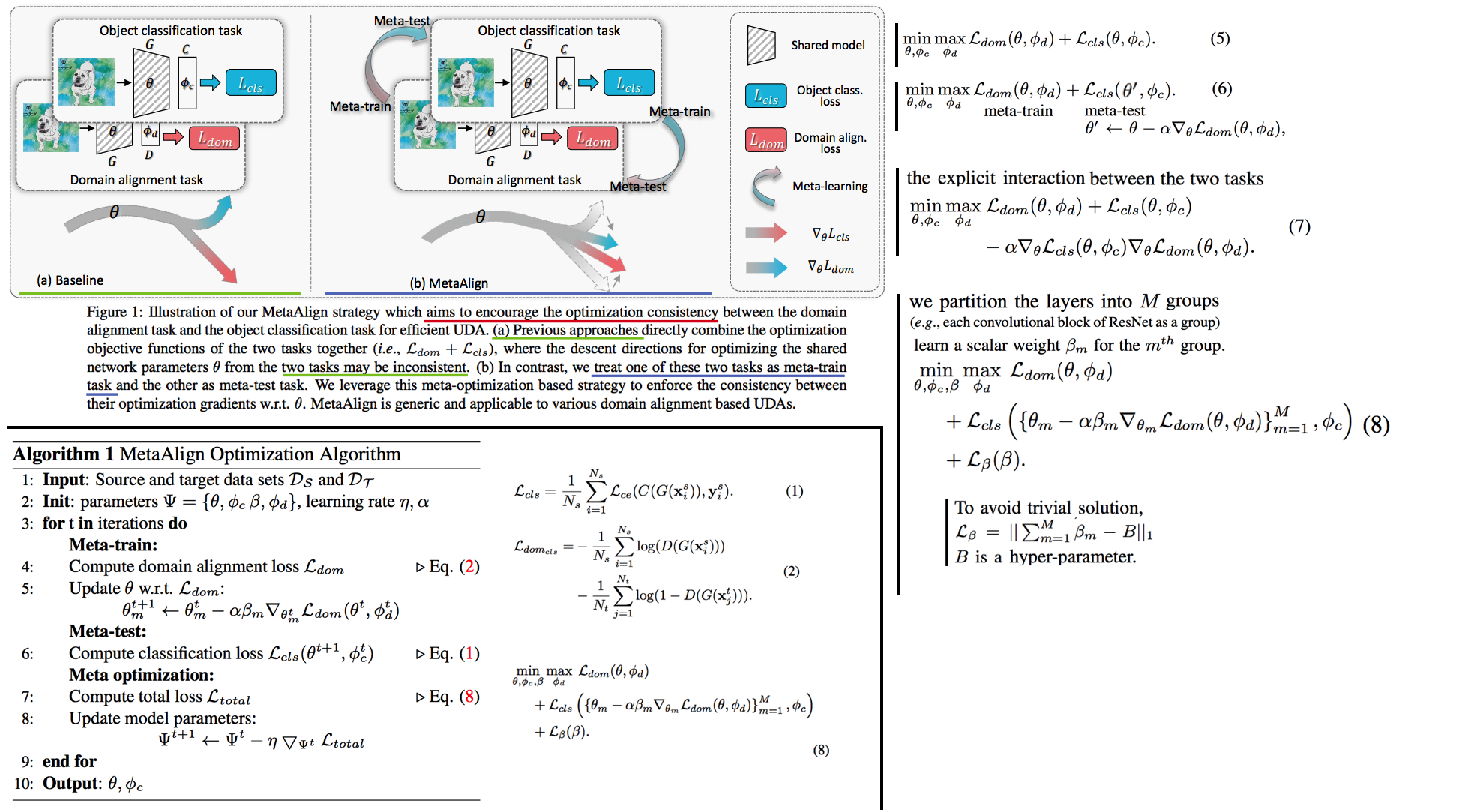
Sample 혹은 Domain 에 따른 split가 아니라, Meta-train & Meta-test 를 task(classification and adversarial)에 따라서 분리하는 Meta learning UAD
Abstract & Introduction
- classification task과 domain alignment task(DANN)을 함께 적용함으로써 general optimization이 이뤄지기는 쉽지 않다. 즉 2 task의 optimizations 관게에서
optimization inconsistency problem이 존재한다. 따라서 Classification loss를 주는 동안 adversarial loss를 주는 것이 classification 성능을 낮추는 결과를 초례할 수도 있다. - 이 문제를 MetaAlign,
effective Meta-Optimization를 이용해서 해결한다.이렇게 함으로써 2 task 모두를 만족하는 gradient로 update 도록 유도한다.
기존 방법론들에 대한 논문 설명
- DANN: Domain Adversarial Neural Network. Discriminator를 사용해서 adversarial learning을 진행하거나, Gradient Reversal Layer를 추가하는 방법
- 이 논문에서는 DANNPE (위 그림 참조) 기법을 기본으로 사용한다. 기존 DANN과의 차이점 1) backbone output feature를 D의 input으로 가져가는게 아닌, classifier 결과를 input으로 가져감 2) prediction결과의 entropy 결과에 따라서, sample reweighting을 적용한다. entropy가 낮은 것에 더 큰 weight를 주어준다. (Easy target image 부터 차근차근 gradient를 줘서 domain alignment가 좀더 안정적으로 되게 만드는 건가?)
- MMD에 대한 수식과 설명은 위 그림 참조
- MAML: sample을 meta-train과 meta-test로 나누고, meta-train에서 얻은 지식을 활용하여 meta-test에서 optimized 되도록 모델을 학습시킨다.
- MLDG: domain을 meta-train과 meta-test로 나누고 training-test 간의 domain shift를 simulation 한다. training domain 성능을 올리는 동시에 test domain 성능도 함께 올라가도록 학습을 유도한다.
- classification task과 domain alignment task(DANN)을 함께 적용함으로써 general optimization이 이뤄지기는 쉽지 않다. 즉 2 task의 optimizations 관게에서
Method
- Sample을 meta-train과 meta-test으로 나누는 것보다는, classification task와 alignment task를 번갈아가며 meta-train, meta-test task로 여기며 학습을 진행한다. 이때 task에서는 the same set of samples을 사용한다.
- 공식 설명
- (1): classification cross-entory loss
- (2): domain alignment loss 즉 discriminator를 활용한 adversarial learning loss
- (5): AdaptSeg, ADVENT 에서 사용하는 Loss
- (6): domain loss를 meta-train task로써 파라미터가 updated된 상태에서, (meta-test) classification loss를 meta-optimization 수식
- (7): Equ(5)에서 마지막항을 추가한 수식. 마지막 항은 두 task loss의 theta 편미분 값을 dot-production한 것으로써, [classification으로 파라미터가 update되는 방향]과 [domain alignment로 파라미터가 update되는 방향]이 일치하면 Loss를 줄여주고 (방향이 일치한다는 말은 두 task를 모두 만족하는 theta방향으로 이미 잘 가고 있다는 것을 의미하니 Loss를 크게 줄 필요가 없다), 방향이 다르면 Loss를 높혀주는 식으로 theta가 업데이트 되도록 유도한다.
- (8): 모든 Layer를 동일한 Learning rate로 update하는 것은 옳지 못하다. 왜냐하면 Layer마다 가지는 semantics가 다르기 때문이다. 따라서 Layer들을 M개의 group으로 나누고 자신에게 맞는 β_m 라는 scalar weight를 할당해줌으로써, group 마다 학습되는 정도를 다르게 만들었다.
- 최종적으로 사용하는 Total Loss는 Equ(8) 이다. 하지만 실제 학습에서는 classification, domain alignment 2개의 task를 번갈아가면서 meta-train, meta-test task로 사용했다.
4.7. Adversarially Adaptive Normalization for Single Domain Generalization -CVPR21
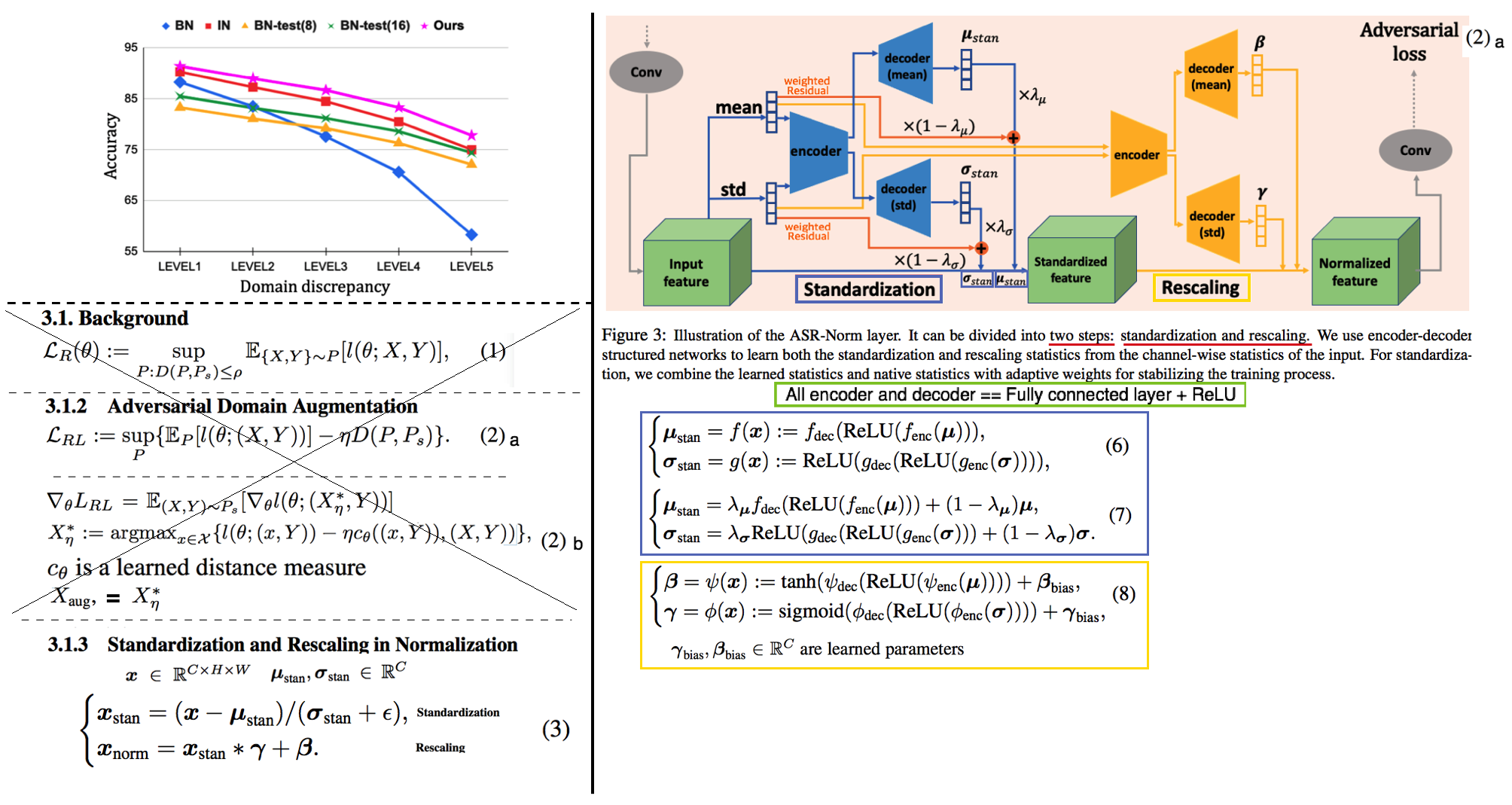
- Adaptive Normalization을 활용한 DG. Normalization을 할때 Mean, Std을 BN, IN 처럼 하는게 아니라, 신경망에 들어온 Input이미지에 맞게 Mean, Std가 설정되도로, 적절한 Mean, Std를 예측하는 Network를 추가로 삽입한 모델.
- Abstract & Introduction
- 지금까지 (IBN-Net 그 이상으로) 각 Layer feature의 statistics을 DG와 연관하여 분석한 논문은 없었다.
adaptive standardization and rescaling normalization (ASR-Norm): Normalization의 새로운 형태로써, 지금까지 Norm의 포괄적인 형태라고 할 수 있다.adversarial domain augmentation (ADA)를 사용하여 모델이 학습되는 동안, 다른 domain image에 적응할 수 있는 statistics in ASR-Norm을 학습한다.
- Method (Adversarially Adaptive Normalization)
- 공식 설명
(1): (DA, DG 세팅도 모두 아닌) 새로운 Domain을 P라고 하고 P에 X,Y가 모두 존재할 때, Ps(source distribution)과의 거리가 ρ 이내인 domain P를 사용해서 ERM으로 학습시킴으로써 DG 성능을 올리는 기법. (가장 Naive, Simple한 기법)(2): ADA 세팅의 수식 (Adversarial Domain Augmentation). (2).a Domain distance가 가까운 P라면 더 큰 Loss를 주어주고, distance가 멀면 작은 Loss를 준다. (2).b복잡하게 쓰여있어서 정확하게 모르겠다.(텍사스 대학, google의 합작이라서 무시할 수는 없다) 간단히 표현하면, original 이미지와 augmented 이미지 사이의 예측결과가 동일하도록 adversarial learning 혹은 contrastive learning 을 적용한다.- (3): BN, GN, LN, SN(switchable) 에 사용되는 수식
- DG 성능 향상을 위한
adaptive normalization방법을 소개한다. (그림참조) 그림의 Adversarial Learing == Adversarially Adaptive Normalization: Standardization과 Rescaling에서 [encoder& decoder]를 이용해서 mean과 std를 조정했을때와 안했을 때에 대해서 adversarial learning을 수행했거나, original & augmented Image 사이의 adversarial learning을 수행한다. (논문에서는 Equ(2)를 사용했다고 하지만, 아무리 봐도 이해가 안되는 식이다. 코드를 봐야할 듯 하다.)
- 공식 설명
- 내가 생각하는 이 논문의 문제점
- Normalization과 Rescaling Network의 input은 feature의 mean/std이다. source feature의 channel-mean/std에만 집중하는것도 문제고 (spatial feature 등 고려할 수 있는 요소는 더 많다), (unseen에서 나올 법한) 더 다양한 mean/std가 들어가면서 학습되지 못한다는 문제점도 있다.
- 위 문제점 해결방법: Encoder의 input으로 들어가기 전에 (AdaIN을 활용한) feature augmentation.
- 긍정적으로 생각하면 Unseen image에 가장 적합한 mean/std를 뽑아주는 좋은 방법이라고 생각할 수 있다. 하지만, encoder와 decoder에 source bias가 생기지 않았다고 확신할 수 없다. 따라서 semi adaptive DG 라고 할 수 있을 듯 하다.
- 하지만 또 이런 식으로 계속 극단적으로 생각하면, manifold projecting도 source bias가 있지 않냐? 라고도 할 수 있고, adaptive module 논문의 방법도 domain embedding network를 source로만 학습시키므로 source bias가 있지 않냐? 라고도 할 수 있다. 이 (#3.7) 논문의 bias 보다는 덜 하다고는 할 수 있다.
- 극단적으로 생각하면 source 만 가지고 학습하는 DG 세팅에서 bias를 100프로 지우는 것은 불가능할 수 있다. 하지만 더욱 bias를 줄이는 방법은 어딘가 분명히 존재할 것이다. 나는 최~~대한 bias를 줄일 수 있는 adaptive network를 개발하고자 노력하면 된다.
4.8. MeGA-CDA: Memory Guided Attention for Category-Aware Unsupervised Domain Adaptive Object Detection -CVPR21
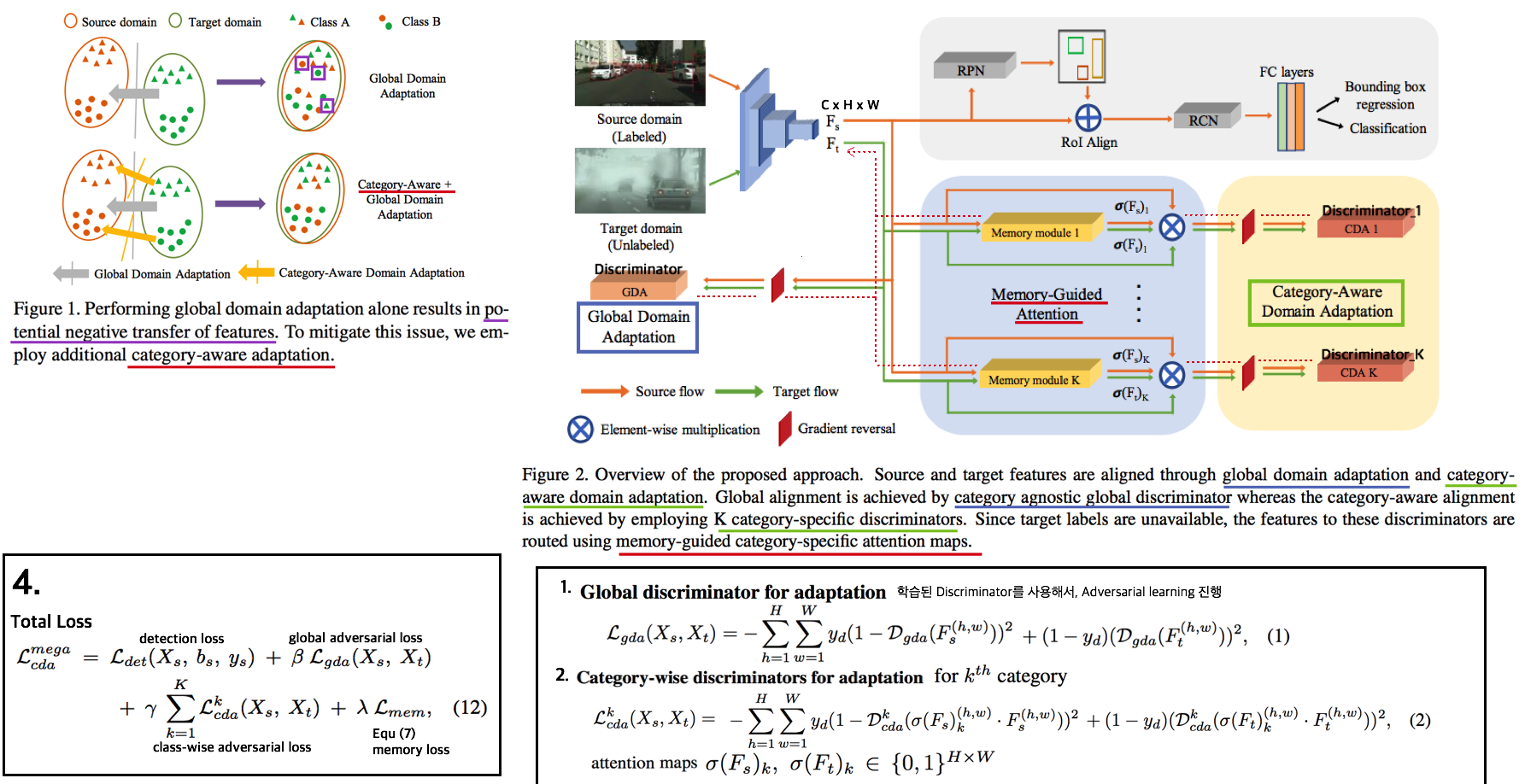
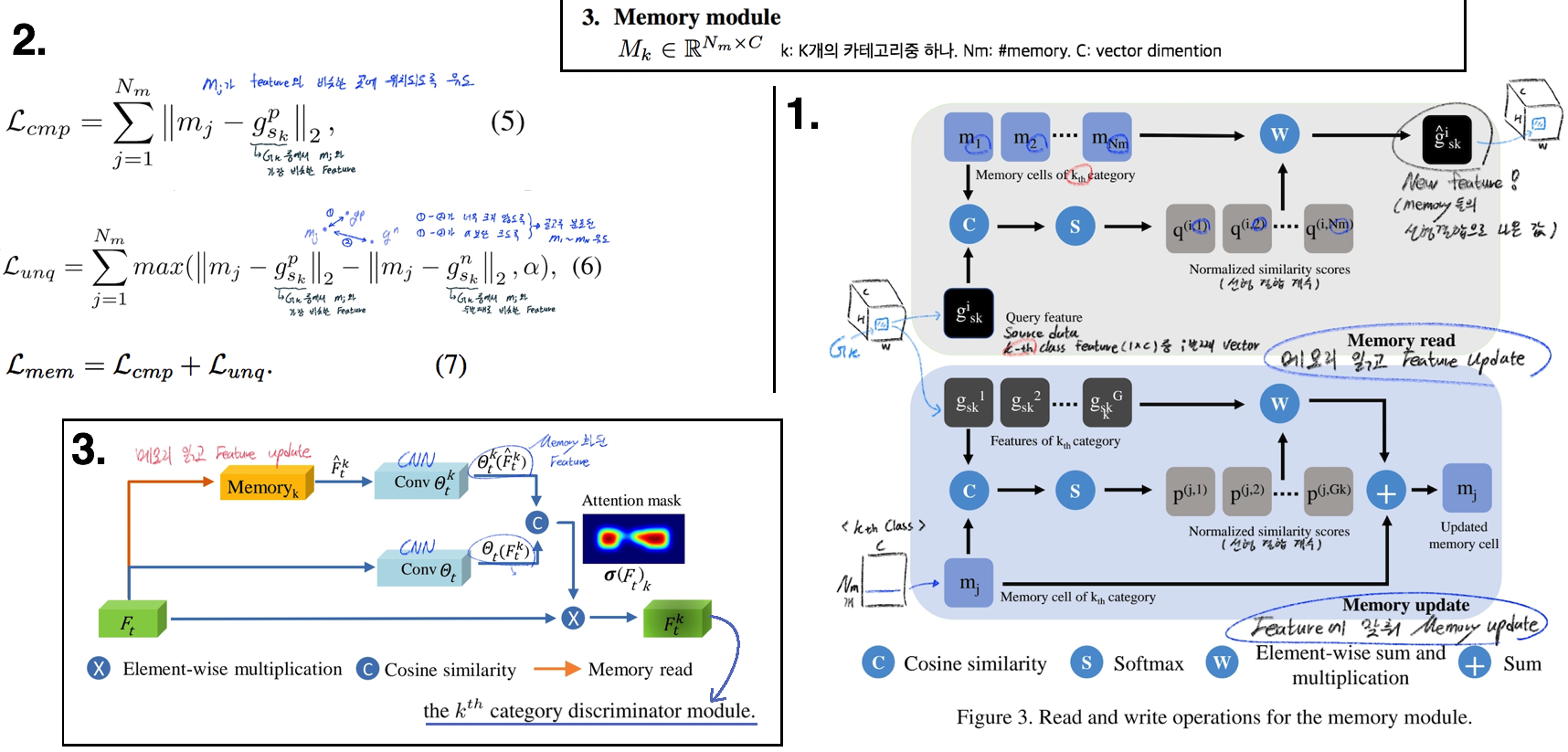
- Source에서 얻어진 memory(centroids)들를 활용해, target image에 대해서도 적절한 class-specific faeture를 뽑고 adversarial learning에 사용하여 [전체+Class-wise] Alignment를 수행한 DA
- Object Detection Task에서 memory를 사용해 중간 feature의 category를 파악하고, 그 정보를 활용해 만들어진 Updated feature 는 class-specific faeture이다. 이 feature를 discriminator 에 넣어서 class-wise adversarial leraning을 수행한다.
- Abstract & Introduction
- 기존 방식들의 문제점 category-agnostic(=global) domain alignment 만을 적용하면, negative transfer이 발생할 수 있다. 따라서 category-wise alignment가 필요하다.
- cateory 정보가 target samples에 유효하지 않을 수 있으므로,
memory-guided category-specific attention maps을 사용한다. 이는 discriminator에 적절히 attention된 feature 만을 보내주는 역할을 한다.
- Method
- 핵심 모듈 3개
Global discriminator adaptation(gda): AdaptSegNet 그대로Category-wise discriminators adaptationMemory-guided attention mechanism: feature map에서 각 카테고리마다 어디에 attetention 해야하는지 알려준다. 그리고 이 attention은category-specific memory module을 이용해 생성된다.- memory read를 유심히 생각해보면, memory 비슷한 pixel-feature값만을 memory들의 선형결합으로 살려두고, 아니면 0 vector가 되도록 유도한다.
- 그림 3번은 target test하는 동안의 과정이다. 따라서 memory read는 feature map 전체에 대해서 적용된다.
- 그림 3번의 conv Θ는 적절한 attention mask(similarity metric)를 추출하기 위해서, 사용되는 3층 conv network이다.
- 핵심 모듈 3개
4.@. AdverL: Domain Invariant Adversarial Learning -CVPR21
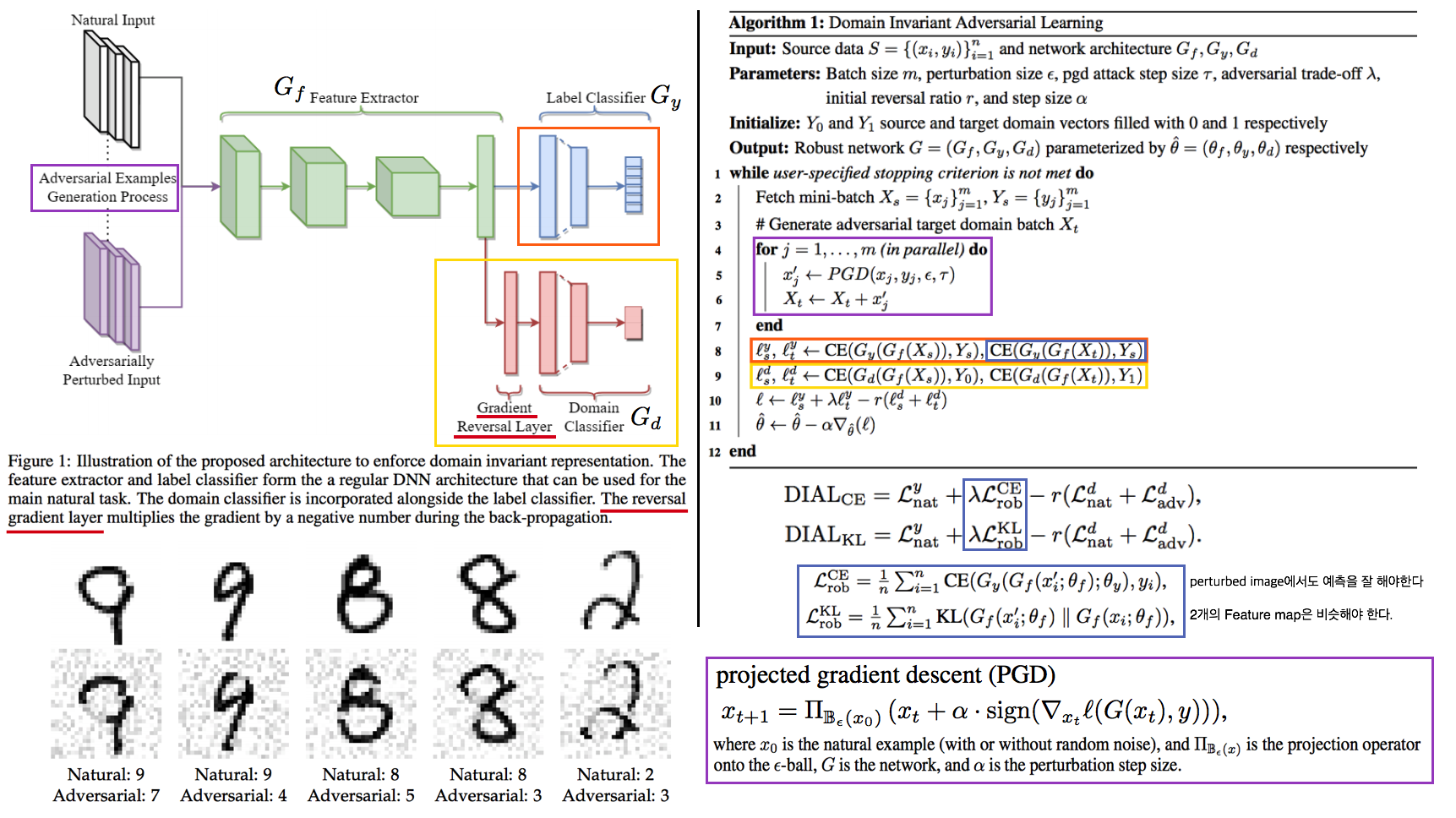
- Adversarial attack을 사용해 Target을 시뮬레이션하는 Adversarail Learning / DG (별거 없지만 깃발 꽂기 성공한 논문이랄까…)
- Abstract & Introduction
- Adversarial Learning == efficient strategy to achieve robustness
- Domain Invariant Adversarial Learning (DIAL) == robust representation
- source domain == natural examples / target domain == adversarial attacked (perturbed) examples
- 특히 Adversarial exampled 을 만드는 PGD (코드 참조) 이라는 기법은 Adversarial learning에서 많이 사용되는 기법으로 강한 attack에서도 좋은 성능을 유지하게 도와주는 좋은 모델중 하나라고 한다.
- 성능 결과 및 비교는, Adversarial Attack 성능 비교를 위한 실험들만 나와있다. DG 세팅 아니다.
- Q 왜 gradient reversal layer를 사용했지? discriminator를 사용하지 않고??: 아무리 찾아봐도 없다. DG 논문이 아니니까.
- Method
- 그림참조
4.@. DA: RPN Prototype Alignment For Domain Adaptive Object Detector - CVPR21
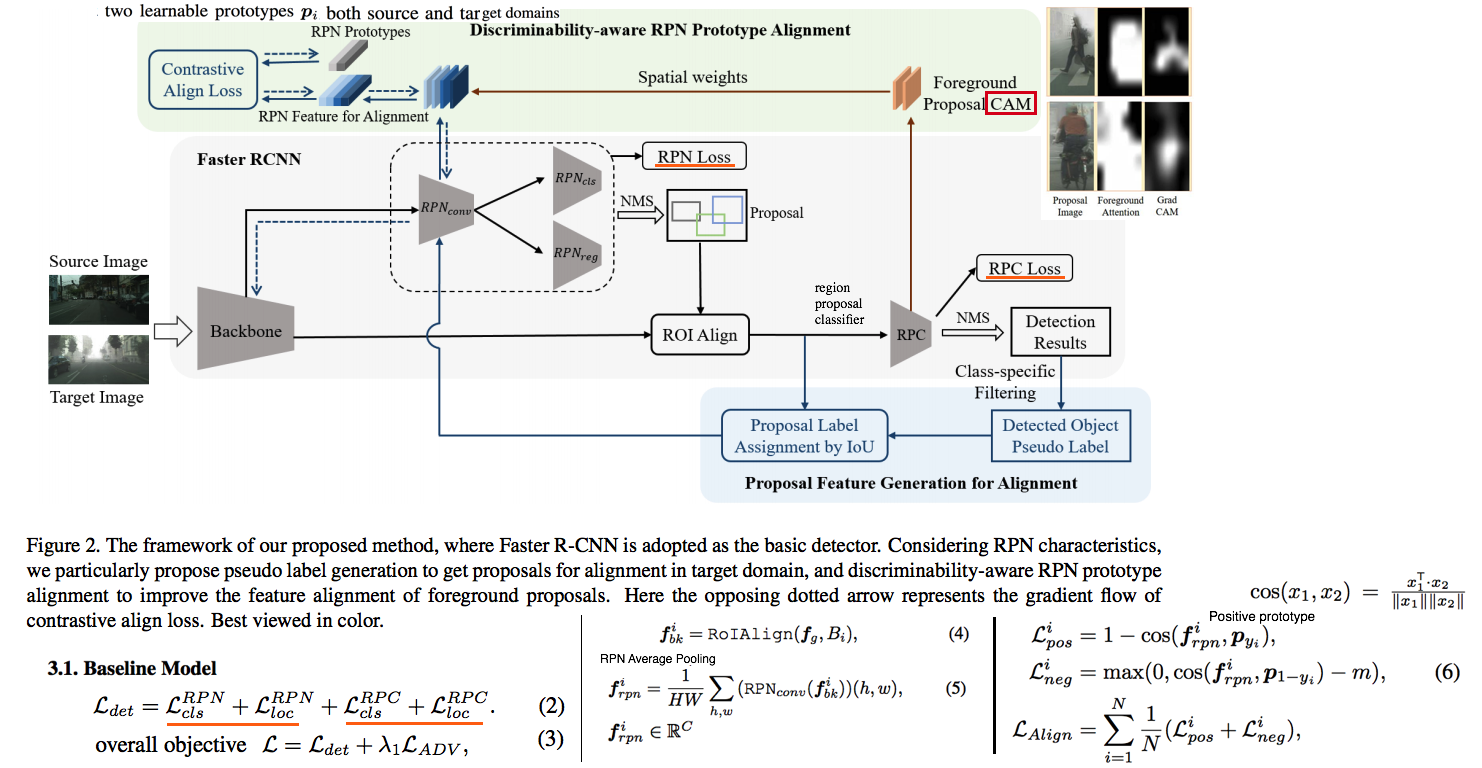
- 근본없는 방법으로 좀 그럭저럭 붙여서 만든 모델 같다. Adaptive라는 이름은 그냥 DA를 의미할뿐, Inference time Adaptive를 의미하는게 아니었다.
- Abstract and Instruction
- 지금까지 Detector의 DA 모델들은 backbone, classifier 등에 transferability(invariance)이 학습되도록 유도했지만, 이 논문에서는 RPN의 feature alignment 성능을 올리는데 집중한다.
- RPN에서의 foreground and background ROI가 확실히 분리되게 만든다.
- one set of learnable RPN prototpyes 을 먼저 구성한다. source와 target 모두에서 prototypes에 align 되도록 유도한다. 즉 forground region을 Grad CAM을 이용해서 찾음으로써
RPN feature alignment를 수행함으로써 high-quality pseudo label 을 생성한다.
- Method
- Baseline Model: 기본적인 faster-rcnn 모델에 domain adversarial learning을 수행함으로써, domain invariance를 학습한다. 여기서 adversarial learning을 discriminator를 사용하지만, Gradient Reverse Layer (GRL)를 이용해 adversarial learning을 수행한다.
4.@. 학습전략?: Deep Stable Learning for Out-Of-Distribution Generalization -CVPR21
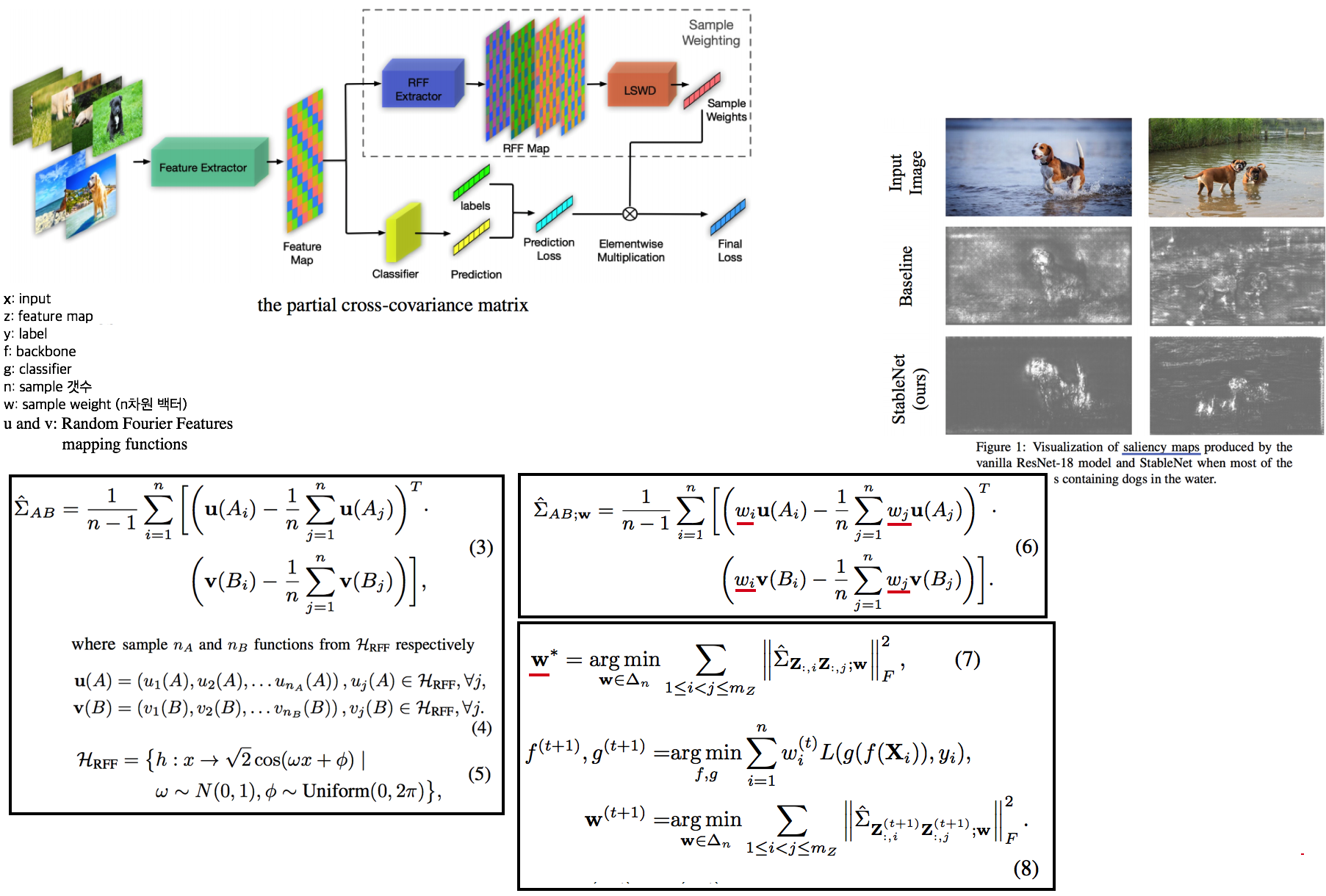
- HSIC같은 이상한 이해도 안되는거 사용해서, 같은 class 이미지의 feature사이의 연관성을 끊기 위한 Loss를 적용하는 기법. 이렇게 학습시키면 오른쪽 결과 이미지와 같은 성능을 보인다고 한다.
- A saliency map 이란? 이미지에서 특정 class를 지지하는 spatial 부분이 어디인지 측정하는 방법이다. (Grad-CAM 과 비슷한 것으로, 구체적인 내용은 나중에 공부하자.)
- Abstract & Introduction
- 과거 기법들은 domain label을 안다고 가정하거나, 다른 domain에서도 network가 어느정도의 예측 능력을 가질거라고 가정한다.
weights for training samples을 학습함으로써, feature 사이의 의존/관련성/연관성을 제거하여 DG 성능을 획득한다.
- Method (the saving and reloading global correlation method)
Kernel과 HSIC(Hilbert-Schmidt Independence Criterion)를 사용하는 거라서 뭐라는지 모르겠다.Learning sample weighting for decorrelation(LSWD),Random Fourier Features (RFF)- 그냥 이런걸 사용해서, 같은 class의 sample들 사이의 feature 연관성을 최소화하는 방향으로 Loss weighting이 이뤄진다.
4.@. DA: Dynamic Domain Adaptation for Efficient Inference -CVPR21
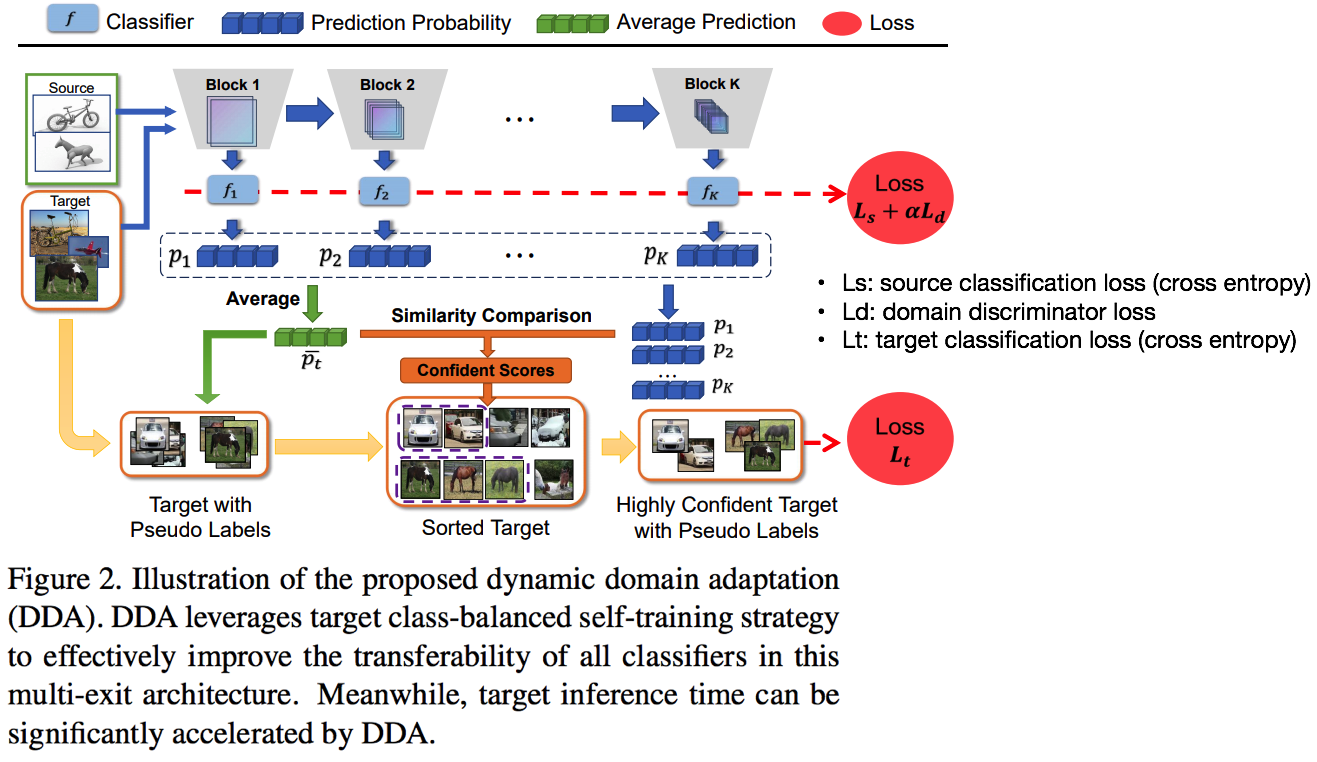
- DG가 아닌 DA 세팅, Target을 위한 Pseudo label을 만들고 높은 confidence score를 가진 Target pseudo label에 대해, Target Loss를 준다.
- 새로운 학습 전략
- 그림과 같이, 모든 Layer feature에 대해서 classifier을 학습시키고, 모든 classifier의 예측결과를 토대로 좀더 정확한 target pseudo labe을 만든다.
- a class-balanced self-training strategy (필요하면 찾아보고, 그 이외의 많은 전략이 있다. 하지만 나에게 굳이 필요 없을듯 하니 패스)
- Domain discriminaor를 놓고, adversarial learning을 적용함으로써 DA/DG 성능을 높히려 노력했다.
- Ls: source classification loss (cross entropy)
- Ld: domain discriminator loss
- Lt: target classification loss (cross entropy)
