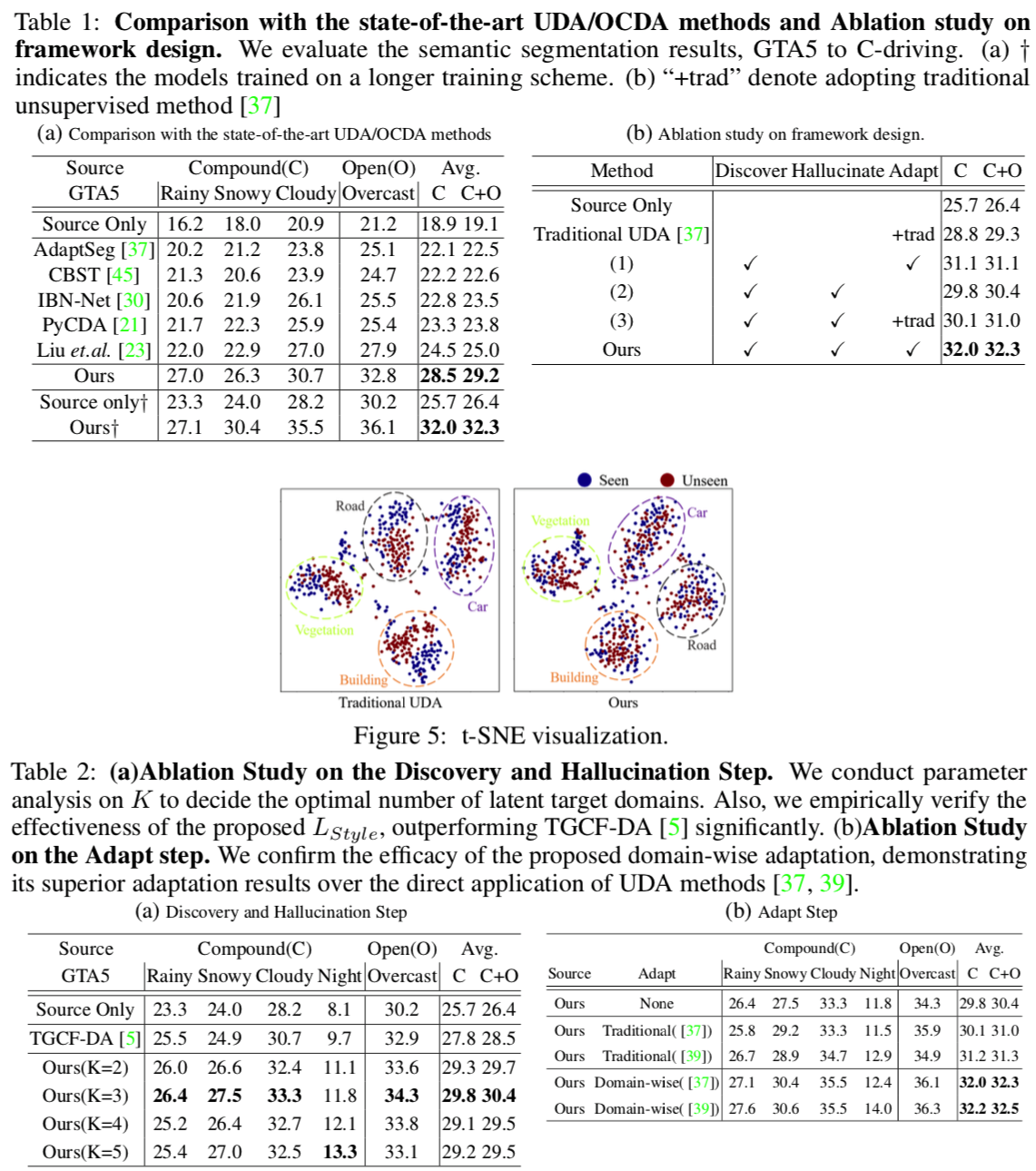
【DA】 DHA-Open compound domain adaptation
- Paper: Discover, Hallucinate, and Adapt: Open Compound Domain Adaptation for Semantic Segmentation
- Type: Domain adaptation & Domain generalization
- Opinion: 선배님 논문 & NIPS paper
- Target domain들을 Domain latent로 분리한 것은 매우 흥미로웠다.
- 하지만 결과를 살펴뵤면 K=3 일 때, 가장 성능이 좋다. 음.. K가 10이상으로 아주 클 줄 알았는데.. 의외다. Target Latent를 정확하게 찾아서 clusttering 한 것은 아닌듯 하다. Style imformation을 다른 곳에서 정확히 추출할 필요가 있다.(물론 여기서 Target dataset은 매우 제한적으로 사용한다. DG task가 아니다.)
- 생각보다 Original. Open compound domain adaptation (for classification) 논문과 연관이 전혀 없었다.
DHA - Open compound domain adaptation
1. Abstract, Instruction
기본의 UDA의 문제점과 Proposed framework
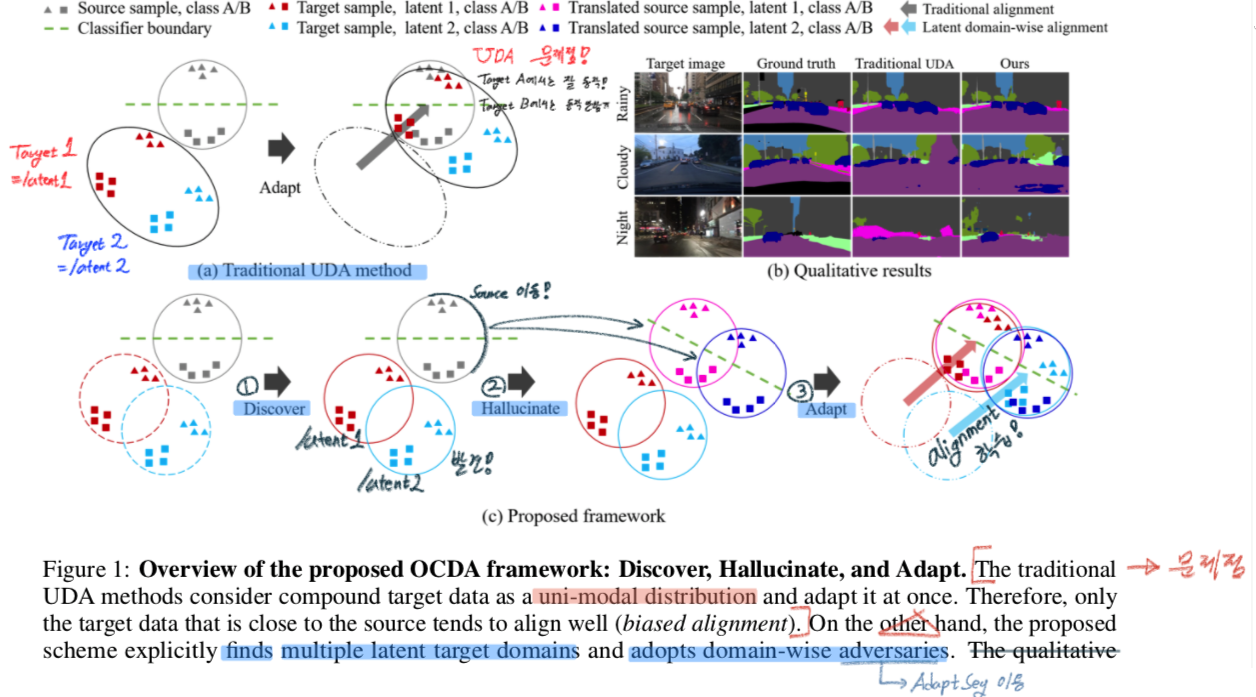
Three main design.
- Discover
- Style을 기반으로, 전체 Target dataset을 분류/clusttering 한다.
- Target Images를 K개의 latent domains 정보(feature)로 분류한다. (K-mean clustering)
- Hallucinate
- Source들을 target style로 hallucinate(환각에 빠트리다) 한다.
- Style Transform 한다. = Style Translation 적용한다.
- 하나의 Source 이미지에 대해서, K개의 Target style 이미지를 생성한다. Image translation network (=Style transform)를 사용한다.
- Adapt
- Target-to-source alignment 를 학습시킨다.
- Style마다 Source인지 Target인지 분별하는, K개의 Discriminator를 학습시키고 Adversarial learning을 수행하여, F(Segmentation Network)를 Fine tuning 한다.
더 자세한 내용과 수식은 아래의 Method를 통해 알아보자.
3. Method
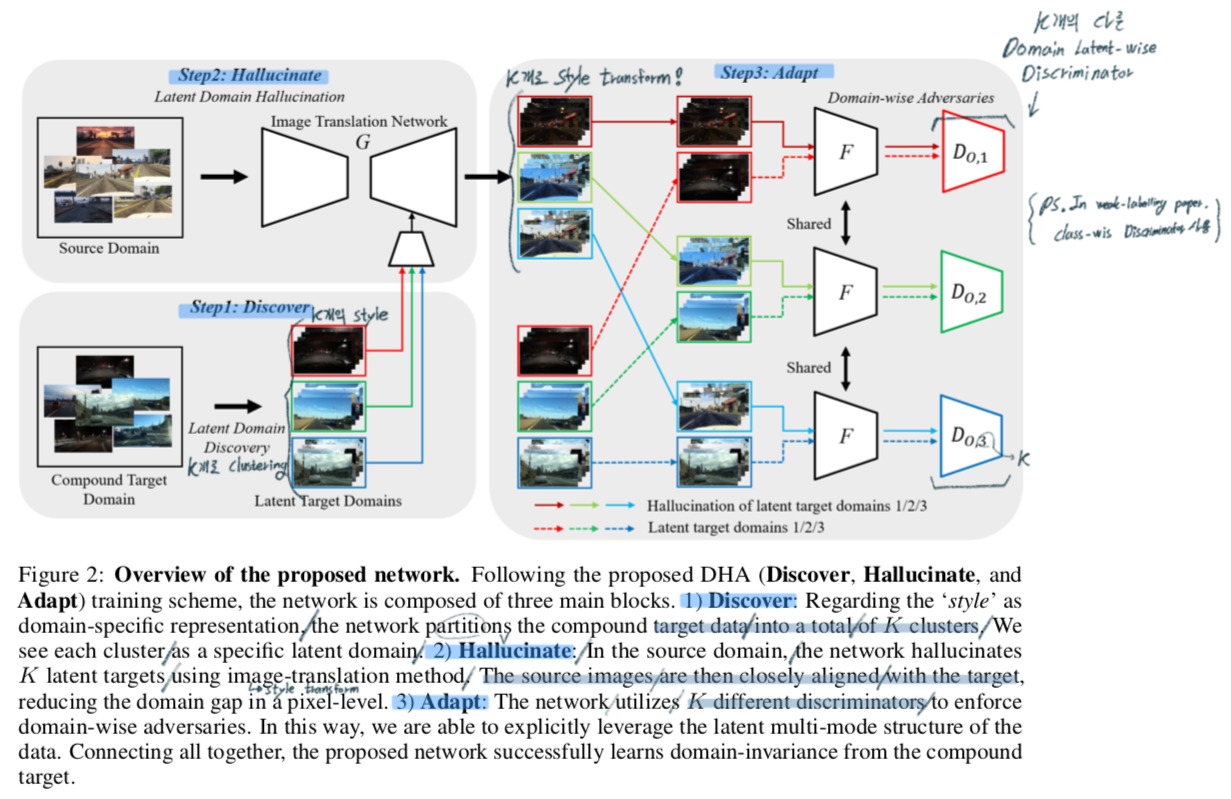
(1) Discover: Multiple Latent Target Domains Discovery
- Target 이미지들에서 K개의 Style 정보를 추출하고, 각 이미지를 분류한다.
- 이때 Style information은 convolutional feature statistics(mean & standard deviations) 를 사용한다.
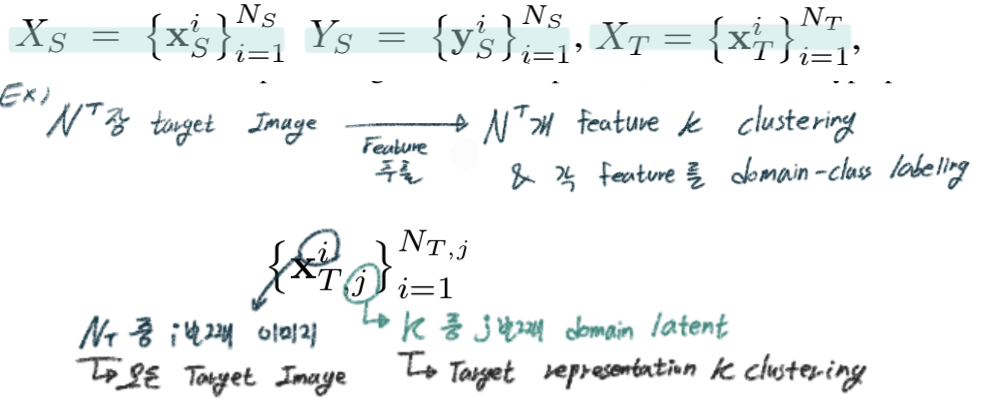
(2) Hallucinate: Latent Target Domains Hallucination in Source
- Style Transform을 해주는 G network(=Image translation network)가 필요하다. G가 만족해야할 조건은 아래와 같다.
- high resolution image translation 또한 가능해야한다.
- Source-Content 를 보존해야 한다. (Style만 바꿈)
- Target-style을 반영한 이미지를 만들어 줘야한다.
- TGCF-DA 라는 논문은 위의 1, 2번 조건을 만족하는 GAN모델이 있다. 이 모델의 Loss_GAN & Loss_sem 을 사용한 학습을 적용하므로 해당 논문 참고.
- 하지만 이 모델은, K개의 Latent domain의 다중 이미지 변환 능력이 떨어졌다 그래서 아래의 Style consistency loss를 사용해서 Discriminator를 학습시켰다. 자세한 내용은 아래 필기 참조.

- 이 과정을 통해서, G network의 target style-reflection를 향상시켰다.
(3) Adapt
- 1개의 Discriminator를 사용하면, 학습이 잘 되지 않는다. 따라서 K개의 domain-wise discriminator를 사용한다.
자세한 수식과 학습 과정은 아래 필기 참조.
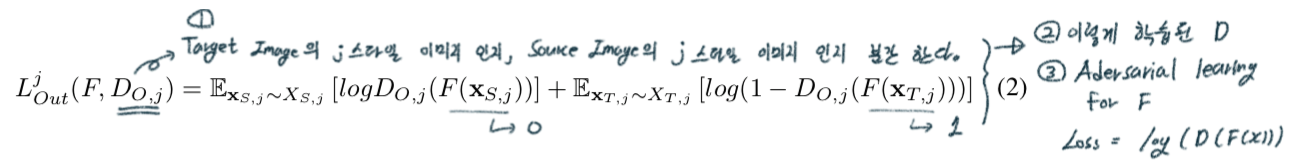
- Total Loss
- F는 Segmentation Network로 standard cross entropy로 학습시킨다.
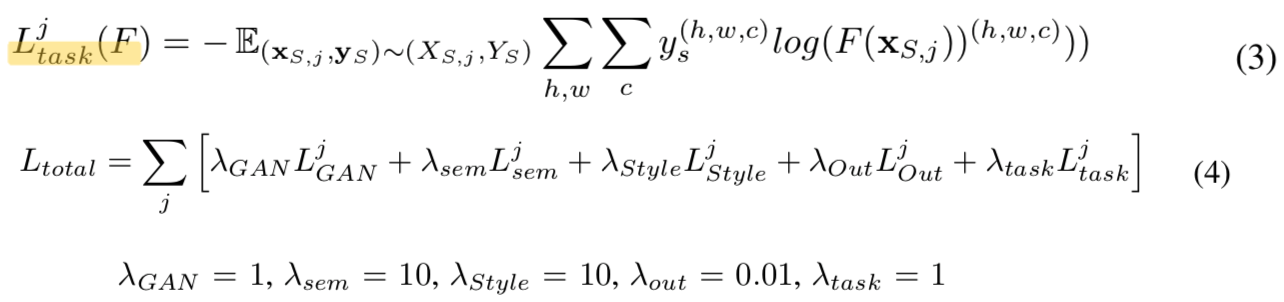
- F는 Segmentation Network로 standard cross entropy로 학습시킨다.
4. Experiments setting
- 추가 내용 논문 참조
5. Results