【DG】 Survey DG papers 2.5 - RobustNet and relative papers
Survey DG papers
2.9. MAML 먼저보기!
2.5 DG: Learning to generalize: Meta-learning for domain generalization:MLDG -arXiv17
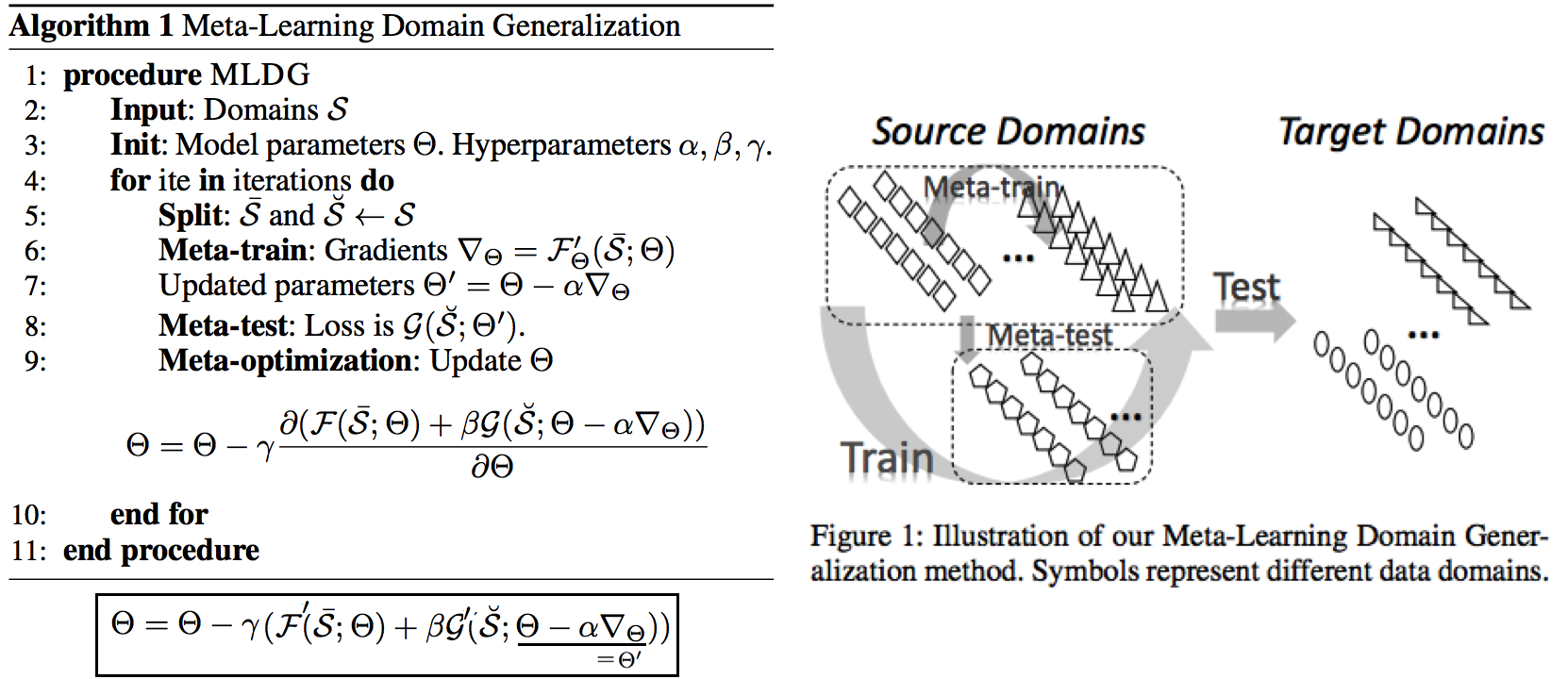
Meta Learning을 활용한 D. 그냥 Source domains 데이터를 그냥 한꺼번에 Supervised로 학습하지말고 (그냥 우걱우걱 학습하지 말고), Train-Test 과정을 시물레이션 함으로써 Network가 해당 시뮬레이션을 통해서 좀 더 옯바른 방향으로 학습되도록 유도한다. Loss를 1차적으로 거는게 아니라, 2차적으로 걸어준다. MetaTrain set에서 학습되는 Loss에 대해서, MetaTest set에서 학습되는 Loss를 추가적으로 걸어주는 방식이다.- meta-learning method(이란?) 을 적용한 첫 DG 모델이라고 할 수 있겠다.
- a model agnostic training procedure(=미니배치 안에 가상 Target이미지 사용) 을 적용함으로써 train/test domain shift 를 시뮬레이션 할 수 있다. 아래의 알고리즘을 사용해서 모델을 학습시킨다. 코드로 공부
total_loss = meta_train_loss + meta_val_loss * flags.meta_val_beta - S = 6 source domains into V = 2 meta-test and S − V = 4 meta-train domains. 데이터셋 분리는 다음과 같이 한다.
- Why! 왜 이러한 작용이 Generalization에 도움을 줄까??? 그대로 전체 Data에 대한 Gradient를 주면, 한쪽 방향으로 쏠리고 Source Optimization이 일어난다. 중간중간에 Meta-dataset에 대한 Loss를 추가해줌으로써 One-dataset-overfitting-optimization 을 피하게 만들어 준다.
2.6 DG: Unified deep supervised domain adaptation and generalization -ICCV17

Contrastive Learning을 활용한 DG- Task: Supervised DA or DG in Classification. using Contrastive Loss
- 만약 UDA를 한다면, (#1.3) MMD 기법으로 위 Equ(2) 를 적용한다. (p 는 softmax 정도로만 생각하자)
2.7 DG: Domain generalization with adversarial feature learning -CVPR18
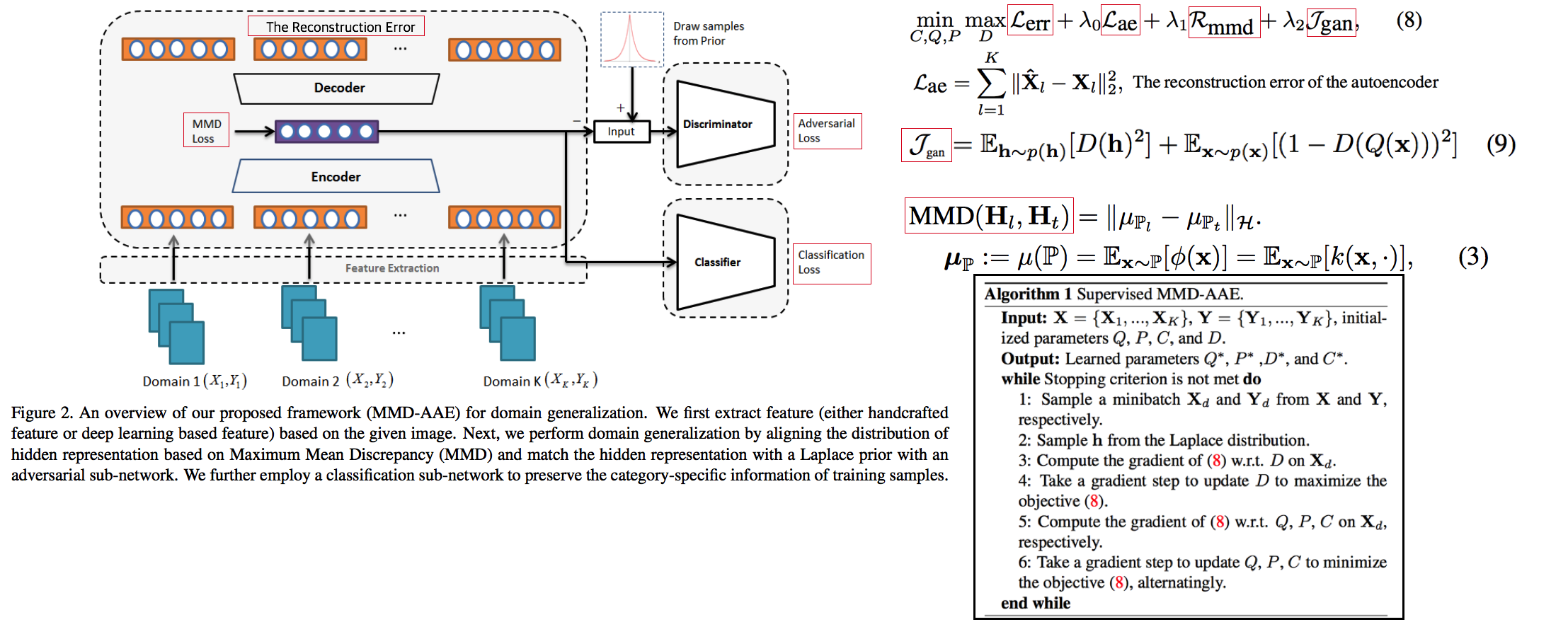
MMD regularizing Adversarial Learning을 활용한 DG 효과를 더욱 이끌어 낸다.- “모든 Domain을 고려하면, Hidden code는 결국 특정 분포(Ex.the Laplace distribution)를 따를 것이다” 라는 가정을 이용
- Total Loss
- Reconstruction Loss: Hidden Code가 Input Image 로 reconstruction 잘 되었는가? (Contenct 유지 유도)
- Classification Loss (Contenct 유지 유도)
- Adversarial Loss: MMD에 의해서 generalization 성능은 높아질 수 있지만, 오직 Source domains에만 Overfitting 되는 것을 막아준다. Discriminator는 a prior distribution에서 나온 Sample 인지, Hidden code 인지 분별하는 역할을 하고, Discriminator가 혼동하도록, 즉 Hidden code가 a prior distribution에서 나온 값과 비슷하도록 유도해 준다. 여기서 prior distribution(=arbitrary distribution)은 the Laplace distribution 을 사용했다. Gaussian distribution and the Uniform distribution 를 사용하는 것보다 성능이 좋았다고 한다. (Generalization And Not-overfitting 유도)
- MMD Loss: 어떤 domain 이디든 Hidden Code가 비슷한 Embeding Space (공간)에 위치하도록 도와줌. (Generalization 유도)
2.8. DG: Metareg: Towards domain generalization using metaregularization -NIPS18


meta regularization이라는 새로운 신경망을 사용한 DG.- MAML가 DA이지만, 우리는 DG이고, MLDG의 Generalization cost가 많이 필요하지만 우리는 Fixed F 를 사용해서 Cost 낮다.
- Regularizer 라는 신경망을 먼저 이렇게 정의한다. “Generalization에 도움을 주는, Task Network가 하나의 Domain으로 학습될 때 overfitting 되지 않도록 규제해주는 역할을 하는 신경망” 처음에는 Φ(파이) 신경망을 무작정 사용하고, 이게 Iteration을 돌수록 점점 저런 역할을 하는 신경망이 될거라고 기대한다. (강화학습의 Policy, Q network 처럼.. 처음에는 아무 역할도 안하는 신경망이지만, 점점 원하는 역할을 하는 신경망이 되도록 유도한다.)
- (주의! 코드가 이상하니 신경쓰지 말기 // (#2.12) 내용과 거의 일치하다 **) novel regularization function in meta-learning framework: 아래의 순서로 Regularizer(nn.Linear( T network weight, 1))가 학습된다. 코드 확인 Regularizer는 T network에 새로운 Loss를 줌으로써 T가 Generalization 되도록 도와주는 신경망이다. T network를 받고 Loss값이 스칼라값으로 나오는 신경망이다. 다시말해, **Generalization을 위해서 a domian을 학습하는 동안, “b와 c domain도 고려하니까 적당히 학습해!” 라는 느낌으로 beta 갱신에 사용된다
- (Step1) Base model updates: 각 Domain data를 사용해서, 공통된 F 그리고 T1~Tp 모델을 학습시킨다.
- Episode creating: 랜덤으로 2개의 domain을 선택해서, (1) metatrain set (
adomain) (2) metatest set (bdomain) 으로 설정한다. - (Step2) Re-traing using metatrain set: 위 1번에서 학습되된
adomain 으로 파라미터로 Init한 F+Ta 모델을lgradient steps 까지.adomain dataset으로 F+Ta를 학습시킨다. - (Step3) Regularizer updates: model_regularizer는 input으로 T의 weight가 들어가고 output이 스칼라값이 나오는 nn.Linear 인데, 이 스칼라값이 Loss로 동작해서 “Final F+T”를 update해준다. 신기하게도 model_regularizer는
b이미지를 사용해 F+Ta 신경망에 의해서 계산 Loss값 backward 값으로 update된다.
2.9. Meta: Model-Agnostic Meta-Learning for Fast Adaptation:MAML-ICML17
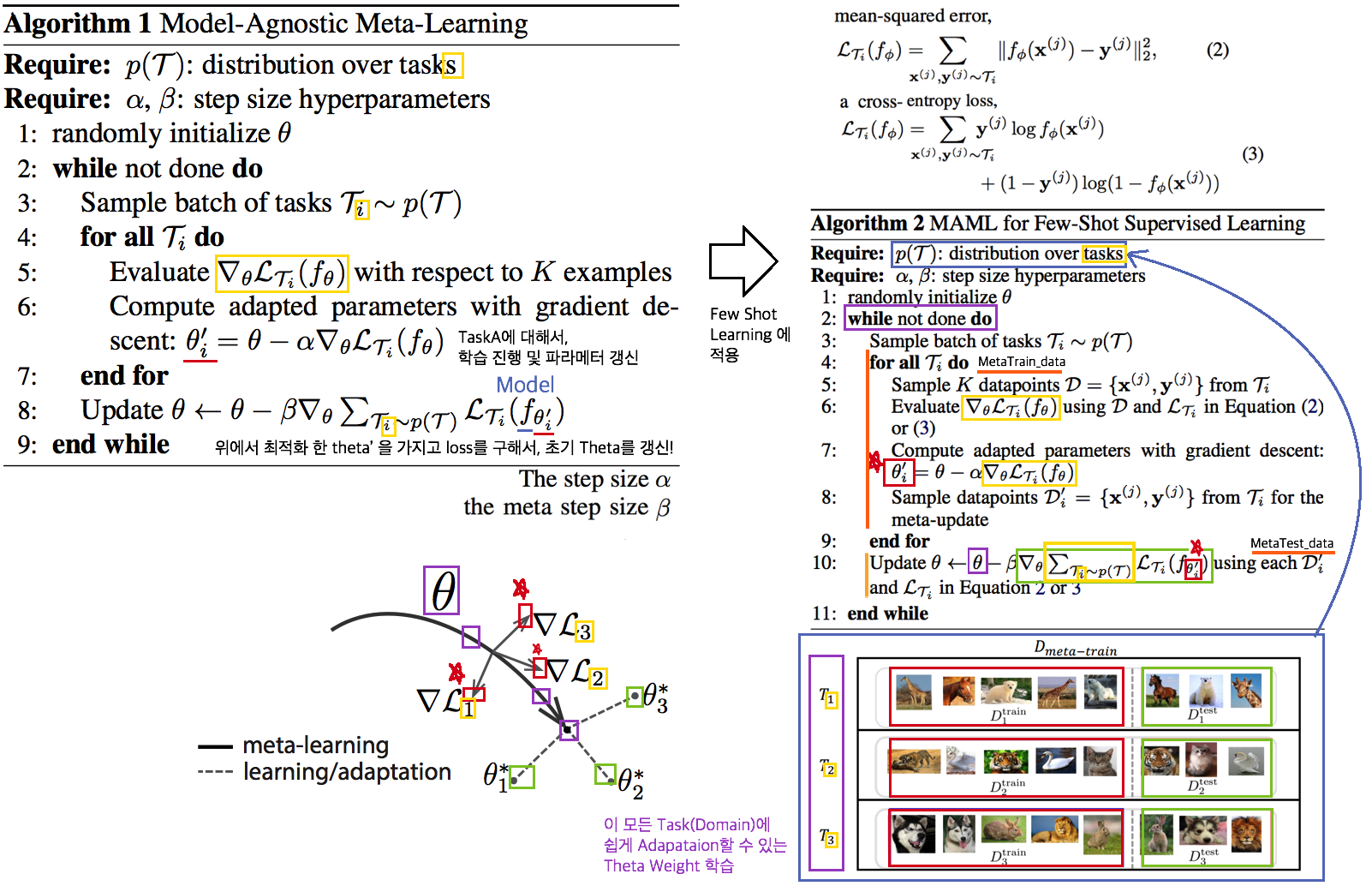
- Tasks(Domains)를 사용해서, 어떤 Task에도 빠르게 adaptation 할 수 있는 pretrained-model 만들기를 목표로 한다.
- The objective of the MAML approach is to find a good initialization θ such that few gradient steps from θ results in a good task specific network. (모델의 init weight(=Theta(보라색))를 적절하게 만드는 방법을 소개한다. 이 weight 는 새로운 Task에 init으로 사용해서 빠르게 적응/일반화 가능하다.)
- 가장 아래 보라색 지점(theta)에서 파라미터 갱신을 하기 위해, 각 Task에 대해 학습한 결과인 빨간색 (theta’)를 사용해서, 모든 Task에 적합한 파라미터의 지점 (연두색의 중간지점 쯤) 으로 Theta가 갱신되도록 유도하다.
- 지금은 이해하기 힘들지만, 엄청 높은 Citation과 많은 논문에서 이 기법을 적용한다. 따라서 차근차근 이해하려고 노력해보자. 참고 유투브
- PS. Few-shot-learning이란? N-way(Classes), K-shot(Samples) 총 NK개의 데이터만 사용해서 모델이 적절히 학습되게 만드는 알고리즘을 찾는 연구.
- (#2.10 논문에서 차용) Intuitively, the training procedure/ is learning/ how to generalize/ under domain shift./ In other words, parameters/ are updated/ such that/ future updates with given source domains/ also improve/ the model/ regarding some generalizable aspects/ on unseen target domains. (직관적으로 이러한 학습 절차는 Domain shift를 고려한 generalization 이다. 다시말해서, 처음 파라미터 업데이트된
theta'는 ‘미래의 파라미터 업데이트’를 위해서만 잠시 존재한다. ‘미래의 파라미터 업데이트’는 (Unseen target domains을 위한 Generalization 성능을 위해)theta'와 MetaTest dataset을 활용해 구해진 gradient로 업데이트가 이뤄진다.)
2.10. DG: Domain Generalization via Model-Agnostic Learning of Semantic Features -NIPS19

MAML meta-learning,Contrastive Learning을 활용한 DG- 즉. a model-agnostic learning: (domain shift 를 시뮬레이션 하기 위해서) meta-train and meta-test procedures (to expose the optimization to domain shift. |#D_train| = 2 and |#D_test| = 1.
- 궁극적 목표: consistent features 얻기 (:= Domain Invariance)
- two complementary losses를 통해서 semantic features via global class alignment and local sample clustering 을 만들어 낸다.
soft confusion matrix: 각 Domain의 Class cluster 구조관계가 유사해야한다.metric-learning component: Domain에 상관없이 같은 Class는 당기고 다른 Class는 밀어서, Class 마다의 Cluster를 가져야 한다.
- Global Class Alignment Objective (코드)
- MetaTrain_dataset에서의 각 Domain 각 Class 의 Centoids 위치가, MetaTest_dataset에서도 유사해야 한다. 즉 각 Domain 마다 Class centrois 위치는 비슷해야 한다.
- (그림에서는 Covariance, Position simillarity 같이 생겼지만 아니다. )
- Local Sample Clustering Objective
- 모든 Domain에 대해서 Class 별 Contrastive Loss
2.11. DG: Episodic Training for Domain Generalization -ICCV19

Backprobagation의 흐름을 바꿔 학습시키는 DG- 현재 domain과는 정반대의 partner model과 상호작용하면서, Domain shift를 시뮬레이션 한 episodic로 Traning 진행했다.
- Equ(5) 에서 ψ_r 은 Label space를 어떤 것을 가지든 상관없는 Classifier이다. 따라서
heterogeneous domains generalization이 된 Feature Extractor (theta) 획득이 가능하다. - Figure 그림 추가 설명
- Figure1: Aggregation multi domain learning (AGG) 그냥 모든 Domain을 한꺼번에 묶어서 학습시킨다.
- Figure2: N개의 Domain, N개의 모델
- Figure3: 하나의 AGG 모델을 두고, Figure2에서 Domain Sepecific Model을 가져와서 AGG의 Generalization 성능을 높힌다.
- Figure4: 하나의 AGG 모델을 두고, heterogeneous DG Feature Extractor (Theta, Equ(5))를 학습시키고, 원하는 Classifier(ψ) 를 Equ(4)로 학습시킨다.
2.12. DG: Feature-critic networks for heterogeneous domain generalization -ICML19

- 한 줄 정리: Regularizer Network으로써, Feature-critic Network를 사용한다.
- Feature-critic Network
- “현재의 Feature Extractor 파라미터가, MetaTest-domain의 성능일 올려줄지 아닐지”를 예측해주는 네트워크이다.
- 이 Network를 사용해 Train 과정에서 Ausilliary loss를 뽑아내고, Validation 과정에서 이 Network를 update한다.
- Equation 설명
- Equ (2): 전체 Classification 모델을 학습시키는데 사용할 Loss
- Equ (6), (7): 다양한 종류의 h(w) = Feature-critic Network
- Equ (3): h(w)의 parameter인 w가 가져야할 조건. (Meta_test Domain에서 더 좋은 결과를 가지도록 Loss를 유도해 줘야 함)
- Euq (5): h(w)를 optimize 하기 위해서, 사용하는 h(w) Loss function. Old theta보다 New theta에 의해서 Validation 이미지의 예측결과가 더 좋아지도록 유도하면서, 동시에 Ausilliary loss에 의해서 새롭개 갱신된, New theta가 generalization 능력을 갖춘 theta가 되도록 유도한다.
2.13. DG: Domain Generalization by Solving Jigsaw Puzzles -CVPR19
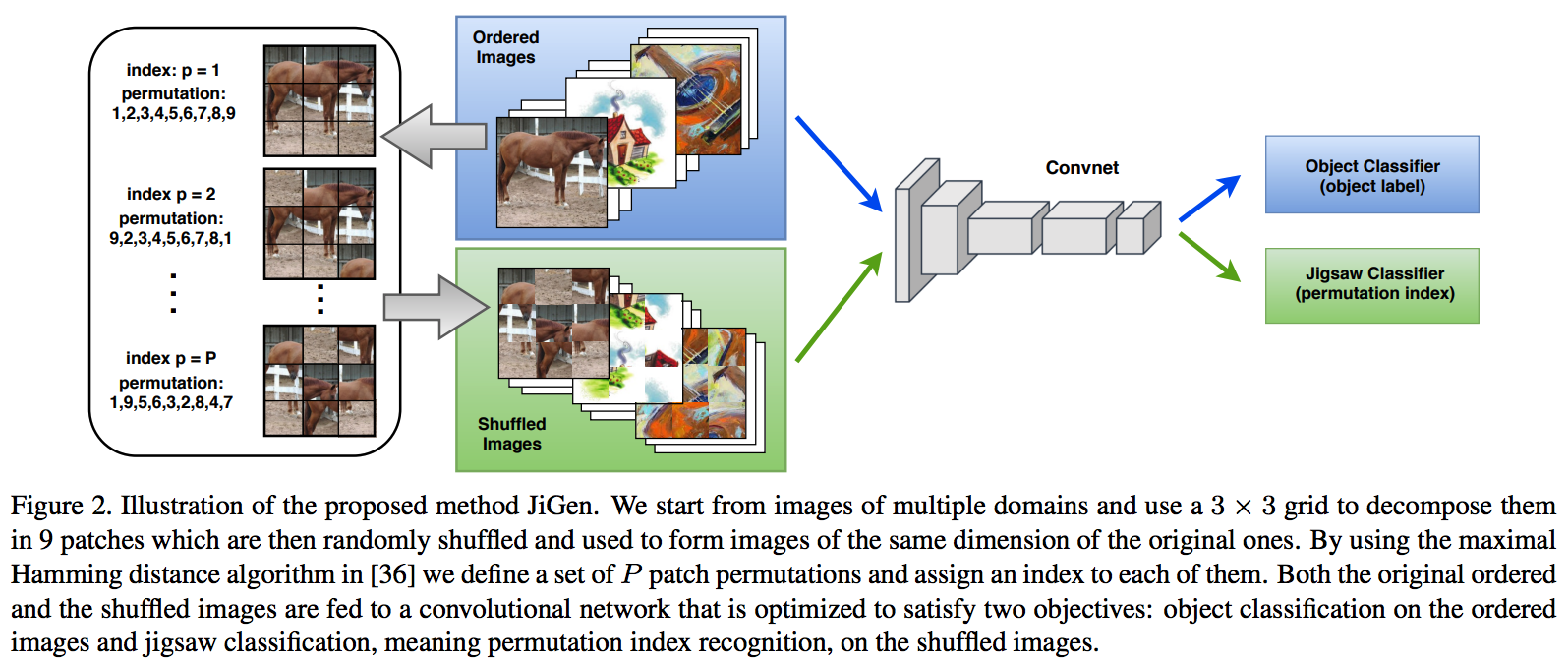
jigsaw puzzles task를 추가한 DG- Jigsaw puzzle task는 (generalization을 위한/ overfitting을 막는) Network Regularizer 역할을 한다.
- Episodic Training 논문에서 주장하는 그당시 SOTA 논문이다. (개인적으로 Contrstive와 Classification을 동시에 하면 당연히 Generalization 성능이 좋아지는 거랑 같은 원리인듯 하다)
- 그림 추가 설명
- 1~P 개의 permutation 중에서 하나를 골라 맞추면 되는 Jigsaw classifier task
- Original ordered image 뿐만아니라 Shuffled Images 까지 Label Classication loss가 주어진다.
2.14. WT: Iterative Normalization: Beyond Standardization towards Efficient Whitening -CVPR19
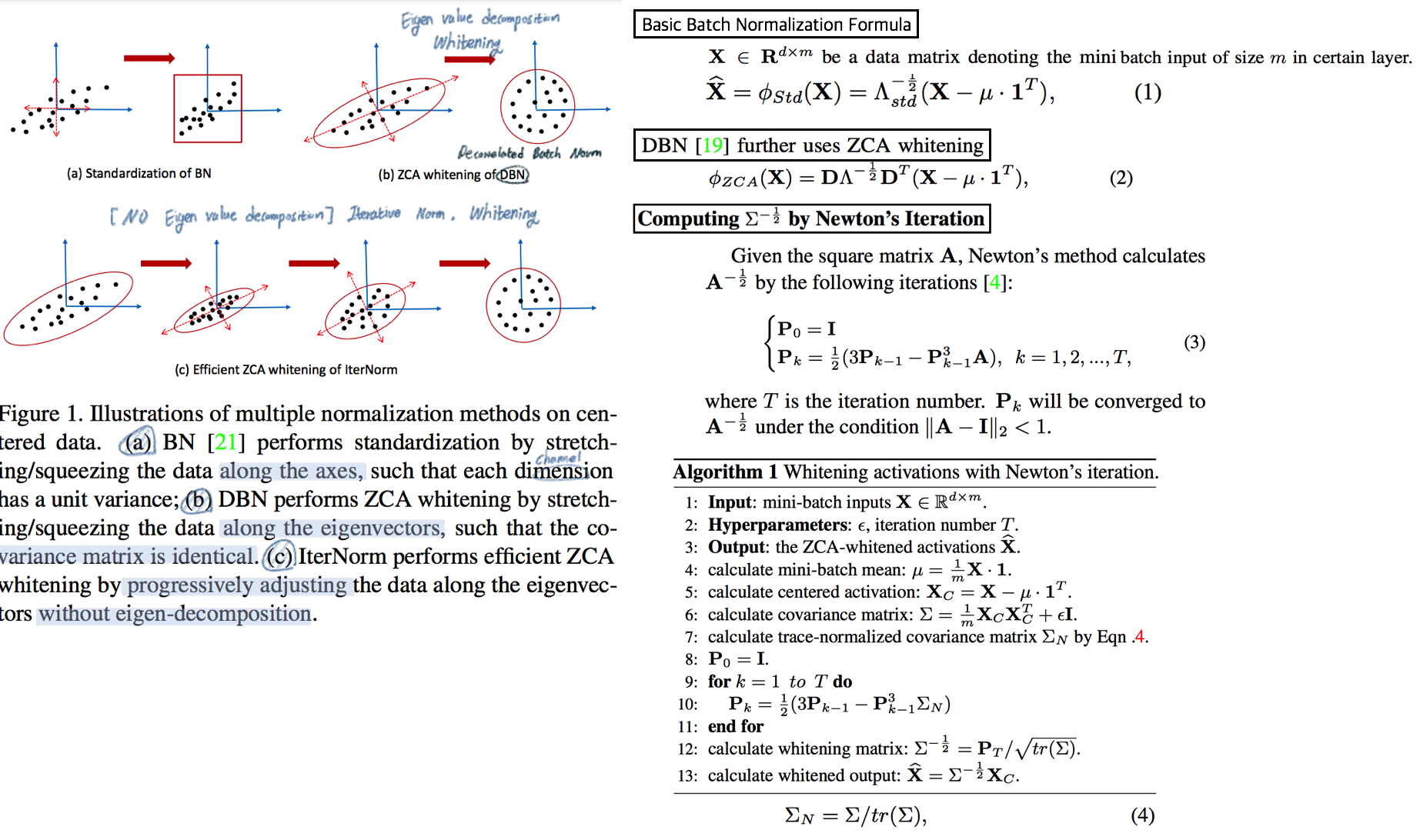
- RobustNet에 따르면, IBN-net보다는 성능이 낮고 SW(Switchable whitening) 보다는 성능이 좋은 WT Method
- ( Stochastic Normalization Disturbance 개념을 소개하고 이용해서, 왜 group-wise whitening 이 좋았는지, BN에서 Batch size가 작으면 왜 성능이 떨어지는지 확인해본다. )
- DBN(Decorrelated Batch Norm)은 Eigen value decomposition을 한다는 문제점이 있었다. (Back-propagation는 DBN 논문에서 되도록 만들었지만, Computer Cost 문제는 어쩔 수 없었다.)
- Whitening의 핵심 연산은 covariance matrix^(-1/2) 를 구하는 것이다. 이것을 구하기 위해
Eigen value decomposition이 필수적이었다. 하지만, 이 논문에서는Newton’s iteration methods를 사용해서 구하고자 한다.
2.15. WT: Switchable whitening for deep representation learning -ICCV19
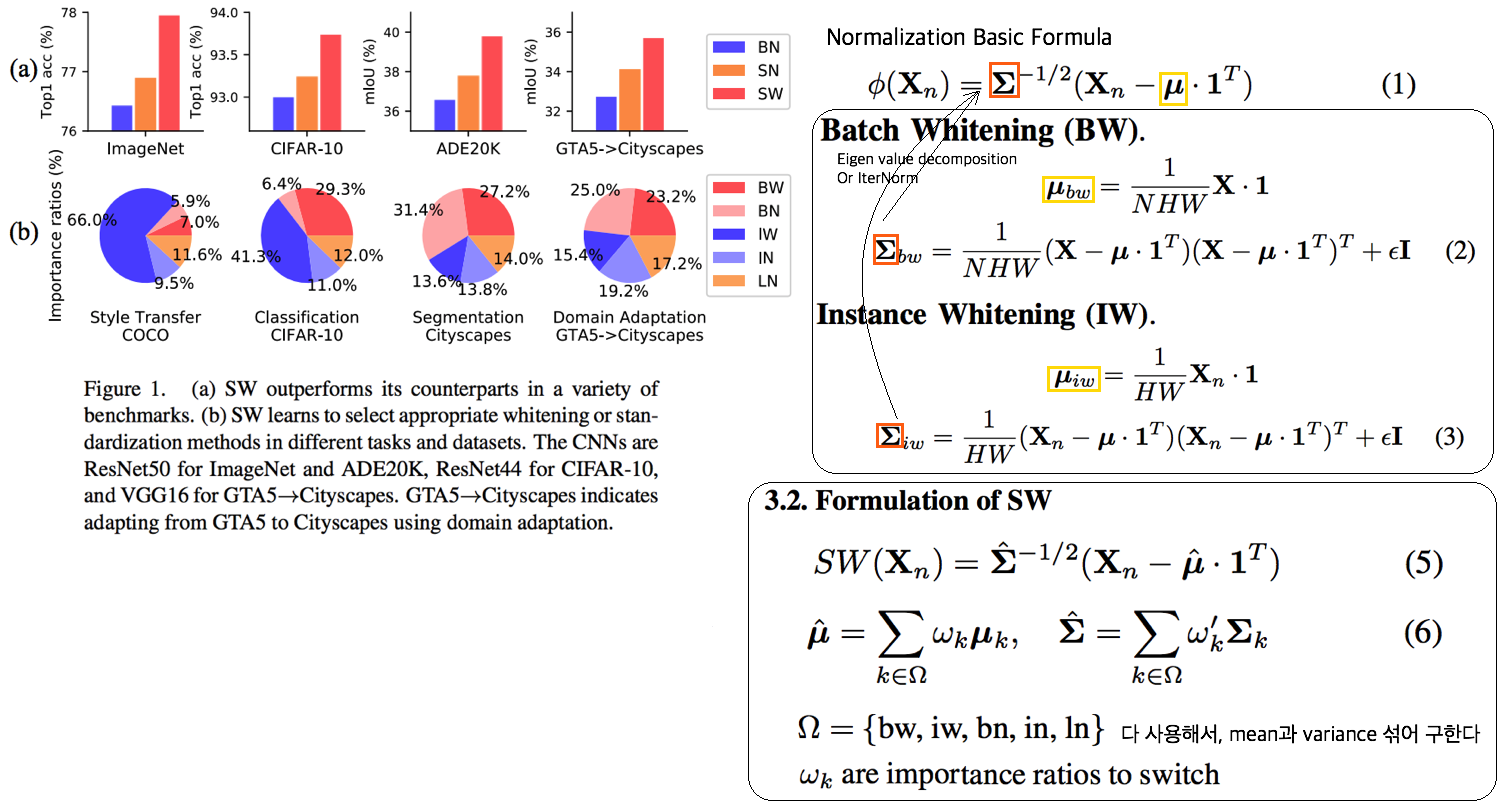
- RobustNet에 따르면, IBN-net과 Iter-Norm에 비해 Generalization 성능은 낮지만, 같은 Domain에서의 mIoU 성능유지는 가장 좋은 WT Method
- BW(Batch Whiten) // IW(Instance Whiten) // BN // IN // LN(Layer Norm) // SN(Switchable Norm=왼쪽 3개의 Norm을 섞어 사용) // SW(Switchable Whiten=왼쪽 모든 Whiten, Norm 방법을 적절히 섞어 사용)
- Switchable whitening
- SW adaptively selects appropriate “whitening” or “standardization” statistics for different tasks
- SW controls the ratio of each technique by learning their importance weights
