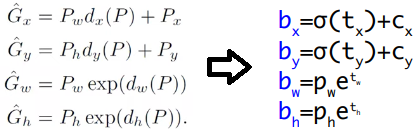겨우 5페이지 밖에 안되는 논문이기 때문에, 궁금한것만 대충 읽고 Youtube의 발표 자료를 이용해 공부하려고 한다. 또한 모르는 것은 코드 중심으로 공부해야겠다. 그럼에도 불구하고, 역시 내가 직접 논문을 읽는게 직성이 풀린다. 그리고 누군가의 설명을 들으면 솔직히 의심된다. 이게 맞아? 그리고 정확히 이해도 안된다. 물론, 논문도 자세하지 않기 때문에 누군가의 설명을 참고해서 직관적인 이해를 하는 것도 좋지만, Yolov3는 논문이 신기한 논문이라서, 논문 그 자체로도 이해가 잘 됐다.
Anchor(=bounding box != GT_object)를 이용한 the relative offset 개념을 그대로 사용한다.
이전 모델들과 다르게, 각 bounding-box가 an objectness score 개념을 사용한다. 한 객체에 대해서 가장 많이 겹친 box만 objectness score target = 1을 준다. (지금까지 IOU (+confidence)를 이용해서 일정 이상의 값이면 Positive라고 판별하고 objectness score = confidence = 1 을 주었다.)
only assigns one bounding box prior for each ground truth object
한 객체 GT에 대한 하나의 bounding box 이외에, 다른 박스들은 class predictions와 coordinate(offset)으로 어떤 loss도 발생시키지 않는다. 단지 objectness sore에 의한 loss만 적용된다.
Class Prediction
not use a softmax for multilabel classification. Yes logistic classifiers
binary cross-entropy loss
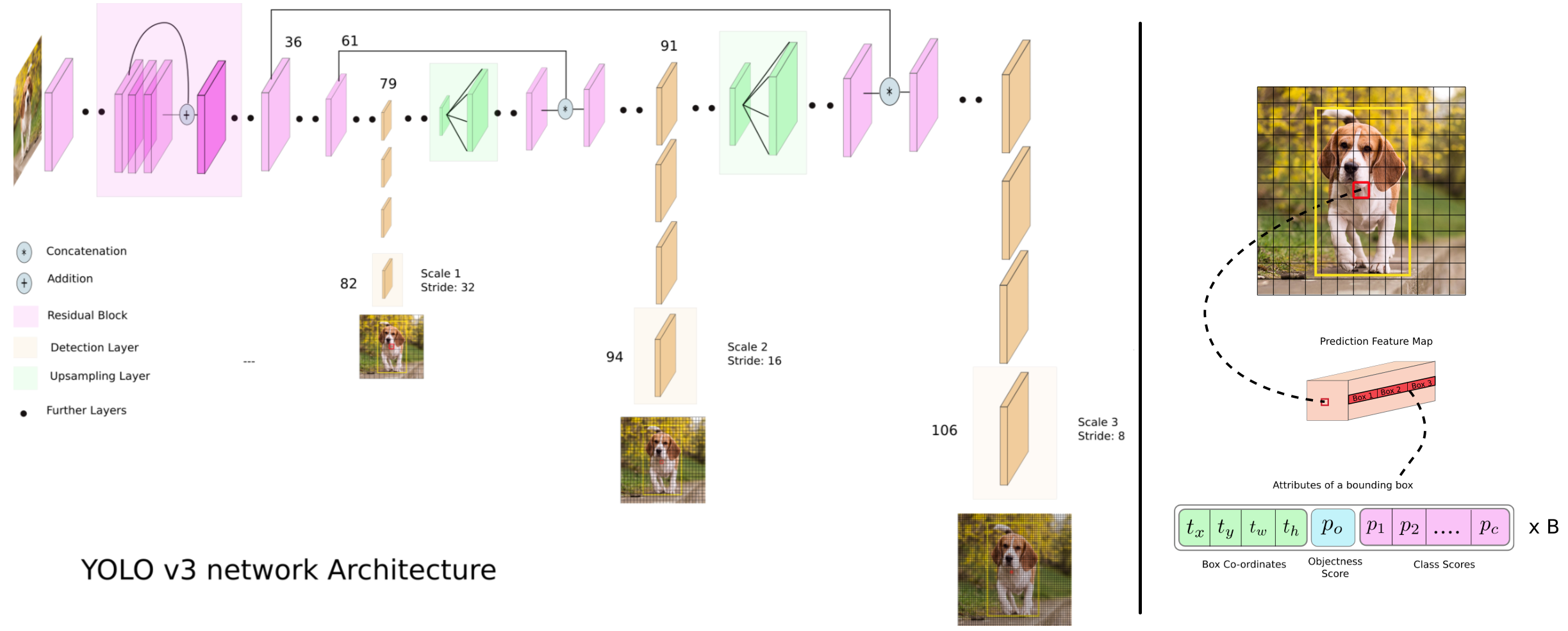
Predictions Across Scales
주황색 단이 우리가 SSD나 RetinaNet에서 보는 detect-head classification, regression 단이다.
위와 같이 3개의 P(pyramid feature)를 사용한다. 그리고 하나의 cell에 대해서, 3개의 Anchor box만 사용한다.
COCO dataset에 대해서, K-mean clustering을 사용해서 가장 적절한 bounding box(Anchor box 크기)값을 찾는다. 결론적으로 (10×13),(16×30),(33×23) // (30×61),(62×45),(59× 119) // (116 × 90),(156 × 198),(373 × 326) 를 사용한다. (동영상 : 내가 찾고자 하는 객체의 특징을 반영해서 bounding box크기를 적절히 설정하는 것도 아주 중요하다. 예를 들어 사람을 detect하고 싶다면 가로로 긴 박스는 필요없다)
당연히 작은 bounding box는 가장 마지막 단의 cell에서 사용되는 box, 큰 bounding box는 가장 첫번째 단의 cell에서 사용되는 box이다.
Things We Tried That Didn’t Work
Offset predictions : linear 함수를 사용해봤지만 성능 저하.
Focal Loss : objectness score라는 개념이 들어가서, 이것으로 easy, hard Image에 따른 성능 저하는 없었다. 차라리 Focal Loss를 사용해서 성능 저하가 일어났다. 또한 objectness score 덕분에 hard negative mining과 같은 작업을 하지 않았다. 즉 objectness score를 통해 class imbalance 문제를 다소 해결했다.
Dual IOU thresholds and truth assignment : Faster RCNN 에서는 2개의 IOU thresholds를 사용했다. (0.7과 0.3) 0.7을 넘으면 Positive example, 0.7과 0.3 사이는 학습에 사용하지 않고, 0.3 이하는 Negative example로 background 예측에 사용했다. 비슷한 전력을 사용했지만 결과는 좋지 않았다.
COCO의 AP 계산에 대한 비판
YOLOv3는 좋은 detector이다. 하지만 COCO AP는 IOU를 [0.5부터 : 0.95까지 : 0.05단위로] 바꾸며 mAP를 계산한다. 이건 의미가 없다! 인간이 IOU 0.3~0.5를 눈으로 계산해보라고 하면 못하더라!
COCO에서는 Pascal voc보다 labelling 이 정확한건 알겠다.(Bounding Box를 정확하게 친다는 등) 하지만 IOU가 0.5보다 정확하게 Detect해야한다는 사실은 의미가 없다. 0.5보다 높게 Threshold를 가져가면… classification은 정확하게 됐는데, regression 좀 부정확하게 쳤다고 그걸 틀린 판단이라고 확정해버리는 것은 억울하다.
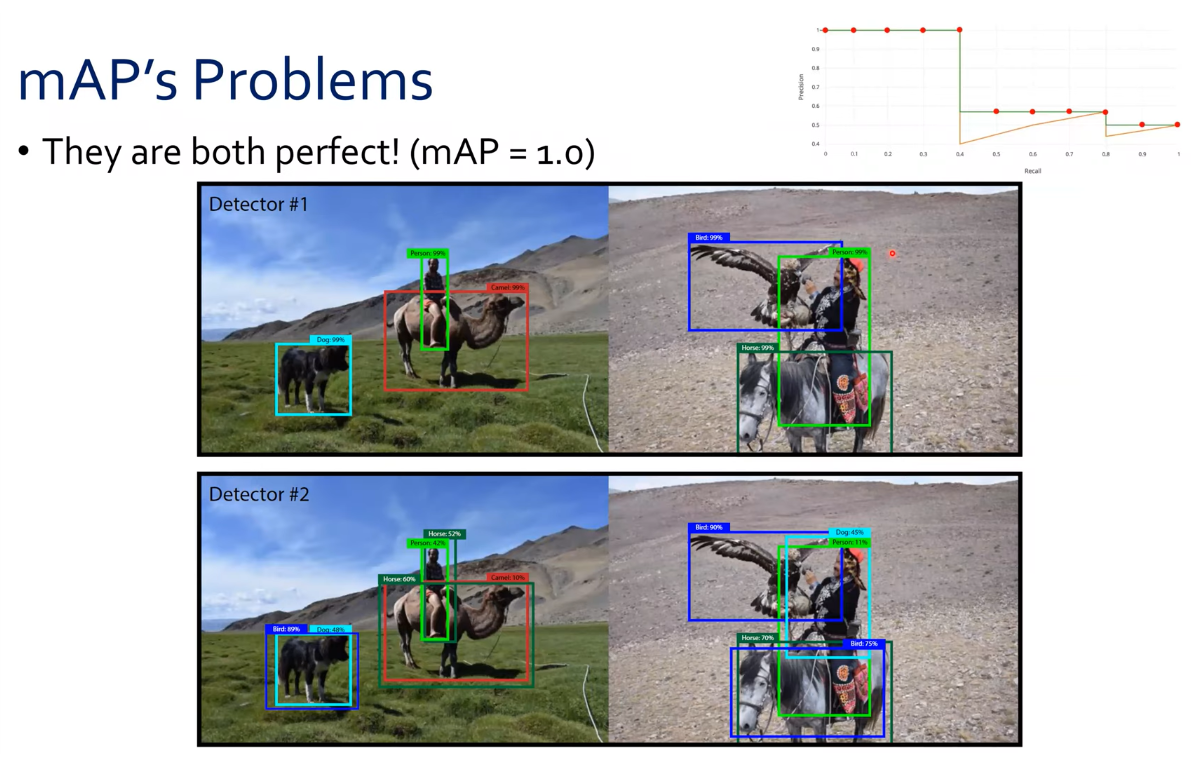
mAP는 옳지 않은 지표이다.
이 그림에서 위의 Detector 1 이 훨씬 잘했다고 우리는 생각한다. 하지만 둘다 mAP를 계산하면 놀랍게도 1이 나온다. 2개를 이용해 recall, precise 그래프를 그려보면 오른쪽 위와 같은 그래프가 된다. 초록색 라인이 Detector1이고 주황색 라인이 Detector2이다!