【In-Segmen】Understanding Mask-RCNN(+RPN) paper with code
- 논문 : Mask R-CNN
- 분류 : Original Instance Segmentation
- 저자 : Kaiming He, Georgia Gkioxari (Facebook AI Research)
- 읽는 배경 : Recognition Basic. Understand confusing and ambiguous things.
- 읽으면서 생각할 포인트 : 코드와 함께 최대한 완벽히 이해하기. 이해한 것 정확히 기록해두기.
- 느낀점 :
- RoIAlign 논문 보면 이해할 수 있게 만들어 놓은 줄 알았는데, 그렇지도 않다. 차라리 아래의 Post글을 보는게 훨씬 좋다. 이런걸 보면, 논문을 읽고, 나의 생각을 조금 추가해서 이해하는게 정말 필요한듯 하다. 논문에는 정확한 설명을 적어놓은게 아니므로.
- 논문 요약본 보다는, 직관적(intuitive) 이해를 적어놓은 유투브나, 아래의 Bilinear interpolation과 같은 블로그를 공부하는게 자세한 이해, 완벽한 이해를 가능케 하는 것 같다.
- 내 블로그 관련 Post :
- (1) Mask R-CNN by DVCR
- FCN : Pixel wise Classification
- (2) Mask R-CNN Youtube 내용 정리
- bounding box 내부의 객체 class에 상관없이, Box 내부에 masking 정보만 따내는 역할을 하는 Mask-branch를 추가했다.
- Equivariance 연산(<-> Invariant)을 수행하는 Mask-Branch는 어떻게 생겼지? Mask-branch에 가장 마지막 단에 나오는 feature map은 (ROI Align이후 크기가 w,h라 한다면..) 2 x w * 2 x h * 80 이다. 여기서 80은 coco의 class별 mask 모든 예측값이다. 80개의 depth에서 loss계산은, box의 class에 대상하는 한 channel feature만을 이용한다. 나머지는 loss 계산시 무시됨.
- ROI Align 이란? : Input-EachROI. output-7x7(nxn) Pooled Feature. nxn등분(첫번째 quantization)->각4등분(두번째 quantization)->Bilinear interpolation->각4등분에 대해 Max Pooling->(nxn) Pooled Feature Map 획득.
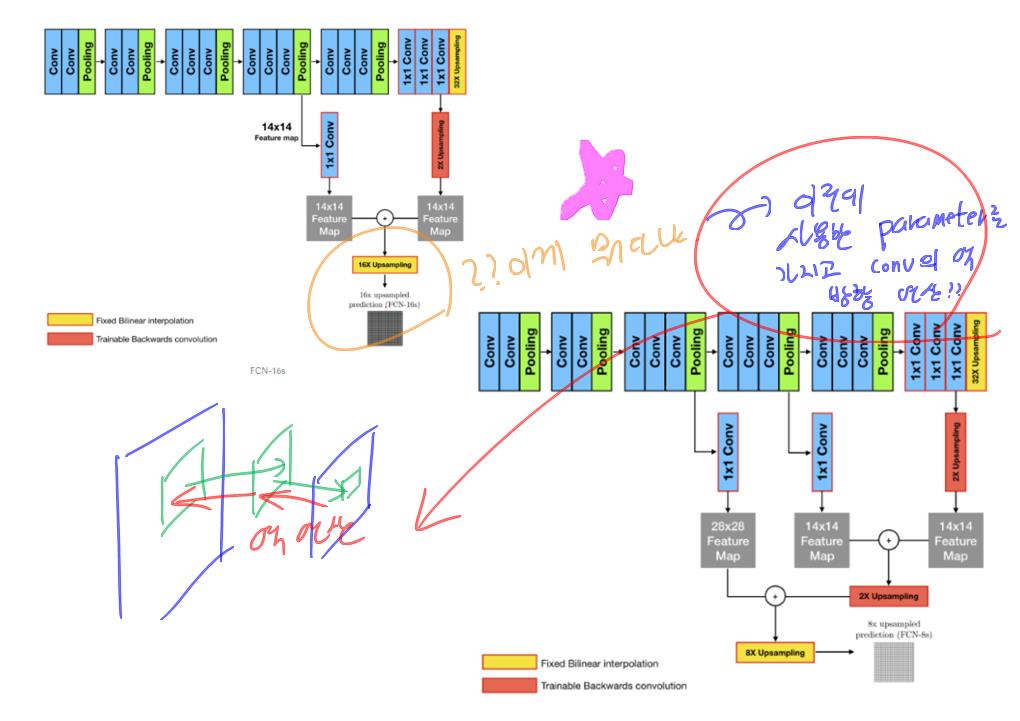
- (3) FCN
- 해당 이미지(필기 무시)를 확인해보면, 어디서 deconv(파라메터 학습 필요)를 사용하고, 어디서 Bilinear Interpolation이 이뤄지는지 알 수 있다.
- 최종 아웃풋 image_w x image_h x 21(classes+background)
- (1) Mask R-CNN by DVCR
1. Mask-RCNN
- Abstract, Introduction, Related Work
- Mask R-CNN
- Mask Representation :
- mask-branch output : [m^2 x K channel] binary(sigmoid) mask (K-classes, mxm masks of resolution)
- fc layer를 사용하는 것보다, FCN 개념의 convolutions을 사용함으로써 더 좋은 결과. spatial dimensions information을 읽지 않을 수 있었다.
- but Loss_mask is only defined on the k-th mask(K channel 중 k번째 채널)
- RoIAlign : bilinear interpolation, ROI를 n x n으로 자른 후의 한 cell을 논문에서는 bin이라고 표현함. ROIAlign은 논문에서 이해할 수 없게 적어놓았다.
- Network Architecture : straightforward structure bask-branch
- RPN 개념은 faster-rcnn을 그대로 이용했으므로, mask-rcnn 코드를 보고 RPN의 활용을 좀 더 구체적으로 공부해 보자. faster-rcnn 논문 보지말고 이전 나의 블로그 포스트 참조(20-08-15-FastRCNN)
- Mask Representation :
- 특히 Localization Loss function & default(Anchor) boxes about scales and aspect ratios 에 대한 내용은 SSD w/ code Post 를 참고 하면 좋은 이해가 가능하다.
2. Detectron2 - MaskRCNN
- Detectron2 전반적인 지식은 다음 게시물 참조 (Detectron2 Tutorial and Overview)
- config 파일 분석하기 - mmdetection에서는 py 파일의 dict 형식을 이용한 것과 다르게, yaml 형식 이용
from detectron2.config import get_cfg분석하기- detectron2/config/config.py :
def get_cfg() -> CfgNode: - detectron2/config/config.py :
class CfgNode(_CfgNode): from fvcore.common.config import CfgNode as _CfgNode- facebookresearch/fvcorefvcore : github ->
from yacs.config import CfgNode as _CfgNode - 즉 yacs 모듈을 이용한 config 파일 생성
- 어렵게 생각할거 없이(중간과정 공부할 필요 없이), 나는 아래의 작업만 하면 된다.
- cfg = get_cfg() 로 생성한 변수 cfg에 들어가는 모든 변수 확인 (config/defaults.py)
- 여기서 필요한 cfg 자료만 수정하기
- 그 이후 detectron2의 모든 파일들은
cfg.DATALOADER.NUM_WORKERS이와 같이 cfg파일 내부에 저장된 변수만 그대로 불러 사용한다. (그래서 더더욱 fvcore, yacs 몰라도 됨) - self.model = build_model(self.cfg) (
class DefaultPredictor: IN engine/defaults.py)
- detectron2/config/config.py :
- class
DefaultPredictorin engine/defaults.py- class DfaultPredictor에 대한 “”” 주석 설명 (defaults.py#L161- 별거없음)
- def __init__(self, cfg) : self.model = build_model(self.cfg)
- detectron2/modeling/meta_arch/build.py :
def build_model(cfg): model = META_ARCH_REGISTRY.get(meta_arch)(cfg)- cfg.MODEL.META_ARCHITECTURE 에 적혀있는 model architecture 를 build한다. ( weight는 load하지 않은 상태이다. DfaultPredictor에서 model weight load 해준다.
checkpointer.load(cfg.MODEL.WEIGHTS)) from detectron2.utils.registry import Registry->META_ARCH_REGISTRY = Registry("META_ARCH")- detectron2/utils/registry.py :
from fvcore.common.registry import Registry - fvcore로 넘어가는거 보니… 이렇게 타고 가는게 의미가 없는 듯 하다.
- cfg.MODEL.META_ARCHITECTURE 에 적혀있는 model architecture 를 build한다. ( weight는 load하지 않은 상태이다. DfaultPredictor에서 model weight load 해준다.
- 따라서 다음과 같은 디버깅을 수행해 보았다.

- model의 핵심은
GeneralizedRCNN인듯하다. 따라서 다음의 파일을 분석해보기로 하였다.- detectron2/modeling/meta_arch/rcnn.py :
class GeneralizedRCNN(nn.Module): - 이 과정은 다음을 수행한다
- Per-image feature extraction (aka backbone)
- Region proposal generation
- Per-region feature extraction and prediction
- detectron2/modeling/meta_arch/rcnn.py :
- 여기까지 결론 :
- 내가 원하는 것은, 원래 이해가 안됐다가 이해가 된 부분의 코드를 확인해 보는 것 이었다.(3.2 참조) 하지만 이 같은 코드 구조로 공부를 하는 것은 큰 의미가 없을 듯 하다.
- 어쨋든 핵심은 detectron2/detectron2/modeling 내부에 있는 코드들이다. 코드 제목을 보고 정말 필요한 내용의 코드만 조금씩 읽고 이해해보는게 좋겠다. 여기있는 클래스와 함수를, 다른 사용자가 ‘모듈로써’ 가져와서 사용하기 쉽게 만들어 놓았을 것이다. 따라서 필요하면 그때 가져와서 사용해보자.

3. multimodallearning/pytorch-mask-rcnn
Github Link : multimodallearning/pytorch-mask-rcnn
코드가 모듈화가 거의 안되어 있다. model.py에 거의 모든 구현이 다 되어 있다. 그래서 더 이해하기 쉽다.
아래의 내용들이 코드로 어떻게 구현되었는지 궁금하다.
- (1) RPN-Anchor사용법
- (2) ROI-Align
- (3) Mask-Branch
- (4) Loss_mask
- (5) RPN의 output값이 Head부분의 classification/localization에서 어떻게 쓰이는지
원래는 공부하려고 했으나… 나중에 필요하면 다시 와서 공부하도록 하자.
2020.02.04 - RefineDet까지 공부하면서 코드를 통해서 헷갈리는 것을 분명히 파악하는 것이 얼마나 중요한 것인지 깨달았다. 따라서 그나마 가장 궁금했던 것 하나만 빠르게 분석하려고 한다.
(5) RPN의 output값이 Head부분의 classification/localization에서 어떻게 쓰이는가?
RPN에서 나오는 2(positive, negative objectness score)+4(offset relative) = 6개의 정보.
위에서 나온 ROI 중에서, 정말 객체가 있을 법한 정제된 ROI 즉 rpn_rois를 추출
rpn_rois에서 4(offset relative) 값만 이용한다. Backbone에서 나온 Feature Map에서 저 4(offset relative)에 대한 영역만 ROI Pooing (ROI Align)을 수행한다.
**pytorch-mask-rcnn/model.py ** 코드로 확인
# pytorch-mask-rcnn/model.py def proposal_layer(inputs, proposal_count, nms_threshold, anchors, config=None): """ RPN에서 나온 결과들 중 정말 필요한 ROI만을 걸러주는 Layer 아래의 (bg prob, fg prob) = (negative=easy confidence, pasitive=hard confidence)를 이용해서 적당한 Inputs: rpn_probs: [batch, anchors, (bg prob, fg prob)] rpn_bbox: [batch, anchors, (dy, dx, log(dh), log(dw))] Returns: Proposals in normalized coordinates [batch, rois, (y1, x1, y2, x2)] """ outputs = list(zip(*layer_outputs)) # BackBone + RPN을 통과하고 나온느 결과들 outputs = [torch.cat(list(o), dim=1) for o in outputs] rpn_class_logits, rpn_class, rpn_bbox = outputs # rpn_rois 위의 함수에 의해 나온 정제된 rpn_rois rpn_rois = proposal_layer([rpn_class, rpn_bbox], proposal_count=proposal_count, nms_threshold=self.config.RPN_NMS_THRESHOLD, anchors=self.anchors, config=self.config) # rpn_rois가 self.classifier에 들어가는 것에 집중 if mode == 'inference': mrcnn_class_logits, mrcnn_class, mrcnn_bbox = self.classifier(mrcnn_feature_maps, rpn_rois) # rpn_rois가 detection_target_layer함수에 의해 rois가 되고, self.classifier에 들어가는 것에 집중 elif mode == 'training': rois, target_class_ids, target_deltas, target_mask = detection_target_layer(rpn_rois, gt_class_ids, gt_boxes, gt_masks, self.config) mrcnn_class_logits, mrcnn_class, mrcnn_bbox = self.classifier(mrcnn_feature_maps, rois)# self.Classifier가 무엇인가? self.classifier = Classifier(256, config.POOL_SIZE, config.IMAGE_SHAPE, config.NUM_CLASSES) # Line 908 class Classifier(nn.Module): def forward(self, x, rois): # x : backbone 통과하고 나온 feature map x = pyramid_roi_align([rois]+x, self.pool_size, self.image_shape # ** [rois]+x 에 집중!! list에 append 되는 거다! ** # 그 이후 conv2 계속 통과... def pyramid_roi_align(inputs, pool_size, image_shape): """ feature map을 받고 거기서 ROI Pooing => ROP Align 을 수행해 reture해주는 함수 Inputs = [rois]+x Input[0] : refined boxes by 'proposal_layer' func - [batch, num_boxes, (y1, x1, y2, x2) Input[1] : Feature maps - List of feature maps from different levels Input[0] 가 가리키는 영역에 대해서 Input[1]에서 부터 ROI Aling(Pooing)을 수행한다. return [pooled feature map : RPN이 알려준, Feature Map 중에서 '객체가 있을법한 영역'만 뽑아낸 조각난 Feature map] """

{kind=link}