【Detection】Understanding SSD paper with code w/ my advice
- 논문 : SSD: Single Shot MultiBox Detector
- 분류 : Original Object Detection
- 저자 : Wei Liu , Dragomir Anguelov, Dumitru Erhan , Christian Szegedy
- 읽는 배경 : Recognition Basic. Understand confusing and ambiguous things.
- 읽으면서 생각할 포인트 : 이전 나의 SSD 정리 Post, 코드와 함께 최대한 완벽히 이해하기. 이해한 것 정확히 기록해두기.
- 느낀점 :
- 논문을 정말 깔끔하게 정리해놓은 사이트(SSD 분석)이 있다. 내용도 좋지만, 어떻게 논문을 정리 했는지를 참고하자. 지금은 논문을 추후에 작성하기 위해, 내용을 아주 짧게 요악하는 것 보다는 논문의 논리전개가 어떤지 기록하고 있다. 하지만 어느정도 익숙해지면, 이와 같은 논문 정리가 필요한 것 같다. 정말 핵심적인 내용만! 사실 논문이 말하는 ‘핵심’은 한 문단으로도 충분히 설명 가능하다. 그것만 기억해 두면 된다는 사실을 잊지 말자.
- 하지만 내가 위의 사이트를 참고하지 않는 이유는, 저런 논문 정리는 이미 많이 봤다. 내가 직접 논문을 읽고 도대체!! Bounding Box를 어떻게 사용하고, Loss함수를 어떻게 정의해서 사용하는지. 내가 직접 논문 읽고 이해하고 싶었기 때문이다.
- SSD논문 자체도 그리 자세하지 않다… 원래 논문이 이렇게 자세하지 않을 수 있나보다. 만약 논문을 읽으면서 완벽하게 이해되지 않았다면, (1) 논문에는 잘 적혀있는데 내가 이해하지 못했거나 (2) 논문이 원래 자세하지 않거나. 둘 중 하나이다. 따라서 논문을 읽고 100프로 이해가 안됐다고 해도, (2)경우일 수 있으니, 모른다고 좌절하지 말자.
- 선배 조언
- 날 먼저 판단하지 마라. 박사나 석사나 학사나 똑같다. 동급이다. 누가 더 잘하고 못하고가 없다. 내가 궁금한 분야를 좀만 공부하면, 금방 그 이상의 실력을 가질 수 있다.
- 자신있게 하고 싶은걸 해라.
- 느낀점 :
- 카이스트는 주중과 주말 상관없이 모든 사람이 열심히 공부하고 연구하고 그러는 줄 알았다. 하지만 내가 상상한 그 정도는 아니었다. 여기 계신 분들도 토일 쉬고 점심,저녁 2시간씩 쉬고 쉬고 싶은날 쉬고 그러시는 것 같다. (물론 집에서도 조금씩 공부하시지만..) 그러면 여기 계신 분들이 우리나라에서 많은 좋은 결과,논문들을 만들어 내는 이유가 뭘까? 생각해보았다. 그냥 맘먹으면 무언가를 해낼 수 있는 사람들이 모여있기 때문인 것 같다.(즉, 좋은 사람들이 함께 모여있기 때문.) 여기에 좋은 사람들이 너무 많다. 내가 노력하면 정말 좋은 conference의 논문에 2저자 3저자로 내가 들어갈 수 있게 해줄 똑똑한 사람들, 착한 사람들, 그리고 뭔가를 독하게 해본 사람들, 좋은 조언을 해줄 수 있는 사람들이 아주 많다. 이런 분들이 많이 보여 있기 때문에 나같은 후배들이 더 빠르게 위로 올라올 수 있는 것 같고, 그렇게 빠르게 올라온 사람들은 다음에 올 아래의 사람들(후배)들을 똑같이 빠르게 끌어올려 줄 수 있는 것 같다. 이런 ‘선 순환’으로 대한민국 최고의 대학이 될 수 있지 않았나 싶다. 절대적인 공부시간은 다른 대학의 사람들과 똑같다 할지라도.
- 따라서. 나도 할 수 있다. 여기 계신 분들이 주말에는 푹 쉬고 점심저녁에 좀 놀고 가끔은 노는 시간에..! 나는 공부하고 공부하고 노력하면, 나도 충분히 여기 계신 분들처럼 좋은 결과를 내고, 좋은 논문을 낼 수 있겠다는 자신감이 생긴다. 지금은 여기 계신 분들보다 지식은 많이 부족해도. 여기 계신 그 어떤 분보다, 노력이 부족한 사람은 되지 말자. 따라잡고 싶으면, 보다 더 해야지. 닮고 싶다면, 더 일찍 더 늦게까지 공부해야지. 당연한거다.
1. Single Shot Detector - SSD
Abstract, Introduction
SSD
each default box를 통해서 예측하는 2가지. (1) the shape offsets relative and (2) the confidences
In Traning, Default Box와 GT Box를 matching값을 비교한다. 아래의 사진의 빨간색, 파란색 점선처럼 Positive인 것만을 다른다. 나머지는 Negative. 이다. 이때 사용하는 Loss함수는, localization loss (e.g. Smooth L1) and confidence loss (e.g. Softmax)
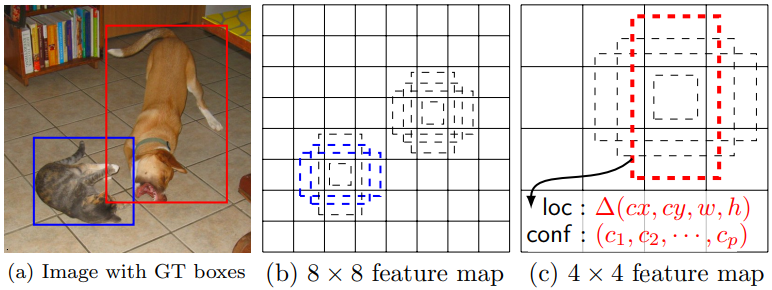
Positive에 대해서는 Confidence & regressing Loss를 모두 학습시키고, Negative에 대해서는 Confidence에 대해서만 학습 시킨다.
Predictions of detections at multiple scale object.
m × n with p channels의 feature map -> 3 × 3 × p small kernel -> m × n x (class confidence score + shape offset relative(GT에 대한 Default box의 상대적 offset값)) = [(c + 4)*k] channels
Training
Matching strategy : IOU가 0.5 이상인 것만을 Positive로 사용했다. (그 이외 자세한 내용 없음)
Loss 함수 이해하기
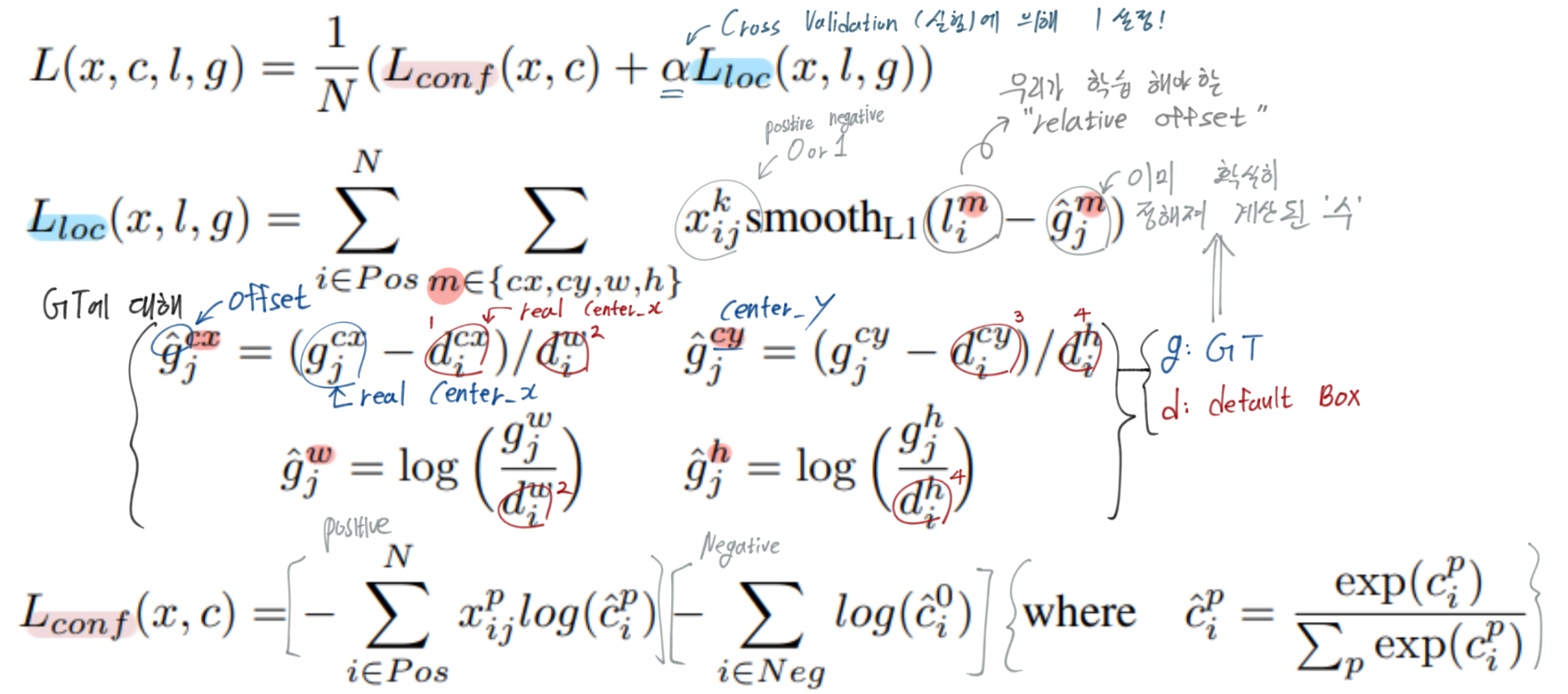
N : positive dafault box 갯수 = the number of matched default boxes N이 0이면 loss는 0이다. (최저 Loss값 따라서 학습 이뤄지지 않음) k : category x : i번재 default box, j번째 GT box에 대한 매칭 값 {1 positive,0 negativ} l : the predicted offset relative g : the ground truth box d : the default bounding box localization : For the center (cx, cy) and r its width (w) and height (h)- sharing parameters across all object scales (가장 마지막 단의 classification, localization에 대해)
default boxes about scales and aspect ratios
- 논문에 나오는 ‘s와 m’에 대한 개념은 논문 보다, a-PyTorch-Tutorial-to-Object-Detection#priors에 더 잘 나와 있다.

- 핵심은 s (Prior Sclase) are precalculated. Feature Map Dimensions에 대해 한 1 x 1 cell이 이미지에서 몇 퍼센트 비율의 receptive field를 차지하는지를 대강 계산해서 표현해 놓은 값이다.
- 논문과 위 사이트에 있는 수식들을 정리하면 아래와 같다.
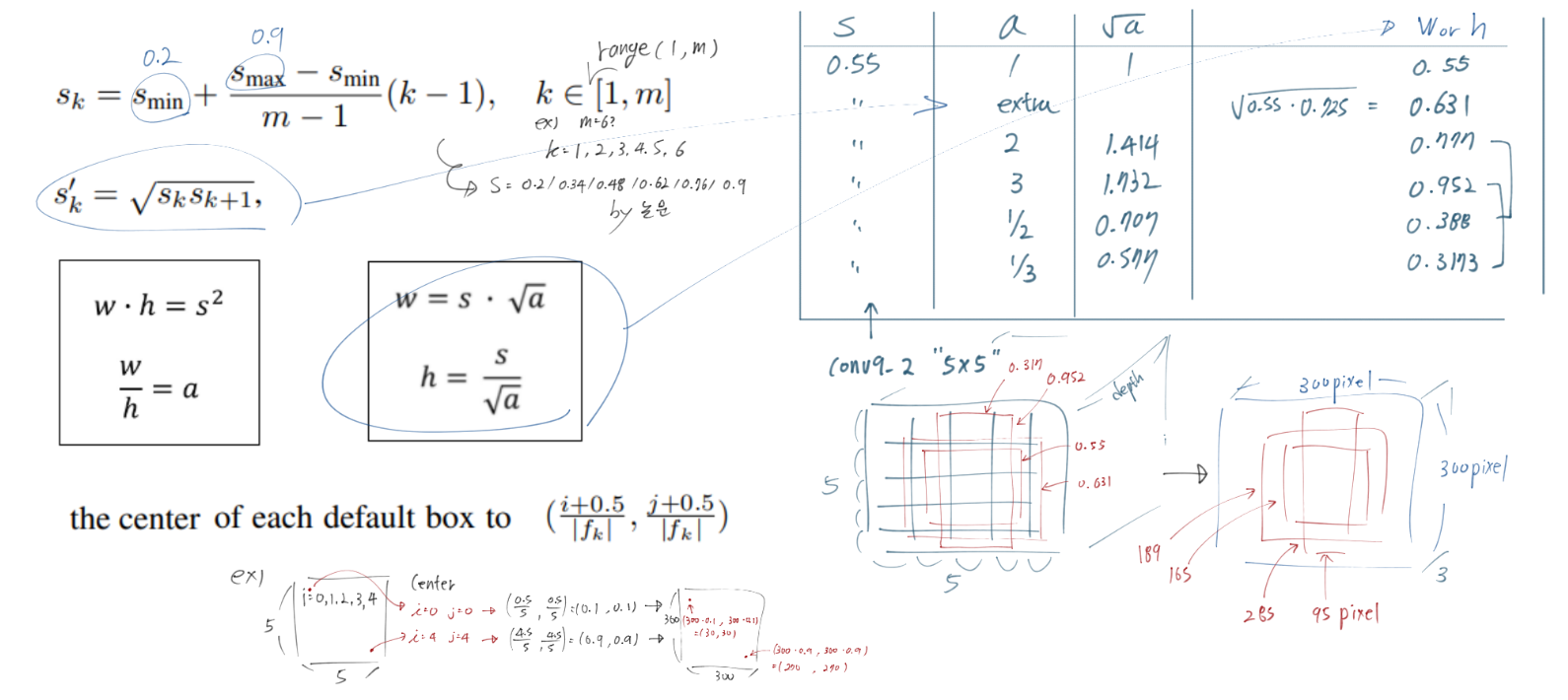
- 논문에 나오는 ‘s와 m’에 대한 개념은 논문 보다, a-PyTorch-Tutorial-to-Object-Detection#priors에 더 잘 나와 있다.
Hard negative mining : the negatives and positives is at most 3:1 비율 학습
Data augmentation - 정해진 몇가지 data augmentation 사용
Experimental Results
2. mmdetection for SSD
init_detector를 통해서 SSD inference 되는 과정- def init_detector(config, checkpoint=None, device=’cuda:0’, cfg_options=None):
- model = build_detector(config.model, test_cfg=config.get(‘test_cfg’))
- def build_detector(cfg, train_cfg=None, test_cfg=None):
- return build(cfg, DETECTORS, dict(train_cfg=train_cfg, test_cfg=test_cfg))
- def build(cfg, registry, default_args=None):
- return build_from_cfg(cfg, registry, default_args)
- from mmcv.utils import Registry, build_from_cfg
- def build_from_cfg(cfg, registry, default_args=None):
- 후.. 여기까지. 일단 패스
- 아래의 과정을 통해 Config과정을 통해서 SSD가 이뤄지는지 보기 위한 작업들이다.

- 위의 결과를 통해 나는 이런 결과를 낼 수 있었다. mmdetection을 가지고 모델 내부 구조 코드를 볼 생각을 하지 말자.
3. lufficc/SSD
- 전체를 분석하는 것은 이전 Post SSD Pytorch Research 에 잘 기록해 두었다.
- 이번에 다시 보는 이유는, SSD paper를 읽고, SSD에서 이해가 안됐던 내용을 코드를 통해 공부하고, 혹은 이 논문 부분을 코드로 어떻게 구현했지? 를 알아보기 위해 공부한 내용을 정리하기 위함이다.
- 원래 이해가 안됐다가, 이해가 된 [(1)Localization Loss function 이해하기] [(2)default boxes about scales and aspect ratios] 는 코드에서 정확히 어떻게 구현되어 있는지 공부해 보자.
- 이라고 생각했으나, RetinaNet의 코드가 너무 깔끔하고 이쁘다.(물론 모듈화는 SSD이 코드가 더 잘되어 있지만.. 모듈화가 많이 되었다고 좋은 건 아닌 듯 하다. 코드를 처음 보는 사람이 머리 아프다.) 위의 (1)(2) 또한RetinaNet 코드로 대강 알 수 있기 때문에 그것을 보는게 더 좋을 듯 하다.
- 2021-02-04 : SSD 코드를 공부했을때 모듈화가 심각해서 보기가 힘들었다. 하지만 그것은 “처음부터 끝까지 다 봐야지.” 라는 욕심때문에 보기 힘들었던 것 같다. 하지만 사실 그렇게 코드를 보는 경우는 드믄것 같다. “내가 궁금한 부분만 찾아보거나, 내가 사용하고 싶은 모듈만 찾아서 사용한다.”라는 마음으로 부분 부분 코드를 본다면, 내가 원하는 부분을 전체 코드에서 찾는 것은 그리 어렵지 않다. 라는 것을 오늘 느꼈다.
