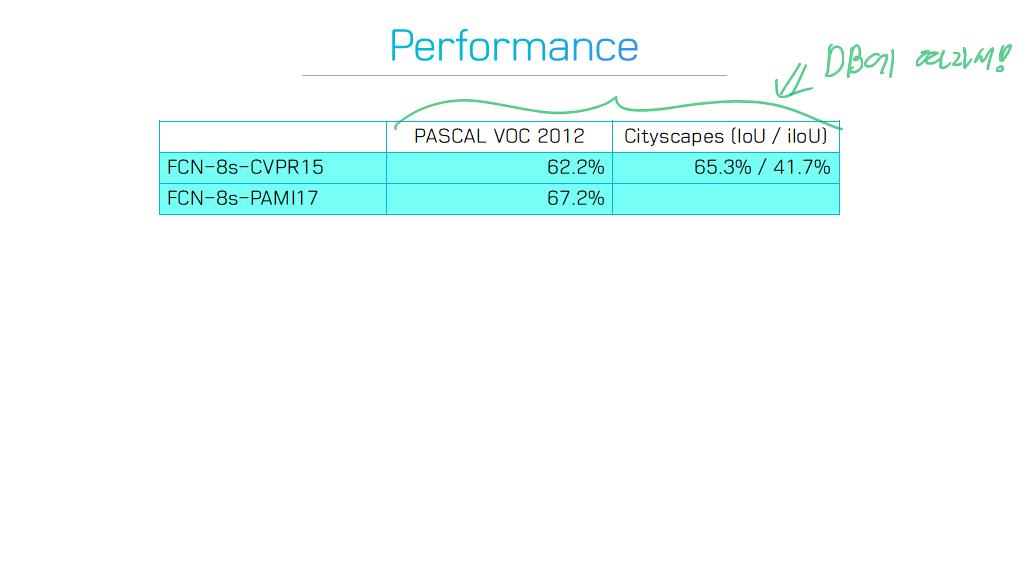
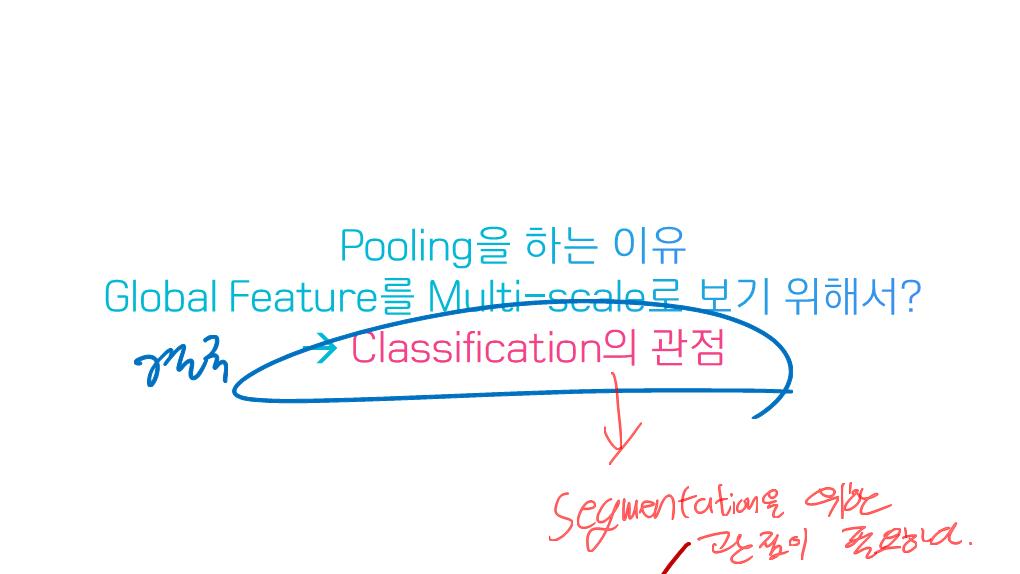
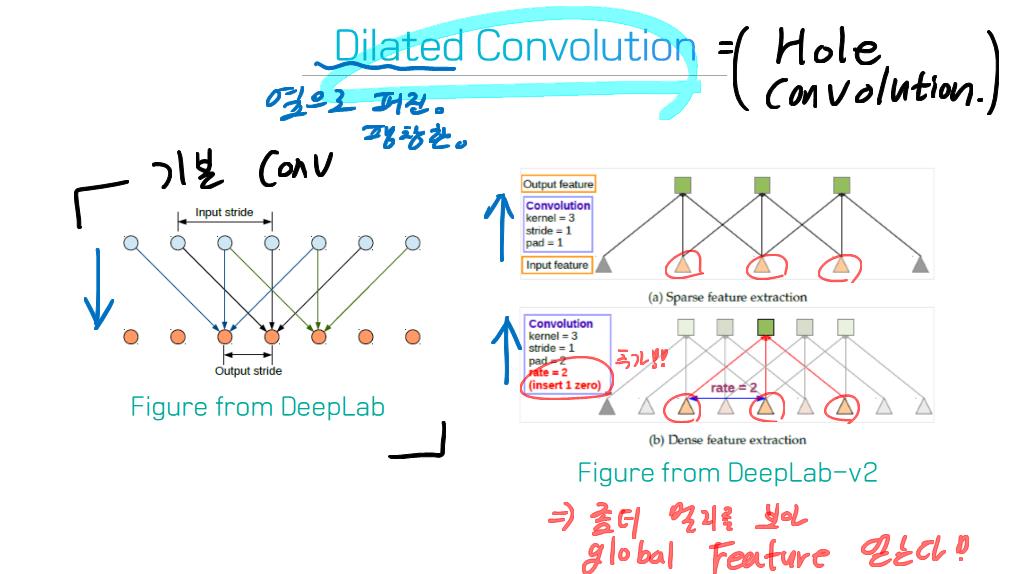
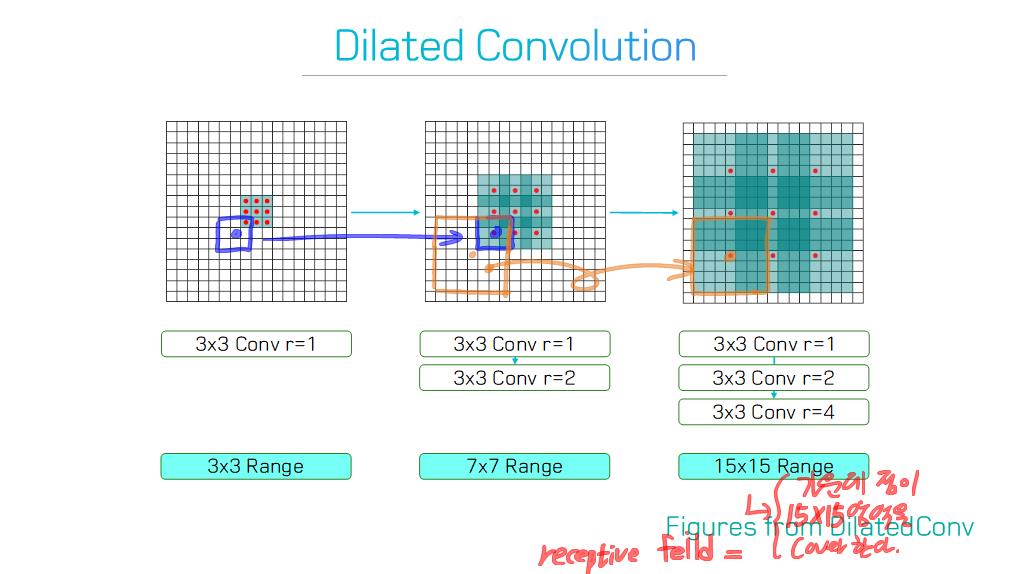
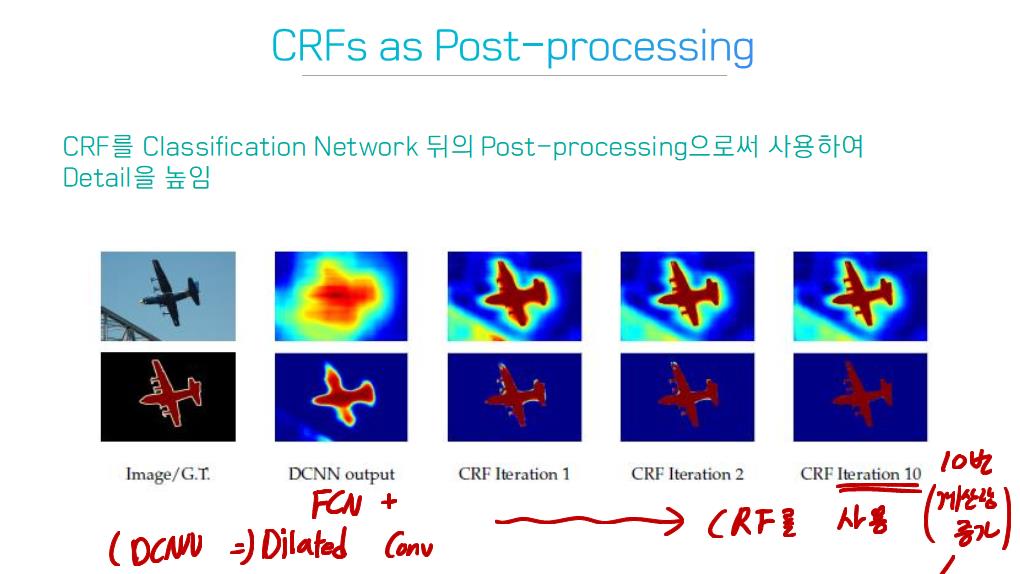
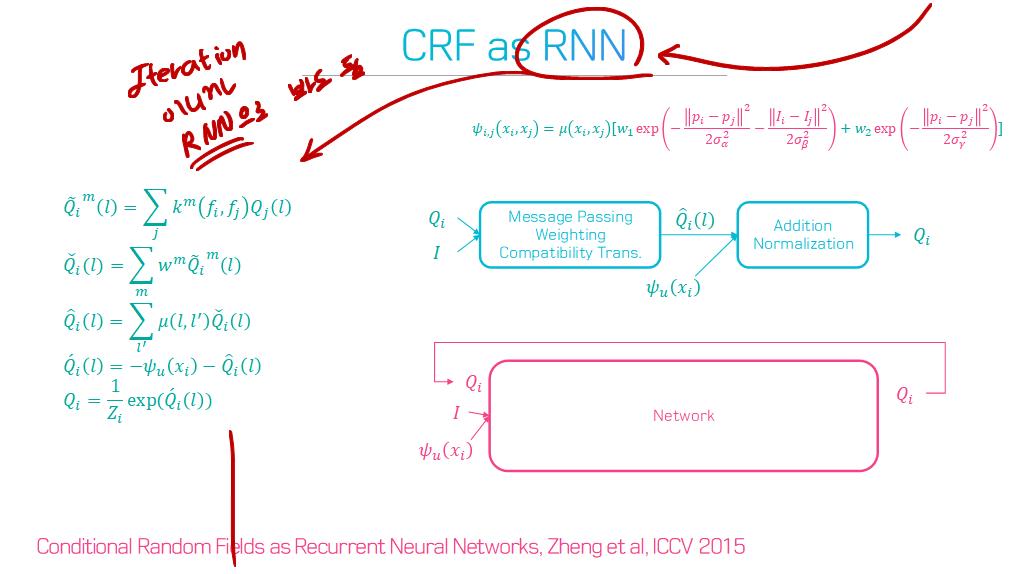
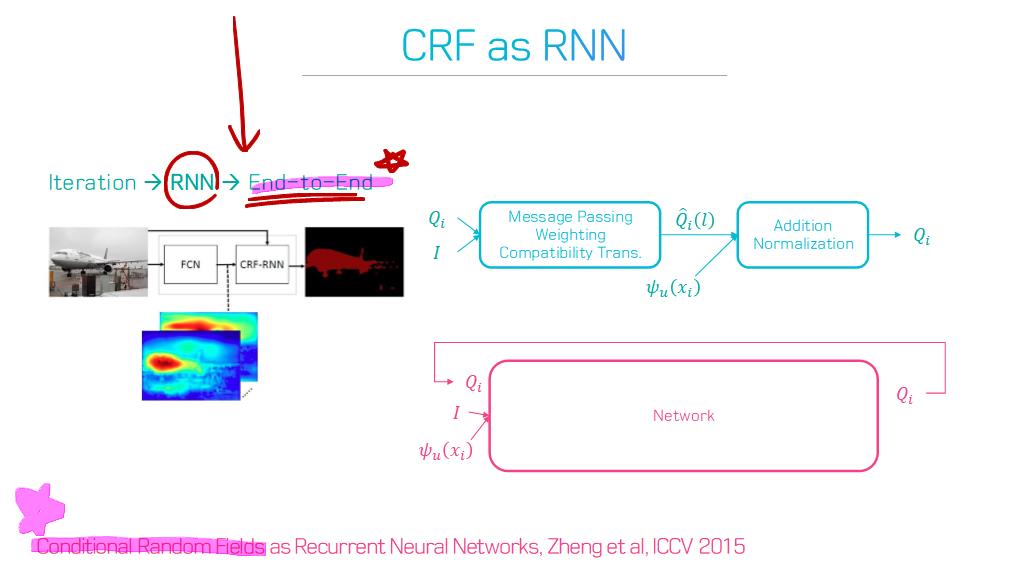
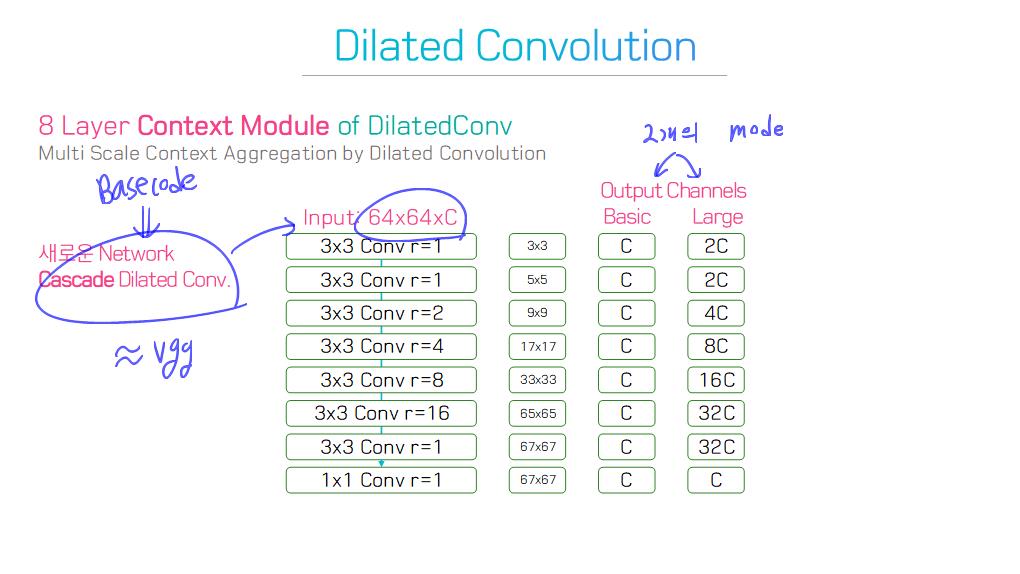
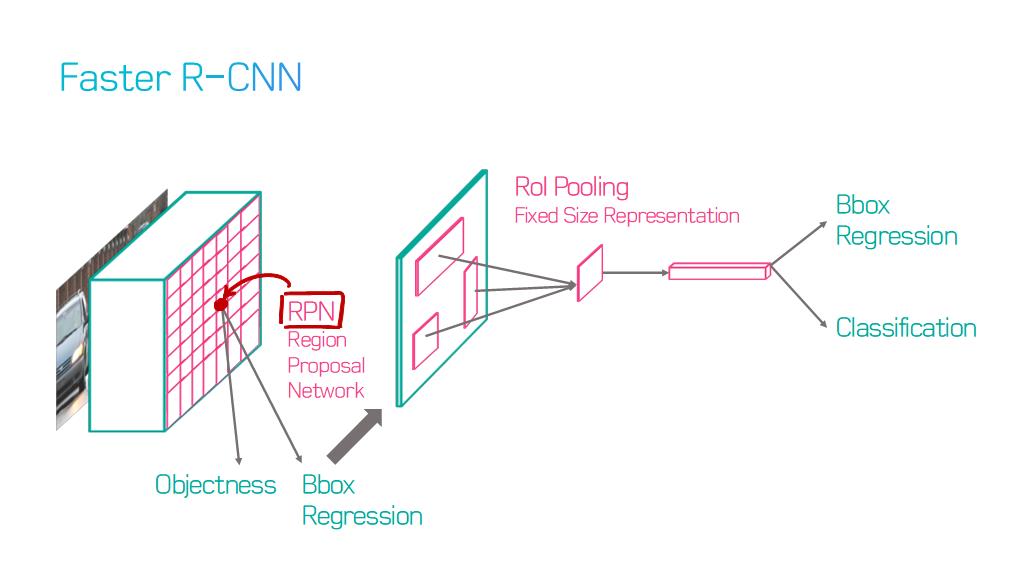
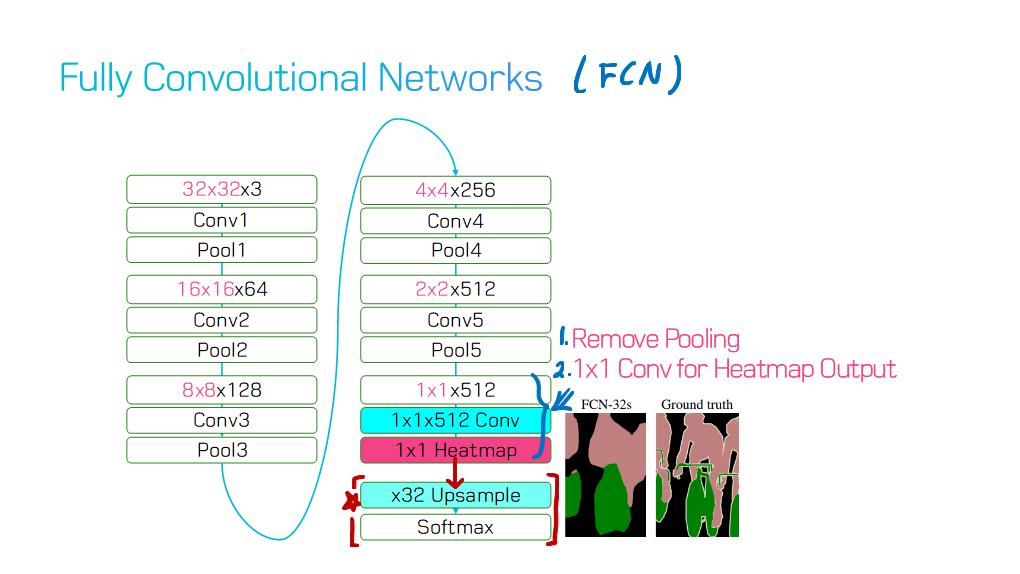
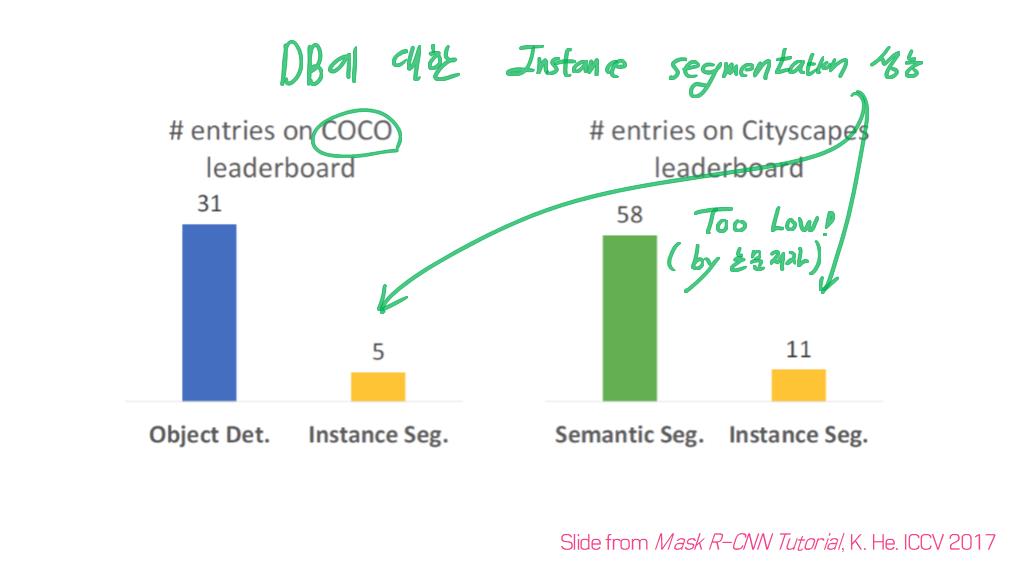
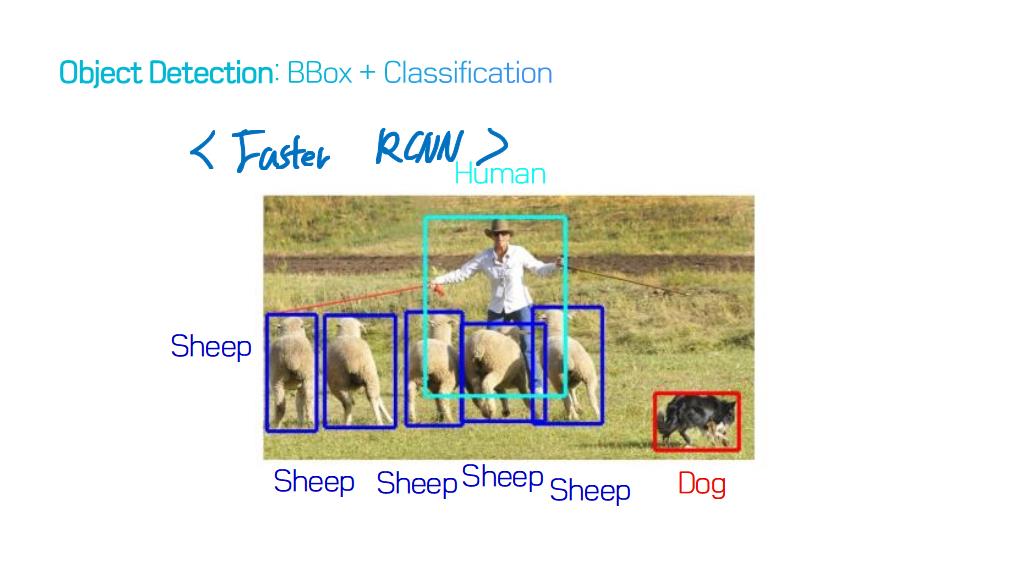
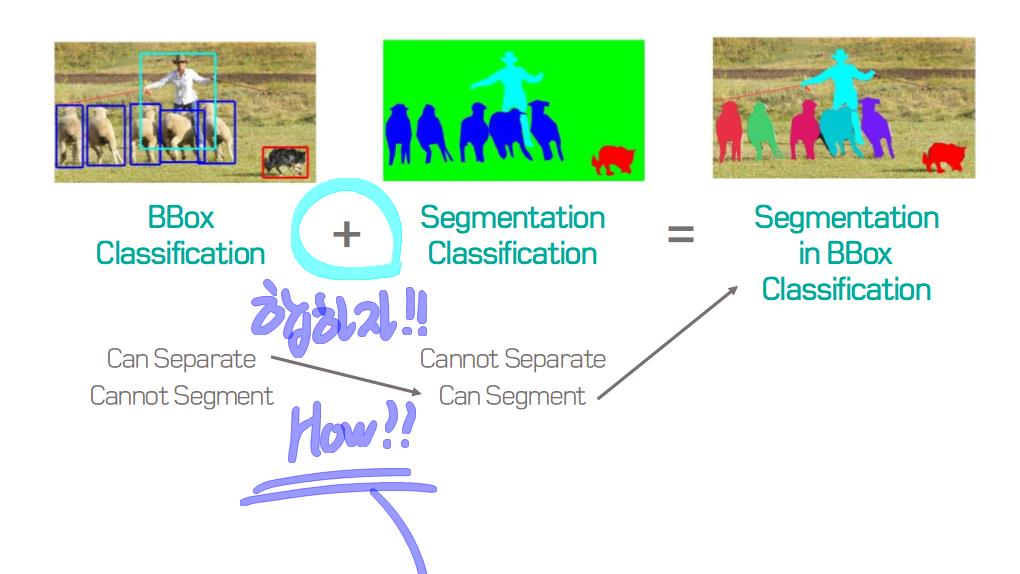
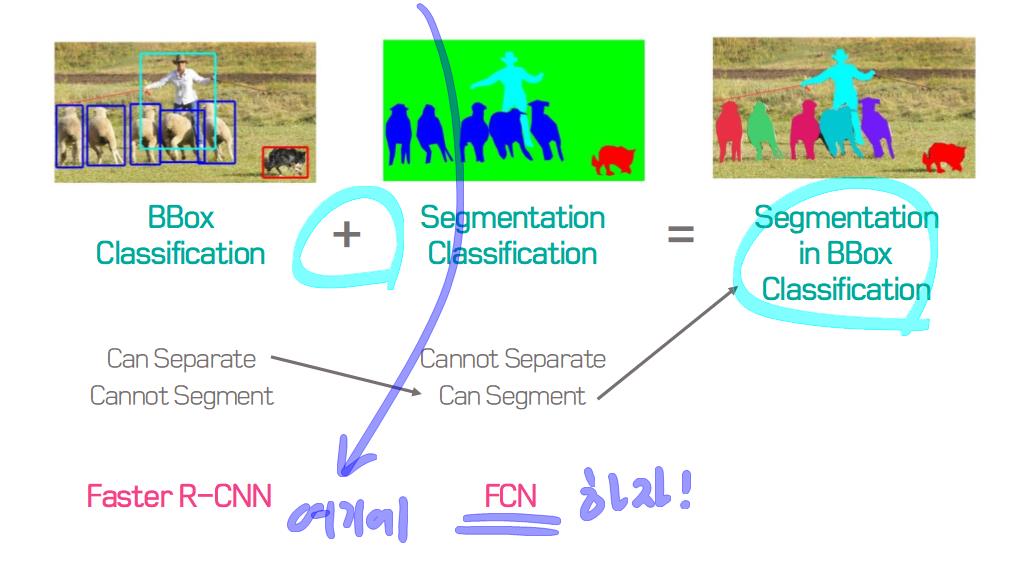
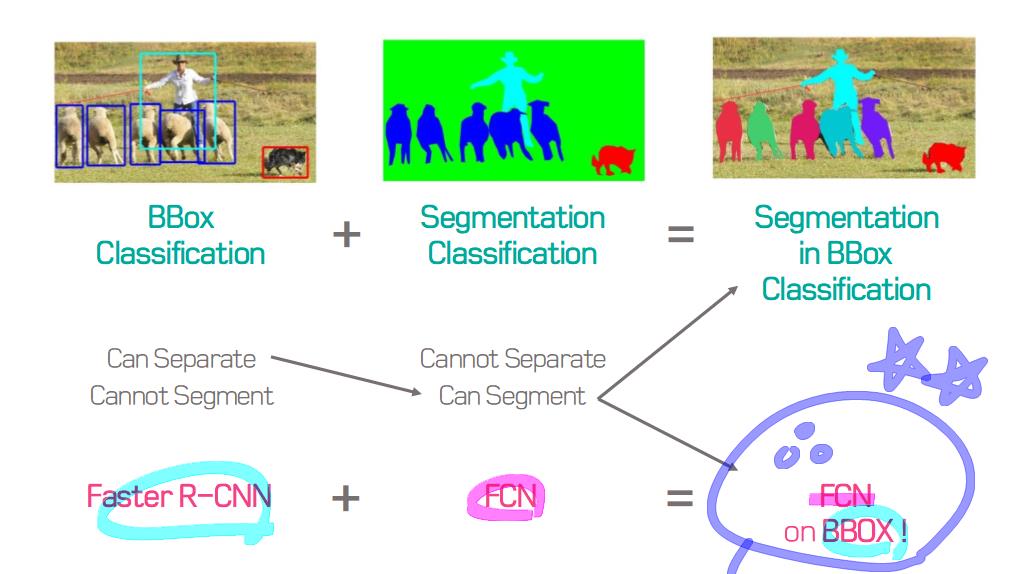
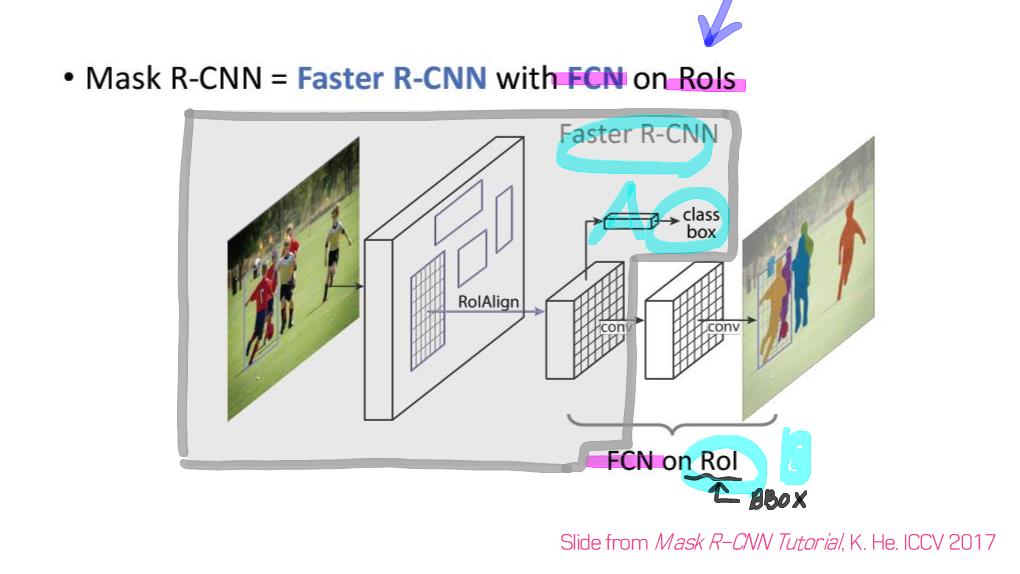
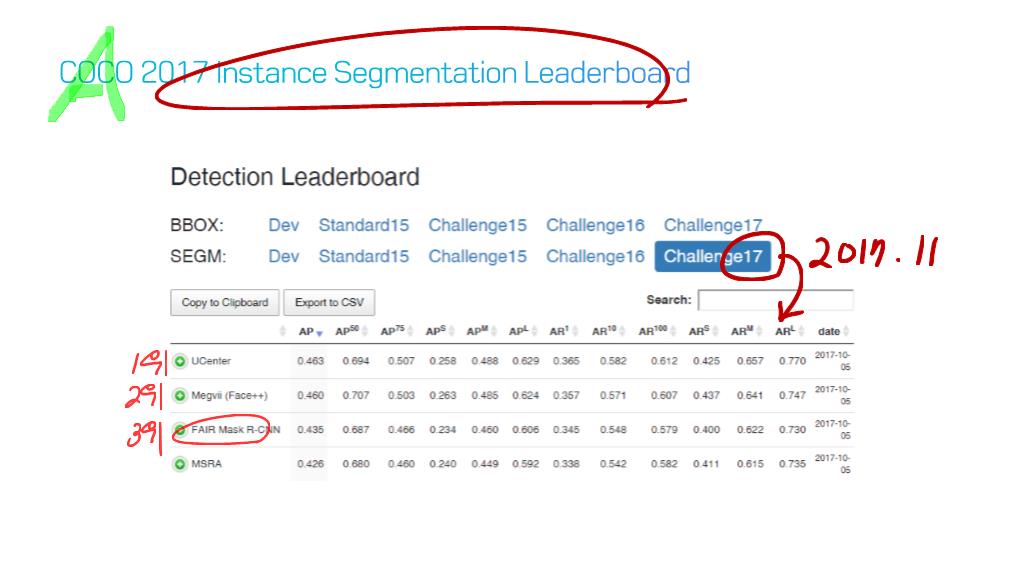
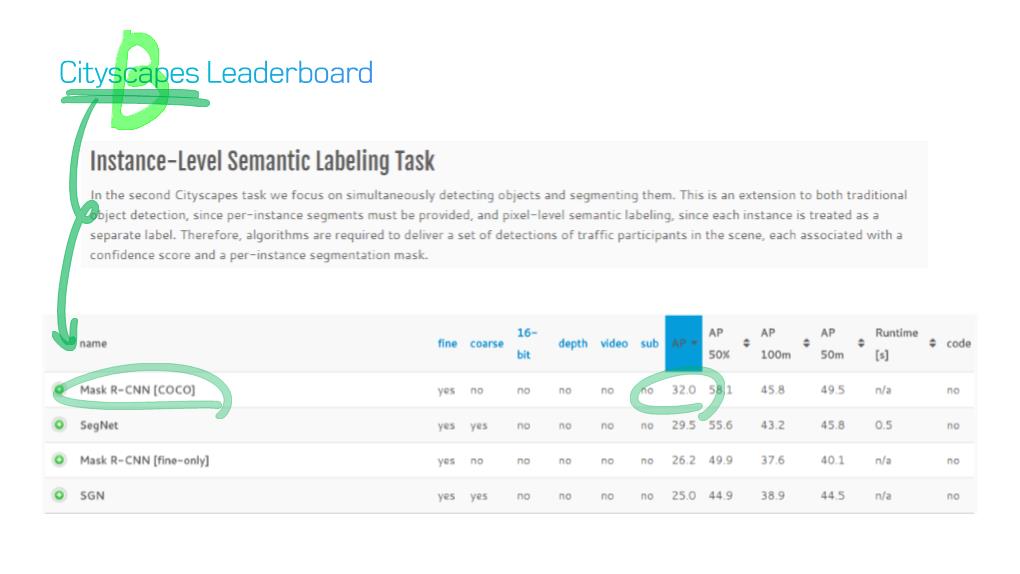
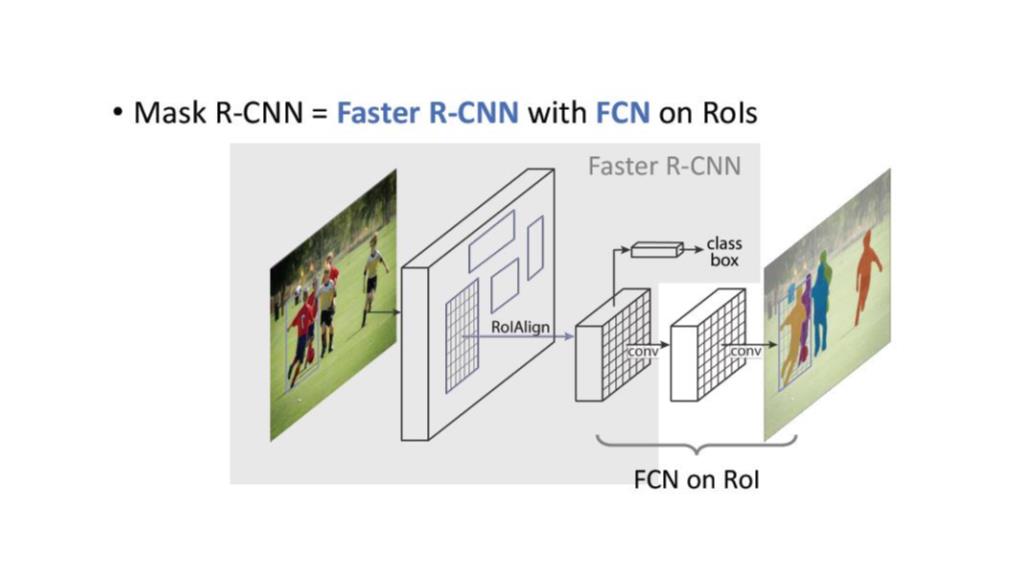
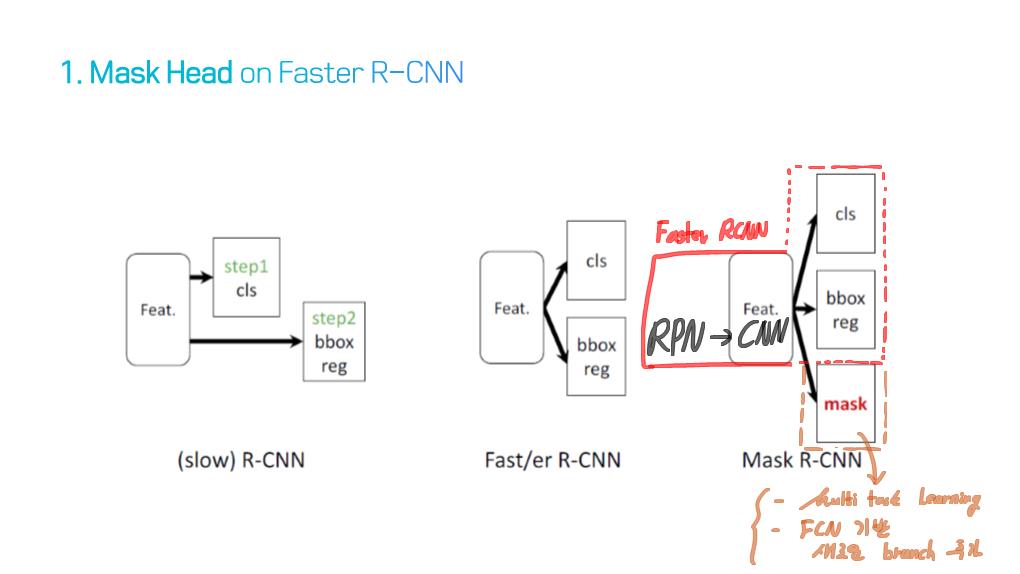
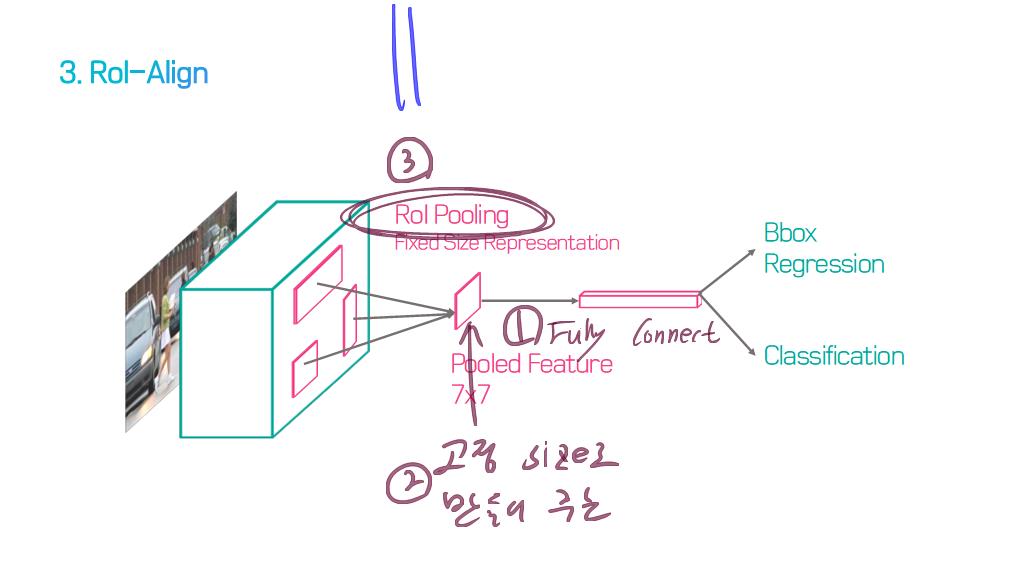
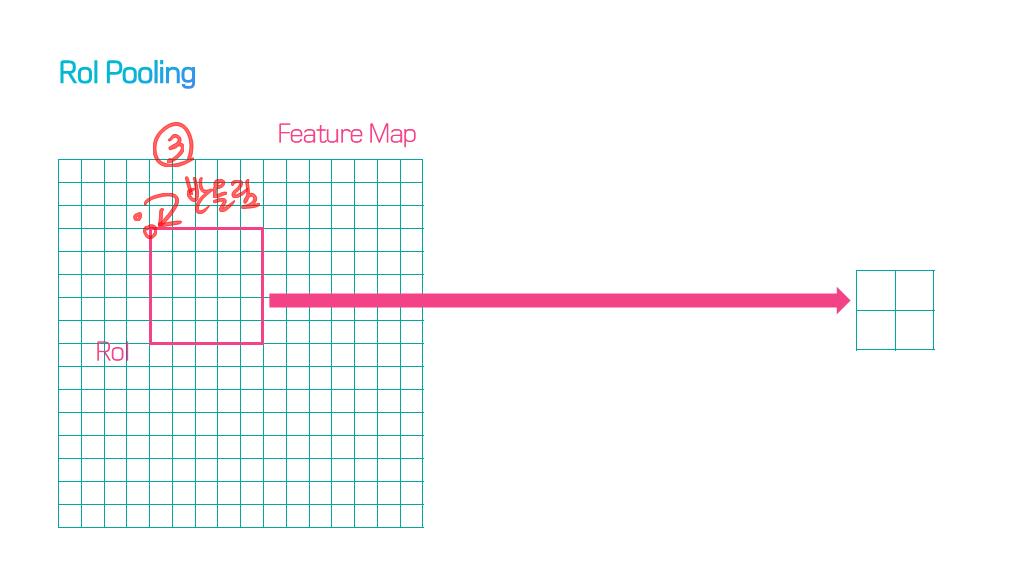
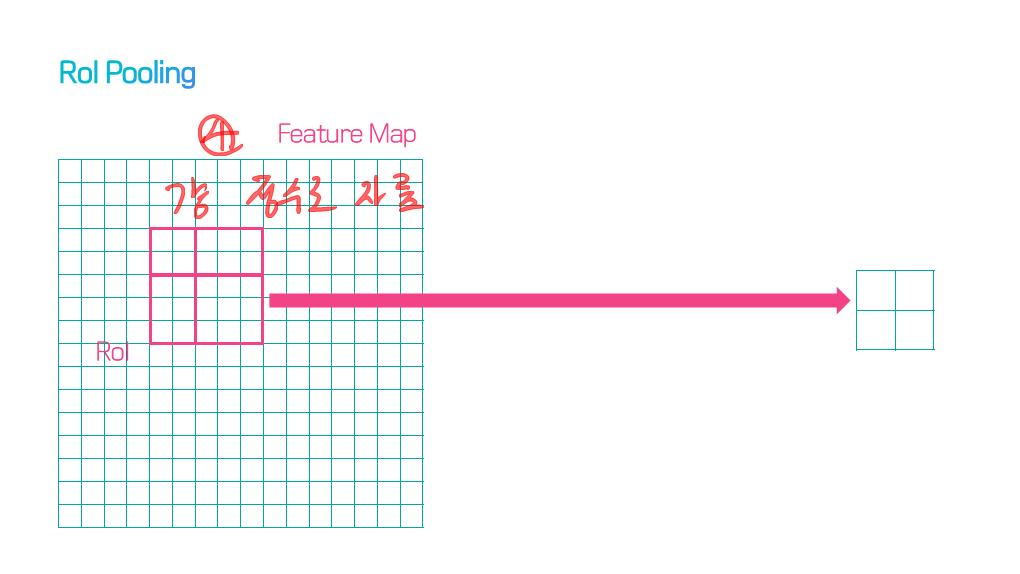
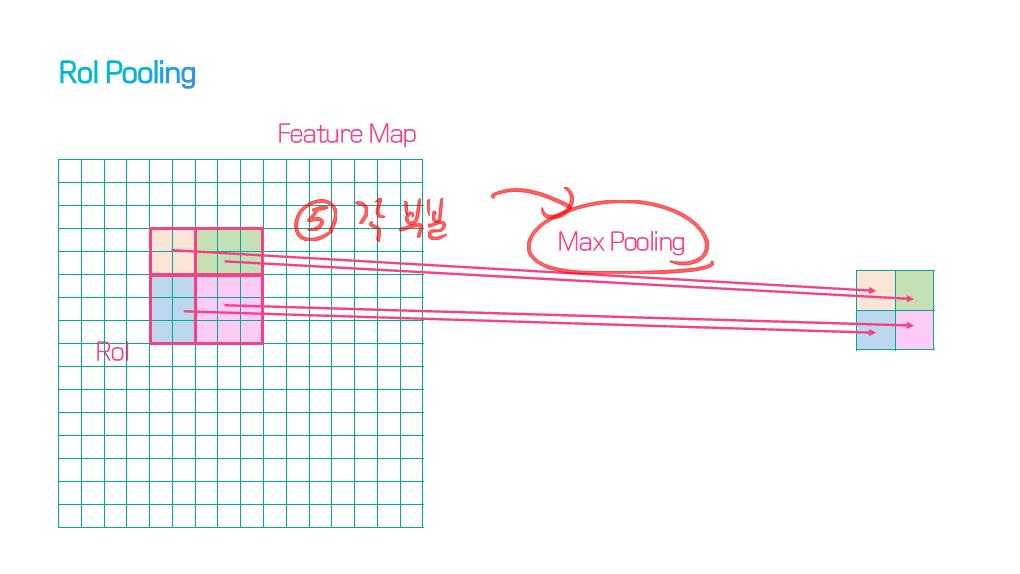
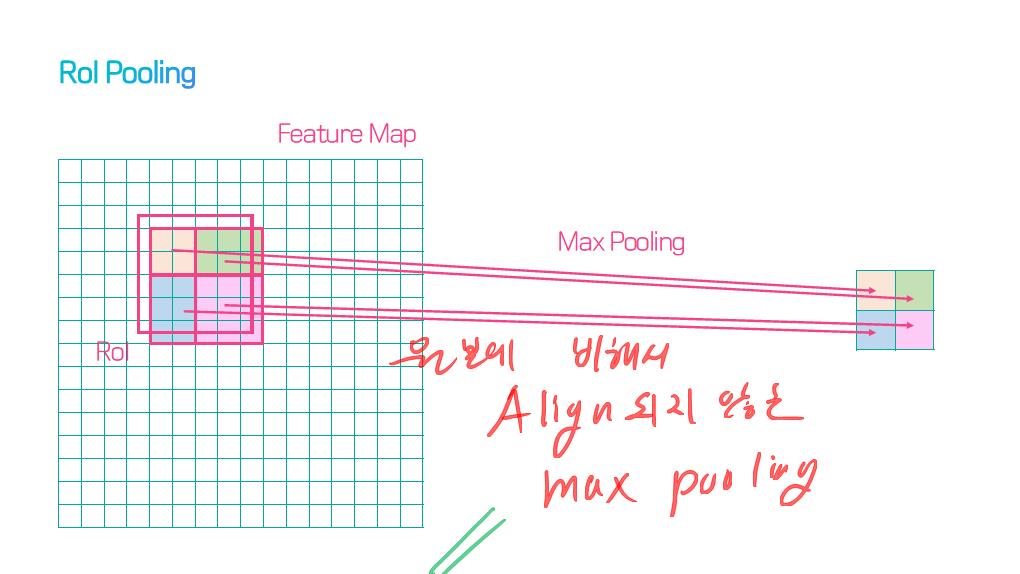
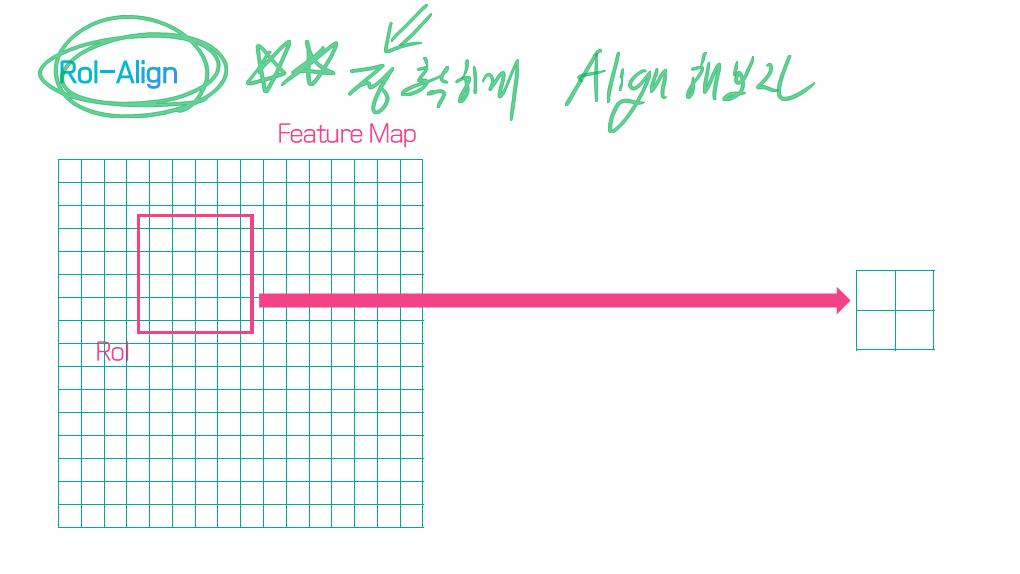
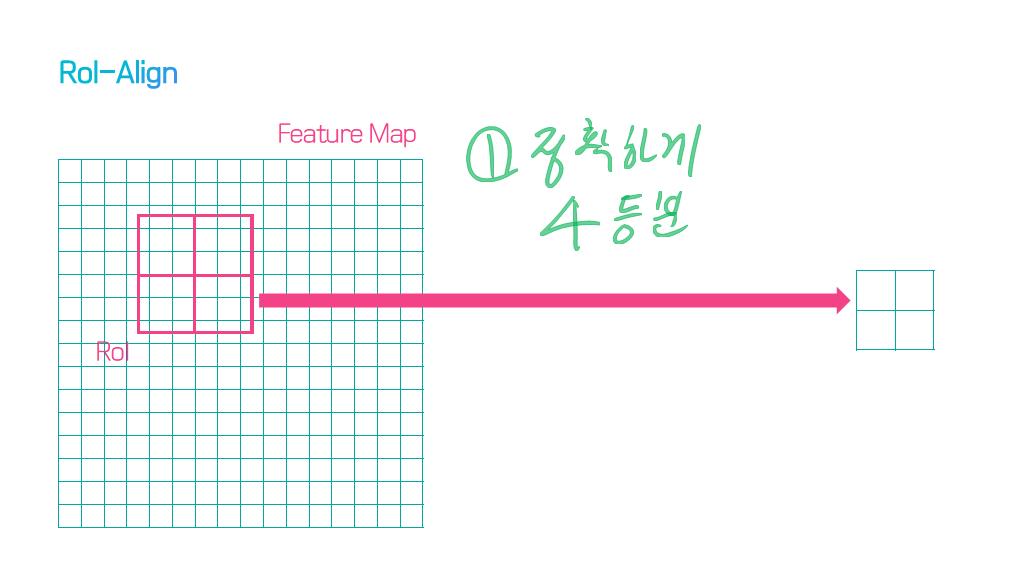
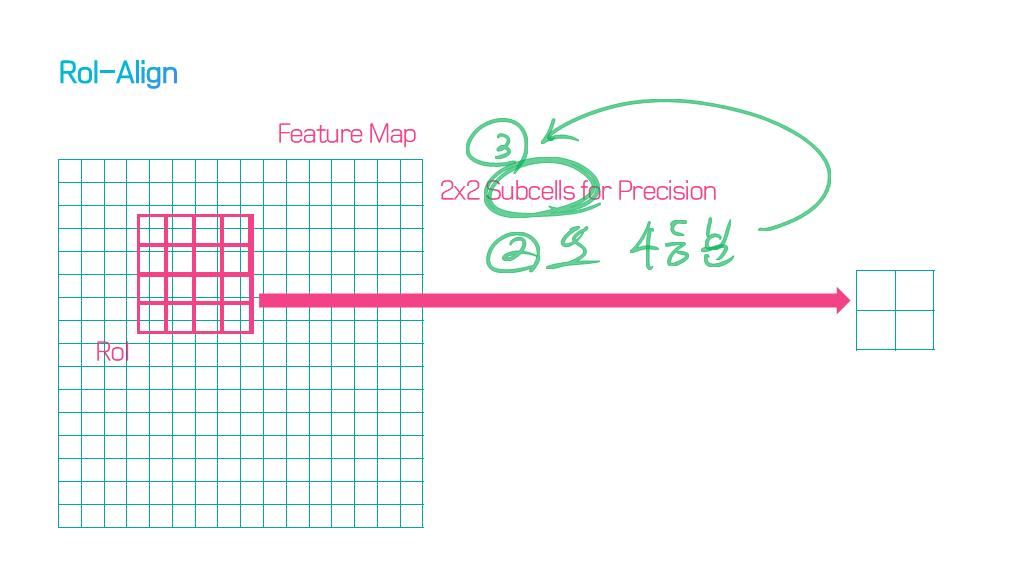
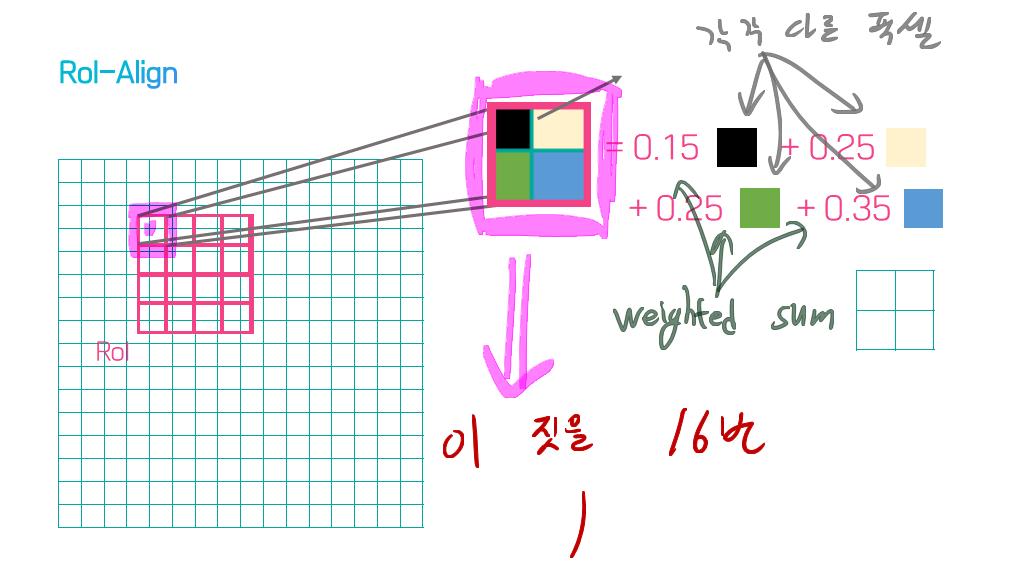
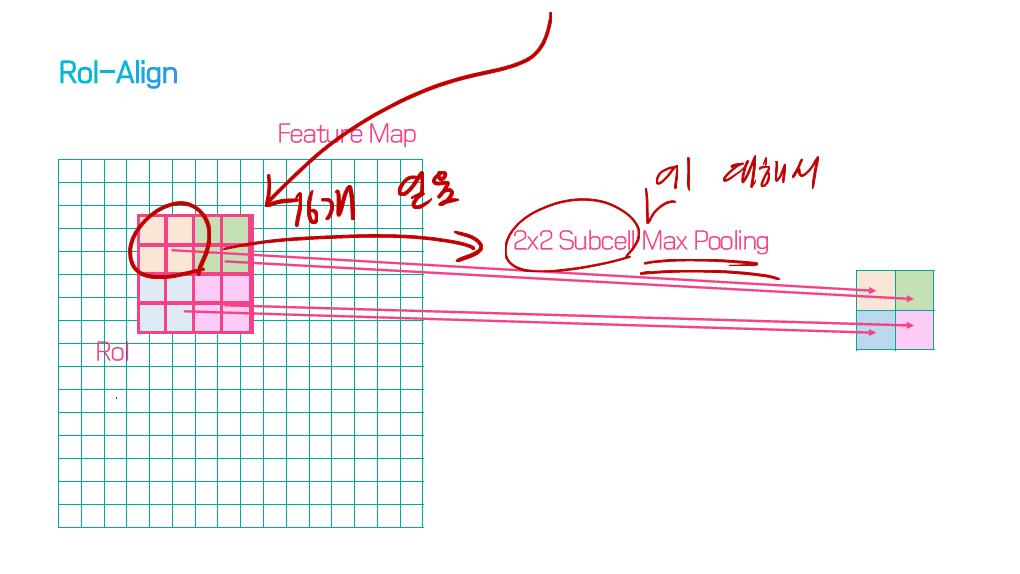
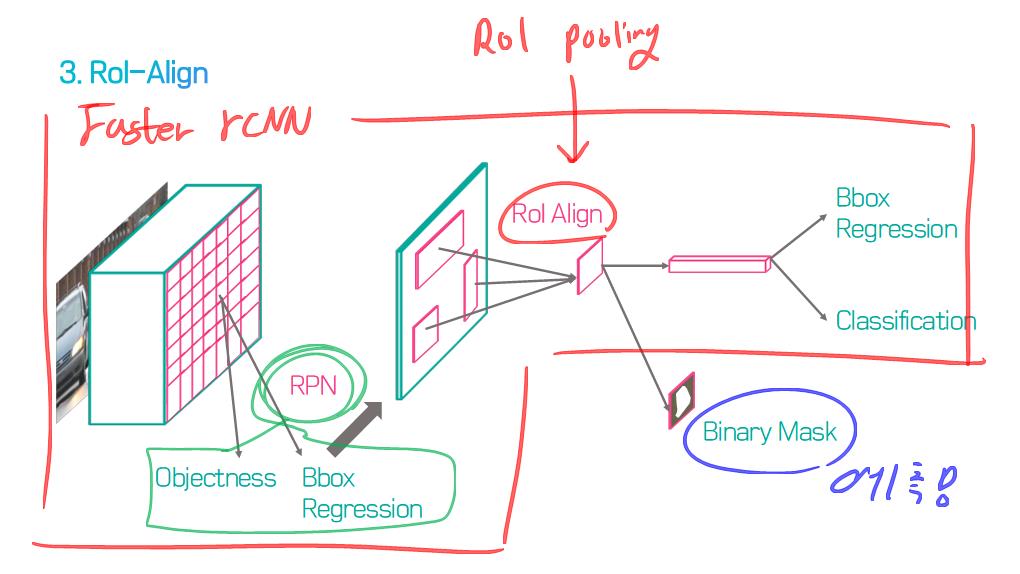
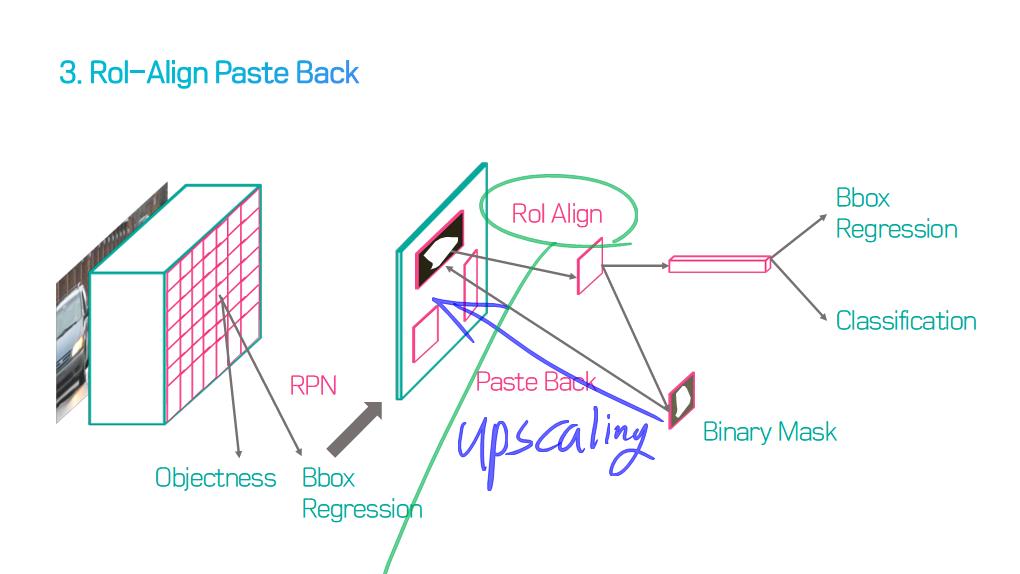
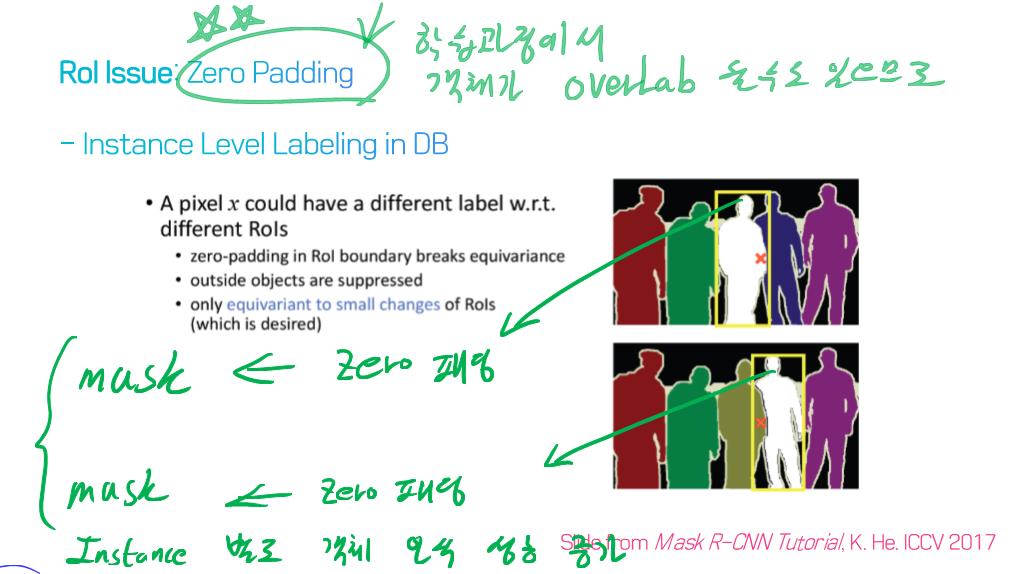
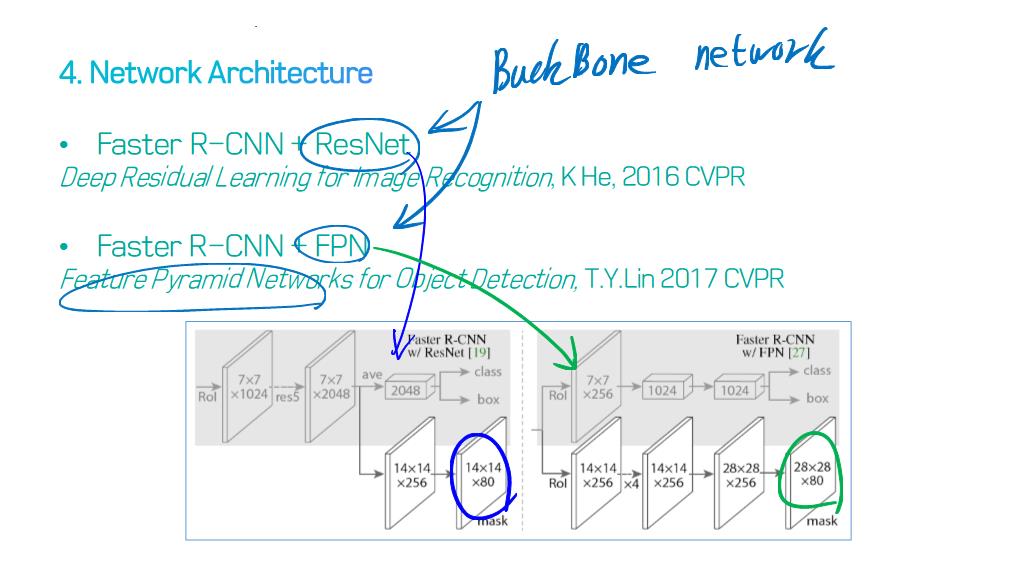
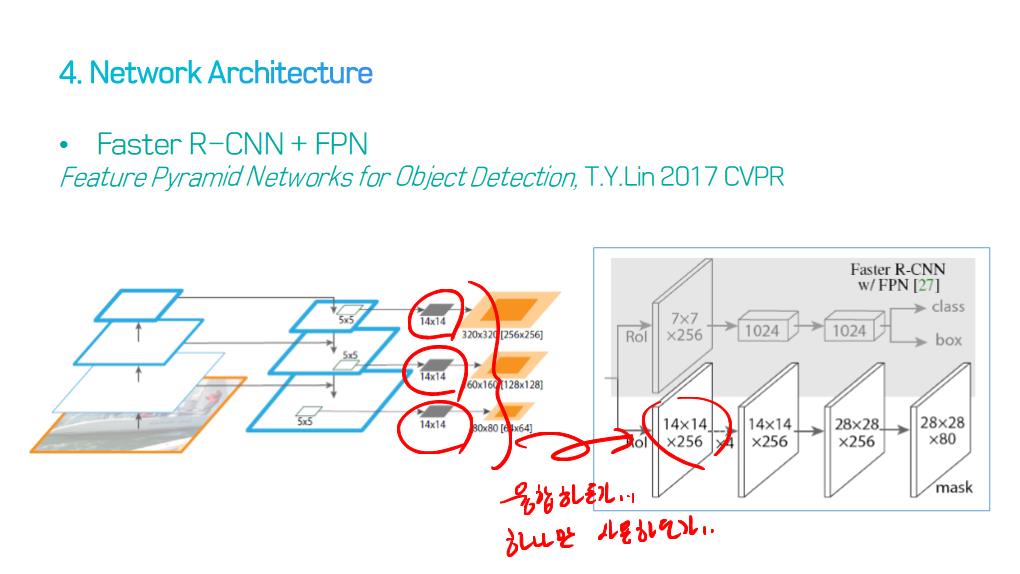
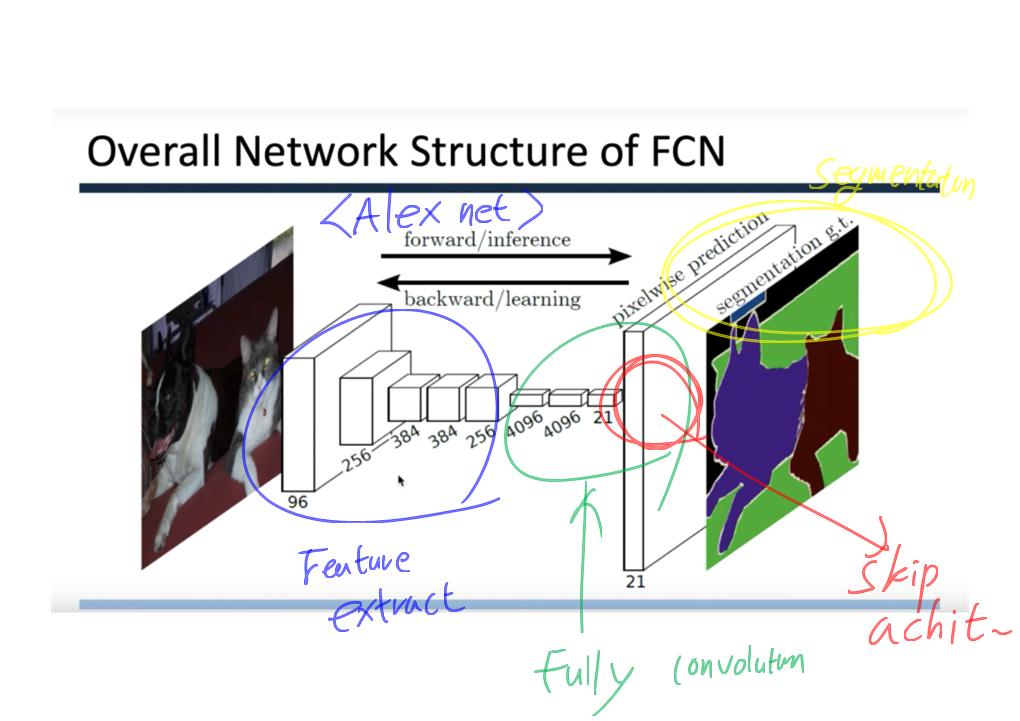
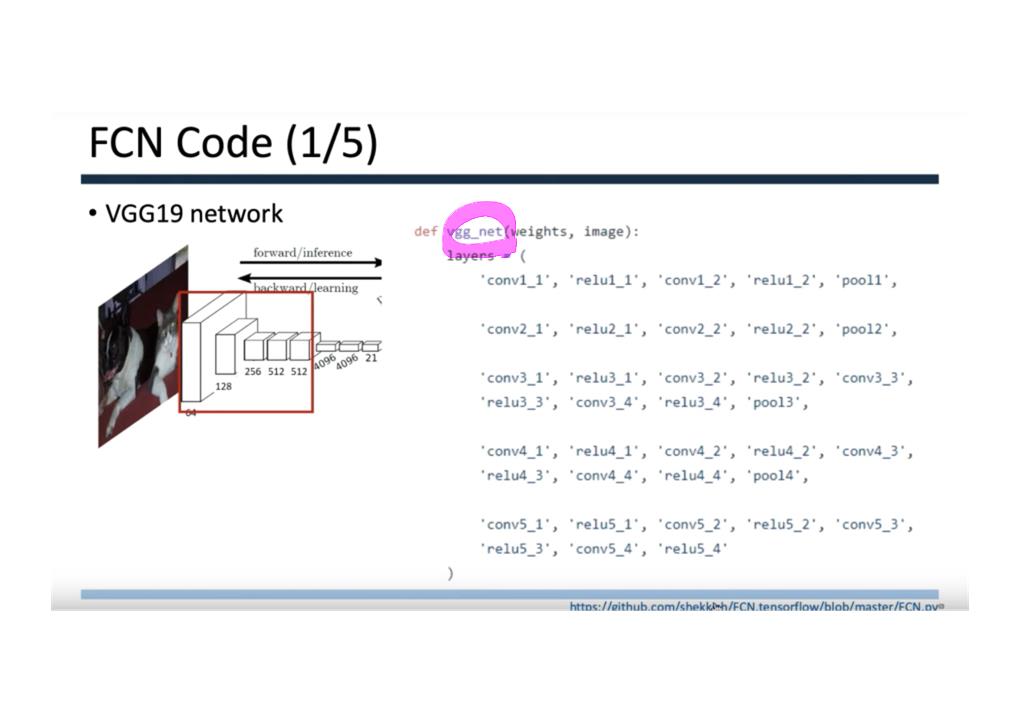
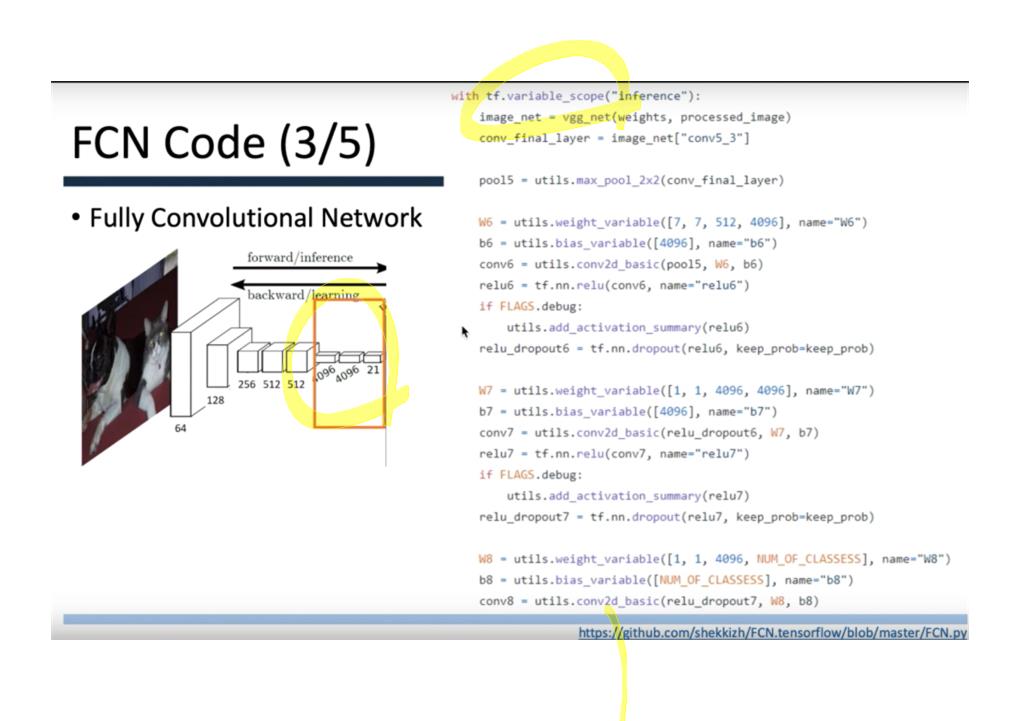
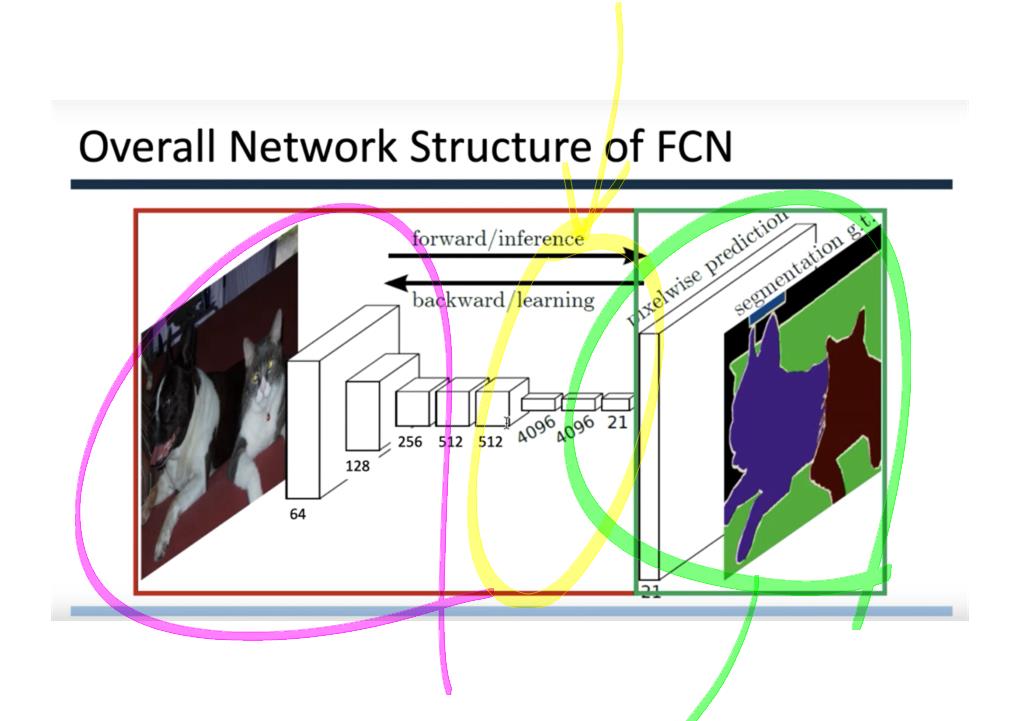
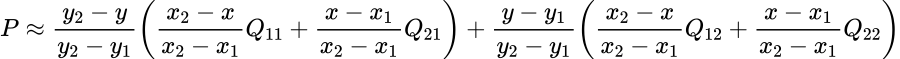이 논문에서는 Segmentation을 위해, 선구적인 기술들에 대한 Survey를 다룬다.
예를 들어, 1. fully convolutional pixel-labeling networks, 2. encoder-decoder architectures, 3. multi-scale and pyramid based approaches, 4. recurrent networks, 5. visual attention models, and 6. generative models in adversarial settings.
각 모델에 대해서, 널리 사용되는 데이터셋을 사용해서, 유사성, 강점(장점), 성능을 비교한다.
마지막으로 독자들에게 유망한 미래 연구&공부 방향도 제시해준다.
Instruction
image segmentation의 필요성(중요성):
image segmentation은 시각적 이해 시스템(visual understanding system)에 있어 필수적인 요소이다.
의료 영상 분석 (예 : 종양 경계 추출 및 조직 체적 측정), 자율 주행 차량 (예 : 탐색 가능한 표면 및 보행자 감지), 비디오 감시 및 증강 현실을 포함하여 광범위한 응용 사례에 있어 중요한 역할을 수행한다.
image segmentation 연구에 활용된 알고리즘:
과거 :
thresholding
histogram-based bundling
region-growing
k-means clustering
watersheds
더 나아가:
active contours
graph cuts
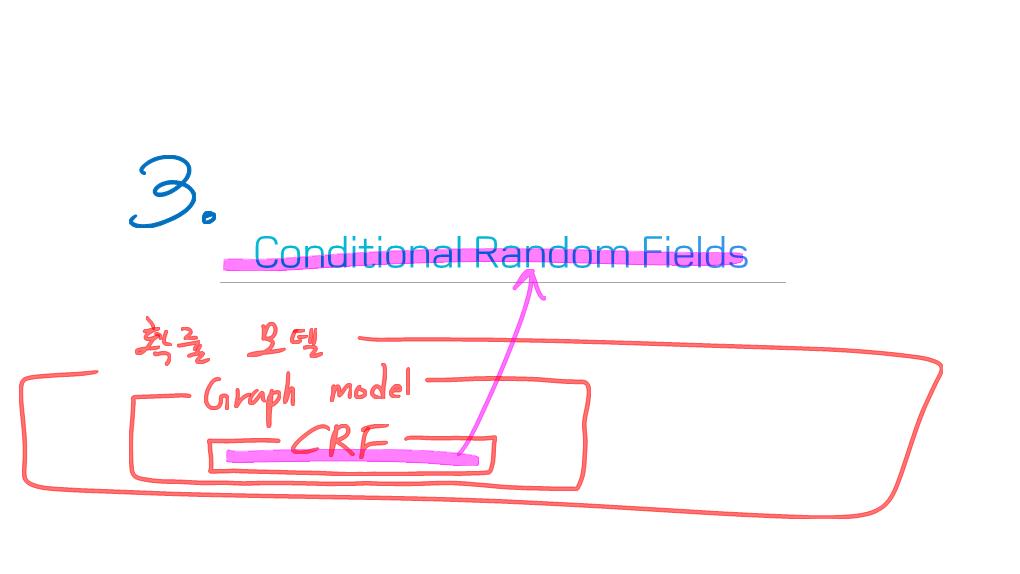
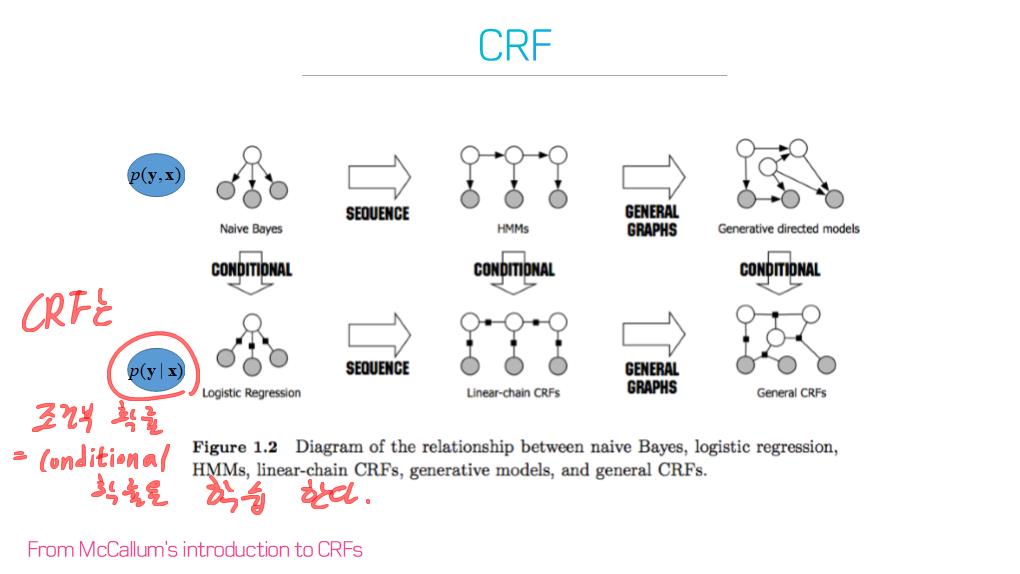
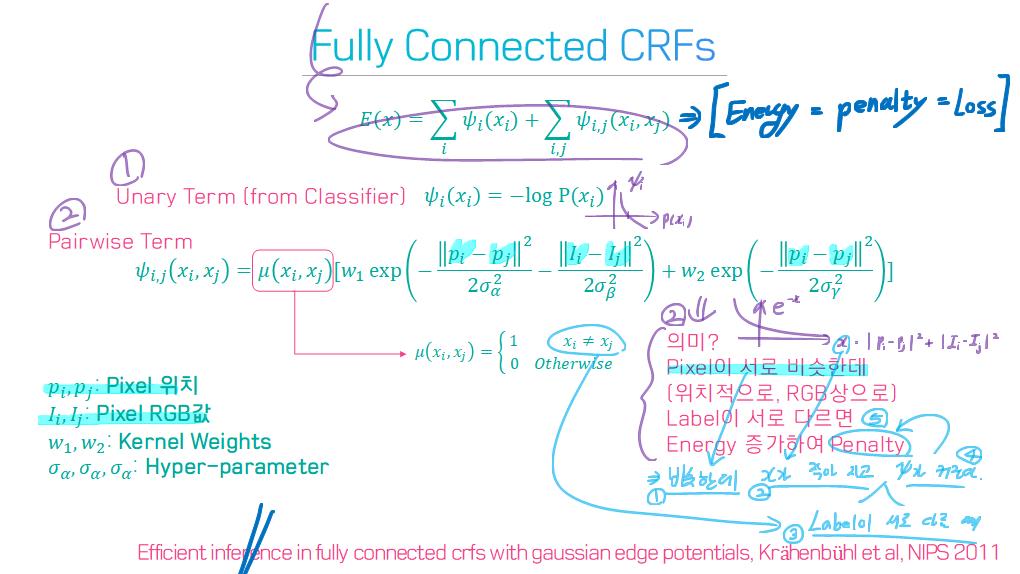
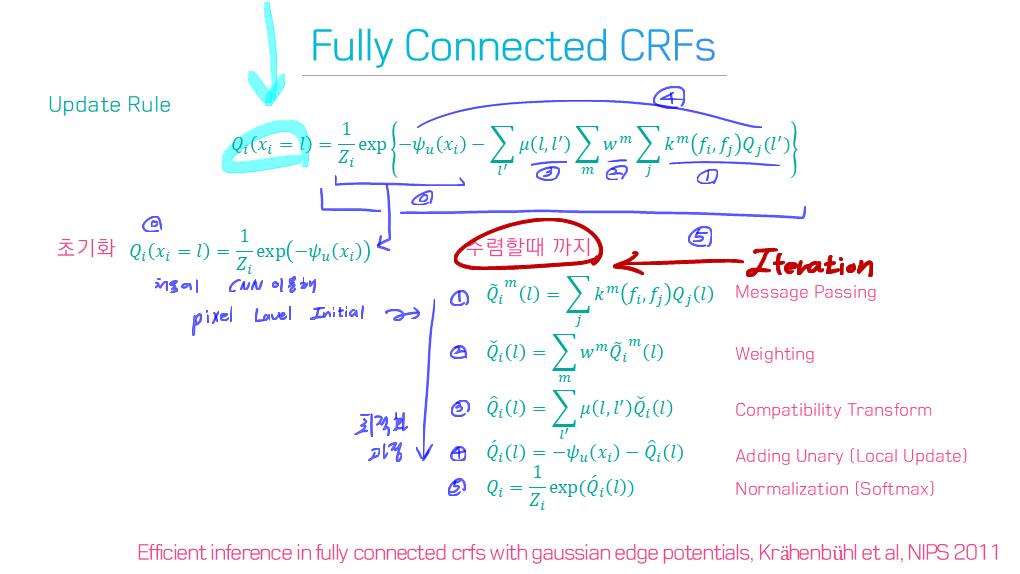
conditional and Markov random fields
sparsity-based methods
최근 경향:
Deep Learning을 이용한 image segmentation 모델들이 많이 나왔다.
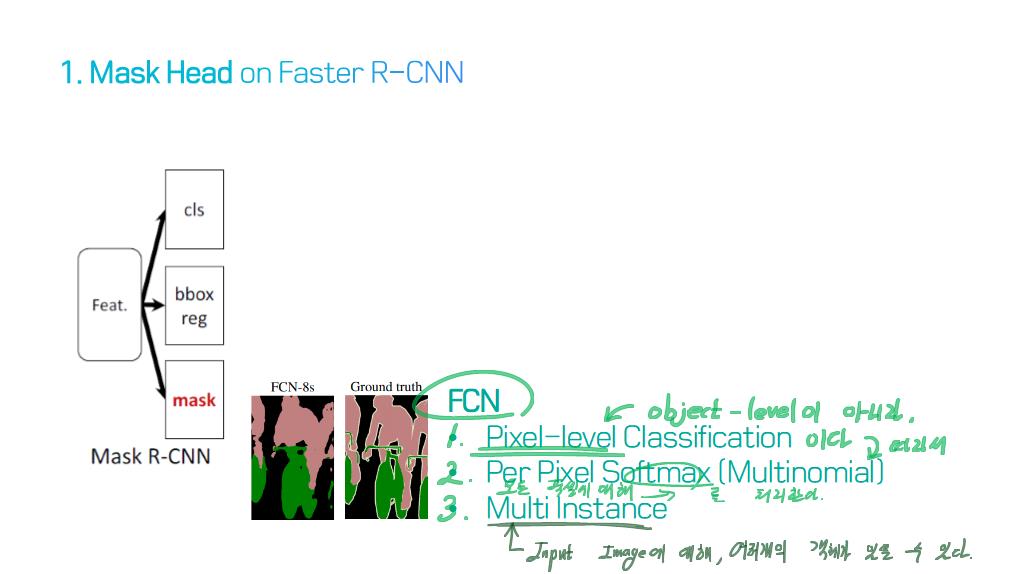
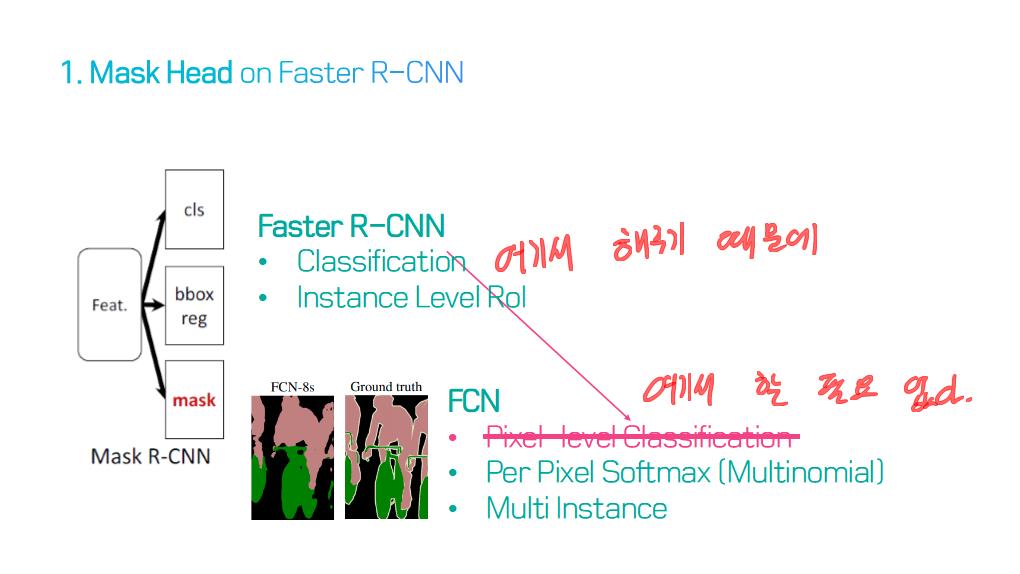
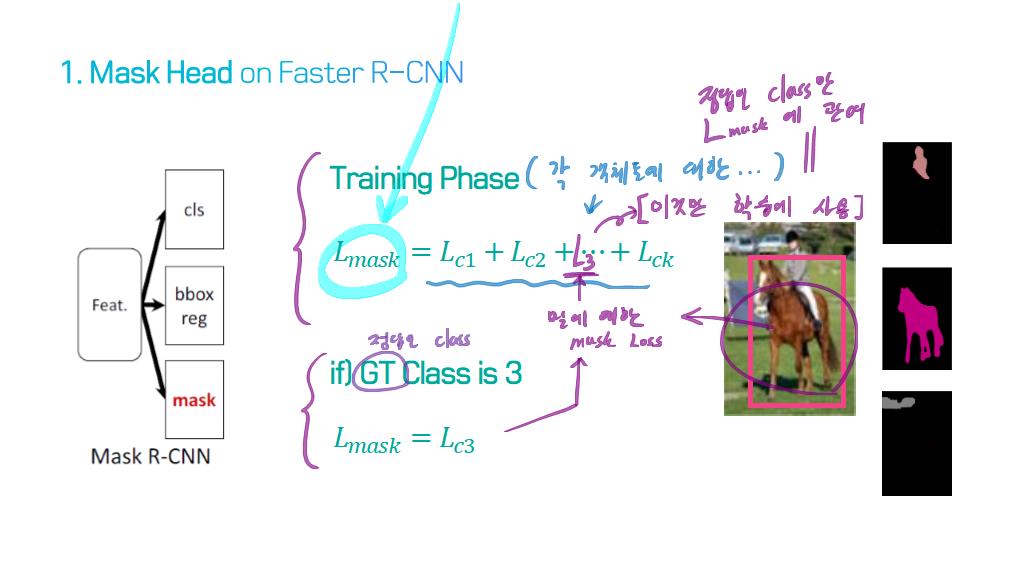
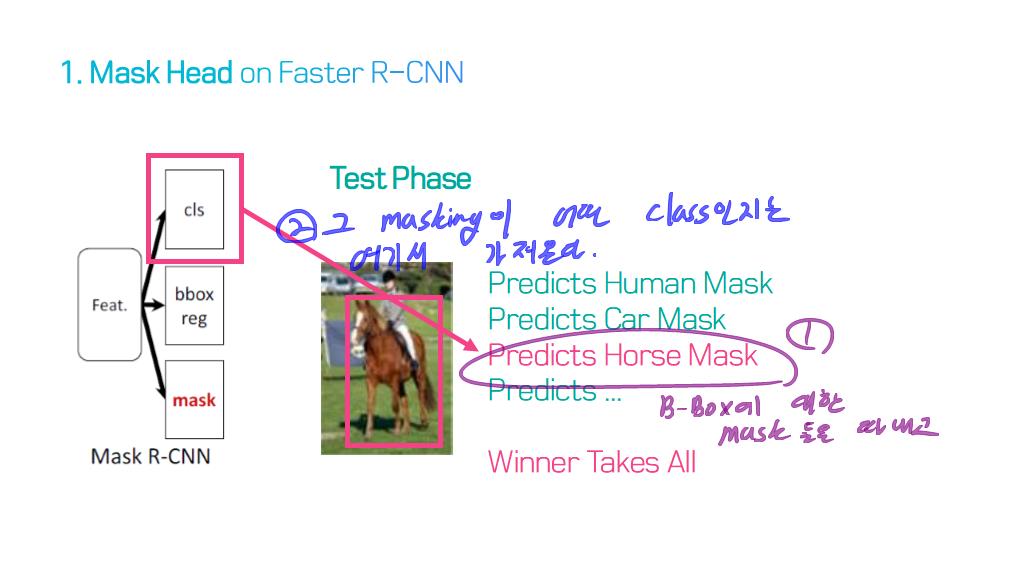
image segmentation의 종류?
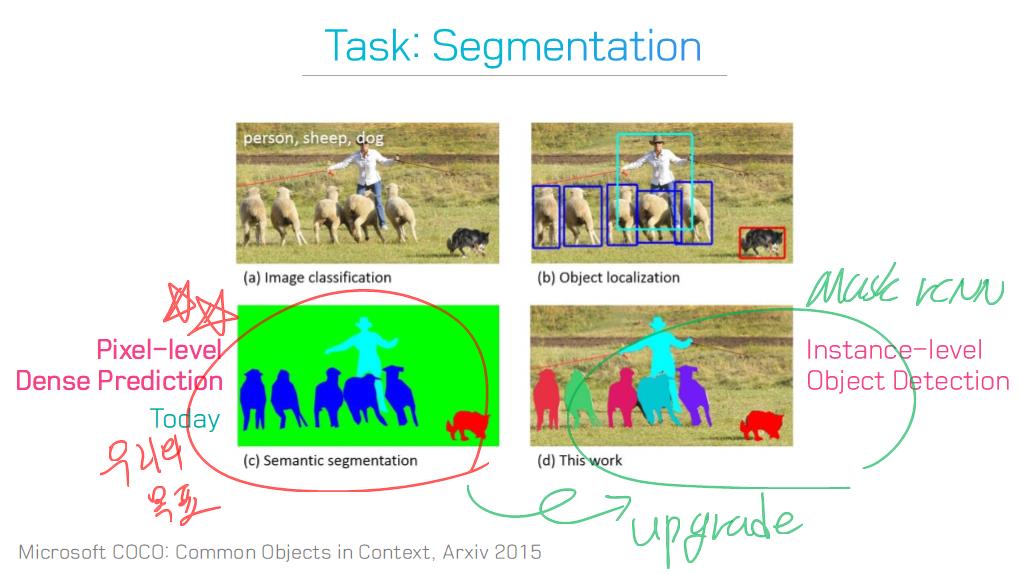
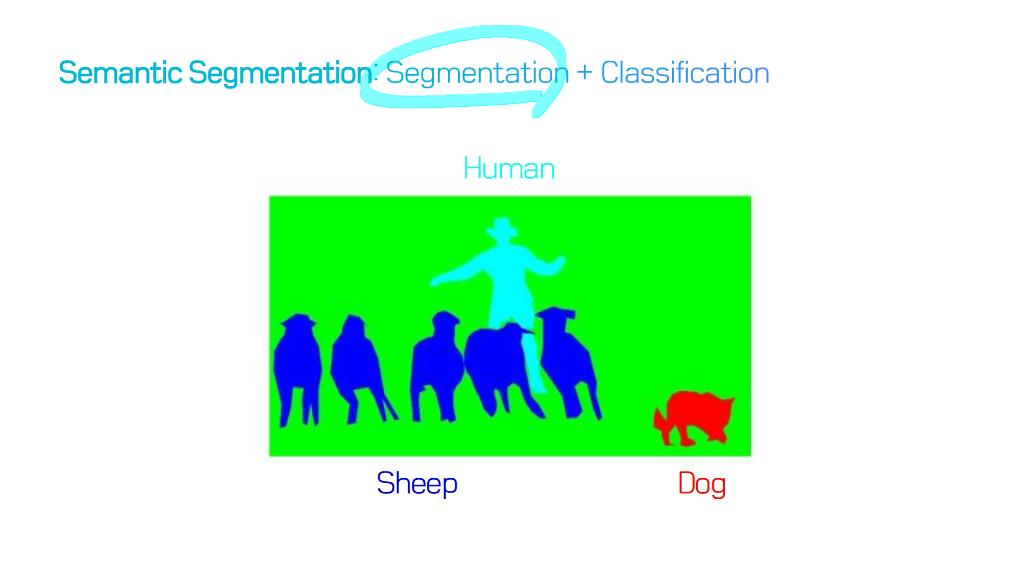
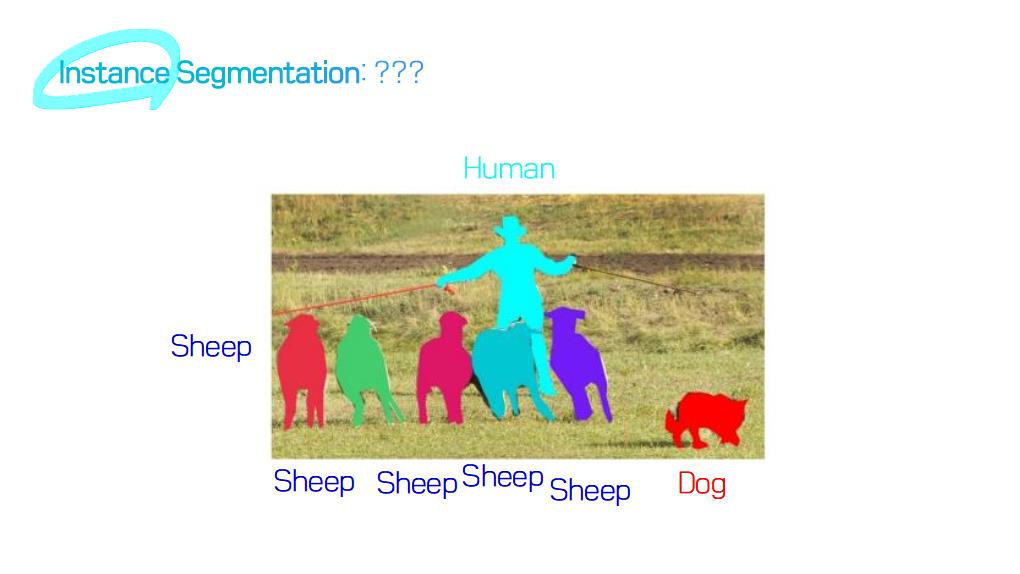
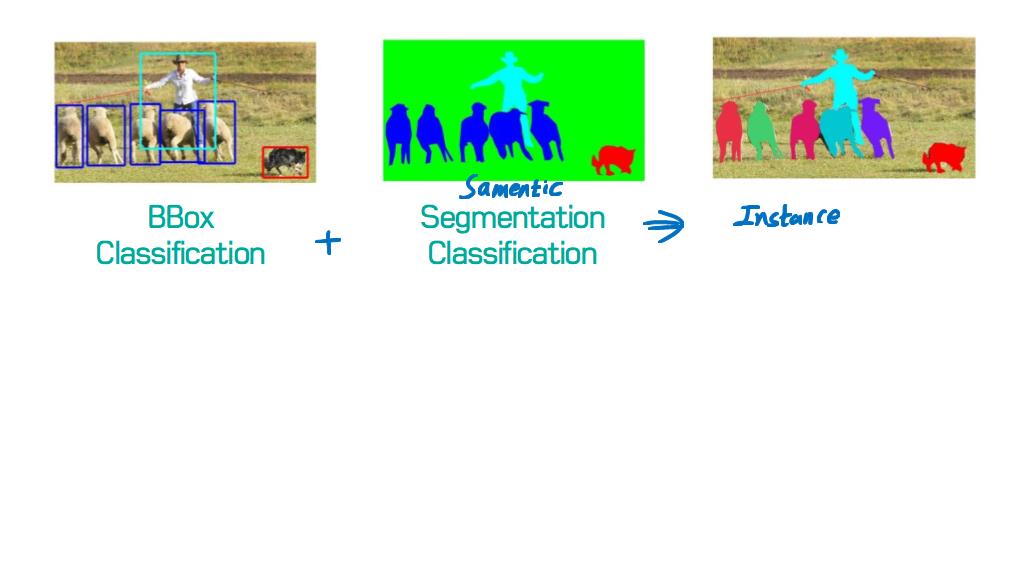
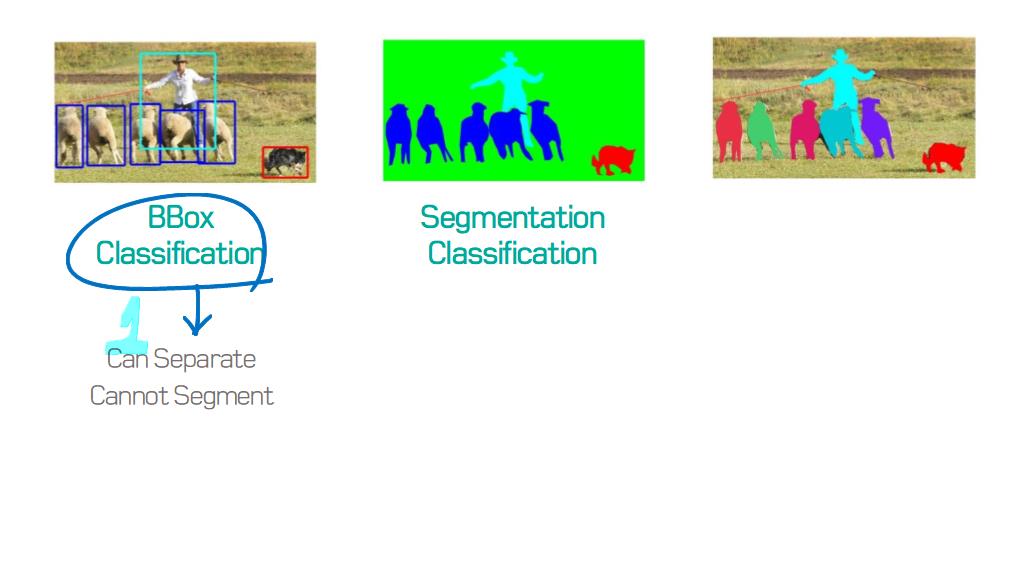
image segmentation은 semantic label에 대한 각 픽셀의 분류 문제(semantic segmentation) 혹은 개별 객체의 분할(instance segmentation)의 문제로 공식화 할 수 있습니다.
semantic segmentation는 모든 이미지 픽셀에 대해 일련의 객체 범주 (예 : 사람, 자동차, 나무, 하늘)를 사용하여 픽셀 수준 레이블링을 수행하므로 일반적으로 전체 이미지에 대한 하나의 label을 예측(predict)하는 이미지 분류보다 어려운 작업입니다.
instance segmentation은 이미지에서 관심있는 각 객체를 감지하고 묘사함으로써 semantic segmentation 범위를 더 확장합니다 (예 : 개인의 partitioning).
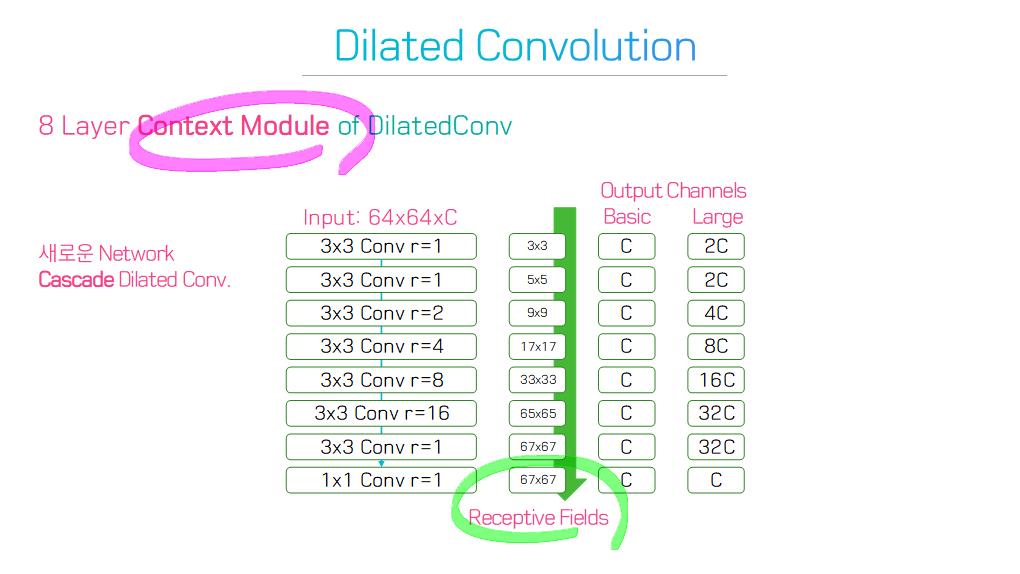
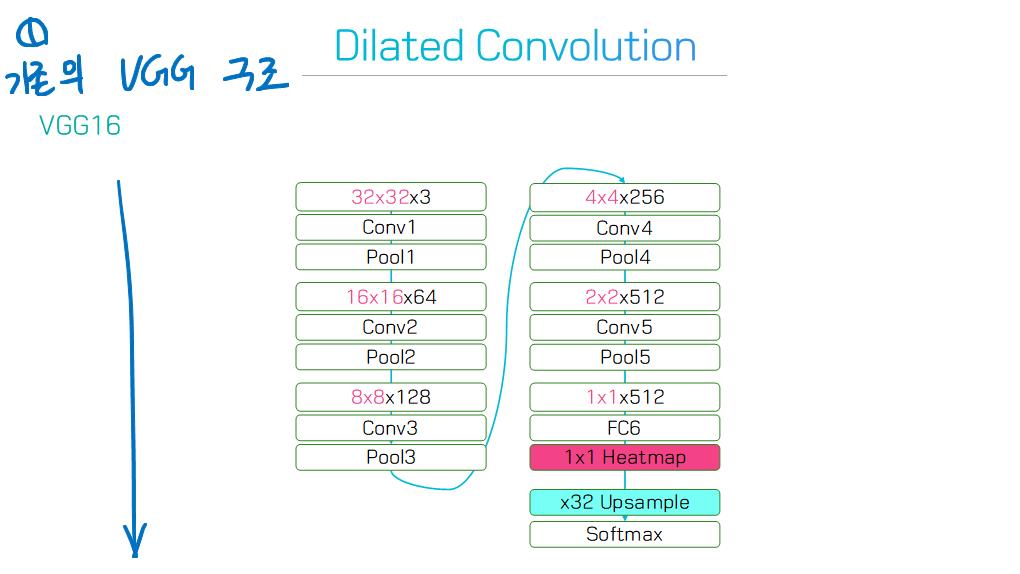
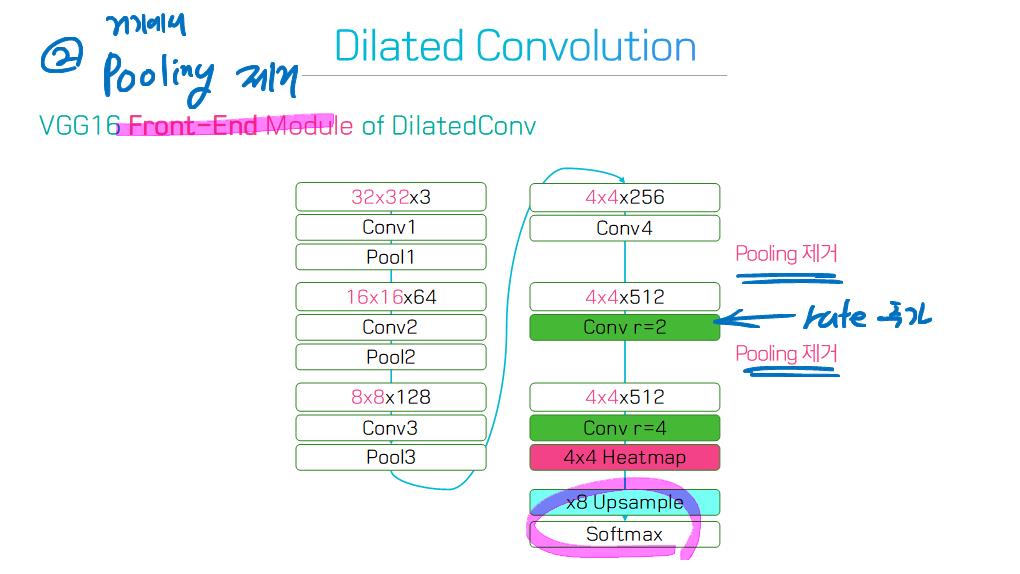
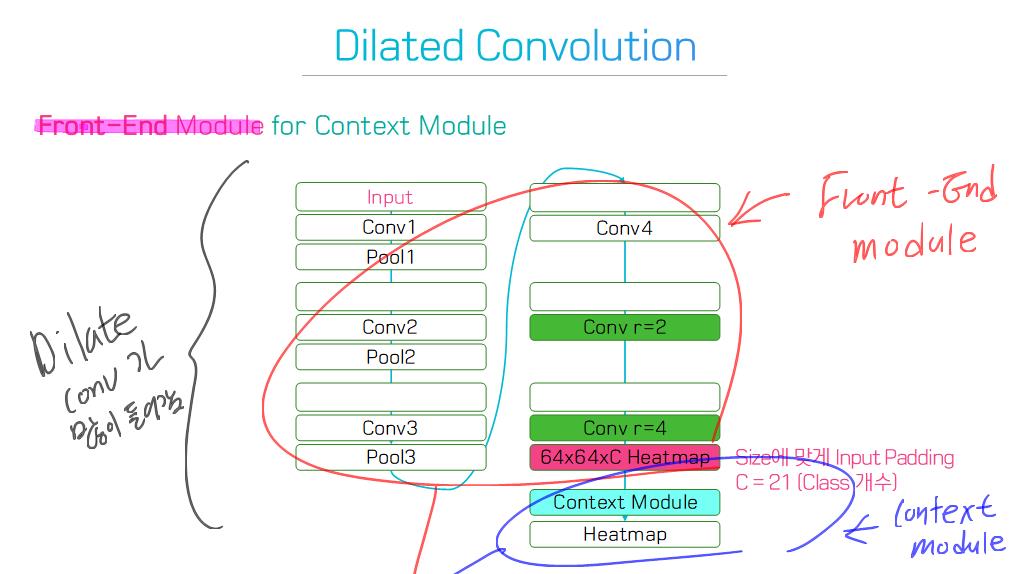
주요 기술 Contributions(특성, 계보)를 기준으로, 100개의 모델들을 다음 범주로 그룹화 할 수 있다.
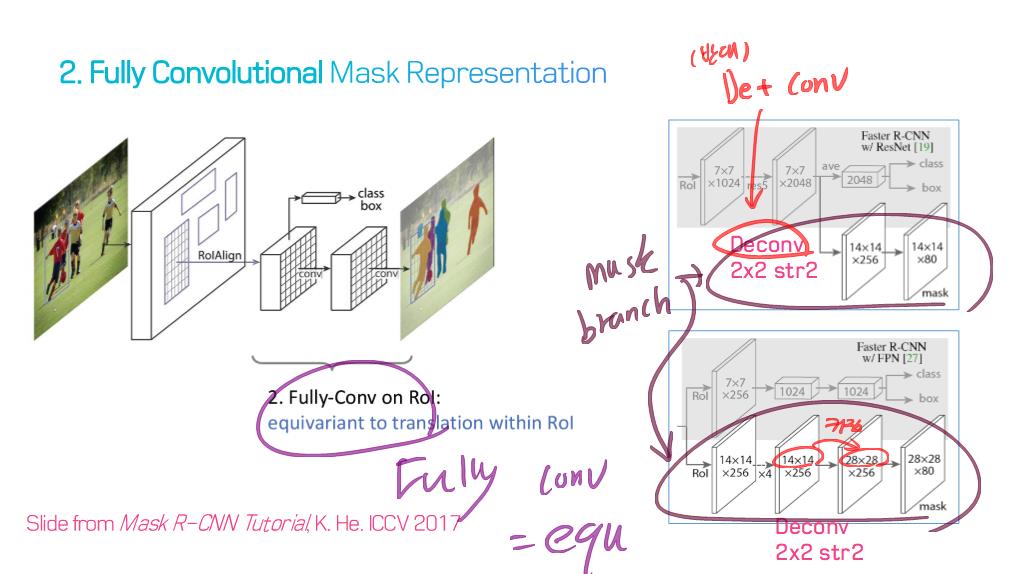
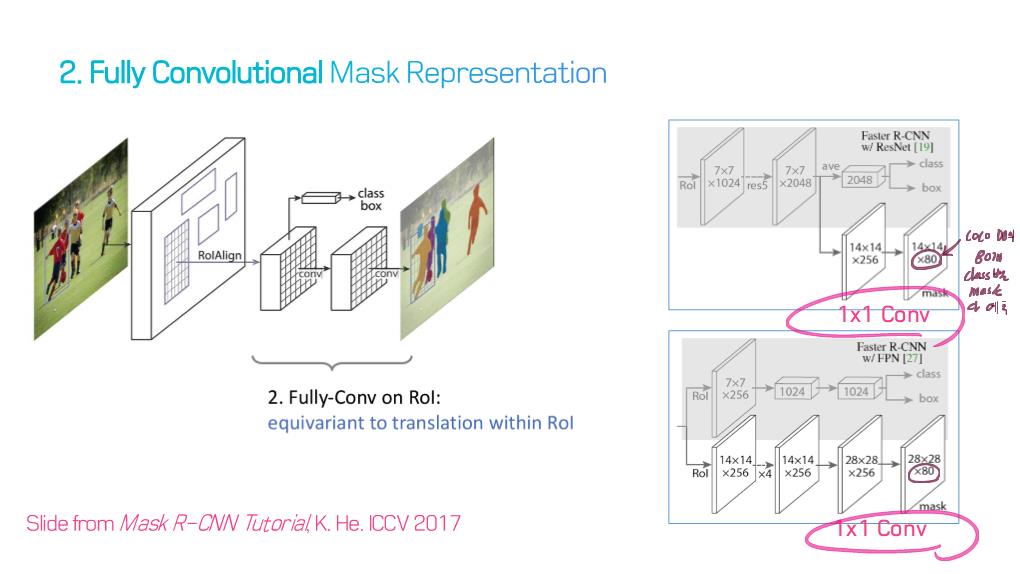
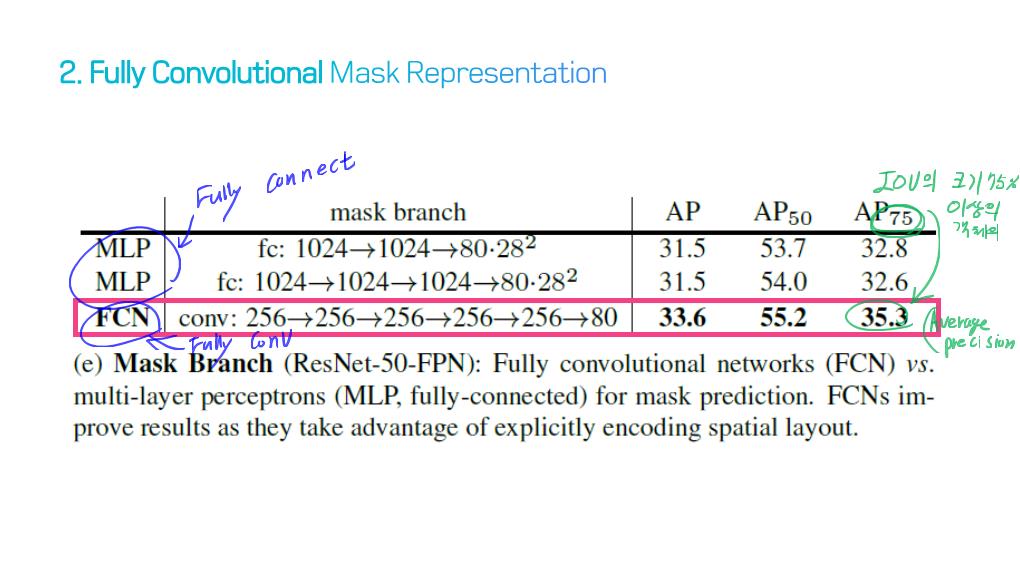
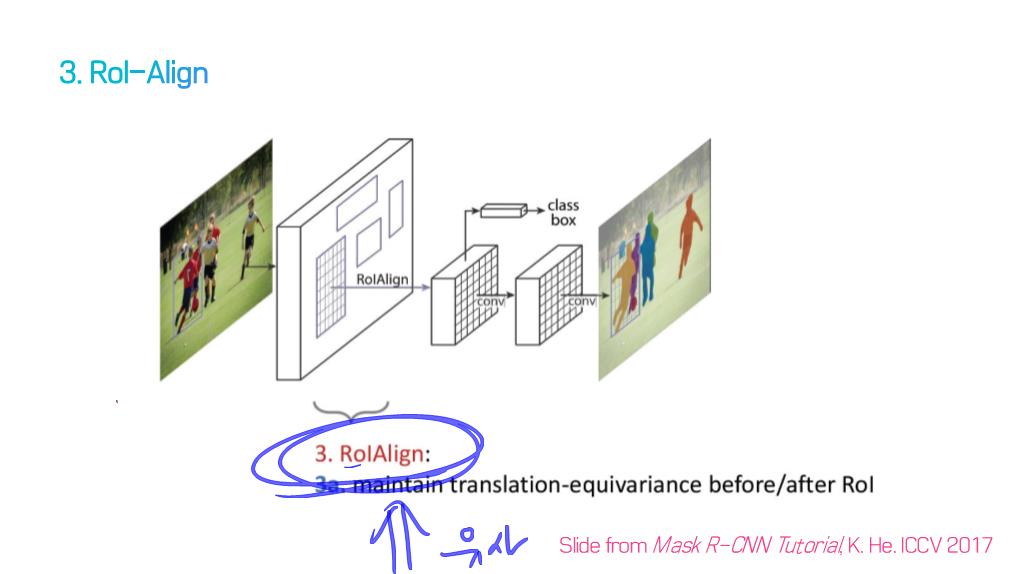
1) Fully convolutional networks
2) Convolutional models with graphical models
3) Encoder-decoder based models
4) Multi-scale ad pyramid network based models
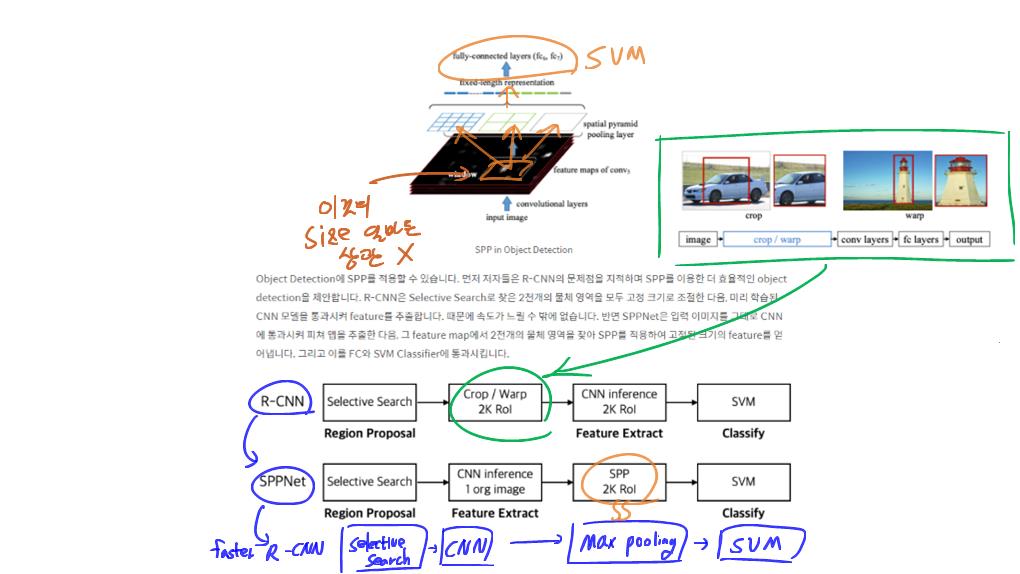
5) R-CNN based models (for instance segmentation)
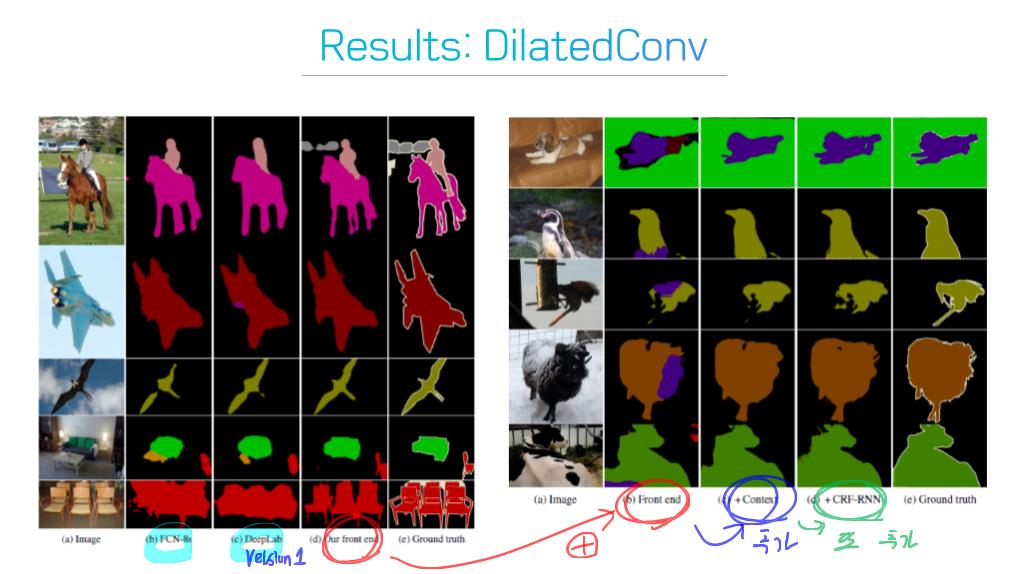
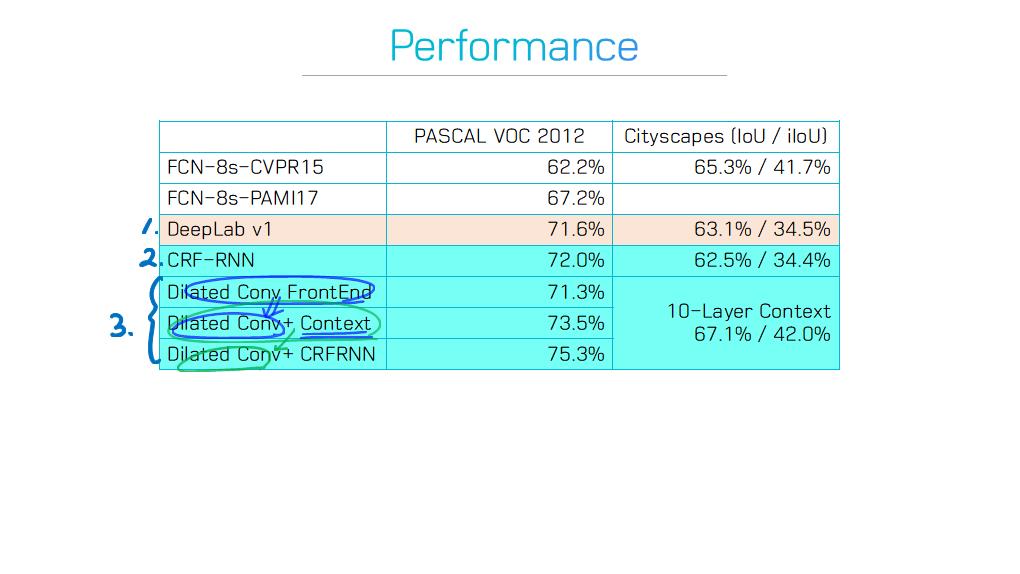
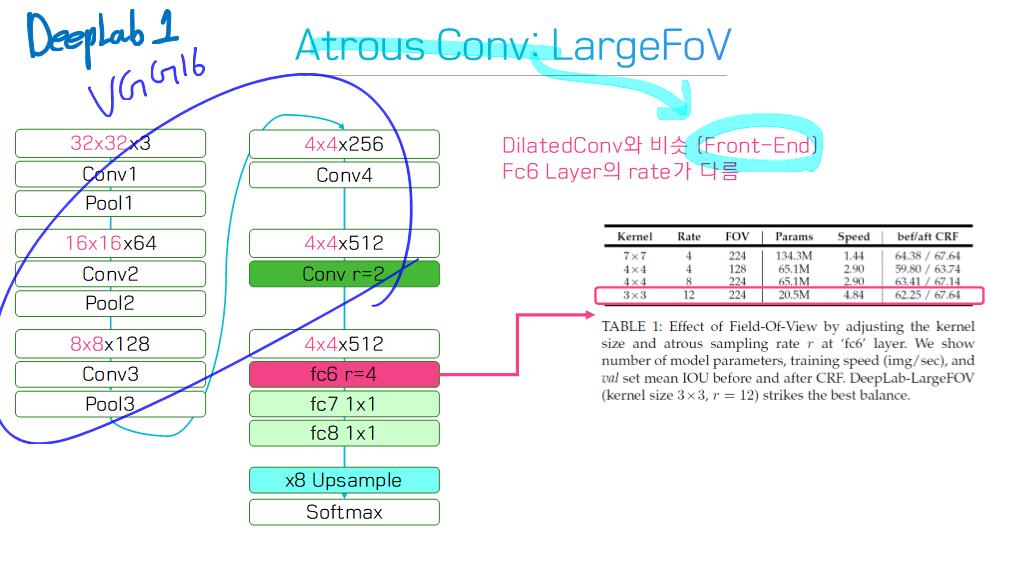
6) Dilated convolutional models and DeepLab family
7) Recurrent neural network based models
8) Attention-based models
9) Generative models and adversarial training
10) Convolutional models with active contour models
11) Other models
이 논문을 전체요약하면 다음과 같이 적을 수 있다.
1) 2019년 이후의 100개 이상의 Segmentation 알고리즘을 10가지 범주로 그룹화 했다.
2) 학습 데이터, 네트워크 아키텍처, Loss 함수, 학습 전략, 모델의 주요 특성(어떤 계보를 따르는가?)를 달리하여 만든 많은 모델들의 Review, 통찰력 있는 분석 결과를 제시한다.
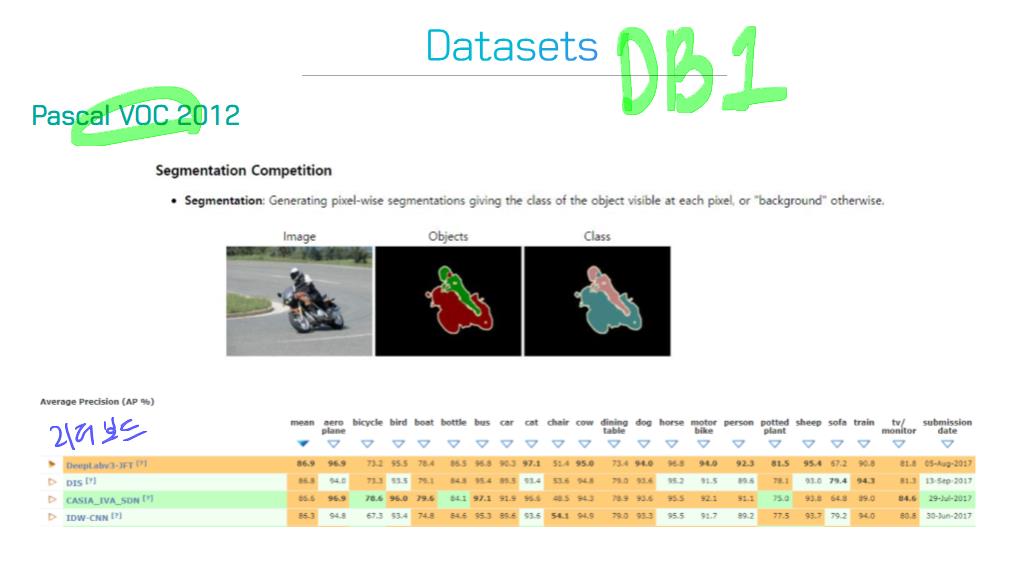
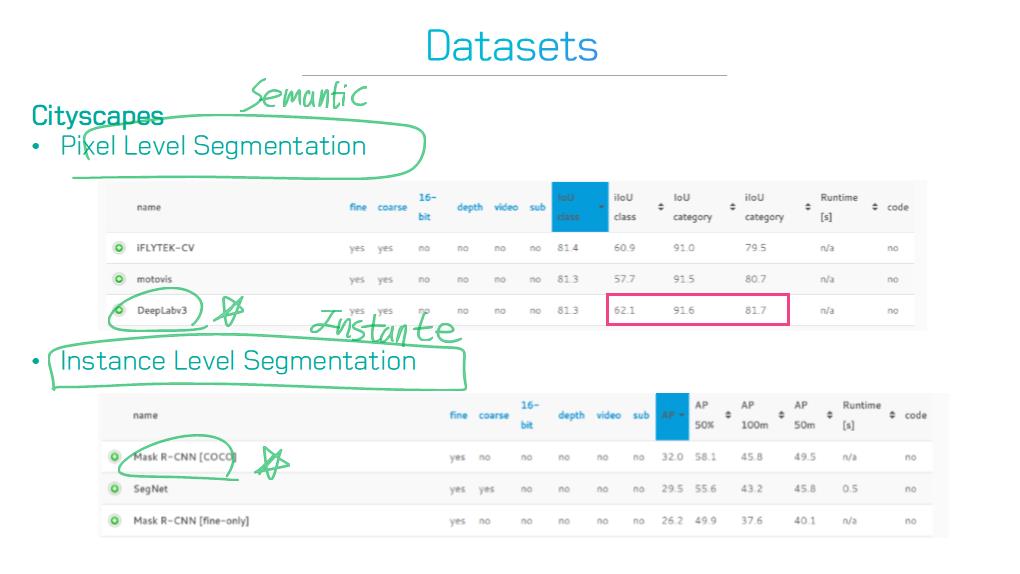
3) 2D, 3D를 포함한 20개의 인기 있는 segmentation 데이터 셋의 개요를 제공 한다.
4) 이 모델들을 비교, 요약하여 앞으로의 Image segmentation의 몇가지 과제와 해결방향 그리고 잠재적 미래 방향을 제시한다.
이 논문을 각 파트를 전체요약하면 다음과 같이 적을 수 있다.
1) Section 2 : 모든 모델의 Backbone이 되는 인기 있는 deep neural network architectures 개요 제공
2) Section 3 : 100개 이상의 중요한 Segmentation 모델에 대한 포괄적 개요, 그리고 그들의 장점, 특성 제공
3) Section 4 : 유명한 Segmentation Dataset의 개요와 각각의 특성을 검토
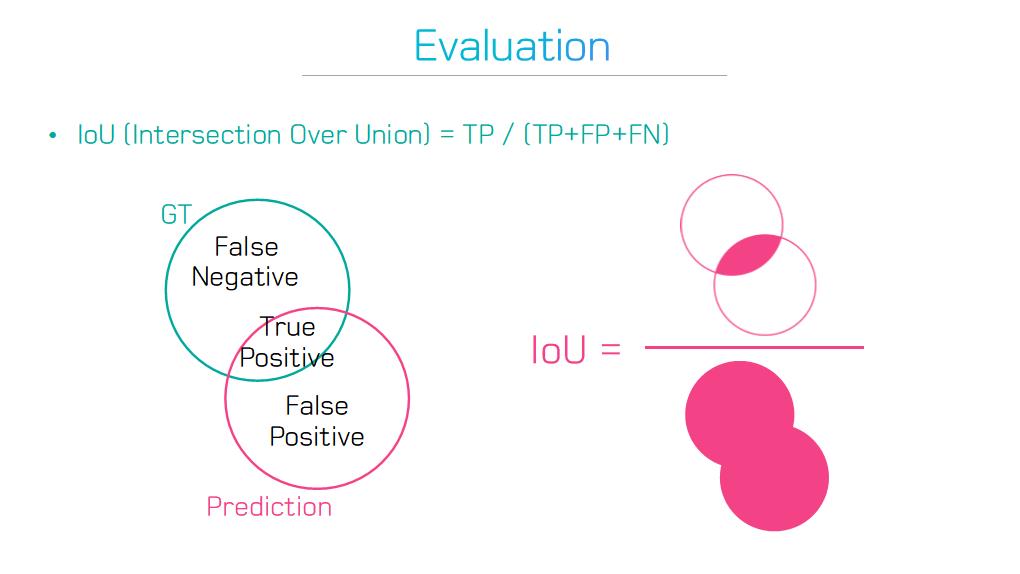
4) Section 5.1 : Segmentation 성능 지표 검토
5) Section 5.2 : 모든 모델들의 (위에서 설명한 성능 지표에 따른) 정량적 성능 검토
6) Section 6 : Image sementation의 주요 과제와 해결방향, 향후 방향들을 검토
7) Section 7 : 결론
Section 2: Overview of Deep Neural Networks
2.1 Convolutional Neural Network (CNNs)
CNN은 주로 3 가지 유형의 layer로 구성된다.
1) convolutional layer: 특징을 추출하기 위해 가중치 (kernel) (또는 필터)의 가중치 (kernel)가 있다.
ii) nonlinear layer: 네트워크에 의한 비선형 함수의 모델링을 가능하게하기 위해 피쳐 맵에 활성화 함수를 적용한다. (보통 요소별로)
iii) pooling layer: 특징 맵의 작은 이웃을 이웃에 대한 일부 통계 정보 (평균, 최대 등)로 대체하고 공간 해상도를 감소시킨다.
레이어의 단위는 로컬로 연결되어 있다.
즉, 각 유닛은 이전 계층의 유닛의 수용 장으로 알려진 작은 이웃으로부터 가중 된 입력을 수신한다.
다중 해상도 피라미드를 형성하기 위해 레이어를 쌓으면서 더 높은 레벨의 layer는 점점 더 넓은 수용 영역에서 기능을 학습합니다.
CNN의 주요 계산 이점:
레이어의 모든 수용 필드가 가중치를 공유하여 완전히 연결된 신경망보다 훨씬 적은 수의 매개 변수를 생성한다는 것이다.
RNN은 음성, 텍스트, 비디오 및 시계열과 같은 순차적 데이터를 처리하는 데 널리 사용된다.
여기서 주어진 시간 / 위치의 데이터는 이전에 발생한 데이터에 의존한다.
RNN의 구조
각 타임 스탬프에서 모델은 현재 시간 Xi의 입력과 이전 단계 hi-1의 숨겨진 상태를 수집하고 목표 값과 새로운 숨겨진 상태를 출력한다.
RNN의 한계점?
RNN은 일반적으로 많은 실제 응용 프로그램에서 장기적인 종속성(long-term dependencies)을 캡처 할 수 없다. 이 때문에 gradient vanishing 또는 exploding 문제로 고통받는 경우가 많으므로 일반적으로 long sequences에 있어 한계점이 있다.
위와 같은 RNN의 한계점을 극복하기 위해 LSTM(Long Short Term Memory)이 등장하였다.
LSTM 구조
추가 내용 : 백업완료_2020.03\ML\CS231n 의 RRN 파일 참조
LSTM 아키텍처에는 메모리 셀로 들어오고 나가는 정보의 흐름을 조절하는 3 개의 게이트 (input gate, output gate, forget gate)가 포함되어 임의의 시간 간격에 걸쳐 값을 저장한다.
input, forget states 및 다른 gate 사이의 관계는 다음과 같다.
\(x_t \Subset R^d\) : time-step \(t\)의 input
\(d\) : 각 word의 feature dimension
\(\sigma\) : 요소별 시그모이드 함수 ([0,1])
\(\bigodot\): 요소별 곱셈
\(c_t\) : 메모리 셀 ( gradient vanishing/exploding의 위험을 낮추기 위함, 이를 통해 따라서 기존 RNN에서 실행 가능한 오랜 기간 동안 종속성 학습 가능)
\(f_t\) : forget gate (메모리셀을 reset 하기 위한)
\(i_t\) : input gate (메모리 셀의 input을 제어)
\(o_t\) : output gate (메모리 셀의 output을 제어)
2.3 Encoder-Decoder and Auto-Encoder Models
인코딩 함수는 입력을 잠재 공간 표현(Latent Representation)으로 압축한다.
디코더 함수는 위에서 만든 Latent Representation을 이용해서 출력을 만들어낸다(예측한다).
여기서 Latent Representation는 입력의 주요한 feature들을 표현한 것이다
Loss는 reconstruction loss라고 불리우는 L(y; y^)를 사용한다.
NLP에서 많이 사용된다. Output이 초해상화된 사진, Segmentation 결과 등이 될 수 있다.
Auto-Encoder Models
Input과 output이 동일한 특별한 경우에 사용한다. (즉 input과 같은 output 생성 원할 때)
2가지 종류가 있다.
(1) SDAE (stacked denoising auto-encoder)
가장 인기 있음. 여러개의 auto-encoder를 쌓아서 이미지 deNoising 목적에 많이 사용
(2) VAE (variational auto-encoder)
Latent representation에 prior distribution(확률 분포)의 개념을 추가 시킨다.
위의 확률 분포를 사용해서 새로운 이미지 y를 생성시킨다.
ps. (3) adversarial auto-encoders
prior distribution와 유사한 latent representation를 만들기 위해 adversarial loss를 사용
2.4 GANs(Generative Adversarial Networks)
2개의 network 모델 : Generator(위조 지폐 제작사) VS Discriminator(경찰. 감별사)
x : 실제 이미지/ z : 노이즈 이미지/ y : G가 생성한 이미지
초기 GAN 이후의 발전
(Mr. Radford) fully-connected network가 아니라, convolutional GAN model 사용
(Mr. Mirza) 특정 label 이미지를 생성할 수 있도록 class labes로 conditional된 GAN
(Mr. Arjovsky) 새로운 loss function 사용. y x의 확률 분포가 완전히 겹치지 않게 한다.
추가 : https://github.com/hindupuravinash/the-gan-zoo
2.5 Transfer Learning
이미 학습된 모델은 이미지에서 the semantic information를 뽑아낼 수 있는 능력을 가지므로, 많은 DL(deep learning)모델들은 충분한 train data가 없을 수 있다. 이때 Transfer Learning이 효율적이다.
다른 곳에 사용되던 model을 repurpose화(우리의 데이터에 맞는 신경망으로 학습)시키는 것이다.
Image segmentation에서 많은 사람들은 (인코더 부분에서) ImageNet(많은 데이터셋)으로 학습된 모델을 사용한다.
"""
Point
- def(A) 내부에 다시 def(B)을 사용함으로써, 전역변수나 함수(B)의 많은 매개변수 사용을 줄였다.
- banned_id 원소 하나 당, 매핑이 되는 user_id 하나를 골라낸다.
"""defsolution(user_id,banned_id):defcheck(b_id,user):"""
하나의 user_id와 b_id를 비교한다.
user_id가 b_id에 속하는 것이라면, return True.
아니라면, return False.
"""forsinrange(len(b_id)):ifb_id[s]!='*':ifb_id[s]!=user[s]:returnFalseelifb_id[s]=='*':continueelse:returnTruedefback(u,b):ifb==N2:# Reculsivd Function의 Base condition이다. "user_id 하나와 banned_id 모두를 다 비교했다면."
ifunotinresult:result.append(u[:])# u를 copy by value해서 result 에 넣는다. **중요**
returnforiinrange(N1):# user_id의 원소를 하나씩 살펴본다.
# 위에서 고른 user_id의 하나와, banned_id의 원소 모두와 비교해본다.
ifu[i]==0andlen(banned_id[b])==len(user_id[i]):# 중요한 전제 조건. 2 문자열의 길이가 같아야 한다.
ifcheck(banned_id[b],user_id[i])==True:# banned_id 원소 하나 당, 매핑이 되는 user_id 하나를 골라냈다면,
u[i]=1# 위에서 매핑한 user_id임을 표기해논다.
back(u,b+1)# 다음 banned_id 원소에, 매핑되는 user_id 하나를 골라낸다.
u[i]=0# 맨 처음부터 원상 복귀.
# 1 : 변수 선언 및 정의
answer=0N1=len(user_id)N2=len(banned_id)u=[0foriiinrange(N1)]# u[k]=1 는 user_id[k]가 banned_id 중 하나에 해당함을 의미한다.
result=[]# 가능한 u 배열의 경우와 수를 저장한다.
# 2 : reculsive 돌기 시작!
back(u,0)# 3 : 최종 결과 return.
answer=len(result)# 입출력 예 1의 result = [[1,0,0,1,0] , [0,1,0,1,0]]. 즉 2가지 경우가 존재한다.
returnanswerif__name__=="__main__":user_id=["frodo","fradi","crodo","abc123","frodoc"]banned_id=["fr*d*","abc1**"]print(solution(user_id,banned_id))pass"""
Reculsive 흐름도
[1, 1, 0, 0, 0]
[1, 0, 1, 0, 0]
[0, 0, 0, 1, 0]
[1, 0, 0, 0, 1]
[0, 0, 0, 0, 0]
[0, 1, 1, 0, 0]
[0, 1, 0, 1, 0]
[0, 1, 0, 0, 1]
[0, 0, 0, 0, 0]
[0, 0, 1, 1, 0]
[0, 0, 1, 0, 1]
[0, 0, 0, 0, 0]
[0, 0, 0, 1, 1]
[0, 0, 0, 0, 0]
"""
참고할 만한 다른 사람 코드
"""
우선 와일드카드가 포함된 문자(banned_id)로 가능한 모든 user_id의 idx를 추출한다.
이를 가지고 완전 탐색 방법을 이용하여 답을 구한다
"""importredefsolution(user_id,banned_id):possible_id=[]# 각 banned_id로부터 가능한 user_id들의 index들이 저장될 배열
cases_arr=[]# 모든 정답들을 저장할 배열
len_banned_id=len(banned_id)#
defcalc_cases_idx(id):# 가능한 모든 경우의 수를 추출하는 함수
id+="$"regex=re.compile(id.replace('*','.'))matches=[ifori,stringinenumerate(user_id)ifre.match(regex,string)]returnmatchesdefrecSolution(n,arr):#현재 몇번째 banned_id인지, 어떠한 user_id들이 선택되었는지에 대한 배열
ifn==len_banned_id:arr.sort()ifarrnotincases_arr:cases_arr.append(arr)return1else:return0rec_answer=0fornuminpossible_id[n]:ifnumnotinarr:rec_answer+=recSolution(n+1,arr+[num])returnrec_answerforiinrange(len(banned_id)):possible_id.append(calc_cases_idx(banned_id[i]))print(possible_id)returnrecSolution(0,[])
awesome-semantic-segmentation-pytorch : (1k stars)Semantic Segmentation과 관련된 (살짝 과거) 기술들을 모아서 코드화 시켜놓았다. 다 읽고 정독하면 좋을 듯 하다. On PyTorch (include FCN, PSPNet, Deeplabv3, Deeplabv3+, DANet, DenseASPP, BiSeNet, EncNet, DUNet, ICNet, ENet, OCNet, CCNet, PSANet, CGNet, ESPNet, LEDNet, DFANet)
semantic-segmentation-pytorch : (3.1k stars) 최근 Segmentation 기술들을 코드화 시켜놓았다. Pytorch implementation for Semantic Segmentation/Scene Parsing on MIT ADE20K dataset
2. Survey paper - segmentation
(1) 위의 Really-awesome-semantic-segmentation 에 있는 논문들
여기 있는 논문들은 semantic-segmentation를 어디에 사용했는가 가 중심인듯 하다.
2학년 후반 산학장학생과 장학재단의 장학생 등 8곳 정도에 지원을 했었다. 대부분 서류합격은 했지만 꼭 면접에서 떨어져 결국엔 모든 곳에서 지원을 받을 수 없었다. (운이 좋아 3학년 초반에 한국장학재단의 국가이공계장학생이 되긴했지만..)
그때의 충격이 생각보다 컸다. 나도 나름 대학생때 열심히 공부했는데.. (학점이 거의 만점이었기에.. ) 라는 생각을 많이 했다. 하지만 면접관 분들이 시선은 학점만 높고 활동은 안한 학생. 어쩌면 사회성이 떨어지는 학생을 바라보는 시선이었다.
그 후 학점이 전부가 아니라는 것을 절실히 깨닫고, 내가 하고 싶은 공부를 하고, 최대한 어떤 모임이나 동아리에서 프로젝트를 진행하며 살아왔다. 그리고 그렇게 살아왔다는 증거이자 흔적을 남기고 내가 공부하는 내용을 최대한 정리해서 올려놓자. 라는 마음으로 생각날 때 마다 블로그에 글을 올려 놓았다.
이제 인공지능&자율주행 쪽으로 진로를 완전히 정한 만큼. 깃을 이용해 나의 공부 내용, 연구 노트, 나의 프로젝트와 활동들에 대한 이야기를 적어놓으려고 한다.^^
연구노트로 매일매일 공부한 내용을 글로 올리기 때문에, 글의 내용이 작성자만 알아볼 수 있는 내용으로 채워질 수도 있지만, 최대한 성실하고 친절하게 내용을 정리할 계획입니다. 이 깃 블로그 페이지를 방문해주신 모든 분들 모두모두 항상 건강하고 행복하시길 바랍니다. ^^
오류 및 주의사항
Tstory에 올려놓았던 게시물을 그대로 복붙해서 가져오다보니 다음과 같은 문제가 생겼다.
$ sudo docker start <Contain ID>
이와 같은 글에서 $ sudo docker start 이 처럼 <> 가 안보이는 현상이 일어난다. Blog 포스트 말고, Git 공식 홈페이지에서 찾아보면 <>가 보이는데도 불구하고 말이다.
따라서 해결방법 :
다음에 게시물을 작성할때는 꼭 아래와 같이 작성해야 겠다
이전 게시물(Tstory 복붙)을 보고 공부하다가 뭔가 이상하다 싶으면 Git 공식 홈페이지에 가서 원본 .md파일을 읽어봐야 겠다.
defcur_next(lis,cur_min,cur_pos,n,l):foriinrange(cur_pos+1,l):ifcur_min<lis[i]:returnlis[i],ireturn-1,l+1deffine_index(food_times,m,cur_min):forindex,Valueinenumerate(food_times):ifcur_min<=Value:ifm==0:returnindex+1else:m-=1defsolution(food_times,k):# 1
lis=food_times[:]lis.sort()# 2
cur_min=lis[0]diff=cur_mincur_pos=0# list 0부터 시작
n=len(lis)# 남은 음식 수
l=n# 처음 음식의 총 갯수
# 3
whilediff*n<=k:k=k-diff*ntemp,cur_pos=cur_next(lis,cur_min,cur_pos,n,l)iftemp==-1:return-1# k가 충분히 커, 음식을 다 먹었을 경우.
diff=temp-cur_mincur_min=tempn=l-cur_pos# 4
cur_min=lis[cur_pos]answer=fine_index(food_times,k%n,cur_min)returnanswerif__name__=="__main__":food_times=[3,1,2,2,3,2]k=13print(solution(food_times,k))
$ 수학적 수식(문장 사이에 적기 가능) $ \[수학적 수식( 무조건 가운데 정렬)\] \[x + y = z\]
17. Struct
ㅂ + 한자 를 사용해 찾을 수 있다.
```
├──
├──
├──
└──
```
적은 것 같지만 잘 사용하면 이것만으로 충분하고, 이게 전부이다.
더 필요한 내용은 추가적으로 직접 더 찾아서 공부하도록 하자.
Typora
하지만 typora에서도 더 많은 좋은 기능을 제공한다. typora도 추가적으로 공부해보도록 하자.
Visual studio code
마크다운을 활동하는 방법이 Typora도 있지만, Visual studio code를 활용하는 방법도 있다. ‘.md’ 파일을 만들고 ctrl+shift+v 를 눌러 previewer를 같이 띄어놓음으로써 마크다운을 쓰고 난 직후의 모습을 바로바로 확인할 수 있다. 아무리 그래도 VScode는 Typora보다는 실시간성이 떨어지지만 적절히 사용한다면 충분히 좋은 마크다운 편집기라고 할 수 있다.
---
layout: list
title: <아무거나 가능 But foler name with Capa>
slug: <new folder name>
menu: true
permalink: /<new folder name>/
order: 1
sitemap: false
description: >
지도학습 비지도학습 강화학습**^^**
# accent_color: rgb(38,139,210)
# accent_image:
# background: rgb(32,32,32)
# overlay: false
---
_config 수정하기
# Add links to the sidebar.
menu:
- title: <여기가 아무이름이나 다 됨>
url: /<New Folder Name>/
각 목차에 사용하는 게시물(md 파일)에 꼭 넣어야 하는 템플릿.
---
layout: post
title: Example Content III
description: >
A page showing Hydejack-specific markdown content.
image: /assets/img/blog/example-content-iii.jpg
---
20.08.22 블로그 재 정검
오랜만에 들어와서 블로그를 업그레이드 하고 싶었다. 그래서 이것저것 확인하는 중 다음의 과정을 거쳤다. 그 과정을 혹시 몰라 기록해 놓는다.
다음과 같이 gemfile을 수정했다.
bundle exec jekyll serve를 하기 전에 빌드를 하란다. $ bundle install
뭔가 버전이 엄청 안맞는다고 안된단다. 에러 메세지에 $ bundle update 를 하라고 해서 업데이트를 했다.
다시 bundle install 아주 잘된다.
$ bundle exec jekyll serve
_config.yml 파일에서 문제가 생긴다. 여기가 원래 주석이었는데 주석을 풀어놔서 그런가…..