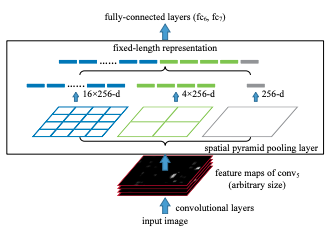
【Python-Module】 Faster RCNN 수행하기 - OpenCV DNN 모듈
이전 Post를 통해서 Faster RCNN이론에 대해서 공부했다. OpenCV DNN 모델을 사용해서 Faster RCNN을 수행해보자.
OpenCV DNN 모듈을 사용해서 Detection 수행하기
/DLCV/Detection/fast_rcnn/OpenCV_FasterRCNN_ObjectDetection.ipynb 참조
0. OpenCV 모듈 과정 요약
- cs_net = cv2.dnn.readNetFromFramwork(‘inference 가중치 파일’,’config파일’) 를 사용해서
- img_drwa = cv2.dnn.blobFromImage(cv2로 read한 이미지, 변환 형식1 , 변환 형식2)
- cv_out = cv_net.forward()
- for detection in cv_out[0,0,:,:] 으로 접근해서 output정보 가져오기.
1. OpenCV DNN 패키지를 이용하여 Faster R-CNN
- Tensorflow 에서 Pretrained 된 모델 파일을 OpenCV에서 로드하여 이미지와 영상에 대한 Object Detection 수행.
1-0 입력 이미지로 사용될 이미지 보기
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
img = cv2.imread('../../data/image/beatles01.jpg')
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
print('image shape:', img.shape)
plt.figure(figsize=(12, 12))
# plt.imshow(img_rgb)
image shape: (633, 806, 3)
<Figure size 864x864 with 0 Axes>
<Figure size 864x864 with 0 Axes>
1-1. Tensorflow에서 Pretrained 된 Inference모델(Frozen graph)와 환경파일을 다운로드 받은 후 이를 이용해 OpenCV에서 Inference 모델 생성
- https://github.com/opencv/opencv/wiki/TensorFlow-Object-Detection-API 에 다운로드 URL 있음.
- Faster-RCNN ResNet-50 2018_01_28 사용할 예정
- pretrained 모델은 http://download.tensorflow.org/models/object_detection/faster_rcnn_resnet50_coco_2018_01_28.tar.gz 에서 다운로드 후 압축 해제
- pretrained 모델을 위한 환경 파일은 https://github.com/opencv/opencv_extra/blob/master/testdata/dnn/faster_rcnn_resnet50_coco_2018_01_28.pbtxt 에서 다운로드
- download된 모델 파일과 config 파일을 인자로 하여 inference 모델을 DNN에서 로딩함.
%cd /home/sb020518/DLCV/Detection/fast_rcnn
!mkdir pretrained
%cd ./pretrained
#!wget http://download.tensorflow.org/models/object_detection/faster_rcnn_resnet50_coco_2018_01_28.tar.gz
#!wget https://raw.githubusercontent.com/opencv/opencv_extra/master/testdata/dnn/faster_rcnn_resnet50_coco_2018_01_28.pbtxt
# !tar -xvf faster*.tar.gz
!mv faster_rcnn_resnet50_coco_2018_01_28.pbtxt graph.pbtxt
%cd /home/sb020518/DLCV/Detection/fast_rcnn

.pdtxt 파일 다운받기 : github raw 파일 전체 복붙을 해서 다운받기 여기에서 raw클릭해서 나오는 주소를 wget의 입력으로 넣어주어야 한다.
- .pdtxt파일 : OpenCV를 위한 Config파일이다.
- .pb 파일 : tensorflow inferecne를 위한 가중치 파일
1-2 dnn에서 readNetFromTensorflow()로 tensorflow inference 모델을 로딩
cv_net = cv2.dnn.readNetFromTensorflow('./pretrained/faster_rcnn_resnet50_coco_2018_01_28/frozen_inference_graph.pb',
'./pretrained/graph.pbtxt')
- 유의 사항 : object ouput은 class index를 return한다. object 이름을 그대로 return해주지 않는다.
COCO는 91번까지의 ID 번호 object가 있는데, 11개가 COCO2017 에서는 사용하지 않아서 80개의 Object name이 존재한다.
- coco 데이터 세트의 클래스id별 클래스명 지정해 주어야 한다.
- Class ID가 0 ~ 90 , 0 ~ 91 , 0~79 로 다양하게 사용된다. 이것은 모델별로, 프레임워크별로 다 다르다… 아래와 같이. 아래의 표를 파악하는 방법은 실험적으로 알아내는 방법 밖에 없다.
- 여기서는 OpenCV tensorflow FasterRCNN이므로 0 ~ 90을 사용한다

# OpenCV Yolo용
labels_to_names_seq = {0:'person',1:'bicycle',2:'car',3:'motorbike',4:'aeroplane',5:'bus',6:'train',7:'truck',8:'boat',9:'traffic light',10:'fire hydrant',
11:'stop sign',12:'parking meter',13:'bench',14:'bird',15:'cat',16:'dog',17:'horse',18:'sheep',19:'cow',20:'elephant',
21:'bear',22:'zebra',23:'giraffe',24:'backpack',25:'umbrella',26:'handbag',27:'tie',28:'suitcase',29:'frisbee',30:'skis',
31:'snowboard',32:'sports ball',33:'kite',34:'baseball bat',35:'baseball glove',36:'skateboard',37:'surfboard',38:'tennis racket',39:'bottle',40:'wine glass',
41:'cup',42:'fork',43:'knife',44:'spoon',45:'bowl',46:'banana',47:'apple',48:'sandwich',49:'orange',50:'broccoli',
51:'carrot',52:'hot dog',53:'pizza',54:'donut',55:'cake',56:'chair',57:'sofa',58:'pottedplant',59:'bed',60:'diningtable',
61:'toilet',62:'tvmonitor',63:'laptop',64:'mouse',65:'remote',66:'keyboard',67:'cell phone',68:'microwave',69:'oven',70:'toaster',
71:'sink',72:'refrigerator',73:'book',74:'clock',75:'vase',76:'scissors',77:'teddy bear',78:'hair drier',79:'toothbrush' }
labels_to_names_0 = {0:'person',1:'bicycle',2:'car',3:'motorcycle',4:'airplane',5:'bus',6:'train',7:'truck',8:'boat',9:'traffic light',
10:'fire hydrant',11:'street sign',12:'stop sign',13:'parking meter',14:'bench',15:'bird',16:'cat',17:'dog',18:'horse',19:'sheep',
20:'cow',21:'elephant',22:'bear',23:'zebra',24:'giraffe',25:'hat',26:'backpack',27:'umbrella',28:'shoe',29:'eye glasses',
30:'handbag',31:'tie',32:'suitcase',33:'frisbee',34:'skis',35:'snowboard',36:'sports ball',37:'kite',38:'baseball bat',39:'baseball glove',
40:'skateboard',41:'surfboard',42:'tennis racket',43:'bottle',44:'plate',45:'wine glass',46:'cup',47:'fork',48:'knife',49:'spoon',
50:'bowl',51:'banana',52:'apple',53:'sandwich',54:'orange',55:'broccoli',56:'carrot',57:'hot dog',58:'pizza',59:'donut',
60:'cake',61:'chair',62:'couch',63:'potted plant',64:'bed',65:'mirror',66:'dining table',67:'window',68:'desk',69:'toilet',
70:'door',71:'tv',72:'laptop',73:'mouse',74:'remote',75:'keyboard',76:'cell phone',77:'microwave',78:'oven',79:'toaster',
80:'sink',81:'refrigerator',82:'blender',83:'book',84:'clock',85:'vase',86:'scissors',87:'teddy bear',88:'hair drier',89:'toothbrush',
90:'hair brush'}
labels_to_names = {1:'person',2:'bicycle',3:'car',4:'motorcycle',5:'airplane',6:'bus',7:'train',8:'truck',9:'boat',10:'traffic light',
11:'fire hydrant',12:'street sign',13:'stop sign',14:'parking meter',15:'bench',16:'bird',17:'cat',18:'dog',19:'horse',20:'sheep',
21:'cow',22:'elephant',23:'bear',24:'zebra',25:'giraffe',26:'hat',27:'backpack',28:'umbrella',29:'shoe',30:'eye glasses',
31:'handbag',32:'tie',33:'suitcase',34:'frisbee',35:'skis',36:'snowboard',37:'sports ball',38:'kite',39:'baseball bat',40:'baseball glove',
41:'skateboard',42:'surfboard',43:'tennis racket',44:'bottle',45:'plate',46:'wine glass',47:'cup',48:'fork',49:'knife',50:'spoon',
51:'bowl',52:'banana',53:'apple',54:'sandwich',55:'orange',56:'broccoli',57:'carrot',58:'hot dog',59:'pizza',60:'donut',
61:'cake',62:'chair',63:'couch',64:'potted plant',65:'bed',66:'mirror',67:'dining table',68:'window',69:'desk',70:'toilet',
71:'door',72:'tv',73:'laptop',74:'mouse',75:'remote',76:'keyboard',77:'cell phone',78:'microwave',79:'oven',80:'toaster',
81:'sink',82:'refrigerator',83:'blender',84:'book',85:'clock',86:'vase',87:'scissors',88:'teddy bear',89:'hair drier',90:'toothbrush',
91:'hair brush'}
1-3 이미지를 preprocessing 수행하여 Network에 입력하고 Object Detection 수행 후 결과를 이미지에 시각화
# 원본 이미지가 Faster RCNN기반 네트웍으로 입력 시 resize됨.
# resize된 이미지 기반으로 bounding box 위치가 예측 되므로 이를 다시 원복하기 위해 원본 이미지 shape정보 필요
img = cv2.imread('../../data/image/beatles01.jpg')
rows = img.shape[0]
cols = img.shape[1]
# cv2의 rectangle()은 인자로 들어온 이미지 배열에 직접 사각형을 업데이트 하므로 그림 표현을 위한 별도의 이미지 배열 생성.
draw_img = img.copy()
# 원본 이미지 배열 BGR을 RGB로 변환하여 배열 입력.
# Tensorflow Faster RCNN은 size를 고정할 필요가 없는 것으로 추정. 따라서 size = (300, 300)과 같이 파라메터 설정 안해줌
# hblobFromImage 매개변수 정보는 ttps://www.pyimagesearch.com/2017/11/06/deep-learning-opencvs-blobfromimage-works/
# 신경망에 이미지를 Inference 시킬 것이라는 것을 명시
cv_net.setInput(cv2.dnn.blobFromImage(img, swapRB=True, crop=False))
# Object Detection 수행하여 결과를 cvOut으로 반환
# 이미지 Inference 수행
cv_out = cv_net.forward()
print('cvout type : ', type(cv_out))
print('cvout shape : ', cv_out.shape)
# cv_out에서 0,0,100,7 에서 100은 object의 수. 7은 하나의 object 정보
# 0,0은 Inference도 배치로 할 수 있다. 이미지를 여러개를 넣는다면, 한꺼번에 detection값이 나올때를 대비해서 4차원 cv_out이 나오게 한다.
# bounding box의 테두리와 caption 글자색 지정. BGR
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# detected 된 object들을 iteration 하면서 정보 추출
# cv_out[0,0,:,:]은 (100 x 7) 배열. detection에는 cv_out[0,0,:,:]의 하나의 행. 즉 7개의 원소가 들어간다.
for detection in cv_out[0,0,:,:]:
score = float(detection[2]) # confidence
class_id = int(detection[1])
# detected된 object들의 score가 0.5 이상만 추출
if score > 0.7:
# detected된 object들은 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
# 아래의 값은 좌상단. 우하단. 의 좌표값이다.
left = detection[3] * cols # detection[3],[4],[5],[6] -> 0~1 값이다.
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
# labels_to_names_seq 딕셔너리로 class_id값을 클래스명으로 변경.
caption = "{}: {:.4f}".format(labels_to_names_0[class_id], score)
print(caption)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
# cv2를 이용해서 상자를 그리면 무조건 정수값을 매개변수로 넣어줘야 한다. 실수를 사용하고 싶다면 matplot이용할것
# putText : https://www.geeksforgeeks.org/python-opencv-cv2-puttext-method/
cv2.rectangle(draw_img, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.4, red_color, 1)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(img_rgb)
cvout type : <class 'numpy.ndarray'>
cvout shape : (1, 1, 100, 7)
person: 0.9998
person: 0.9996
person: 0.9993
person: 0.9970
person: 0.8995
car: 0.8922
car: 0.7602
car: 0.7415

1-4 위에서 했던 작업을 def 함수로 만들어보자!
- 추후에 비디오에서도 사용할 예정
import time
def get_detected_img(cv_net, img_array, score_threshold, use_copied_array=True, is_print=True):
rows = img_array.shape[0]
cols = img_array.shape[1]
draw_img = None
if use_copied_array:
draw_img = img_array.copy()
else:
draw_img = img_array
cv_net.setInput(cv2.dnn.blobFromImage(img_array, swapRB=True, crop=False))
start = time.time()
cv_out = cv_net.forward()
green_color=(0, 255, 0)
red_color=(0, 0, 255)
# detected 된 object들을 iteration 하면서 정보 추출
for detection in cv_out[0,0,:,:]:
score = float(detection[2])
class_id = int(detection[1])
# detected된 object들의 score가 함수 인자로 들어온 score_threshold 이상만 추출
if score > score_threshold:
# detected된 object들은 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
# labels_to_names 딕셔너리로 class_id값을 클래스명으로 변경. opencv에서는 class_id + 1로 매핑해야함.
caption = "{}: {:.4f}".format(labels_to_names_0[class_id], score)
print(caption)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(draw_img, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(draw_img, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.4, red_color, 1)
if is_print:
print('Detection 수행시간:',round(time.time() - start, 2),"초")
return draw_img
## 방금 위에서 만든 함수를 사용해서 다시 추론해보자.
# image 로드
img = cv2.imread('../../data/image/beatles01.jpg')
print('image shape:', img.shape)
# tensorflow inference 모델 로딩
cv_net = cv2.dnn.readNetFromTensorflow('./pretrained/faster_rcnn_resnet50_coco_2018_01_28/frozen_inference_graph.pb',
'./pretrained/graph.pbtxt')
# Object Detetion 수행 후 시각화
draw_img = get_detected_img(cv_net, img, score_threshold=0.6, use_copied_array=True, is_print=True)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(img_rgb)
# image 로드
img = cv2.imread('../../data/image/baseball01.jpg')
print('image shape:', img.shape)
# tensorflow inference 모델 로딩
cv_net = cv2.dnn.readNetFromTensorflow('./pretrained/faster_rcnn_resnet50_coco_2018_01_28/frozen_inference_graph.pb',
'./pretrained/graph.pbtxt')
# Object Detetion 수행 후 시각화
draw_img = get_detected_img(cv_net, img, score_threshold=0.7, use_copied_array=True, is_print=True)
img_rgb = cv2.cvtColor(draw_img, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(12, 12))
plt.imshow(img_rgb)

2. Video Object Detection 수행
2-1 원본 영상 보기
# Video API는 mp4에서만 사용가능함
from IPython.display import clear_output, Image, display, Video, HTML
Video('../../data/video/John_Wick_small.mp4')
2-2 VideoCapture와 VideoWriter 설정하기
- VideoCapture를 이용하여 Video를 frame별로 capture 할 수 있도록 설정
- VideoCapture의 속성을 이용하여 Video Frame의 크기 및 FPS 설정.
- VideoWriter를 위한 인코딩 코덱 설정 및 영상 write를 위한 설정
video_input_path = '../../data/video/John_Wick_small.mp4'
# linux에서 video output의 확장자는 반드시 avi 로 설정 필요.
video_output_path = '../../data/output/John_Wick_small_cv01.avi'
cap = cv2.VideoCapture(video_input_path)
codec = cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS) # 프레임 속도 값. 동영상의 1초 프레임 갯수
vid_writer = cv2.VideoWriter(video_output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt)
총 Frame 갯수: 58
2-3 총 Frame 별로 iteration 하면서 Object Detection 수행.
- 개별 frame별로 위에서 한 단일 이미지 Object Detection을 수행해서 vid_writer에 프래임을 차곡차곡 쌓음
- 여기서는 위에서 만든 함수 사용 하지 않음
# bounding box의 테두리와 caption 글자색 지정
green_color=(0, 255, 0)
red_color=(0, 0, 255)
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
rows = img_frame.shape[0]
cols = img_frame.shape[1]
# 원본 이미지 배열 BGR을 RGB로 변환하여 배열 입력
cv_net.setInput(cv2.dnn.blobFromImage(img_frame, swapRB=True, crop=False))
start= time.time()
# Object Detection 수행하여 결과를 cv_out으로 반환
cv_out = cv_net.forward()
frame_index = 0
# detected 된 object들을 iteration 하면서 정보 추출
for detection in cv_out[0,0,:,:]:
score = float(detection[2])
class_id = int(detection[1])
# detected된 object들의 score가 0.5 이상만 추출
if score > 0.5:
# detected된 object들은 scale된 기준으로 예측되었으므로 다시 원본 이미지 비율로 계산
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
# labels_to_names_0딕셔너리로 class_id값을 클래스명으로 변경.
caption = "{}: {:.4f}".format(labels_to_names_0[class_id], score)
#print(class_id, caption)
#cv2.rectangle()은 인자로 들어온 draw_img에 사각형을 그림. 위치 인자는 반드시 정수형.
cv2.rectangle(img_frame, (int(left), int(top)), (int(right), int(bottom)), color=green_color, thickness=2)
cv2.putText(img_frame, caption, (int(left), int(top - 5)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, red_color, 1)
print('Detection 수행 시간:', round(time.time()-start, 2),'초')
vid_writer.write(img_frame)
# end of while loop
vid_writer.release()
cap.release()
Detection 수행 시간: 5.24 초
Detection 수행 시간: 5.04 초
Detection 수행 시간: 5.02 초
Detection 수행 시간: 5.01 초
Detection 수행 시간: 5.03 초
Detection 수행 시간: 5.0 초
더 이상 처리할 frame이 없습니다.

# Google Cloud Platform의 Object Storage에 동영상을 저장 후 Google Cloud 에 접속해서 다운로드
# 혹은 지금의 Jupyter 환경에서 다운로드 수행
!gsutil cp ../../data/output/John_Wick_small_cv01.avi gs://my_bucket_dlcv/data/output/John_Wick_small_cv01.avi
2-4 위에서 만든 함수를 사용해서 ,video detection 전용 함수 생성.
def do_detected_video(cv_net, input_path, output_path, score_threshold, is_print):
cap = cv2.VideoCapture(input_path)
codec = cv2.VideoWriter_fourcc(*'XVID')
vid_size = (round(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),round(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
vid_fps = cap.get(cv2.CAP_PROP_FPS)
vid_writer = cv2.VideoWriter(output_path, codec, vid_fps, vid_size)
frame_cnt = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print('총 Frame 갯수:', frame_cnt)
green_color=(0, 255, 0)
red_color=(0, 0, 255)
while True:
hasFrame, img_frame = cap.read()
if not hasFrame:
print('더 이상 처리할 frame이 없습니다.')
break
img_frame = get_detected_img(cv_net, img_frame, score_threshold=score_threshold, use_copied_array=False, is_print=is_print)
vid_writer.write(img_frame)
# end of while loop
vid_writer.release()
cap.release()
do_detected_video(cv_net, '../../data/video/John_Wick_small.mp4', '../../data/output/John_Wick_small_02.avi', 0.2, True)
!gsutil cp ../../data/output/John_Wick_small_02.avi gs://my_bucket_dlcv/data/output/John_Wick_small_02.avi