【Recog】 Organization for Recognition tasks (Tracking 2 Re-ID)
- These contents were for the project.
Task settings
OT (object tracking)
Task 정의: 아래와 같이 추적(=객체 경로 파악)을 희망하는 대상(query)이 정해졌을 때, 하나의 동영상 안에서 연속적으로, 동일한 객체(key)를 찾는 기술
Training: query와 GT key(모든 동영상 프레임)를 사용해 학습.
Test: query가 주어졌을 때, 모든 동영상 프레임에서 Key 탐색 (모든 프레임 정보를 모으면, 객체의 이동경로 파악 가능)

MOT (multi object tracking)
Task 정의: OT에서 확장된 기술로써, 하나의 동영상 안에서 발견되는 모든 객체의 경로를 파악하는 기술. MOT는 DFT(Detection Free Tracking)과 DBT(Detection Based Tracking)으로 나뉠 수 있다. 통상적으로는 MOT=DBT 로 여겨지고 있다.
DFT(Detection Free Tracking): 동영상 첫 프레임의 BB(bounding box) 정보만 알고 있다고 가정. (이후 프레임 BB정보 없음)
DBT(Detection Based Tracking): 모든 프레임 안 객체의 BB(bounding box)를 이미 알고 있다고 가정.
Training: 모든 동영상 프레임의 Detection 정보(=모든 객체의 BB정보)와 GT tracking정보(=모든 프레임에 대해서, [t-1프레임의 BB]와 [t프레임의 BB]의 매칭 정보가 담겨있는 파일)를 사용해 학습.
Test: 모든 동영상 프레임의 Detection 정보가 주어졌을 때, 모든 프레임에 대해 [t-1프레임의 BB]와 [t프레임의 BB]의 매칭 정보를 추론한다.
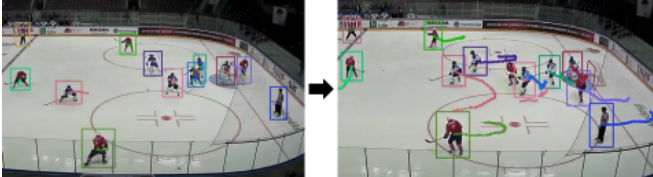
Detection+MOT
대표 논문: DeepSORT (Simple Online and Realtime Tracking).
Task 정의: 모든 프레임의 Detection정보가 미리 주어지는 MOT세팅과는 다르게, Detection까지 직접해서, MOT를 수행하는 기술.
Training: 하나의 동영상이 주어진다. GT detection 정보와 GT tracking 정보를 사용해 모델을 학습힌다.
Test: 매 프레임마다 Detection을 먼저 수행해서, 객체들의 BB를 찾는다. 이전 프레임의 BB와 현재 찾은 BB의 매칭 정보를 추론한다.
참고 영상 해석: 첫번째 프레임에서 버스,차,사람에 대한 Detection을 수행한다. (각 객체마다 랜덤한 ID가 주어진다.) 두번째 프레임에서도 버스,차,사람에 대한 Detection을 수행한다. 두 프레임간의 매칭 정보를 추론한다. (동일한 객체에 대해, 두번째 프레임에서 동일한 ID가 주어지는 것을 확인할 수 있다.)

ReID (Re-identification)
OT, MOT와의 공통점: Detection 정보과 이미 주어져 있다고 가정한다.
위 Task들과의 차이점: 다중 카메라가 고려된다.
Task 정의: 찾고 싶은 객체(qeury)가 주어졌을 때, 다중 객체 안에서 qeury와 동일한 객체인 Key를 이미지 레벨에서 찾아낸다.
Training: 다중 카메라 영상과 query가 주어진다. 모든 영상들의 프레임 안의 GT key를 사용해 모델을 학습한다.
Test: 다중 카메라 영상과 query가 주어진다. 모든 영상들의 프레임 안의 query와 동일한 객체를 가리키는 key들을 모두 찾아낸다. key의 연속적 동선 이동은 고려하지 않고, 동영상 전체에서 query와 비슷한 객체라면 과감하게 모두 keys에 포함시킨다.
참고영상 query와 동일한 객체를 가리키는 key는 아래와 같이 이미지 단위로 따로 저장된다. 각 key들은 “어떤 동영상 몇번째 프레임 어느 위치에서 탐색된 것인가”에 대한 정보도 함께 저장된다.

VIDEO ReID
Multi camera object tracking (MCOT) 라고 해석할 수 있다.
ReID와 공통점: Detection정보가 이미 주어져있다고 가정한다.
Task 정의: ReID와 차이점: 이미지 단위로 Key를 저장하는 ReID와는 다르게, Video 단위로 key를 저장함으로써 객체의 동선정보를 추론할 수 있다.
Training: Re-ID와 동일
Test: Re-ID와 동일. 다만 key의 연속적 동선 이동을 고려한다. 즉 다음의 2 조건을 모두 만족해야 keys에 저장한다. (1) 동영상 전체에서 query와 비슷한 객체 (2) 이전 프레임에서 검출된 key와 근접한 key.
참고영상 위 이미지에서 key들이 랜덤한 ID를 가지는 것과 다르게 아래 이미지는 같은 객체가 동일한 ID를 가지는 것을 확인할 수 있다. 동영상 프레이마다 동일한 ID를 가지는 객체를 연결하면 객체의 동선정보를 추론할 수 있다.

OURS
- ReID, VIDEO ReID와 차이점: OURS에서는 Detection정보가 주어지지 않으므로 Detection을 직접 수행한다.
- Detection+MOT과 차이점: OURS에서는 보다 정확한 Detection을 위해 meta정보까지 추가 활용한다. 단일 카메라 셋팅이 아닌, 다중 카메라 셋팅이다, Query를 사용하는 검색 기능이 있다.
- Task 정의: meta정보를 추가로 활용해 Detection을 수행한다. Detection 결과를 바탕으로 VIDEO ReID를 수행함으로써 다중 카메라에서 key 식별 및 추적을 동시에 수행한다.
- Training setting: 다중 카메라 영상과 qeury의 meta정보가 주어진다. GT tracked keys 정보를 활용해 모델을 학습시킨다.
- Test setting: 다중 카메라 영상과 qeury의 meta정보가 주어졌을 때, 추적이 가능하도록 key를 추론한다.
3) mAP/Accuracy 수치가 다른 이유
- 객체 탐지: mAP :
- 각 class마다 한 AP를 갖게 되는데, AP란 precision과 recall을 그래프로 나타냈을 때의 면적값이다. 이 지표는 모델의 성능을 측정하는 지표로 사용된다.
- 모든 class의 AP에 대해 평균값을 낸 것이 바로 mAP(mean AP)이다.
- 객체 식별 : Accuracy
- 다중 카메라 내에서 객체 탐지가 이미 이뤄졌다는 가정에서 시작한다. qeury와 정확히 일치하는 keys를 얼마나 정확히 찾아냈는가? 를 의미한다.
- (단일 카메라) 실동자 동선 추적 기술 정확도 = MOTA (Matrix for object tracking)
- 다중 카메라 내 실종자 추적 정확도 = Rank-1, Rank-5 (Matrix for Re-ID)
ReID and MOT
1) Video-ReID
- Baseline, papers
- CVPR17: Video-based Person Re-identification by Deep Feature Guided Pooling
- ICCV2021: Pyramid Spatial-Temporal Aggregation for Video-Based Person Re-Identification” [paper] [github]
- ICCV2021: “Video-Based Person Re-Identification With Spatial and Temporal Memory Networks” **[paper] [github]
- CVPR18: Exploit the Unknown Gradually: One-Shot Video-Based Person Re-Identification by Stepwise Learning [github]
- AAAI20: Video Person Re-ID: Fantastic Techniques and Where to Find Them [github]
- [the highest star] Official baseline: Revisiting Temporal Modeling for Video-based Person ReID [github]
- Setting
- [paper] subset of DukeMTMC, the DukeMTMC-VideoReID dataset, is specially for video-based re-ID. Each identity only has one tracklet under a camera.
- [DukeMTMC-re-ID] We crop pedestrian images from the videos every 120 frames, yielding in total 36,411 bounding boxes with IDs. There are 1,404 identities appearing in more than two cameras and 408 identities (distractor ID) that appear in only one camera. We randomly select 702 IDs as the training set and the remaining 702 IDs as the testing set. In the testing set, we pick one query image for each ID in each camera and put the remaining images in the gallery.
- matrix
- 위 링크의 논문의 Rank1, Rank5 수치 확인 (80이상)
2) MOT
- MOTA score
- reference1 - Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking
- reference2 - StrongSORT: Make DeepSORT Great Again
- reference3 - ByteTrack: Multi-Object Tracking by Associating Every Detection Box
