【DA】 Self-Loss methods 2 in DA & DG
- Self Loss 관련 논문
- TTA 관련 논문
- Clustering 관련 논문
Paper List
- Online k-means Clustering
- Sequential K-means
- Test-Time Classifier Adjustment Module for Model-Agnostic Domain Generalization
- Semi Segmentation with Pixel-Level Contrastive Learning from a Class-wise Memory Bank
- PseudoSeg: Designing Pseudo Labels for Semantic Segmentation
- SITA: Single Image Test-time Adaptation
- Semi-Supervised Semantic Segmentation via Adaptive Equalization Learning
- Efficient Multi-Domain Learning by Covariance Normalization
Online k-means Clustering, AISTATS 2021
- Online machine learning 중 가장 대표적인 방법이 SGD 이다. 이 이전에, Follow the Leader(FTL) 와 같은 방법도 존재했다.
- 이 논문은 FTL의 Increamental work이다. 구체적으로는 기존에 FTL에서 Multiplicative weight-update algorithm 을 사용해서 초기 Center (regret (회기 함수)의 weight, bias)를 initialization을 더 적절히 하는 것을 목표로 한다. 이를 Loss (Online mahcine learning - Offline machine learning 으로 했을때의 weight차이)와 Time consuming 및 Efficiency관점으로 해석했다. 그 이외에 2개의 추가적 Contribution이 존재한다.
- 내가 하고 있는 연구와 큰 관련없는 논문이므로 구체적 이해는 넘어간다.
Test-Time Classifier Adjustment Module for Model-Agnostic Domain Generalization, NIPS 2021
- 개인적으로 Prototype을 사용하는 이 논문의 Novelty가 Unclear하다. 하지만 정말 Well written Paper라는 생각이 든다. Review도 있으므로 나중에 논문 쓰는 동안 참조하도록 하자. 왜 TTA가 필요한지, 왜 Test time 때 new distribution 사용에 대한 고려가 필요한지 잘 서술해간다. 나도 논문을 이렇게 써야겠다. 왜 필요한지 과거에 어떻게 문제였는지. Adaptive methods for real-world domain generalization 논문의 내용을 많이 참고하자.
- 핵심 정리
- Prototype을 사용해서 Prediction을 Rectifying 하는 것만으로 (SGD하지 않고) DG 성능향상에 도움을 준다.
- SGD를 사용한다면 (Pseudo Label, Cross Entropy Loss), 가장 마지막 nn.Linear 만을 update하는 게 가장 효율적이다. (BN을 Update하는 것과 성능차이가 제시되지 않아 아쉽다. 하지만 backpropagation을 아주 짧게하며 성능 향상 가성비를 최대로 얻기 위한 관점에서 가장 마지막 nn.Linear만 업데이트하는 것이 가장 좋다고 주장한다.)
- Abstract & Introduction & Relatied works (TTA & DG)
- Domain Generalization을 위한 새로운 Method (test-time template(=prototype, centroids) adjuster, T3A) 는 unknown distribution shift에 대해 모델이 robust 해지는 것을 목표로 한다.
- 과거 딥러닝 모델들은 fail to generalize to out-of-distribution samples를 격어왔다.
- ‘In search of lost DG’논문에 따르면 많은 DG method들이 존재하지만 이들이 significant improvement를 가져오진 않았다고 나와있었다. 이것은 기존 DG 방법들이 매우 어렵다는 것을 의미하고 새롭고 다른 관점으로의 접근이 필요하다는 것을 의미한다.
- Test time data들은 unlabeled, only available online이라는 특성을 가지고 있다. 이 데이터를 사용할 수 있다면 target distiribution에 적응하는 중요한 단서로써 사용할 수 있을 것이다.
- 기존 TTA 방법들은 SGD를 사용한다. 이는 computational costs를 증가시킬 뿐만 아니라, stochastic optimization은 주어진 limited test data에 대해 (특히 data가 noise하면) catastrophic failure를 유도한다.
- Source-free와 다른점: Online-manner이다.
- TENT와 다른점: 가장 마지막 nn.linear를 adapt하거나 prototype rectifying작업만을 이루므로 어떤 모델에도 plug-and-play로 동작할 수 있다. prototype rectifying작업만을 추가한다면 SGD를 사용하지 않으므로 catastrophic forgetting을 완와할 수 있다.
- Prototypical networks와 다른점: entropy minimization과 Prototype 을 연관시키는 첫번째 논문이다.
Methods
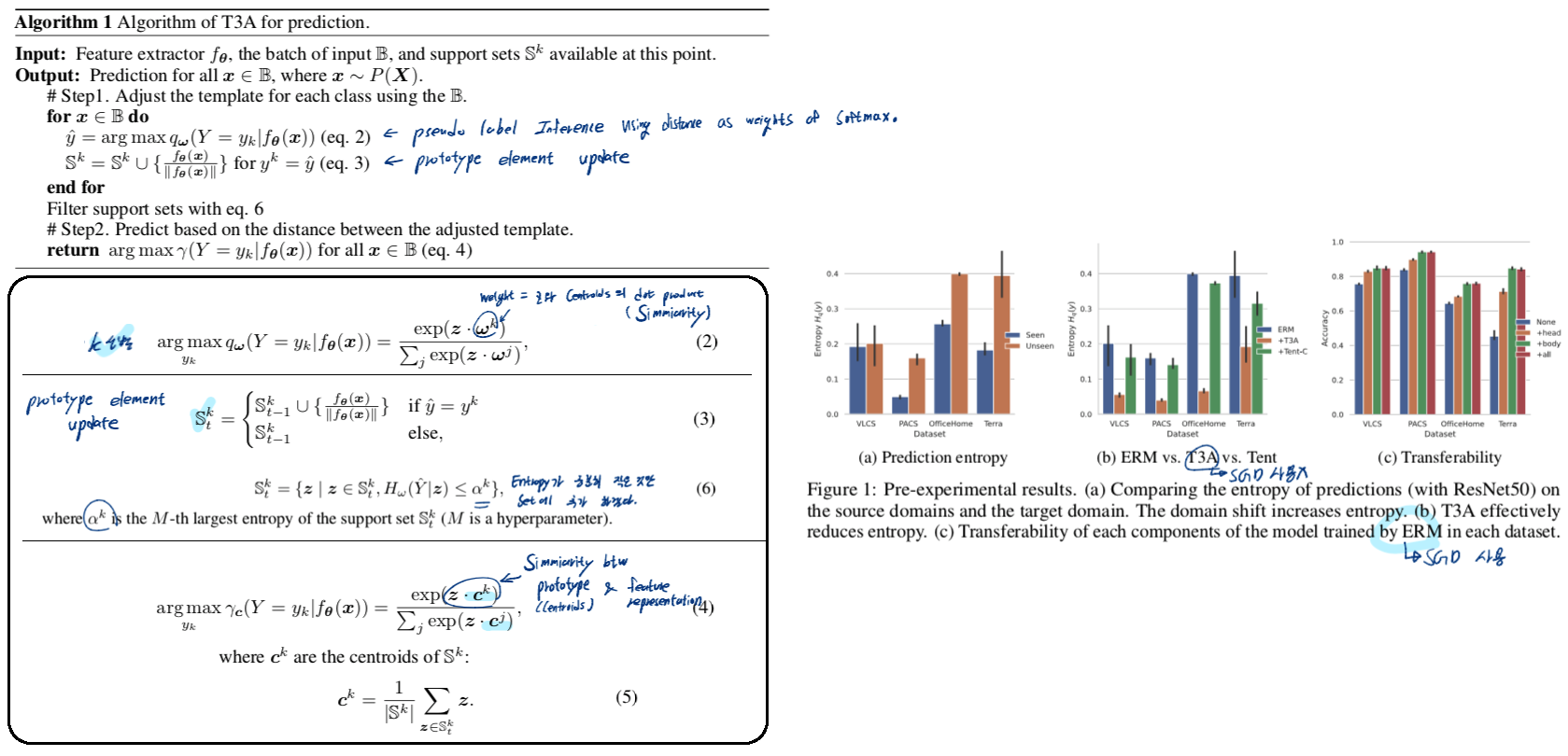
Remarks
- T3A implicitly reduces prediction entropy. (위 Figure1의 (b) 참조)
- T3A is computationally light. (SGD를 사용하지 않고, 모델 마지막에 Prototype recifying 작업만 추가했을 때)
- Adjusting the linear classifier can significantly improve performance. (위 Figure1의 (c)를 보면 성능 향상 가성비는 주황색이 짱이다. Head(classifier)와 body(backbone)을 Update하는 것은 가성비 별로다.)
Semi-Supervised Semantic Segmentation with Pixel-Level Contrastive Learning from a Class-wise Memory Bank, CVPR 2021
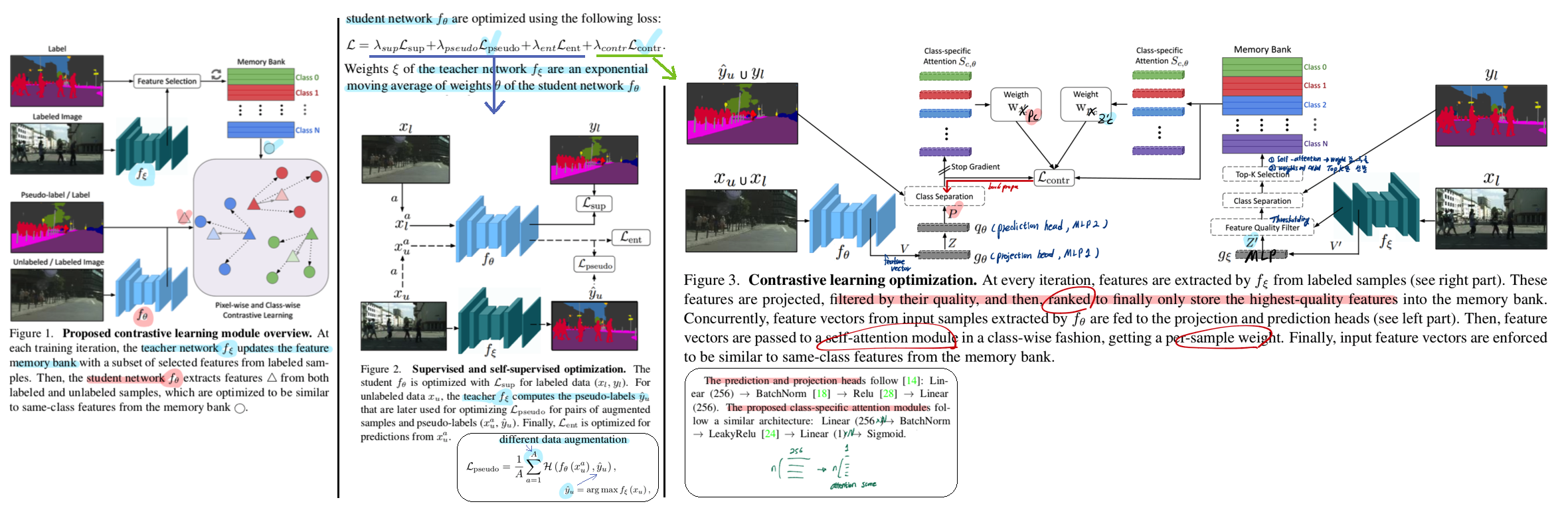
- Semi-supervised learning이기 때문에 나의 연구와 연관성은 떨어진다. 하지만 Attention을 사용한 Ranking은 흥미롭다. Labeled data에서 나오는 적절한 Signal이 Attention module을 적절히 학습시켜 줄 것 같다. 하지만 Label이 없으면 Attentions 모듈이 적절히 학습될지는 실험이 필요하다.
- Contrastive learning을 통해서 모델이 yield similar pixel-level feature represen- tations for same-class samples across the whole dataset 하도록 유도한다. 다시 말해
a better class separationas well asaligning the unlabeled data distribution에 도움을 줄 것이다. - 위 Contrastive learning에서 세세한 수식은 패스한다. 대신 Teacher에서 좋은 Feature만 가져오는 과정은 참조할만하다.
- Threshold filtering (Feature quality filter)
- Attention modules을 사용한 weight sorting (오른쪽 그림 아래 attention score 만드는 layer 참조)
- 위 sort 결과에서 TopK개만 선발하여 memory에 저장
- Inference는 어떤 모델로 한는가? Following [29, 37], the segmentation is performed with “the student” in the experimental validation, although the teacher would lead to a slightly better performance [34].
Multi-Target Domain Adaptation with Collaborative Consistency Learning, CVPR 2021
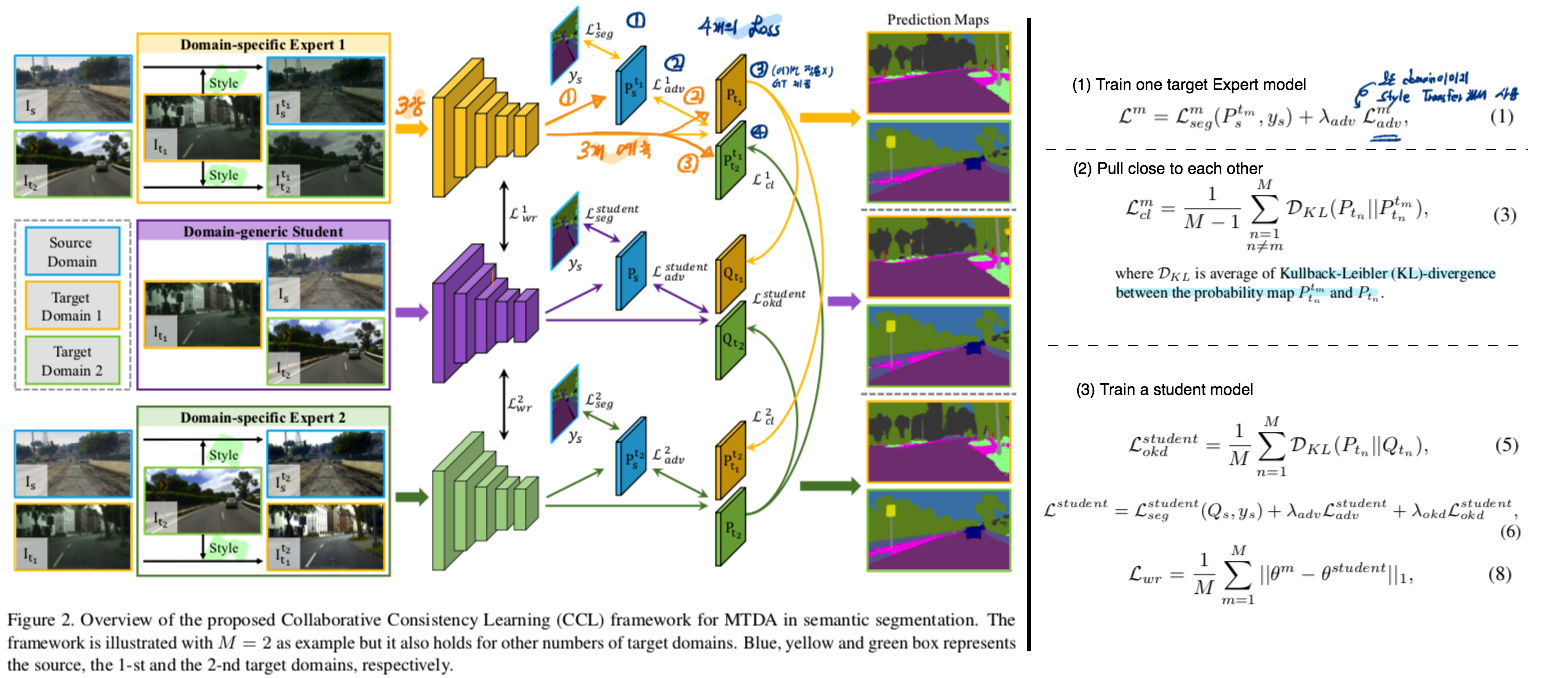
- KL divergency로 이렇게 심플하게 Multi Expert를 학습하게 유도하는지는 몰랐다. Shared Affine Parameter를 사용하는 나로써, 모델의 혼란을 막기 위해 Regulization term이나 Momentum teacher model을 진지하게 고민해봐야겠다.
- 학습 순서 간단하다.
- Train Unsupervised multi-target DA: 각 Target에 Specific한 Expert 모델을 만든다. Adversarial learning을 사용한다. Target 이미지로 모든 도메인 이미지를 Style transfer하여 사용할 수 있다.
- Encourage to collaborate with each other: KL-divergence Loss를 사용해서 각 Expert 모델이 pull close to each other되도록 유도한다.
- Training single student model: KL-divergence Loss를 사용해서 모든 Expert에서 학습되게 한다. Weight L1 Loss를 적용하여 getting confused를 막는다.
- Abstract & Introduction
- Multi Target Semantic Segmentation을 고려하는 첫번째 work 이다.
- Naive Multi target method1: 각 Target specific 모델 만들고 앙상블 ➔ 문제점: 앙상블이 적절한 효과를 play하지 못할 수 있다. 부정확한 모델은 the risk of danger in practical applications를 유도한다.
- Naive Multi target method1: Combined target data로 a single model 학습 ➔ 문제점: domain discrepancy로 인한 performance degradation 이 발생할 수 있다. 직관적으로 생각해도 generic expert는 specialized expert보다 좋을 수 없다.
- 학습 순서 3에서 Student모델은 domain discrepancy로 인한 Confusing이 발생할 수 있다. 따라서 Equ(8) 같은 Regulization을 추가한다.
PseudoSeg: Designing Pseudo Labels for Semantic Segmentation, ICLR 2021
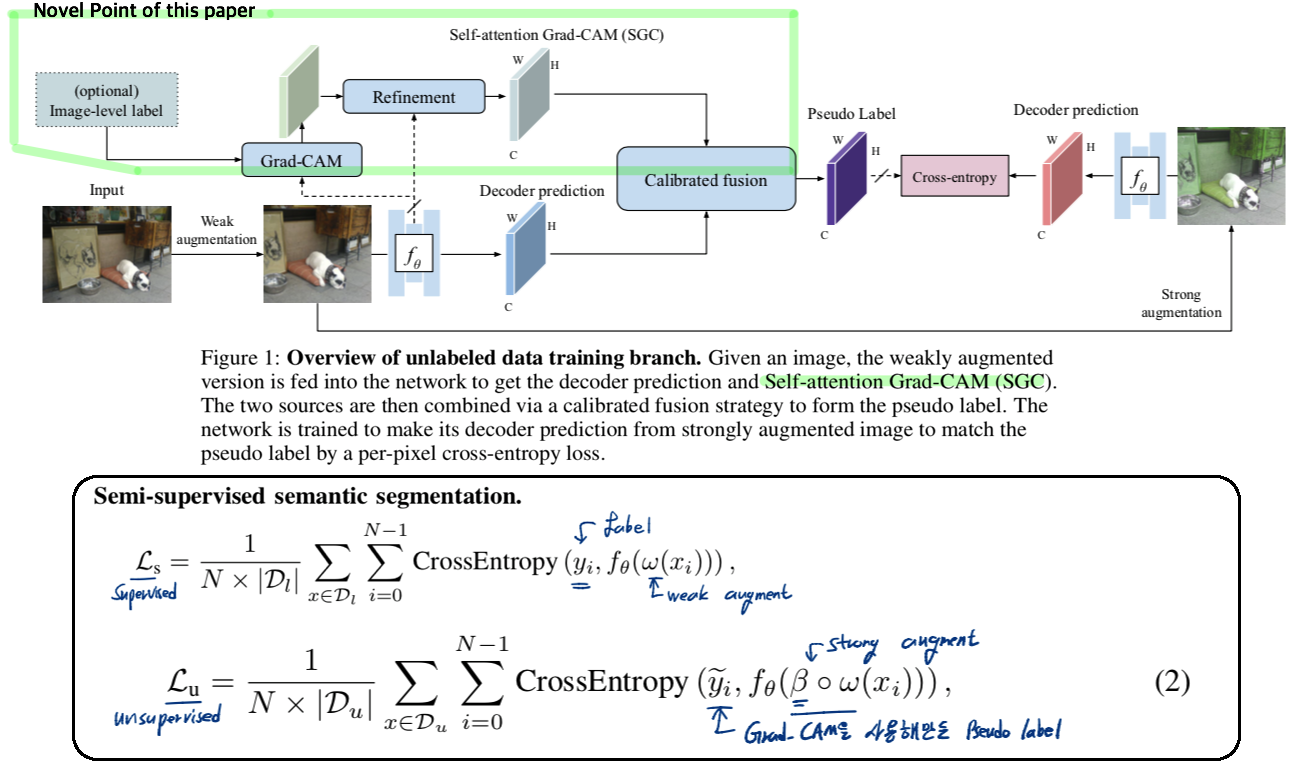
- 이 논문은 나의 연구에 활용하기에 힘들다. 우선 Grad-CAM이 GTA5와 Cityscape에서도 잘 동작하는지 모른다. 하지만 prediction결과에 추가적인 메카니즘을 찾으려는 노력과 그것을 잘 calibration한 것은 매우 의미있는 것 같다. 더 쉬운 메카니즘이 없을까?
- 작년 10월에 아카이브에 올라온 논문이며, 7개월이 지나서 ICLR에 붙은 논문이다. 인용수는 벌써 25이다. 공개된 코드는 Tensorflow를 사용한다. 이 논문은 Semi-supervised 논문과 Grad-CAM을 사용하는 논문들에 대한 깊은 통찰이 담긴 논문이라는 느낌이 들었다.
- Grad-CAM을 사용해서 Pseudo-label을 더 완벽하게 만들고자 하는 노력이 담겨 있다. 하지만 Grad-CAM을 사용하는 과정이 매우 복잡하고 어렵다. 오직 논문만으로 이해가 힘들고 코드를 깊게 봐야한다.
- 그럼에도 불구하고 Prediction(=decoder) only로 Pseudo lable을 만들어서 Semi-supervised learning을 했을 때보다 Grad-CAM을 활용할 때 Pascal VOC에서 성능이 훨씬 좋다.
- 논문 내용 정리
- Classification, Semi-supervised learning에서 (1) multiple augmented images들 사이의 consistency training 방법 (2) Pseudo lables 기법이 많이 사용되어 왔다. 하지만 structured outputs이 다르기 때문에 이것들을 Segmentation에 직접 적용하기에는 어려움이 있다.
- Prediction only만을 사용해서 pseudo labels을 만들고 어떤 다른 post-processing을 거치더라도 만족스러운 성능향상을 얻지 못했다. 그래서 prediction의 potential errors를 보상해줄 다른 decision mechanisms이 필요했다. 그리고 그들을 잘 calibration하는 방법도 필요했다.
- CAM (class activation map, Grad-CAM(2017)) 은 class-specific region을 localization하는 능력을 가지고 있다. 이런 관점에서 decoder prediction을 향상시키는데 도움이 될 것이라는 motivation을 근간으로 했다. CAM을 사용한 과거 몇가지 논문들도 있지만 이들은 CRF를 사용하등능 매우 복잡한 절차를 필요로 한다.
- CAM을 사용해서 Calibrated fusion을 하는 방법은 논문만으로 이해가 힘들다 코드 확인이 필요할 듯 하다.
SITA: Single Image Test-time Adaptation
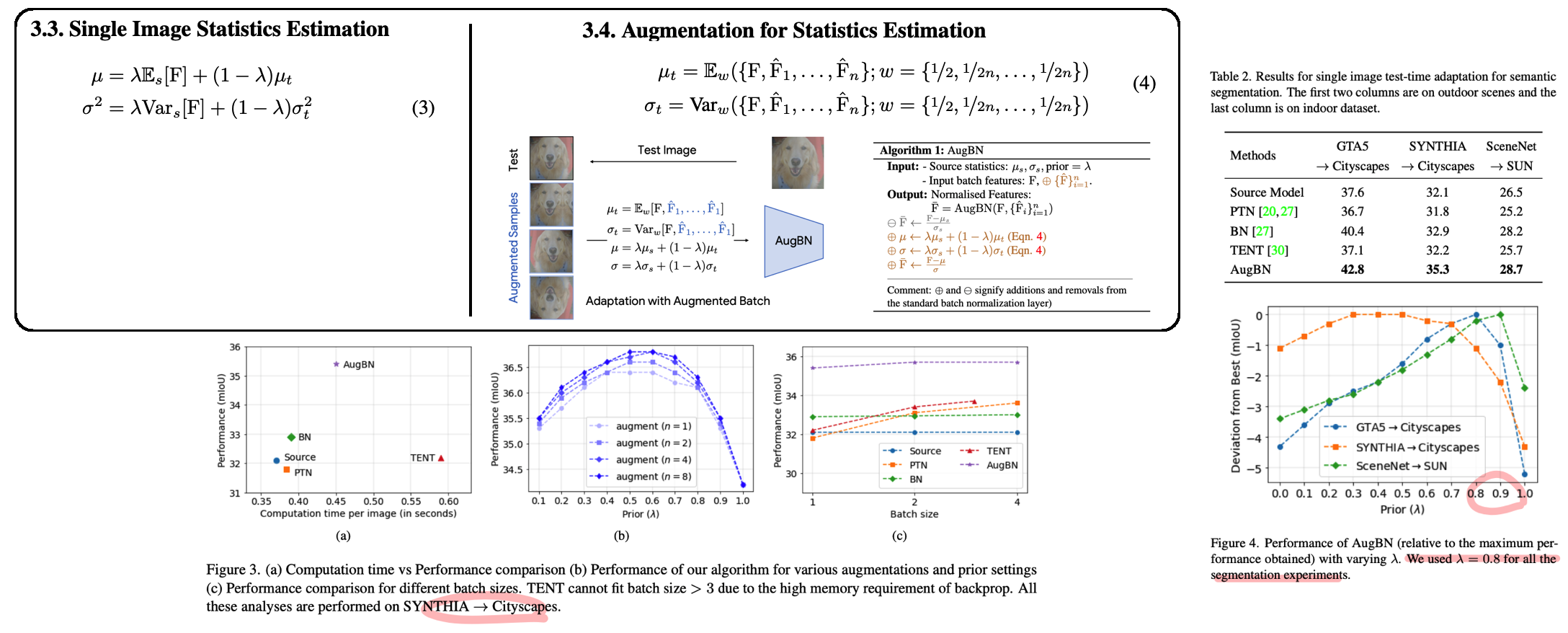
이 논문은 저자가 버리는 논문이다. TTC-Generalization 논문과 비교했을때 아주 쓰레기 같은 논문이다. 자신들의 Setting이 더 Practical하고 좋다고 주장하지만 나는 받아들여지지 않는다. 특히 주장하는 Setting이 Application관점에서 언제 어떻게 쓰일 수 있을까? 라는 질문에 답변을 할 수가 없다. 또한 Method는 a-BN이고 augBN은 자신들의 주장에 역설적이다. a-BN논문을 citation했지만 차이점을 서술하진 않았다.
Abstract & Instruction
- 우리 work은 batch 사용을 피한다. 이유는 아래와 같다. 또한 back-propagation을 하지 않는다.
- Mobile phone에서 batch를 사용하기는 힘들거다.
- Batch 내부에 다른 distribution이 섞여있다면 TTA의 성능이 떨어진다. (CIFAR-10-C를 마구 섞어서 TENT하면 성능이 떨어진다)
- Streaming으로 이미지가 들어오는데 Large batch size를 사용하고자 한다면, 이미지가 충분히 들어오길 기다려야한다. 즉 delay가 발생한다.
Method
- Single Image statistics estimation: a-BN과 동일
- AugBN: Batch를 한이미지에 augmet한 것들을 모아 구성한다. 이때 강한 augment에 의해 norm statistics가 안맞는 것을 막기 위해, equ(4)와 같이 weight를 추가한다. (이 weight를 사용해 var를 어떻게 구하는지 안 나와있다.)
Semi-Supervised Semantic Segmentation via Adaptive Equalization Learning, NeurIPS 2021
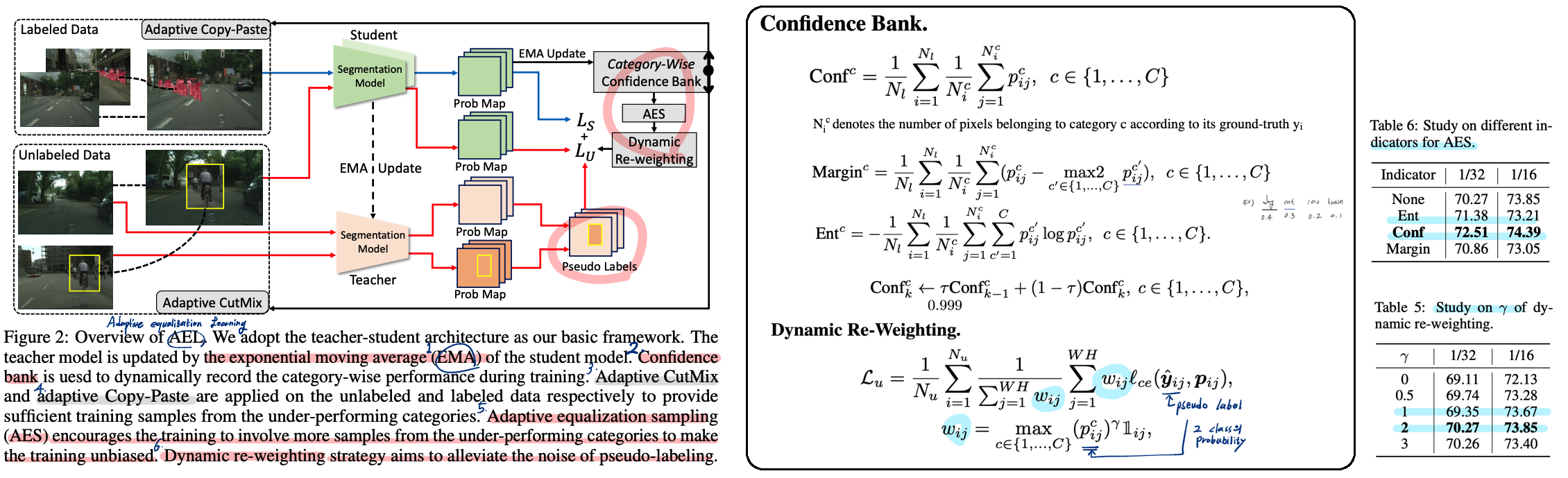
- 이 논문에서 내가 사용할 기법들이 많다. NIPS spotlight인 만큼 논문도 잘 씌어져 있다. 자신들의 목적이 확고하고 Method도 좋다.
- Abstract & Instruction
- Semi-supervised semantic segmentation
- Semantic segmentation논문들은 pixel categroties imbalance가 심각하다. 특히 Cityscaep에서 long-tailed 문제가 크다.
- Method
- Teacher 모델은 Student model의 exponential moving average (EMA, github code) 로 만든다.
- Confident Bank
- Active learning(참고논문)에서 사용된 방법에서 착안했다.
- (아쉽게도) Labeled data만을 이용해서 bank를 update한다.
- Bank의 종류는 3가지가 될 수 있다. Confidence, Margin, Entropy. 성능과 수식은 위 이미지 참조.
- Moving average를 사용해서 confidence를 update한다.
- Daynaic Re-weighting
- SSL에서 Pseudo label의 퀄리티가 성능향상에 핵심적인 Key이다.
- 그래서 기존 방법들은 High threshold를 사용해서 Pseudo label를 만들었다. 하지만 이는 Long-tailed 문제를 더욱 심각하게 만든다.
- 다른 방법은 모든 Pixels을 고려하고 weighting을 적용하는 방법이다. 이를 통해서 아래의 2가지 장점을 얻을 수 있다.
- Convincing samples에 대한 기여도를 더욱 높힐 수 있다.
- Pseudo labeling에서 noise의 영향을 줄일 수 있다.
- Adaptive CutMix, Adaptive Copy-Paste는 위 이미지 참조. 자세한 내용은 논문 참조.
Efficient Multi-Domain Learning by Covariance Normalization, CVPR 2019
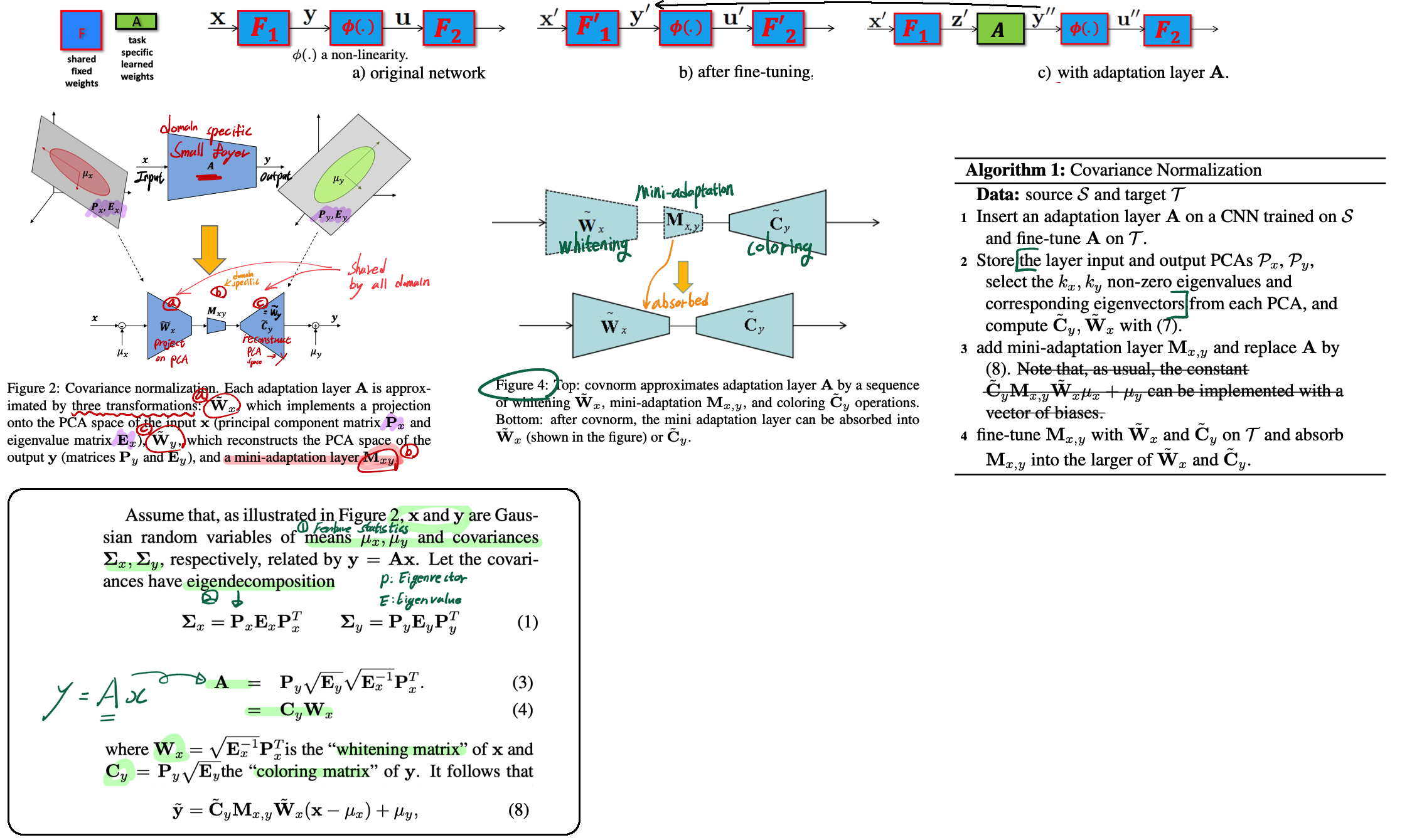
- source data를 통해서 PCA(주성분 분석) 값들을 저장해야한다. 따라서 나의 Work에 사용하기는 힘들다.
- Abstract & Instruction
- 집에 GPU는 한개이고, 집 안에 많은 디바이스가 이 GPU를 공유한다고 가정해보자. 많은 디바이스가 자신만의 Specific model을 가지고 있다면 GPU 장치에서 모델이 in & out 되는데 시간이 걸릴 것이다. 이런 overhead 문제점을 해결하기 위해서 디바이스들의 Model들이 최대한 많은 parameter를 공유해야한다.
- Multi Domain Learning은 shared para를 최대화하고, domain specific para를 최소화하는 것을 목적으로 한다. 이런 관점에서 이 논문에서는 PCA를 사용하여 서로 다른 distribution끼리의 Align을 맞추고자 한다. (Feature restoration)
- Method
- Source data를 사용해서, whitening matrix (W) 와 coloring matix (C) 를 만들어 놓는다.
- W와 C 중간에 새로운 small adaptive layer (M)을 추가해서, 각각의 Target data를 사용해 M을 fine-tune한다.
- Target fine-tune과정에서 Multi target 모두 labeled image가 있다는 가정이 있다.
- 위 Figure 주석을 통해서 큰그림을 잡을 수 있다. 자세한 이해는 코드와 논문을 참조.
