그 다음 Figure4의 Constant Threshold Self-loss로 다시 warn up
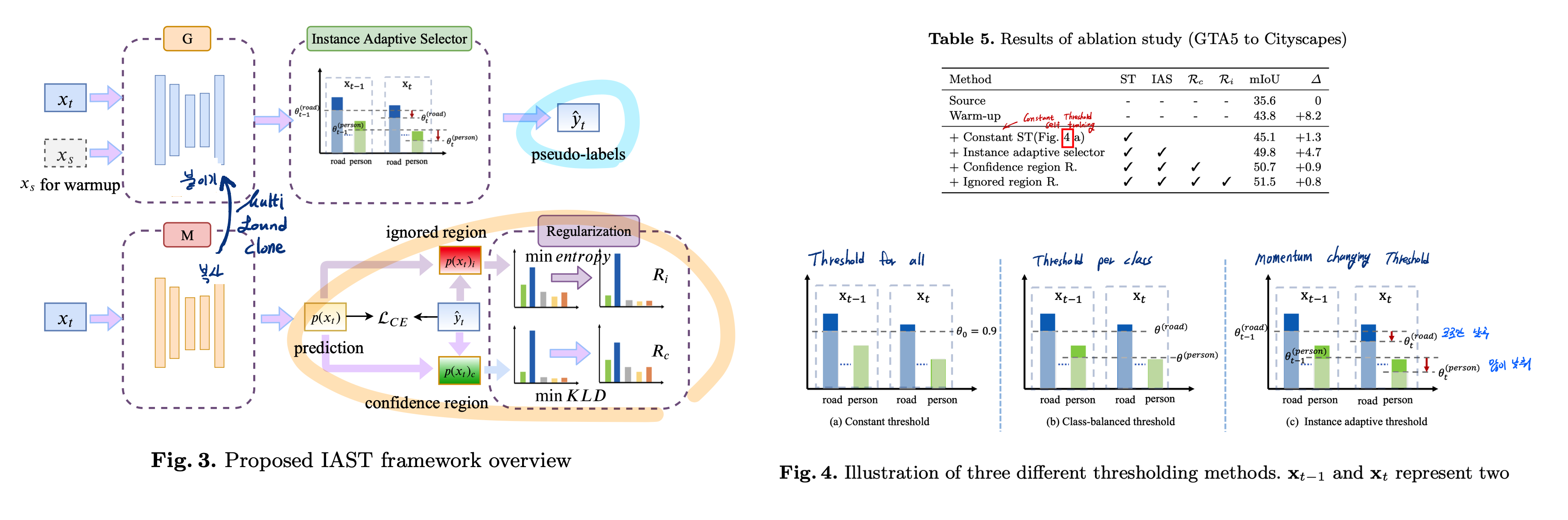
ISAT의 주요 Method 2개
(아래 그림 왼쪽) pseudo-label generation strategy with an instance adaptive selector
(아래 그림 오른쪽) the region-guided regularization
학습을 반복하면서 M을 학습시키고, G(pseudo label generator)를 붙여넣음으로써 Pseudo Label 생성 모델을 Step-by-step으로 갱신했다.
논문 해몽 정리
이전 논문들은 Adversarial learning을 많이 사용했지만 과정이 매우 복잡해 scalability and flexibility 가 낮다. 또한 Self-loss를 위한 Pseudo label은 information redundancy and noise에 취약하고 높은 confidence에만 의존하는 문제점이 있었다. (The generator tends to keep pixels with high confidence as pseudo-labels and ignore pixels with low confidence) 이런 논문의 대표적인 예시가 CBST 였다.
instance adaptive selector:
Hard class (threshold 낮은) 를 살리기 위해서 이미지가 들어올 때마다, Dynamic하게 Threshold를 갱신해서 Pseudo label을 만든다. 이렇게 하면 noise가 제거 된단다.
그렇게 찾은 Threshold로 Pseudo Label을 만들어 M 모델을 갱신시킨다.
Regularization: 아래와 같이 2가지로 분류된다.(그림 왼쪽 위 내용 참조)
Confident region: Pseudo label에 overfitting 되기 쉽다. 따라서 probability를 넓게(Smooth) 펴주는 Loss를 걸어준다.
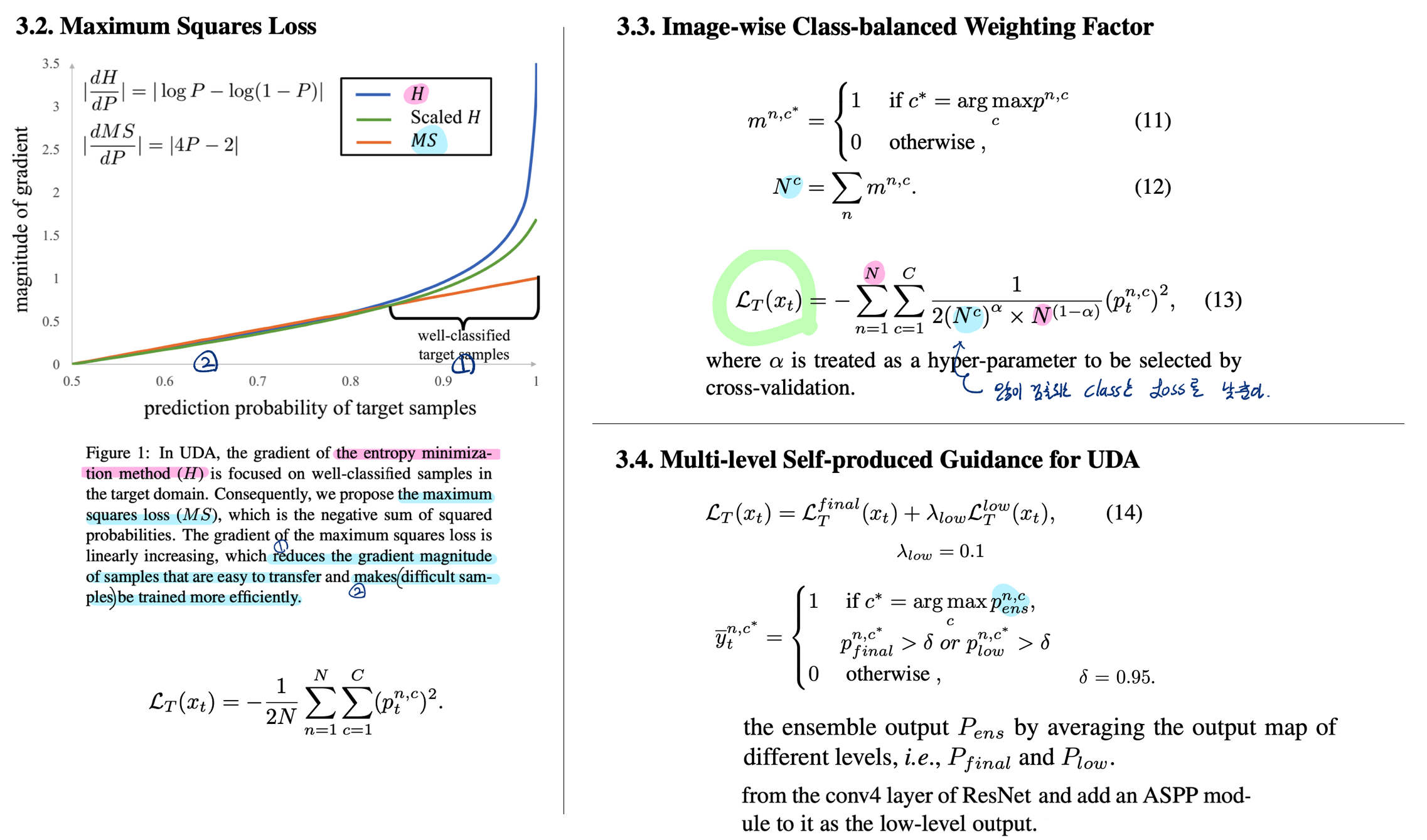
DA for Semantic Segmentation with Maximum Squares Loss - ICCV19
Entropy Loss 문제점: 위 그래프와 같이 Easy sample에 대해서 훨씬 강한 gradient를 만든다. 이를 probability imbalance라고 한다. (the entropy minimization method will allow for adequate training of samples that are easy to transfer, which hinders the training process of sam- ples that are difficult to transfer)
Scaled H는 (논문 주황색 형광 필기) 추가 파라미터가 필요하다. 이것은 tricky to select 이다.
Maximum squas Loss: a more balanced gradient for different classes 를 만들어 낸다.
Image-wise Class-balanced Weighting Factor: 이미지 안에 Class 갯수를 사용해서 Loss를 Regularize한다.
Multi-level Self-produced Guidance: ResNet 중간에 ASPP를 하나 더 달고, Low-level output을 만들어 낸다. 그리고 Pseudo label은 high-level output + 자신의 output의 Ensemble 결과를 사용해 만들어 낸다. high-level 이 low-level 보다 더 정확할 것이라는 점을 이용해서, Low-level feature representation 능력을 향상시켜 high final performance를 유도한다.