【Writing】 Review refered papsers of ICLR papers
Batch Normalization Embeddings for Deep Domain Generalization
- [2] Transferable Normalization: Towards Improving Transferability of Deep Neural Networks, Nips 2019
- [4] Matsuura and Harada, Domain generalization using a mixture of multiple latent domains, AAAI’20
1. Transferable Normalization: Towards Improving Transferability of Deep Neural Networks, Nips 2019

- Unsupervised Domain Adaptation
- Transferability: 다른 Domain에 적벌한 Model로 쉽고 빠르게 전환될 수 있는 능력
- Transferable Normalization (TransNorm) 을 사용함으로써, Target에 더 적절한 적응을 하는 모델을 만들 수 있다.
- Method
- domain specific normalization
- 강압적인 Norm parameter share는 transferability를 저하시킨다.
- normalization을 각 domain에 맞춰 적절히 수행함으로써, domain shift 영향을 줄이고자 한다. (As the inputs of both domains are normalized to have zero mean and univariance, the domain shift in the low-order statistics is partially reduced.)
- Sharing Gamma and Beta
- zero mean and univariance feature가 norm에 의해서 이뤄졌다면, the identity transform을 통해서 feature를 복구하기 위해서 shared affine parameter를 사용하는게 옳다.
- Domain Adaptive Alpha
- 하나의 feature 안에 각각의 channel 은 서로 다른 특성을 가질 수 있다. 특히 각 channel 마다 다른 transferability를 가지고 있을 수 있다.
- Distance(Source statistics - target statistics) 를 계산함으로써 해당 channel의 transferability를 비교한다. 만약 distance가 크다면 transferability가 작은 channel 이므로 중요도를 낮춘다. 반대로 distance가 작다면 transferability가 큰 channel 이므로 중요도를 높힌다.
- Residual (1+α) 형태로 수식이 이뤄져있다. 이것으로 avoid overly penalizing the informative channels.
- domain specific normalization
- Results
- UDA기법은 DANN, CDAN 이라는 기법을 활용했고, 거기서 BN을 TransNorm으로 바꿔 사용했다.
- Classification Task에서 [DANN, CDAN] + BN를 한 것 보다 [DANN, CDAN] + TransNorm 를 한 것이 2~4 정도의 성능향상을 가져왔다.
- 계산된 α 값에 따른 Visualization 결과도 매우 흥미롭다.
2. Domain Generalization Using a Mixture of Multiple Latent Domains, AAAI 2020
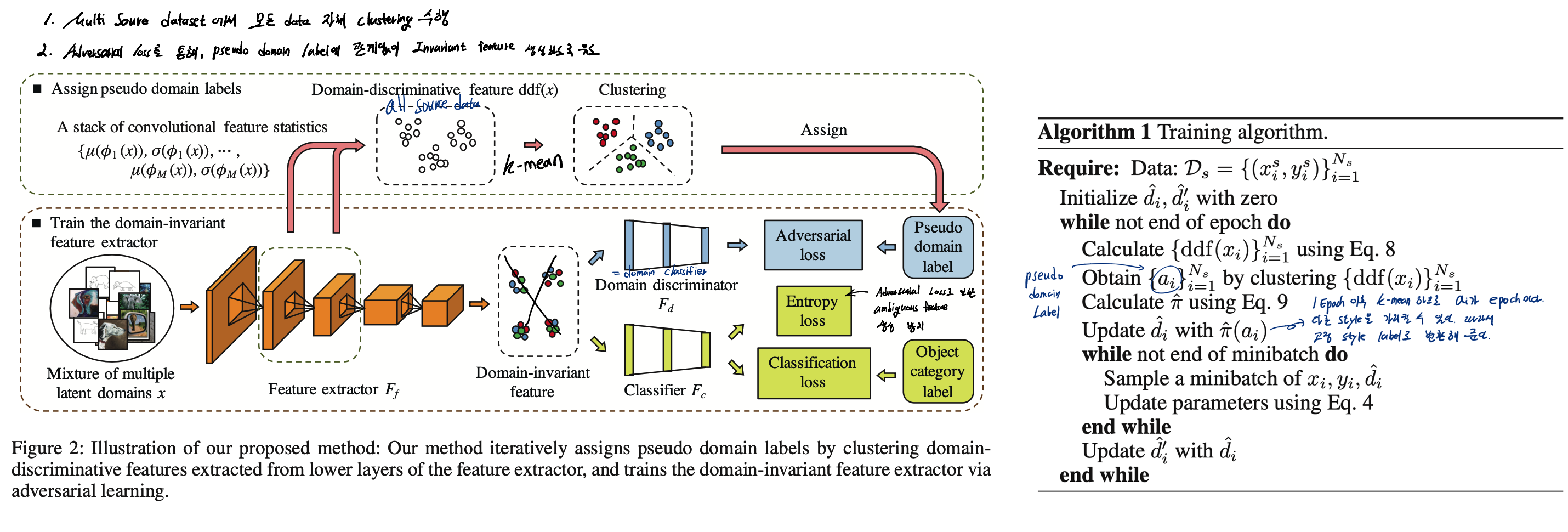
- Multi Source dataset에는 multiple latent domains가 존재한다. 하지만 지금까지 이것을 고려하지 않고 모델을 그대로 학습시켰다. 이 논문에서는 이것을 고려하여 DG 모델 만드는 것을 목표로 한다.
- “Intro / Domain-discriminative Features” 부분에서 Feature statistics를 사용해서 pseudo domain label을 만든것을 길게 풀어썼다. 나중에 필요시 참고하자.
- 웹에서 크로링한 데이터는 Multi Source임에도 Domain label이 존재하지 않다. 이것이 주어지지 않았다는 가정으로 mixture of multiple latent domains을 clustering 한다.
- 전체적인 Method는 위의 그림 참조.
- 성능 결과
- Pseudo domain label의 갯수(K)를 몇개로 하든, 다른 비교 논문들보다 높은 DG성능을 가지는 모델을 만들어냈다. (전체적으로 K=2일때 성능이 가장 좋다)
- Figure3에서 K를 2~14까지 실험한 결과 그래프가 있다. K=2일때 가장 성능이 높다. 이런 약점같은 약점을 논문에서는 아래와 같이 서술했다.
- Note that in reality, the number of original domains is three. Based on the results obtained, there is no significant correlation between the number of pseudo domains and the clas- sification accuracy, (하지만) which highlights the robustness of our method to varying numbers of pseudo domains.
- 위와 깉은 “나의 약점은 약점 아닌 듯 놔두고, 강점을 강조하는 위와 같은 논문 작성법”을 배워둬야 겠다.
