【DG】 Survey DG papers 5 - recent papers
- DG survey
- DG paper list 참조
5.1. In Search of Lost Domain Generalization - ICLR21
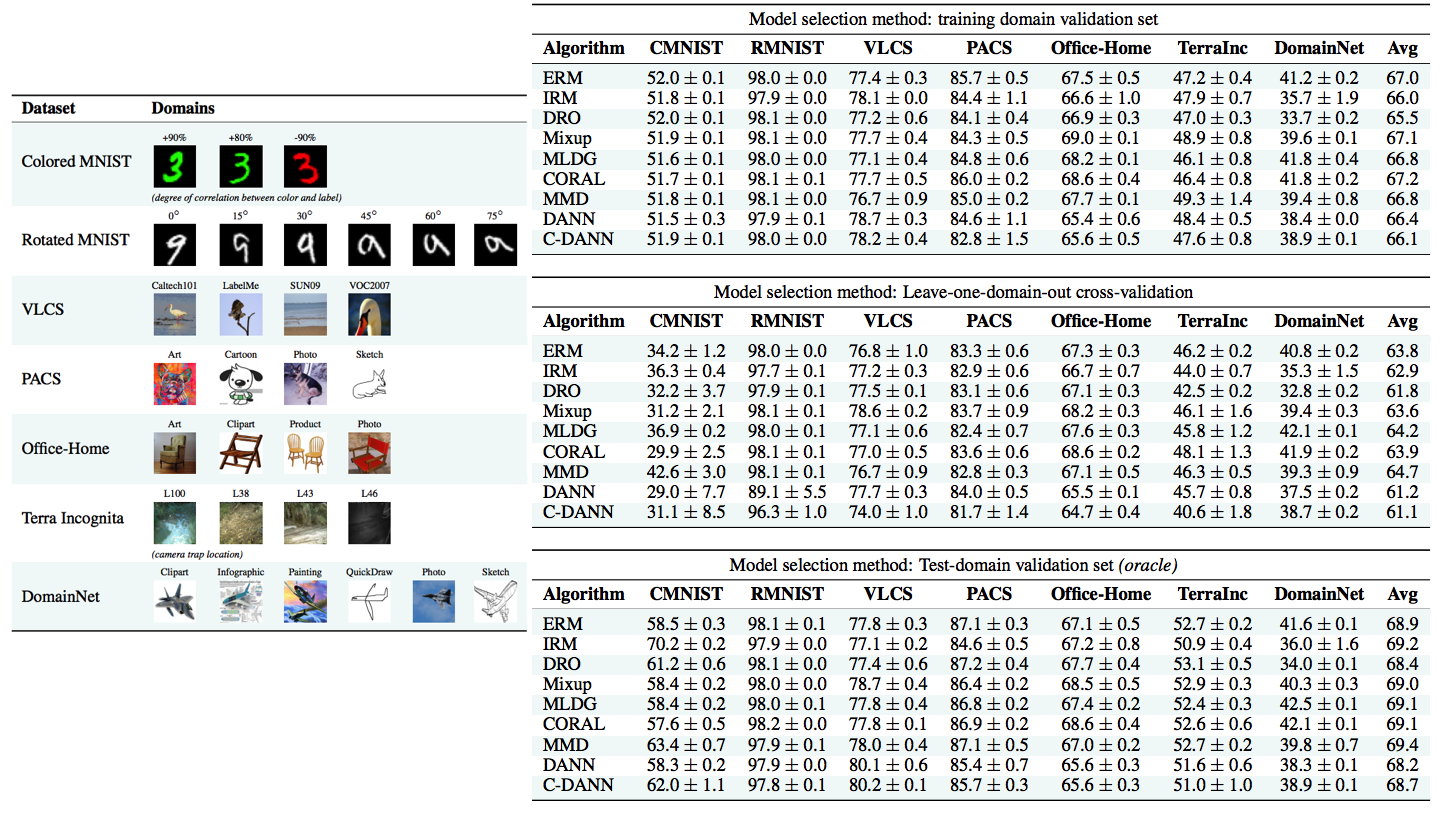
- 내가 한 논문에 대한 깊은 이해: 지금까지 algorithm들은 하이퍼 파라미터 설정을 위한 evaluation 방법과 final ckpt weight 확정에 대한 애매모호함이 있었기 때문에, 서로의 algorithm과의 성능 및 효과 비교가 적절하고 공정하지 못했다. 이들은 어떻게 evaluation을 해서 하이퍼파라미터를 찾고 final ckpt weight 확정하는지에 대한 몇가지 기준을 제시한다. 그리고 다른 저자들도 이러한 방법과 기준으로 하이퍼파라미터 및 final ckpt weight를 찾고, 성능을 평가해놓아야 한다고 조언한다.
- Github: (1) https://github.com/facebookresearch/DomainBed, (2) ERM code , (3) Algorithms
- 공정한 DG 성능 평가를 위해서 datasets, network architectures, and model selection criteria 통일 방안을 제시한 논문
when evaluated in a consistent and realistic setting, How useful are different DG algorithms? - Abstract
DOMAINBED를 통해서, 7개의 Benchmarks, 14개의 알고리즘, 3개의 model selection 기준을 제시한다.- SOTA는 여전히 ERM (Empirical risk minimization) 이다.
- 자율주행 장애물 요소: Light, weather, object pose
- Biase 이유: Texture statistics, object backgrounds, racial biases
- Paper chepter 3.0) Model selection as part of the learning problem
- 지금까지 많은 알고리즘들이 각자 자신만의 model selecition을 해서 결과를 도출하고 있다. 이것은 옳지 못하고, 공정한 평가라고 할 수 없다.
(시벌 이게 뭔 개소리야) 예를들어 test data가 train data와 얼마나 관련되어 있는지? 에 대한 가정(assumptions)는 매우 힘들다. 하지만 이것이 model selction 기준에 많은 영향을 끼친다. 옳바른 가정을 가지고 model selction을 하는것이 DG에서 매우 중요한 포인트이다.DG 연구자에게 중요한 Recommendation (1) model section method를 충분히 설명해야 한다. oracle model selection method (oracle을 학습하기 위한 최적의 하이퍼파라미터들)을 가지고, DG algorithm을 평가해보는게 합리적이다. (2) oracle model selection을 부인하고 Test domain에 대한 접근을 제한하는 정책을 명시하는 것이 중요하다.
- Paper chepter 3.1) Three model selection methods (논문에서 추천하는 (1) hyperparametor를 설정하는 방법 / (2) DG에 최적화된 weight를 찾는 방법)
- source들을 각자 train/val으로 나누고, 모든 source의 val들의 모임을 validation-set 으로 사용해본다. Train/test distribution이 비슷하다는 가정이 있다면 이렇게 함으로써 hyperparametor를 설정하는게 의미가 있을거다.
- n개 Network를 학습시킬 것이다. source n개 중 n-1개=train set/ 1개=val set 으로 지정한다. 각각의 n개의 모델은 n개 domain 하나하나를 val set으로 설정된 모델이다. n개의 모델을 학습한다. n개의 모델에 대해서 validation을 동시에 수행한다. n개 모델의 validation 성능의 평균을 구한다. hyperparametor를 바꿔가면서 n개 모델 val 성능의 평균이 가장 높게 나오는 hyperparametor/weight 를 최종선택한다.
- test set을 기반으로 validation하여 hyperparameter를 찾을 수도 있다. 하지만 이것은 test domain에 접근할 수 없다는 DG의 제한을 어기기 때문에 유요한 방법론이라고 인정받을 수는 없고, 부정적인 시각을 받을 수 있다는 것을 감안해야 한다. 하지만 최적 모델을 찾는데 시간을 절약해 준다는 장점이 있다. 대신 이 조건에서는 early stopping을 하지 않고 각 실험마다 모두 같은 step으로 학습하여 나온 weight만을 사용하여 성능 실험을 해야한다.
- Paper chepter 4.3) Implementation choices for realistic evaluation
- 실험을 할때, Large model (ResNet50), Data augmentation 을 충분히 사용하였고, 가능한 모든 데이터셋을 사용해서 모델을 학습시켰다. 인위적으로 한 domain을 제한하거나 하는 방법은 unrealistic way 방법이다.
- 위 그림에서, 각 행이 domain들의 모임이다. 각 행 안에 있는 domain data들을 전부 사용한다. 전부 사용한다는 의미는 위 chep3.1의 model selection방법을 통해서 evaluation을 진행하고 좋은 결과가 나온 hyperparameter와 weight를 가지고 각 domain에 대해 test를 진행하여 나온 평균을 위의 실험 결과표에 기록해 두었다.
- 많은 실험을 통해서 깨달은 takeaways
- average performance 관점에서는 Carefully tuned ERM 가 SOTA 이다.
- ResNet50이 ResNet18 보다 당연히 DG에 좋다. 하지만 기존 알고리즘은 ResNet18을 사용하곤 했다.
- 따라서 ResNet50을 사용하고, 하이퍼파라메터를 적절히 튜닝한 ERM 모델이 더 좋은 성능을 가져와 주었다.
- 14가지 DG 알고리즘 중 ERM 보다 1점 이상 높은 성능을 가지는 것은 없었다.
- 새로운 알고리즘이 DG에 좋을 수는 있지만.. 엄격한 방식으로 평가하다면 ERM 보다 높은 DG 성능을 얻은 것은 상당히 challenging 할 것이다.
- 대부분의 DG 알고리즘들은 ERM-like performance 을 가졌다.
- Our advice to DG practitioners is to use ERM (which is a safe contender) or CORAL (Sun and Saenko, 2016) (which achieved the highest average score)
- DG에서 Model Selection은 매우 중요하다. 따라서 DG 알고리즘들은 자신의 모델 선택 기준 (model selection criteria) 을 명시해야한다.
- average performance 관점에서는 Carefully tuned ERM 가 SOTA 이다.
5.2. Adaptive Risk Minimization: A Meta-Learning Approach for Tackling Group Distribution Shift -ICLR21 Rejected

- (Practical한 새로운 setting에 대해서 소개하고, 이 setting에서 효과적인 성능을 보이는 모델/algorithm을 소개한다.) 나도 나만의 practical한 setting을 찾고 그 setting에서 잘되는 algorithm을 찾아 논문을 써보는 것도 좋겠다.
- 내가 한 논문에 대한 깊은 이해: Meta-learing에서 [θ에서 θ’를 만들고 θ’으로 gardient를 구하고 그 grad를 θ에 적용하는 기법]을 사용했다. 특히 Test time때도 test data를 사용해서 θ에서 θ’를 구하고 θ’로 prediction을 수행한다. 이처럼, [Test 과정에서도 동일하게 적용가능하고 Unseen adaptation을 유도할 수 있는 새로운 Train process 무언가를 찾아야 한다. Adpative module에서는 domain code를 뽑아 feature를 upgrade해주는 process였고, 이 논문에서는 New data를 보고 새로운 θ’를 만드는 Process 이다. 무엇이 또 다른, 더 좋은 Process가 될 수 있을까?]
- Abstract & Introduction
- Meta learning을 활용해서 θ를 갱신함으로써, Domain shift에서의 성능저하를 막는다. multi domain에서 z가 무작위로 선택되는것도 domain shift를 시뮬레이션한 것이다.
- 이 논문의 목표: “Aim to find models (not single) that adapt test-time-domain shift” 이를 위해서 (Meta learning처럼) group shift를 시뮬레이션하며 모델을 학습시키기 위해, iter당 load되는 domain이 계속해서 바뀌는 train_loader사용한다.
- Method
- S개의 group(domain). x_i, y_i, z_i. input output domain_label.
- Meta-learing에서 θ에서 θ’를 만들고 θ’으로 gardient를 구하고 그 grad를 θ에 적용하는 기법을 사용했다. 여기서 (주황 밑줄) θ’을 구하기 위해서 adaptation model을 사용하고 (보라 밑줄) grad를 구하기 위해 g(predictor)의 ERM loss를 적용한다.
- Algorithm Line5: Adaptation model (h, Φ)는 input으로 [g(predictor)의 parameter(θ)와 Unlabeled datas K]가 들어가서 K에 잘 적응할 수 있는, 새로운 θ’를 예측/출력해 낸다. (meta-learning(MAML)에서 meta-train data를 가지고 θ -> θ’ 을 만드는 것과 유사하다.)
- (논문의 메인 핵심) (파랑 밑줄) Algorithm 1 그림의 Line 3에서 source domain이 바뀌면서 batch가 선택되기 때문에, group shift (domai shift)를 시뮬레이션하며 모델이 학습되게 유도할 수 있다. 이러한 시뮬레이션은 실제 Test 과정에서 새로운 domain 이미지가 들어와도 쉽게 적응할 수 있게 도와준다.
- ARM 형태의 분류 (ARM 뿐만아니라, 추가적으로 아래의 과정을 통해서 빠른 Adaptation을 유도하고자 한다) (아니 도대체 θ -> θ’ 하는건지 안하는건지, 추가적인 network를 두는 건지 뭔지 도저히 모르겠다. 씹세끼들 Domain Bed에서는 ARM-CML 방법만 적어놓았고, θ -> θ’ 과 같는 과정 하나도 안한다.)
- ARM-CML: (θ -> θ’ 만드는 과정은 하지 않고) (Adaptive module 논문에서 domain predictor와 완전히 동일한) h = context network 사용. Batch 이미지가 들어가고 각각의 예측백터 c_k를 average해서, g가 예측하는데 추가적인 정보를 제공해준다.
- ARM-BN: 한 domain의 batch가 들어가서, training과정에서 만들어진 BN의 running_avg, running_var을 사용하지 않고, feature statics를 그대로 사용한다. Algorithm 1 line6 에서 (h를 전혀 사용하지 않으며 θ -> θ’ 만드는 과정은 하지 않고), loss를 구하는 과정에서 부터 feature statics을 그대로 사용한다. BN자체가 inductive bias를 심하게 가져서 domain-shift에서의 성능저하가 생기는 문제점을, 효과적으로 해결해주는 방법이었다.
- ARM-LL: Algorithm 1의 과정에서 Line5가 다르다. 대체로, 그림의 왼쪽 아래 수식을 사용한다. 여기서 Loss는 supervised loss가 아니다. 파라미터 θ가 새로 들어오는 batch 이미지들에 대해서 얼마나 적응가능한지 Loss를 뱉어 주는 구조이다. 즉 h는 Ausilliary loss를 주는 network로 동작한다. ( Feature-critic networks 논문과 완전히 동일. #2.12 논문의 알고리즘 그림의 파랑색 박스 마지막 라인과 동일)
5.3.Test-Time Adaptation to Distribution Shift by Confidence Maximization and Input Transformation -arXiv21
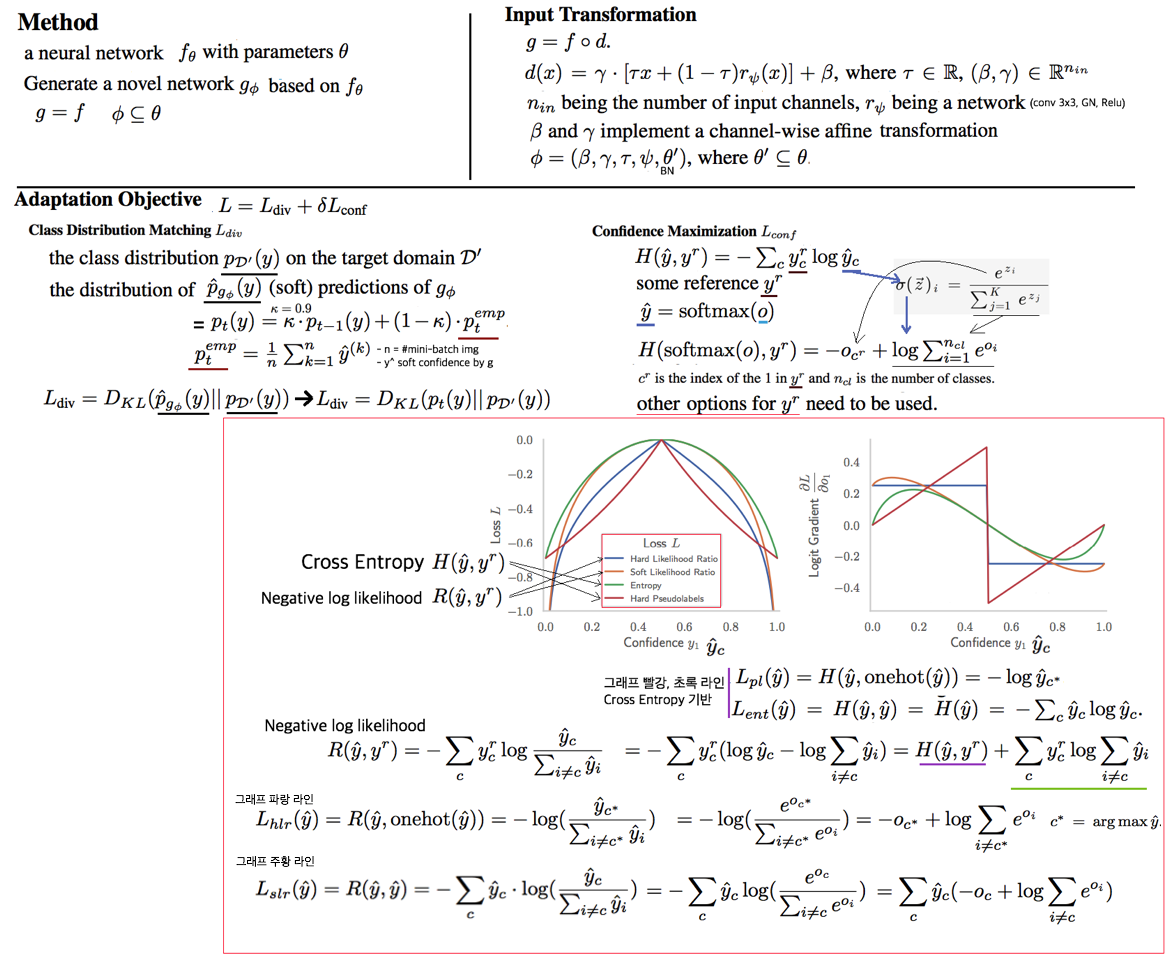
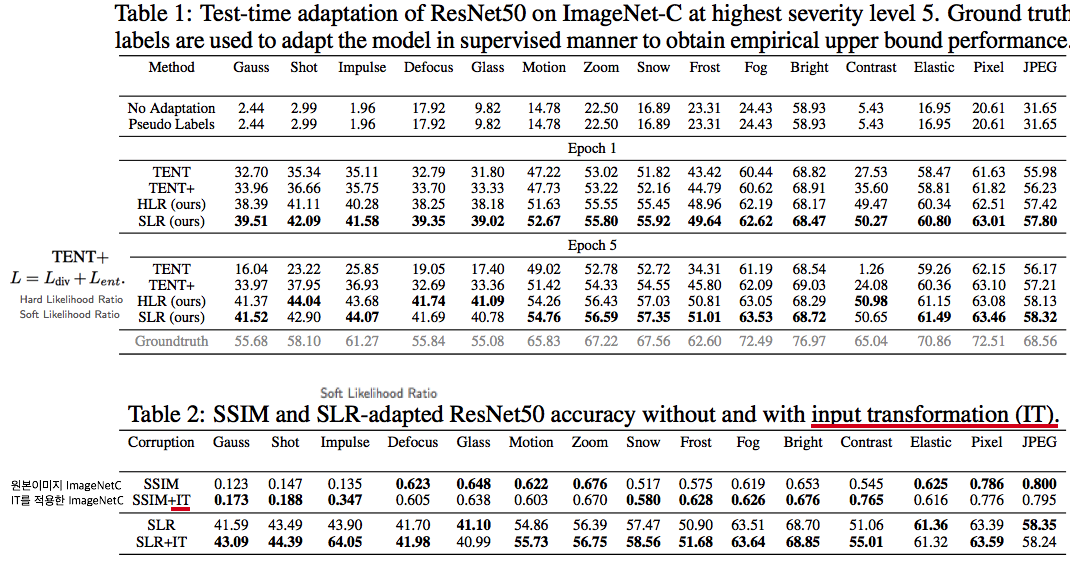
내가 한 논문에 대한 깊은 이해: Tent의 단점을 해결하고 보충할 수 있는 3가지 추가 방법을 소개한다. Arbitrarily pretrained model 이라고 하지만, 내가 실험해본 결과 self-sup 기법은 target에서 어느정도 성능 이상이 나와야 그 효과가 나타났다. (예를 들어서, miou 30이상이어야 TENT에서 성능이 향상된다 던가.)
Abstract & Introduction
- fully test-time adaptation setting 이란? arbitrary pretrained network에 unlabel data로 적응하기 or End-to-end fashion Without any target domain labels or source domain data
- TENT 기존 문제점 (1) premature convergence (trivial collapsed solutions/ domainat한 class만을 예측) (b) instability of entropy minimization
- 문제점을 해결하는 추가 2가지 기법
- trainable input transformation module (test-time distribution shift을 약화하기 위해)
- 2가지 새로운 Loss (1) non-vanishing gradients for high-confidence (2) regularizer based on batch-wise entropy maximization
- 많은 augmentation으로 domain shift 문제를 해결해려고 노력했지만, augmentation의 한계로 wide range of potential data shift를 모두 커버할 수 없었다. 그래서 Test time adaptation 방법이 고안되기 시작했다. DA,DG와 같은 방법들은 test time에 source에 접근할 수 있다는 가정이 들어가 있지만, 이것까지 제한하여 좀더 practical한 세팅으로 바라보고자 하는 철학이 fully test-time adaptation이다. (1) only target data로만 adaptation을 수행하고 (2) arbitrarily pretrained model에 적응할 수 있는 기법을 찾고자 한다.
- TENT 논문이 처음 위와 같은 철학을 가지고 나온 논문이다. TENT의 가장 큰 문제점은 high confidence 예측을 한 경우에 loss gradient가 vanishing된다는 점이다. 이것은 큰 drawback이라고 할 수 있다. 왜냐하면 self-supervised learning에서 high confidence(0 or 1) 에 의해서 생기는 gradient가 강해야 좋은 방향으로 모델이 학습될 것이기 때문이다. 반대로 low confidence (0.5)에 의한 gradient가 dominate한다면,모델이 불안정한 예측만 가지고 학습을 한다는 뜻이므로 모델 전체가 불안정해진다. 이러한 문제를 (Cross) Entropy loss를 사용하는 것이 아닌, Negative log likelihood를 사용함으로써 해결하고자 한다. Negative log likelihood loss는 high confidence에 대해서 gradient vanishing이 생기지 않는 non-saturating gradients 을 만든다 즉, high confidence 에 의해 생기는 gradient vanishing되지 않는다.
- 일반적으로 self-sup에서는 confidence maximization 기법들 (Entropy loss)을 활용해서 모델을 계속 학습시킨다. 하지만 이것은 collapsed trivial solution (domainat한 class만을 예측하는 문제점)을 야기한다. 이 문제를 해결하기 위해서 Class distribution matching loss를 사용했다. 이것은 trivial solution이 일어나지 못하게 막는 regularizer 역할을 한다.
Method
- Image Transformation
- undo “domain shift” 를 목표로 한다.. 즉 original domain이미지 변환 Network이다.
- r_ψ(x) 네트워크와 β, γ, τ가 아래의 L_div, L_conf loss 에 의해서, fully test-time adaptation에서 추가적으로 학습된다.
- backbone인 f에 들어가기 이전에, domain shift를 완화시켜주기 위한 input augmentation model이라고 할 수 있다.
- Adaptation Objective
- Class distribution matching loss
- target domain의 class distribution을 안다는 가정하에, 이 loss를 적용할 수 있다.
- entropy loss와 함께 작용하며, collapsed prediction (same class, very few class만 예측하는 현상)을 막아준다.
- P_D’(y) : 예를 들어서 cat, cow, dog의 비율이 (2,1,5) 라면, (0.25, 0.125, 0.625) 로 uniform하게 설정할 수 있다
- P^_g(y) = P^_t(y): (모든 target data의 total 값인) 좌항을 알아내기엔 cost가 많이 든다. 따라서 (momentum update로 구한) 우항을 사용한다.
- Confidence Maximization loss:
- entropy loss 같이 high confidence prediction을 유도한다.
- target domain label을 알고 있다면, y^r (reference) 로 그대로 사용하며 된다. 하지만 label이 없기 때문에 우리는 y^r이 될 수 있는 몇가지에 대해서 고려해볼 수 있다. (other option of y^r)
- (그래프 빨강 라인) hard pseudo-labels: prediction 결과에 대한 one-hot encoding. Self-sup의 [예측 불확실성/least reliable 예측]을 무시한다는 단점이 있다. low confident (0.5) 예측을 했을때 high gradient 를 발생시킨다. 이렇게 특정한 경우에만 high gradient를 발생시키는 현상은 옳지 못하다. 모든 data에 대하서 어떤 confident하게 예측을 하든 동등한 gradient가 발생시키는게 옳다.
- (그래프 초록 라인) Soft pseudo-labels: prediction 결과 그 자체를 y^r로 사용하는 것이다. TENT의 Entropy minimization loss와 동일하다. 이 loss의 문제점은 y^이 1로 가면 gradient가 0이 된다는 것이다. 이것은 same class collapsed prediction 문제를 야기한다. (TENT 학습 후기에) high confident 에 대해서는 0 gradient가 발생되면 (gradient vanishing), low confident 에 대해서만 gradient가 남게 되므로 위 hard pseudo-label과 동등한 문제가 발생한다.
- both soft and hard pseudo-labels: 위 2개의 label은 동등한 문제점을 가지고 있다. high gradient at low confidence. 이것은 모델의 불안정성을 야기하므로 2가지를 동시에 사용한다고 해결될 문제가 아니다.
- 1,2,3 번은 모두 cross entropy 수식을 기반으로 만들어지만, 이제 Negative log likelihood 사용하겠다.
- (그래프 파랑, 주황 라인) Negative log likelihood: H항의 오른쪽 항(연두색 밑줄)에 의해서, High confident일때 R자체가 -∞ 로 가게 되고, gradient는 0이 아닌 값을 가지게 할 수 있다. (gradient vanishing 해결) (나의 개인적인 질문: gradient가 살아 있다고 해서.. confidence 0은 더 0이 되게 하고 1은 더 1이 되게 하는 gradient만 남아있을 뿐인데 이것이 어째서 좋은건지 이해가 안된다. 단지 gradient vanishing은 나쁜거니까 없애야한다? 라는 생각이 전부인건가? -> Introduction에서 간접적인 해답을 준다.)
- (그래프 파랑 라인) high likelihood ratio: ([40] FTC20에서) fully-supervised cross entropy loss 를 대체하기 위해서 만들어진 수식이다. 이 수식은 gradient vanishing 문제가 없다는 장점이 있기에, self-sup, test-time adaptation 에서 이 loss를 적용하는게 적절하다고 판단했다 한다.
- (그래프 주황 라인) soft likelihood ratio: self-sup의 예측 불확실성을 고려한 loss 함수 이다. High confidence에서 gradient vanishing이 발생하지 않고, low confidence에서 low gradient가 발생한다.
- 결론적으로 likelihood ratio loss는 일부 weight(BN)만 갱신하는 test time training 상황에서 useful and non-vanishing gradient signal for network adaptation 을 제공해 줄 것이다. 또한 calibrating confidences in a self-supervised test-time adaptation setting is an open and important direction for future work…
- Class distribution matching loss
5.4 Universal Source-Free Domain Adaptation -CVPR20
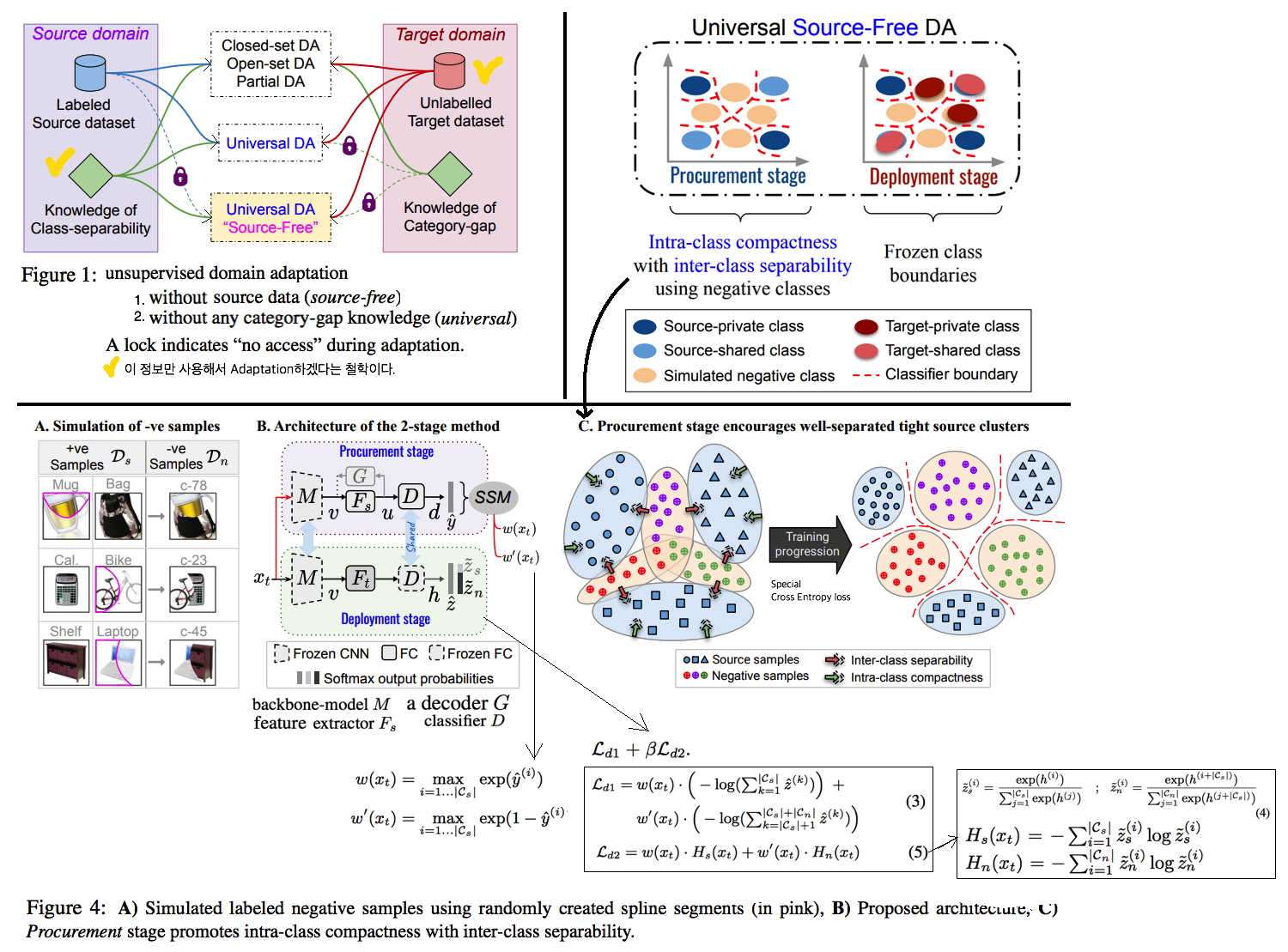
- 내가 한 논문에 대한 깊은 이해: 이 논문은 깊게 읽지 않았다. 이 논문은 새로운 Setting을 제시하고, 그 Setting에서 적응하기 위한 approach들을 제시한다. 하지만 내 생각에, 그 approach들은 너무나 trivial & complex하다. 아무래도 새로운 setting이 너무나 제한적이기 때문에, 그 setting에서 살아남기 위한 approach가 복잡할 수 밖에 없는 것 같다. 그래서 이 논문을 굳이 자세히 읽지 않았다. 그냥 “ 이렇게 새롭게 setting을 제시할 수 있구나” 정도만 알아두고 넘어가도록 하자.
- Abstract
- DA setting은 source와 target의 label set 정보에 의지한다. UDA setting은 source와 target sample이 coexistence 해야한다는 조건이 있다. 이러한 setting은 모두 practical 하지 않다.
- 좀 더 practical assumptions 으로 아래와 같은 setting을 제시한다.
- upcoming category-gap and domain-shift에 대한 어떠한 정보와 지식도 모른다는 가정에서 모델을 학습시킨다. 즉 generative classifier framework을 만들기 위해서, available source data만을 사용하고,target/unseen distribution 정보는 전혀 사용하지 않는다.
- (Source free)이전에 보았던 source samples을 전혀 사용하지 않는 adaptation 을 수행한다. Source Similarity Metric을 사용함으로써 source free adaptation objective을 달성할 수 있다.
- Proposed approach
- Stage1, Procurement stage: labeled source data를 가지고 학습을 한다. 이때 미래의 domain shift와 category-gap에 미리 적응해 놓기 위해서, artificially generated negative dataset을 사용한다.
- 미래 source free domain alignment를 용이하게 만든다. 모든 종류의 category-gap에 적응할 수 있도록 모델이 a certain placement 를 학습하도록 유도해야한다. (위 그림 simulated negative class 영역 참조)
- (의문점. Source free는 source data가 private해서 접근을 못한다는 가정이 들어간것 같은데, 이것은 just pretrained network를 사용하는게 아니라 source에서 학습할때의 조건이 따로 존재한다. 이것이 진짜 source free라고 할 수 있을까? 새로운 setting을 제안하고 그 setting에 위반된 설계를 하고 있다는 생각이 든다.)
- Stage2, Deplyment stage: unlabeled target data이 들어오기 시작한다. 이때, source dataset에 접근하지 못하며, Cs (source의 label space)와 Ct (target label space) 사이의 관계 정보 또한 알지 못한다. 이런 상황 속에서, shared label space Cn (Cs ∩ Ct) 와 private label(각 domain에 독자적인 label space) 에 대한 정보를 define 해야한다.
- Stage1, Procurement stage: labeled source data를 가지고 학습을 한다. 이때 미래의 domain shift와 category-gap에 미리 적응해 놓기 위해서, artificially generated negative dataset을 사용한다.
5.5 Source-Free Domain Adaptation for Semantic Segmentation -CVPR21
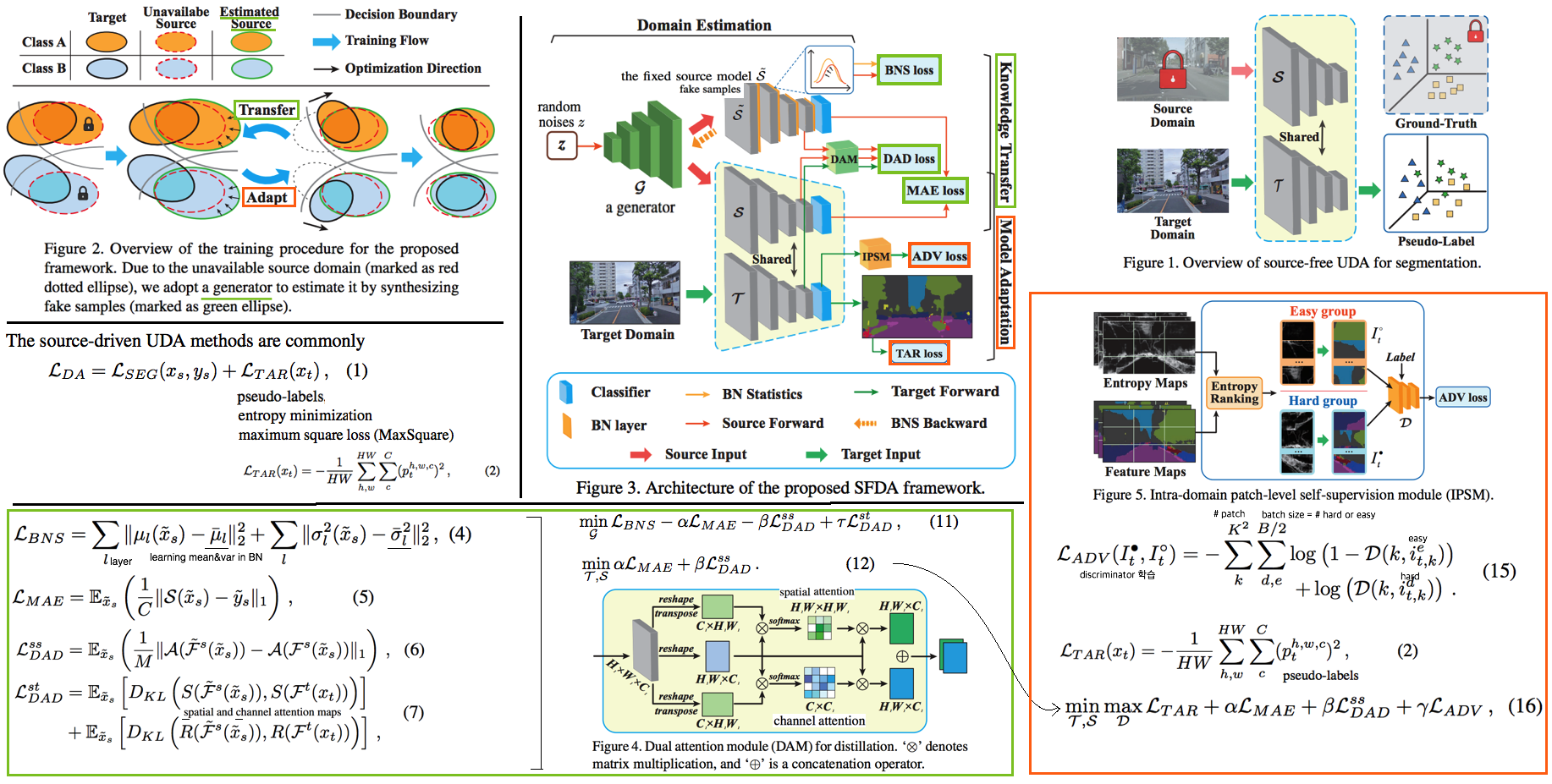
- 내가 한 논문에 대한 깊은 이해: generator total loss의 adversarial learning을 위한 - loss들의 역할에 대해 확실하게 모르겠다. Pixel lavel classification을 위해서 추가했다는게… Dual Attention module이 전부인건가? 이게 정말 classification에서 semantic segmenation으로 task가 바뀌는데 큰 도움을 주었나? 라고 하면 잘 모르겠다. 좀더 생각이 필요하다.
- Abstract & Instruction
- Source Free이란? Adaptation을 위해 ‘private and commercial source dataset’ 에는 접근하지 못한다는 조건을 추가한다. 따라서 Only pretrained network와 unlabeled target domain dataset만 사용해서 target 예측에 필요한 모델을 만들어야 한다.
- 이전에 많은 source free 방법론들이 제시되었지만, 모두 classification을 위함이었다. Figure1에서 보듯이 segmentation에서는 더 복잡하고 많은 “ multiple classes shifting on diverse distributions” 이 존재하기 때문에, semantic segmentation을 위해 pixel and patch-level optimization이 필요하다.
- Methodology
- Source Domain Estimation (Knowledge Transfer)
- Step1, data-free knowledge distillation approaches: Source data에 접근할 수 없으므로, source domain을 예측하기 위해 Generator를 사용해 fake source sample을 만든다. Source에 대한 정보는 Source optimized model에 남아있으므로, 이를 활용한다.
- BNS loss: batch normalization statistics 이 동일하도록 Generator를 학습시킨다.
- MAE(mean absolute error) loss: a semantic-aware adversarial knowledge transfer.
- DAD loss (dual attention distillation mechanism)
- Lss: Source model의 contextual 정보를 New model에 전달하기 위해 사용된다.
- Lst: Target Image의 contextual feature relationships을 활용해서 generator가 더욱 그럴듯한 fake sample을 만들도록 유도한다. (KL divergence를 사용한 이유는 MSE보다는 좀 더 고차원 적으로 distribution distance of the dual attention maps을 align하기 위해서 사용하는 듯 하다. 논문에서는 구체적인 이유에 대한 언급은 없었다.)
- Self-supervised Model Adaptation
- Step2. Model Adaptation: intra-domain patch-level self-supervision module (IPSM)
- Fei의 IntraDA에서 영감을 받았다. 다른 점은 Image level로 split하는게 아니라 patch level로 split한다. Entropy를 base로 해서 Hard patch & Easy patch로 데이터셋을 나누고 Adversarial Learning을 진행한다. patch level로 데이터를 분리함으로써, pseudo-label의 안정성을 높힐 수 있다 한다.
- Source Domain Estimation (Knowledge Transfer)
