【DG】 Survey DG papers 3.5 - recent papers
Survey DG papers
3.7. DG: ImageNet-trained CNNs are biased towards texture -ICLR19
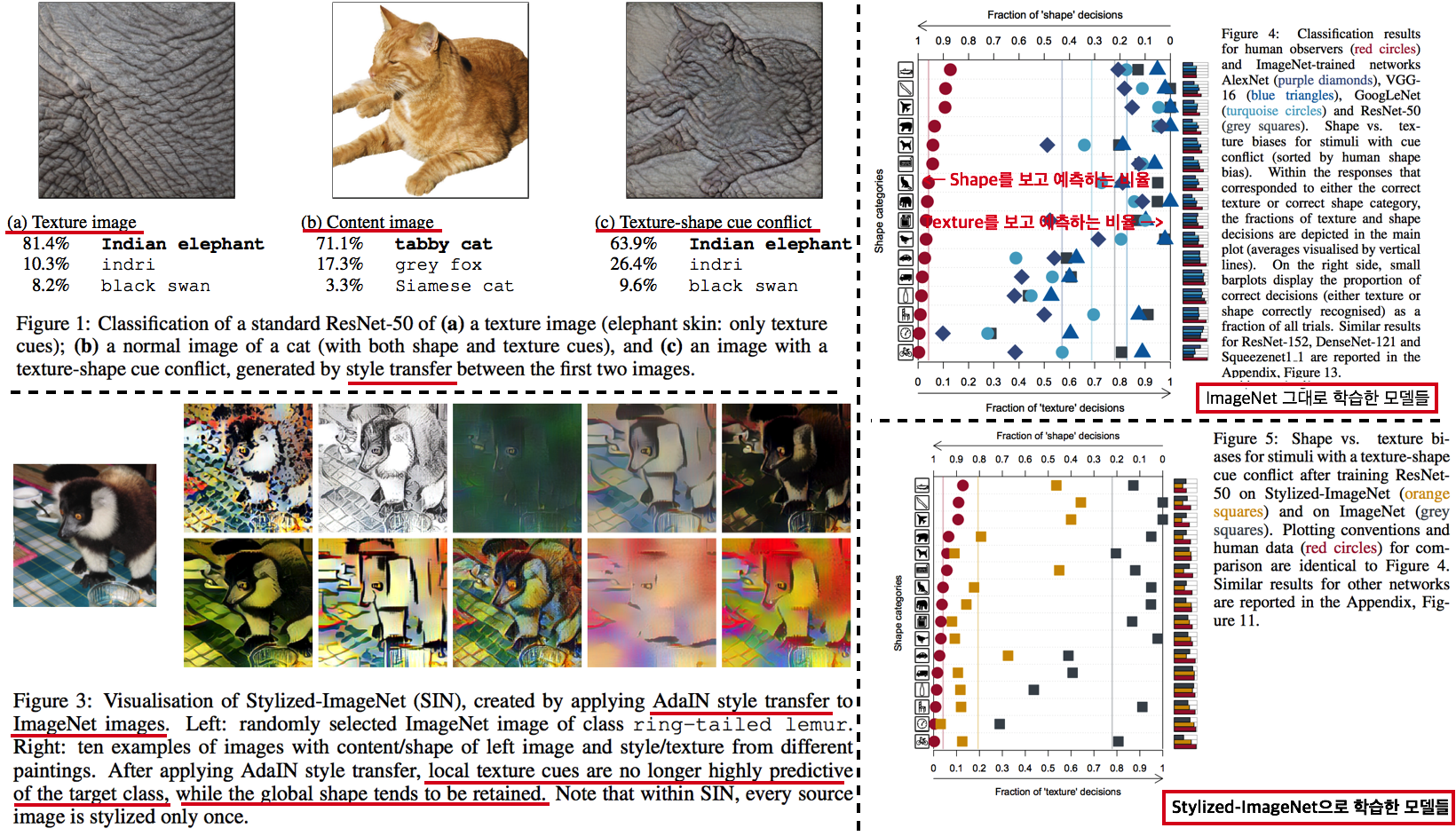
- (Citation 미친 논문) 사실 DG는 아니고, ImageNet으로 학습시킨 모델들의 문제점을 확실히 파악하고,
New Stylized Dataset을 사용하면 이 문제점을 완화할 수 있다고 말하는 논문이다. - ImageNet을 가지고 학습시킨 CNN이 Shpae/Contenct가 아닌 Strong Texture/Style Bias를 가지는 것을 확인했다.
- 자신들이 새롭게 만든 Dataset인
Stylized ImageNet을 통해서, Texture/Style가 아닌 Shpae/Contenct를 집중해서 학습하도록 만들 수 있다.
3.8. DG: Domain Generalization with MixStyle -ICLR21

- AdaIN 개념의 γ (감마) and β (배타) 값을 Random/Mixing 해서 줌으로써 Style-Invariance를 주는 DG
- Source domains 간의
mixing instance level feature statistics를 수행함으로써 DG성능을 올린다. - Introduction and Relative work 정리
- DG를 성취하는 가장 단순한 방법은, 아주 많은 source domains을 가지고 Dataset을 학습하는 것이다. 이러한 방법은 상업적으로 얼굴인식이나 자율주행 분야에서 큰 효과(성공)을 가져왔다.
- Key Sentence
- Mixing styles of training instances results in novel domains being synthesized implicitly, which increase the domain diversity of the source domains, and hence the generalizability.
- MixStyle fits into mini-batch training perfectly and is extremely easy to implement.
3.9. Deep Domain Generalization via Conditional Invariant Adversarial Networks -ECCV18
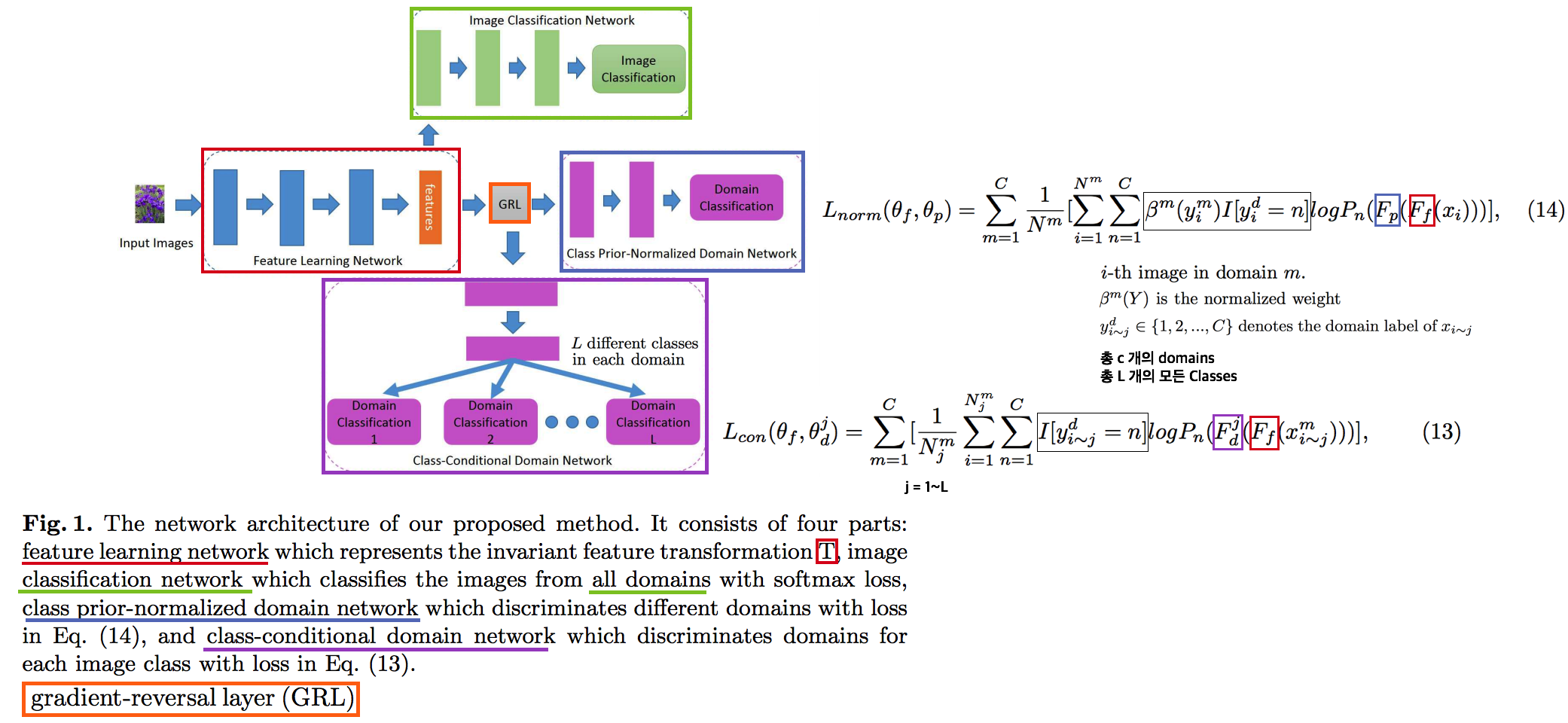
Conditional invariant adversarial network를 활용한 DG- 이 논문이 유명한 이유는 Gradient-reversal Layer를 사용하는게 왜 DG에 도움이 되는지 수학 수식으로 구체적으로 증명해놓았기 때문이다. (증명은 굳이 이해하지 않았다) 따라서 Method 및 실험결과 자체만 보면 별거 없다는 생각이 들수도 있다.
- 기존의 GRL 논문과 다른 것은 Class-wise Adversarial Nework를 사용했다는 것이 전부이다.
3.10. Deep domain-adversarial image generation for domain generalisation -AAAI20
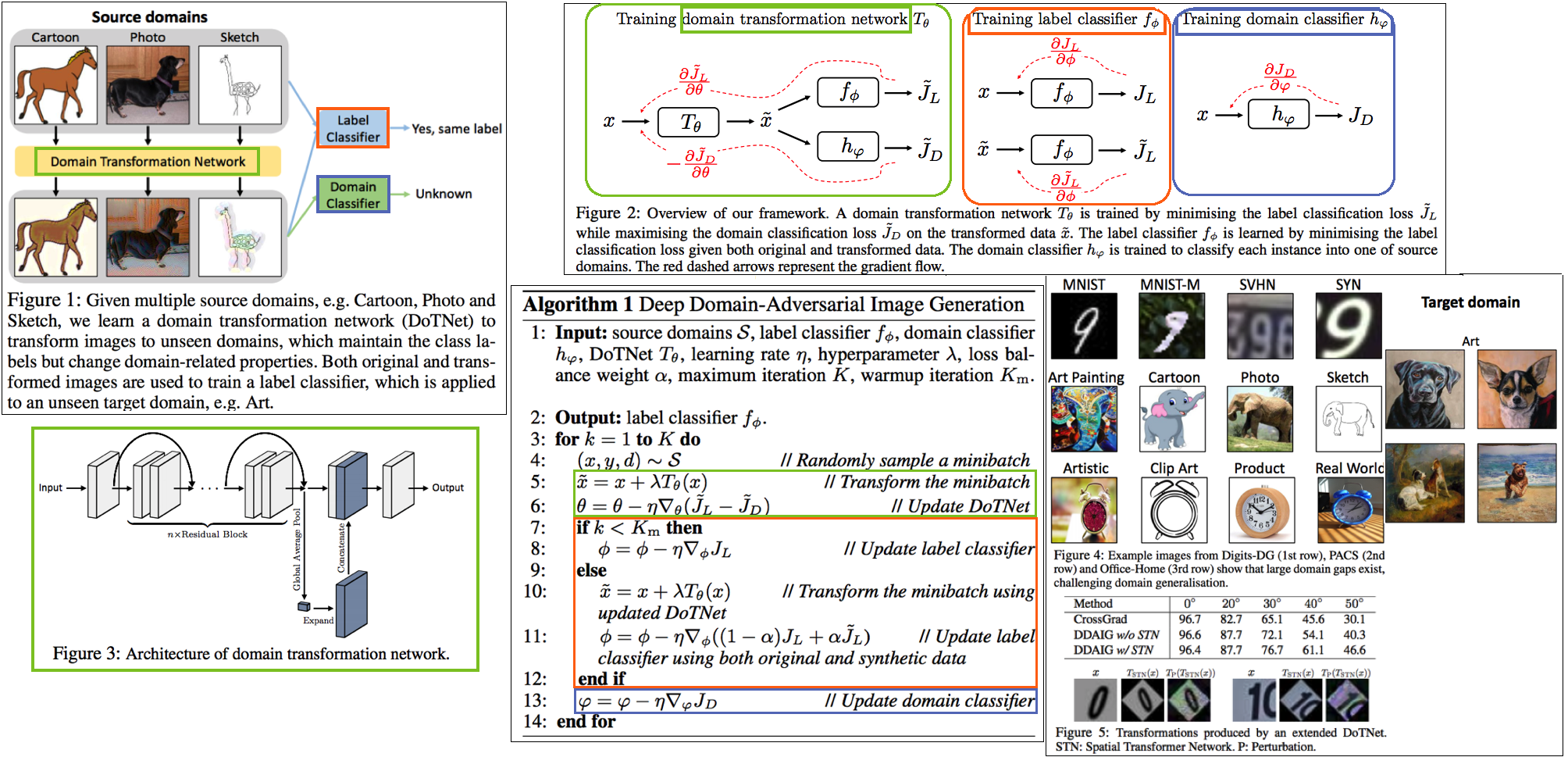
- 새로운 Style의 Image를 만들기 위해서, Domain Transformation Network (=New Style Generating Network) 를 활용하는 DG
- 중간 초록색 상자를 주목하면 되는데, (Style Transfer Network) T는 [ (1) Label Classificaton 이 잘되게 하는 이미지 (2) 어떤 Domain 인지 Domain classifier가 예측하지 못할만한 이미지를 Reconstruction 하도록 학습된다.
3.11. In Search of Lost Domain Generalization - ICLR21
- Github: (1) https://github.com/facebookresearch/DomainBed, (2) ERM code , (3) Algorithms
- 공정한 DG 성능 평가를 위해서 datasets, network architectures, and model selection criteria 통일 방안을 제시한 논문 ` How useful are different DG algorithms when evaluated in a consistent and realistic setting?`
- Abstract
DOMAINBED를 통해서, 7개의 Benchmarks, 14개의 알고리즘, 3개의 model selection 기준을 제시한다.- SOTA는 여전히 ERM (Empirical risk minimization) 이다.
- 자율주행 장애물 요소: Light, weather, object pose
- Biase 이유: Texture statistics, object backgrounds, racial biases
- 많은 실험을 통해서 깨달은 takeaways
- average performance 관점에서는 Carefully tuned ERM 가 SOTA 이다.
- ResNet50이 ResNet18 보다 당연히 DG에 좋다. 하지만 기존 알고리즘은 ResNet18을 사용하곤 했다.
- 따라서 ResNet50을 사용하고, 하이퍼파라메터를 적절히 튜닝한 ERM 모델이 더 좋은 성능을 가져와 주었다.
- 14가지 DG 알고리즘 중 ERM 보다 1점 이상 높은 성능을 가지는 것은 없었다.
- 새로운 알고리즘이 DG에 좋을 수는 있지만.. 엄격한 방식으로 평가하다면 ERM 보다 높은 DG 성능을 얻은 것은 상당히 challenging 할 것이다.
- 대부분의 DG 알고리즘들은 ERM-like performance 을 가졌다.
- Our advice to DG practitioners is to use ERM (which is a safe contender) or CORAL (Sun and Saenko, 2016) (which achieved the highest average score)
- DG에서 Model Selection은 매우 중요하다. 따라서 DG 알고리즘들은 자신의 모델 선택 기준 (model selection criteria) 을 명시해야한다.
- (예를 들어서 choosing hyperparameters, training checkpoints, architecture variants 구체적인 것은 논문 추가 참조)
- 이렇게 되어 있는데, 이해가 안된다. We observe that model selection with a training domain validation set outperforms leave-one-domain-out cross-validation across multiple datasets and algorithms. This does not mean that using a training domain validation set is the right way to tune hyperparameters. In fact, the stronger performance of oracle-selection (+2.3 points for ERM) suggests headroom to develop improved DG model selection criteria.
- average performance 관점에서는 Carefully tuned ERM 가 SOTA 이다.
