【DG】 Survey DG papers 2 - RobustNet and relative papers
Survey DG papers

2. RobustNet
- Main Goal: Multi Source에 의지하지 않고, Domain/ Appearance/ Weather/ Location/ Environment/ illumination/ Style Invariance 가진 모델 만들기! 단, ‘domain-specific style’ and ‘domain-invariant content’ 를 분리하여, content에는 방해가지 않도록 한다.
- DNN에서 어떤 것이 Style 정보를 담고 있는가? Channel wise Correlation Matrix에 집중! (저자는 IBN-net에서는 IN이 DG를 위해 불충분하다며, Correlation을 고려하지 않았다고 했다. 하지만 내가 조사한 바에 따르면 Style에 관련된 요소는 더욱 많다. (DG survey post 1.14 참조) )
- Whitening Transformation 이란, 초기 Layer의 Feature map에 대해 채널 방향 공분산 행렬이 단위행렬이 되도록 만든 변환이다. (==Feature map (CxHxW)를 [HW 백터 C개] 로 변환한 후, C개의 백터들에 대한 Covariance Matrix 를 Identity Matirx 형태가 되도록 하는 것이다.), 이렇게 하면 이미지의 Style 정보가 제거 된다는 가설이 있기 때문에, 이 논문에서는 WT를 적절히 적용하기 위한 노력들을 하고 있다.
- Instance Whitening Loss (IW loss): Covariance Matrix 전체 == Identity Matrix
- Margin-based relaxation of whitening loss (IRW loss): Covariance Matrix 전체 == Identity Matrix + ε (엡실론)
- Instance selective whitening loss (ISW loss): Covariance Matrix 일부 (domain-specific element position) == Identity Matrix
2.0 Relative work & Paper list
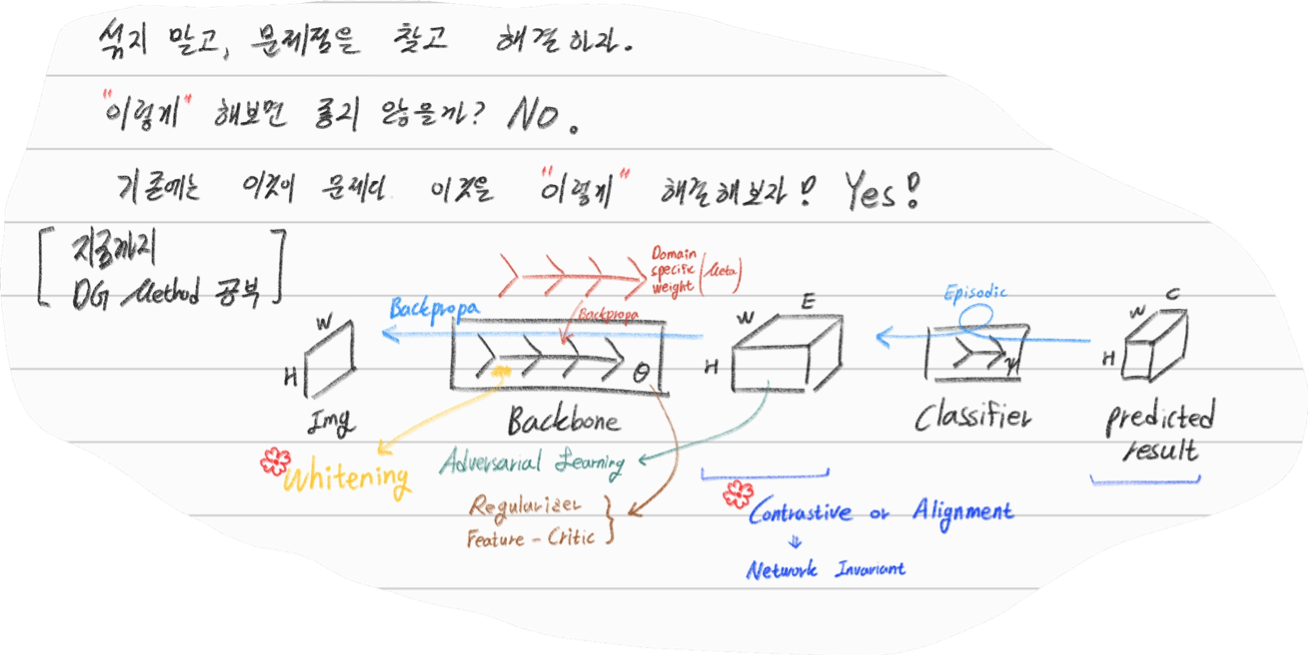
- Multiple Source Domains DG 논문들: Shared representation (general feature extractor) 학습하기.
- 아래 과거 DG들의 문제점: 어쨋든 Multi Domain에 너무 많이 의지. Sources 갯수에 성능 변화 큼.
- (#2.7) [29] Domain generalization with adversarial feature learning -CVPR18
- (#2.10) (#2.10) [10] Domain generalization via model-agnostic learning of semantic features -NIPS19
- (#2.6) [39] Unified deep supervised domain adaptation and generalization -ICCV17
- (#1.8) [40] Domain generalization via invariant feature representation. -ICML13
- (#1.9) [15] Domain generalization for object recognition with multi-task autoencoders -ICCV2015
- (#2.5) [27] Learning to generalize: Meta-learning for domain generalization -arXiv17
- (#2.8) [2] Metareg: Towards domain generalization using metaregularization -NIPS18
- (#2.11) [28] Episodic training for domain generalization -ICCV19
- (#2.12) [33] Feature-critic networks for heterogeneous domain generalization -ICML19
- Generalizing Across Domains via Cross-Gradient Training -ICLR18
- Generalizing to unseen domains via adversarial data augmentatio -NIPS18
- (#2.13) Domain generalization by solving jigsaw puzzles -CVPR19
- Sementic Segmentation DG
- [64]
- [44] IBN net
- Correlation Matrix(CM) 은 Image Style 정보를 담고 있다.
- (#2.3) Texture synthesis using convolutional neural networks -NIPS15
- (#2.4) Image style transfer using convolutional neural networks -CVPR16 (= A neural algorithm of artistic style)
- domain adaptation [51, 57]
- networks architecture [36, 45, 21, 56]
- channel-wise mean and variance 이 담고있는 Style 정보를 이용하는 논문 [23], [25] (WT사용하는 [7]보다 성능 낮은)
- Whitening Transformation(WT) 가 이미지의 Style 정보를 제거한다는 가설
- (#2.2) Image-to-Image Translation via Group-wise Deep Whitening-and-Coloring Transformation -CVPR19
- (#2.1) Universal Style Transfer via Feature Transforms -NIPS17
- domain adaptation [45, 57, 51]
- approximating the whitening transformation matrix using Newton’s iteration [22, 21]
- WT의 단점1: diminish feature discrimination [45, 61]
- WT의 단점2: distort the boundary of an object [31, 30]
- 성능 비교 논문
- IBN net
- Iterative normalization: Beyond standardization towards efficient whitening -CVPR19
2.1 WT&ST: Universal Style Transfer -NIPS17
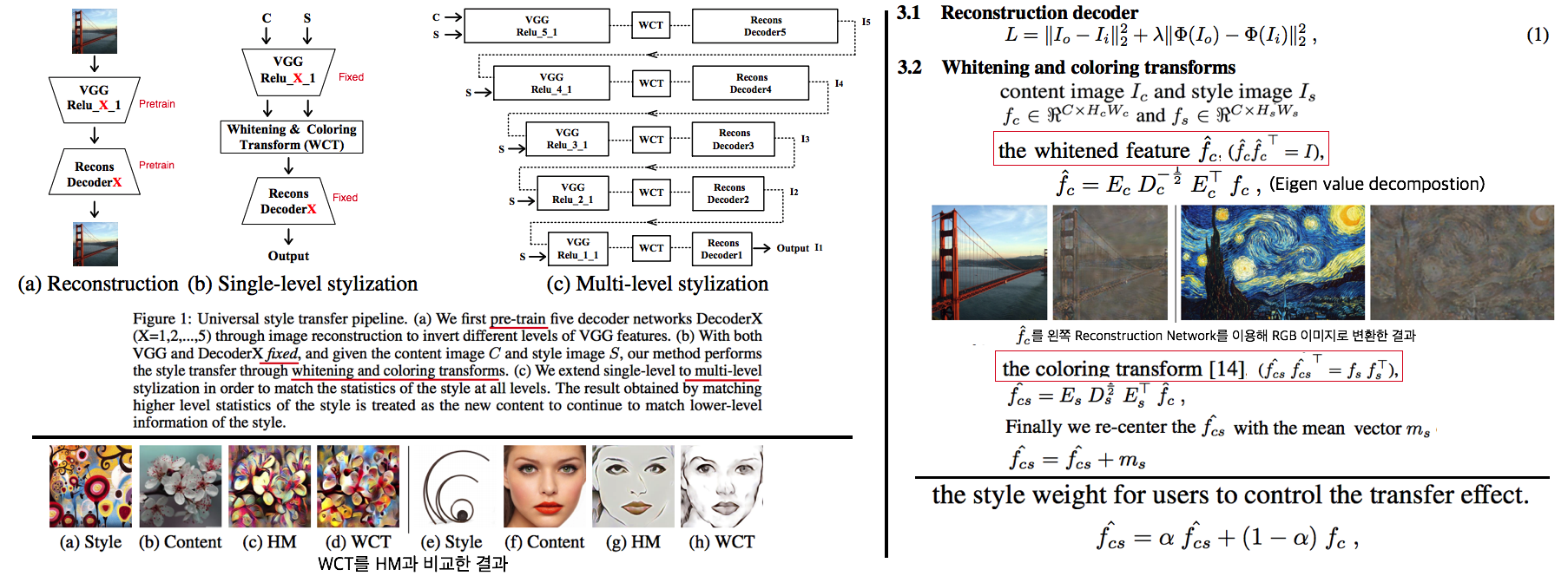
- 기존 Style Transfer 모델들 문제점: Unseen style에 대한 generalizaing 능력과 visual quality가 부족하다.
- Feature Covariance Matrix를 이용하는 (2가지 Feature transforms)
(1) whitening (2) coloring를 사용해서 이 문제를 해결하고자 한다. - WCT (Whitening and Coloring) 으로 최종 만들어진 Feature를 Reconstruction 해서 RGB 이미지를 만든다. 결과로 확인해 보면, WCT 이 HM(histogram matching) 을 사용한 것보다 Style 특성을 더 강렬하게 담아주는 것을 확인할 수 있었다. (= Covariance Matrix matching 이 HM 보다 더 강한 Style 정보를 전달해 주는가보다)
- (Me: Recon된 결과를 보아하니, WT를 통해서 확실히 Feature에서 Style 정보를 제거해준다. (Style이 아니라 Color정보를 지우는 것 뿐인가? Weather과 같이 Color 그 이상의 Style 정보를 지우러면 어떻게 해야할까? –> Weather-wise dataset을 가지고 각 Weather 마다 Deeplab을 fine-tuning을 한 후, Con, FC, Covariance, IN,BN 파라미터의 변화가 어디서 가장 많이 일어놨는지 확인해보면 되지 않을까??)
2.2 WT&ST: Image-to-Image Translation via Group-wise DWCT Transformation -CVPR19
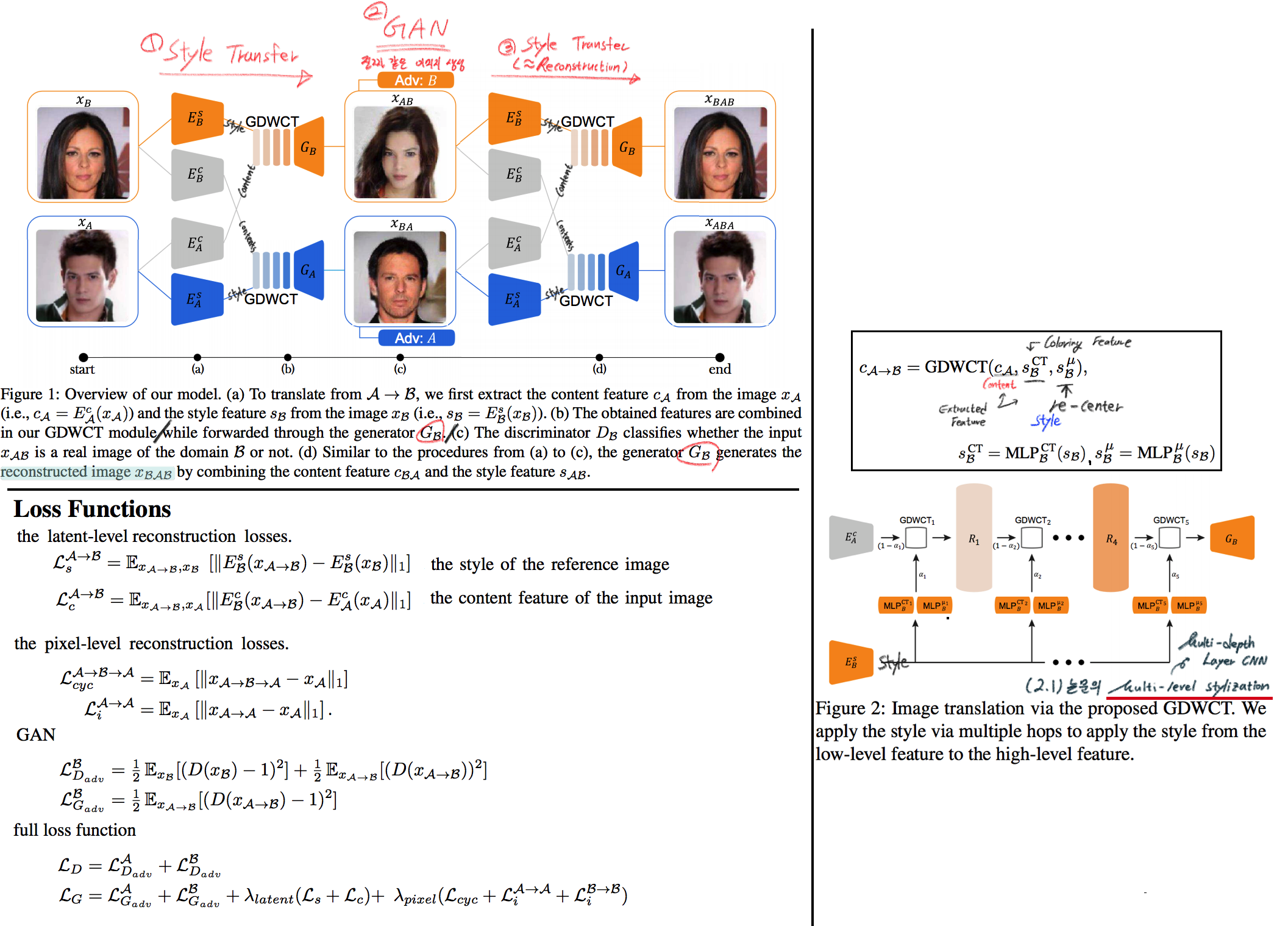
- Motivation: MUNIT (Adaptive IN) 에다가, WCT (whitening and coloring Transform) 기법을 추가하면 어떨까?? Eigen value decomposion말고 Deep WT과 Deep CT를 적용한다.
- (2.1) 논문의 내용을 베이스로 사용한다. WT과 CT를 Backpropa가 안되는 Eigen value decomposition을 사용하지 말고, Deep Learning 기법으로 사용해보자. 우선 DWCT 에 대해 아래와 같이 자세히 알기 전에, DWCT가 잘된다는 가정하에 위의 전체 아키텍처를 학습시켜서, Image Tranlation 모델을 만들어 낸다.
- 위 사진의 오른쪽과 같이 Multi level (depth) 구조를 사용하는 이유는 논문에서 주장하는 이 가설 때문이다. (the low-level feature captures a local fine pattern, whereas the high-level one captures a complicated pattern across a wide area)
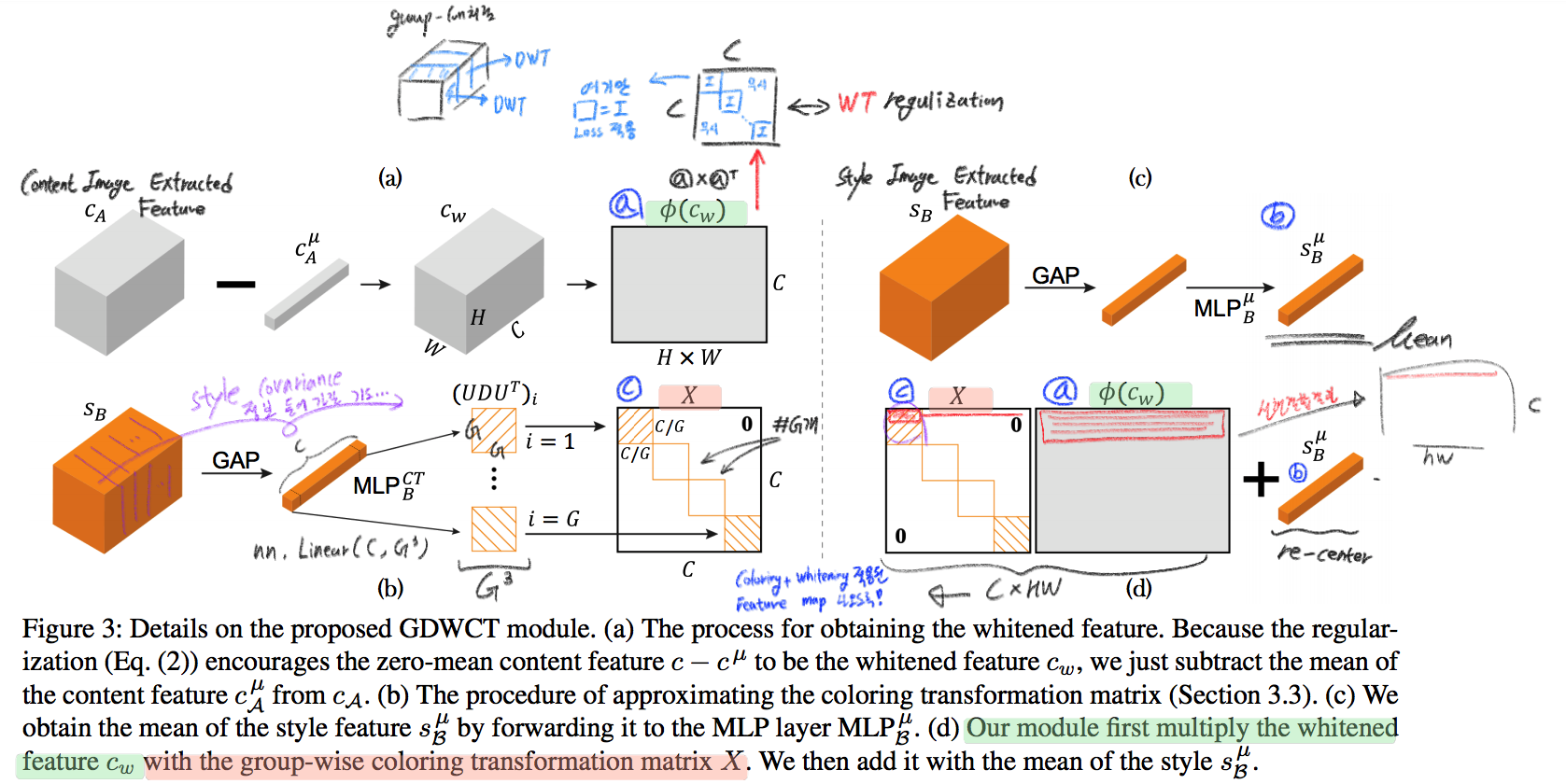
- GDWCT 를 하는 과정을 그림으로 표현했다. WT는 RobustNet에서 이미 잘 설명했다. 하지만 CT는 음.. 아직 잘 모르겠다. 수식을 봐도 잘 모르겠다. 근본적인 CT의 목표는 “Contents Feature 의 Covariance Matric == WCT Feature 의 Covariance Matirc” 로 만드는 것이다. 이것을 이와 같이 구현했다. 정도만 이해하자.
2.3 ST: Texture synthesis using convolutional neural networks -NIPS15
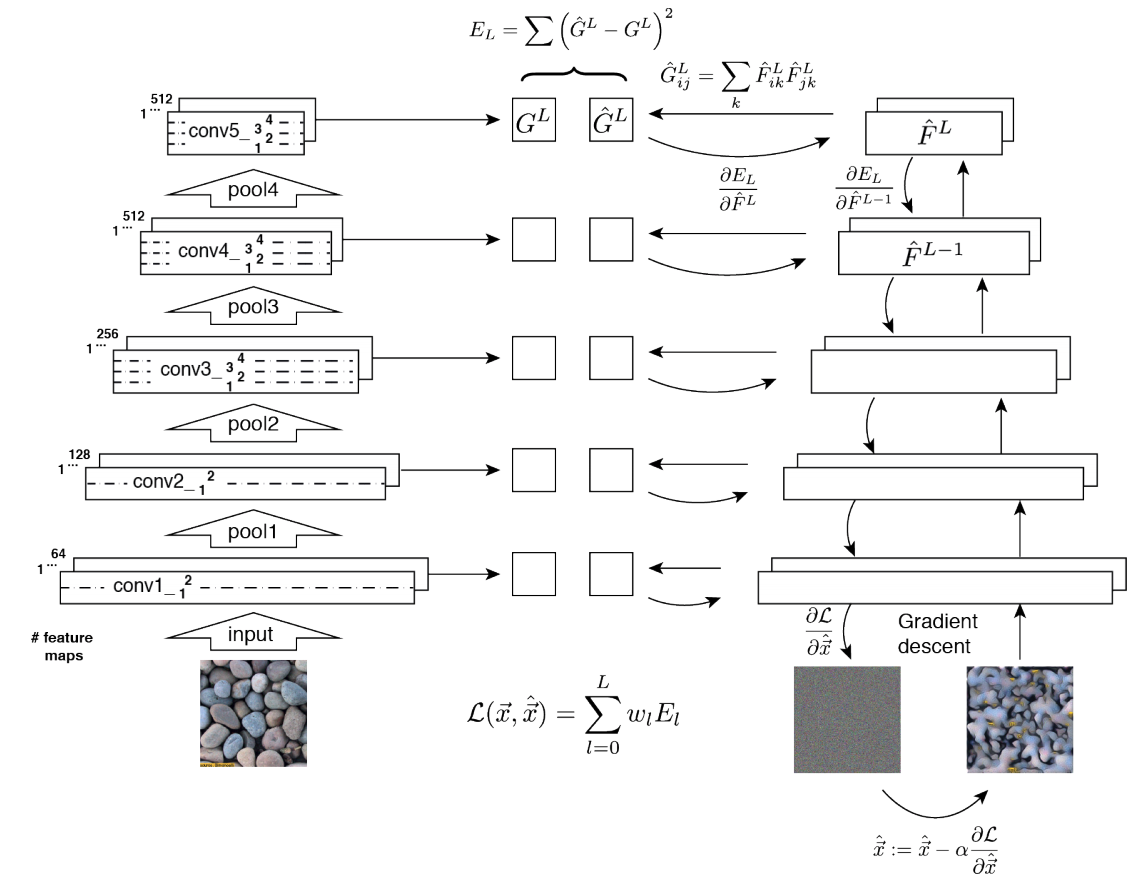
- One spatial summary statistic: the correlations between feature responses in each layer of the network 을 직접 이용하는 첫 논문. 자세한 내용은 아래의 2.4 논문과 비슷하다.
- 이 논문에서 Channel-wise Correlation matrix를 사용한 이유는
- 2000년대 논문 에서 Image Texture를 탐지하기 위해서, 이미지 자체의 Correlation 정보를 이용했었다.
- Texture는 spatial information에 대해서 agnostic 해야하는데 Correlation이 이 조건을 만족한다. 다시 말해, 저자는 feature maps에서 the spatial information 를 제거하면서 Texture 정보를 담고 있을 만한 지표가 Correlation이라고 생각었나보다.
2.4 ST: Image style transfer using convolutional neural networks -CVPR16
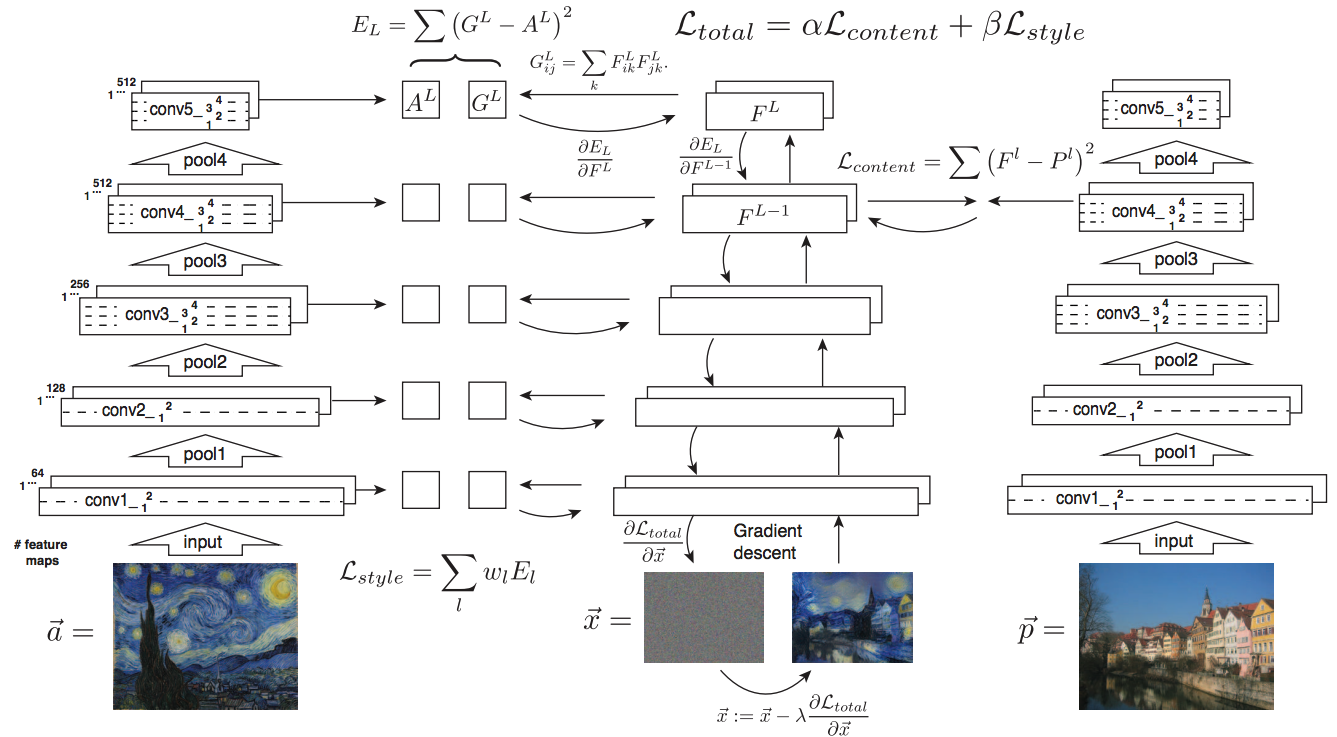

- Style Image 를 생성하는 방법은 하나의 Recon Network를 사용하는게 아니라, Gradient를 직접 활용해 이미지를 생성하는 아주 고전적인 방법이다.
- 위 실험을 통해서 아래의 2개를 가정을 증명할 수 있다.
- Content Loss를 적용하기 위해서는 Sauared-error loss (Euclidean Distance) 정도만 적용해도 무방하다.
- Style(Texture) Loss는 Channel-wise Covariance Matrix를 사용한다. (Feature map의 channel == c 일때, c개의 채널 각각은 서로다른 필터(k x k x c_input) 에 의해 생성된 결과이라는 사실을 상기하자)
