【DG】 Survey DG papers 1.5 - IBN-net and Relative papers
Survey DG papers1.5
1.11. ST: Perceptual Losses for Real-Time Style Transfer -arXiv16

- Style Transformer의 시작, 유명한 저자(Justin Johnson, Alexandre Alahi, Li Fei-Fei), RobustNet correlation (covariance) Matric 계산그림, dot_similarity != correlation (covariance) 서로 다르니 주의하자.
- Feature Reconstruction Loss
- Euclidean distance, Contenct 를 유지하도록 만든다.
- Higer layers 에서 Loss를 적용하기 때문에,
Content and overall spatial structure는 보존하면서color, texture는 따라하지 않도록 만든다.
- Style Reconstruction Loss
style: colors, textures, common patterns만을 따라하도록 만든다.- Gram matrices(=Channel Wise dot_similarity matrices)의 Frobenius norm (L2-norm) 차이(로스)가 작아지도록 유도한다.
- Gram matrices 계산 코드
- Style Loss를 처음 제안한 논문 (아래 논문을 통해서 RobustNet에서 주장한 “correlation (covariance) Matrix가 Style 정보를 담고 있다“라는 가설에 대해 분석해볼 수 있겠다)
- (DG survey2 참조) Texture synthesis using convolutional neural networks
- (DG survey2 참조) A neural algorithm of artistic style
1.12. ST: Instance Normalization -arXiv16
- Paper: Instance Normalization: The Missing Ingredient for Fast Stylization
- 바로 위 논문과는 조금 다른 형태의 Generator를 가지며 비슷한 시기에 나온 Style transform 논문. 심플하게 이 안에서 BN들을 IN으로 바꿨다.
- Style Transfer의 기본 모델들은 ImageNet으로 Pretrained 된 network를 사용했다. 그래서 BN을 그대로 사용한다.
- IN를 사용함으로써, Sample/Image/Instance에 특화된 Feature를 유지하게 해주어, 더 좋은 Style Transform이 가능하게 한다.
1.13. ST: Learned Representation For Artistic Style -ICLR17
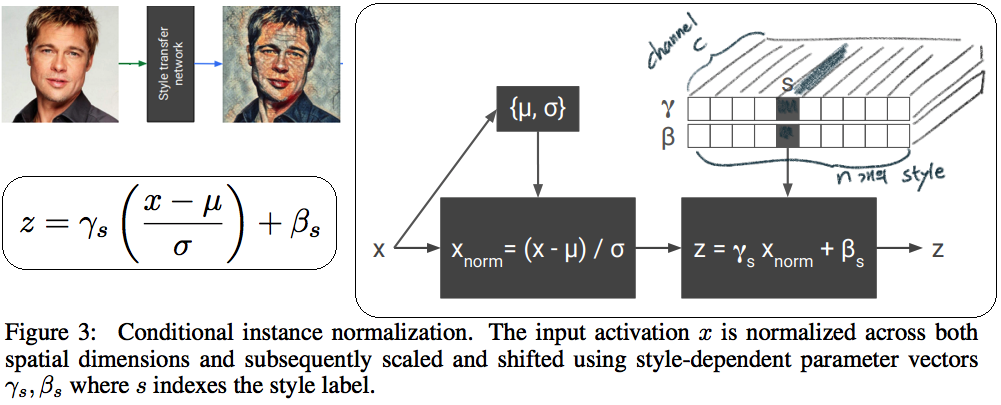

- 이용할 만한 핵심 내용
- Style Transfer Network 에서, Style에 영향을 주는 파라미터는 γ (감마) and β (배타) 이다. 그 외 Conv layer의 파라미터는 거의 영향을 미치지 않는다.
- 따라서 영향이 적은 파라미터는 완전히 고정시키고, 스타일 마다 다른 γ (감마) and β (배타) 를 학습시키고, γ (감마) and β (배타) 를 다르게 설정하는 것 만으로, 놀랍게도 다른 스타일의 이미지를 쉽게 생성할 수 있다.
- 논문 내용 정리
- (1.11) Old style transfer 모델은 하나의 transfer network가 하나의 스타일만 만들 수 있는
single-purpose nature문제점이 존재했다. 이 논문은 이러한 문제를 해결하고자 한다. 각 스타일을 만드는 모델들이 비슷한 파라미터 값을 가지는 것이 확인하고 연구가 시작되었다. - 원하는 Style을 조건적으로 선택하여 하나의 Style Tansfer가 N개의 Style을 생성할 수 있는 Network를 만든다.(
conditional style transfer network) 선택적으로 감마와 베타를 고르는 작업을conditional instance normalization이라고 표현한다. - 새로운 Style에 대한 Style transfer network를 만들고 싶다면, conv와 같은 Layer는 놔두고 γ (감마) and β (배타) 만 학습시키면 되니, 학습도 매우 빠르게 가능하다.
- (1.11) Old style transfer 모델은 하나의 transfer network가 하나의 스타일만 만들 수 있는
1.14. ST: Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization -ICCV17

이 논문의 핵심은 위 (1.13)과 동일하다. (1.13) 과의 핵심 차이점은 (learnable parameter) γ (감마) and β (배타) 를 -» (No learnable parameter) standard_deviation( y ), Mean( y ) 로 바꾼것이다. 하지만 이 논문이 해석과 분석을 완벽하게 하였다. 그래서 내가 “왜 IN을 통해서 저런 효과를 얻을 수 있는지” 이해할 수 있었다. 매우 좋은 논문이었다. 따라서 정리를 좀 더 완벽하게 할 계획이다.
- 문제점과 해결: 지금까지 Style Transfer 기법들은 1개 혹은 N개의 제한된 Style만을 변환할 수 있는 모델들이었다. 이 논문 기법을 통해서 어떤 Style의 이미지가 들어와도 Style Transfer를 수행할 수 있는 모델을 만들었다.
adaptive instance normalization (AdaIN) layer가 핵심이다. Contents Loss는 Euclidean distance를 그대로 사용한다. 하지만Style Loss는 아래와 같이 다양한 Loss가 있다. 이렇게 다양한 Loss를 통해서, 나는Deep Network에서 Style 정보를 담고 있는 부분을 정리&분석해 볼 수 있었다.- 다양한 종류의
Style Loss: MRF loss [30], adversarial loss [31], histogram loss [54], CORAL loss [41], MMD loss [33], and distance between channel-wise mean and variance [33]. 특히 이 논문에서 사용하는 Loss는 Distance between channel-wise mean and variance loss (코드링크) 이다. 하지만 Gram matrix 를 사용해도 비슷한 성능이 나왔다고 한다. (따라서 Distance 와 gram 은 Style 정보를 비슷하게 가지고 있겠구나!) Deep Network에서 Style 정보를 담고 있는 부분(내가 이용할 만한 내용 분석)- IN 의 파라미터 값
- Channel-wise dot_similarity Matrix = Gram matrices
- Channel-wise correlation (covariance) Matrix (in CORAL, RobustNet)
- Channel-wise mean and variance
- 다양한 종류의
이 논문이 IN에 대해 분석한 핵심- “IN은 Feature를 Normalization함으로써 일종의
style normalization을 수행한다. 즉, 어떤 Style이 들어와도 Normalize하여 (적절한 위치로 이동시키는 것을 도와주어), Network가 빨리 수렴되고 Style Invariance 를 가지게 도와준다. - 반대로 BN은 한 Batch의 이미지를 하나의 Style로 Normalize 해버린다. 그래서 Style Transfer Network가 학습되는 동안 Batch 속 이미지 각각이 자신의 Content와 Style을 유지하는데 방해를 주어, 학습 수렴이 잘 안되게 만든다.
- 논문의 Figure1을 통해서 IN의 성질에 대해 증명하였다. (증명과 실험 내용은 필요하면 참고. 핵심만 적어 놓는다)
- “IN은 Feature를 Normalization함으로써 일종의
