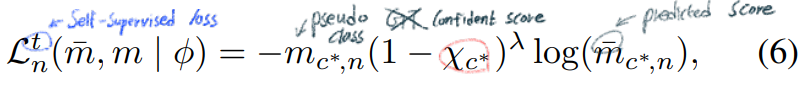Paper: Self-supervised Augmentation Consistency for Adapting Semantic Segmentation
Type: Self-supervised learning, Domain Adaptation
Contents
Dualing DQN network 기법을 사용할 방법이 없을까?
핵심 요약
Self supervised learning의 기법을 사용해서, Domain Adaptation의 Sementic Sementation에 잘 적용했다.
The momentum network (:= Target-Q in RL)
Data augmentation & Noisy Student
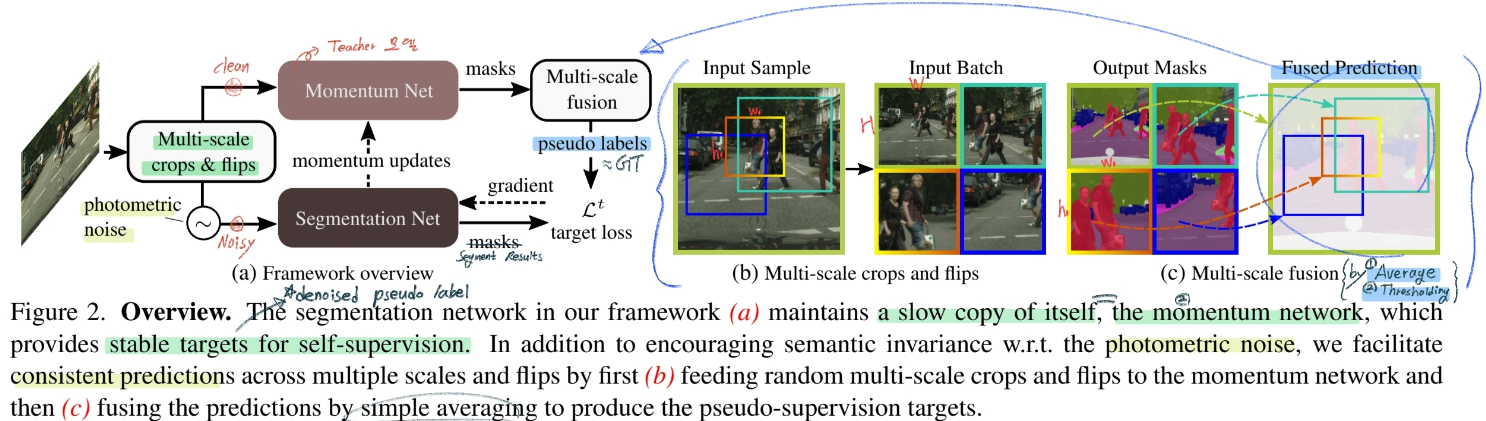
New augmentation: Multi-scale crops & flips (좀 더 신뢰성 높은 Pseudo Labels을 만들기 위해)
Long-tail 문제를 2가지 방향으로 바라본다.
Long-tail Classes with a high image frequency: (100장 이미지에 90장에 존재하는) 이미지에 자주 나오지만, 작은 영역만 차지하는 것 (ex, 기둥, 신호등): 한 이미지 내에 클래스 마다 Threshold를 다르게 설정한다
Few Samples: (100장 이미지에 10장에 존재하는) 이미지에 잘 나오지 않는 것 (ex, 버스, 트럭, 전차): Importance sampling을 통해, 10장의 이미지가 더 많이 batch에 들어가게 설정한다.
학습 전체 흐름
Source only로 Network Pre-Training 수행
Target domain 이미지에, Figure2와 같이 Crop하고 HW로 resize한 후, Network에 통과시켜 결과 추출
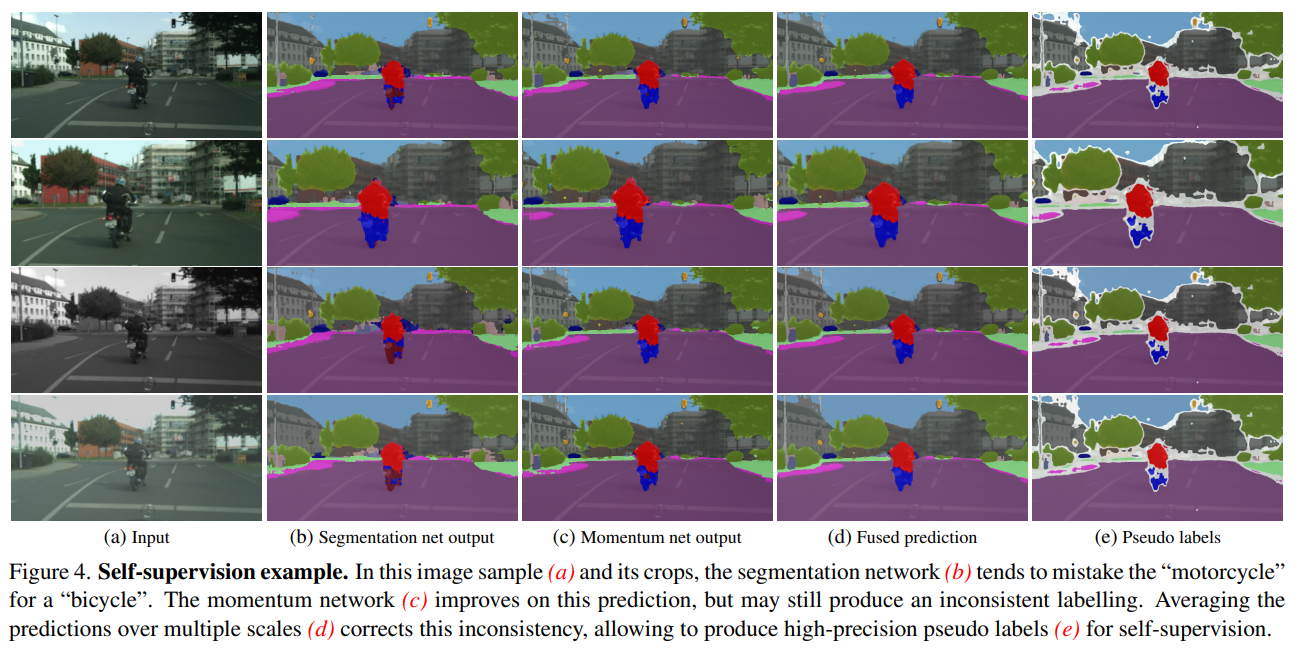
각 결과를 Average하고 Threshold 처리하여 Pseudo Labels 생성 (Target Image GT로 사용)
Target Image에 Data Augmentation 적용 후 Network에 통과시켜 Predicted label 추출.
Target Image (GT, Predicted)로, Class prior 을 이용한 Focal Loss 적용해 Backward.
Augmentation Consistency for DA
1. Abstract, Instruction, Relative work
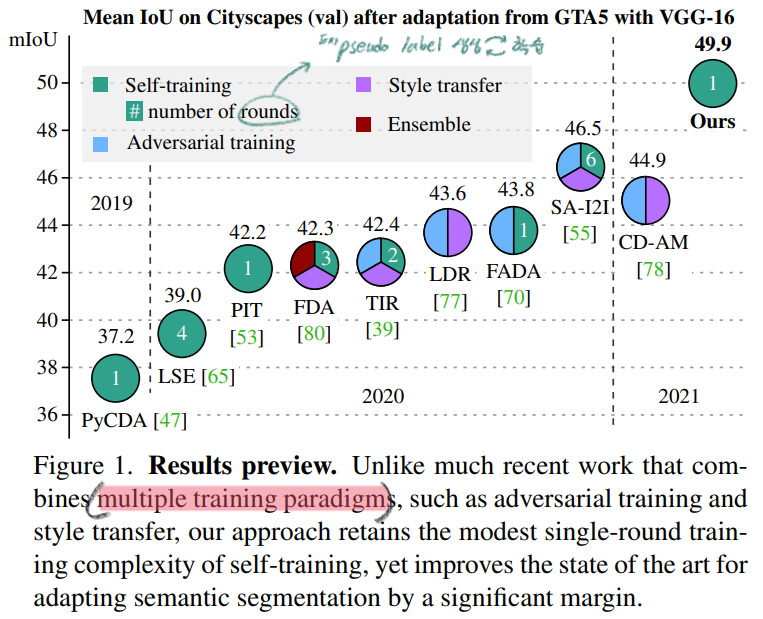
adversarial objectives, network ensembles and style transfer 와 같이 cost가 많이 드는 작업 하지 않았다.
data augmentation techniques (MoCo) 의 기법을 아주 잘 사용했다.
2. Method
Momentum Net 해몽
the mean teacher framework
temporal ensembling model
Critic network (Q function in RL)
our momentum network provides stable targets
(개인 의견: 개인적으로 Momemtun Net이 좋은 예측을 한다고 할 수 있는지 모르겠다. 그것보다는 Target-Q function을 적용했다. 라고 생각하는게 좋겠다. Target-Q function은 일정 Iteration이후에 Network를 갱신하지만, 여기서는 Momentum 방식을 사용했군. 이라고 생각하자. )
Batch construction
Momentum Net이 Clean Input + Multi-Scale fusion에 의해, 신뢰성 높은 Pseudo Label을 생성한다.
Segmentation Model은 Noisy Input을 받는다.
(Noisy Student 기법 + Contrastive Learning 기법)
Sample-based moving threshold
학습을 중간에 멈추기는 싫고, Threshold는 초반에는 좀 낮췄다가 높히는게 맞고… 하니까! 자동으로 Threshold on-the-go 기법을 만들었다. (an exponentially moving class prior)
이해 안되는 것은 논문 및 코드 참조
Focal loss with confidence regularisation (=class prior)
Cross Entropy Loss를 적용하면서 Long-tail problem 해결 관련 Term 추가한다.
아래의 X_c의 정의는 위 사진의 Equ(1) 참조.
X_c 가 낮으면 higer weight가 loss에 주어진다.
Adaptive Batch Normalisation
Adaptive Batch Normalisation (ABN) [45] 사용
Source only로 모델을 학습시킬 때, 가끔 Target Images를 넣어준다. 그리고 BN안의 파라메터인 Mean and Standard Deviation을 갱신해준다. 나머지 Conv와 같은 파라미터는 학습되지 않도록 한다.
Importance sampling
3번의 Threshold 조정공식을 사용하는 것은 Long-tail Classes with a high image frequency 에게 좋을 수는 있지만 Few Samples 에서는 별 도움 안된다. 따러서 아래의 기법을 사용한다. (뭔가 정확하지 않을 수 있으니 코드 참조)