【HDR】 Single-Image HDR Reconstruction
- Paper: Single-Image HDR Reconstruction by Learning to Reverse the Camera Pipeline
- Type: High Dynamic Range Image Enhancement
- Opinion:
- Reference site:
- Contents
핵심 요약
Single-Image HDR Reconstruction
1. Abstract
The main task: missing details in under-/over-exposed regions 을 찾아내고 복원하는 것.
The core idea: HDR(그 현장을 눈으로 그대로 봤을 때의 이미지) –(카메라 내부의 일렬의 과정을 거쳐서)–> LDR (역광과 강한 빛에 영향을 많이 받은 이미지) 이 과정을 정확히 반대로 하는 모델을 만든다.
카메라 내부의 일렬의 과정을 정확하게 분리하고, 분리된 부분(sub-task)들을 각각 하나의 Network로 구성했다. (PS. 개인적인 생각으로 Low-level CNN 모델 개발에서 이 과정이 정말 중요한 것 같다. 하나의 Task를 sub-task로 분류하고, 분류된 task를 각각 하나의 Network로 구성하고 따로 학습시키고, 나중에 Joint-training을 진행함으로써 더 안정된 학습을 가능하게 한다.)
2. Instruction, Relative work
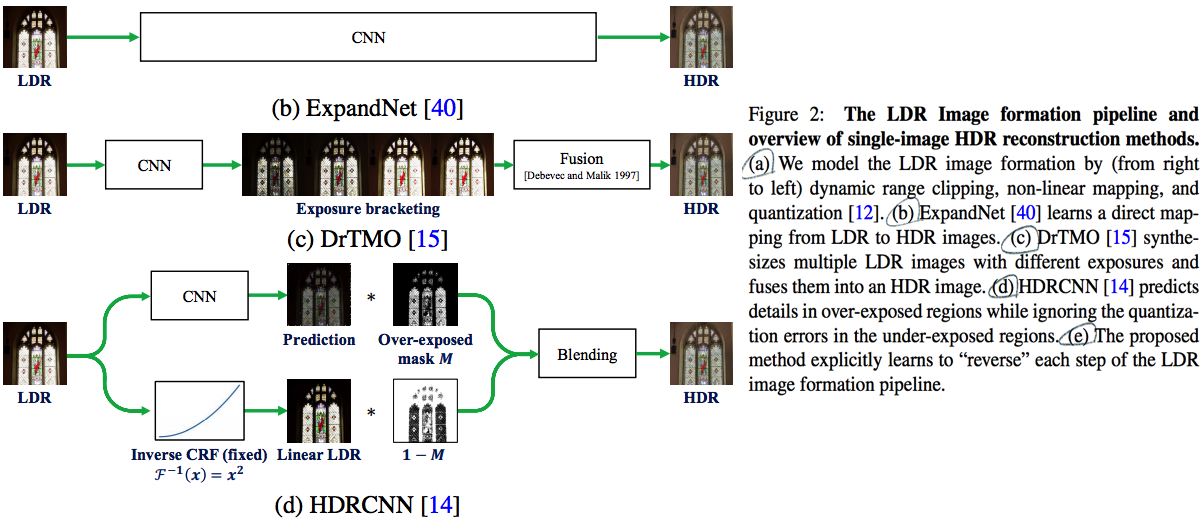
- HDR 이미지 생성의 가장 정통적인 방법: 같은 장면 multiple LDR 이미지들을 융합하기.
- 문제점: ghosting artifacts(error) 발생
- 전통 해결책: image alignment, post-processing [25, 37, 50]
- 딥러닝이용 해결책: multiple flow-aligned LDR images [23], unaligned LDR images [52]
- 한계점 : 인터넷 상의 LDR 이미지는 이미 1개 뿐이다.
- Single-image HDR reconstruction
- SOTA deep learning approaches [14, 15, 40]
- [14, 위 그림 참조] the over-exposed regions 탐색 및 사용
- [15, 위 그림 참조] synthesizing several up-/down-exposed LDR images and fusing them
- 하지만 learning a direct LDR-to-HDR mapping is difficult. 왜냐하면 LDR pixels (8-bit) but HDR pixels (32-bit).
- 따라서 우리의 방법은, 정확하게 LDR 2 HDR 과정을 inverse하여 네트워크를 모델링함으로써, 어려움 해결.
- Quantization
- 문제점: quantization errors가 발생한다. 예를 들어서 scattered noise and contouring artifacts
- 정통 해결책: adaptive spatial filter [9] or selective average filter [49].
- 딥러닝 해결책: 2bits, 4bits input -> 8bit 로 복구시키는 모델 이용.
- 이 논문 기법: 8-bit LDR -> 32-bit floating-point image
- Radiometric calibration (CRF 찾기)
- LDR을 HDR로 복구하기 위해, CRF를 찾는 것은 필수적이다.
- CRF를 찾는 과정은, [16, 2003, 31, 2017] 논문의 개념을 사용한다.
- a set of real-world CRFs 들의 선형결합 weight(vector from PCA)를 이용해서 해당 이미지의 CRF를 추론한다.
- 이 논문에서는 # a set of real-world CRFs = K = 11개 를 사용했다.
- CRF 선형결합 weight를 찾는 과정에서, 이 논문에서는 추가적으로 새로운 features(image feature, soft histogram, sobel edge) 를 사용했으며, monotonically increasing 성질을 고려한 operating (Using cumulative function) 과정도 추가했다.
- Camera Pipeline
- HDR 2 LDR pipeline의 다양한 algorithms을 이용했지만, [12, 논문 참조] 방법을 차용했다.
- 이 논문의 핵심은, HDR image reconstruction을 위해서 가장 중요한 components만을 독립된 모듈로 구성하여 Network를 설계한 것이다.
3. Method
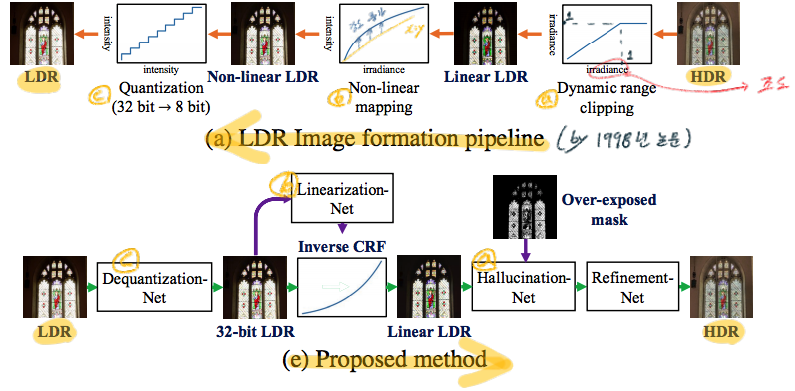
(a) LDR Image formation pipeline
Dynamic range clipping: clipping 함수를 사용한다. I = min(H, 1) H는 HDR원본이미지 이고 대략 0~1.8 범위의 값을 가진다고 상상할 수 있다. 1~1.8값을 가지는 부분은 모두 1로 만들어 버리므로, over-exposed regions에 대한 정보손실이 일어난다.Non-linear mapping: non-linear CRF(camera response funciton)이 적용한다. 이 함수는 각 카메라 디바이스마다 다른 함수이지만, 공통점인 “0~1까지 1대1 대응 단순 증가 함수” 라는 것을 이용한다.Quantization: 알다시피 RGB 각 8비트 값을 가지게 만들어야 하므로, float값을 int로 바꾸며 이산화를 시켜야 한다. 그때 사용하는 공식은 이와 같다. Q(In) = [ceil(255 × Image_pixel + 0.5) /255]
(e) Proposed method 는 위의 과정을 완전히 반대로 하는 네트워크로 구성된다. 각각의 CNN 모듈을 따로 학습시키고, 나중에 Joint Training을 수행한다. 아래와 같은 Network가 존재한다. 하나씩 자세히 알아보자.
- Dequantization
- Linearization
- Hallucination
3.1 Dequantization
원래 quantization 작업에 의해서 발생하는 문제점은 이와 같았다. (1) scattered noise (2) contouring artifacts (이미지 검색하면 나온다)
Architecture: 1Level(2conv + leaky Relu)로 이뤄진, 6Level U-Net, 마지막에 Tanh activation. [-1 ~ +1] output 생성
| Training: L2 loss. Loss_deq = | Img_deq − Img_GT | ^2 |
3.2 Linearization
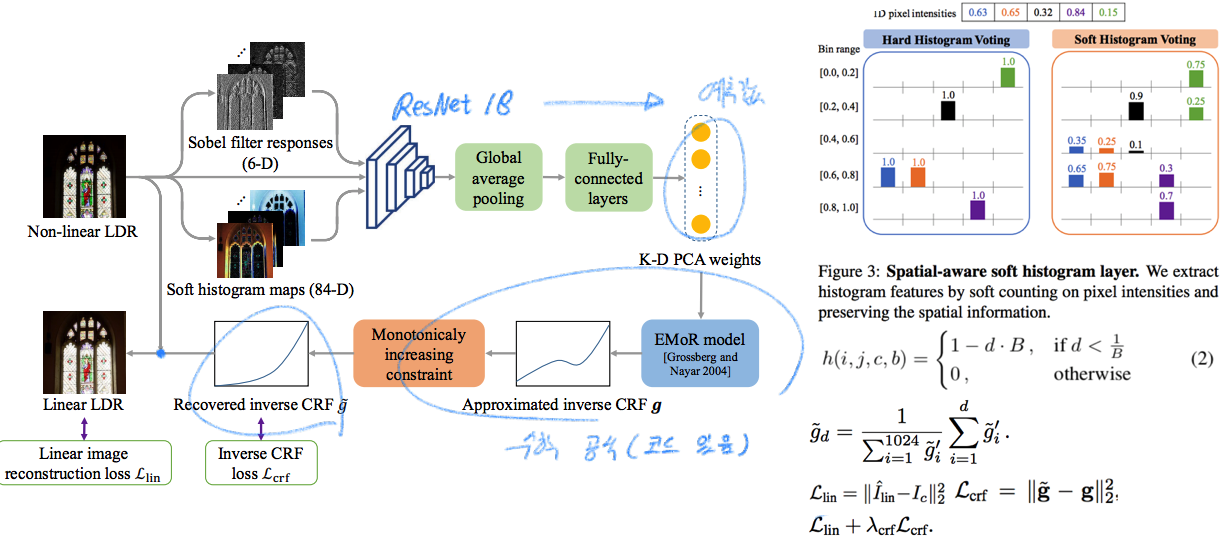
해당 부분은 코드를 통해 이해해야 한다. 특정 부분의 코드 링크를 남겨 놓는다. [Soft Histogram 위 그림 중 h 값], [Monotonicaly Increasing constraint 위 그림 중 g 값], [주성분분석 EMoR]
- Input feature는 Sobel filter responses, Soft histogram 결과, Image 가 들어간다. CRF를 추정하는데 이미지의 Edge정보와 Color Histogram 정보가 유용하기 때문에 Feature로 사용했다고 한다. soft-histogram layer를 사용하는 것은 이미지의 “spatial information”를 유지해주는 장점이 있고, fully differentiable 하다.
- CRF의 역함수를 구하기 위해서, 0~1를 1024개로 분리(x)하고 y = invertCRF(x) 값을 담고 있는 g vector를 정의한다. 우리의 목표는 GT_g와 가까운 g를 찾는 것이다. 이를 위해서 [16, 2003, 31, 2017] 논문의 개념을 사용한다. 이 개념은 다음과 같다 “일반적으로 많이 사용되는 K개의 PCA(주성분 분석) 선형결합으로 inverse CRF를 근사회할 수 있다.”여기서 ResNet18 모델이 선형결합의 weight를 예측하게 만든다. 논문에서는 K=11로 사용했다.
- 위에서 말했듯이, CRF는 각 카메라 마다 다른 함수를 가진다. 하지만 “1대1 대응 단순 증가 함수”라는 특징은 일정하다. 이 조건을 만족시키기 위해서 위 이미지의 g 가 포함된 수식을 적용한다. 필요하면 논문과 코드를 참조해 이해하자.
- Loss는 위 이미지 오른쪽 하단과 같다.
3.3 Hallucination
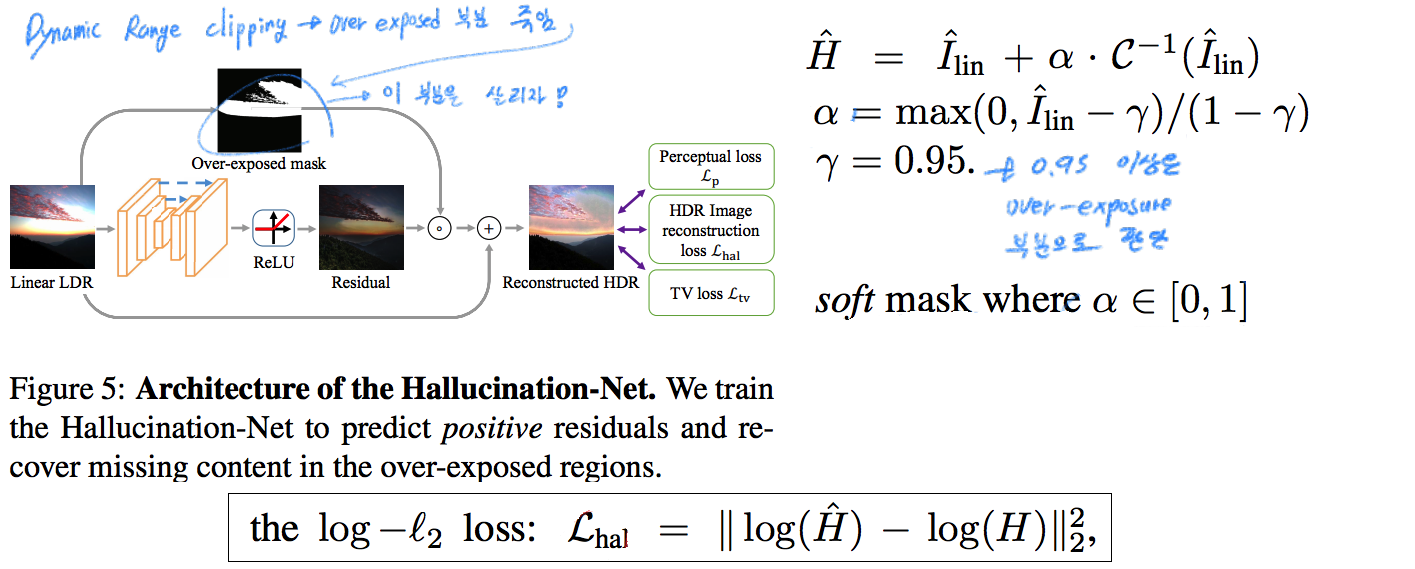
Architecture: [14] (HDR 2017) 논문에서 사용된 Backbone 그대로 사용하고 마지막에 Relu 추가한다.
Training: 3가지 종류의 Loss가 존재한다.
- Loss_hal: 위 이미지에 나온 그대로이다. log domain loss를 사용하는 것이 경험적으로 안정적인 학습, 높은 성능을 가져왔다고 한다. 그 이유로는 Linear domain loss를 그대로 적용했을 경우 highlight regions에 대해서 상대적으로 높은 loss가 나와 학습이 그 부분에만 일어난다고 한다. 모든 region에 대해서 학습이 골고루 일어나게 하기 위해서 log domain loss가 더 적절하다고 한다.
- Loss_p: [22, Fei-Fei. Perceptual losses for real-time style transfer and super-resolution] 논문에서 사용되는 loss이다.
a differentiable global tone-mapping operator[52](Deep high dynamic range imaging with large foreground motions. In ECCV, 2018)를 이용해서 찾은 the tone-mapped HDR images 와의 perceptual loss를 구해 적용한다. 이 과정을 통해서, Non-linear RGB space이미지를 에측해야하는 VGG(Backbone)이 잘 학습되도록 유도된다. - Loss_tv: 예측 결과의 spatial smoothness를 증가시키기 위해서 Total variation(TV) loss를 적용한다. [코드를 통해 공부하기]
3.4 Joint Training
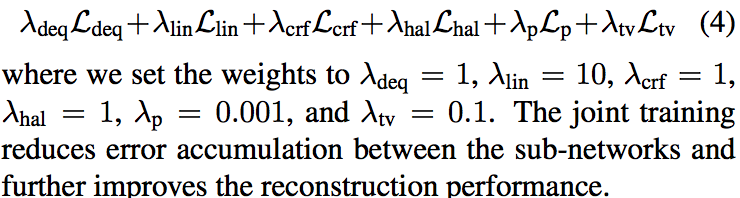
3.5 Refinement
사실 카메랑에서 HDR 이미지가 LDR가 되는 과정에는 수많은 ISP effects가 포함되어 있다. (e.g. local tone-mapping, sharpening, chroma denoising, lens shading correction, and white balancing)
Refinement Network는 위의 작업을 sub-task로써 담당하는 Network이다.
Architecture: U-Net
Training: 위 Joint Training이 적절히 완료된 후, minimize the same Loss_total for end-to-end fine-tuning (with λdeq, λlin, λcrf, and λhal set to 0 as there are no stage-wise supervisions), and replace the output of Hallucination-Net Hˆ with refined HDR image Hˆ ref.
4. Experiments
Dataset
- HDR-SYNTH, HDR-REAL: 2가지 종류의 데이터셋으로 구성 ()
- 퍼블릿 데이터셋:
- (1) RAISE(RAW-jpeg pairs)
- (2) HDR-EYE
- 논문의 설명에는 3개의 핵심 모듈을 각각 학습시키기 위해, GT가 위의 Dataset에 존재하는 것 처럼 말한다. GT가 각 모듈을 위해서 분리되어 존재하는지 dataset을 직접 다운 받아봤지만, 그런것 같지는 않다. Supplementary에 Dataset에 대한 정보가 좀 더 자세히 있으니 좀 더 참고해야할 듯 하다.
Evaluation metrics
- PSNR
- SSIM
- HDR-VDP-2 [39. 논문참조필요]: HDR reconstruction 정확성 판별 지표
- Perceptual Score with the LPIPS Metric [57, 논문참조필요] (using the tone-mapped HDR images)
5. Results


