【DG】 RobustNet- Improving Domain Generalization
- Paper: RobustNet: Improving Domain Generalization in Urban-Scene Segmentation via Instance Selective Whitening
- Type: Domain Generalization
- Opinion:
- 여기 있는게 다 새로워보이지만, 사실은 다 어디있던 개념이라는 것을 잊지말자.
- 이미 normalization 에 대한 연구나, Style Transform에 대한 연구에 있던 내용들이다.
- Key words
- Whitening Transformation이란, 초기 Layer의 Feature map에 대해 채널 방향 공분산 행렬이 단위행렬이 되도록 만든 변환이다. (==Feature map (CxHxW)를 [HW 백터 C개] 로 변환한 후, C개의 백터들에 대한 Covariance Matrix를 Identity Matirx 형태가 되도록 하는 것이다.), 이렇게 하면 이미지의 Style 정보가 제거 된다는 가설이 있기 때문에, 이 논문에서는 WT를 적절히 적용하기 위한 노력들을 하고 있다.
- Whitening Transformation을 정확하게 하려면 Eigen-decomposion이 필요하다. 하지만 이것은 computation-cost가 크다.
- 이것을 대체하기 위해서, deep whitening transformation Loss를 적용하면, Whitening Transformation이 이미 적용된 Feature가 나오도록 유도된다.
- deep whitening transformation Loss(Equ(5)) 함수를 그대로 적용해 학습시키면, 사실 수렴이 잘 되지 않는다.
- Feature map에 Instance normalization 을 적용하고, Equ(5) 를 적용하면 수렴가능하다!
- 하지만, Equ(5)이 covariance metric 내부 원소들에 모두 적용되면(-> Equ(10)와 같이) 그건 domain-specific info, domain-invariant info를 모두 지워버리는 행동이다.
- Covariance metrix에서 domain-specific element position만! 딱 그 부분에만 deep whitening transformation Loss(-> Equ(17)과 같이) 를 적용한다.
- 이렇게 하면 domain-specific info에 대한 covariance는 죽이고, domain-invariant info는 살릴 수 있어서, 옮바른 segmentation(recognition)이 가능하다!
- Reference Site
- Normalization: batch, layer, instance, group
- Quastion
- domain-invariant info를 굳이 Covariance metric에서 찾을 필요가 있나?
- Feature map에서 찾으면 안되나.
- 지금까지는 Channel-wise domain-specific/invariant info만을 찾았고, Spatial-wise specific/invariant info도 같이 찾으면 좋지 않을까?
- K-mean cluster를 이용해서 기존의 n차원 원소들을 k개로 나누는 방법은, 심박하다. 언젠간 쓸모가 있으려나.
- Figure7을 어떻게 생성한거지? whitening이 된 feature map을 어떻게 다시 이미지로 mapping 시켰을까? 코드 레벨로
- 나머지 의문은 성능을 직접 테스트 해보고 알아보자.
- domain-invariant info를 굳이 Covariance metric에서 찾을 필요가 있나?
RobustNet
1. Conclusion, Abstract
- instance selective whitening loss 방법을 통해서 아래의 두 목적을 달성한다.
- Feature representation에서 the domain-specific style 그리고 domain- invariant content 를 분리한다.
- Domain 변화에 의해서 생성되는 Style information을 제거한다. 즉 위에서 찾아낸 domain-specific style을 제거한다.
- 간단하지만 효율적인 방법으로, axillary loss 를 적용해서 학습시키기 때문에 additional computational cost가 발생하지 않는다.
2. Instruction, Relative work
- Domain Generalization: DA는 특정한 target domain이 있다면, DG는 unseen domain 을 다룬다.
- Feature covariance
- 기존의 연구실에 의해서, feature correlations(covariance matix)자체가 이미지의 style information을 담고 있다고 밝혀졌다.
- 이와 같은 토픽의 연구들에서 밝혀진 내용이다. style transfer, image-to-image translation, domain adaptation
- 따라서 이미지의 style을 제거하기 위해서, whitening transformation 라는 기술이 있다. 다음 장에서 에서 자세히 공부해보자.
3. Preliminaries
3-1 이미지의 Style을 지워주는 Whitening Transformation(WT)
- 아래의 조건에 맞춰 feature map을 바꿔주는 것을 Whitening Transformation 이라고 한다. 이 작업을 통해서 이미지의 Style 정보를 제거할 수 있다. (조건1: 참고로 이 변환은 선형변환)
- 조건2: 각 채널의 Variance(분산)이 1이 되도록 만든다.
- 조건3: 각 채널끼리의 covariance이 0이 되도록 만든다.
- 이 조건을 수식으로 쓰면 이렇게 된다. 아래의[관점 1] 내부의 내용에 조건 2, 조건 3 이 모두 들어가 있다.
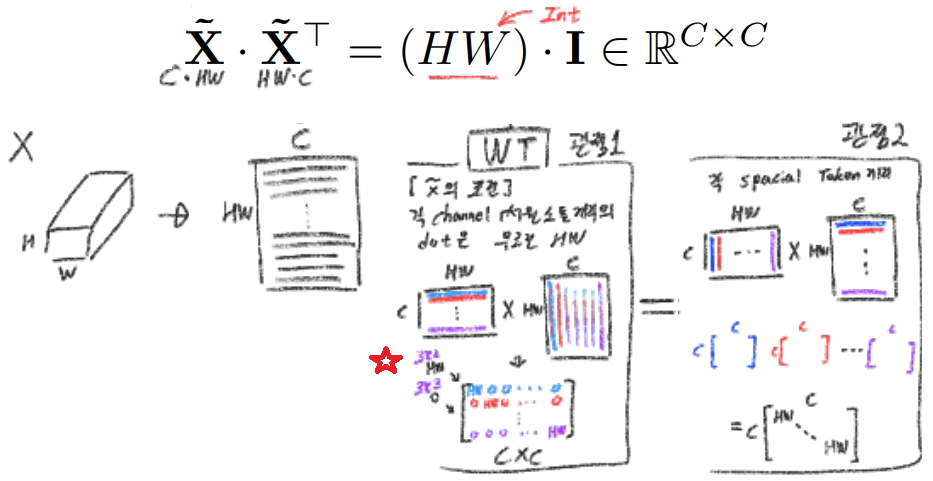
- 그리고 위 수식을 만족하는 X는 아래와 같이 정의할 수 있다. sqrt(공분산행렬)을 구하기 위해 고유값 분해를 한다. 이 내용은 선형대수3 - 49강 부분을 참고할 것.

3-2 WT가 이미 된 Feature map이 나오도록 유도하는 Deep WT Loss
- 위 공식을 사용해서 Whitening Transformation을 수행하는 것은 2가지 문제점이 있다.
- 문제점1: 고유값 분해는 computational cost가 크다
- 문제점2: back-propagation을 막는 연산이다.
- 따라서 처음부터 WT이 된 feature가 나오도록 신경망에 추가적인 Loss함수를 사용하는 방법이, Deep WT이다. 또는 Approximating the whitening transformation matrix (using Newton’s iteration) 방법도 있다. 하지만 우리는 아래 공식과 같이 DWT Loss를 적용할 것이다. 이 Loss를 통해 학습시키면, Feature map 자체가 (처음부터) WT 조건을 만족하는 feature map이 나오도록 유도된다.

- 하지만 위 Loss를 적용해서 WT처리가 된 feature map이 나오도록 유도하는 것은, Network에게 Domain-specific representation과 Domain-invariant representation을 모두 지워버리게 만든다. 특히 Domain-invariant representation는 class간의 특징차이, boundary 검출등에 사용되어야 하므로, 다 지워버리면 안된다. (문제점 Z)
4. Proposed Method
이 논문의 핵심은 instance selective whitening loss이다! Style을 지우는 WT는 Style change 관련 논문 [23, 25]에서 이미 많이 사용된 기술이다.
4.1. IW loss: Instance Whitening Loss
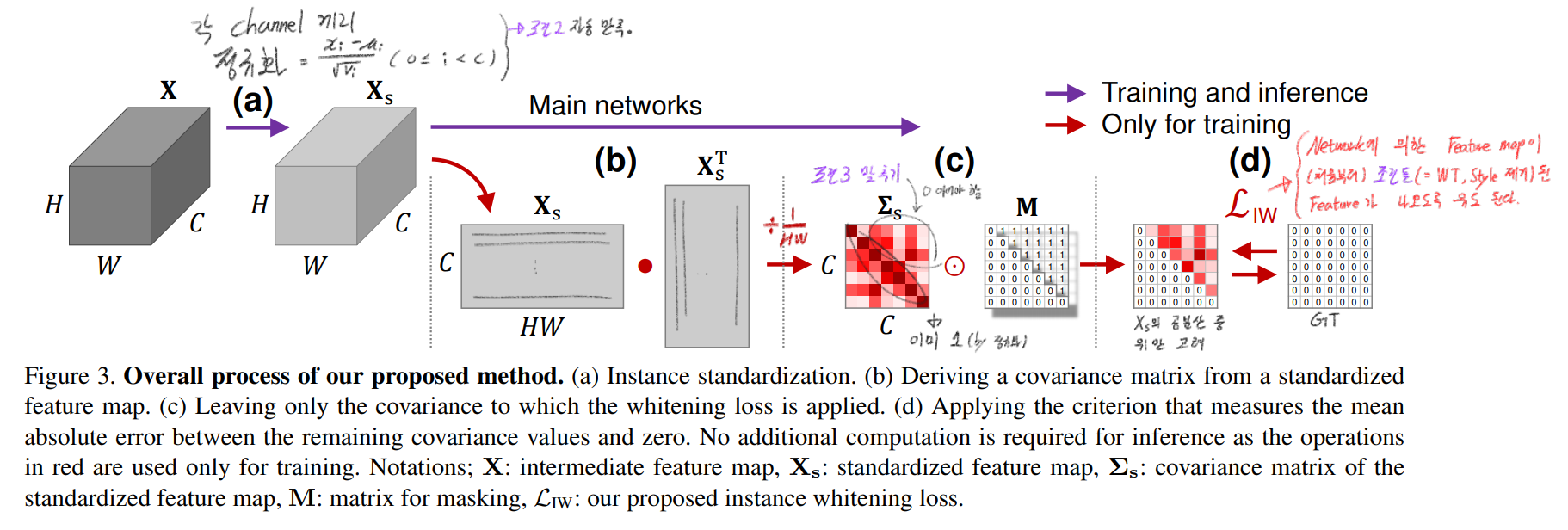
- Equation(5)를 분리해서, 아래의 Equation(6), Equation(7) 과 같이 표현할 수 있다.
- Equation(6), Equation(7)를 모두 동시에 만족하는, xi 를 얻기는 힘들기 때문에, instance normalization Equ(8) 을 해준다. (Equation(6)은 |xi| -> sqrt(HW) 이 되도록, Equation(7)은 |xi| -> 0 이 되도록 유도한다. 동시에 만족하는 xi를 얻을 수는 없다!)
- 이것을 해주면 Equation(6)는 자동으로 만족된다. 따라서 Equation(7, 9, 10) 만 만족하도록 유도해주면 된다.이 식은 xi와 xj의 cosθ 값에 의해서만 결정된다.
- 위 그림에 필요한 수식들을 정리하면, 아래와 같이 정리할 수 있다.

4.2 IRW loss: Margin-based relaxation of whitening loss
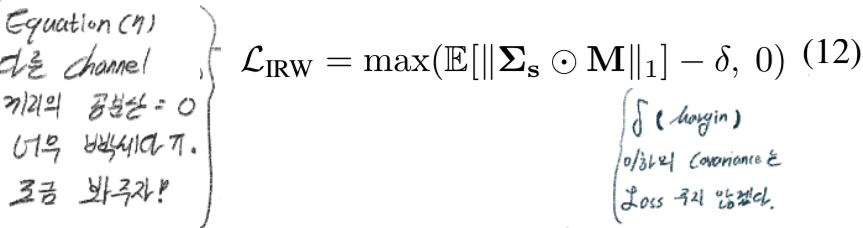
4.3 ISW loss: Separating Covariance Elements
- IW loss는 covariance matrix에서 대각 원소가 아닌 원소를 모두 0이 되도록 유도한다.
- 이렇게 되면 domain-specific & domain-invariant representation 모두 제거된다. 따라서 domain-specific representation만 제거해보자.
- 이 방법의 가정은 다음과 같다.
- domain에 의한 변화는 color jittering and Gaussian blurring 으로 시뮬레이션 할 수 있다.
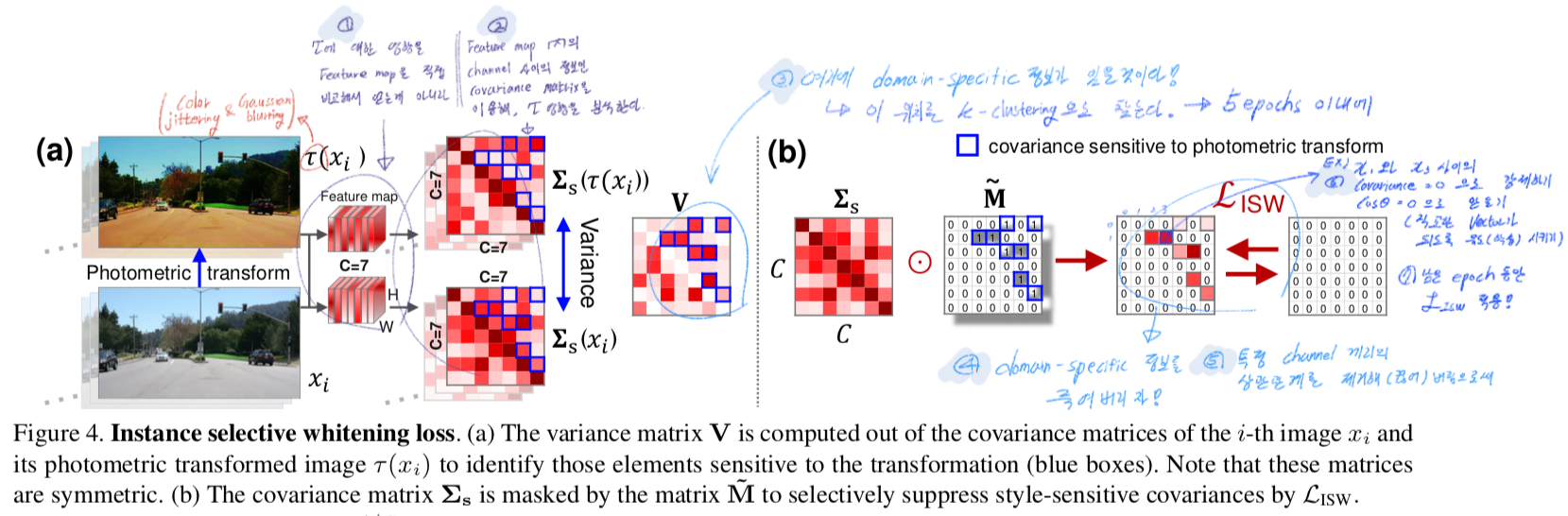
- 위 그림에서 variance(분산이 아니라, 차이) matrix V를 찾는 수식은 아래와 같다.

- V값 중에서, 작은 값들의 위치는 domain-invariant info이고 V값 중에서 큰 값들은 위치는 domain-specific info라고 가정할 수 있다. 따라서 V값 중에서 큰 값들의 위치를 찾기 위해서 아래와 작업을 한다. (코드 레벨로 이해한 내용이다.)

4.4 Network architecture with proposed ISW loss
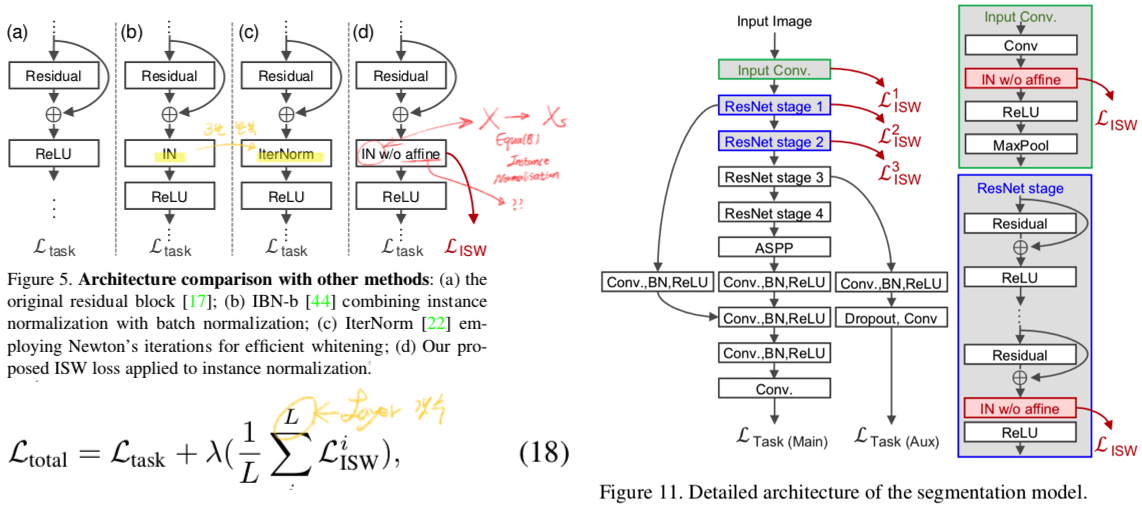
- IBN-Net에 따르면, Earlier layers는 style information을 encoding하는 경향이 있다고 한다. 따라서 이논문에서는 ISW loss를 layer 초기에 적용한다.
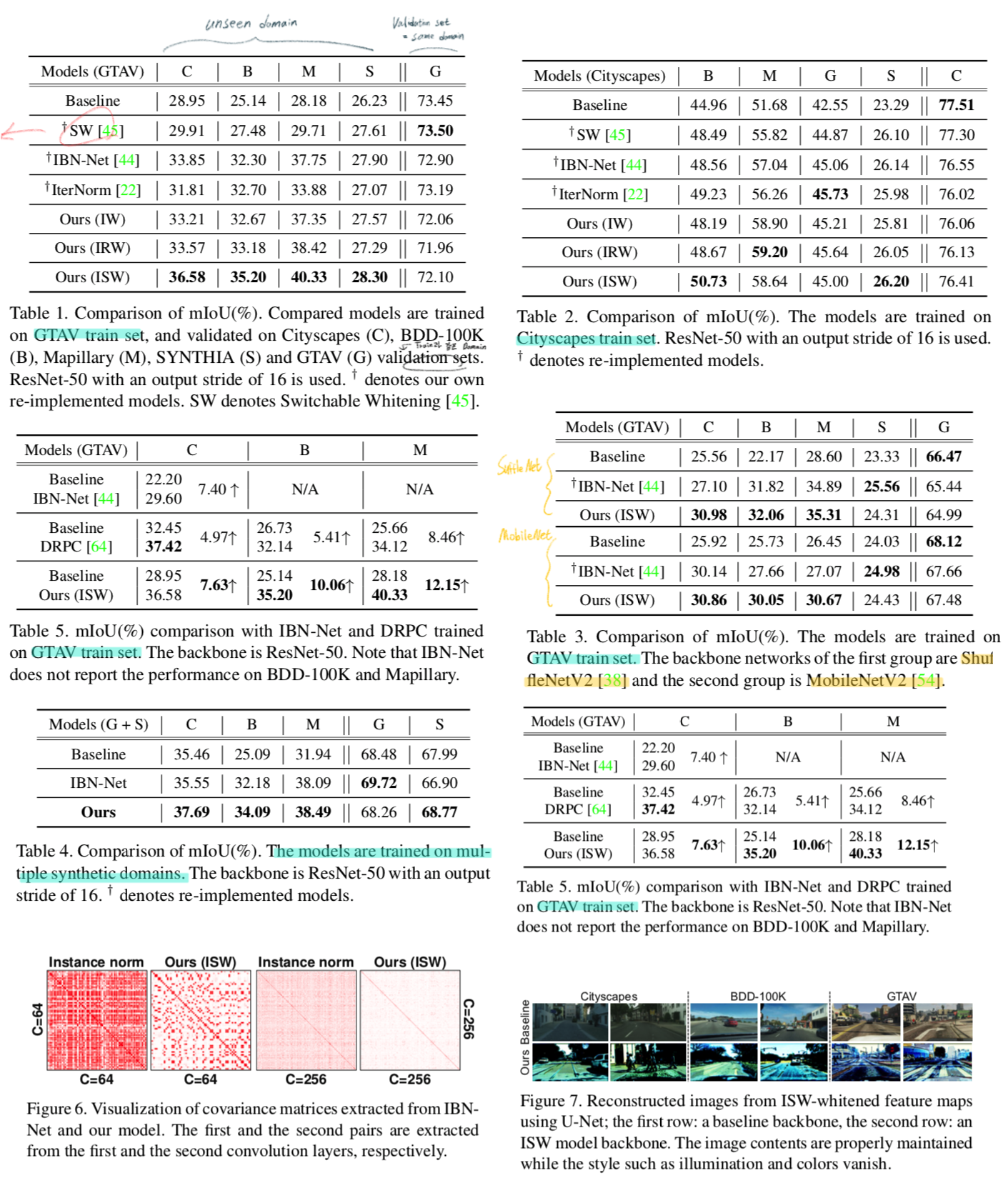
4. Experiments
- Experimental Setup
- Source: several datasets (e.g., Cityscapes)
- Targer(Unseen): other datasets (e.g., BDD- 100K, Mapillary, GTAV, and SYNTHIA)
- 평가 지표 : mIoU
- Implementation details
- DeepLabV3+
- train for 40K iteration
- Dataset
- Real world: Cityscapes, BDD-100K, Mapillary
- Synthetic dataset: GTAV, SYNTHIA
5. Results