【Attention】 Dual-attention & Scale-aware for segmentation
- Paper:
- Type: Attentino & Segmentation
- Opinion: 좋은 논문이고 각자 citatione도 1100,900으로 매우 높다. 하지만 2021년에 보기엔 좀 구식이다.
- Contents
- 간단하게 논문에서 핵심이라고 생각하는 내용만 정리하였다. 결과 표와 같은 추가적인 내용은 직접 논문을 통해서 공부하도록 하자
Attention to Scale: Scale-aware
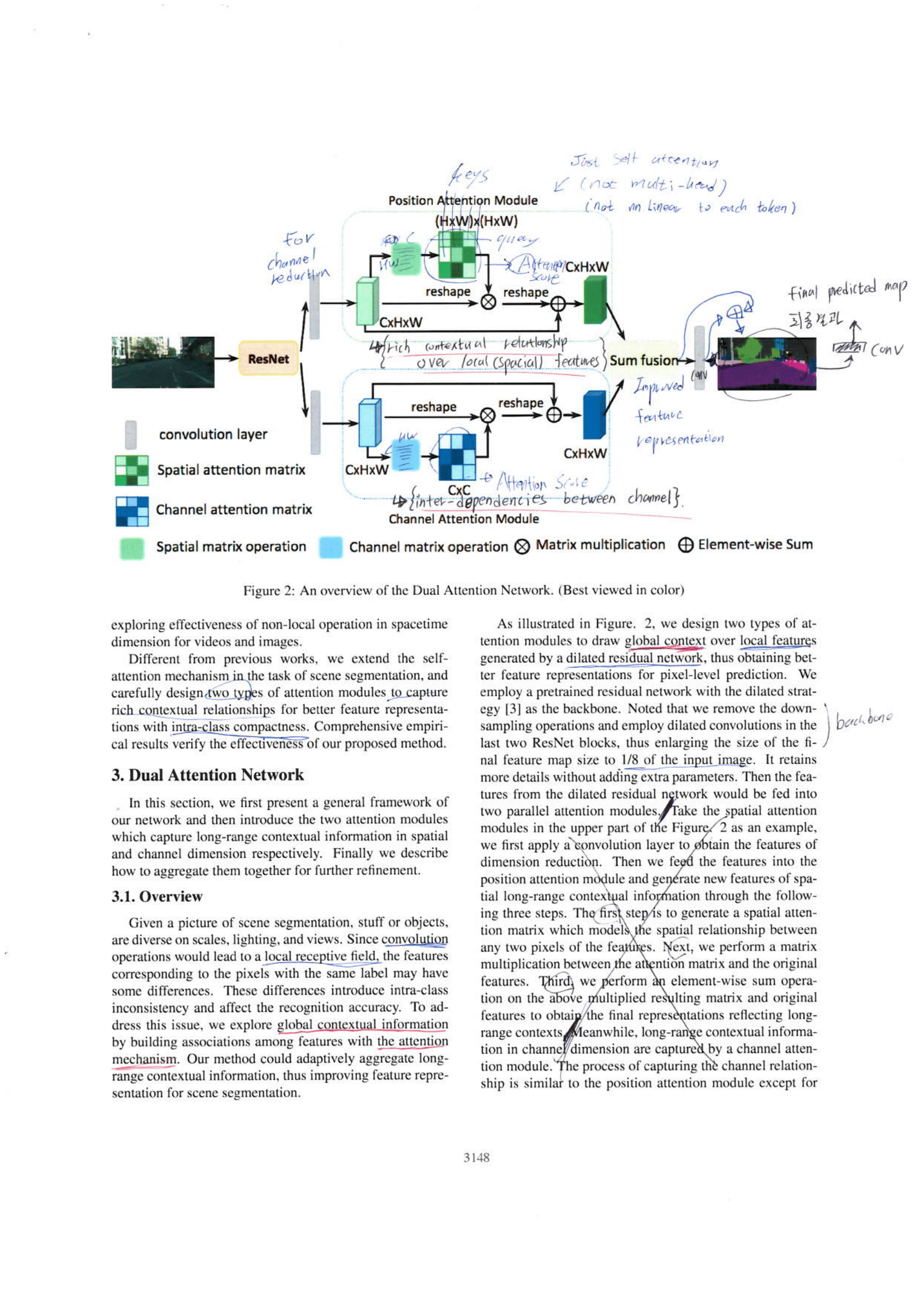
- FPN이 없던 시대이다. 이미지를 다중으로 Resize하여 나온 이미지들을, 각각 backbone에 통과시켜서 Feature map을 얻어낸다.
- 기억해야 할 논문의 핵심 Key: 어떤 Scale Feature map에 더 집중할지, Attentino score w를 FCN으로 만들어 낸다.
- w는 각 Scae Feature map에 HxW shape를 가진다. 그리고 HxW는 Scae Feature map의 각 channel에 똑같이 곱해진다.
- 이 w의 동작은 다음과 같이 이해할 수 있다.
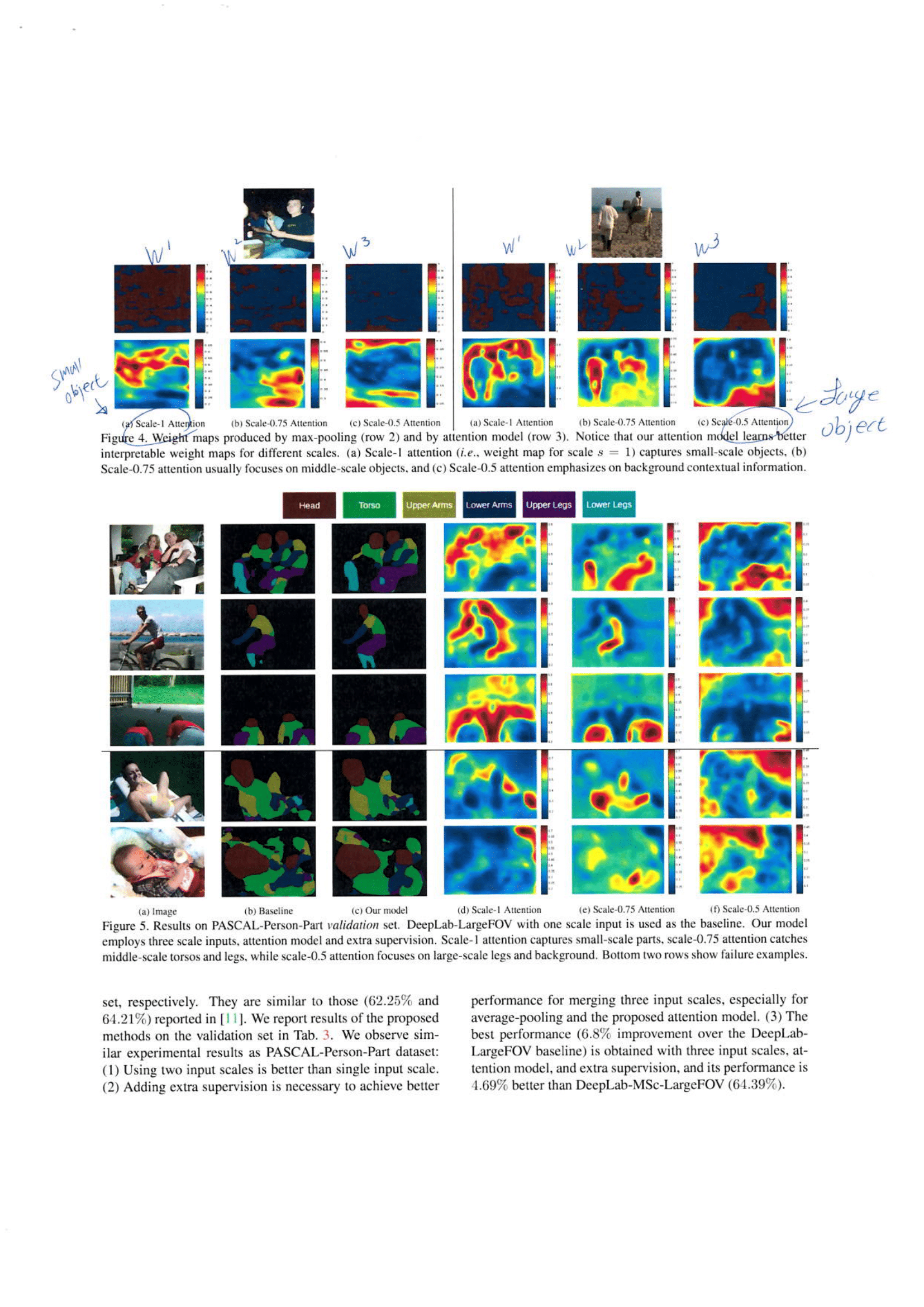
- Large Image에 의해 나온 Featuer map에 Small object가 존재하는 위치에 대해서 큰 w값이 곱해진다.
- Small Image에 의해 나온 Featuer map에 Large object가 존재하는 위치에 대해서 큰 w값이 곱해진다.
- Figure 3 설명 추가
- Figure 3 (b): 각 Scale Feature map에 대해서 attention score w를 추출하는 과정. (논문 2page 하단 오른쪽에 나의 필기 부분)
- Figure 3 (a): 각 Scale Feature map에 대해서 자신에게 할당된 w값이 곱해지고, 모두 sum되어 Final feature map g_i,c를 얻는다.
- 논문 2page 하단에 논문에 나온 Architecture에 대한 내용들을 다시 정리해 그려 놓았다.
- 3.3 Extra Supervision:
Auxilary loss를 추가했다. Discriminator를 하나 생성해서 학습시킨다. (Adversarial 과정은 하지 않는다.) 이 Discriminator는 주어진 Feature map이 어떤 Scale factor s 에서 나온 feature map인지 추론한다. s의 class는 예를 들어 아래와 같다. 이로써, 각 Scale에 나오는 Feature map이 서로서로 좀 다른 결과가 나오도록 유도된다.- Input: Final ouput g_ic -> Discriminator output: 0
- Input: s=1 feature map -> Discriminator output: 1
- Input: s=0.75 feature map -> Discriminator output: 2
- Input: s=0.5 feature map -> Discriminator output: 3
- 여기서 의문점
- s=0.5 인 작은 이미지는 작은 Feature map이 나올텐데, 서로 Resolution이 다른 Feature map들을 어떻게 동일하게 맞춰주는 건지 코드를 봐야 겠다.
- 아래 Attention map의 결과를 보면 그리 잘 되는 것 같지 않다.



Dual Attention Network
- 기억해야 할 논문의 핵심 Keys
- Transformer와는 달리, Multi head가 아닌, self-attention 이다.
- 처음에 token들에 대해서 nn.linear를 하지 않는 것 처럼 보일 수 있다. 하지만 Figure3에서 보면
Position(spacial) attention module에서 맨 처음에 1x1 conv를 적용하여 nn.linear과 동일한 효과를 얻는다. 반면에Channel attention module에서는 1x1 conv를 적용하지 않는다 channel 사이의 관계를 파악하는데 방해가 될 수 있기 때문이란다. (논문 3150page 맨 처음 부분) - Transformer와는 달리, attention score를 곱한 feature map을 얼마나 적용할지를 결정하는 α(Alpha) β(Beta) 항을 사용한다. 논문 equation(2), (4) 참조.
- 논문에서 말하는 Archtecture의 구성과 흐름은 Figure2에 추가적으로 필기했으니 참고할 것. 특히 Attention부분은 Figure2만 보지말고, Figure3에 더 자세한 그림이 나와 있음
- Channel attention module이 내면적 작용을 하는지에 대한 분석은 논문에 많지 않다. 하지만 논문의 내용을 정리해 적어보자면 이처럼 나타낼 수 있다. “Self attention구조를 통해서 CxC attention score를 얻는다. 다시말해, 한 channel (특정 class specific channel)이 query가 되어 나머지 channel의 key들에게 질문을 한다. 그렇게 해서 종합된 결과가 도출된다. 이 과정을 통해서
inter-dependencies between channel즉, 각 class에 specific한 channel들에 대한 상호의존성을 갖춘 feature map을 탄생시키는 것 이라고 한다. “