【Self】Self-Supervised-Learning & BYOL(Bootstrap Your Own Latent)
- 논문 : Bootstrap Your Own Latent
- 분류 : Self-Training
- 참고 사이트 :
- Self-training overview: https://hoya012.github.io/blog/Self-Supervised-Learning-Overview/
- BYOL: https://hoya012.github.io/blog/byol/
- BYOL 발표자료: https://www.youtube.com/watch?v=BuyWUSPJicM
- 이전 나의 Post: Self-Supervised-Learning Basics
- 목차
Self-training overview
이전 나의 Post 핵심 정리
- Self-Supervision을 통해서 Feature Extrator를 생성하고, 그렇게 얻은 (self를 해서 얻은) FeatureExtractor를 가지고, 적은 데이터 만을 가지고 (supervision 처럼) Classifier(가장 마지막 단의 multi layer perceptron)를 학심시켜 모델을 완성한다.
Self-training overview 블로그 정리 (자세한 내용은 그냥 블로그를 다시 참조할 것)
- Image를 이용한 대표적인 pretext task를 정의하여, Self-training을 진행하는 10가지 논문들
- Exemplar, 2014 NIPS
- Context Prediction, 2015 ICCV
- Jigsaw Puzzle, 2016 ECCV
- Autoencoder-Base Approaches
- Denoising Autoencoder
- Image Colorization
- Context Autoencoder
- Split-Brain Autoencoder 5. Count, 2017 ICCV 6. Multi-task, 2017 ICCV 7. Rotation, 2018 ICLR
- Task & Dataset Generalization of Self-Supervised Learning
- downstream task: feature extractor를 freeze하고 MLP(1층) classifier를 붙여서, Supervised learning으로 fine-tuning을 진행한다.
- (보충설명) Random, Random rescaled는 conv layer가 init된 그 상태에 freeze하고 MLP(1층)만 붙여서 fine-tuning한다.
- 반대로 PASCAL VOC를 이용한 다양한 recognition task에서도 self-sup으로 pretrained한 backbone을 사용하지만 freeze하지 않고, finetuning-all 하여 학습한다.
결론
- Unlabeled datas가 정말 무수하게 많다면, Self-Supervised Learning도 언젠간 좋은 방법,대안이 될 수 있을 것이다.
BOYL 발표 핵심 정리
- SimCLR에서 사용하는 Contrastive Learning
- Positive pair: 한장에 이미지에 다른 종류의 Agumentation을 적용한다. 그렇게 나온 Representation이 서로 같도록 학습시킨다.
- Negative pair: 다른 이미지에 다른 종류의 Agumentation을 적용한다. 그렇게 나온 Representation이 서로 다르도록 학습시킨다.
- Contrastive Learning의 문제점
- 충분한 양의 Negative pair가 필요하다. (이미지가 보기에 달라선 안되고, 확실히 representation까지 다른 이미지 쌍이 필요)
- Data Augmentation의 종류 선택에 따라서 모델의 성능이 심하게 차이난다.
- 학습시키는 Batch Size에 대해서도 민감하게 성능이 변함
- 해결하고나 하는 문제점과 Solution
- Negative Pair 사용 안해! (+ 2번 3번 문제 해결) -> 2개의 다른 Network를 사용한다.
- 핵심 Method
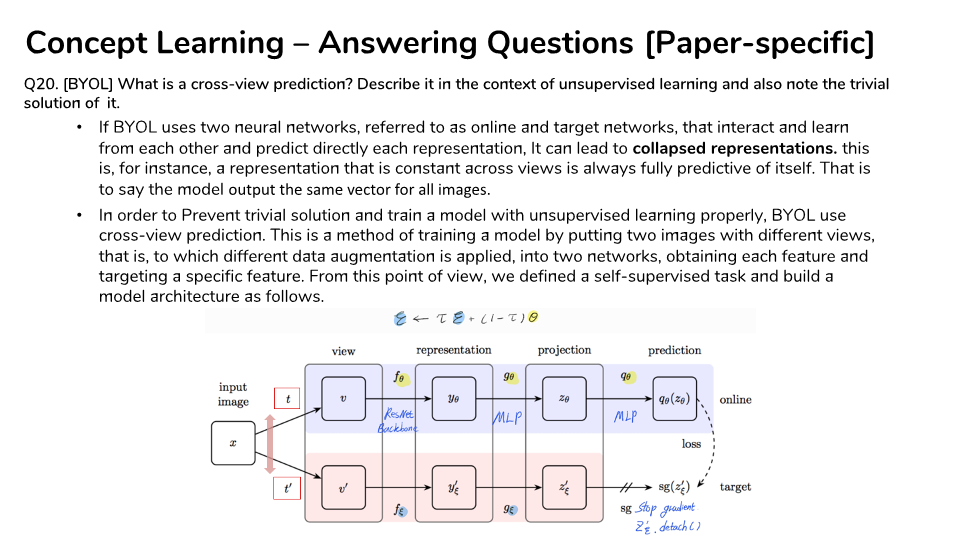
- Online Nework, Target Network 2개를 사용한다. 각 네트워크에는 다른 종류의 Agumentation이 들어간다.
- Online Nework는 Target Network에서 나오는 representation을 추론하도록 학습된다.
- Target Network의 weight 갱신은 Online Nework weight의 Moving average에 의해 갱신되도록 한다.
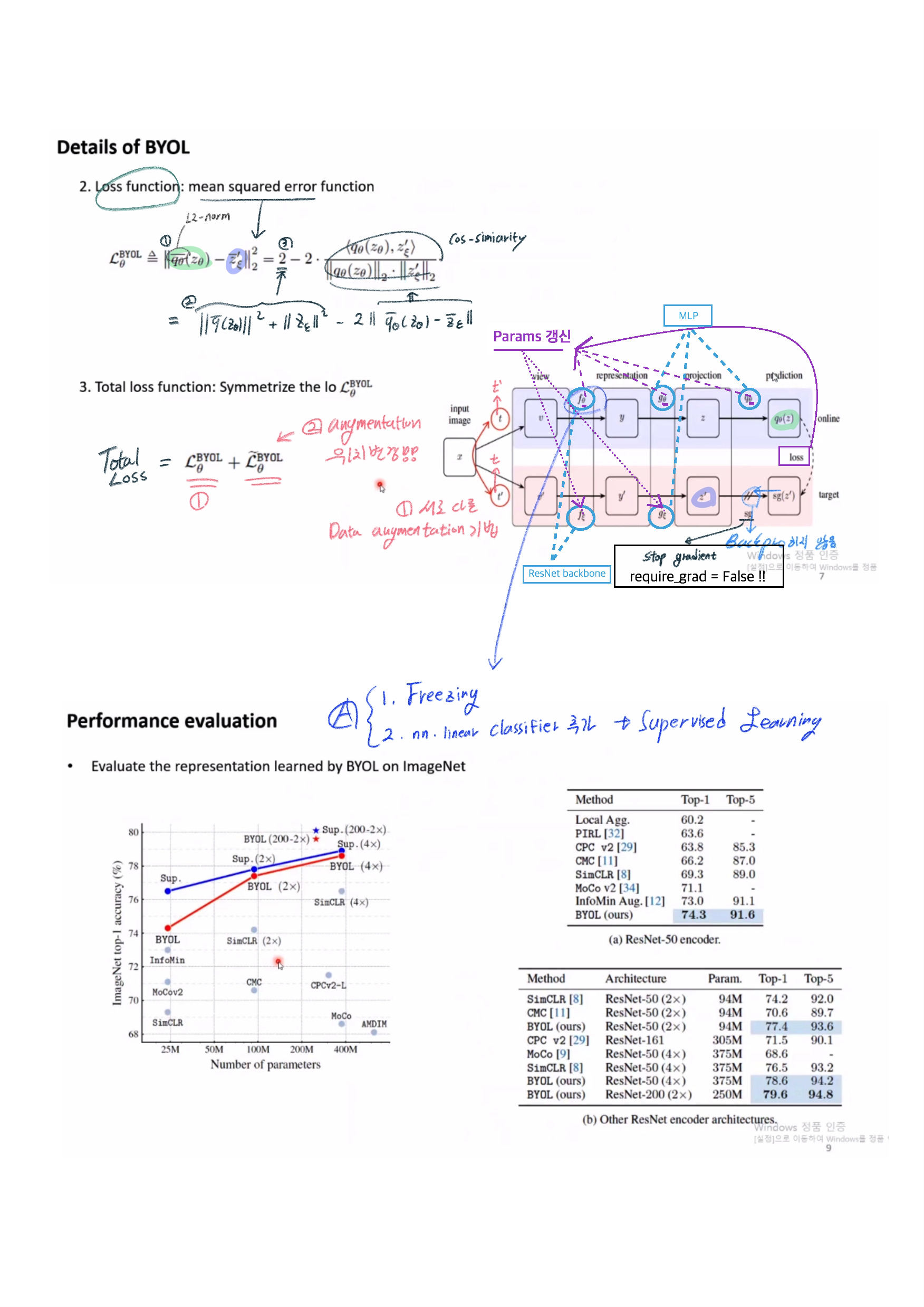
- 각자의 Agumentation을 서로 바꿔서 loss를 다시 추출하는 loss symmetrize(대칭화)도 진행하여, Total loss를 만든다.
- Experiment / Test 방법
- (Self-sup + DownStream) Encoder Freezing! nn.linear classifier 추가해서, Supervised Learning 진행
- (Semi-sup) No Freezing. 데이터셋의 몇프로만 사용해서 Fine-tuning
- 특 장점 (문제점 해결)
- batch size 적게 학습시켜도 성능 하락 폭이 적다.
- Agumentation 종류에 따른, 성능 하락 폭이 적다.
BYOL 과제 자료

BYOL Blog 핵심 정리
- 참조 링크 : https://hoya012.github.io/blog/byol/ 아래의 내용에서, Details는 그냥 블로그를 다시 참조할 것
- MOCO 2019.11
- 다양한 구조를 실험해 봄으로써, 학습이 가장 안정적인 Contrastive Learning을 적용했다.
- momentum encoder를 사용하여, 학습이 불안정한 이슈를 해결했다.
- SimCLR 2020.1
- 기존의 contrastive learning에서 추가적으로
적절한 data augmentation, learnable nonlinear transformation, contrastive loss를 적용했다. - 하지만 무지막지한 batch size학습이 필요
- 기존의 contrastive learning에서 추가적으로
- MOCO V2 2020.3
- 2page 논문. 추가 기법들을 SimCLR에서 차용해서 성능을 올린 모델
- 256 batch size에서도 좋은 성능
- SimCLR v2 2020.6
- (ImageNet dataset에서) Label Fraction 10%만을 사용하는 식의 Semi-Supervised Learning에 초점을 둔다.
- FixMatch (Semi-Supervised Learning에서 좋은 성능을 가졌던 모델) 보다 훨씬 더 좋은 성능이 나왔다.
- BYOL

- 지금까지 contrastive learning은 2개의 모델을 사용하기는 하는데, A모델이 B모델의 결과를 학습하는 BYOL과는 달리, A모델과 B모델에 이미지에서 통과하고 나온 결과가 서로 같거나 다르게 만드는 작업이었었다.
- core motivatoin은 A모델인 scratch(random init) CNN을 통과하고 나온 결과를 target으로 삼아서 B모델을 학습시켜도 B의 성능이 올라간다는 것이다.
- projector와 predictor는 MLP 이다.
- sg는 stop-gradient를 의미하며, back propagation을 시키지 않겠다는 의미
- 비유를 하자면.. 과거의 내(online)가 오늘의 스승(target)이 된다..
- 2개의 network에 서로 다른 augmentation을 적용하여 feature vector(prediction)을 뽑은 뒤, l2 normalize 시킨 후 mean squared error를 최소화시키는 방향으로 Online Network가 학습된다.
- 결과 표에서 Supervised-IN[8]는 ImageNet-Pretrained 모델이다.
BYOL으로 만들어진 Feature extractor가ImageNet-Pretrained 모델보다, 다른 Task(classification, detection, segmenation)에 fine-tuning했을 때 더 좋은 성능이 나왔다. - 결론! 이 분야의 싸움은 Google과 Facebook 의 양강 구도이다. 나대지말자..
BOYL PPT 발표자료