【DA】ADVENT-Entropy Minimization for DA
- 논문 : ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation
- 분류 : Domain Adaptation
- 읽는 배경 : Domain Adaptation 기본, Adversarial code의 좋은 예시
- 느낀점 :
- 참고 사이트 : Github page,
- 목차
ADVENT
1. Conclusion, Abstract, Instruction
- Task: unsupervised domain adaptation for semantic segmentation
- Motivation: Real world와 비교해보면, Data distribution(데이터 분포, 이미지의 통계적 성질)의 많은 차이가 존재한다.
- Simple observation
- (1) Source이미지에 대해서, over-confident, low-entropy predictions
- (2) Target이미지에 대해서, under-confident, high-entropy predictions
- 과거에는 Pseudo label을 사용해서 Self-Training을 하는 방법, Feature output에 대해서 Adversarial Learning을 적용하는 방법을 사용했지만, 우리는 Target도 high-confident를 예측하게 만듬으로써, domain gap을 줄이는 방법을 고안했다.
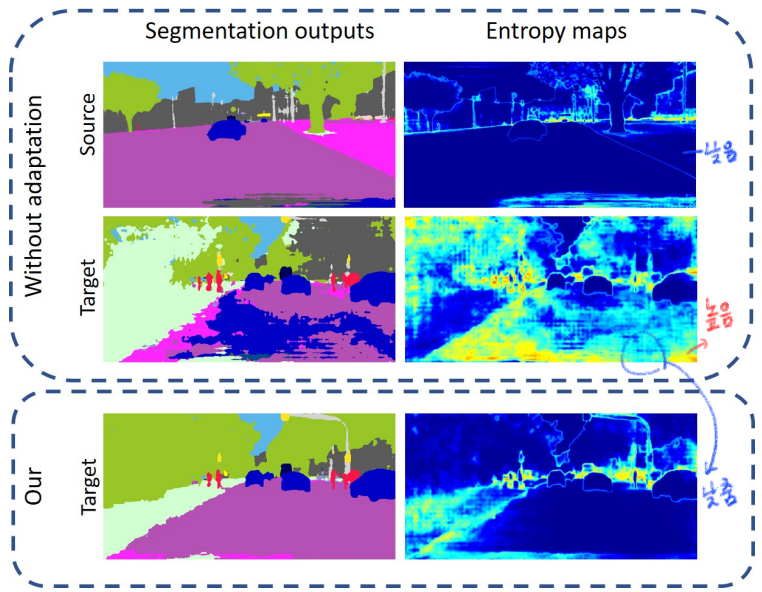
- 핵심 모듈
- (1) an entropy loss: target 예측 결과가 high-confident 혹은 low-confident 가 되도록 강제한다. 에매하게 [0,1] 중간 값인 0.5 confident를 가지면 Loss를 준다.
- (2) entropy-based adversarial training approach : AdaptSeg가 Output을 이용했다면, 여기서는
Output에 대해서 entropy를 계산한 feature map을 이용해서 Adversarial learning을 적용한다. 이로써, Target 예측결과도 Source 예측 결과처럼 적은 Entropy를 갖도록 유도한다. - 추가적인 성능향상을 위해서, 아래의 기법을 적용했다.
- (i) training on specific entropy ranges (Entropy_x_target ∈ [0, 1] (H×W)
- (ii) incorporating class-ratio priors. (그저 자주 나오는 class가 1 confident가 나와 버리는 문제를 막는다)
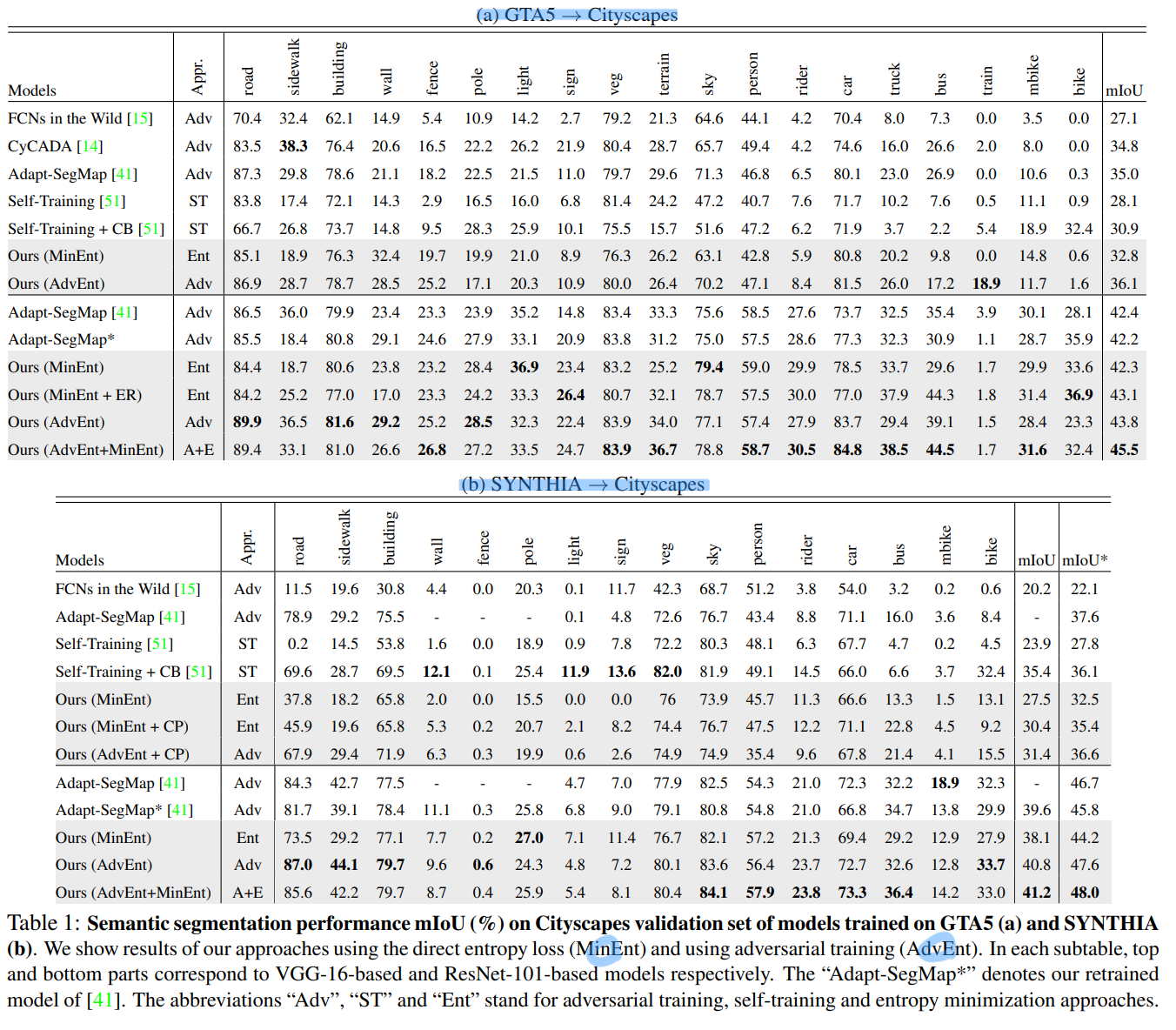
- 성능
- SOTA / Two main synthetic-2-real benchmarks / GTA5 → Cityscapes / SYNTHIA → Cityscapes.
3. Approaches
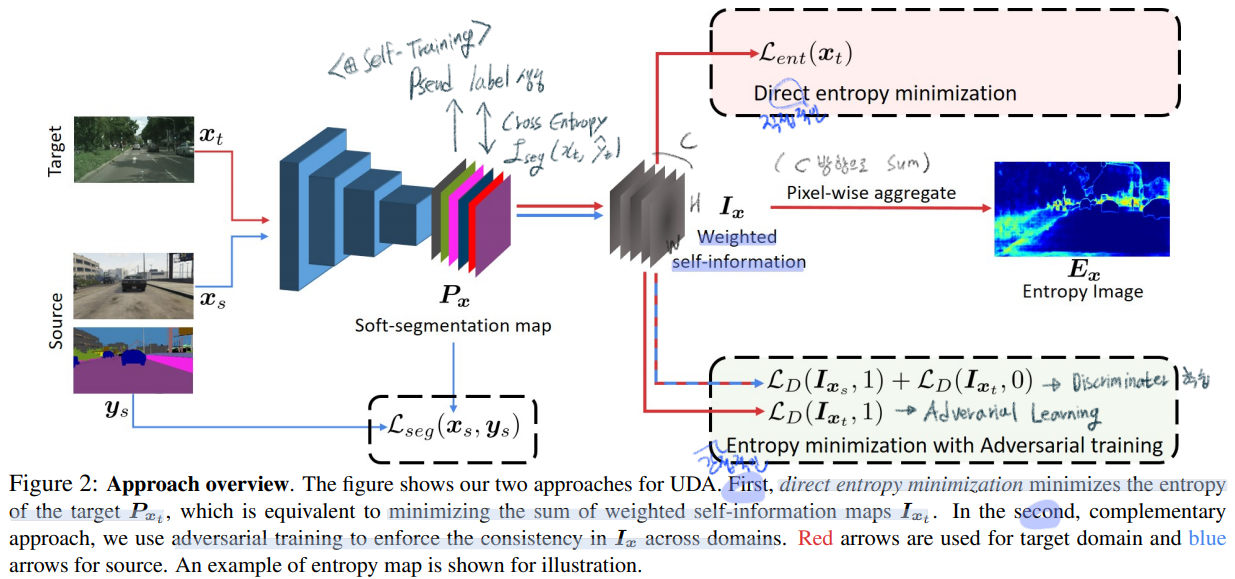
3.0 Prerequisite

- 위와 같은 Segmentation Network를 Source data로 학습시킨다,
3.1.1 Direct entropy minimization
- 위 전체 Architecture에서 상단부분에 있는 모듈이다.
- 간접적으로는 Domain adaptation이 되도록 만들지만, 엔트로피 관점의 직접적인 최소화 과정이 수행된다.
- Target Image에 대해서 high confidence를 추축해내는 F(Network)를 만들어내는 것이 목적이다.
- prediction output에 대해서, the Shannon Entropy [36]라는 Entropy를 계산하는 공식을 적용해서 Entropy map을 만들어 낸다.
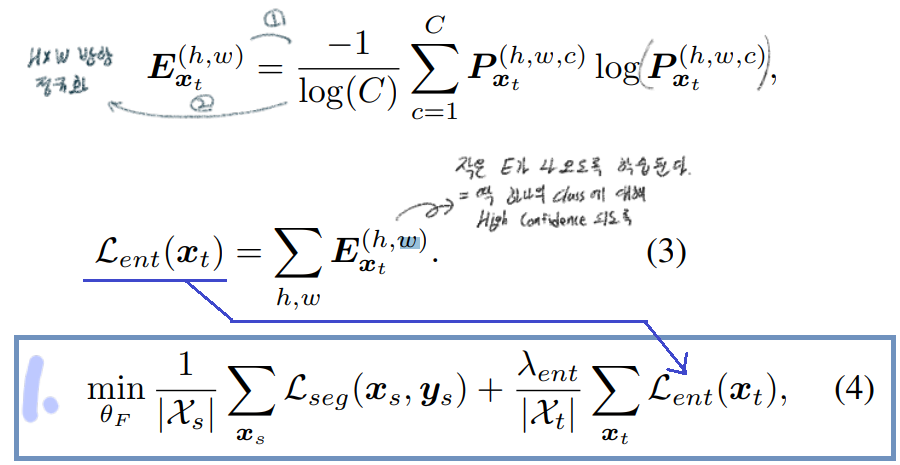
- 계산되는 E를 구체적으로 예시를 통해서 알아보자. 아래와 같이 아에 높은 confident, 아에 낮은 confident이여야 낮은 Loss를 얻는다.
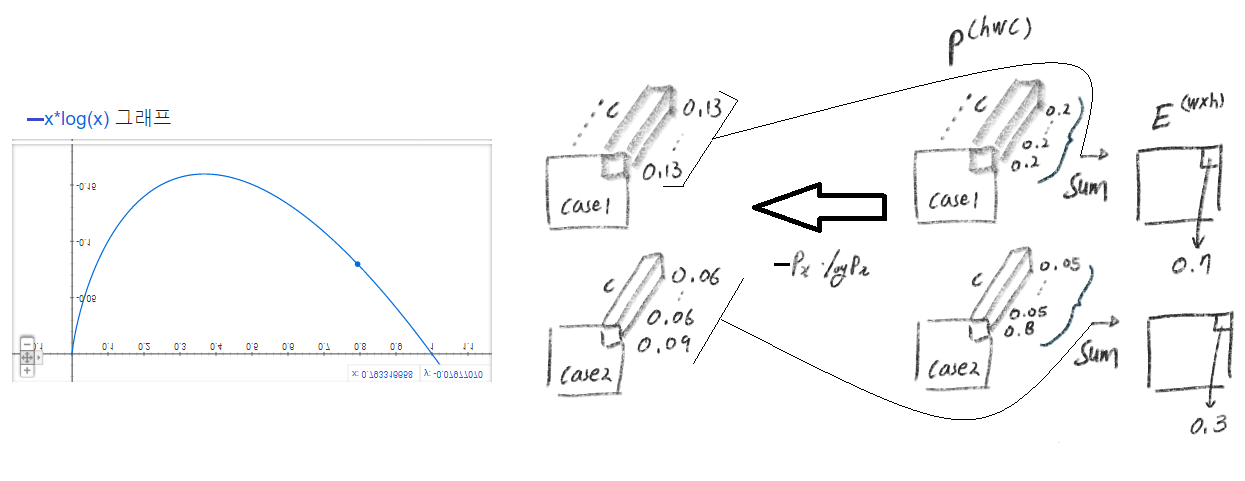
- 위의 그래프에서 x값과 y값의 범위는 각각, [0,1], [0,0.16] 이다. 위 Entropy를 계산해준 후 y값을 [0,1] 사이의 값으로 정규화해준다. 즉 [0, 0.16] -> [0,1]
- entropy loss는 soft-assignment version of the pseudo-label이다. 따라서 hard Image dataset에 대해서 좋은 성능을 보여준다. 그리고 threshold를 고르거나 One-hot encoding을 하는 a complex scheduling procedure가 필요없다.
- 아래의 과정을 통해서 성능을 더욱 끌어올린다.
3.1.2 Self-training = Pseudo Label

3.2 Minimizing entropy with adversarial learning
- 3.1.1을 보면 c방향으로 sum을 해서 E (W,H)를 구하는 것을 알 수 있다. 이 sum 때문에 자칫하면, 지역에 담긴 구조적인 의존적 의미(? the structural dependencies between local semantics)를 무시할 수 있다. (?)
- AdaptSeg가 Output을 이용했다면, 여기서는 Output의 각각의 pixel 스스로의 entropy를 계산한 map(
weighted self-information space)을 이용해서 Adversarial learning을 적용한다. weighted self-information space=I_x: Shape (C x H x W).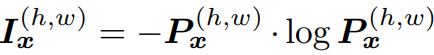 (단순하게 생각해서, 그냥 각 픽셀마다 이 연산이 수행됐다고 생각하면 되겠다.) 이것을 사용하는 장점은 아래와 같다.
(단순하게 생각해서, 그냥 각 픽셀마다 이 연산이 수행됐다고 생각하면 되겠다.) 이것을 사용하는 장점은 아래와 같다.- Source에서 출력되는 I_x 와 Target에서 출력되는 I_x가 유사해지도록 만든다.
- 간접적으로 Entropy를 낮추게 만드는 방법이라고 할 수 있다.
- Discriminator, Adversarial Loss, Total Loss이다.

3.3. Incorporating class-ratio priors
- 위의 방법들 처럼 단순하게 Entropy minimization만 하다보면 한가지 문제점이 생긴다.
- 그 문제점은 발생 빈도가 높은 class, 쉬운 class를 우선적으로 1로 만들어 버리는 문제이다.
- ProDA의 degeneration issue라고 생각하면 된다. 따라서 우리는 regularization 을 하는 과정이 필요하다. (ProDA의 방법이 더 좋을 거다. 아래의 방법은 구식인 것 같다)
- 아래의 수식을 통해서, Class 발생 빈도 Histogram이 Source와 유사하도록 만든다. 여기서
Mu는 얼마나 유사하게 만들것 인가? 를 나타내는 강도 값이다. 0=약하게, 1=강하게.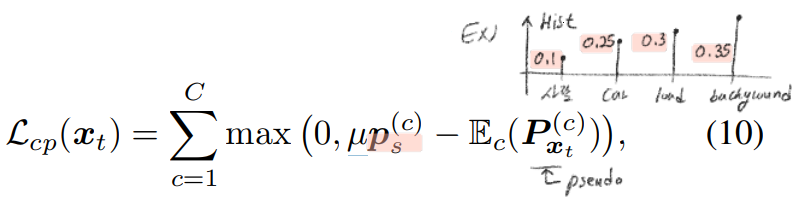
the class-prior vector p_s: 각 클래스당 픽셀의 갯수의 L_1 histogram 이다.
4. Experiments
- Dataset
- Source: GTA5 or SYNTHIA
- Traget: Cityscape
- DA: 2, 975 unlabeled Cityscapes images are used for trainin
- DA test: Evaluation is done on the 500 validation images
- Network architecture
- Deeplab-V
- VGG-16 and ResNet101
- Discriminator in DCGAN [28] : 4conv, leaky-ReLU laye
- Implementation detail
- single NVIDIA 1080TI GPU with 11 GB memory
- discriminator: Adam optimizer [19] with learning rate 10−4 to train the discriminator
- 나머지 모델들: SGD with learning rate 2.5 × 10-4 , momentum 0.9 and weight decay 10-4
- Weighting factors
- λ_ent = 0.001
- λ_adv = 0.001
5. Results