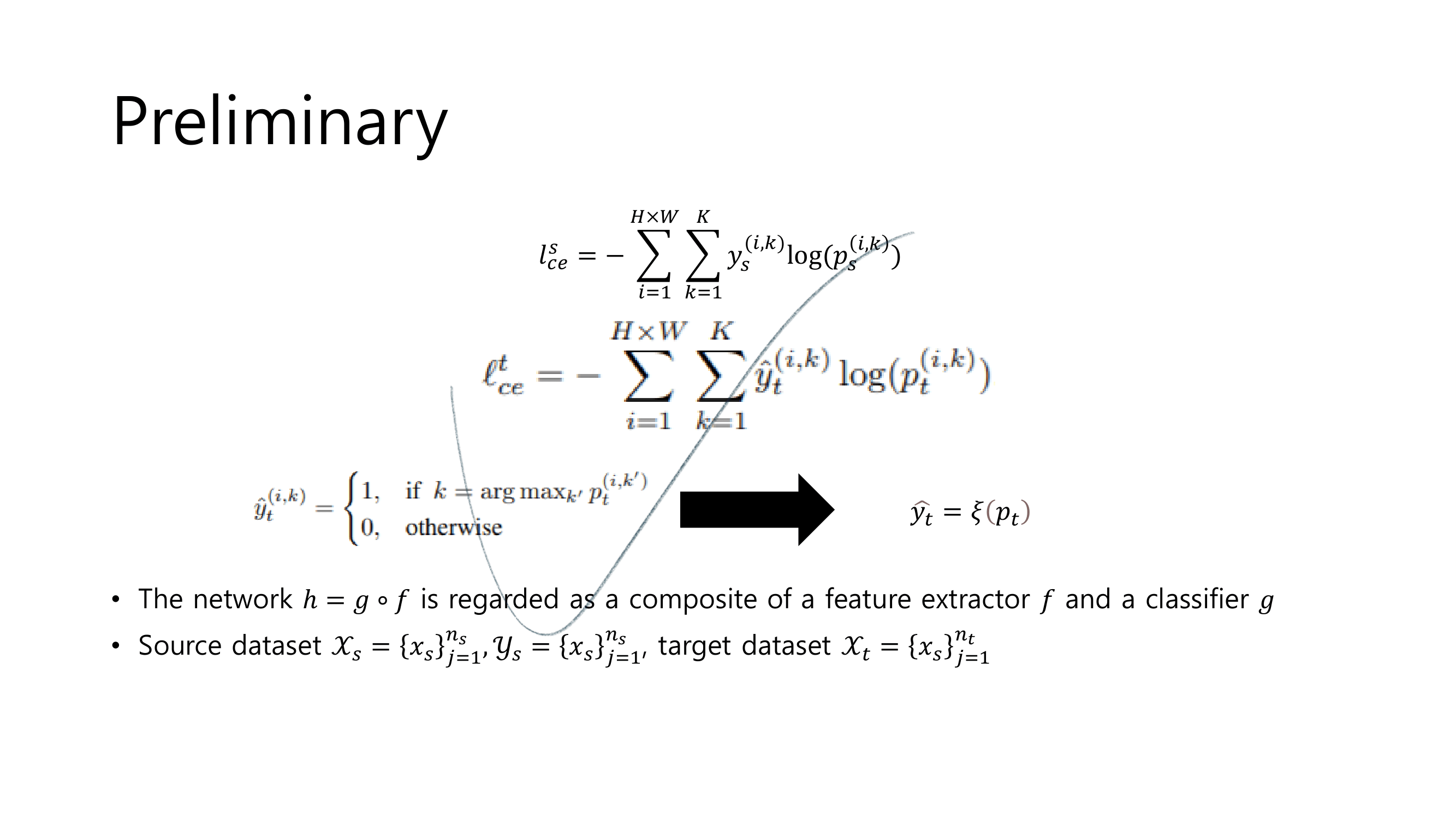【DA】ProDA -Prototypical Pseudo Label Denoising by Microsoft
- 논문 : Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation
- 분류 : Domain Adaptation
- 읽는 배경 : 선배 추천, Microsoft에서 연구된 현재까지 UDA 끝판왕
- 느낀점 :
- 앞으로 이렇게 알지도 못하면서 Abstract와 Conclusion 미리 정리하지 말자. Abstract와 Conclusion 제대로 이해하지도 못했는데, 일단 대충 때려 맞춰서 이해한 것을 정리한다고 시간을 쏟는거 자체가 시간 아깝다. Method 읽고 다시 처음부터 다시 Abstract와 Conclusion 읽고 정리하면 더 깔끔하고, 보기 좋고, 완벽한 정리를 할 수 있고, 시간도 절약할 수 있다.
- 뭔지 알지도 못하면서 그냥 배경지식으로 나혼자 짜맞춰서 Abstract, Conclusion, Instruction을 정리하는 것은 무식한 것 같다.
- 이 논문은 Few shot learning을 하던 사람이 거기서 사용하는 기법을 가져와서 DA에 잘 적용한 논문인 것 같다.
- 읽어야 하는 논문
- CVPR2019, FAIR, Momentum Contrast for Unsupervised Visual Representation Learning (Momentom Encoder)
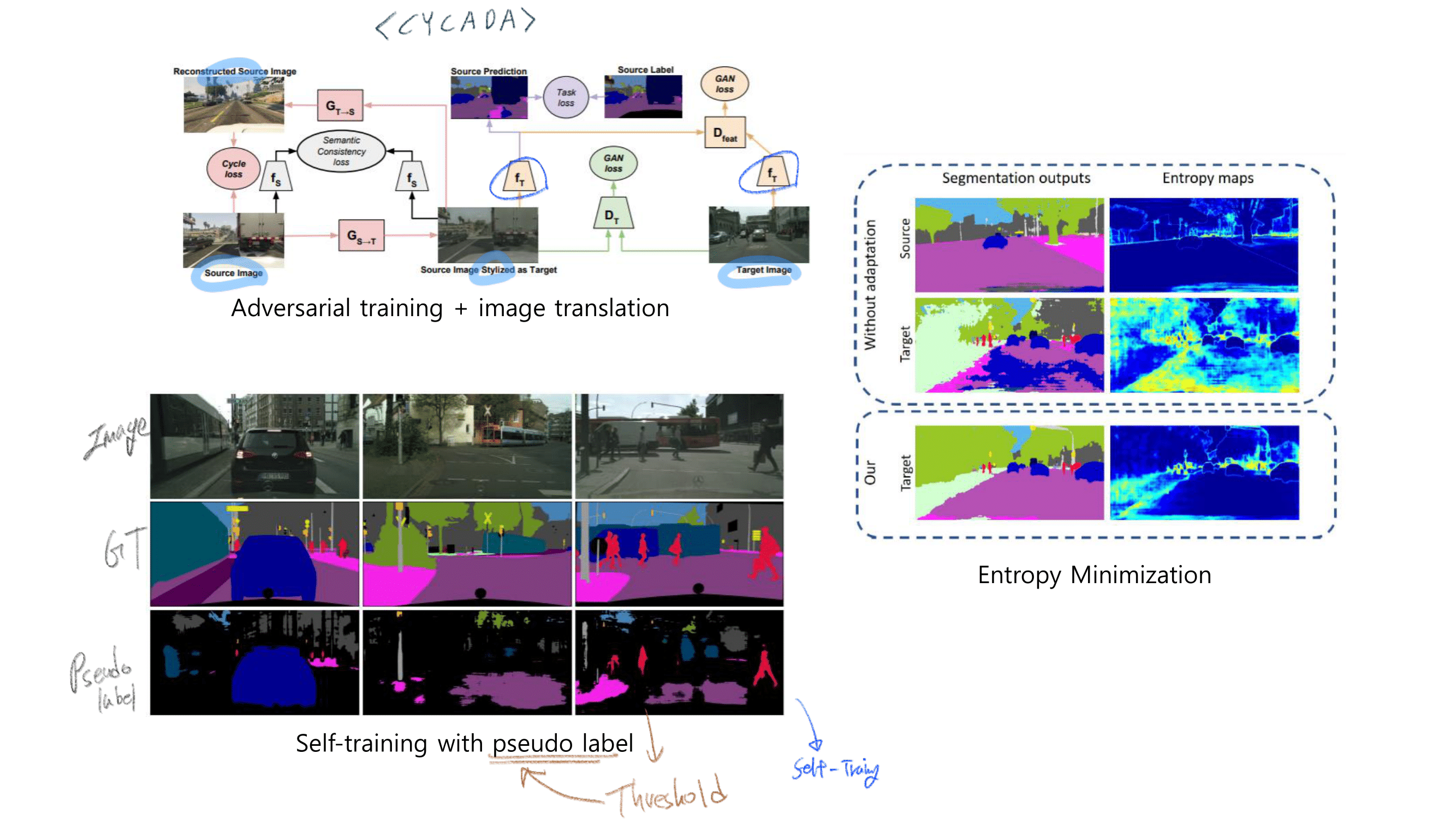
- CVPR2018, Learning to adapt structured output space for semantic segmentation
- Arxiv, 2019, Confidence Regularized Self-Training (output-feature map regularization)
- SimCLRv2 [11]
- 목차
- 논문리뷰
- 논문 세미나 이후 인사이트 추가
ProDA
1. Conclusion, Abstract
기존 방법들의 문제점
- source로 학습시킨 모델로 target image를 inference한 결과인,
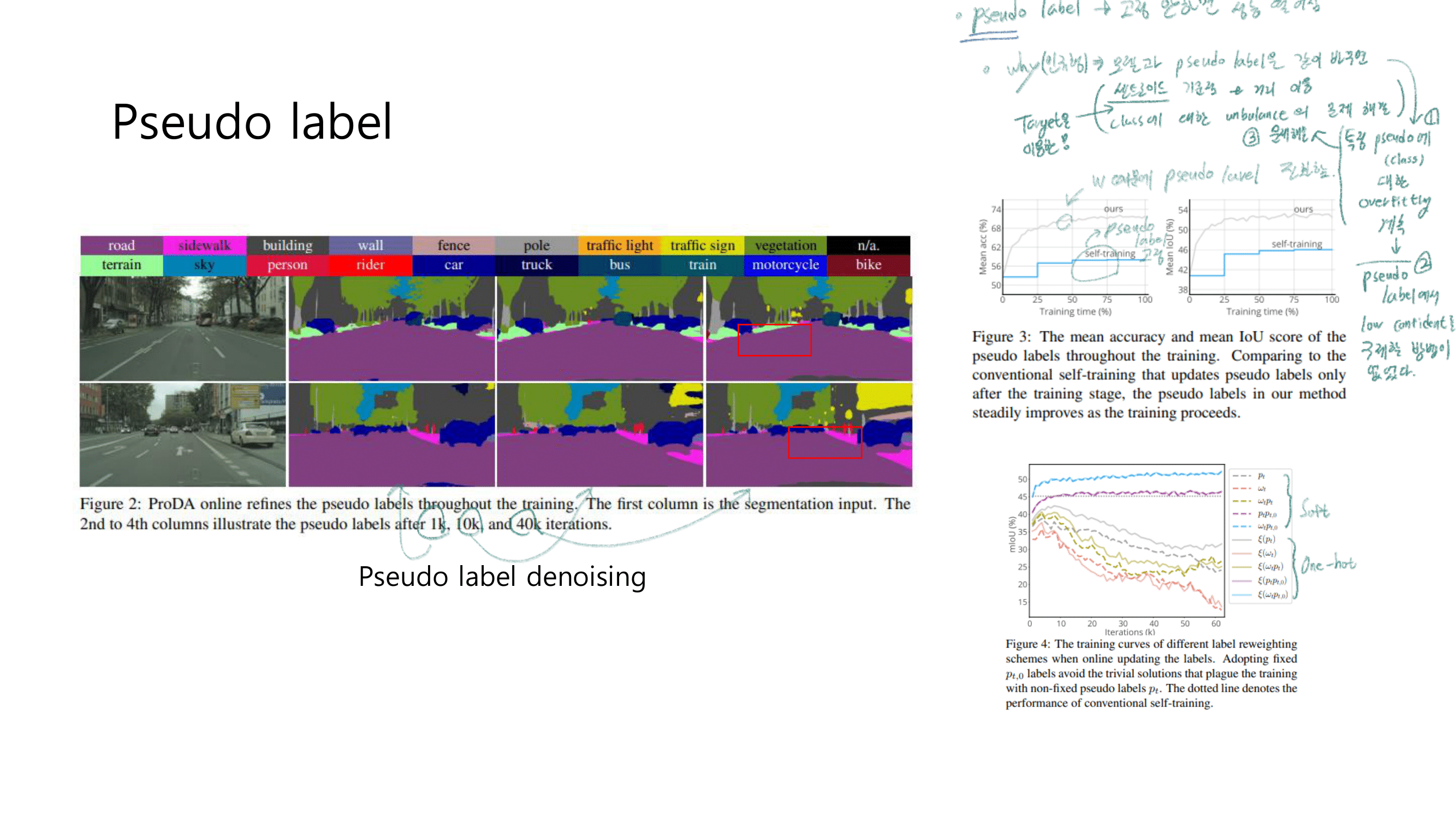
Pseudo labels은 너무 Noisy하고 신뢰할 수 없다. - the target features(feature map이 embedinge된 공간의 모습이) are dispersed (너무 흩어져있다. 해산되어 있다.)
- source로 학습시킨 모델로 target image를 inference한 결과인,
- 논문 핵심 우선 정리
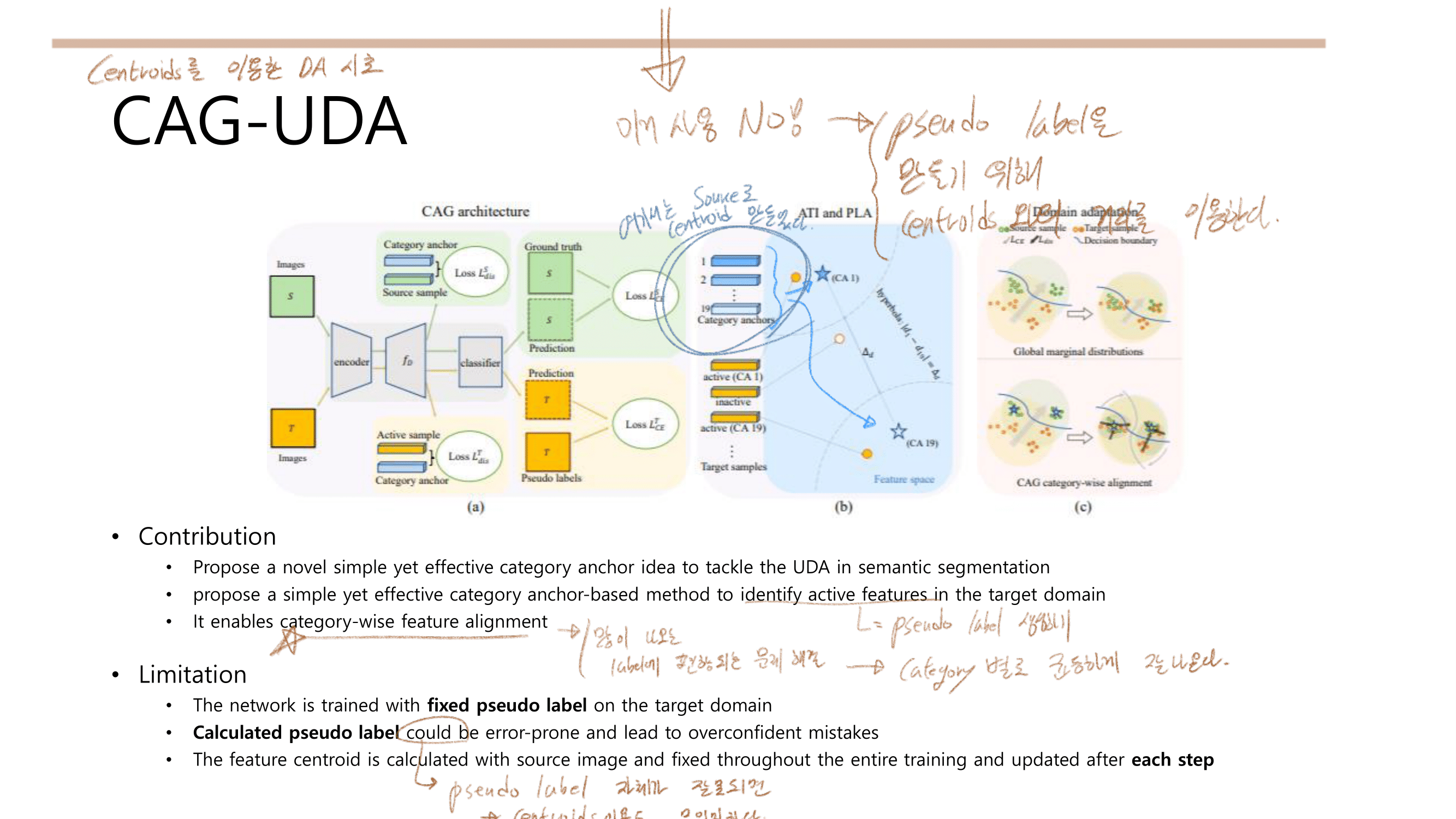
- Prototypes(centroids) 사용해서 Pseudo label을 Online으로 denoise (rectify) 하기
- 여기서
Representative prototypes이란?The feature centroids of classes이랑 동의어이다. the feature distance from centroids를 사용해서,the likelihood of pseudo labels를 계산하고online correction(donoise)를 수행한다.
- 여기서
- target’s structure가 compact! feature space 모양이 되도록 만들었다. data augmentation 기법을 적절히 활용하였다.
- 위의 과정으로 +17.1%의 성능향상을 주었다. 그후에 Knowledge distillation을 적용함으로써 최종적으로 20.9% 성능을 획득했다.
- Prototypes(centroids) 사용해서 Pseudo label을 Online으로 denoise (rectify) 하기
- 추가 알아야 할 것
- Kullback–Leibler (KL) divergence : 두 확률분포의 엔트로피 차이를 계산하는 식. CrossEntropy랑 비슷한 거이다. 단순이 두 확률분포의 거리 차이랑은 개념이 조금 다르다. (기계학습 책에 잘 적혀 있었고, 공부했었으니 필요하면 참고하자.)
2. Instruction, Relative work
- 읽어야 하는데… 선배들이 Instruction이 가장 중요하다고 했는데… Method에도 조금조금씩 분석과 Motivation에 대한 내용이 이미 나왔어서 그런지 읽기가 싫다.
- 나중에 필요하면 읽자… ㅎㅎ
- 이 논문의 Relative work는 따로 없고,
5.2. Comparisons with state-of-the-art methods부분에 짧게 존재한다.
3. Preliminary (Requirement)

- 위에 아래의 내용들을 순서대로 정리. 나중에 참고 할 것.
- denoting(변수정의)
- (un) self-supervised Domain adaptation에서 Loss함수
- Pseudo label 생성하는 수식 및 추가 Details
4. Method
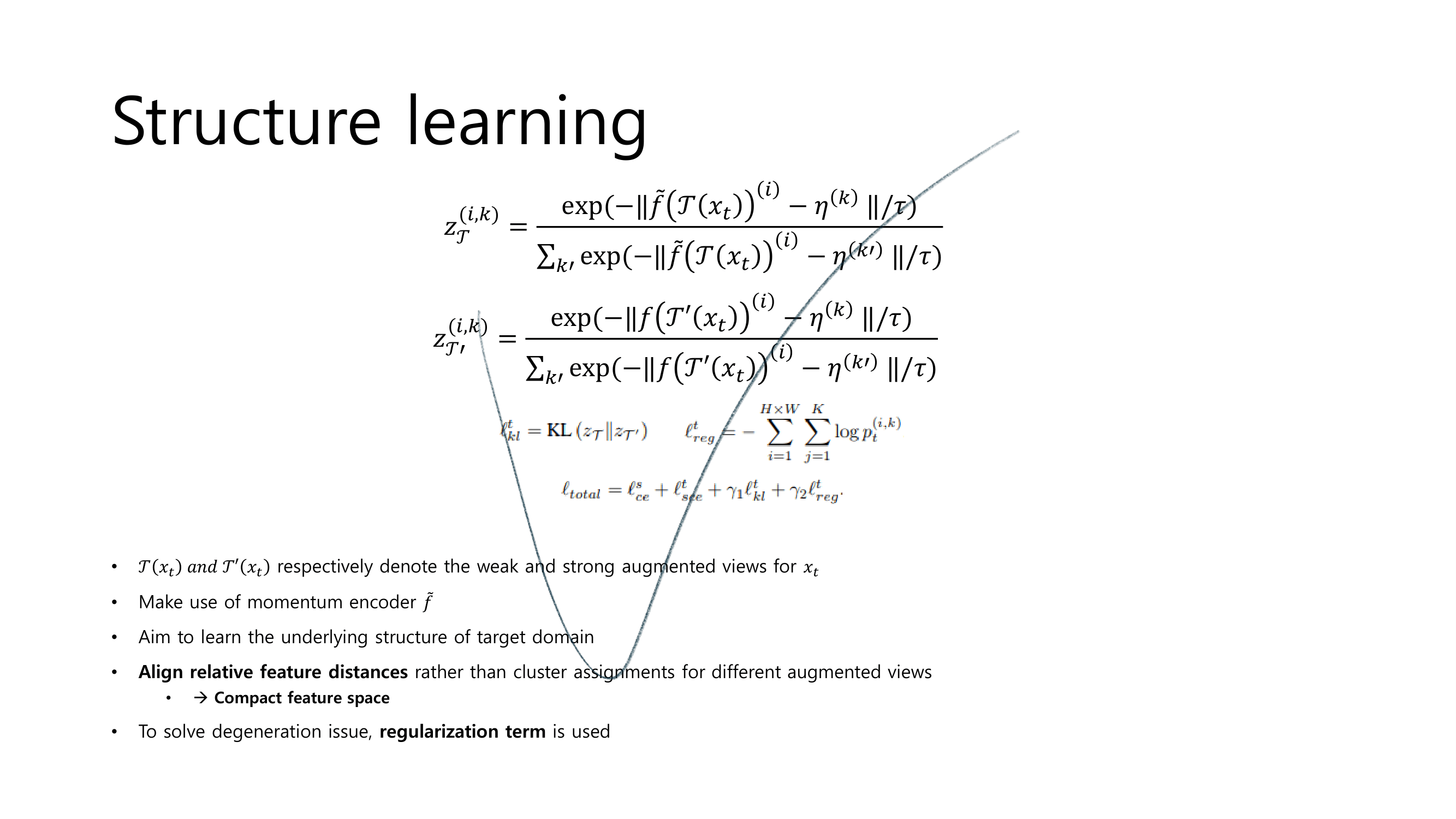
4.1. Prototypical pseudo label denoising
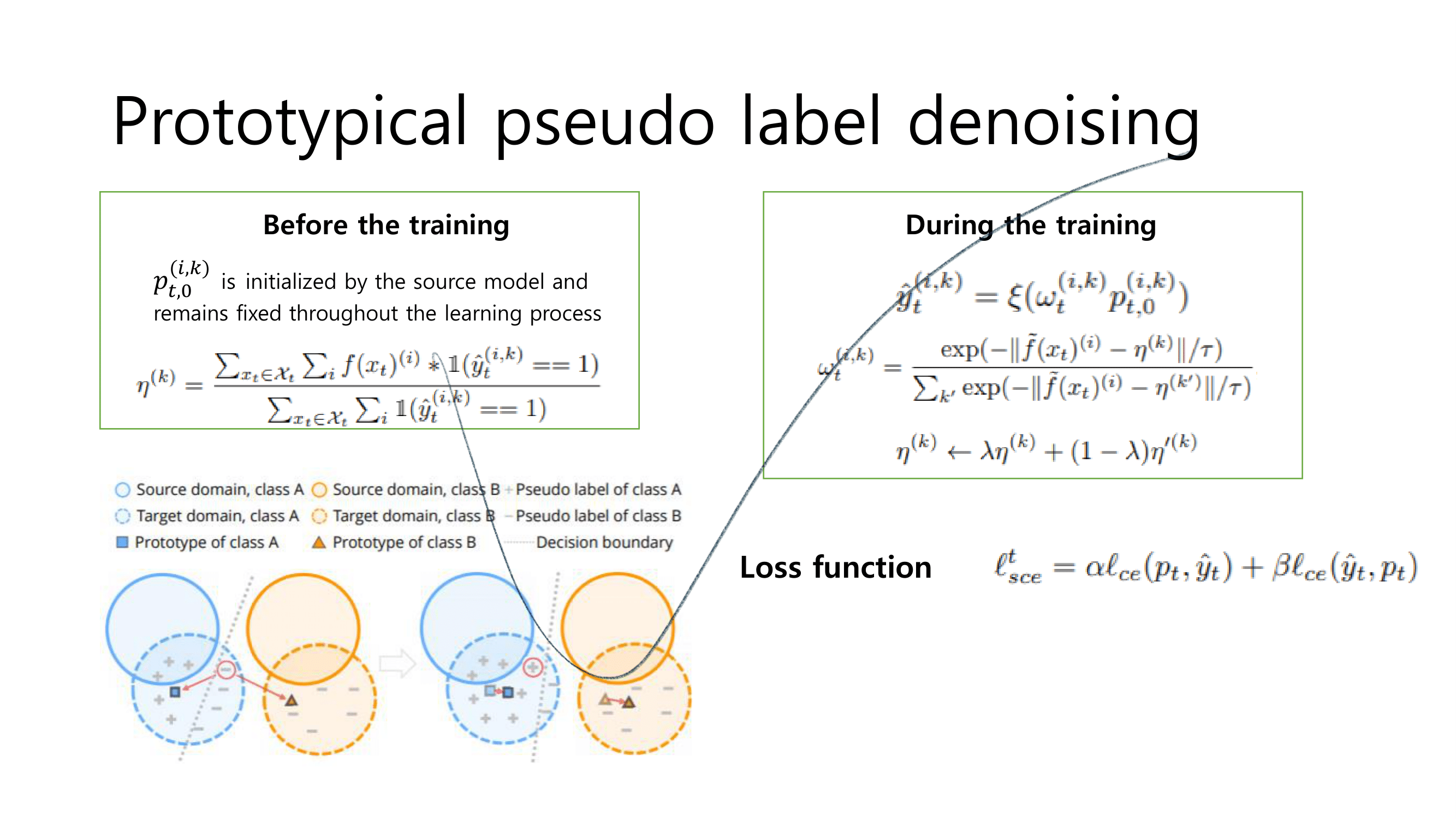
- Centroids를 사용해서 Pseudo label 보정하기 (아래 과정으로 설명 되어 있다.)
- formula to rectify nosiy pseudo label
- weight calculate
- Prototype(centroids) computation
- Pseudo label training loss
- Why are prototypes useful? 분석
formula to rectify nosiy pseudo label
문제점 : Source로 학습된 모델은, Target Image에 대한 inference결과로 Noisy labels을 생성하는데 Overfitting되었다. 그래서 Threshold를 넘는 Pseudo label을 생성하기까지 너무 오랜시간이 걸린다.
not good 해결책 : Pseudo label과 Network weight를 동시에 update하는 것은 그리 좋은 방법이 아니다. 학습이 불안정하게 이뤄지므로.
good 해결책2 :
online update the pseudo labels(the pseudo labels을 그 이미지 배치 학습 그 순간순간 마다, noisy를 제거해서 다시 생성해 주는 것)해결책 2 수행 방법 : fix the soft pseudo labels & progressively weight(가중치를 주다) them by class-wise probabilities using Centroids(Prototypes) (주의!) 이때, 아래의 수식에서 P_t,o는 처음 source model에 의해서 정해진 값이고 학습과정 내내 고정되어 있다고 한다.(? 코드 확인하기)
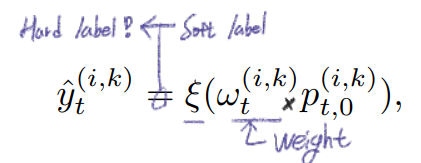
weight calculate
- 아래 공식의 ω_t는 직관적으로 p_t의 비슷할테지만, 실험적으로 trust confidence(label)과 비슷한 것을 확인할 수 있다.
- 이 weight공식은 few-shot learning에서 많이 사용되는 기술이다. few-shot learning에서는 classifying new samples을 목적으로 사용하지만 우리는 당연히 recity pseudo labels을 하기 위에서 사용한다.
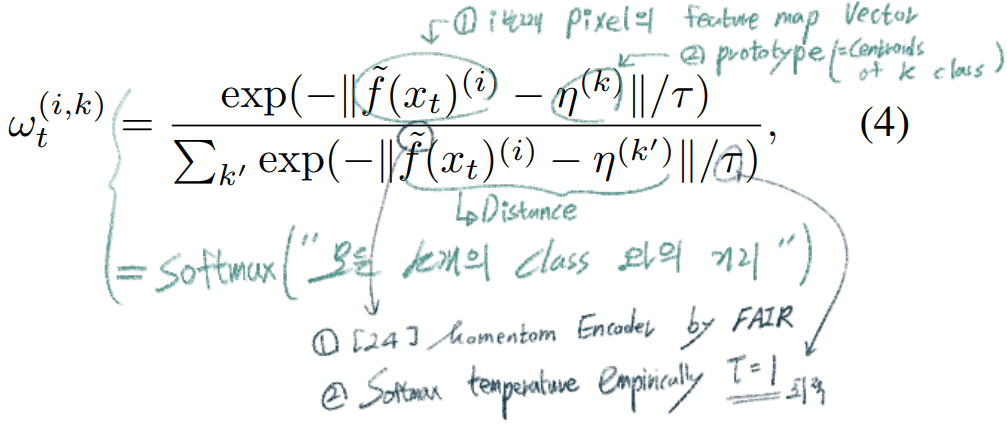
Momentom Encoder가 무슨 느낌이냐면,data augmentation처럼 “모델을 힘들게 하고, 다른 결과를 생성하게 만드는 그런 혼동의 존재”의 반대이다. 비슷한 이미지가 들어오면 비슷한 결과를 추론하게 만들어 준다.
Prototype(centroids) computation
- 위의 weight공식에서 η가 각 class마다 가지고 있는 Prototype(centroids)이다. 이 것을 계산하는 공식은 아래와 같다.
- 이 값은 on-the-fly으로 계산되고 업데이트 된다. 이 값을 계산하는 것은
computational-intensive(계산 집약된 무거운) 문제를 가질 수 있기 때문에, 아래의 수식과 같이moving average of the cluster centroids in mini-batches을 사용해서 centroids를 업데이트 한다.

Pseudo label training loss
symmetric cross-entropy (SCE)을 사용한다. in order to further enhance the noise-tolerance to stabilize the early training phase(?)
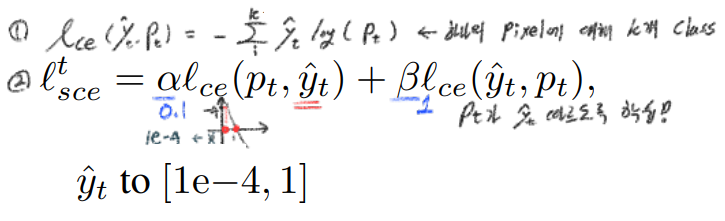
Why are prototypes useful? 분석
- 아래의 이미지에서 볼 수 있듯이, centroids는 outliers(dicision boundary)에 덜 sensitive하다. 그래서 아래 이미지의 필기 1~4 번 과정이 이뤄지면서 rectify pseudo label이 가능하다.
- centroids를 사용함으로써 class inbalance문제에도 덜 sensitivie하다. 만약 사람 class의 occurrence frequency(발생 빈도 = class를 가지는 이미지 수)가 매우 높다면, 비슷한 위치에 존재하는 feature이지만 다른 class인 원숭이의 학습이미지가 별로 없다면, 모델은 p(추측결과)로 사람 class를 선택할 가능성이 높다. 하지만 centroids는 그런 occurrence frequency와 관련이 없다.
- 실험적으로 denoise한 결과가 실제 target label에 더 가까운 값을 가지는 것을 확인했다.
- 따라서 centroids를 사용함으로써 gradually rectify the incorrect pseudo labels를 수행할 수 있다.
4.2. Structure learning by enforcing consistency
- 문제점 1
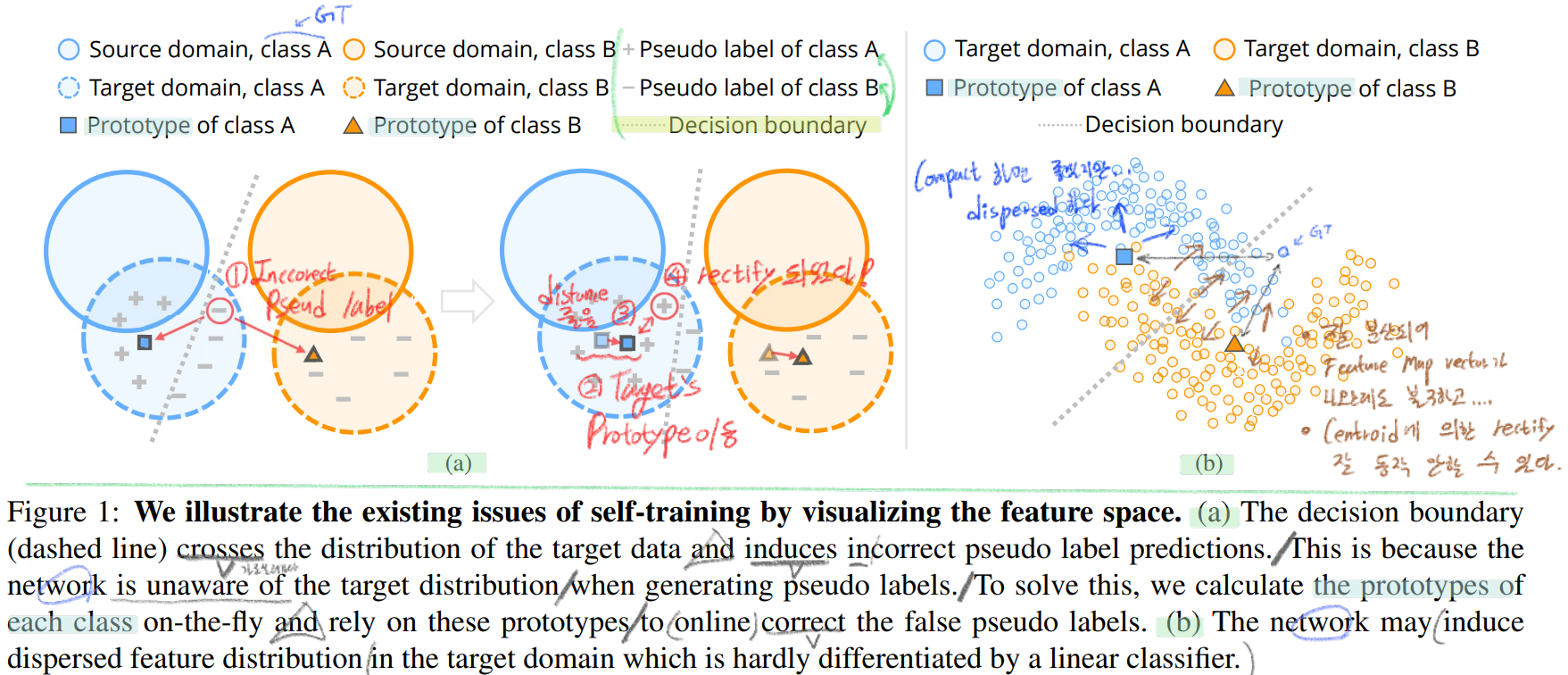
- 위 이미지의 Figure1 (a)과 같은 도식이 나오려면 조건이, feature extractor의 최종 결과가 class마다 compact한 feature들이 나온다는 조건에서 저렇게 그려질 수 있다.
- [42]에서 찾아진 문제점 : 만약 Figure1 (b) 처럼 각 class에 대해서 feature가 compact한 결과가 나오지 않는다면 centroids를 사용하는게 의미가 없고 차라리 성능이 더 떨어질 수도 있다. (If the darget distribution is dispersed, the prototypes fail to rectify the pseudo label)
- 이러한 문제가 발생하는 가장 큰 이유는, 매우 적은 수의 target pseudo label들이 target domain의 모든 distribution을 커버할 수 없기 때문이다. (즉 feature embeding 공간상에서 feature vector가 너무 드문드문 존재하기 때문이다. 이러니 dispersed한 형상일 수 밖에 없다.)
- 해결책 1
- target domain의 underlying structure (근본적인 본질적인 구조 정보)를 사용한다! 더 compact한 feature embeding 모습을 가지기 위해서.
- 그래서 최근
unsupervised learning에서 성공적으로 사용되고 있는,simultaneously clustering and representation learning기법을 사용한다. 그 기법은 data augmentation을 적절히 사용한다. - we use the prototypical assignment under weak augmentation to guide the learning for the strong augmented view

- 위 필기(우상단)의 soft, hard는 label을 의미하는 것이 아니라, soft augmentation, hard augmentation을 의미한다.
- 이 과정을 통해서 produce consistent assignments(consistent prototypical labeling for the adjacent feature points) 할 수 있게 한다. 즉 f가 좀 더 compact한 feature를 생성하도록 만드는 것이다.
- 새로운 문제점 2
- 위 과정의 장점이 있지만, 단점으로
degeneration issue가 발생할 수있다. (one cluster becomes empty = P_k에서 하나만 1이 되고 나머지는 0이라면 모든 feature가 가장 compact하게 뭉치는 것이므로, 의도치 않게 f가 이런 p를 생성하는 모델이 되어진다.)
- 위 과정의 장점이 있지만, 단점으로
- 2 해결책
- use a regularization term from [76]

- use a regularization term from [76]
- Total loss
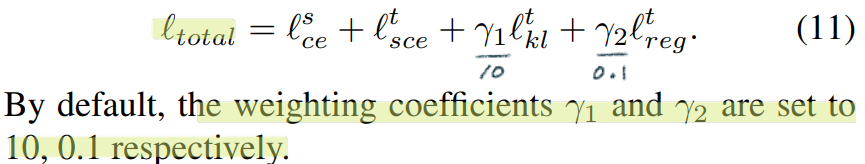
4.3. Distillation to self-supervised model
- 진짜 Target model을 supervised로 학습시킨 모델과 비슷한 모델이 되도록, 영혼을 다해 끌어당긴다. Knowledge distillation을 사용해서.
- Knowledge distillation을 사용하기는 하지만, student model은 teacher와 same architecture를 가지지만 self-supervised manner(SimCLRv2 [11])로 pretrained된 모델을 사용한다.
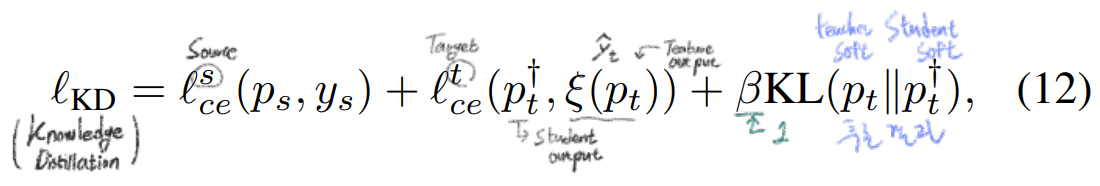
- 첫 Loss_ce값은 model의 source data에 대한 성능 저하를 막기위해 사용된다.
- 실제 실험에서는 Knowledge distillation을 한번만 하는게 아니고 여러번 반복한다.
- Knowledge distillation을 통해서 DA결과가 achieve even higher performance하도록 만든다.
5. Experiments
- Training
- DeepLabv2 [8] with ResNet-101 [25]
- a warm-up으로
Learning to adapt structured output space논문의 기법을 사용한다. - the initial learning rate as 1e-4 which is decayed by 0.9 every training epoch
- training lasts 80 epochs
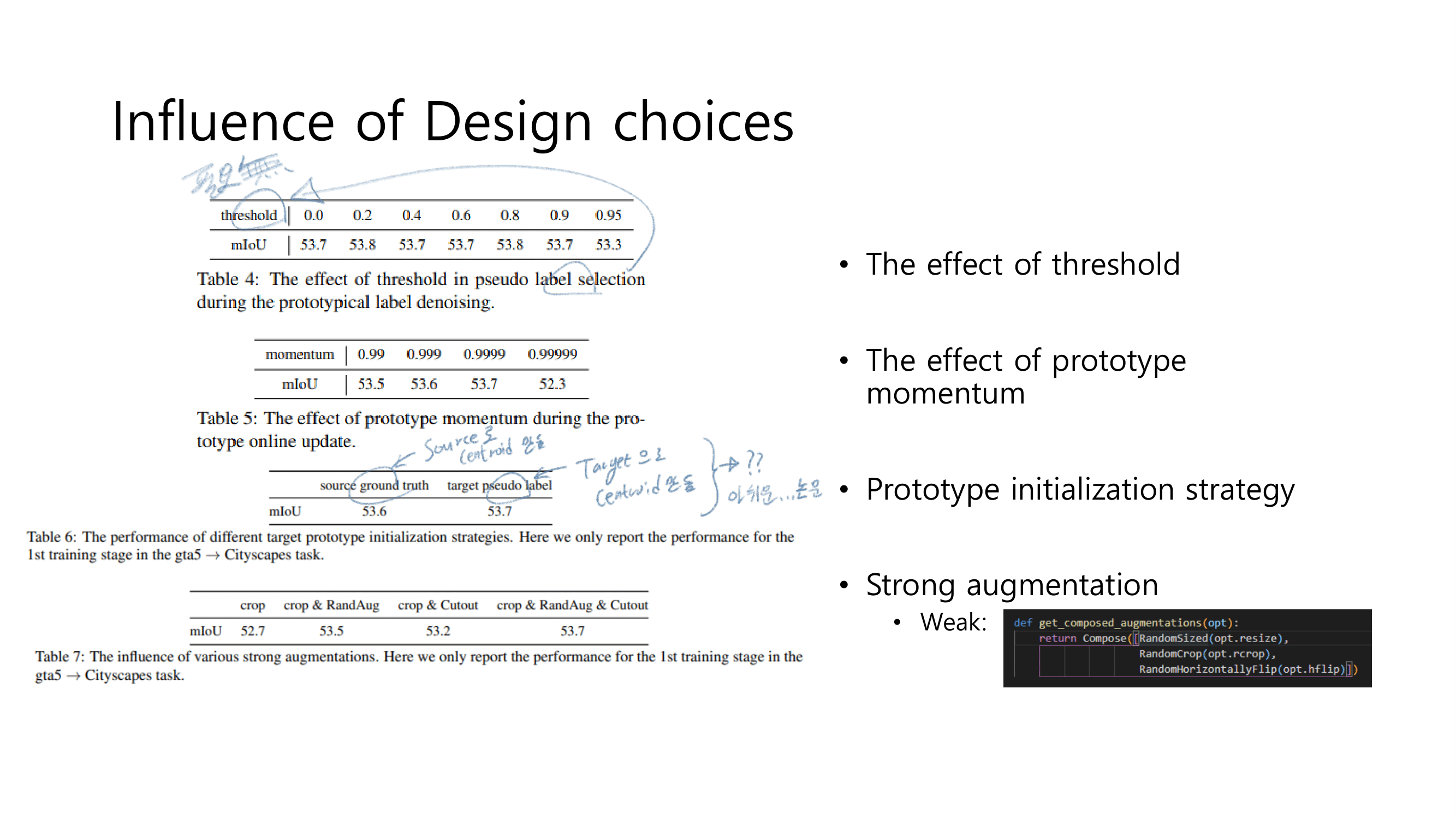
- data augmentation : random crop, RandAugment [15] and Cutout [16]
- SimCLRv2 model with the ResNet-101 backbone as well
- Extra batch normalization (BN) (?)
- distillation stage, we use hard pseudo labels with the selection threshold 0.95
- 4 Tesla V100 GPUs
- Dataset
- game scenes : GTA5 [45] and SYNTHIA [46] datasets
- real scene, the Cityscapes [14] dataset
- The Cityscapes는 500 images for validation을 가진다. GT를 제공하지 않는 validation set이기 때문에, we conduct evaluations on its validation set.
- Ablation Study
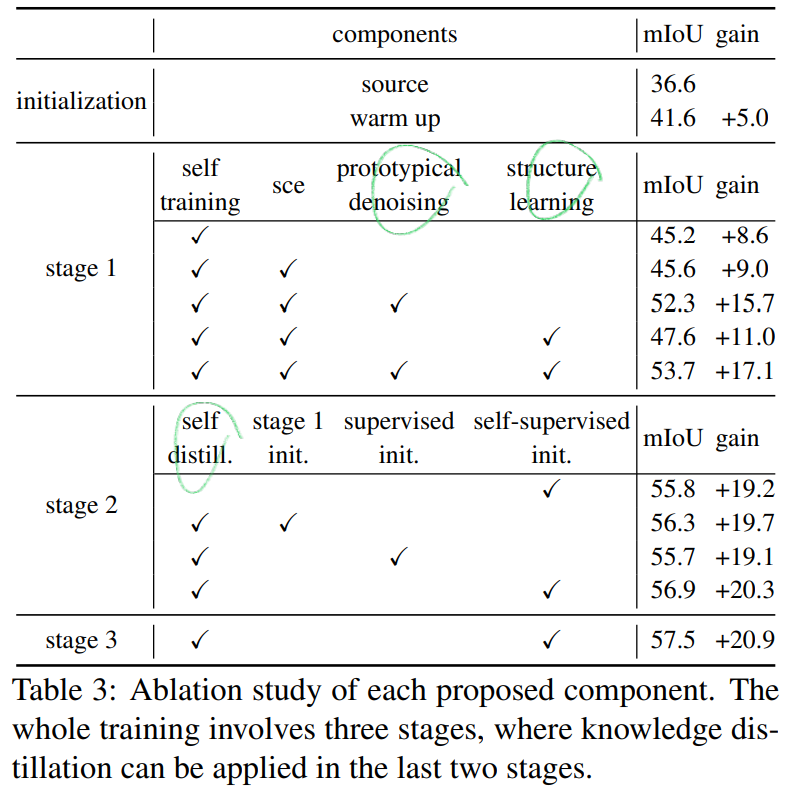
- Result Matrix
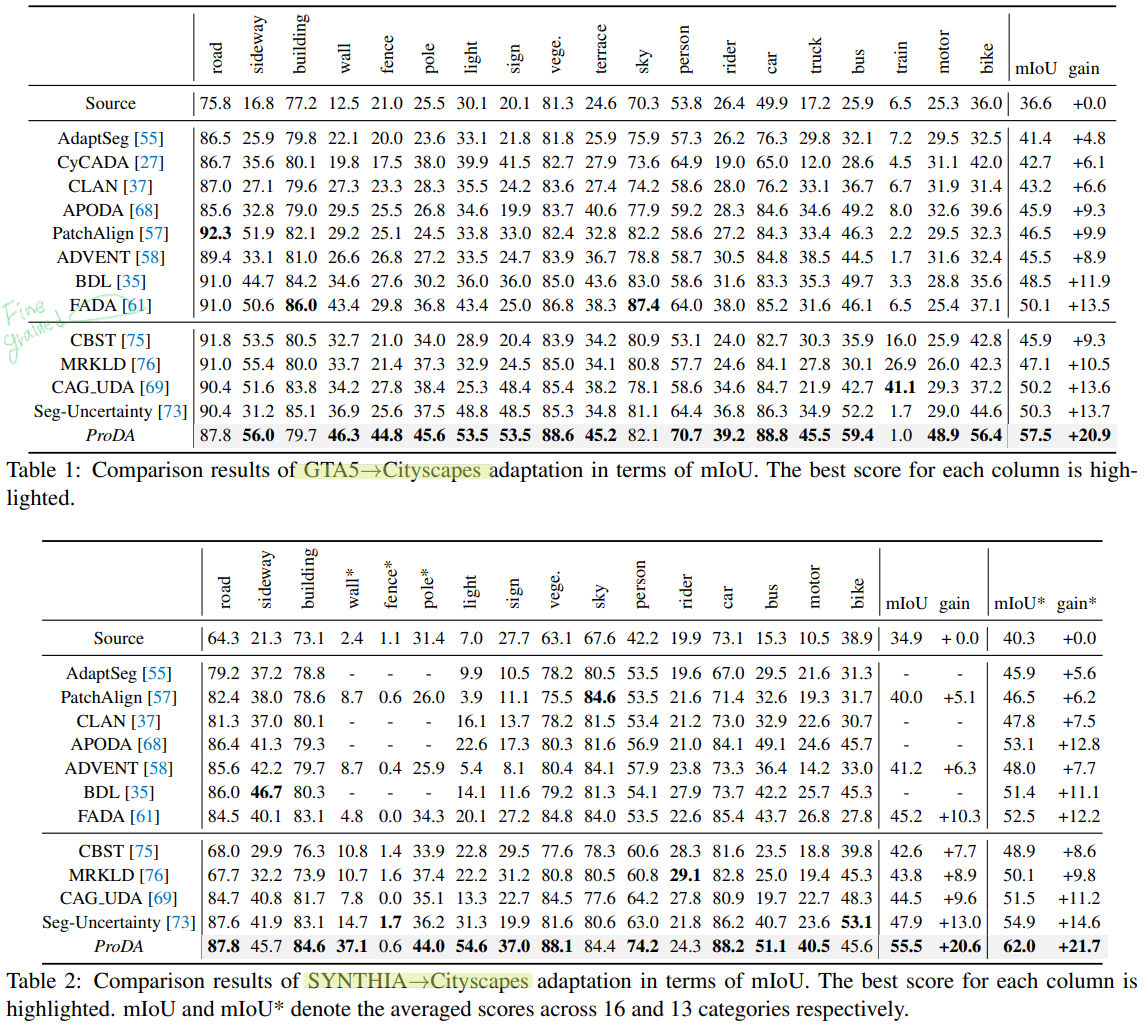
세미나 이후 인사이트 추가