pre-trained transformer model (IPT)을 사용해서, 기본적인 이미지 프로세싱 문제(Denoising, Deraining, SRx2=super resolution 2배, SRx4)를 해결한다.
Class, Image Color도 다양하게 가지고 있는 종합적인 ImageNet datesets를 degraded한 이미지 데이터를 pre-trained dataset으로 사용했다. 모델이 low-level image processing을 위한 intrinsic features를 capture하는 능력을 향상시킬 수 있었다.
(1) supervised and self-supervised approaches (2) contrastive learning approaches 모두 융합해서 모델을 학습시킨다.
Abstract
pre-trained deep learning models을 사용해서, 원하는 Task의 모델을 만드는 것은 좋은 방법이다. 특히나 transformer module을 가지고 있는 모델은 이런 과정이 주요한 이바지를 할 것이다.
그래서 우리가 image processing transformer (IPT)을 개발했다.
다른 image processing task들에서도 금방 적응할 수 있도록, Contrastive learning을 수행했다!
3. Image Processing Transformer
위 이미지 그림과 필기 먼저 확실히 파악하기
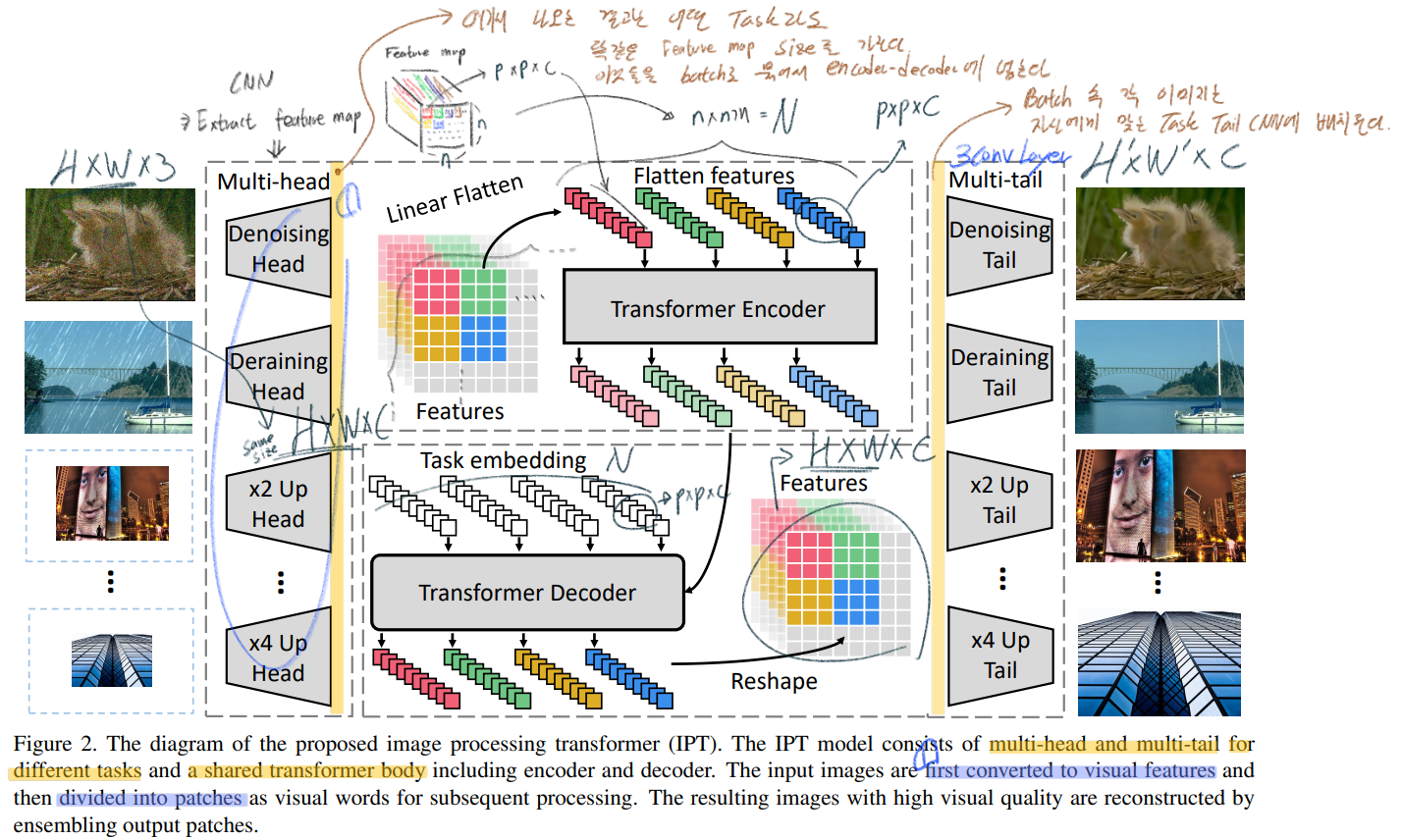
3.1 IPT architecture
4개의 components : (1) Head = extract features from input imaeg) (2) Encoder = (3) Decoder = 이미지에 중요한 missing 정보를 capture&recover 한다. (4) tails = Final restored images를 만들어 낸다.
Head
각각의 Task에 대해, 3 conv layer로 이뤄진다. 이미지 x가 input으로 들어가서 f_H가 만들어진다.
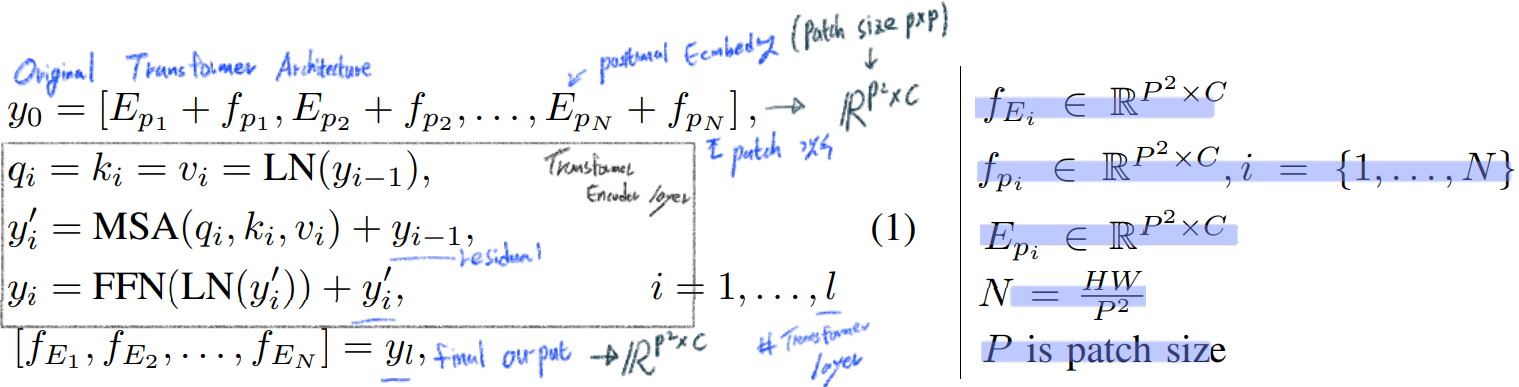
Transformer encoder
Almost same Transformer in All you need is Attention
Split the given features into patches
Learnable position encodings -> Element-wise SUM
Transformer decoder
Almost same encoder Transformer : 다른 점은 a task-specific embedding (Task에 따라서 다른 emdedding 백터 사용)
two multi-head self-attention (MSA)
Tails
Head와 같이 3 conv layer로 이뤄진다.
여기서 H’그리고 W’는 각 Task에 적절한 Size가 되면 된다. 예를 들어 Task가 SRx2 이라면 W’ = 2W, H’ = 2H가 되겠다.
3.2 Pre-training on ImageNet
the key factors for successfully training은 바로, the well use of large-scale datasets 이다!
하지만 image processing task에 특화된 Dataset 별로 없다. 예를 들어 DIV2K (only 2000 Images). (이 Dataset은 ImageNet을 manually degrading한 것과는 다르다고 한다. 이러한 다름을 고려하여 추후에 generalization ability에 대해 분석해본다.)
따라서 ImageNet을 사용해서 we generate the entire dataset for several tasks. 이것을 이용해서 Pre-training model을 만든다!
ImageNet에서 Label에 대한 정보는 버려버리고,, 인위적으로 여러 Task에 맞는 a variety of corrupted images를 만들었다.
이 과정을 통해서, Model은 a large variety of image processing tasks에 대해서 the intrinsic features and transformations을 capture할 수 있는 능력이 생긴다. 그리고 추후에 Fine-tuning과정을 거치기는 해야한다. 그때는 당연히 원하는 Task에 맞는 desired task using the new provided dataset를 사용하면 된다.
Contrastive Learning
we introduce contrastive learning for learning universal features.
이 과정을 통해서 the generalization ability (= adaptation, robustness of Tasks or Image domains)을 향상하는데 도움을 준다. 다시 말해, pre-trained IPT 모델이 unseen task에 빠르게 적응하고 사용되는데 도움을 받는다.
한 이미지로 나오는 Feature map의 Patch들의 관계성은 매우 중요한 정보이다. NLP에서 처럼(?) 하나의 이미지에서 나오는 patch feature map은 서로 비슷한 공간에 최종적으로 embeding되어야 한다.
We aims to (1) minimize the distance between patched features from the same images (2) maximize the distance between patches from different images
최종 수식은 아래와 같이 표현할 수 있다. 맨아래 수식이 Final 목적 함수이다
4. Experiments and Results
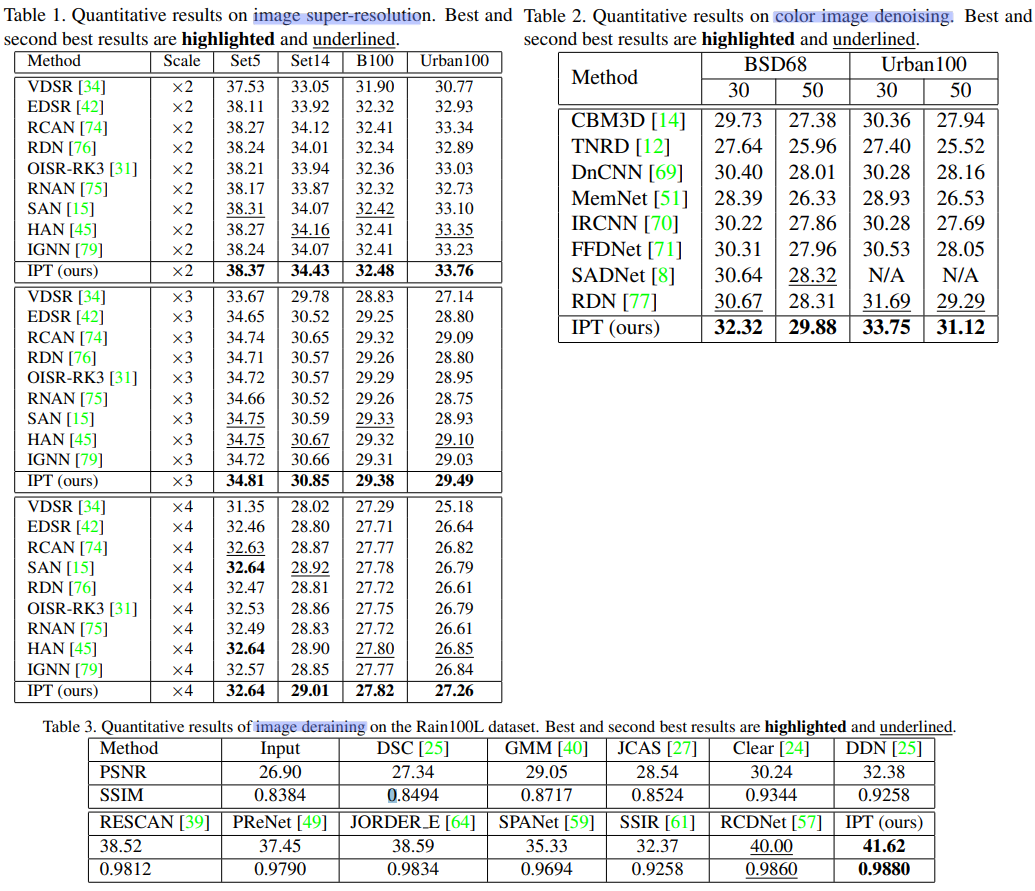
각 Task에 따른, 결과 비교는 아래와 같다.
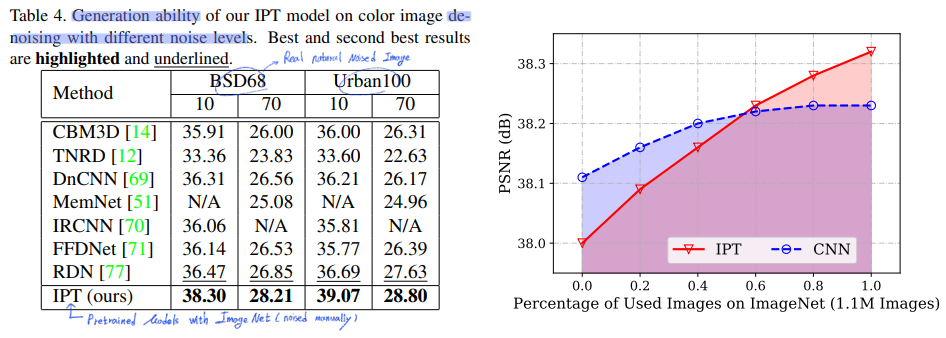
Generalization Ability
비록 우리가 ImageNet으로 currupted image를 만들었지만, 이 이미지와 실제 DIV2K와 같은 dataset과는 차이가 존재하고 실제 데이터셋이 더 복잡하다.
데이터셋에 따라서, 모델의 성능에서도 차이가 존재할 것이기에, generalization ability를 실험해보았다. 실험은 denoised Image Task에 대해서 실험한 결과가 나와있다.