【Transformer+OD】Deformable DETR w/ advice
- 논문 : Deformable DETR- Deformable Transformers for End-to-End Object Detection
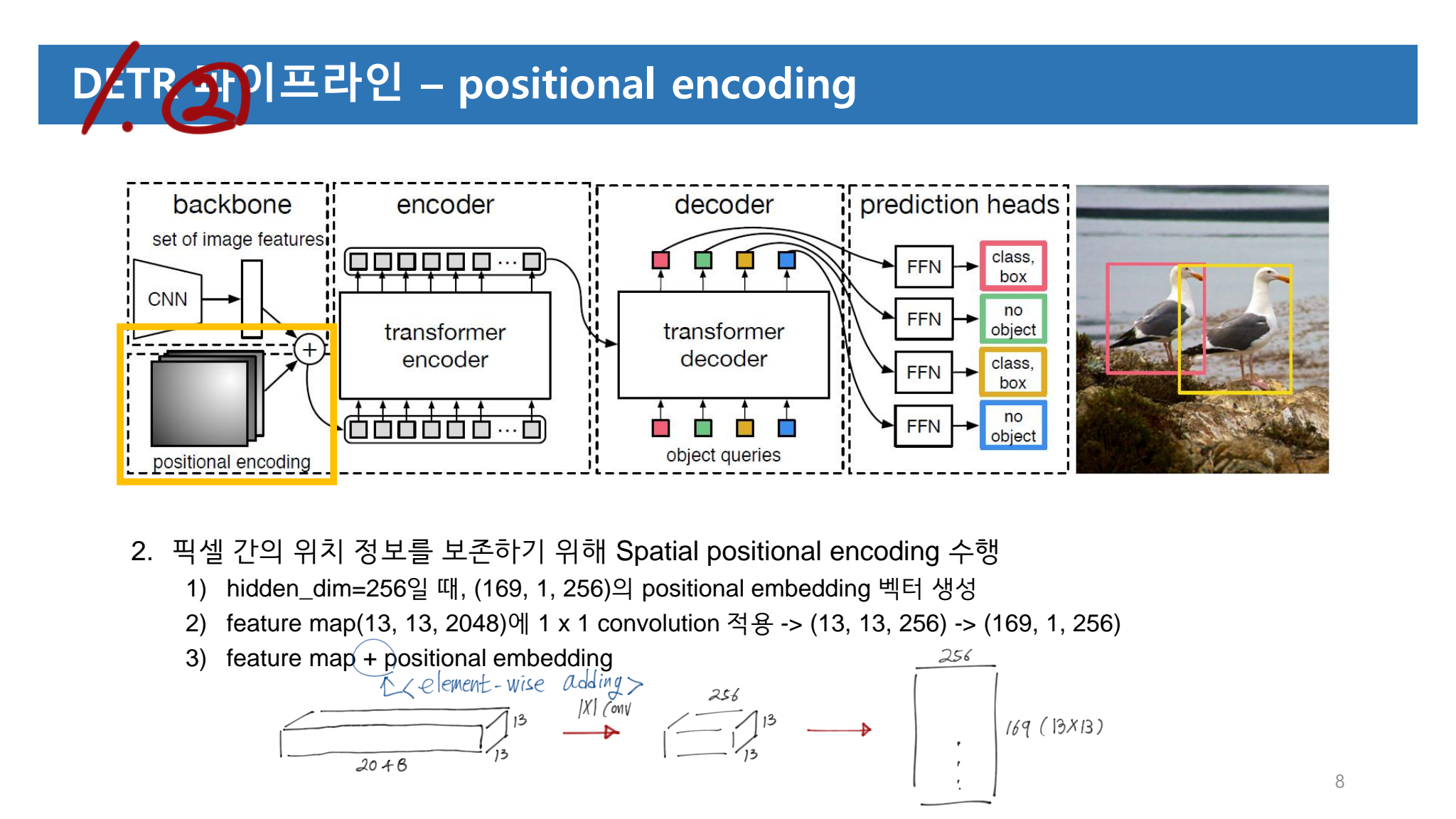
- 분류 : Transformer + Object Detection
- 저자 : Xizhou Zhu , Weijie Su, Lewei Lu , Bin Li
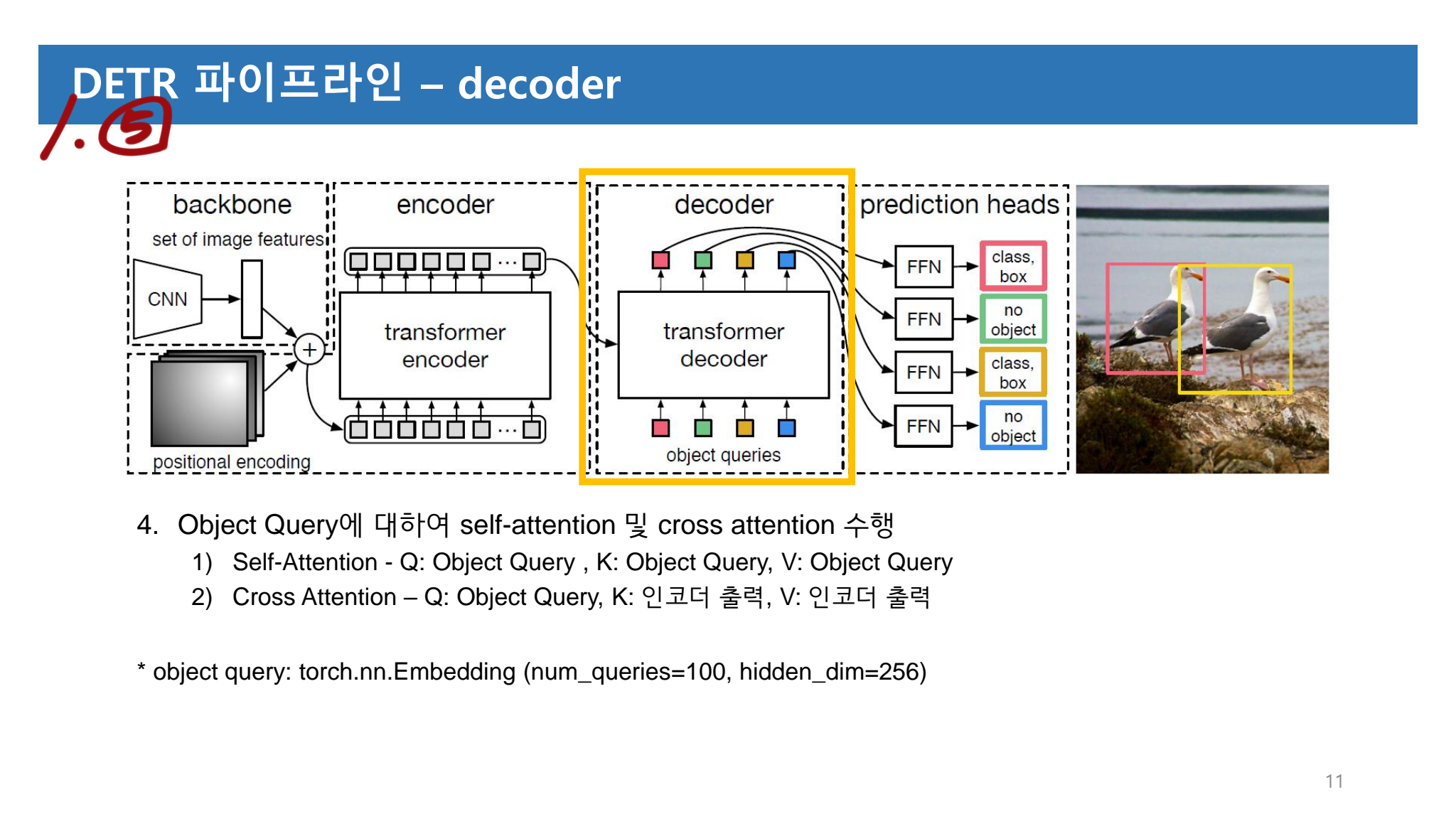
- 느낀점
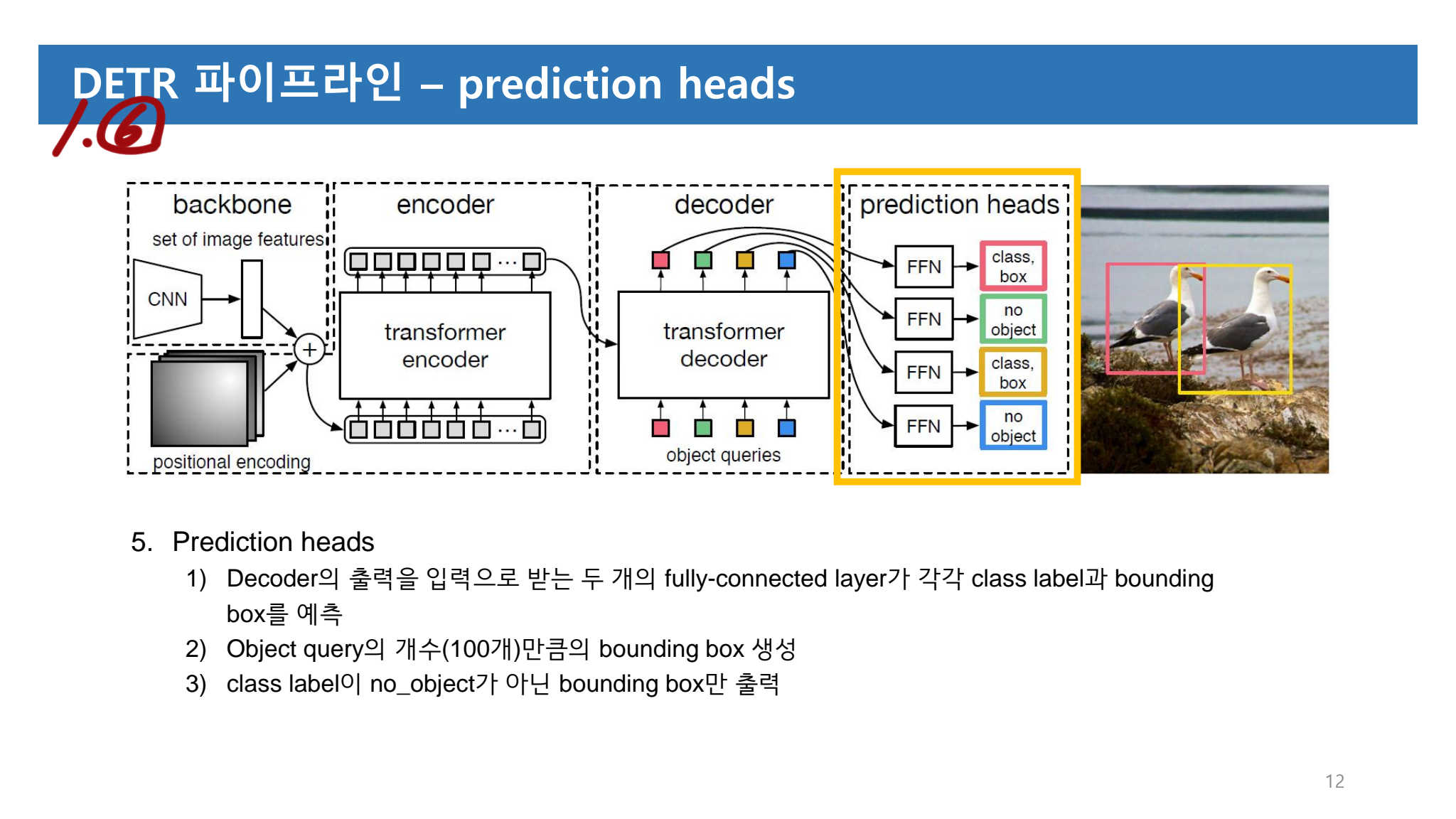
- 이해가 안되는 부분이 몇몇 있다. 논문 자체에서 구체적이지 않은것 이므로 어쩔 수 없는 것 같다. 코드를 확인하자.
- 공부 순서는 먼저 아래의 PPT를 보고, 그리고 Review를 보자.
- 목차
Deformable DETR
1. Conclusion, Abstract
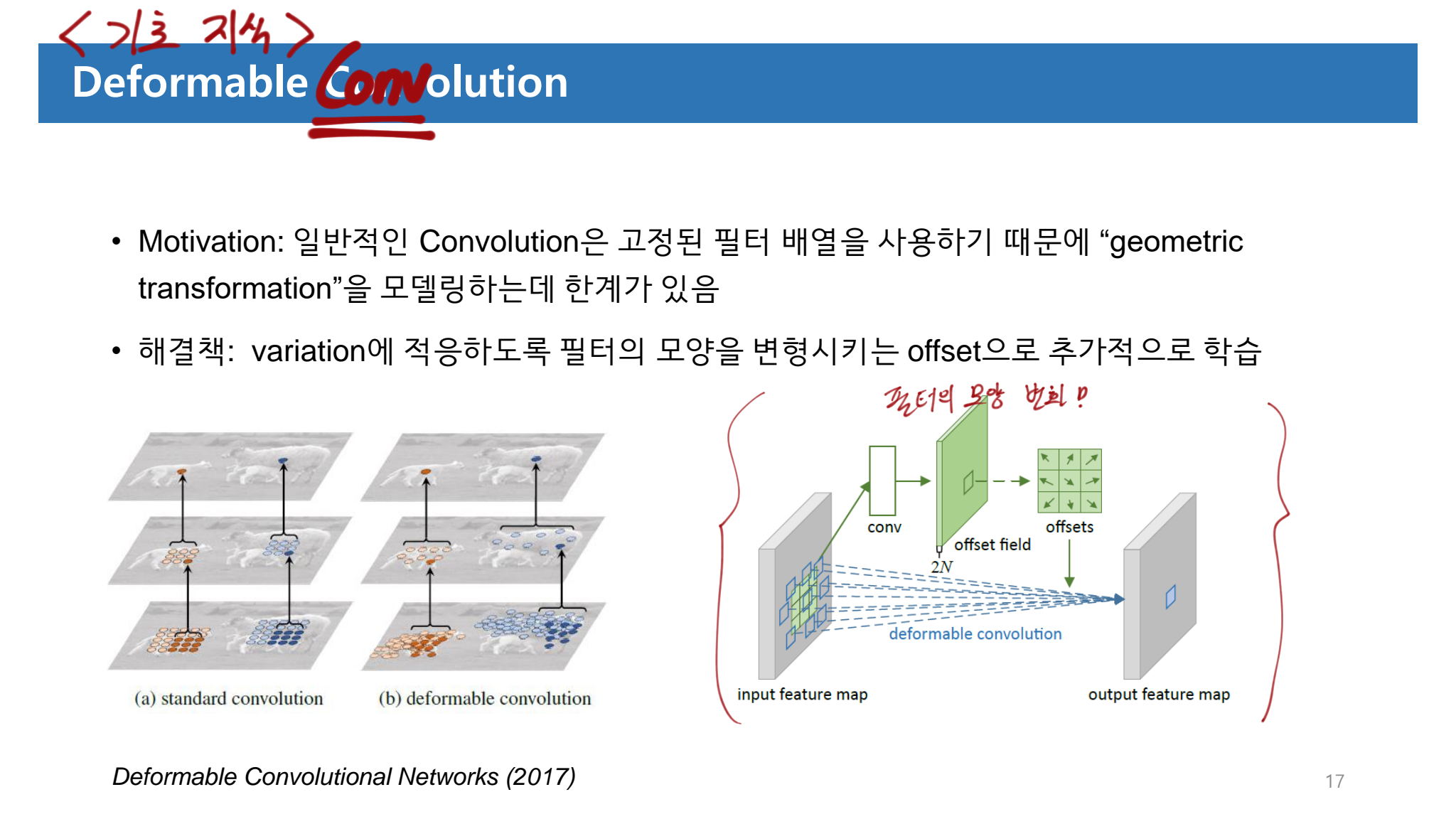
- 핵심은 “the (multi-scale) deformable attention modules” 이다. 이것은 image feature maps를 처리하는데 효율적인 Attention Mechanism 이다.
- 아래의 Transformer attention modules 의 가장 큰 단점을 a small set of key sampling 를 사용함으로써 해결 했다.
- slow convergence
- limited feature spatial resolution
- 장점으로 fast convergence, and computational and memory efficiency 를 가지고 있다.
- two-stage Deformable DETR 를 만들기도 하였다. region proposal이 먼저 생성되고, 그것들을 Decoder에 넣는 방식으로 만들었다.
2. Revisiting Transformers and DETR
- 특히 이 부분의 수학적 수식을 통해서, 지금까지 직관적으로만 이해했던 내용을 정확하게 이해할 수 있었다. 왜 NIPS에서 수학 수식을 그렇게 좋아하는지 알겠다. 정확하고 논리적이다.
2.1 Multi-Head Attention in Transformers
z_q,query element: a target word in the output sentence (“이 단어에 대해서는 어떻게 생각해?” 질문용 단어) =x_k,key elements: source words in the input sentence (문장 안에 있는 모든 단어. 모든 단어들에게 위의 query에 대해 질문할 거다.)- 특히 Encoder에서 z_q와 x_k는 element contents(word in 문장, patch in Image) 와 positional embeddings(sin, learnable) 의 concatenation or summation 결과이다.
multi-head attention module: query-key pairs 에 대한 Attention(= compatibility, Softmax) 정도 를 파악해 그것을 attention weights 라고 하자. 이 attention weights와 각각의 the key와 융합하는 작업을 한다.multi-head: 단어와 단어끼리의 compatibility(상관성 그래프)를 한번만 그리기엔, 애매한 문장이 많다. 그래서 그 그래프를 여러개 그려서 단어와 단어사이의 관계를 다양하게 살펴봐야한다. 이것을 가능하게 해주는 것이 multi-head 이다. Different representation subspaces and different positions을 고려함으로써, 이 서로서로를 다양하게 집중하도록 만든다.- multi-head에서 나온 값들도 learnable weights (W_m)를 통해서 linearly하게 결햅해주면 최종 결과가 나온다. 아래의 필기와 차원 정리를 통해서, 한방에 쉽게 Attention module과 MHA(multi head attention)에 대해서 명확히 알 수 있었다.
- 아래 필기 공부 순서 : 맨 아래 그림 -> 보라색 -> 파랑색 -> 대문자 알파벳 매칭 하기. 위의 보라색 필기는, Softmax 까지의 Attention weight를 구하는 과정을 설명한다. 파랑색 필기는 MHA의 전체과정을 설명한다.

- 하지만 이 방법에는 2가지 문제점이 존재한다.
long training schedules: 학습 초기에 attention weight는 아래와 같은 식을 따른다. 만약 Key가 169개 있다면, 1/169 너무 작은 값에서 시작한다. 이렇게 작은 값은 ambiguous gradients (Gradient가 너무 작아서, 일단 가긴 가는데 이게 도움이 되는지 애매모호한 상황) 이 발생한다. 이로 인해서 오랜 학습을 거쳐야 해서, long training schedule and slow convergence가 발생한다.computational and memory complexity(복잡성, 오래걸림, FPS 낮음) : 위의 MHA의 시간 복잡도를 계산하면 아래와 같다. 만약 N_q가 100 or 169개, N_k가 169개 라면, N_q x N_k 에 의해서 quadratic(제곱) complexity growth with the feature map size 이 발생한다.
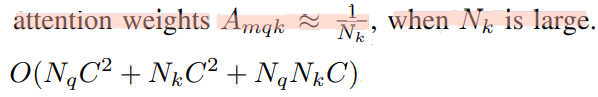
2.2 DETR
- input feature maps x ∈ R ^ (C=256×H=13×W=13) extracted by a CNN backbone
- 각 모듈의 시간복잡도
Encoder's MHA- query and key는 모두 pixels in the feature maps 이다.
- 시간 복잡도는 O(H^2 * W^2 * C) 이다. 따라서 이것도 Feature Size 증가에 따른 quadratic(제곱) complexity 를 가진다.
query's Masked MHA- self-attention modules
- Nq = Nk = N, and the complexity of the self-attention module
decoder's MHA- cross-attention
- N_q = N=100, N_k = H × W (encoder에서 나온 차원이, (HxW) xC 라는 것을 증명한다!)
- 시간 복잡도 : O(H*W*C^2 + N*H*W*C)
- (anchor & NMS와 같은) many hand-designed components 의 필요성을 제거했다.
- 하지만 아래와 같은 2가지 문제점이 있다.
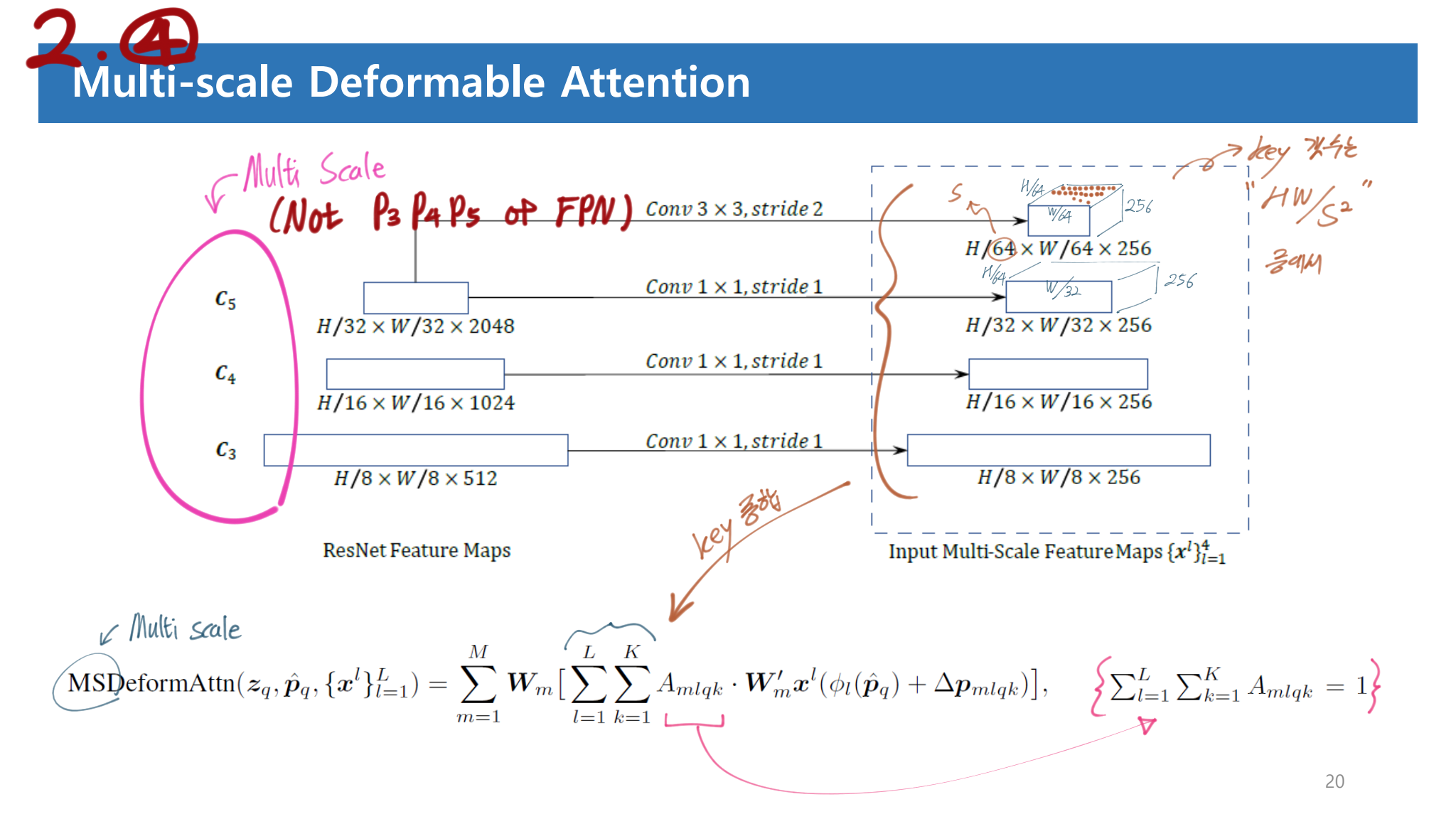
Low performance in detecting small objects: 다른 모델들에서는 Multi Scale Feature (C_3 ~ C_5) 혹은 FPN (P_3 ~ P_5) 를 사용하는데 여기서는 그럴수 없다. 시간복잡도가 quadratic(제곱) complexity 로 증가하기 때문이다.many more training epochs to converge
4. Method
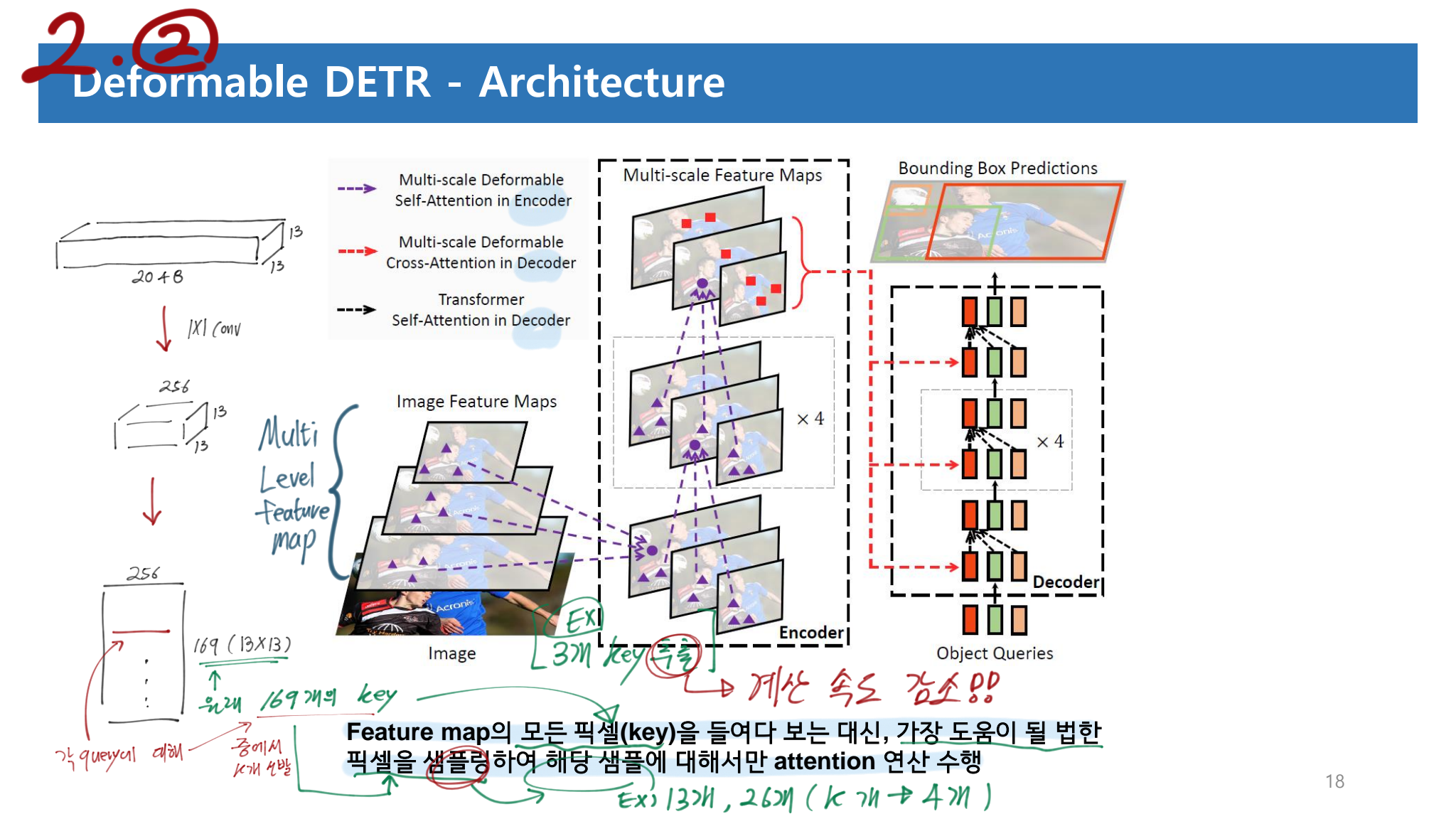
DETR에서 Key를 all possible spatial locations 로 모두 가져간다. 하지만 deformable DETR에서는 only attends to a small set of key 로 Keys를 사용한다. 이를 통해서 우리는 원래 DETR의 가장 큰 문제점이었던,
the issues of convergence그리고feature spatial resolution 을 키울 수 없는 상황을 해결할 수 있게 되었다.Deformable Attention Module 그리고 Multi-scale Deformable Attention Module 의 수식은 아래와 같다. 수식을 이해하는 것은 그리 어렵지 않지만, 실제로 어떻게 정확하게 사용하는지는 코드를 통해서 이해할 필요가 있다. 코드를 확인하자.
(아래 내용을 추가 의견) BlendMask 또한 '모든' Feature Pixel에게 "RxR에 대해서 어떻게 생각해" 라고 물어본다. 이것을 '모든' 으로 하지말고, 일부만 (like small K set) 선택하는건 어떨까? 아니면 query를 RxR ROI 라고 치고 Transformer를 사용해보니는 것은 어떨까?

Deformable Transformer Encoder
- Input과 Output 모두 multi-scale feature maps with the same resolution(256 channel) 이 들어간다.
- 특히 Input은 stages C3 through C5 in ResNet 의 Feature map을 선발 사용한다. 위 이미지 참고할 것. 그리고 FPN을 사용해서 P3~P5를 이용하지는 않는다. 사용해봤지만, 성능 향상이 거의 없기 때문이다.
- query로 Feature map을 줄때, feature level each query pixel 에 대한 정보를 담기 위해서, e_i 라는 positional embeding을 추가했다. e_i은 L의 갯수 만큼 있으며, 초기에는 랜덤하게 initialize가 되고, Learnable parameter로 학습이 된다.
Deformable Transformer Decoder
- 2가지 모듈이 있다.
cross attention modules: object-query와 Encoder의 출력값이 들어간다.,self-attention modules: object-query 끼리 소통하여 N=100개의 output을 만들어내는 모듈이다. - we only replace each
cross-attention moduleto be themulti-scale deformable attention module - 어차피 self-attention module은 HW개의 query가 들어가는게 아니라 key, value, query가 모두 100개 일 뿐이다.
multi-scale deformable attention module은 reference point 주변에 image features를 추출하는 모듈이다. 따라서 decoder 마지막 FFN의detection head가 그냥 BB의 좌표를 출력하는 것이 아니라,the bounding box as relative offsets을 출력하도록 만들었다. 이를 통해서optimization difficulty를 줄이는 효과를 얻을 수 있었다. (slow converage) (reference point 를 BB center로써 사용했다고 하는데, BB center는 어디서 가져오는거지?)
- 2가지 모듈이 있다.
Additional Improvements and variants for deformable DETR
- 많은 성능향상 방법을 실험해보았는데, 도움을 주었던 2가지 방법에 대해서만 소개한다. (추가 설명은 Appendix A.4 를 참고 하라.) (솔직히 아래의 내용만으로는 이해가 안됐다. 코드를 보기 전에 부록을 보면서 함께 공부하도록 하자. 아래의 그림은 설명을 보고 그럴듯하게 그려놓은 것이지, 정답이 아니다.)
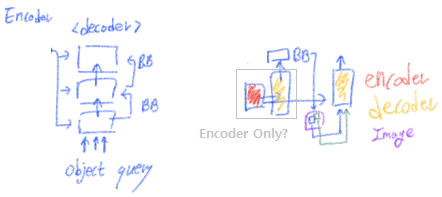
- Iterative Bounding Box Refinement : optical flow estimation (Teed & Deng, 2020) 에서 영감을 받아서 만들었다. 간단하고 효율적으로 각 decoder layer에서 나오는 detect BB결과를 다음 Layer에 넘겨서 다음 Layer는 이 BB를 기반으로 더 refine된 BB를 출력한다.
- Two-Stage Deformable DETR :
- 첫번째 stage에서는 region proposal과 objectness score를 예측하고 이 값을 다음 stage에 넘김으로써, 정확한 BB와 Class를 출력하는 2-stage Deformable DETR를 만들었다.
- 시간과 메모리 복잡도가 너무 올라가는 것을 막위해서 encoder-only of Deformable DETR을 region proposal Network로 사용한다.(?)
- 그리고 그 안의 each pixel is assigned as an object query. 그래서 시간, 메모리 복잡도가 급등하는 것을 막는다. (?)
- 많은 성능향상 방법을 실험해보았는데, 도움을 주었던 2가지 방법에 대해서만 소개한다. (추가 설명은 Appendix A.4 를 참고 하라.) (솔직히 아래의 내용만으로는 이해가 안됐다. 코드를 보기 전에 부록을 보면서 함께 공부하도록 하자. 아래의 그림은 설명을 보고 그럴듯하게 그려놓은 것이지, 정답이 아니다.)
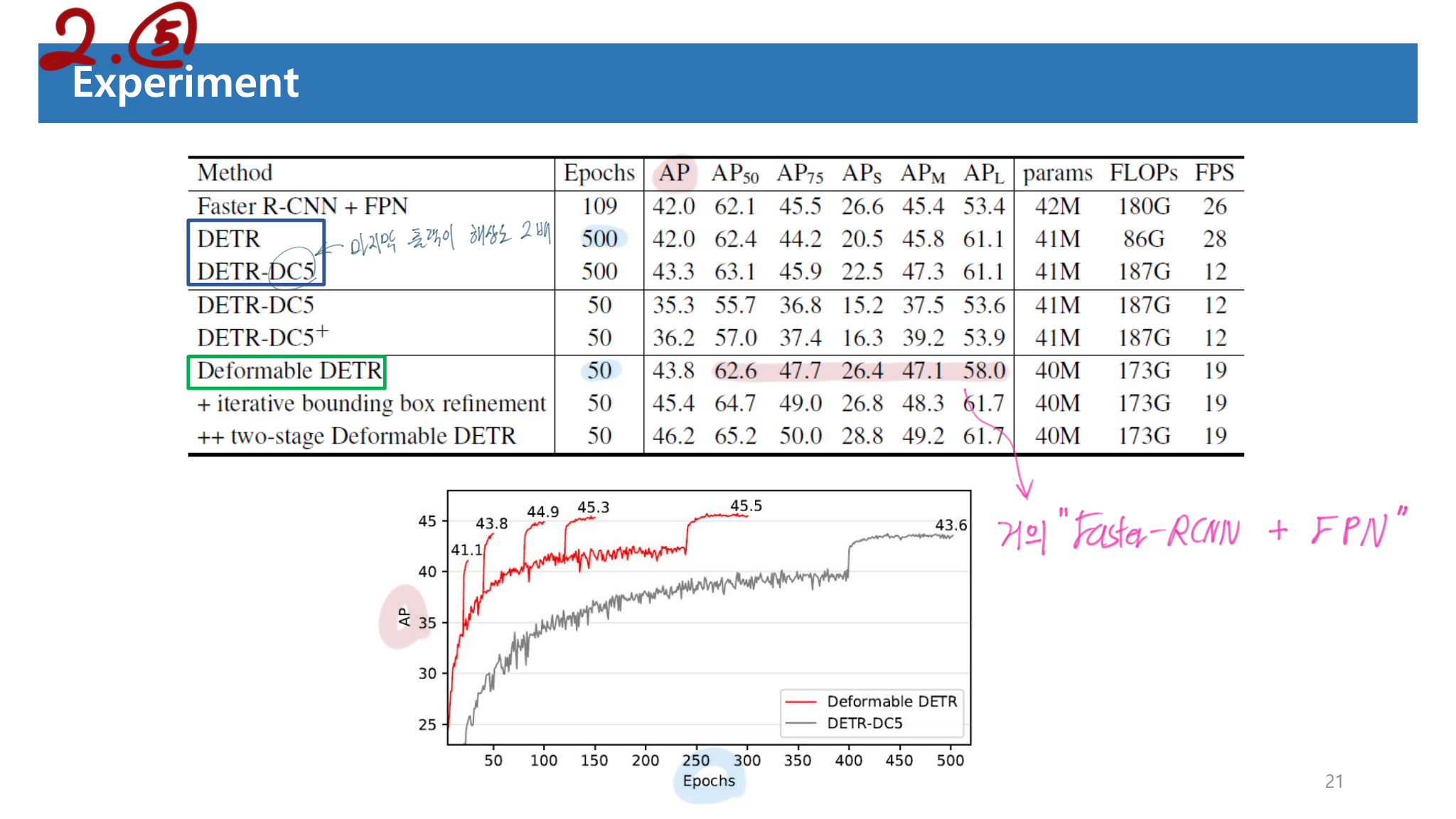
5. Experiment

Deformable DETR PPT