【In-Segmen】YOLACT - Real-time Instance Segmentation w/ my advice
- 논문 : YOLACT
- 분류 : Real-time Instance Segmentation
- 저자 : Daniel Bolya Chong Zhou Fanyi Xiao Yong Jae Lee
- 읽는 배경 : the devil boundary 의 기반이 되는 논문
- 느낀점 :
- 읽으면 좋을 것 같은 논문
- FCIS[24, 2017, Fully convolutional instance-aware semantic segmentation]
- 확실히 창의적이고 심박하다. 이러한 설계를 통해서도 원하는 결과가 추출된다는게 매우 신기하다.
- 하지만 Transformer 도 그렇고, 아래의 ProtoNet과 Mask head의 결과를 Linear combination하는 것도 그렇고, 이런 생각이 든다.
- “사람들은 대충 이렇게 설계하면 나의 직관적 의도대로 동작할 거 같은데?? 라는 생각으로 설계한 모델을 학습시킨다. 어찌되든 딥러닝 특성상 어떻게든 그럴듯하게 학습이 된다. 그렇다면… 나도 그냥 일반적인 설계말고, 좀더 심박하고 창의적이고 신기한 모양을 가진 Network를 설계해보면 어떨까? 마치 새로운 미로 문제를 만들어 보듯이. 심박하고 창의적이고 뒤죽박죽하게 하지만 직관적으로 생각해보면 심플하게. 하지만 이런 도전은 무조건 실패를 가져다 준다. 따라서 정말 다양한 아이디어로 실험해봐야한다. 다양한 아이디어 중 하나는 대박나지 않겠는가?”
- 읽으면 좋을 것 같은 논문
- 목차
- Paper Review
- Code Review
- Github link : https://github.com/dbolya/yolact
YOLACT
1,2. Abstract, Introduction
- fully-convolutional model for realtime instance segmentation / 29.8 mAP on MS COCO / 33.5 fps on a single Titan Xp / after training on only one GPU
- two parallel subtasks 이 이뤄진다.
- (global, holistic, non-local) generating a set of prototype masks
- predicting per-instance mask coefficients
- Fast NMS 를 적용하여 12ms faster 성능을 얻었다.
- Mask-RCNN 은, 객체에 따른 mask 데이터를 뽑아 내기 위해서 feature localization step (=re-pooling, ROI-Pooing, ROI-Align) 과 같은 작업이 필요했다. Instance 정보를 뽑아내는 작업이 다 완료되어야 Mask 정보를 뽑을 수 있으므로, 빠른 성능은 얻기 어렵다.
- FCIS[24, 2017, Fully convolutional instance-aware semantic segmentation] 논문이 One-stage methods 라고 거론되고 있지만, localization 이후에 후처리 작업이 너무 오래걸려서, 실시간성을 확보할 정도로 속도가 빠르지 않았다.
- 이 모델의 장점은 “빠르다. 비교적 좋은 성능이다.” 이다. ResNet101을 사용해서 30fps가 나오고, any loss of quality from repooling 가 없기 때문에 이미지 전체를 보고 좋은 instance mask 결과를 추출 할 수 있다.
- Related Work
- (복붙) One-stage instance segmentation methods generate position sensitive maps that are assembled into final masks with position-sensitive pooling [6, 24] or combine semantic segmentation logits and direction prediction logits [4]. -> slow
- (복붙 - top-down 방식의 instance segmentation) some methods first perform semantic segmentation followed by boundary detection [22], pixel clustering [3, 25], or learn an embedding to form instance masks [32, 17, 9, 13]
- Real-time Instance Segmentation : Straight to Shapes [21] and Box2Pix [42] 와 같은 모델이 있었지만, 성능이 너무 안 좋았다.
3. YOLACT
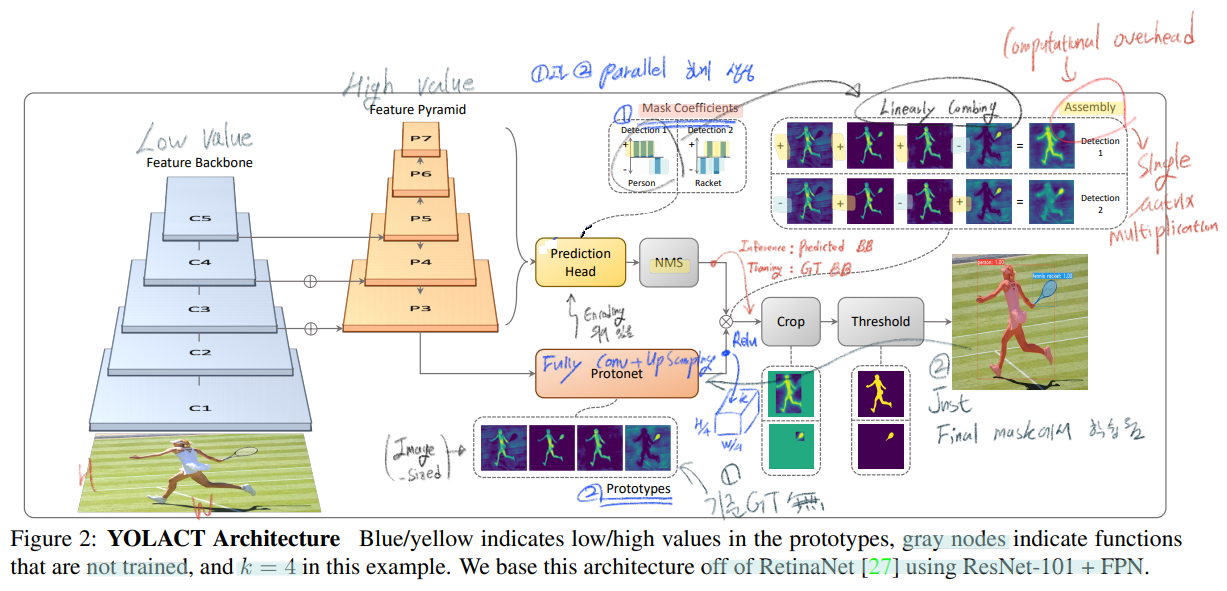
- two parallel subtasks 이 이뤄진다.
- first branch uses an FCN -> prototype masks - pixel 끼리는 서로서로의 소통과 관계 파악이 필요한데, global gerneralizing 을 통해 성취할 수 있다.
- predict a vector of “mask coefficients” , for each anchor , that encode an instance’s representation , in the prototype space.
- 그 이후 NMS, Linearly combining이 이뤄진다.
- 참고로 위의 Assembly step에서 computational overhead가 일어날 수 있는데, 아래의 수식처럼, 한번의 행렬곱으로 GPU의 장점을 살려 빠른 계산을 할 수 있게 해놨다.
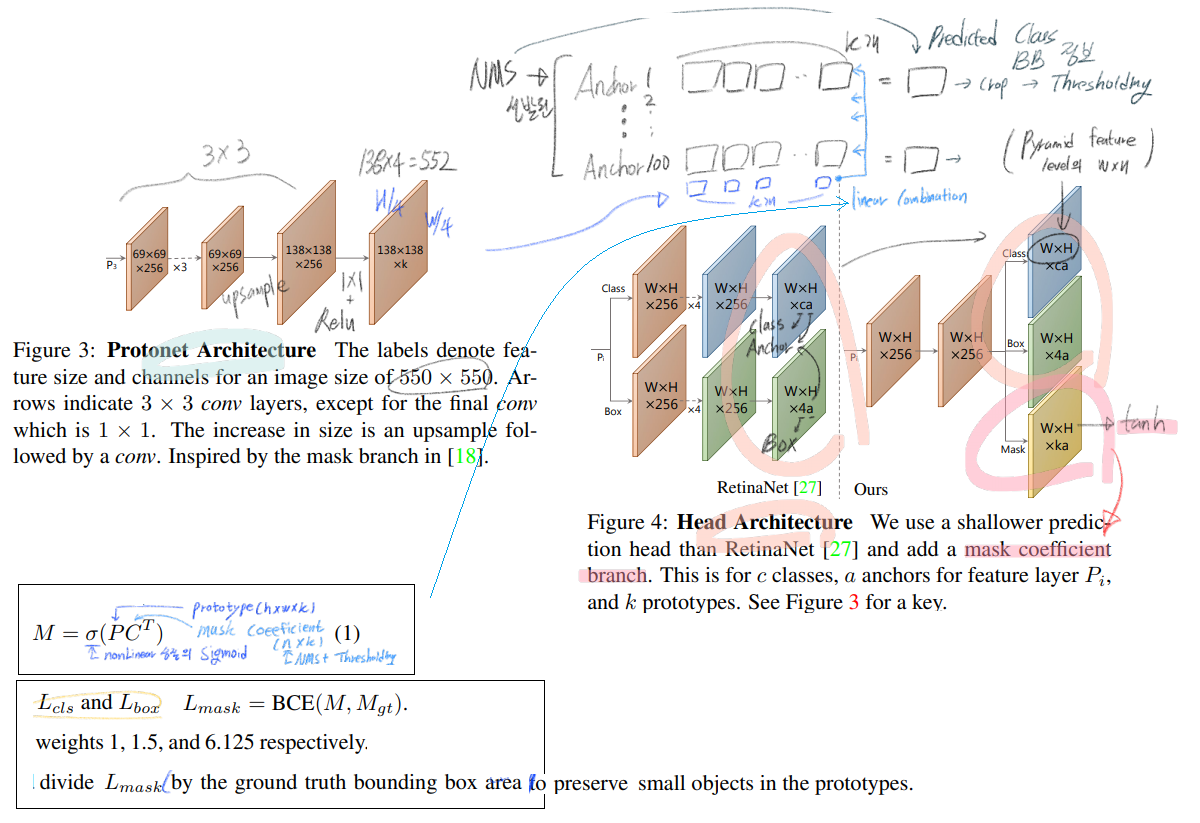
3.1 Prototype Generation (FCN)
- 위의 Figure 3 참조.
- 최종적으로 k 개의 prototype masks를 만들거고, k channels 에서 하나하나의 채널이, 하나의 prototype mask가 된다.
- 여기서 특이한 점은, 위 이미지에서, 138x138xk feature map에 필요한 GT는 없다. 그냥 the final mask loss after assembly 에 의해서 나오는 Loss에 의해서 supervision 될 뿐이다.
- 더 큰 Feature map 을 사용해서 FCN을 할 수록 작은 객체 탐지에 좋았다. 그래서 FPN의 P3 만을 사용했다.
- Upsample을 하는데, 원본 input 이미지 크기의 4분의 1 크기가 될 때까지 upsampling 시켜준다고 한다.
- 마지막으로 그림처럼, 1x1을 통과해서 channel을 k로 맞춰주고, relu를 통과시켜준다. 여기서 relu를 사용할지 안할지 고민을 했다고 한다. 왜냐면 여기서 나오는 pixel값이 +,- 양방향에서 무한하다면 더 좋은 confident pixel about obvious background 이 라고 여길 수 있기 때문이다. 하지만 Relu를 사용했다고 한다.
3.2. Mask Coefficients
- 위의 Figure 4 참조.
- Typical anchor-based object detectors 모델을 기반으로 한다.
- per anchor에 따라서 4 + c + k channel을 생성한다.
- tanh 를 수행한다. 그래야 linear combination을 적절히 수행할 수 있다고 한다.
- (논문에 fc-mask라는 말이 있다. 그리고 Mask-head에서는 fc layer (fully connected layer)를 썼다는 듯이 이야기하고 있는데, Architecture 그림에서도, 코드에서도 Mask_branch에서 nn.linear를 만든 흔적도 없다. 내가 논문 해석을 못하는건가? 나중에 더 알아보자.) )
3.3. Mask Assembly
- 위의 그림 중 첫번째 수식 참조.
- sigmoid nonlinearity를 이용했고, single matrix multiplication을 사용하면 되므로 빠르게 처리할 수 있도록 했다.
- linear combination 말고도 더 복잡한 방법을 사용할 수 있었겠지만, 속도와 단순성을 확보하기 위해서 linear combination 을 사용했다.
- Loss : 위의 그림 중 두번째 수식 참조
- 여기서 M은 assembled masks 이고, M_gt는 ground truth masks Mgt 이다.
- BCE loss는 pytorch document, 블로그 에서 참조.
- Cropping Masks
- 위 그림에 적어 놓은 것 같이, 학습 동안에는 GT BB를 사용해서 crop 하고 (+L_mask에 GT BB의 크기(넓이)로 값을 나눠 준다. (큰 객체에 큰 loss가 커지는 문제를 막기 위해서)), Inference 하는 동안에는 Predicted BB를 사용해서 Crop한다.
- 다음 설명에도 나오겠지만, 사실 너무 작지 않은, large+midium size의 객체는 crop을 하지 않고도 thresholding 만으로 적절한 mask 결과가 나온다고 한다.
3.4. Emergent Behavior
- 솔직히 이 반 페이지 이해가 잘 안된다. 그래도 내가 최대한 이해한 내용을 바탕으로 정리하면 다음과 같다.
- 우선 알아야 할 용어 : translation invariant (병진 대칭) 에 대한 정리
- translation invariant이란, translation invariance란 input의 위치가 달라져도 output이 동일한 값을 갖는것을 말한다. 그 반대를 논문에서는 translation equivariance이라고 표현하는 것 같다..
- 그냥 conv연산은 translation equivariance 하다. (input value의 위치가 변함에 따라 feature map value도 변한다) Max pooling과 Softmax는 translation invariant 하다. 전체적으로 생각하면 Classification관점에서 CNN연산은 translation invariance 하다고 할 수 있다.
- FCN은 translation invariant 하기 때문에, instance의 특정 위치를 파악하려면 ROI-pooing이나 ROI-Align과 같은 translation variance 한 작업이 필요하다. 하지만 우리가 하는 translation variance 작업은 단순히 crop을 하는 것 뿐이다.
- 하지만 우리의 Network는 큰 객체, 중간 크기의 객체는 crop을 하지 않더라도, Tresholding 만으로 적절한 mask를 뽑을 수 있었다. 따라서 Crop을 translation variance라고 말하기에는 무리가 있다.
- YOLACT는 FCN을 통해서 각각의 Instance에 대한 Localization을 찾는다. 어떻게 이것이 가능할까?
- 첫번째는 ResNet에서 충분한 translation variance 이 이뤄진다. corner, edge 등등을 이미 찾아내고, localization을 할 수 있을 정보를 FCN에게 쥐어 준다.
- 두번째는 k = 32개의 prototypes 이, Mask head에서 나온 정보를 통해서 Linear combination을 하기 때문이다. 이 과정을 통해서 different activations in its prototypes 들은 서로서로 Comunication (Multi haed attentino module은 어떨까?) 을 하여, 최종적으로 Instance Localization을 뽑아낼 수 있는 것이라고 한다.
- 우선 알아야 할 용어 : translation invariant (병진 대칭) 에 대한 정리
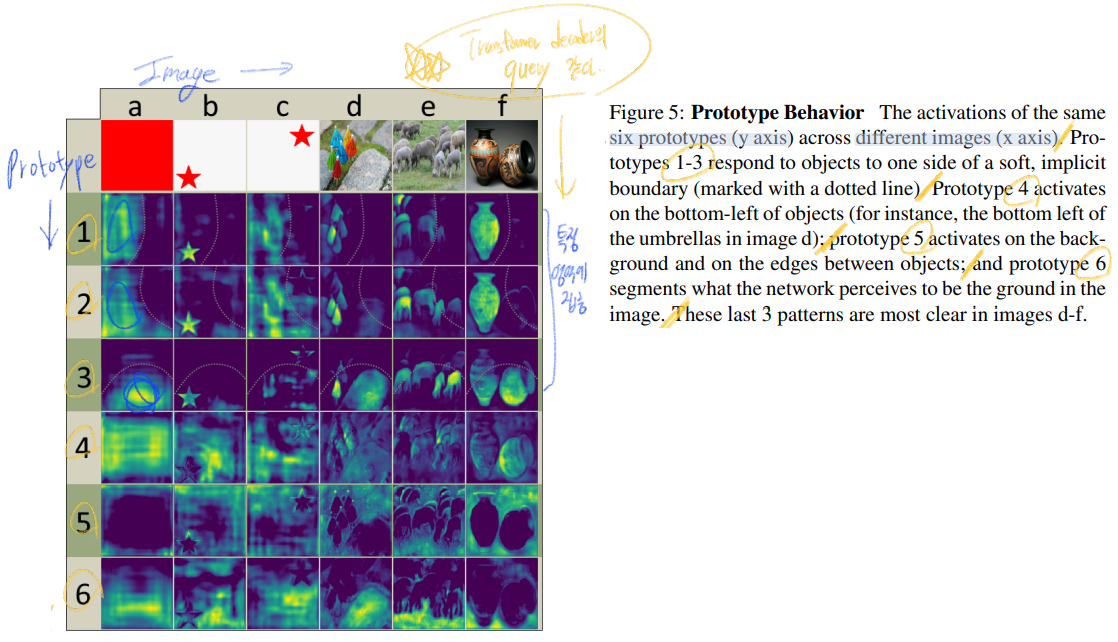
- 아래의 그림은 Prototype activation map이 어떻게 동작하는지 시각화를 해 놓은 것이다. 이해가 어렵지 않으니 읽고 확인하자.
4. Backbone Detector
- good features를 뽑기 위한, backbone은 RetinaNet과 비슷한(동일한) 것을 사용했다.
- YOLACT Detector
- 무조건 550 × 550 이미지가 들어간다. 일정한 fps가 나오게 하기 위해서, aspect ratio 이미지 비율은 보존하지 않았다.
- 3 anchors [1, 1/2, 2]. P3부터 feature map pixel size를 [24, 48, 96, 192, 384]로 사용했다.
- [smooth-L1] loss for box regressors
- [softmax cross entropy] with c positive labels + 1 background label
- 3:1 neg:pos ratio의 Negative mining 기법 사용.
- Focal Loss 사용하지 않았다.
5. Other Improvements
- Fast NMS
- 원래 NMS는 (이전 Post의 자료를 찾아봐도 된다) confidence score로 sort를 한 후, 높은 것과 일정 이상 IOU를 가지는 Predicted Box를 제거한다. 하지만 이 작업이 수행 속도에 방해가 된다. 그래서 이것을 수정했다.
- Fast NMS의 직관적인 이해는 다음과 같다. (논문 부분 그대로 해석하자면..) Predicted Box를 최종 결과로 가져갈지 혹은 버려 버릴지를 정하는 작업이 Parallel하게 수행된다. 단순하게 already-removed detections to suppress other detections (한번 아니라고 제거된 박스는 다시는 고려하지 않는다. 라고 이해하면 되려나?) 라고 표현할 수 있다. (아래의 공식으로 이게 충분히 이해되지는 않는다. 쩃든 이런거 있다 정도만 알아두자.)
- Fast NMS 수행방법은 다음과 같다. 첫째 class 마다 n개의 predicted box만을 선별한다. 총 c x n 개. 박스 서로에 대한 IOU를 계산한다. 행렬곱으로 처리하면 되므로 순식간이다. 그러면 c x n x n feature map이 생성된다.
- 그 후 대각, 하삼각행렬의 값을 0으로 바꿔버리고, column-wise max를 수행한다. 그 후 마지막 thresholding 과정을 거쳐, 최종적으로 살아남은 Predicted Box를 검출해 낸다. 아래의 그림을 보면 이해가 좀 더 쉽다. 하지만 이게 정확히 어떻게 작동되는지는, 예시를 만들어 손으로 직접해보거나, 코드를 한줄한줄 확인하면서 이해할 필요가 있다.

- Semantic Segmentation Loss
- 전체 AP를 +0.4 를 시켜주었다. 학습과정에만 적용하고 inference에서는 사용하지 않는 방법이라 test time에는 영향이 없다.
- P_3 feature map에 1x1 conv를 통과시키고 c channel이 나오게 한다. 그리고 sigmoid function을 거친다. (softmax and c + 1 channel이 아니다)
- 이렇게 나온 H x W x C 와, Sementic Segmentation GT를 정답갑으로 하여, Loss를 주어 학습시킨다.
- (이 과정을 통해서 P3는 물론 FPN의 Feature map들은 Segmentation 결과를 더 잘 추출 할 수 있는 feature extractor로 변화될 것이다. 그리고 이 P3를 사용해서 FCN을 통과시켜 Prototypes를 찾아낸다.)
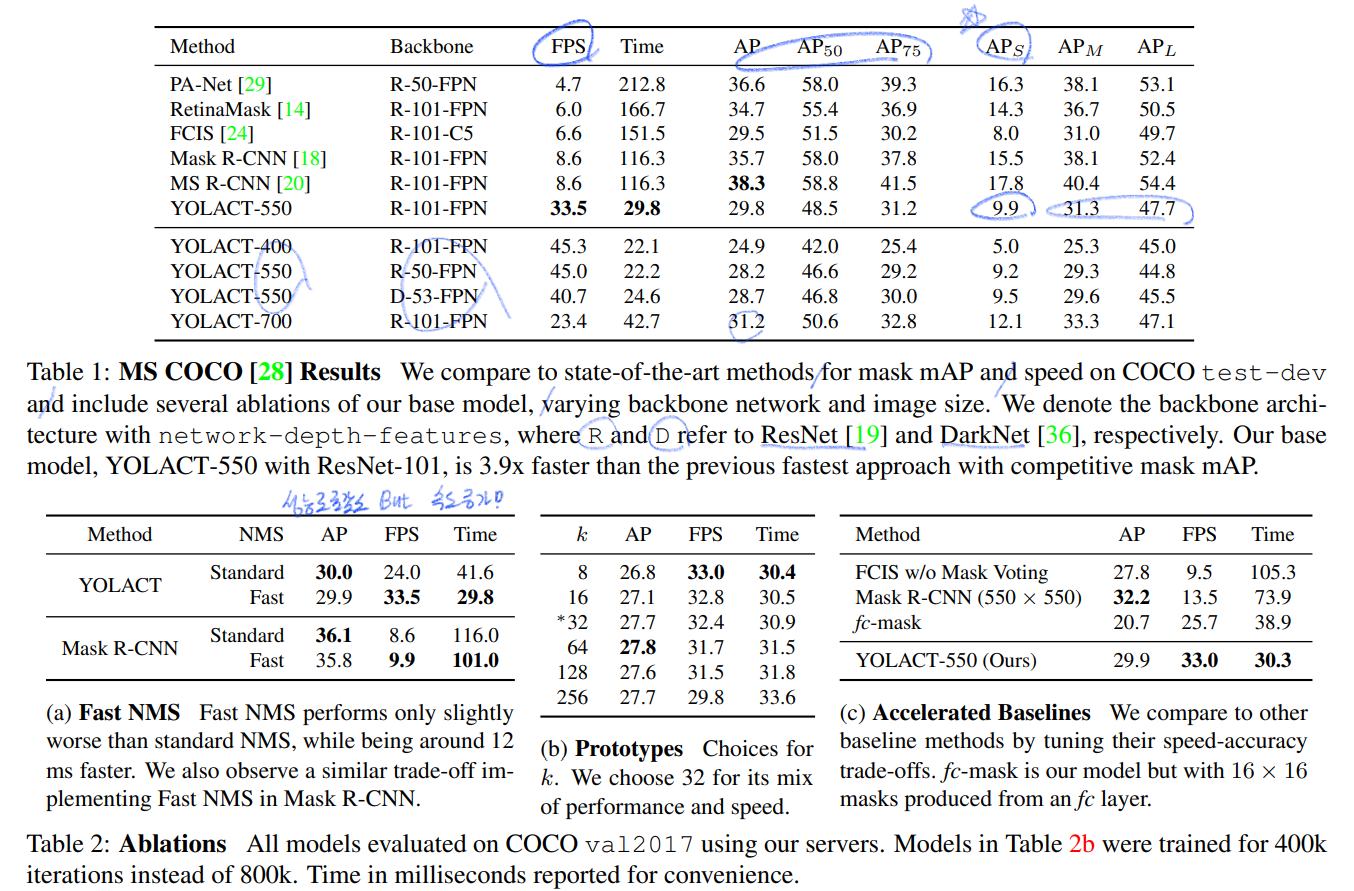
6. Results
YOLACT - code
- 지금 궁금한 코드 내용
- Fast NMS
- NMS
- Semantic Segmentation Loss
- Linear combination
- Mask Loss
- 32개의 Prototpyes 를 생성하는, ProtoNet
나중에 필요할 떄 코드를 참조하자.
num_priors : Anchor의 갯수
mask_dim : k (prototypes의 갯수)
# yolact/yolact.py self.bbox_layer = nn.Conv2d(out_channels, self.num_priors * 4, **cfg.head_layer_params) self.conf_layer = nn.Conv2d(out_channels, self.num_priors * self.num_classes, **cfg.head_layer_params) self.mask_layer = nn.Conv2d(out_channels, self.num_priors * self.mask_dim, **cfg.head_layer_params) # 코드볼 때, 여기서 src는 self라고 이해하면 된다. bbox = src.bbox_layer(bbox_x).permute(0, 2, 3, 1).contiguous().view(x.size(0), -1, 4) conf = src.conf_layer(conf_x).permute(0, 2, 3, 1).contiguous().view(x.size(0), -1, self.num_classes) mask = src.mask_layer(mask_x).permute(0, 2, 3, 1).contiguous().view(x.size(0), -1, self.mask_dim)
