【MOT】MOTS - Multi-Object Tracking and Segmentation
- 논문 : MOTS: Multi-Object Tracking and Segmentation
필기 완료된 파일은OneDrive\21.겨울방학\RCV_lab\논문읽기에 있다. - 분류 : MOT
- 저자 : Paul Voigtlaender, Michael Krause, Aljosa sep, Jonathon Luiten
- 읽는 배경 : 연구실 과제 참여를 위한 선행 학습
- 느낀점 :
- 코드를 많이 보고 싶은데, Tensorflow….
- 솔직히, 결과들을 보면 이 모델이 정말 좋은 모델인가..? 라는 생각이 든다. Conv3D 그리고 Association head에서 다른 것들에 비해서 좋은 성능이 나왔다는 생각이 많이 들지 않는다.
- 그들의 성능평가 matrix 자체 점수를, 원래 조금이라도 올리기가 매우 힘든건가? 확실히 아직은 MOTS 에 대해서 더 많은 연구가 이뤄져야 할 듯 하다.
- 이 논문보다는 다른 (bounding box) MOT 논문을 찾아 다시 공부하자. 그렇게 신박한 방법은 없다. 아래의 내용정리만으로 이해가 어려우니, 필요하면 논문을 다시 보고 + 코드를 다시보고 공부해야한다. 아니면 MOT 논문을 공부해보고 이 논문을 다시 보자.
0. Abstract, Conclusion
- (문제점) 지금까지 MOT + Segmentation을 같이 수행하는 benchmark model과 dataset이 존재하지 않았다.
- (해결) 우리가 semi-automatic annotation procedure을 사용해서 만든 2개의 MOT dataset을 소개했다. 이미 존재하는 MOT 데이터(Bounding Box detection only) 에서 Segmentation 정보를 직접 추출해서, 그거를 Training data로 사용했다.
- 기존의 MOTA matrics(평가지표)을 기반으로 새로 만들어낸 MOTSA, sMOTSA를 소개했다.
- baseline model을 개발했다. detection + tracking + segmentation 을 모두 동시에 하는 single convolutional network 이다.
1. Introduction
- (현재) bounding box level tracking 성능이 Saturation 되었다.
- (문제점) 하지만 bounding box level tracking 에는 문제점이 있다. 겹처진 객체에 대해서 too coarse 한 BB를 가진다는 점이다. 또한 BB는 object에 대한 roughly fit 이기 때문에, overlapping BB(서로 겹치게 예측된 BB)와 그 GT를 비교하면, ambiguities 존재하는 것을 알 수 있다. (predicted BB가 맞는것(Positive)… 같기도 하면서 아니기도 한 그런…)

- (해결책) BB와 다르게 Segmentation 정보는 non-overlapping 하므로 GT와 비교할 때 아주 단순한 방법으로 비교 가능하다.
- (그래서 우리는) Mask R-CNN에 3D convolution을 사용한 TrackR-CNN을 만들어 냈다.
- 논문 전체 contributions(summary)
- KITTI [13] and MOTChallenge [38] datasets 를 기반으로 MOTS를 위한 dataset 생성
- soft Multi-Object Tracking and Segmentation Accuracy (sMOTSA) measure(평가지표) 소개
- TrackR-CNN
- 우리 모델의 유용함 증명한다. 그 뿐만 아니라, 우리의 데이터 셋과, segmentation + tracking single network가 충분히 있음직하고 좋은 성능을 발휘한다는 것을 증명할 것이다.
2. Related work
- Multi-Object Tracking Datasets : a known set of classes로부터 unknown number of targets을 추적한다. Bounding box를 기반으로 한다. + 논문에 데이터셋 몇가지가 소개되어 있다.
- Video Object Segmentation Datasets : instance segmentations을 수행하기는 하나, 일렬의 비디오에 only few objects 만이 존재한다. 우리의 MOTS 모델은 미리 정의된 classes들과 crowded objects를 고려한다. + 논문에 데이터셋 몇가지가 소개되어 있다.
- Video Instance Segmentation Datasets : Cityscapes처럼 automotive scenario를 사용하는 3개의 데이터 소개한다. 하지만 이들은 동영상이 아주 작은 subset(짧은 frame 수)으로 구성되어 있거나, 특히 ApollloScape 데이터는 객체의 identities 정보가 없다. (tracking dataset으로 사용 불가)
- Methods
- MOTS와 비슷한 작업을 하는 다른 논문들 몇가지 소개. 필요하면 찾아보기. 다른 논문들과 달리 MOTS는 많은 객체들이 동영상에서 들어가고 나간다. 또한 다른 논문들은 segmentation tracking 정보를 추출할 수는 있지만, MOTS annotation dataset이 없었기 때문에, 그들의 performance를 평가할 수 없었다.
- LSTM을 사용해서 Tracking을 수행하는 2개의 논문 소개한다. [34, 2017], [51, 2017] 하지만 이들은 detection을 수행한 Frame들에 대해서 Hungarian matching procedure라는 전통적인 후처리 방법을 사용한다. MOTS에서는 그런 후처리 작업 수행하지 않는다.
- Semi-Automatic Annotation (반 자동 instance segmentation 주석 처리 방법)
- deep learning을 사용하지 않는 전통적 컴퓨터 비전 방식의 annotation 기술들 몇가지가 소개 된다.
- MOTS에서는 Polygon-RNN 이라는 방법을 사용한다. 다각형의 꼭지점을 정의하는 모델이다.
- Fluid Annotation(사진 전체 mask-rcnn) 방법은, Tracking을 고려하지 않고, base dataset의 bounding box annotation 정보도 사용하지 않기 때문에, MOTS에서 사용하지 않는다.
3. Datasets
- Semi-automatic Annotation Procedure
- DeepLabV3+ 모델을 사용한다. Input에는 BB에 의해 crop된 + 아주 작은 region added(BB보다 조금 크게) 가 이뤄진 이미지를 사용한다.
- COCO, Mapillary dataset으로 pre-train 된 DeepLabV3+모델이라 할지라도, [KITTI MOTS, MOTSChallenge] dataset을 1번과 같은 방법으로 inference를 수행하면 성능이 poor하다고 한다. (아마 domain change 때문에) 그래서 초반에는 all manually created masks 를 가지고 학습시켜준다. 그러다 보면 상대적으로 괜찮은 Mask predict 값을 추출하게 되는데, 이때도 아직은 완벽하지는 않다.
- 위 과정 이후, DeepLabV3+을 이용해서 우선 predict segmentation를 하고, 그렇게 나오는 결과값(flawed generated masks)을 직접 manually 수정한다. 이렇게 수정한 이미지를 사용해 training을 다시 수행한다.
- 일정수준의 pixel-level accuracy이 나올때까지 위의 작업을 계속 반복하며 수행한다.
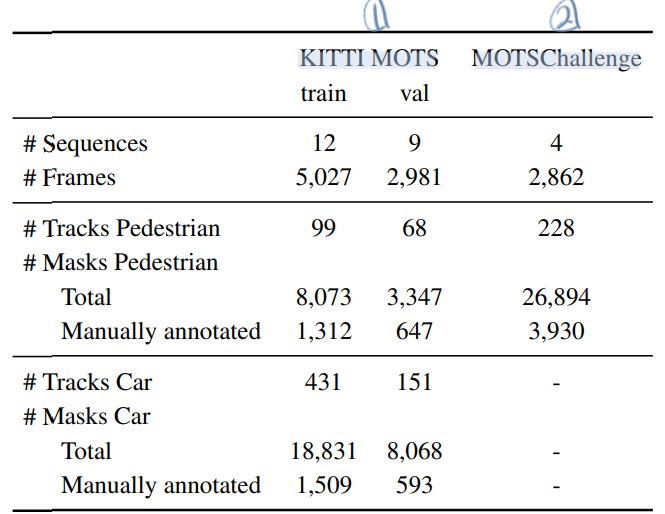
- KITTI MOTS dataset
- 원래 이 데이터는 21개의 training sequences를 가지고 있다. 이것을 MOTS를 하기 위해 적절히 나눈다. car, pedstrian의 전제 숫자가 비슷하도록 데이터를 최대한 잘 분배했다. training set : validation set = 12 : 9
- 특히나, 이 데이터를 pre-train 된 DeepLabV3+에서 inference를 하면 poorly 성능을 보인다. 이것은 “instance segmentation model들이 temporal reasoning을 사용(결합)해야만 한다는” 주요한 동기부여가 된다. (뭔소린지 정확히 모르겠다. instance segmentation을 하기 위해 temporal 정보를 어떻게든 사용한다면 성능이 훨씬 좋아질 수 있다는 건가? 이 방법을 사용해서 연구를 해도 좋을 것 같다.)
- MOTS Challenge dataset
- 이 데이터 셋은 특히나 pedestrians in crowded scenes으로 이루어져 있다. 따라서 많은 occlusion(겹침) 문제가 발생한다. 따라서 pixel-wise description(mask 정보) 를 사용함으로써 특별히 이득을 볼것으로 예상된다고 한다.
4. Evaluation Measures
- 변수 정의
- M은 Ground True Segmentation 정보 ( 1 instance -> 1 channel bool 형식 )
- H가 Predicted Segmentation hypothesis (예측 Instance Segmentation 값)

- Establishing Correspondences (Predict를 얼마나 Correct하게 했는지 수치화)

- 위 그림에 숫자 동그리마 필기 찾기.
- 0번째 수식 : c(h) = IOU 값을 이용해선 correctness 수치화량 값. 보통 Segmentation에서는 IOU(h,m) > at most 0.5 를 겨우 넘는 수준이라고 한다. 즉 BB보다 IOU값이 높게 나오기 힘들다.
- 1번째 수식 ~ 3번째 수식 : h (prediced mask instance 집합의 원소), m (ground ture mask instance 집합의 원소) 를 활용한 TP, FP, FN 정의
- 4번째 수식 : mask 뿐만 아니라, id까지 동일해야 한다. t에 관한 수식은 GT dataset에서 (논문의 주석5) does not count id switches if the target was lost by the tracker 이기 때문에 저런 수식이 나오는 듯 하다. 그리고 같은 ID인지 판단하는 알고리즘은 정확하게 적혀있지 않아있다. 따라서 필요하면 직접 코드를 보고 공부를 해야할 듯 하다.
- 5번째 수식은 (IDS 수식은 정확히 이해되지 않는다. 필요하면 다시 공부하자.) m들 중에서, h들과 고려해봤을때 (같은 mask를 가르키고 있다고 판명할 만한 h가 있기는 하지만) ID까지 일치하는 객체가 없는 m의 갯수이다. 이것도 높으면 안 좋은 것.
- Mask-based Evaluation Measures
- 아래의 수식들은 CLEAR MOT metrics [4, 2008]의 내용들을 기반으로 한다. 따라서 완벽한 이해가 안되면, CLEAR MOT 수식에 대해서 먼저 공부해야할 듯 하다.

- 얼마나 MOTS를 잘 수행하고 있는지 계산하는 matrix들이다.
- 6번째 ~ 9번째 수식들을 사용하면 되고, 이 값이 높을 수록 MOTS가 잘 수행되고 있다고 판단할 수 있다.
5. Method
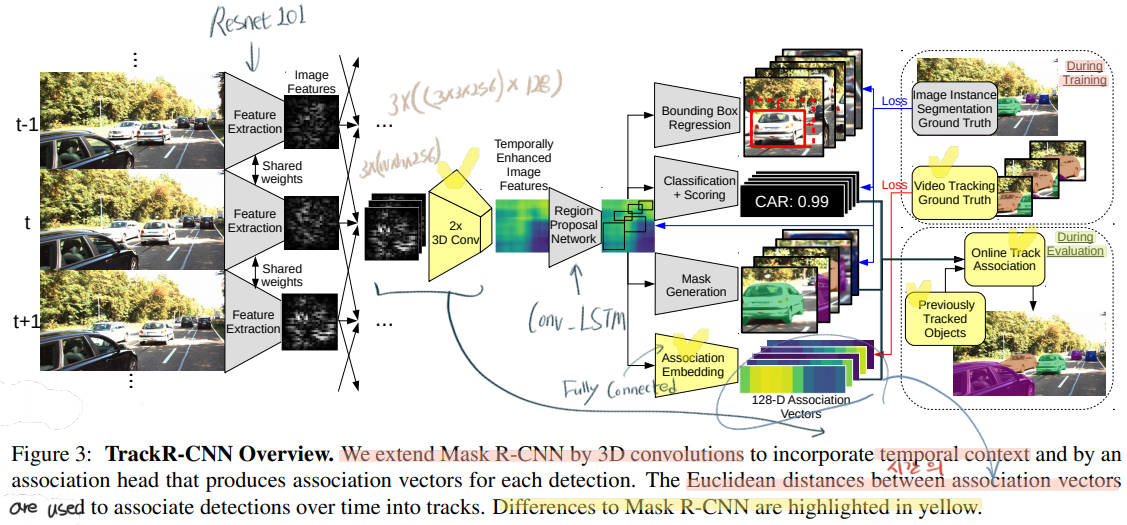
- 아래의 내용들이 그렇게 구체적이지 않다. 따라서 이용하고 싶다면, 코드를 꼭 봐야할 필요가 있다. (Tensorflow 1.13 코드)
- Integrating temporal context
- depthwise separable 3D convolution layers with 3×3 (spatial) ×3 (time) filter kernels. 즉 위의 필기에서 (3x3x256)은 filter 는 필터 차원이고, x128은 filter 의 갯수이고, 3x는 3D conv를 필요한 추가 차원이다.
- ResNet-101
- 위의 사진에서는 3D conv가 들어가지만, 대체신경망으로 (일반 LSTM과 다르게 the spatial structure 를 유지하고 있는) Convolutional LSTM (+ skip connection) 을 사용하는 것도 고려해 보았다고 한다. 논문에서
Convolutional LSTM를 검색하면, 이것을 사용할 때의 장점, 효과, 실험과정, 에 대해서 간단히 살펴볼 수 있다.
- Association Head
- Association Head를 사용한 Inference
- fully connected layer
- Association Vectors 를 생성한다. 두 백터 사이의 유사도 판별은 단순하게 Euclidean distance 방법을 사용한다.
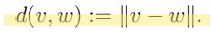
- Association Head 학습시키기
- the batch hard triplet loss (proposed by Hermans et al. [18] adapted for video sequences) 의 방법을 사용하여 학습시킨다.
Ddenote the set of detections for a video (비디오에서 검출되는 모든 객체의 갯수)- d ∈
Dconsists of a maskmask_dand an association vectora_d - 아래 수식에서 margin alpha = 0.2가 가장 좋았다.

- Association Head를 사용한 Inference
- Mask Propagatio
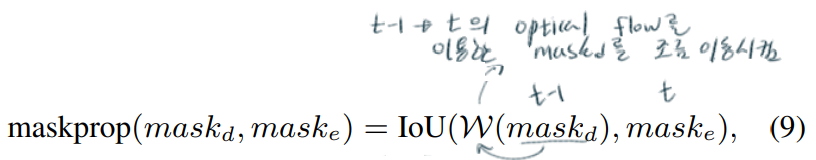
- PWC-Net [55, 2018] 모델을 사용해서 Optical flow 계산
- Tracking
- 이 내용은 논문에서 수식과 디테일 없이 간단하게 적어놓았다. 논문을 봐도 이해가 잘 안된다.
- their association vector similarity (Euclidean distance)를 기반으로 Tracking을 수행한다. γ threshold 이상을 가지는 detections를 찾는다.
- the Hungarian Algorithm을 사용햐서 Matching을 수행한다. threshold of β 이상을 가지는 detection을 찾는다.
- 적절한 tracking hyper-parameter (δ, β, γ)를 찾기 위해 random search(이것저것으로 다 실험해봄)를 사용했다고 한다.
- The resulting tracks (tracking하기 위해 찾아낸 detections) 들 서로서로가 겹칠 수 있다. (다중으로 뽑힐 수 있다.) 여기서는 MNS와 같은 방식으로 a higher confidence를 가지는 mask detections들을 선택한다.
6. Experiments
- 40 epochs
- a learning rate of 5 · 10^(−7) using the Adam optimizer
- mini-batches which consist of 8 adjacent frames
- Titan X
- a speed of around 2 frames per second (아마 1번 mini-batch 결과가 나오는데, 4초 정도 걸리나 보다)
- Main Results
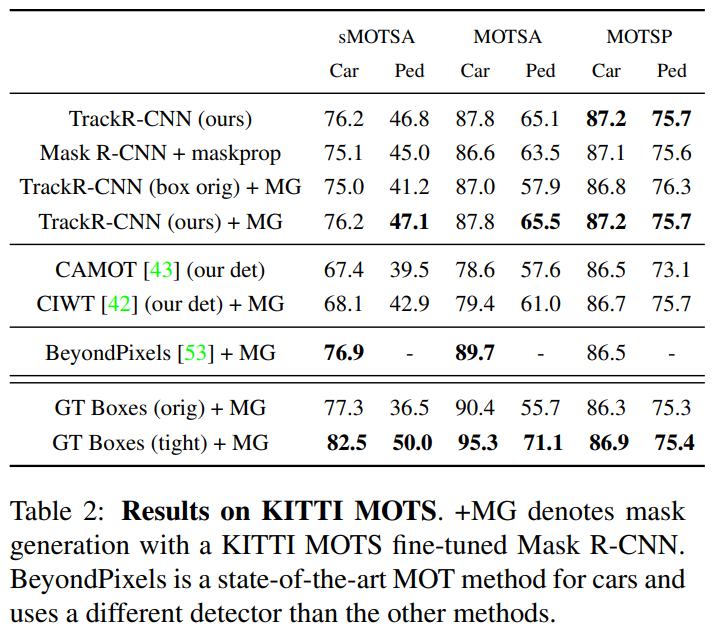
- 맨위의 TrackR-CNN(box orig)는 mask head 가 없는 TracR-CNN이다. (PS. CAMOT [43] : stereo 정보를 사용)
+MG : segmentation masks as a post-processing step. 즉 Mask R-CNN의 the mask head 이라고 한다.
- 코드 사용이 가능한 Segmentation-based tracker 가 없다. 대신 the bounding box-based tracker인 CIWT [42] and BeyondPixels [53]에 fine-tunning된 Mask R-CNN의 the mask head를 결합한 모델을 사용해 보았다.
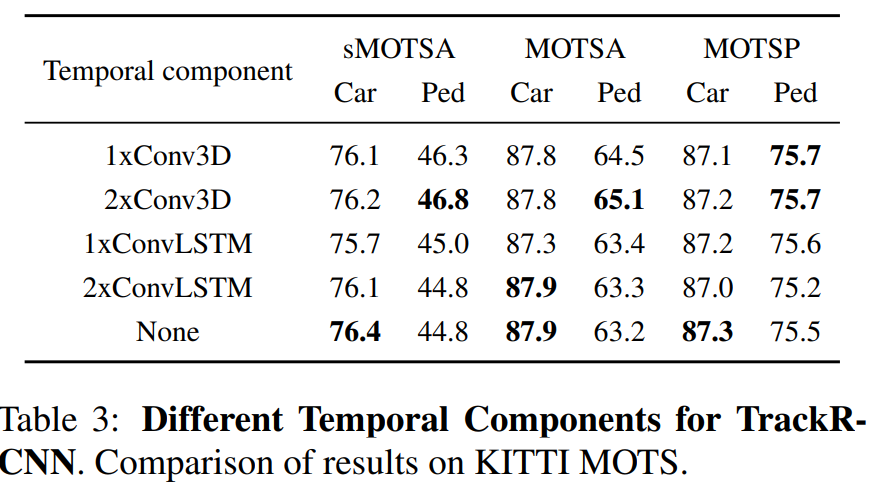
- Temporal Component
- backbone feature map과 RPN 사이의 2개의 Conv3D (two depthwise separable 3D convolutional layers)를 넣었을 때의 장점
- Association Mechanism

- Association head를 사용하지 않고, 다른 기본적인 방법을 사용했을 때 성능의 증가율
- Results on MOTS Challenge

- four methods that perform well on the MOT17 benchmark + Mask R-CNN fine-tuned on MOTSChallenge 이 모델들에 비해서는 좋은 성능을 보이고 있다.
- 마지막 결과을 보면 확실히 segmenting all pedestrians 이 매우 어려운 문제로 남아있다는 것을 확인할 수 있다.
