【Re-ID】Person Re-identification A Survey and Outlook w/ my advice
- 논문 : Deep Learning for Person Re-identification: A Survey and Outlook
필기 완료된 파일은OneDrive\21.겨울방학\RCV_lab\논문읽기에 있다. - 분류 : Re-identification
- 저자 : Mang Ye, Jianbing Shen
- 읽는 배경 : 연구실 과제 참여를 위한 선행 학습
- 느낀점 :
- 이 논문의 특징은, reference가 200개가 넘는다. 정말 자세하고 많은 것을 담고 있는 논문이다. 어차피 이 것을 다 이해하려면 1년이 더 걸린다. 따라서 지금 하나하나 이해해서 다 기록해 두려고 하지말고, 전체 그림만 그릴 수 있도록 스키밍을 하면서 빠르게 읽어나간다. 그리고 정리는 핵심과 큰 윤곽만 정리해 나간다.
- 이 논문의 Reference의 핵심 논문이 너무 너무 많아서, 뭐 읽어야 겠다.. 라는 생각이 드는 논문이 거의 없다. 결국에는 나중에 SOTA 찍는 모델과 논문을 다시 보면서 공부해야한다. 여기서는 아주아주 큰 그림만 잡는다.
- 이 논문을 읽다보니, 나는 우주 속 먼지보다 작은 존재로 느껴졌다. 정말 보고 읽어야 할게 산더미다!! 근데 차라리 이래서 더 안심이다. 차라리 이렇게 산더미니까 다 읽지는 못한다. 따라서 그냥 하루하루 하나씩 꾸준히 읽어가는 것에 목표를 둬야 겠다. 논문은 “다 읽어버리겠다!가 아니다. 꾸준히 매일 읽겠다! 이다.” 라는 마음을 가지자!
0. Abstract
- Person re-ID란? 겹치지 않는 다중 카메라들 사이에 person of interest를 검색(retrieving)하는 것
- 쉽게 설명해 보겠다. 3개의 카메라가 있다. 각 카메라는 구도와 공간이 다르다. 3개 이미지에는 많은 사람이 들어가 있고, 공통적으로 query person이 들어가 있다. 만약, 첫번째 이미지안의 query person이 query로 주어졌을 때, 나머지 2개의 이미지에서 다른 사람(boudning box는 이미 제공됨)이 아닌, 같은 query를 찾는 것이 Re-ID 과제 이다.
- 3개의 다른 perscpecitve를 가지는 closed world Person-Re-ID (상용화를 위한 것이 아닌 연구 단계의 연구들 = research-oriented scenarios)에 대한 종합적 개요가 있다. with (1) in-depth analysis (2) deep feature representation learning (3) deep metric learning (4) ranking optimization. 이 연구는 이미 거의 포화 상태다.
- 그래서 5개의 다른 perscpective를 가지는 Open-world setting으로 넘어가고 있다. (상용화를 위한 연구 단계의 연구 = practical applications)
- 이번 논문에서 새로 소개하는 것은 이런 것이 있다.
- a powerful AGW baseline
- 12개의 Dataset
- 4개의 다른 Re-ID task
- e a new evaluation metric (mINP)
1. Introduction
<Introduction 서론>
- 초기에는 a! specific person를 찾기 위함이었다. 시대의 발전과 공공 안전 중요도의 증가, 지능형 감시 시스템 need에 의한 기술 발전이 이뤄지고 있다.
- Person Re-ID의 Challenging task (방해요소들) : [the presence of different viewpoints [11], [12], varying low-image resolutions [13], [14], illumination changes [15], unconstrained poses [16], [17], [18], occlusions [19], [20], heterogeneous modalities [10], [21], complex camera environments, background clutter [22], unreliable bounding box generations, etc. the dynamic updated camera network [23], [24], large scale gallery with efficient retrieval [25], group uncertainty [26], significant domain shift [27], unseen testing scenarios [28], incremental model updating [29] and changing cloths [30] also greatly increase the difficulties.] 이런 요소들이 있기 때문에 연구들은 더욱 더 이뤄져야 한다.
- 딥러닝 이전에는 이런 기술들을 사용했다. the handcrafted feature construction with body structures [31], [32], [33], [34], [35] or distance metric learning [36], [37], [38]
- 딥러니 이후에는 [5], [42], [43], [44] 이 논문이 놀라운 성능을 내었다
- 이 Survey 논문의 특별한 차별점
- powerful baseline (AGW: Attention Generalized mean pooling with Weighted triplet loss) 제시한다.
- new evaluation metric (mINP: mean Inverse Negative Penalty) 제시한다. mINP는 현재 존재하는 지표인 CMC/mAP를 보충하는 것으로써, 정확한 matches를 발견하는 cost를 측정한다.
<Introduction 본론>
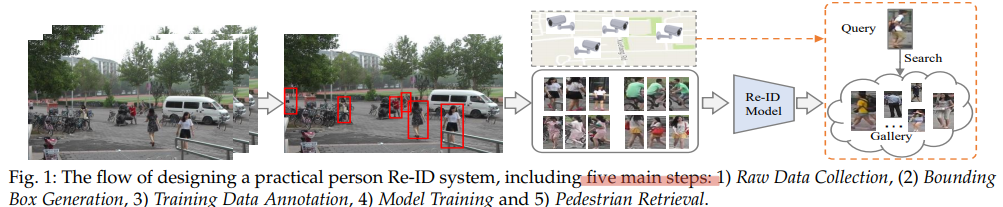
일반적인 Re-ID 시스템은 아래의 5 절차를 거친다.
- Raw Data Collection : 감시 카메라로 부터 영상 받아오기
- Bounding Box Generation : Detecting, Tracking Algorithms 이용하기
- Training Data Annotation : Close world에서는 Classification 수행하기. Open world에서는 unlabel classification 수행하기
- Model Training : Re-ID 수행하기 (다른 카메라, 같은 Label data를 묶고, 전체를 Gallery에 저장하기.
- Pedestrian Retrieval : Query person 검색하기(찾기). 여기서 query-to-gallery similarity를 비교해서 내림차순으로 나열하는 A retrieved ranking를 수행한다. 이 작업을 위해 retrieval performance를 향상시키기 위한, the ranking optimization을 수행해야 한다.
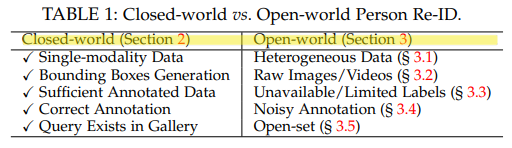
Closed-world 에서 Open-world Person Re-ID 으로의 필요한 핵심 포인트(또는 closed-world 연구에서의 핵심 가정 - 미리 위와 같은 5개의 과정을 해놓고 연구를 진행했던 것이다. 하지만 Open World에서의 저 가정은 옳지 않을 것이다.)
- ingle-modality vs. Heterogeneous Data : 지금은 카메라 영상 만을 이용하는데, infrared images [21], [60], sketches [61], depth images [62] 등을 활용한 Re-ID연구와 사용이 필수적이다.
- Bounding Box Generation vs. Raw Images/Videos : close world에서는 “Search + Predict + Bouning Box는 이미 되었다” 라고 가정하고 Re-ID를 수행한다. 하지만 이제는 이 모두를 수행하는 end-to-end person search가 필요하다.
- Sufficient Annotated Data vs. Unavailable/Limited Labels : label classification은 실생활에서 불가능하다. limited labels이기 때문이다. 따라서 unsupervised and semi-supervised Re-ID 연구가 필요하다.
- Correct Annotation vs. Noisy Annotation : close world에서는 정확한 Bounding Box가 주어진다. 하지만 실제 Detection 결과는 부정확하고 Noise가 있다. noise-robust person Re-ID를 만드는 연구가 필요하다.
- Query Exists in Gallery vs. Open-set : close world에서는 Gallery에 query person이 무조건 존재한다고 가정한다. 하지만 없을 수도 있는거다. 검색(retrieval)보다는 the verification(존재 유무 확인 및 검색)이 필요하다.
<Introduction 결론>
논문 전체 목차
- § 2 : closed-world person Re-ID
- § 2.4 : datasets and the state-of-the-arts
- § 3 : the open-world person Re-ID
- § 4 : outlook(견해) for future Re-ID
- § 4.1 : new evaluation metric
- § 4.2 : new powerful AGW baseline
- § 4.2 : under-investigated open issues (아직 연구가 덜 된 분야)
2. Closed-world Person Re-ID
2-1 Feature Representation Learning
- 이미 Detected 된 사람의 Bounding box에 대해, 이 Feature Representation(이하, Feature)을 어떻게 추출할 것인가? 사람의 포즈가 변해도, 바라보는 방향이 변해도, 카메라의 조도 등이 변해도 같은 Feature(descriptor)가 나오도록 하는 방법이 무엇일까? 크게 아래와 같이 4가지 방법이 있다.

- Global Feature Representation Learning
- Box 전체를 이용해서 Feature를 뽑아 낸다.
- 대표적인 논문 : (1) ID-discriminative Embedding (IDE) model [55, 2017] (2) a multi-scale deep representation learning [84, 2017]
- Attention Information는 feature 향상을 위해서(좀더 의미있는 정보추출) 사용된다. 아래 2개 논문이 핵심.
- pixel level attention : [90, 2019], robustness를 향상시켜주었다.
- A context-aware attentive feature learning : multiple images 사용 [95, 2019], the feature learning 향상시켜줌.
- Local Feature Representation Learning
- 과거에는 human parsing/pose detector를 이용해 human parsing/pose을 먼저 추출하고, 각 부분에 대해서 Feature를 뽑아냈다. 이렇게 하면 성능은 좋지만 추가적인 detector가 필요하고, 이 detector 또한 완벽하지 않으므로 추가의 Noisy를 만들어 냈다.
- 위와 같은 단점 때문에 horizontal-divided region features 를 사용한다. Fig2(b) 처럼. 가장 기초 논문은 Part-based Convolutional Baseline (PCB) [77]이고, 이것으로 SOTA를 찍은 논문은 [28], [105], [106]이다. 이 방법은 more flexible하다는 장점이 있지만, occlusions and background clutter(box내부 사람이 차지하는 공간이 아닌 다른 공간)에는 약한 단점이 있다.
- Auxiliary Feature Representation Learning = 추가 데이터를 활용한 Feature Learning = 아래의 방법으로 모두 좀 더 좋은 성능의 the feature representation를 추출할 수 있었다.
- Semantic Attributes : male, short hair, red hat 과 같은 추가 정보를 이용하는 것이다.
- Viewpoint Information
- Domain Information : 다른 카메라 이미지를 다른 도메인이라고 여기고, 최종적으로 globally optimal Feature를 얻는다.
- GAN Generation : the cross camera variations를 해결하고 robustness를 추가하기 위해서, the GAN generated images를 사용한다.
- Data Augmentation
- Video Feature Representation Learning
- a video sequence with multiple frames를 사용함으로써, 더 강력한 feature와 temporal information를 추출한다.
- Challenge1 : the unavoidable outlier tracking frames(?뭔지 모름) 그리고 이것을 해결하려는 논문들 소개. 특히 매우 흥미로운 논문인 [20] [Vrstc: Occlusion-free video person re-identification in CVPR, 2019] 에서는 auto-complete occluded region를 수행하기 위해서, the multiple video frames를 사용한다.
- Challenge2 : handle the varying lengths of video sequences. 그리고 이것을 해결하려는 논문들 소개.
- Architecture Design
- Re-ID features를 더 잘 추출하기 위해서, Backbone을 수정하는 논문들
- the last convolutional stripe/size to 1 [77]
- adaptive average pooling in the last pooling layer [77], [82]
- Re-ID 전체 과정 수행 논문 추천 : [112], [137], An efficient small scale network [138]
- Auto-ReID [139] model : NAS를 사용하여, 효율적이고 효과적인 model architecture 추출.
- Re-ID features를 더 잘 추출하기 위해서, Backbone을 수정하는 논문들
2.2 Deep Metric Learning
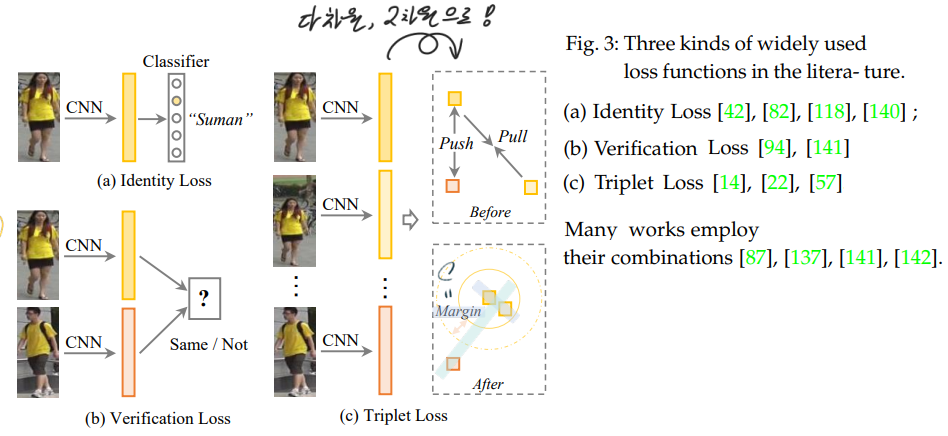
(a) Identity Loss.
- an image classification problem 사용함. 이 Loss를 바꿔서 만든 다른 Loss 수식 또한 이와 같이 있다. (1) the softmax variants (2) the sphere loss (3) AM softmax (4) label smoothing(overfitting을 피하는데 효과적인 Loss) 과 같은 방법이 있다.
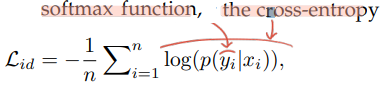
(b) Verification Loss :
- The contrastive loss :
- The verification loss with cross-entropy
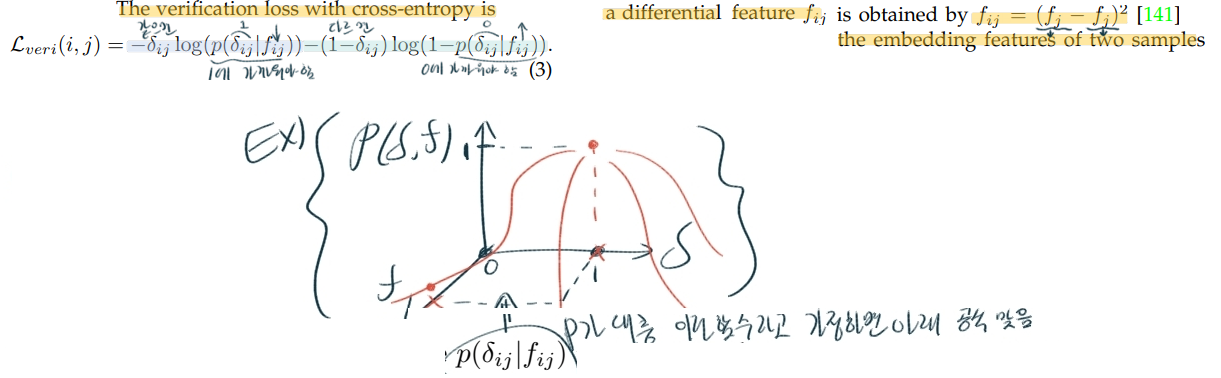
- 사실 이 수식의 p 가 무슨 함수를 사용한 건지 모르겠다. 논문을 몇번이나 다시 읽고, reference paper도 확인해 봤는데, 어떤 곳에서도 p는 그냥 probability of an input pair (xi and xj) being recognized as δij (0 or 1) 이라고만 적혀 있다. 나중에 코드를 통해서 확인해 봐야겠다.

(c) Online Instance Matching (OIM) loss
- unlabelled identities들이 존재할 때 = unsupervised domain adaptive Re-ID에서 사용하는 방법
- 아래의 memory bank가 unlabeled classes에 대해서, 각각의 class를 표현하는 feature(representation)의 정보를 저장하고 있는 memery가 되겠다. labeled class라면, 저 memory bank의 v값들이 one-hot-encoding으로 되어있을 텐데…

2.2.2 Training strategy
- 핵심 문제점 : the severely imbalanced positive and negative sample pairs 그리고, 이것을 해결하는 방법들.
- The batch sampling strategy (the informative positive and negative minings)
- adaptive sampling (adjust(조정하기) the contribution(기여도) of positive and negative samples)
- 위의 Loss들을 하나만 쓰는게 아니라, , a multiloss dynamic training strategy를 사용한다.
- adaptively reweights the identity loss and triplet loss. 두 loss에 적절한 알파, 배타 값을 곱하고 이 알파, 배타 값을 이리저리 바꿔가면서, 학습을 진행하는 방법.
- consistent performance gain 을 얻을 수 있다.
2.3 Ranking Optimization
- testing stage에서 검색 성능(retrieval performance)를 증가시키기 위해서(=ranking list의 순서를 다시 정렬하는 방법들) 필요한 작업을 아래에 소개한다. 그냥 저런 방법과 이미지가 있다 정도로만 알아두자. 정확하게 이해는 안된다.
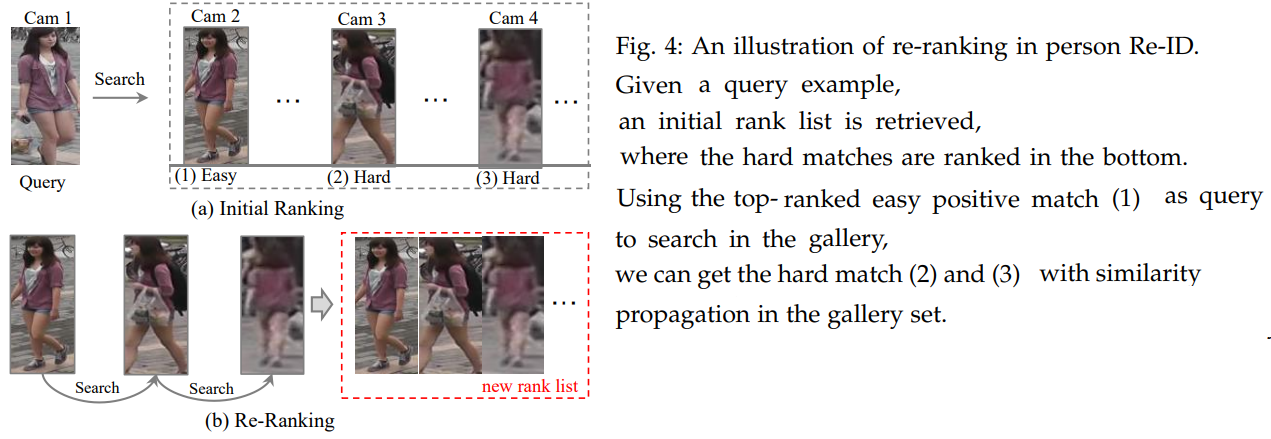
- optimizes the ranking order [58], [157]
- by automatic gallery-to-gallery similarity mining : 위의 이미지 (b) 처럼 초기의 주어진 ranking list를 기준으로 Gallery안에서 계속 기준 Query를 바꿔가며 Search를 진행해 나간다. 그렇게 list를 다시 획득하는 방법. (?? 정확히 모르겠다.)
- human interaction : using human feedback을 계속 받으므로써, supervised-learning을 진행하며 Re-ID ranking performance를 높힌다.
- Rank/Metric fusion [160], [161] (??)
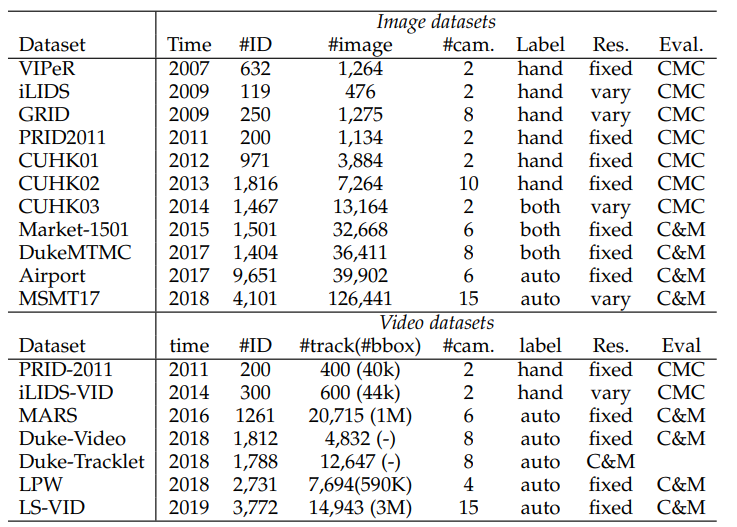
2.4.1 Datasets and Evaluation Metrics
- closed-world setting으로 많이 사용하는 dataset 11개에 대해서 소개한다. (NEU-Gou/awesome-reid-dataset)
- Evaluation Metrics : (1) Cumulative Matching Characteristics (CMC) (2) mean Average Precision (mAP)
- CMC-k (a.k.a, Rank-k matching accuracy) : ranked된 retrieved results에서 top-k안에 정확한 match가 몇퍼센트로 일지하는가? 예를 들어서 ranked된 retrieved results에 100장의 BB가 있고, 그 중 query를 정확하게 맞춘 BB가 80장이라면 0.8 이다.
- CMC = CMC-1 , the first match 만을 고려한다. 하지만 the gallery set에는 다수의 GT bounding box in image가 존재하기 때문에 이것으로는 multiple camera setting에서 정확한 지표라고 할 수 있다.
2.4.2 In-depth Analysis on State-of-The-Arts
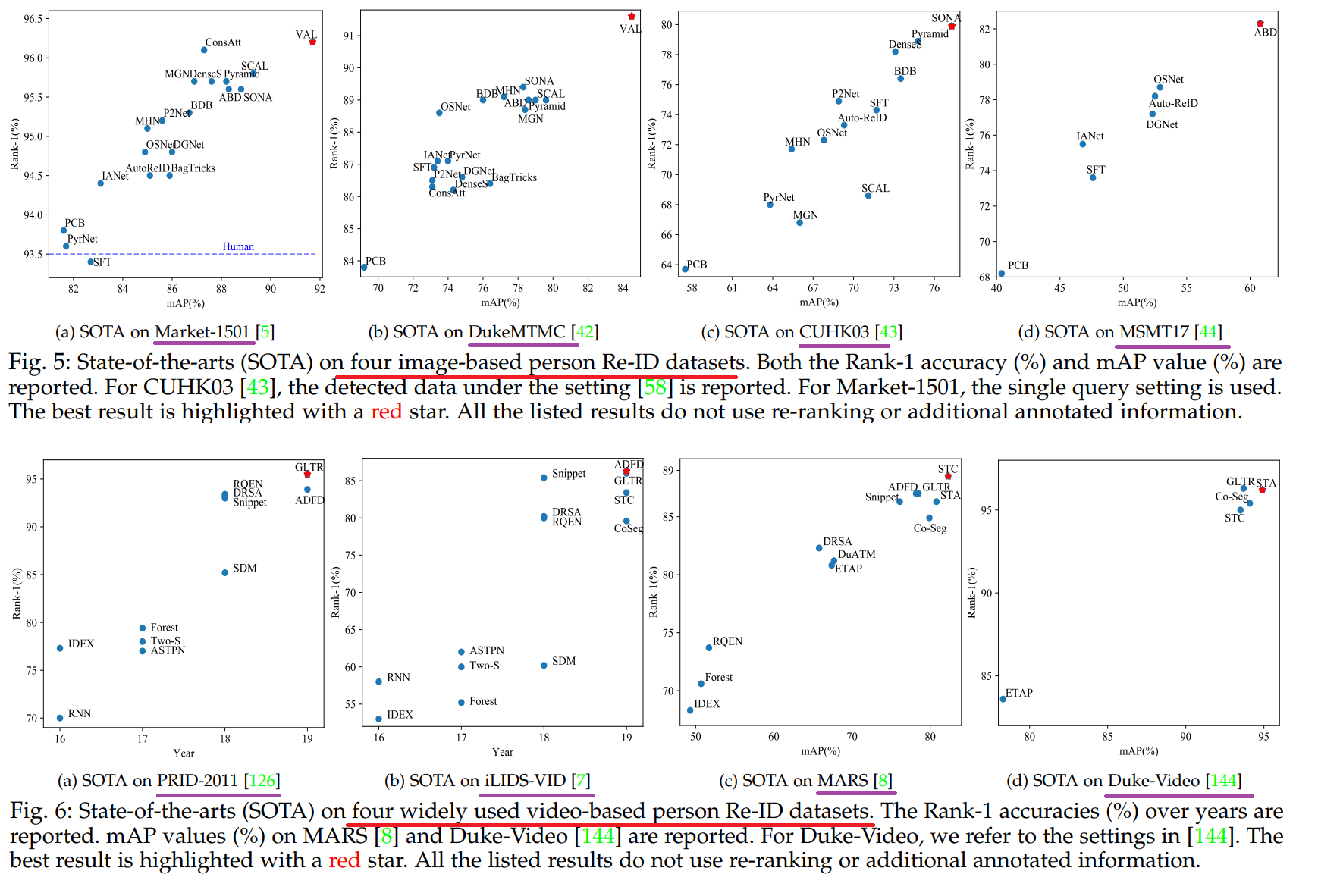
- 빨간색 줄은 데이터셋 종류, 보라색 줄은 데이터셋 이름.
- image-based(위 사진) and video-based(아래 사진) 이렇게 2개의 관점에서 SOTA 모델이 무엇인지 확인해 본다.
- 이 논문의 8 Page를 살표보면, 각 그래프에 대해서, 왜 SOTA 빨간색점의 모델이 최고의 성능을 낼 수 있었던 이유에 대해서 짧게 설명하는 부분도 있다. 따라서 필요하면 참고하기.
- 이 성능 비교는, 저자가 직접, 많은 데이터셋 중, 가장 핵심이 되는 4개의 데이터셋을 이미지와 비디오에서 각각 선별하고, 모델을 돌려 성능을 확인하고 나온 결과를 기록한 것이다.
3. Open World Person Re-ID
- 윗 내용 중
Closed-world 에서 Open-world Person Re-ID 으로의 필요한 핵심 포인트꼭꼭 다시 읽고 아래 내용 공부하기
3.1 Heterogeneous Re-ID
- [3.1.1] Depth-based Re-ID
- Depth images 를 활용한 몇가지 논문들 소개
- RGB and depth info.를 결합합으로써, Re-ID 성능을 높이고 the clothes-changing challenge 를 해결했다.
- 몇가지 논문이 제시되어 있는데, 직접 찾아 확인을 해보니, 6m정도 이내에서 사람을 검출한다. 작은 복도 구석에 카메라를 설치해서 사용하는 방법이다. 확실히 Depth 카메라의 Range를 고려한 것 같다.
- [3.1.2] Text-to-Image Re-ID
- visual image of query를 얻을 수 없고, only a text description만이 주워질 때 필수적으로 사용해야하는 방법이다.
- the shared features (between the text description and the person images)를 학습한다.
- [3.1.3] Visible-Infrared Re-ID (적외선)
- the cross-modality matching(= modality sharable features) between the daytime visible and night-time infrared images 를 다루는 방법이다.
- GAN을 사용해서 cross-modality person images 를 생성해서, the cross-modality discrepancy 를 제거하는 방법도 있다.
- 2019 ~ 2020 논문들이 많다. 이 쪽 연구가 활발히 이뤄지는 것 같다. 필요하면 참고할 것.
- [3.1.4] Cross-Resolution Re-ID
- 높고 낮은 해상도 이미지 사이의, the large resolution variations 를 해결하기 위한 목적의 논문들 소개
3.2 End-to-End Re-ID
- Re-ID in Raw Images/Videos
- the person detection and reidentification 을 모두 수행하애 한다.
- 2017 년도에 나온 [55], [64] 논문이 기초 논문
- [196, 2019] a graph learning framework
- [197, 2019] squeeze-and-excitation network to capture the global context info
- [198, 2019] generate more reliable bounding boxes
- Multi-camera Tracking
- 1개 query가 아니라 multi-person, multi-camera tracking [52, 2018] 에 대한 고려 논문.
- 이 외 다른 논문 소개 A graph-based formulation [201, 2017], a locality aware appearance metric [202, 2019]
3.3 Semi-supervised and Unsupervised Re-ID
- [3.3.1] Unsupervised Re-ID
- invariant components(각 Label에 대해서 변함없는 feature 저장 구성) (i.e., dictionary [203], metric [204] or saliency [66]) 를 학습하는데 목적이 있다.
- (1) deeply unsupervised methods 들에 대해서, 1문단으로 논문들 소개
- (2) end-to-end unsupervised Re-ID 들에 대해서, 1문단으로 논문들 소개
- 이런 많은 논문들과 연구들에도 불구하고, newly arriving unlabelled data를 model updating하는데 아직도 어려움이 많다.
- (3) 일부 end-to-end unsupervised Re-ID 방법들 중에서, 특히 learn a part level representation ( local parts than that of a whole imag ) 를 학습하려고 하는 모델들이 있다. [153, 212]
- Semi-/Weakly supervised Re-ID : (1) With limited label information, a one-shot metric learning [213] (2) A stepwise one-shot learning method [144] (3) A multiple instance attention learning framework uses the video-level labels [214]
- [3.3.2] Unsupervised Domain Adaptation
- a labeled source dataset의 지식(Feature Extractor)을 the unlabeled target dataset에게 넘겨주는데 목적을 가지고 있는 모델들이다. = unsupervised Re-ID without target dataset labels
- Target Image Generation : GAN을 사용해서, source-domain 이미지를 target-domain style이미지로 transfer generation한다. 이러한 방식을 사용하는 9가지 논문 소개
- Target Domain Supervision Mining : source dataset을 이용해서 아주 잘 학습된 model을 사용해서 target dataset의 supervision(annotation정보)룰 직접적으로 mining(추출하는) 하는 방법이다. 이러한 방식을 사용하는 7가지 논문 소개
- [3.3.3] State-of-The-Arts for Unsupervised Re-ID
- 우선 아래의 전체 모델 성능 비교 참조.
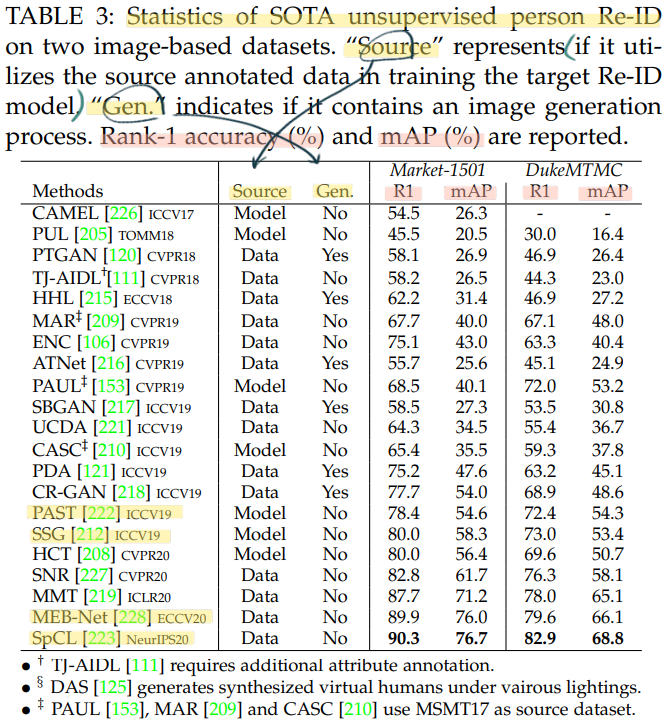
- 최근, He et al. [229, 2020] 논문을 보면 large-scale unlabeled training data를 사용하여 unsupervied learning을 적용하면, 다수의 tasks에서 supervised learning을 이용한 것보다 훨씬 더 좋은 성능이 나올 수 있다고 증명한다. 따라서 앞으로도 미래의 breakthroughs가 될 것으로 기대된다.
3.4 Noise-Robust Re-ID
- 여기서는 3가지 관점으로 noise-robust Re-ID 논문들에 대해서 소개한다.
- 논문에서는, 여러 다른 기술이 들어간 논문들을 아주 짧게 소개한다. 그러니 내가 이해못하는게 너무 당연하다. 정독을 하던, 스키밍을 하던 이해 안되는 것은 똑같았고, 그래서 큰 그림만을 아래에 적어 놓았다.
- the Re-ID problem with heavy occlusions (Partial Re-ID) : Deep Spatial feature Reconstruction (DSR) [232], Visibility-aware Part Model (VPM) [67], A foreground-aware pyramid reconstruction scheme [233]
- the problem caused by poor detection/inaccurate tracking results : Detected BB에서 noisy regions이 기여하는 정도를 suppress 하는것이 Basic Idea 이다. 특히 [20]에서는 multiple video frames to auto-complete occluded regions(비디오 이미지를 사용해서, 한 프레임에서는 보이지 않는 occulded 부분을, 여러 프레임을 사용해서 자동 복원하는 방법이다.)
- the problem due to annotation error : [42], [235], [236] 위에 처럼 각 논문에 따른 이름을 적어 놓는게 무슨 의미가 있나… 안 적었다. 필요하면 알아서 참고.
3.5 Open-set Re-ID and Beyond
- Open-set Re-ID를 처리하는 가장 기본적인 방법은, a learned condition τ를 사용해서, similarity(query, gallery) > τ (τ보다 크면, matching시키고, τ보다 작으면 gallery에 query가 없다고 판단.)를 이용하는 것이다.
- 위와 같은 방법을 handcrafted systems이라고 하며 [26], [69], [70] 이런 논문들이 있다.
- handcrafted 가 아닌, deep learning methods를 사용한 Adversarial PersonNet (APN) [237] 이라는 방법도 있다. GAN module and the Re-ID feature extractor를 사용해서, similarity를 판별하고, gallery에 query가 있는지 없는지 판단한다.
- Group Re-ID : associating the persons in groups rather than individuals. Group을 associationg(?) 하는 방법으로는, (1) sparse dictionary learning 기반, (2) the group as a graph 기반. 2개이다. 각 기반 방법에 해당하는 논문들이 소개 되어 있다.
- Dynamic Multi-Camera Network : new cameras or probes(데이터 분포&유사도)에 대한 adaptation challenging를 고려하는 몇가지 논문들 소개되어 있음.
4. An Outlook Re-ID (new metric, baseline)
4.1 - mINP: A New Evaluation Metric for Re-ID
- computationally efficient metric 를 표현하는 metric
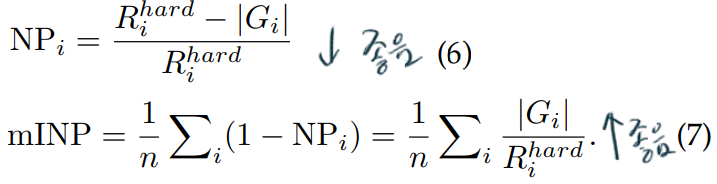
- 여기서 R은 Rank position of the hardest match, G는 correct matches for query의 총 갯수이다. 아래의 예시를 참고하자.

- 이런 성능 지표가 필요한 이유는 다음과 같다. 위 그림의 Rank List 1은 Rank List 2에 비해서 AP가 높다. (AP수식은 논문의 초반부분에서 참고) 하지만 NP를 계산해보면, Rank List 1이 더 높다. (NP는 낮아야 좋은것)이 말은 즉, “hardest true matching를 찾기 이전까지, too many false matchings 이 포함되었다.”를 의미한다. 따라서 Rank List 1의 computing 효울은 낮다고 판단할 수 있다.
4.2 - A New Baseline(AGW) - Single-/Cross-Modality Re-ID
three major improved components 를 포함하는 새로운 Baseline 모델이다. github code - pytorch
여기 있는 아이디어를 나중에 착안해 사용해도 좋을 것 같다.
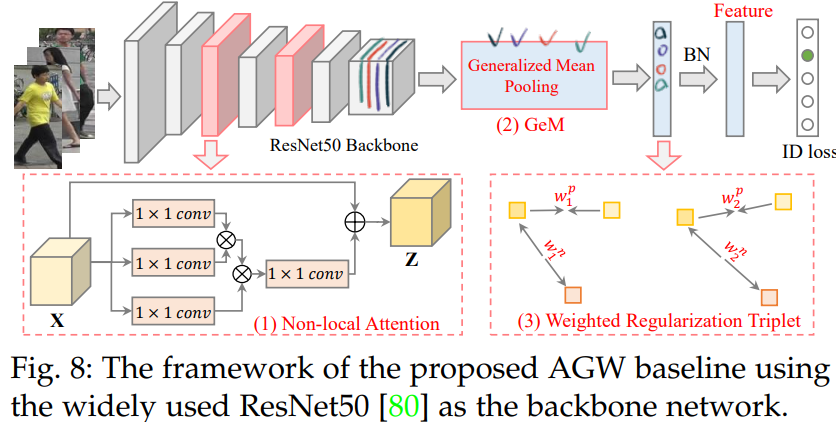
Non-local Attention (Att) Block : nonlocal attention block [246, 2019] 사용
Generalized-mean (GeM) Pooling
- a learnable pooling layer이다.
- generalized-mean (GeM) pooling [247, 2018] 를 참고했다.
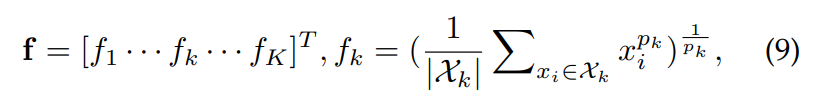
- 여기서 Xk는 feature map의 각 channel들이다. pk는 training 중에 학습되는 pooling hyper-parameter이다. 만약 Pk가 무한하게 크면, Max pooling이 이뤄지는 것이고, Pk가 1이면, average pooing이 이뤄지는 것이다.
Weighted Regularization Triplet (WRT) loss
- weighted regularized triplet loss.
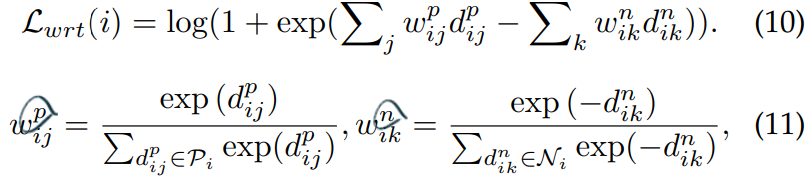
- 위의 수식을 사용한다. (i, j, k)가 의미하는 것은 a hard triplet within each training batch 이다.
- 3개의 이미지 중, 서로 2개가 같은 ID의 이미지이면 positive, 다르면 Negative이다. 위의 수식을 사용해서 positive인 weight 끼리는 거리가 가깝도록, negative인 weight 끼리는 거리가 멀더록 만든다.
좀 더 확실한 이해는, 논문을 통해서도 힘들다. 나중에 코드도 함께 봐야겠다.
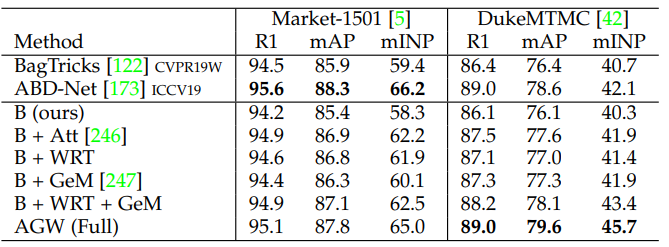
4.2.a - Results
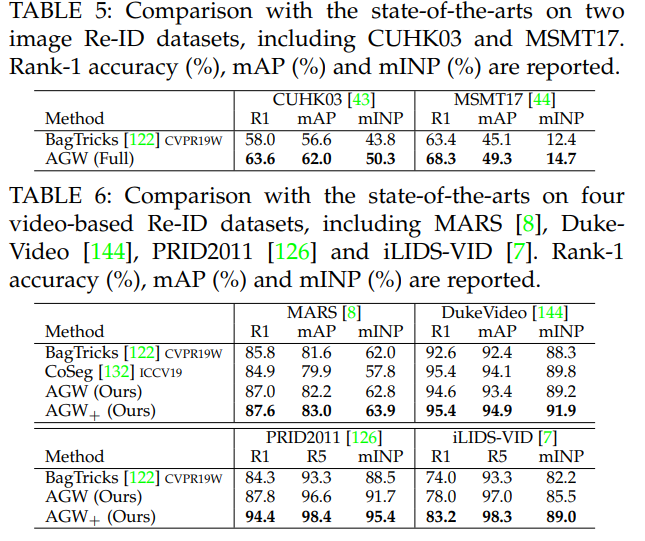
4.3 Under-Investigated Open Issues (challenge)
- 4.3.1 Uncontrollable Data Collection - 자동 데이터 수집기 필요
- 4.3.2 Human Annotation Minimization - 비용 절감을 위해 사람의 라벨링 작업 최소화 필요
- 4.3.3 Domain-Specific/Generalizable Architecture Design - Domain 변화에도 일정한 성능을 가지는 NN
- 4.3.4 Dynamic Model Updating - online learning 필요
- 4.3.5 Efficient Model Deployment - fast and efficient 한 모델. 작고 강한 모델.
자세한 내용은 논문 참조
