【LightWeight】Understanding Xception, MobileNet V1,V2 from youtube w/ advice
- 논문1 : MobileNet V1 paper link / Youtube Link1
- 논문2 : MobileNet V2 paper link / Youtube Link2
- 논문2 : Xception YoutubeLink
- 분류 : LightWeight
- 공부 배경 : MobileNetV3 Paper 읽기 전 선행 공부로 youtube 발표 자료 보기
- 선배님 조언:
- Experiment와 Result 그리고 Ablation는 구체적으로 보시나요? 핵심 부분을 읽다가, 핵심이 되는 부분을 캐치하고 이것에 대해서 호기심이 생기거나, 혹은 이게 정말 성능이 좋은가? 에 대한 지표로 확인하기 위해서 본다. 따라서 필요거나 궁금하면 집중해서 보면 되고 그리 중요하지 않은 것은 넘기면 된다. 만약 핵심 Key Idea가 Experiment, Result, Ablation에 충분히 설명되지 않는다면 그건 그리 좋지 않은 아이디어 혹은 논문이라고 판단할 수 있다.
- 공부와 삶의 균형이 필요하다. 여유시간이 나서 유투브를 보더라도 감사하고 편하게 보고 쉴줄 알아야 하고, 공부할 때는 자기의 연구분야에 대한 흥미를 가지는 것도 매우 중요하다. 또한 취미나 릴렉스할 것을 가지고 가끔 열심히 공부하고 연구했던 자신에게 보상의 의미로 그것들을 한번씩 하는 시간을 가지는 것도 중요하다.
- 여러 선배들과 소통하고, 완벽하게 만들어가지 않더라도 나의 아이디어로 무언가를 간단하게 만들어 보고 제안해 보는것도 매우 중요하다. 예를 들어서, “나에게 이런 아이디어가 있으니, 이 분야 논문을 더 읽어보고 코드도 만들어보고 연구도 해보고 비교도 해보고 실험도 많이 해보고, 다~~ 해보고 나서 당당하게! ㅇㅇ선배님께 조언을 구해봐야겠다!” 라는 태도 보다는 “나에게 이런 아이디어가 있고… 논문 4개만 더 읽고 대충 나의 아이디어를 PPT로 만들어서 ㅇㅇ선배님께 보여드려보자! 그럼 뭐 좋은건 좋다고 고칠건 고치라고 해주시겠지…! 완벽하진 않더라도 조금 실망하실지라도 조금 철면피 깔고 부딪혀 보자!!” 라는 마인드.
- 논문. 미리미리 써보고 도전하자. 어차피 안하면 후회한다. 부족한 실력이라고 생각하지 말아라. 어려운 거라고 생각하지 말아라. 일단 대가리 박치기 해봐라. 할 수 있다. 목표를 잡고 도전해보자.
- 느낀점 : 말만 삐까번쩍, 번지르르 하게 해놓은 글이 너무 많다. 사실 몇개 대충 실험해보고 성능 잘나오니까.. 이거를 말로 포장을 해야해서 뭔가 있어보이게 수학적으로 마치 증명한것 마냥 이야기하는 내용이 머신러닝 논문에 너무 많다. 정말 유용한 지식만 걸러서 듣자. Experiment, Result, Ablation 를 통해서 증거를 꼭 찾아보자.
- 목차
강의 필기 PDF는 “OneDrive\21.겨울방학\RCV_lab\논문읽기”
- <아래 이미지가 안보이면 이미지가 로딩중 입니다>
1. Inception Xception GoogleNet










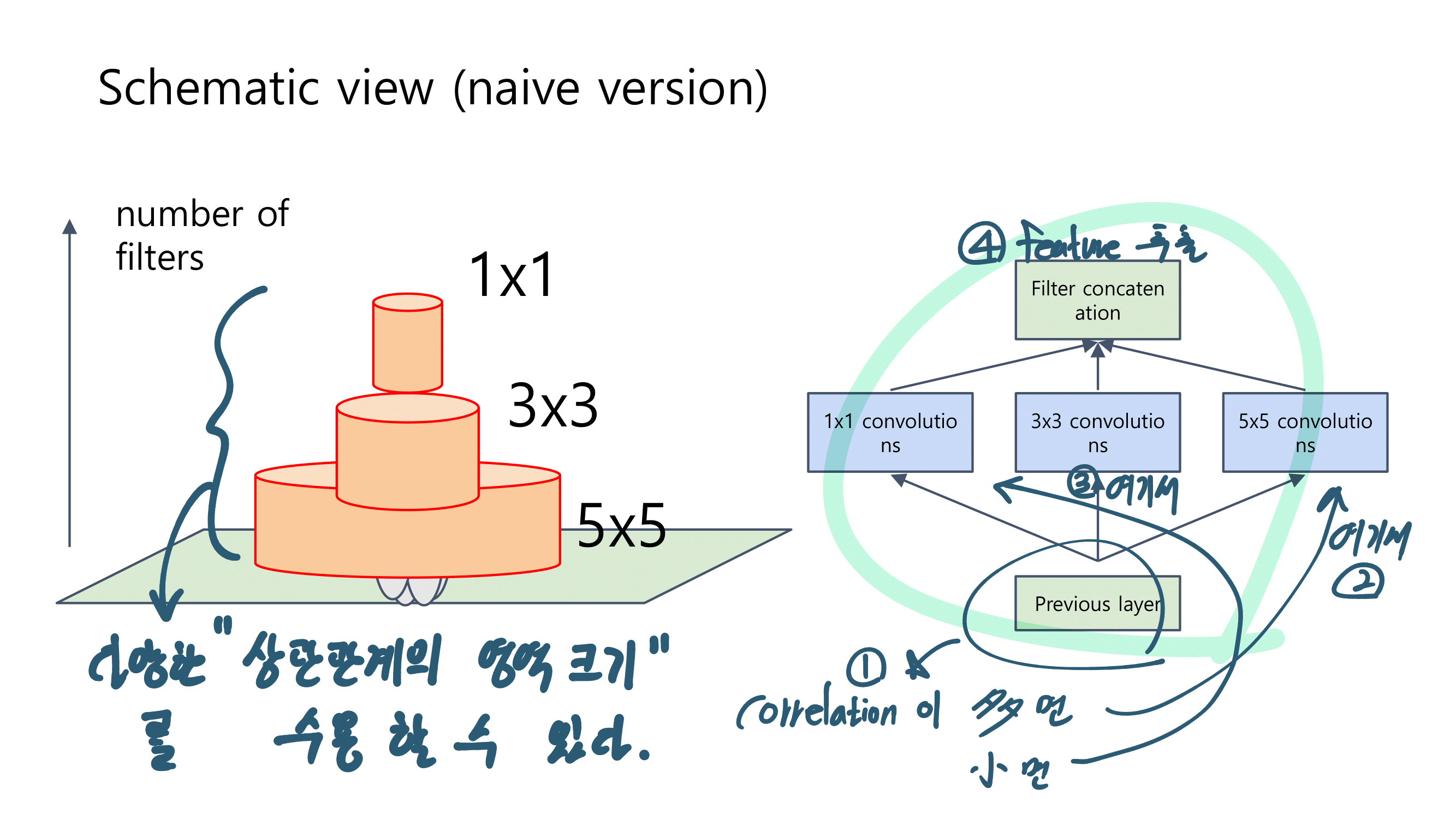
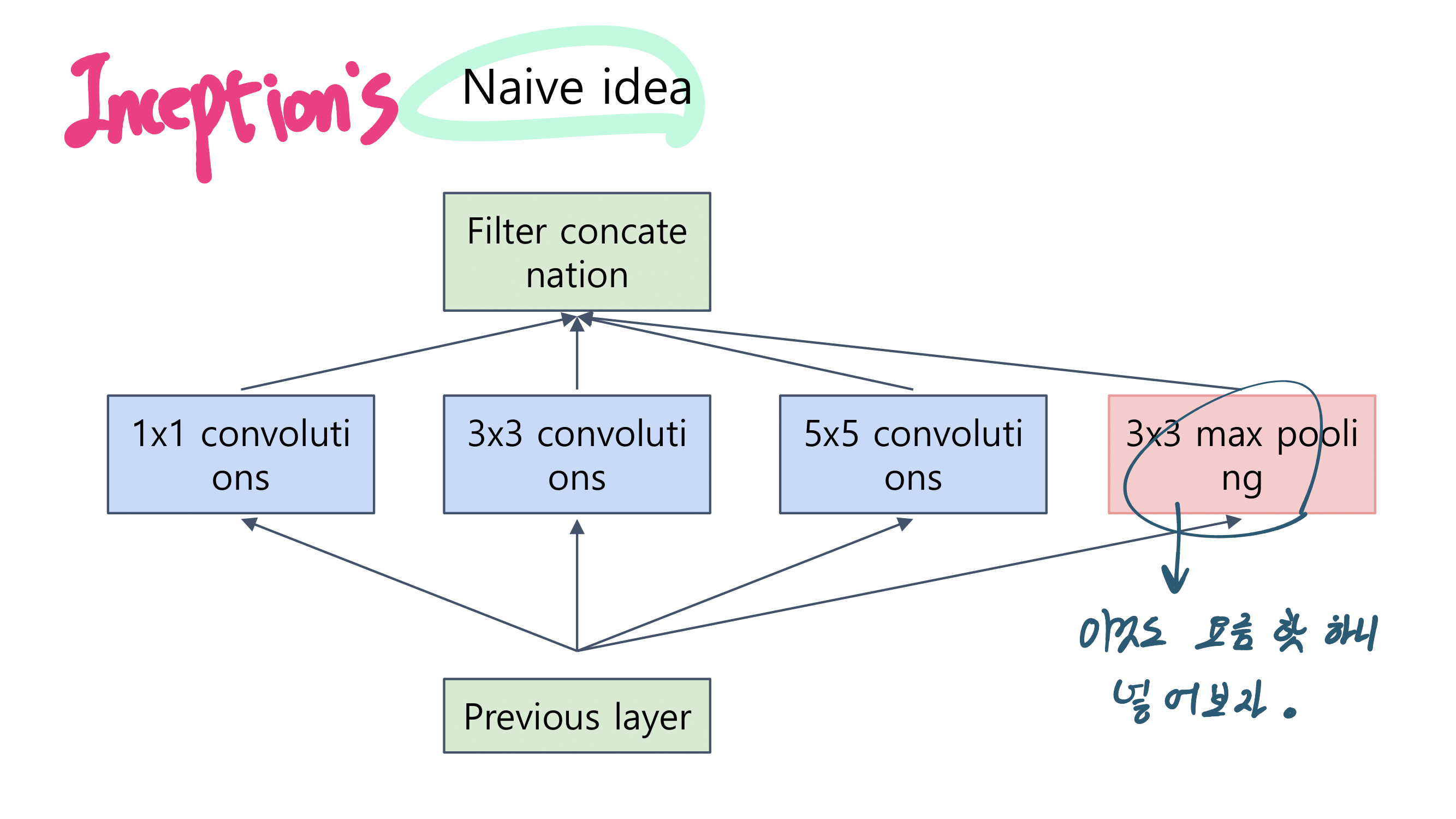
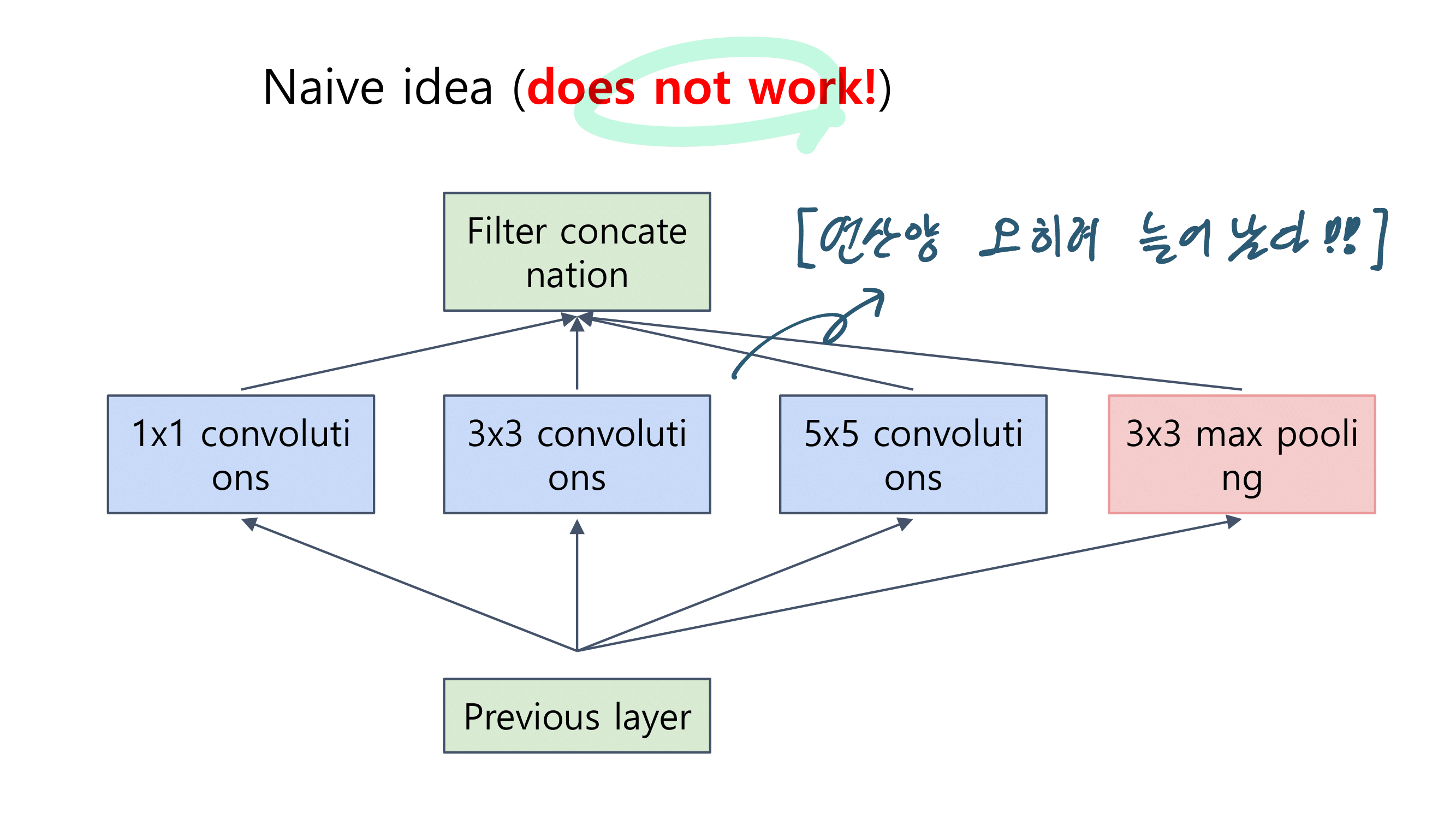
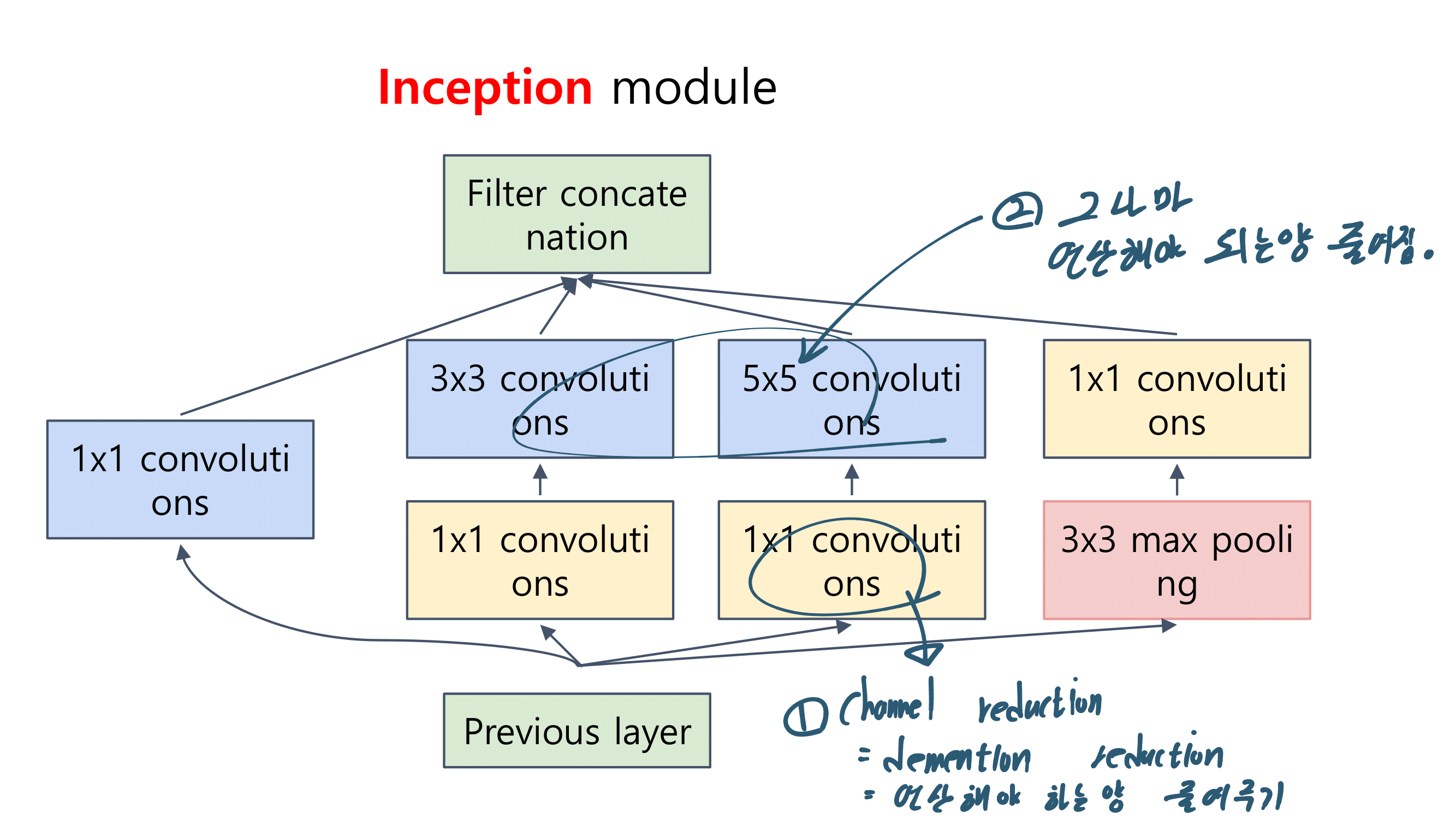
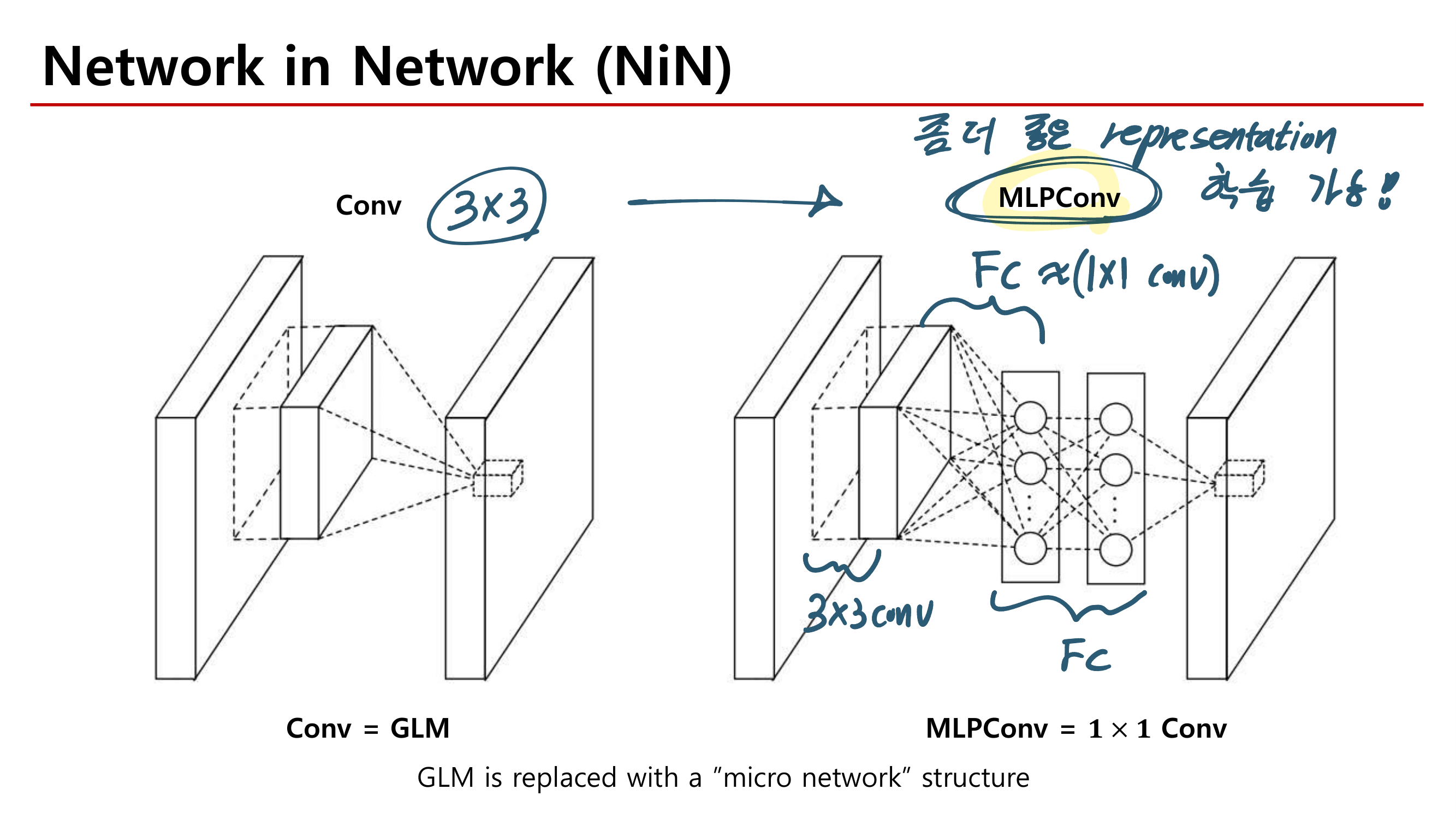


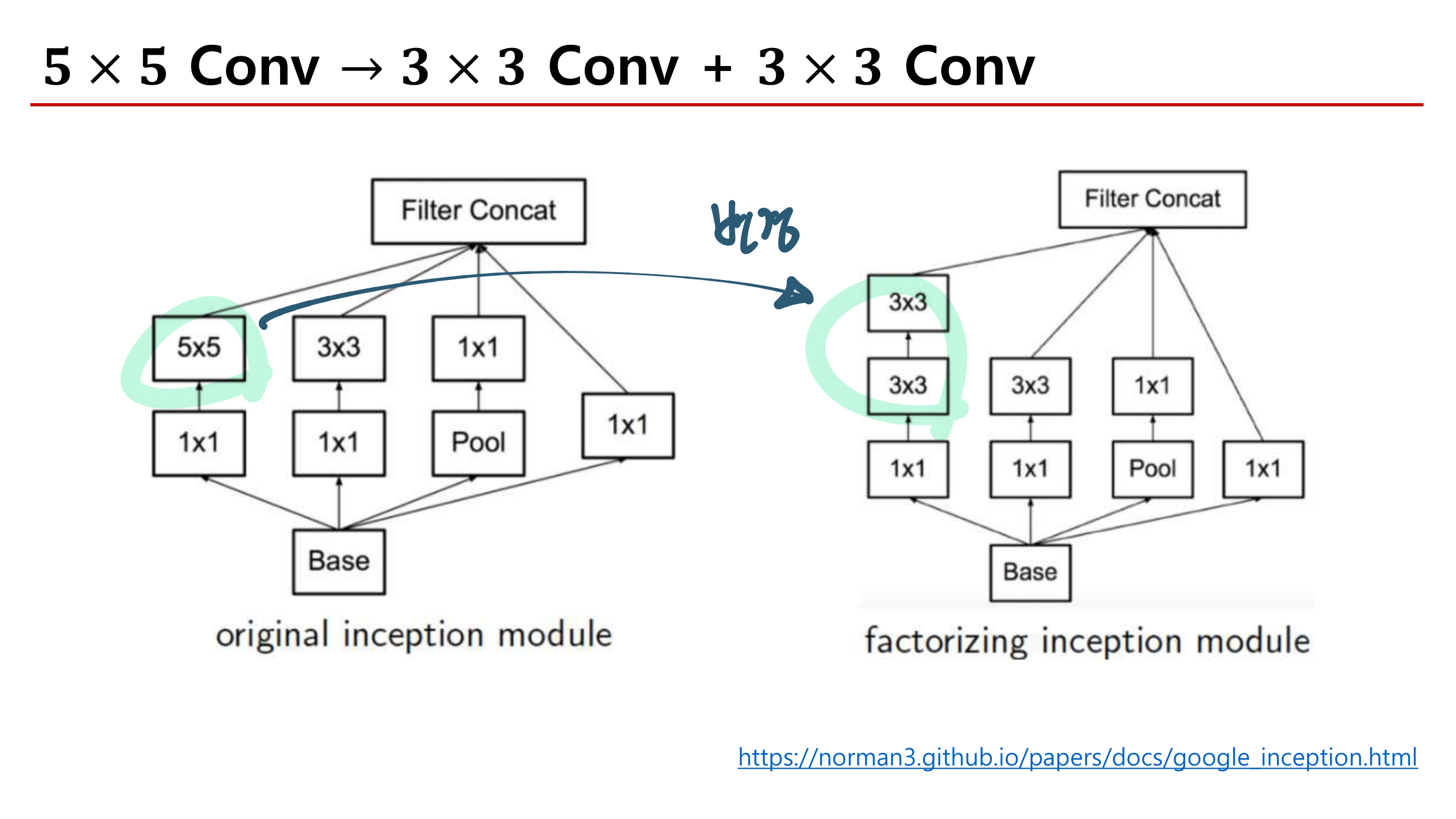


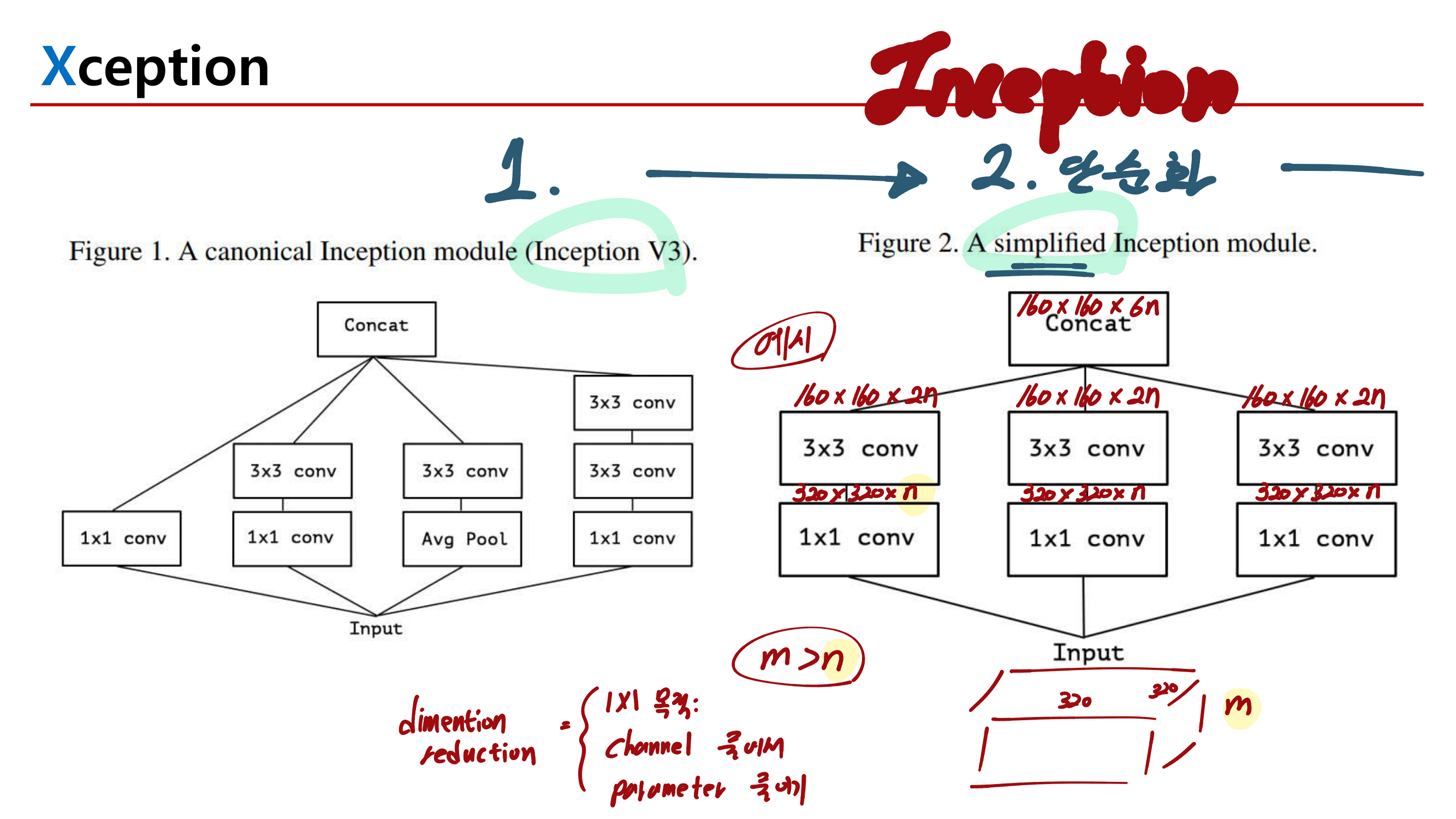
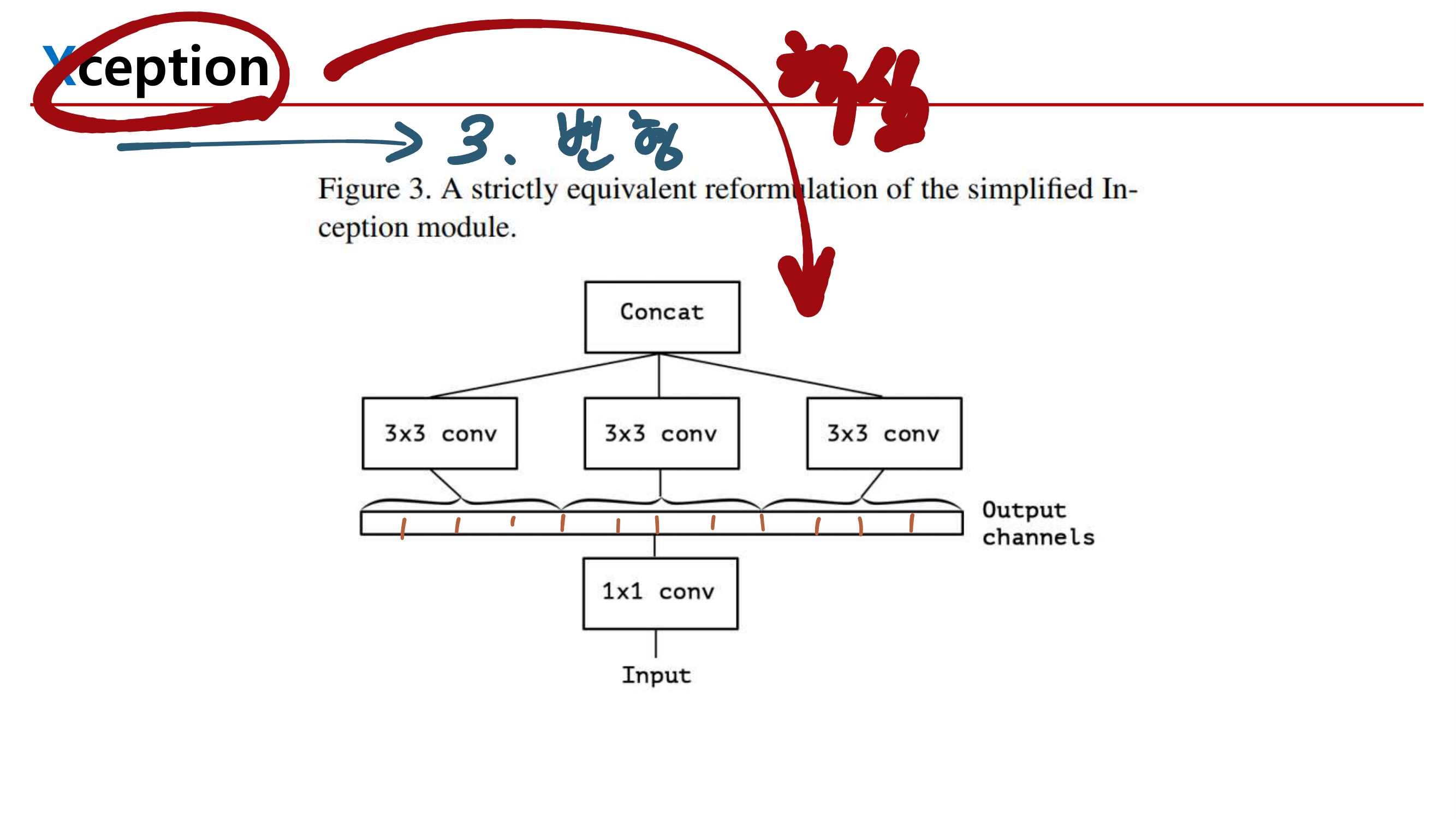
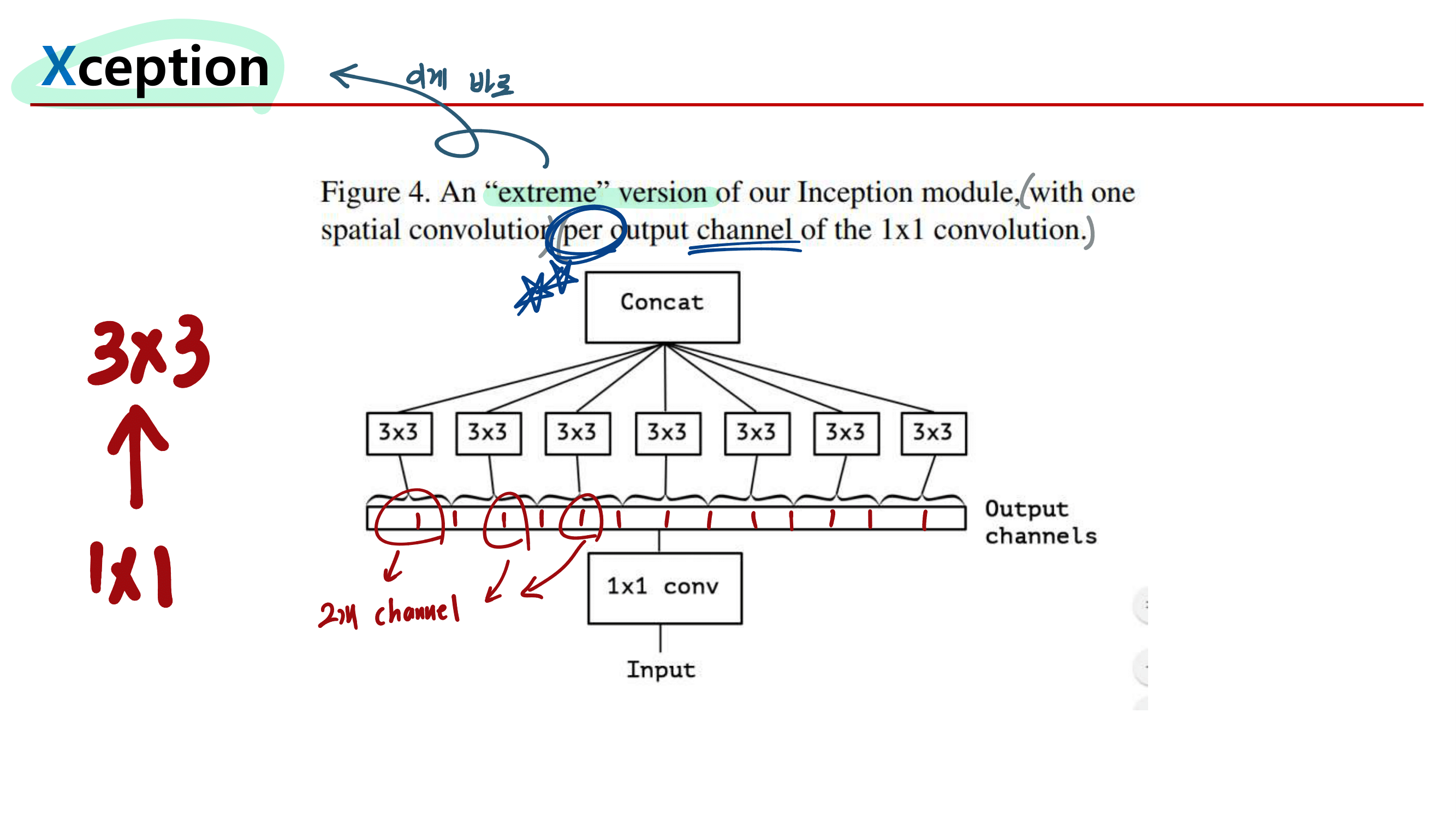
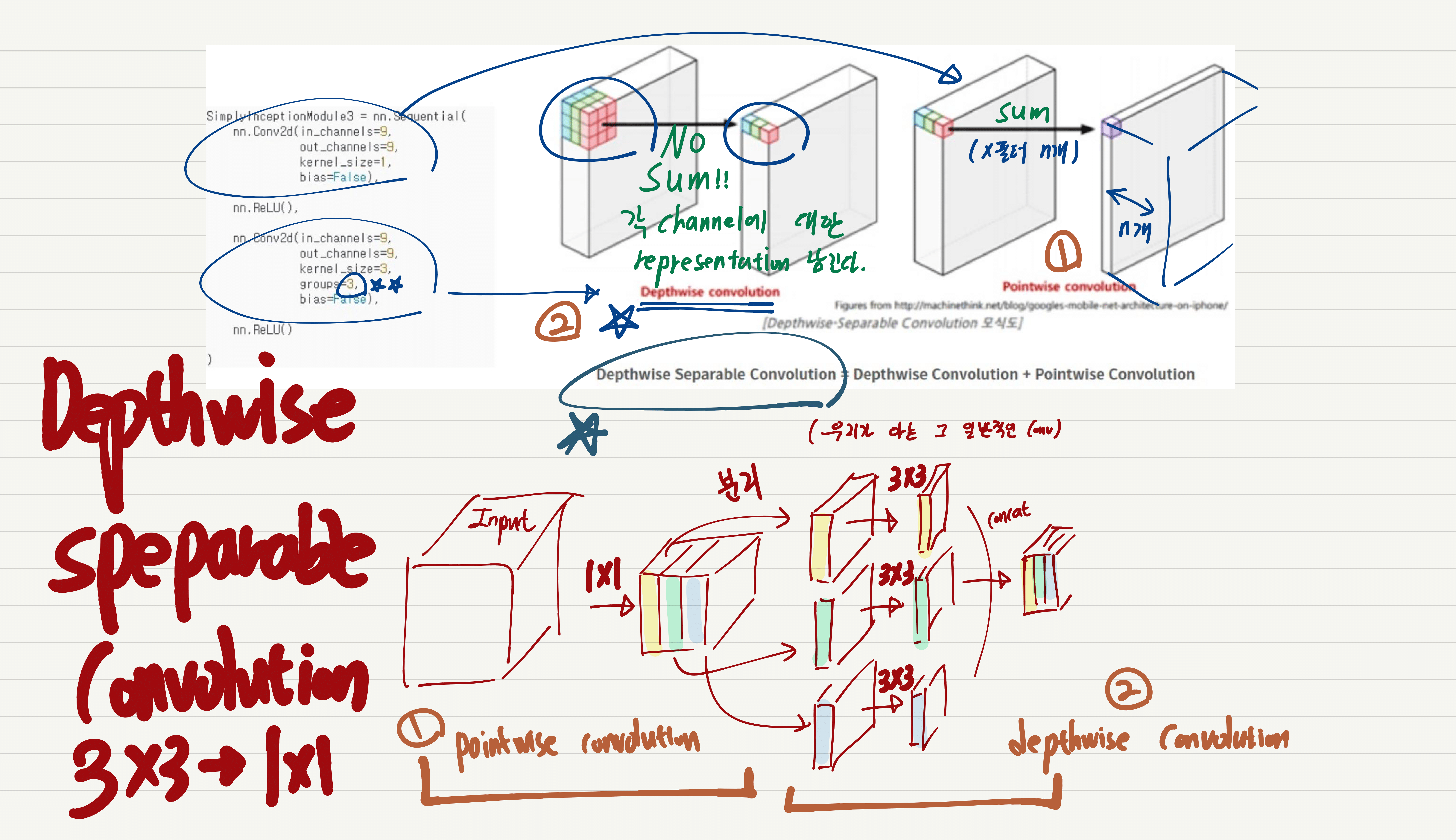

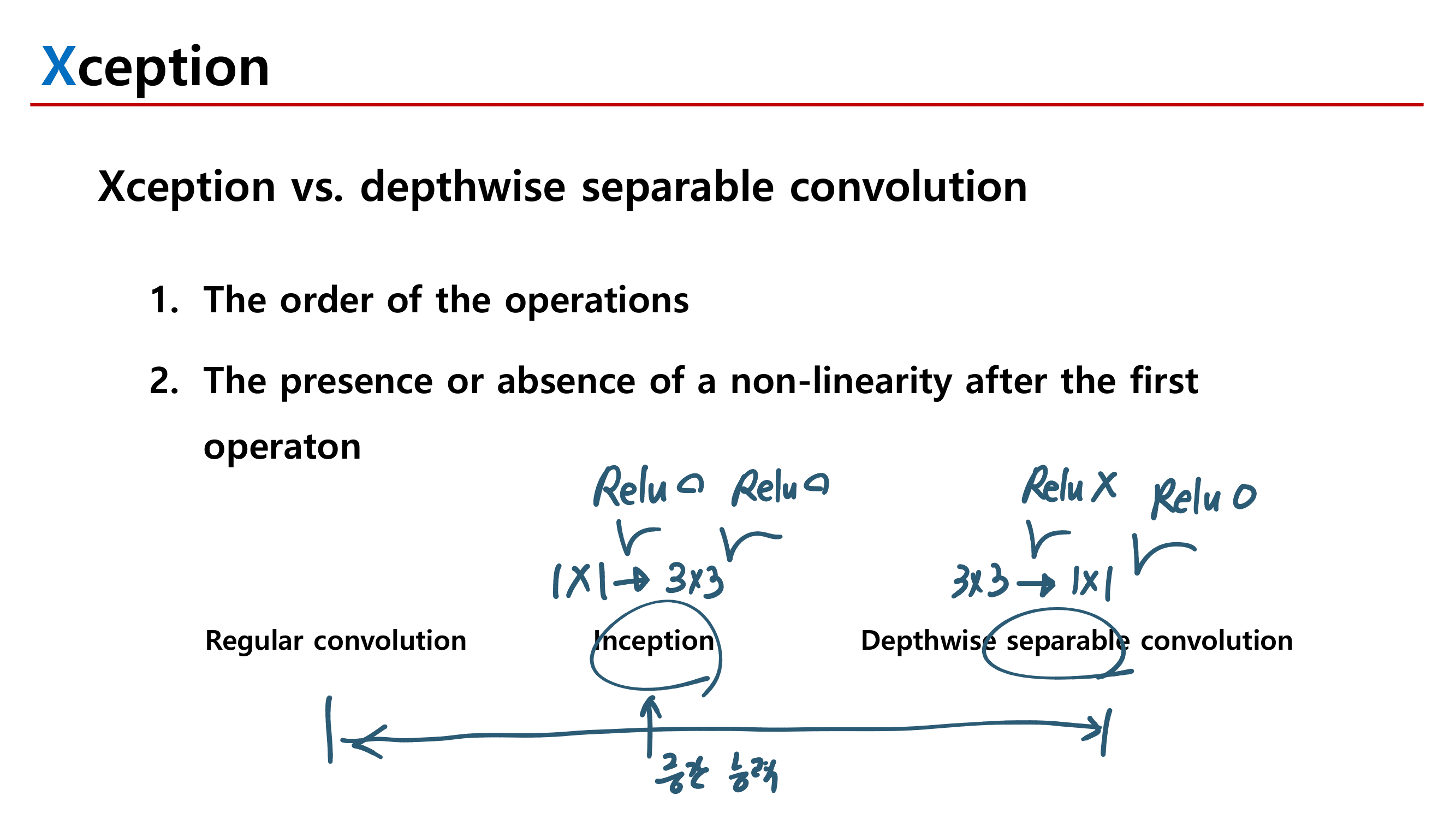

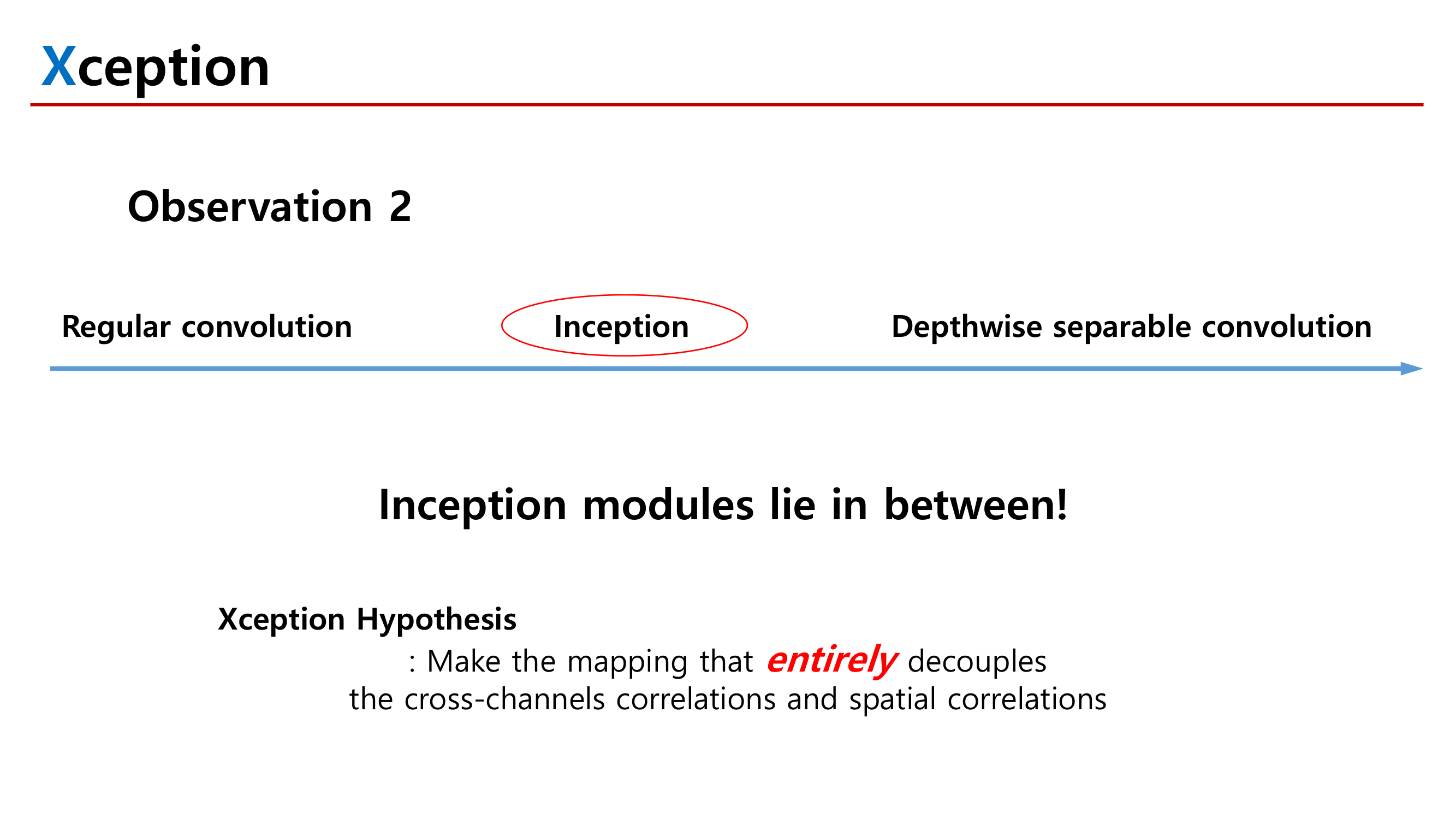


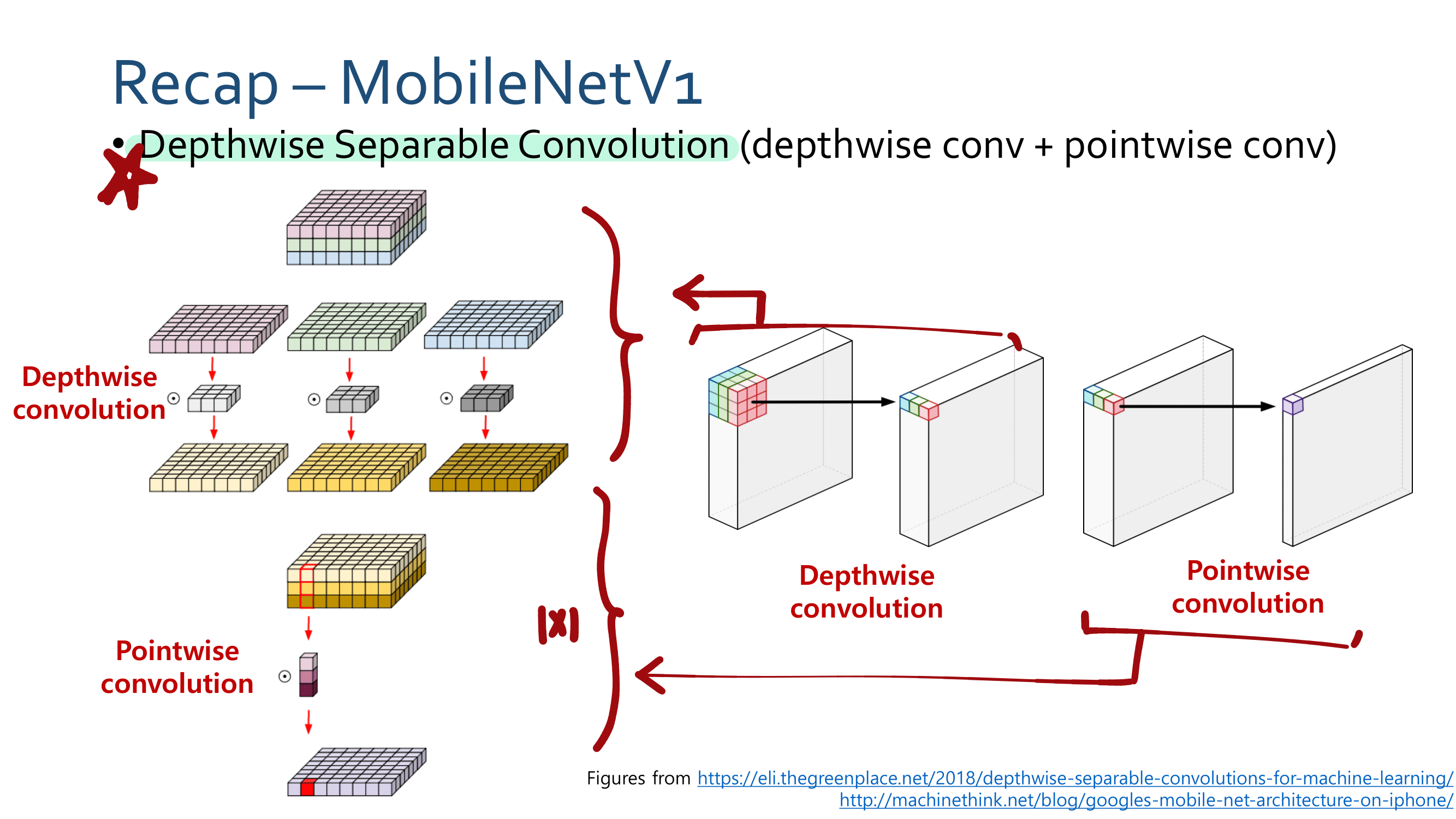
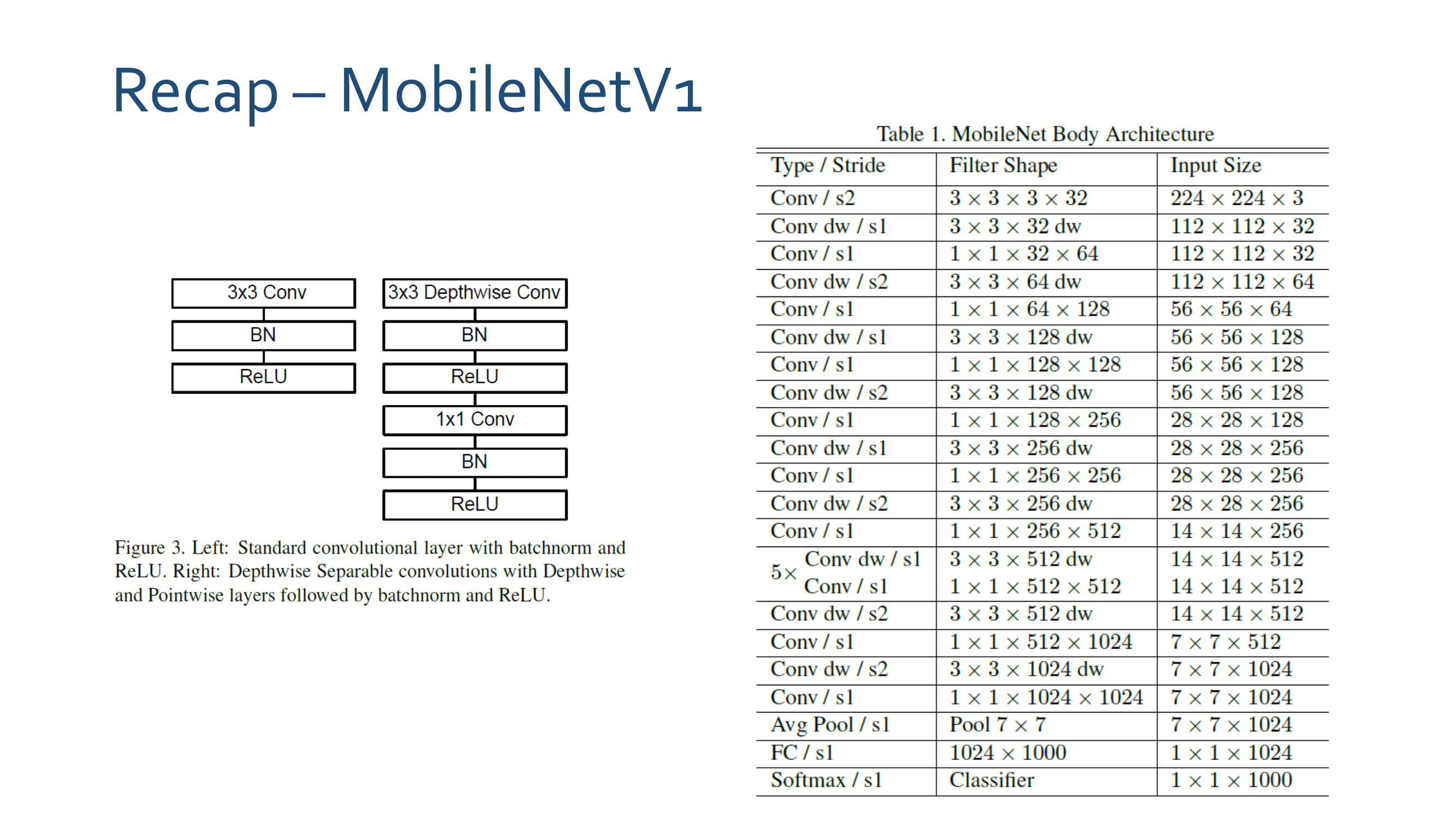
2. MobileNetV1







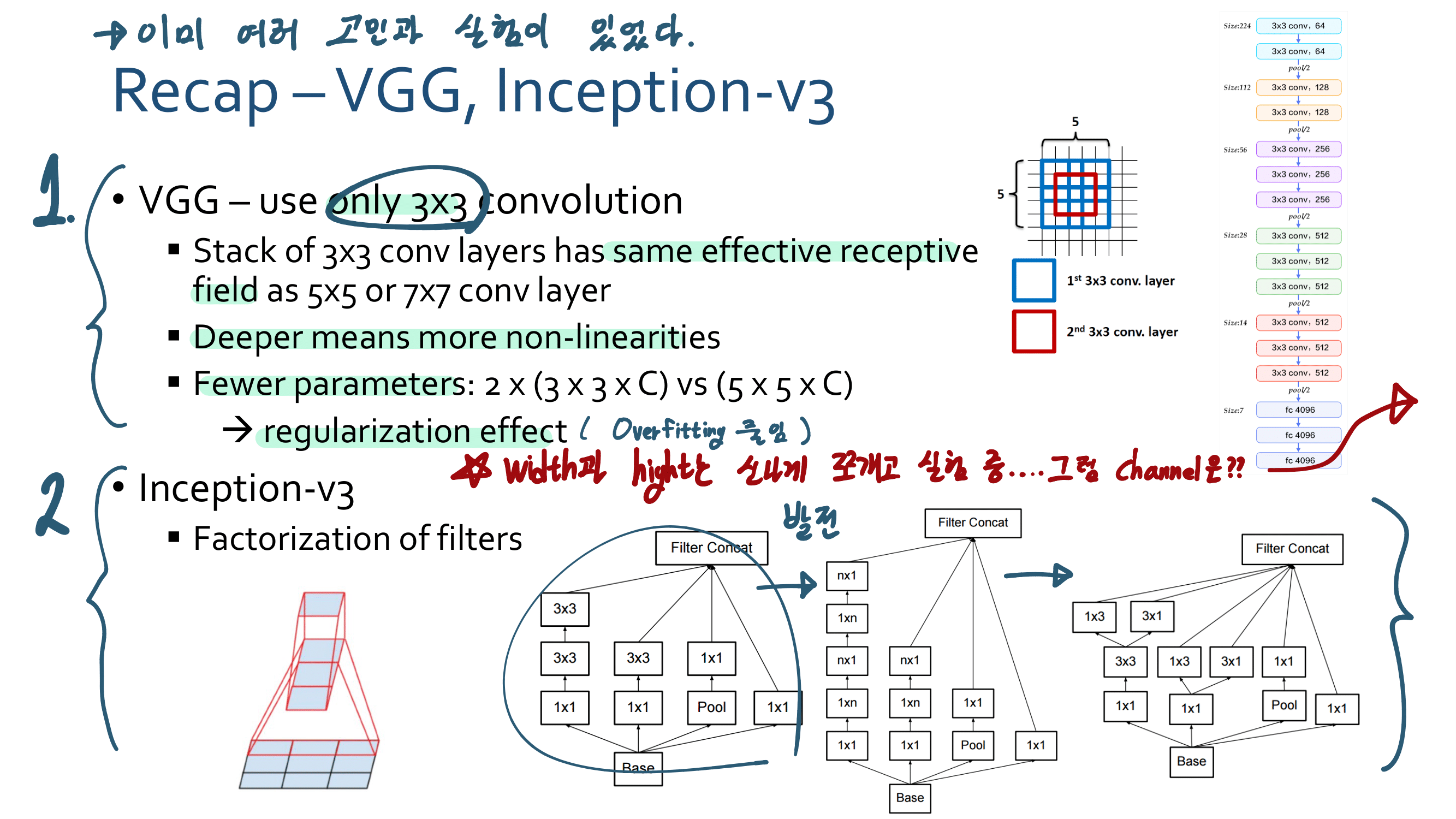

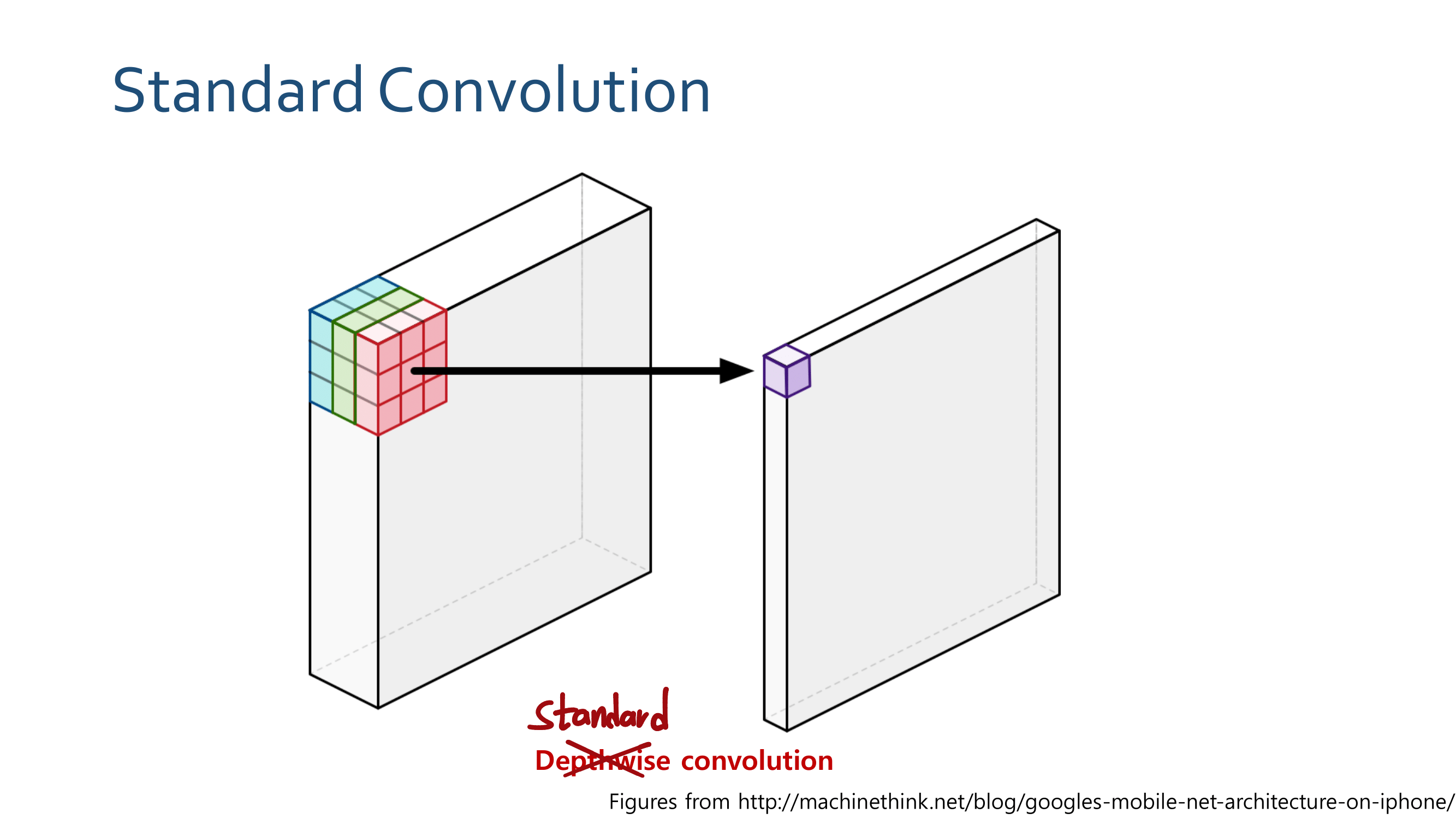
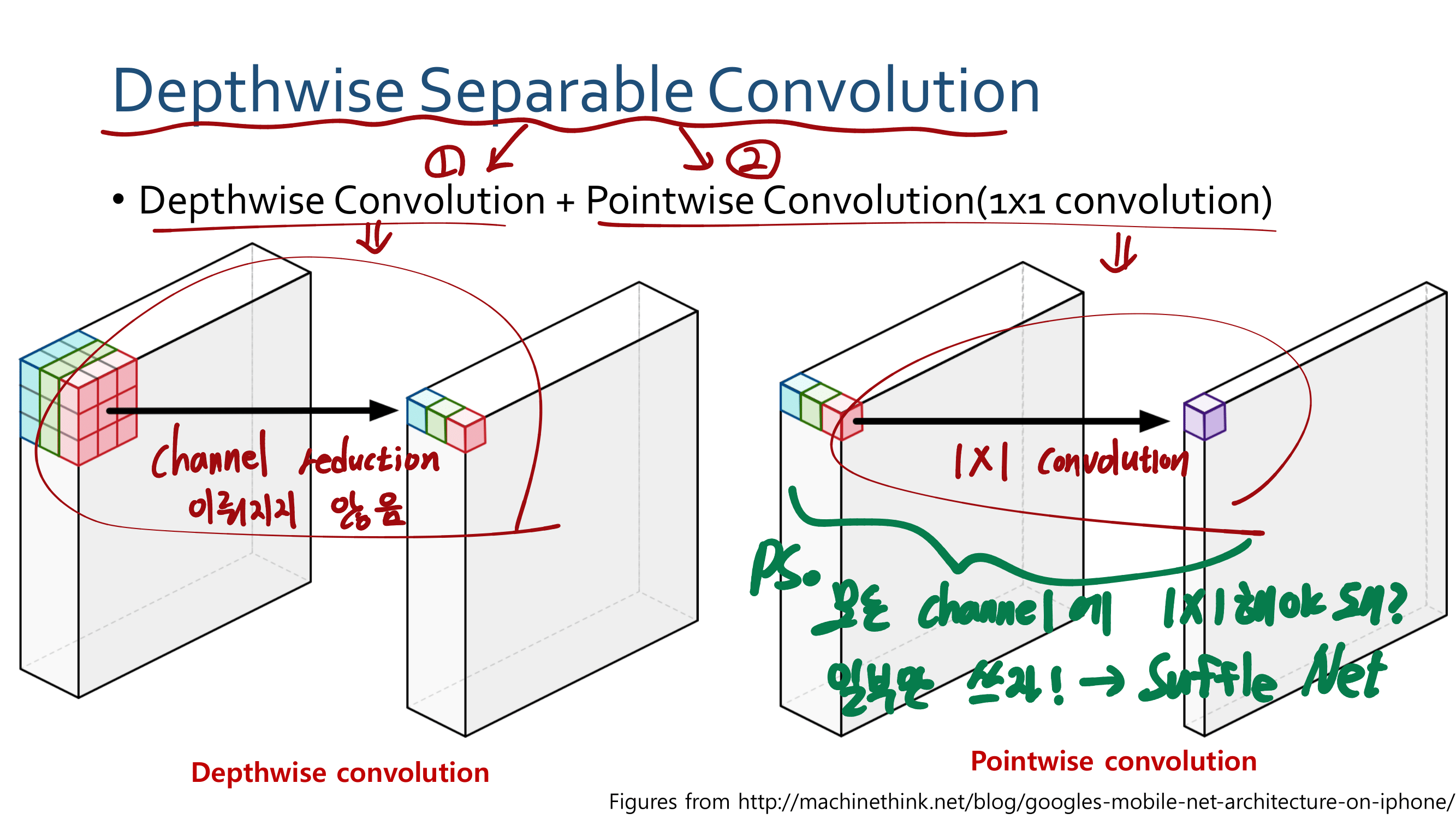
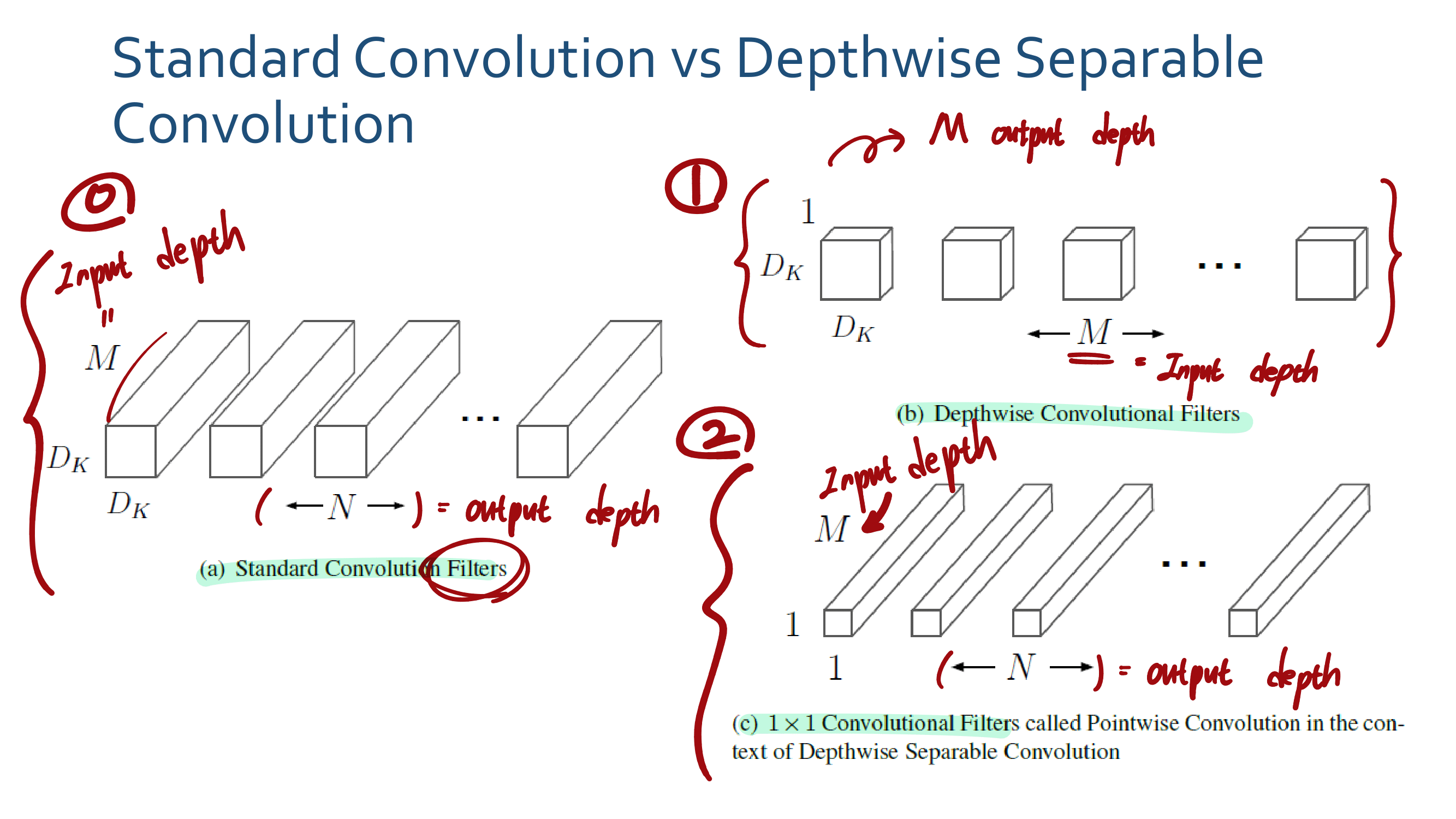

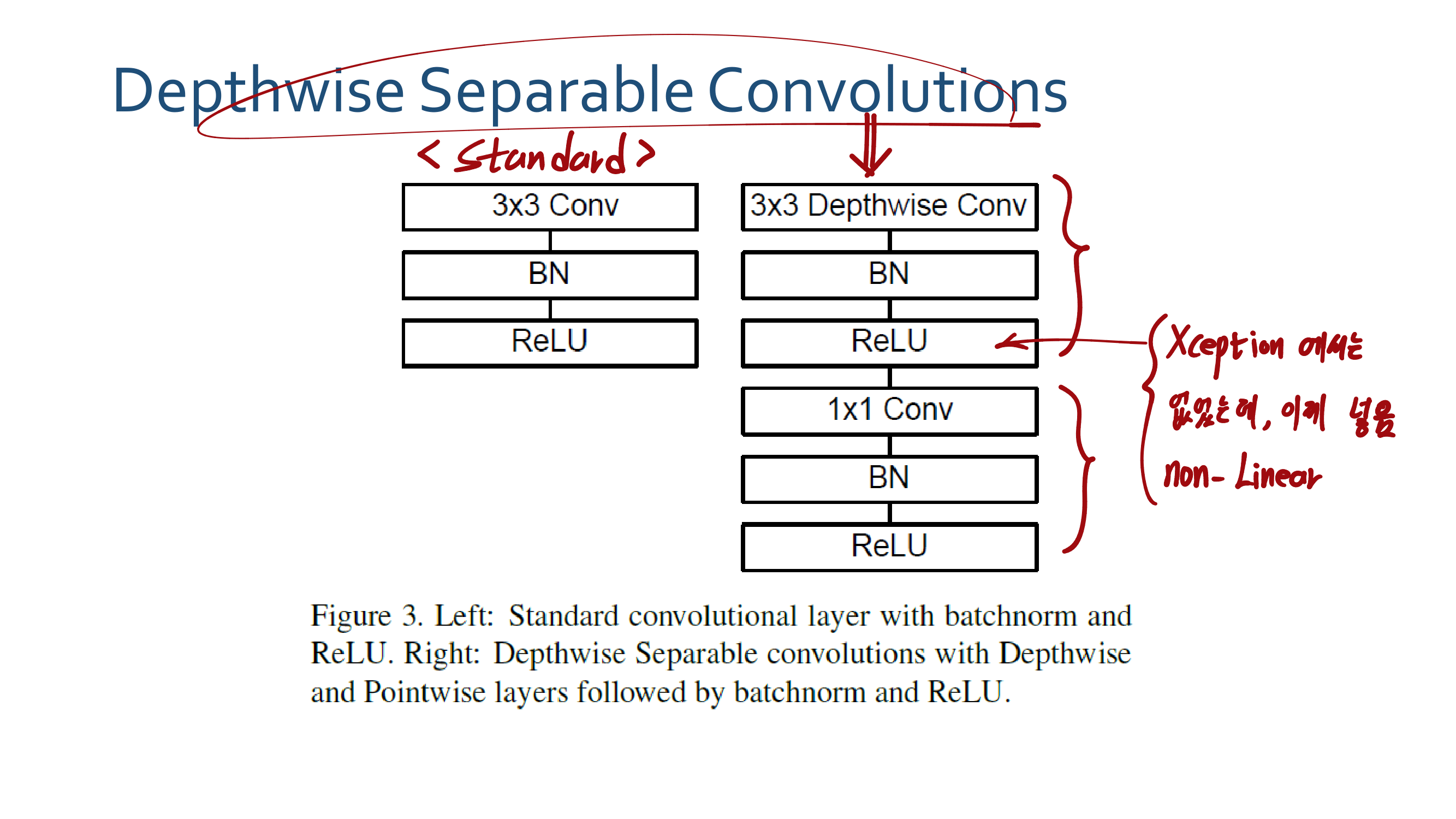
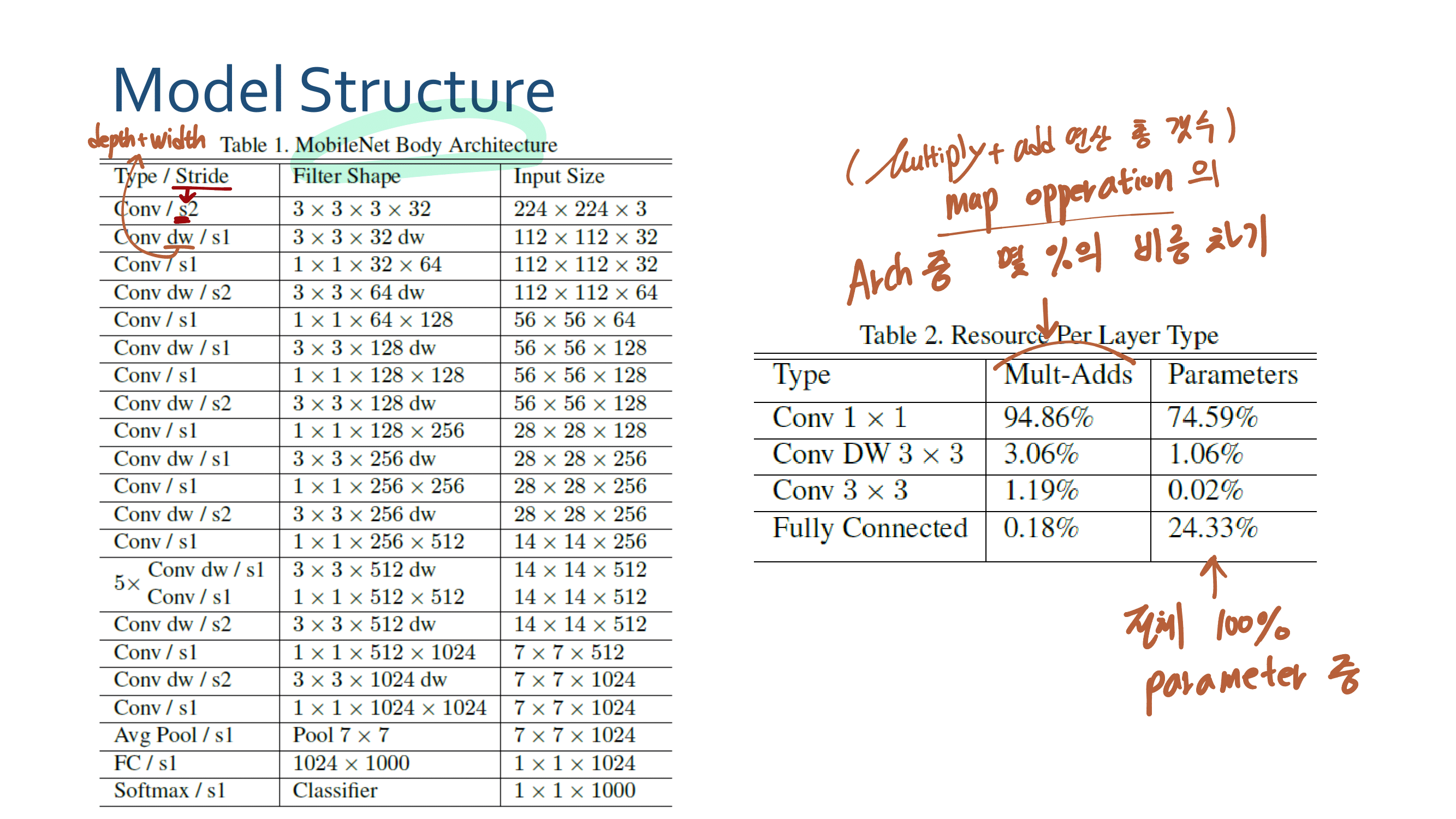


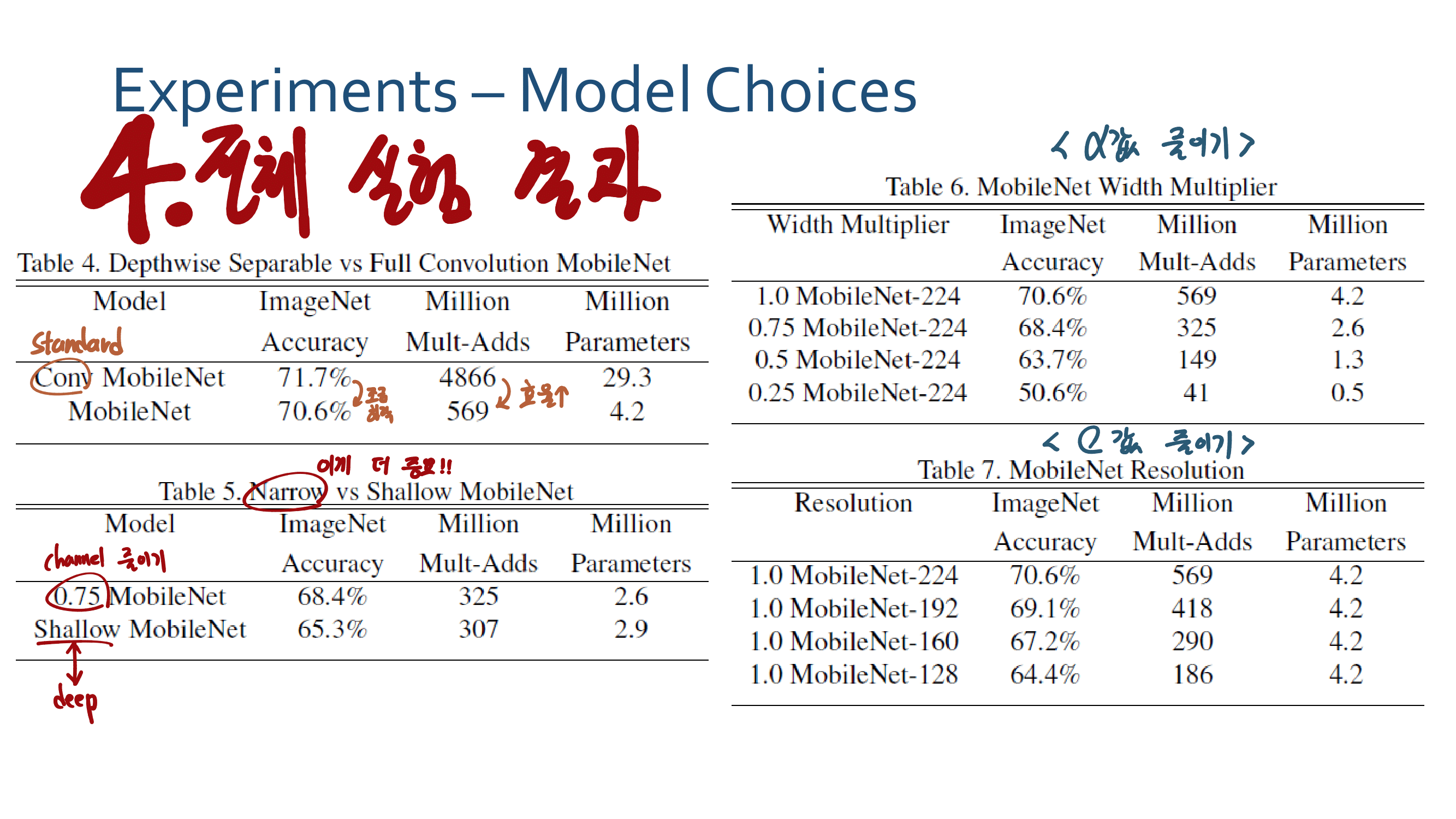
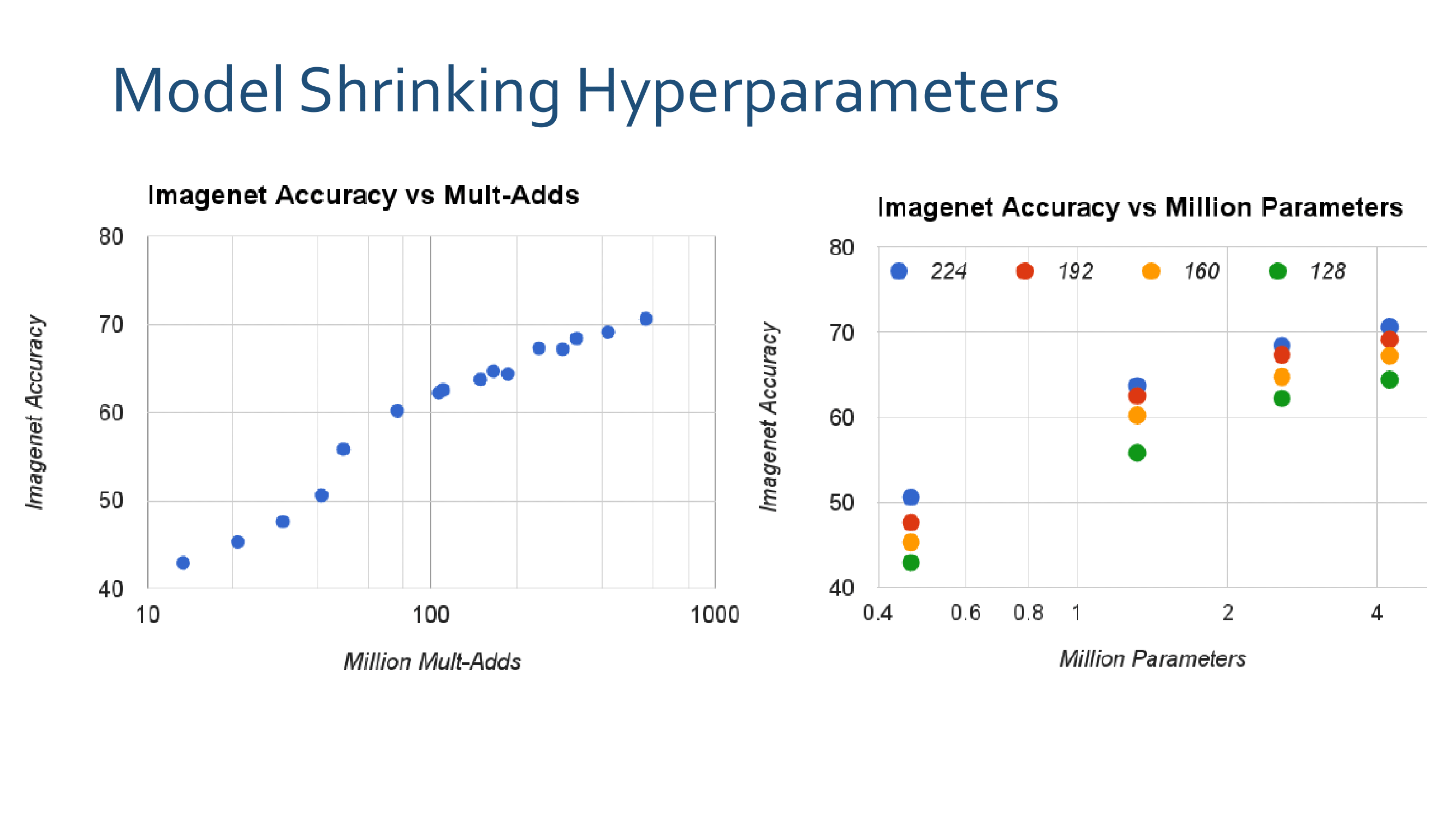
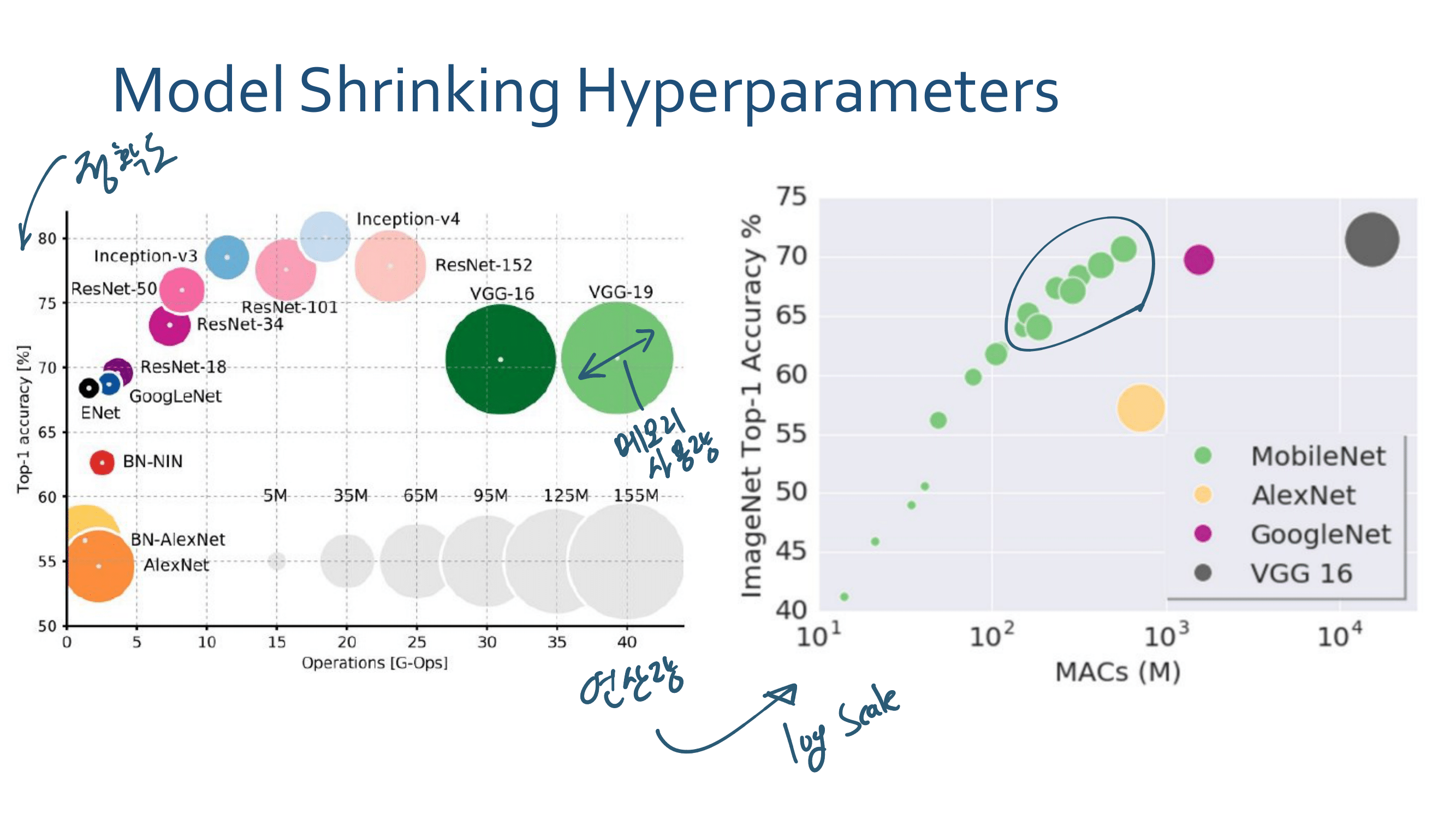
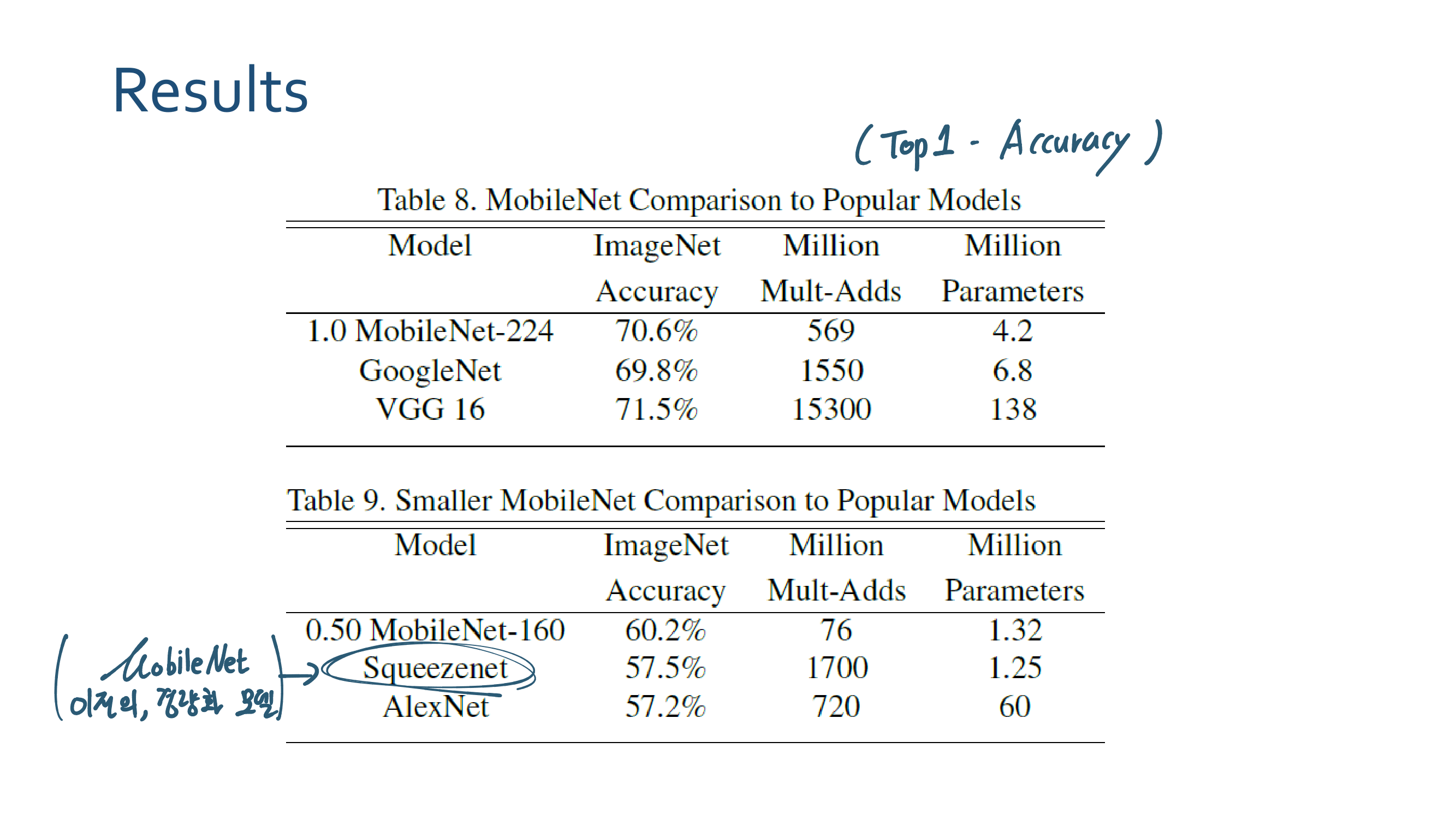
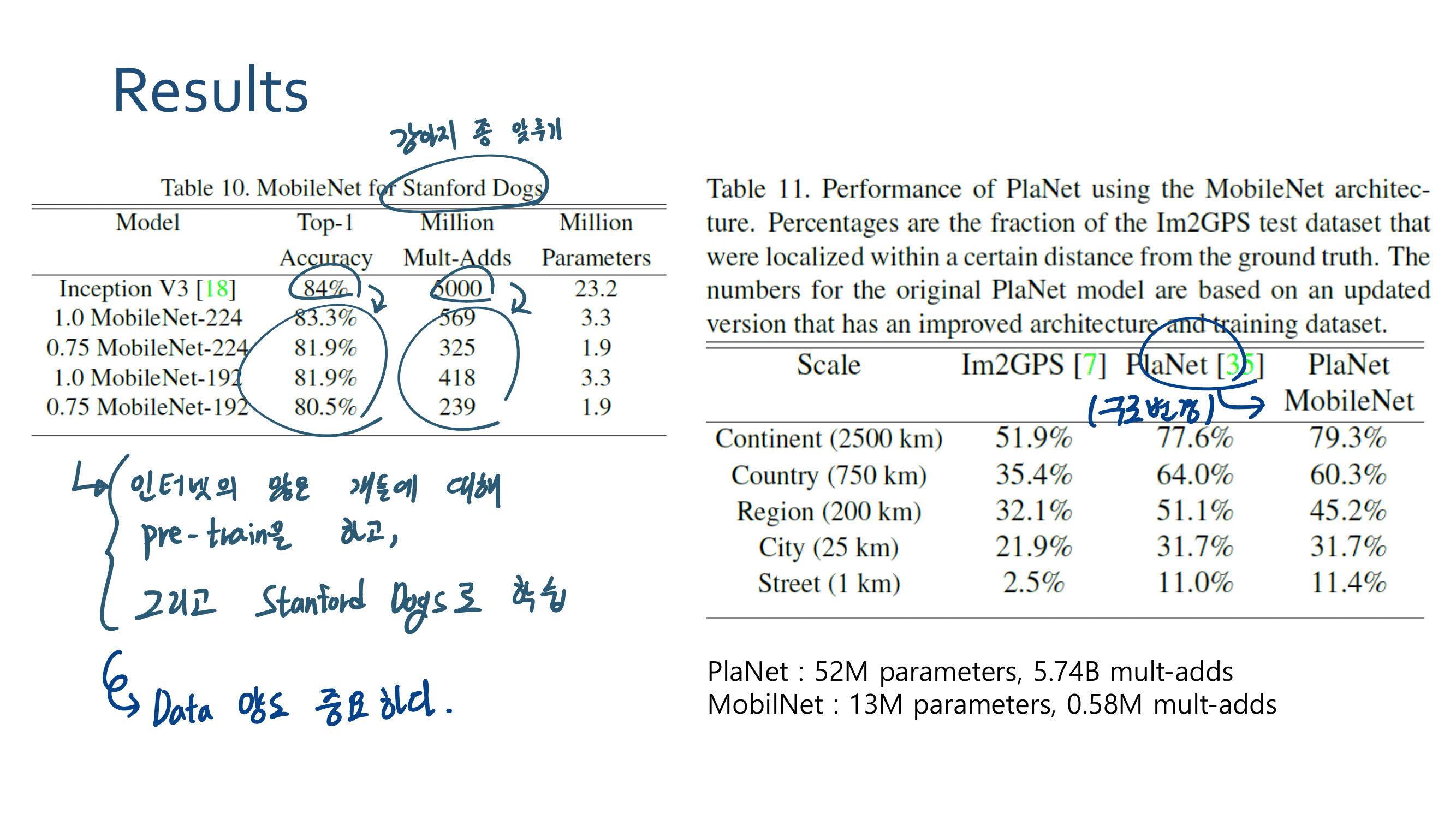
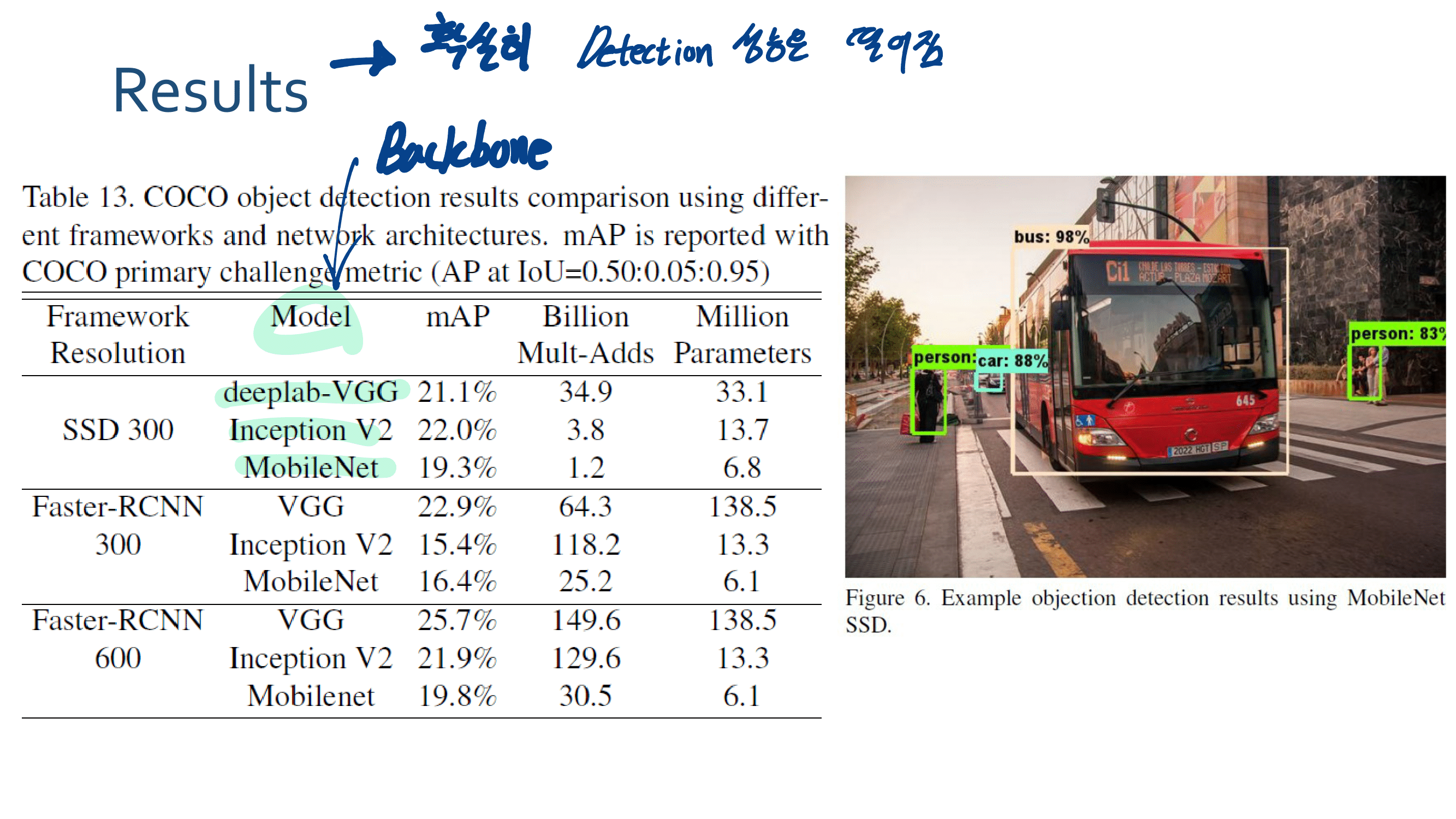

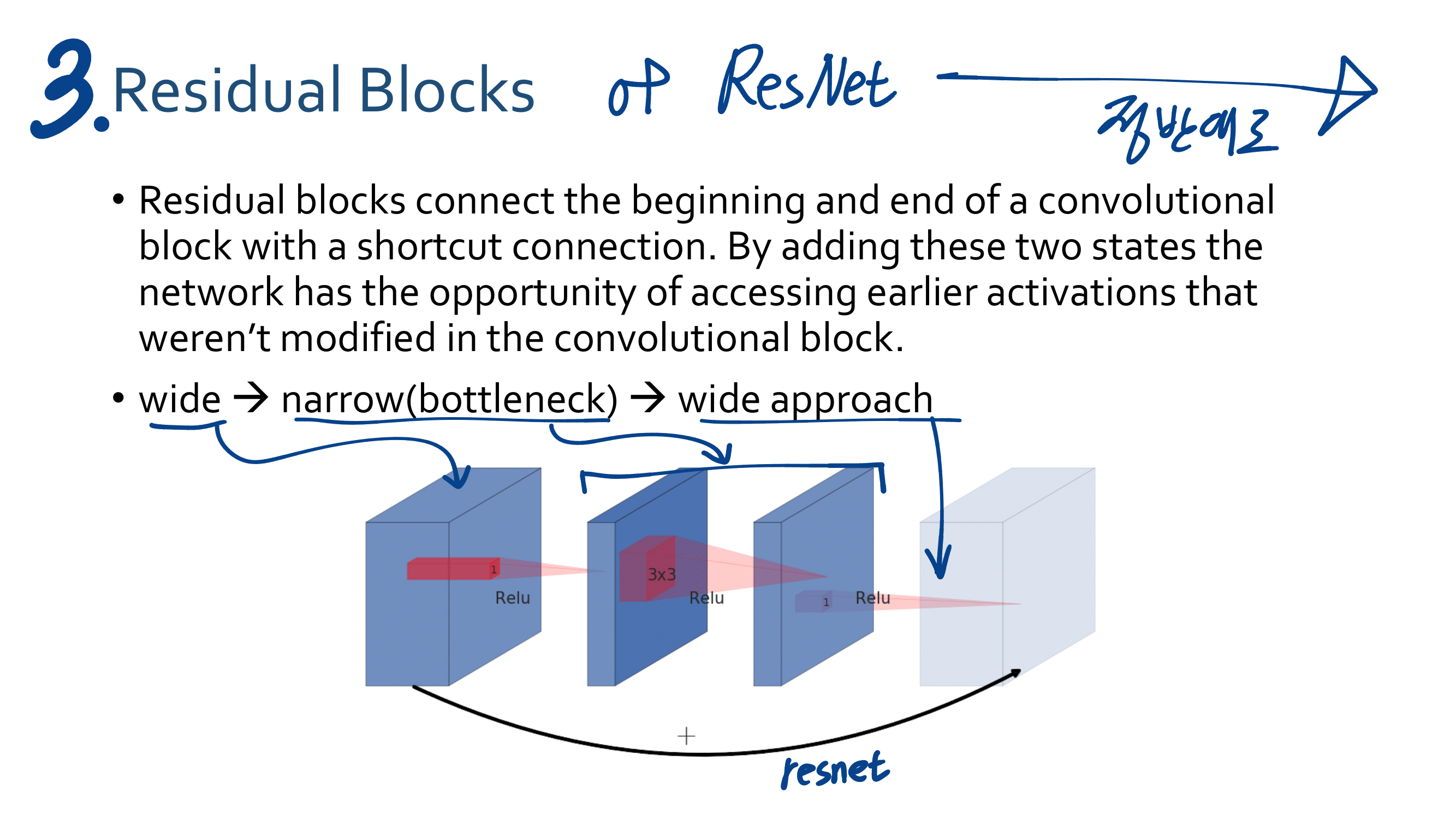
3. MobileNetV2








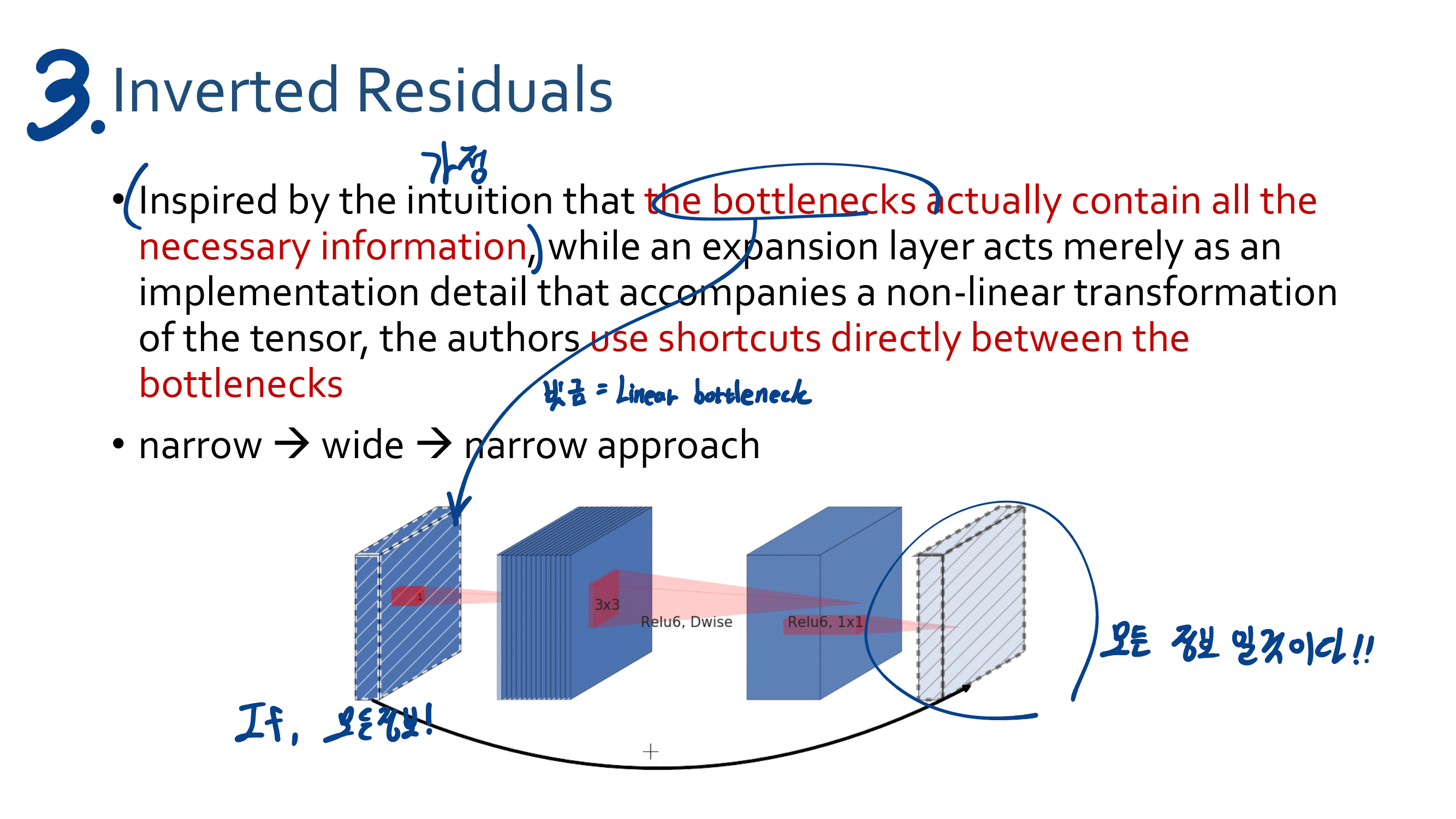
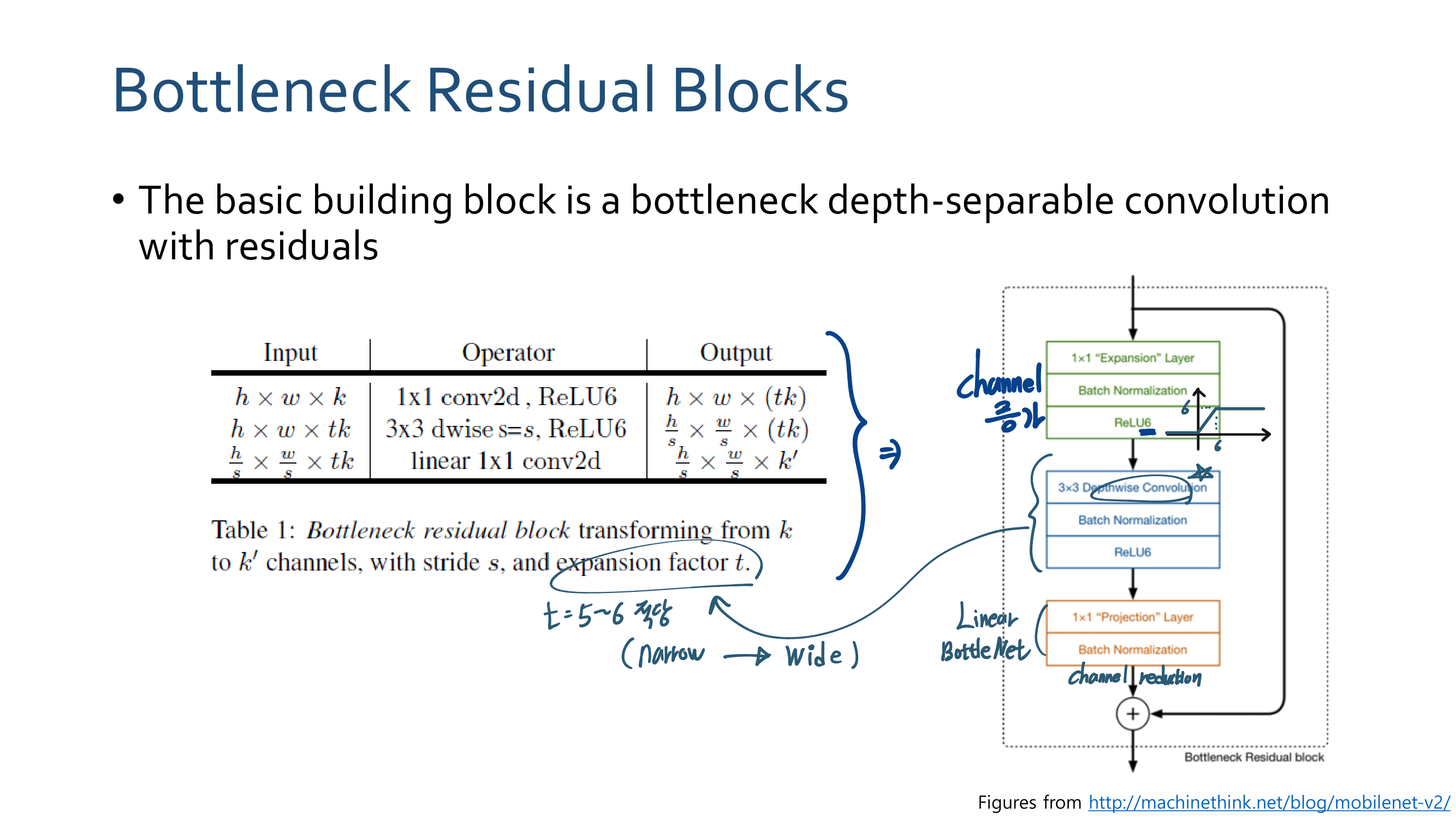

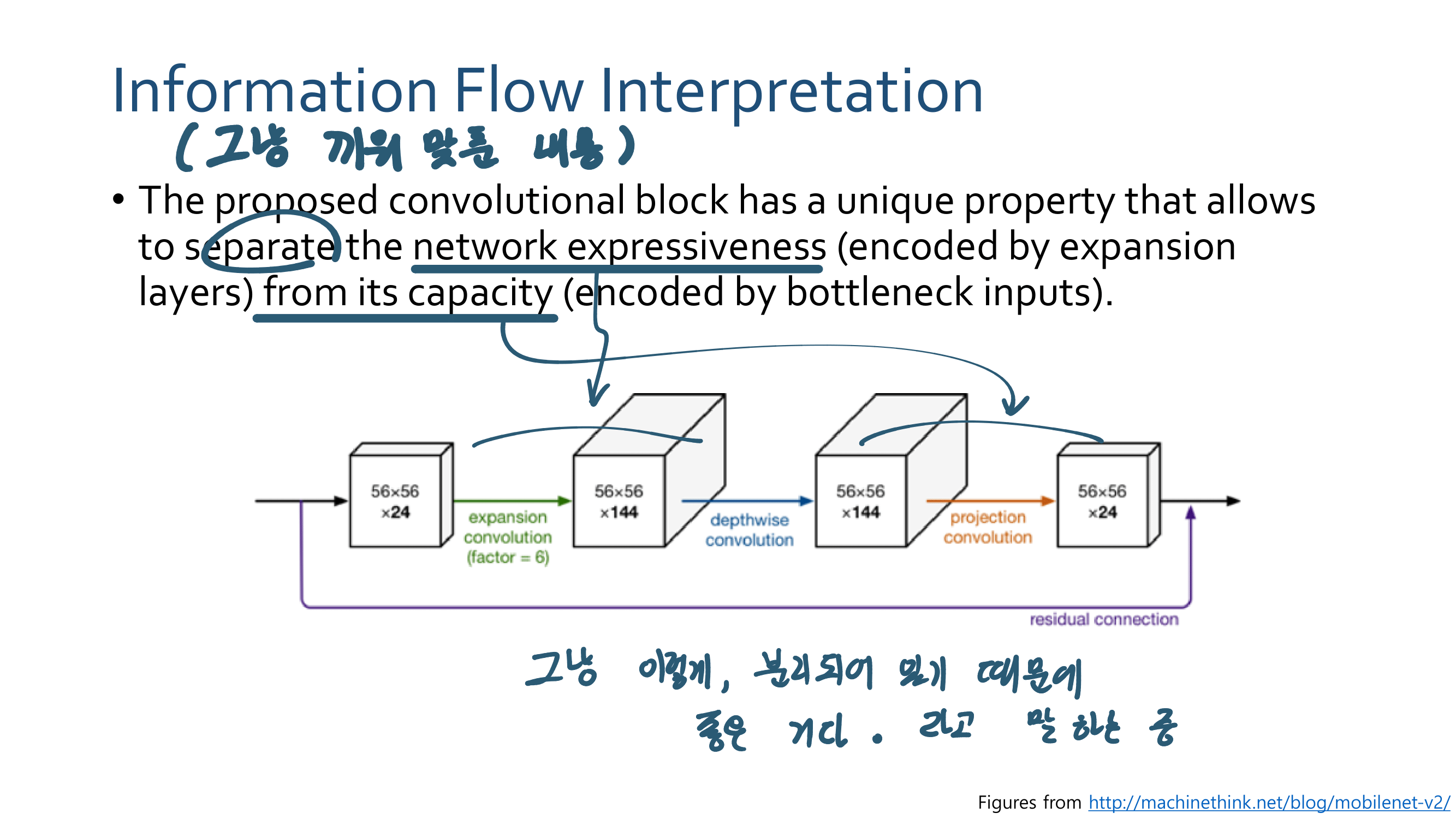


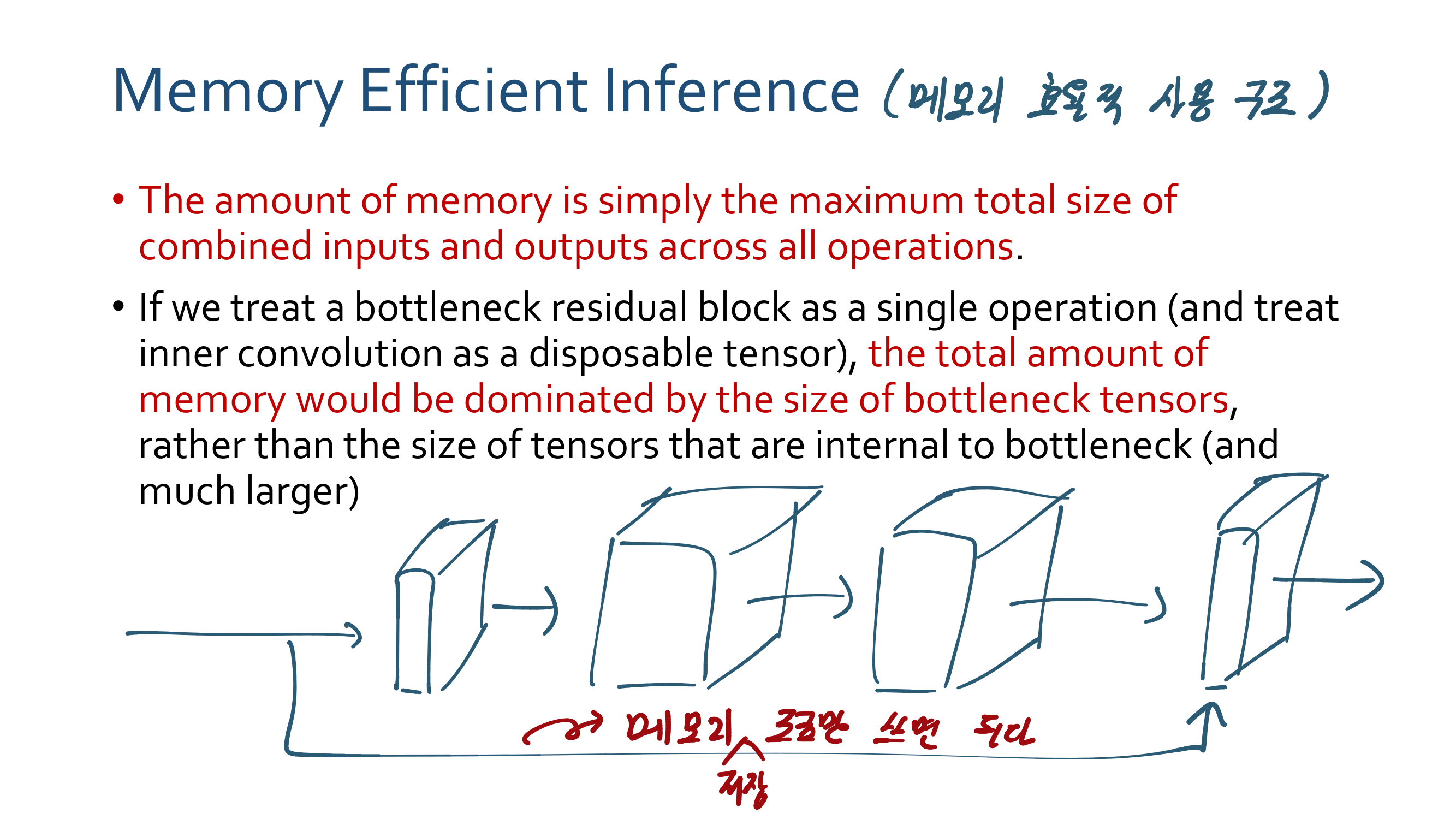


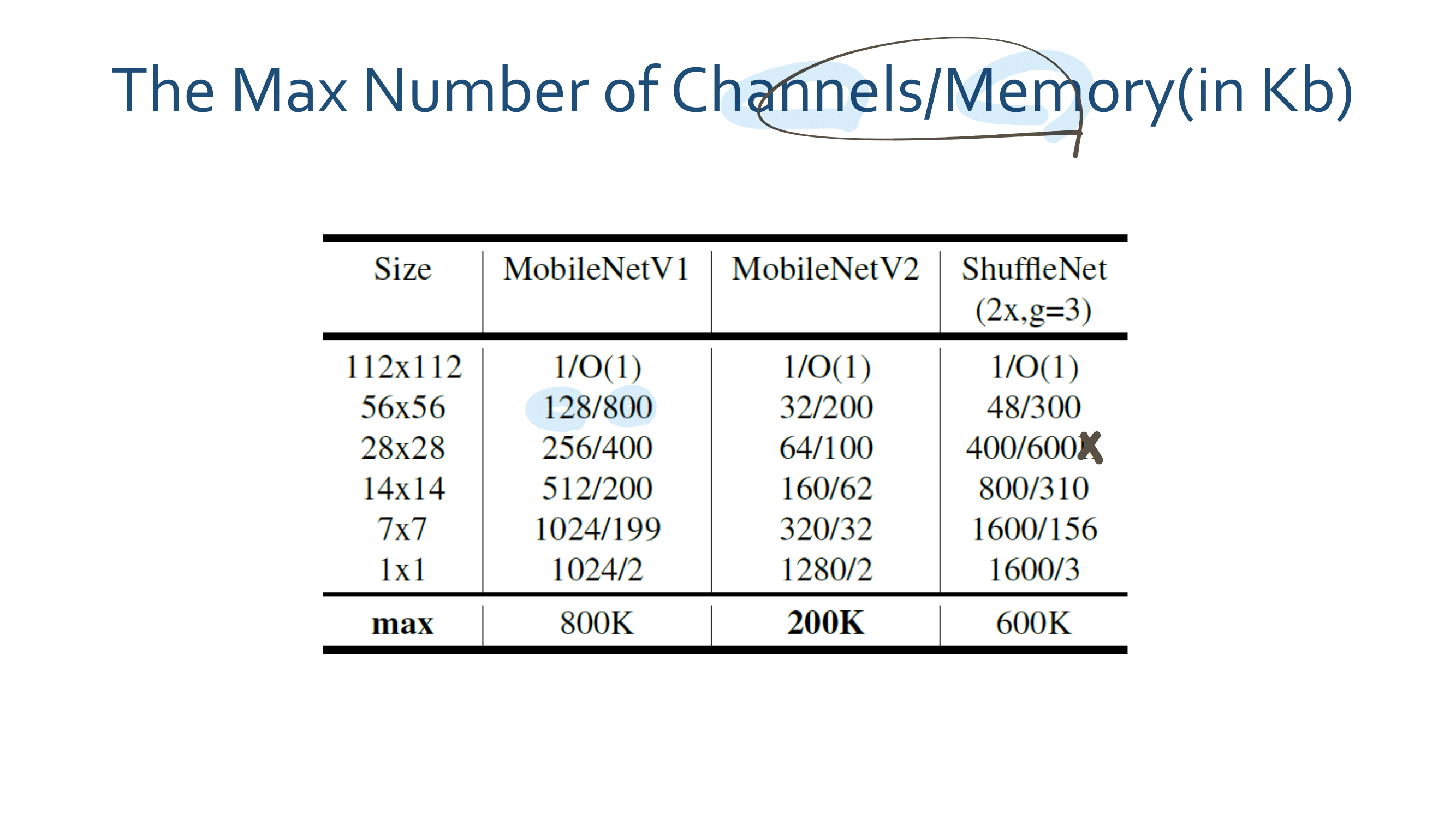
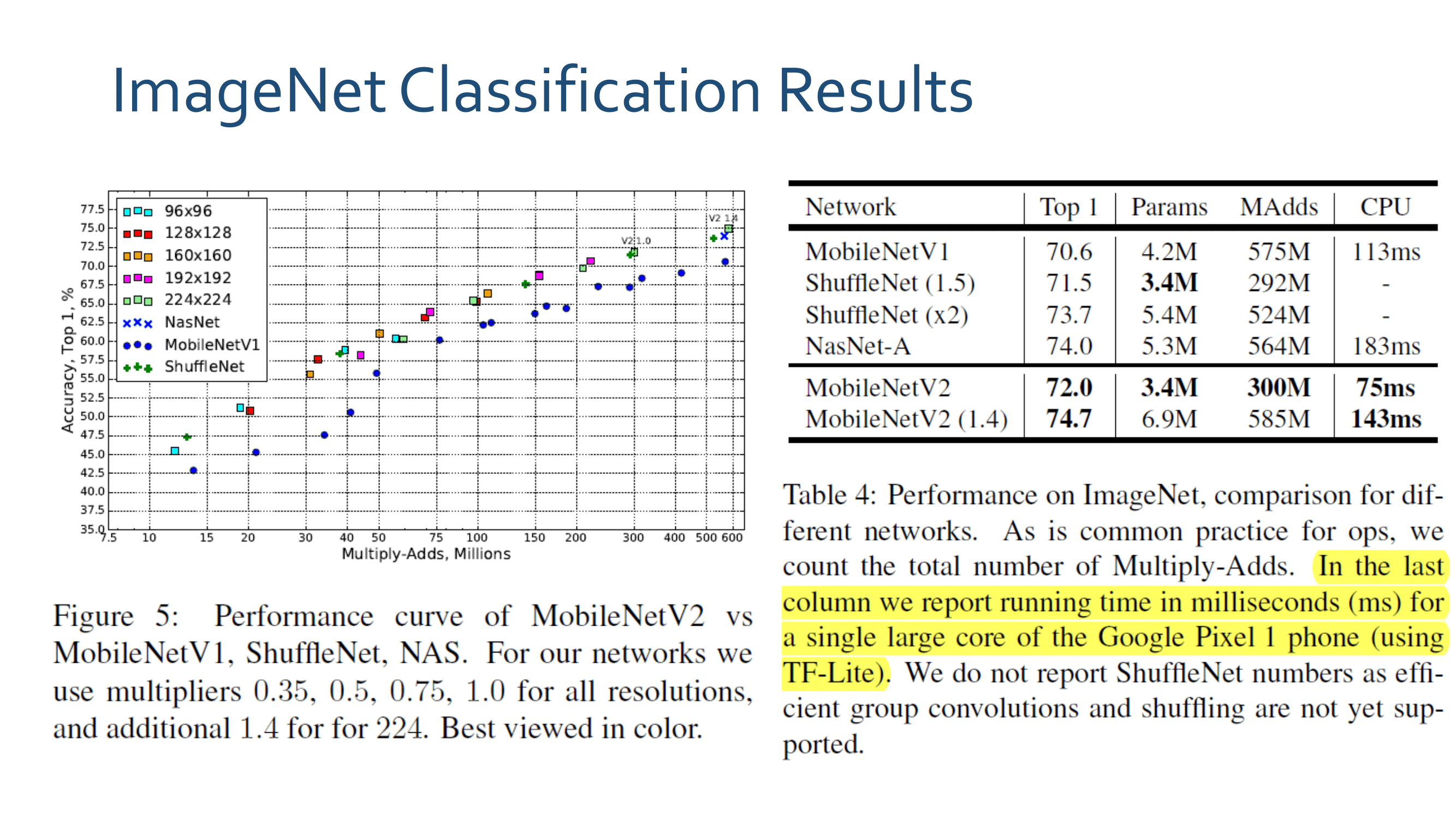
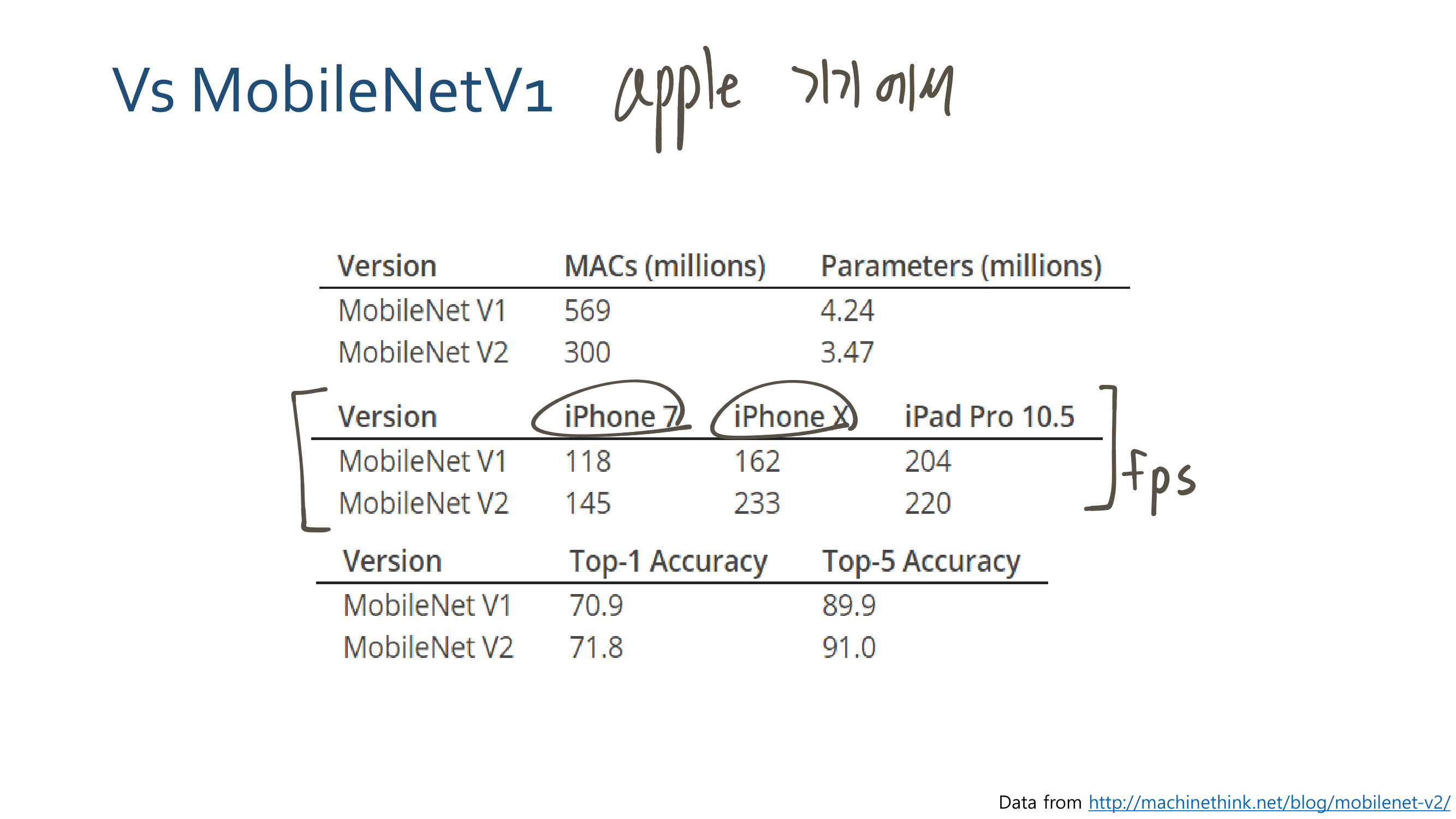


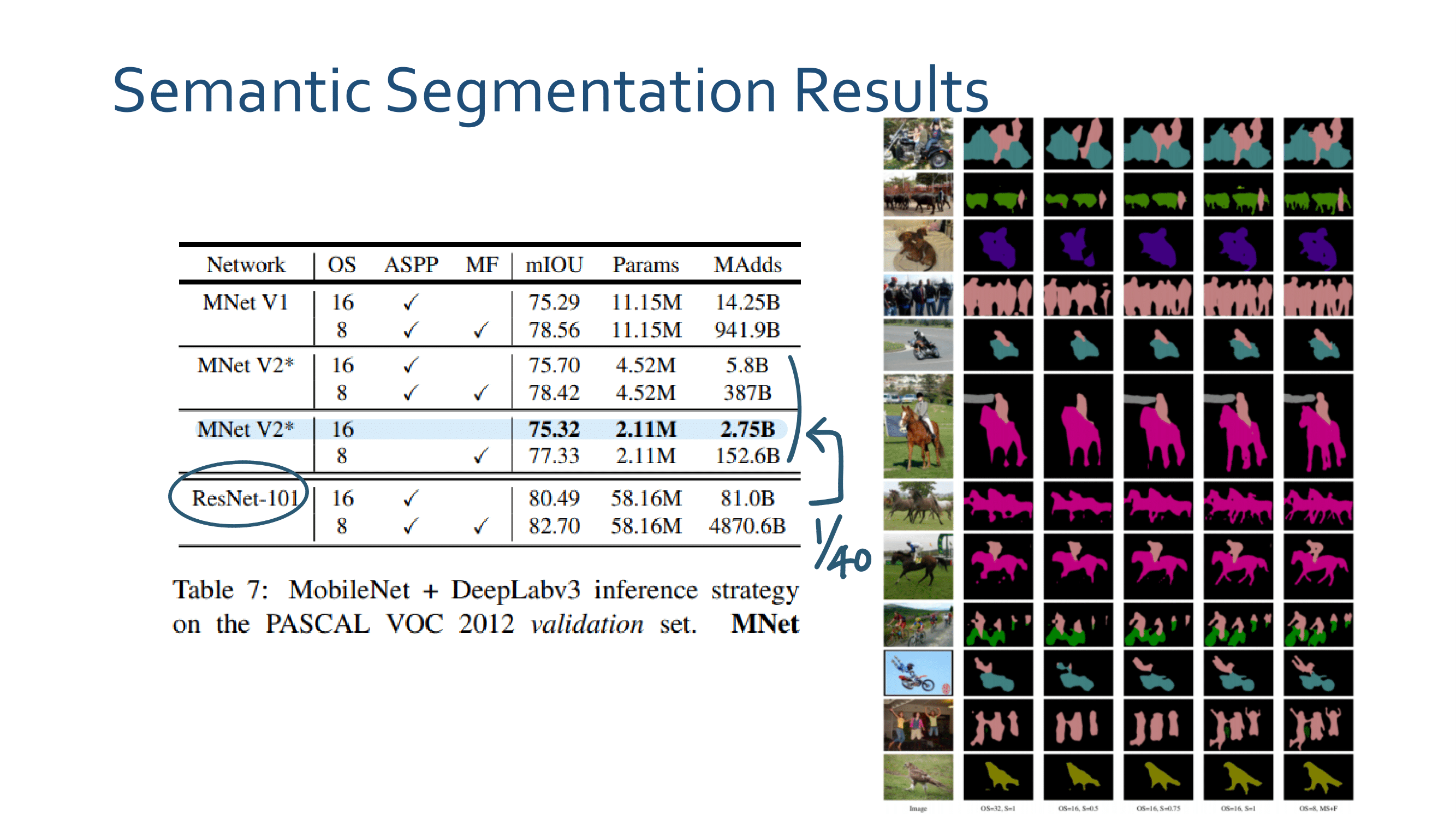
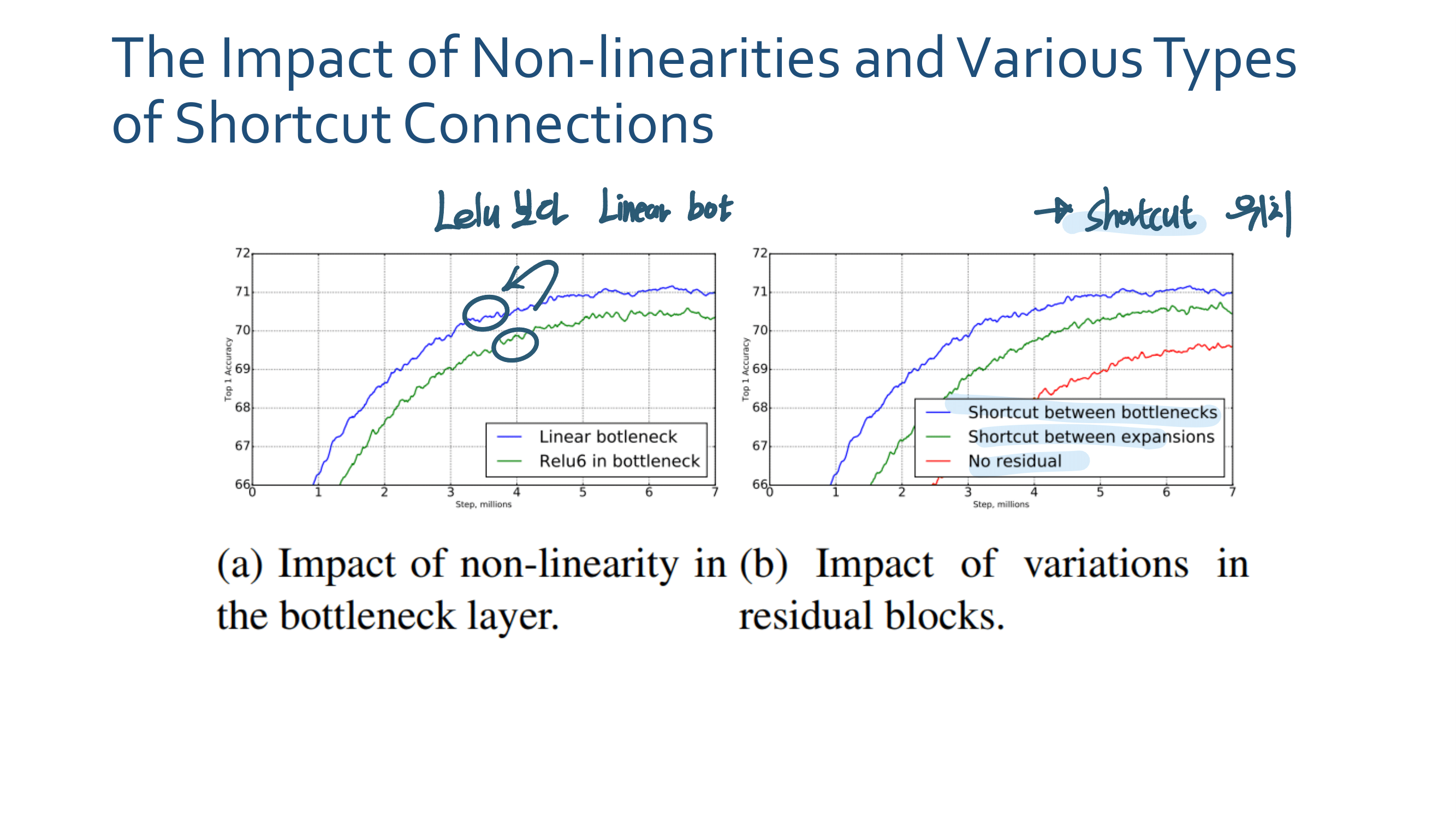
4. Linear Bottlenecks Code
결국 Relu안하는 Convolution Layer이다. ㅅ… 욕이 나온네. “별것도 아닌거 말만 삐까번쩍하게 한다. 이게 정말 수학적으로 증명을 해서 뭘 알고 논문에서 어렵게 설명하는건지?, 혹은 그냥 그럴 것 같아서 실험을 몇번 해보니까 이게 성능이 좋아서 멋진 말로 끼워맞춘건지 모르겠다.
MobileNet V2 코드 - 파일이 1개 뿐이고 생각보다 엄청 쉽다. 이건 뭐 FPN 파일 하나 코드보다 훨씬 이해하기 쉽다.
class InvertedResidual(nn.Module): def __init__(self, inp, oup, stride, expand_ratio): super(InvertedResidual, self).__init__() self.stride = stride assert stride in [1, 2] hidden_dim = int(inp * expand_ratio) self.use_res_connect = self.stride == 1 and inp == oup if expand_ratio == 1: self.conv = nn.Sequential( # dw nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False), nn.BatchNorm2d(hidden_dim), nn.ReLU6(inplace=True), # pw-linear ***** 이거가 Linear Bottlenecks ***** nn.Conv2d(hidden_dim, oup, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(oup), ) else: self.conv = nn.Sequential( # pw nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False), nn.BatchNorm2d(hidden_dim), nn.ReLU6(inplace=True), # dw nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False), nn.BatchNorm2d(hidden_dim), nn.ReLU6(inplace=True), # pw-linear ***** 이거가 Linear Bottlenecks ***** nn.Conv2d(hidden_dim, oup, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(oup), )
- 매니폴드 학습이란, <그림 1>과 같은 형태로 수집된 정보로부터 <그림 2>와 같이 바르고 곧은 유클리디안 공간을 찾아내는 것을 말합니다.
- 아래의 그림처럼, 100차원 vector들이 100차원 공간상에 놓여있다. 하지만 유심히 보면, 결국 백터들은 2차원 평면(왼쪽 그림) 혹은 3차원 공간(오른쪼 그림) 으로 이동 시킬 수 있다. 즉 100차원 공간이라고 보여도 사실은 2차원 3차원으로 더 잘 표현할 수 있는 백터들 이었다는 것이다.
- 이렇게 높은 차원의 백터들을, 낮은 차원의 직관적이고 곧은 공간으로 이동시킬 수 있게 신경망과 신경망의 파라메터를 이용한다.


- 스위스롤(왼쪽그림)을 우리가 보면 3차원이지만, 그 위에 올라가 있는 개미가 느끼기엔 2차원이다.
- 매니폴드 학습이란 ‘눈을 감고(학습이되지 않은 상태에서) 비유클리디안 형태를 만져가며(데이터를 이용해) 모양을 이해해(모델을 학습해) 나가는 것이다’. 즉, 스위스롤을 2차원 평면으로 피는 과정이다.
- 오른쪽 그림과 같이 2차원 데이터를, 1차원으로 필 수 있다면 데이터와의 유사도 측정등에 매우 좋을 것이다.
- 혹은 차원을 늘리기도 한다. 예를 들어 오른쪽 그림의 실을 잡고 들어올리는 행위가, 차원을 늘리는 행위이고, 그것은 신경망의 Layer를 추가하는 행위라고도 할 수 있다.
Manifold of Interest 위의 내용까지 간략히 요약 정리!
- 실용적으로 말해서! “conv혹은 fc를 통과하고 activation function을 통과하고 나온 (Subset) Feature가 Manifold 이다!” 그리고 “그 Manifold 중에 우리가 관심있어하는 부분, 가장 많은 이미지의 정보를 representation하는 일부를 논문에서는 Manifold of interest 라고 한다.”

- 논문 설명 + 나의 이해 : Input data = x 가 맨 왼쪽과 같이 표현 된다고 하자. 그리고 Activation_Function( T * x) 를 수행한다. 여기서 T는 Input data의 차원을 위 사진의 숫자와 같이 2,3,5,15,30 차원으로 늘려주는 FC Layer라고 생각하자.
- 결과를 살펴보면, 낮은 차원으로 Enbeding하는 작업은, 특히 (비선형성 발생하게 만드는) Relu에 의해서 (low-dimensional subspace = 윗 이미지 그림을 살펴 보면) 정보의 손실이 많이 일어난다. 하지만 고차원으로의 Enbeding은 Relu에 의해서도 정보의 손실이 그리 많이 일어나지 않는다.
- 솔직히 논문이나 PPT내용이 무슨소리 하는지는 모르겠다.
- 결국에는 위와 같은 “정보 손실”을 줄이기 위해서, 비선형이 Relu를 쓰지 않고 Linear Function을 쓰겠다는 것이다.
